

Abstract
Solvation is a fundamental contribution in many biological processes and especially in molecular binding. Its estimation can be performed by means of several computational approaches. The aim of this review is to give an overview of existing theories and methods to estimate solvent effects giving a specific focus on the category of implicit solvent models and their use in Molecular Dynamics. In many of these models, the solvent is considered as a continuum homogenous medium, while the solute can be represented at the atomic detail and at different levels of theory. Despite their degree of approximation, implicit methods are still widely employed due to their trade-off between accuracy and efficiency. Their derivation is rooted in the statistical mechanics and integral equations disciplines, some of the related details being provided here. Finally, methods that combine implicit solvent models and molecular dynamics simulation, are briefly described.
Keywords: Implicit solvent models, Poisson-Boltzmann equation, Generalized Born model, continuum electrostatics, molecular dynamics
Introduction
It is well accepted that the role of solvent in biochemical processes is crucial. The estimation of hydration energy, binding energy, pKa of ligands or titratable protein residues heavily depends on a good description of the solvent behavior. The delicate balance between entropic desolvation penalty and enthalpic gain, that often characterize protein-protein and protein-ligand binding, is an example of a phenomenon extremely challenging to be quantitatively described [1]. In Molecular Dynamics, the calculation of the evolution and the equilibration of the solvent degrees of freedom often constitute the main sources of computational cost of the simulation. When performing a Monte Carlo move in a system composed by biomolecules surrounded by explicit solvent, the probability of randomly drawing a configuration where the solute and solvent displacements are compatible is practically negligible. Interestingly, one is not usually interested in knowing the solvent behavior per se, but rather its effects on the solute. In this context, implicit solvent methods find their application, aiming at reproducing the overall, thermally averaged, solvent effect at a lower computational cost.
This approach can be justified by a mean field approximation of the solvent in statistical mechanical terms [2]. Intuitively, one of the underlying assumptions that justify considering water molecules as a continuum medium is their relatively short relaxation time. The time typically needed by water molecules to react to a perturbation is much shorter than that corresponding to macromolecular conformational changes. In a pictorial view, and within the time frame of a typical water molecule displacement, the aqueous solvent ‘sees’ the protein in a fixed conformation, and, conversely, the protein cannot ‘distinguish’ among contributions of individual bulk water molecules. Of course, this kind of reasoning cannot be applied to water molecules that are undergoing a specific interaction and its validity can be also questioned in the case of water molecules located in deep pockets where the diffusion can be very different from that in the bulk solvent. However, implicit solvent models neglect the individual molecular behavior of the solvent with respect to explicit solvent simulations. As a consequence, some important phenomena that involve, for instance, hydrogen bonds, hydrophobic effects and, in general, a non-bulk solvent behavior can be missed [2]. Despite the mentioned approximations, implicit methods are still of wide interest because of their algorithmic efficiency, the much reduced number of degrees of freedom requiring simulation and equilibration, and the relatively good compromise between model accuracy and efficiency [3].
Implicit solvent methods can be used for several aims: fixed point calculations, polarizable solvent simulations and scoring docking poses [4–6]. They can be run in conjunction with either a classical atomistic treatment of the solute [7,8], or with quanto-mechanical calculations [9]. The physical phenomenon that is mostly, but not exclusively, represented in implicit solvent approaches is the linear response to the electric field generated by the solute. Usually, this response is originated by molecular polarization but also the salt effects can be, to some extent, accounted for.
Here, a general derivation of several implicit solvent models from statistical mechanical foundations is provided and then some specific approaches are described, grouped in: Semi-Heuristic, Poisson-Boltzmann (PB) based, Generalized Born (GB), Integral Equation based and combined methods, i.e. those that join PB or GB methods with atomistic simulations. Finally, other approaches are mentioned with their own peculiarities.
1. Implicit solvent description in the statistical mechanics framework
Let us distinguish the Cartesian coordinates of a system in those, X, describing the solute, and those, Y, describing the solvent, which can also possibly contain a dissociated salt. For a system at the thermodynamic equilibrium characterized by the temperature T, the joint probability of given configuration, that is of the (X,Y) pair, is given by [2]:
| (1) |
where U(X,Y) is the total potential energy of the system, the denominator is a normalization coefficient called partition function and kB is the Boltzmann constant. We assume that the potential energy can be written as the sum of intra-solute (SS), intra-solvent (WW), and solvent-solute (WS) interactions. This assumption, which is always verified in traditional pair-wise additive force fields, reads:
| (2) |
Due to the fact that P(X,Y) is the probability density of the system, any macroscopic quantity can be obtained by computing the corresponding statistical average, or expectation value. Henceforth, the expectation of the microscopic function Q(X,Y) corresponding to the observable Q will be indicated as EX,Y {Q(X,Y)}, where the subscript specifies on which variables the expectation operator acts, or, alternatively, by < Q(X,Y) >.
Let us now consider an observable Q corresponding to the average of a microscopic function of only the solute coordinates {X}:
| (3) |
From this equation it is clear that in order to get the needed average, the knowledge of the possible solvent configurations, together with their statistical weights, is needed. The global probability distribution governing the thermodynamic equilibrium in the canonical ensemble is the Boltzmann distribution. An important question that may arise is whether we can still get an average value of a solute observable without having a specific knowledge of the configurations of the solvent.
To this aim, instead of considering the joint probability, one can consider the restriction of the probability to the solute, by integrating over the solvent space. Therefore one can write:
| (4) |
This can be formally considered as the average value over Y, (expectation operator is over Y) of an observable always equal to 1 for each value of the pair X, Y. Then, in a system at temperature T, the reduced probability is:
| (5) |
that we can more compactly rewrite as:
| (6) |
This last formula has a nice analogy with the general form of the joint distribution. This time, however, the joint probability is replaced by its solvent-averaged version P(X) and for this reason the potential W(X) is called Potential of Mean Force (PMF). It can be shown that in cartesian coordinates if the chosen observable is the force then it holds:
| (7) |
From this fact derives the name potential of “mean force”, where “mean” means, in this case, average with respect to the solvent degrees of freedom. As other potentials, its absolute value is up to a constant offset. It is usual to set the PMF reference as the value where there are no interactions between solvent and solute, that is U(X, Y)ws = 0, in particular we can set this relation:
| (8) |
This relation is particularly interesting because it mixes the free energy ΔGs(X) (solvent-solute related) to the intra-solute potential energy U(X)ss; hence W(X) is a free energy.
In this setting, we can observe that the following relation holds:
| (9) |
In particular when U(X, Y)ws = 0, then we must have ΔGs(X) = 0. Consistently, the term ΔGs is named solvation free energy and it is the energy needed to transfer the solute from vacuum to the solvent.
We can introduce now the concept of thermodynamic integration. We write the potential energy as:
| (10) |
where λ is a coupling parameter between the uncoupled (λ = 0) and the coupled system λ = 1). We can estimate the solvation free energy by again integrating over the solvent degrees of freedom and then over the coupling parameter λ. In other terms, we estimate the reversible work for moving from state λ = 0 to λ = 1:
| (11) |
The solvation free energy can be decomposed in both a polar (electrostatics) ΔGes term and a non polar (van der Waals, Pauli exclusion principle), ΔGnp energy term [2]:
| (12) |
Implicit methods are a way to estimate ΔGs; other methods try to capture the full free energy of the system thus also estimating the expectation over X of U(X)ss [10,11]. Following [12] and further detailing the term ΔGnp, one has:
| (13) |
where ΔGvdW accounts for solute-solvent the van der Waals interactions and ΔGcav is the energy needed to create a cavity into the solvent to accommodate the solute. Figure 1 shows the thermodynamic cycle underlying this model.
Figure 1. Representation of the thermodynamic cycle for computing the solvation energy.
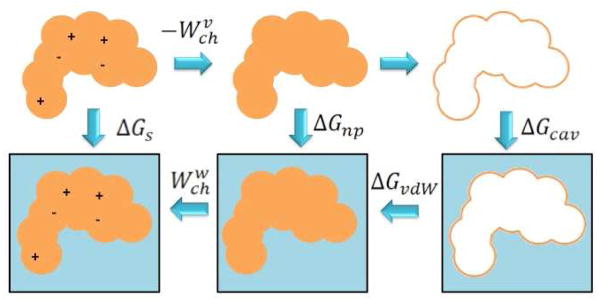
In the cycle the electrostatic energy component is split in the discharging in vacuum , and charging in solvent . “np” subscript stands for “non polar”, “cav” for “cavitation”, “s” for “solvation” and “vdW” for “Van der Waals”.
A key quantity very often estimated is the binding energy between a ligand and a target protein, it can be computed by:
| (14) |
Where is the solvation free energy of the complex, and are the solvation free energy of the ligand and the target, respectively.
2. Implicit solvent
With the aim of estimating ΔGs within an implicit solvent framework, one can approximate the set of water molecules as a continuum, isotropic, linearly reactive medium. This mean-field approximation of the underlying system opposes to the more accurate explicit solvent modeling where each single particle is modeled in a “classical” way, in a deterministic or stochastic dynamics [13]. In statistical mechanical terms, as already discussed, one is approximating the total energy of the system with the Potential of Mean Force, that is, the solvent-averaged version of the energy.
A crucial role in implicit modeling is played by the electrostatic contribution (or its approximations) to the energy of the system, the polar part. Electrostatics is of particular relevance because of its long range nature; in biological molecular system we can say that at long distances electrostatic is the only interaction that takes place between molecules. From another perspective, at short distances, electrostatic interactions give specificity, for instance, to the binding between an enzyme and its substrate. Intensity and peculiarity of the electrostatic field in DNA minor/major grooves provides high specificity and permits its key role in biological processes [14].
Several specific implicit models have been proposed in the past. Some of them estimate the electrostatic potential and then deduce the energy of the system, while others skip the ‘potential computation’ and directly estimate the energy. We can try to split the methods in the following categories: some ad-hoc semi-heuristic methods (among other examples are ASP [15], EEF1 [16]), those based on Poisson-Boltzmann theory (PB) [17], those based on Generalized-Born (GB) approximation [18], ‘combined methods’, which use as internal ‘routines’ the previous models such as in the case of MMPB [19], LIE [20], LIECE [21], and other peculiar methods [22–27]. In the following, the above mentioned models will be discussed with particular emphasis on PB and GB that are among the most frequently used approaches.
