

Abstract
Infants and children have difficulty categorizing objects in new contexts. However, learning in both same and varied contexts can help young word learners overcome contextual learning difficulties. We examined the relation between infants' visual attention to the category member and background context during learning and their ability to generalize a new category member in a new context. Of particular interest is how this relation is affected by learning in various contextual conditions. Infants (16-20 months; n=48) were presented with eight novel noun categories in one of three contextual conditions (same context, varied context, or a combination of same and varied context), and tested for their generalization abilities in a new context. Context was defined as the colored and patterned fabric upon which the object was presented. Results suggest that visual attention during learning is associated with category generalization abilities in a new context only for infants whose learning took place in a combination of same and varied background contexts. The results are discussed in terms of the mechanisms by which context affects generalization.
Keywords: context, generalization, visual attention, word learning, aggregate, decontextualize
Children's category generalization is affected by surrounding contextual information (Vlach & Sandhofer, 2011). Past research suggests that young children have difficulty generalizing category labels in a new context when learning takes place in either all of the same background context, or all varied background contexts. However, when learning takes place in both same and varied contexts, young children's ability to generalize category labels in a new context increases (Goldenberg & Sandhofer, 2013). Despite previous research, it is unknown how visual attention supports category generalization in a new context, specifically when learning takes place in different contextual conditions. To understand the role of visual attention, the current study examined infants' visual attention to the category member and the background context during a category generalization task to further understand the mechanisms by which context affects generalization.
1.1 Learning in Context
Memory and generalization are affected by the context in which information is learned and tested. Specifically, recall is more accurate when the information in recalled in the same context in which it was learned (e.g., Borovsky & Rovee-Collier, 1990; Godden & Baddeley, 1975; Hartshorn et al., 1998; Hayne, Boniface, & Barr, 2000; Hayne, MacDonald, & Barr, 1997; Learmonth, Lamberth, & Rovee-Collier, 2004; Rovee-Collier & Dufault, 1991; Rovee-Collier, Griesler, & Earley, 1985; Smith 1982; Suss, Gaylord & Fagen, 2012). Context dependency has been robustly demonstrated across a wide range of contexts, tasks and ages (Amabile & Rovee-Collier, 1991; Smith, Glenberg, & Bjork, 1978)
Likewise, young word learners' ability to generalize category labels is context dependent. When 2- and 3-year-old children were presented with category members one at a time in a distinct context (a colored and patterned fabric square on which the object was placed) and subsequently tested for generalization of the category label to a new category exemplar, performance was enhanced when training and testing took place in the same context (i.e., the same fabric) relative to a condition in which training and testing took place in different contexts (i.e., a new fabric; Vlach & Sandhofer, 2011).
One possible reason children's word learning is context dependent is that the to-be-learned information was strongly associated with the context in which it was learned. For example, participants tested by Vlach and Sandhofer (2011) may have associated the object-label pair with the fabric. When generalization performance was tested on a new fabric, the novice word learners had difficulty generalizing the object label to the new category exemplar at test because the fabric they had associated with the object-label pair during learning was not present (Goldenberg & Sandhofer, 2013).
Consistent with the possibility that context dependency is due to a lack of decontextualizing the to-be-learned information from the context, context dependency can be overcome (in some cases) by learning in varied contexts (Jones, Pascalis, Eacott & Herbert, 2011; Smith, Glenberg & Bjork, 1987). When 3- and 4-year-olds were presented with category exemplars across multiple varied contexts, for example, they were able to generalize the category label to a new exemplar in a new context (Vlach and Sandhofer, 2011), perhaps because variability helps decontextualize the learning process, increasing the likelihood that information can be generalized to new settings (Amabile & Rovee-Collier, 1991; Rovee-Collier & Dufault, 1991). Varied contexts, therefore, may signal to the child that the to-be-learned information (object-label pair) is not associated with any specific context.
