

Abstract
We propose a new method named calibrated multivariate regression (CMR) for fitting high dimensional multivariate regression models. Compared to existing methods, CMR calibrates the regularization for each regression task with respect to its noise level so that it is simultaneously tuning insensitive and achieves an improved finite-sample performance. Computationally, we develop an efficient smoothed proximal gradient algorithm which has a worst-case iteration complexity O(1/ε), where ε is a pre-specified numerical accuracy. Theoretically, we prove that CMR achieves the optimal rate of convergence in parameter estimation. We illustrate the usefulness of CMR by thorough numerical simulations and show that CMR consistently outperforms other high dimensional multivariate regression methods. We also apply CMR on a brain activity prediction problem and find that CMR is as competitive as the handcrafted model created by human experts.
1 Introduction
Given a design matrix X ∈ ℝn×d and a response matrix Y ∈ ℝn×m, we consider a multivariate linear model Y = XB0 + Z, where B0 ∈ ℝd×m is an unknown regression coefficient matrix and Z ∈ ℝn×m is a noise matrix [1]. For a matrix A = [Ajk] ∈ ℝd×m, we denote Aj* = (Aj1, …, Ajm) ∈ ℝm and A*k = (A1k, …, Adk)T ∈ ℝd to be its jth row and kth column respectively. We assume that all Zi*’s are independently sampled from an m-dimensional Gaussian distribution with mean 0 and covariance matrix Σ ∈ ℝm×m.
We can represent the multivariate linear model as an ensemble of univariate linear regression models: , k = 1, …, m. Then we get a multi-task learning problem [3, 2, 26]. Multi-task learning exploits shared common structure across tasks to obtain improved estimation performance. In the past decade, significant progress has been made towards designing a variety of modeling assumptions for multivariate regression.
A popular assumption is that all the regression tasks share a common sparsity pattern, i.e., many ’s are zero vectors. Such a joint sparsity assumption is a natural extension of that for univariate linear regressions. Similar to the L1-regularization used in Lasso [23], we can adopt group regularization to obtain a good estimator of B0 [25, 24, 19, 13]. Besides the aforementioned approaches, there are other methods that aim to exploit the covariance structure of the noise matrix Z [7, 22]. For instance, [22] assume that all Zi*’s follow a multivariate Gaussian distribution with a sparse inverse covariance matrix Ω = Σ−1. They propose an iterative algorithm to estimate sparse B0 and Ω by maximizing the penalized Gaussian log-likelihood. Such an iterative procedure is effective in many applications, but the theoretical analysis is difficult due to its nonconvex formulation.
In this paper, we assume an uncorrelated structure for the noise matrix Z, i.e., . Under this setting, we can efficiently solve the resulting estimation problem with a convex program as follows
| (1.1) |
where λ > 0 is a tuning parameter, and is the Frobenius norm of a matrix A. Popular choices of p include p = 2 and and . Computationally, the optimization problem in (1.1) can be efficiently solved by some first order algorithms [11, 12, 4].
The problem with the uncorrelated noise structure is amenable to statistical analysis. Under suitable conditions on the noise and design matrices, let σmax = maxk σk, if we choose , for some c > 1, then the estimator B̂ in (1.1) achieves the optimal rates of convergence1 [13], i.e., there exists some universal constant C such that with high probability, we have
where s is the number of rows with non-zero entries in B0. However, the estimator in (1.1) has two drawbacks: (1) All the tasks are regularized by the same tuning parameter λ, even though different tasks may have different σk’s. Thus more estimation bias is introduced to the tasks with smaller σk’s to compensate the tasks with larger σk’s. In another word, these tasks are not calibrated. (2) The tuning parameter selection involves the unknown parameter σmax. This requires tuning the regularization parameter over a wide range of potential values to get a good finite-sample performance.
