

Abstract
Protein function prediction is a complex multiclass multilabel classification problem, characterized by multiple issues such as the incompleteness of the available annotations, the integration of multiple sources of high dimensional biomolecular data, the unbalance of several functional classes, and the difficulty of univocally determining negative examples. Moreover, the hierarchical relationships between functional classes that characterize both the Gene Ontology and FunCat taxonomies motivate the development of hierarchy-aware prediction methods that showed significantly better performances than hierarchical-unaware “flat” prediction methods. In this paper, we provide a comprehensive review of hierarchical methods for protein function prediction based on ensembles of learning machines. According to this general approach, a separate learning machine is trained to learn a specific functional term and then the resulting predictions are assembled in a “consensus” ensemble decision, taking into account the hierarchical relationships between classes. The main hierarchical ensemble methods proposed in the literature are discussed in the context of existing computational methods for protein function prediction, highlighting their characteristics, advantages, and limitations. Open problems of this exciting research area of computational biology are finally considered, outlining novel perspectives for future research.
1. Introduction
Exploiting the wealth of biomolecular data accumulated by novel high-throughput biotechnologies, “in silico” protein function prediction can generate hypotheses to drive the biological discovery and validation of protein functions [1]. Indeed, “in vitro” methods are costly in time and money, and automatic prediction methods can support the biologist in understanding the role of a protein or of a biological process or in annotating a new genome at high level of accuracy or more, in general, in solving problems of functional genomics [2].
The Automated Function Prediction (AFP) is a multiclass, multilabel classification problem characterized by hundreds or thousands of functional classes structured according to a predefined hierarchy. Even in principle, also unsupervised methods can be applied to AFP, due to the inherent difficulty of extracting functional classes without exploiting any available a priori information [3, 4]; usually supervised or semisupervised learning methods are applied in order to exploit the available a priori information about gene annotations.
From a computational standpoint, AFP is a challenging problem for several reasons.
The number of functional classes is usually large: hundreds for the Functional Catalogue (FunCat) [5] or thousands for the Gene Ontology (GO) [6].
Proteins may be annotated for multiple functional classes: since each protein may belong to more than one class at the same time, the classification problem is multilabel.
Multiple sources of data are available for each protein: high-throughput biotechnologies make an increasing number of sources of genomic and proteomic data available. Hence, in order to exploit all the information available for each protein, we need to learn methods that are able to integrate different data sources [7].
Functional classes are hierarchically related: annotations are not independent because functional classes are hierarchically organized; in general, known functional relationships (such as taxonomies) can be exploited to incorporate a priori knowledge in learning algorithms or to introduce explicit constraints between labels.
Small number of annotations for each class: typically, functional classes are severely unbalanced, with a small number of available “positive” annotations.
Multiple possible definitions of negative examples: since we only have positive annotations (the total number of GO negative annotations is about 2500, considering all species (August 2013)), the notion of negative example is not uniquely determined, and different strategies of choosing negative examples can be applied in principle [8].
Different reliability of functional labels: functional annotations have different degrees of evidence; that is, each label is assigned to a gene with a specific level of reliability.
Complex and noisy data: data are usually complex (e.g., high-dimensional, large-scale, and graph-structured) and noisy.
Most of the computational methods for AFP have been applied to unicellular organisms (e.g., S. cerevisiae) [9–11], but recently several approaches have been applied to multicellular organisms (such as M. musculus or the A. thaliana plant model organisms [2, 12–16]).
Several computational approaches, and in particular machine learning methods, have been proposed to deal with the above issues, ranging from sequence-based methods [17] to network-based methods [18], structured output algorithm based on kernels [19], and hierarchical ensemble methods [20].
Other approaches focused primarily on the integration of multiple sources of data, since each type of genomic data captures only some aspects of the genes to be classified, and a specific source can be useful to learn a specific functional class while being irrelevant to others. In the literature, many approaches have been proposed to deal with this topic, for example, functional linkage networks integration [21], kernel fusion [11], vector space integration [22], and ensemble systems [23].
Extensive experimental studies showed that flat prediction, that is, predictions for each class made independently of the other classes, introduces significant inconsistencies in the classification, due to the violation of the true path rule that governs the functional annotations of genes both in the GO and in FunCat taxonomies [24]. According to this rule, positive predictions for a given term must be transferred to its “ancestor” terms and negative predictions to its descendants (see Appendix A and Section 7 for more details about the GO and the true path rule). Moreover flat predictions are difficult to interpret because they may be inconsistent with one another. A method that claims, for example, that a protein has homodimerization activity but does not have dimerization activity is clearly incorrect, and a biologist attempting to interpret these results would not likely trust either prediction [24].
It is worth noting that the results of the Critical Assessment of Functional Annotation (CAFA) challenge, a recent comprehensive critical assessment and comparison of different computational methods for AFP [16], showed that AFP is characterized by multiple complex issues, and one of the best performing CAFA methods corrected flat predictions taking into account the hierarchical relationships between functional terms, with an approach similar to that adopted by hierarchical ensemble methods [25]. Indeed, hierarchical ensemble methods embed in the learning process the relationships between functional classes. Usually, this is performed in a second “reconciliation” step, where the predictions are modified to make them consistent with the ontology [26–29]. More, in general, these methods exploit the relationships between ontology terms, structured according to a forest of trees [5] or a directed acyclic graph [6] to significantly improve prediction performances with respect to “flat” prediction methods [30–32].