However, 2-year-olds' category generalization performance is context-dependent even when learning takes place in varied contexts. When 2-year-olds were presented with category exemplars on multiple varied fabrics and tested on a never before seen fabric, generalization was not different from chance levels (Goldenberg & Sandhofer, 2013; Vlach & Sandhofer, 2011). The support to decontextualize that aided 3- and 4-year-olds (learning across multiple varied contexts) was not sufficient to aid 2-year-olds when generalizing was tested in a new context. Goldenberg and Sandhofer (2013) suggest this difficulty is because when learning takes place in varied contexts, novice word learners have little support to aggregate the different instances in memory. Category learning requires the learner to aggregate similarities between the object-label instances. For example, to learn the category “spoon,” the learner must aggregate what is similar across all instances of spoons (i.e., shape; Gentner & Namy, 1999). When learning takes place in varied contexts, there is little support for a novice word learner to aggregate the category exemplar instances; there is a lack of aggregative cues.
Redundant correlated cues, such the category label and repetitive contexts, support aggregation of category exemplar features (Dueker & Needham, 2005; Smith & Yu, 2008; Thiessen & Saffran, 2003; Yoshida & Smith, 2005). The only aggregative cue provided when learning takes place in varied contexts is the label, which may not be sufficient for novice word learners (Goldenberg & Sandhofer, 2013). Repetitive contexts, however, do support category learning. When 2-year-old children learned object labels in one repetitive context (on top of one colored and patterned fabric), and tested for their generalization in the same context (on top of the same colored and patterned fabric as learning), they were able to successfully generalize (Vlach & Sandhofer, 2011).
Novice word learners, therefore, may need two distinct types of support when generalizing category labels in a new context in order to decontextualize the object label pair and to aggregate features common to the category exemplars presented during training. Support for decontextualization is provided by learning in varied contexts, signaling to the learner that object-label pairs are not to be associated with the context. Support for aggregation of the category exemplar features is provided by learning in the same repetitive context, which may highlight feature similarities. Goldenberg and Sandhofer (2013) found that 2-year-olds overcome context dependency when learning provided support to decontextualize (learning in varied context) and support to aggregate (learning in the same context). Yet decontextualization and aggregation will facilitate word learning only if infants attend to this information. Our goal in the present study was to examine how individual differences in visual attention to category members and contexts yield categorization under conditions that vary by context.
1.2 Visual Attention
Learning categories requires attention to the right aspects of the learning situation (Smith, Jones, Landau, Gershkoff-Stowe, Samuelson, 2002; Samuelson & Smith, 1998). Past research has focused on infants' attention to specific aspects of the object-label category, such as the object's features and syntactic properties. For example, when learning a new object-label category, young children are reliably able to focus on features by which the category is organized. That is, early in word learning, children focus on object shape when learning to categorize (Smith et al., 2002).
When learning object categories in context, learners are presented with two distinct visual stimuli: the object and the background context. Infants presented with an object on a background context were found to attend to both the object and the background. Haaf, Lundy and Coldren (1996) habituated 6-month-old infants to a stimulus presented on a colorful patterned background. The stimulus was presented on either the same background or varied backgrounds. Infants were slower to habituate when the background varied, suggesting that infants attended to both the background and the stimuli; longer looking times were interpreted as indicating attention to the changes in background across trials, which are presumably more interesting than a single background across trials.
However, little is known regarding how visual attention supports category generalization in various contextual conditions. It is unknown how visual attention to the object exemplar and the background context during learning affects infant's ability to generalize the category label to a new exemplar in a new context. Further, it is unknown whether various types of contextual support affect infants' attention to the object and context when learning new categories.
The current study investigated how visual attention during learning affects infants' ability to generalize a category label in a new context. Further, we examined how different types of contextual support during training affect visual attention during training and generalization performance. We presented infants with novel categories in contexts that provided support for decontextualization (i.e., varied contexts), for aggregation (i.e., the same context), or for both (i.e., both the same and varied contexts). Infants' category generalization abilities were then tested in a never before seen context. We examined three hypotheses. First, we hypothesized that infants would look more to the target object when presented with an object on a background context during the learning phase regardless of what type of contextual support they were provided. Second, we hypothesized that infants who were provided with support to decontextualize and aggregate during learning would have higher rates of looking to the target object during testing (when the label was presented) than infants who were only provided support to either decontextualize or aggregate. Lastly, we hypothesized that infants' visual attention to the target object during learning would facilitate category generalization, specifically for infants provided with support to decontextualize and aggregate.
