

Abstract
Purpose:
Colorectal cancer is an important cause of mortality in the developed world. Hereditary forms are due to germ-line mutations in APC, MUTYH, and the mismatch repair genes, but many cases present familial aggregation but an unknown inherited cause. The hypothesis of rare high-penetrance mutations in new genes is a likely explanation for the underlying predisposition in some of these familial cases.
Methods:
Exome sequencing was performed in 43 patients with colorectal cancer from 29 families with strong disease aggregation without mutations in known hereditary colorectal cancer genes. Data analysis selected only very rare variants (0–0.1%), producing a putative loss of function and located in genes with a role compatible with cancer. Variants in genes previously involved in hereditary colorectal cancer or nearby previous colorectal cancer genome-wide association study hits were also chosen.
Results:
Twenty-eight final candidate variants were selected and validated by Sanger sequencing. Correct family segregation and somatic studies were used to categorize the most interesting variants in CDKN1B, XRCC4, EPHX1, NFKBIZ, SMARCA4, and BARD1.
Conclusion:
We identified new potential colorectal cancer predisposition variants in genes that have a role in cancer predisposition and are involved in DNA repair and the cell cycle, which supports their putative involvement in germ-line predisposition to this neoplasm.
Keywords: colorectal neoplasm, genetic variant, genetic predisposition to disease, hereditary disease, next-generation sequencing
Introduction
Colorectal cancer (CRC) is a very common disease, and its associated mortality rate is quite significant in the developed world. It is estimated that around 5% of the general population will be diagnosed with CRC. Also, as life expectancy increases, the number of CRC cases is also presumed to increase. As an illustrative example, there will be ~473,200 new CRC diagnoses and ~233,900 deaths related to this neoplasm in Europe during 2015.1
Germ-line predisposition and environmental factors affect CRC susceptibility, as established for many other complex diseases. Importantly, the inherited germ-line contribution is known to influence about 35% of all cases.2 Included in this previous group, the Mendelian CRC syndromes are the best characterized CRC cases because an inherited cause corresponds to 5% of total CRC cases. Lynch syndrome and familial adenomatous polyposis are the most frequent forms of Mendelian CRC syndromes. Classic hereditary CRC syndromes are mainly due to germ-line mutations in APC, MUTYH, and the mismatch repair genes (i.e., MLH1, MSH2, MSH6, PMS2).3,4 Finding the causative mutation in familial CRC also has implications that apply to genetic counseling practices that are of critical importance for the analyzed family. Once it is established in a particular family which individuals are carriers and which are noncarriers, prevention strategies can be directed more precisely to those individuals carrying the causative mutation and who are therefore at risk of developing CRC and other related malignancies. On the other hand, noncarriers can be spared excessive clinical monitoring.
In addition to hereditary forms, around 30% of CRC cases also present familial aggregation but an unknown inherited cause. Among these cases, familial CRC type X can be used as an example in which the clinical criteria of Lynch syndrome are fulfilled but no alteration of the mismatch repair system is found.5 Then, the hypothesis of rare high-penetrance mutations in genes yet to be discovered is a very likely explanation for the underlying predisposition in a portion of these familial CRC cases. Therefore, past efforts in this direction included some low-throughput sequencing studies in familial CRC cases of some plausible candidate genes such as EPHB2, GALNT12, PTPRJ, BMP4, and BMPR1A.6,7,8,9,10 Next-generation sequencing technologies added a new unbiased approach to facilitate the identification of new genes responsible for predisposition to human disease. Palles et al.11 recently reported the identification of germ-line mutations in the POLE and POLD1 genes in individuals with multiple colorectal adenomas, carcinoma, or both, or early onset of this disease using whole-genome sequencing. Smith et al.12 recently performed exome sequencing in a cohort of patients with sporadic CRC enriched for early onset, and variants in genes showing biallelic inactivation were selected. In addition, exome sequencing was completed in CRC familial cases and shared variants were selected within families in an additional study.13 Finally, a Finnish cohort of familial CRC was also sequenced in order to find rare truncating variants present in two or more cases.14
Accordingly, the aim of our study was to find rare predisposition variants in new genes by performing exome sequencing in patients with familial CRC compatible with an autosomal dominant inheritance and without an alteration in the previously known hereditary CRC genes. In doing so, our final goal is to facilitate genetic counseling and to be able to correctly address prevention strategies in these families.
Materials and Methods
Patients
Forty-three CRC patients from 29 families with strong CRC aggregation compatible with an autosomal dominant pattern of inheritance were selected. Alterations in APC or the mismatch repair genes, and homozygous or compound heterozygous mutations in MUTYH were previously excluded. Families were chosen based on the following criteria: three or more relatives with CRC, two or more consecutive affected generations, and at least one case of CRC diagnosed before the age of 60. In two families, advanced adenomas (i.e., size ≥1 cm, villous architecture, or high-grade dysplasia) were taken into account as early disease presentation. In addition, other extracolonic cancers were considered in six families. Fourteen families were collected in high-risk CRC clinics (Hospital Clínico San Carlos in Madrid, Hospital Clinic in Barcelona, and Hospital Donostia in San Sebastián), and two patients with CRC were selected to be sequenced from among available affected individuals, preferentially those most distantly related. On the other hand, 15 families were chosen from the EPICOLON Consortium15 and one patient with CRC per family was selected to be sequenced. This study was approved by the institutional ethics committee of each participating hospital. Written informed consent was obtained at CRC diagnosis on a systematic basis.
Germ-line DNA samples used for exome sequencing were obtained from peripheral blood, whereas formalin-fixed, paraffin-embedded tumor DNA was isolated in some cases for loss of heterozygosity (LOH) studies using the QIAamp DNA Blood Kit or QIAamp Tissue Kit (Qiagen, Redwood City, CA) and following the manufacturer's instructions.