To overcome the above two drawbacks, we formulate a new convex program named calibrated multivariate regression (CMR). The CMR estimator is defined to be the solution of the following convex program:
| (1.2) |
where is the nonsmooth L2,1 norm of a matrix A = [Ajk] ∈ ℝd×m. This is a multivariate extension of the square-root Lasso [5]. Similar to the square-root Lasso, the tuning parameter selection of CMR does not involve σmax. Moreover, the L2,1 loss function can be viewed as a special example of the weighted least square loss, which calibrates each regression task (See more details in §2). Thus CMR adapts to different σk’s and achieves better finite-sample performance than the ordinary multivariate regression estimator (OMR) defined in (1.1).
Since both the loss and penalty functions in (1.2) are nonsmooth, CMR is computationally more challenging than OMR. To efficiently solve CMR, we propose a smoothed proximal gradient (SPG) algorithm with an iteration complexity O(1/ε), where ε is the pre-specified accuracy of the objective value [18, 4]. Theoretically, we provide sufficient conditions under which CMR achieves the optimal rates of convergence in parameter estimation. Numerical experiments on both synthetic and real data show that CMR universally outperforms existing multivariate regression methods. For a brain activity prediction task, prediction based on the features selected by CMR significantly outperforms that based on the features selected by OMR, and is even competitive with that based on the handcrafted features selected by human experts.
Notations
Given a vector v = (v1, …, vd)T ∈ ℝd, for 1 ≤ p ≤ ∞, we define the Lp-vector norm of v as
if 1 ≤ p < ∞ and ||v||p = max1≤j≤d |vj| if p = ∞. Given two matrices A = [Ajk] and C = [Cjk] ∈ ℝd×m, we define the inner product of A and C as
, where tr(A) is the trace of a matrix A. We use A*k = (A1k, …,
Adk)T and Aj* = (Aj1, …,
Ajm) to denote the kth column and jth row of A. Let
 be some subspace of ℝd×m, we use
be some subspace of ℝd×m, we use
 to denote the projection of A onto
:
. Moreover, we define the Frobenius and spectral norms of A as
and ||A||2 = ψ1(A), ψ1(A) is the largest singular value of A. In addition, we define the matrix block norms as
, ||A||2,∞ = max1≤k≤m ||A*k||2,
, and ||A||∞,q = max1≤j≤d ||Aj*||q, where 1 ≤ p ≤ ∞ and 1 ≤ q ≤ ∞. It is easy to verify that ||A||2,1 is the dual norm of ||A||2,∞. Let 1/∞ = 0, then if 1/p + 1/q = 1, ||A||∞,q and ||A||1,p are also dual norms of each other.
to denote the projection of A onto
:
. Moreover, we define the Frobenius and spectral norms of A as
and ||A||2 = ψ1(A), ψ1(A) is the largest singular value of A. In addition, we define the matrix block norms as
, ||A||2,∞ = max1≤k≤m ||A*k||2,
, and ||A||∞,q = max1≤j≤d ||Aj*||q, where 1 ≤ p ≤ ∞ and 1 ≤ q ≤ ∞. It is easy to verify that ||A||2,1 is the dual norm of ||A||2,∞. Let 1/∞ = 0, then if 1/p + 1/q = 1, ||A||∞,q and ||A||1,p are also dual norms of each other.
2 Method
We solve the multivariate regression problem by the following convex program,
| (2.1) |
The only difference between (2.1) and (1.1) is that we replace the L2-loss function by the nonsmooth L2,1-loss function. The L2,1-loss function can be viewed as a special example of the weighted square loss function. More specifically, we consider the following optimization problem,
| (2.2) |
where is a weight assigned to calibrate the kth regression task. Without prior knowledge on σk’s, we use the following replacement of σk’s,
| (2.3) |
By plugging (2.3) into the objective function in (2.2), we get (2.1). In another word, CMR calibrates different tasks by solving a penalized weighted least square program with weights defined in (2.3).