2.1. Semi-Heuristic methods
This class of methods comprises a common geometry-driven approach. Among the others we consider here ASP and EEF1. These kinds of ‘geometric’ methods need the notion of Solvent Accessible Surface (SAS). The SAS or, Lee and Richards surface [28], is the union of a set of balls (atoms) whose van der Waals radii are increased by a probe radius. The probe radius represents the spherical approximation of a water molecule and is usually set to 1.4 Å.
The ASP [15] method, implemented in CHARMM [8] (a well known molecular dynamics software) is based on the concept of Solvent Accessible Surface Area: the Solvent Accessible Surface Area (SASA) of an atom is the area of the Lee and Richards solvent-accessible portion of an atom. All the approaches based on the SASA assume that the free solvation energy ΔGs is a linear combination of the contribution of each single atom in the molecule, namely:
| (15) |
where Ai is the SASA of the i-th atom and Δσi is its atomic solvation parameter. The atomic solvation parameter Δσi, in units of [cal mol−1 Å.2], is an estimate of the free solvation energy required to transfer the atom from vacuum to water divided by the exposed surface area and depends on the atom type. In [15] the atom types are the following: C, uncharged O or N, S, O−, and N+.
From the previous equation we observe that the energy is not a function of a particular unknown (let’s say the potential) of a model equation, but it is a direct consequence of the geometry of the molecule. The formula is linear in the SASA elements thus leading to the simplest energy model and, practically, its accuracy depends on how ‘well’ the coefficients Δσi are estimated; the usual approach is the least squares fitting. The key advantage of the SASA approach is that its easy formula allows computing forces analytically for a molecular dynamics simulation [15]. This advantage is counterbalanced by the high degree of the approximation of the model.
Another proposed model, less heuristic and fitted on experimental data, is EEF1 from Karplus and Lazaridis [16]. This model combines an excluded volume approach with a modified version of the polar hydrogen energy function [8]. Again, as in the SASA/ASP method, the free solvation energy is a superposition of local energy components. This aspect is corroborated by theoretical studies on solvation thermodynamics [16]. In particular, the atoms are grouped so as that the contribution of each group to the total energy is equal to the energy of the group in a reference compound minus the energy due to the presence of the other atom groups. Consequently, the solvation free energy can be decomposed into a sum of pairwise interactions. EEF1 assumes that the decay with distance of the solvation free energy density is Gaussian-shaped. A distance dependent dielectric function is employed and the neutralization of ionic side chains is required. EEF1 has been successfully applied in molecular dynamics simulations.
2.2. Poisson-Boltzmann theory
Poisson-Boltzmann equation (PB) was historically first proposed by Gouy in 1910 and by Chapman in 1913. The version of the equation that nowadays we use is due to Debye and Huckel whose theory was successfully applied to ionic solutions. A key result is the study of Kirkwood who introduced the concept of Potential of Mean Force (PMF) and observed that the Poisson-Boltzmann assumption consists in the substitution of the PMF with the mean electrostatic potential. Despite this approximation and the non complete consistency with statistical mechanics of the non linear version of the equation [29], the Poisson-Boltzmann machinery was, and still is, able to explain interesting phenomena involving biomolecules in solution.
PB equation, as anticipated, is a non linear partial differential equation and the first numerical attempts to solve it were carried first via simple geometric models such as spheres (protein) and cylinders (DNA) [30][31] and, subsequently, by employing more realistic representations of the molecular surface [32]. The choice and definition of the molecular surface was [28] and still is [33] a matter that deserves a deep attention from several viewpoints.
In order to build the PB equation we can start from considering the electrostatic potential equation in a non-uniform dielectric medium in a region devoid of free charge. Its space varying value is described by ε(r) where r is a vector in R3. Differential Gauss’s law for the electric displacement sets a relationship for the electrostatic potential ϕ(r):
| (16) |
When a charge density ρ(r) is present, the equation has to be complemented by a source term:
| (17) |
The assumption needed to obtain the PB equation consists in saying that the ionic potential of mean force is equal to the average electrostatic potential multiplied by the charge borne by the ion. In the light of this fact, the PB equation reads (in m.k.s units):
| (18) |
where ρfixed(r) includes only fixed molecular (solute) charges and:
| (19) |
where is the bulk concentration of the i-th ionic species, Zi is its valency, q is the proton charge, kB is the Boltzmann constant, T is the temperature and χ(r) is 1 if the position r is accessible to the ionic cloud and zero otherwise. PB equation is often linearized by assuming that the potential has a small value, therefore inducing a linear relation between the solvent charge and the potential:
| (20) |
In this context, a key parameter is the Debye constant kD, which accounts for the screening effect of the salt and thus characterizes the rate of the exponential decay of the potential in the solvent:
| (21) |
Where λD is the Debye length and εw is the dielectric constant of bulk water. Based on these premises, a possibly important discrepancy in the computed potential between the linearized equation and the full non linear version of the equation can be obtained for highly charged systems such as DNA/RNA. The linear version of the equation could lead to a wrong estimation of the electric field and to a lower screening effect. For most of the proteins, however, the linearized version of the equation gives sufficiently accurate electrostatic energy estimations.
Once the potential field is computed (i.e. the PB equation is solved) it can be shown by a variational argument [17] that the total electrostatic energy can be decomposed in the sum of three terms:
| (22) |
The first is the usual energy due to fixed charges (solute) , the second term arises from ions , and lastly we have a term due to the solvent . The term is
| (23) |
Then the so-called osmotic term is:
| (24) |
This term is non zero when the ions concentration is space-varying and we indicate by ci(r) the local ionic concentration:
| (25) |
And finally the last solvent term:
| (26) |
When the linearized PB equation is considered it can be shown that all the energy terms boil down to .
Following [3], the electrostatic energy term can be split in three further terms. In a first term, , the Coulombic energy involving direct interaction between fixed charges, assuming each of them lie in uniform dielectric medium, is accounted for. The second term is the so-called reaction field energy, , which is the energy due to the interaction between fixed charges and polarization charges, which are located where there is a change in dielectric constant. Finally, the third term accounts for the interaction with the potential generated by mobile ions in solution; it is called since it originates from excess charge in solution. Therefore, the total electrostatic energy can be written as:
| (27) |
With this writing we can distinguish the solvent independent energy contribution from ΔGes, which arises from the solvent.
In the linearized PB equation framework the energy reduces to:
| (28) |
Further, if no salt is present (i.e. no ions), the energy reduces to the Poisson equation (i.e. Laplace plus a discontinuous dielectric):
| (29) |
In other terms, the only way the solute ‘feels’ the solvent is by the reaction field energy that is the energy due to the polarization charge localized at the solute-solvent interface. It is worth adding that this polarization charge arises from both the solute and the solvent media, the largest part being however contributed by the latter due to its large polarizability.
The numerical solution of the Poisson-Boltzmann equation poses interesting questions not only about efficiency but also from the geometrical model point of view. Indeed, a preliminary step that one must perform in order to solve the equation is defining the dielectric constant, ε(r), in space and the ion cloud characteristic function χ(r). This aspect is particularly interesting since the definition of the surface literally shapes the discontinuity of the system. Early implementations of PB solvers used the van der Waals surface as dielectric function and a Finite Difference Solver scheme [34][3]. More recently, the Solvent Excluded Surface, or Connolly surface has been widely used as a reference surface together with Boundary Element and Finite Element methods [34–41]. Despite the physical soundness and the widespread utilization of the Connolly surface, the latter however present some limitations [33] and alternative approaches have been investigated [33][41,42]. Finite difference PB solvers map fixed charges on point of a grid and use molecular surface information to assign a dielectric value to each grid midpoint (middle point between two grid points) and, indirectly, to map also the ionic accessibility function. In the simplest approaches, the latter is simply the geometric complement to the solvent excluded volume. In more advanced ones, however, a further region surrounding the molecular surface, named Stern layer, is considered, where the dielectric behavior is assumed to be the same as that of bulk water but where no ions are allowed to be present. Its width is usually quite short, around 2Å, and avoids unphysically high ionic concentrations in response to high charges located near the molecular surface. The resulting linear system can be solved via Gauss-Seidel or other iterative methods [34][3].
In order to compute the full PMF also non-polar energy term must be included. This energy component is often roughly estimated based on the Solvent Accessible surface area. Here, in contrast to what is done in the ASP approach, the SASA is only used to estimate the non polar component, that is:
| (30) |
where γ has the physical dimension of a surface tension, its value is typically in the range of 20 to 30 [cal mol−1 Å.2] and Asasa is the total solvent accessible surface area. The method by which one estimates the solvent free energy using both PB equation and the SASA is usually referred as PBSA [19]. SASA approach is quite a crude one, and still work has to be done to get a full modeling of hydrophobic effects.
2.3. Generalized Born
Poisson-Boltzmann equation is an elegant theory that captures some of the most relevant aspects of the underlying physics. However, the solution of either the linear or non-linear PB equation is a non trivial task from both the numerical and computational time point of view. For this reason, the so-called Generalized Born models [18] gained more attention. This is due to their relatively simple conceptual basis, their highly advanced parametrization, and their efficient practical implementation, largely originating from the fact that forces can be calculated analytically.
