

Abstract
Age-dependent branching processes are increasingly used in analyses of biological data. Despite being central to most statistical procedures, the identifiability of these models has not been studied. In this paper, we partition a family of age-dependent branching processes into equivalence classes over which the distribution of the population size remains identical. This result is applicable to study identifiability of the offspring and lifespan distributions for parametric families of branching processes. For example, we identify classes of Markov processes that are not identifiable. We show that age-dependent processes with (non-exponential) gamma distributed lifespan are identifiable and that Smith-Martin processes are not always identifiable.
Keywords: Identifiability, Bellman-Harris Process, Sevastyanov Process, Smith-Martin process
1. Introduction
Let Z(t) denote the size of a population governed by an age-dependent branching process started at t = 0 with a single particle or cell of age 0. Upon completion of its lifespan, every cell produces a random number of offspring ξ ∈
 = {0, 1, 2, …, J}, where J is a given positive integer. Let p := (p0, …, pJ), where pj :=
= {0, 1, 2, …, J}, where J is a given positive integer. Let p := (p0, …, pJ), where pj :=
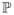 (ξ = j), j ∈
, denote the offspring distribution. Put h(u; p) :=
(ξ = j), j ∈
, denote the offspring distribution. Put h(u; p) :=
 pjuj, u ∈ [−1, 1], and μ :=
pjuj, u ∈ [−1, 1], and μ :=
 (ξ) =
jpj for its probability generating function (p.g.f.) and expectation. A cell that produces a single offspring (ξ = 1) is said to be quiescent. This feature is relevant when modeling tumor growth ([1]; see also [5]). Throughout, we shall implicitly assume that p1 ∈ [0, 1). Put
(ξ) =
jpj for its probability generating function (p.g.f.) and expectation. A cell that produces a single offspring (ξ = 1) is said to be quiescent. This feature is relevant when modeling tumor growth ([1]; see also [5]). Throughout, we shall implicitly assume that p1 ∈ [0, 1). Put
 (p) := {j ∈
: pj > 0}. For every j ∈
(p), let Gj(t) :=
(τ ≤ t|ξ = j), t ≥ 0, denote the conditional cumulative distribution function (c.d.f.) of the lifespan τ, given ξ = j. Write
(p) := {j ∈
: pj > 0}. For every j ∈
(p), let Gj(t) :=
(τ ≤ t|ξ = j), t ≥ 0, denote the conditional cumulative distribution function (c.d.f.) of the lifespan τ, given ξ = j. Write
 for the class all absolutely continuous (a.c.) c.d.f. F that are proper and satisfy F(0+) = 0 (the assumption of a.c. is not needed but simplifies the presentation). Assume that Gj ∈
, j ∈
(p). As usual, every cell evolves independently of all other cells. Put G = {Gj, j ∈
(p)}. We shall refer to C = (p, G) as the characteristics of the process. The process is of Bellman-Harris type if the c.d.f. Gj are identical for all j ∈
(p). Otherwise it allows the lifespan and offspring to be dependent, and belongs to the class of Sevastyanov processes [7, 4, 3].
for the class all absolutely continuous (a.c.) c.d.f. F that are proper and satisfy F(0+) = 0 (the assumption of a.c. is not needed but simplifies the presentation). Assume that Gj ∈
, j ∈
(p). As usual, every cell evolves independently of all other cells. Put G = {Gj, j ∈
(p)}. We shall refer to C = (p, G) as the characteristics of the process. The process is of Bellman-Harris type if the c.d.f. Gj are identical for all j ∈
(p). Otherwise it allows the lifespan and offspring to be dependent, and belongs to the class of Sevastyanov processes [7, 4, 3].
In this paper, we study the following question: are there distinct characteristics (p, G) under which the distribution of the process Z(t) is identical? This question is relevant to the problem of model identifiability, which is a central prerequisite to most statistical procedures. Although age-dependent branching processes are widely used in biology, this question does not appear to have been studied for this class of models [2, 5, 9]. Answering this question will inform us about what can or cannot be estimated by only observing Z(t), a situation that arises frequently in cell biology.
Let
 denote the class of all processes that satisfy the above assumptions. It will be useful to define a subclass of processes included in
, say
denote the class of all processes that satisfy the above assumptions. It will be useful to define a subclass of processes included in
, say
 , with characteristics (p, G) satisfying p1 = 0. We shall say that two processes with characteristics (p, G) and (p̂, Ĝ) are equivalent if, for all t ≥ 0, the distribution of Z(t) is the same under either characteristics. Let
, with characteristics (p, G) satisfying p1 = 0. We shall say that two processes with characteristics (p, G) and (p̂, Ĝ) are equivalent if, for all t ≥ 0, the distribution of Z(t) is the same under either characteristics. Let
 denote the collection of processes included in
that are equivalent to the process with characteristics (p, G). It forms an equivalence class, and our objective is to identify all the processes included in this class for any admissible set of characteristics (p, G). If the class includes processes other than the process with characteristics (p, G), then p and G cannot be unequivocally identified by the marginal distribution of Z(t) for all t ≥ 0.
denote the collection of processes included in
that are equivalent to the process with characteristics (p, G). It forms an equivalence class, and our objective is to identify all the processes included in this class for any admissible set of characteristics (p, G). If the class includes processes other than the process with characteristics (p, G), then p and G cannot be unequivocally identified by the marginal distribution of Z(t) for all t ≥ 0.
