

Abstract
Generalized linear models play an essential role in a wide variety of statistical applications. This paper discusses an approximation of the likelihood in these models that can greatly facilitate computation. The basic idea is to replace a sum that appears in the exact log-likelihood by an expectation over the model covariates; the resulting “expected log-likelihood” can in many cases be computed significantly faster than the exact log-likelihood. In many neuroscience experiments the distribution over model covariates is controlled by the experimenter and the expected log-likelihood approximation becomes particularly useful; for example, estimators based on maximizing this expected log-likelihood (or a penalized version thereof) can often be obtained with orders of magnitude computational savings compared to the exact maximum likelihood estimators. A risk analysis establishes that these maximum EL estimators often come with little cost in accuracy (and in some cases even improved accuracy) compared to standard maximum likelihood estimates. Finally, we find that these methods can significantly decrease the computation time of marginal likelihood calculations for model selection and of Markov chain Monte Carlo methods for sampling from the posterior parameter distribution. We illustrate our results by applying these methods to a computationally-challenging dataset of neural spike trains obtained via large-scale multi-electrode recordings in the primate retina.
Keywords: Neural coding, Generalized linear models, Computationally efficient algorithms, Expected log-likelihood
1 Introduction
Systems neuroscience has experienced impressive technological development over the last decade. For example, ongoing improvements in multi-electrode recording (Brown et al. 2004; Field et al. 2010; Stevenson and Kording 2011) and imaging techniques (Cossart et al. 2003; Ohki et al. 2005; Lütcke et al. 2010) have made it possible to observe the activity of hundreds or even thousands of neurons simultaneously. To fully realize the potential of these new high-throughput recording techniques, it will be necessary to develop analytical methods that scale well to large neural population sizes. The need for efficient computational methods is especially pressing in the context of on-line, closed-loop experiments (Donoghue 2002; Santhanam et al. 2006; Lewi et al. 2009).
Our goal in this paper is to develop scalable methods for neural spike train analysis based on a generalized linear model (GLM) framework (McCullagh and Nelder 1989). This model class has proven useful for quantifying the relationship between neural responses and external stimuli or behavior (Brillinger 1988; Paninski 2004; Truccolo et al. 2005; Pillow et al. 2008; Truccolo et al. 2010), and has been applied successfully in a wide variety of brain areas; see, e.g., (Vidne et al. 2012) for a recent review (Of course, GLMs are well-established as a fundamental tool in applied statistics more generally). GLMs offer a convenient likelihood-based approach for predicting responses to novel stimuli and for neuronal decoding (Paninski et al. 2007), but computations involving the likelihood can become challenging if the stimulus is very high-dimensional or if many neurons are observed.
The key idea presented here is that the GLM log-likelihood can be approximated cheaply in many cases by exploiting the law of large numbers: we replace an expensive sum that appears in the exact log-likelihood (involving functions of the parameters and observed covariates) by its expectation to obtain an approximate “expected log-likelihood” (EL) (a phrase coined by Park and Pillow in (2011). Computing this expectation requires knowledge, or at least an approximation, of the covariate distribution. In many neuroscience experiments the covariates correspond to stimuli which are under the control of the experimenter, and therefore the stimulus distribution (or least some moments of this distribution) may be considered known a priori, making the required expectations analytically or numerically tractable. The resulting EL approximation can often be computed significantly more quickly than the exact log-likelihood. This approximation has been exploited previously in some special cases (e.g., Gaussian process regression (Sollich and Williams 2005; Rasmussen and Williams 2005) and maximum likelihood estimation of a Poisson regression model (Paninski 2004; Field et al. 2010; Park and Pillow 2011; Sadeghi et al. 2013)). We generalize the basic idea behind the EL from the specific models where it has been applied previously to all GLMs in canonical form and discuss the associated computational savings. We then examine a number of novel applications of the EL towards parameter estimation, marginal likelihood calculations, and Monte Carlo sampling from the posterior parameter distribution.
2 Results
2.1 Generalized linear models
Consider a vector of observed responses, r = (r1, ..., rN), resulting from N presentations of a p dimensional stimulus vector, xi (for i = 1, ..., N). Under a GLM, with model parameters θ, the likelihood for r is chosen from an exponential family of distributions (Lehmann and Casella 1998). If we model the observations as conditionally independent given x (an assumption we will later relax), we can write the log-likelihood for r as
| (1) |
for some functions a(), G(), and c(), with φ an auxiliary parameter (McCullagh and Nelder 1989), and where we have written terms that are constant with respect to θ as const(θ). For the rest of the paper we will consider the scale factor c(φ) to be known and for convenience we will set it to one. In addition, we will specialize to the “canonical” case that is the identity function. With these choices, we see that the GLM log-likelihood is the sum of a linear and non-linear function of θ,
| (2) |
This expression will be the jumping-off point for the EL approximation. However, first it is useful to review a few familiar examples of this GLM form.
First consider the standard linear regression model, in which the observations r are normally distributed with mean given by the inner product of the parameter vector θ and stimulus vector x. The log-likelihood for r is then
| (3) |
| (4) |
where for clarity in the second line we have suppressed the scale factor set by the noise variance σ2. The non-linear function G(.) in this case is seen to be proportional to .
As another example, in the standard Poisson regression model, responses are distributed by an inhomogeneous Poisson process whose rate is given by the exponential of the inner product of θ and x. (In the neuroscience literature this model is often referred to as a linear-nonlinear-Poisson (LNP) model (Simoncelli et al. 2004)). If we discretize time so that rn denotes the number of events (e.g., in the neuro-science setting the number of emitted spikes) in time bin n, the log-likelihood is
| (5) |
| (6) |
In this case we see that G(.) = exp(.).
As a final example, consider the case where responses are distributed according to a binary logistic regression model, so that rn only takes two values, say 0 or 1, with defined according to the canonical “logit” link function
| (7) |
Here the log-likelihood is
| (8) |
| (9) |
| (10) |
so G(.) = log (1 + exp(.)).
2.2 The computational advantage of using expected log-likelihoods over log-likelihoods in a GLM
Now let's examine Eq. (2) more closely. For large values of N and p there is a significant difference in the computational cost between the linear and non-linear terms in this expression. Because we can trivially rearrange the linear term as , its computa a single evaluation of the weighted sum over vectors , no matter how many times the log-likelihood is evaluated. (Remember that the simple linear structure of the first term is a special feature of the canonical link function; our results below depend on this canonical assumption.) More precisely, if we evaluate the log-likelihood K times, the number of operations to compute the linear term is O(Np + Kp); computing the non-linear sum, in contrast, requires O(KNp) operations in general. Therefore, the main burden in evaluating the log-likelihood is in the computation of the non-linear term. The EL, denoted by , is an approximation to the log-likelihood that can alleviate the computational cost of the non-linear term. We invoke the law of large numbers to approximate the sum over the non-linearity in Eq. (2) by its expectation (Paninski 2004; Field et al. 2010; Park and Pillow 2011; Sadeghi et al. 2013):
| (11) |
| (12) |
where the expectation is with respect to the distribution of x. The EL trades in the O(KNp) cost of computing the nonlinear sum for the cost of computing E [G(xT θ)] at K different values of θ, resulting in order O(Kz) cost, where z denotes the cost of computing the expectation E [G(xT θ)]. Thus the nonlinear term of the EL can be be computed about times faster than the dominant term in the exact GLM log-likelihood. Similar gains are available in computing the gradient and Hessian of these terms with respect to θ.
How hard is the integral E [G(xT θ)] in practice? I.e., how large is z? First, note that because G only depends on the projection of x onto θ, calculating this expectation only requires the computation of a one-dimensional integral:
| (13) |
where ζθ is the (θ-dependent) distribution of the one-dimensional variable q = xT θ. If ζθ is available analytically, then we can simply apply standard unidimensional numerical integration methods to evaluate the expectation.
In certain cases this integral can be performed analytically. Assume (wlog) that E [x] = 0, for simplicity. Consider the standard regression case: recall that in this example
| (14) |
implying that
| (15) |
where we have abbreviated E [xxT] = C. It should be noted that for this Gaussian example one only needs to compute the non-linear sum in the exact likelihood once, since and can be precomputed. However, as discussed in Section 2.3, if C is chosen to have some special structure, e.g., banded, circulant, Toeplitz, etc., estimates of θ can still be computed orders of magnitude faster using the EL instead of the exact likelihood.
