

Abstract
We evaluated the hypothesis that listeners can generate expectations about upcoming input using anticipatory deaccenting, in which the absence of a nuclear pitch accent on an utterance-new noun is licensed by the subsequent repetition of that noun (e.g. Drag the SQUARE with the house to the TRIangle with the house). The phonemic restoration paradigm was modified to obscure word-initial segmental information uniquely identifying the final word in a spoken instruction, resulting in a stimulus compatible with two lexical alternatives (e.g. mouse/house). In Experiment 1, we measured participants’ final interpretations and response times. Experiment 2 used the same materials in a crowd-sourced gating study. Sentence interpretations at gated intervals, final interpretations, and response times provided converging evidence that the anticipatory deaccenting pattern contributed to listeners’ referential expectations. The results illustrate the availability and importance of sentence-level accent patterns in spoken language comprehension.
Keywords: language comprehension, prosody, deaccenting, phoneme restoration, sentence gating
Introduction
In recent years, there has been increased interest in how listeners use prosodic information during online spoken language comprehension. Information structure is a central factor modulating the relative prominence of syllables in an utterance, and so relative prominence can be expected to serve as a cue to information structure during comprehension. The association between prosody and discourse status makes the presence or absence of pitch accent a potentially useful cue to the information structure of a sentence. A growing literature has focused on the processing of pitch accent types, especially differences in the interpretation of presentational and contrastive pitch accents (e.g. Watson et al., 2008; Ito & Speer, 2008). In contrast, the contribution of deaccenting to processing of sentence-level accent patterns has received comparatively little attention (but see Dahan et al., 2002). This paper focuses on a particular accent pattern that has heretofore received little attention in the processing literature—anticipatory deaccenting.
Like accenting, deaccenting functions as part of the larger accent pattern of a sentence to indicate the status of a word or phrase with respect to the surrounding discourse. A pitch accent can be found in any utterance, whereas deaccenting is not always present. When deaccenting does occur, a syllable is deaccented relative to accented material elsewhere in the same utterance. Thus, a system that makes use of deaccenting must be sensitive to both local (absolute) and relational cues. Here we report novel evidence that the anticipatory deaccenting pattern functions as a cue to sentence-level information structure, and therefore lexical content. The results provide support for the broader idea that listeners are sensitive to relative prominence and accent patterns, in addition to being influenced by the properties of a specific accent shape or tonal boundary.
Information structure and anticipatory deaccenting
Pitch accent shape and placement contribute to information-structural aspects of sentence meaning by marking parts of an utterance according to their status in the discourse as given vs. new information, topic vs. comment, or background vs. focus (cf. Buring, 2007; Steedman, 2000; Roberts, 1998; Selkirk, 1996; Rooth, 1992; Pierrehumbert & Hirschberg, 1990). For example, (1) and (2) have the same lexical content and truth conditions but differ in their prosody, with relatively prominent and pitch-accented syllables indicated by capitalization.
-
1
SArah gave DANny a MIcroscope.
-
2
SArah gave DANny a microscope.
Discourse contexts in which microscopes have not previously been mentioned license utterances like (1), where microscope is accented, but not (2), where microscope lacks a sentence-level accent. In contrast, utterances like (2) are more appropriate in discourse contexts in which microscopes have been previously mentioned. As a result, (1) could be used as an “all-new” response to a general question such as What are you guys talking about? while (2) would be more suitable in response to What was that about a microscope? The lack of accent on the final word is associated with its givenness.
Strictly speaking, pitch accents apply to the stressed syllable of a word, and not to the word itself. However, for simplicity, in this paper we will refer to a word as accented if the stressed syllable of the word receives a pitch accent, and unaccented in all cases where the stressed syllable of the word receives no pitch accent. We further distinguish between words that are unaccented (simply lacking an accent) and those that are more specifically deaccented. Following Ladd’s (1980; 2008) usage, we reserve the term deaccented for cases like microscope in (2), where the unaccented word appears in the structurally significant phrase-final position associated with “broad”, or “all-new”, focus in English. An accent must be present on this element if the sentence is to receive the “all-new” interpretation, as is possible for (1). Deaccenting occurs when an unaccented word occupies a position where an accent would be required for a broad or “all-new” interpretation of the sentence. Notice that gave and a, though unaccented in both sentences, do not qualify as being deaccented in either sentence because neither requires an accent for the sentence to receive a broad interpretation.
Much of the processing work on accenting to date has concentrated on hypothesized differences between accent shapes, in particular the L+H* “contrastive” accent vs. the H* “presentational” accent (Pierrehumbert & Hirschberg, 1990). Without denying that accent shape plays an important role in sentence processing, we draw attention here to the possibility that decisions about the placement of accents overall (the sentence-level accent pattern, as we refer to it) are to some extent separable from accent shape. In particular, the pattern of (2), where microscope is deaccented, does not support an all-new interpretation even with standard H* accents on the accent-bearing elements. Substituting a “contrastive” accent on Danny in (2) could introduce additional contextual implications, but the contribution of deaccenting – the sense that microscopes are familiar from previous discourse – remains intact across accentual variations.1
The association between deaccenting and givenness is arguably stronger than the association between accenting and discourse-new status. A deaccented element must normally be given, whereas an accented element need not be new (Cruttenden, 1986; Schwarzschild, 1999). From a processing perspective, sorting out whether and how deaccenting contributes to the interpretation of information structure presents unique challenges. The association with givenness means that deaccenting is typically best understood as backward looking – a deaccented word is normally given and previously uttered. Because deaccenting typically occurs relatively late in the sentence or phrase, much of the lexical content and structure of the utterance is already available by the time a deaccented word is reached, making it difficult to evaluate independent contributions of deaccenting (but see Birch & Clifton, 1995 and Terken & Nooteboom, 1987 for earlier processing work that examines deaccenting).
Fortunately, there are special cases in English where deaccenting does not merely indicate discourse status of the deaccented element itself, but is associated with the upcoming information structure of the sentence as well. Van Deemter (1999) described anticipatory deaccenting as a systematic exception to the requirement that a deaccented element must be previously given. For example, in (3), the first occurrence of fugue can be deaccented (indicated by the subscript d), even though it is new to the discourse at that point:
-
3
MOZart wrote FEW [fugues]d, and BACH wrote MAny [fugues]d.
Previous work has noted that anticipatory deaccenting is licensed for a discourse-new noun if and only if that noun will be repeated in a parallel position (see Chomsky, 1971; Rooth, 1992; Van Deemter, 1999). Therefore, the deaccenting of a new noun signals that it will be repeated, constraining upcoming information structure and sentence content. After hearing the deaccented instance of the word fugues at the end of the first phrase in (3), the listener can be fairly confident that the word fugues will occur again, most likely in a parallel position. Any continuation not containing a repetition of fugues would be infelicitous following the deaccenting on the initial (discourse-new) occurrence of the word, as in (4) and (5).
-
4
* MOZart wrote FEW [fugues]d, and BACH wrote MAny concertos.
-
5
* MOZart wrote FEW [fugues]d and everyone knows it.