The optimization problem in (2.1) can be solved by the alternating direction method of multipliers (ADMM) with a global convergence guarantee [20]. However, ADMM does not take full advantage of the problem structure in (2.1). For example, even though the L2,1 norm is nonsmooth, it is nondifferentiable only when a task achieves exact zero residual, which is unlikely in applications. In this paper, we apply the dual smoothing technique proposed by [18] to obtain a smooth surrogate function so that we can avoid directly evaluating the subgradient of the L2,1 loss function. Thus we gain computational efficiency like other smooth loss functions.
We consider the Fenchel’s dual representation of the L2,1 loss:
| (2.4) |
Let μ > 0 be a smoothing parameter. The smooth approximation of the L2,1 loss can be obtained by solving the following optimization problem
| (2.5) |
where is the proximity function. Due to the fact that , we obtain the following uniform bound by combing (2.4) and (2.5),
| (2.6) |
From (2.6), we see that the approximation error introduced by the smoothing procedure can be controlled by a suitable μ. Figure 2.1 shows several two-dimensional examples of the L2 norm smoothed by different μ’s. The optimization problem in (2.5) has a closed form solution ÛB with .
Figure 2.1.
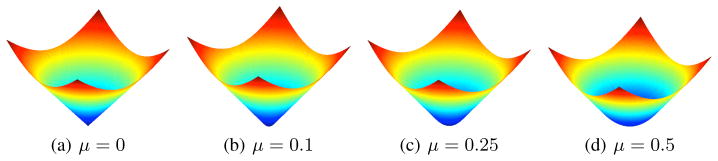
The L2 norm (μ = 0) and its smooth surrogates with μ = 0.1, 0.25, 0.5. A larger μ makes the approximation more smooth, but introduces a larger approximation error.
The next lemma shows that ||Y − XB||μ is smooth in B with a simple form of gradient.
Lemma 2.1
For any μ > 0, ||Y − XB||μ is a convex and continuously differentiable function in B. In addition, Gμ(B)—the gradient of ||Y − XB||μ w.r.t. B—has the form
| (2.7) |
Moreover, let , then we have that Gμ(B) is Lipschitz continuous in B with the Lipschitz constant γ/μ, i.e., for any B′, B″ ∈ ℝd×m,
Lemma 2.1 is a direct result of Theorem 1 in [18] and implies that ||Y − XB||μ has good computational structure. Therefore we apply the smooth proximal gradient algorithm to solve the smoothed version of the optimization problem as follows,
| (2.8) |
We then adopt the fast proximal gradient algorithm to solve (2.8) [4]. To derive the algorithm, we first define three sequences of auxiliary variables {A(t)}, {V(t)}, and {H(t)} with A(0) = H(0) = V(0) = B(0), a sequence of weights {θt = 2/(t + 1)}, and a nonincreasing sequence of step-sizes {ηt > 0}. For simplicity, we can set ηt = μ/γ. In practice, we use the backtracking line search to dynamically adjust ηt to boost the performance. At the tth iteration, we first take V(t) = (1 − θt)B(t−1) + θtA(t−1). We then consider a quadratic approximation of ||Y − XH||μ as
Consequently, let H̃(t) = V(t) − ηtGμ(V(t)), we take
| (2.9) |
When p = 2, (2.9) has a closed form solution . More details about other choices of p in the L1,p norm can be found in [11] and [12]. To ensure that the objective value is nonincreasing, we choose
| (2.10) |
At last, we take . The algorithm stops when ||H(t)−V(t)||F ≤ ε, where ε is the stopping precision.
The numerical rate of convergence of the proposed algorithm with respect to the original optimization problem (2.1) is presented in the following theorem.
Theorem 2.2
Given a pre-specified accuracy ε and let μ = ε/m, after iterations, we have ||Y − XB(t)||2,1 + λ||B(t)||1,p ≤ ||Y − XB̂||2,1 + λ||B̂||1,p + ε.
The proof of Theorem 2.2 is provided in Appendix A.1. This result achieves the minimax optimal rate of convergence over all first order algorithms [18].