Exome sequencing
Quality control was applied to DNA samples (3–5 µg needed per reaction at a concentration of 50–300 ng/µl measured by PicoGreen, A260/280 = 1.7–2, integrity check by agarose electrophoresis). The whole exome was characterized by using the HiSeq2000 platform (Illumina, San Diego, CA) and SureSelectXT Human All Exon V4 for exon enrichment (Agilent, Santa Clara, CA). Initial DNA shearing was performed using the Covaris S2 equipment, achieving an optimal range in the size distribution of fragments. Library size and concentration were checked by capillary electrophoresis (Bioanalyzer 2100; Agilent). Adapters with different indexes for each sample were incorporated during enrichment, allowing samples to be multiplexed before sequencing. After enrichment, the indexed libraries were pooled and massively parallel sequenced using a paired-end 2 × 75–base pair (bp) read length protocol.
Data analysis
Base calling and quality control were performed using the Real-Time Analysis software sequence pipeline (Illumina). Sequence reads were trimmed to keep only those bases with a quality >10 and then mapped to the human genome build (hg19/GRCh37) using Genome Multitool,16 allowing up to four mismatches. Reads not mapped by Genome Multitool were submitted to a last round of mapping with BLAT-like Fast Accurate Search Tool.17 Uniquely mapping nonduplicate read pairs were locally realigned with Genome Analysis Toolkit.18 The SAMtools suite (http://samtools.sourceforge.net) was used to call single-nucleotide variants and short insertions/deletions, taking into account all reads per position.19 Variants with high strand bias (P > 0.001 in at least one sample) or regions with low mappability (identified with the Genome Multitool mappability tool as having 75-bp reads and two mismatches)16 were filtered out. Variant annotation took into account data available in dbSNP (http://www.ncbi.nlm.nih.gov/SNP/), the 1000 Genomes Project (http://www.1000genomes.org), the Exome Variant Server (http://evs.gs.washington.edu), and the Geuvadis European Exome Variants Server (http://geevs.crg.eu) and from an in-house database (100 whole genomes of Spanish ancestry from Centre Nacional d'Anàlisi Genòmica (http://www.cnag.cat)). Functional consequences of variants were also predicted by SnpEff (http://snpeff.sourceforge.net) (stop codon, frameshift, splicing, missense, synonymous), as well as by position (coding, intronic, exon–intron junction, untranslated regions). Regarding missense changes, six bioinformatic predictions for pathogenicity were available (PhyloP (http://compgen.bscb.cornell.edu/phast/help-pages/phyloP.txt), SIFT (Sorting Intolerant From Tolerant; http://sift.bii.a-star.edu.sg), PolyPhen (http://genetics.bwh.harvard.edu/pph2), MutationTaster (http://www.mutationtaster.org), GERP (Genomic Evolutionary Rate Profiling; http://mendel.stanford.edu/SidowLab/downloads/gerp), LRT (likelihood ratio test)).
Because a dominant inheritance pattern was expected, homozygous variants were removed, except for chromosome X nonpseudoautosomal regions in male samples. When analyzing two affected individuals from the same family, only shared variants were selected. Variants with low sequencing coverage (<10) and those with an allelic frequency ≥0.5% in the 1000 Genomes Project, Exome Variant Server, Geuvadis European Exome Variants Server, or the Centre Nacional d'Anàlisi Genòmica in-house database were filtered out. Variants present in >10 of the 43 individuals in our data set were discarded because they most likely corresponded to polymorphisms. Also, only variants predicted to have a strong effect on gene function (frameshift, splice-site canonical, nonsense, and missense) were chosen. Regarding missense variants, we used six bioinformatics tools to select for a deleterious amino acid change, namely, PhyloP (score >0.85), SIFT (score <0.05), PolyPhen (score >0.85), GERP (score >2), Mutation Taster (score >0.5), and LRT (score >0.9), and only those with four or more deleterious predictions were further considered.
Biological functions and pathways of the genes containing variants were annotated with terms and previous bibliography according to NCBI Gene (http://www.ncbi.nlm.nih.gov/gene), Gene Ontology (http://www.geneontology.org/GO), KEGG (http://www.genome.jp/kegg/), and Reactome (http://www.reactome.org/PathwayBrowser/). A list of cancer terms was created from these previous databases (Supplementary Table S1 online) and used to select variants from among genes that had those terms annotated. All previous filters were performed using an automated pipeline encoded with R software (http://CRAN.R-project.org). CRC specificity of this pipeline regarding function and bibliography was tested by comparing our data with an external germ-line exome sequencing data set with equivalent coverage, which included the same number of patients with chronic lymphocytic leukemia from the International Cancer Genome Consortium (https://www.icgc.org/). Also, variants present in both data sets were filtered out.
Once a variant list per sequenced CRC patient was generated, a thorough manual annotation using NCBI Gene corroborated variant genome position and annotated protein interactions. The amino acid position of missense variants in functional domains, disulfide bonds, or posttranslational modifications was verified, as well as their effect on protein tridimensional structure, when available, using NCBI Protein (http://www.ncbi.nlm.nih.gov/protein) and UniProtKB (http://www.uniprot.org/). Also, their conservation in 46 vertebrates was checked (comparative alignment UCSC (https://genome.ucsc.edu/)).
Variant prioritization
Once all previous information was available, variant prioritization selected those variants more plausible to be causative of CRC genetic predisposition when they fulfilled more stringent criteria (0–0.1% allelic frequency; present in ≤4 individuals in our data set; ≥5 missense pathogenicity predictions; gene terms and bibliography compatible with cancer; interesting interactions and protein information; and amino acid species conservation). It is noteworthy that variants in genes previously involved in hereditary CRC were carefully checked, as were those genes near previous CRC genome-wide association studies (GWAS) hits (Supplementary Table S2 online) with less strict criteria (missense considered deleterious by four or more bioinformatics tools). As previously specified, thresholds to select variants were applied for sequencing coverage, allelic frequency, presence in our data set, predictions by bioinformatics tools, presence in the functional and bibliography term list, and absence in the external exome set. On the other hand, there were no thresholds for some other additional variant/gene information that was used if available to further select for variants present within each family. This information included protein function and interactions; amino acid position in functional domains, disulfide bonds, or posttranslational modification sites; effect on protein tridimensional structure; and amino acid species conservation. Therefore, variants also complying with these last criteria were considered more interesting functionally and were further selected as final candidates. Some studied CRC families had up to four variants prioritized, whereas other families had none.