Although anticipatory deaccenting is strongly indicative of the upcoming repetition of a noun, it does not occur in every case where it is licensed. When a noun is to be repeated, the speaker is never obligated to signal the upcoming repetition by deaccenting the first occurrence of the noun. Although anticipatory deaccenting is a highly valid cue signaling upcoming repetition, it is never required for comprehension. Like many prosodic cues, anticipatory deaccenting does not contribute directly to truth-conditional meaning. Therefore, both (3) and (6) are acceptable – although some readers might find (3) to be more felicitous than (6) – and both convey the same propositional content.2
-
6
MOZart wrote FEW FUGUES, and BACH wrote MAny [fugues]d.
The goal of the current work was to test the hypothesis that listeners can use the sentence-level accent pattern associated with anticipatory deaccenting as a cue to upcoming noun repetition.
Motivations for experimental approach
We report two experiments that utilize a variation of the phonemic restoration paradigm, in which part of a word is replaced by a cough or sound (Warren, 1970; Sherman, 1971; Samuel, 1981, 1996). This variation was introduced by Stoyneshka et al. (2010) to examine effects of prosody on the interpretation of Bulgarian sentences containing temporary syntactic ambiguities, disambiguated by a single word. When the disambiguating segment of the critical word was replaced with noise, participants perceived the variant of the critical word that was consistent with whichever syntactic alternative was suggested by the prosody of the sentence. The paradigm was subsequently used by Mack et al. (2012) to examine sentence-level cues that convey non-semantic information.
We presented listeners with sentences such as (7) and (8), in which the consonantal onset and the initial part of the vowel in the utterance-final word were replaced by a cough (Figure 1), indicated by #.
Figure 1.
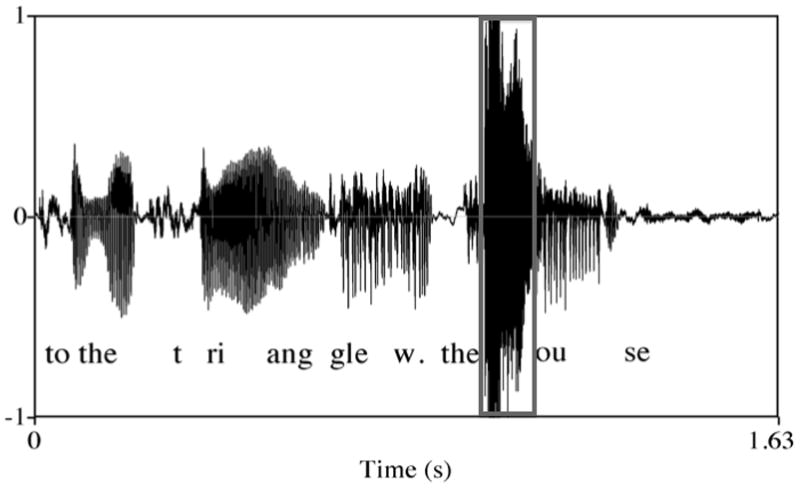
The placement of the cough relative to the rest of sentence-final word is shown in a box. The remainder of the word was segmentally ambiguous between two members of a minimal pair, e.g. mouse and house. Note the high amplitude of the cough, which created the perception that segmental information might have been present but obscured, as in the classic phonemic restoration study by Warren (1970).
-
7
Drag the SQUARE with the [house]d to the TRIangle with the #ouse.
-
8
Drag the SQUARE with the HOUSE to the TRIangle with the #OUSE.
Crucially, this created a lexical ambiguity between two nouns (house and mouse) in the context of a visual display containing both a house on a triangle and a mouse on a triangle (Figure 2). Experiment 1 examined referent choice and response time to determine whether accent pattern can be used to disambiguate a potential referent. Experiment 2 used a sentence-gating paradigm to assess listeners’ expectations at multiple points in the unfolding utterance.
Figure 2.
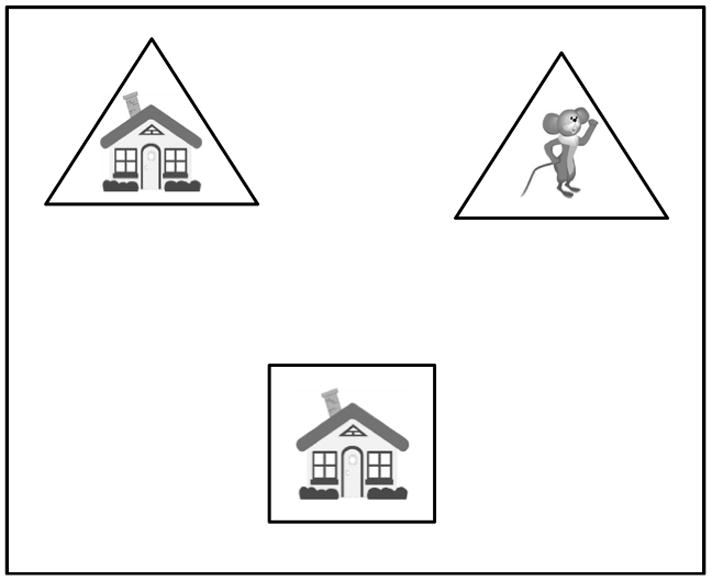
Example display containing 3 related pictures: the target to be moved (the square with the house) at the bottom of the screen, and two destination pictures at the top of the screen. Participants heard an instruction that was segmentally ambiguous given the destinations, and had to choose the same-attribute destination (the triangle with the house) or the other-attribute destination (the triangle with the mouse). House and mouse clipart © 2013 www.clipart.com
We used the phonemic restoration paradigm for two related reasons, each of which would have made using stimuli with an unmasked final word problematic. First, learning effects complicate the investigation of prosodic cues during comprehension. The acoustic correlates of intonational categories and the use of different types of pitch accents to denote various information-structural and pragmatic contrasts vary considerably between and within speakers (e.g. Ladd, 2008; Terken & Hirschberg, 1994). In the face of this variability, listeners must update their beliefs about how a particular speaker uses prosodic cues to convey intentions based on recently encountered utterances (for evidence supporting this hypothesis, see Kurumada, Brown & Tanenhaus, 2012). Therefore, counter-balanced experimental designs containing infelicitous prosody are likely to obscure effects of prosody on comprehension, by teaching participants that prosody is an unreliable cue to reference resolution for that speaker (Grodner & Sedivy, 2011; Kurumada et al., 2012). Conversely, experimental designs using prosodic contours that are always felicitous may be problematic, because the results could be attributed to participants having learned the systematic association between prosodic cues and specific interpretations during the experiment. Introducing lexical ambiguity enabled us to mitigate both of these risks.
Second, because anticipatory deaccenting is not required to understand a sentence’s meaning, it is unlikely to override segmental cues to spoken word recognition. Segmental cues are reliable and readily available in typical laboratory conditions in which recordings of clearly articulated utterances are presented with minimal noise. In natural settings, environmental noise may degrade some components of the speech signal while leaving prosodic contours relatively intact, making accent pattern an important cue in real-world sentence processing. However, in controlled experiments, observing effects of accent patterns may require methods that allow weaker cues to be evaluated while masking stronger cues that would support the same interpretation. We reasoned that using the modified phonemic restoration paradigm to reduce the availability of disambiguating segmental information would increase the likelihood of observing effects of preceding sentence-level accent patterns on interpretation.
Experiment 1
Methods
Participants
Eighteen participants from the University of Rochester and surrounding community were paid to participate in Experiment 1. All were native speakers of American English and had normal hearing and normal or corrected-to-normal vision.