The LNP model provides another example. If p(x) is Gaussian with mean zero and covariance C, then
| (16) |
| (17) |
where we have recognized the moment-generating function of the multivariate Gaussian distribution.
Note that in each of the above cases, E [G(xT θ)] depends only on θT Cθ. This will always be the case (for any nonlinearity G(.)) if p(x) is elliptically symmetric, i.e.,
| (18) |
for some nonnegative function h(.)1. In this case we have
| (19) |
| (20) |
= where we have made the change of variables y = C−1/2x, α’ = C1/2α. Note that the last integral depends on θ’ only through its norm; the integral is invariant with respect to transformations of the form θ’ → Oθ’, for any orthogonal matrix O (as can be seen by the change of variables z = OT y). Thus we only need to compute this integral once for all values of , up to some desired accuracy. This can be precomputed off-line and stored in a one-d lookup table before any EL computations are required, making the amortized cost z very small.
What if p(x) is non-elliptical and we cannot compute ζθ easily? We can still compute E [G(xT θ)] approximately in most cases with an appeal to the central limit theorem (Sadeghi et al. 2013): we approximate q= xTθ in Eq. (13) as Gaussian, with mean E [θT x] = θT[x] = 0 and variance var(θT x) θT Cθ. This approximation can be justified by the classic results of Diaconis and Freedman (1984), which imply that under certain conditions, if d is sufficiently large, then ζθ is approximately Gaussian for most projections θ. (Of course in practice this approximation is most accurate when the vector x consists of many weakly-dependent, light-tailed random variables and θ has large support, so that q is a weighted sum of many weakly-dependent, light-tailed random variables). Thus, again, we can precompute a lookup function for E [G(xT θ)], this time over the two-d table of all desired values of the mean and variance of q. Numerically, we find that this approximation often works quite well; Fig. 1 illustrates the approximation for simulated stimuli drawn from two non-elliptic distributions (binary white noise stimuli in A and Weibull-distributed stimuli in B).
Fig. 1.
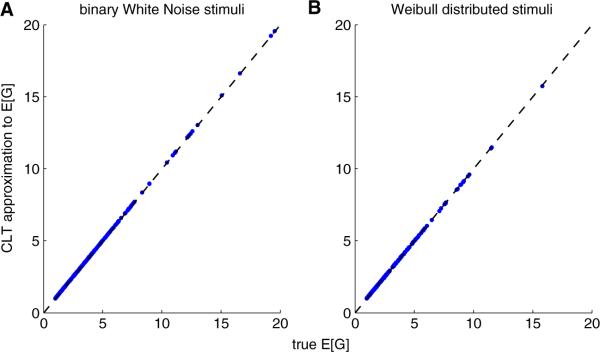
The normal approximation for ζθ is often quite accurate for the computation of E [G] (Eq. (13) in the text). Vertical axis corresponds to central limit theorem approximation of E [G], and horizontal axis corresponds to the true E [G], computed numerically via brute-force Monte Carlo. We used a standard Poisson regression model here, corresponding to an exponential G function. The stimulus vector x is composed of 600 i.i.d. binary (a) or Weibull (b) variables; x has mean 0.36 in panel A, and the Weibull distribution in panel B has scale and shape parameters 0.15 and 0.5, respectively. Each dot corresponds to a different value of the stimulus filter θ. These were zero-mean, Gaussian functions with randomly-chosen norm (uniformly distributed on the interval 0 to 0.5) and scale (found by taking the absolute value of a normally distributed variable with variance equal to 2)
2.3 Computational efficiency of maximum expected log-likelihood estimation for the LNP and Gaussian model
As a first application of the EL approximation, let us examine estimators that maximize the likelihood or penalized likelihood. We begin with the standard maximum likelihood estimator,
| (21) |
Given the discussion above, it is natural to maximize the expected likelihood instead:
| (22) |
where “MELE” abbreviates “maximum EL estimator.” We expect that the MELE should be computationally cheaper than the MLE by a factor of approximately Np/z, since computing the EL is approximately a factor of Np/z faster than computing the exact likelihood. In fact, in many cases the MELE can be computed analytically while the MLE requires a numerical optimization, making the MELE even faster.
Let's start by looking at the standard regression (Gaussian noise) case. The EL here is proportional to
| (23) |
where we have used Eq. (15) and defined X = (x1, ..., xN)T . This is a quadratic function of θ; optimizing directly, we find that the MELE is given by
| (24) |
Meanwhile, the MLE here is of the standard least-squares form
| (25) |
assuming XT X is invertible (the solution is non-unique otherwise).
The computational cost of determining both estimators is determined by the cost of solving a p-dimensional linear system of equations; in general, this requires O(p3) time. However, if C has some special structure, e.g., banded, circulant, Toeplitz, etc. (as is often the case in real neuroscience experiments), this cost can be reduced to O(p) (in the banded case) or O(p log(p)) (in the circulant case) (Golub and van Van Loan 1996). The MLE will typically not enjoy this decrease in computational cost, since in general XT X will be unstructured even when C is highly structured. (Though counterexamples do exist; for example, if X is highly sparse, then XT X may be sparse even if C is not, for sufficiently small N).
As another example, consider the LNP model. Somewhat surprisingly, the MELE can be computed analytically for this model (Park and Pillow 2011) if p(x) is Gaussian and we modify the model slightly to include an offset term so that the Poisson rate in the n-th time bin is given by
| (26) |
with the likelihood and EL modified appropriately. The details are provided in Park and Pillow (2011) and also, for completeness, the methods section of this paper; the key result is that if one first optimizes the EL Eq. (12) with respect to the offset θ0 and then substitutes the optimal θ0 back into the EL, the resulting “profile” expected log-likelihood maxθ0 , is a quadratic function of θ, which can be optimized easily to obtain the MELE:
| (27) |
| (28) |
| (29) |
Note that this is essentially the same quadratic problem as in the Gaussian case Eq. (23) with the total number of spikes replacing the number of samples N in Eq. (23). In the neuroscience literature, the function is referred to as the spike-triggered average, since if time is discretized finely enough so that the entries of r are either 0 or 1, the product is simply an average of the stimulus conditioned on the occurrence of a ‘spike’ (r = 1). The computational cost for computing here is clearly identical to that in the Gaussian model (only a simple linear equation solve is required), while to compute the MLE we need to resort to numerical optimization methods, costing O(KNp), with K typically depending superlinearly on p. The MELE can therefore be orders of magnitude faster than the MLE here if Np is large, particularly if C has some structure that can be exploited. See Park and Pillow (2011), Sadeghi et al. (2013) for further discussion.
What about estimators that maximize a penalized likelihood? Define the maximum penalized expected log-likelihood estimator (MPELE)
| (30) |
where log(f (θ)) represents a penalty on θ; in many cases f (θ) has a natural interpretation as the prior distribution of θ. We can exploit special structure in C when solving for the MPELE as well. For example, if we use a mean-zero (potentially improper) Gaussian prior, so that for some positive semidefinite matrix R, the MPELE for the LNP model is again a regularized spike-triggered average (see Park and Pillow (2011) and methods)
| (31) |
For general matrices R and C, the dominant cost of computing will be O(Np + p3). (The exact maximum a posteriori (MAP) estimator has cost comparable to the MLE here, O(KNp)). Again, when C and R share some special structure, e.g. C and R are both circulant or banded, the cost of drops further.
If we use a sparsening L1 penalty instead (David et al. 2007; Calabrese et al. 2011), i.e., log(f (α)) = −λ||θ||1, with λ a scalar, under a Gaussian model is defined as
| (32) |
the MPELE under an LNP model is of nearly identical form. If C is a diagonal matrix, classic results from subdifferential calculus (Nesterov 2004) show that is a solution to Eq. (32) if and only if satisfies the subgradient optimality conditions
| (33) |
| (34) |
for j = 1, ..., p. The above equations imply that is a soft-thresholded function of if |(XT r)j| ≤λ, and otherwise
| (35) |
for j = 1, ..., p. Note that Eq. (35) implies that we can independently solve for each element of along all values of λ (the so-called regularization path). Since only a single matrix-vector multiply (XT r) is required, the total complexity in this case is just O(Np). Once again, because XT X is typically unstructured, computation of the exact MAP is generally much more expensive.
