

Abstract
Accurate incidence forecasting of infectious disease provides potentially valuable insights in its own right. It is critical for early prevention and may contribute to health services management and syndrome surveillance. This study investigates the use of a hybrid algorithm combining grey model (GM) and back propagation artificial neural networks (BP-ANN) to forecast hepatitis B in China based on the yearly numbers of hepatitis B and to evaluate the method's feasibility. The results showed that the proposal method has advantages over GM (1, 1) and GM (2, 1) in all the evaluation indexes.
1. Introduction
Hepatitis B is a vaccine preventable disease caused by the hepatitis B virus (HBV) that can induce potentially fatal liver damage. It has infected approximately 2 billion people worldwide, which represents one-third of the world population. Each year around the world, HBV infection is responsible for about one million deaths due to liver failure and cirrhosis and more than 75% of the hepatocellular carcinomas world-wide develop from HBV infection [1–3]. HBV is most prevalent in China, South East Asia, sub-Saharan Africa, and the Amazon basin of South America where health care resources are most limited [4]. In the Chinese population of 1.3 billion individuals, there are estimated to be 93 million HBV carriers. Each year, 300,000 deaths are attributed to chronic hepatitis B, including deaths associated with liver cirrhosis and hepatocellular carcinoma (HCC) [5]. Therefore, it is critical for early prevention of hepatitis B and an accurate forecasting which would enable public health officials to evaluate intervention strategies and make educated decisions.
Mathematical and computational models have gained in importance in the public-health domain, especially in infectious disease epidemiology, by providing rationales and quantitative analysis to support decision-making and policy-making processes in recent years. And many researchers advocate the use of these models as predictive tools [6–12].
The accurate forecasting of hepatitis B can be obtained by analyzing the sufficient historical data. However, in China and perhaps some other developing countries, the current public health surveillance system does not collect detailed essential epidemiological information as they are often difficult to obtain. The forecasted of hepatitis B will be inaccurate only by the limited data. Therefore, it is significant to make the limited data-processing.
The grey systems theory chiefly including the theory of grey system analysis, modeling, prediction, decision-making, and control is established by Deng, which focuses on uncertainty problems with small samples, discrete data and incomplete information that are difficult for probability, and fuzzy mathematics to handle. Grey prediction is an important embranchment of grey systems theory, which makes scientific, quantitative forecasts about the future states of grey systems. The precise prediction of system can be performed by generating and extracting the useful information from the small samples and the partially known information [13–15].
Artificial neural networks (ANN) are complex and flexible nonlinear systems with properties not found in other modeling systems. It allows a method of forecasting with understanding of the relationship among variables and in particular nonlinear relationships. ANN function by initially learning a known set of data from a given problem with a known solution (training) and then the networks, inspired by the analytical processes of the human brain, are able to reconstruct the imprecise rules. Once a model is trained, the forecasted outputs can be generated from novel records [16–19].
The aim of this study is to investigate the use of a hybrid method combining grey model (GM) and back propagation artificial neural networks (BP-ANN) to forecast hepatitis B in China based on the yearly numbers of hepatitis B from the years 2002 to 2012 and to evaluate the method's performances of prediction.
2. Materials and Methods
2.1. Data Sources
The incidence data of hepatitis B are collected from the Ministry of Health of the People's Republic of China from the years 2002 to 2012, which are opening government statistics data [20].
2.2. Methods
The proposed method is established based on the grey systems theory and BP-ANN theory. MATLAB software version 2011b is used for the statistical analysis.
The incidence data are considered as the original time series X = (x 0, x 1, x 2,…, x n), where n is the length of the time series.
Through grey generations or the effect of sequence operators to weaken the randomness, grey prediction models are designed to excavate the hidden laws; through the interchange between difference equations and differential equations, a practical jump of using discrete data sequences to establish continuous dynamic differential equations is materialized. Here, GM (1,1) is the main and basic model of grey predictions, that is, a single variable first order grey model, which is able to acquire high prediction accuracy despite requiring small sample size (but the sample size must be at least 4). The GM (1,1) model is suitable for sequences that show an obvious exponential pattern and can be used to describe monotonic changes. As for nonmonotonic wavelike development sequences, or saturated sigmoid sequences, one can consider establishing GM (2,1) model.