In the case of a simple ion of radius a and charge q immersed in a dielectric εw both the potential and the electrostatic component of the solvation free energy can be found analytically. This result is known as the Born formula:
| (31) |
If we try to model a molecule as set of N atoms (spheres) of radii a1, a2, … , aN and charges q1, q2, … , qN and if we denote by rij the pairwise distances of the atom centers, then the electrostatic solvation energy can be written.
| (32) |
This formula contains both Born terms and pairwise Coulomb terms. This formula holds if we are assuming that rij ≫ ai, ∀i. The purpose of GB theory consists in finding a form for the energy that somehow recalls equation (32) but that removes the hypothesis rij ≫ ai, ∀i.. In order to overcome the limitations of (32), GB tries to give a unified model to ai and to rij. GB theory prescribes to estimate the electrostatic solvation energy as:
| (33) |
Where fGB is a function that should be equal to the product of the “effective Born radii” Ri and Rj when rij is small and equal to rij at larger distances. Note that in this equation the reference to the interior dielectric constant is not present, and the geometry is assumed to be intrinsically spherical. Thus it is intuitive that the method will be as accurate as fGB captures the geometry of the problem and the correct parameterization of this term is crucial. A typical [18] form for fGB is the following:
| (34) |
where Ri are the effective Born radii of atoms which, not only are different from van der Waals radii, but usually depend also on the position of other atoms. Depending on how these radii are approximated, different GB approaches can be obtained: however in all GB methods the key approximation to compute the radii stands in assuming that the electric displacement field behaves as a Coulomb term. Under this approximation, the Born radii are computed as:
| (35) |
Several improvements can be added to the baseline model. It can be shown that if the internal dielectric constant εin is taken into account then GB equation becomes:
| (36) |
The GB equations can also be modified in order to incorporate salt effects: in particular it has been shown that, at low salt concentrations, PB and GB methods give similar results [18]. Among other variations we cite: the Surface GB (SGB) [43] in which the pairwise nature of GB is mitigated by an integral of the entire surface, GBSA in which non polar energy terms are estimated by using the SASA [44], the Generalized Born using Molecular Volume or Generalized Born with simple Switching [45], multiple dielectric GB [46] and Generalized Born like models [47].
In general, a common trait of most of the GB literature consists in slightly different parameterizations and empirical correction terms used to better fit experimental or PB data with the consequent risk of over-fitting and a decrease of predictivity. Another caveat, as we already mentioned, is the key assumption of GB for which the displacement field behaves as a Coulombic term. Despite these drawbacks, GB models are interesting because not only they are able to capture a significant part of the electrostatic behavior of molecules, but, additionally, their closed form allows an easy manipulation, for instance in the computation of forces, thus leading to a relatively simple embedding of GB routines in molecular dynamics codes. In the following, we detail the state of the art AGBNP1/2 method proposed by Gallicchio and Coworkers [12][48].
2.3.1. Analytical Generalized Born Plus Non Polar
A particularly elaborate method is due to Gallicchio and coworkers [12][48]. In this model the solvation free energy is split in three components:
| (37) |
where the non polar term is further partitioned into a cavity solvation free energy ΔGcav and a solute-solvent van der Waals dispersion interaction component ΔGvdW. The solute volume is modeled using Gaussian overlap, as discussed in [49], where the solute volume is computed using the Poincaré formula (inclusion-exclusion principle); in order to speed-up calculations switching functions are used for trimming Gaussian tails.
From the electrostatics point of view, this method is based on the pairwise descreening GB scheme where the Born radius of each atom is obtained by summing a suitably defined descreening function over its neighbors [12]. In contrast to other GB implementations, in AGBNP the volume scaling factors, which account for atomic overlap, are computed from the geometry of the molecule rather than being fitted either experimentally or with respect to Poisson-Boltzmann calculations. In this way AGBNP method has much less degrees of freedom with respect to other methods thus improving its prediction ability (transferability) across possibly new functional groups. Additionally, the inverse Born radii are clipped by a filter function that sets as lower and upper bounds respectively the values of 0 and 50 Å.
Concerning the non polar component of the energy, the cavity term is accounted using a SASA approach that employs augmented heavy atoms radii. These radii are defined as the van der Waals radii augmented by 0.5 Å. The solute-solvent van der Waals free energy is modeled by the expression:
| (38) |
where αi is a dimensionless parameter whose value is usually in the order of the unity and:
| (39) |
where ρw = 0.03328 Å−3 is the density of water at standard conditions, σiw, εiw are respectively the OPLS force field Lennard-Jones interaction parameters for the interaction of solute atom i with the oxygen atom of the TIP4P water model [50] and Rw = 1.4 Å is the radius of water molecule modeled as a sphere. AGBNP1 has been successfully applied to several applications involving molecular dynamics simulations [12].
In contrast to AGBNP1, in AGBNP2 the solvation free energy model takes into account explicitly hydrogen bonding with a dedicated energy term. The total energy reads as:
| (40) |
where ΔGhb represents a first solvation shell correction accounting for the solvation free energy that the continuum model for the solvent is not able to capture. Additionally, the pairwise descreening model is based on the Solvent Excluded Volume, rather than the van der Waals volume as per AGBNP1.
The model for ΔGhb is based on the geometry of the molecule, and tries to guess how much a solute atom can interact with a hydration site at the solute surface. The basic idea is to find the points in space where a sphere of radius Rw, representing a water molecule, can be located in order to form a hydrogen bond. The position rw of this water probe is a function of the positions of two or more neighboring atoms and can be written as:
| (41) |
where rD is the position of the heavy solute atom, rH is the position of the polar hydrogen and dHB is the distance between the heavy atom donor and the center of the water sphere. Similar relations hold for linear, triangular and tetrahedral displacements. Given the displacements, one has to estimate the magnitude of the hydrogen bonding correction. The latter is a function of the estimated water occupancy in the previously identified positions [48]. Let ww be the mentioned occupancy, the formula for hydrogen bonding reads:
| (42) |
where hw is a correction energy term that depends on the type of solute-water hydrogen bond, S(ww; wa, wb) is a polynomial switching function in which the two switching limits are wa = 0.15 and wb = 0.5.
AGBNP2 was successfully applied in molecular dynamics simulations: among other results it was shown, rather impressively, that this model was able to recover both the solvation barrier at 5 Å and the “second minimum” of the PMF simulation of propyl guanidinium and ethyl acetate in a bidentate coplanar formation where classical continuum models fail [51][33].
3. Implicit solvent in the calculation of binding free energies
The methods discussed on the previous sections represent the basic different frameworks used in implicit solvent modeling. In the context of biophysical simulations, PB and GB are typically coupled with higher level of theories, or further external parameterizations, in order to improve their accuracy in the description, for instance, of the solute. In particular, implicit solvent modeling has received great interest for estimating the binding affinity via MD or MC sampling, and it has been applied quite successfully in several cases.
The underlying idea of most free energy methods based on implicit solvent modeling, is to take advantage of the fact that the free energy is a state function and, as such, it can be decomposed in several contributions that are separately calculated. In other words, rather than explicitly simulating the binding between the two interacting partners (typically a protein and a small molecule ligand), a Born-Haber-like thermodynamic cycle is envisioned, where one is only concerned in estimating free energy differences. This procedure can be computationally convenient in terms of convergence. Any physical or unphysical transformation can therefore be exploited, provided that the cycle is properly closed. The estimation of relative binding free energies (ΔΔG) with this approach is straightforward. However absolute binding free energies (ΔG∘) could also be calculated with due precautions [52]. In the context of implicit solvent modeling, the solvation free energy comes as a natural contribution to the free energy of binding, and for this reason this quantity is usually (but not necessarily) used to build thermodynamic cycles.
It must be highlighted that whenever the transformation between states is performed by gradually mutating one state into another through intermediate steps, the free energy difference can be rigorously calculated by means of free energy perturbation [53] or thermodynamic integration [54] theories. These approaches, usually referred to as “pathway methods” regardless of the physical or unphysical nature of the transformation, are still relatively time consuming. For this reason, in the field of computer-assisted drug design, faster, albeit approximate, methods are often more advisable. The so called “end-points methods” necessitate the calculation of ensemble averages only for the initial and final states of the transformation, thus saving up valuable computational time. In general, the price to be paid for this is a loss in accuracy, and hence the need to introduce here and there corrections or ad hoc empirical parameters depending on the validity of the underlying approximations. Among these methods, in the following, we will focus our attention on two approaches which turned out to be particularly effective in calculating the binding free energy in the framework of implicit solvation models: the Linear Interaction Energy (LIE) method, and the Molecular Mechanics-Poisson Boltzmann/Generalized Born Surface Area (MM-PB/GB SA) methods.
3.1. Linear Interaction Energy (LIE) methods
The LIE method has been originally introduced by Åqvist and coworkers to calculate the absolute binding free energy of a series of 5 peptidomimetic inhibitors against endothiapepsin in the context of explicit solvent MD simulations [20]. Later, Sham and coworkers [55] have shown that LIE can be thought of as a special case of a more general and rigorous approach: it derives from a unified thermodynamic cycle based on the use of the Linear Response Approximation (LRA) to evaluate the electrostatic contribution to the binding free energy, and the Protein Dipoles Langevin Dipoles method (PDLD, or its semi-microscopic variant PDLD/S) [56] to estimate the non-electrostatic part. In particular, it can be shown that most of the weakest approximations underlying LIE are rooted in the latter contribution. Properly accounting for this term would require a formal derivation from statistical mechanics arguments similar to that employed in more advanced approaches such as the double-decoupling method [52]. The interested reader is referred to the paper by Sham and coworkers as well as to specific reviews [57] for further details. Here, our attention is rather directed on the theoretical basis of the linear response theory and on some technicalities required to employ LIE in the framework of implicit solvent models.
3.1.1. Linear response theory
The basic idea behind LIE and related methods is the possibility to calculate the electrostatic contribution of the solvation free energy by using the LRA. As it will be clear later, within the LIE terminology the word “solvation” is used in a fairly broad sense, meaning that the contribution one aims to calculate is related to the embedding of the solute in a certain medium having peculiar features, being it either the solvent itself or even the protein.
The linear response theory has been developed to describe electron transfer processes within a semi-macroscopic formalism, including quantum mechanical effects as well as solvent reorganization phenomena. It is based on the assumption, valid only under certain conditions, that the response of the system to the perturbation is linear with respect to the magnitude of the perturbation [58]. Here, the perturbation is represented by an electron transfer process (or, more in general, by a charge transfer process), and the response basically consists of the polarization of the solvent. It is worth noting that the linear regime is indeed the underlying assumption of most of implicit solvent approaches.