Stimuli
One set of stimuli was created for use in Experiment 1 and Experiment 2. Original recordings consisted of two parallel phrases where a noun from the first phrase was repeated in the second phrase, licensing anticipatory deaccenting. Stimuli were recorded in a female voice and were not spliced or altered except for the masking manipulation. We used the H* accent type on all accented syllables because as compared to L+H*, H* is arguably an unmarked accent type in English: H* can be used with a noun whether or not it has been previously mentioned (Watson, et al., 2008). Additionally, L+H* is a known cue to contrastive information structure (Pierrehumbert & Hirschberg, 1990; Ito & Speer, 2008), and could therefore introduce biases independent of deaccenting.
The crucial difference between the deaccented and accented original recordings occurred in the first instance of the attribute noun (house), as shown in (9)–(10).
-
9
Drag the SQUARE with the [house]d to the TRIangle with the [house]d.
-
10
Drag the SQUARE with the HOUSE to the TRIangle with the HOUSE.
The final word of the sentence as originally recorded was always a repetition of the earlier noun (i.e., house in (9)–(10)), regardless of condition (accented or deaccented). The initial segment – including the consonantal onset and part of the vowel – was replaced with a cough (#ouse) as shown in Figure 1, allowing for ambiguity between the original noun (house) and a rhyming candidate introduced visually (mouse). The cough-spliced portion of the final word varied in duration from 105ms to 149ms (μ=128ms), depending on the amount of phonetic material distinguishing the members of the minimal pair (see Appendix A for list of word pairs).
The repeated nouns were originally produced to match the accent pattern of the first mention in the sentence. That is, if the first phrase of the sentence involved anticipatory deaccenting, the final word was deaccented (e.g. [house]d, as in (9)); and if it did not, the final word was accented (e.g. HOUSE, as in (10)). Critically, after insertion of the cough changed the acoustic properties of the final word so that originally deaccented cough-spliced words and originally accented ones were very similar. As shown in Appendix B, none of the acoustic measurements differed significantly between conditions for the final cough-spliced word except mean intensity, which was marginally higher in the accenting condition than in the deaccenting condition. The .6 dB difference between accented and unaccented cough-spliced words is less than the expected 1 dB intensity discrimination threshold (Moore, 2012). Several factors contributed to the neutralization of between-condition differences in the final word: (1) the cough replaced a substantial portion of the accent-bearing part of the word, including part of the vowel; (2) the cough gave the final word a high amplitude and pitch (characteristic of both coughs and accented syllables); and (3) differences between the original accents were reduced by the natural pitch declination of English declaratives. The absence of significant between-condition differences for the final cough-spliced word makes it unlikely that prosodic characteristics of the final word affected participants’ interpretations.
The effects can instead be attributed to the accent pattern on the material prior to the final word. As summarized in Appendix B, there were no significant between-condition acoustic differences for the first shape word (e.g. SQUARE, in 9 and 10). The second content word in the deaccenting condition (e.g. [house]d in 9) was significantly different than the second content words in the accenting condition (e.g. HOUSE in 10) on all six acoustic measures that we assessed (duration, mean F0, minimum F0, maximum F0, mean intensity, and maximum intensity). This shows that a significant acoustic difference first occurred at the time point where deaccenting occurs in the deaccenting condition. The second shape word (e.g. TRIangle in 9 and 10) differed significantly between conditions only in maximum intensity (81.2 dB vs. 80.5 dB); regression analysis (described below) showed that this difference did not contribute to the significance of the results observed in this experiment. The primary detectable difference between the two conditions was anticipatory deaccenting on the relevant word (e.g. the first occurrence of house).
Images to accompany each modified sound file were created using colored pictures from clipart.com superimposed on basic shapes (triangle, square, or circle). As Figure 2 shows, images for each trial consisted of the first mentioned shape and attribute (e.g. a square with a house) and two possible alternatives for the second mentioned shape (e.g. a triangle with a house, and a triangle with a mouse).
Procedure
Participants followed instructions to move the pictures around on a computer screen.3 They completed one initial practice trial. The entire experiment took each participant 5–10 minutes. Each participant heard 16 accented and 16 deaccented instructions presented in a random order, and indicated their interpretation by clicking the first mentioned picture (e.g. the square with the house) and dragging it to one of the two possible destinations corresponding to the alternative interpretations of the ambiguous word (e.g. the triangle with the house). The final choice of destination and response time was recorded.
Although they are typically used in psycholinguistic experiments, fillers were not included in our design. We made this choice because we believed that the potential problems that might have resulted from including fillers would have exceeded any potential benefits. The primary purpose of fillers is to prevent participants from identifying the purpose or hypothesis of the experiment. In this case, the hypothesis was that the ambiguous word at the end of the sentence would be identified based on the accent pattern of the sentence. Including fillers with masked segmental cues that relied on a different prosodic pattern would not have obscured the purpose of the experiment. Including fillers that did not contain masked segmental cues would have created conditions that called additional attention to the differences between experimental items. We were also concerned that adding additional trials to the experiment would have given participants more time to adapt to the prosody of the speaker’s voice, increasing the possibility that learning might play a role in any observed effects.
Item Bias Rating and Lexical Frequency
Three potential confounds could have affected the results. First, for each pair of images, participants could have been biased toward one picture over the other because of the features of the specific pictures. Second, any subtle coarticulatory cues remaining in the sound file after the cough was inserted could have interacted with accent pattern to influence the results. A third possible confound was that the word final word with the cough would sound more like one of the targets because of differential overlap between the acoustic features of the cough and the acoustic-phonetic features of the lexical alternatives.
To control for these factors, we conducted an independent item bias rating study with ten separate participants to obtain a measure of any item-specific biases present in the auditory and visual stimuli. This allowed us to use item bias in our regression analyses to partial out preferences for one picture over the other, item-specific biases due to any remaining coarticulatory cues, and biases due to differential similarity between the cough sound and the onsets of competing names. We note that we still would have needed to include item bias as a covariate if we had used a multiple list design in which each type of accent pattern was used with each pair of items. Nonetheless, in future research it will important to rotate a larger set of items through different accent conditions, including accent patterns that were not manipulated in the current experiments
On each trial of the item bias rating study, participants saw the same two destination pictures that were used in Experiment 1. Instead of the entire sentence, participants heard only the final cough-spliced word and the preceding determiner (e.g. the #ouse). The clips were taken from the sound files used in Experiment 1 with no changes. Participants’ interpretations of these clips in isolation yielded the “item bias score” for each item, capturing the degree to which each ambiguous word and picture set was biased toward one lexical interpretation or the other in the absence of sentence-level cues. Item bias scores obtained in this norming study were included as a planned controlled effect in subsequent regression models. The item bias scores were included to control for the possibility that the main effect of accent pattern condition on reaction times might otherwise have been due to the specific nouns assigned to each accent condition.
Finally, because items were not crossed with condition, it was important to rule out the possibility of lexical frequency differences between the two conditions. Noun frequencies for the pairs of words were obtained from the Corpus of Contemporary American English (Davies, 2008). For each item, the ratio of the frequencies of the same-attribute target vs. the other-attribute target was calculated and log-transformed to get a normally distributed measure. This normalized measure of frequency was included in regression analysis of the data.