The establishment for a GM (1,1) model is derived as follows.
(1) Let nonnegative time sequence expressing X 0 = (x 0(1), x 0(2),…, x 0(n)) be an original time sequence. Where n is the sample size of the data.
(2) First-order accumulative generation operation (1-AGO) is used to convert X 0 into X 1 = (x 1(1), x 1(2),…, x 1(n)) = (∑i=1 1 x 0(i), ∑i=1 2 x 0(i),…, ∑i=1 n x 0(i))
(3) Let Z 1 = (z 1(2), z 1(3),…, z 1(n), ) be the sequence generated from X 1 by adjacent neighbor means. That is, z 1(t) = 0.5(x 1(t) + x 1(t − 1)), t = 2,3,…, n. The least square estimate sequence of the grey difference equation of GM (1,1) is defined as x 0(t) + az 1(t) = b, where −a and b are referred to as the development coefficient and grey action quantity, respectively.
Then
| (1) |
where
| (2) |
(4) The whitenization equation is given by dx 1/dt + ax 1 = b
(5) The forecasting model can be obtained by solving the above equation, which is shown as follows:
| (3) |
(6) The predicted value of the primitive data at time point (t + 1) is extracted:
| (4) |
The procedure for a GM (2,1) model is derived as follows.
(1) For a given sequence of original data X 0 = (x 0(1), x 0(2),…, x 0(n)), let its sequences of accumulation generation and inverse accumulation generation be X 1 = (x 1(1), x 1(2),…, x 1(n)) and α 1 X 0 = (α 1 x 0(1),…, α 1 x 0(n)), respectively, where α 1 x 0 = x 0(t) − x 0(t − 1)), t = 2,3,…, n and the sequence of adjacent neighbor mean generation of X 1 is Z 1 = (z 1(2), z 1(3),…, z 1(n), ).
(2) The GM (2,1) model is α 1 x 0(t) + a 1 x 0(t) + a 2 z 1(t) = u and the whitenization equation is given by d 2 x 1/dt 2 + α 1(dx 1/dt) + α 2 x 1 = u. The least squares estimate of the parametric sequence is
| (5) |
where
| (6) |
(3) Solve the whitenization equation. If X 1∗ is a special solution of the whitenization equation and the general solution of the corresponding homogeneous equation d 2 x 1/dt 2 + α 1(dx 1/dt) + α 2 x 1 = 0, then is the general solution of the GM (2,1) whitenization equation. There are three cases for the general solution of the homogeneous equation: (i) when the characteristic equation r 2 + α 1 r + α 2 = 0 has two distinct real roots ; (ii) when the characteristic equation has a repeated root ; (iii) when the characteristic equation has two complex conjugate roots r 1 = α + iβ and r 2 = α − iβ, . A special solution of the whitenization equation may take of the three possibilities: (i) when 0 is not a root of the characteristic equation, X 1∗ = C; (ii) when 0 is one of the two distinct roots of the characteristic equation, X 1∗ = Cx; and (iii) when 0 is the only root of the characteristic equation, X 1∗ = Cx 2.
The steps of the forecasting method can be described as follows.
Step 1 (train the BP-ANN). —
In order to obtain the input of the BP-ANN, the GM (1,1) and GM (2,1) model are used to predict for the original time series of hepatitis B, respectively. The two groups of predicted are taken as the input of the BP-ANN. At the same time, the original time series are taken as the output. Thus the structure of a three-layer BP-ANN is constructed and the trained BP-ANN model will be obtained by training.
Step 2 (forecast by the trained BP-ANN). —
The GM (1,1) and GM (2,1) model are used to forecast for the original time series of hepatitis B, respectively, at first. Then the two groups of forecasted data are taken as the input of the trained BP-ANN. Finally, the forecasted of hepatitis B will be obtained by running the trained BP-ANN.