The change in free energy associated to the charge transfer between the initial and final states of the solute, can be described in terms of a coupling parameter λ varying from 0 to 1. Within a classical description, the 0 state represents an “uncharged” state of the solute, i.e. a solute with all partial charges set to zero. The 1 state rather indicates a “charged” solute where all partial charges are turned “on”, regardless of the overall net charge. In other words, the 0 and 1 states represent a solute that is electrostatically decoupled and coupled to the solvent, respectively. More formally, the electrostatic interaction energy between solute and solvent U in the state λ can be expressed as:
| (43) |
where qi represents the partial charge at the solute’s atom i, ϕi is the electrostatic potential on the same atom due to instantaneous position and orientation of the solvent molecules, and the sum runs over all the atoms of the solute [59]. As the system evolves, the value of the electrostatic potential fluctuates around the average value for the given state (0 or 1), and so does the interaction energy Uλ, leading to a Gaussian probability distribution function. Now, suppose to instantaneously change the charge state of the system by operating on λ, and to measure the corresponding interaction energy while keeping on propagating the Newton’s equation of motions for the system in the reference state. If enough statistics is collected, the probability distribution function of the energy difference p(ΔU) will be Gaussian shaped too. By applying such procedure on two independent simulations, one sampling from the “uncharged” state and the other from the “charged” one, the average values <ΔU0→1>0 and <ΔU1→0>1 can be calculated, where the <…>λ notation means that the ensemble average is evaluated over the configurations of the system sampled in the λ state. The probability distribution functions p(ΔU) can also be expressed as a configurational average, which for state 0 and state 1 takes the form [60]:
| (44) |
| (45) |
where dX indicates integration over the whole configurational space. The Dirac delta function δ is needed in order to consider only those configurations satisfying the condition: ζ = ΔU. These probabilities lead to free energy functions up to an additive constant:
| (46) |
| (47) |
where ΔG0→1 is the free energy difference between state 1 and state 0. Under the assumption that the probability distribution functions of eq. (44) and (45) are Gaussians, the corresponding free energy functions would be harmonic. It is useful to represent the free energy curves for the two states in a single plot. By borrowing the terminology from electron transfer theory, the “diabatic” free energy curves for two hypothetical states are reported in Figure 3. We stress that the reaction coordinate between the two states is the electrostatic energy difference between solute and solvent or, in other words, the solvent polarization energy. The free energy minima for state 0 and 1 are exactly located at <ΔU0→1>0 and <ΔU1→0>1, respectively, and it is possible to show that if the two curves are perfect parabolas with same curvature (meaning that the linear response approximation holds), they intersect exactly at ΔU = 0. This construction allows us to consider the charge transfer process as a jumping between surfaces driven by thermal fluctuations of the solvent [60]. By taking advantage of the cumulant expansion of the free energy characteristic of the perturbation theory,[53] the energetic components of this process can be made explicit. Accordingly, by truncating the expansion at the second order, the free energy difference from state 0 to 1 is:
| (48) |
where the first term on the left (average fluctuations in energy) represents the static energy gap between surfaces, that is the energy required to perturb the system while keeping it constrained in the reference state configuration, whereas the second term (mean squared fluctuations in energy) represents the relaxation (or reorganization) energy due to solvent polarization in response to the perturbation (see Figure 3). As pointed out by Levy and coworkers, [59] eq. (48) corresponds to a “one-step” thermodynamic perturbation calculation with a Gaussian fluctuation distribution. In a similar way, by taking state 1 as a reference, we have:
| (49) |
Figure 3. Pictorial representation of the linear-response approximation for a charging process of a solute in a polar solvent.

First, the interaction energy between solute and solvent <ΔU 0→1 >0 and <ΔU 1→0 >1 is calculated over time from two independent simulations sampling from the “uncharged” and “charged” state of the solute, respectively. Then, the probability distribution functions p(ΔU) and hence the free energy functions for both states are recovered. Under the assumption that fluctuations in interaction energies are Gaussian shaped, the free energy functions are harmonic, and they intersect exactly at zero. The charging process is finally described as a vertical jump from the red to the blue curve, followed by a dynamical relaxation on the latter free energy function. The free energy difference between the two states ΔG 0→1 is obtained by construction.
It is convenient to rearrange eq. 49 in order to express the free energy ΔG0→1 as a function of the configurations sampled in state 1:
| (50) |
Then, summing eq. 48 with eq. 50, and recalling that, under the assumption of a linear response, the mean squared fluctuations in state 0 and 1 are equal and then will cancel out, we finally obtain the LRA master equation [20]:
| (51) |
Obviously, a similar expression would have been obtained for the reverse transition.
3.1.2. LIE variants and significance of the empirical parameters
As previously mentioned, the LIE method can be derived in the context of the thermodynamic cycle reported by Sham and coworkers,[55] and illustrated in Figure 4. According to that cycle, the binding process is decomposed in several contributions that have to be estimated in order to recover the standard free energy of binding. Here, we will denote this quantity as ΔG∘1,1, where the subscript means that the binding free energy is evaluated for a ligand molecule having both electrostatic and van der Waals interactions “on”. This measure has to be distinguished from ΔG∘0,1, which represents the binding free energy of an “uncharged” ligand, and with ΔG∘0,0, that accounts for the free energy of binding of a ligand having both electrostatic and van der Waals interactions decoupled from the surroundings. Thus, the uppermost cycle of Figure 4 involves the estimation of the free energy required to “charge” a ligand in the solvent and in the protein environment (vertical legs on the right and on the left, respectively), and the estimation of the standard free energy of binding for the “uncharged” ligand. The binding free energy can be therefore calculated as:
| (52) |
Figure 4. Example of the thermodynamic cycle that can be used to calculate the free energy of binding by exploiting the LRA approximation.

Within the LIE class of methods, only the uppermost cycle is explicitly employed. “Ele” subscript stands for “electrostatics” and “vdW” for “Van der Waals”. Superscript “p” means protein, and “w” means solvent.
The exact value for ΔG∘0,1 can be estimated by further considering the cycle at the bottom of Figure 4, that can be expressed as:
| (53) |
where ΔGpvdw and ΔGwvdw are the free energy contributions required to create the ligand’s van der Waals cavity in the protein and in the solvent, whereas ΔG∘0,0 is a term related to the entropy loss for restraining a non-interacting ligand in the protein binding site with respect to the molar volume available at the standard concentration in water. We will not further describe these terms, we will rather focus on eq. 52 which, after some approximations, will lead us directly to the LIE master equation.
As already anticipated, the leading approximation behind LIE is to calculate the electrostatic contributions ΔGpele and ΔGwele relying on the linear response theory. Thus, according to eq. 51, these terms can be estimated as [20,61]:
| (54) |
where Up/wele is the solute-environment electrostatic interaction energy, and the second equality in eq. 54 is only introduced in order to simplify the notation and to get closer to the typical LIE formalism. We note that, while the linear response is a reasonable approximation to estimate such contribution in a solvent environment (see below), the same approximation cannot be equally justified for the same process in the protein, since in general protein binding sites do not behave as linear media. A second approximation virtually employed in all LIE implementations is to neglect <Up/wele>0, reducing ΔGp/wele to:
| (55) |
In an isotropic environment such as bulk water, this is justified by the assumption that solvent molecules will be randomly oriented around an “uncharged” solute (state 0). Again, since protein binding sites are intrinsically anisotropic, this approximation for the protein environment is not as appropriate as in water, and its use should only be regarded as a convenient way to simplify the calculations. Indeed, within this approximation, the electrostatic contribution to the free energy can be estimated by only sampling from the configurational space of the “charged” state, thus halving the computational cost of the whole procedure. Interestingly, in a thorough study aimed at investigating the validity of the linear response in polar solvents, Åqvist and Hannson have shown that LRA generally holds for monovalent ionic solutes, and deviations from predictions are mostly due to the neglect of <Uwele>0, rather than to a real breakdown of the linear response approximation [61]. This means that solvent structure is not completely random even around an “uncharged” solute. On the contrary, for dipolar solutes, the major source of nonlinearity was actually found in the assumption of parabolic free energy functions with same curvature for the “charged” and “uncharged” states, with the larger deviations observed for solutes forming H-bond network with solvent [61].
By introducing eq. 55 in eq. 52, we obtain the following expression:
| (56) |
that can be further arranged in order to finally achieve the general form of the LIE master equation for explicit solvent calculations:
| (57) |
where the “1” subscript in the ensemble averages has been dropped for simplicity, since only the “charged” state sampling is considered from now on. In eq. 57, it is possible to recognize β as the LRA coefficient for the electrostatic term, which is equal to ½ in case of an ideally linear response, whereas α and γ are empirical parameters of less rigorous physical interpretation. Nonetheless, we note that the first term in eq. 57 can be considered as a measure of the non-polar contribution to the binding free energy, that is assumed to have a linear relationship with the van der Waals interaction energy difference in analogy with the observation that solvation energies of non-polar compounds scale approximately linearly with molecular size, [62] whereas γ is a correction term exploited to calibrate the offset of the absolute free energy. From this standpoint, it is also possible to relate the first and third terms of eq. 57 with the free energy contributions required to create the ligand’s van der Waals cavity in the protein and in the solvent, and the binding free energy of a non-interacting ligand, respectively, as shown in eq. 53.
In the original LIE formulation by Åqvist and coworkers, γ was set to zero and a van der Waals scaling factor of α = 0.163 was found to provide the best fit with experimental data [20]. It was only in later implementations that the use of γ as a further adjustable parameter started to be investigated. In the so-called “improved LIE”, Marelius and coworkers addressed the possibility to use α and γ as free parameters together with specific values of β assigned to different classes of compounds. Thus, chemical composition-dependent deviations from linear response were tabulated for their use in different practical applications (0.5 for compounds with ionic groups; 0.43, dipolar without hydroxyl groups; 0.37, dipolar with one hydroxyl group; 0.33, dipolar with more than one hydroxyl group)[63]. In the same study, the development of a more general version of eq. 57 was also attempted by using environment specific α and β parameters that, however, converged to similar values in the specific case investigated by the authors. Differently, in an alternate version of the method proposed by Jones-Hertzog and Jorgensen, the dependence of the non-polar contributions of the free energy of binding on the difference of the solvent accessible surface area (SASA) of the ligand in the two environments was considered [64,65]:
| (58) |
It is worth noting that all the coefficients in eq. 58 (as well as those in eq. 57) can be conveniently tuned in order to fit the computed free energies to available experimental data as in a linear-regression equation. By doing so, the method is clearly more resembling to a QSAR-like approach rather than a statistical mechanics derived method.
