

Summary
We consider estimation of the causal effect of a binary treatment on an outcome, conditionally on covariates, from observational studies or natural experiments in which there is a binary instrument for treatment. We describe a doubly robust, locally efficient estimator of the parameters indexing a model for the local average treatment effect conditionally on covariates V when randomization of the instrument is only true conditionally on a high dimensional vector of covariates X, possibly bigger than V. We discuss the surprising result that inference is identical to inference for the parameters of a model for an additive treatment effect on the treated conditionally on V that assumes no treatment–instrument interaction. We illustrate our methods with the estimation of the local average effect of participating in 401(k) retirement programs on savings by using data from the US Census Bureau's 1991 Survey of Income and Program Participation.
Keywords: Instrumental variables, Local average treatment effect, Local efficiency, Multiplicative effect
1. Introduction
Economists and biostatisticians have long been concerned with the problem of how to estimate the causal effect of a treatment on an outcome of interest, and how this effect is modified by baseline covariates. Estimation of average treatment effects is often facilitated by the unconfoundedness assumption that a vector of measured covariates suffices to control for all confounding of the treatment–outcome relationship. When this assumption is thought implausible, but instrumental variables (IVs) satisfying the monotonicity assumption given in Section 2.1 are available, it is possible to estimate the so-called local average treatment effect contrasts. These are treatment effect contrasts for the subpopulation of compliers, i.e. subjects for whom treatment and instrument agree. Beginning with the seminal paper of Imbens and Angrist (1994), non-parametric and semiparametric IV methods for estimation of local average treatment effects have received considerable attention in the literature (Angrist and Imbens, 1995; Angrist et al., 1996, 2000; Abadie, 2002, 2003; Abadie et al., 2002; Froelich, 2007; Tan, 2006a, 2010; Kasy, 2009, Cheng et al., 2009a, b).
In this paper we consider estimation of models for the dependence of local average treatment effects on baseline covariates V. We assume that the treatment and instrument are binary and that the outcome support is either the real line, the non-negative real line or the non-negative integers. Like Abadie (2003), Tan (2006a), Froelich (2007), and Uysal (2011), we consider settings in which conditioning on a set of covariates X is necessary for the identifying IV assumptions to be valid. These settings are important because in practice the instrument may itself be confounded, and conditioning on covariates X may be required to make the key condition of instrument randomization plausible (Abadie, 2003). We extend this previous work to allow X to be larger than V. This is an important contribution of our methodology, providing desirable flexibility in the definition of the target estimand as often investigators wish to report the treatment effect at low aggregation levels. Specifically, the covariate vector X is the set of variables that must be conditioned on for the instrument–outcome and instrument–treatment relationships to be unconfounded within levels of covariates; however, local average treatment effects conditional on V, a subset of X, may be the relevant contrasts to help guide decision makers who, because of limited resources, will have access only to information about the subset V of X. For example, consider a study conducted in a sophisticated health maintenance organization. Suppose that the instrument is the therapy prescribed by the physician, the treatment is the therapy actually followed by the patient and X is a vector of measured risk factors for the outcome that were used by the health maintenance organization physician to decide on the therapy prescription. The covariates X could include the results of expensive tests administered to patients at high risk for disease, such as magnetic resonance angiograms, that would not be available to community physicians. Thus, community physicians would need to decide what therapy to prescribe on the basis of just the subset V of X that encodes the data that are available to them. Estimation of effect modification of the local average treatment effects by V is then critical to enable community physicians to make informed treatment decisions.
The literature on local average treatment effects has primarily focused on the estimation of the local average treatment effect on the additive scale, LATE, defined as the difference in means of the two potential outcomes (under treatment and under no treatment) in the subpopulation of compliers. Identification of the multiplicative local average treatment effect contrast, MLATE, i.e. the ratio of the potential outcome means among compliers, follows trivially from results of Abadie (2003) but, to our knowledge, estimators of parametric specifications for the dependence of MLATE on covariates has not been discussed in the literature. In this paper we consider estimation of models for LATE and MLATE as functions of V.
When the dimension of the covariate vector X is large, as will often be required in practice for the assumption of a conditionally unconfounded instrument to hold, non-parametric estimation of LATE (Froelich, 2007), of MLATE and of parametric specifications for the dependence of these contrasts on covariates V is not feasible, owing to the curse of dimensionality. When V is null, Tan (2006a) and Uysal (2011) derived estimators of LATE that are consistent provided that either two models for two specific conditional means given the instrument and X or a model for the instrument propensity score (the probability that the instrument is equal to 1 conditionally on the covariates X) are correctly specified. In this paper we derive a new class of doubly robust estimators of parametric specifications for the dependence of LATE or MLATE on covariates V which remain consistent and asymptotically normal provided that either the propensity score model or a model for another conditional mean given the instrument and X is correctly specified. When V is non-null, the conditional mean models that are required by our doubly robust estimator are guaranteed to cohere with a parametric specification for the dependence of the local average treatment effect on V. Extensions of the doubly robust methods that were proposed by Tan (2006a) and Uysal (2011) to the case V non-null do not have this property.
In Section 2 we introduce the notation, models and assumptions. We also review existing non-parametric and semiparametric methods for estimating local average treatment effects with instruments confounded by X. In Section 3 we describe the doubly robust estimating procedures proposed and discuss efficiency properties and estimation under incorrect specifications for the dependence of LATE or MLATE on V. In Section 4 we explain a surprising result that was earlier noted in the absence of covariates X by Clarke and Windmeijer (2010): inference under our models for the local average treatment effects is identical to inference under models proposed by Robins (1994) and Tan (2010) for a very different causal effect measure, namely the treatment effect on the treated. In Section 5 we reanalyse the data used in Póterba et al. (1995) and Abadie (2003) with the goal of estimating the causal effect of participating in 401(k) retirement programmes on savings by using eligibility for a 401(k) programme as a binary instrument. Section 6 concludes the paper.
2. Background and notation
Suppose that we observe a random sample of size n of the vector O = (Z, D, X, Y), where D is a binary variable denoting the presence (D = 1) or the absence (D = 0) of a treatment whose effect on the outcome Y we wish to investigate, X is a vector of baseline covariates and Z is a binary IV. Define Dz to be the potential treatment status that would be observed if Z were externally set to z, and define Ydz to be the potential outcome that would be observed if D were externally set to d and Z to z, with d, z = 0, 1. Following Angrist et al. (1996), we say a subject is a complier if D1 > D0, an always-taker if D1 = D0 = 1, a never-taker if D1 = D0 = 0, and a defier if D1 < D0.
2.1. Assumptions and identification
Following Abadie (2003), Tan (2006a), Froelich (2007), and Uysal (2011), we make the following assumptions:
conditional unconfoundedness of the instrument, i.e. (Y00, Y01, Y10, Y11, D0, D1) is conditionally independent of Z given X;
exclusion of the instrument, i.e. P(Y1d = Y0d) = 1 for d ∈ {0, 1};
common support of the instrument, i.e. 0 < P(Z = 1|X) < 1 with probability 1;
instrumentation, i.e. P(D1 = 1|V) ≠ P(D0 = 1|V) with probability 1;
monotonicity, i.e. P(D1 ⩾ D0) = 1;
consistency, i.e. Y = DY1 + (1 − D)Y0 and D = ZD1 + (1 − Z)D0, where Yd ≡ Y1d = Y0d by assumption (b).
When assumptions (a)–(d) and (f) hold, Z is said to be an IV for the effect of D on Y. Assumption (a) says that, within levels of X, Z is as good as randomly assigned. Assumption (b) postulates that the effect of Z on the outcome is entirely mediated by D. It implies that Ydz is independent of z, and therefore we write Yd throughout. Assumption (c) requires that there is a positive probability of receiving each instrument value within each level of X or, equivalently, that the support of X is the same among those with Z = 1 and Z = 0. Assumption (e) excludes the existence of defiers. Assumption (f) states that the observed outcome is equal to the potential outcome evaluated at the observed treatment value, and that the observed treatment is equal to the potential treatment evaluated at the observed instrument value. Finally, under assumption (e), assumption (d) is the same as P(D1 = 1|V) > P(D0 = 1|V) which, in turn, under (a) and (f) it is the same as P(D = 1|Z = 1, V) > P(D = 1|Z = 0, V). So it is tantamount to the assumption of positive correlation between Z and D. Abadie (2003) noted that assumptions (a)–(f) are conditional versions of the assumptions that were made by Angrist et al. (1996), and Vytlacil (2002) noted that they are equivalent to the assumptions imposed by a non-parametric selection model (Heckman, 1976) in which treatment is seen as an indicator of whether a latent index, e.g. expected treatment utility, has crossed a particular threshold.