The method flow chart is shown in Figure 1.
Figure 1.
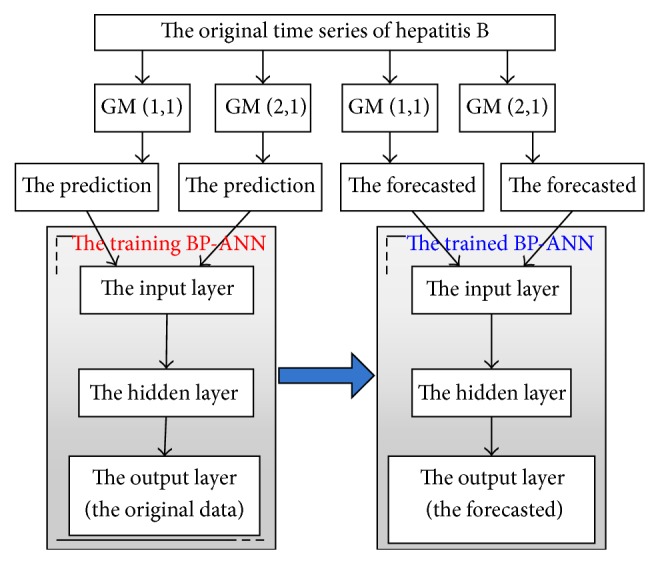
Flow chart of the hybrid method.
3. Evaluation Criteria
The metrics used are relative error (RE), , i = 1,2,…, n, where is the forecasted data and y i is the actual data; correlation coefficient (R), , where is the covariance between y and ; mean square error (MSE), ; root mean square error (RMSE); ; mean average error (MAE), ; mean average percentage error (MAPE), , and sum of squared error (SSE), .
4. Result
The incidence data of hepatitis B are collected year by year from 2002 to 2012 in China and taken as the original time series, which is shown in Figure 2.
Figure 2.
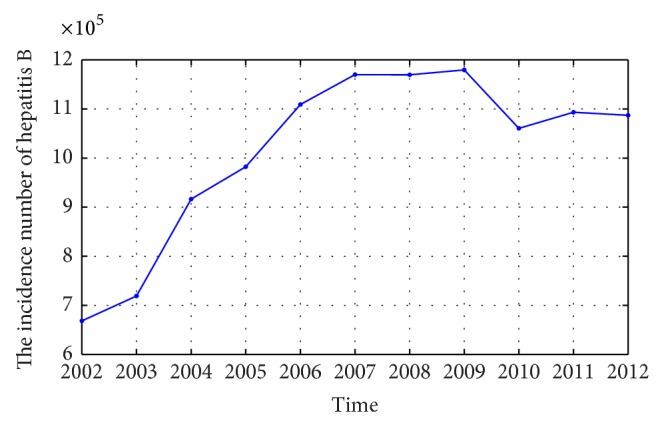
The incidence number of hepatitis B in China from 2002 to 2012.
4.1. The GM (1, 1) and GM (2, 1) Models Calculation
The GM (1,1) and GM (2,1) models are calculated and shown as follows.
4.1.1. The Parameters
GM (1, 1) Model. Consider the following: −a = 0.027523, b = 893075.402372. Therefore, the GM (1,1) model of this time series can be forecasted for long term forecasting for the reasons that GM (1,1) can be used for long term forecasting when −a ≤ 0.3 and for short term forecasting when 0.3 < −a ≤ −0.5. −a reflects the development states of the accumulation generated sequence and the sequence of raw data .
GM (2, 1) Model. Consider the following: a 1 = 0.4083, a 2 = 0.0158, u = 583425.10336, r 1 = −0.04329, r 2 = −0.36502, c 1 = −38764735.45099, and c 2 = 2527585.93078.
