

Summary
We introduce effective balancing scores for estimation of the mean response under a missing at random mechanism. Unlike conventional balancing scores, the effective balancing scores are constructed via dimension reduction free of model specification. Three types of effective balancing scores are introduced: those that carry the covariate information about the missingness, the response, or both. They lead to consistent estimation with little or no loss in efficiency. Compared to existing estimators, the effective balancing score based estimator relieves the burden of model specification and is the most robust. It is a near-automatic procedure which is most appealing when high dimensional covariates are involved. We investigate both the asymptotic and the numerical properties, and demonstrate the proposed method in a study on Human Immunodeficiency Virus disease.
Keywords: Balancing score, Dimension reduction, Missing at random, Nonparametric kernel regression, Prognostic score, Propensity score
1. Introduction
In social and medical studies, the primary interest is usually the mean response, the estimation of which can be complicated by missing observations due to nonresponse, drop out or death. The data observed are triplets {(Yi, δi, Xi), i = 1, ···, n}, where Yi is the response, δi = 1 if Yi is observed and δi = 0 if Yi is missing, and Xi is the vector of covariates and always observed. Under the missing at random mechanism (Rosenbaum & Rubin, 1983); that is, Pr(δ = 1 | X, Y) = Pr(δ = 1 | X), estimation of E(Y) is mostly developed using the parametric form of the missingness pattern π(X) = Pr(δ = 1 | X) or the response pattern m(X) = E(Y | X). Important methods include regression estimation (Rubin, 1987; Schafer, 1997), inverse propensity score estimation (Horvitz & Thompson, 1952), augmented inverse propensity weighting estimation (Robins et al., 1994), and their modified versions such as D’Agostino (1998), Scharfstein et al. (1999), Little & An (2004), Vartivarian & Little (2008), and Cao et al. (2009). A review of most methods can be found in Lunceford & Davidian (2004) and Kang & Schafer (2007). Consistency and efficiency of these estimators rely on correct model specification. Even for the “doubly robust” estimators, either π(X) or m(X) needs to be correctly specified for consistency and both correctly specified for efficiency (Robins & Rotnitzky, 1995; Hahn, 1998). When X ∈ ℝp is high dimensional, model specification is challenging: it is hard for a parametric model to be sufficiently flexible to capture all the important nonlinear and interaction effects yet parsimonious enough to maintain reasonable efficiency.
One family of estimators are built upon the balancing score. According to Rosenbaum & Rubin (1983), a balancing score b(X) has the property E(Y | b(X)) = E(Y | b(X), δ = 1). Therefore, E(Y) can be estimated via b(X) over the complete cases {(Yi, δi, Xi) : δi = 1}. The most well known balancing scores include the propensity score (Rosenbaum & Rubin, 1983) and the prognostic score (Hansen, 2008). The mean response can be estimated via the balancing score by such nonparametric approaches as stratification (Rosenbaum & Rubin, 1983) and nonparametric regression (Cheng, 1994). Of course, the naive balancing score is X. However, estimation using X as a balancing score is subject to the curse of dimensionality when X ∈ ℝp is high dimensional (Abadie & Imbens, 2006).
Balancing scores have been estimated through parametric modeling. In comparison to the other estimators, balancing score based estimators are less sensitive to model misspecification, largely due to the nonparametric approaches to utilize the balancing score (Rosenbaum, 2002). One important property of the balancing score based estimator, which has rarely been utilized, is that full parametric modeling is actually unnecessary. For example, if π(x) = f{b(x)} for some function b(X) and unknown function f, then E(Y) can be estimated via b(X) through stratification or nonparametric regression as subjects with similar values in b(X) have similar values in π(X). Provided that we can find such a function b(X), there is no need for the full parametric form of π(X).
In this work, we introduce the effective balancing score. Like the propensity score and the prognostic score, the effective balancing score creates a conditional balance between the subjects with response observed and the subjects with response missing. Unlike the conventional balancing scores, estimation of the effective balancing score is free of model specification via the technique of dimension reduction (Li, 1991; Cook & Weisberg, 1991; Cook & Li, 2002; Li & Zhu, 2007; Li & Wang, 2007). The effective balancing score carries all X information about the missingness or the response in the sense δ ⊥ X | S or Y ⊥ X | S, where S stands for the effective balancing score and ⊥ stands for conditional independence. It thus leads to consistent estimation of E(Y) with little or no loss in efficiency. As a parsimonious summary of X, the effective balancing score is of dimension much smaller than p. Compared with existing methods, the effective balancing score based estimator has the following advantages: (1) It relieves the burden of model specification and is the most robust with potentially optimal efficiency; (2) Through the technique of dimension reduction, the effective balancing score is of low dimension which enables the effective use of stratification and nonparametric regression; (3) It avoids the shortcoming of inverse propensity weighting, i.e., instability caused by estimates of π(X) that are close to zero.