Variant validation, segregation analysis, and tumor loss of heterozygosis
Exome sequencing results for prioritized variants were validated using specific primers for polymerase chain reaction amplification designed using Primer3Plus (http://primer3plus.com/cgi-bin/dev/primer3plus.cgi) and Sanger sequencing (GATC Biotech, Cologne, Germany).
Segregation analysis of the prioritized variants was performed in additional family members (those with CRC and advanced adenoma) when germ-line DNA was available. When possible, somatic LOH was studied in tumor DNA of patients carrying the selected variants. LOH was tested by comparing Sanger sequencing results for germ-line and tumor DNA of the same individual. In addition, microsatellite markers within and around the gene of interest were used when LOH of the wild-type allele was suspected. Sanger and microsatellite markers results were always concordant. Primer details are listed in Supplementary Table S3 online.
Network analysis
Ingenuity Pathway Analysis (IPA; Qiagen; http://www.qiagen.com/ingenuity) was used to perform a core analysis to check the putative enrichment for canonical pathways, disease and biological functions, and molecular networks among the 18 final candidate genes carrying variants that either fulfilled CRC family segregation or could not be tested (variants without correct family segregation were not included). IPA was run with an experimentally observed filter, aiming to obtain information based on confirmed data. The IPA networks generation algorithm transformed the gene list into a network set using Global Molecular Network connections and Ingenuity Pathways Knowledge Base.
Results
Whole-exome sequencing was performed in 43 patients with CRC from 29 families (2 affected relatives from 14 families and 15 unrelated patients with CRC) with strong disease aggregation compatible with an autosomal dominant pattern of inheritance but without mutations in known hereditary CRC.
After sequencing, mean coverage was >95× in all samples. Raw data were analyzed using an automatic pipeline that selected only very rare variants (0–0.1%) producing a putative loss of function and located in genes with a role compatible with cancer. Also, variants in genes previously involved in hereditary CRC or nearby previous CRC GWAS hits were prioritized (Figure 1). Initial filtering removed variants in homozygosis, those with low coverage, those not shared in the same family, those with a frequency ≥0.5% and those present in ≥10 of the 43 individuals in our data set. On the other hand, frameshift, nonsense, canonical splice-site, and missense variants were selected (4,447 variants: 675 frameshift, splice-site canonical, or nonsense and 3,772 missense). When missense variants complying with most pathogenicity prediction tools (designated deleterious by at least 4 of 6 tools) were selected, 2,353 remained. Of these, 1,411 variants annotated with functional or bibliographical terms from our cancer list were selected.
Figure 1.

Schematic of the data analysis steps after whole-exome sequencing. Forty-three patients with colorectal cancer (CRC) from 29 families with strong CRC aggregation compatible with an autosomal dominant pattern of inheritance were sequenced. Variants remaining after each filtering step are indicated. GWAS, genome-wide association study.
CRC specificity of this pipeline regarding function and bibliography was tested by comparing our set with an external germ-line exome sequencing data set for a different disease. After applying frequency, heterozygosity, function, and bibliography filters, a t test was used to compare the mean number of frameshift, splice-site canonical, or nonsense variants per individual in the two exome data sets. In doing so, our pipeline selected more variants in our exome data set (meanCRC = 41.87; meanexternal = 34.05; P = 3.75 × 10−10), supporting the CRC specificity of our pipeline.
After checking the aforementioned pipeline specificity, we continued with variant filtering, and 1,353 variants that were not present in the external data set were further considered. At this stage, 10 variants in genes previously implicated in CRC predisposition and CRC GWAS hits that fulfilled previous criteria had been selected as final candidates. Stricter filtering was applied to prioritize variants in new genes, including allelic frequency 0–0.1%, presence in ≤4 of the 43 individuals in our data set, and compliance with most pathogenicity prediction tools for missense classification (designated deleterious by ≥5 tools), leaving 424 selected variants (125 frameshift, splice-site canonical, or nonsense and 299 missense), ranging from 6 to 36 variants per family. Filtering for the 10 variants in genes previously implicated in CRC predisposition and CRC GWAS hits was the same except for pathogenicity prediction tools for missense classification (designated deleterious by ≥4 tools). Finally, as previously specified, thresholds regarding sequencing coverage, allelic frequency, presence in our data set, prediction by bioinformatics tools, presence in functional and bibliography term lists, and absence from the external exome set were applied in order to select variants. On the other hand, there were no thresholds for some other additional variant/gene information that was used, if available, to further select for variants present within each family. This information included protein function and interactions; amino acid position in functional domains, disulfide bonds, or posttranslational modification sites; effect on protein tridimensional structure; and amino acid species conservation. Therefore, variants also complying with these last criteria were considered more interesting functionally and were further selected as final candidates. Some CRC families had up to four selected variants, whereas other families had none. The final 28 prioritized variants are shown in Table 1.
Table 1. Description of the final 28 prioritized variants, including gene category, frequency, and functional information.
