

Abstract
We investigated whether the cognitive mechanism of suppression underlies differences in adult comprehension skill. Less skilled comprehenders reject less efficiently the inappropriate meanings of ambiguous words (e.g., the playing card vs. garden tool meaning of spade), the incorrect forms of homophones (e.g., patients vs. patience), the highly typical but absent members of scenes (e.g., a tractor in a farm scene), and words superimposed on pictures or pictures surrounding words. However, less skilled comprehenders are not less cognizant of what is contextually appropriate; in fact, they benefit from a biasing context just as much (and perhaps more) as more skilled comprehenders do. Thus, less skilled comprehenders do not have difficulty enhancing contextually appropriate information. Instead, we suggest that less skilled comprehenders suffer from a less efficient suppression mechanism, which we conclude is an important component of general comprehension skill.
Many of the processes and mechanisms that are involved in language comprehension are general cognitive processes and mechanisms. We have described a few of those processes and mechanisms using a very simple framework as a guide; we call it the structure building framework (Gernsbacher, 1990). According to the structure building framework, comprehension entails building coherent mental representations or “structures.” Several component processes are involved. First, comprehenders lay foundations for their mental structures. Next, comprehenders develop their mental structures. They map incoming information onto their developing structures when that incoming information coheres or relates to the previous information. However, if the incoming information is less related, comprehenders use another process: They shift and develop a new substructure.
The building blocks of mental structures are memory nodes. Memory nodes represent previously stored memory traces. Their representation might be either in the traditional sense of an individual node representing an individual trace or in the distributed sense of a group of nodes representing an individual trace. Memory nodes are activated by incoming stimuli. Once activated, the information they represent can be used by cognitive processes.
Furthermore, according to the structure building framework, activated memory cells transmit processing signals. These processing signals either suppress or enhance the activation of other memory cells. In other words, once memory cells are activated, two mechanisms modulate their level of activation: suppression and enhancement. Suppression decreases or dampens the activation of memory nodes when the information they represent is no longer as necessary for the structure being built. Enhancement increases or boosts the activation of memory nodes when the information they represent is relevant to the structure being built. By modulating the activation of memory nodes, the mechanisms of suppression and enhancement contribute to structure building.
According to the structure building framework, the mechanisms of suppression and enhancement are instrumental to successful comprehension. For instance, they play a vital role in how comprehenders access the meanings of words. According to many models of word understanding, when comprehenders first hear or read a word, information provided by that word activates various potential meanings. Then constraints provided by lexical, semantic, syntactic, and other sources of information alter those meanings’ levels of activation. Eventually, one meaning becomes most strongly activated. That meaning is what comprehenders access and incorporate into their developing mental structures (Becker, 1976; Kintsch, 1988; Marslen-Wilson & Welsh, 1978; McClelland & Rumelhart, 1981; Norris, 1986).
What the structure building framework adds to these ideas is the proposal that suppression and enhancement modulate the different meanings’ levels of activation. For instance, the mechanism of suppression dampens the activation of the less likely meanings. An excellent arena for demonstrating this vital role is provided by ambiguous words (e.g., words like spade that have at least two diverse meanings). Contrary to intuition, immediately after comprehenders hear or read ambiguous words in context, multiple meanings are often activated. In fact, multiple meanings are often activated even though only one meaning is suggested by the preceding semantic context (Duffy, Morris, & Rayner, 1988; Rayner & Frazier, 1989; Swinney, 1979) or the preceding syntactic context (Seidenberg, Tanenhaus, Leiman, & Bienkowski, 1982; Tanenhaus, Leiman, & Seidenberg, 1979). According to the structure building framework, ambiguous words are accurately understood because the memory cells representing the semantic context, the syntactic context, or other source of information transmit processing signals; these processing signals suppress the contextually inappropriate meanings. In other words, according to the structure building framework, the mechanism of suppression dampens the activation of contextually inappropriate meanings.
Some theories assume that the inappropriate meanings of ambiguous words become less activated in other ways. For instance, according to some theories, the inappropriate meanings are inhibited by the appropriate meanings (McClelland & Kawamoto, 1986; Waltz & Pollack, 1985), and according to others the inappropriate meanings simply decay (Anderson, 1983). Unfortunately, neither assumption is strongly supported by empirical data (Gernsbacher & Faust, 1990). We suggest that dampening the activation of inappropriate meanings is one of the most important roles that the mechanism of suppression plays in comprehension.
According to the structure building framework, suppression and enhancement are general cognitive mechanisms. They are not dedicated to language; they play vital roles in nonlinguistic processes too. Indeed, according to the structure building framework, the same processes and mechanisms that build coherent mental structures during language comprehension build coherent mental structures during the comprehension of nonlinguistic media. This commonality might arise because, as Lieberman (1984) and others suggest, language comprehension evolved from nonlinguistic cognitive skills. Alternatively, the commonality might arise simply because the mind is best understood by reference to a common architecture. Both proposals support our orientation that many processes and mechanisms involved in comprehending language are also involved in comprehending nonlinguistic media.
Our orientation also suggests that some of the reasons why individuals differ in comprehension skill might not be specific to language. The research we report here investigated that suggestion. In particular, we investigate whether individuals who differ in general comprehension skill have differences in the efficiency of their suppression and enhancement mechanisms.
General comprehension skill is the ability to comprehend linguistic as well as nonlinguistic media. In our previous research (Gernsbacher, Varner, & Faust, 1990), we constructed a Multi-Media Comprehension Battery (Gernsbacher & Varner, 1988), which comprises six stories: Two are presented through written sentences, two through spoken sentences, and two through nonverbal pictures. Twelve comprehension questions are asked after each story; these questions are similar to those found in more traditional comprehension tests. We administered the Multi-Media Comprehension Battery to a large sample of college-aged subjects, and found that skill at comprehending written and spoken stories is highly correlated with skill at comprehending nonverbal picture stories. A principal-components analysis suggested only one underlying factor: that which we labeled general comprehension skill.
Why Do Individuals Differ in General Comprehension Skill?
Consider a marker of less proficient general comprehension skill: Less skilled comprehenders have poorer access to recently comprehended information. Of course, all comprehenders quickly lose access to recently comprehended information (Sachs, 1967). However, less skilled comprehenders lose access even more quickly, and this occurs regardless of whether they are reading, listening, or watching nonverbal picture stories (Gernsbacher et al., 1990, Experiment 2).
Why does poorer access to recently comprehended information mark less proficient general comprehension skill? According to the structure building framework, all comprehenders lose access to recently comprehended information when they shift from actively building one substructure to initiate another. Information represented in one substructure is most accessible while comprehenders are actively building that substructure; once comprehenders have shifted to initiate a new substructure, information from the previous substructure becomes less accessible. However, yoking the structure building framework’s explanation for why all comprehenders have poor access to recently comprehended information with less skilled comprehenders’ trademark (even poorer access to recently comprehended information) yields a rather unusual hypothesis: Less skilled comprehenders shift too often; they develop too many substructures. Indeed, less skilled comprehenders do shift too often (Gernsbacher et al., 1990, Experiment 3).
Why does a greater tendency toward shifting characterize less proficient general comprehension skill? According to the structure building framework, mental structures are built by enhancing the activation of relevant information while suppressing the activation of less relevant information. All comprehenders shift to initiate substructures when the incoming information seems less relevant, but less skilled comprehenders might shift too often because they suppress irrelevant information less efficiently. When irrelevant information remains activated, its activation lays the foundation for a new substructure. Therefore, one consequence of an inefficient suppression mechanism is that too many substructures are initiated; in other words, one consequence of an inefficient suppression mechanism is the greater tendency toward shifting exhibited by less skilled comprehenders.
This reasoning suggests that less skilled comprehenders have less efficient suppression mechanisms. There are also data that suggest this: Less skilled comprehenders are less able to reject the contextually inappropriate meanings of ambiguous words (Gernsbacher et al., 1990, Experiment 4). Consider the following task: Subjects read a sentence, for example, She dropped the plate. Then they see a test word; for example, BREAK. Their task is to judge whether the test word fits the meaning of the sentence they just read. On half the trials, the test word does indeed fit the meaning, but on the other half it does not.
On half of the trials in which the test word does not fit the meaning of the sentence, the last word of the sentence is an ambiguous word, for example, spade in the sentence He dug with the spade. The test word on those trials is related to one meaning of the ambiguous word; however, it is not the meaning implied by the sentence. For example, the test word for the sentence He dug with the spade is ACE. How long subjects take to reject a test word like ACE after they read a sentence like He dug with the spade can be compared with how long subjects take to reject ACE after they read the same sentence but with the last word replaced by an unambiguous word, for example, He dug with the shovel. This comparison demonstrates how quickly comprehenders can suppress the inappropriate meanings of ambiguous words; the more time comprehenders need to reject ACE after the spade versus shovel sentence, the more activated the ACE-related meaning of spade must be.
When the test words are presented immediately (100 ms) after subjects finish reading each sentence, both more and less skilled comprehenders experience a significant amount of interference. For example, both groups take longer to reject ACE after they read He dug with the spade than after they read He dug with the shovel. In fact, the amount of interference experienced immediately by less skilled comprehenders does not differ statistically from the amount experienced immediately by more skilled comprehenders. Therefore, 100 ms after more and less skilled comprehenders read ambiguous words, contextually inappropriate meanings are activated.1
However, when the test words are presented 850 ms after subjects finish reading the sentences, more skilled comprehenders no longer experience a reliable amount of interference. By this time, more skilled comprehenders can effectively reject the inappropriate meanings. Unlike more skilled comprehenders, less skilled comprehenders still experience a significant amount of interference even after the delay. In fact, less skilled comprehenders experience the same amount of interference after the delay as they experience immediately. In other words, less skilled comprehenders are less able to reject the contextually inappropriate meanings of ambiguous words.
Do Less Skilled Comprehenders Have Less Efficient Suppression Mechanisms?
We propose that the ability to reject the inappropriate meanings of ambiguous words derives from a general cognitive mechanism: suppression. Less skilled comprehenders are less able to reject the inappropriate meanings of ambiguous words because they are plagued by less efficient suppression mechanisms.
Successful comprehension must surely involve efficiently suppressing irrelevant information. In many situations, irrelevant or inappropriate information is automatically activated, unconsciously retrieved, or naturally perceived. However, for successful comprehension, this irrelevant or inappropriate information must not affect ongoing processes; it must be efficiently suppressed.
In the research we report here, we investigated whether less skilled comprehenders are less efficient in suppressing various types of information while they are comprehending linguistic as well as nonlinguistic media. We investigated whether less skilled comprehenders less efficiently suppress the incorrect forms of homophones (e.g., patients vs. patience) that are activated when less skilled comprehenders read sentences. We also investigated whether less skilled comprehenders suppress less efficiently typical but absent objects that are activated when less skilled comprehenders view nonverbal scenes. In addition, we investigated whether less skilled comprehenders suppress information across modalities less efficiently, for example, whether they suppress less efficiently words super-imposed on pictures or pictures surrounding words.