We construct the class
in the next section. We proceed in three steps. Firstly, we identify a collection of equivalent processes (Section 2.1). Next, by inverting the transformation that defines this collection about a properly chosen process, we find a larger collection of equivalent processes (Section 2.2). Finally, we prove, when J = 2, which is typical of most biological applications, and J = 3, that the larger collection is identical to
(Section 2.3). Each equivalence class contains a single process such that p1 = 0. When J = 2, the equivalence classes are fully characterized by the expectation and the variance of Z(t) (Section 2.4). Our results are applicable to study identifiability of families of parametric models. For example, we find that the Markov version of the process is not always identifiable (Section 3.1). The age-dependent process with (non-exponential) gamma distributed lifespan is identifiable (Section 3.2). We also find that the Smith-Martin process is not always identifiable (Section 3.3).
2. Main results
2.1. A collection of equivalent processes
For every p1 ∈ [0, 1) and a ∈ [0, p1], define , where
| (1) |
Notice that
(p)\{1} =
(p(a))\{1}. By convention, when p1 = 0, G1 will denote any c.d.f. in
. For every t ≥ 0, j ∈
(p), a ∈ [0, p1], put
| (2) |
where denotes the convolution of Gj and F1, and where is the k-fold convolution of G1 with itself. For every p1 ∈ [0, 1) and a ∈ [0, p1], it can be verified that is the c.d.f. of a proper distribution; it can be interpreted as the c.d.f. of a (non-Markov) phase-type distribution, and the Laplace transform of is:
| (3) |
where
 is the Laplace transforms of gj(t) := dGj(t)/dt. Write
and C(a) = (p(a), G(a)).
is the Laplace transforms of gj(t) := dGj(t)/dt. Write
and C(a) = (p(a), G(a)).
Let
 denote the collection of processes with characteristics (p(a), G(a)), a ∈ [0, p1]. Since (p(0), G(0)) = (p, G),
includes the process with characteristics (p, G). Thus it is never empty. Moreover, since
,
always includes at least one process from
. This process will play a central role in constructing
.
denote the collection of processes with characteristics (p(a), G(a)), a ∈ [0, p1]. Since (p(0), G(0)) = (p, G),
includes the process with characteristics (p, G). Thus it is never empty. Moreover, since
,
always includes at least one process from
. This process will play a central role in constructing
.
Theorem 1
For all t ≥ 0, the distribution of the population size process Z(t) is identical under all processes included in
; that is,
⊆
.
Proof
Let ΦC(u, t) :=
{uZ(t)|Z(0) = 1}, u ∈ [−1, 1] and t ≥ 0, denote the p.g.f. of Z(t) under the process with characteristics C. Conditioning on the lifespan of the cell initiating the population yields
| (4) |
For every j ∈
and u ∈ [−1, 1], let
denote the Laplace transform of ΦC(u, t)j. Put
. Since |ΦC(u, t)| ≤ 1 for every u ∈ [−1, 1], and t ≥ 0, we have that
for every s > 0. Also, it follows from eqn. (4) that
 (u, s), s > 0, satisfies:
(u, s), s > 0, satisfies:
| (5) |
For every a ∈ [0, p1], eqn. (5) can be rearranged into
Dividing both sides of the equation by 1 − a
 (s) yields
(s) yields
| (6) |
By comparing eqns. (5) and (6), we deduce that
(u, s) =
 (u, s), hence the processes with characteristics (p, G) and (p(a), G(a)), a ∈ [0, p1], are equivalent.
(u, s), hence the processes with characteristics (p, G) and (p(a), G(a)), a ∈ [0, p1], are equivalent.
2.2. A larger collection of equivalent processes
By inverting the transformation (p, G) → (p(a), G(a)), a ∈ [0, p1], about a properly chosen process in
, we will construct a collection of equivalent processes that is larger than
. Setting a = p1 in eqns. (1) and (3) yields
which identifies a process in
. We remark that ΦC(p1)(u, t) does not depend on
. Also, any process with characteristics (p̂, Ĝ) that satisfy
| (7) |
belongs to
because ΦĈ(u, t) = ΦĈ(p̂1)(u, t) = ΦC(p1)(u, t) = ΦC(u, t). By solving eqns. (7) we find that (p̂, Ĝ) satisfies
| (8) |
where p̂1 ∈ [0, 1) and Ĝ1 ∈
 , and where
⊆
is a set of distributions such that
, and where
⊆
is a set of distributions such that
 (s), j ∈
(p̂)\{1}, are the Laplace transforms of distributions in
. Write (pp̂1, Ĝ1, Gp̂1, Ĝ1) for any characteristics that satisfy eqns. (8). Then, the collection of processes
(s), j ∈
(p̂)\{1}, are the Laplace transforms of distributions in
. Write (pp̂1, Ĝ1, Gp̂1, Ĝ1) for any characteristics that satisfy eqns. (8). Then, the collection of processes
is included in
. It is also clear that
⊂
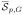 .