Abadie (2003) showed that under assumptions (a)–(f) E(Y1|D1 > D0, V) and E(Y0|D1 > D0, V) are identified, and consequently so is
Under the additional assumption
-
(g)
non-null complier mean under control, i.e. E (Y0 | D1 > D0, V) ≠ 0 with probability 1, the contrast
is well defined with probability 1 and is identified.
For conciseness, we shall refer to assumptions (a)–(f) if referring to inference about LATE(·) or (a)–(g) if referring to inference about MLATE(·) as the IV assumptions.
The curves LATE(v) and MLATE(v) describe how treatment effects in the complier subpopulation vary with values v of V, the first quantifying the effects on an additive scale and the second on a multiplicative scale. Theorem 1 of Tan (2006a) implies that under the IV assumptions LATE(v) is equal to the conditional version of the IV estimand,
| (1) |
and MLATE(v) is
| (2) |
(see also theorem 3.1 of Abadie, (2003)). The M in front of the functional MIV is a reminder that this functional identifies a multiplicative treatment effect. The functionals IV(·) and MIV(·) are the target of inference when, as we shall assume throughout, the IV assumptions are valid and interest is in estimation of LATE(·) and MLATE(·).
2.2. Review of existing estimators
The estimators that we shall propose in Section 3 can accommodate any setting in which V is a subset of X. Previous proposals for estimators of LATE have generally cosidered only the special cases in which V is null or V is equal to X; to our knowledge the case in which V is a strict, non-empty subset of X has not been addressed in the literature.
For the special case in which V is null, Froelich (2007) studied the asymptotic distribution theory of estimators of the IV functional that rely on two distinct non-parametric estimation methods for the four curves E(Y|Z = z, X = ·) and E(D|Z = z, X = ·), z = 0, 1, namely local polynomial regression and non-parametric series regression. His estimators, however, suffer from the curse of dimensionality. If the dimension of X is large, as will be so in many applications to render the unconfoundedness assumption plausible, the IV functional will not in general be estimable in moderately sized samples, essentially because no two units will have values of X that are sufficiently close to each other to allow for the borrowing of information that is needed for the smoothing implicit in these methods. Again, for the special case in which V is null, Tan (2006a) considered estimating the IV functional under parametric models for each of the conditional means E(Y|D = d, Z = z, X = ·) and E(D|Z = z, X = ·), d, z = 0, 1. The consistency of the estimator of the IV functional then hinges on the correct specification of both of these models. See Section 3 for a contrast between these models and the models that must be specified to carry out the doubly robust estimation approach that is proposed in this paper.
Neither Froelich (2007) nor Tan (2006a) addressed the case when V is a non-empty, strict subset of X, but further difficulties arise for each of their strategies in this case. Extending Froelich's approach to estimate the functionals IV(V) and MIV(V) non-parametrically not only requires smooth estimators of the aforementioned conditional means, but also of the conditional means given V of the differences that are involved in the numerators and denominators of these functionals. One possible extension of Tan's (2006a) fully parametric approach along the lines proposed there for the case X = V, would also require specifying parametric models for the conditional means given V in the numerator and denominator of the IV(V) functional. As noted by Abadie (2003), this approach will generally produce parametric specifications for the LATE(·) and MLATE(·) curves that are difficult to interpret. For example, linear specifications for each of the four conditional-on-V mean functions involved in the IV(V) functional do not imply a linear model for LATE(V). An alternative strategy that avoids this particular difficulty would be to use the approach of Tan (2010); however that approach involves specifying working models that may not cohere with the assumed model for LATE(·).
For the special case in which V is null, and with the goal of reducing sensitivity to model misspecification, Tan (2006a) and Uysal (2011) described doubly robust estimators of the IV functional whose consistency depends on correct parametric specification either of the instrument propensity score or, in the case of Uysal, of E(Y|Z = z, X = ·) and E(D|Z = z, X = ·), z = 0, 1, and, in the case of Tan, of E(Y|D = d, Z = z, X = ·) and E(D|Z = z, X = ·), d, z = 0, 1.
The special case of V = X was considered by Abadie (2003), Tan (2006a), Hirano et al. (2000), and Little and Yau (1998). Tan's (2006a) estimator of LATE(X) again requires parametric specifications of the four conditional expectations that are involved in the IV(X) functional, which results in a specification of LATE(X) that may be difficult to interpret. Hirano et al. (2000) and Little and Yau (1998) specified fully parametric likelihood functions for the observed data and unobserved compliance types (complier, defier, always-taker, never-taker) and used Bayesian methods to estimate the posterior distribution of Y conditionally on compliance type, treatment and instrument. Abadie (2003) proposed an estimating procedure in which models for E(Yd|D1 > D0, X = ·), d = 0, 1 ensure that the resulting model for LATE(X) is easily interpretable. His method hinges on consistent estimation of the instrument propensity score P(Z = 1|X = ·). Abadie considered estimation of the propensity score under a parametric model as well as by nonparametric power series methods. When X is high dimensional and the sample size is moderate, non-parametric propensity score estimation yields poorly behaved estimators of parametric specifications of E(Yd|D1 > D0, X = ·), d = 0, 1 owing to the curse of dimensionality.
3. New methods
In this section we describe estimation of the parameters indexing the following parsimonious models for LATE(V) and MLATE(V):
| (3) |
and
| (4) |
for specified functions mj (·, ·) smooth in β, j = 1, 2. For inference under model (ℱ1 we assume that Y has unbounded support and for inference under model (ℱ2 we assume that Y has support equal to the non-negative real line or the non-negative integers.
For the special case in which V = X, Abadie (2003) also considered estimation of LATE(X) under a parametric specification for the curve. However, his approach estimates LATE(X) as the difference of the estimators of the means E(Yd|D1 > D0, X), d = 0, 1, under separate parametric models for each of them. We prefer to estimate LATE(X) under a model that parameterizes just this contrast rather than under separate models for each of the counterfactual means to reduce the opportunities of model misspecification.
For estimation of LATE and MLATE, i.e. when V is null, the doubly robust estimators that we describe in this section, like the doubly robust estimators that were proposed by Tan (2006a) and Uysal (2011), are consistent under a correct parametric specification of the propensity score curve P(Z = 1|X = ·). Like the estimators of Tan and Uysal, our estimators remain consistent even under incorrect specification of the propensity score curve provided another set of curves is correctly parameterized. Tan's approach requires modeling E(Y|Z = ·, D = ·, X = ·,) and E(D|Z = ·, X = ·), and Uysal's approach requires modeling E(Y|Z = ·, X = ·) and E(D|Z = ·, X = ·). Our approach, by contrast, requires modeling the conditional mean E{φ(X)|V = ·} of a user-specified function φ (X) (if V ≠ X) and the conditional expectation E(Hj|Z = ·, X= ·) (j = 1 if inference is about LATE and j = 2 if is about MLATE), where
and
The issue of which curves must be modeled in the doubly robust procedure, i.e. those in Tan (2007), Uysal (2011) or our proposal, is inconsequential when V is null. However, it is an important issue if V is non-empty. As shown in the supplementary Web appendix, when Y has unbounded support, E{φ(X)|V = ·}, E(H1|Z = ·, X = ·) and P(Z = 1|X = ·) are variation independent with IV(·) and, when Y has support equal to [0, ∞) or the non-negative integers, E{φ(X)|V = ·}, E(H2|Z = ·, X = ·) and P(Z = 1|X = ·) are variation independent with MIV(·). Therefore, our doubly robust procedure offers two genuine independent opportunities to produce consistent estimators of parametric specifications for LATE(·) or MLATE(·), as neither the models for E{φ(X)|V = ·} and E(H1|Z = ·, X = ·) nor the model for P(Z = 1|X = ·) can conflict with parametric specifications of IV(V = ·) and neither the models for E{φ(X)|V = ·} and E(H2|Z = ·, X = ·) nor the model for P(Z = 1|X = ·) can conflict with parametric specifications of MIV(V = ·). Essentially, the variation independence of H1 and H2 respectively with IV(·) and MIV(·) is a consequence of the fact that the restrictions imposed on the law of H1 and H2 by the IV assumptions do not depend on the functional form of IV(·) and MIV(·)respectively. In contrast, restrictions on E(Y|Z = ·, X = ·) and E(D|Z = ·, X = ·) or on E(Y|Z = ·, D = ·, X = ·) and E(D|Z = ·, X = ·) impose restrictions on IV(·) and therefore may conflict with parametric specifications for it. One could reasonably argue that this conflict is of no great importance for practice because all models are almost certainly misspecified to a larger or smaller extent. Furthermore, it may be easier to build and check models for E(Y|Z = ·, D = ·, X = ·) and E(D|Z = ·, X = ·) than models for E(Hj|Z = ·, X = ·). Although we do not disagree with these points, we nevertheless find it conceptually important to demonstrate that there is methodology that, under the assumptions stated, is internally consistent.
