

Abstract
In biomedical studies, covariates with measurement error may occur in survival data. Existing approaches mostly require certain replications on the error-contaminated covariates, which may not be available in the data. In this paper, we develop a simple nonparametric correction approach for estimation of the regression parameters in the proportional hazards model using a subset of the sample where instrumental variables are observed. The instrumental variables are related to the covariates through a general nonparametric model, and no distributional assumptions are placed on the error and the underlying true covariates. We further propose a novel generalized methods of moments nonparametric correction estimator to improve the efficiency over the simple correction approach. The efficiency gain can be substantial when the calibration subsample is small compared to the whole sample. The estimators are shown to be consistent and asymptotically normal. Performance of the estimators is evaluated via simulation studies and by an application to data from an HIV clinical trial. Estimation of the baseline hazard function is not addressed.
Keywords: Generalized methods of moments, Nonparametric correction, Survival
1. INTRODUCTION
Survival data often arise in biomedical studies where the outcome of interest is time to an event of interest (failure). The proportional hazards model is the most widely used survival model to characterize the relationship between survival time and covariates. However, some covariates, say X, could be measured with error in practice. For example, important covariates such as CD4 counts in HIV studies are subjected to substantial measurement error due to both imperfect instruments and biological fluctuation.
It is well-known that the naive approach that ignores measurement error can lead to biased estimation and erroneous inference (e.g. Prentice, 1982). Various approaches have been proposed to deal with measurement error. The regression calibration (Prentice, 1982; Wang et al. 1997; Dafni and Tsiatis, 1998; Liao et al., 2011) approximates the hazard function conditional on the observed covariates. It can reduce estimation bias but is still inconsistent. Likelihood based approaches are usually computationally intensive (e.g. Wulfson and Tsiatis, 1997; Hu, Tsiatis and Davidian, 1998, Song et al., 2002a; Wang, 2008). Consistent estimation based on corrected scores (parametric correction) was first proposed by Nakamura (1992) which required no distributional assumption on the underlying true covariates, but the standard deviation was assumed known. Huang and Wang (2000) developed a nonparametric correction approach that further relaxed the distributional assumption on the measurement error, but required repeated measurements. The correction approaches were extended to more general measurement error models (Hu and Lin, 2002; Wang, 2006; Tapsoba et al., 2011) and more general error assessment sets (Huang and Wang, 2006). A related approach is the conditional score (Tsiatis and Davidian, 2001; Song et al., 2002b), which is asymptotic equivalent to the corrected score. The conditional score approach has better finite sample performance (Song and Huang, 2005), but still depends on the normality assumption of the error. Motivated by the difference in the corrected score and conditional score estimating functions, Song and Huang (2005) proposed refined parametric correction and nonparametric correction approaches. The refined parametric correction estimator has comparable finite sample performance as the conditional score estimator. While the literature of proportional hazards regression with covariate measurement error is rich, to our knowledge, existing approaches require either knowledge of the measurement error standard deviation, repeated error-prone measurements, longitudinal error-prone measurements, or a validation set. Such information may not be available in practice.
Instead, instrumental variables may be observed in a subset of the sample. Instrumental variables are variables correlated with X, independent of the measurement error, and independent of the outcome given the covariates (Carroll et al., 2006, chapter 6; Stock and Watson, 2010, chapter 12). They are widely used in econometrics when the covariates are correlated with disturbance due to omitted variables, errors-in-variables, or simultaneous causality (Stock and Watson, 2010, chapter 12). Standard approaches that ignore the correlation between the covariates and disturbance usually lead to inconsistent estimators. Instrumental variables are used to obtain consistent estimators of the regression coefficients under this situation. Here we consider the case when the instrumental variables are observed in a subset of the sample. An example is AIDS clinical Trials Group (ACTG) 175, a randomized trial to compare zidovudine alone, ziduvudine plus didanosine, zidovudine plus zalcitabine, or didanosine alone in HIV-infected subjects on the basis of time to progression to AIDS or death (Hammer et al., 1996). It is of interested to assess the effect of treatments on survival time adjusted for baseline CD4 counts X. The closest CD4 measurement within one week before randomization was taken as the baseline CD4 measurements. It is well known that observed CD4 counts are contaminated by substantial measurement error. Among the 2174 randomized patients with at least one baseline CD4 measurements, there were no replicated baseline CD4 measurements on the same day. However, 989 patients had at least one CD4 measurement between one to three weeks prior to randomization. Since the underlying true CD4 counts might change over time, these CD4 measurements were not simple replication of baseline CD4 counts. But they may be used as instrumental variables. Figure 1 shows the scatter plot and a Loess smooth of log CD4 counts within one to three weeks versus one week before randomization. The logarithmic transformation was applied to CD4 counts to achieve approximate constant variance. The Loess curve indicates a possible nonlinear relationship between log CD4 counts during these two time periods.
Figure 1.

Scatter plot of log(CD4) within one to three weeks versus one week before randomization. The curve was obtained by Loess smooth.
Instrumental variables have been used in literature to deal with measurement error when there are no replicates or validation datasets (Carroll et al., 2006, chapter 6), mostly based on a parametric model between the instrumental variables and the covariates. But it may not be easy to identify the relationship between the instrumental variables and the covariates when the covariates are measured with error. Carroll et al. (2004) relaxed the parametric model assumption and adopted a varying coefficient model that is linear in X. The linearity assumption may still be too restricted as indicated in Figure 1. In this paper, we adopt a more general nonparametric model for the instrumental variables. The instrumental variables may be observed only in a subsample as in the ACTG 175 study. As in Huang and Wang (2001, 2006), we assume a functional measurement error model with no specification on the error distribution. We develop novel nonparametric correction methods under this general framework. The methods will have broader applications than those described by Huang and Wang (2006) due to the flexibility of the instrumental variable model.
The paper is organized as follows. In Section 2, we give the model definition. We develop a simple nonparametric correction estimator in Section 3 and propose an improved generalized methods of moments nonparametric correction estimator in Section 4. The asymptotic properties are derived with the proofs given in the Appendix. The performance of the estimators is assessed by simulations in Section 5 and illustrated by an application in Section 6. The paper concludes with a discussion in Section 7.