.
2.3. Exhaustivity of
when J = 2 and J = 3
Our final step toward identifying
is to prove that it coincides with
. Let
denote the k-th order partial derivative of ΦC(u, t), k = 1, 2 ···. Let
, t ≥ 0, k = 1, 2 ···, denote the k-th order factorial moment of Z(t) under the process with characteristics C, and write m(t) = m1(t). We have that mk(t) = Φ(k)(1, t). Differentiating both sides of eqn. (4) with respect to u at u = 1 yields the following integral equation for the expectation of the process:
| (9) |
The second and third order factorial moments satisfy
| (10) |
and
| (11) |
Let
 (s) denote the Laplace transform of mk(t), k = 1, 2, 3. Taking the Laplace transform of both sides of eqns. (9–11) and rearranging the terms yields
(s) denote the Laplace transform of mk(t), k = 1, 2, 3. Taking the Laplace transform of both sides of eqns. (9–11) and rearranging the terms yields
| (12) |
| (13) |
and
| (14) |
where
 (s) denotes the Laplace transform of m(t)m2(t).
(s) denotes the Laplace transform of m(t)m2(t).
Lemma 1
Suppose that J = 2 or J = 3. For every admissible (p, G), the equivalence class
includes a single process in
.
Proof
Assume first that J = 3. Consider two processes in
with characteristics C = (p, G) and Ĉ = (p̂, Ĝ). Thus, p1 = 0 and p̂1 = 0. Suppose that these processes are equivalent; that is, they both belong to
. Then ΦC(u, t) = ΦĈ(u, t) and
, u ∈ [−1, 1], t ≥ 0, and k = 1, 2, 3. Write m̂k(t) for the k-th order factorial moment of the process with characteristics Ĉ. Hence,
, which, using Identities (12–14), yields
where d(s) = 1 − 2p2
 (s) − 3p3
(s) − 3p3
 (s) and d̂(s) = 1 − 2p̂2
(s) and d̂(s) = 1 − 2p̂2
 (s) − 3p̂3
(s) − 3p̂3
 (s). Since
(s) =
(s). Since
(s) =
 (s), k = 1, 2, 3, and
(s) =
(s), k = 1, 2, 3, and
(s) =
 (s), the above system reduces to
(s), the above system reduces to
| (15) |
The above equations obtained when j = 2, 3 yield
which implies that 2p2
(s) + 3p3
(s) = 2p̂2
(s) + 3p̂3
(s), hence d(s) = d̂(s), and the system of equations (15) reduces to pj
(s) = p̂j
(s), j = 0, 2, 3. Hence (p̂, Ĝ) = (p, G) since the distributions Gj and Ĝj, j ∈
(p), are all proper. This completes the proof when J = 3. The case J = 2 is treated similarly except that we only use the first and second equations of the system (15), and we set p3 = p̂3 = 0.
Theorem 2
We have
=
for every admissible (p, G) when J = 2 and J = 3.
Proof
We already know that
⊆
. To prove that the converse holds true, let (p̂, Ĝ) denote the characteristics of any process included in
. Then, by construction, the process with characteristics (p̂(p̂1), Ĝ(p̂1)) belongs to
. We also know from Lemma 1 that (p̂(p̂1), Ĝ(p̂1)) = (p(p1), G(p1)). Hence the process with characteristics (p̂, Ĝ) belongs to
, which implies that
⊆
. This completes the proof.
2.4. Characterization of
using moments when J = 2
In data analyses, model parameters are sometimes estimated using moments of the process rather than its distribution. Then, a relevant question is which moments are sufficient to fully characterize the equivalence class
? We show below that the answer is simply the expectation and variance when J = 2. This property does not appear to generalize when J > 2, however.
Theorem 3
Assume that J = 2 and that the marginal distribution of {Z(t), t ≥ 0}, is determined by its moments. Then,
= {processes with characteristics (p̂, Ĝ) : m̂(t) = m(t), m̂2(t) = m2(t), t ≥ 0}.