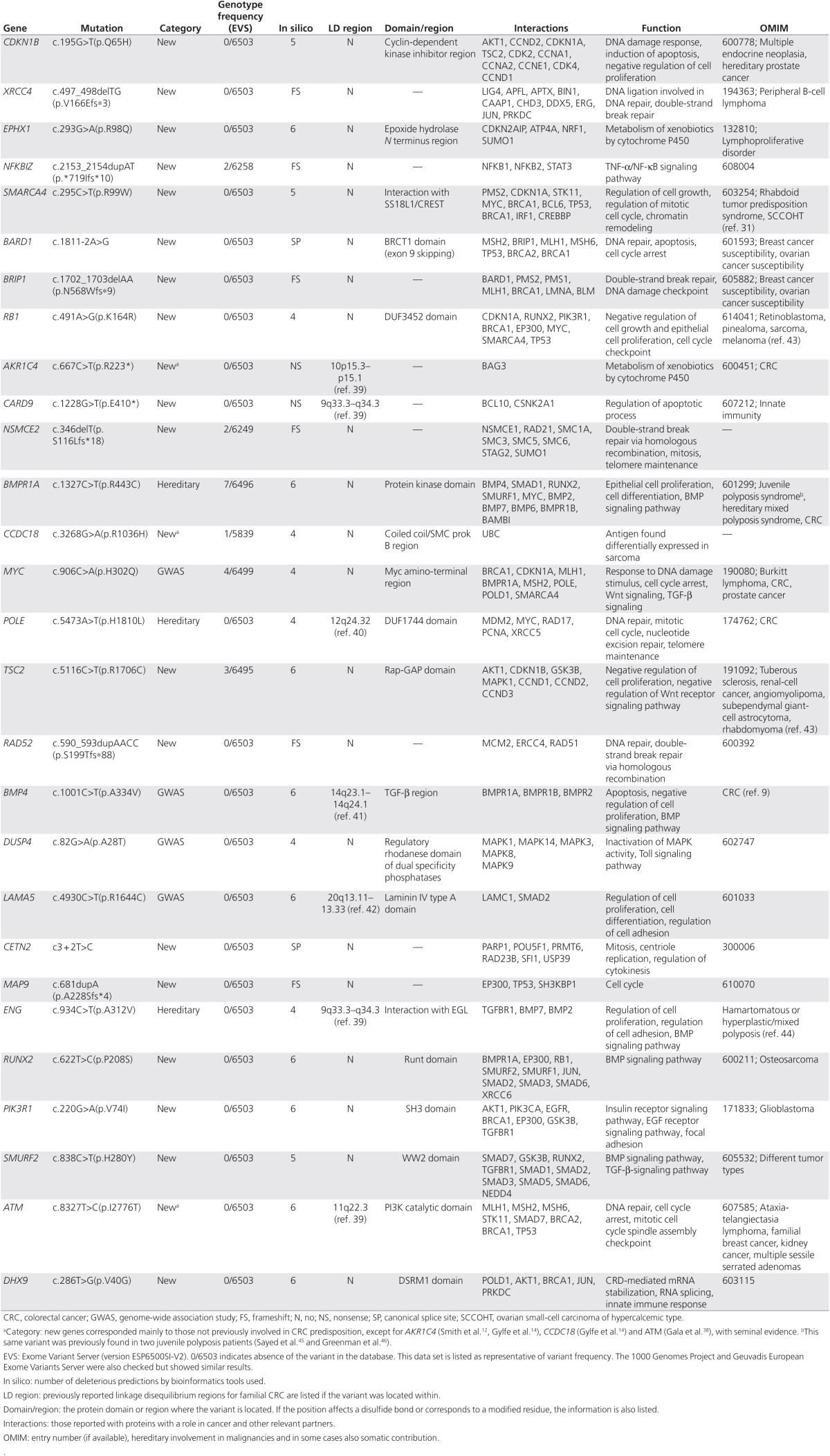
Candidate variants were subsequently validated by Sanger sequencing, and, if confirmed, segregation was studied in additional affected family members when available (Table 2). A variant in DHX9 was not confirmed (1 of 28 prioritized variants). LOH in tumor DNA was analyzed in variants with correct disease segregation when possible (Table 2; Supplementary Figure S1 online). Among the 28 prioritized variants, the best candidates for being involved in CRC genetic predisposition included those located in genes such as CDKN1B, XRCC4, EPHX1, NFKBIZ, SMARCA4, and BARD1 because they segregated correctly with disease presentation (Figure 2; the rest of families are shown in Supplementary Figure S2 online). Regarding variants in these genes, it is expected that three of them abolish protein function and the other three are missense changes with strongly deleterious in silico predictions. Family segregation and tumor LOH of the wild-type allele was positive for variants in CDKN1B, XRCC4, and EPHX1. Other interesting variants were found in BRIP1, RB1, AKR1C4, CARD9, NSMCE2, BMPR1A, CCDC18, MYC, POLE, and TSC2, although segregation analysis was not feasible. Nevertheless, tumor LOH of the wild-type allele was present for the BRIP1 and RB1 variants. It is noteworthy that variants in BMP4 and RAD52 showed correct family segregation for CRC, but they did not correlate with advanced adenoma presentation, although they can still be considered interesting candidates. As reported in the COSMIC database, somatic mutations in sporadic CRC were more common for the RB1, SMARCA4, and POLE genes (Table 2). Candidate variants within genes previously implicated in CRC predisposition and CRC GWAS hits included those located in AKR1C4, BMPR1A, CCDC18, MYC, POLE, BMP4, DUSP4 (present in two independent families), LAMA5, ENG, and ATM. The variant in the BMP4 gene segregated with CRC but not with advanced adenoma. DUSP4, LAMA5, ENG, and ATM variants did not segregate with disease, whereas disease segregation could not be tested for variants in AKR1C4, BMPR1A, CCDC18, MYC, and POLE. The POLE variant did not correspond to those previously reported and did not fall within the exonuclease or polymerase domains.11
Table 2. Results for the final 28 prioritized variants regarding Sanger validation, family segregation, and somatic status.