2. MODEL DEFINITION
Let T denote the survival time and C the censoring time. The observed survival data are V = min(T, C) and Δ = I(T ≤ C), where I(·) is the indicator function. Let X denote a vector of p covariates that can be measured with error and Z denote a vector of q accurately measured covariates. The hazard of failure depends on covariates X and Z through the proportional hazard model
where λ0(t) is an unspecified baseline hazard function, and (β0, γ0) are the regression parameters. We assume that the survival time T is independent of the censoring time C given (X, Z).
Suppose that the true value of X is not observable. Only an error contaminated measurement W is available, which satisfies the classical measurement error model
where e denotes the additive measurement error with E(e) = 0, and X and e are independent. In addition, measurements are available on an instrumental variable R in a subset of subjects such that
| (1) |
where g(·) is an unknown function, and ε is a set of unspecified random variables that are independent of (T, C) given (X, Z) and independent of e. This includes as special cases the replicates R = X + ε, linear instrument R = a0 + a1X + ε, varying coefficient instrument R = a0(Z)+a1(Z)+ ε (Carroll et al., 2004), and nonparametric instrument R = g*(X, Z) + ε, where g*(X, Z) is an unspecified function of (X, Z). The instrumental variable R may depend on both X and Z. It may also depend on other variables as included in ε, but R and (T, C) are independent given (X, Z). The dimension s of R should satisfy s ≥ p to ensure identifiability. For simplicity, we assume s = p. An extension to s > p is discussed in Section 7. Assume that the errors e and ε are independent of (T, C, X, Z) and each other. Note that no other assumptions are placed on X, e, ε and the function g(·). Let η = I(R is observed) be the indicator of whether the instrument variable is observed. Assume η is independent of {T, C, X, Z, e, ε}.
Suppose {Ti, Ci, Vi, Δi, Xi, Wi, Zi, ei, εi, ηi} are independent and identically distributed samples of {T, C, V, Δ, X, W, Z, e, ε, η} and the observed data set is {(Vi, Δi, ηi, Wi, ηiRi, Zi) : i = 1, …, n}. For brevity of notations, we may drop the subscript i throughout the paper when there is no confusion. We focus on estimating the regression parameters .
3. SIMPLE NONPARAMETRIC CORRECTION
Huang and Wang (2000, 2006) proposed nonparametric correction estimation based on (V, Δ, W). The essential idea is to correct the naive estimating function such that the bias is removed. However, their approach requires replicated measurements on W or a linear instrument variable, and thus cannot be used directly in our case. Alternatively, using the instrumental variable R, we may develop a nonparametric correction estimator in the same spirit.
Let θ = (βT, γT)T, Ni(t) = I(Vi ≤ t, Δi = 1) be the counting process of failures, and Yi(t) = I(Vi ≥ t) the at risk process. For any scalar, vector or matrix Hi, let Fi(t, θ; H, X) = Yi(t)Hi exp(βTXi + γTZi). Here Hi can be either fixed or random. Note that Fi also depends on (Zi, Vi, Δi), which are dropped in the notation for simplicity. Let and G(t, θ; H, X) = E{Fi(t, θ; H, X)}. Note that G(t, θ; H, X) is a fixed function of t and θ.
The naive estimating function replaces the true covariates X by W in the partial likelihood function and can be written as
at a given time L. This estimating function is biased (Prentice, 1982), which is essentially due to the “bias” of the ratio term Ĝ(t, θ; (WT, ZT)T, W)/Ĝ(t, θ; 1, W) from Ĝ(t, θ; (XT, ZT)T, X)/Ĝ(t, θ; 1, X) when replacing X by W. When the measurement error is normal with known variance, Nakamura (1992) proposed a corrected score approach which added a correction term to compensate the bias. In the same spirit, Huang and Wang (2000) took an nonparametric correction when replications of Wi were available. The key idea of Huang and Wang (2000) was to substitute different replicates for W in the ratio term. Due to the independence of the errors in the replicates, the bias of the ratio term is corrected. The estimating function can be represented by ÛNR(θ; ( , ZT)T, W) with W* being another replicate of W and averaging over all possible combinations of replicates. We do not have a replicated W*, but we may consider replacing W* by R in ÛNR(θ; ( , ZT)T, W).
As R is only observed on a subset of the subjects, we consider
| (2) |
Note that ÛC(θ) converges to
| (3) |
When R = X, U0(θ) is the limit of the standard partial likelihood estimating function. Let
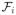 (t) = {Ni(u), Yi(u), Xi, Wi, Ri, Zi : u ≤ t}. By lemma 1 and the independence of η from (V, Δ, W, R, Z), with iterated expectations,
(t) = {Ni(u), Yi(u), Xi, Wi, Ri, Zi : u ≤ t}. By lemma 1 and the independence of η from (V, Δ, W, R, Z), with iterated expectations,
In addition, we have , G(t, θ; η, W) = E(η)E{exp(βTe)}G(t, θ; 1, X),and
Hence it can be easily seen that U0(θ) = 0. Therefore ÛC(θ; (RT, ZT)T, W) is asymptotically unbiased and (2) is a simple nonparametric correction equation.
Let
| (4) |
We derive the asymptotic properties of the simple nonparametric correction estimator using empirical process theory.
Theorem 1
Under conditions A–E given in the Appendix, a solution θ̃ = (β̃T, γ̃T)T of (2) exists and converges to θ0 almost surely. Further, n1/2(θ̃ − θ0) is asymptotically normal with mean zero and variance , where
and
A consistent estimator of the variance can be obtained by substituting θ̃ for θ0 and the empirical means for the population means in the variance formula.
Remark
Condition E requires Γ(θ0) to be nonsingular. It can be easily shown that Γ(θ0) = 0 when R is independent of X. Thus R and X should be dependent. But R and X may have a nonlinear association, for example, R = X2 + ε with X having a distribution symmetric around zero and ε independent of X, although the linear correlation is zero. This is due to the nonlinearity of the model, which is different from the linear instrumental model in econometrics (Stock and Watson, 2010, chapter 12).