Proof
To simplify the presentation, we assume, when pj = 0, that Gj is any arbitrary c.d.f in
. For k = 2, 3 ···, it can be shown by induction and using the identity
that
where ⌊k/2⌋ denotes the largest integer less than or equal to k/2, and ckr are some positive integers. Then,
| (16) |
where lk(s) is the Laplace transform of . Hence,
Let Ĉ = (p̂, Ĝ) denote the characteristics of any process in
. Then ΦĈ(u, t) = ΦC(u, t), t ≥ 0, u ∈ [−1, 1]. By assumption, Φc(u, t) is determined by its moments. Hence,
= {processes with characteristics (p̂, Ĝ) : m̂k(t) = mk(t), t ≥ 0, k ∈
 }, where
= {1, 2 ···}. We notice that m̂k(t) = mk(t) implies that
(s) =
}, where
= {1, 2 ···}. We notice that m̂k(t) = mk(t) implies that
(s) =
 (s) and l̂k(s) = lk(s), k ∈
, from which we deduce, when k = 2, that
(s) and l̂k(s) = lk(s), k ∈
, from which we deduce, when k = 2, that
| (17) |
and, when k = 3, 4 ···, that
| (18) |
Eqns. (17) and (18) are clearly equivalent when lk(s) ≠ 0. When lk(s) = 0, we deduce from eqn. (16) that
(s) = 0 and mk(t) = 0, k = 3, 4 ···. Thus, in either case, we conclude that
= {processes with characteristics (p̂, Ĝ) : m̂k(t) = mk(t), t ≥ 0, k =1, 2}, which completes the proof.
3. Application to model identifiability
Results obtained in Section 2 are applicable to study identifiability of branching processes when specific parametric assumptions are made about the lifespan distributions. To shorten the discussion, we only consider the case where J = 2.
3.1. Exponentially distributed lifespan
We assume here that τ is conditionally exponentially distributed, given {ξ = j}: Gj(t) = 1 − e−ψjt, t ≥ 0, for some
, j ∈
(p). The resulting class of processes is denoted by
 . We remark that
(s) = ψj/(ψj + s), j ∈
(p). It is defined for s ∈ (−ψj, ∞), and extendable to s ∈ (−∞, −ψj) ∪ (−ψj, ∞) by analytic continuation.
. We remark that
(s) = ψj/(ψj + s), j ∈
(p). It is defined for s ∈ (−ψj, ∞), and extendable to s ∈ (−∞, −ψj) ∪ (−ψj, ∞) by analytic continuation.
For every admissible (p, G), let
denote the class of all processes included in
that are equivalent to the process with characteristics (p, G). We say that the characteristics (p, G) are identified by {Z(t), t ≥ 0} if and only if
includes only the process with characteristics (p, G). To establish identifiability of (p, G), or lack thereof, it suffices to construct the class
. Let (p̂ Ĝ) denote the characteristics of any process in
. Then Ĝj, j ∈
(p̂), is exponential.
Assume first that p1 = 0. If p̂1 = 0, Lemma 1 implies that (p̂, Ĝ) = (p, G). If p̂1 ∈ (0, 1), we know from Theorem 2 and eqn. (8) that for every j ∈
(p)\{1},
Rearranging the terms in the above identity leads to the polynomial equation
| (19) |
This identity holds if and only if ψ̂j = ψ̂1 = ψj/(1 − p̂1). Hence, for any j1, j2 ∈
(p), ψj1 = ψj2, and the process with the characteristics (p, G) must be Bellman-Harris. Write ψ := ψj, j ∈
(p), and we have ψ̂j = ψ/(1 − p̂1). Using the first equation in (8), we deduce that p̂j = pj(1 − p̂1), p̂1 ∈ (0, 1).
Assume next that p1 ∈ (0, 1). If p̂1 = 0, a similar line of arguments shows that the process with characteristics (p̂, Ĝ) satisfying ψ̂j = ψ(1 − p1), p̂j = pj/(1 − p1), j ∈
(p){1}, belongs to
if ψj = ψ, j ∈
(p)
Now assume that p1 ∈ (0, 1) and p̂1 ∈ (0, 1). Then, for every j ∈
(p), we have
Rearranging the terms in the above identity leads to the polynomial equation
| (20) |
Solving this equation together with the first equation in (8) for each j ∈
(p)\{1} separately leads to three admissible sets of equations, denoted by Aj, Bj and Cj (indexed by j):
| (21) |
and
| (22) |
Assume first that p0p2 > 0. Then the collection of Markov processes that are equivalent to the process with characteristics (p, G) is determined by simultaneously solving the equations X0 and Y2, where X and Y stand symbolically for either A, B, or C. There are 9 such combinations:
For equations A0 and A2, it is easy to show that the only solution is (p̂, Ĝ) = (p, G). Thus, here, (p̂, Ĝ) identifies the process with characteristics (p, G).