3.1. Estimation of LATE(·) and MLATE(·) under models for the propensity score or outcome regression
The following theorem gives two key expressions for the moment restrictions that are satisfied by the functionals IV(V) and MIV(V) on which our proposed estimators rely.
Theorem 1. For j ∈ {1, 2}, if the denominators of IV(V) and MIV(V) are non-zero with probability 1, then
| (5) |
and
| (6) |
where p(Z|X) ≡ P(Z = 1|X)Z {1 − P(Z = 1|X) }1 −Z.
Proof. Equation (5) with j = 1 follows by algebra from the definition (1) and with j = 2 it follows from the definition (2). Specifically, to arrive at result (5) from definition (1) when j = 1 note that the difference between the numerator on the right-hand side of definition (1) and the product of IV(v) with the denominator on the right-hand side of definition (1) is the same as the left-hand side of result (5). Likewise, to arrive at result (5) from (2) when j = 2 note that the sum of the denominator on the right-hand side of definition (2) with the product of the numerator on the right-hand side of definition (2) times MIV(v)−1 is the same as the left-hand side of equation (5). Equation (6) is equivalent to equation (5) because
and
Theorem 1 suggests that well-behaved estimators of β can be obtained under parametric specifications of either P(Z = 1 |X) or E (Hj|Z, X) where throughout we assume j = 1 if β indexes the parametric specification (3) for LATE(V) and j = 2 if β indexes the specification (4) for MLATE(V). We now describe such estimators.
Define
and
where m1 (V; β) and m2 (V; β) are the parametric specifications for LATE(v) defined in equation (3) and for MLATE(v) defined in equation (4) respectively. Throughout we let β0 denote the true the value of β under the given specification (3) or (4).
A consistent and asymptotically normal estimator β̂ipw of β0 under a parametric class for the instrument probabilities
| (7) |
where π(·; ·) is a specified function that is smooth in α and
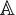 is a specified subset of Rd, is computed as the solution of
is a specified subset of Rd, is computed as the solution of
| (8) |
where p(Z|X; α) ≡ π(X; α)Z {1 − π(X; α)}1 − Z,q(V; β) is a user specified p × 1 vector-valued function (e.g. q(V; β) = ∂mj (V; β) /∂β), and
| (9) |
is the maximum likelihood estimator of α. Throughout En(·) stands for the empirical mean operator. Identity (6) implies that under the IV assumptions, under the parametric specification (3), and with j = 1 in display (5), √n(β̂ipw − β0) converges in law to a mean 0 normal distribution when condition (7) and regularity conditions hold and, in addition, for some σ and z = 0, 1, P(Z = z|X; α) > σ > 0. The same holds under the parametric specification (4) and with j = 2 in display (5).
Alternatively, one can compute a consistent and asymptotically normal estimator β0 under a parametric class for E(Hj | Z, X) that respects the constraint (5). To aid the specification of such a parametric class, we re-express the constraint (5) as the condition that, for some r(X),
When V ≠ X we derive a flexible parametric specification for E(Hj | Z, X) that respects constraint (5) from the following three specifications:
-
a linear parametric specification for r(X),
(10) where φ (X) ≡ (φ1 (X), …, φK (X))T and φs, s ∈ {1, …, K}, are user-specified real-valued functions,
-
a linear model for the mean of φ(X) given V,
(11) where ϕ (V; γ) ≡ (ϕ1 (V; γ), …, ϕK(V; γ))T, Γ is a subset of a Euclidean space and φk, k ∈ {1, …, K}, are user-specified real-valued functions (when V is null we set ϕ(V; γ) = γ, thus leaving ℳ unrestricted) and
-
a parametric specification for E(Hj| Z = 0, X), i.e.
(12) where k (·; ·) is a specified function smooth in ν and ϒ is a subset of a Euclidean space.
Specifications (10)–(12) imply the following model respects the constraint (5):
| (13) |
where η ≡ (ρ, ν) and h (z, x; η, γ) = k (x; ν) + ρT {φ(x) − ϕ(v; γ)} z.
When V = X, we ignore specification (11) and replace specification (13) with
| (14) |
where h(·; ·) is a specified function that is smooth in η and ϒ is a subset of a Euclidean space. This specification also respects the constraint (5) because when V = X this constraint is the same as the condition that E(Hj |Z, X = x) does not depend on Z.
An estimator β̂reg that is consistent and asymptotically normal for β0 under specifications (11) and (13) when V ≠ X or specification (14) when V = X can be computed as the first component of the vector (β̂reg, η̂) solving
| (15) |
where l(·, ·; ·, ·, ·) is a user-specified vector-valued function of the same dimension as (β, η),
and γ̂ solves En[{ ∂ϕ(V; γ)T/∂γ} {φ(X) − ϕ(V; γ)}] = 0 if V ≠ X, εj(β, η, γ) ≡ Hj(β) − h(X; η) if V = X. One practical choice of l(Z, X; β, η, γ̂) is
| (16) |
Under specifications (11) and (13) when V ≠ X or specification (14) when V = X, the IV assumptions and the parametric specification (3) if j = 1 or specification (4) if j = 2, E{εj (β0, η0, γ0)|Z, X} = 0 where (η0, γ0) are the true values of (η, γ), so √n(β̂reg − β0) converges in law to a mean 0 normal distribution provided standard regularity conditions for convergence of M-estimators hold.
Selection of the parametric class for E(Hj|Z, X) can be aided with the following α-level score type test of the null hypothesis ℍ0 : η2 = 0 where and η2 is of dimension, say, d2. Let
where (β̃reg, η̃1) solves
Under ℍ0, √nRn converges in law to a mean 0 d2-variate normal distribution with variance–covariance matrix, say, J. Thus, if Ĵ is a consistent estimator of J, a test that rejects ℍ0 when Ĵ Rn > χ1 −α,d2 where χ1 −α,d2 is the (1 − α)-quantile of a χ2-distribution with d2 degrees of freedom is an asymptotic α-level test of ℍ0. A consistent variance estimator Ĵ can be derived from standard Taylor expansion arguments for M-estimators (Stefanski and Boos, 2002).
3.2. Doubly robust estimation of LATE (·) and MLATE (·)
In this section we derive a doubly robust estimator β̂dr of β which satisfies that √n(β̂dr − β0) converges to a mean 0 normal distribution under the IV assumptions and regularity conditions provided that one of the following two conditions (a) or (b) holds, even if both do not hold simultaneously:
specifications (11) and (13) are correct when V ≠ X, or specification (14) is correct when V = X,
specification (7) is correct.
The estimator β̂dr solves the estimating equations
| (17) |
where, for each fixed β, η̂(β) solves En{lη (Z, X; β, η, γ̂) εj (β, η, γ̂)} = 0 with lη defined as in equation (16) and
if V ≠ X or a(X; α, η, γ) ≡ h(X; η) if V = X.
The estimator β̂dr is consistent for β0 when (b) holds because
for all β since E{(−1)1−Z p(Z|X; α0)|X} = 0.
In contrast, consistency when condition (a) holds can be seen after re-expressing equation (17) as
and noting that, by virtue of equality (5) of theorem 1, E[q(V; β){h(1, X; η0, γ0) − h(0, X; η0, γ0)}] = 0 and, by E{εj(β, η0, γ0)|Z, X} = 0, E{b(Z, X) εj(β, η0, γ0)} = 0 for all b(Z, X) and, in particular, for b(Z, X) = q(V; β)(−1)1−Z p(Z|X; α)−1 with arbitrary α.
The convergence of √n(β̂dr − β0) to a normal distribution follows after noticing that (β̂dr, η̂, γ̂, α̂) where η̂ ≡ η̂(β̂dr) is an M-estimator, i.e. it solves a joint system of estimating equations. The accuracy of this asymptotic result in finite samples hinges on the strength of the instrument Z, i.e. on how close Δ(V) = E{E(D|Z = 1, X) − E(D|Z = 0, X)|V} is to 0. Theoretical results exploring the asymptotic distribution of β̂dr as Δ(V) shrinks to 0 at different rates with sample size, similarly to those in the conventional IV literature, should be explored but are beyond the scope of this paper.
The asymptotic variance of β̂dr can be consistently estimated with the standard empirical sandwich variance estimator (Stefanski and Boos, 2002) or with the non-parametric bootstrap (Gill, 1989).