To better understand what factors affect the variance of θ̃, we expand VC in Theorem 1 although it is not needed for estimation of VC. With some algebra, it can be shown that Γ(θ0) = Γ*(θ0), where Γ*(θ0) is Γ(θ0) with W replaced by X, that is,
Further,
| (5) |
where
with
It can be easily seen that VI is the variance of θ̃ when var(e) = 0, and VA is a nonnegative definite matrix. Expression (5) indicates that the efficiency of θ̃ improves with the increase of Pr(η = 1) = E(η) or the decrease of E{exp(2βe)}/E2{exp(βTe)}. When the error e is normal, E{exp(2βTe)}/E2{exp(βTe)} = exp{3βTvar(e)β/2} is an increasing function of var(e). In the special case that R = g*(X, Z) + ε with ε independent with (V, Δ, X, Z, e), it can be shown that Vc increases with the increase of var(ε). Although the variance VC may depend on the variance of e and other unknown quantities, estimation of VC does not require estimating these quantities.
A drawback of the simple nonparametric approach is that it only uses the calibration subsample ΩC = {(Vi, Δi, Zi, Wi, Ri) : ηi = 1} where both the error contaminated variable Wi and the instrumental variable Ri are observed. The information in the non-calibration subsample ΩC̄ = {(Vi, Δi, Zi, Wi) : ηi = 0} with missing Ri is not used. When the calibration subsample is small compared to the sample size, it can be very inefficient. It is expected that the efficiency can be improved if we could use the whole sample Ω = ΩC ∩ΩC̄. This motivates us to develop an improved estimator.
4. GMM NONPARAMETRIC CORRECTION
Note that the nonparametric correction based on Wi only uses the whole sample (Song and Huang, 2005; Huang and Wang, 2006). The corresponding estimating equation can be written as
| (6) |
where
However, to estimate θ based on (6), the correction term c(θ) needs to be estimated by replicated measurements on Wi, which is not available in our case. Note that, if θ is known, we may estimate c0 = c(θ0) based on the first p-equations of (6). As we have already obtained an estimate θ̃ based on (2), we may plug it in (6) and obtain an estimator of c0 based on the calibration subsample ΩC,
where Ê is the operator for empirical mean such that .
To utilize the information on the whole sample, we propose an improved nonparametric correction estimator θ̂(A) by minimizing the quadratic form
where A is a (2p + q) × (2p + q) nonzero semi-positive definite matrix and
The (2p + q) dimensional vector Û(θ; ĉ) contains the estimating functions in (2) and (6), which include the information on the whole sample Ω. Since the number of estimating functions in Û(θ; ĉ) is larger than the number of parameters (p + q), there is generally no estimate for Û(θ; ĉ) = 0. To derive an estimator, the quadratic form Q(θ; ĉ, A) is minimized instead. The derivation of the improved estimator has adopted similar techniques for the generalized methods of moments (GMM) (Hansen, 1982), and thus we call it the GMM nonparametric correction estimator. The GMM is a general methodology in econometrics literature (e.g. Cragg, 1983; Newey 1988; Newey and McFadden, 1994; Stock and Wright, 2000). It combines economic data with population moment conditions to produce estimators of parameters in statistical models. It is an extension of the method of moments to allow more moment conditions than the parameters to estimate. The GMM estimator is obtained by minimizing a quadratic form in the sample moments conditions.
The matrix A plays a role similar to weights for the estimating functions. The estimator will be different with a different choice of the matrix A. Our goal is to find an optimal matrix Aopt such that the estimator θ̂(Aopt) is most efficient among such estimators.
For this purpose, we first derive the asymptotic properties of θ̂(A). Let Is denote an s-dimensional identity matrix.
Theorem 2
Under conditions A–H, θ̂(A) is a consistent estimator of θ0. Further, n1/2(θ̂(A) − θ0) is asymptotically normal with mean zero and variance
where
A consistent estimator of the variance can be obtained by substituting θ̂(A) for θ0 and the empirical means for the population means in the variance formula.
To find the optimal matrix Aopt, we minimize the variance V(A) of the estimator θ̂(A). This can be achieved by simple matrix algebra by analogy to the generalized methods of moments (Newey and McFadden, 1994) and the result is given in the following theorem.
Theorem 3
Under conditions A–H, the most efficient estimator of θ̂(A) is achieved at Aopt = B−1(θ0) with the variance V(Aopt) = {DT(θ0)B−1D(θ0)}−1.
The GMM estimator θ̂(Aopt) is generally more efficient than the simple estimator θ̃ This can be easily seen when there is no Z is the model. Specifically, without Z, noting that , the simple nonparametric correction estimator minimizes Q(θ, ĉ, Ac) with Ac = diag(Ip, 0q×q), where 0q×q is a q × q zero matrix. In practice, Aopt can be approximated by Âopt = B̃−1 with B̃ = n−1 Σ{φ̂i(θ̃) − Êφ̂(θ̃)}⊗2, where φ̂i(θ̃) is obtained by substituting the unknown quantities in φi(θ̃) by their empirical estimates. The variance of θ̂(Âopt) can be estimated by {D̂TÂopt D̂}−1 D̂T Âopt B̂ ÂoptD̂{D̂T Âopt D̂}−1, where D̂ = −∂Û(θ̂(Âopt))/∂θT, and B̂ = Σ{φ̂i(θ̂(Aopt)) − Êφ̂(θ̂(Aopt))}⊗2.
Remark
There could be a few variations of the above estimator by varying the data set used in estimating the correction term c0 and the data set in the objective function Q(·) corresponding to the covariates W. Let Θc denote the former and ΘQ the latter. Both data sets could be elements of {Ω, ΩC, ΩC̄} as long as Θc ≠ ΘQ. Our numerical studies indicate that the performance of the GMM estimator seems similar for various choices of Θc and ΘQ except in some extreme cases, such as a very small sample calibration subsample or non-calibration subsample. We use Θc = ΘC and ΘQ = Ω in our illustration.