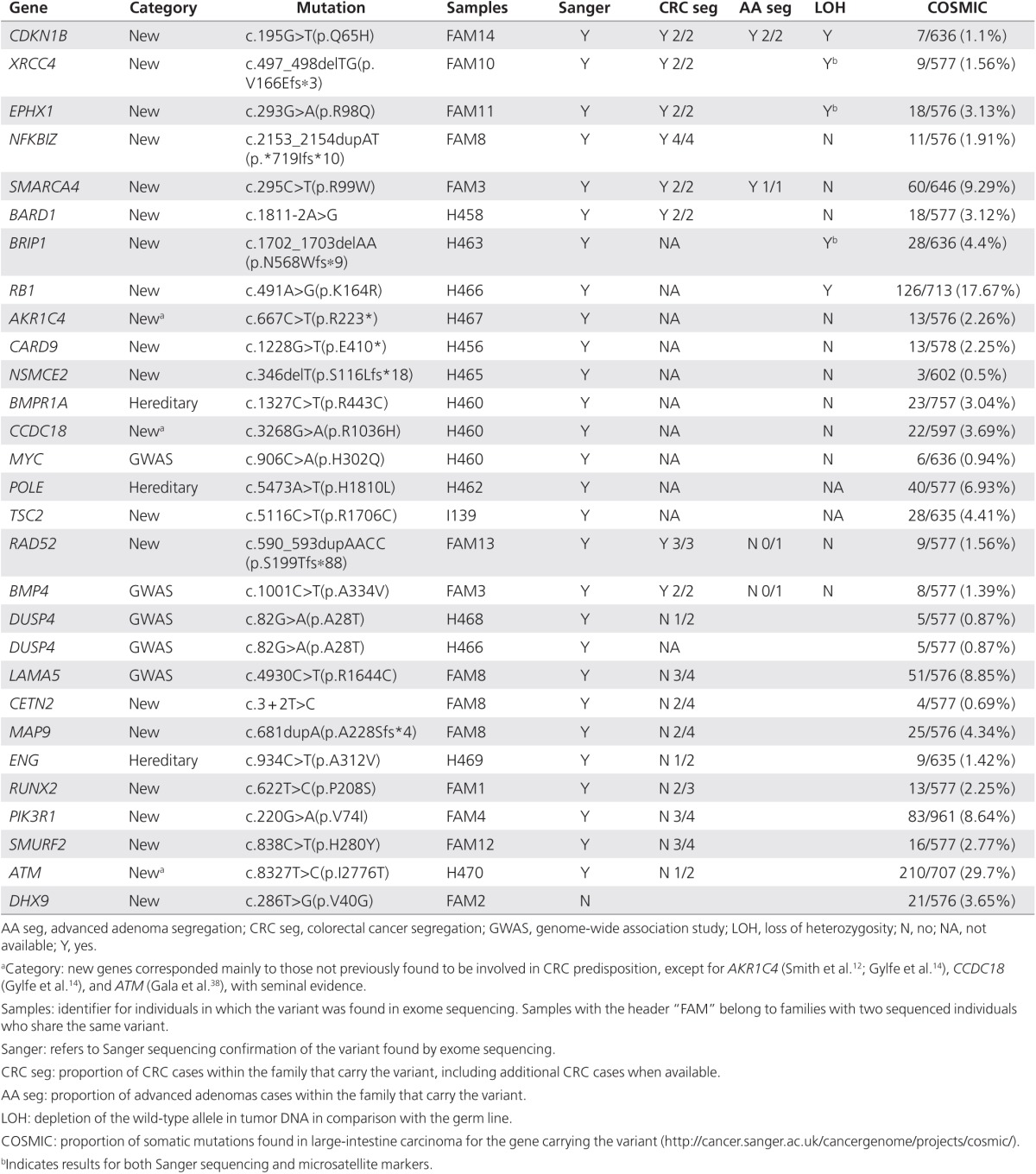
Figure 2.

Pedigrees from families FAM3, FAM8, FAM10, FAM11, FAM14, and H458 are shown. Filled symbols indicate those affected by colorectal cancer (upper right quarter), adenoma(s) (lower right quarter), stomach cancer (lower left quarter), or breast cancer (upper left quarter). Colon, breast, stomach, thyroid, lung, prostate, and nasopharynx refer to the type of cancer. (+), mutation carrier; (−), wild type. AA, advanced adenoma; ACV, cerebrovascular accident; Duode, duodenum carcinoma; non-AA, nonadvanced adenoma.
In addition, we performed IPA to test for a putative enrichment for canonical pathways, disease and biological functions, and molecular networks among the 18 final candidate genes carrying variants that either fulfilled CRC family segregation or for which segregation analysis was not possible. A relevant network that contains 9 of the 18 genes was obtained with an overrepresentation of the DNA Replication, Recombination and Repair, Cell Cycle, Connective Tissue Development and Function terms (Supplementary Figure S3a online). On the other hand, when testing for canonical pathways in our set, the “Role of BRCA1 in DNA damage response” network included some of our more interesting candidates, such as SMARCA4, BARD1, BRIP1, and RB1 (Supplementary Figure S3b online).
Discussion
Exome sequencing in 43 patients with CRC from 29 families with strong disease aggregation identified new potential CRC predisposition variants in CDKN1B, XRCC4, EPHX1, NFKBIZ, SMARCA4, and BARD1.
CDKN1B (p27, Kip1) binds to cyclin E/A-CDK2 and cyclin D-CDK4 complexes and hinders their activation. By doing so it exerts control on cell cycle progression.20 The c.195G>T (p.Q65H) mutation is located inside the cyclin-dependent kinase inhibitor region, particularly in the β-hairpin (residues 61–71), which interacts with CDK2.21 Therefore, this variant most likely affects the normal interaction between CDKN1B and CDK2, causing a deregulation in cell cycle progression. Interestingly, germ-line mutations in this gene have been previously implicated in multiple endocrine neoplasia.22 Moreover, a polymorphism in this gene has been significantly associated with hereditary prostate cancer.23
XRCC4 is involved in the repair of DNA double-strand breaks by nonhomologous end joining and the completion of V(D)J recombination events, along with DNA ligase IV and the DNA-dependent protein kinase.24 The c.497_498delTG (p.V166Efs*3) mutation is predicted to abolish protein function, and it is likely to contribute to genomic instability and tumorigenesis.