2. Effective balancing score
2·1. Effective balancing score
Let
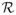 be the response from X ∈ ℝp. Usually
relates to X through only a few linear combinations; that is,
with βk ∈ ℝp : k = 1, ···, K distinctive vectors. Let B = (β1, ···, βK) with β1, ···, βK orthonormal and K the smallest dimension to satisfy the conditional independence, then B is a basis of the central dimension-reduction space
be the response from X ∈ ℝp. Usually
relates to X through only a few linear combinations; that is,
with βk ∈ ℝp : k = 1, ···, K distinctive vectors. Let B = (β1, ···, βK) with β1, ···, βK orthonormal and K the smallest dimension to satisfy the conditional independence, then B is a basis of the central dimension-reduction space
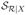 with K the structural dimension (Cook, 1994). The columns of B are arranged in descending order of importance; that is, λ1 ≥ λ2 ≥ ··· ≥ λK > 0 where λk measures the amount of X information carried by
and is explained in §3.2. In general, K is much smaller than p. If we let S = B′X, then S ∈ ℝK is a parsimonious summary of X: it is of lower dimension than X but carries all X information about
. In this paper, we refer to B = (β1, ···, βK) as the effective directions.
with K the structural dimension (Cook, 1994). The columns of B are arranged in descending order of importance; that is, λ1 ≥ λ2 ≥ ··· ≥ λK > 0 where λk measures the amount of X information carried by
and is explained in §3.2. In general, K is much smaller than p. If we let S = B′X, then S ∈ ℝK is a parsimonious summary of X: it is of lower dimension than X but carries all X information about
. In this paper, we refer to B = (β1, ···, βK) as the effective directions.
Let
= δ and Bδ be the effective directions of
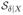 , then
, then
| (1) |
and we refer to as the effective propensity score.
Let
= Y and denote BY as the effective directions of
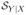 , then
, then
| (2) |
Obviously, is a prognostic score satisfying the definition of Hansen (2008). We refer to as the effective prognostic score.
Each effective score creates the conditional balance
| (3) |
where S is either Sδ or SY. For S = Sδ, (3) follows similarly as in Theorem 3 of Rosenbaum & Rubin (1983). For S = SY,
where the second equation is due to missingness at random and the last equation to (2). Since the last expectation is E(δ | S) = Pr(δ = 1 | S), (3) follows. It is immediate from (3) that both effective scores are balancing scores.
Example 1
Suppose Y | X is normal with mean m(X) = X1 + exp(X2 + X3) + X1X4 and variance , with the probability of observing Y as . Then, the prognostic score is {m(X), σ2(X)} and the propensity score is π(X). The effective prognostic score is { } and the effective propensity score is { }.
The effective balancing scores may have higher dimensions than their conventional counterparts. However, estimation of the propensity score and the prognostic score requires correct model specification and is subject to the challenges discussed in §1. The effective balancing scores, on the other hand, can be obtained without model specification.
We can also let
= (δ, Y) be a bivariate response. Denote Bd as the effective directions for
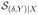 , then
, then
| (4) |
In other words, carries all X information about both δ and Y, and creates both propensity balance and prognostics balance. We refer to as the effective double balancing score. In Example 1, is the same as SY.
Remark 1
As shown by (1) and (2), so long as either independence in (4) holds, Sd is a balancing score satisfying the conditional balance (3). It is for this reason that we refer to Sd as the effective double balancing score.
In summary, both the effective prognostic score and the effective double balancing score have the properties
The first property implies E(Y | S) = E(Y | S, δ = 1), which ensures unbiased estimation of E(Y) via S from the complete cases. The second property implies that S carries all X information about the response, which ensures efficient estimation of E(Y) via S. The effective propensity score possesses only the first property and is not as efficient as the other two. We will show in §3 and §4 that Sd can improve over SY under certain situations. Without loss of generality, we assume E(X) = 0 and cov(X) = Ip the identity matrix.
2·2. Estimation of effective balancing score
To find the effective balancing scores is to find the effective directions: the effective directions of
for the effective propensity score and the effective directions of
for the effective prognostic score. For the effective double balancing score, we need the effective directions of
.
Remark 2
Under missingness at random, there is the relationship
=
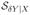 for continuous response Y. The effective directions of
can be estimated through the univariate response δY. A similar approach applies if Y is categorical. See Appendix 1.
for continuous response Y. The effective directions of
can be estimated through the univariate response δY. A similar approach applies if Y is categorical. See Appendix 1.
There are many dimension reduction methods for estimating the effective directions. The most fundamental methods are the sliced inverse regression (Li, 1991) and the sliced average variance estimation (Cook & Weisberg, 1991). Both methods are developed under the linearity condition; that is, E(X | B′X) is a linear function of B′X. Many new methods have been developed to improve over these two. To improve estimation efficiency, there are the likelihood based methods of Cook (2007), Cook & Forzani (2008) and Cook & Forzani (2009). To relax the distribution assumption, Li & Dong (2009) and Dong & Li (2010) proposed methods to remove the linearity condition, and Ma & Zhu (2012) successfully applied a semiparametric approach to eliminate all distributional assumptions. These methods lead to root-n consistent estimates under proper conditions. As to be shown in Theorem 2, the proposed estimation of E(Y) requires only the effective direction estimates to be root-n consistent. In this work, we adopt the fitted principal component method of Cook (2007) in the numerical studies unless stated otherwise. More information about these dimension reduction methods is given in §6.
Remark 3
Under missingness at random, there is the relationship
following Chiaromonte et al. (2002). That is, the effective directions of
include both the effective directions of
and the effective directions of
.
In addition to the method in Remark 2, Remark 3 suggests a pooling method for the effective directions of
. Since δ and Y are mostly related, there is likely overlap between
and
. Therefore, the pooling method needs to be followed by such a method as Gram-Schmidt’s orthogonolization to remove redundancy.