Method
2.1 Participants
A total of 48 English monolingual infants, ages 16-20 months (25 males, Mage = 17.42 months, SDage= 1.46 months), were included in the final sample. Infants were randomly assigned to one of three conditions (n=16 per condition). Thirteen infants were excluded due to fussiness (n=6), technical/experimenter error (n=2), poor calibration (n=4), or outlier status (n=1; this infants' data were more than two standard deviations away from the mean on all analyzed eye tracking measurements). All infants were recruited from a university child-database and given a t-shirt for their participation.
2.2 Design
Infants were presented with eight novel noun generalization categories on a video screen, each of which consisted of a training phase and testing phase. During the training phase, infants were presented with five exemplars of the novel category and one novel label (e.g., “wug”). During the test phase, infants were presented with a sixth exemplar of the novel category, a never before seen distractor object, and the novel category label (e.g., “wug”). All six category exemplars were shape-matches, but differed in color and texture.
This study used one between-subjects variable, which was contextual condition. All three contextual conditions differed in the training phase, but were identical in the testing phase (Figure 1). Context was defined as the color and pattern of the background the novel objects were presented on while they were labeled. In the same context condition, all five category-exemplars were presented on the same colored and pattern background (i.e., context A). In the varied context condition, the five category exemplars were presented on different colored and patterned backgrounds (i.e., context A, context B, context C, context D, context E). In the interleaved context condition, the first, third, and fifth target exemplars were presented on the same colored and patterned background, and the second and fourth exemplars were presented on different colored and patterned backgrounds (i.e., context A, context B, context A, context C, context A). In all conditions the testing phase was presentd on a never-before-seen colored and patterned background.
Figure 1.

Example stimuli presented on background contexts. Each row depicts one category. All objects and contexts were randomized between and within participants.
2.3 Apparatus and stimuli
Novel objects were constructed out of arts and crafts supplies, photographed and presented on the video screen. Each category consisted of six category exemplars (five presented in the training phase and one presented in the testing phase) and a distractor object (presented in the testing phase). To equate for the size of all of the objects, each object occupied between 12% and 20% of the screen. Large (21×26 inch) pieces of colorful patterned fabric were photographed and presented on the video screen to serve as the background “context”. Object labels that followed the phonotactic probabilities of English (e.g., dax, wug, toma, blicket, fop, gipple, modi and riff), but were not English words, served as object labels (see: Berko, 1958). All object label recordings were one second in duration and recorded using a female voice. All objects, object-label pairs, and fabrics were randomized and counterbalanced within and between participants in order to ensure that performance differences were not due to particular fabric patterns or object shapes.
All of the objects were positioned on top of the fabric and presented on a Viewsonic vx2268wm 22-inch monitor and the labels were presented through the monitor's speakers. Eye tracking data were collected using an SR Research Eyelink 1000. The eye-tracking system recorded infants' point-of-gaze in terms of x and y coordinates (spatial resolution within <1.0 degree of visual angle) at a rate of 500 Hz. The areas of interest (AOI) for the target and distractor objects were defined as the area inside the object's border. The AOI for the background context was defined as the area inside of the background's border that was not occluded an object.
2.4 Procedure
Before the experiment began, the infant was seated on the parents lap 60 cm from the monitor. The experimenter asked the caregiver to not comment on anything presented on the screen or instruct the infant in any way. Once the infant and parent were seated, the experimenter dimmed the lights and began the calibration procedure. To attract the infant's attention and calibrate the infant's point of gaze, retracting circular stimuli, with sound, were presented in five different locations on the screen (bottom left, bottom right, top left, top right, and the center). Following calibration the infant was shown an “attention getter” (small moving toy with sound in the center of screen) to regain their attention. After the initial attention getter, the infant was presented with the eight novel noun categories, each consisting of training and testing phases. For each category the testing phase immediately followed the training phase. In between each category, an attention getter was presented to retain the infant's attention.