Our research also investigated a counterhypothesis: Perhaps less skilled comprehenders are less able to reject contextually inappropriate information not because they have less efficient suppression mechanisms, but because they are less cognizant of what is appropriate. Perhaps less skilled comprehenders’ enhancement mechanisms are at fault, not their suppression mechanisms. By this logic, less skilled comprehenders have difficulty rejecting ACE after reading “He dug with the spade” because they fail to appreciate that the context of digging with a spade implies a garden tool, not a playing card. We tested this counterhypothesis in two experiments. In one experiment, we investigated whether less skilled comprehenders enhance less efficiently the contextually appropriate meanings of ambiguous words; in another experiment, we investigated whether less skilled comprehenders enhance less efficiently the contextually appropriate objects in nonverbal scenes.
To summarize, our research answered five questions: (a) Do less skilled comprehenders suppress less efficiently the incorrect forms of homophones? (b) Do less skilled comprehenders suppress less efficiently information that is activated when they view nonverbal scenes? (c) Do less skilled comprehenders suppress information across modalities less efficiently? (d) Do less skilled comprehenders enhance less efficiently the contextually appropriate meanings of ambiguous words? (e) Do less skilled comprehenders enhance less efficiently the contextually appropriate objects in a nonverbal scene?
To answer these five questions, we conducted five experiments. Each experiment was based on a well-established finding in the cognitive psychology literature. We based our experiments on these well-established findings so that we could anticipate what normative data would look like; we used those expectations to make predictions about our more skilled versus less skilled comprehenders.
The subjects in our experiments were United States Air Force recruits whom we tested during their sixth day of basic training. We eliminated subjects if their accuracy on our laboratory tasks suggested they were not giving the task enough effort.2 Air Force recruits are high school graduates, and typically 20% have completed some college courses. Their ages range from 17 to 23 years, and approximately 18% are female.
We selected more versus less skilled comprehenders according to our subjects’ scores on the Multi-Media Comprehension Battery (Gernsbacher & Varner, 1988). Each subject was tested for 3 hr. During the first hour, we administered the Multi-Media Comprehension Battery (as described in the Appendix). During the second and third hours, the subjects participated in the experiments we describe next.
Experiment 1: Do Less Skilled Comprehenders Suppress the Incorrect Forms of Homophones Less Efficiently?
Reading a string of letters activates an array of information. Almost always, reading a letter string activates orthographic information—information about the individual letters in the string and their relative position to one another. Often reading a letter string activates semantic, lexical, and phonological information. In fact, these three types of information are often activated even if the string does not form an English word (Coltheart, Davelaar, Jonasson, & Besner, 1977; Rosson, 1985).
Activation of phonological information is what we focused on in our first experiment. By activation of phonological information, we mean the phenomenon in which reading the letter string rows activates the phonological sequence /roz/. Indeed, reading the letter string rows can activate the phonological sequence /roz/, which can then activate the lexical form rose. In other words, reading a homophone (rows) can activate a phonological sequence (/roz/), which can then activate another form of the homophone (rose). How do we know that a letter string often activates phonological information, which in turn activates other forms of homophones? Consider the following finding: Comprehenders have difficulty rejecting the word rows as not being an exemplar of the category A Flower (van Orden, 1987; van Orden, Johnston, & Hale, 1988).
To successfully comprehend a written passage, these incorrect lexical forms cannot remain activated. We propose they are suppressed. In fact, we suggest that the same cognitive mechanism that suppresses the inappropriate meanings of ambiguous words also suppresses the incorrect forms of homophones. If this is the same mechanism, and if this general suppression mechanism is less efficient in less skilled comprehenders, then less skilled comprehenders should also be less efficient in suppressing the incorrect forms of homophones.
This prediction is supported by developmental data. Consider the sentence She blue up the balloon. Six-year-olds are more likely to accept that sentence than are 10-year-olds even if the 6-year-olds clearly know the difference between blue and blew (Doctor & Coltheart, 1980; see also Coltheart, Laxon, Rickard, & Elton, 1988). If we assume that 6-year-olds are less skilled at comprehension than are 10-year-olds, this finding suggests that less skilled comprehenders are less able to suppress the incorrect lexical forms that are activated by phonology.
In our first experiment, we tested this hypothesis directly with adult subjects whom we knew differed in their general comprehension skill. Subjects read a short sentence, for instance, She dropped the plate. Then the subjects saw a test word, for instance, BREAK. The subjects’ task was to decide quickly whether the test word matched the meaning of the sentence they had just read. On half the trials, the test word did indeed match the meaning (e.g., BREAK fits the meaning of She dropped the plate). However, on the other half of the trials, the test word did not match the meaning of the sentence. Those were the trials that interested us most.
On half of those trials, the last word of the sentence was one form of a homophone, for example, He had lots of patients. On these trials, the test word was related to the homophone’s other lexical form; for example, the test word CALM is related to patience. We compared how long subjects took to reject CALM after reading He had lots of patients with how long they took to reject CALM after reading the same sentence with the last word replaced by a nonhomophone He had lots of students. This comparison showed us how activated the incorrect lexical form was; the more time subjects took to reject CALM after the patients versus students sentence, the more activated the patients form of the homophone must have been.
We presented the test words at two intervals: immediately (100 ms) after subjects finished reading each sentence and after a 1-s delay. We predicted that in the immediate condition, both the more and less skilled comprehenders would take longer to reject test words after reading homophones than nonhomophones. For example, both groups would take longer to reject CALM after reading He had lots of patients than after reading He had lots of students. That result would corroborate van Orden (1987; van Orden et al., 1988). It would also demonstrate that comprehenders of both skill levels often activate phonological information during reading.
Our novel predictions concerned what would happen after the delay. We predicted that after the 1-s delay the more skilled comprehenders would no longer take more time to reject test words following homophones versus nonhomophones. We assumed that after a 1-s delay, the more skilled comprehenders could successfully suppress the incorrect lexical forms that were activated through phonology. However, we made a different prediction for our less skilled comprehenders. If less skilled comprehenders are characterized by less efficient suppression mechanisms, then even after the 1-s delay the less skilled comprehenders should still take more time to reject test words following homophones versus non-homophones.
Methods
Materials and design
We constructed our materials by first selecting 80 homophones from Kreuz’s (1987) norms. We only selected homophones that we strongly suspected would be familiar to all our subjects. We wrote two sentences for each homophone, which differed by only their final words. In one sentence, the final word was the homophone (He had lots of patients); in the other sentence, the final word was a semantically comparable, although not necessarily synonymous, nonhomophone (He had lots of students). We also selected a test word for each of the 80 homophones. Each test word represented the meaning of the homophone that was not captured in the sentence. For example, the test word CALM was selected for the sentence He had lots of patients. The test words were also unrelated to the sentences when the nonhomophones occurred as the final words (e.g., CALM is unrelated to He had lots of students). All sentences were four to seven words long and comprised very simple vocabulary.
We also constructed 80 filler sentences. These sentences were identical in structure to the experimental sentences, and the final words for approximately half were homophones. However, these filler sentences differed from the experimental sentences because their test words were related to their sentences’ meaning; thus, subjects should have responded yes to these test words. For example, we followed the filler sentence She liked the rose with the test word FLOWER, and we followed the filler sentence She dropped the plate with the test word BREAK.
During pretesting, we presented our experimental and filler sentences to 25 University of Oregon students and asked them to make unspeeded judgments about whether the test words were related to the sentences. We used experimental sentences and test words only if 95% of our students agreed that the test words did not match the sentences, and we used filler sentences and test words only if 95% of our students agreed that the test words did match the sentences.
During the experiment, we counterbalanced our experimental sentences by manipulating two variables. First, half the subjects of each skill level read the homophone as the sentence’s final word, and the other half read the nonhomophone. Second, half the subjects of each skill level received the test word at the immediate interval, and half received it after the delayed interval. By counterbalancing these two variables, we created four between-subjects material sets. Twenty-four subjects, 12 of each comprehension skill level, were tested with each material set.
Procedure
Each trial began with a warning signal, which was a plus sign flanked by dashes (—— + ——). The warning signal appeared for 500 ms in the center of the screen. Then, each sentence was presented, one word at a time, in the center of the screen, with each successive word replacing the previous one. Each word’s presentation duration was a function of its number of characters plus a constant. The constant was 300 ms, and the function was 16.7 ms per character. The interval between words was 150 ms. After the sentence–final word disappeared, the test word appeared either 100 ms later (the immediate interval) or 1,000 ms later (the delayed interval). Each test word was capitalized and flanked by a space and two asterisks, for example: ** CALM **. The test words remained on the screen until either the subjects responded or 2 s elapsed. Subjects responded by pressing either the Z key (to answer yes) or the ? key (to answer no). They pressed the Z key with their left index finger and the ? key with their right index finger. After each trial, the subjects received feedback: They were told whether they were correct, and if correct, they were shown their reaction times. Subjects completed 22 practice trials before performing the actual experiment.
Subjects
The subjects were 48 more and 48 less skilled comprehenders. These 96 subjects were selected from 170 subjects. First, we excluded 9 subjects for failing to perform the task with an adequate degree of accuracy (which, for this experiment, we estimated at no more than 15% errors). Then we arranged the remaining 161 subjects according to their performance on the Multi-Media Comprehension Battery. This arrangement provided 53 subjects in the top third of the distribution, 55 subjects in the middle third of the distribution, and 53 subjects in the bottom third of the distribution. We selected 48 more skilled comprehenders by drawing an equal number of subjects who had been tested on each of the four material sets from the top third of the distribution. We selected 48 less skilled comprehenders by drawing an equal number of subjects who had been tested on each of the four material sets from the bottom third of the distribution.
Although the 48 more versus the 48 less skilled comprehenders differed in their performance on the Multi-Media Comprehension Battery, t(47) = 4.70, p < .001, they did not differ in their performance on the Air Force Qualifying Exam (p > .15). Neither did they differ in their performance on the three subtests of the Armed Services Vocational Aptitude Battery for which we were able to obtain complete sets of data.3 Those three subtests measured general knowledge, administrative ability, and mechanical ability (all three ps > .15).
Results
Table 1 presents the subjects’ mean reaction times, standard errors of those means, and error rates on the experimental trials.4 As Table 1 illustrates, the more skilled comprehenders responded more rapidly than the less skilled comprehenders, F(1, 94) = 4.11, p < .05. From the reaction times presented in Table 1, we computed an interference score by subtracting subjects’ latencies to reject test words like CALM after reading homophones like patients from their latencies to reject CALM after reading nonhomophones like students.5 Figure 1 displays how much interference our more versus less skilled comprehenders experienced at the 100-ms immediate interval and the 1-s delayed interval. The more skilled comprehenders are presented by hashed lines, and the less skilled comprehenders by unfilled bars.
Table 1.
Subjects’ Mean Reaction Times, Standard Errors, Error Rates in Experiment 1
| Group | Sentence–final word
|
|||
|---|---|---|---|---|
| Immediate interval
|
Delayed interval
|
|||
| Homophone | Nonhomophone | Homophone | Nonhomophone | |
| More skilled comprehenders | ||||
| Reaction time (ms) | 1,074 ± 49 | 986 ± 38 | 897 ± 37 | 895 ± 37 |
| Error rate (%) | 11 | 6 | 6 | 5 |
| Less skilled comprehenders | ||||
| Reaction time (ms) | 1,216 ±60 | 1,121 ± 52 | 1,061 ± 51 | 972 ± 42 |
| Error rate (%) | 14 | 7 | 10 | 5 |
Figure 1.