When C is not diagonal we can typically no longer solve Eq. (32) analytically. However, we can still solve this equation numerically, e.g., using interior-point methods (Boyd and Vandenberghe 2004). Briefly, these methods solve a sequence of auxiliary, convex problems whose solutions converge to the desired vector. Unlike problems with an L1 penalty, these auxiliary problems are constructed to be smooth, and can therefore be solved in a small number of iterations using standard methods (e.g., Newton-Raphson (NR) or conjugate gradient (CG)). Computing the Newton direction requires a linear matrix solve of the form (C + D)θ = b, where D is a diagonal matrix and b is a vector. Again, structure in C can often be exploited here; for example, if C is banded, or diagonal plus low-rank, each Newton step requires O(p) time, leading to significant computational gains over the exact MAP.
To summarize, because the population covariance C is typically more structured than the sample covariance XT X, the MELE and MPELE can often be computed much more quickly than the MLE or the MAP estimator. We have examined penalized estimators based on L2 and L1 penalization as illustrative examples here; similar conclusions hold for more exotic examples, including group penalties, rank-penalizing penalties, and various combinations of L2 and L1 penalties.
2.4 Analytic comparison of the accuracy of EL estimators with the accuracy of maximum-likelihood estimators
We have seen that EL-based estimators can be fast. How accurate are they, compared to the corresponding MLE or MAP estimators? First, note that the MELE inherits the classical consistency properties of the MLE; i.e., if the model parameters are held fixed and the amount of data N tends to infinity, then both of these estimators will recover the correct parameter θ, under suitable conditions. This result follows from the classical proof of the consistency of the MLE (van der Vaart 1998) if we note that both (1/N)L(θ) and converge to the same limiting function of θ.
To obtain a more detailed view, it is useful to take a close look at the linear regression model, where we can analytically calculate the mean-squared error (MSE) of these estimators. Recall that we assume
| (36) |
| (37) |
(For convenience we have set σ2 1). We derive the following MSE formulas in the methods:
| (38) |
| (39) |
see Shaffer (1991) for some related results. In the classical limit, for which p is fixed and N → ∞ (and the MSE of both estimators approaches zero), we see that, unless θ = 0, the MLE outperforms the MELE:
| (40) |
However, for many applications (particularly the neuro-science applications we will focus on below), it is more appropriate to consider the limit where the number of samples and parameters are large, both N → ∞ and p → ∞, but their ratio is bounded from zero and In this limit we see that
| (41) |
| (42) |
See Fig. 7 for an illustration of the accuracy of this approximation for finite N and p.
Fig. 7.

Finite sample comparisons to the limiting values of the MLE and MELE MSE as p, N → ∞, . We plot the true mean-squared error (MSE) (colored lines) as a function of finite sample size for different values of for both the MLE (left column) and MELE (right column). Black dashed lines show limiting MSE when p, N → ∞, . The quality of the approximation does not seem to depend on for the MELE and is within 1% accuracy after about 100 samples. For the MLE, this approximation depends on . However, while the quality of the approximation depends on the estimator used, for data regimes common in neuroscience applications the limiting approximation is acceptable
Figure 2a (left panel) plots these limiting MSE curves as a function of ρ. Note that we do not plot the MSE for values of ρ > 1 because the MLE is non-unique when p is greater than N; also note that Eq. (42) diverges as ρ ↗ 1, though the MELE MSE remains finite in this regime. We examine these curves for a few different values of θT θ; note that since σ2 = 1, θT θ can be interpreted as the signal variance divided by the noise variance, i.e., the signal-to-noise ratio (SNR):
| (43) |
| (44) |
The second line follows from the fact that we choose stimuli with identity covariance. The key conclusion is that the MELE outperforms the MLE for all . (This may seem surprising, since for a given X, a classic result in linear regression is that the MLE has the lowest MSE amongst all unbiased estimators of θ (Bickel and Doksum 2007). However, the MELE is biased given X, and can therefore have a lower MSE than the MLE by having a smaller variance).
Fig. 2.

Comparing the accuracy of the MAP and MPELE in the standard linear regression model with Gaussian noise. a (left) The mean squared error (MSE) for the MELE (solid lines) and the MLE (dotted line) is shown as a function of p/N the ratio of the number of parameters to number of samples. We plot results for the asymptotic case where the number of samples and dimensions goes to infinity but the ratio p/N remains finite. Different colors denote different values for the true filter norm; recall that the MSE of the MLE is independent of the true value of θ, since the MLE is an unbiased estimator of θ in this model. The MLE mean squared error is larger than that of the MELE when p/N is large. b MSE for both estimators when L2 regularization is added. The MSE is similar for both estimators for a large range of ridge parameters and values of p/N. a (right) For each value of p/N, separate ridge parameters are chosen for the MPELE and MAP estimators to minimize their respective mean squared errors. Solid curves correspond to MPELE (as in left panel); dotted curves to MAP estimates. The difference in performance between the two optimally-regularized estimators remains small for a wide range of values of SNR and p/N. Similar results are observed numerically in the Poisson regression (LNP) case (data not shown)
What if we examine the penalized versions of these estimators? In the methods we calculate the MSE of the MAP and MPELE given a simple ridge penalty of the form , for scalar R. Figure 2b (top panel) plots the MSE for both estimators (see Eqs. (85, 101) in the methods for the equations being plotted) as a function of R and ρ for an SNR value of 1. Note that we now plot MSE values for ρ > 1 since regularization makes the MAP solution unique. We see that the two estimators have similar accuracy over a large region of parameter space. For each value of ρ we also compute each estimator's optimal MSE—i.e., the MSE corresponding to the the value of R that minimizes each estimator's MSE. This is plotted in Fig. 2a (right panel). Again, the two estimators perform similarly.
In conclusion, in the limit of large but comparable N and p, the MELE outperforms the MLE in low-SNR or high-(p/N) regimes. The ridge-regularized estimates (the MPELE and MAP) perform similarly across a broad range of (p/N) and regularization values (Fig. 2b). These analytic results motivate the applications (using non-Gaussian GLMs) on real data treated in the next section.
2.5 Fast methods for refining maximum expected log-likelhood estimators to obtain MAP accuracy
In settings where the MAP provides a more accurate estimator than the MPELE, a reasonable approach is to use as a quickly-computable initializer for optimization algorithms used to compute . An even faster approach would be to initialize our search at , then take just enough steps towards to achieve an estimation accuracy which is indistinguishable from that of the exact MAP estimator. (Related ideas based on stochastic gradient ascent methods have seen increasing attention in the machine learning literature (Bottou 1998; Boyles et al. 2011)). We tested this idea on real data, by fitting an LNP model to a population of ON and OFF parasol ganglion cells (RGCs) recorded in vitro, using methods similar to those described in Shlens et al. (2006), Pillow et al. (2008); see these earlier papers for full experimental details. The observed cells responded to either binary white-noise stimuli or naturalistic stimuli (spatiotemporally correlated Gaussian noise with spatial correlations having a 1/F power spectrum and temporal correlations defined by a first-order autoregressive process; see Appendix for details). As described in the methods, each receptive field was specified by 810 parameters, with . For the MAP, we use a simple ridge penalty of the form .
Many iterative algorithms are available for ascending the posterior to approximate the MAP. Preconditioned conjugate gradient ascent (PCG) (Shewchuk 1994) is particularly attractive here, for two reasons. First, each iteration is fairly fast: the gradient requires O(Np) time, and multiplication by the preconditioner turns out to be fast, as discussed below. Second, only a few iterations are necessary, because the MPELE is typically fairly close to the exact MAP in this setting (recall that as N/p ∞), and we have access to a good preconditioner, ensuring that the PCG iterates converge quickly. We chose the inverse Hessian of the EL evaluated at the MELE or MPELE as a pre-conditioner. In this case, using the same notation as in Eqs. (27) and (31), the preconditioner is simply given by or . Since the EL Hessian provides a good approximation for the log-likelihood Hessian, the preconditioner is quite accurate; since the stimulus covariance C is either proportional to the identity (in the white-noise case) or of block-Toeplitz form (in the spatiotemporally-correlated case), computation with the preconditioner is fast (O(p) or O(p log p), respectively).