4.1.2. The Forecasting Models
GM (1, 1) Model. Consider the following:
| (7) |
GM (2, 1) Model. Consider the following:
| (8) |
4.2. The Forecasted
In the three-layer BP-ANN, the hidden node n 2 and the input node n 1 are related by n 2 = 2n 1 + 1. The two groups of prediction created by the two GM models are taken as the input of the BP-ANN and the observed data is taken as the output. Therefore, a three-layer proposed model with 2 input nodes, 5 hidden nodes, and 1 output node is obtained. The topology structure is shown in Figure 3.
Figure 3.
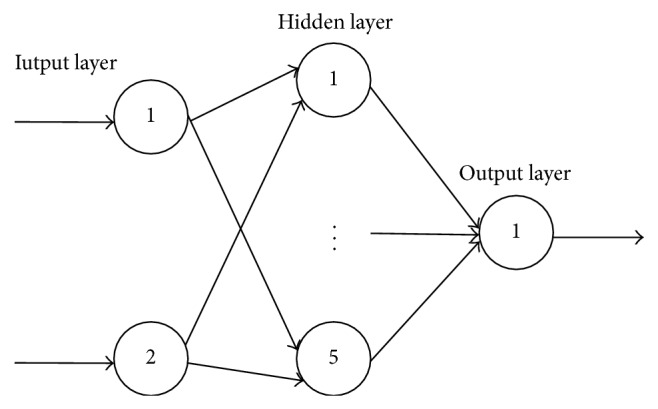
The topology structure of the proposal method.
The weights and thresholds of the proposal model will be obtained by training. Let the training time be 1000, the learning rate be 0.9, the momentum factor be 0.95, and the error be 0.001; Levenberg Marquardt is used as training algorithm.
The prediction of the original time series by the GM (1,1) and GM (2,1) model, respectively, are taken as the input of the trained BP-ANN. Then the forecasted of hepatitis B will be obtained by running the trained BP-ANN. The forecasted is shown in Figure 4.
Figure 4.
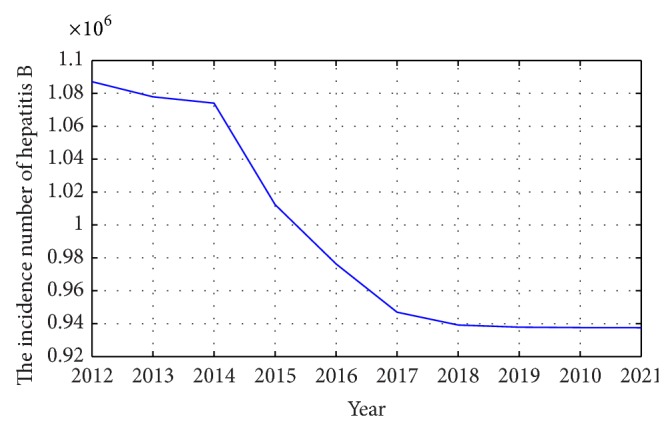
The forecasted incidence of hepatitis B in China from 2013 to 2021 by the proposal method.
5. Discussion
In order to compare the prediction created by the two GM models and the proposed method, a prediction is performed under the same conditions. The results are listed in Table 1 and the scatter diagram is shown in Figure 5. It can be seen from Figure 5 that the prediction generated by the two GM models has greater dispersion than that by the proposed method.
Table 1.
The prediction created by the GM (1, 1), GM (2, 1), and the proposal model.
| Year | The observed data | GM (1, 1) | GM (2, 1) | The proposal method |
|---|---|---|---|---|
| 2003 | 719011 | 924130 | 882183 | 736600 |
| 2004 | 916396 | 949918 | 1036306 | 884300 |
| 2005 | 982297 | 976426 | 1133758 | 1027700 |
| 2006 | 1109130 | 1003674 | 1183850 | 1096300 |
| 2007 | 1169946 | 1031682 | 1201811 | 1118200 |
| 2008 | 1169569 | 1060471 | 1198178 | 1124300 |
| 2009 | 1179607 | 1090065 | 1180237 | 1125900 |
| 2010 | 1060582 | 1120484 | 1153018 | 1126400 |
| 2011 | 1093335 | 1151751 | 1119982 | 1126500 |
| 2012 | 1087086 | 1183892 | 1083509 | 1126500 |
Figure 5.