3 Statistical Properties
For notational simplicity, we define a re-scaled noise matrix W = [Wik] ∈ ℝn×m with Wik = Zik/σk, where . Thus W is a random matrix with all entries having mean 0 and variance 1. We define G0 to be the gradient of ||Y − XB||2,1 at B = B0. It is easy to see that
does not depend on the unknown quantities σk for all k = 1, …, m. works as an important pivotal in our analysis. Moreover, our analysis exploits the decomposability of the L1,p norm [17]. More specifically, we assume that B0 has s rows with all zero entries and define
| (3.1) |
| (3.2) |
Note that we have B0 ∈
and the L1,p norm is decomposable with respect to the pair (
,
 ), i.e.,
), i.e.,
The next lemma shows that when λ is suitably chosen, the solution to the optimization problem in (2.1) lies in a restricted set.
Lemma 3.1
Let
B0 ∈
and
B̂
be the optimum to (2.1), and 1/p + 1/q = 1. We denote the estimation error as
Δ̂ = B̂ − B0. If λ ≥ c||G0||∞,q for some c > 1, we have
| (3.3) |
The proof of Lemma 3.1 is provided in Appendix B.1. To prove the main result, we also need to assume that the design matrix X satisfies the following condition.
Assumption 3.1
Let
B0 ∈
, then there exist positive constants κ and c > 1 such that
Assumption 3.1 is the generalization of the restricted eigenvalue conditions for analyzing univariate sparse linear models [17, 15, 6], Many common examples of random design satisfy this assumption [13, 21].
Note that Lemma 3.1 is a deterministic result of the CMR estimator for a fixed λ. Since G is essentially a random matrix, we need to show that λ ≥ cR*(G0) holds with high probability to deliver a concrete rate of convergence for the CMR estimator in the next theorem.
Theorem 3.2
We assume that each column of X is normalized as for all j = 1, …, d. Then for some universal constant c0 and large enough n, taking
| (3.4) |
with probability at least , we have
The proof of Theorem 3.2 is provided in Appendix B.2. Note that when we choose p = 2, the column normalization condition is reduced to . Meanwhile, the corresponding error bound is further reduced to
which achieves the minimax optimal rate of convergence presented in [13]. See Theorem 6.1 in [13] for more technical details. From Theorem 3.2, we see that CMR achieves the same rates of convergence as the noncalibrated counterpart, but the tuning parameter λ in (3.4) does not involve σk’s. Therefore CMR not only calibrates all the regression tasks, but also makes the tuning parameter selection insensitive to σmax.
4 Numerical Simulations
To compare the finite-sample performance between the calibrated multivariate regression (CMR) and ordinary multivariate regression (OMR), we generate a training dataset of 200 samples. More specifically, we use the following data generation scheme: (1) Generate each row of the design matrix Xi*, i = 1, …, 200, independently from a 800-dimensional normal distribution N(0, Σ) where Σjj = 1 and Σjℓ = 0.5 for all ℓ ≠ j.(2) Let k = 1, …, 13, set the regression coefficient matrix B0 ∈ ℝ800×13 as , and for all j ≠ 1, 2, 4. (3) Generate the random noise matrix Z = WD, where W ∈ ℝ200×13 with all entries of W are independently generated from N(0, 1), and D is either of the following matrices
We generate a validation set of 200 samples for the regularization parameter selection and a testing set of 10,000 samples to evaluate the prediction accuracy.
In numerical experiments, we set σmax = 1, 2, and 4 to illustrate the tuning insensitivity of CMR. The regularization parameter λ of both CMR and OMR is chosen over a grid Λ = {240/4 λ0, 239/4 λ0, ···, 2−17/4 λ0, 2−18/4 λ0}, where . The optimal regularization parameter λ̂ is determined by the prediction error as , where B̂λ denotes the obtained estimate using the regularization parameter λ, and X̃ and Ỹ denote the design and response matrices of the validation set.