The EPHX1 enzyme converts epoxides produced by the degradation of aromatic compounds to trans-dihydrodiols, which afterward are conjugated and excreted from the body. Thus, EPHX1 can be considered an important biotransformation protein.25 The affected residue of the c.293G>A (p.R98Q) mutation is located in the epoxide hydrolase N-terminus region. Because EPHX1 alleles can have a differential efficiency in procarcinogen detoxification, it can be postulated that they may affect cancer risk in a specific manner.26
NFKBIZ is involved in inflammatory response through regulation of nuclear factor-κB transcription factor complexes.27,28 The c.2153_2154dupAT (p.*719Ifs*10) mutation disrupts a stop codon, producing an abnormally long C-terminal region. This could affect the interactions with nuclear factor-κB complexes that bind to that region, altering the transcriptional regulation of its target genes and leading to cancer predisposition.
The SMARCA4 protein is a component in the large SNF/SWI complex involved in chromatin remodeling. This complex is necessary to activate the transcription of genes that are usually repressed by chromatin.29 The c.295C>T (p.R99W) mutation is located in the region necessary for the interaction with SS18L1, which inhibits transcription of c-FOS and is required for dendritic growth and branching in cortical neurons. It can be hypothesized that this variant may cause predisposition to CRC by impairing this network and causing abnormal cell proliferation. Germ-line mutations in this gene can cause rhabdoid tumor predisposition syndrome type 230 and small-cell carcinoma of the ovary, hypercalcemic type.31
BARD1 interacts with the well-known BRCA1 protein. Both proteins, along with others, participate in several cellular pathways involved in DNA damage repair, ubiquitination, and transcriptional regulation to preserve genomic stability.32 The c.1811-2A>G mutation is predicted to cause exon 9 skipping, disrupting the BRCT1 domain, which is postulated to participate in ligand binding according its structure.33 This domain is highly homologous to the BRCA1 BRCT1 domain, which is considered to bind substrates of DNA damage response kinases such as ATM. Moreover, tumor-associated mutations in the BRCT domains of BRCA1 abolish binding to phosphorylated substrates.34 Thus, disruption of this BARD1 domain likely affects its capacity to interact with other proteins, abolishing its tumor suppressor function. Germ-line mutations in this gene predispose to breast and ovarian cancer,35 and its expression has been involved in differential CRC prognosis.36
Focusing on the best candidates to be involved in CRC genetic predisposition (CDKN1B, XRCC4, EPHX1, NFKBIZ, SMARCA4, and BARD1), it is remarkable that, as highlighted by the IPA analysis and previous studies, most of them have been formerly involved in DNA repair, cell cycle, and predisposition to germ-line cancer, which supports their putative involvement in genetic predisposition to CRC as well. Among them, mutated BARD1 and BRIP1 have been found in the germ-line DNA of breast cancer patients described in several reports.35,37 In addition, DNA repair constitutes a cellular mechanism with proven importance in the genetic predisposition for CRC.3
Among those variants within genes previously involved in CRC predisposition or located in CRC GWAS hits, it is remarkable that so far three independent studies, including ours, have identified interesting variants in the AKR1C4 gene.12,14
Taken together, we could conclude that our results highlight some interesting candidates for CRC germ-line predisposition, with an overrepresentation of genes involved in DNA repair and the cell cycle. We identified several putative new genes predisposing to CRC and some with previous involvement in cancer predisposition, including CDKN1B, XRCC4, EPHX1, NFKBIZ, SMARCA4, and BARD1, that deserve to be considered in additional familial CRC cohorts with an unknown hereditary cause. Furthermore, once their role in hereditary CRC is confirmed, more complex functional studies would be warranted to help understand the molecular mechanism of disease predisposition.
Disclosure
The authors declare no conflict of interest.
Acknowledgments
We are sincerely grateful to the Centre Nacional d'Anàlisi Genòmica and the Biobank of Hospital Clínic–IDIBAPS, Barcelona, for technical help, and the International Cancer Genome Consortium for access to exome data set. The work was carried out (in part) at the Esther Koplowitz Centre, Barcelona. CEJ and JM are supported by a contract from CIBERehd. MVC is supported by Ministerio de Educación, Cultura y Deporte (FPU12/05138). PG and SCB are supported by a contract from the Fondo de Investigación Sanitaria (JR13/00013 and CP 03-0070, respectively). CIBERehd and CIBERER are funded by the Instituto de Salud Carlos III. This work was supported by grants from the Fondo de Investigación Sanitaria/FEDER (10/00641, 11/00219, 11/00681, RD12/0036/006, 13/02588), the Ministerio de Economía y Competitividad (SAF2010-19273), Fundación Científica de la Asociación Española contra el Cáncer (GCB13131592CAST), COST Action BM1206 (SCB and CRP), Beca Grupo de Trabajo “Oncología” AEG (Asociación Española de Gastroenterología), and Agència de Gestió d'Ajuts Universitaris i de Recerca (Generalitat de Catalunya, 2014SGR255).