For binary white-noise stimuli we find that the MELE (given by Eq. (27) with C = I) and MLE yield similar filters and accuracy, with the MLE slightly outperforming the MELE (see Fig. 3a). Note that in this case, can be computed quickly, O(pN), since we only need to compute the matrix-vector multiplication XT r. On average across a population of 126 cells, we find that terminating the PCG algorithm, initialized at the MELE, after just two iterations yielded an estimator with the same accuracy as the MAP. To measure accuracy we use the cross-validated log-likelihood (see Appendix). It took about 15× longer to compute the MLE to default precision than the PCG-based approximate MLE (88±2 vs 6±0.1 seconds on an Intel Core 2.8 GHz processor running Matlab; all timings quoted in this paper use the same computer). In the case of spatiotemporally correlated stimuli (with given by Eq. (31)), we find that 9 PCG iterations are required to reach MAP accuracy (see Fig. 3b); the MAP estimator was still slower to compute by a significant factor (107±8 vs 33±1 seconds).
Fig. 3.

The MPELE provides a good initializer for finding approximate MAP estimators using fast gradient-based optimization methods in the LNP model. a The spatiotemporal receptive field of a typical retinal ganglion cell (RGC) in our database responding to binary white-noise stimuli and fit with a linear-nonlinear Poisson (LNP) model with exponential non-linearity, via the MLE. The receptive field of the same cell fit using the MELE is also plotted. The goodness-offit of the MLE (measured in terms of cross-validated log-likelihood; see Appendix) is slightly higher than that of the MELE (12 versus 11 bits/s). However, this difference disappears after a couple pre-conditioned conjugate gradient (PCG) iterations using the true likelihood initialized at the MELE (see label +2PCG). Note that we are only showing representative spatial and temporal slices of the 9×9×10 dimensional receptive field, for clarity. b Similar results hold when the same cell responds to 1/f correlated Gaussian noise stimuli (for correlated Gaussian responses, the MAP and MPELE are both fit with a ridge penalty). In this case 9 PCG iterations sufficed to compute an estimator with a goodness-of-fit equal to that of the MAP. c These results are consistent over the observed population. (top) Scatterplot of cross-validated log-likelihood across a population of 91 cells, responding to binary white-noise stimuli, each fit independently using the MLE, MELE or a couple PCG iterations using the true likelihood and initialized at the MELE. (bottom) Log-likelihood for the same population, responding to 1/f Gaussian noise, fit independently using an L2 regularized MAP, MPELE or 9 PCG iterations using the true regularized likelihood initialized at the MPELE
2.5.1 Scalable modeling of interneuronal dependencies
So far we have only discussed models which assume conditional independence of responses given an external stimulus. However, it is known the predictive performance of the GLM can be improved in a variety of brain areas by allowing some conditional dependence between neurons (e.g., (Truccolo et al. 2005; Pillow et al. 2008); see Vidne et al. (2012) for a recent review of related approaches). One convenient way to incorporate these dependencies is to include additional covariates in the GLM. Specifically, assume we have recordings from M neurons and let ri be the vector of responses across time of the ith neuron. Each neuron is modeled with a GLM where the weighted covariates, , can be broken into an offset term, an external stimulus component xs, and a spike history-dependent component
| (45) |
for n = 1, ..., N, where τ denotes the maximal number of lags used to predict the firing rate of neuron i given the activity of the the observed neurons indexed by j. Note that this is the same model as before when for j = 1, 2, ...., M; in this special case, we recover an inhomogeneous Poisson model, but in general, the outputs of the coupled GLM will be non-Poisson. A key challenge for this model is developing estimation methods that scale well with the number of observed neurons; this is critical since, as discussed above, experimental methods continue to improve, resulting in rapid growth of the number of simultaneously observable neurons during a given experiment (Stevenson and Kording 2011).
One such scalable approach uses the MELE of an LNP model to fit a fully-coupled GLM with history terms. The idea is that estimates of θs fit with will often be similar to estimates of θs without this hard constraint. Thus we can again use the MELE (or MPELE) as an initializer for θs, and then use fast iterative methods to refine our estimate, if necessary. More precisely, to infer θi for i = 1, 2, ...., M, we first estimate , assuming no coupling or self-history terms ( for j = 1, 2, ...., M) using the MELE (Eq. (27) or a regularized version). We then update the history components and offset by optimizing the GLM likelihood with the stimulus filter held fixed up to a gain factor, αi, and the interneuronal terms for i ≠ j:
| (46) |
Holding the shape of the stimulus filter fixed greatly reduces the number of free parameters, and hence the computational cost, of finding the history components. Note that all steps so far scale linearly in the number of observed neurons M. Finally, perform a few iterative ascent steps on the full posterior, incorporating a sparse prior on the interneuronal terms (exploiting the fact that neural populations can often be modeled as weakly conditionally dependent given the stimulus; see Pillow et al. (2008) and Mishchenko and Paninski 2011 for further discussion). If such a sparse solution is available, this step once again often requires just O(M) time, if we exploit efficient methods for optimizing posteriors based on sparsity-promoting priors (Friedman et al. 2010; Zhang 2011).
We investigated this approach by fitting the GLM specified by Eq. (45) to a population of 101 RGC cells responding to binary white-noise using 250 stimulus parameters and 105 parameters related to neuronal history (see Appendix for full details; ). We regularize the coupling history components using a sparsity-promoting L1 penalty of the form ; for simplicity, we parametrize each coupling filter with a single basis function, so that it is not necessary to sum over many k indices. (However, note that group-sparsity-promoting approaches are also straightforward here Pillow et al. (2008)). We compute our estimates over a large range of the sparsity parameter λ using the “glmnet” coordinate ascent algorithm discussed by Friedman et al. (2010).
Figure 4b compares filter estimates for two example cells using the fast approximate method and the MAP. The filter estimates are similar (though not identical); both methods find the same coupled, nearest neighbor cells. Both methods achieve the same cross-validated prediction accuracy (Fig. 4b). The fast approximate method took an average of 1 minute to find the entire regularization path; computing the full MAP path took 16 minutes on average.
Fig. 4.

Initialization with the MPELE using an LNP model, then coordinate descent using a sparsity-promoting prior, efficiently estimates a full, coupled, non-Poisson neural population GLM. a Example stimulus, self-history, and coupling filters for two different RGC cells (top and bottom rows). The stimulus filters are laid out in a rasterized fashion to map the three-dimensional filters (two spatial dimensions and one temporal dimension) onto the two-dimensional representation shown here. Each filter is shown as a stack (corresponding to the temporal dimension) of two dimensional spatial filters, which we outline in black in the top left to aid the visualization. MAP parameters are found using coordinate descent to optimize the exact GLM log-likelihood with L1-penalized coupling filters (labeled MAP). Fast estimates of the self-history (see Appendix for details of errorbar computations) and coupling filters are found by running the same coordinate descent algorithm with the stimulus filter (SF) fixed, up to a gain, to the MELE of an LNP model (labeled ‘w fixed SF’; see text for details). Note that estimates obtained using these two approaches are qualitatively similar. In particular, note that both estimates find coupling terms that are largest for neighboring cells, as in Pillow et al. (2008), Vidne et al. (2012). We do not plot the coupling weights for cells 31–100 since most of these are zero or small. b Scatter-plot comparing the cross-validated log-likelihood over 101 different RGC cells show that the two approaches lead to comparable predictive accuracy
2.6 Marginal likelihood calculations
In the previous examples we have focused on applications that require us to maximize the (penalized) EL. In many applications we are more interested in integrating over the likelihood, or sampling from a posterior, rather than simply optimization. The EL approximation can play an important role in these applications as well. For example, in Bayesian applications one is often interested in computing the marginal likelihood: the probability of the data, p(r), with the dependence on the parameter θ integrated out (Gelman et al. 2003; Kass and Raftery 1995). This is done by assigning a prior distribution f (θ|R), with its own “hyper-parameters” R, over θ and calculating
| (47) |
Hierarchical models in which R sets the prior over θi for many neurons i simultaneously are also useful (Behseta et al. 2005); the methods discussed below extend easily to this setting.