3. Mean response estimation via effective balancing score
In this section, let S stand for the effective balancing score and B the matrix of effective directions. We first consider B as known and later investigate the impact from the estimation of B. As S = B′X consists of linear combinations of X, it is always observed. As B has columns of orthonormal vectors, S has the identity covariance matrix. Since S carries all X information about the missingness or the response, we can use S ∈ ℝK instead of X ∈ ℝp for the estimation of E(Y) through stratification or nonparametric regression. In this work, we focus on nonparametric regression.
3·1. Nonparametric regression via effective balancing score
Let m(S) = E(Y | S) be the conditional mean response given the effective balancing score, then E(Y) = E{m(S)} can be estimated through the estimation of m(S). To obviate model specification, we estimate m(·) by nonparametric kernel regression (Silverman, 1986)
| (5) |
where Si = B′Xi,
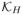 (u) = det(H)−1
(u) = det(H)−1
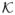 (H−1u) for u = (u1, ···, uK) with H the bandwidth matrix and
(·) the kernel function. Since S has identity covariance, we take H = hnIK with hn a scalar bandwidth (Härdle et al., 2004). We then estimate E(Y) by
(H−1u) for u = (u1, ···, uK) with H the bandwidth matrix and
(·) the kernel function. Since S has identity covariance, we take H = hnIK with hn a scalar bandwidth (Härdle et al., 2004). We then estimate E(Y) by
| (6) |
We refer to μ̂ as the nonparametric regression via effective balancing score estimator, or briefly the nonparametric balancing score estimator. By the result of Devroye & Wagner (1980), m̂(s) converges in probability to E(δY | s)/E(δ | s). It is immediate from (3) that E(δY | s) = E(δ | s)E(Y | s). Therefore, m̂(s) converges in probability to m(s), and consequently (6) to μ = E(Y).
Theorem 1
Under the regularity conditions, the nonparametric balancing score estimator μ̂ is asymptotically normally distributed. If as n → ∞, hn → 0 and , then
with
where π(S) = E(δ | S).
For S = SY or S = Sd, due to (2) and (4), we have Y ⊥ X | S and thus var(Y | S) = var(Y | X). It follows that
, which is the optimal efficiency for the semiparametric estimators of E(Y), see Hahn (1998). This means that the nonparametric balancing score estimation via SY or Sd is both consistent and optimally efficient. For S = Sδ, as var(Y | S) ≥ var(Y | X), the optimal efficiency may not be reached.
Theorem 2
With B replaced by its root-n consistent estimate B̂, the nonparametric balancing score estimators have the same asymptotic properties as in Theorem 1.
Proof of Theorem 1 and 2 are given in the Appendix. Due to Theorem 2, we will use Sδ, SY, and Sd for the effective balancing scores whether B is known or estimated.
3·2. Dimension of effective balancing score
To determine the dimension of the effective balancing score is to determine K, the number of effective directions. A simple approach is the sequential permutation test of Cook & Yin (2001).
The dimension of the effective balancing score affects performance of the proposed estimator through nonparametric regression (5). Following Theorem 1, the impact from nonparametric regression is asymptotically negligible for hn ~ n
−α with 0 < α < 1/K. For larger K, selection of hn is more constrained as α falls in a narrower range. More specifically, nonparametric regression introduces bias
and variance
to μ̂, see Appendix 2. The mean squared error of μ̂ is minimized at hopt ~ n
−2/(K+4). At hopt, the asymptotic variance is n
−1
σ2 + n
−8/(K+4)
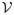 . If K ≤ 3, μ̂ is root-n consistent and the variance from nonparametric regression is asymptotically negligible. If K = 4, μ̂ is root-n consistent but the variance from nonparametric regression is not asymptotically negligible. If K > 4, μ̂ converges slower than n−1/2. Ideally, we would like S of dimension no more than 3 to reach the minimum mean squared error, root-n consistency, and negligible impact from nonparametric regression. Note that without dimension reduction; that is, S = X ∈ ℝp, the proposed estimator reduces to the nonparametric regression estimation of Cheng (1994) which can perform poorly for large p.
. If K ≤ 3, μ̂ is root-n consistent and the variance from nonparametric regression is asymptotically negligible. If K = 4, μ̂ is root-n consistent but the variance from nonparametric regression is not asymptotically negligible. If K > 4, μ̂ converges slower than n−1/2. Ideally, we would like S of dimension no more than 3 to reach the minimum mean squared error, root-n consistency, and negligible impact from nonparametric regression. Note that without dimension reduction; that is, S = X ∈ ℝp, the proposed estimator reduces to the nonparametric regression estimation of Cheng (1994) which can perform poorly for large p.
We compare the three effective balancing scores. The effective double balancing score and effective prognostic score improve over the effective propensity score, as SY and Sd lead to more efficient estimation than Sδ as shown by Theorem 1. The effective double balancing score can improve over the effective prognostic score when
is more than three-dimensional but
is less than three-dimensional. Here is a hypothetical example. Suppose
has 5 effective directions,
has one effective direction, and Bd = (Bδ, BY) has the effective propensity direction Bδ as the most important. To maintain conditional balance (3), SY needs to be of dimension 5. For Sd, we can use only the first three components: while the first component ensures conditional balance and thus consistency, the other two components enhance efficiency.