2.4.1 Training phase
During each of the eight category training phases the infant was presented with five successive trials. In each trial a category exemplar was presented on a colored patterned background for three seconds. For the first second there was no audio; during the middle second, the target label was played (e.g., “toma”); and for the third second there was no audio.
2.4.2 Testing phase
During each of the eight category testing phases the infant was presented with two successive trials. In each trial a category exemplar and a distractor object were presented (side by side) on a colored and patterned background for nine seconds. During the first three seconds no audio was played; during the fourth second the target label was played for one second (e.g., “toma”); during the fifth and sixth seconds no audio was played; during the seventh second the target label was played for one second (e.g., “toma”); during the eight and ninth seconds no audio was played. The two testing trials only differed in the side of the screen each object was presented. The position was counterbalanced between the two presentations.
Results
We first asked whether there were differences between the three contextual conditions in infants' proportion looking to the target object or background context during the training phase. Infants' proportion looking to target during training was defined as looking to the target divided by looking to both the target and background, averaged across all training trials. Infants' proportion looking to background during training was defined as looking to the target divided by looking to both the background and target, averaged across all training trials. A 2(AOI) × 3 (Condition) mixed ANOVA revealed a significant main effect of AOI across conditions, F(1,45)=154.79, p<.001. Infants looked significantly longer to the target object (M=.72, SD=.14) than the background context (M=.33, SD=.14) during the training trials. No main effect of condition or interaction between condition and AOI were revealed (ps>.05).
Second, we asked whether there were differences between the three contextual conditions in infants' proportion looking to the target object, distractor object or background context during the testing phase. All analyses for the testing phase were split into two time frames, 1) before the onset of the first label and 2) after the onset of the first label. All measures were averaged across all testing trials. For the first time frame, proportion looking to target during testing- before onset of label, was defined as looking to the target divided by total looking (target, distractor, and background combined) before the onset of the first label. Proportion looking to distractor during testing- before onset of label and Proportion looking to background during testing- before onset of label were defined as looking to the distractor and background, respectively, divided by total looking, before the onset of the first label. A 3(AOI) × 3 (Condition) mixed ANOVA revealed a significant main effect of AOI, F(2,90)=55.41, p<.001. Repeated measures t-tests with a Bonferroni correction to maintain an alpha of .05 revealed that infants looked significantly longer to the target object (M=.37, SD=.07) than the background context (M=.22, SD=.08), t(47)=7.09, p=<.001 and significantly longer to the distractor object (M=.48, SD=.06) than the background context, t(47)=10.31, p=<.001. There was no significant difference between infants' looking to the target and distractor objects (p>.016). No main effect of condition or interaction between condition and AOI were revealed (ps>.05).
The second time frame within the testing phase was the 6 s after the onset of the first label. The proportion looking to target during testing- after onset of label was defined as looking to the target divided by total looking, after the onset of the first label. Proportion looking to distractor or background during testing- after onset of label were defined in similar fashion. A 3(AOI) × 3 (Condition) mixed ANOVA revealed a significant main effect of AOI across conditions, F(2.20)=16.29, p<.001. Infants looked significantly longer to the target object (M=.39, SD=.08) than the distractor object (M=.26, SD=.11), t(47)=5.20, p=<.001. Further, infants looked significantly longer to background context (M=.35, SD= .09) than to the distractor object, t(47)=3.41, p<.001. There was no significant difference between infant's looking to the target object and background context across conditions after the onset of the first label (p>.016). No main effect of condition or interaction between condition and AOI were revealed (ps>.05).
Lastly and most importantly, we asked whether looking to the target during training predicted looking to the target during testing, and whether this association differed based on condition. We regressed proportion looking to the target during testing on proportion looking to the target during training, condition (interleaved, same, or varied) and their interaction. We conducted separate analyses for the two testing measurements: before the onset of the first label and after the onset of the first label. For all regression analyses, the same and varied conditions were combined because past research suggests the interleaved condition provides a qualitatively different type of support to infants learning new categories (Goldenberg & Sandhofer, 2013).