Equations B0 and B2 admit solutions if and only if ψj = ψ, j ∈
(p); that is, the process with characteristics (p, G) must be Bellman-Harris. When this condition is met, the solutions to the two equations satisfy ψ̂j = ψ̂, j ∈
(p), where ψ̂ = ψ(1 − p1)/(1 − p̂1), p̂j = pj(1 − p̂1)/(1 − p1), and p̂1 ∈ (0, 1). Thus, any Markov Bellman-Harris process admits infinitely many equivalent processes in
, which are also (Markov) Bellman-Harris.Equations C0 and C2 admit solutions if and only if ψ0 = ψ2 and ψ0 ≤ ψ1. Under these constraints, the unique solution to the two sets of equations is: ψ̂1 = ψ1, ψ̂0 = ψ̂2 = (1 − p1)ψ1, p̂1 = 1 − ψ0/ψ1, and p̂j = pjψ0/{(1 − p1)ψ1}, j = 0, 2. This solution always differs from (p, G), except when p1 = 1 − ψ0/ψ1. Thus, processes that satisfy the conditions ψ0 = ψ2 and ψ0 ≤ ψ1 are identifiable only if p1 = 1 − ψ0/ψ1. Otherwise, there exists a unique (p̂, Ĝ) that differs from (p, G) under which the distribution of the process Z(t) does not change.
Any other pair of equations admits solutions only under specific restrictions on (p, G). For example, equations A0 and B2 will have a solution provided that ψ1 = ψ2. When the conditions are met, the only solution to the equations is (p̂, Ĝ) = (p, G), and, therefore, identifies the initial process.
When either p0 = 0 or p2 = 0, we obtain the same set of solutions as above (details are omitted). We summarize the above findings in the following Corollary:
Corollary 1
Suppose that J = 2 and, for every j ∈
(p), that Gj(t) = 1 − e−ψjt, t ≥ 0, for some
. Then, (p, G) is uniquely identified by the process {Z(t), t ≥ 0}, except in the following cases:
Case 1: If ψj = ψ, j ∈
(p) (Bellman-Harris case), then
includes the Markov processes with characteristics (p̂, Ĝ) ∈ {p̂1 ∈ [0, 1), p̂j = pj(1 − p̂1)/(1 − p1), j ∈
(p)\{1}, ψ̂j = ψ(1 − p1)/(1 − p̂1), j ∈
(p̂)}.Case 2: If ψj = ψ, j ∈
(p)\{1}, p1 ∈ (0, 1), ψ < ψ1, and p1 ≠ 1 − ψ/ψ1 (“extended” Bellman-Harris case), then
consists of the processes in
with characteristics (p, G) and (p̂, Ĝ) where p̂1 = 1 − ψ/ψ1, p̂j = pjψ/{(1 − p1)ψ1}, ψ̂1 = ψ1, ψ̂0 = ψ̂2 = (1 − p1)ψ1, j ∈
(p)\{1}.
Remark 1
Corollary 1 identifies two classes of processes in
that are not identifiable. The characteristics of the equivalent processes differ widely over
when (p, G) identifies a Bellman-Harris process. As an illustration, consider the Markov process with offspring distribution
and exponentially distributed lifespan with parameters ψ0 = ψ1 = ψ2 = 1. This process is of Bellman-Harris type. The class of processes in
equivalent to this process is determined by Case 1 of Corollary 1, and it includes the processes with offspring distributions
and exponentially distributed lifespan with parameters
, where p̂1 ∈ [0, 1). In particular, if p̂1 = 0, we obtain the process parameterized by
and ψ̂0 = ψ̂2 = 0.5, which belongs to
. Figure 1.A displays examples of probability density functions ĝ2 for a sample of processes that belong to the equivalence class. Figures 1.B–C show the set of probability density functions ĝ2 when the Bellman-Harris structure of the process is relaxed. For example, in Figure 1.B, we set ψ1 = 1.5 (all other parameter values are identical to those used in Figure 1.A), and find using Case 2 of Corollary 1 that the class of equivalent Markov processes includes a second process with offspring distribution
and exponentially distributed lifespan with parameters ψ̂1 = 1.5, and ψ̂0 = ψ̂2 = 0.75. In Figure 1.C, we set ψ1 = 0.5, while in Figure 1.D, we set ψ1 = 1 and ψ0 = 2. In these two cases, the class of equivalent processes includes only the original process, which is therefore identifiable.
Figure 1.

Representation of the set of probability density functions ĝ2 over the class of equivalent processes for four Markov processes: (A) ψ0 = ψ1 = ψ2 = 1 (Bellman-Harris process); (B) ψ0 = ψ2 = 1 and ψ1 = 1.5 (> ψ0 and > ψ2) (“extended” Bellman-Harris process); (C) ψ0 = ψ2 = 1 and ψ1 < 1 (“extended” Bellman-Harris process); (D) ψ0 ≠ ψ2, ψ1 > 0, ψ2 = 1. We set
in all cases. Each plot shows g2 and ĝ2 (whenever ∃ĝ2 ≠ g2) for: the process with characteristics (p, G) (solid line); representative processes of the equivalence class (dashed grey lines); equivalent Markov process in
(dashed black lines). The model is non-identifiable in cases (A) and (B), and identifiable in cases (C) and (D).