Since the noise level σk’s are different in regression tasks, we adopt the following three criteria to evaluate the empirical performance: , and , where X̄ and Ȳ denotes the design and response matrices of the testing set.
All simulations are implemented by MATLAB using a PC with Intel Core i5 3.3GHz CPU and 16GB memory. CMR is solved by the proposed smoothing proximal gradient algorithm, where we set the stopping precision ε = 10−4, the smoothing parameter μ = 10−4. OMR is solved by the monotone fast proximal gradient algorithm, where we set the stopping precision ε = 10−4. We set p = 2, but the extension to arbitrary p > 2 is straightforward.
We first compare the smoothed proximal gradient (SPG) algorithm with the ADMM algorithm (the detailed derivation of ADMM can be found in Appendix A.2). We adopt the backtracking line search to accelerate both algorithms with a shrinkage parameter α = 0.8. We set σmax = 2 for the adopted multivariate linear models. We conduct 200 simulations. The results are presented in Table 4.1. The SPG and ADMM algorithms attain similar objective values, but SPG is up to 4 times faster than ADMM. Both algorithms also achieve similar estimation errors.
Table 4.1.
Quantitive comparison of the computational performance between SPG and ADMM with the noise matrices generated using DI. The results are averaged over 200 replicates with standard errors in parentheses. SPG and ADMM attain similar objective values, but SPG is up to about 4 times faster than ADMM.
| λ | Algorithm | Timing (second) | Obj. Val. | Num. Ite. | Est. Err. |
|---|---|---|---|---|---|
| 2λ0 | SPG | 2.8789(0.3141) | 508.21(3.8498) | 493.26(52.268) | 0.1213(0.0286) |
| ADMM | 8.4731(0.8387) | 508.22(3.7059) | 437.7(37.4532) | 0.1215(0.0291) | |
|
| |||||
| λ0 | SPG | 3.2633(0.3200) | 370.53(3.6144) | 565.80(54.919) | 0.0819(0.0205) |
| ADMM | 11.976(1.460) | 370.53(3.4231) | 600.94(74.629) | 0.0822(0.0233) | |
|
| |||||
| 0.5λ0 | SPG | 3.7868(0.4551) | 297.24(3.6125) | 652.53(78.140) | 0.1399(0.0284) |
| ADMM | 18.360(1.9678) | 297.25(3.3863) | 1134.0(136.08) | 0.1409(0.0317) | |
We then compare the statistical performance between CMR and OMR. Tables 4.2 and 4.3 summarize the results averaged over 200 replicates. In addition, we also present the results of the oracle estimator, which is obtained by solving (2.2), since we know the true values of σk’s. Note that the oracle estimator is only for comparison purpose, and it is not a practical estimator. Since CMR calibrates the regularization for each task with respect to σk, CMR universally outperforms OMR, and achieves almost the same performance as the oracle estimator when we adopt the scale matrix DI to generate the random noise. Meanwhile, when we adopt the scale matrix DH, where all σk’s are the same, CMR and OMR achieve similar performance. This further implies that CMR can be a safe replacement of OMR for multivariate regressions.
Table 4.2.
Quantitive comparison of the statistical performance between CMR and OMR with the noise matrices generated using DI. The results are averaged over 200 simulations with the standard errors in parentheses. CMR universally outperforms OMR, and achieves almost the same performance as the oracle estimator.
| σmax | Method | Pre. Err. | Adj. Pre.Err | Est. Err. |
|---|---|---|---|---|
| 1 | Oracle | 5.8759(0.0834) | 1.0454(0.0149) | 0.0245(0.0086) |
| CMR | 5.8761(0.0673) | 1.0459(0.0123) | 0.0249(0.0071) | |
| OMR | 5.9012(0.0701) | 1.0581(0.0162) | 0.0290(0.0091) | |
|
| ||||
| 2 | Oracle | 23.464(0.3237) | 1.0441(0.0148) | 0.0926(0.0342) |
| CMR | 23.465(0.2598) | 1.0446(0.0121) | 0.0928(0.0279) | |
| OMR | 23.580(0.2832) | 1.0573(0.0170) | 0.1115(0.0365) | |
|
| ||||
| 4 | Oracle | 93.532(0.8843) | 1.0418(0.0962) | 0.3342(0.1255) |
| CMR | 93.542(0.9794) | 1.0421(0.0118) | 0.3346(0.1063) | |
| OMR | 94.094(1.0978) | 1.0550(0.0166) | 0.4125(0.1417) | |
Table 4.3.