5. SIMULATION STUDIES
Simulation studies were conducted to evaluate the performance of the estimators. First, we considered the case of a single covariate X, which was generated from a standard normal distribution. The instrumental variable was set as R = 0.5X2 + 2X +1+0.5ε1 +Xε1 +ε2, where ε1 was generated from a standard normal distribution correlated with X with correlation −0.3 which may denote a variable that was not in the proportional hazard model, and ε2 from a normal distribution independent of X with mean 0 and variance 0.4 which may denote independent noise. The error e was generated from a normal or a skewed bimodal mixture of two normals as described in Davidian and Gallant (1993, mixing proportion p = 0.3 and distance between the means equal to sep = 2 times standard deviation) with mean 0 and variance σ2 = 0.1 or 0.2. The true Cox model coefficient was taken to be β0 = −1. The baseline hazard λ0(t) = exp{−2}t−0.5. The censoring time was generated from a uniform distribution on [0,40], leading to a censoring rate of about 37%. The proportion of calibration subsample Pr(η = 1) was set to 0.3, 0.5 or 0.7.
We carried out simulations for n = 500 and 2000. In each scenario, 1000 Monte Carlo data sets were simulated. For each data set, we fitted the model using (i) the “ideal” approach, in which the true values of X were used; (ii) the naive approach, in which W substituted for X in the partial likelihood estimating equation; (iii) the simple nonparametric correction estimator θ̃; (iv) the GMM nonparametric correction estimator θ̂ (Âopt). For each estimator, the 95% Wald confidence interval was constructed.
The results are shown in tables 1 and 2 respectively for the normal and the mixture normal error models. The naive estimator is biased with a coverage probability well below the nominal level. The performance gets worse with the sample size growing or the error variance increasing. The nonparametric correction estimators have negligible bias close to the unachievable “ideal” estimator and the coverage probabilities are close to the nominal level. Their performance improves when the sample size increases or the error variance decreases. The GMM estimator is more efficient than the simple estimator, especially when Pr(η = 1) is small. For either correction approach, the standard deviations are close to the standard errors, and the efficiency improves with the increase of the proportion of calibration subsample or the decrease of the magnitude of measurement error.
Table 1.
Simulation Results in the case of a single covariate contaminated with normal error.
| n = 500 | n = 2000 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pr(η = 1) | Est | SD | SE | CP | Est | SD | SE | CP | ||
|
|
|
|||||||||
| Ideal | −1.001 | 0.070 | 0.069 | 0.947 | −0.999 | 0.035 | 0.035 | 0.948 | ||
| σ2 = 0.1 | Naive | −0.874 | 0.065 | 0.064 | 0.476 | −0.871 | 0.033 | 0.032 | 0.034 | |
| 0.3 | SNC | −1.014 | 0.178 | 0.165 | 0.930 | −1.005 | 0.084 | 0.080 | 0.936 | |
| INC | −1.005 | 0.142 | 0.127 | 0.931 | −1.003 | 0.068 | 0.063 | 0.947 | ||
| 0.5 | SNC | −1.012 | 0.136 | 0.126 | 0.935 | −1.004 | 0.065 | 0.062 | 0.947 | |
| INC | −1.007 | 0.118 | 0.107 | 0.930 | −1.002 | 0.057 | 0.053 | 0.932 | ||
| 0.7 | SNC | −1.008 | 0.111 | 0.107 | 0.939 | −1.001 | 0.056 | 0.053 | 0.935 | |
| INC | −1.004 | 0.104 | 0.096 | 0.928 | −0.999 | 0.051 | 0.048 | 0.943 | ||
| σ2 = 0.2 | Naive | −0.777 | 0.062 | 0.060 | 0.054 | −0.773 | 0.031 | 0.030 | 0.000 | |
| 0.3 | SNC | −1.021 | 0.193 | 0.171 | 0.931 | −1.007 | 0.090 | 0.081 | 0.923 | |
| INC | −1.004 | 0.160 | 0.137 | 0.927 | −1.002 | 0.074 | 0.066 | 0.931 | ||
| 0.5 | SNC | −1.016 | 0.146 | 0.129 | 0.928 | −1.005 | 0.069 | 0.063 | 0.928 | |
| INC | −1.008 | 0.130 | 0.111 | 0.921 | −1.001 | 0.062 | 0.054 | 0.923 | ||
| 0.7 | SNC | −1.011 | 0.116 | 0.108 | 0.922 | −1.002 | 0.059 | 0.053 | 0.919 | |
| INC | −1.004 | 0.110 | 0.098 | 0.915 | −0.999 | 0.054 | 0.049 | 0.925 | ||
SNC, simple nonparametric correction; INC, GMM nonparametric correction. SD, empirical standard deviation across simulated data sets; SE, average of estimated standard errors; CP, coverage probability of the 95% Wald confidence interval.
Table 2.
Simulation Results in the case of a single covariate contaminated with a mixture of normal error.
| n = 500 | n = 2000 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pr(η= 1) | Est | SD | SE | CP | Est | SD | SE | CP | ||
|
|
|
|||||||||
| Ideal | −1.000 | 0.070 | 0.069 | 0.958 | −1.001 | 0.034 | 0.035 | 0.951 | ||
| σ2 = 0.1 | Naive | −0.877 | 0.066 | 0.064 | 0.515 | 0.877 | 0.032 | 0.032 | 0.026 | |
| 0.3 | SNC | −1.021 | 0.184 | 0.167 | 0.932 | −1.003 | 0.085 | 0.080 | 0.940 | |
| INC | −1.006 | 0.143 | 0.127 | 0.934 | −1.001 | 0.064 | 0.063 | 0.944 | ||
| 0.5 | SNC | −1.007 | 0.138 | 0.126 | 0.931 | −1.003 | 0.063 | 0.062 | 0.943 | |
| INC | −1.006 | 0.117 | 0.106 | 0.933 | −1.002 | 0.054 | 0.053 | 0.942 | ||
| 0.7 | SNC | −1.006 | 0.112 | 0.106 | 0.935 | −1.004 | 0.055 | 0.052 | 0.944 | |
| INC | −1.006 | 0.103 | 0.096 | 0.936 | −1.003 | 0.051 | 0.048 | 0.938 | ||
| σ2 = 0.2 | Naive | −0.784 | 0.062 | 0.061 | 0.074 | −0.783 | 0.030 | 0.030 | 0.000 | |
| 0.3 | SNC | −1.027 | 0.195 | 0.170 | 0.929 | −1.005 | 0.088 | 0.081 | 0.927 | |
| INC | −1.006 | 0.153 | 0.133 | 0.930 | −1.000 | 0.069 | 0.066 | 0.935 | ||
| 0.5 | SNC | −1.010 | 0.146 | 0.127 | 0.922 | −1.004 | 0.066 | 0.062 | 0.935 | |
| INC | −1.006 | 0.126 | 0.110 | 0.913 | −1.002 | 0.058 | 0.054 | 0.938 | ||
| 0.7 | SNC | −1.009 | 0.118 | 0.107 | 0.925 | −1.004 | 0.058 | 0.052 | 0.932 | |
| INC | −1.005 | 0.110 | 0.098 | 0.923 | −1.003 | 0.053 | 0.049 | 0.927 | ||
SNC, simple nonparametric correction; INC, GMM nonparametric correction. SD, empirical standard deviation across simulated data sets; SE, average of estimated standard errors; CP, coverage probability of the 95% Wald confidence interval.