We can use in case of K > 3, which shows generally good performance in numerical studies. Most dimension reduction methods estimate βk’s as the eigenvectors of a kernel matrix, and the corresponding eigenvalue λk reflects the amount of X information carried by , see §6. When the first three components carry enough X information in the sense that (λ1 + λ2 + λ3)/(λ1 + ···, λK) is no less than 0.90, S* leads to good estimation. We refer to S* as the dimension further reduced effective score. If K > 3 and the first three components carry a low percentage of X information, which rarely happens in practice, we can use generalized additive modeling for the estimation of E(Y | S). That is, instead of the multivariate kernel regression (5), E(Y | S) is estimated through the additive model , where each gk is nonparametric and estimated by smoothing on a single coordinate, see Hastie & Tibshirani (1986). Though the generalized additive model is a bit restrictive by assuming the additivity, it relieves the curse of dimensionality that hinders multivariate kernel regression when K is big.
3·3. Estimation procedure
Step 1. Estimate the effective directions B and determine the dimension K;
Step 2. If K ≤ 3, compute the effective balancing score S = B̂′X; if K > 3, let be the dimension further reduced effective score;
Step 3. Estimate E(Y) by nonparametric regression via the effective balancing score S or the dimension further reduced effective score S*.
For bandwidth selection, the optimal bandwidth is hopt ~ n−2/(K+4) which minimizes the mean squared error of μ̂ and can be estimated by the plug in method (Fan & Marron, 1992), see Appendix 2. This optimal bandwidth is smaller than the conventional bandwidth hn ~ n −1/(K+4), which is optimal for the estimation of conditional mean m(S) (Härdle et al., 2004). At the conventional bandwidth, though the proposed estimator does not attain the minimal mean squared error, the bias and variance from nonparametric regression are asymptotically negligible. Therefore, when the sample size is large, we can use the conventional bandwidth which is easier to determine (Sheather & Jones, 1991).
For variance estimation, we can use the asymptotic variance formula in Theorem 1. The asymptotic variance leaves out the negligible terms; that is, the variability introduced by the estimation of the effective directions and the nonparametric regression of m(S). We recommend bootstrap for variance estimation: bootstrap n samples from the original triplets {(Yi, Xi, δi) : i = 1, ···, n} with replacement; compute the nonparametric balancing score estimate μ̂(b) over the bootstrapped data {(Yi, Xi, δi)(b) : i = 1, ···, n}; repeat these two steps many times and use the sample variance of μ̂(b) as the estimate of var(μ̂). The bootstrap estimate includes all sources of variation.
4. Numerical Studies
We investigate the numerical performance of the proposed estimators: μ̂δ uses the effective propensity score, μ̂Y uses the effective prognostic score, and μ̂d uses the effective double balancing score. Also computed are the commonly used model based estimators: the parametric regression estimation μ̂reg, the inverse propensity weighted estimator μ̂ipw, and the augmented inverse propensity weighted estimator μ̂aipw. In the model based estimations, we use linear regression for m(X) and linear logistic regression for π(X). In all simulations, 200 datasets with n = 200 or n = 1000 are used.
In simulation 1, X = (X1, ···, X10) has components of independent N(0, 1), π = expit(X1) and Y = 3X1 + 5X2 + ε with ε of independent N(0, 1). Estimation results are in Table 1. With m(X) linear and π(X) logistic linear, both working models are correct for the model based estimations. We see the nonparametric balancing score estimators have comparable performance to the model based estimators. Due to adoption of the nonparametric procedures, additional bias and variation are introduced to the proposed estimators. However, the additional bias and variation diminish as sample size gets large. The estimators μ̂Y and μ̂d reach the optimal efficiency, and μ̂δ is less efficient. The last observation agrees with the discussion following Theorem 1.
Table 1.
Results for simulation 1: Monte Carlo bias (Bias), standard deviation (SD), root mean squared error (RMSE), and the estimated standard deviation (ESD) and coverage percentage (CP) of the 95% confidence interval from bootstrap with 200 replications.
| μ̂δ | μ̂Y | μ̂d | μ̂reg | μ̂ipw | μ̂aipw | ||
|---|---|---|---|---|---|---|---|
|
|
|||||||
| n = 200 | Bias | 0.04 | 0.09 | 0.09 | −0.04 | 0.00 | −0.03 |
| SD | 0.57 | 0.43 | 0.45 | 0.42 | 0.58 | 0.43 | |
| RMSE | 0.57 | 0.44 | 0.46 | 0.43 | 0.58 | 0.43 | |
| ESD | 0.63 | 0.45 | 0.48 | 0.43 | 0.61 | 0.43 | |
| CP | 96.5 | 94.0 | 95.5 | 95.0 | 95.0 | 95.0 | |
| n = 1000 | Bias | 0.02 | 0.04 | 0.05 | 0.00 | 0.02 | 0.00 |
| SD | 0.23 | 0.20 | 0.19 | 0.19 | 0.23 | 0.19 | |
| RMSE | 0.23 | 0.20 | 0.20 | 0.19 | 0.23 | 0.19 | |
| ESD | 0.24 | 0.20 | 0.20 | 0.19 | 0.24 | 0.19 | |
| CP | 96.5 | 96.0 | 95.5 | 96.5 | 96.0 | 95.5 | |
In simulation 2, X = (X1, ···, X10) has components of independent N(0, 1), π = expit{exp(X2)} and with ε of independent N(0, 1). Estimation results are in Table 2. As m(X) is nonlinear and π(X) is log-logistic, the working models are incorrect and we see large bias in the model based estimators. The nonparametric balancing score estimators show negligible bias and good efficiency.
Table 2.