Data from Experiment I. (RT = reaction time; hphone = homophone; nonhphone = nonhomophone.)
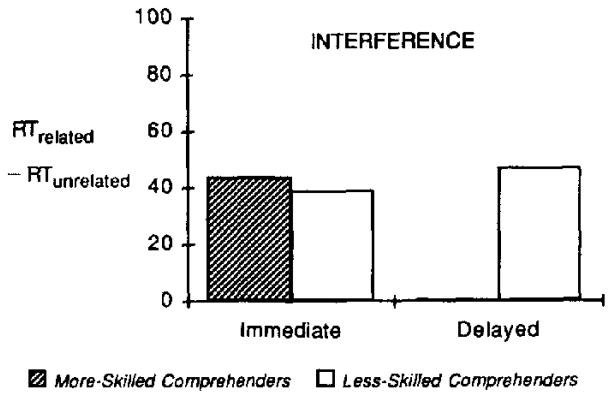
First, examine what happened at the immediate test interval. As Figure 1 illustrates, immediately after both the more and less skilled comprehenders read the homophones, both groups experienced a significant amount of interference, F(1, 47) = 29.53, p < .001, for the more skilled comprehenders, and F(1, 47) = 16.99, p < .001, for the less skilled comprehenders. In fact, the amount of interference experienced immediately by the more versus less skilled comprehenders did not differ, F(1, 94) < 1. These data demonstrate that 100 ms after comprehenders of both skill levels read homophones other lexical forms are often activated.
Now examine what happened after the 1-s delay. As Figure 1 illustrates, 1 s after the more skilled comprehenders read the homophones, they no longer experienced a reliable amount of interference, F(1, 47) < 1. We suggest that, by this point, the more skilled comprehenders had successfully suppressed the incorrect lexical forms. However, as Figure 1 also illustrates, this was not the case for the less skilled comprehenders. Even after the delay, the less skilled comprehenders were still experiencing a significant amount of interference, F(1, 47) = 33.48, p < .001. In fact, the less skilled comprehenders experienced the same amount of interference after the delay as they experienced immediately, F(1, 47) < 1. Thus, even a full second after the less skilled comprehenders read the homophones, they were still unable to suppress the incorrect lexical forms.
This pattern, in which both the more and less skilled comprehenders immediately experienced interference but only the less skilled comprehenders experienced interference after the 1 -s delay, produced a reliable three-way interaction between comprehension skill, test interval, and amount of interference, F(1, 94) = 6.40, p < .01. These data support the hypothesis that less skilled comprehenders are plagued by less efficient suppression mechanisms.
Experiment 2. Do Less Skilled Comprehenders Suppress Information Less Efficiently When Viewing Scenic Arrays?
We envision general comprehension skill as underlying the ability to comprehend linguistic stimuli: words, sentences, and passages. We also envision general comprehension skill as underlying the ability to comprehend nonlinguistic stimuli, for instance, naturalistic scenes. Other researchers also consider scene perception as “comprehension” (Biederman, 1981; Friedman, 1979; Mandler & Johnson, 1976).
Furthermore, the mechanisms of enhancement and suppression appear to play an equally vital role in scene comprehension. For instance, Biederman wrote about the difficulty in “suppressing the interpretations of visual arrays that comprise scenes” (Biederman, Bickle, Teitelbaum, & Klatsky, 1988, p. 456). This difficulty is manifested in the following phenomenon: After viewing a scene, subjects often incorrectly report that an object was present if that object is typically found in that type of scene. For instance, subjects are likely to incorrectly report that a tractor was present in a farm scene, but they are unlikely to incorrectly report that a tractor was present in a kitchen scene (Biederman, Glass, & Stacy, 1973; Biederman, Mezzanotte, & Rabinowitz, 1982; Biederman, Teitelbaum, & Mezzanotte, 1983; Palmer, 1975).
We suggest that these typical but absent objects are often automatically activated by the components of scenes in the same way that incorrect forms of homophones and inappropriate meanings of ambiguous words are often automatically activated by the components of sentences. When comprehenders read a sentence that contains a homophone, other forms of that homophone are often activated even though those other forms are not present in the sentence. In addition, when comprehenders read a sentence that contains an ambiguous word, meanings of that ambiguous word are often activated even though those other meanings are not “present” in the sentence (i.e., those other meanings are not relevant to the sentence). In the same way, when comprehenders view a scene, for instance, one that contains barns, pitchforks, and roosters, any of those objects could activate the concept tractor, even though no tractor is present in the scene.
However, to successfully comprehend a scene, comprehenders must suppress typical but absent objects, just as comprehenders must suppress the incorrect forms of homophones and the inappropriate meanings of ambiguous words. We propose that the same cognitive mechanism that suppresses the activation of inappropriate linguistic information suppresses the activation of inappropriate nonlinguistic information. If this is the same mechanism, and if this general suppression mechanism is less efficient in less skilled comprehenders, then less skilled comprehenders should also be less efficient in suppressing the activation of typical but absent objects when viewing scenes.
We tested this hypothesis in Experiment 2 using Biederman et al.’s (1988) stimuli.6 Biederman et al. (1988) replicated the phenomenon in which subjects incorrectly report that an object is present in a scene when the object is typical of that scene (for instance, subjects incorrectly report that a tractor was present in a farm scene). However, instead of viewing actual scenes, the subjects in Biederman et al.’s (1988) experiment viewed clock-face arrangements of objects, as illustrated in Figure 2. For example, the top left panel of Figure 2 illustrates a clock-face arrangement of six objects normally found in a farm scene: a barn, a pig, a pitchfork, a farmer, a rooster, and an ear of corn. We refer to these clock-face arrangements as scenic arrays.
Figure 2.

Example stimuli for Experiment 2.
We presented all of Biederman et al.’s (1988) scenic arrays that comprised three, four, five, or six objects. However, we slightly modified Biederman et al.’s task so that it would better parallel our Experiment 1 task. In Experiment 2, subjects first viewed a scenic array; then they saw the name of a test object. Their task was to verify whether the test object had been present in the array they just viewed. On half the trials, the test object had been present, but in half it had not. We were interested in the trials in which the test object had not been present.
On half of those trials, the objects in the array were typical of a particular scene, for instance, objects that typically occur in a farm scene, as illustrated in the top left panel of Figure 2. On these trials, the test object was something that also typically occurs in this type scene. However, the test object had not been present in the scenic array the subjects just viewed. For instance, a TRACTOR typically occurs in a farm scene, but no TRACTOR occurs in the scenic array illustrated in the top panel of Figure 2. We compared how long subjects took to reject TRACTOR after viewing the farm array with how long they took to reject TRACTOR after viewing another scenic array, for instance, objects belonging to a kitchen scene, as illustrated in the bottom panel of Figure 2. This comparison showed us how activated the typical but absent object was; the more time subjects took to reject TRACTOR after viewing the typical (farm) versus the atypical (kitchen) array, the more activated the typical but absent object must have been.
We presented the names of the test objects at two intervals: immediately (50 ms) after subjects viewed each array and after a 1 -s delay. We predicted that in the immediate condition both the more and less skilled comprehenders would take longer to reject test objects after typical than atypical scenic arrays. For example, both groups would take longer to reject TRACTOR after viewing the farm array than after viewing the kitchen array. This result would corroborate Biederman and his colleagues’ results. It would also demonstrate that comprehenders of both skill levels often activate typical but absent objects when viewing scenic arrays.
However, what would happen after the delay? We predicted that after the 1 -s delay the more skilled comprehenders would no longer take more time to reject test objects after viewing typical than atypical arrays. We assumed that after a 1 -s delay the more skilled comprehenders could successfully suppress the activation of typical but absent objects. However, we made a different prediction for our less skilled comprehenders. If less skilled comprehenders are characterized by less efficient suppression mechanisms, then even after the 1-s delay, the less skilled comprehenders should still take longer to reject test objects after viewing typical than atypical scenic arrays.
Methods
Materials and design
We constructed 40 experimental scenic arrays from Biederman et al.’s (1988) stimuli. These 40 arrays were based on 10 types of scenes: farm, nursery, kitchen, backyard, office, city street, living room, campsite, bathroom, and orchestra. The objects in the scenic arrays were easy-to-identify line drawings. We constructed 40 experimental arrays from these 10 scene types by varying the number of objects in an array. One array of each of the 10 scene types contained three objects (e.g., ear of corn, barn, and pig); one array of each scene type contained four objects (ear of corn, barn, pig, and rooster); one array of each scene type contained five objects (ear of corn, barn, pig, rooster, and farmer); and one array of each scene type contained six objects (ear of corn, barn, pig, rooster, farmer, and pitchfork). Therefore, there were 10 arrays with three objects, 10 with four objects, 10 with five objects, and 10 with six objects. For each scene type, we selected one test object. The 10 test objects were TRACTOR, KETTLE, LAMP, FILE CABINET, TRAFFIC LIGHT. RATTLE, GRILL, HATCHET, TOILET, and HARP.
Each of the 40 experimental arrays served as both a typical array and an atypical array. When serving as a typical array, its test object was typical of the objects in the array. For example, when the array comprising an ear of corn, barn, pig, rooster, farmer, and pitchfork served as a typical array, its test object was TRACTOR. When the same array served as an atypical array, its test object was KETTLE.
We also constructed 80 filler arrays. The filler arrays were identical in structure to the experimental arrays. They too were based on 10 types of scenes (farm, nursery, kitchen, backyard, office, city street, living room, campsite, bathroom, and orchestra). They too had three, four, five, or six objects displayed in each array. However, these filler arrays differed from the experimental arrays because the test objects had been present in their respective array; thus, subjects should have responded yes. For example, a filler array for a farm scene contained an ear of corn, a barn, a pig, and a tractor. The same 10 objects that served as test objects for the experimental trials served as test objects for the filler trials. The only difference was that the test objects were present in the scenic arrays presented on filler trials (but they were not present in the scenic arrays presented on experimental trials).
On half of the 80 filler trials, the test object was typical of the scene represented by the other objects in the array. For example, the array contained an ear of corn, a barn, a pig, and a tractor, and the test object was TRACTOR. On the other half of the 80 filler trials, the test object was atypical of the scene represented by the other objects in the array. For example the array contained a salt shaker, an oven, a frying pan, a spice rack, and a tractor, and the test object was TRACTOR.
Procedure
Throughout the experiment, a filled white square (15 × 15 cm), bordered by a 4-mm blue line, occupied the center of the otherwise black computer screen. The scenic arrays and the names of the test objects were displayed inside the blue border of the white square.
Each trial began with a warning signal, which was a plus sign that appeared for 1,000 ms in the center of the screen. Then the scenic array was displayed for 250 ms. After the scenic array disappeared, the name of the test object appeared either 50 ms later (the immediate interval) or 1,000 ms later (the delayed interval). Each test name was capitalized. The names of the test objects remained on the screen until either the subjects responded or 2 s elapsed. Subjects responded by pressing either the Z key (to answer yes) or the ? key (to answer no). They pressed the Z key with their left index fingers and the ? key with their right index fingers. After each trial, the subjects received feedback: They were told whether they were correct, and if correct, they were shown their reaction times.