In the special case of estimation of β0 ≡ LATE, i.e. when V is null, we have that H1(β) = Y − βD and our doubly robust estimator is similar to that in Tan (2006a) and that in Uysal (2011), except that they replaced h{Z, X; η̂(β), γ̂} with Ê(Y|Z, X) − βÊ(D|Z, X). Tan computed estimators Ê(Y|Z, X) and Ê(D|Z, X) under parametric models for E(Y|D = d, Z = z, X = ·) and E(D|Z = z, X = ·), d, z = 0, 1 whereas Uysal (2011) computed them under parametric models for E(Y|Z = z, X = ·) and E(D|Z = z, X = ·), z = 0, 1.
3.3. Local efficiency under correct parametric specification of the propensity score model
In addition to β̂ipw and β̂dr, there are other consistent and asymptotically normal estimators of β0 under the propensity score specification (7) and the IV assumptions. Specifically, given a user-specified p × 1 function s(x; β), consider the estimator β̂S solving
Because E{q(V; β)(−1)1−Z p(Z|X)−1 s(X)} = 0 it follows that under regularity conditions, when condition (7) holds, √n(β̂s − β0) converges to a mean 0 normal distribution with variance Σq,s, where Σq,s depends on q(·) and on s(·). Invoking the theory of inverse-probability-weighted (IPW) estimation in Robins and Rotnitzky (1992), in the supplementary Web appendix we show that for each fixed q(·) the optimal choice sopt,j(X), in the sense that Σq,s − Σq,sopt,j ⩾ 0 (i.e. semipositive definite), is given by
In the supplementary Web appendix we also show that, when the specifications (11), (13) and (7) hold if V is not equal to X or when the specifications (14) and (7) hold if V = X, the limiting distribution of √n(β̂dr − β0) has variance precisely equal to the bound Σq,sopt,j. The estimator β̂dr, however, may have asymptotic variance even larger than that of β̂ipw if specification (11) and/or (13) is incorrect when V ≠ X or if specification (14) is incorrect when V = X. Using ideas similar to those in Tan (2006b, 2010) we can construct another doubly robust estimator β̃dr that remedies this flaw. The estimator β̃dr is computed by solving
| (18) |
where Id is the p × p identity matrix and Ĉ(β) is the p × p matrix formed by the first p columns of the p × (p + d) matrix
with
Like β̂dr, the estimator β̃dr is doubly robust and has asymptotic variance equal to Σq,sopt,j when specifications (11), (13) and (7) are correct (specifications (14) and (7) are correct if V = X), but unlike β̂dr, it is guaranteed to be the most efficient estimator, asymptotically, among the class of estimators solving equations of the form (18) with Ĉ(β) replaced by an arbitrary p × p constant matrix C. In particular, letting C = 0 we conclude that under model (7), β̃dr is never less efficient asymptotically than β̂ipw. See the supplementary Web appendix for a sketch of the proof of the asymptotic properties of β̃dr.
A further result, which is derived in the supplementary Web appendix, establishes that for j ∈ {1, 2} the optimal function qopt,j(·), in the sense that Σq,sopt,j − Σqopt,j,sopt,j ⩾ 0 for any q (·), is
where
The optimal function qopt,j(·) depends on the unknown observed data distribution and hence it is not available for data analysis. However, we can estimate it under working parametric specifications for its unknown constituents,
| (19) |
and
| (20) |
where ej (·; ·) and tj (·) are smooth functions and Δ and Ω are included in Euclidean spaces. To do so we estimate δ and ω with the weighted least squares estimators δ̂ and ω̂ by regressing (−1)1−Z p(Z|X; α̂)−1 DYj−1 and p(Z|X; α̂)−2[Hj(β̂dr) − a{X;α̂, η̂(β̂dr), γ̂}]2 on V under models (19) and (20) respectively, where β̂dr is a preliminary doubly robust estimator of β computed using an arbitrary q(V; β). We then estimate qopt,j(V; β) with
When specification (7) is correct and P(Z = z|X) > σ > 0 for z = 0 or z = 1, the estimators β̂dr and β̃dr that use q̂opt,j(V; β) for q(V; β) and the estimator β̃C that solves equation (18) with Ĉ(β) replaced by an arbitrary p × p constant matrix C and with q̂opt,j(V; β) instead of q(V; β) satisfy under regularity conditions
√n(β̂dr − β0), √n(β̃dr − β0) and √n(β̃C − β0) converge to mean 0 normal distributions with variances Σdr, Σbetter.dr and ΣC respectively. Furthermore, Σbetter.dr − ΣC ≤ 0 and Σbetter.dr − Σdr ≤ 0.
If, additionally, the specifications (11) and (13) are correct when V ≠ X, or specification (14) is correct when V = X, then Σdr = Σbetter.dr = Σqopt,j,sopt,j .
3.4. Estimation of least squares approximations under incorrect specifications of local average treatment effect curves
A slight modification of the procedure for computing β̂dr and β̃dr yields estimators that are doubly robust for least squares approximations of the true local average treatment effect curves when the parametric specifications for these curves are incorrect.
Given a real-valued function w(v), the w-weighted least squares approximation of the LATE(·) curve is
| (21) |
In the supplementary Web appendix we show that, under the IV conditions, βw,0 satisfies
| (22) |
where qw(V) ≡ w(V) ∂m1(V;β)/∂β|β=βw,0. Arguing as in section 3.2, we conclude that, when condition (b) of Section 3.2 holds (i.e. when the propensity score specification (7) is correct), the estimators β̂dr and β̃dr that use q(V; β) = qw(V; β) ≡ w(V)∂m1(V; β)/∂β converge in probability to βw,0 even if the specification (3) is incorrect.
However, unfortunately, β̂dr and β̃dr need not converge to βw,0 for any w when the propensity score model is incorrect even if condition (a) of Section 3.2 holds. This happens essentially because equation (22) is equivalent to
| (23) |
which involves E{H1(βw,0)|Z, X} but not E(H1|Z, X). Nevertheless, the equality (23) suggests that consistent and asymptotically normal estimators of βw,0 under parametric models for E{H1(βw,0)|Z, X} should exist. However, some care must be taken in formulating such models. For instance, one cannot postulate that E{H1(βw,0)|Z, X} ∈ ℋ where ℋ is defined in specification (13) with j = 1 since this specification is necessarily wrong if the model (11) is correct. This happens because ℋ respects the constraint (5) but E {H1(βw,0)|Z, X} does not, since of all random variables of the form H1(m) = Y − m(V)D for any m(V), only H1 = Y − IV(V)D satisfies the constraint (5) as this constraint identifies the IV(·) curve.
A slight modification to the class ℋ yields a new class that respects the constraint (23) but not necessarily the stronger constraint
and thus gives the opportunity of formulate a correctly specified model for E{H1(βw,0)|Z, X}. Specifically, the parametric specification
| (24) |
where φ(·) and k(·; ·) are user-chosen functions as defined in Section 3.1 and
| (25) |
necessarily respects constraint (23) but not the aforementioned stronger constraint.
A modification in the computation of β̂dr yields a new estimator β̂̂dr, which is described below, that satisfies for a given, user-specified, weight function w(·) the following two conditions:
√n(β̂̂dr − β0) converges to a normal distribution if the parametric specification (3) for LATE(·) is correct and either condition (a) or condition (b) of Section 3.2 holds, and
√n(β̂̂dr − βw,0) converges to a normal distribution if the parametric specification (3) for LATE(·) is incorrect but either condition (b) of Section 3.2 or the parametric specification (24) holds.
Consider first the case V ≠ X. The estimator β̂̂dr solves equation (17) with qw(V; β) instead of q(V; β), and with a{X; α̂, η̂(β), γ̂} replaced by
where η = (ν, ρ, λ),
| (26) |
η̂(β) solves
with
γ̂ solves
and
When V = X, β̂̂dr is computed analogously except that ρ is set to 0 and γ is absent.
The desired properties (a) and (b) of the estimator β̂̂dr are deduced from the following considerations. When condition (b) holds, the estimator β̂̂dr is consistent and asymptotically normal for βw,0 regardless of whether or not specification (3) holds because En[qw(V; β)(−1)1−Z × p(Z|X; α̂)−1 b{X; β, α̂, η̂(β), γ̂, θ̂(β)}] converges to 0 in probability for all β. In contrast, the convergence of β̂̂dr to β0 when specification (3) and condition (a) hold, and the convergence of β̂̂dr to βw,0 when specification (3) is incorrect but condition (24) holds follows arguing as in Section 3.2 for the convergence of β̂dr to β0 when condition (a) holds, after noting that the class
with θ defined as in equation (25) includes both the class ℋ (corresponding to λ = 0) and the class ℋw (corresponding to ρ = 0).