Next we added a covariate Z = ε1 to the proportional hazards model with γ0 = −1. The censoring rate was 38%. The results for the normal error model with σ2 = 0.1 and var(ε2) = 0.4 are shown in Table 3. We observe similar results for estimation of β0 as above. The estimation of γ0 shows similar pattern. Note that the naive estimator of γ0 also shows some bias and the coverage probability is only 83% for n = 500 and 52% for n = 2000. This indicates that estimation of the coefficient of the error free covariate Z can be affected by the measurement error on X as well.
Table 3.
Simulation Results in the case of two covariates.
| n = 500 | n = 2000 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pr(η = 1) | Est | SD | SE | CP | Est | SD | SE | CP | ||
|
|
|
|||||||||
| β | Ideal | −1.002 | 0.071 | 0.072 | 0.951 | −1.000 | 0.036 | 0.036 | 0.948 | |
| Naive | −0.868 | 0.068 | 0.067 | 0.466 | −0.864 | 0.034 | 0.033 | 0.026 | ||
| 0.3 | SNC | −1.019 | 0.194 | 0.180 | 0.939 | −1.005 | 0.092 | 0.088 | 0.943 | |
| INC | −1.007 | 0.155 | 0.139 | 0.944 | −1.002 | 0.076 | 0.070 | 0.934 | ||
| 0.5 | SNC | −1.014 | 0.148 | 0.137 | 0.942 | −1.003 | 0.071 | 0.068 | 0.935 | |
| INC | −1.008 | 0.130 | 0.117 | 0.930 | −1.001 | 0.062 | 0.059 | 0.935 | ||
| 0.7 | SNC | −1.012 | 0.118 | 0.115 | 0.955 | −1.003 | 0.060 | 0.057 | 0.934 | |
| INC | −1.008 | 0.108 | 0.105 | 0.949 | −1.001 | 0.054 | 0.053 | 0.940 | ||
| γ | Ideal | −1.002 | 0.073 | 0.072 | 0.941 | −1.002 | 0.037 | 0.036 | 0.939 | |
| Naive | −0.935 | 0.072 | 0.070 | 0.829 | −0.933 | 0.037 | 0.035 | 0.518 | ||
| 0.3 | SNC | −1.013 | 0.161 | 0.148 | 0.923 | −1.009 | 0.075 | 0.072 | 0.943 | |
| INC | −1.007 | 0.107 | 0.095 | 0.926 | 1.003 | 0.050 | 0.048 | 0.943 | ||
| 0.5 | SNC | −1.011 | 0.121 | 0.114 | 0.935 | −1.005 | 0.058 | 0.056 | 0.952 | |
| INC | −1.007 | 0.097 | 0.087 | 0.920 | −1.003 | 0.046 | 0.043 | 0.941 | ||
| 0.7 | SNC | −1.009 | 0.100 | 0.095 | 0.940 | −1.002 | 0.051 | 0.047 | 0.935 | |
| INC | −1.007 | 0.087 | 0.082 | 0.931 | −1.003 | 0.044 | 0.041 | 0.921 | ||
SNC, simple nonparametric correction; INC, GMM nonparametric correction. SD, empirical standard deviation across simulated data sets; SE, average of estimated standard errors; CP, coverage probability of the 95% Wald confidence interval.
The relationship between R and X may impact the performance of the estimators as well. We conducted simulations in the case of one covariate with normal error as described above with different instrumental variables. We considered two cases when R and X were non-linearly associated with zero linear correlation, R = X2 + ε and R = X4 + ε, and compared them to the case when R = X + ε, where ε was normal and independent of X with mean 0 and variance 0.2. The results for σ2 = 0.1, Pr(η = 1) = 0.5 and n = 2000 are shown in Table 4. The nonparametric corrections estimators still work when R = X2 + ε or X4 + ε, but the standard errors are larger than when W = X + ε. The performance is better when R = X2 + ε than when R = X4 + ε.
Table 4.
Simulation Results when R = X + ε, X2 + ε, and X4 + ε.
| Est | SD | SE | CP | ||
|---|---|---|---|---|---|
|
|
|||||
| Ideal | −0.999 | 0.035 | 0.035 | 0.948 | |
| Naive | −0.871 | 0.033 | 0.032 | 0.034 | |
| R = X + ε | SNC | −1.003 | 0.058 | 0.056 | 0.939 |
| INC | −1.001 | 0.048 | 0.046 | 0.940 | |
| R = X2 + ε | SNC | −1.006 | 0.123 | 0.115 | 0.943 |
| INC | −0.979 | 0.116 | 0.103 | 0.913 | |
| R = X4 + ε | SNC | −1.020 | 0.141 | 0.134 | 0.940 |
| INC | −0.989 | 0.131 | 0.119 | 0.916 | |
SNC, simple nonparametric correction; INC, GMM nonparametric correction. SD, empirical standard deviation across simulated data sets; SE, average of estimated standard errors; CP, coverage probability of the 95% Wald confidence interval.
We also conducted simulations to assess the sensitivity of nonparametric correction approaches to the assumption that R is independent of (T, C) given X and Z. In the single covariate model described above, the proportional hazards model can be rewritten as log(T) = a + 2X + 2ε*, where a is a constant and ε* is an extreme-value-distributed random variable with variance π2/6 and independent of X. We replaced v the instrumental variable by so that R and T are correlated given X if b ≠ 0. We show the results for b = 0, 0.5, 1, 2 with normal error, σ2 = 0.1, Pr(η = 1) = 0.5 and n = 500 and 1000 in Table 5. The nonparametric correction estimators are not consistent in this case. Their performance tends to get worse with increasing b, which represents an increasing association between R and T given X. The bias may be large if violation of conditional independence is not small.