Remark 2
From a statistical standpoint, when Z(t) is observed at discrete time points, the likelihood function can be solely expressed using the marginal distribution of {Z(t), t ≥ 0}, and the model parameters are therefore not always identifiable. The maximum likelihood estimator is not consistent, at least in the traditional sense [6]. If modeling quiescence is not of primary interest this non-identifiability issue may be avoided by imposing p̂1 = p1 = 0. Under such a restriction, the interpretation of Gj, j ∈
(p), may change because the time to producing j offspring could now include a resting phase latently embedded in the lifespan.
3.2. Gamma distributed lifespan
We now extend the Markov process by assuming that the lifespan is gamma distributed:
for some
, j ∈
(p). We have
, defined for s ∈ (−κj, ∞), but also extendable to s ∈ (−∞, −κj) ∪ (−κj, ∞) by analytic continuation. The assumption of gamma distributed lifespan is frequently made in practice [3, 9]. We obtain the Markov process of the previous section if ωj = 1, j ∈
(p). We show, when ωj ≠ 1, that it is identifiable:
Corollary 2
Suppose that J = 2 and, for every j ∈
(p), that Gj is a gamma distribution with parameters κj > 0, ωj > 0 and ωj ≠ 1. Then, (p, G) is uniquely identified by the process {Z(t), t ≥ 0}.
Proof
Let (p̂, Ĝ) denote the characteristics of any process included in
. Assume first that p1 = 0. If p̂1 = 0, Lemma 1 implies that (p̂, Ĝ) = (p, G). If p̂1 ∈ (0, 1), eqn. (7) gives
Rearranging the terms in the above identity leads to the equation
| (23) |
Dividing both sides of eqn. (23) by (κ̂1 + s)ω̂1 (κj + s)ωj and letting s → ∞ yields
In order for the R.H.S. to converge to a constant, we must have ω̂j = ωj, which implies that . Then, eqn. (23) reduces to . Setting s = −κ̂1 gives , from which we deduce that κ̂j = κ̂1, and eqn. (23) reduces further to . Letting s → −κ̂1, the L.H.S. converges to (κj − κ̂1)ωj whereas the R.H.S. diverges to −∞. Hence, eqn. (23) has no admissible solutions.
Assume next that p1 ∈ (0, 1). If p̂1 = 0, a similar line of arguments shows that there are no admissible solutions. If p̂1 ∈ (0, 1), eqn. (7) gives
Rearranging the terms in the above identity leads to the equation
| (24) |
Divide both sides of eqn. (24) by (κ1 +s)ω1 (κ̂1 +s)ω̂1 (κ̂j +s)ω̂j and let s → ∞. Then
| (25) |
In order for the R.H.S. to converge to a constant, we must have ωj = ω̂j, which implies that . Then, eqn. (24) reduces to
| (26) |
Setting s = −κ1 gives , from which we deduce that either κ̂1 = κ1 or κj = κ1. We study these two cases separately.
-
Case 1: κ̂1 = κ1. Assume first that ω1 > ω̂1. Eqn. (26) becomes
(27) Setting s = −κ1 gives . Hence, we must have κ1 = κj, and eqn. (27) becomes(28) We distinguish two sets of solutions:
If κ̂j = κ1, eqn. (28) reduces to . Setting s = −κ1 yields , which is not admissible here because p1κ1 > 0.
-
If κ̂j ≠ κ1, dividing both sides of eqn. (28) by (κ1 + s)ωj and letting s → −κ1 entails that ωj = ω1 − ω̂1 > 0, and eqn. (28) reduces to . Differentiating both sides of the equation with respect to s gives
Letting s → −κ̂j, the L.H.S. of the equation converges to 0 if ωj > 1 and diverges to −∞ if 0 < ωj < 1, whereas the R.H.S. converges to ω1(κ1 − κ̂j)ω1−1 ∈ (0, ∞). Hence, eqn. (26) has no admissible solutions in this case either. By using a similar line of arguments, one can show that eqn. (26) has no admissible solutions either when ω1 < ω̂1.
When ω̂1 = ω1, eqn. (26) reduces to(29) If κ̂j ≠ κj, setting s = −κ̂j gives and setting s = −κj gives . This implies that κ1 ≠ κ̂j and κ1 ≠ κj. Taking the derivative with respect to s on both sides of eqn. (29) yields(30) As s → −κ̂j, the L.H.S. of eqn. (30) converges to 0 if ωj > 1 and diverges to −∞ if 0 < ωj < 1, whereas the R.H.S. converges to ω1(κj − κ̂j)ωj (κ1 − κ̂j)ω1−1 ∈ (0, ∞). Hence, eqn. (29) has no admissible solutions.