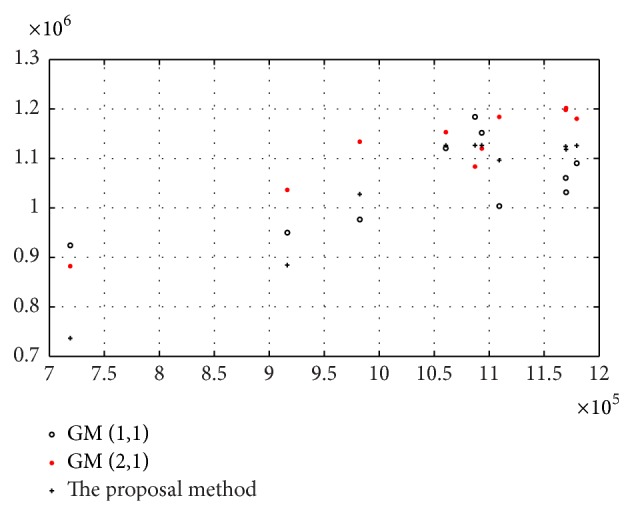
The scatter diagram of the relationship between the observed data and the prediction.
The RE of prediction is shown in Figure 6. From the figure, we know that the prediction obtained by the proposed method has higher accuracy and smaller RE than that by the GM approaches. Figure 6 indicates that the smaller the relative error is, the closer prediction is to the observed data.
Figure 6.
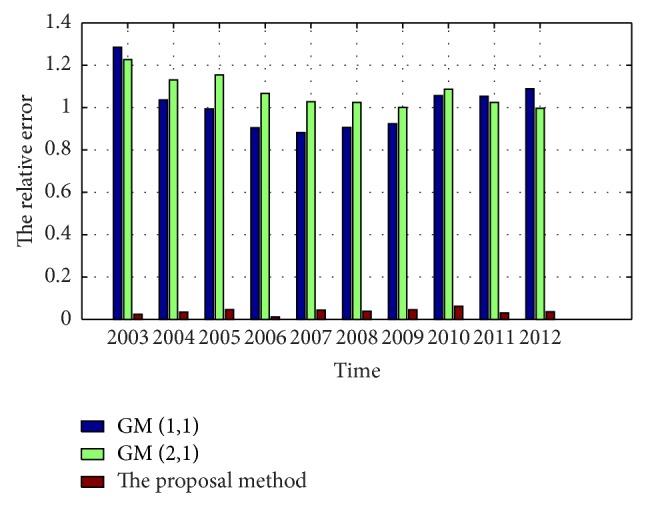
Comparison of the RE of the prediction by the proposal method and the GMs.
The comparison of R, MSE, MAE, RMSE, MAPE, and SSE are listed in Table 2. It can be seen that the proposed method has advantages over GMs in all the evaluation indexes.
Table 2.
The evaluation indexes comparison.
| Index | R | MSE | MAE | RMSE | MAPE | SSE |
|---|---|---|---|---|---|---|
| The proposal method | 0.9495 | 2.3649 × 107 | 3.9704 × 104 | 4.863 × 103 | 3.9704 × 106 | 1.8162 × 1010 |
| GM (1, 1) model | 0.6365 | 2.2867 × 108 | 1.0492 × 106 | 1.5122 × 104 | 1.0492 × 108 | 1.1078 × 1013 |
| GM (2, 1) model | 0.9392 | 1.6798 × 108 | 1.1173 × 106 | 1.5122 × 104 | 1.1173 × 108 | 1.2570 × 1013 |
The forecasted generated by the GM (1,1), GM (2,1), and the proposal model are listed in Table 3 and shown in Figure 7.