Results for simulation 2: Monte Carlo bias (Bias), standard deviation (SD), root mean squared error (RMSE), and the estimated standard deviation (ESD) and coverage percentage (CP) of the 95% confidence interval from bootstrap with 200 replications.
| μ̂δ | μ̂Y | μ̂d | μ̂reg | μ̂ipw | μ̂aipw | ||
|---|---|---|---|---|---|---|---|
|
|
|||||||
| n = 200 | Bias | 0.08 | 0.14 | 0.06 | 3.12 | −7.72 | −7.39 |
| SD | 8.80 | 8.47 | 7.91 | 8.98 | 24.45 | 23.83 | |
| RMSE | 8.80 | 8.47 | 7.91 | 9.50 | 25.64 | 24.95 | |
| ESD | 9.20 | 8.85 | 8.35 | 7.45 | 12.69 | 16.96 | |
| CP | 93.5 | 92.0 | 92.5 | 78.0 | 93.5 | 94.0 | |
| n = 1000 | Bias | 0.06 | 0.11 | 0.04 | 1.91 | −10.74 | −10.88 |
| SD | 3.86 | 3.38 | 3.32 | 4.06 | 10.67 | 10.45 | |
| RMSE | 3.86 | 3.38 | 3.32 | 4.49 | 15.14 | 15.09 | |
| ESD | 3.83 | 3.67 | 3.56 | 3.91 | 7.49 | 7.52 | |
| CP | 95.0 | 95.5 | 95.0 | 88.0 | 80.5 | 82.0 | |
In this simulation,
has one effective direction,
has four effective directions, and
has four effective directions. For μ̂Y and μ̂d, we use only the first three components of the estimated SY and Sd. Among its first three components, Sd has X2 as information conveyer for δ and the other two components as primary information conveyers for Y. Therefore, the dimension reduced score
still maintains the conditional balance (3) and leads to consistent estimate with good efficiency. For SY, its first three components carry around 93% X information about Y. The dimension reduced score
does not maintain the conditional balance, but it conveys enough X information for the proposed estimation: μ̂Y has much smaller bias and is more stable than the model based estimators. This simulation also shows that μ̂d can outperform μ̂δ and μ̂Y : it outperforms the former in efficiency and the latter in consistency.
Dimension reduction methods are mostly developed under certain distributional assumptions. It is thus worth investigating robustness of the proposed estimation to the distribution assumptions under which the effective directions are estimated. For this purpose, we have the following simulation. In simulation 3, Z1, ···, Z4 are independent N(0, 1), π = expit(−Z1 + 0.5Z2−0.25Z3−0.1Z4), and Y = 210 + 4Z1 + 2Z2 + 2Z3 + Z4 + ε. Suppose the covariates actually observed are X1 = exp(Z1/2), X2 = Z2/(1 + exp(Z1)), X3 = (Z1Z3/25 + 0.6)3, X4 = (Z3 + Z4 + 20)2, X5 = X3X4, and X6, ···, X10 of independent uniform (0, 1). This setup mimics that of Kang & Schafer (2007). Here we use the sliced inverse regression to estimate the effective directions, even though X does not satisfy the linearity condition, to explore robustness.
Estimation results are in Table 3. Here we see that the proposed estimation is quite robust to mild violation of the linearity condition. This is not surprising, as sliced inverse regression is not sensitive to the linearity condition (Li, 1991). The effective balancing scores are all 4-dimensional, and we use the dimension reduced effective scores in the proposed estimation. Though the dimension reduced effective scores lose some X information, the proposed estimators still outperform the model based estimators. The inverse propensity weighting estimator μ̂ipw has huge bias and variability, demonstrating the instability associated with inverse propensity weighting. The doubly robust estimator μ̂aipw has poor performance, exemplifying the drawback of doubly robust estimators whose performance relies on model specification.
Table 3.
Results for simulation 3: Monte Carlo bias (Bias), standard deviation (SD), root mean squared error (RMSE).
| μ̂δ | μ̂Y | μ̂d | μ̂reg | μ̂ipw | μ̂aipw | ||
|---|---|---|---|---|---|---|---|
|
|
|||||||
| n = 200 | Bias | −0.17 | 0.08 | −0.12 | 0.33 | 247.21 | −2.70 |
| SD | 0.50 | 0.42 | 0.42 | 0.46 | 184.3 | 3.21 | |
| RMSE | 0.53 | 0.43 | 0.44 | 0.57 | 308.35 | 4.20 | |
| n = 1000 | Bias | −0.14 | 0.07 | −0.09 | 0.27 | 261.72 | −4.38 |
| SD | 0.20 | 0.19 | 0.19 | 0.23 | 110.06 | 6.48 | |
| RMSE | 0.24 | 0.2 | 0.21 | 0.35 | 283.92 | 7.82 | |
In summary, the proposed estimators have comparable performance to the model based estimators when the parametric models are correctly specified, and outperform the model based estimators otherwise. The proposed estimators also show roughly root-n consistency. When the effective balancing score is more than three dimensional, its first three components lead to good estimate.
5. Application
We demonstrate the proposed estimation by an Human Immunodeficiency Virus study, where 820 infected patients received combination antiretroviral therapy and had baseline characteristics measured prior to therapy, see Matthews et al. (2011). The baseline characteristics included weight, body mass index, age, CD4 counts, HIV viral load, hemoglobin, platelet, SGPT, and albumin. We are interested in the CD4 counts 96 weeks post therapy. Due to drop out and death, around 50% patients were lost to follow-up at 96 weeks. It is plausible to assume missing at random; that is, whether a patient stayed in the study depended on his/her baseline characteristics. In this study, X is the vector of baseline characteristics and Y is the CD4 counts at 96 weeks. Our interest is the mean CD4 count E(Y).