Table 5.
Simulation Results when .
| n = 500 | n = 1000 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Est | SD | SE | CP | Est | SD | SE | CP | ||
|
|
|||||||||
| Ideal | −1.009 | 0.073 | 0.070 | 0.940 | −1.003 | 0.049 | 0.049 | 0.940 | |
| Naive | −0.878 | 0.068 | 0.064 | 0.514 | −0.873 | 0.046 | 0.045 | 0.210 | |
| b = 0.0 | SNC | −1.016 | 0.137 | 0.125 | 0.934 | −1.008 | 0.091 | 0.088 | 0.932 |
| INC | −1.007 | 0.118 | 0.105 | 0.925 | −1.003 | 0.079 | 0.074 | 0.928 | |
| b = 0.5 | SNC | −1.095 | 0.145 | 0.127 | 0.882 | −1.085 | 0.096 | 0.088 | 0.843 |
| INC | −1.084 | 0.125 | 0.107 | 0.868 | −1.078 | 0.083 | 0.075 | 0.821 | |
| b = 1.0 | SNC | −1.179 | 0.155 | 0.129 | 0.722 | −1.166 | 0.101 | 0.089 | 0.565 |
| INC | −1.164 | 0.134 | 0.109 | 0.699 | −1.158 | 0.088 | 0.077 | 0.468 | |
| b = 2.0 | SNC | −1.362 | 0.185 | 0.136 | 0.246 | −1.342 | 0.117 | 0.092 | 0.052 |
| INC | −1.339 | 0.159 | 0.117 | 0.179 | −1.329 | 0.102 | 0.081 | 0.024 | |
SNC, simple nonparametric correction; INC, GMM nonparametric correction. SD, empirical standard deviation across simulated data sets; SE, average of estimated standard errors; CP, coverage probability of the 95% Wald confidence interval.
6. APPLICATION
We applied the approaches to the AIDS Clinical Trial Group (ACTG) 175 study. Our aim was to evaluate the effect of treatments for the time to AIDS or death adjusted for baseline CD4 counts. The primary analysis found ziduvudine alone to be inferior to the other three therapies; thus, further investigations focused on two treatment groups, zidovudine alone and the combination of the other three.
This dataset has been analyzed previously. By definition, baseline CD4 counts should be true CD4 counts at randomization. However, CD4 counts were only measured for less than 50% of the patients on randomization day. Huang and Wang (2000) assumed the CD4 measurements within three weeks of randomization were replicates of the underlying baseline CD4 counts. As the underlying CD4 counts may change over time during the three weeks period, these CD4 measurements may not be simple replicates of the baseline CD4 counts. We took an alternative strategy here. Assuming the CD4 counts is relatively stable within a short period, say one week, the closest measurement W within one week before randomization was taken as the baseline CD4 measurement. The closest measurement R between one to three weeks before randomization was used as an instrumental variable. Among the 2174 subjects with baseline CD4 measurement, the instrumental variable was observed among 989 patients. The median follow up time was 33 months. A total of 275 events was observed.
A proportional hazards model was adopted with two covariates, the true baseline X = log(CD4) and the treatment indicator Z = I(treatment ≠ ziduvudine). The logarithm transformation was applied to the CD4 counts to achieve approximate constant variance. The same transformation was applied on the observed CD4 counts W and R. We first examine whether R is an appropriate instrumental variable. It is reasonable to assume that R is independent of the measurement error at baseline. Under this assumption, Figure 1 indicates that R is correlated with X. To be an instrumental variable, R needs to be independent of the time to AIDS or death given X and Z. This assumption seems to be appropriate based on our understanding of CD4 counts and AIDS risk, but cannot be tested from the data (Stock and Watson, 2010, chapter 12). Note that the assumption that R is a instrumental variable is weaker than R and W are replicates.
We estimated the regression coefficients using the naive, simple and GMM non-parametric correction approaches. The results are shown in Table 4. Both baseline CD4 and treatment are significant. The nonparametric correction estimates show stronger effects than the naive estimates, and the GMM estimates have smaller estimated standard errors than the simple estimates.
7. DISCUSSION
We have proposed nonparametric correction estimators for the proportional hazards model with error-contaminated covariates. The estimators are useful when no replicated observations are available on the error-prong covariates while observations available on instrumental variables.
For simplicity, we only consider the case when the dimension of the instrumental variables s equals the dimension p of the error-prone covariates. In the case of s > p, θ̃ may be obtained by minimizing the quadratic form and the optimal AC can be obtained by analogy to Aopt. The GMM estimator θ̂; can then be derived similarly as in section 4.
The function g(·) and the variables ε are unspecified in (1), this allows great flexibility in adopting instrumental variables. However, the format of g(·) may affect the efficiency of the simple and the GMM nonparametric correction estimators. The instrumental variables need not be linearly correlated with X, but cannot be independent of X. The proposed methods may break down if the instrumental variables are only weakly related with the underlying true covariates.
Our simulation studies reveal that the performance of the approaches depends on the magnitude of the measurement error, the sample size and the relationship between the error contaminated variables and the instrumental variables. When the measurement error is large, the methods might not work properly for small sample sizes with the possibility of nonconvergence and outlier estimates. This is a common issue for parametric/nonparametric correction approaches (Song and Huang, 2005). A possible improvement for the finite sample performance is to use the refined non-parametric correction technique (Song and Huang, 2005). The bootstrap confidence interval may work better when the measurement error is large (Huang and Wang, 2001).
Table 6.
Results for ACTG 175 data.
| logCD4 (β)
|
Treatment (γ)
|
|||
|---|---|---|---|---|
| Est | SE | Est | SE | |
| Naive | −1.465 | 0.162 | −0.474 | 0.129 |
| SNC | −2.359 | 0.398 | −0.618 | 0.193 |
| INC | −2.562 | 0.358 | −0.581 | 0.133 |
SNC, simple nonparametric correction; INC, GMM nonparametric correction.