Quantitive comparison of the statistical performance between CMR and OMR with the noise matrices generated using DH. The results are averaged over 200 simulations with the standard errors in parentheses. CMR and OMR achieve similar performance.
| σmax | Method | Pre. Err. | Adj. Pre.Err | Est. Err. |
|---|---|---|---|---|
| 1 | CMR | 13.565(0.1408) | 1.0435(0.0108) | 0.0599(0.0164) |
| OMR | 13.697(0.1554) | 1.0486(0.0142) | 0.0607(0.0128) | |
|
| ||||
| 2 | CMR | 54.171(0.5771) | 1.0418(0.0110) | 0.2252(0.0649) |
| OMR | 54.221(0.6173) | 1.0427(0.0118) | 0.2359(0.0821) | |
|
| ||||
| 4 | CMR | 215.98(2.104) | 1.0384(0.0101) | 0.80821(0.25078) |
| OMR | 216.19(2.391) | 1.0394(0.0114) | 0.81957(0.31806) | |
In addition, we also examine the optimal regularization parameters for CMR and OMR over all replicates. We visualize the distribution of all 200 selected λ̂’s using the kernel density estimator. In particular, we adopt the Gaussian kernel, and the kernel bandwidth is selected based on the 10-fold cross validation. Figure 4.1 illustrates the estimated density functions. The horizontal axis corresponds to the rescaled regularization parameter as . We see that the optimal regularization parameters of OMR significantly vary with different σmax. In contrast, the optimal regularization parameters of CMR are more concentrated. This is inconsistent with our claimed tuning insensitivity.
Figure 4.1.
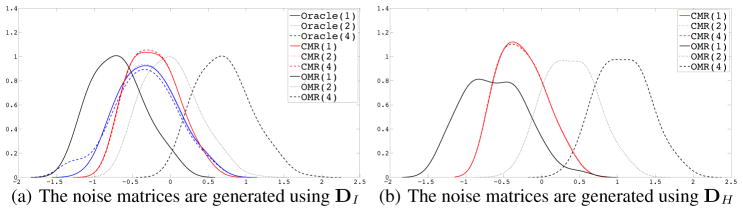
The distributions of the selected regularization parameters using the kernel density estimator. The numbers in the parentheses are σmax’s. The optimal regularization parameters of OMR are spreader with different σmax than those of CMR and the oracle estimator.
5 Real Data Experiment
We apply CMR on a brain activity prediction problem which aims to build a parsimonious model to predict a person’s neural activity when seeing a stimulus word. As is illustrated in Figure 5.1, for a given stimulus word, we first encode it into an intermediate semantic feature vector using some corpus statistics. We then model the brain’s neural activity pattern using CMR. Creating such a predictive model not only enables us to explore new analytical tools for the fMRI data, but also helps us to gain deeper understanding on how human brain represents knowledge [16].
Figure 5.1.
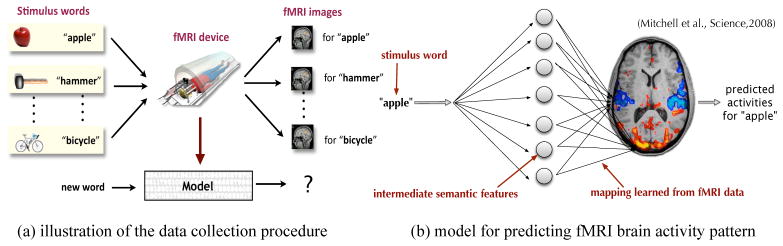
An illustration of the fMRI brain activity prediction problem [16]. (a) To collect the data, a human participant sees a sequence of English words and their images. The corresponding fMRI images are recorded to represent the brain activity patterns; (b) To build a predictive model, each stimulus word is encoded into intermediate semantic features (e.g. the co-occurrence statistics of this stimulus word in a large text corpus). These intermediate features can then be used to predict the brain activity pattern.