Supplementary Material
References
- Ferlay J, Shin HR, Bray F, Forman D, Mathers C, Parkin DM. Estimates of worldwide burden of cancer in 2008: GLOBOCAN 2008. Int J Cancer. 2010;127:2893–2917. doi: 10.1002/ijc.25516. [DOI] [PubMed] [Google Scholar]
- Lichtenstein P, Holm NV, Verkasalo PK, et al. Environmental and heritable factors in the causation of cancer–analyses of cohorts of twins from Sweden, Denmark, and Finland. N Engl J Med. 2000;343:78–85. doi: 10.1056/NEJM200007133430201. [DOI] [PubMed] [Google Scholar]
- Jasperson KW, Tuohy TM, Neklason DW, Burt RW. Hereditary and familial colon cancer. Gastroenterology. 2010;138:2044–2058. doi: 10.1053/j.gastro.2010.01.054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Castells A, Castellví-Bel S, Balaguer F. Concepts in familial colorectal cancer: where do we stand and what is the future. Gastroenterology. 2009;137:404–409. doi: 10.1053/j.gastro.2009.06.015. [DOI] [PubMed] [Google Scholar]
- Lindor NM, Rabe K, Petersen GM, et al. Lower cancer incidence in Amsterdam-I criteria families without mismatch repair deficiency: familial colorectal cancer type X. JAMA. 2005;293:1979–1985. doi: 10.1001/jama.293.16.1979. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zogopoulos G, Jorgensen C, Bacani J, et al. Germline EPHB2 receptor variants in familial colorectal cancer. PLoS One. 2008;3:e2885. doi: 10.1371/journal.pone.0002885. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Guda K, Moinova H, He J, et al. Inactivating germ-line and somatic mutations in polypeptide N-acetylgalactosaminyltransferase 12 in human colon cancers. Proc Natl Acad Sci USA. 2009;106:12921–12925. doi: 10.1073/pnas.0901454106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Venkatachalam R, Ligtenberg MJ, Hoogerbrugge N, et al. Germline epigenetic silencing of the tumor suppressor gene PTPRJ in early-onset familial colorectal cancer. Gastroenterology. 2010;139:2221–2224. doi: 10.1053/j.gastro.2010.08.063. [DOI] [PubMed] [Google Scholar]
- Lubbe SJ, Pittman AM, Matijssen C, et al. Evaluation of germline BMP4 mutation as a cause of colorectal cancer. Hum Mutat. 2011;32:E1928–E1938. doi: 10.1002/humu.21376. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nieminen TT, Abdel-Rahman WM, Ristimäki A, et al. BMPR1A mutations in hereditary nonpolyposis colorectal cancer without mismatch repair deficiency. Gastroenterology. 2011;141:e23–e26. doi: 10.1053/j.gastro.2011.03.063. [DOI] [PubMed] [Google Scholar]
- Palles C, Cazier JB, Howarth KM, et al. CORGI Consortium; WGS500 Consortium Germline mutations affecting the proofreading domains of POLE and POLD1 predispose to colorectal adenomas and carcinomas. Nat Genet. 2013;45:136–144. doi: 10.1038/ng.2503. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith CG, Naven M, Harris R, et al. Exome resequencing identifies potential tumor-suppressor genes that predispose to colorectal cancer. Hum Mutat. 2013;34:1026–1034. doi: 10.1002/humu.22333. [DOI] [PubMed] [Google Scholar]
- DeRycke MS, Gunawardena SR, Middha S, et al. Identification of novel variants in colorectal cancer families by high-throughput exome sequencing. Cancer Epidemiol Biomarkers Prev. 2013;22:1239–1251. doi: 10.1158/1055-9965.EPI-12-1226. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gylfe AE, Katainen R, Kondelin J, et al. Eleven candidate susceptibility genes for common familial colorectal cancer. PLoS Genet. 2013;9:e1003876. doi: 10.1371/journal.pgen.1003876. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Piñol V, Castells A, Andreu M, et al. Gastrointestinal Oncology Group of the Spanish Gastroenterological Association Accuracy of revised Bethesda guidelines, microsatellite instability, and immunohistochemistry for the identification of patients with hereditary nonpolyposis colorectal cancer. JAMA. 2005;293:1986–1994. doi: 10.1001/jama.293.16.1986. [DOI] [PubMed] [Google Scholar]
- Marco-Sola S, Sammeth M, Guigó R, Ribeca P. The GEM mapper: fast, accurate and versatile alignment by filtration. Nat Methods. 2012;9:1185–1188. doi: 10.1038/nmeth.2221. [DOI] [PubMed] [Google Scholar]
- Homer N, Merriman B, Nelson SF. BFAST: an alignment tool for large scale genome resequencing. PLoS One. 2009;4:e7767. doi: 10.1371/journal.pone.0007767. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McKenna A, Hanna M, Banks E, et al. The Genome Analysis Toolkit: a MapReduce framework for analyzing next-generation DNA sequencing data. Genome Res. 2010;20:1297–1303. doi: 10.1101/gr.107524.110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li H, Handsaker B, Wysoker A, et al. 1000 Genome Project Data Processing Subgroup The Sequence Alignment/Map format and SAMtools. Bioinformatics. 2009;25:2078–2079. doi: 10.1093/bioinformatics/btp352. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee J, Kim SS. The function of p27 KIP1 during tumor development. Exp Mol Med. 2009;41:765–771. doi: 10.3858/emm.2009.41.11.102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Russo AA, Jeffrey PD, Patten AK, Massagué J, Pavletich NP. Crystal structure of the p27Kip1 cyclin-dependent-kinase inhibitor bound to the cyclin A-Cdk2 complex. Nature. 1996;382:325–331. doi: 10.1038/382325a0. [DOI] [PubMed] [Google Scholar]
- Pellegata NS, Quintanilla-Martinez L, Siggelkow H, et al. Germ-line mutations in p27Kip1 cause a multiple endocrine neoplasia syndrome in rats and humans. Proc Natl Acad Sci USA. 2006;103:15558–15563. doi: 10.1073/pnas.0603877103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chang BL, Zheng SL, Isaacs SD, et al. A polymorphism in the CDKN1B gene is associated with increased risk of hereditary prostate cancer. Cancer Res. 2004;64:1997–1999. doi: 10.1158/0008-5472.can-03-2340. [DOI] [PubMed] [Google Scholar]