If κ̂j = κj, then (κ̂i, ω̂i) = (κi, ωi), i = 1, j. We also deduce from eqn. (29) that p̂1 = p1. Hence p̂j = pj using eqn. (19).
-
Case 2: κ̂1 ≠ κ1 and κj = κ1. Eqn. (26) reduces to
(31) Setting s = −κ̂1 gives . Because κ̂1 ≠ κ1, we must have κ̂1 = κ̂j, and eqn. (31) reduces to(32) We consider the following cases separately:
If ω1 > ωj, setting s = −κ1 yields , which has no admissible solutions.
If ω̂1 > ωj, setting s = −κ̂1 yields , which has no admissible solutions.
-
If ωj > ω1 and ωj > ω̂1, eqn. (32) can be rewritten as
(33) Setting s = −κ̂1 yields , and setting s = −κ1 yields . Differentiating eqn. (33) w.r.t. s givesLetting s → −κ̂1, the L.H.S. of the equation either converges to 0 (if ωj − ω̂1 > 1) or diverges to −∞ (if ωj − ω̂1 < 1), whereas the R.H.S. converges to ω1(κ1 − κ̂1)ωj−1 ∈ (0, ∞). Hence, eqn. (33) has no admissible solutions.
-
If ωj = ω1 and ωj > ω̂1, eqn. (32) can be rewritten as
(34) Taking the derivative with respect to s on both sides of eqn. (34) givesLetting s → −κ̂1, the L.H.S. of the equation either converges to 0 (if ωj − ω̂1 > 1) or diverges to −∞ (if ωj − ω̂1 < 1), whereas the R.H.S. converges to ω1(κ1 − κ̂1)ωj−1 ∈ (0, ∞). Hence, eqn. (34) has no admissible solutions. The case ωj > ω1 and ωj = ω̂1 is handled similarly, and has no solutions either.
If ωj = ω1 and ωj = ω̂1, eqn. (32) reduces to , which has no admissible solutions because κ̂1 ≠ κ1.
3.3. A Smith-Martin process
We consider a generalization of the Smith-Martin (S.M.) model originally proposed in [8]. The process assumes that, conditional on ξ = j, j ∈
(p), the lifespan takes the form τ = τAj + δj, where τAj follows an exponential distribution with parameter ψj, and where δj is a non-negative constant. In the original formulation of the model, τA2 represents essentially the duration spent by the cell in the G0/G1 phases, and δ2 is the time spent by the cell in the S, G2, M (and part of G1) phases. Here,
(s) = e−δjsψj/(ψj + s), where it can be extended to s ∈ ℝ\{−ψj} by analytic continuation. This process is identical to the process of Section 3.1 if δj = 0, j ∈
(p). Let
 denote the family of S.M. processes. Write
for the class of S.M. processes equivalent to the process with characteristics (p, G). This process is not always identifiable:
denote the family of S.M. processes. Write
for the class of S.M. processes equivalent to the process with characteristics (p, G). This process is not always identifiable:
Corollary 3
Suppose that J = 2 and, for every j ∈
(p), that Gj(t) = 1−e−ψj(t−δj) (t ≥ δj). Then, (p, G) is uniquely identified by {Z(t), t ≥ 0} except:
Case 1: If ψj = ψ, j ∈
(p), and δ1 = 0 when p1 = 0 (Bellman-Harris case),
includes the S.M. processes with characteristics (p̂, Ĝ) ∈ {p̂1 ∈ (0, 1), p̂j = pj(1−p̂1)/(1−p1), δ̂1 = 0, δ̂j = δj, ψ̂1 = ψ̂j = ψ(1−p1)/(1−p̂1), j ∈
(p)\{1}} ∪ {p̂1 = 0, p̂j = pj/(1 − p1), δ̂j = δj, ψ̂j = ψ(1 − p1), j ∈
(p)\{1}}.Case 2. If p1 ∈ (0, 1), p1 ≠ 1 − ψ/ψ1, δ1 = 0, ψj = ψ, j ∈
(p)\{1}, and ψ < ψ1 (“extended” Bellman-Harris case),
consists of the S.M. processes with characteristics (p, G) and (p̂, Ĝ) where p̂1 = 1−ψ/ψ1, p̂j = pjψ/{(1−p1)ψ1}, δ̂1 = 0, δ̂j = δj, ψ̂1 = ψ1, ψ̂j = (1 − p1)ψ1, j ∈ {0, 2}.