Our experiments involves 9 participants, and Table 5.1 summarizes the prediction performance of different methods on these participants. We see that the prediction based on the features selected by CMR significantly outperforms that based on the features selected by OMR, and is as competitive as that based on the handcrafted features selected by human experts. But due to the space limit, we present the details of the real data experiment in the technical report version.
Table 5.1.
Prediction accuracies of different methods (higher is better). CMR outperforms OMR for 8 out of 9 participants, and outperforms the handcrafted basis words for 6 out of 9 participants
| Method | P.1 | P.2 | P.3 | P.4 | P.5 | P.6 | P.7 | P.8 | P.9 |
|---|---|---|---|---|---|---|---|---|---|
| CMR | 0.840 | 0.794 | 0.861 | 0.651 | 0.823 | 0.722 | 0.738 | 0.720 | 0.780 |
| OMR | 0.803 | 0.789 | 0.801 | 0.602 | 0.766 | 0.623 | 0.726 | 0.749 | 0.765 |
| Handcraft | 0.822 | 0.776 | 0.773 | 0.727 | 0.782 | 0.865 | 0.734 | 0.685 | 0.819 |
6 Discussions
A related method is the square-root sparse multivariate regression [8]. They solve the convex program with the Frobenius loss function and L1,p regularization function
| (6.1) |
The Frobenius loss function in (6.1) makes the regularization parameter selection independent of σmax, but it does not calibrate different regression tasks. Note that we can rewrite (6.1) as
| (6.2) |
Since σ in (6.2) is not specific to any individual task, it cannot calibrate the regularization. Thus it is fundamentally different from CMR.
Footnotes
The authors are listed in alphabetical order. This work is partially supported by the grants NSF IIS1408910, NSF IIS1332109, NSF Grant DMS-1005539, NIH R01MH102339, NIH R01GM083084, and NIH R01HG06841.
The rate of convergence is optimal when p = 2, i.e., the regularization function is ||B||1,p
Contributor Information
Han Liu, Department of Operations Research and Financial Engineering, Princeton University.
Lie Wang, Department of Mathematics, Massachusetts Institute of Technology.
Tuo Zhao, Department of Computer Science, Johns Hopkins University.
References
- 1.Anderson TW. An introduction to multivariate statistical analysis. Wiley; New York: 1958. [Google Scholar]
- 2.Ando Rie Kubota, Zhang Tong. A framework for learning predictive structures from multiple tasks and unlabeled data. The Journal of Machine Learning Research. 2005;6(11):1817–1853. [Google Scholar]
- 3.Baxter J. A model of inductive bias learning. Journal of Artificial Intelligence Research. 2000;12:149–198. [Google Scholar]
- 4.Beck A, Teboulle M. Fast gradient-based algorithms for constrained total variation image denoising and deblurring problems. IEEE Transactions on Image Processing. 2009;18(11):2419–2434. doi: 10.1109/TIP.2009.2028250. [DOI] [PubMed] [Google Scholar]
- 5.Belloni A, Chernozhukov V, Wang L. Square-root lasso: pivotal recovery of sparse signals via conic programming. Biometrika. 2011;98(4):791–806. [Google Scholar]
- 6.Bickel Peter J, Ritov Yaacov, Tsybakov Alexandre B. Simultaneous analysis of lasso and dantzig selector. The Annals of Statistics. 2009;37(4):1705–1732. [Google Scholar]
- 7.Breiman L, Friedman JH. Predicting multivariate responses in multiple linear regression. Journal of the Royal Statistical Society: Series B. 2002;59(1):3–54. [Google Scholar]