Table 3.
The forecasted generated by the three methods.
| Year | GM (1, 1) | GM (2, 1) | The proposal method |
|---|---|---|---|
| 2013 | 1216929.0 | 1045223.6 | 1077864.1 |
| 2014 | 1250888.2 | 1006228.6 | 1074038.2 |
| 2015 | 1285795.1 | 967267.6 | 1012371.7 |
| 2016 | 1321676.0 | 928834.0 | 976301.8 |
| 2017 | 1358558.3 | 891248.9 | 946959.7 |
| 2018 | 1396469.7 | 854715.0 | 939194.1 |
| 2019 | 1435439.1 | 819353.3 | 937881.5 |
| 2020 | 1475496.0 | 785229.0 | 937607.7 |
| 2021 | 1516670.7 | 752369.4 | 937531.5 |
Figure 7.
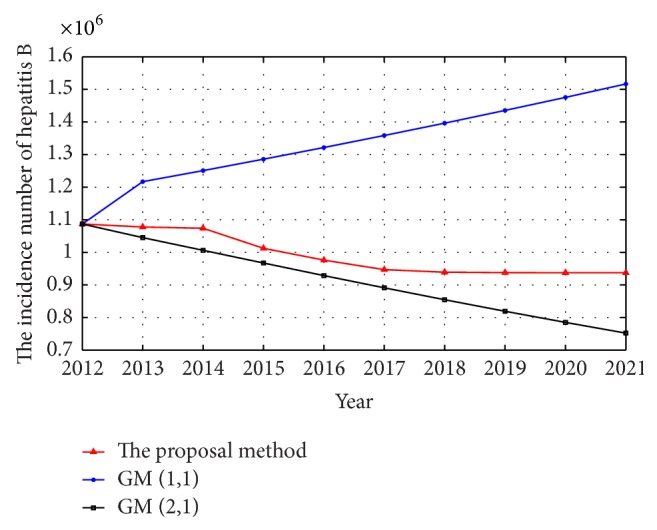
The forecasted incidence of hepatitis B in China from 2013 to 2021 by the three methods.
The weights and thresholds of BP-ANN will generate randomly at first when the model is training. This will make the predicted and forecasted uncertainty. To describe this clearer, the proposal model is ran 100 times and the mean value will be taken as predicted or forecasted value. The 95% confidence interval and predicted or forecasted value are shown in Figures 8 and 9, respectively.
Figure 8.
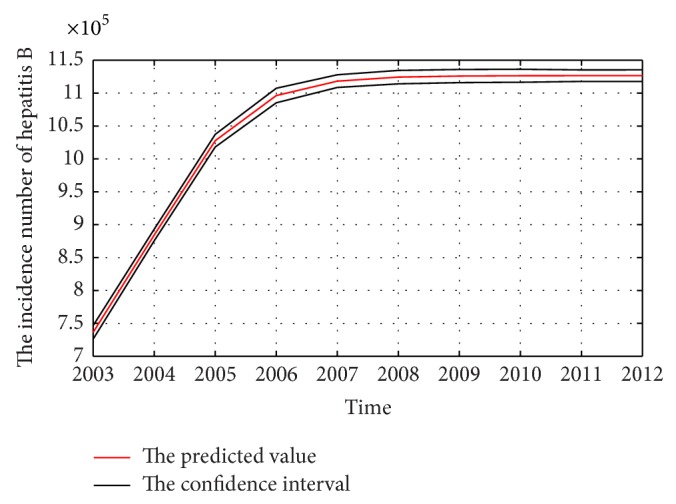
The predicted incidence of hepatitis B in China from 2003 to 2012 by the proposal methods.
Figure 9.