Acknowledgments
This research was partially supported by NIH grants R01ES017030, HL121347 (Wang and Song), CA53996 (Wang) and CA152460 (Song), NSF grant DMS-1106816 (Song), and a travel award from the Mathematics Research Promotion Center of the National Science Council of Taiwan (Wang).
APPENDIX A: PROOFS
Regularity Conditions
We assume the following mild regularity conditions.
λ0(u) is continuous in [0, L].
Pr(V ≥ L) > 0.
-
E(XTX) < ∞, E{RTR < ∞, E(ZTZ) < ∞, E(eTe) < ∞.
For a compact neighborhood
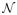 (θ0) of θ0,
(θ0) of θ0,E [
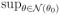 XTX exp {2(βTX + γTZ)}]< ∞,
XTX exp {2(βTX + γTZ)}]< ∞,E [
ZTZ exp {2(βTX + γTZ)}]< ∞,E [
RTR exp {2(βTX + γTZ)}]< ∞,E [
exp {2(βT e)}]< ∞. E(η) > 0.
The matrix Γ(θ0) defined in (4) is nonsingular.
Pr(T < C, T < L) > 0.
The matrix A is positive definite.
Lemma 1
Suppose Hi is a predictable random vector with respect to the filtration
(t) = {Ni(u), Yi(u), Xi, Wi, Ri, Zi: u ≤ t}. If
, then
Proof
Note that
is a martingale with respect to the filtration
(t) as Ni(u) is independent of (Wi, Ri) given (Xi, Zi). By iterated expectations and the predictability of Hi,
Substituting Mi by in the left side of the above equation, we have
Taking derivative with respect to t, under conditions A and C together with , we obtain
This completes the proof.
Proof for Theorem 1
First consider the consistency. Conditions B–D ensure G(t, θ; η) and G(t, θ; 1) are bounded away from zero in
(θ0). Note that ÛC(θ) can be rewritten as
| (7) |
Follow the extended strong law of large numbers as given in Appendix III of Andersen and Gill (1982), under condition C, the four empirical processes in (7) converge almost surely (a.s.) to their limits uniformly for t ∈ (0, L) and θ ∈
(θ0). By the chain law, ÛC(θ) converges uniformly a.s. for θ ∈
(θ0) to
By Lemma 1 and the independence of η from (V, Δ, X, Z), we have
It follows that UC(θ0) = 0. Similarly it can be shown that ∂ÛC(θ)/∂θ converges uniformly a.s. to Γη(θ) = E(η)Γ(θ) for θ ∈
(θ0). Under Condition E, θ0 is the unique zero crossing for UC(θ) in a neighborhood of θ0. The consistency of θ̃ then follows.
Next, we show the asymptotic normality. By a Taylor expansion of ÛC(θ̃) at θ0,
where θ̃* lies between θ0 and θ̃ Thus
With a functional Taylor expansion and straight algebra,
| (8) |
This, together with the uniform convergence of ∂ÛC(θ; (RT, ZT)T)/∂θT, establishes the asymptotic normality. One can then show the consistency of the variance estimator with similar arguments.
Proof of Theorem 2
First, we consider the asymptotic properties of the estimator ĉ. Under condition F, . By similar arguments as for the consistency in Theorem 1, we have
| (9) |
With some simple algebra, it can be shown that
By Lemma 1, we have dE {ηN(t)} = λ0(t)E(η)G(t, θ0; 1,X) and dE {ηWN(t)} = dE [ηXN(t)] = λ0(t)E(η)G(t, θ0;X,X). Thus the right side of (9) equals c0. With a functional Taylor expansion and some algebra, it can be shown that
| (10) |
Applying a Taylor expansion at θ0, together with (8), we have
| (11) |
A combination of (10) and (11) gives
| (12) |
Now we consider the asymptotic properties of θ̂ (A). By the consistency of ĉ and empirical process theory, Û (θ; ĉ) converges uniformly a.s. to
Note that U(θ0) = 0. Under condition C, θ0 is the unique solution to U(p+1;p+2q)(θ) = 0, where U(p+1;p+2q)(θ) denote the p+1 to p+2q elements of U(θ) (Huang and Wang, 2000). Thus θ0 is the unique solution to U(θ) = 0 and hence the unique minimum of UTAU. The consistency of θ̂(A) then follows.
Next we consider the asymptotic normality. Note that Û (θ; c) is linear in c, and
| (13) |
where ,
and 0p×p is a p × p zero matrix. It can be shown by a functional Taylor expansion that
Substituting this and (12) into (13), we have
Since θ̂ (A) is the minimum of Q(θ; ĉ, A),
By a Taylor expansion on ÛT(θ̂(A); ĉ) at θ0, we have
where θ̂*(A) lies between θ̂(A) and θ0. Thus
It can be shown that −∂Û (θ; ĉ)/∂αT converges uniformly a.s. to D(θ). Therefore,
where DT(θ0)AD(θ0) is positive definite under conditions D, E and G. The asymptotic normality follows from the central limit theorem and the Slutsky Theorem.
Contributor Information
Xiao Song, Email: xsong@u.uga.edu, Associate Professor, Department of Epidemiology and Biostatistics, University of Georgia, Athens, GA 30602.
Ching-Yun Wang, Email: cywang@fhcrc.org, Member, Division of Public Health Sciences, Fred Hutchinson Cancer Research Center, Seattle, WA 98109.