For the 3 s of the testing phase before the first label was presented we hypothesized that there would be no association between looking to the targeting during training and testing. Analysis revealed that neither of the main effects (looking to the target during training or condition) nor the interaction were significant predictors of looking to the target during testing (|ßs| < 0.173, ps > .350). This suggests that looking to the target during training did not predict looking to target during testing before the first label was presented. This was expected because this is the portion of the testing phase during which no label was presented.
For the 6 s after the first label was presented, we hypothesized that increased looking to the target during training would be associated with increased looking to the target during testing. This hypothesis was supported: Looking to the target during training was a significant predictor of looking to the target during testing (ß = .31, t[44] =2.2, p = .033). Infants who looked more to the target during training tended to look more to the target during testing when the label was presented. Importantly, because this study focused on differences between contextual support during training, the interaction between condition and proportion looking to the target during training was tested. The interaction between condition and proportion looking to the target during training was a significant predictor of proportion looking to target during testing after the label was presented (ß = -.38, t[14] = 2.4, p = .021; Figure 2). Tests of simple effects revealed that proportion looking to the target was a significant predictor of proportion looking to the target during testing for infants in the interleaved condition (ß = .76, t[30] = .76, p = .001), but not for infants in the same and interleaved conditions combined (ß = .09, t[30] = .52, p = .610). These results suggest that when provided with both types of contextual support (interleaved condition), greater looking to the target during training leads to greater looking to the target during testing when the target label is presented.
Figure 2.
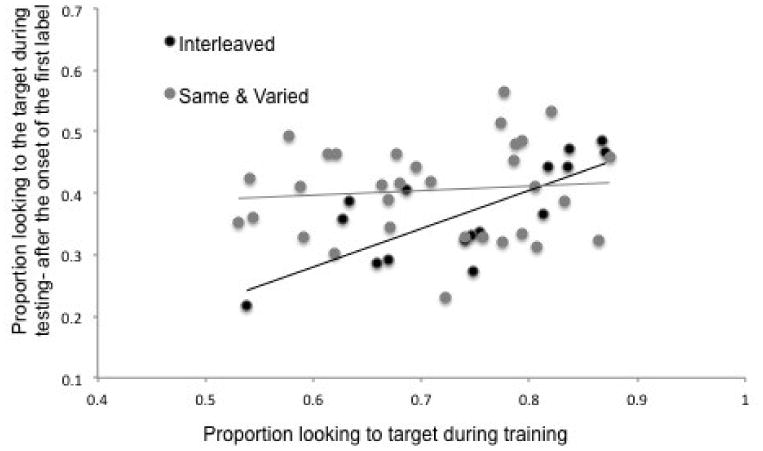
Regression of proportion looking to target during training on proportion looking to target during testing, after the onset of the first label. Proportion looking to target during training significantly predicts proportion looking to target during testing after the first label is presented for infants in the interleaved condition, but not for infants in the same and varied conditions.
Discussion
Our principal question was whether infant's visual attention during object category learning predicted category generalization performance in a new context. During training infants were provided with support to 1) decontextualize, 2) aggregate or 3) decontextualize and aggregate. Based on past research, we hypothesized that support for both decontextualization and aggregation would be the most supportive contextual condition to infants' category generalization performance in a new context. Specifically, we hypothesized that looking to the target during learning would predict looking to the target during testing for infants who were provided with support to decontextualize and aggregate. To test this hypothesis, we examined the relation between looking to the target object during training and looking to the target object during testing, and we investigated the possibility that the relation between looking to the target during training and testing was influenced by the contextual condition (same, varied or interleaved) infants experienced during training.
For infants who were provided support to decontextualize and aggregate (i.e., training that took place in the interleaved context), visual attention during object training predicted category generalization. Category generalization was defined as looking to the labeled object during the testing phase while the label was presented. Past research suggests that when presented with a label, and two objects (a match to the label and a mismatch), infants look more to the object that matched the label (Fernald, Pinto, Swingley, Weinberg, McRoberts, 1998; Golinkoff, Hirsh-Pasek, Cauley, & Gordon, 1987). Infants' visual attention to the correctly labeled object is a reliable measure of their ability to match the label to the object. Thus, in the current study, looking to the target when the label was presented during the testing phase was a measure of infants' ability to generalize the category label to the never before seen category exemplar.