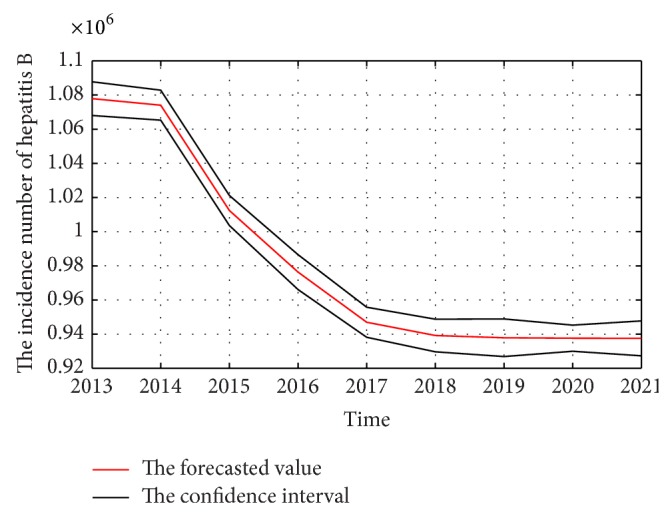
The forecasted incidence of hepatitis B in China from 2013 to 2021 by the proposal methods.
Although the prediction result created by the proposal method in the paper has more accurate than that by the two gray models, the proposal model has its limitations. Firstly, since the proposal model is built on the basis of gray model, the sample size, namely, the number of historical data must be not less than 4. Secondly, the prediction result will be inaccuracy if the weights and thresholds in BP-ANN ran into local optimum in the process of training. Intelligent algorithms can be used to optimize the weights and thresholds of BP-ANN [21].
6. Conclusion
The hepatitis B epidemiological information is often difficult to obtain. Forecasting of hepatitis B will be inaccurate by the limited data. The grey systems theory focuses on uncertainty problems with small samples and incomplete information. At the same time, the BP-ANN is a method of forecasting with understanding of the relationship among variables and nonlinear relationships. The research proposes a new forecasting method, which combines the GM and BP-ANN, to forecast hepatitis B in China. The useful information can generate and extract from the small samples and the BP neural networks can train data more sufficiently. The prediction results show that this method can obtain better forecasting.
Acknowledgments
The authors thank Zola Banh for carefully correcting grammar errors. This work was supported by Youth Science Foundation of Guangxi Medical University (GXMUYSF201208), the open project of Guangxi Medical Science Experimental Center (KFJJ2011-31), the training programs of innovation and entrepreneurship for undergraduates in Guangxi province (2012xjcxcy006), and the training programs of innovation and entrepreneurship for undergraduates in China (201210598002). The funders had no role in study design, data collection, and analysis, decision to publish, or preparation of the paper.
Conflict of Interests
The authors have declared that no competing interests exist.
References
- 1.Gourley S. A., Kuang Y., Nagy J. D. Dynamics of a delay differential equation model of hepatitis B virus infection. Journal of Biological Dynamics. 2008;2(2):140–153. doi: 10.1080/17513750701769873. [DOI] [PubMed] [Google Scholar]
- 2.Liu F., Chen L., Yu D.-M., et al. Evolutionary patterns of hepatitis B virus quasispecies under different selective pressures: correlation with antiviral efficacy. Gut. 2011;60(9):1269–1277. doi: 10.1136/gut.2010.226225. [DOI] [PubMed] [Google Scholar]
- 3.Torpy J. M., Burke A. E., Golub R. M. JAMA patient page. Hepatitis B. Journal of the American Medical Association. 2011;305(14, article 1500) doi: 10.1001/jama.305.14.1500. [DOI] [PubMed] [Google Scholar]
- 4.Nwokediuko S. C. Chronic hepatitis B: management challenges in resource-poor countries. Hepatitis Monthly. 2011;11(10):786–793. doi: 10.5812/kowsar.1735143x.757. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.The guideline of prevention and treatment for chronic hepatitis B (2010 version) Chinese Journal of Hepatology. 2011;19(1):13–24. doi: 10.3760/cma.j.issn.1007-3418.2011.01.007. [DOI] [PubMed] [Google Scholar]
- 6.Zhang T., Teng Z. On a nonautonomous SEIRS model in epidemiology. Bulletin of Mathematical Biology. 2007;69(8):2537–2559. doi: 10.1007/s11538-007-9231-z. [DOI] [PubMed] [Google Scholar]