An estimator β̃̃dr satisfying properties (a) and (b) and additionally guaranteed to be at least as efficient asymptotically as β̂ipw is constructed just like β̃dr in Section 3.2 but replacing a{X; α̂, η̂(β), γ̂} with b{X; β, α̂, η̂(β), γ̂, θ̂(β)}, q(V; β) with qw(V; β) and h{Z, X; η̂(β), γ̂} with hw{Z, X; β, η, γ̂, θ̂(β)}. In the supplementary Web appendix we also describe an estimator β̂̂opt,dr which satisfies property (a) and has limiting normal distribution with variance equal to Σqopt,1,sopt,1 when conditions (a) and (b) of Section 3.2 hold and yet converges to a weighted least squares approximation when the specification (3) for LATE(V) is wrong.
For estimation of the MLATE(·) curve in the supplementary Web appendix we show that the estimator β̂̂dr that is computed by using H2(β) instead of H1(β) and with qw(V; β) redefined as m2(V; β) {∂m2(V; β) /∂β}w(V) satisfies properties (a) and (b) where in the statements of these properties, specifications (3) and (24) are replaced with specification (4) and the specification that E{H2(βw,0)|Z = z, X = x} ∈ ℋw respectively, and βw,0 is redefined as
with e0(v) ≡ E(Y0|D1 > D0, V = v). Note that, unlike definition (21), βw,0 is now a weighted least squares approximation with weights that are unknown to the data analyst since they depend on the unknown function e0(V). It does not appear to be possible to construct doubly robust estimators of weighted least squares approximations to the MLATE(·) curve for known, i.e. user-specified, weights.
4. Connections to models for the treatment effect on the treated
Robins (1994) and Tan (2010) considered estimation of the so-called additive treatment effect on the treated contrast
This contrast quantifies the effect of treatment D on the subset of the subpopulation with baseline covariates V = v comprised of subjects who would be treated with D = 1 if Z were set to z. Robins (1994) showed for V = X and Tan (2010) showed for V a strict subset of X, that ATT(z, v) is identified under the IV assumptions (a)–(d) and (f) in Section 2.1 and specific restrictions on ATT(·, ·). In particular, Robins (1994) showed that, when V = X, ATT(z, v) is identified under assumptions (a)–(d) and (f), and the no additive treatment–instrument interaction on the treated: ATT(z, v) = ATT(v) does not depend on z (assumption v-ATT).
Remarkably, Robins showed that under these assumptions ATT(v) = IV(v).
In fact, it is easy to show that the preceding assertions remain true when V is a strict subset of X. We thus see that, under assumptions (a)–(d) and (f) in Section 2.1, the structural interpretation of the observed data functional IV(v) depends on which of the assumptions (e) or (v-ATT) is adopted. The only exception is when P(D0 = 1) = 0, or equivalently when P(D = 1|Z = 0) = 0, since in such a case the complier subpopulation is the same as the subpopulation defined by condition D1 = 1, and consequently LATE(v) = ATT(v).
A further deep connection exists between the works of Robins (1994) and Tan (2010) and the problem that is addressed in this paper. For short, refer to the model defined by assumptions (a)–(f) in Section 2.1 as ‘our additive model’ and to the model defined by assumptions (a)–(d), (f) and v-ATT as the ‘Robins–Tan additive model’. Remarkably, the problem of estimating the parameter β indexing a parametric specification m1 (v; β) for LATE(v) under our additive model is formally identical to the problem of estimating the parameters β indexing a parametric specification m1 (v; β) for ATT(v) under the Robins–Tan additive model. This surprising fact is explained by the following three results whose proofs will be sketched below:
under the intersection model that assumes (a)–(f) in Section 2.1 and v-ATT, i.e. the model that makes simultaneously the assumptions of our additive model and of the Robins–Tan additive model, LATE(v) and ATT(v) are indeed identical causal effect contrasts;
our model is statistically indistinguishable from the intersection model, i.e., given our model, the intersection model imposes restrictions that always fit the observed data perfectly and hence cannot be rejected by any statistical test;
the restrictions that are imposed on the observed data law by the intersection model and not imposed by the Robins–Tan additive model are only inequality constraints.
Results (a) and (b) imply that a functional of the observed data law is equal to LATE(v) = ATT(v) under the intersection model if and only if it is equal to LATE(v) under our additive model. If this were not so, there would be some observed data law functional equal to LATE(v) under the intersection model but not under our additive model (the opposite is not possible because our additive model is bigger than the intersection model). But in such a case, there would be a restriction, specifically the restriction that sets the new functional equal to LATE(v), that would be satisfied under the intersection model but not under our additive model, thus contradicting result (b).
Result (c) implies that a functional of the observed data law is equal to ATT(v) under the intersection model if and only if it is equal to ATT(v) under the Robins–Tan additive model. If this were not so, the intersection model would satisfy an equality constraint that is not satisfied by the Robins–Tan additive model, namely the constraint that sets a new functional of the observed data law equal to ATT(v), thus contradicting result (c).
Results (a)–(c) then imply that any functional of the observed data law that is equal to ATT(v) under the Robins–Tan model must be equal to LATE(v) under our additive model and vice versa. This, in turn, proves that the problem of conducting inference about the parameters β of models m1(v; β) for ATT(v) under the Robins–Tan assumptions is formally the same as the problem of conducting inference about the parameters β indexing a parametric specification m1(v; β) for LATE(v) under our additive model.
A further result (result (d) stated below) implies that IV(v) is indeed the only functional of the observed data law that is equal to LATE(v) under our additive model and, consequently, the only observed data functional equal to ATT(v) under the Robins–Tan additive model:
-
(d)
the only restrictions imposed on the observed data law by our additive model are inequality constraints on certain conditional distributions.
As indicated, result (d) implies that no functional of the observed data law other than IV(v) can be equal to LATE(v) under our additive model. If this were not so, then the observed data law would satisfy an equality constraint under our model, namely the equality that sets IV(v) equal to the other functional that agrees with LATE(v), thus contradicting result (d).
We now demonstrate results (a)–(d). Results (a) and (b) are a consequence of the fact that the intersection model can be equivalently defined as the model that imposes restrictions (a)–(f) in Section 2.1 and the additional restriction
| (27) |
where T denotes compliance type, i.e. T = at if and only if D1 = D0 = 1 (always-taker), T = nt if and only if D1 = D0 = 0 (never-taker), T = co if and only if D1 > D0 (complier) and T = de if and only if D1 < D0 (defier). This equivalence holds because assumption v-ATT is the same as the assumption that
| (28) |
Thus, when no defiers exist, i.e. when assumption (e) holds, equation (28) is equivalent to equation (27).
Result (a) follows because restriction (27) implies that ATT(v) ≡ E(Y1 − Y0|T ∈ {co, at}, V = v) = E(Y1 − Y0|T = co, V = v) ≡ LATE(v), so under the intersection model, LATE(v) is indeed equal to ATT(v). Result (b) follows because, under assumptions (a)–(f), a test of the intersection model is a test that restriction (27) holds. No test can be constructed with power to detect departures from equation (27) because E(Y0|T = at, V) is not identified and the law of the observed data does not bound its range, when, as we have assumed throughout, Y has unbounded support.
Results (c) and (d) are a consequence of the following lemmas whose proofs are given in the supplementary Web appendix.
Lemma 1. The only restrictions on the observed data law encoded by our additive model are 0 < P(Z = 1|X) < 1 and the following inequality constraints. For any y < y′,
| (29) |
| (30) |
| (31) |
Lemma 2. The only restrictions on the observed data law that are imposed by the Robins–Tan additive model are 0 < P(Z = 1|X) < 1 and E {E (D|Z = 1, X) |V} − E{E(D|Z = 0, X) |V} ≠ 0.
It is interesting to contrast the structural interpretation of the functional E(H1|Z, X) under our additive model and the Robins–Tan additive models. In the supplementary Web appendix we show that, under the Robins–Tan additive model,
and under our additive model,
| (32) |
Abadie (2003) has previously derived result (32) in the special case V = X under our additive model. Observe that only under the Robins–Tan additive model and only for the special case V = X, E(H1|Z, X) has a simple structural interpretation, namely as E(Y0|X = x) (since by v-ATT implies ATT(z, X) = ATT(X) when V = X). No simple structural meaning can be given to E(H1|Z, X) in all other cases. It is this counterintuitive aspect of the functional E(H1|Z, X) that we believe may have delayed the discovery of the doubly robust estimators of β proposed in this paper.
Robins (1994) and Tan (2010) also discussed inference about models for the multiplicative treatment effect on the treated curve MTT(z, v) ≡ E(Y1|Dz = 1, V = v) /E(Y0|Dz = 1, V = v). Deep connections along the lines made in this section also exist between the work of Robins (1994) and Tan (2010) for inference about MTT(z, v) and the proposal for estimation about MLATE(v) in this paper.