We first consider a case for which this integral is analytically tractable. We let the prior on θ be Gaussian, and use the standard regression model for r|θ:
| (48) |
| (49) |
where I is the identity matrix. Computing the resulting Gaussian integral, we have
| (50) |
| (51) |
If R and XT X do not share any special structure, each evaluation of F (R) requires O(p3) time.
On the other hand, if we approximate p(r|X, θ) by the the expected likelihood, the integral is still tractable and has the same form as Eq. (50), but with assuming are faster for example, if C and R can be diagonalized (or made banded) in a convenient shared basis, then F (R) can often be computed in just O(p) time.
When the likelihood or prior is not Gaussian we can approximate the marginal likelihood using the Laplace approximation (Kass and Raftery 1995)
| (52) |
again neglecting factors that are constant with respect to R. H (θMAP) is the posterior Hessian
| (53) |
evaluated at θ = θMAP. We note that there are other methods for approximating the integral in Eq. (47), such as Evidence Propagation (Minka 2001; Bishop 2006); we leave an exploration of EL-based approximations of these alternative methods for future work.
We can clearly apply the EL approximation in Eqs. (52–53). For example, consider the LNP model, where we can approximate E [G(θ0 + xT θ)] as in Eq. (16); if we use a normal prior of the form f (θs|R) = N (0, R−1), then the resulting EL approximation to the marginal likelihood looks very much like the Gaussian case, with the attending gains in efficiency if C and R share an exploitable structure, as in our derivation of the MPELE in this model (recall Section 2.3).
This EL-approximate marginal likelihood has several potential applications. For example, marginal likelihoods are often used in the context of model selection: if we need to choose between many possible models indexed by the hyperparameter R, then a common approach is to maximize the marginal likelihood as a function of R (Gelman et al. 2003). Denote R̂ = arg maxR F (R). Computing R̂ directly is often expensive, but computing the maximizer of the EL-approximate marginal likelihood instead is often much cheaper. In our LNP example, for instance, the EL-approximate R̂ can be computed analytically if we can choose a basis such that C = I and R ∝ I:
| (54) |
with and ; see Appendix for the derivation. Since , an infinite value of R corresponds to equal to zero: infinite penalization. The intuitive interpretation of Eq. (54) is that the MPELE should be shrunk entirely to zero when there isn't enough data, quantified by , compared to the dimensionality of the problem p. Similar results hold when there are correlations in the stimulus, C ≠ I, as discussed in more detail in the methods.
Figure 5 presents a numerical illustration of the resulting penalized estimators. We simulated Poisson responses to white-noise Gaussian stimuli using stimulus filters with p = 250 parameters. We use a standard iterative method for computing the exact R̂: it is known that the optimal R̂ obeys the equation
| (55) |
under the Laplace approximation (Bishop 2006). Note that this equation only implicitly solves for R̂, since R̂ is present on both sides of the equation. However, this leads to the following common fixed-point iteration:
| (56) |
with R̂ estimated as limi→∞ R̂i, when this limit exists. We find that the distance between the exact and approximate R̂ values increases with , with the EL systematically choosing lower values of R̂ (Fig. 5a top). This difference shrinks after a single iteration of Eq. (56) initialized using Eq. (54) (Fig. 5a bottom). The remaining differences in R̂ between the two methods did not lead to differences in the corresponding estimated filters (Fig. 5b). In these simulations the exact MAP typically took about 20 times longer to compute than a single iteration of Eq. (56) initialized using Eq. (54) (10 versus 0.5 sec).
Fig. 5.

The EL can be used for fast model selection via approximate maximum marginal likelihood. Thirty simulated neural responses were drawn from a linear-nonlinear Poisson (LNP) model, with stimuli drawn from an independent white-noise Gaussian distribution. The true filter (shown in black in B) has p = 250 parameters and norm 10. a Optimal hyper-parameters R (the precision of the Gaussian prior distribution) which maximize the marginal likelihood using the EL (top left column, vertical axis) scale similarly to those which maximize the full Laplace-approximated marginal likelihood (top left column, horizontal axis), but with a systematic downward bias. After a single iteration of the fixed point algorithm used to maximize the full marginal likelihood (see text), the two sets of hyper-parameters (bottom left column) match to what turns out to be sufficient accuracy, as shown in (b): the median filter estimates (blue lines) (± absolute median deviation (light blue), based on 30 replications) computed using the exact and one-step approximate approach match for a wide range of . The MSE of the two approaches also matches for a wide range of
We close by noting that many alternative methods for model selection in penalized GLMs have been studied; it seems likely that the EL approximation could be useful in the context of other approaches based on cross-validation or generalized cross-validation (Golub et al. 1979), for example. We leave this possibility for future work. See Conroy and Sajda (2012) for a related recent discussion.
2.7 Decreasing the computation time of Markov chain Monte Carlo methods
As a final example, in this section we investigate the utility of the EL approximation in the context of Markov chain Monte Carlo (MCMC) methods (Robert and Casella 2005) for sampling from the posterior distribution of θ given GLM observations. Two approaches suggest themselves. First, we could simply replace the likelihood with the exponentiated EL, and sample from the resulting approximation to the true posterior using our MCMC algorithm of choice (Sadeghi et al. 2013). This approach is fast but only provides samples from an approximation to the posterior. Alternatively, we could use the EL-approximate posterior as a proposal density within an MCMC algorithm, and then use the standard Metropolis-Hastings correction to obtain samples from the exact posterior. This approach, however, is slower, because we need to compute the true log-likelihood with each Metropolis-Hastings iteration.
Figure 6 illustrates an application of the first approach to simulated data. We use a standard Hamiltonian Monte Carlo (Neal 2012) method to sample from both the true and EL-approximate posterior given N = 4000 responses from a 100-dimensional LNP model, with a uniform (flat) prior. We compare the marginal median and 95 % credible interval computed by both methods, for each element of θ. For most elements of the θ vector, the EL-approximate posterior matches the true posterior well. However, in a few cases the true and approximate credible intervals differ significantly; thus, it makes sense to use this method as a fast exploratory tool, but perhaps not for conclusive analyses when N/p is of moderate size. (Of course, as N/p → ∞, the EL approximation becomes exact, while the true likelihood becomes relatively more expensive, and so the EL approximation will become the preferred approach in this limit).
Fig. 6.

The EL approximation leads to fast and (usually) accurate MCMC sampling from GLM posteriors. 4000 responses were simulated from a 100-dimensional LNP model using i.i.d. white-noise Gaussian stimuli. 106 Markov Chain Monte Carlo samples, computed using Hybrid Monte Carlo, were then drawn from the posterior assuming a flat prior, using either the exact Poisson likelihood or the EL approximation to the likelihood. The left column displays the median vector along with 95 % credible regions for each marginal distribution (one marginal for each of the 100 elements of θ); approximate intervals are shown in blue, and exact intervals in red. In the middle and right column we have zoomed in around different elements for visual clarity. Statistics from both distributions are in close agreement for most, but not all, elements of θ. Replacing the EL-approximate likelihood with the EL-approximate profile likelihood yielded similar results (green). The Laplace approximation to the exact posterior also provided a good approximation to the exact posterior (black)
For comparison, we also compute the median and credible intervals using two other approaches: (1) the standard Laplace approximation (computed using the true likelihood), and (2), the profile EL-posterior, which is exactly Gaussian in this case (recall Section 2.3). The intervals computed via (1) closely match the MCMC output on the exact posterior, while the intervals computed via (2) closely match the EL-approximate MCMC output; thus the respective Gaussian approximations of the posterior appear to be quite accurate for this example.