Proof
Let (p̂, Ĝ) denote the characteristics of any process in
. Assume first that p1 = 0. If p̂1 = 0, Lemma 1 yields (p̂, Ĝ) = (p, G). If p̂1 ∈ (0, 1), eqn. (8) gives
| (35) |
Taking the logarithm of both sides of the equation, we obtain
Dividing both sides of the equation by s and letting s → ∞ entails that δ̂j = δj, and eqn. (35) reduces to (1−p̂1)ψ̂j(ψj+s)(ψ̂1+s)−ψj(ψ̂j+s)(ψ̂1+s) = ψj(ψ̂j+s)p̂1ψ̂1e−δ̂1s. Taking again the logarithm of both sides of the equation, dividing by s, and letting s → ∞ yields δ̂1 = 0. Hence, eqn. (35) leads to eqn. (19), from which we deduce that ψ̂1 = ψ̂j = ψ/(1 − p̂1), where ψ: = ψj, j ∈
(p), and p̂j = pj(1 − p̂1), p̂1 ∈ (0, 1). This proves part of Case 1 of Corollary 3.
Assume next that p1 ∈ (0, 1). If p̂1 = 0, the same line of arguments applies, and, by symmetry, we find that the process with characteristics (p̂, Ĝ) satisfying δ̂j = δj, ψ̂j = ψ(1 − p1), and p̂j = pj/(1 − p1), j ∈
(p)\{1}, belongs to
if ψj = ψ, j ∈
(p), and δ1 = 0. This proves also part of Case 1.
Assume now that p1 ∈ (0, 1) and p̂1 ∈ (0, 1). Then, for every j ∈
(p)\{1}, eqn. (7) gives
| (36) |
Taking the logarithm, dividing both sides of eqn. (36) by s, and letting s → ∞ implies that δ̂j = δj, and eqn. (36) reduces to
Multiplying both sides by s and letting s → ∞, we obtain that (1 − p̂1)ψ̂j = (1 − p1)ψj. Then eqn. (36) becomes
| (37) |
We distinguish four sets of solutions:
If δ1 > 0 and δ̂1 > 0, dividing both sides of eqn. (37) by s2 and letting s → ∞ yields ψ̂j = ψj. Then, eqn. (37) reduces to p1ψ1e−δ1s (ψ̂1+s) = p̂1ψ̂1e−δ̂1s (ψ1+s), from which we deduce that δ̂1 = δ1, p̂1 = p1, and ψ̂1 = ψ1. Hence, (p̂, Ĝ) = (p, G).
If δ1 > 0 and δ̂1 = 0, rearranging the terms of eqn. (37) leads to (ψ1 + s){(ψj − ψ̂j)(ψ̂1 + s) + p̂1ψ̂1(ψ̂j + s)} = p1ψ1e−δ1s(ψj + s)(ψ̂1 + s). Letting s → ∞, the L.H.S of the equation diverges to infinity, whereas the R.H.S. converges to zero. Hence, eqn. (37) has no admissible solutions.
If δ1 = 0 and δ̂1 > 0, a similar line of arguments shows that eqn. (37) has no admissible solutions.
If δ1 = 0 and δ̂1 = 0, eqn. (37) is equivalent to eqn. (20). The values of p̂ and ψ̂j, j ∈
(p̂) that solves the equation are given in Corollary 1, and leads to part of Case 1 and to Case 2.
Acknowledgments
This research was supported by NIH R01 grants NS039511, CA134839, and AI069351 to OH.
Contributor Information
RUI CHEN, University of Rochester.
OLLIVIER HYRIEN, University of Rochester.
References
- 1.Gyllenberg M, Webb GF. A nonlinear structured population model of tumor growth with quiescence. Journal of Mathematical Biology. 1990;28:671–694. doi: 10.1007/BF00160231. [DOI] [PubMed] [Google Scholar]
- 2.Haccou P, Jagers P, Vatutin VA. Branching Processes: Variation, Growth, and Extinction of Populations. Cambridge University Press; 2005. [Google Scholar]
- 3.Hyrien O, Mayer-Pröschel M, Noble M, Yakovlev A. A stochastic model to analyze clonal data on multi type cell populations. Biometrics. 2005;61:199–207. doi: 10.1111/j.0006-341X.2005.031210.x. [DOI] [PubMed] [Google Scholar]
- 4.Jagers P. Branching Processes with Biological Applications. John Wiley and Sons; London: 1975. [Google Scholar]
- 5.Kimmel M, Axelrod DE. Branching Processes in Biology. Springer; New York: 2002. [Google Scholar]
- 6.Redner R. Note on the consistency of the maximum likelihood estimate for nonidentifiable distributions. Annals of Statistics. 1981;9:225–228. [Google Scholar]
- 7.Sevastyanov BA. Branching Processes. Nauka; Moscow: 1971. in Russian. [Google Scholar]
- 8.Smith JA, Martin L. Do cells cycle? Proceedings of the National Academy of Science. 1973;70:1263–1267. doi: 10.1073/pnas.70.4.1263. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Yakovlev AY, Yanev NM. Transient Processes in Cell Proliferation Kinetics. Springer-Verlag; Heidelberg: 1989. [Google Scholar]