The combination of the LIE framework with continuum representations of the solvent is particularly attractive because, compared to explicit solvent formulations, a higher efficiency of sampling and a higher accuracy in the treatment of long-ranged electrostatics can be simultaneously achieved. Moreover, since continuum solvent models do rely on the LRA, the computation of the ligand-water interaction energy is straightforward, and equals to twice the electrostatic contribution to the solvation free energy:
| (59) |
In spite of this, the use of implicit solvent models also introduces some complications in the LIE formalism related to the fact that, in general, they are not pairwise decomposable, and care must be taken when evaluating the ligand-water interaction energies in the protein-bound state.
The first attempt to combine the LIE approach with a continuum representation of the solvent was made by Zhou and coworkers [66]. Relying on a surface-generalized Born (SGB) continuum solvation model, [67] the SGB-LIE directly follows from the Jones-Hertzog and Jorgensen version of the method, where the solvent accessible surface area term is naturally replaced by a cavity term which is more appropriate in an implicit solvent representation:
| (60) |
However, in the SGB solvation model, the van der Waals energy is no longer explicit as it is included in the cavity term. Moreover, the implicit solvent contribution to the electrostatic energy is calculated for the whole protein-ligand complex, whereas the ligand interaction energy is rather required in eq. 60. To address this aspect, the authors evaluated the implicit ligand-water interactions in the bound state by counting the pairwise screened Coulomb energies as a whole if atoms are from the ligand, as half if one of the atoms is of the protein, and zero if both atoms are of the protein (see eq. 3). Then, <Upele> is obtained by adding twice of this contribution (by virtue of the LRA) to the protein-ligand Coulomb energies [66]. The validity of such approach has been later questioned by Carlsson and coworkers who observed that the SGB-LIE model basically lacked the protein desolvation electrostatic contribution [68]. In their implementation, the LIE master equation takes the form:
| (61) |
In eq. 61, the interaction energy for the protein-bound ligand is split in two terms, one evaluating the protein-ligand Coulomb interactions (<Upele,l-p>), and the other accounting for the implicit ligand-water interactions (<Upele,l-w>). This latter term is in turn evaluated by taking twice the difference between the electrostatic contribution to the solvation energy of a protein-ligand complex with the ligand in the “charged” state, and a protein-ligand complex with the ligand in the “uncharged” state. During these two calculations, only the terms involving ligand atoms are counted in the evaluation of the pairwise screened Coulomb energies. Both the use of GB and PB implicit solvent models were investigated, and, interestingly, the sampling was performed using an explicit solvent model that was later replaced by a continuum representation in a post-processing phase. In this respect, the methodology resembles some MM-PB/GB SA implementations that will be covered in the next section. A similar version of the LIE approach was developed by Su and coworkers in the context of the AGBNP implicit solvent model [69]. In that case, the electrostatic contribution included all the previous terms introduced by Carlsson and coworkers, plus a proper accounting for the desolvation of the protein (change in protein self-energies and pairwise screened Coulomb energies) due to the introduction of the ligand. Furthermore, differently from the two previous models, the AGBNP-LIE takes also into account changes in the protein-water and ligand-water van der Waals interactions. This is achieved through the following expression:
| (62) |
In eq. 62, the terms (Gplx − Gpx) stand for the difference in the xth implicit solvent energy contribution evaluated for the protein-ligand complex with the ligand in the “on” and “off” state for the given interaction. Another fundamental difference between the AGBNP-LIE models compared to the above discussed methods, is the derivation of the linear-regression coefficients shown in eq. 62. The authors elegantly demonstrated that, under the linear response regime, the proportionality coefficient β might adopt different values depending on the magnitude of the mean squared fluctuations in energy, measured as <(δV)2>0/kBT, compared to the average electrostatic energy evaluated for the “uncharged” ligand state. In particular, they showed that when the fluctuations are much smaller than the average energy, β is equal to ½, whereas in the opposite limit, β = 1. Indeed, the former case is consistent with explicit solvent interactions energies, while when the solute is treated implicitly, a β value closer to 1 should be expected. A similar reasoning also applies to the van der Waals and the cavity term. We refer the interested reader to the original paper for the technicalities required to obtain eq. 62. Here, we limit ourselves to highlight the fact that an alternative version of the AGBNP-LIE model was also proposed, where the terms describing the ligand formation in protein and in water are decoupled and grouped together, thus leading to a fourth proportionality coefficient ω:
| (63) |
In general, the LIE method allows an efficient estimation of the binding free energy for a set of chemically diverse compounds even when large and flexible ligands are considered. From the literature it emerges that estimates are generally in fair agreement with experimental data as long as substantially polar binding sites are considered. On the other hand, caution must be paid when hydrophobic binding sites are studied, where hydrophobic effects rather than electrostatics might play a dominant role in the binding free energy.
3.2. Molecular Mechanics-Poisson Boltzmann/Generalized Born Surface Area (MM-PB/GB SA) methods
The MM-PB SA (Molecular Mechanics Poisson-Boltzmann Surface Area) and its variant MM-GBSA (Molecular Mechanics Generalized-Born Surface Area) are approximate methods, originally introduced by Kollman and coworkers, aimed at calculating the binding free energy [70,11]. Unlike LIE, these methods do not contain any empirically adjustable parameter, thus a clear connection with fundamental statistical mechanics may be established [71]. Within the MM-PB/GB-SA framework the binding free energy is estimated exploiting a thermodynamic cycle were for each solute p, l, and pl, the solvation free energy is considered (see Figure 5). Accordingly, the binding free energy is expressed as follows [72]:
| (64) |
Figure 5. Thermodynamic cycle employed in the MM-PB/GB SA method.
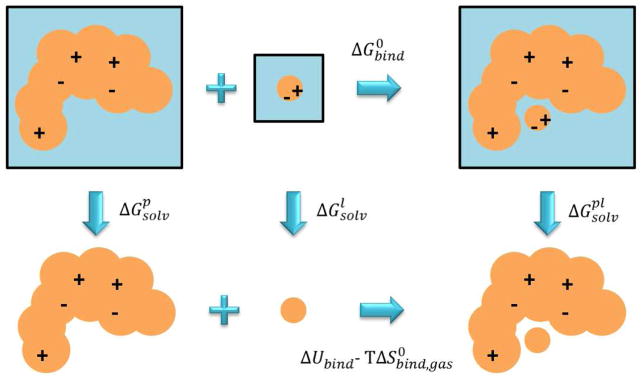
“Solv” subscript stands for “solvation”.
Within the approximation of implicit solvation models, the solvation free energy is expressed in terms of electrostatic and non-polar components. In particular, the electrostatic contribution is usually calculated by making use of PB solvers or GB solvation models, whereas the non-polar contribution is considered as proportional to the solvent-accessible surface area plus an additional surface tension term. The most difficult component to compute of the whole framework is the rightmost term of eq. 64, that is the one involving the internal energy and entropy differences for solutes in gas phase. The internal energy difference ΔUbind,gas is calculated exploiting the following approximation:
| (65) |
In order to estimate such a difference, ensemble average estimates from MD simulation are employed. To this end, two different approaches may be used: the two-states and the one-state model [73]. In the two-states model, the energies of each reactant and product are collected separately, meaning that a total of three simulations need to be performed:
| (66) |
Conversely, in the one-state model only the bound complex is actually simulated, and the difference is recovered by calculating the average energies of the artificially isolated reactants from the ensemble of the sampled configurations belonging to the complex:
| (67) |
Clearly, the two-state model is more attractive because, in principle, it should naturally take into consideration the ligand and protein reorganization upon binding, which is, in general, not negligible. However, due to the difficulty to achieve an exhaustive sampling with the currently available computational resources, different metastable states for reactants and products may be preferentially sampled and not properly relaxed, yielding the energy difference of eq. 66 very difficult to converge. For these reasons, in order to reduce the statistical uncertainty, the more naïve one-state model is often preferred [71,73]. From a practical standpoint, it should be stressed that, although the flexibility of the framework allows different solutions, MD simulations are usually performed in explicit solvent in order to better capture the physics of the system. Thus, the gas-phase energies and solvation free energies are calculated after water removal from configurations collected along the trajectory. The same sampled solute configurations are then used for the calculation of the entropic contribution. Regarding this point, harmonic or quasi harmonic approximations are generally employed, although the intrinsic plasticity of some proteins may invalidate the underlying assumption. The idea is to calculate vibrational frequencies for each of the species involved in the reaction, and to substitute them into the statistical mechanics vibrational entropy formula to obtain the respective absolute entropies (Spvib, Slvib, and Splvib)[73]. If the normal mode approximation is employed, frequencies are calculated from the eigenvalues obtained upon diagonalization of the mass weighted matrix of the potential energy second derivatives with respect to coordinates. In contrast, when relying upon quasi-harmonic approximation, the mass weighted covariance matrix of atomic fluctuations is used instead. Besides, the entropy difference between products and reactants is estimated as:
| (68) |
where ΔS0trans and ΔSrot are the differences of the translational and rotational entropy of the solutes upon binding, which can be analytically calculated. As usual, the dependence on standard state must be properly taken into account [73]. Alternatively, the entropy difference may be calculated by separating the rigid body translational and rotational degrees of freedom of the ligand with respect to the protein frame. Thus, still relying upon a quasi-harmonic approximation, the entropy difference takes the following form [71,73]:
| (69) |
Due to the contribution separations, in eq. 69 the vibrational entropies of the protein and ligand in the complex must be calculated separately for consistency. The advantage of this approach is that the terms ΔSl,0trans and ΔSlrot may be directly estimated from the simulations by evaluating the translational and orientational volumes sampled by the ligand in the bound state (their correction to account for the standard state must be considered as well)[71,73]. As a matter of fact, the entropy estimate represents the weakest part of the whole framework since both inadequate sampling and assuming harmonic behaviors may severely hamper the accuracy of the entire calculations. To this extent, different corrections have been suggested [74,75]. From a practical perspective, because of the intrinsic challenging issue related to the entropy calculation, if a congeneric set of ligands is considered, the ΔS0bind,gas term is sometimes neglected and assumed to be almost constant over the series of compounds. Despite those limitations, the MM-PB/GB-SA methods have been used by the biophysical community proving their helpfulness in rationalizing structure-activity relationships in different contexts.
4. Other methods
In this section we give a brief account of other implicit models that somehow are not easily classifiable in a given category and that possess some intrinsic peculiarities; in particular we concentrate on RISM, COSMO and ‘hybrid’ methods.