Data Analysis
Multiple regression models were used to evaluate the significance of the effects. Continuous variables were standardized by subtracting the mean value and dividing by the standard deviation. Categorical variables were sum-coded. All models included random intercepts and slopes by participants and items to account for systematic response variability across participants and items. Maximal random effects were included except in the event that models failed to converge, in which case random slopes were removed stepwise beginning with the highest-order slopes associated with the lowest variance (Barr et al., 2013). In the event that a model failed to converge with random effects for both participants and items, we computed models containing random effects for participants and items separately. Final models were chosen by removing fixed effects stepwise and comparing each smaller model to the more complex model using the likelihood ratio test, in order to reduce the risk of over-fitting the data (Baayen, Davidson & Bates, 2008). We established that collinearity between factors was low by calculating the condition number using the kappa function in R (R Development Core Team, 2010). The condition number was less than seven for all models, indicating that collinearity was sufficiently low so as not to interfere with reliability of model estimates.
The destination picture chosen by the participant on each trial was expected to depend on accent condition, with deaccenting biasing participants toward the picture with the previously mentioned attribute. The effect of accent pattern on response choices was assessed in a logistic regression model including as fixed effects accent condition, trial number (the position of the item in the sequence encountered by the participant), normed item bias score, and relative noun frequency.
The effect of accent pattern on response times was assessed in a multi-level linear regression model with fixed effects including: deaccenting condition, trial number, item bias score, relative noun frequency, the destination object chosen by the participant, squared trial number, and interactions between these factors. Squared trial number was included to address the possibility of non-linear trial order effects after examination of the data.
By including trial number as a control variable in the models, we were able to factor out the proportion of variance that may have otherwise been attributed to learning over the course of the experiment. As noted earlier, there was a small but statistically significant difference in the maximum intensity of the second shape name between conditions. This was the only significant acoustic difference between conditions prior to the cough that could not be attributed to deaccenting. Inclusion of this maximum intensity difference in regression models did not result in a significant improvement in model fit, and effects of condition remained significant (see Appendix B for details). Therefore, this paper reports the simpler models, without the variable of maximum intensity on the second shape.
The regression models were constructed using the lmer function within the lme4 package in R (R Development Core Team, 2010; Bates et al. 2008). Logistic regression models were fit by the Laplace approximation, whereas linear regression models were fit using restricted maximum likelihood estimation. The significance of each predictor in the linear regression models was estimated by assuming convergence of the t distribution with the z distribution, given the relatively large number of observations (Baayen et al., 2008).
Results and Discussion
As predicted, the anticipatory deaccenting pattern increased the likelihood that participants would interpret the final word as a repetition of the initially deaccented word. Participants chose the same-attribute destination more often in the deaccented condition (μ=82%) than in the accented condition (μ=60%). Because the logistic regression model of response choices failed to converge with random effects for both participants and items, we computed models containing random effects for participants and items separately. Both models showed that participants’ interpretations of the ambiguous words were significantly predicted by anticipatory deaccenting, normed item bias score, and squared trial number (Table 1). Participants had an overall bias to select the destination with the same attribute as the first mentioned shape in both conditions. This bias had a non-linear relation with trial number, manifesting itself most strongly at the beginning and end of the experiment. In addition, relative noun frequency had an effect on responses in the model containing random effects by participants, but this effect was not reliable in the model containing random effects by items. Crucially, accent condition had a significant effect above and beyond effects of trial number, frequency, residual segmental cues biasing listeners’ lexical interpretations, and effects specific to individual items or participants. Thus, in the absence of disambiguating segmental information, listeners used the anticipatory deaccenting pattern as a cue to word identity later in the sentence.
Table 1.
Parameters of the final logistic regression model of response choices in Experiment 1 with random effects for (a) participants and (b) items. The random effects structure of each model is specified in the model formula.
| (a) | β | SE | z | p |
|---|---|---|---|---|
| Intercept | 0.16 | 0.26 | 0.58 | n.s. |
| Condition = deaccented | 0.55 | 0.25 | 2.22 | <0.05 |
| Same-attribute lexical bias rating | 1.26 | 0.16 | 7.92 | <0.0001 |
| Relative noun frequency | 0.41 | 0.13 | 3.02 | <0.005 |
| Squared trial number | 0.71 | 0.16 | 4.32 | <0.0001 |
| (b) | β | SE | z | p |
|---|---|---|---|---|
| Intercept | 0.46 | 0.21 | 2.22 | <0.05 |
| Condition = deaccented | 1.05 | 0.41 | 2.60 | <0.01 |
| Same-attribute lexical bias rating | 1.02 | 0.16 | 6.55 | <0.0001 |
| Squared trial number | 0.35 | 0.16 | 2.22 | <0.05 |
Formula: lmer(response ~ condition + rating + frequency + trialnumber2 + (1 + condition + rating + frequency + trialnumber2 + condition:rating + condition:trialnumber2 + rating:trialnumber2 + condition:frequency | subj), family=binomial, data=data)
Formula: lmer(response ~ condition + rating + trialnumber2 + (1 + condition + trialnumber2 + condition:trialnumber2 | item), family=binomial, data=data)
This effect of accent pattern on response choices did not depend on whether control covariates – trial number, item bias score, destination object chosen, relative noun frequency, squared trial number, and interactions between these factors – were included in the model. At a reviewer’s suggestion, we fit a model without fixed effect control variables to ensure that our main effect was not dependent on controlling for other factors, a concern that has been recently raised by Simmons, Nelson & Simonsohn (2011). The reduced model with accent pattern as the only fixed effect (and with random intercepts and slopes for condition by participants and items) confirmed that the effect of deaccenting on response choice was still significant in the absence of any control variables (β = −1.86; p <0.01). We can therefore be confident that the main effect of deaccenting on interpretation was not a spurious effect that only emerged when control variables were included in the model.
We hypothesized that processing of the final ambiguous word would be facilitated in the deaccenting condition relative to the accenting condition, because the accent pattern associated with anticipatory deaccenting is more restrictive and informative about downstream reference. Response times were measured from the offset of the ambiguous final word to eliminate any between-item differences in the durations of the instructions. The response times thus reflected the time taken for participants to process the final word, make a decision about which word they had heard, and initiate a response (i.e. dragging the target shape to the destination shape).
The final multi-level linear regression model of log-transformed response times confirmed that participants were significantly faster to respond in the deaccenting condition (μ=380ms) than the accenting condition (μ=590ms; Table 2). Because cough-spliced word durations did not differ significantly between conditions (Appendix B, Table B3), and because response times were measured from the offset of the final word, between-condition differences in word or sentence length could not account for this effect. Response times were also faster when participants selected same-attribute destinations, which may have reflected the additional time necessary for listeners to process what they perceived to be a previously unmentioned word and to map it onto the other-attribute destination. Additionally, response times were predicted by item bias rating scores from the norming study, indicating that responses were facilitated when some aspect of the signal favored one lexical alternative over the other (e.g. residual coarticulatory information or differential acoustic similarity between the cough and the segmental alternatives). Crucially, the effect of accent condition on response time was significant above and beyond these other effects, suggesting that deaccenting provided information that facilitated processing. As with the response choice data, we fit a model without fixed effect control variables to ensure that the main effect was not dependent on controlling for other factors. The reduced model with accent pattern as the only fixed effect (and with random intercepts and slopes for subject and items) confirmed that deaccenting had a significant effect on log transformed response times in the absence of control variables (β = −0.12; p <0.05).