Subjects completed 40 practice trials before performing the actual experiment. The first 20 practice trials familiarized subjects with the pictures of the 10 test objects. Then the subjects completed 20 test trials with scenic arrays composed of objects typically found in a baseball field and objects typically found in a battlefield.
Subjects
The subjects were 20 more and 20 less skilled comprehenders. These 40 subjects were drawn from 70 subjects. First, we excluded 3 subjects for failing to perform the task with an adequate degree of accuracy (which, for this experiment, we estimated at no more than 5% errors). Then we arranged the remaining 67 subjects according to their performance on the Multi-Media Comprehension Battery. This arrangement provided 22 subjects in the top third of the distribution, 23 subjects in the middle third of the distribution, and 22 subjects in the bottom third of the distribution. We selected 20 more skilled comprehenders by drawing an equal number of subjects who had been tested on each of the four material sets from the top third of the distribution. We selected 20 less skilled comprehenders by drawing an equal number of subjects who had been tested on each of the four material sets from the bottom third of the distribution.
Although the more skilled and less skilled comprehenders differed in their performance on the Multi-Media Comprehension Battery, t(19) = 2.12, p < .05, they did not differ in their performance on the Air Force Qualifying Exam (t < 1). Neither did the more skilled versus less skilled comprehenders differ in their performance on the general knowledge, administrative ability, and mechanical ability subtests of the Armed Services Vocational Aptitude Battery (all three ts < 1).
Results
Table 2 presents the subjects’ mean reaction times, standard errors of those means, and error rates on the experimental trials. As Table 2 illustrates, the more skilled comprehenders responded more rapidly than the less skilled comprehenders, F(1, 38) = 10.17, p < .03. From the reaction times presented in Table 2, we computed an interference score by subtracting subjects’ latencies to reject names of test objects after viewing typical arrays from their latencies to reject names of test objects after viewing atypical arrays. For example, we subtracted subjects’ latencies to reject TRACTOR after viewing a farm array from their latencies to reject TRACTOR after viewing a kitchen array. Figure 3 displays how much interference our more skilled versus less skilled comprehenders experienced at the 50-ms immediate interval and the 1-s delayed interval. The more skilled comprehenders are represented by hashed lines, and the less skilled comprehenders are represented by unfilled bars.
Table 2.
Subjects’ Mean Reaction Times, Standard Errors, and Error Rates in Experiment 2
| Group | Scenic array
|
|||
|---|---|---|---|---|
| Immediate interval
|
Delayed interval
|
|||
| Typical | Atypical | Typical | Atypical | |
| More skilled comprehenders | ||||
| Reaction time (ms) | 847 ± 48 | 773 ± 36 | 699 ± 40 | 691 ± 38 |
| Error rate (%) | 4 | 2 | 3 | 1 |
| Less skilled comprehenders | ||||
| Reaction time (ms) | 1,082 ± 66 | 1,000 ± 55 | 946 ± 59 | 860 ± 57 |
| Error rate (%) | 5 | 2 | 4 | 2 |
Figure 3.

Data from Experiment 2. (RT = reaction time.)
First, examine what happened at the immediate test interval. As Figure 3 illustrates, immediately after both the more skilled and less skilled comprehenders viewed the scenic arrays, both groups experienced a significant amount of interference, F(1, 19) = 10.83, p < .004, for the more skilled comprehenders, and F(1, 19) = 12.57, p < .002, for the less skilled comprehenders. In fact, the amount of interference experienced immediately by the more skilled versus less skilled comprehenders did not differ, F(1, 38) < 1. These data demonstrate that 50 ms after comprehenders of both skill levels view scenic arrays typical but absent objects are activated.
Now examine what happened after the 1-s delay. As Figure 3 illustrates, 1 s after the more skilled comprehenders viewed the scenic arrays, they no longer experienced a reliable amount of interference, F(1, 19) < 1. We suggest that, by this point, the more skilled comprehenders had successfully suppressed the typical but absent objects. However, as Figure 3 also illustrates, this was not the case for the less skilled comprehenders. Even after the delay, the less skilled comprehenders were still experiencing a significant amount of interference, F(1, 19) = 8.05, p < .01. In fact, the less skilled comprehenders were experiencing the same amount of interference after the delay as they experienced immediately, F(1, 19) < 1. Thus, even a full second after the less skilled comprehenders viewed the arrays, they were still unable to sup press the typical but absent objects.7 These data support the hypothesis that less skilled comprehenders are plagued by less efficient suppression mechanisms.
Experiment 3: Do Less Skilled Comprehenders Suppress Information Across Modalities Less Efficiently?
An attractive aspect of the construct of general comprehension skill is that it reflects the multiple demands placed on human comprehenders. To understand the environment, humans must make sense of stimuli that originate from various modalities. Humans would be severely handicapped if they were skilled only at reading written words, listening to spoken words, or comprehending graphic displays.
Information originates from different modalities, often simultaneously. Classic examples are reading while listening to music or driving while carrying on a conversation. Comprehenders often experience interference across modalities. For instance, it is harder to name an object such as an ashtray if a letter string such as INCH is written across the object, as illustrated in the upper left panel of Figure 4 (Rayner & Posnansky, 1978; Rosinski, Golinkoff, & Kukish, 1975). The opposite is also true: It is harder to read a word such as RIVER if it is superimposed on a picture, as illustrated in the bottom left panel of Figure 4 (Smith & McGee, 1980).
Figure 4.

Example stimuli for Experiment 3.
Successful comprehension often requires suppressing information across modalities. We propose that the same cognitive mechanism that suppresses information within a modality suppresses information across modalities. If this is the same mechanism, and if this general suppression mechanism is less efficient in less skilled comprehenders, then less skilled comprehenders should also be less efficient in suppressing information across modalities.
We tested this hypothesis in Experiment 3. We modified Tipper and Driver’s (1988) experimental task (see also Neill, 1977; Tipper, 1985; Tipper & Cranston, 1985). In our modification, subjects first viewed a context display, which contained a line drawing of a common object and a familiar word. For example, the top panel in Figure 4 contains a picture of an ashtray with the word INCH written across it. The bottom panel of Figure 4 contains the word RIVER superimposed on a picture of a baseball player. All context displays contained both a picture and a word.
After subjects viewed each context display, they were shown a test display. Each test display contained either another picture or another word. Half the time the test display contained another picture, and we refer to those trials as picture trials; half the time the test display contained another word, and we refer to those trials as word trials. Subjects were told before each trial whether that trial would be a picture trial or a word trial.
The top panel of Figure 4 illustrates a picture trial. On picture trials, subjects were supposed to focus on the picture in the context display and ignore the word. For example, for the picture trial shown in Figure 4, subjects should have focused on the ashtray and ignored the word INCH. After each context display, subjects were shown a test display. On the picture trials, the test display contained another picture. The subjects’ task (on picture trials) was to verify whether the picture shown in the test display was related to the picture shown in the context display. For the picture trial shown in Figure 4, subjects should have responded yes because the picture shown in the test display, the pipe, was related to the picture shown in the context display, the ashtray.
The bottom panel of Figure 4 illustrates a word trial. On word trials, subjects were supposed to focus on the word in the context display and ignore the picture. For example, for the word trial shown in Figure 4, subjects should have focused on the word RIVER and ignored the baseball player. The test display on word trials contained another word. The subjects’ task was to verify whether the word written in the test display was related to the word written in the context display. For the word trial shown in Figure 4, subjects should have responded yes because the word written in the test display, STREAM, was related to the word written in the context display, RIVER.
On half the picture trials and half the word trials, the test display was related to what the subjects were to focus on in the context display, just as they are in Figure 4. However, we were more interested in trials in which the test display was unrelated to what the subjects were supposed to focus on in the context display. On half of those trials, although the test display was unrelated to what the subjects were to focus on in the context display, it was related to what they were supposed to ignore.
For example, the top panel in Figure 5 illustrates an experimental picture trial. The context display contains a picture of a hand with the superimposed word RAIN. Because this is a picture trial, subjects, should have focused on the picture of the hand and ignored the word. The test display is a picture of an umbrella. So the test display is unrelated to what the subjects were supposed to focus on in the context display; subjects should have responded no. However, the test display is related to what the subjects were supposed to ignore. We measured how long subjects took to reject the test display, the picture of the umbrella, after viewing the context display, the picture of the hand with the superimposed word RAIN. In addition, we compared that with how long subjects took to reject the same test display, the picture of the umbrella, after viewing the same context display, the picture of the hand, but with another word superimposed, SOUP. This comparison showed us how quickly comprehenders could suppress information across modalities. Experimental word trials worked similarly, as illustrated by the bottom half of Figure 5.
Figure 5.

Example stimuli for Experiment 3.
As in our other experiments, we presented the test displays at two intervals: immediately (50 ms) after the context-setting display and after a 1-s delay. We predicted that in the immediate condition both the more skilled and less skilled comprehenders would take longer to reject a test display when it was related to the ignored picture or word in the context display. This result would corroborate Tipper (1985) and his colleagues’ results. It would also demonstrate that both more skilled and less skilled comprehenders have immediate difficulty suppressing information across modalities.
In contrast, we predicted that after the 1-s delay the more skilled comprehenders would no longer take more time to reject test displays when they were related to the ignored items of the context displays. This is because we assumed that after a 1-s delay the more skilled comprehenders could successfully suppress information across modalities. We made a different prediction for our less skilled comprehenders. If less skilled comprehenders are characterized by less efficient suppression mechanisms, then even after the 1-s delay the less skilled comprehenders should still take more time to reject test displays when they were related to the ignored items of the context displays.
Methods
Materials and design
We constructed 80 experimental context displays. Each context display contained a line drawn picture and a superimposed word. Most pictures were from the Snodgrass and Vanderwart (1980) norms. All words were very familiar. The pictures and words in each context display were unrelated (e.g., ashtray and INCH, hand and SOUP). Forty of the 80 experimental context displays were used as experimental picture trials, and 40 were used as experimental word trials.
After creating the context displays for the 40 experimental picture trials, we selected 40 additional pictures for test displays. The 40 test- display pictures were unrelated to the pictures in the context displays, but they were related to the should-be-ignored words. For example, in Figure 5, the picture in the test display, the umbrella, is unrelated to the picture in the context display, the hand. However, the umbrella is related to the should-be-ignored word RAIN in the context display.
After creating the context displays for the 40 experimental word trials, we selected 40 additional words for test displays. These 40 test-display words were unrelated to the words in the context displays, but they were related to the (should-be-ignored) pictures in the context display. For example, in Figure 5, the word in the third test display, SWEEP, is unrelated to the word in the context display, MONTH. However, SWEEP is related to the should-be-ignored picture of the broom in the context display.