4.1. Molecular Integral Equations
The modern molecular integral equations, which basically provide a way to calculate pair correlations between molecules, are rooted in molecular Ornstein-Zernike equation coupled with a closure ansatz [76]. Such set of equations is six-dimensional in the case of homogeneous systems making them practically unsolvable (one must specify the distance between two molecules and their mutual orientations by five Euler angles). In early seventies Chandler and Andersen [23] proposed to average out the orientational degrees of freedom, thus giving rise to the well-known Reference Interaction Site Model (RISM) formalism. The first success in prediction of the structure of liquids comprising small non-polar molecules was followed by the problems with aqueous solutions, which were fully overcome only 20 years later, when the problem of trivial dielectric constant was solved within the dielectrically consistent RISM, which uses a special closure [77].
The advent of modern computers partially shifted the focus of the scientific community towards the simulations at the expense of new developments of the theory of integral equations, however, the newly available computational power made possible the solution of the three dimensional integral equations derived by Beglov and Roux [78]. In that work they proposed to average out the orientational degrees of freedom of solvent only, preserving thus the proper 3D geometry of the solute. These equations are now referred to as 3D-RISM theory. Interestingly, the nonlinear Poisson-Boltzmann equation can be considered as a special case of 3D-RISM where the short-range correlations are neglected.
Here we briefly consider the results achieved by the use of both RISM and 3D-RISM formalisms keeping in mind the model limitations of the former and computational demands of the latter. The application of RISM to bio molecules was aimed mainly to conformational equilibria of short polypeptide chains and the influence of solvent and co-solvents on these equilibria in Met-enkephalin [79] and C-peptide [80]. The simulated annealing combined with RISM treatment of water environment has given good agreement with the NMR [80] data and, moreover, appeared to be quite effective, since the convergence of simulated annealing algorithm was much faster in solution environment than in vacuum. The converged conformation was found to expose polar groups to solvent, which can be expected from the chemical intuition. Under the addition of alcohols, such as methanol and ethanol, the transition of the C-peptide from extended conformation to helix occurred, consistently with experimental findings.
Applications of 3D-RISM as an implicit solvent started only recently, when the solvers and the software have come to maturity and were implemented as a part of the AMBER package [7]. Due to its computational cost, the 3D-RISM solver must still be invoked a limited number of times during molecular dynamics evolution to get a significant performance improvement over conventional simulated evolution. Thus, most of the work in the recent years focused on increasing the time step to be used in implicit solvent MD simulations. The results show that a speedup of up to 100–500 [81] can be achieved over explicit-solvent MD simulations, making long time scaled studies of conformational changes in large biomolecules feasible. Although the 3D-RISM algorithms have a modest memory footprint and are difficult to be mapped into a GPU-computing hardware, latest solvers take advantage of the Tesla architecture and achieve speedups by a factor of 4–8 when compared to standard CPU implementations [82].
4.2. Conductor-Like Screening Model
COSMO method stands for Conductor-Like Screening Model [22]. The basic assumption of the method is that screening effects in media, such as water that exhibit high dielectric constants, can be well approximated by using an infinite dielectric constant i.e. a conductor. It is shown, from electrostatics, how, in this setting key quantities can be easily manipulated. Starting from the sphere case the Authors generalize the methodology to the case in which an arbitrary geometry (set of spheres) is possible. This approach allows to analytically compute the gradient of the energy with respect to atom positions. Also, this method assumes a rigid spherical geometry for each atom and employs a fast calculation method of the SAS. In CHARMM [8] a smooth version of COSMO has been developed to allow molecular dynamics simulations. A possible limit of COSMO is that it cannot easily deal with salts or space varying dielectrics.
4.3. Hybrid methods
Another class is that of ‘hybrid’ methods [24][25], which envision a mixed implicit/explicit solvent environment. The solute molecule is embedded in a sphere such that in the nearby of the molecule one has a reduced (with respect to the purely explicit solvent simulation) number of explicit water molecules. Beyond this sphere one retains the classical continuum representation (see Fig 6). The key advantage and purpose of this method is to maintain in the nearby of the molecule an accurate description, while at the same time avoiding the computational burden of explicit water, which beyond the sphere is replaced by a continuum medium. This method is particularly well suited when an accurate description of a binding site, or in general, of a part of a protein is required.
Figure 6.
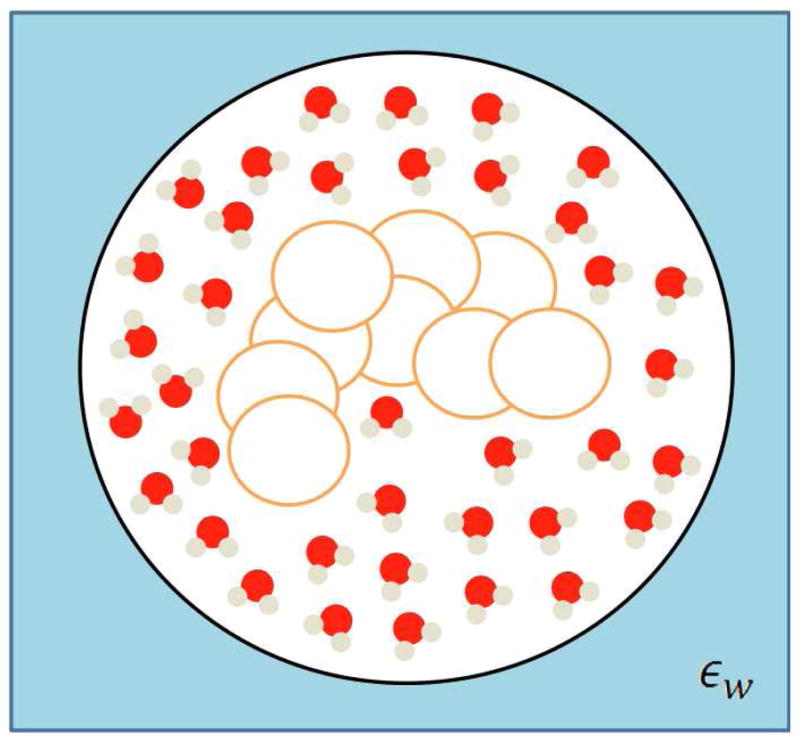
Pictorial representation of hybrid implicit/explicit methods.
Finally, other methods try to combine different approaches, such as Gran Canonical Monte Carlo, implicit and explicit solvent, in separate steps to characterize the water behavior in binding sites. In the so-called Watermap approach [83], one performs a molecular dynamics run to get a statistical thermodynamics analysis of the water molecules: this analysis is used to get both entropic and enthalpic properties of water within each hydration site. Differently, in SZMAP [26][27] a semi-continuum model is proposed where a single water molecule is explicitly used to probe the space and collect useful thermodynamics quantities.
5. Conclusions
In this review we discuss some of the most significant implicit solvent approaches in computational biophysics, and devote some attention to their use in molecular dynamics simulations and free energy estimation. What emerges is that there is no “one size fits all” method good for all intents and purposes. The user has to find the best compromise between the limitations of the underlying model, the desired accuracy and the available computational time, keeping in mind the numerical stability of the method, its applicability to the specific case and, importantly, the availability of a reliable and consistent parameterization. Implicit solvent modeling, as shown, has an approximate character but can be derived from statistical mechanics arguments, and relies on a strong theoretical background. These approximations, such as the hypothesis of linear response, go together with the need of suitable parameters and concepts such as the definition of the molecular surface and the computation of Born radii, just to name a few, the realization of which may heavily affect the effectiveness of the approaches. Finally, the most recent implementations try to move from full implicit models to hybrid ones where the solvent behavior is reconstructed from a combination of short explicit waters simulation (hybrid, single probe etc..) and suitable post processing analysis.
Figure 2. Discretization of the dielectric function in a finite difference solver of PB equation in a 2D domain.

The dielectric constant needs to be mapped on all the midpoints of the grid. For a cubic grid of side n, a data structure of size 3n3 must be allocated.
Highlights.
We review several implicit solvent methods.
Basic statistical mechanical foundations and derivations are provided.
Implicit methods can be combined with molecular dynamics to estimate free energy.
No “one size fits all” approach, the best method depends on the problem at hand.