Table 2.
Parameters of the final linear regression model of log-transformed response times in Experiment 1. In addition to the fixed effects described here, the model included random effects as specified in the model formula.
| β | SE | t | p | |
|---|---|---|---|---|
| Intercept | 7.54 | 0.08 | 92.84 | <0.0001 |
| Condition = deaccented | −0.11 | 0.06 | −2.02 | <0.05 |
| Same-attribute lexical bias rating | 0.11 | 0.04 | 3.07 | <0.005 |
| Response = same-attribute | −0.14 | 0.07 | −2.12 | <0.05 |
| Lexical rating x response = same-attribute | −0.11 | 0.05 | −2.17 | <0.05 |
Formula: lmer(logRT ~ condition + rating + response + rating:response + (1 + condition + rating + response + frequency + trialnumber + response:trialnumber + condition:frequency| subj) + (1 + response | item), data=data)
Finally, although participants were not instructed to respond quickly, they sometimes programmed and initiated their motor responses before the end of the inserted cough. We used 200ms, a conservative lower bound estimate for planning and launching linguistically-mediated eye movements (Salverda, Kleinschmidt & Tanenhaus, in press), as a measure of the time it would take participants to plan and initiate a motor response. On 18.6% of critical trials, participants responded within 200ms of cough offset, indicating the response was planned during or prior to the cough. These early responses followed the general response choice pattern. In the accenting condition, the same-attribute shape was chosen 28 times and the different-attribute shape was chosen 19 times, a relatively weak bias toward same-attribute responses. But in the deaccenting condition, the same-attribute shape was chosen 47 times, whereas the different-attribute shape was chosen only 10 times, indicating a much stronger preference for the same attribute. This condition-contingent response pattern was significant (χ2 =5.62, p<0.05), indicating that anticipatory deaccenting biased listeners toward the same-attribute destination before the end of the sentence, and suggesting that participants generated expectations based on accent pattern as the sentence unfolded.
Experiment 2
Experiment 1 established that deaccenting affected the interpretation of a referential expression in which the part of the noun providing disambiguating information was replaced by a cough. However, the design of Experiment 1 did not allow us to determine the earliest point in the utterance at which listeners might be sensitive to anticipatory deaccenting. As mentioned in footnote 3, we had hoped to obtain this information from eye movements, but that proved problematic because the relationship between the structure of the utterance and the structure of the task did not allow for clear interpretations of the eye-tracking data prior to the onset of the target word. Therefore, we conducted a sentence gating study using the stimuli from Experiment 1 as an alternative way to evaluate the time course of anticipatory deaccenting effects. The gating methodology allowed us to sample participants’ expectations at multiple time points throughout the sentence, making it possible to identify when the different accent patterns first began to influence listeners’ expectations.
Methods
Participants
Eighteen participants were paid to complete the experiment using Amazon’s Mechanical Turk, an online crowd-sourcing platform. All participants completed the experiment in the United States and were self-reported speakers of American English with normal hearing and normal or corrected-to-normal vision.
Stimuli
The auditory stimuli were fragments of the cough-spliced sentences from Experiment 1. Eight fragments, hereafter gates, were created by segmenting the stimuli at the sentence positions (denoted by slashes): “Drag the/[shape]/with the [attribute]/to the/[shape]/with the/[#attribute]”. Listeners were exposed to sentence fragments of successively increasing duration beginning at the onset of each stimulus (e.g. “Drag the…”, “Drag the house…”, “Drag the house with the…”, etc.).
Procedure
Picture choices were collected at each gate of each sentence. On each trial, the picture displays used in Experiment 1 were presented on a website. Participants triggered the audio instruction by clicking on a button in the center of the display. After the sound finished playing, participants were asked to click on the destination picture that they thought would be mentioned at the end of the sentence. At the end of each set of 8 gates, the start of the next trial was clearly indicated by a progress screen. The order of trials was randomized across participants. As in Experiment 1, participants completed 16 trials in each of the two conditions.
Participants were informed that all of the sentences used the same syntactic frame, and were given an example sentence (using non-rhyming and non-repeating attributes). They were told that some of the words would contain noise, like a cough. The first trial was a practice trial. For maximal clarity, instructions summarizing the task structure were presented at the beginning of the experiment and remained at the top of the website throughout the experiment. These instructions reminded participants to use their best judgment even if they were very unsure about their picture choices.
Results
If accent pattern incrementally contributed to interpretation, as listeners heard more of the accent pattern, they would be expected to increasingly favor the same-attribute shape after it is first mentioned in the deaccenting condition, but not the accenting condition. Given the complexity of the anticipatory deaccenting pattern, we did not have an a priori prediction about the exact time point when this would occur. The earliest point at which we might expect an effect to occur, however, would be after the fourth gate (“Drag the SQUARE with the [house]d …”). A logistic regression model predicting same-attribute picture choices from gate number, condition, and the interaction of gate and condition showed a significant main effect of condition, qualified by a significant gate by condition interaction (Table 3). Over the course of the sentence, there was an increase in same-attribute picture responses for the deaccenting condition and a decrease in same-attribute picture responses for the accenting condition (Figure 3).
Table 3.
Results of omnibus regression model predicting same-attribute shape selection in Experiment 2 from the fixed effects shown below. In addition to the fixed effects described here, the model included random intercepts for participant and sound file.
| β | SE | z | p | |
|---|---|---|---|---|
| Intercept | 1.92 | 0.51 | 3.9 | <0.001 |
| Condition = deaccented | 0.66 | 0.17 | 3.9 | <0.0001 |
| Gate | 0.035 | 0.041 | 0.85 | 0.393 |
| Gate x Condition = deaccented | 0.233 | 0.083 | 2.80 | <0.01 |
Formula: lmer(SamePictureSelected ~ Condition=deaccented * Gate + (1 | subj) + (1 | item), family=binomial, data=data)
Figure 3.

The proportion of trials on which the same-attribute destination picture was chosen, as a function of gate number and condition (deaccenting=DA; accenting=AA). * = Statistically significant at 0.05 level after Holm’s correction.
To evaluate the time point at which the difference between the two accent conditions became significant, we tested for between-condition differences in response choices at each gate, using eight regression models and correcting for multiple comparisons with Holm’s (1979) sequential multiple test procedure (Table 4). Response choices did not differ significantly between conditions at gates one, two, or three. Beginning at gate four, participants were significantly more likely to choose the same-attribute picture in the deaccenting condition than in the accenting condition. The difference between conditions remained significant (and increased numerically) with every subsequent gate. This indicates that provisional choices about upcoming lexical content were affected as soon as anticipatory deaccenting could be detected in the instruction. This occurred prior to the availability of any segmental or prosodic cues in the final phrase of the sentence. However, as the sentence continued, provisional expectations became more strongly biased as more of the sentence-level accent pattern became available. This result suggests that while anticipatory deaccenting is a prosodic cue that listeners can use as soon as it is encountered, it also contributes to a larger sentence-level accent pattern that provides increasingly reliable information about sentence-level information structure.
Table 4.