- 8.Bunea Florentina, Lederer Johannes, She Yiyuan. The group square-root lasso: Theoretical properties and fast algorithms. IEEE Transactions on Information Theory. 2013;60:1313–1325. [Google Scholar]
- 9.Johnstone Iain M. Chi-square oracle inequalities. Lecture Notes-Monograph Series. 2001:399–418. [Google Scholar]
- 10.Ledoux Michel, Talagrand Michel. Probability in Banach Spaces: isoperimetry and processes. Springer; 2011. [Google Scholar]
- 11.Liu H, Palatucci M, Zhang J. Blockwise coordinate descent procedures for the multi-task lasso, with applications to neural semantic basis discovery. Proceedings of the 26th Annual International Conference on Machine Learning; ACM; 2009. pp. 649–656. [Google Scholar]
- 12.Liu J, Ye J. Technical report. Arizona State University; 2010. Efficient ℓ1/ℓq norm regularization. [Google Scholar]
- 13.Lounici K, Pontil M, Van De Geer S, Tsybakov AB. Oracle inequalities and optimal inference under group sparsity. The Annals of Statistics. 2011;39(4):2164–2204. [Google Scholar]
- 14.Meinshausen N, Bühlmann P. Stability selection. Journal of the Royal Statistical Society: Series B. 2010;72(4):417–473. [Google Scholar]
- 15.Meinshausen Nicolai, Yu Bin. Lasso-type recovery of sparse representations for high-dimensional data. The Annals of Statistics. 2009;37(1):246–270. [Google Scholar]
- 16.Mitchell TM, Shinkareva SV, Carlson A, Chang KM, Malave VL, Mason RA, Just MA. Predicting human brain activity associated with the meanings of nouns. Science. 2008;320(5880):1191–1195. doi: 10.1126/science.1152876. [DOI] [PubMed] [Google Scholar]
- 17.Negahban Sahand N, Ravikumar Pradeep, Wainwright Martin J, Yu Bin. A unified framework for high-dimensional analysis of m-estimators with decomposable regularizers. Statistical Science. 2012;27(4):538–557. [Google Scholar]
- 18.Nesterov Y. Smooth minimization of non-smooth functions. Mathematical Programming. 2005;103(1):127–152. [Google Scholar]
- 19.Obozinski G, Wainwright MJ, Jordan MI. Support union recovery in high-dimensional multivariate regression. The Annals of Statistics. 2011;39(1):1–47. [Google Scholar]
- 20.Ouyang Hua, He Niao, Tran Long, Gray Alexander. Stochastic alternating direction method of multipliers. Proceedings of the 30th International Conference on Machine Learning; 2013. pp. 80–88. [Google Scholar]
- 21.Raskutti Garvesh, Wainwright Martin J, Yu Bin. Restricted eigenvalue properties for correlated gaussian designs. The Journal of Machine Learning Research. 2010;11(8):2241–2259. [Google Scholar]
- 22.Rothman AJ, Levina E, Zhu J. Sparse multivariate regression with covariance estimation. Journal of Computational and Graphical Statistics. 2010;19(4):947–962. doi: 10.1198/jcgs.2010.09188. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Tibshirani R. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society, Series B. 1996;58(1):267–288. [Google Scholar]
- 24.Turlach BA, Venables WN, Wright SJ. Simultaneous variable selection. Technometrics. 2005;47(3):349–363. [Google Scholar]
- 25.Yuan M, Lin Y. Model selection and estimation in regression with grouped variables. Journal of the Royal Statistical Society: Series B. 2005;68(1):49–67. [Google Scholar]
- 26.Zhang Jian. PhD thesis. Carnegie Mellon University, Language Technologies Institute, School of Computer Science; 2006. A probabilistic framework for multi-task learning. [Google Scholar]