- Li Z, Otevrel T, Gao Y, et al. The XRCC4 gene encodes a novel protein involved in DNA double-strand break repair and V(D)J recombination. Cell. 1995;83:1079–1089. doi: 10.1016/0092-8674(95)90135-3. [DOI] [PubMed] [Google Scholar]
- Fretland AJ, Omiecinski CJ. Epoxide hydrolases: biochemistry and molecular biology. Chem Biol Interact. 2000;129:41–59. doi: 10.1016/s0009-2797(00)00197-6. [DOI] [PubMed] [Google Scholar]
- Liu F, Yuan D, Wei Y, et al. Systematic review and meta-analysis of the relationship between EPHX1 polymorphisms and colorectal cancer risk. PLoS One. 2012;7:e43821. doi: 10.1371/journal.pone.0043821. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Totzke G, Essmann F, Pohlmann S, Lindenblatt C, Jänicke RU, Schulze-Osthoff K. A novel member of the IkappaB family, human IkappaB-zeta, inhibits transactivation of p65 and its DNA binding. J Biol Chem. 2006;281:12645–12654. doi: 10.1074/jbc.M511956200. [DOI] [PubMed] [Google Scholar]
- Cowland JB, Muta T, Borregaard N. IL-1beta-specific up-regulation of neutrophil gelatinase-associated lipocalin is controlled by IkappaB-zeta. J Immunol. 2006;176:5559–5566. doi: 10.4049/jimmunol.176.9.5559. [DOI] [PubMed] [Google Scholar]
- Wilson BG, Roberts CW. SWI/SNF nucleosome remodellers and cancer. Nat Rev Cancer. 2011;11:481–492. doi: 10.1038/nrc3068. [DOI] [PubMed] [Google Scholar]
- Schneppenheim R, Frühwald MC, Gesk S, et al. Germline nonsense mutation and somatic inactivation of SMARCA4/BRG1 in a family with rhabdoid tumor predisposition syndrome. Am J Hum Genet. 2010;86:279–284. doi: 10.1016/j.ajhg.2010.01.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Witkowski L, Carrot-Zhang J, Albrecht S, et al. Germline and somatic SMARCA4 mutations characterize small cell carcinoma of the ovary, hypercalcemic type. Nat Genet. 2014;46:438–443. doi: 10.1038/ng.2931. [DOI] [PubMed] [Google Scholar]
- Irminger-Finger I, Jefford CE. Is there more to BARD1 than BRCA1. Nat Rev Cancer. 2006;6:382–391. doi: 10.1038/nrc1878. [DOI] [PubMed] [Google Scholar]
- Birrane G, Varma AK, Soni A, Ladias JA. Crystal structure of the BARD1 BRCT domains. Biochemistry. 2007;46:7706–7712. doi: 10.1021/bi700323t. [DOI] [PubMed] [Google Scholar]
- Manke IA, Lowery DM, Nguyen A, Yaffe MB. BRCT repeats as phosphopeptide-binding modules involved in protein targeting. Science. 2003;302:636–639. doi: 10.1126/science.1088877. [DOI] [PubMed] [Google Scholar]
- Ratajska M, Antoszewska E, Piskorz A, et al. Cancer predisposing BARD1 mutations in breast-ovarian cancer families. Breast Cancer Res Treat. 2012;131:89–97. doi: 10.1007/s10549-011-1403-8. [DOI] [PubMed] [Google Scholar]
- Sporn JC, Hothorn T, Jung B. BARD1 expression predicts outcome in colon cancer. Clin Cancer Res. 2011;17:5451–5462. doi: 10.1158/1078-0432.CCR-11-0263. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cantor SB, Bell DW, Ganesan S, et al. BACH1, a novel helicase-like protein, interacts directly with BRCA1 and contributes to its DNA repair function. Cell. 2001;105:149–160. doi: 10.1016/s0092-8674(01)00304-x. [DOI] [PubMed] [Google Scholar]
- Gala MK, Mizukami Y, Le LP, et al. Germline mutations in oncogene-induced senescence pathways are associated with multiple sessile serrated adenomas. Gastroenterology. 2014;146:520–529. doi: 10.1053/j.gastro.2013.10.045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Saunders IW, Ross J, Macrae F, et al. Evidence of linkage to chromosomes 10p15.3-p15.1, 14q24.3-q31.1 and 9q33.3-q34.3 in non-syndromic colorectal cancer families. Eur J Hum Genet. 2012;20:91–96. doi: 10.1038/ejhg.2011.149. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cicek MS, Cunningham JM, Fridley BL, et al. Colorectal cancer linkage on chromosomes 4q21, 8q13, 12q24, and 15q22. PLoS One. 2012;7:e38175. doi: 10.1371/journal.pone.0038175. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Djureinovic T, Skoglund J, Vandrovcova J, et al. A genome wide linkage analysis in Swedish families with hereditary non-familial adenomatous polyposis/non-hereditary non-polyposis colorectal cancer. Gut. 2006;55:362–366. doi: 10.1136/gut.2005.075333. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Laiho P, Hienonen T, Karhu A, et al. Genome-wide allelotyping of 104 Finnish colorectal cancers reveals an excess of allelic imbalance in chromosome 20q in familial cases. Oncogene. 2003;22:2206–2214. doi: 10.1038/sj.onc.1206294. [DOI] [PubMed] [Google Scholar]
- Rahman N. Realizing the promise of cancer predisposition genes. Nature. 2014;505:302–308. doi: 10.1038/nature12981. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ngeow J, Heald B, Rybicki LA, et al. Prevalence of germline PTEN, BMPR1A, SMAD4, STK11, and ENG mutations in patients with moderate-load colorectal polyps. Gastroenterol. 2013;144:1402–1409. doi: 10.1053/j.gastro.2013.02.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sayed MG, Ahmed AF, Anderson ME, et al. Germline SMAD4 or BMPR1A mutations and phenotype of juvenile polyposis. Ann Surg Oncol. 2002;9:901–906. doi: 10.1007/BF02557528. [DOI] [PubMed] [Google Scholar]
- Greenman C, Stephens P, Smith R, et al. Patterns of somatic mutation in human cancer genomes. Nature. 2007;446:153–158. doi: 10.1038/nature05610. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.