Interestingly, the relation between looking to the target during the training phase and the testing phase (when the label was presented) only emerged for the infants in the interleaved condition, and not for infants in the same or varied conditions. This suggests that only when provided with support to 1) decontextualize the target object from the background (provided by training in varied context) and 2) aggregate the category instances (provided by training in same repeated context) does visual attention to the target object during training predict category generalization in a new context. Further, because proportion looking to target during training and proportion looking to the background context during training are inverse measures, our results suggest that more attention to the background context during training predicts less attention to the target during testing for infants in the interleaved condition.
The interleaved condition provided infants with support to both decontextualize the object from the background and aggregate the multiple category exemplars. Because this association was not found in the same or varied condition, which provided infants with either support to de-contextualize or support to aggregate, we conclude that only when infants have both types of support is looking to target during training beneficial to category generalization. The support to de-contextualize the object from the background or the support to aggregate category instances is not enough in isolation.
Further, only in the interleaved condition did the infants who looked more at the object during training look more to the object during testing. In other words, the infants who had a high amount of looking to the target object during training were more likely to generalize the object label (evidenced by looking to the target object when the label was presented). This result suggests that the infants who had more overall looking to the target during training were able to benefit from the superior support of the interleaved condition. These results are consistent with previous research suggesting that 2-year-old children's generalization performance is higher in a new context when learning takes in interleaved context, than the same or varied contexts (Goldenberg & Sandhofer, 2013).
As a control, we measured infants looking before the label was presented during the testing phase. We found no relation between looking to the target during training and looking to the target during testing phase (before the label was presented) for any condition. In other words when both the target object and distractor object were presented, without a label, looking to the target during learning did not predict looking to the target during testing. We used this interval as a control to rule out any relation between looking to the target during training and testing that was not due to category generalization. If a relation were found during this interval, it would suggest that looking to the target during training predicts looking to the target during testing regardless of if the label is presented. Because no relation was found during the interval where no label was presented, we suggest that the relation found between looking during the training and testing phases when the label was presented is due a true relation between looking to the target during training and infants generalization of the category label.
A second question we asked was how infants would allocate their visual attention when presented with a target object on a background context as a novel label was heard during learning. Consistent with our prediction, infants spent more time looking to the target object than the background context. However, infants did look at the background object as well (about 30% of the time). This finding is consistent with results reported by Haaf, Lundy and Coldren (1996), who suggested infants as young as 6 months old look to the background an object is presented on. Interestingly, there was no difference between contextual conditions in infants' attention to the target object or background object during training. These results suggest that no matter what type of contextual support is provided (aggregation, decontextualization or both), infants successfully attend to the labeled object during the training phase. Lastly, we examined differences between conditions in visual attention during the testing phase. We found no significant differences between conditions in looking to any of the aspects on the screen (background context, target object, distractor object) during the first 3 s. Thus, before the label was presented there was no effect of condition on looking during testing. Interestingly, across conditions, infants did not look longer to the distractor or target object, suggesting neither a novelty nor familiarity preference. Rather, infants scanned both objects before the label was presented during the testing phase.