References
- Andersen PK, Gill RD. Cox’s Regression Model for Counting Processes: A Large Sample Study. The Annals of Statistics. 1982;10:1100–1120. [Google Scholar]
- Carroll RJ, Ruppert D, Crainiceanu CM, Tosteson TD, Karagas RM. Nonlinear and Nonparametric Regression and Instrumental Variables. Journal of the American Statistical Association. 2004;99:736–750. [Google Scholar]
- Carroll RJ, Ruppert D, Stefanski LA, Crainiceanu CM. Meaurement Error in Nonlinear Models. New York: Chapman & Hall/CRC; 2006. [Google Scholar]
- Cragg JG. More Efficient Estimation in the Presence of Heteroskedasticity of Unknown Form. Econometrica. 1983;51:751–763. [Google Scholar]
- Dafni UG, Tsiatis AA. Evaluating Surrogate Markers of Clinical Outcome Measured With Error. Biometrics. 1998;54:1445–1462. [PubMed] [Google Scholar]
- Davidian M, Gallant AR. The Nonlinear Mixed Effects Model With a Smooth Random Effects Density. Biometrika. 1993;80:475–488. [Google Scholar]
- Ding J, Wang JL. Modeling Longitudinal Data With Nonparametric Multiplicative Random Effects Jointly With Survival Data. Biometrics. 2008;64:546–556. doi: 10.1111/j.1541-0420.2007.00896.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hammer SM, Katezstein DA, Hughes MD, Gundaker H, Schooley RT, Haubrich RH, Henry WK, Lederman MM, Phair JP, Niu M, Hirsch MS, Merigan TC for the AIDS Clinical Trials Group Study 175 Study Team . A Trial Comparing Nucleoside Monotherapy With Combination Therapy in HIV-infected Adults With CD4 Cell Counts From 200 to 500 Per Cubic Millimeter. New England Journal of Medicine. 1996;335:1081–1089. doi: 10.1056/NEJM199610103351501. [DOI] [PubMed] [Google Scholar]
- Hansen LP. Large Sample Properties of Generalized Method of Moments Estimators. Econometrica. 1982;50:1029–1054. [Google Scholar]
- Hu C, Lin DY. Cox Regression With Covariate Measurement Error. Scandinavian Journal of Statistics. 2002;29:637–655. [Google Scholar]
- Huang Y, Wang CY. Cox Regression With Accurate Covariates Unascertainable: A Nonparametric Correction Approach. Journal of the American Statistical Association. 2000;95:1209–1219. [Google Scholar]
- Huang Y, Wang CY. Consistent Functional Methods for Logistic Regression With Errors in Covariates. Journal of the American Statistical Association. 2001;96:1469–1482. [Google Scholar]
- Huang Y, Wang CY. Errors-In-Covariates Effect on Estimating Functions: Additivity in Limit and Nonparametric Correction. Statisitica Sinica. 2006;16:861–881. [Google Scholar]
- Li Y, Ryan L. Survival Analysis With Heterogeneous Covariate Measurement Error. Journal of the American Statistical Association. 2004;99:724–735. [Google Scholar]
- Liao X, Zucker DM, Li Y, Speigelman D. Survival Analysis with Error-Prone Time-Varying Covariates: A Risk Set Calibration Approach. Biometrics. 2011;67:50–58. doi: 10.1111/j.1541-0420.2010.01423.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nakamura T. Proportional Hazards Model With Covariates Subject to Measurement Error. Biometrics. 1992;48:829–838. [PubMed] [Google Scholar]
- Newey W. Adaptive Estimation of Regression Models via Moment Restrictions. Journal of Econometrics. 1988;38:301–339. [Google Scholar]
- Newey W, McFadden D. Handbook of Econometrics. Vol. 36. Elsevier Science; 1994. Large Sample Estimation and Hypothesis Testing. [Google Scholar]
- Prentice R. Covariate Measurement Errors and Parameter Estimates in a Failure Time Regression Model. Biometrika. 1982;69:331–42. [Google Scholar]
- Song X, Davidian M, Tsiatia AA. A Semiparametric Likelihood Approach to Joint Modeling of Longitudinal and Time-to-Event Data. Biometrics. 2002a;58:742–753. doi: 10.1111/j.0006-341x.2002.00742.x. [DOI] [PubMed] [Google Scholar]
- Song X, Davidian M, Tsiatia AA. An Estimator for the Proportional Hazards Model With Multiple Longitudinal Covariates Measured With Error. Biostatistics. 2002b;3:511–528. doi: 10.1093/biostatistics/3.4.511. [DOI] [PubMed] [Google Scholar]
- Song X, Huang Y. On Corrected Score Approach for Proportional Hazards Model With Covariate Measurement Error. Biometrics. 2005;61:702–714. doi: 10.1111/j.1541-0420.2005.00349.x. [DOI] [PubMed] [Google Scholar]
- Song X, Wang CY. Semiparametric Approaches for Joint Modeling of Longitudinal and Survival Data with Time Varying Coefficients. Statistica Sinica. 2008;27:3178–3190. doi: 10.1111/j.1541-0420.2007.00890.x. [DOI] [PubMed] [Google Scholar]
- Stock JH, Watson WW. Introduction to Econometrics. New-York: Addison-Wesley; 2010. [Google Scholar]
- Stock JH, Wright JH. GMM With Weak Identification. Econometrica. 2000;68:1055–1096. [Google Scholar]
- Tapsoba JD, Lee SM, Wang CY. Joint Modeling of Survival Time and Longitudinal Data With Subject-Specific Change Points in The Covariates. Statistics in Medicine. 2011;30:232–249. doi: 10.1002/sim.4107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tsiatis AA, Davidian M. A Semiparametric Estimator for the Proportional Hazards Model With Longitudinal Covariates Measured With Error. Biometrika. 2001;88:447–458. doi: 10.1093/biostatistics/3.4.511. [DOI] [PubMed] [Google Scholar]
- Tsiatis AA, DeGruttola V, Wulfsohn MS. Modeling the Relationship of Survival to Longitudinal Data Measured With Error: Applications to Survival and CD4 Counts in Patients With AIDS. Journal of the American Statistical Association. 1995;90:27–37. [Google Scholar]
- Xu J, Zeger SL. The Evaluation of Multiple Surrogate Endpoints. Biometrics. 2001;57:81–87. doi: 10.1111/j.0006-341x.2001.00081.x. [DOI] [PubMed] [Google Scholar]
- Wang CY. Corrected Score Estimator for Joint Modeling of Longitudinal and Failure Time Data. Statistica Sinica. 2006;16:235–353. [Google Scholar]
- Wang CY. Non-parametric Maximum Likelihood Estimation for Cox Regression With Subject-Specific Measurement Error. Scandinavian Journal of Statistics. 2008;35:613–628. [Google Scholar]
- Wang CY, Hsu L, Feng ZD, Prentice RL. Regression Calibration in Failure Time Regression. Biometrics. 1997;53:131–145. [PubMed] [Google Scholar]
- Wulfsohn MS, Tsiatis AA. A Joint Model for Survival and Longitudinal Data Measured With Error. Biometrics. 1997;53:330–339. [PubMed] [Google Scholar]