Acknowledgments
This work was supported by NIGMS, NIH, grant number 1R01GM093937-01.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- 1.Shoichet BK. No free energy lunch. Nature Biotechnology. 2007;25(10):1109–1110. doi: 10.1038/nbt1007-1109. [DOI] [PubMed] [Google Scholar]
- 2.Roux B. Implicit Solvent Models. Biophysical Chemistry. 1999;78(1,2):1–20. doi: 10.1016/s0301-4622(98)00226-9. [DOI] [PubMed] [Google Scholar]
- 3.Rocchia W, Alexov E, Honig B. Extending the Applicability of the Nonlinear Poisson Boltzmann Equation: Multiple Dielectric Constants and Multivalent Ions. The Journal of Physical Chemistry B. 2001;105(28):6507–6514. doi: 10.1021/jp010454y. [DOI] [Google Scholar]
- 4.Honig B, Nicholls A. Classical electrostatics in biology and chemistry. Science. 1995;268(5214):1144–9. doi: 10.1126/science.7761829. [DOI] [PubMed] [Google Scholar]
- 5.Tomasi J, Mennucci B, Cammi R. Quantum Mechanical Continuum Solvation Models. Chemical Reviews. 2005;105(8):2999–3094. doi: 10.1021/cr9904009. [DOI] [PubMed] [Google Scholar]
- 6.Abagyan RA, Totrov MM, Kuznetsov DA. ICM: A New Method For Protein Modeling and Design: Applications To Docking and Structure Prediction From The Distorted Native Conformation. Journal of Computational Chemistry. 1994;15:488–506. [Google Scholar]
- 7.Case DA, Babin V, Berryman JT, Betz RM, Cai Q, Cerutti DS, Cheatham TE, III, Darden TA, Duke RE, Gohlke H, Goetz AW, Gusarov S, Homeyer N, Janowski P, Kaus J, Kolossváry I, Kovalenko A, Lee TS, LeGrand S, Luchko T, Luo R, Madej B, Merz KM, Paesani F, Roe DR, Roitberg A, Sagui C, Salomon-Ferrer R, Seabra G, Simmerling CL, Smith W, Swails J, Walker RC, Wang J, Wolf RM, Wu X, Kollman PA. AMBER. Vol. 14. University of California; San Francisco: 2014. [Google Scholar]
- 8.Brooks BR, Brooks CL, III, MacKerell AD, Jr, Nilsson L, Petrella RJ, Roux B, Won Y, Archontis G, Bartels C, Boresch S, Caflisch A, Caves L, Cui Q, Dinner AR, Feig M, Fischer S, Gao J, Hodoscek M, Im W, Kuczera K, Lazaridis T, Ma J, Ovchinnikov V, Paci E, Pastor RW, Post CB, Pu JZ, Schaefer M, Tidor B, Venable RM, Woodcock HL, Wu X, Yan W, York DM, Karplus M. CHARMM: The Biomolecular Simulation Program. Journal Computational Chemistry. 2009;30(10):1545–1614. doi: 10.1002/jcc.21287. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Cossi M, Rega N, Scalmani G, Barone V. Energies, structures, and electronic properties of molecules in solution with the C-PCM solvation model. Journal of Computational Chemistry. 2009;24(6):669–681. doi: 10.1002/jcc.10189. [DOI] [PubMed] [Google Scholar]
- 10.Srinivasan J, Cheatham TE, Cieplak P, Kollman PA, Case DA. Continuum Solvent Studies of the Stability of DNA, RNA, and Phosphoramidatea DNA Helices. Journal of the American Chemical Society. 1998;120(37):9401–9409. doi: 10.1021/ja981844+. [DOI] [Google Scholar]
- 11.Massova I, Kollman PA. Computational Alanine Scanning To Probe Protein-Protein Interactions: A Novel Approach To Evaluate Binding Free Energies. Journal of the American Chemical Society. 1999;121(36):8133–8143. doi: 10.1021/ja990935j. [DOI] [Google Scholar]
- 12.Gallicchio E, Levy RM. AGBNP: An Analytic Implicit Solvent Model Suitable for Molecular Dynamics Simulations and High-Resolution Modeling. Journal of Computational Chemistry. 2004;25:479–499. doi: 10.1002/jcc.10400. [DOI] [PubMed] [Google Scholar]
- 13.Masetti M, Rocchia W. Molecular mechanics and dynamics: numerical tools to sample the configuration space. Frontiers in Bioscience. 2014;19:578–604. doi: 10.2741/4229. [DOI] [PubMed] [Google Scholar]
- 14.Rohs R, West SM, Sosinsky A, Liu P, Mann R, Honig B. The role of DNA shape in protein–DNA recognition. Nature. 2009;461 doi: 10.1038/nature08473. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Wesson L, Eisemberg D. Atomic solvation parameters applied to molecular dynamics of proteins in solution. Protein Science. 1992:227–235. doi: 10.1002/pro.5560010204. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Lazaridis T, Karplus M. Effective Energy Function for Proteins in Solution, Proteins: Structure. Function, and Genetics. 1999;35:133–152. doi: 10.1002/(sici)1097-0134(19990501)35:2<133::aid-prot1>3.0.co;2-n. [DOI] [PubMed] [Google Scholar]
- 17.Sharp KA, Honig B. Calculating Total Electrostatic Energies with the Nonlinear Poisson-Bottzmann Equatlon. Journal of Physical Chemistry. 1990;94:7684–7692. [Google Scholar]
- 18.Bashford D, Case DA. Generalized Born Models of Macromolecular Solvation Effects. Annual Reviews In Physical Chemistry. 2000;51:129–52. doi: 10.1146/annurev.physchem.51.1.129. [DOI] [PubMed] [Google Scholar]
- 19.Kollman PA, Massova I, Reyes C, Kuhn B, Huo S, Chong L, Lee M, Lee T, Duan Y, Wang W, Donini O, Cieplak P, Srinivasan J, Case DA, Cheatham TE. Calculating Structures and Free Energies of Complex Molecules: Combining Molecular Mechanics and Continuum Models. Accounts of Chemical Research. 2000;33(12) doi: 10.1021/ar000033j. [DOI] [PubMed] [Google Scholar]
- 20.Aqvist J, Medina C, Samuelsson JE. A new method for predicting binding affinity in computer-aided drug design. Protein Engineering. 1994;7(3):385–391. doi: 10.1093/protein/7.3.385. [DOI] [PubMed] [Google Scholar]
- 21.Huang D, Caflisch A. Efficient Evaluation of Binding Free Energy Using Continuum Electrostatics Solvation. Journal of Medicinal Chemistry. 2004;47:5791–5797. doi: 10.1021/jm049726m. [DOI] [PubMed] [Google Scholar]
- 22.Klamt A, Schuurmann G. COSMO, A New Approach to Dielectric Screening in Solvents with Explicit Expressions for the Screening Energy and its Gradient. Journal of the Chemical Society Perkin Transactions. 1993;2:799–805. doi: 10.1039/P29930000799. [DOI] [Google Scholar]
- 23.Chandler D, Andersen HC. Optimized Cluster Expansions for Classical Fluids. II. Theory of Molecular Liquids. The Journal Of Chemical Physics. 1972;57:5. [Google Scholar]
- 24.Brancato G, Rega N, Barone V. A hybrid explicit/implicit solvation method for first-principle molecular dynamics simulations. Journal of Chemical Physics. 2008;128:144501. doi: 10.1063/1.2897759. [DOI] [PubMed] [Google Scholar]
- 25.Im W, Bernèche S, Roux B. Generalized solvent boundary potential for computer simulations. Journal of Chemical Physics. 2001;114:2924. doi: 10.1063/1.1336570. [DOI] [Google Scholar]
- 26.Tanger JC, Pitzer KS. Calculation of the thermodynamic properties of aqueous electrolytes to 1000° C and 5000 bar from a semi-continuum model for ion hydration. Journal of Physical Chemistry. 1989;93:4941–4951. [Google Scholar]
- 27.Rashin AA, Bukatin MA. Continuum based calculations of hydration entropies and the hydrophobic effect. Journal of Physical Chemistry. 1991;95:2942–2944. [Google Scholar]
- 28.Lee B, Richards FM. The interpretation of protein structures: estimation of static accessibility. Journal of Molecular Biology. 1971;55:379400. doi: 10.1016/0022-2836(71)90324-x. [DOI] [PubMed] [Google Scholar]
- 29.Fogolari F, Brigo A, Molinari H. The Poisson–Boltzmann equation for biomolecular electrostatics: a tool for structural biology. Journal Of Molecular Recognition. 2002;15:377–392. doi: 10.1002/jmr.577. [DOI] [PubMed] [Google Scholar]
- 30.Parodi M. Behaviour of mobile ions near a charged cylindrical surface: Application to linear polyelectrolytes. Journal of Electrostatics. 1985;17(3):255–268. [Google Scholar]
- 31.Morro Angelo, Parodi Mauro. A variational approach to non-linear dielectrics: Application to polyelectrolytes. Journal of Electrostatics. 1987;20(2):219–232. [Google Scholar]
- 32.Rocchia W, Sridharan S, Nicholls A, Alexov E, Chiabrera A, Honig B. Rapid grid based construction of the molecular surface for both molecules and geometric objects: Applications to the finite difference poisson-boltzmann method. Journal of Computational Chemistry. 2002;23:128–137. doi: 10.1002/jcc.1161. [DOI] [PubMed] [Google Scholar]
- 33.Decherchi S, Colmenares J, Catalano CE, Spagnuolo M, Alexov E, Rocchia W. Between algorithm and model: different Molecular Surface definitions for the Poisson-Boltzmann based electrostatic characterization of biomolecules in solution. Communications in Computational Physics. 2013;13:61–89. doi: 10.4208/cicp.050711.111111s. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Luo R, David L, Gilson MK. Accelerated Poisson–Boltzmann Calculations for Static and Dynamic Systems. Journal of Computationa Chemistry. 2002;23:1244–1253. doi: 10.1002/jcc.10120. [DOI] [PubMed] [Google Scholar]
- 35.Baker NA, Sept D, Joseph S, Holst MJ, McCammon JA. Electrostatics of nanosystems: Application to microtubules and the ribosome. Proceedings of the National Academy of Sciences of the United States of America. 2001;98(18):10037–10041. doi: 10.1073/pnas.181342398. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Bardhan JP, Altman MD, Willis DJ, Lippow SM, Tidor B, White JK. Numerical integration techniques for curved-element discretizations of molecule-solvent interfaces. Journal of Chemical Physics. 2007;127 doi: 10.1063/1.2743423. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Zhoua YC, Zhaoa S, Feigb M, Weia GW. High order matched interface and boundary method for elliptic equations with discontinuous coefficients and singular sources. Journal of Computational Physics. 2006;213(1):1–30. [Google Scholar]
- 38.Bashford D. Macroscopic Electrostatic Models for Protonation States in Proteins. Frontiers in Bioscience. 2004;99:1082–1099. doi: 10.2741/1187. [DOI] [PubMed] [Google Scholar]
- 39.Ilin A, Bagheri B, Scott LR, Briggs JM, McCammon JA. ACS Symposium Series, Parallel Computing in Computational Chemistry. 1995. Parallelization of Poisson Boltzmann and Brownian Dynamics Calculations. [Google Scholar]