The second testing time frame we examined during the testing phase was the 6 s after the onset of the first label. As in the first 3 s of the testing trial, there were no differences between conditions in looking to any of the AOIs. Thus, we conclude that the training condition did not systematically influence infants' overall looking during testing, although we had predicted that infants in the interleaved condition would look longer to the target object during testing (after then label was presented) than infants in the same or varied conditions. Previous studies suggested, in contrast to our results, that generalization in a new context is more successful when learning takes place in interleaved contexts than in either the same context or varied contexts (Goldenberg & Sandhofer, 2013). One possible reason for the difference in results between these studies may be the ages of participants in the two studies (16-20 months in the current study vs. 20- to 28-month-old participants in the Goldenberg & Sandhofer, [2013] study). Vlach and Sandhofer (2011) suggested that older children are more likely to generalize in a new context when training takes place in either the same or varied context, and Hartshorn et al. (1988) suggested that memory is more contextually bound earlier in life. It is possible that the children in the current study had difficulty separating the object and context due to their younger age. This difficulty segregating the object for the background could have led to the lack of overall differences in looking to the target during training or testing between the three conditions. Another possible reason for the difference in the results may be attributed to the methodological differences in the two studies. The infants in the current study were not able to pick up the object and physically separate it from the background, but they were in the Goldenberg and Sandhofer (2013) study. Perhaps, such action experience facilitates independence from context under these conditions
The current study aimed to understand the relation between visual attention and category generalization in context. Infants were provided with three types of contextual support. Past research suggests that support to decontextualize and aggregate during learning enhances generalization performance in a new context. By examining infants' visual attention during training and testing, we suggest that when provided with both types of support, infants' looking to the object during training leads to greater generalization performance. Taken together, the results of this study suggest that visual attention supports generalization in a new context, when provided with support to aggregate and decontextualize during learning.
Highlights.
We tested infants' category generalization in a new context.
Training was presented in one of three contextual conditions.
When training was in both same and varied context, visual attention predicted categorization.
When training was in either same or varied contexts, visual attention did not predict categorization.
Acknowledgments
This research was supported by NIH Grants R01-HD73535. We thank Bryan Nguyen for his invaluable technical support. We also thank all of the families who participated and the research assistants and graduate students in the UCLA Baby Lab for their help on this project.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Amabile TA, Rovee-Collier C. Contextual variation and memory retrieval at six months. Child Development. 1991;62:1155–66. doi: 10.1111/j.1467-8624.1991.tb01596.x. [DOI] [PubMed] [Google Scholar]
- Berko J. The child's learning of English morphology. Word. 1958;14:150–177. [Google Scholar]
- Borovsky D, Rovee-Collier C. Contextual constraints on memory retrieval at 6 months. Child Development. 1990;61:558–594. doi: 10.1111/j.1467-8624.1990.tb02884.x. [DOI] [PubMed] [Google Scholar]
- Dueker G, Needham A. Infants' object category formation and use: Real world context effects on category use in object processing. Visual Cognition. 2005;12:1177–1198. doi: 10.1080/13506280444000706. [DOI] [Google Scholar]
- Fernald A, Pinto JP, Swingley D, Weinberg A, McRoberts GW. Rapid gains in speed of verbal processing by infants in the 2nd year. Psychological Science. 1998;9:228–231. doi: 10.1111/1467-9280.00044. [DOI] [Google Scholar]
- Gentner D, Namy L. Comparison and the development of categories. Cognitive Development. 1999;14:487–513. doi: 10.1016/S0885-2014(99)00016-7. [DOI] [Google Scholar]