Results of post-hoc regression models predicting same-attribute shape selection in Experiment 2 at each of the eight gates. The tests included participant and item intercepts as random effects and were corrected for multiple comparisons using Holm’s (1979) sequential multiple test procedure.
| Gate | z | p-value | Holm’s corrected α | Significant at 0.05 level |
|---|---|---|---|---|
| 1. Drag the… | 1.04 | 0.298 | 0.05 | No |
| 2. Drag the square… | 2.06 | 0.0391 | 0.0167 | No |
| 3. Drag the square with the… | 1.68 | 0.0915 | 0.025 | No |
| 4. Drag the square with the house… | 2.69 | 0.00715 | 0.0125 | Yes |
| 5. Drag the square with the house to the… | 3.66 | 0.000250 | 0.00625 | Yes |
| 6. Drag the square with the house to the triangle… | 3.29 | 0.000996 | 0.00833 | Yes |
| 7. Drag the square with the house to the triangle with the… | 3.55 | 0.000391 | 0.00715 | Yes |
| 8. Drag the square with the house to the triangle with the #ouse. | 2.95 | 0.00316 | 0.01 | Yes |
Formulas: lmer(SamePictureSelected ~ Condition=deaccented + (1 | subj) + (1 | item), family=binomial, data=data)
Conclusions and Future Directions
Taken together, these experiments demonstrate that listeners can use anticipatory deaccenting to make inferences about intended referents during language comprehension. The time course of the effects suggests that anticipatory deaccenting has early effects on listeners’ expectations about upcoming sentence content, and that the available information from sentence-level accent patterns increases as the sentence unfolds.
Because distal accent pattern is a comparatively weak cue to lexical identity, it might not be observable in situations where other stronger cues carry most of the weight. However, as Mattys, Davis, Bradlow & Scott (2012) note, a wide range of adverse conditions affect everyday language comprehension and are part of the normal speech recognition process. Therefore listeners must frequently use compensatory strategies in the face of a complex and noisy auditory environment. Thus, while it is possible that listeners adopted compensatory strategies in order to identify the missing word segments in the stimuli used here, these strategies are arguably a natural part of the speech recognition process.
How listeners process deaccented words in these contexts is revealing, because in order for anticipatory deaccenting to affect downstream word recognition, the accent pattern of the sentence must be tracked by a listener as the sentence is processed, so that the information associated with it will be available in case an ambiguity or other adverse speech recognition condition is encountered. While the adverse conditions we created in this experiment were extreme and arguably even unnatural, barriers to speech recognition of a similar quality occur regularly in a less extreme form (e.g. partial masking of speech due to background noise). The use of early anticipatory deaccenting in situations where segmental information is unreliable suggests that cues that do not appear to strongly affect language comprehension during controlled low-noise speech are still tracked by speakers and weighed accordingly when other cues are weaker than usual.
The experiments reported here could be extended in the future to address how anticipatory deaccenting – or more generally, sentence-level prosody – affects speech recognition in cases where the reliability of segmental cues varies. Additionally, future work could address the role of prosodic cues under a gradient range of noisy speech recognition conditions. Different levels of noise could be superimposed on a syllable to vary the availability of segmental cues. Noise-added and noise-replaced stimuli (Samuel, 1981, 1996) could be used to test whether deaccenting imposes a response bias or combines with segmental cues to influence phoneme recognition. This approach could also be valuable in studying adaptation, including the time-scale over which adaptation might differ for more and less reliable cues.
The effects of anticipatory deaccenting reported in this paper appear earlier in the sentence than effects previously observed under low-noise conditions where segmental information is highly reliable (Carbary, Gunlogson & Tanenhaus, 2009). We note, however, that the effect of deaccenting on response choice and response times in previous studies conducted by the first author and her colleagues followed the same pattern as the present study, and that the effects, though smaller, were statistically reliable. One problem with these previous studies is that the most reliable information was always presented at the final noun. Moreover, in order to avoid infelicitous materials, the choice of referent for the deaccented stimuli was necessarily the mentioned attribute. Thus, any effects could have been attributed to within-experiment probability matching.
The Stoyneshka et al., (2010) approach avoids the problems associated with using infelicitous prosody and the problems with using only felicitous prosody which might teach participants the hypothesized mapping between prosody and potential referents. In the current experiments, we were able to observe effects of distal prosodic cues to information structure when those cues are typically weak when compared to segmental information. This lends further support to the Stoyneshka et al. (2010) approach for studying the processing effects of subtle prosodic cues, which may have previously eluded characterization due to the comparative strength of segmental cues, or susceptibility to within-experiment adaptation effects.
Finally, these results highlight the importance of sentence-level accent patterns, in addition to local pitch accent placement and shape, in language processing. The effects of the deaccenting pattern in this study were not dependent on a particular type of accent, e.g., a “contrastive” accent shape on the preceding accented noun. We conclude that the deaccenting pattern in the initial noun phrase served as a cue to upcoming content independent of pitch accent shape. This finding is theoretically important; although sentence-level accent patterns have been tacitly assumed to play a role in interpretation, the literature has primarily focused on the contribution of the presence of an accent and its shape. Theories that concentrate on distinctions between pitch accent shapes (e.g., Pierrehumbert & Hirschberg 1990) do not make clear predictions about how the lack of a pitch accent on an accentable element functions to convey meaning. The results reported in this paper draw attention to the fact that the prominence change associated with a deaccented element following an accented one could carry meaning independent of the shape of the accent placed on any individual syllable. This is not to deny that stronger effects might have been observed in our study if the L+H* accent shape had appeared in conjunction with the deaccenting pattern, but such effects remain compatible with sentence-level explanations as well as with purely local shape contrasts. Investigating the relationship between discrete cues, such as accent shape, and sentence-level cues, such as overall accent pattern, will be an important area for future work investigating intonational meaning.
Acknowledgments
This research was supported by NIH grants HD27206 and HD073890 to MKT and an NSF graduate research fellowship to MB. We thank Sarah Glacken and Rebekah Goldstein for contributions to a pilot study, and Dana Subik for lab assistance. We are grateful to Michael Wagner for providing supplemental acoustic analyses and for providing arguments that convinced us that the eye-movement data were problematic for the reasons discussed in footnote 3.