- 7.Tizzoni M., Bajardi P., Poletto C., et al. Real-time numerical forecast of global epidemic spreading: case study of 2009 A/H1N1pdm. BMC Medicine. 2012;10, article 165 doi: 10.1186/1741-7015-10-165. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Eubank S., Guclu H., Kumar V. S. A., et al. Modelling disease outbreaks in realistic urban social networks. Nature. 2004;429(6988):180–184. doi: 10.1038/nature02541. [DOI] [PubMed] [Google Scholar]
- 9.Ren H., Li J., Yuan Z.-A., Hu J.-Y., Yu Y., Lu Y.-H. The development of a combined mathematical model to forecast the incidence of hepatitis E in Shanghai, China. BMC Infectious Diseases. 2013;13(1, article 421) doi: 10.1186/1471-2334-13-421. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Bai Y., Jin Z. Prediction of SARS epidemic by BP neural networks with online prediction strategy. Chaos, Solitons and Fractals. 2005;26(2):559–569. doi: 10.1016/j.chaos.2005.01.064. [DOI] [Google Scholar]
- 11.Ture M., Kurt I. Comparison of four different time series methods to forecast hepatitis A virus infection. Expert Systems with Applications. 2006;31(1):41–46. doi: 10.1016/j.eswa.2005.09.002. [DOI] [Google Scholar]
- 12.Thornley S., Bullen C., Roberts M. Hepatitis B in a high prevalence New Zealand population: a mathematical model applied to infection control policy. Journal of Theoretical Biology. 2008;254(3):599–603. doi: 10.1016/j.jtbi.2008.06.022. [DOI] [PubMed] [Google Scholar]
- 13.Shen X., Ou L., Chen X., Zhang X., Tan X. The application of the grey disaster model to forecast epidemic peaks of typhoid and paratyphoid fever in China. PLoS ONE. 2013;8(4) doi: 10.1371/journal.pone.0060601.e60601 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Deng J. L. Introduction to grey system theory. The Journal of Grey System. 1989;1(1):1–24. [Google Scholar]
- 15.Liu S. F., Lin Y. Grey Systems: Theory and Applications. Berlin, Germany: Springer; 2010. [DOI] [Google Scholar]
- 16.Amaritsakul Y., Chao C.-K., Lin J. Multiobjective optimization design of spinal pedicle screws using neural networks and genetic algorithm: mathematical models and mechanical validation. Computational and Mathematical Methods in Medicine. 2013;2013:9. doi: 10.1155/2013/462875.462875 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Zou J., Han Y., So S. S. Overview of artificial neural networks. Methods in Molecular Biology. 2008;458:15–23. doi: 10.1007/978-1-60327-101-1_2. [DOI] [PubMed] [Google Scholar]
- 18.Terrin N., Schmid C. H., Griffith J. L., D'Agostino R. B., Selker H. P. External validity of predictive models: a comparison of logistic regression, classification trees, and neural networks. Journal of Clinical Epidemiology. 2003;56(8):721–729. doi: 10.1016/s0895-4356(03)00120-3. [DOI] [PubMed] [Google Scholar]
- 19.Grossi E., Buscema M. Introduction to artificial neural networks. European Journal of Gastroenterology and Hepatology. 2007;19(12):1046–1054. doi: 10.1097/meg.0b013e3282f198a0. [DOI] [PubMed] [Google Scholar]
- 20.The Science Data Center of Public Health of China. http://www.phsciencedata.cn/Share/ky_sjml.jsp?id=8defcfc2-b9a4-4225-b92c-ebb002321cea&show=0.
- 21.Huang D., Gong R., Gong S. Prediction of wind power by chaos and BP artificial neural networks approach based on genetic algorithm. Journal of Electrical Engineering & Technology. 2015;10(1):41–46. [Google Scholar]