- Godden DR, Baddeley AD. Context-dependent memory in two natural environments: On land and underwater. British Journal of Psychology. 1975;66:325–331. doi:10.1111/j. 2044-8295.1975. tb01468. X. [Google Scholar]
- Goldenberg ER, Sandhofer CM. Same, varied, or both? Contextual support aids young children in generalizing category labels. Journal of Experimental Child Psychology. 2013;115:150–162. doi: 10.1016/j.jecp.2012.11.011. [DOI] [PubMed] [Google Scholar]
- Hartshorn K, Rovee-Collier C, Gerhardstein PC, Bhatt RS, Klein PJ, Aaron F, et al. Wurtzel N. Developmental changes in the specificity of memory over the first year of life. Developmental Psychobiology. 1998;33:61–78. doi: 10.1002/(SICI)1098-2302(199807)33:1<61∷AID-DEV6>3.0.CO;2-Q. [DOI] [PubMed] [Google Scholar]
- Haaf RA, Lundy BL, Coldren JT. Attention, recognition, and the effects of stimulus context in 6-month-old infants. Infant Behavior and Development. 1996;19:93–106. doi: 10.1016/S0163-6383(96)90047-8. [DOI] [Google Scholar]
- Hayne H, Boniface J, Barr R. The Development of declarative memory in human infants: Age related changes in deferred imitation. Behavioral Neuroscience. 2000;114:77–83. doi: 10.1037//0735-7044.114.1.77. [DOI] [PubMed] [Google Scholar]
- Hayne H, MacDonald S, Barr R. Developmental changes in the specificity of memory over the second year of life. Infant Behavior and Development. 1997;20:233–245. doi: 10.1016/S0163-6383(97)90025-4. [DOI] [Google Scholar]
- Golinkoff RM, Hirsh-Pasek K, Cauley KM, Gordon L. The eyes have it: Lexical and syntactic comprehension in a new paradigm. Journal of Child Language. 1987;14:23–45. doi: 10.1017/S030500090001271X. [DOI] [PubMed] [Google Scholar]
- Jones EJ, Pascalis O, Eacott MJ, Herbert JS. Visual recognition memory across contexts. Developmental Science. 2011;14:136–147. doi: 10.1111/j.1467-7687.2010.00964.x. [DOI] [PubMed] [Google Scholar]
- Learmonth AE, Lamberth R, Rovee-Collier C. Generalization of deferred imitation during the first year of life. Journal of Experimental Child Psychology. 2004;88:297–318. doi: 10.1016/j.jecp.2004.04.004. [DOI] [PubMed] [Google Scholar]
- Rovee-Collier C, Dufault D. Multiple Contexts and Memory Retrieval at Three Months. Developmental Psychobiology. 1991;24:39–49. doi: 10.1002/dev.420240104. [DOI] [PubMed] [Google Scholar]
- Rovee-Collier C, Griesler PC, Early LA. Contextual Determinants of Retrieval in Three-Month-Old Infants. Learning and Motivation. 1985;16:139–157. doi: 10.1016/0023-9690(85)90009-8. [DOI] [Google Scholar]
- Samuelson LK, Smith LB. Memory and attention make smart word learning: An alternative account of Akhtar, Carpenter, and Tomasello. Child Development. 1998;69:94–104. doi: 10.1111/j.1467-8624.1998.tb06136.x. [DOI] [PubMed] [Google Scholar]
- Smith LB, Jones SS, Landau B, Gershkoff-Stowe L, Samuelson LK. Object name learning provides on-the-job training for attention. Psychological Science. 2002;13:13–19. doi: 10.1111/1467-9280.00403. [DOI] [PubMed] [Google Scholar]
- Smith LB, Yu C. Infants rapidly learn word-referent mappings via cross-situational statistics. Cognition. 2008;106:1558–1568. doi: 10.1016/j.cognition.2007.06.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith SM. Enhancement of recall using multiple environmental contexts during learning. Memory & Cognition. 1982;10:405–412. doi: 10.3758/bf03197642. 309. [DOI] [PubMed] [Google Scholar]
- Smith SM, Glenberg A, Bjork RA. Environmental context and human memory. Memory and Cognition. 1978;6:342–353. [Google Scholar]
- Suss C, Gaylord S, Fagen J. Odor as a contextual cue in memory reactivation in young infants. Infant Behavior & Development. 2012;35:580–583. doi: 10.1016/j.infbeh.2012.05.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thiessen ED, Saffran JR. When cues collide: Use of statistical and stress cues to word boundaries by 7- to 9-month old infants. Developmental Psychology. 2003;39:706–716. doi: 10.1037/0012-1649.39.4.706. [DOI] [PubMed] [Google Scholar]
- Vlach HA, Sandhofer CM. Developmental differences in children's context-dependent word learning. Journal of Experimental Child Psychology. 2011;108:394–401. doi: 10.1016/j.jecp.2010.09.011. [DOI] [PubMed] [Google Scholar]
- Yoshida H, Smith LB. Linguistic cues enhance the learning of perceptual cues. Psychological Science. 2005;16:90–95. doi: 10.1111/j.0956-7976.2005.00787.x. [DOI] [PMC free article] [PubMed] [Google Scholar]