We also constructed 80 context displays that were used for comparison with the experimental context displays. The comparison context displays were identical to the experimental context displays except that the should-be-ignored picture or word was replaced by an unrelated picture or word. For example, in the second panel of Figure 5, the word SOUP replaces the word RAIN. SOUP is unrelated to an umbrella. As another example, in the fourth panel of Figure 5, the picture of a sandwich replaces the picture of a broom. A sandwich is unrelated to SWEEP. The comparison words (e.g., SOUP) were the same length as the experimental words (e.g., RAIN), and the comparison pictures (e.g., the sandwich) occluded about the same amount of the superimposed words as the experimental pictures (e.g., the broom).
Finally, we constructed context and test displays for 80 filler trials. The context and test displays for the filler trials were identical in structure to the context and test displays for the experimental trials; half were picture trials and half were word trials. However, the filler trials differed from the experimental trials because the should-be-focused-on picture or word in the context display was related to the picture or word in the test displays. The two panels in Figure 4 illustrate filler (yes) trials.
We counterbalanced our experimental trials by manipulating two variables. First, half the subjects of each skill level were presented with the experimental context display, and the other half were presented with the comparison context display. Second, half the subjects of each skill level were presented with the test display at the immediate interval, and half were presented with it after the delayed interval. By counterbalancing these two variables, we created four between-subjects material sets. Forty subjects, 20 of each comprehension skill level, were tested with each material set.
Procedure
Throughout the experiment, a filled white (9×9 cm) square, bordered with a 2-mm blue line, occupied the center of the otherwise black computer screen. All context and test displays were presented inside the blue border of the white square.
Each trial began with a warning signal, which was either a P or a W flanked by dashes (-P- or -W-). This warning signal remained on the screen for 1,000 ms and told the subject whether the trial was a picture or word trial. One second after the warning signal disappeared, the context display was presented for 700 ms. After the context display disappeared, the test display appeared either 50 ms later (the immediate interval) or 1,000 ms later (the delayed interval). The test display remained on the screen until either the subjects responded or 2 s elapsed. Subjects responded by pressing either the Z key (to answer yes) or the ? key (to answer no). They pressed the Z key with their left hands and the ? key with their right hands. After each trial, the subjects received feedback: They were told whether they were correct, and if correct, they were shown their reaction times. Subjects completed 20 practice trials before performing the actual experiment.
Subjects
The subjects were 80 more skilled and 80 less skilled comprehenders. These 160 subjects were selected from 255 subjects. First, we excluded 12 subjects for failing to perform the task with an adequate degree of accuracy (which, for this experiment, we estimated at no more than 5% errors). Then we arranged the remaining 243 subjects according to their performance on the Multi-Media Comprehension Battery. This arrangement provided 81 subjects in the top third of the distribution, 81 subjects in the middle third of the distribution, and 81 subjects in the bottom third of the distribution. We selected 80 more skilled comprehenders by drawing an equal number of subjects who had been tested on each of the four material sets from the top third of the distribution. We selected 80 less skilled comprehenders by drawing an equal number of subjects who had been tested on each of the four material sets from the bottom third of the distribution.
The more skilled versus less skilled comprehenders differed in their performance on the Multi-Media Comprehension Battery, t(79) = 6.6, p <.001. In addition, unlike the subjects in the other experiments we report here, the more skilled versus less skilled comprehenders also differed slightly in their performance on the Air Force Qualifying Exam, t(79) = 1.65, p < .06. However, the more skilled versus less skilled comprehenders did not differ reliably in their performance on the general knowledge, administrative ability, and mechanical ability subtests of the Armed Services Vocational Aptitude Battery (all three ps > .10).
Results
Table 3 presents the subjects’ mean reaction times, standard errors of those means, and error rates on the experimental trials. As Table 3 illustrates, the more skilled comprehenders responded more rapidly than the less skilled comprehenders, F(1, 58) = 8.91, p < .03. From the reaction times presented in Table 3, we computed an interference score by subtracting subjects’ latencies to reject test displays that were related to the to-be-ignored items from their latencies to reject test displays that were unrelated to the to-be-ignored items.8 Figure 6 displays how much interference our more skilled versus less skilled comprehenders experienced at the 50-ms immediate interval and the 1-s delayed interval. The more skilled comprehenders are represented by hashed lines, and the less skilled comprehenders are represented by unfilled bars.
Table 3.
Subjects’ Mean Reaction Times, Standard Errors, and Error Rates in Experiment 3
| Context display
|
||||
|---|---|---|---|---|
| Immediate interval
|
Delayed interval
|
|||
| Related | Unrelated | Related | Unrelated | |
| Picture trials | ||||
| More skilled comprehenders | ||||
| Reaction time (ms) | 804 ± 26 | 753 ± 21 | 710 ± 25 | 710 ± 24 |
| Error rate | 2% | 1% | 1% | 1% |
| Less skilled comprehenders | ||||
| Reaction time (ms) | 919 ± 38 | 879 ± 30 | 841 ± 34 | 794 ± 28 |
| Error rate | 2% | 1% | 2% | 1% |
|
| ||||
| Word trials | ||||
| More skilled comprehenders | ||||
| Reaction time (ms) | 835 ± 27 | 797 ± 22 | 732 ± 21 | 731 ± 22 |
| Error rate | 2% | 1% | 1% | 1% |
| Less skilled comprehenders | ||||
| Reaction time (ms) | 948 ± 35 | 909 ± 34 | 860 ± 33 | 814 ± 28 |
| Error rate | 2% | 2% | 1% | 1% |
Figure 6.
Data from Experiment 2. (RT = reaction time.)
First, examine what happened at the immediate test interval. As Figure 6 illustrates, immediately after both the more skilled and less skilled comprehenders saw the context displays, they experienced a significant amount of interference, F(1, 79) = 27.21, p < .001, for the more skilled comprehenders, and F(1, 79) = 6.67, p < .01, for the less skilled comprehenders. In fact, the amount of interference experienced immediately by the more skilled versus less skilled comprehenders did not differ, F(1, 158) < 1. These data demonstrate that 50 ms after viewing pictures with superimposed words or reading words surrounded by pictures, comprehenders of both skill levels have difficulty suppressing related pictures or words, even when they are told explicitly to ignore them.
Now examine what happened after the 1-s delay. As Figure 6 illustrates, 1 s after the more skilled comprehenders saw the context displays, they no longer experienced a reliable amount of interference, F(1, 79) < 1. We suggest that, by this point, the more skilled comprehenders had successfully suppressed the ignored pictures or words. However, as Figure 6 also illustrates, this was not the case for the less skilled comprehenders. Even after the delay, the less skilled comprehenders were Still experiencing a significant amount of interference, F(1, 79) = 12.83, p < .001. In fact, the less skilled comprehenders were experiencing the same amount of interference after the delay as they experienced immediately, F(1, 79) < 1. Thus, even a full second after the less skilled comprehenders viewed pictures with superimposed words or read words surrounded by pictures, they still had difficulty suppressing the ignored pictures or words.
This pattern, in which both the more skilled and less skilled comprehenders immediately experienced interference but only the less skilled comprehenders experienced interference after the 1-s delay, produced a reliable three-way interaction between comprehension skill, test interval, and amount of interference, F(1, 158) = 4.68, p < .03. These data support the hypothesis that less skilled comprehenders are plagued by less efficient suppression mechanisms.
Experiment 4: Do Less Skilled Comprehenders Enhance the Appropriate Meanings of Ambiguous Words Less Efficiently?
We have found that less skilled comprehenders suppress less efficiently the inappropriate meanings of ambiguous words (Gernsbacher et al., 1990; Experiment 4), the incorrect forms of homophones (Experiment 1), objects that are activated during the comprehension of nonverbal scenes (Experiment 2), and information across modalities (e.g., suppressing words while viewing pictures or suppressing pictures while reading words, Experiment 3).
These experiments demonstrate a critical characteristic of less skilled comprehenders: They suppress irrelevant or inappropriate information less efficiently. These experiments suggest that an efficient suppression mechanism is a critical component of general comprehension skill. A counterexplanation is that less skilled comprehenders have difficulty rejecting inappropriate information not because they have less efficient suppression mechanisms, but because they less fully appreciate what is contextually appropriate. Perhaps they have less efficient enhancement mechanisms.
According to the structure building framework, comprehension requires enhancing the activation of memory nodes when those nodes are relevant to the structure being built. Thus, perhaps less skilled comprehenders’ enhancement mechanisms—not their suppression mechanisms—are at fault. By this logic, less skilled comprehenders have difficulty rejecting ACE after reading He dug with the spade because they less fully appreciate that the context of digging with a spade implies a garden tool, not a playing card.
This explanation seems unlikely given the repeated finding that less skilled comprehenders are not less able to appreciate predictable sentence contexts; in fact, less skilled comprehenders often benefit more from predictable contexts than more skilled comprehenders. For example, the word dump is very predictable in the context The garbage men had loaded as much as they could onto the truck. They would have to drop off a load at the garbage dump. In contrast, dump is less predictable in the context Albert didn’t have the money he needed to buy the part to fix his car. Luckily, he found the part he wanted at the dump. All comprehenders pronounce the word dump more rapidly when it occurs in the predictable context than when it occurs in the less predictable context; in other words, all comprehenders benefit from the predictable context. However, less skilled fourth-grade readers benefit even more than skilled fifth-grade readers; the difference in the time needed to name dump in the predictable versus unpredictable context is greater for the less skilled readers than for the more skilled readers (Perfetti & Roth, 1981). This finding does not support the hypothesis that less skilled comprehenders are characterized by less efficient enhancement mechanisms.
Nevertheless, we tested this hypothesis with our adult comprehenders and with tasks similar to those we used in our previous experiments. In Experiment 4, subjects read short sentences, and after each sentence they saw a test word. As in our other experiments, the subjects’ task was to verify whether the test word fit the meaning of the sentence they just read. However, unlike our other experiments, in Experiment 4 we were interested in the trials in which the test word did indeed fit the meaning of the sentence (and, therefore, the subjects should have responded yes).
On half of those trials, the last word of the sentence was an ambiguous word, for example, spade, and the verb in the sentence was biased toward one meaning of the ambiguous word, for example, He dug with the spade. The test word was related to the meaning of the ambiguous word that was biased by the verb, for example, GARDEN. In a comparison condition, we presented the same sentence, but the biasing verb was replaced with a neutral verb, for example, He picked up the spade. The spade in this sentence could be either a garden tool or a playing card.
We measured how rapidly subjects accepted GARDEN after reading the sentence with the biasing verb, He dug with the spade. In addition, we compared that with how rapidly subjects accepted GARDEN after reading the sentence with the neutral verb as in He picked up the spade. This comparison showed us how fully comprehenders could appreciate the biasing context: The faster subjects were to accept GARDEN after the sentence with the biasing verb versus the sentence with the neutral verb, the more fully they appreciated the semantic context.
We presented the test words at two intervals: immediately (100 ms) after subjects finished reading each sentence and after a 1-s delay. We predicted that both the more and less skilled comprehenders would benefit from the biasing contexts; that is, both groups of comprehenders would accept test words more rapidly when the sentences contained biasing as opposed to neutral verbs. However, we were especially interested in whether the less skilled comprehenders would benefit less than the more skilled comprehenders.