Experiments using the second approach described above (using Metropolis-Hastings to obtain samples from the exact posterior) were less successful. The Hamiltonian Monte Carlo method is attractive here, since we can in principle evaluate the EL-approximate posterior cheaply many times along the Hamiltonian trajectory before having to compute the (expensive) Metropolis-Hastings probability of accepting the proposed trajectory. However, we find (based on simulations similar to those described above) that proposals based on the fast EL-approximate approach are rejected at a much higher rate than proposals generated using the exact posterior. This lower acceptance probability in turn implies that more iterations are required to generate a sufficient number of accepted steps, sharply reducing the computational advantage of the EL-based approach. Again, as N/p → ∞, the EL approximation becomes exact, and the EL approach will be preferred over exact MCMC methods—but in this limit the Laplace approximation will also be exact, obviating the need for expensive MCMC approaches in the first place.
3 Conclusion
We have demonstrated the computational advantages of using the expected log-likelihood (EL) to approximate the log-likelihood of a generalized linear model with canonical link. When making multiple calls to the GLM likelihood (or its gradient and Hessian), the EL can be computed approximately O(Np/z) times faster, where N is the number of data samples collected, p is the dimensionality of the parameters and z is the cost of a one-dimensional integral; in many cases this integral can be evaluated analytically or semi-analytically, making z trivial. In addition, in some cases the EL can be analytically optimized or integrated out, making EL-based approximations even more powerful. We discussed applications to maximum penalized likelihood-based estimators, model selection, and MCMC sampling, but this list of applications is certainly far from exhaustive.
Ideas related to the EL approximation have appeared previously in a wide variety of contexts. We have already discussed previous work in neuroscience (Paninski 2004; Park and Pillow 2011; Field et al. 2010; Sadeghi et al. 2013) that exploits the EL approximation in the LNP model. Similar approximations have also been used to simplify the likelihood of GLM models in the context of neural decoding (Rahnama Rad and Paninski 2011). In the Gaussian process regression literature, the well-known “equivalent kernel” approximation can be seen as a version of the EL approximation (Rasmussen and Williams 2005; Sollich and Williams 2005); similar approaches have a long history in the spline literature (Silverman 1984). Finally, the EL approximation is somewhat reminiscent of the classical Fisher scoring algorithm, in which the observed information matrix (the Hessian of the negative log-likelihood) is replaced by the expected information matrix (i.e., the expectation of the observed information matrix, taken over the responses r) in the context of approximate maximum likelihood estimation. The major difference is that the EL takes the expectation over the covariates x instead of the responses r. A potential direction for future work would be to further explore the relationships between these two expectation-based approximations.
Acknowledgments
We thank the Chichilnisky lab for kindly sharing their retinal data, C. Ekanadham for help obtaining the data, and E. Pnevmatikakis, A. Pakman, and W. Truccolo for helpful comments and discussions. We thank Columbia University Information Technology and the Office of the Executive Vice President for Research for providing the computing cluster used in this study. LP is funded by a McKnight scholar award, an NSF CAREER award, NEI grant EY018003, and by the Defense Advanced Research Projects Agency (DARPA) MTO under the auspices of Dr. Jack Judy, through the Space and Naval Warfare Systems Center, Pacific Grant/Contract No. N66001-11-1-4205.
Appendix: methods
A.1 Computing the mean-squared error for the MPELE and MAP in the linear-Gaussian model
In this section we provide derivations for the results discussed in Section 2.4. We consider the standard linear regression model with Gaussian noise and a ridge (Gaussian) prior of the form , with c a scalar. We further assume that the stimuli x are i.i.d. standard Gaussian vectors. We derive the MSE of the MPELE and MAP, then recover the non-regularized cases (i.e., the MLE and MELE) by setting c to zero. Note that we allow the regularizer to scale with the dimensionality of the problem, p, for reasons that will become clear below. The resulting MAP and MPELE are then found by
| (57) |
| (58) |
| (59) |
| (60) |
j where we consider Xij ~ N (0, 1) ᗊi, j . For convenience notation we defione the quantity S̃ = XT X + cpI and therefore write the MAP as.
As usual the MSE can be written as the sum of a squared bias term and a variance term
| (61) |
The bias of the MAP equals
| (62) |
| (63) |
| (64) |
| (65) |
The second line follows from the law of total expectation (Johnson and Wichern 2007) and the fourth follows from the fact E[r|X] = xθ.
From the law of total covariance, the variance can be written as
| (66) |
| (67) |
The term equals
| (68) |
| (69) |
In the second line we use the fact that Cov(r|X) = I. The term was used to derive Eq. (65 and equals S̃–1 XT Xθ.
Substituting the relevant quantities into Eq. (61), we find that the mean squared error of the MAP is
| (70) |
The MSE of the MPELE can be computed in a similar fashion. The bias of the MPELE equals
| (71) |
| (72) |
| (73) |
| (74) |
| (75) |
To derive the fourth line we have again used the fact E[r|X] Xθ = Xθ to show that . The fifth line follows E [XT X] = NI. To compute the variance we again use the law of total covariance which requires the computation of a term ,
| (76) |
| (77) |
| (78) |
We use the fact that Cov(r|X) = I to derive the second line and the definition E [XT X] = NI to derive the third.
Using the bias-variance decomposition of the MSE, Eq. (61), we find that the mean squared error of the MPELE estimator is
| (79) |
The term tr (Cov(XT Xθ) can be simplified by taking advantage of the fact that rows of X are i.i.d normally distributed with mean zero, so their fourth central moment can be written as the sum of outer products of the second central moments (Johnson and Wichern 2007).
| (80) |
| (81) |
We then have
| (82) |
Without regularization (c = 0) the MSE expressions simplify significantly:
| (83) |
| (84) |
(The expression for the MSE of the MLE is of course quite well-known.) Noting that (XT X)−1 is distributed according to an inverse Wishart distribution with mean (Johnson and Wichern 2007), we recover Eqs. (38) and (39).
For c ≠ 0 we calculate the MSE for both estimators in the limit N, p → ∞ , with . In this limit Eq. (82) reduces to
| (85) |
To calculate the limiting MSE value for the MAP we work in the eigenbasis of XT X. This allows us to take advantage of the Marchenko-Pastur law (Marchenko and Pastur 1967) which states that in the limit N, p → ∞ but remains finite, the eigenvalues of converge to a continuous random variable with known distribution. We denote the matrix of eigenvectors of XT X by O:
| (86) |
with the diagonal matrix L containing the eigenvalues of XT X.
Evaluating the first and last term in the MAP MSE Eq. (70) leads to the result
| (87) |
To evaluate the last term in the above equation, first note that
| (88) |
Abbreviate D = (L + cpI)−1L, for convenience. Now we have
| (89) |
| (90) |
| (91) |
| (92) |
| (93) |
In the last line we have used the law of total expectation. Since the vector OT θ is uniformly distributed on the sphere . given L, . Thus
| (94) |
We can use similar arguments to calculate the second term in Eq. (87).
| (95) |
| (96) |
Substituting this result and Eq. (94) into Eq. (87) we find
| (97) |
| (98) |
| (99) |
Using the result given above and noting that , the MAP MSE can be written as
| (100) |
Taking the limit N, p → ∞ with finite,
| (101) |
where l is a continuous random variable with probability density function found by the Marchecko-Pastur law
| (102) |
| (103) |
| (104) |
Using Eq. (102) we can numerically evaluate the limiting MAP MSE. The results are plotted in Fig. 2.
Figure 7 evaluates the accuracy of these limiting approximations for finite N and p. For the range of N and p. For the range of N and p used in our real data analysis , the approximation is valid.
A.2 Computing the MPELE for an LNP model with Gaussian stimuli
The MPELE is given by the solution of Eq. (30), which in this case is
| (105) |
Since xθ is Normally distributed, xθ ~ N (0, θT Cθ), we can analytically calculate the expectation, yielding
| (106) |
Optimizing with respect to θ0 we find
| (107) |
Inserting into Eq. (106) leaves the following quadratic optimization problem
| (108) |
Note that the first two terms here are quadratic; i.e., the EL-approximate profile likelihood is Gaussian in this case. If we use a Gaussian prior, f (θ) ∝ exp(θT Rθ/2), we can optimize for analytically to obtain Eq. (31).