5. Data Analysis
We apply the procedures that are discussed in this paper to estimate the local average treatment effect of participation in 401(k) programs on household saving. 401(k) tax-deferred retirement plans were introduced in the 1980s with the goal of encouraging household saving; they have since grown to be the most popular retirement plans in the USA. But economists have hypothesized that 401(k) plans may not represent increased saving; rather they may replace other modes of saving for those who participate. Among people who are eligible to participate in 401(k) plans, those who choose to participate are likely to be more inclined to save than those who choose not to participate. Therefore, standard methods for examining the effect of 401(k) participation on savings based on covariate adjustment are inappropriate as underlying saving preference is an unmeasured confounder of the treatment–outcome relationship. Using 401(k) eligibility as an instrument for 401(k) participation, estimation of the local average treatment effect of 401(k) participation on savings is feasible.
Poterba et al. (1994, 1995) and Abadie (2003) analysed data from the US Census Bureau's 1991 Survey of Income and Program Participation to test whether participation in 401(k) plans increases household savings. Here we reanalyze the data that were analyzed by Abadie (2003), consisting of a sample of 9725 household reference subjects aged 25–64 years and their spouses, with annual income between $10000 and $200000. In our analysis as in Abadie's, the outcome Y is net financial assets, the instrument Z is an indicator of 401(k) eligibility, the treatment D is an indicator of 401(k) participation and the vector of covariates is X = (X1, X2, X3, X4) where X1 is age (approximated to the closest integer year after subtracting the minimum age in the sample), X2 is an indicator of marital status (married or not), X3 is family size and X4 is annual household income (in thousands of dollars).
In this example, the instrumentation assumption (d) and monotonicity assumption (e) hold trivially because it is not possible to choose to participate in 401(k) plans if not eligible to do so (D0 = 0 with probability 1). The exclusion restriction (b) is very plausible because 401(k) plans are run through employers with only some employers granting eligibility to their employees; evidence suggests that the effect of an employer's offer of 401(k) eligibility on an employee's saving behaviour operates only through the employee's choice to participate or not in the programme (Poterba et al., 1995). Finally, the randomization assumption is also likely to hold when we include in X the measured predictors income, age, marital status and family size of eligibility and savings. Because D0 = 0 there can be no defiers or always takers and the complier subpopulation is comprised of all eligible subjects who chose to participate; consequently LATE(·) = ATT(·) is estimable with these survey data.
To illustrate our methodology we considered estimation of the parameters indexing models for LATE(V) for two choices of V, namely V =X4 (income) and V = null. We shall see that the analysis when V = X4 showed that income was a significant determinant of LATE. This gave us the opportunity to explore the behaviour of the proposed estimators under misspecification of the model for the LATE(·) curve. Specifically, we applied the procedures in this paper to estimate a scalar parameter β under the specification m(X;β) = β, i.e. under a, probably misspecified, model that assumes that LATE(X) does not depend on income or any of the other covariates in X. This specification was also used to analyze these data in Abadie (2003).
Table 1 reports the estimators of β with their bootstrap standard errors in parentheses in the case V = X4 under the specification m(X4;β) = β0 + β1X4. Table 1 reports results for eight estimators: five doubly robust estimators β̂dr, two IPW estimators β̂ipw and one outcome regression estimator β̂reg. The estimator β̂reg was computed by using the function l(Z, X; β, η, γ) given in expression (16). Three of the doubly robust estimators, denoted by , , , used q(V) equal to q̂opt,1 (V) as defined in Section 3.3. In the calculation of q̂opt,1 (V), log [e1(V; δ)/{1 − e1(V; δ)}] and log{t1(V; ω)} were linear functions of income and income2. (When, as in this data set, Z = 0 implies D = 0, e1(V; δ) is a model for E{E(D|X, Z = 1) |V}.) The fourth doubly robust estimator, which is denoted with , used q(V) = ∂m(V;β) /∂β = (1, X4)T and the last doubly robust estimator, which is denoted by used q(V) = (1, X4)T {expit(ζ̂0 + ζ̂1X4) − expit(ζ̂0 + ζ̂1X4)2} where expit(ζ̂0 + ζ̂1X4)dr was the fitted value from a logistic regression of Z on X4. These last two choices of q(V) were also used to construct the two IPW estimators, which are denoted by and respectively.
Table 1. Estimators of (β0,β1) and their bootstrap standard errors under model LATE(income) =β0 + β1 income.
| Parameter | Results for the following powers k of income in the outcome regression and propensity score models: | ||||||
|---|---|---|---|---|---|---|---|
|
| |||||||
| 1 | 2 | 3 | 4 | 5 | 8 | ||
| Intercept | |||||||
|
|
−4640 (2940) | −1845 (3220) | −1888 (2940) | −1490 (2900) | −1623 (2907) | −1566 (2896) | |
|
|
1774 (5720) | −12860 (10720) | −3846 (5797) | −14201 (11244) | −3877 (7061) | −1578 (7009) | |
|
|
−418 (4827) | −4958 (5547) | −2049 (4385) | −1814 (4527) | −2448 (4465) | −1590 (4543) | |
|
|
−1572 (3292) | −1411 (3146) | −1285 (2873) | −1490 (2900) | −1592 (2989) | −1674 (2914) | |
|
|
−2093 (2961) | −1421 (2947) | −1911 (2816) | −1490 (2900) | −1650 (2826) | −1517 (2920) | |
|
|
17075 (7870) | −18515 (11587) | −4905 (6487) | −858 (6841) | −1980 (6732) | −593 (7655) | |
|
|
12331 (6076) | −3489 (5632) | −2775 (4101) | −1478 (4019) | −1537 (4202) | −1179 (4409) | |
| β̂reg | −6992 (7019) | 1929 (7665) | −2652 (6886) | −1266 (6796) | −1721 (6702) | −1494 (7004) | |
| Income | |||||||
|
|
382 (88) | 337 (92) | 338 (83) | 328 (82) | 330 (83) | 328 (83) | |
|
|
205 (171) | 634 (290) | 390 (165) | 351 (197) | 392 (197) | 329 (196) | |
|
|
272 (128) | 425 (149) | 345 (115) | 340 (123) | 354 (122) | 331 (120) | |
|
|
319 (96) | 323 (90) | 326 (80) | 328 (82) | 329 (82) | 332 (84) | |
|
|
342 (84) | 328 (82) | 340 (84) | 328 (82) | 332 (82) | 328 (79) | |
|
|
−139 (218) | 785 (306) | 425 (178) | 320 (181) | 347 (181) | 311 (201) | |
|
|
14 (161) | 385 (154) | 368 (119) | 339 (117) | 336 (114) | 329 (123) | |
| β̂reg | 510 (187) | 272 (210) | 361 (181) | 345 (183) | 357 (180) | 353 (194) | |
In the calculation of the doubly robust and IPW estimators we used the propensity score model
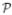 kπ which assumed that log[π (x; α) / {1 − π (x; α)}] was linear in indicator variables of the combined levels of marital status and age as well as in all powers of income up to the power kπ. As in Abadie (2003), we did not include family size because it did not significantly predict Z. Also, the outcome regression model in the calculation of the doubly robust estimators and of β̂reg, which is denoted in what follows by
, assumed that E{H1(β0)|Z, X} = k(X; ν) + ρT{φ(X) − φ(V; γ)}Z. The function k(x; ν) was linear in powers of income up to power kh and in indicators of the combined levels of age, marital status and family size (dichotomized at its mean). The function φ(x) was a vector of indicators of combined levels of age, marital status and family size; each entry of φ(v; γ) was a linear logistic regression model for the corresponding entry of φ(x) with covariates being income, income2, …, incomekh. The estimators
,
and
were computed by using models (
kπ and
with kπ = kh ≡ k. In Table 1 the first three rows report these estimators by using k as indicated by the column labels. The estimator
had kπ fixed at 4 and kh as indicated by the column labels. Likewise the estimator
had kh fixed at 4 and kπ as indicated by the column labels. The estimators
and
had kπ as indicated by the column labels. Finally, the estimator β̂reg had kh as indicated by the column labels. In the data set as well as in each bootstrap replication we first estimated the propensity scores, then threw out the data from subjects in the bottom and top 1% of the estimated values of π(X; α̂), and finally carried through the entire procedure for arriving at the estimators of β using the remaining data. In the data set, this pruning did not noticeably change the values of our estimators, suggesting that the data pruning did not result in substantial bias, but it had a dramatic effect on stabilizing the bootstrap standard error estimators.