If less skilled comprehenders are less efficient at rejecting contextually inappropriate information (as we found in our previous experiments) because they are less appreciative of context, then the less skilled comprehenders should have benefited less from the biasing contexts. In contrast, if less skilled comprehenders are less efficient at rejecting inappropriate information because they have less efficient suppression mechanisms, then the less skilled comprehenders should have benefited just as much from the biasing contexts as the more skilled comprehenders. On the basis of previous literature, we predicted that the less skilled comprehenders would benefit even more from the biasing contexts than the more skilled comprehenders.
Methods
Materials and design
We constructed our materials by first selecting 80 ambiguous words from various norms (Cramer, 1970; Kausler & Kollasch, 1970; Nelson, McEvoy, Walling, & Wheeler, 1980). We selected ambiguous words only if at least two of their meanings were relatively equal in frequency. For each ambiguous word, we wrote two sentences. The two sentences differed by only their verbs. In one sentence, the verb was biased toward one meaning of the ambiguous word (He dug with the spade); in the other sentence, the verb was neutral (He picked up the spade). We also selected a test word for each of the 80 ambiguous words. Each test word was related to the meaning of the ambiguous word that was implied by the biased verb. For example, the test word GARDEN was selected for the sentence He dug with the spade. The test words were also related to the sentences when the neutral verbs replaced the biased verbs (e.g., GARDEN is also related to He picked up the spade). All sentences were four to seven words long and were composed of very simple vocabulary.
We also constructed 80 filler sentences. These sentences were identical in structure to the experimental sentences, and the final words for approximately half were ambiguous words. However, these filler sentences differed from the experimental sentences because their test words were unrelated to their sentences’ meaning; thus, subjects should have responded no to these test words. For example, we followed the filler sentence She like the rose with the test word STAND, and we followed the filler sentence She dropped the plate with the test word DANCE.
During pretesting, we presented our experimental and comparison sentences to 25 University of Oregon students and asked them to make unspeeded judgments about the meanings of the ambiguous words. We only used biased verbs if 95% of our students selected the meaning of the ambiguous word that we intended, and we only used neutral verbs if our students were roughly split over which meaning we intended (e.g., when given the sentence He picked up the spade, approximately 50% chose GARDEN TOOL and approximately 50% chose PLAYING CARD).
During the experiment, we counterbalanced our experimental sentences by manipulating two variables: First, half the subjects of each skill level were presented with the biasing verb, and the other half were presented with the neutral verb. Second, half the subjects of each skill level were presented with the test word at the immediate interval, and half were presented with it after the delayed interval. By counterbalancing these two variables, we created four between-subjects material sets. Thirty subjects, 15 from each comprehension skill level, were tested with each material set.
Procedure
Each trial began with a warning signal, which was a plus sign flanked by dashes (—— + ——). The warning signal appeared for 500 ms in the center of the screen. Then each sentence was presented, one word at a time, in the center of the screen; each successive word replaced the previous one. Each word’s presentation duration was a function of its number of characters plus a constant. The constant was 300 ms, and the function was 16.7 ms per character. The interval between words was 150 ms. After the sentence–final word disappeared, the test word appeared either 100 ms later (the immediate interval) or 1,000 ms later (the delayed interval). Each test word was capitalized and flanked by a space and two asterisks, for example: ** GARDEN **. The test words remained on the screen until either the subjects responded or 2 s elapsed. Subjects responded by pressing either the Z key (to answer yes) or the ? key (to answer no). They pressed the Z key with their left hand and the ? key with their right hand. After each trial, the subjects received feedback: They were told whether they were correct, and if correct, they were shown their reaction times. Subjects completed 30 practice trials before performing the actual experiment.
Subjects
The subjects were 60 more skilled and 60 less skilled comprehenders. These 120 subjects were selected from 208 subjects. First, we excluded 10 subjects for failing to perform the task with an adequate degree of accuracy (which, for this experiment, we estimated at no more than 15% errors). Then we arranged the remaining 198 subjects according to their performance on the Multi-Media Comprehension Battery. This arrangement provided 66 subjects in the top third of the distribution, 66 subjects in the middle third of the distribution, and 66 subjects in the bottom third of the distribution. We selected 60 more skilled comprehenders by drawing an equal number of subjects who had been tested on each of the four material sets from the top third of the distribution. We selected 60 less skilled comprehenders by drawing an equal number of subjects who had been tested on each of the four material sets from the bottom third of the distribution.
Although the more skilled versus less skilled comprehenders differed in their performance on the Multi-Media Comprehension Battery, t(59) = 6.35, p < .001, they did not differ in their performance on the Air Force Qualifying Exam (t < 1). Neither did the more skilled versus less skilled comprehenders differ in their performance on the general knowledge, administrative ability, and mechanical ability subtests of the Armed Services Vocational Aptitude Battery (all three ts < 1).
Results
Table 4 presents the subjects’ mean reaction times, standard errors of those means, and error rates on the experimental trials. As Table 4 illustrates, the more skilled comprehenders responded more rapidly than the less skilled comprehenders, F(1, 118) = 10.16, p < .002. From the reaction times presented in Table 4, we computed a facilitation score by substracting subjects’ latencies to accept test words like GARDEN after reading sentences with biasing verbs like dug with from their latencies to accept GARDEN after reading sentences with neutral verbs like picked up. Figure 7 displays how much facilitation our more skilled versus less skilled comprehenders experienced at the 100-ms immediate interval and the 1 -s delayed interval. The more skilled comprehenders are represented by hashed lines, and the less skilled comprehenders are represented by unfilled bars.
Table 4.
Subjects’ Mean Reaction Times, Standard Errors, and Error Rates in Experiment 4
| Group | Verb
|
|||
|---|---|---|---|---|
| Immediate interval
|
Delayed interval
|
|||
| Neutral | Biased | Neutral | Biased | |
| More skilled comprehenders | ||||
| Reaction time (ms) | 884 ± 36 | 769 ± 24 | 803 ± 32 | 693 ± 22 |
| Error rate | 10% | 3% | 9% | 3% |
| Less skilled comprehenders | ||||
| Reaction time (ms) | 1,027 ± 36 | 877 ± 28 | 958 ± 34 | 806 ± 28 |
| Error rate | 11% | 3% | 9% | 3% |
Figure 7.

Data from Experiment 4. (RT = reaction time.)
As Figure 7 illustrates, at both the immediate and the delayed test intervals, both the more skilled and less skilled comprehenders experienced a significant amount of facilitation; in other words, there was a main effect of facilitation, F(1, 118) = 218.44, p < .001. Indeed, as Figure 7 also illustrates, at both test intervals, the less skilled comprehenders enjoyed even more facilitation than the more skilled comprehenders, F(1, 118) = 4.75, p < .03. These data do not support the hypothesis that less skilled comprehenders are characterized by less efficient enhancement mechanisms.
Experiment 5: Do Less Skilled Comprehenders Enhance Typical Objects in Scenic Arrays Less Efficiently?
Just as sentence comprehension requires enhancing the contextually appropriate meanings of words, perhaps scene comprehension requires enhancing the objects actually present in the visual array. In addition just as less skilled comprehenders might be less efficient at enhancing the contextually appropriate meanings of words, they might also be less able to enhance the objects present in a visual scene.
We tested this hypothesis in our fifth and last experiment. Experiment 5 was actually part of Experiment 2. Subjects first viewed a scenic array of objects, and then they read the name of a test object. For instance, subjects first viewed the scenic array illustrated in the top panel of Figure 8, and then they saw the test object, TRACTOR. The subjects’ task was to verify whether the test object had been present in the array they just viewed. On half the trials, the test object had not been present, but in half it had. In Experiment 5, we were interested in the trials in which the test object had been present (and, therefore, the subjects should have responded yes).
Figure 8.

Example stimuli for Experiment 5.
On half of those trials, the other objects in the array were typical of the type of scene in which the test object typically occurs. For example, the other objects in the top panel of Figure 8 typically occur in a farm scene, just as a tractor does. In a comparison condition, the other objects in the array were atypical of the scene in which the test object typically occurs. For example, the other objects in the array shown in the bottom panel of Figure 8 do not typically occur in a farm scene. We compared how rapidly subjects accepted TRACTOR after viewing it in an array of typical objects with how rapidly they accepted TRACTOR after viewing it in an array of atypical objects. This comparison showed us how fully comprehenders could appreciate the scenic contexts: The faster subjects were to accept TRACTOR after viewing the array of typical versus atypical objects, the more fully the subjects must have appreciated the context.
We presented the names of the test objects at two intervals: immediately (50 ms) after subjects finished viewing each scenic array and after a 1-s delay. We expected that both the more skilled and less skilled comprehenders would benefit from the typical contexts. That is, both groups of comprehenders would accept test objects more rapidly when the arrays contained typical objects as opposed to atypical objects. This result would corroborate those of Biederman et al. (1988).
However, we were interested in whether the less skilled comprehenders would benefit less from the typical contexts. If less skilled comprehenders are less efficient at rejecting contextually inappropriate information (as we found in our previous experiments) because they are less appreciative of context, then they should have benefited less from the typical contexts. In contrast, if less skilled comprehenders are less efficient at rejecting inappropriate information because they have less efficient suppression mechanisms, then they should have benefited just as much from the typical contexts as the more skilled comprehenders did.
Methods
This experiment was conducted concurrently with Experiment 2. The experimental and comparison arrays for this experiment were the filler arrays for Experiment 2. Similarly, the experimental and comparison arrays for Experiment 2 were the filler arrays for this experiment. Therefore, there were 40 experimental arrays, 40 comparison arrays, and 80 filler arrays. For the experimental and comparison arrays, the test object had been present; for the filler arrays, the test object had not been present. The test objects were typical of the experimental arrays but atypical of the comparison arrays. Similarly, half of the test objects for the filler arrays were typical (although absent), and the other half of the test objects for the filler arrays were atypical (although also absent). The procedure was identical to what we described for Experiment 2, and so were the subjects.
Results
Table 5 presents the subjects’ mean reaction times, standard errors of those means, and error rates on the experimental trials. As Table 5 illustrates, the more skilled comprehenders responded more rapidly than the less skilled comprehenders, F(1, 38) = 9.91, p < .003. From the reaction times presented in Table 5, we computed a facilitation score by subtracting subjects’ latencies to accept test objects like TRACTOR after viewing a tractor in a typical farm array from their latencies to accept TRACTOR after viewing a tractor in an atypical kitchen array. Figure 9 displays how much facilitation our more skilled versus less skilled comprehenders experienced at the 50-ms immediate and the 1-s delaed intervals. The more skilled comprehenders are represented by hashed lines, and the less skilled comprehenders are represented by unfilled bars.
Table 5.
Subjects’ Mean Reaction Times, Standard Errors, and Error Rates in Experiment 5
| Group | Scenic array
|
|||
|---|---|---|---|---|
| Immediate interval
|
Delayed interval
|
|||
| Atypical | Typical | Atypical | Typical | |
| More skilled comprehenders | ||||
| Reaction time (ms) | 758 ± 45 | 710 ± 39 | 567 ± 42 | 526 ± 33 |
| Error rate | 3% | 2% | 3% | 1% |
| Less skilled comprehenders | ||||
| Reaction time (ms) | 1,014 ± 66 | 933 ± 54 | 816 ± 54 | 732 ± 45 |
| Error rate | 3% | 2% | 3% | 2% |
Figure 9.