A.3 Calculating R̂ for the LNP model
For the LNP model with E [G(xT θ) approximated as in Eq. (16) and f (θ|R) = N (0, R−1), the Laplace approximation (52) to the marginal likelihood yields
| (109) |
| (110) |
| (111) |
where the second line follows from substituting in Eq. (107) and we have denoted as Ns in the third line. Note that from the definition of the L2 regularized MPELE Eq. (31) we can write
| (112) |
and simplify the first two terms
| (113) |
Noting that C I, R = βI Eq. (113) simplifies further to (N + β)−1 q with q ≡ . Using the fact that the profile Hessian is and the assumptions C I, R = βI the last two terms in Eq. (111) reduce to
| (114) |
Combining these results we find
| (115) |
Taking the derivative of Eq. (115) with respect to β we find that the critical points, obey
| (116) |
| (117) |
If , the only critical points is ∞ β is constrained to be positive. When , the critical point is the maximum since log F Eq. (115) evaluated at this point is greater than log F evaluated at ∞:
| (118) |
Therefore R̂ satisfies Eq. (54) in the text.
We can derive similar results for a more general case if C and R are diagonalized by the same basis. If we denote this basis by M, we then have the property that the profile Hessian CNs + R = M(DcNs + Dr)MT where Dc and Dr are diagonal matrices containing the eigenvalues of C and R. In this case the last two terms of Eq. (111) reduce to
| (119) |
Defining XT r rotated in the coordinate system specified by M as , Eq. (113) simplifies to
| (120) |
Combining terms we find
| (121) |
Taking the gradient of the above equation with respect to the eigenvalues of R, , we find that the critical points obey
| (122) |
| (123) |
If , the only critical point is ∞ since is constrained to be positive (R is constrained to be positive definite).
A.4 Real neuronal data details
Stimuli are refreshed at a rate of 120 Hz and responses are binned at this rate (Fig. 3) or at 10 times (Fig. 4) this rate. Stimulus receptive fields are fit with 81 (Fig. 3) or 25 (Fig. 4) spatial components and ten temporal basis functions, giving a total of 81×10 = 810 or 25 × 10=250 stimulus filter parameters. Five basis functions×are=delta functions with peaks centered at the first 5 temporal lags while the remaining 5 are raised cosine ‘bump’ functions (Pillow et al. 2008). The self-history filter shown in Fig. 4 is parameterized by 4 cosine ‘bump’ functions and a refractory function that is negative for the first stimulus time bin and zero otherwise. The coupling coefficient temporal components are modeled with a decaying exponential of the form, exp (−bτ), with b set to a value which captures the time-scale of cross-correlations seen in the data. The errorbars of the spike-history functions in Fig. 4a show an estimate of the variance of spike-history function estimates. These are found by first estimating the covariance of the spike-history basis coefficients. Since the L1 penalty is non-differentiable we estimate this covariance matrix using the inverse log-likelihood Hessian of a model without coupling terms, say , evaluated at the MAP and MPELE solutions, which are found using the full model that assumes non-zero coupling weights. The covariance matrix of the spike-history functions are then computed using the standard formula for the covariance matrix of a linearly transformed variable. Denoting the transformation matrix from spike-history coefficients to spike-history functions as B, the covariance of spike-history function estimates is . Figure 4 plots elements off the diagonal of this matrix. We use the activity of 100 neighboring cells yielding a total of 100 coupling coefficient parameters, 5 self-history parameters, 250 stimulus parameters, and 1 offset parameter (356 parameters in total). The regularization coefficients used in Fig. 3b and 4 are found via cross-validation on a novel two minute (14,418 samples) data set. Model performance is evaluated using 2 minutes of data not used for determining model parameters or regularization coefficients. To report the log-likelihood in bits per second, we take the difference of the log-likelihood under the model and log-likelihood under a homogeneous Poisson process, divided by the total time.
The covariance of the correlated stimuli was spatiotemporally separable, leading to a Kronecker form for C. The temporal covariance was given by a stationary AR(1) process; therefore this component has a tridiagonal inverse (Paninski et al. 2009). The spatial covariance was diagonal in the two-dimensional Fourier basis. We were therefore able to expoit fast Fourier and banded matrix techniques in our computations involving C.
Footnotes
Examples of such distributions include the multivariate normal and Student's-t, and exponential power families (Fang et al. 1990). Elliptically symmetric distributions are important in the theory of GLMs because they guarantee the consistency of the maximum likelihood estimator for θ even under certain cases of model misspecification; see Paninski (2004) for further discussion.
Conflict of interests
No conflict of interest.
Contributor Information
Alexandro D. Ramirez, Weill Cornell Medical College, New York, NY, USA
Liam Paninski, Department of Statistics, Center for Theoretical Neuroscience, Grossman Center for the Statistics of Mind, Columbia University, New York, NY, USA.
References
- Behseta S, Kass R, Wallstrom G. Hierarchical models for assessing variability among functions. Biometrika. 2005;92:419–434. [Google Scholar]
- Bickel PJ, Doksum KA. Mathematical statistics: basic ideas and selected topics. 2nd edn. Vol. 1. Pearson Prentice Hall; Upper Saddle River, N.J.: 2007. [Google Scholar]
- Bishop C. Pattern recognition and machine learning. Springer; New York: 2006. [Google Scholar]
- Bottou L. Online algorithms and stochastic approximations. In: Saad D, editor. Online learning and neural networks. Cambridge University Press; Cambridge: 1998. [Google Scholar]
- Boyd S, Vandenberghe L. Convex optimization. Oxford University Press; New York: 2004. [Google Scholar]
- Boyles L, Balan AK, Ramanan D, Welling M. Statistical tests for optimization efficiency.. In: Shawe-Taylor J, Zemel RS, Bartlett P, Pereira F, Weinberger KQ, editors. Advances in neural information processing systems; Proceedings of the 25th Annual Conference.2011. pp. 2196–2204. [Google Scholar]
- Brillinger D. Maximum likelihood analysis of spike trains of interacting nerve cells. Biological Cyberkinetics. 1988;59:189–200. doi: 10.1007/BF00318010. [DOI] [PubMed] [Google Scholar]
- Brown E, Kass R, Mitra P. Multiple neural spike train data analysis: state-of-the-art and future challenges. Nature Neuroscience. 2004;7(5):456–461. doi: 10.1038/nn1228. [DOI] [PubMed] [Google Scholar]
- Calabrese A, Schumacher JW, Schneider DM, Paninski L, Woolley SMN. A generalized linear model for estimating spectrotemporal receptive fields from responses to natural sounds. PLoS One. 2011;6(1):e16104. doi: 10.1371/journal.pone.0016104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Conroy B, Sajda P. Fast, exact model selection and permutation testing for l2-regularized logistic regression. Journal of Machine Learning Research-Proceedings Track. 2012;22:246–254. [PMC free article] [PubMed] [Google Scholar]
- Cossart R, Aronov D, Yuste R. Attractor dynamics of network up states in the neocortex. Nature. 2003;423:283–288. doi: 10.1038/nature01614. [DOI] [PubMed] [Google Scholar]
- David S, Mesgarani N, Shamma S. Estimating sparse spectro-temporal receptive fields with natural stimuli. Network. 2007;18:191–212. doi: 10.1080/09548980701609235. [DOI] [PubMed] [Google Scholar]
- Diaconis P, Freedman D. Asymptotics of graphical projection pursuit. The Annals of Statistics. 1984;12(3):793–815. [Google Scholar]
- Donoghue JP. Connecting cortex to machines: recent advances in brain interfaces. Nature Neuroscience. 2002;5(Suppl):1085–1088. doi: 10.1038/nn947. [DOI] [PubMed] [Google Scholar]