Appendix A: Experimental Items
| Condition | Target (to be moved) | Same-Attribute Destination | Other-Attribute Destination |
|---|---|---|---|
| Accenting | Triangle with the bed | Square with the bed | Square with the sled |
| Accenting | Square with the bug | Triangle with the bug | Triangle with the pug |
| Accenting | Circle with the rake | Square with the rake | Square with the cake |
| Accenting | Square with the rug | Circle with the rug | Circle with the jug |
| Accenting | Square with the man | Circle with the man | Circle with the van |
| Accenting | Circle with the fire | Triangle with the fire | Triangle with the tire |
| Accenting | Circle with the tie | Square with the tie | Square with the pie |
| Accenting | Triangle with the bowl | Circle with the bowl | Circle with the troll |
| Accenting | Triangle with the sword | Square with the sword | Square with the board |
| Accenting | Circle with the fan | Triangle with the fan | Triangle with the pan |
| Accenting | Triangle with the pants | Circle with the pants | Circle with the ants |
| Accenting | Square with the pillow | Triangle with the pillow | Triangle with the willow |
| Accenting | Square with the shirt | Circle with the shirt | Circle with the skirt |
| Accenting | Circle with the sink | Square with the sink | Square with the ink |
| Accenting | Triangle with the swing | Square with the swing | Square with the wing |
| Accenting | Circle with the shower | Square with the shower | Square with the flower |
| Deaccenting | Triangle with the box | Square with the box | Square with the fox |
| Deaccenting | Square with the clock | Triangle with the clock | Triangle with the lock |
| Deaccenting | Square with the coat | Circle with the coat | Circle with the goat |
| Deaccenting | Triangle with the duck | Circle with the duck | Circle with the truck |
| Deaccenting | Square with the lamp | Triangle with the lamp | Triangle with the stamp |
| Deaccenting | Triangle with the lock | Circle with the lock | Circle with the block |
| Deaccenting | Circle with the phone | Triangle with the phone | Triangle with the bone |
| Deaccenting | Triangle with the cat | Circle with the cat | Circle with the bat |
| Deaccenting | Square with the train | Circle with the train | Circle with the plane |
| Deaccenting | Square with the house | Triangle with the house | Triangle with the mouse |
| Deaccenting | Circle with the rat | Square with the rat | Square with the bat |
| Deaccenting | Triangle with the candle | Square with the candle | Square with the sandal |
| Deaccenting | Triangle with the chair | Circle with the chair | Circle with the bear |
| Deaccenting | Square with the dog | Triangle with the dog | Triangle with the log |
| Deaccenting | Circle with the nest | Square with the nest | Square with the vest |
| Deaccenting | Square with the tree | Circle with the tree | Circle with the bee |
Appendix B: Acoustic Details of Experimental Stimuli
Here we illustrate similarities and differences in the acoustic properties of the auditory stimuli across experimental conditions, by providing acoustic measurements for each of the shapes and attributes (Table B1). Measurements were taken from the segment of speech including each word and the preceding determiner (e.g. “the square”, “the house”). Accented and deaccented items differ significantly with respect to the acoustic characteristics of the first mention of the attribute (and the second mention, prior to cough-splicing), but not with respect to the acoustic characteristics of the shape names (Table B2) or of the cough-spliced target words (Table B3), with the exception of a small but statistically significant difference in the maximum intensity of the second shape name between conditions. To confirm that apparent effects of anticipatory deaccenting in Experiment 1 are not in fact due to listeners using the difference in maximum intensity of the second shape name between conditions as a more proximal cue to the accent status of the target word, we ran additional regression models including the maximum intensity of the second shape name as a control factor. This did not result in a significant improvement in model fit, and effects of condition remained significant, suggesting that anticipatory deaccenting influenced listeners’ responses above and beyond effects of more proximal acoustic cues to the accent status of the final word.
Table B1.
Means and standard errors for the acoustic measurements of each shape and attribute from the deaccenting (DA) and accenting (AA) conditions, prior to the addition of the cough.
| Shape 1 | Attribute 1 | Shape 2 | Attribute 2 | ||
|---|---|---|---|---|---|
| Duration (ms) | DA AA |
572 (20.8) 571 (21.5) |
476 (24.3) 556 (21.3) |
567 (21.2) 569 (15.9) |
528 (21.9) 575 (17.5) |
| Mean F0 (Hz) | DA AA |
233 (7.22) 234 (2.69) |
188 (1.39) 207 (2.25) |
227 (3.45) 220 (2.50) |
221 (6.41) 208 (2.24) |
| Minimum F0 (Hz) | DA AA |
189 (6.11) 192 (2.30) |
179 (1.74) 188 (2.93) |
182 (4.60) 187 (3.54) |
161 (4.20) 175 (4.57) |
| Maximum F0 (Hz) | DA AA |
283 (3.50) 288 (3.55) |
212 (5.54) 237 (5.64) |
289 (6.26) 294 (4.81) |
275 (7.65) 264 (8.70) |
| Mean intensity (dB) | DA AA |
78.8 (.196) 78.3 (.365) |
74.2 (.388) 76.8 (.654) |
77.3 (.187) 76.8 (.283) |
71.9 (.312) 75.6 (.490) |
| Maximum intensity (dB) | DA AA |
82.9 (.207) 82.5 (.329) |
78.9 (.531) 80.9 (.231) |
81.2 (.169) 80.5 (.309) |
78.1 (.483) 80.9 (.545) |
Table B2.
Unpaired two-tailed t-test results comparing the acoustic measurements for each shape and attribute in the accenting vs. deaccenting conditions, prior to the addition of the cough.
| Shape 1 | Attribute 1 | Shape 2 | Attribute 2 | |
|---|---|---|---|---|
| Duration (ms) |
t=0.013 n.s. |
t=2.55 p<0.05* |
t=0.822 n.s. |
t=1.68 p<0.10° |
| Mean F0 (Hz) |
t=0.196 n.s. |
t=7.33 p<0.001*** |
t=1.68 p<0.10° |
t=1.83 p<0.10° |
| Minimum F0 (Hz) |
t=0.577 n.s. |
t=2.84 p<0.01** |
t=0.918 n.s. |
t=2.3 p<0.05* |
| Maximum F0 (Hz) |
t=1.04 n.s. |
t=3.21 p<0.005* |
t=0.689 n.s. |
t=0.928 n.s. |
| Mean intensity (dB) |
t=1.21 n.s. |
t=3.46 p<0.05* |
t=1.53 n.s. |
t=5.82 p<0.001*** |
| Maximum intensity (dB) |
t=0.92 n.s. |
t=3.10 p<0.01* |
t=2.06 p=0.05* |
t=3.78 p<0.001*** |
°Marginally significant;
Significant at 0.05 level;
Significant at 0.01 level;
Significant at 0.001 level.
Table B3.
Between-condition (deaccenting=DA; accenting=AA) comparison of the acoustic measurements of the final determiner and cough-spliced word.
| Mean | Standard error | t | p | ||
|---|---|---|---|---|---|
| Duration (ms) | DA AA |
441 440 |
28.4 21.5 |
0.03 | n.s. |
| Mean F0 (Hz) | DA AA |
206 204 |
6.23 3.45 |
0.29 | n.s. |
| Minimum F0 (Hz) | DA AA |
169 175 |
8.41 7.06 |
0.51 | n.s. |
| Maximum F0 (Hz) | DA AA |
233 229 |
7.31 4.63 |
0.46 | n.s. |
| Mean intensity (dB) | DA AA |
78.6 79.2 |
0.22 0.21 |
1.85 | < 0.10 |
| Maximum intensity (dB) | DA AA |
88.6 88.6 |
0.0005 0.0004 |
0.10 | n.s. |
Footnotes
It is also possible that accent shape differences arise along a continuum rather than being as strictly categorical as the distinction between “contrastive” and “standard” accents implies. The point about deaccenting is unaffected.
One reason that a speaker might not consistently use anticipatory deaccenting in language production is because of variation in the amount of upcoming material a speaker has planned when he or she begins to speak. For example, when a speaker has not yet planned the second phrase in (6), the trigger for anticipatory deaccenting (i.e. the upcoming repetition of fugues) is not available when fugues is first produced. Therefore, repetition across parallel phrases sometimes elicits anticipatory deaccenting, as in (3), and sometimes does not, as in (6).