Data from Experiment 5. (RT = reaction time.)
As Figure 9 illustrates, at both the immediate and the delayed test intervals, both the more skilled and less skilled comprehenders experienced a significant amount of facilitation; in other words, there was a main effect of facilitation, F(1, 38) = 19.66, p < .0001. As Figure 9 also illustrates, the less skilled comprehenders appeared to enjoy more facilitation than the more skilled comprehenders, although the interaction was not reliable. Nevertheless, these data do not support the hypothesis that less skilled comprehenders are characterized by less efficient enhancement mechanisms.
Conclusions
We have found that less skilled comprehenders suppress less efficiently various types of information that is activated during the comprehension of linguistic as well as nonlinguistic media. While reading, less skilled comprehenders suppress less efficiently the inappropriate meanings of ambiguous words (Gernsbacher et al., 1990) and the incorrect forms of homophones. While comprehending nonverbal scenes, less skilled comprehenders suppress typical but absent objects less efficiently. While viewing pictures with superimposed words or reading words surrounded by pictures, less skilled comprehenders suppress information across modalities less efficiently.
We have also found that less skilled comprehenders do not enhance less efficiently the contextually appropriate meanings of ambiguous words; neither do they enhance less efficiently contextually appropriate objects that are present in nonverbal scenes. In fact, less skilled comprehenders often benefit from predictable context more than more skilled comprehenders do. Thus, less skilled comprehenders are not less able to reject contextually inappropriate information because they are less appreciative of context. Rather, we suggest they have less efficient suppression mechanisms.
Our findings parallel results observed with other populations who might have comprehension difficulty. For instance, 1 s after reading a sentence such as The man moved the piano, less skilled fifth-grade readers still show activation of a semantically associated but contextually less relevant word such as music; in contrast, 1 s after reading the same sentence, more skilled fifth-grade readers only show activation of contextually relevant words such as heavy (Merrill, Sperber, & McCauley, 1981). Thus, less skilled fifth-grade readers suppress contextually irrelevant semantic associates less efficiently.
Some older adults might also be characterized by less efficient suppression mechanisms. After younger adults focus on one object and ignore another, they are less able to identify the object they ignored. For example, after younger adults focus on a green A superimposed on a red B, they are less able to identify a red B if it appears on the next display. Presumably, the younger adults have efficiently suppressed the object they were supposed to ignore (e.g., the red B). However, older adults do not experience this carryover effect, suggesting that they suppressed the to-be-ignored item less efficiently (Hasher, Stoltzfus, Zacks, & Rympa, 1991).
Finally, consider a population who experiences considerably grave difficulties in many everyday cognitive tasks: schizophrenics. Among other difficulties they experience, schizophrenics are notoriously less efficient at maintaining the same topic while speaking (Chapman & Chapman, 1973); perhaps they too suffer from less efficient suppression mechanisms.
While answering our five experimental questions, our research raises at least two more. First, do less skilled comprehenders ever suppress irrelevant or inappropriate information? In our experiments, we waited what seemed like an eternity in mental chronometry—one full second. However, even after a second, less skilled comprehenders had still not suppressed the inappropriate or irrelevant information. Our intuitions predict that at some point less skilled comprehenders do suppress inappropriate information. In future research, we will investigate this intuition.
A second question is whether the mechanisms of suppression and enhancement are under comprehenders’ conscious control or whether they are automatic. Some theories of cognition differentiate between automatic mental activity and mental activity that is more conscious, perhaps controllable (Keele & Neill, 1978; Posner & Snyder, 1975). We have described the mechanisms of suppression and enhancement without committing to either position; in fact, we have implied both.
For instance, we have proposed that memory nodes (the building blocks of mental structures) are automatically activated by incoming stimuli. Once activated, memory nodes transmit processing signals: They send signals to suppress other memory nodes when the information represented by those other nodes is less relevant to the structure being developed. In addition, they send signals to enhance other memory nodes when the information represented by those other nodes is more relevant.
This simple description connotes that the mechanisms of suppression and enhancement operate automatically. Suppression and enhancement signals might be obligatorily sent, based on some criterion, for instance, a similarity criterion: The less similar the incoming information is to the previous information, the more likely it is to be suppressed; the more similar the incoming information is to the previous information, the more likely it is to be enhanced.
However, we have also described the mechanisms of suppression and enhancement as something that comprehenders do. We have repeatedly concluded that less skilled comprehenders less efficiently suppress irrelevant or inappropriate information. This conclusion implies that suppression and enhancement depend on comprehenders’ deployment, perhaps their strategic deployment, of those two mechanisms.
Discovering whether suppression and enhancement are amenable to comprehenders’ control is important for both theoretical and applied reasons. If more skilled comprehenders’ greater ability to suppress irrelevant information is a product of their greater control, perhaps this greater control can be taught. However, first we must discover whether the mechanism of suppression—the mechanism that differentiates more skilled versus less skilled adult comprehenders—is under comprehenders’ strategic control.
Acknowledgments
This research was supported by the Air Force Office of Scientific Research (AFOSR) Grant 89-0305, administered through the AFOSR Collaborative Research in Cognitive Psychology Program. While conducting this research, Morton Ann Gernsbacher was supported by National Institutes of Health Research Career Development Award KO4-NS-01376 and AFOSR Grant 89-0258. We collected our data at the Air Force Human Resources Laboratory, Brooks Air Force Base. We are extremely grateful to our Air Force Human Resources Laboratory hosts, Dr. William C. Tirre, Dr. Patrick Kyllonen, and Dr. Dan J. Woltz, and to Life Sciences Directorate Program Manager Dr. John F. Tangney. We are also grateful to Charles C. Perfetti, Keith Rayner, and two anonymous reviewers for their valuable comments. Emily Chow and Andrew Cavie helped prepare our stimuli. Jim Afremow, Maureen Marron, Norine McElhany, Heidi Myers, Michael Wechsler, and Cynthia Wilson scored the comprehension batteries. As always, Rachel R. W. Robertson competently contributed to many stages of our research. Because our research was supported by AFOSR, the U. S. Government is authorized to reproduce and distribute reprints for governmental purposes notwithstanding any copyright notation thereon. The views and conclusions contained in this article are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either express or implied, of the AFOSR or the U.S. government.
Appendix. Administration of the Multi-Media Comprehension Battery
The Multi-Media Comprehension Battery (Gernsbacher & Varner, 1988) comprises six stimulus stories. Two are presented by written sentences, two are presented by spoken sentences, and two are presented by nonverbal pictures. After subjects comprehend each story, they answer 12 short-answer comprehension questions.
The two written and the two auditory stories were modified from four international children’s stories (Arbuthnot, 1976). We modified the stories by shortening them and replacing all colloquial expressions and low-frequency words with familiar terms. The two picture stories were modified from the illustrations in two juvenile books (Barrett & Barrett, 1969; Calmenson, 1972). Each illustration has been photographed and reproduced as a 35-mm color slide.
The two written stories were presented first, followed by the two auditory stories, and then the two picture stories. Groups of 33 subjects were assembled in a classroom. The written stories were presented by an IBM-AT computer, which was projected through a liquid crystal diode (LCD) viewer placed on top of a standard overhead transparency projector. The written stories were projected into a standard size projection screen located at the front of the classroom. The written stories were presented line by line, one paragraph per screen. The two auditory stories were previously recorded by a male speaker at a natural speaking rate and were played to subjects over speakers by means of a tape recorder and amplifier. The two picture stories were projected by a Kodak slide projector yoked to a computer. The slides were projected onto a standard-size projection screen located at the front of the classroom.
The two written stories are 636 and 585 words long, respectively, and both were presented at a rate of 185 words per minute; the two auditory stories are 958 and 901 words long, respectively, and were presented at a rate of 215 words per minute; and the two picture stories are 31 and 32 pictures long, respectively, and were presented at a rate of one slide per 7.75 s, including the time required by the slide projector to change slides. Each story, therefore, lasted between 3 and 4.5 min.
Each story was followed by 12 short-answer questions. Some of the questions measured explicit information (e.g., “What was Ike’s last name?”), whereas others measured implicit information (e.g., “Why did the store attendant get so frustrated with Hiram?). Subjects were allowed 20 s to write their answers to each question.
We scored each question on a 3-point scale according to the scoring criteria presented in Gernsbacher and Varner (1988). In our earlier work, we found that the scoring criteria led to highly reliable data. For instance, in Gernsbacher et al. (1990), 270 subjects’ scores were assigned by 12 judges. Each subject was scored by at least 2 judges. Although the 2 judges who scored the same subject were unaware of each other’s scores, their resulting scores agreed highly: The average correlation between pairs of judges was .993, and all pairs correlated .986 and above. For the rare disagreements, the average of the 2 judges’ scores was assigned. Actually, only 240 of the 270 subjects were scored by 2 judges; the remaining 30 randomly selected subjects were scored by all 12 judges. Cronbach’s alpha for this common set of 30 subjects’ was .987, also demonstrating high interjudge agreement.
Footnotes
We particularly expect inappropriate meanings to be activated when the task requires comprehenders to focus their attention on a subsequent word and try to integrate that word into the previous context (Glucksberg, Kreuz, & Rho, 1986; van Petten & Kutas, 1987).
For each experiment, we examined the distribution of error rates and found that a small proportion of subjects (typically less than 5%) produced relatively high error rates. Because the average error rate for each experiment was typically low (around 8% in Experiments 1 and 4 and 3% in Experiments 2, 3, and 5), we suspect that the few subjects who committed more than 15% errors in Experiment 1 and 4 or 5% errors in Experiments 2, 3, and 5 did not take the experiments seriously. We felt comfortable excluding this small proportion of subjects (who were clearly outliers in the distribution of error rates data) because approximately 5% of our university subject pool also fail to take experiments seriously.
There are 10 subtests on the Armed Services Vocational Aptitude Battery. Unfortunately, the subjects’ scores on only 3 of the subtests were made available to us.
As in all the experiments we report here, the trials in which subjects erred were removed from the analyses of the reaction time data, and they were replaced by the subject’s mean reaction time for that condition.
Although the data presented in our figures are difference scores (e.g., reaction times to the probe words when the sentence–final words were homophones minus reaction times to the probe words when the sentence–final words were nonhomophones), we statistically analyzed “raw” reaction times, not difference scores. For example, a significant amount of interference in Experiment 1 was indicated by a significant effect of the sentence–final word (homophone vs. nonhomophone). As another example, a difference between the amount of interference experienced at the delayed test interval by the more versus less skilled comprehenders was indicated by a significant interaction between comprehenders’ skill level (more vs. less) and sentence–final word (homophone vs. nonhomophone). We also statistically analyzed “speed scores” (the inverse of the raw reaction times), and we observed the same pattern of results with the speed scores as we observed with the raw reaction times.
We are indebted to I. Biederman for providing us with his stimuli.
The three-way interaction between comprehension skill, test interval, and amount of interference was not reliable at a conservative level (p = .14).
Although both more skilled and less skilled comprehenders responded more rapidly to picture trials than word trials, there were no interactions involving modality (picture vs. word). Thus, we collapsed across this variable in our figures.