- Fang KT, Kotz S, Ng KW. CRC monographs on statistics and applied probability. Chapman & Hall; London: 1990. Symmetric multivariate and related distributions. [Google Scholar]
- Field GD, Gauthier JL, Sher A, Greschner M, Machado TA, Jepson LH, Shlens J, Gunning DE, Mathieson K, Dabrowski W, Paninski L, Litke AM, Chichilnisky EJ. Functional connectivity in the retina at the resolution of photoreceptors. Nature. 2010;467(7316):673–7. doi: 10.1038/nature09424. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friedman JH, Hastie T, Tibshirani R. Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software. 2010;33(1):1–22. [PMC free article] [PubMed] [Google Scholar]
- Gelman A, Carlin JB, Stern HS, Rubin DB. Bayesian data analysis. 2nd edn. Chapman and Hall/CRC; London: 2003. [Google Scholar]
- Golub G, van Van Loan C. Matrix computations. (Johns Hopkins Studies in Mathematical Sciences) 3rd edn. The Johns Hopkins University Press; Baltimore: 1996. [Google Scholar]
- Golub GH, Heath M, Wahba G. Generalized cross-validation as a method for choosing a good ridge parameter. Technometrics. 1979;21(2):215–223. [Google Scholar]
- Johnson RA, Wichern DW. Applied multivariate statistical analysis. Pearson Prentice Hall; Upper Saddle River, N.J.: 2007. [Google Scholar]
- Kass R, Raftery A. Bayes factors. Journal of the American Statistical Association. 1995;90:773–795. [Google Scholar]
- Lehmann EL, Casella G. Theory of point estimation. 2nd edn. Springer; New York: 1998. [Google Scholar]
- Lewi J, Butera R, Paninski L. Sequential optimal design of neurophysiology experiments. Neural Computation. 2009;21:619–687. doi: 10.1162/neco.2008.08-07-594. [DOI] [PubMed] [Google Scholar]
- Lütcke H, Murayama M, Hahn T, Margolis DJ, Astori S, Zum Alten Borgloh SM, Göbel W, Yang Y, Tang W, Kügler S, Sprengel R, Nagai T, Miyawaki A, Larkum ME, Helmchen F, Hasan MT. Optical recording of neuronal activity with a genetically-encoded calcium indicator in anesthetized and freely moving mice. Frontiers in Neural Circuits. 2010;4(9):1–12. doi: 10.3389/fncir.2010.00009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marchenko VA, Pastur PL. Distribution of eigenvalues for some sets of random matrices. Math. USSR-Sb. 1967;1:457–483. [Google Scholar]
- McCullagh P, Nelder JA. Generalized linear models. 2nd edn. Chapman and Hall/CRC; London: 1989. [Google Scholar]
- Minka T. PhD thesis. MIT Press; 2001. A family of algorithms for approximate Bayesian inference. [Google Scholar]
- Mishchenko Y, Paninski L. Efficient methods for sampling spike trains in networks of coupled neurons. The Annals of Applied Statistics. 2011;5(3):1893–1919. [Google Scholar]
- Neal R. MCMC using Hamiltonian dynamics. In: Brooks S, Gelman A, Jones G, Meng X, editors. Handbook of Markov chain Monte Carlo. Chapman and Hall/CRC Press; London: 2012. [Google Scholar]
- Nesterov Y. Introductory lectures on convex optimization: a basic course. 1st edn. Kluwer Academic Publishers; Norwell: 2004. [Google Scholar]
- Ohki K, Chung S, Ch'ng Y, Kara P, Reid C. Functional imaging with cellular resolution reveals precise micro-architecture in visual cortex. Nature. 2005;433:597–603. doi: 10.1038/nature03274. [DOI] [PubMed] [Google Scholar]
- Paninski L. Maximum likelihood estimation of cascade point-process neural encoding models. Network: Computation in Neural Systems. 2004;15:243–262. [PubMed] [Google Scholar]
- Paninski L, Pillow J, Lewi J. Statistical models for neural encoding, decoding, and optimal stimulus design. In: Cisek P, Drew T, Kalaska J, editors. Computational neuroscience: progress in brain research. Elsevier; Amsterdam: 2007. [DOI] [PubMed] [Google Scholar]
- Paninski L, Ahmadian Y, Ferreira D, Koyama S, Rahnama K, Vidne M, Vogelstein J, Wu W. A new look at state-space models for neural data. Journal of Computational Neuroscience. 2009;29(1–2):107–126. doi: 10.1007/s10827-009-0179-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Park IM, Pillow JW. In: Shawe-Taylor J, Zemel RS, Bartlett P, Pereira F, Weinberger KQ, editors. Bayesian spike-triggered covariance analysis; Advances in neural information processing systems; Proceedings of the 25th Annual Conference.2011. pp. 1692–1700. [Google Scholar]
- Pillow JW, Shlens J, Paninski L, Sher A, Litke AM, Chichilnisky EJ, Simoncelli EP. Spatio-temporal correlations and visual signalling in a complete neuronal population. Nature. 2008;454(7207):995–999. doi: 10.1038/nature07140. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rahnama Rad K, Paninski L. In: Shawe-Taylor J, Zemel RS, Bartlett P, Pereira F, Weinberger KQ, editors. Advances in neural information processing systems; Proceedings of the 25th Annual Conference.2011. pp. 846–854. [Google Scholar]
- Rasmussen C, Williams C. Gaussian processes for machine learning (Adaptive computation and machine learning series) MIT Press; Cambridge: 2005. [Google Scholar]
- Robert C, Casella G. Monte Carlo statistical methods. Springer; New York: 2005. [Google Scholar]
- Sadeghi K, Gauthier J, Greschner M, Agne M, Chichilnisky EJ, Paninski L. Monte Carlo methods for localization of cones given multielectrode retinal ganglion cell recordings. Network. 2013;24:27–51. doi: 10.3109/0954898X.2012.740140. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Santhanam G, Ryu SI, Yu BM, Afshar A, Shenoy KV. A high-performance brain–computer interface. Nature. 2006;442(7099):195–198. doi: 10.1038/nature04968. [DOI] [PubMed] [Google Scholar]
- Shaffer JP. The gauss-markov theorem and random regressors. The American Statistician. 1991;45(4):269–273. [Google Scholar]
- Shewchuk JR. An introduction to the conjugate gradient method without the agonizing pain. Technical report. Carnegie Mellon University; Pittsburgh: 1994. [Google Scholar]
- Shlens J, Field GD, Gauthier JL, Grivich MI, Petrusca D, Sher A, Litke AM, Chichilnisky EJ. The structure of multi-neuron firing patterns in primate retina. Journal of Neuroscience. 2006;26(32):8254–8266. doi: 10.1523/JNEUROSCI.1282-06.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Silverman BW. Spline smoothing: the equivalent variable kernel method. The Annals of Statistics. 1984;12(3):898–916. [Google Scholar]
- Simoncelli E, Paninski L, Pillow J, Schwartz O. The cognitive neurosciences. 3rd edn. MIT Press; Cambridge: 2004. Characterization of neural responses with stochastic stimuli. [Google Scholar]
- Sollich P, Williams CKI. Proceedings of the first international conference on deterministic and statistical methods in machine learning. Springer; Heidelberg: 2005. Understanding gaussian process regression using the equivalent kernel. pp. 211–228. [Google Scholar]
- Stevenson IH, Kording KP. How advances in neural recording affect data analysis. Nature Neuroscience. 2011;14(2):139–142. doi: 10.1038/nn.2731. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Truccolo W, Eden U, Fellows M, Donoghue J, Brown E. A point process framework for relating neural spiking activity to spiking history, neural ensemble and extrinsic covariate effects. Journal of Neurophysiology. 2005;93:1074–1089. doi: 10.1152/jn.00697.2004. [DOI] [PubMed] [Google Scholar]
- Truccolo W, Hochberg LR, Donoghue JP. Collective dynamics in human and monkey sensorimotor cortex: predicting single neuron spikes. Nature Neuroscience. 2010;13(1):105–111. doi: 10.1038/nn.2455. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van der Vaart A. Asymptotic statistics. Cambridge University Press; Cambridge: 1998. [Google Scholar]
- Vidne M, Ahmadian Y, Shlens J, Pillow JW, Kulkarni J, Litke AM, Chichilnisky EJ, Simoncelli E, Paninski L. Modeling the impact of common noise inputs on the network activity of retinal ganglion cells. Journal of Computational Neuroscience. 2012;33(1):97–121. doi: 10.1007/s10827-011-0376-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang T. Adaptive forward-backward greedy algorithm for learning sparse representations. IEEE Transactions on Information Theory. 2011;57(7):4689–4708. [Google Scholar]