kπ which assumed that log[π (x; α) / {1 − π (x; α)}] was linear in indicator variables of the combined levels of marital status and age as well as in all powers of income up to the power kπ. As in Abadie (2003), we did not include family size because it did not significantly predict Z. Also, the outcome regression model in the calculation of the doubly robust estimators and of β̂reg, which is denoted in what follows by
, assumed that E{H1(β0)|Z, X} = k(X; ν) + ρT{φ(X) − φ(V; γ)}Z. The function k(x; ν) was linear in powers of income up to power kh and in indicators of the combined levels of age, marital status and family size (dichotomized at its mean). The function φ(x) was a vector of indicators of combined levels of age, marital status and family size; each entry of φ(v; γ) was a linear logistic regression model for the corresponding entry of φ(x) with covariates being income, income2, …, incomekh. The estimators
,
and
were computed by using models (
kπ and
with kπ = kh ≡ k. In Table 1 the first three rows report these estimators by using k as indicated by the column labels. The estimator
had kπ fixed at 4 and kh as indicated by the column labels. Likewise the estimator
had kh fixed at 4 and kπ as indicated by the column labels. The estimators
and
had kπ as indicated by the column labels. Finally, the estimator β̂reg had kh as indicated by the column labels. In the data set as well as in each bootstrap replication we first estimated the propensity scores, then threw out the data from subjects in the bottom and top 1% of the estimated values of π(X; α̂), and finally carried through the entire procedure for arriving at the estimators of β using the remaining data. In the data set, this pruning did not noticeably change the values of our estimators, suggesting that the data pruning did not result in substantial bias, but it had a dramatic effect on stabilizing the bootstrap standard error estimators.
According to the theory that is presented in this paper, with kπ = kh sufficiently large should result in optimal inference about β. We therefore first examine the rows corresponding to and the columns with kπ = kh equal 4, 5 and 8 in Table 1. We note that the coefficient of income is roughly 330 with a standard error around 80, suggesting that 401(k) plans have more effect on the savings of families of higher income. For example, for kπ = kh = 4, the estimated effect of 401(k) participation for an eligible person with annual income $50000 who chooses to participate in the programme is to increase her family's net financial assets by $14910 whereas the increase for a person with an income of $100000 is $31310.
Unlike the slope coefficient, the intercept does not appear to be significantly different from 0; a 95% confidence interval for the intercept would include 0 as the point estimate is roughly half its standard error. For this reason, we henceforth focus attention on the behaviour of the remaining estimators of the income coefficient. Since the three doubly robust estimators , and with kπ = kh ⩾ 4 are all approximately equal to 330, we conclude that it is likely that the linear model for LATE(X4) is approximately correct. If it were not, the estimators , and would not be expected to exhibit similar values as they would have different probability limits because they use different functions q(V). Therefore, in what follows, we shall refer to an estimator of the slope coefficient as ‘unbiased’ if it is roughly equal to 330. Observe that, as predicted by theory, the doubly robust estimators that use q̂opt,1(V) are more efficient than the IPW or any of the other doubly robust estimators. (In fact, these doubly robust estimators are even more efficient than the estimator β̂reg; presumably this reflects the fact that the choice (16) that we recommended for ease of calculation is not optimal). A comparison of the IPW estimators with the estimator and of the outcome regression estimator with illustrates the advantage of doubly robust estimation over IPW and outcome regression estimation. These comparisons reveal that doubly robust estimators require only one of the two models to be nearly correct and the analyst does not need to know which one is correct. Note that whereas the IPW estimators are severely ‘biased’ if kπ is 1 or 2, the doubly robust estimator that uses the same model for the propensity score but a model with kh = 4 is roughly ‘unbiased’. Likewise, the outcome regression estimator that has kh equal to 1 or 2 is biased but the ‘bias’ is corrected by the estimator .
Turn now to estimation of β under a model m(X; β) for LATE(X) that assumes that m(X; β) = β. This model is presumably wrong because, as we have already seen from the previous analysis, income modifies the effect of treatment D among the compliers. Additional evidence for misspecification is presented in Fig. 1, which displays the values of three different doubly robust estimators β̂dr, denoted with
,
and
which used respectively q(X) = e1(X; δ̂)t1(X; ω̂), q(X) = ∂m(X; β)/∂β = 1 and q(X) = π(X, α̂) − π(X, α̂)2, where log [e1(X; δ)/{1 − e1(X; δ)}] and log{t1(X; ω)} were linear functions of family size, income, income2 and indicators of age and marital status. The estimators assumed model
kπ for the propensity score and an outcome regression model
that specifies that E{H1(β0)|Z, X} = k(x; ν) where k(x; ν) is the same function as defined earlier. (Recall that under the assumption that the model m(X; β) is correct, E{H1(β0)|Z, X} does not depend on Z). The plot displays the values of
,
and
as kh = kπ ≡ k varies from 1 to 8. Each estimator stabilizes for k ⩾ 3; however each stabilizes to a different value. This is as predicted by the theory of Section 3.4 according to which, when model m(X; β) is incorrect and model
kπ is correct, each estimator converges in probability to a distinct weighted least squares approximation β0,w with a weight that depends on the choice of function q(X). Specifically, when
kπ is correct and the model m(X; β) for LATE(X) is misspecified,
,
and
converge in probability to distinct values β0,wineff, β0,wineff,stable and β0,wopt where wineff(X) = 1, wineff,stable(X) = π(X, α0) − π(X,α0)2 and wopt(X) = e1(X; δ*)t1(X; ω*) with δ* and ω* the probability limits of δ̂ and ω̂.
Fig. 1.
Estimation of the marginal LATE based on incorrectly assuming that
The parameter β0,wineff is of particular interest as an easy calculation shows that β0,wineff is equal to the marginal LATE, i.e. to βnull ≡ LATE(V) when V = null. Thus, the estimator
converges to βnull when the model
kπ is correct. In fact, the IPW estimator
that uses the same q(X) as
and the same model
kπ also converges to βnull when model
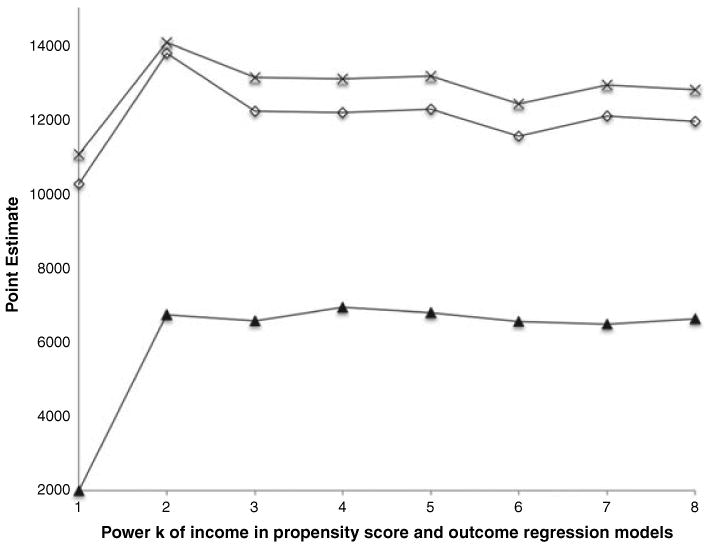
kπ is correct. This is so because β̂dr and β̂ipw have the same probability limits when they use the same correctly specified propensity score model regardless of whether or not the parametric specification for LATE(·) is correct. These theoretical results are confirmed in Fig. 2, which displays the estimators
and
computed under model
kπ and model
with kh = kπ = k. In addition, Fig. 2 displays the doubly robust estimator β̂null,dr of βnull, i.e. of the marginal LATE. This estimator is computed under model
kπ and a model
that assumes that E{H1(βnull)|Z, X} = k(X; ν) + ρT[φ(X) − E{φ(X)}]Z with k(x; ν) as defined earlier and φ(x) a vector function of indicators of the combined levels of age, marital status, family size (dichotomized at its mean) and powers of income up to power kh. Note that in Fig. 2
and
are both close to β̂null,dr for kπ ⩾ 4.
Fig. 2.