We also recorded eye movements in Experiment 1, using an SRI EyeLink 2 eye-tracker. We had hoped that eye movements would provide information about the time course of interpretation. However, because the task was to click and drag the first shape most fixations remained on that shape, only shifting to the target shape late in the utterance. Therefore, the fixation data were not sensitive to any potential effects of deaccenting prior to the onset of the final word.
References
- Baayen RH, Davidson DJ, Bates DM. Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language. 2008;59:390–412. [Google Scholar]
- Barr DJ, Levy R, Scheepers C, Tily HJ. Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language. 2013;68:255–278. doi: 10.1016/j.jml.2012.11.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bates D, Maechler M, Dai B. lme4: Linear mixed-effects models using S4 classes. R package version 0.999375–28. 2008 Available at: http://lme4.r-forge.r-project.org/
- Birch S, Clifton C. Focus, accent, and argument structure: Effects on language comprehension. Language and Speech. 1995;38(4):365–391. doi: 10.1177/002383099503800403. [DOI] [PubMed] [Google Scholar]
- Buring D. Semantics, intonation, and information structure. In: Reiss R, editor. The Oxford Handbook of Linguistic Interfaces. Oxford Univ. Press; 2007. [Google Scholar]
- Carbary KM, Gunlogson C, Tanenhaus MK. Deaccenting cues listeners to upcoming referents. Presented at the LSA Annual Meeting; San Francisco, CA. 2009. [Google Scholar]
- Chomsky N. Deep structure, surface structure, and semantic interpretation. In: Steinberg D, Jakobovits L, editors. Semantics: An Interdisciplinary Reader in Philosophy, Linguistics, and Psychology. Cambridge University Press; Cambridge: 1971. [Google Scholar]
- Cruttenden A. Intonation. Cambridge University Press; Cambridge: 1986. [Google Scholar]
- Dahan D, Tanenhaus MK, Chambers CG. Accent and reference resolution in spoken language comprehension. Journal of Memory and Language. 2002;47:292–314. [Google Scholar]
- Davies M. The Corpus of Contemporary American English: 450 million words, 1990-present. 2008 Available online at http://corpus.byu.edu/coca/
- Grodner DG, Sedivy JC. The effect of speaker-specific information on pragmatic inferences. In: Pearlmutter N, Gibson E, editors. The processing and acquisition of reference. MIT Press; Cambridge, MA: 2011. [Google Scholar]
- Holm S. A simple sequential rejective multiple test procedure. Scandinavian Journal of Statistics. 1979;6:65–70. [Google Scholar]
- Ito K, Speer SR. Anticipatory effects of intonation: eye movements during instructed visual search. Journal of Memory and Language. 2008;58:541–573. doi: 10.1016/j.jml.2007.06.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kurumada C, Brown M, Tanenhaus MK. In: Miyake N, Peebles D, Cooper RP, editors. Prosody and pragmatic inference: It looks like adaptation; Proceedings of the 34th Annual Conference of the Cognitive Science Society; Austin, TX: Cognitive Science Society; 2012. pp. 647–652. [Google Scholar]
- Ladd DR. The structure of intonational meaning: Evidence from English. Bloomington: Indiana University Press; 1980. [Google Scholar]
- Ladd DR. Intonational phonology. 2. Cambridge Studies in Linguistics; 2008. [Google Scholar]
- Mack JE, Clifton C, Frazier L, Taylor PV. (Not) hearing optional subject: the effects of pragmatic usage preferences. Journal of Memory and Language. 2012;67:211–223. doi: 10.1016/j.jml.2012.02.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mattys SL, Davis MH, Bradlow AR, Scott SK. Speech recognition in adverse conditions: a review. Language and Cognitive Processes. 2012;27(7–8):953–978. [Google Scholar]
- Moore BCJ. An introduction to the psychology of hearing. 6. Emerald; Brill, London, UK: 2012. [Google Scholar]
- Pierrehumbert J, Hirschberg J. Intentions in communication. Cohen, Morgan and Pollack: MIT press; 1990. The meaning of intonational contours in the interpretation of discourse; pp. 271–311. [Google Scholar]
- R development core team. R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing; 2010. http://www.R-project.org. [Google Scholar]
- Roberts C. OSU Working Papers in Linguistics. 1998. Information structure in discourse: towards an integrated formal theory of pragmatics. [Google Scholar]
- Rooth M. A theory of focus interpretation. Natural Language Semantics. 1992;1(1):75–116. [Google Scholar]
- Salverda AP, Kleinschmidt D, Tanenhaus MK. Immediate effects of anticipatory coarticulatory information in spoken-word recognition. Journal of Memory and Language. doi: 10.1016/j.jml.2013.11.002. (in press) [DOI] [PMC free article] [PubMed] [Google Scholar]
- Samuel AG. Phonemic restoration: Insights from a new methodology. Journal of Experimental Psychology: General. 1981;110:474–494. doi: 10.1037//0096-3445.110.4.474. [DOI] [PubMed] [Google Scholar]
- Samuel AG. Phoneme restoration. Language and Cognitive Processes. 1996;11:647–653. [Google Scholar]
- Schwarzschild R. GIVENness, avoid F and other constraints on the placement of accent. Natural Language Semantics. 1999;7(2):141–177. [Google Scholar]
- Selkirk EO. Sentence Prosody: Intonation, Stress and Phrasing. In: Goldsmith JA, editor. The Handbook of Phonological Theory. Blackwell; London: 1996. [Google Scholar]
- Sherman BL. Unpublished master’s thesis. University of Wisconsin; Milwaukee, WI, USA: 1971. Phonemic restoration: An insight into the mechanisms of speech perception. [Google Scholar]
- Simmons JP, Nelson LD, Simonsohn U. False-positive psychology: undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological Science. 2011;22(11):1359–1366. doi: 10.1177/0956797611417632. [DOI] [PubMed] [Google Scholar]
- Steedman M. Information structure and the syntax phonology interface. Linguistic Inquiry. 2000;31(4):649–689. [Google Scholar]
- Stoyneshka I, Fodor JD, Fernandez EM. Phoneme restoration methods for investigating prosodic influences on syntactic processing. Language & Cognitive Processes. 2010;25(7):1265–1293. [Google Scholar]
- Terken J, Hirschberg J. Deaccentuation of words representing ‘given’ information: Effects of persistence of grammatical function and surface position. Language and Speech. 1994;37:125–145. [Google Scholar]
- Terken J, Nooteboom SG. Opposite effects of accentuation and deaccentuation on verification latencies for given and new information. Language and Cognitive Processes. 1987;2(3–4):145–163. [Google Scholar]
- Van Deemter K. Contrastive stress, contrariety, and focus. Focus: Linguistic, Cognitive, and Computational Perspectives. 1999:3–17. [Google Scholar]
- Warren RM. Perceptual restoration of missing speech sounds. Science. 1970;167(3917):392–393. doi: 10.1126/science.167.3917.392. [DOI] [PubMed] [Google Scholar]
- Watson D, Tanenhaus MK, Gunlogson C. Interpreting pitch accents in on-line comprehension: H* vs. L+H*. Cognitive Science. 2008;32(7):1232–1244. doi: 10.1080/03640210802138755. [DOI] [PubMed] [Google Scholar]