We first fit the response pattern m(X) = E(Y | X) by linear regression and the propensity score π(X) = Pr(δ = 1 | X) by linear logistic regression. Figure 1 shows poor fit of m̂(X) and π̂(X). With X of dimension 9, it is nearly impossible to try out all possible higher order terms for m(X) and π(X). This casts doubt on the reliability of model based estimators. We turn to the effective balancing scores for the estimation of E(Y).
Fig. 1.

Parametric fit to the response and the missingness. On the left is the observed response versus the fitted response from linear regression. On the right is the box plot of the fitted propensity score from linear logistic regression: 0 for the subjects with Y missing and 1 for the subjects with Y observed.
The estimates of E(Y) are in Table 4, where the standard deviations are estimated by bootstrap with 200 replications. In the proposed estimation, the effective propensity score Sδ; is 1-dimensional, the effective prognostic score SY and the effective double balancing score Sd are 2-dimensional, where the dimensions are determined by the sequential permutation test (Cook & Yin, 2001).
Table 4.
Estimates of mean CD4 counts at 96 weeks: the proposed estimator μ̂δ, μ̂Y, and μ̂d, the inverse propensity weighting estimator μ̂ipw, the regression estimator μ̂reg, and the augmented inverse propensity weighting estimator μ̂aipw.
| μ̂δ | μ̂Y | μ̂d | μ̂reg | μ̂ipw | μ̂aipw | |
|---|---|---|---|---|---|---|
| Estimate | 322.7 | 323.3 | 323.0 | 322.4 | 680.6 | 328.5 |
| SD | 8.6 | 8.8 | 8.8 | 8.4 | 33.2 | 8.9 |
Diagnostic analysis indicates overlapping of
and
. More specifically, the first effective direction of
and that of
are close, both close to the first effective direction of
. As the first effective direction of
conveys about 70% X information about Y, the three nonparametric balancing score estimates are quite close. The inverse propensity weighting estimator π̂ipw shows big bias and variability due to the poor fit of π̂(X) and the sensitivity associated with inverse weighting. In spite of the poor fit of m̂(X), the regression estimator μ̂reg seems to have little bias. This is because the bias of μ̂reg is
, and averaging over the samples can sometimes mitigate the point-wise bias in m̂(X).
6. Discussion
Most dimension reduction methods recover B = (β1, ···, βK) as the eigenvectors of a kernel matrix. The sliced inverse regression takes cov{E(X |
)} as the kernel matrix and the sliced average variance estimation uses E[{I − cov(X |
)}2], both estimated through slicing the response
. The eigenvectors corresponding to the K largest eigenvalues are the estimates. Both methods give root-n consistent estimates under the linearity condition, which is satisfied if X has an elliptically symmetric distribution. The sliced average variance additionally assumes cov(X | B′X) to be constant.
The principal fitted component method of Cook (2007) is an extension of the sliced inverse regression. The method first finds a basis function Fy = {f1(y), ···, fr(y)} for the inverse regression X | Y, and then estimates the effective directions through PF X, the projection of X onto the subspace spanned by Fy. Though derived from normal likelihood function, the method is not tied to normality. It has “double robustness” in the sense that root-n consistency is attained under either normality or Fy is well correlated to E(X | Y). Appropriate selection of Fy allows more effective utilization of the inverse regression information than the sliced inverse regression. Approaches for finding Fy include the inverse response plot of X versus Y (Cook, 1998), spline basis, and inverse slicing. When the inverse regression X | Y has isotropic errors, estimates of β1, ···, βK are simply the K largest eigenvectors of cov(PF X). Cook (2007), Cook & Forzani (2008) and Cook & Forzani (2009) give details about this method under various scenarios. Ding & Cook (2013) further extends this method to matrix-valued covariates.
Recently, Ma & Zhu (2012) proposed the semiparametric dimension reduction method. It is the only method that requires no distributional assumptions for root-n consistency. The estimation of B = (β1, ···, βK) is from an estimating equation derived from a semiparametric influence function. By appropriately defining the terms in the influence function, this semiparametric method includes many dimension reduction methods as special cases. For example, one estimating equation takes the form
which reduces to the sliced inverse regression under the linearity condition. Consistency is achieved if either E(· | Y) or E(· | BT X) is correctly specified, and nonparametric regression is proposed for estimating the two conditional means to circumvent model specification. This method can also handle categorial covariates so long as at least one covariate is continuous. This is a powerful method for dimension reduction but involves intensive computation.
As mentioned in §2, any root-n consistent dimension reduction method is good for finding the effective directions in the proposed method. We can pick a method of our convenience so long as the distributional assumptions are satisfied.
Appendix
Appendix 1. Proof for
=
Denote Bd as the basis for
and Bd* as the basis for
. From (4),
It follows that
and
⊂
.
Note that
where the second equation is due to Pr(Y = 0 | X) = 0 for Y continuous. Since Bd* is the basis for
, the right hand side of the above equation is a function of
. Thus
and
⊂
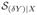 .
.
Note that
The second equation is true due to missing at random. In the above equations, Pr(δY ≤ y | X) is a function of
as Bd* is the basis for
, Pr(δ = 0 | X) and Pr(δ = 1 | X) are functions of
as
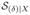 ⊂
. Therefore, Pr(Y ≤ y | X) is a function of
. It follows that
and
⊂
.