Doubly robust estimation of the marginal LATE versus estimation based on incorrectly assuming that
If model
kπ is wrong and m(X; β) = β is an incorrect specification for LATE(X) both
and
are inconsistent for β0,wineff = βnull. This occurs because, as discussed in Section 3.4,
is not doubly robust for β0,wineff under incorrect specification of the model for the LATE(·) curve. In contrast, β̂null,dr is double robust for βnull, i.e. it is consistent either if model
kπ is correct or if model
is correct. In fact, β̂null,dr is a member of the class of estimators β̂̂dr that were described in Section 3.4; it is algebraically equal to the estimator β̂̂dr that uses qw(V) = 1 with V = X. Recall that, unlike β̂dr, the estimator β̂̂dr that uses a given qw(V) is doubly robust for β0,w. Table 2 illustrates these points. The row that is labelled ‘Model
kπ’ lists estimators that were computed under model
kπ with kπ = 4. The row that is labelled ‘Model
wrong’ lists estimators that were computed under the model
wrong that incorrectly sets P(Z = 1|X) to be equal to the constant
. For estimators β̂null,dr and
, kh was chosen to be 4. All the estimators in the first row are approximately equal. However, a column-by-column comparison of the two rows reveals that of the three estimators only β̂null,dr remains approximately unchanged when it is computed under
wrong. This is as predicted by theory (provided that the model
with kh = 4 is approximately correct). To confirm that these findings were unlikely to be due to chance, we computed for each column the ratio
where Δ̂ is the difference between the first and second row, and
is the bootstrap standard error of Δ̂. Under the null hypothesis that the probability limits of the estimators in the two rows are the same, T should approximately have a standard normal distribution. For β̂null,dr, T̂ was 0.51 whereas, for
and
, T̂ was −1.91 and −3.14 respectively.
Table 2. Estimation of the marginal LATE effect.
| Model | Point estimators† | |||
|---|---|---|---|---|
|
| ||||
| β̂null,dr=β̂̂dr |
|
|
||
|
kπ=4
|
12213 | 12179 | 12434 | |
|
wrong
|
11859 | 13140 | 17651 | |
| Test statistic‡ | ||||
|
|
||||
| 0.51 | −1.91 | −3.14 | ||
β̂dr is the estimator of Section 3.4 that uses qw(V) =1.
Test statistic is the difference of the estimators in the first and second rows divided by the bootstrap standard error of the difference.
6. Conclusion
In this paper we introduced a new class of estimators for parametric forms for additive and multiplicative local average treatment effect curves as functions of covariates V, where V may be a subset of the covariates X required for the candidate instrument to be a valid IV Our estimators are doubly robust, i.e. they are consistent and asymptotically normal if either one of two dimension reducing models is correctly specified. Unlike other proposals, these dimension reducing models are always compatible with the assumed parametric functional form for the local average treatment effect on the additive scale if Y has unbounded support, and with the assumed parametric functional form for the effect on the multiplicative scale if Y has support in the positive real line and is unbounded. We discussed the connection between our model for the local average treatment effects and the Robins–Tan model for the effect of treatment on the treated, and we argued that the correspondence between the two models is unsurprising because the restrictions on the observed data law that is imposed by the two models differ only in inequality constraints, and because under an untestable assumption about the distribution of the counterfactual outcomes the two estimands are identified by the same functional of the observed data.
Future work is needed to explore the performance of our estimators for weak instruments in finite samples. Another potential topic for future work arises from the fact that, when Y is binary, the outcome regression model and the model for MLATE(·) are not variation independent. Thus, the model m2(·; β) could conflict with a proposed model for E(H2|Z, X). If the propensity score model is correctly specified the resulting estimator of β0 will still be consistent; however, this variation dependence implies that we may not have two independent opportunities for valid inference about β0. In forthcoming work, we reparameterize the model for MLATE when Y is binary to recover doubly robustness.
Supplementary Material
Acknowledgments
The authors are grateful to Alberto Abadie for his helpful comments on an earlier draft. Elizabeth Ogburn was supported by a training grant from the National Institutes of Health (5T32 AI 7358-22). Andrea Rotnitzky and James Robins were partially supported by grant R01-AI051164 from the National Institutes of Health.
Contributor Information
Elizabeth L. Ogburn, Johns Hopkins University, Baltimore, USA
Andrea Rotnitzky, Di Tella University, Buenos Aires, Argentina and Harvard University, Boston, USA.
James M. Robins, Harvard University, Boston, USA
References
- Abadie A. Bootstrap tests for distributional treatment effects in instrumental variable models. J Am Statist Ass. 2002;97:284–292. [Google Scholar]
- Abadie A. Semiparametric Instrumental Variable Estimation of Treatment Response Models. J Econometrics. 2003;113:213–263. [Google Scholar]
- Abadie A, Angrist JD, Imbens GW. Instrumental variables estimates of the effect of subsidized training on the quantiles of trainee earnings. Econometrica. 2002;70:91–117. [Google Scholar]
- Angrist JD, Graddy K, Imbens GW. The interpretation of instrumental variables estimators in simultaneous equations models with an application to the demand for fish. Rev Econ Stud. 2000;67:499–527. [Google Scholar]
- Angrist JD, Imbens GW. Average causal response with variable treatment intensity. J Am Statist Ass. 1995;90:431–442. [Google Scholar]
- Angrist JD, Imbens GW, Rubin DB. Identification of causal effects using instrumental Variables (with discussion) J Am Statist Ass. 1996;91:444–471. [Google Scholar]
- Cheng J, Qin J, Zhang B. Semiparametric estimation and inference for distributional and general treatment effects. J R Statist Soc B. 2009a;71:881–904. [Google Scholar]
- Cheng J, Small D, Tan Z, Ten Have T. Efficient nonparametric estimation of causal effects in randomized trials with noncompliance. Biometrika. 2009b;96:1–9. [Google Scholar]
- Clarke P, Windmeijer F. Identification of causal effects on binary outcomes using structural mean models. Biostatistics. 2010;11:756–770. doi: 10.1093/biostatistics/kxq024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Froelich M. Nonparametric IV estimation of local average treatment effects with covariates. J Econometrics. 2007;139:35–75. [Google Scholar]
- Gill RD. Non- and semi-parametric maximum likelihood estimators and the Von Mises method (Part 1) Scand J Statist. 1989;16:97–128. [Google Scholar]
- Heckman J. The common structure of statistical models of truncation, sample selection, and limited dependent variables, and a simple estimator for such models. Ann Econ Soc Measmnt. 1976;5:475–492. [Google Scholar]
- Hirano K, Imbens GW, Rubin DB, Zhou XH. Assessing the effect of an Influenza vaccine in an encouragement design. Biostatistics. 2000;1:69–88. doi: 10.1093/biostatistics/1.1.69. [DOI] [PubMed] [Google Scholar]
- Imbens GW, Angrist JD. Identification and estimation of local average treatment effects. Econometrica. 1994;62:467–475. [Google Scholar]
- Kasy M. Semiparametrically efficient estimation of conditional instrumental variables parameters. Int J Biostatist. 2009;5 Article 22. [Google Scholar]
- Little RJ, Yau LHY. Statistical techniques for analyzing data from prevention trials: treatment of no-shows using Rubin's causal model. Psychol Meth. 1998;3:147–159. [Google Scholar]
- Newey W. The asymptotic variance of semiparametric estimators. Econometrica. 1994;62:1349–1382. [Google Scholar]
- Poterba JM, Venti SF, Wise DA. 401(k) Plans and Tax-Deferred Savings. In: Wise D, editor. Studies in the Economics of Aging. Chicago: University of Chicago Press; 1994. pp. 105–138. [Google Scholar]
- Poterba JM, Venti SF, Wise DA. Do 401(k) Contributions Crowd Out Other Personal Saving? J Public Econ. 1995;58:1–32. [Google Scholar]
- Robins JM. Correcting for non-compliance in randomized trials using structural nested mean models. Communs Statist Theor Meth. 1994;23:2379–2412. [Google Scholar]
- Robins JM, Hernan MA. Instruments for causal inference: an epidemiologist's dream? Epidemiology. 2006;17:360–372. doi: 10.1097/01.ede.0000222409.00878.37. [DOI] [PubMed] [Google Scholar]
- Robins JM, Rotnitzky A. Recovery of Information and Adjustment for Dependent Censoring Using Surrogate Markers. In: Jewell N, Dietz K, Farewell V, editors. Aids Epidemiology: Methodological Issues. Boston: Birkhäuser; 1992. pp. 297–331. [Google Scholar]
- Stefanski LA, Boos DD. The Calculus of M-Estimation. Am Statistn. 2002;56:29–38. [Google Scholar]
- Tan Z. Regression and Weighting Methods for Causal Inference Using Instrumental Variables. J Am Statist Ass. 2006a;101:1607–1618. [Google Scholar]
- Tan Z. A Distributional approach for causal inference using propensity scores. J Am Statist Ass. 2006b;101:1619–1637. [Google Scholar]
- Tan Z. Marginal and Nested Structural Models Using Instrumental Variables. J Am Statist Ass. 2010;105:157–169. [Google Scholar]
- Uysal SD. Department of Economics, University of Konstanz, Konstanz; 2011. Doubly robust IV estimation of the local average treatment effects. Available from http://www.ihs.ac.at/vienna/resources/Economics/Papers/Uysal_paper.pdf. [Google Scholar]
- Vytlacil EJ. Independence, monotonicity, and latent index models: an equivalency result. Econometrica. 2002;70:331–341. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.