References
- Anderson JR. The architecture of cognition. Cambridge, MA: Harvard University Press; 1983. [Google Scholar]
- Arbuthnot MH. The Arbuthnot anthology of children’s literature. New York: Lothrop, Lee, & Shephard; 1976. [Google Scholar]
- Barrett J, Barrett R. Old MacDonald had an apartment house. New York: Atheneum; 1969. [Google Scholar]
- Becker CA. Semantic context and word frequency effects in visual word recognition. Journal of Experimental Psychology: Human Perception and Performance. 1976;2:556–566. doi: 10.1037//0096-1523.5.2.252. [DOI] [PubMed] [Google Scholar]
- Biederman I. On the semantics of a glance at a scene. In: Kubovy M, Pomerantz JR, editors. Perceptual organization. Hillsdale, NJ: Erlbaum; 1981. pp. 213–252. [Google Scholar]
- Biederman I, Bickle TW, Teitelbaum RC, Klatsky GJ. Object search in nonscene displays. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1988;14:456–467. [Google Scholar]
- Biederman I, Glass AL, Stacy EW., Jr Searching for objects in real world scenes. Journal of Experimental Psychology. 1973;97:22–27. doi: 10.1037/h0033776. [DOI] [PubMed] [Google Scholar]
- Biederman I, Mezzanotte RJ, Rabinowitz JC. Scene perception: Detecting and judging objects undergoing relational violations. Cognitive Psychology. 1982;14:143–177. doi: 10.1016/0010-0285(82)90007-x. [DOI] [PubMed] [Google Scholar]
- Biederman I, Teitelbaum RC, Mezzanotte RJ. Scene perception: A failure to find a benefit of prior expectancy or familiarity. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1983;9:411–429. doi: 10.1037//0278-7393.9.3.411. [DOI] [PubMed] [Google Scholar]
- Calmenson S. Hiram’s red shirt. New York: Golden Press; 1972. [Google Scholar]
- Chapman L, Chapman J. Disordered thought in schizophrenia. New York: Appleton-Century-Crofts; 1973. [Google Scholar]
- Coltheart M, Davelaar E, Jonasson JT, Besner D. Access to the internal lexicon. In: Dornic S, editor. Attention and performance VI. Hillsdale, NJ: Erlbaum; 1977. pp. 535–555. [Google Scholar]
- Coltheart V, Laxon V, Rickard M, Elton C. Phonological recoding in reading for meaning by adults and children. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1988;14:387–397. [Google Scholar]
- Cramer P. A study of homographs. San Diego, CA: Academic Press; 1970. [Google Scholar]
- Doctor EA, Coltheart M. Children’s use of phonological encoding when reading for meaning. Memory & Cognition. 1980;8:195–209. doi: 10.3758/bf03197607. [DOI] [PubMed] [Google Scholar]
- Duffy SA, Morris RK, Rayner K. Lexical ambiguity and fixation times in reading. Journal of Memory and Language. 1988;27:429–446. [Google Scholar]
- Friedman A. Framing pictures: The role of knowledge in automatized encoding and memory for gist. Journal of Experimental Psychology: General. 1979;108:316–355. doi: 10.1037//0096-3445.108.3.316. [DOI] [PubMed] [Google Scholar]
- Gernsbacher MA. Language comprehension as structure building. Hillsdale, NJ: Erlbaum; 1990. [Google Scholar]
- Gernsbacher MA, Faust M. The role of suppression in sentence comprehension. In: Simpson GB, editor. Understanding word and sentence. Amsterdam: North Holland; 1990. pp. 97–128. [Google Scholar]
- Gernsbacher MA, Varner KR. Tech Rep No 88-03. Eugene: University of Oregon, Institute of Cognitive and Decision Sciences; 1988. The multi-media comprehension battery. [Google Scholar]
- Gernsbacher MA, Varner KR, Faust M. Investigating differences in general comprehension skill. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1990;16:430–445. doi: 10.1037//0278-7393.16.3.430. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Glucksberg S, Kreuz RJ, Rho SH. Context can constrain lexical access: Implications for models of language comprehension. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1986;12:323–335. [Google Scholar]
- Hasher L, Stoltzfus ER, Zacks R, Rympa B. Age and inhibition. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1991;17:163–169. doi: 10.1037//0278-7393.17.1.163. [DOI] [PubMed] [Google Scholar]
- Kausler DH, Kollasch SF. Word associations to homographs. Journal of Verbal Learning and Verbal Behavior. 1970;9:444–449. [Google Scholar]
- Keele SW, Neill WT. Mechanisms of attention. In: Carterette EC, Friedman MP, editors. Handbook of perception. San Diego, CA: Academic Press; 1978. pp. 3–47. [Google Scholar]
- Kintsch W. The role of knowledge in discourse comprehension: A construction-integration model. Psychological Review. 1988;95:163–182. doi: 10.1037/0033-295x.95.2.163. [DOI] [PubMed] [Google Scholar]
- Kreuz RJ. The subjective familiarity of English homophones, Memory & Cognition. 1987;15:154–168. doi: 10.3758/bf03197027. [DOI] [PubMed] [Google Scholar]
- Lieberman P. The biology and evolution of language. Cambridge, MA: Harvard University Press; 1984. [Google Scholar]
- Mandler JM, Johnson N. Some of the thousand words a picture is worth. Journal of Experimental Psychology: Human Learning and Memory. 1976;2:529–540. [PubMed] [Google Scholar]
- Marslen-Wilson W, Welsh A. Processing interactions and lexical access during word recognition in continuous speech. Cognition. 1978;10:29–63. [Google Scholar]
- McClelland JL, Kawamoto AH. Mechanisms of sentence processing: Assigning roles to constituents of sentences. In: McClelland JL, Rumelhart DE, editors. Parallel distributed processing: Explorations in the microstructure of cognition. Volume 1: Foundations. Cambridge, MA: MIT Press; 1986. pp. 272–325. [Google Scholar]
- McClelland JL, Rumelhart DE. An interactive activation model of context effects in letter perception: Part 1. An account of basic findings. Psychological Review. 1981;88:375–407. [PubMed] [Google Scholar]
- Merrill EC, Sperber RD, McCauley C. Differences in semantic encoding as a function of reading comprehension skill. Memory & Cognition. 1981;9:618–624. doi: 10.3758/bf03202356. [DOI] [PubMed] [Google Scholar]
- Neill WT. Inhibitory and facilitatory processes in selective attention. Journal of Experimental Psychology: Human Perception and Performance. 1977;3:444–450. [Google Scholar]
- Nelson D, McEvoy CL, Walling JR, Wheeler JW. The University of South Florida homograph norms. Behavior Research Methods and Instrumentation. 1980;12:16–37. [Google Scholar]
- Norris D. Word recognition: Context effects without priming. Cognition. 1986;22:93–136. doi: 10.1016/s0010-0277(86)90001-6. [DOI] [PubMed] [Google Scholar]
- Palmer SE. The effects of contextual scenes on the perception of objects. Memory & Cognition. 1975;3:519–526. doi: 10.3758/BF03197524. [DOI] [PubMed] [Google Scholar]
- Perfetti CA, Roth S. Some of the interactive processes in reading and their role in reading skill. In: Lesgold AM, Perfetti CA, editors. Interactive processes in reading. Hillsdale, NJ: Erlbaum; 1981. pp. 269–297. [Google Scholar]
- Posner MI, Snyder CRR. Facilitation and inhibition in the processing of signals. In: Rabbitt PMA, Dornic S, editors. Attention and performance V. San Diego, CA: Academic Press; 1975. pp. 669–682. [Google Scholar]
- Rayner K, Frazier L. Selection mechanisms in reading lexically ambiguous words. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1989;15:779–787. doi: 10.1037//0278-7393.15.5.779. [DOI] [PubMed] [Google Scholar]
- Rayner K, Posnansky C. Stages of processing in word identification. Journal of Experimental Psychology: General. 1978;107:64–80. doi: 10.1037//0096-3445.107.1.64. [DOI] [PubMed] [Google Scholar]
- Rosinski RR, Golinkoff RM, Kukish KS. Automatic semantic processing in a picture-word interference task. Child Development. 1975;46:247–253. [Google Scholar]
- Rosson MB. The interaction of pronunciation rules and lexical representations in reading aloud. Memory & Cognition. 1985;13:90–99. doi: 10.3758/bf03198448. [DOI] [PubMed] [Google Scholar]
- Sachs JS. Recognition memory for syntactic and semantic aspects of connected discourse. Perception & Psychophysics. 1967;2:437–442. [Google Scholar]
- Seidenberg MS, Tanenhaus MK, Leiman JM, Bienkowski M. Automatic access of the meanings of ambiguous words in context: Some limitations of knowledge-based processing. Cognitive Psychology. 1982;14:489–537. [Google Scholar]
- Smith MC, McGee LE. Tracing the time course of picture-word processing. Journal of Experimental Psychology General. 1980;109:373–392. doi: 10.1037//0096-3445.109.4.373. [DOI] [PubMed] [Google Scholar]
- Snodgrass JG, Vanderwart M. A standardized set of 260 pictures: Norms for name agreement, image agreement, familiarity, and visual complexity. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1980;6:174–215. doi: 10.1037//0278-7393.6.2.174. [DOI] [PubMed] [Google Scholar]
- Swinney DA. Lexical access during sentence comprehension: (Re)consideration of context effects. Journal of Verbal Learning and Verbal Behavior. 1979;18:645–659. [Google Scholar]
- Tanenhaus MK, Leiman JM, Seidenberg MS. Evidence for multiple stages in the processing of ambiguous words in syntactic contexts. Journal of Verbal Learning and Verbal Behavior. 1979;18:427–440. [Google Scholar]
- Tipper SP. The negative priming effect: Inhibitory priming by ignored objects. The Quarterly Journal of Experimental Psychology. 1985;37A:571–590. doi: 10.1080/14640748508400920. [DOI] [PubMed] [Google Scholar]
- Tipper SP, & Cranston M. Selective attention and priming: Inhibitory and facilitory effects of ignored primes. The Quarterly Journal of Experimental Psychology. 1985;37A:591–611. doi: 10.1080/14640748508400921. [DOI] [PubMed] [Google Scholar]
- Tipper SP, Driver J. Negative priming between pictures and words in a selective attention task: Evidence for semantic processing of ignored stimuli. Memory & Cognition. 1988;16:64–70. doi: 10.3758/bf03197746. [DOI] [PubMed] [Google Scholar]
- van Orden GC. A rows is a rose: Spelling, sound, and reading. Memory & Cognition. 1987;15:181–198. doi: 10.3758/bf03197716. [DOI] [PubMed] [Google Scholar]
- van Orden GC, Johnston JC, Hale BL. Word identification in reading proceeds from spelling to sound to meaning. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1988;14:371–386. doi: 10.1037//0278-7393.14.3.371. [DOI] [PubMed] [Google Scholar]
- van Petten C, Kutas M. Ambiguous words in context: An event-related potential analysis of the time course of meaning activation. Journal of Memory and Language. 1987;26:188–208. [Google Scholar]
- Waltz DL, Pollack JB. Massively parallel parsing: A strongly interactive model of natural language interpretation. Cognitive Science. 1985;9:51–74. [Google Scholar]