⊂
. Therefore, Pr(Y ≤ y | X) is a function of
. It follows that
and
⊂
.
As
⊂
and
⊂
, it follows from Remark 2 that
⊂
.
If Y is categorical, we can perform a shift transformation Y* = Y + c such that Y* > 0. It follows that
=
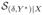 =
=
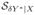 .
.
Appendix 2. Proof of Theorem 1
Theorem 1 is developed under the following regularity conditions:
The kernel function satisfies: ∫u
(u)du = 0, ∫ uuT
(u)du =
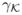 I2, and ∫
I2, and ∫
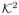 (u)du =
(u)du =
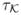 , with
< ∞ and
< ∞.
, with
< ∞ and
< ∞.π(x) is bounded away from 0.
The density of x is bounded away from 0.
We write n1/2(μ̂ − μ) as
with
where
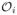 = {(Xj, Yj, δj) : j ≠ i}. It is obvious that n1/2An converges in distribution to N (0, var{m(S)}).
= {(Xj, Yj, δj) : j ≠ i}. It is obvious that n1/2An converges in distribution to N (0, var{m(S)}).
By (5),
with and f(s) the density of S. It follows that
Similar to the argument for Theorem 2.1 of Cheng (1994), it can be shown that with
Due to conditional independence (3), converges in distribution to N (0, E{var(Y | S)/π(S)}).
For Cn, E(Cn) = 0 and , thus Cn = op(n−1/2). As An and are independent, n1/2(μ̂ − μ) is asymptotically normal of mean 0 and variance var{m(S)} + E{var(Y | S)/π(S)}.
Following Ruppert & Wand (1994), the negligible terms involving H are
With H = hnIK, and ,
In the above expressions,
, where ∇m(s) and
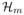 (s) stand for the gradient and the Hessian matrix of m(s), respectively, ∇πf/πf(s) = {π(s)∇f (s) + ∇π(s)f(s)}/{π(s)/{π(s)f(s)} with ∇π(s) and ∇f (s) the gradients of π(s) and f (s), respectively.
(s) stand for the gradient and the Hessian matrix of m(s), respectively, ∇πf/πf(s) = {π(s)∇f (s) + ∇π(s)f(s)}/{π(s)/{π(s)f(s)} with ∇π(s) and ∇f (s) the gradients of π(s) and f (s), respectively.
The mean squared error is
The optimal bandwidth, which minimizes the mean squared error, is
which can be estimated by the plug-in method.
Appendix 3. Proof of Theorem 2
Denote the proposed estimator under B̂, the root-n estimate of B, as which is given as in (6) except that
with Ŝ = B̂X.
The difference between
and μ̂ comes from that between
(Si − Sj) and
. With H = hnIK,
and
. The latter can be further written as
At optimal bandwidth hn ~ n−2/(K+4) and B̂ − B = Op(n−1/2), the second term inside the kernel function is O{n−K/(2K+8)} = op(n−1/2). It follows that , and is asymptotically equivalent to μ̂.
Contributor Information
Zonghui Hu, Email: huzo@niaid.nih.gov, Biostatistics Research Branch, National Institute of Allergy and Infectious Diseases, National Institutes of Health, Maryland 20892-7609, USA.
Dean A. Follmann, Email: dfollmann@niaid.nih.gov, Biostatistics Research Branch, National Institute of Allergy and Infectious Diseases, National Institutes of Health, Maryland 20892-7609, USA
Naisyin Wang, Email: nwangaa@umich.edu, Department of Statistics, University of Michigan, Ann Arbor MI 48109-1107, USA.
References
- Abadie A, Imbens GW. Large sample properties of matching estimators for average treatment effects. Econometrica. 2006;74:235–267. [Google Scholar]
- Cao W, Tsiatis A, Davidian M. Improving efficiency and robustness of the doubly robust estimator for a population mean with incomplete data. Biometrika. 2009;96:732–734. doi: 10.1093/biomet/asp033. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cheng PE. Nonparametric estimation of mean functionals with data missing at random. Journal of the American Statistical Association. 1994;89:81–87. [Google Scholar]
- Chiaromonte F, Cook DR, Li B. Sufficient dimension reduction in regressions with categorical predictors. The annals of Statistics. 2002;30:475–497. [Google Scholar]
- Cook DR, Li B. Dimension reduction for conditional mean in regression. The annals of Statistics. 2002;30:455–474. [Google Scholar]
- Cook RD. On the interpretation of regression plots. Journal of American Statistical Association. 1994;89:177–189. [Google Scholar]
- Cook RD. Regression graphics: ideas for studying regressions through graphics. New York: Wiley; 1998. [Google Scholar]
- Cook RD. Fisher lecture: dimension reduction in regression. Statistical Science. 2007;22:1–26. [Google Scholar]
- Cook RD, Forzani L. Principal fitted components for dimension reduction in regression. Statistical Science. 2008;23:485–501. [Google Scholar]
- Cook RD, Forzani L. Likelihood-based sufficient dimension reduction. Journal of the American Statistical Association. 2009;104:197–208. [Google Scholar]
- Cook RD, Weisberg S. Discussion of “sliced inverse regression for dimension reduction”. Journal of American Statistical Association. 1991;86:328–332. [Google Scholar]
- COOK RD, Yin XR. Dimension reduction and visualization in discriminant analysis. Australian & New Zealand Journal of Statistics. 2001;43:147–177. [Google Scholar]