- 40.Im W, Beglov D, Roux B. Continuum Solvation Model: Computation of Electrostatic Forces from Numerical Solutions to the Poisson-Boltzmann Equation. Computer Physics Communications. 1998;111:59–75. [Google Scholar]
- 41.Grant JA, Pickup BT, Nicholls A. A Smooth Permittivity Function for Poisson–Boltzmann Solvation Methods. Journal of Computational Chemistry. 2001;22(6):608–640. [Google Scholar]
- 42.Decherchi S, Rocchia W. A general and robust ray casting based algorithm for triangulating surfaces at the nanoscale. PLoS ONE. 8(4):e59744. doi: 10.1371/journal.pone.0059744. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Romanov AN, Jabin SN, Martynov YB, Sulimov AV, Grigoriev FV, Sulimov VB. Surface Generalized Born Method: A Simple, Fast, and Precise Implicit Solvent Model beyond the Coulomb Approximation. The Journal of Physical Chemistry A. 2004;108:43. [Google Scholar]
- 44.Still WC, Tempczyk A, Hawley RC, Hendrickson T. Semianalytical Treatment of Solvation for Molecular Mechanics and Dynamics. J Am Chem Soc. 1990;112(16):6127–6129. doi: 10.1021/ja00172a038. [DOI] [Google Scholar]
- 45.Chocolousova J, Feig M. Balancing an Accurate Representation of the Molecular Surface in Generalized Born Formalisms with Integrator Stability in Molecular Dynamics Simulations. Journal of Computational Chemistry. 2006;27:719–729. doi: 10.1002/jcc.20387. [DOI] [PubMed] [Google Scholar]
- 46.Tanizaki S, Feig M. A generalized Born formalism for heterogeneous dielectric environments: Application to the implicit modeling of biological membranes. Journal of Chemical Physics. 2005;122(12):124706. doi: 10.1063/1.1865992. [DOI] [PubMed] [Google Scholar]
- 47.Sigalov G, Fenley A, Onufriev A. Analytical electrostatics for biomolecules: Beyond the generalized Born approximation. Journal of Chemical Physics. 2006;124:124902. doi: 10.1063/1.2177251. [DOI] [PubMed] [Google Scholar]
- 48.Gallicchio E, Paris K, Levy RM. The AGBNP2 Implicit Solvation Model. Journal of Chemical Theory and Computation. 2009;5:2544–2564. doi: 10.1021/ct900234u. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Grant JA, Pickup BT. A Gaussian Description of Molecular Shape. Journal Physical Chemistry. 1995;99:3503–3510. [Google Scholar]
- 50.Jorgensen WL, Madura JD. Temperature and Size Dependence for Monte Carlo Simulations of TIP4P Water. Molecular Physics. 1985;56:1381. [Google Scholar]
- 51.Masunov A, Lazaridis T. Potentials of mean force between ionizable amino acid side chains in water. Journal of the American Chemical Society. 2003;125:1722–1730. doi: 10.1021/ja025521w. [DOI] [PubMed] [Google Scholar]
- 52.Gilson MK, Given JA, Bush BL, McCammon JA. The statistical-thermodynamic basis for computation of binding affinities: a critical review. Biophysical Journal. 1997;72(3):1047–1069. doi: 10.1016/S0006-3495(97)78756-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Zwanzig RW. High Temperature Equation of State by a Perturbation Method. I. Nonpolar Gases. The Journal of Chemical Physics. 1954;22(8):1420–1426. [Google Scholar]
- 54.Kirkwood JG. Statistical Mechanics of Fluid Mixtures. The Journal of Chemical Physics. 1935;3(5):300–313. [Google Scholar]
- 55.Chu ZT, Tao H, Warshel A. Examining methods for calculations of binding free energies: LRA, LIE, PDLD-LRA, and PDLD/S-LRA calculations of ligands binding to an HIV protease. Proteins: Structure. Function, and Bioinformatics. 2000;39(4):393–407. [PubMed] [Google Scholar]
- 56.Lee FS, Chu ZT, Bolger MB, Warshel A. Calculations of antibody-antigen interactions: microscopic and semi-microscopic evaluation of the free energies of binding of phosphorylcholine analogs to McPC603. Protein Engineering. 1992;5(3):215–228. doi: 10.1093/protein/5.3.215. [DOI] [PubMed] [Google Scholar]
- 57.Gallicchio E, Levy RM. Recent theoretical and computational advances for modeling protein–ligand binding affinities. In: Christo C, editor. Advances in Protein Chemistry and Structural Biology. Academic Press; 2011. pp. 27–80. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Marcus RA. Chemical and Electrochemical Electron-Transfer Theory. Annual Review of Physical Chemistry. 1964;15(1):155–196. [Google Scholar]
- 59.Levy RM, Belhadj M, Kitchen DB. Gaussian fluctuation formula for electrostatic free energy changes in solution. The Journal of Chemical Physics. 1991;95(5):3627–3633. [Google Scholar]
- 60.King G, Warshel A. Investigation of the free energy functions for electron transfer reactions. The Journal of Chemical Physics. 1990;93(12):8682–8692. [Google Scholar]
- 61.Åqvist J, Hansson T. On the Validity of Electrostatic Linear Response in Polar Solvents. The Journal of Physical Chemistry. 1996;100(22):9512–9521. [Google Scholar]
- 62.Ben Naim A, Marcus Y. Solvation thermodynamics of nonionic solutes. The Journal of Chemical Physics. 1984;81(4):2016–2027. [Google Scholar]
- 63.Marelius J, Hansson T, Åqvist J. Calculation of ligand binding free energies from molecular dynamics simulations. International Journal of Quantum Chemistry. 1998;69(1):77–88. [Google Scholar]
- 64.Carlson HA, Jorgensen WL. An Extended Linear Response Method for Determining Free Energies of Hydration. The Journal of Physical Chemistry. 1995;99(26):10667–10673. [Google Scholar]
- 65.Jones-Hertzog DK, Jorgensen WL. Binding Affinities for Sulfonamide Inhibitors with Human Thrombin Using Monte Carlo Simulations with a Linear Response Method. Journal of Medicinal Chemistry. 1997;40(10):1539–1549. doi: 10.1021/jm960684e. [DOI] [PubMed] [Google Scholar]
- 66.Zhou R, Friesner RA, Ghosh A, Rizzo RC, Jorgensen WL, Levy RM. New Linear Interaction Method for Binding Affinity Calculations Using a Continuum Solvent Model. The Journal of Physical Chemistry B. 2001;105(42):10388–10397. [Google Scholar]
- 67.Ghosh A, Rapp CS, Friesner RA. Generalized Born Model Based on a Surface Integral Formulation. The Journal of Physical Chemistry B. 1998;102(52):10983–10990. [Google Scholar]
- 68.Carlsson J, Andér M, Nervall M, Aqvist J. Continuum Solvation Models in the Linear Interaction Energy Method. The Journal of Physical Chemistry B. 2006;110(24):12034–12041. doi: 10.1021/jp056929t. [DOI] [PubMed] [Google Scholar]
- 69.Su Y, Gallicchio E, Das K, Arnold E, Levy Ronald M. Linear Interaction Energy (LIE) Models for Ligand Binding in Implicit Solvent: Theory and Application to the Binding of NNRTIs to HIV-1 Reverse Transcriptase. Journal of Chemical Theory and Computation. 2007;3(1):256–277. doi: 10.1021/ct600258e. [DOI] [PubMed] [Google Scholar]
- 70.Srinivasan J, Miller J, Kollman PA, Case DA. Continuum Solvent Studies of the Stability of RNA Hairpin Loops and Helices. Journal of Biomolecular Structure and Dynamics. 1998;16(3):671–682. doi: 10.1080/07391102.1998.10508279. [DOI] [PubMed] [Google Scholar]
- 71.Swanson JMJ, Henchman RH, McCammon JA. Revisiting Free Energy Calculations: A Theoretical Connection to MM/PBSA and Direct Calculation of the Association Free Energy. Biophysical Journal. 2004;86(1):67–74. doi: 10.1016/S0006-3495(04)74084-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Wang J, Morin P, Wang W, Kollman PA. Use of MM-PBSA in Reproducing the Binding Free Energies to HIV-1 RT of TIBO Derivatives and Predicting the Binding Mode to HIV-1 RT of Efavirenz by Docking and MM-PBSA. Journal of the American Chemical Society. 2001;123(22):5221–5230. doi: 10.1021/ja003834q. [DOI] [PubMed] [Google Scholar]
- 73.Lee MS, Olson MA. Calculation of Absolute Protein-Ligand Binding Affinity Using Path and Endpoint Approaches. Biophysical Journal. 2006;90(3):864–877. doi: 10.1529/biophysj.105.071589. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Kongsted J, Ryde U. An improved method to predict the entropy term with the MM/PBSA approach. Journal of Computer-Aided Molecular Design. 2009;23(2):63–71. doi: 10.1007/s10822-008-9238-z. [DOI] [PubMed] [Google Scholar]
- 75.Genheden S, Ryde U. How to obtain statistically converged MM/GBSA results. Journal of Computational Chemistry. 2010;31(4):837–846. doi: 10.1002/jcc.21366. [DOI] [PubMed] [Google Scholar]
- 76.Hansen JP, McDonald IR. Theory of Simple Liquids. 3. Academic Press; 2006. [Google Scholar]
- 77.Perkyns J, Pettitt BM. A dielectrically consistent interaction site theory for solvent—electrolyte mixtures. Chemical Physics Letters. 1992;190:626–630. [Google Scholar]
- 78.Beglov D, Roux B. An Integral Equation To Describe the Solvation of Polar Molecules in Liquid Water. The Journal of Physical Chemistry B. 1997;101:7821–7826. [Google Scholar]
- 79.Kinoshita M, Okamoto Y, Hirata F. Solvation structure and stability of peptides in aqueous solutions analyzed by the reference interaction site model theory. The Journal of Chemical Physics. 1997;107:1586–1599. [Google Scholar]
- 80.Kinoshita M, Okamoto Y, Hirata F. First-Principle Determination of Peptide Conformations in Solvents: Combination of Monte Carlo Simulated Annealing and RISM Theory. Journal of the American Chemical Society. 1998;120:1855–1863. [Google Scholar]
- 81.Omelyan I, Kovalenko A. Multiple time step molecular dynamics in the optimized isokinetic ensemble steered with the molecular theory of solvation: Accelerating with advanced extrapolation of effective solvation forces. The Journal of Chemical Physics. 2013;139 doi: 10.1063/1.4848716. [DOI] [PubMed] [Google Scholar]
- 82.Maruyama Y, Hirata F. Modified Anderson Method for Accelerating 3D-RISM Calculations Using Graphics Processing Unit. Journal of Chemical Theory and Computation. 2012;8:3015–3021. doi: 10.1021/ct300355r. [DOI] [PubMed] [Google Scholar]
- 83.Young T, Abel R, Kim B, Berne BJ, Friesner RA. Motifs for molecular recognition exploiting hydrophobic enclosure in protein ligand binding. Proceedings of the National Academy of Science. 2007;104:808–813. doi: 10.1073/pnas.0610202104. [DOI] [PMC free article] [PubMed] [Google Scholar]