- D’Agostino RB. Propensity score methods for bias reduction in the comparison of a treatment to a non-randomized control group. Statistics in Medicine. 1998;17:2265–2281. doi: 10.1002/(sici)1097-0258(19981015)17:19<2265::aid-sim918>3.0.co;2-b. [DOI] [PubMed] [Google Scholar]
- Devroye LP, Wagner TJ. Distribution-free consistency results in nonparametric discrimination and regression function estimations. The Annuals of Statistics. 1980;8:231–239. [Google Scholar]
- Ding S, Cook RD. Statistica Sinica. 2013. Dimension folding pca and pfc for matrix-valued predictors. To appear. [Google Scholar]
- Dong Y, Li B. Dimension reduction for non-elliptically distributed predictors: second-order moments. Biometrika. 2010;97:279–294. [Google Scholar]
- Fan J, Marron JS. Best possible constant for bandwidth selection. The Annals of Statistics. 1992;20:2057–2070. [Google Scholar]
- Hahn J. On the role of the propensity score in efficient semiparametric estimation of average treatment effects. Econometrica. 1998;66:315–331. [Google Scholar]
- Hansen BB. The prognostic analogue of the propensity score. Biometrika. 2008;95:481–488. [Google Scholar]
- Härdle W, Müller M, Sperlich S, Werwatz A. Nonparametric and semiparametric models. Berlin Heidelberg: Springer-Verlag; 2004. [Google Scholar]
- Hastie T, Tibshirani R. Generalized additive models. Statistical Science. 1986;1:297–318. doi: 10.1177/096228029500400302. [DOI] [PubMed] [Google Scholar]
- Horvitz DG, Thompson DJ. A generalization of sampling without replacement from a finite universe. Journal of American Statistical Association. 1952;47:663–685. [Google Scholar]
- Kang DY, Schafer JL. Demystifying double robustness: a comparison of alternative strategies for estimating a population mean from incomplete data. Statistical Science. 2007;22:523–539. doi: 10.1214/07-STS227. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li B, Dong Y. Dimension reduction for non-elliptically distributed predictors. The Annals of Statistics. 2009;37:1272–1298. [Google Scholar]
- Li B, Wang S. On directional regression for dimension reduction. Journal of the American Statistical Association. 2007;102:997–1008. [Google Scholar]
- Li KC. Sliced inverse regression for dimension reduction. Journal of American Statistical Association. 1991;86:316–327. [Google Scholar]
- Li Y, Zhu LX. Asymptotics for sliced average variance estimation. The Annals of Statistics. 2007;35:41–69. [Google Scholar]
- Little R, An H. Robust likelihood-based analysis of multivariate data with missing values. Statistica Sinica. 2004;14:949–968. [Google Scholar]
- Lunceford J, Davidian M. Stratification and weighting via the propensity score in estimation of causal treatment effects. Statistics in Medicine. 2004;23:2937–2960. doi: 10.1002/sim.1903. [DOI] [PubMed] [Google Scholar]
- Ma Y, Zhu L. A semi parametric approach to dimension reduction. Journal of the American Statistical Association. 2012;107:168–179. doi: 10.1080/01621459.2011.646925. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Matthews GV, Manzini P, Hu Z, Khabo P, Maja P, Matchaba G, Sangweni P, Metcalf J, Pool N, Orsega S, Emery S STUDY TEAM PI. Impact of lamivudine on hiv and hepatitis b virus-related outcomes in hiv/hepatitis b virus individuals in a randomized clinical trial of antiretroviral therapy in southern africa. AIDS. 2011;25:1727–1735. doi: 10.1097/QAD.0b013e328349bbf3. [DOI] [PubMed] [Google Scholar]
- Robins JM, Rotnitzky A. Semiparametric efficiency in multivariate regression models with missing data. Journal of American Statistical Association. 1995;90:122–129. [Google Scholar]
- Robins JM, Rotnitzky A, Zhao LP. Estimation of regression coefficients when some regressors are not always observed. Journal of the American Statistical Association. 1994;89:846–866. [Google Scholar]
- Rosenbaum PR. Observational Studies. 2. New York: Springer; 2002. [Google Scholar]
- Rosenbaum PR, Rubin DB. The central role of the propensity score in observational studies for causal effects. Biometrika. 1983;60:211–213. [Google Scholar]
- Rubin DB. Multiple imputation for nonresponse in surveys. New York: Wiley; 1987. [Google Scholar]
- Ruppert D, Wand MP. Multivariate locally weighted least squares regression. Annals of Statistics. 1994;22:1346–1370. [Google Scholar]
- Schafer JL. Analysis of incomplete multivariate data. London: Chapman and Hall; 1997. [Google Scholar]
- Scharfstein DO, Rotnitzky A, Robins JM. Adjusting for nonignorable drop-out using semi-parametric nonresponse models. Journal of American Statistical Association. 1999;94:1096–1120. [Google Scholar]
- Sheather SJ, Jones MC. A reliable data-based bandwidth selection method for kernel density estimation. Journal of the Royal Statistical Society, Series B. 1991;53:683–690. [Google Scholar]
- Silverman BW. Density estimation for statistics and data analysis, Vol 26. of monographs on statistics and applied probability. London: Chapman and Hall; 1986. [Google Scholar]
- Vartivarian S, Little RJA. Proceedings of the Survey Research Methods Section, American Statistical Association. American Statistical Association; 2008. On the formation of weighted adjustment cells for unit nonresponse. [Google Scholar]