Hierarchical classification and in particular ensemble methods for hierarchical classification have been applied in several domains different from protein function prediction, ranging from text categorization [33–35] to music genre classification [36–38], hierarchical image classification [39, 40] and video annotation [41], and automatic classification of worldwide web documents [42, 43]. The present review focuses on hierarchical ensemble methods for AFP. For a more general review on hierarchical classification methods and their applications in different domains, see [44].
The paper is structured as follows. In Section 2, we provide a synthetic picture of the main categories of protein function methods, to properly position hierarchical ensemble methods in the context of computational methods for AFP. In Section 3, the main common characteristics of hierarchical ensemble algorithms, as well as a general taxonomy of these methods, are proposed. The following five sections focus on the main families of hierarchical methods for AFP and discuss their main characteristics. Section 4 introduces hierarchical top-down methods, Section 5 Bayesian ensemble approaches, Section 6 reconciliation methods, Section 7 true path rule ensemble methods, and the last one (Section 8) ensembles based on decision trees. Section 9 critically discusses the main issues and limitations of hierarchical ensemble methods and shows that this approach, such as the other current approaches for AFP, cannot be successfully applied without considering the large set of complex learning issues that characterize the AFP problem. The last two sections discuss the open problems and future possible research lines in the context of hierarchical ensemble methods and summarize the main findings in this exciting research area. In the Appendix, some basic information about the FunCat and the GO, that is, the two main hierarchical ontologies that are widely used to annotate proteins in all organisms, are provided, as well as the characteristics of the hierarchical-aware performance measures proposed in the literature to assess the accuracy and the reliability of the predictions made by hierarchical computational methods.
2. A Taxonomy of Protein Function Prediction Methods
Several computational methods for the AFP problem have been proposed in the literature. Some methods provided predictions of a relatively small set of functional classes [11, 45, 46], while others considered predictions extended to larger sets, using support vector machines and semidefinite programming [11], artificial neural networks [47], functional linkage networks [21, 48], Bayesian networks [45], or methods that combine functional linkage networks with learning machines using a logistic regression model [12] or simple algebraic operators [13].
Other research lines for AFP explicitly take into account the hierarchical nature of the multilabel classification problem. For instance, structured output methods are based on the joint kernelization of both input variables and output labels, using, for example, perceptron-like learning algorithms [49] or maximum-margin algorithms [50]. Other approaches improve the prediction of GO annotations by extracting implicit semantic relationships between genes and functions [51]. Finally, other methods adopted an ensemble approach [52] to take advantage of the intrinsic hierarchical nature of protein function prediction, explicitly considering the relationships between functional classes [24, 53–55].
Computational methods for AFP, mostly based on machine learning methods, can be schematically grouped in the following four families:
sequence-based methods;
network-based methods;
kernel methods for structured output spaces;
hierarchical ensemble methods.
This grouping is neither exhaustive nor strict, meaning that certain methods do not belong to any of these groups, and others belong to more than one.
2.1. Sequence-Based Methods
Algorithms based on alignment of sequences represent the first attempts to computationally predict the function of proteins [56, 57]: similar sequences are likely to share common functions, even if it is well known that secondary and tertiary structure conservation are usually more strictly related to protein functions. However, algorithms able to infer similarities between sequences are today standard methods of assigning functions to proteins in newly sequenced organisms [17, 58]. Of course, global or local structure comparison algorithms between proteins can be applied to detect functional properties [59], and, in this context, the integration of different sequence and structure-based prediction methods represents a major challenge [60].
Even if most of the research efforts for the design and development of AFP methods concentrated on machine learning methods, it is worth noting that in the AFP 2011 challenge [16] one of the best performing methods is represented by a sequence-based algorithm [61]. Indeed, when the only information available is represented by a raw sequence of amino acids or nucleotides, sequence-based methods can be competitive with state-of-the-art machine learning methods by exploiting homology-based inference [62].
2.2. Network-Based Methods
These methods usually represent each dataset through an undirected graph G = (V, E), where nodes v ∈ V correspond to gene/gene products and edges e ∈ E are weighted according to the evidence of cofunctionality implied by data source [63, 64]. These algorithms are able to transfer annotations from previously annotated (labeled) nodes to unannotated (unlabeled) ones by exploiting “proximity relationships” between connected nodes. Basically, these methods are based on transductive label propagation algorithms that predict the labels of unannotated examples without using a global predictive model [14, 21, 45]. Several method exploited the semantic similarity between GO terms [65, 66] to derive functional similarity measures between genes to construct functional terms, using then supervised or semisupervised learning algorithm to infer GO annotations of genes [67–70].
Different strategies to learn the unlabeled nodes have been explored by “label propagation” algorithms, that is, methods able to “propagate” the labels of annotated proteins across the networks, by exploiting the topology of the underlying graph. For instance, methods based on the evaluation of the functional flow in graphs [64, 71], methods based on the Hopfield networks [48, 72, 73], methods based on the Markov [74, 75] and Gaussian random fields [14, 46], and also simple “guilt-by-association” methods [76, 77], based on the assumption that connected nodes/proteins in the functional networks are likely to share the same functions. Recently, methods based on kernelized score functions, able to exploit both local and global semisupervised learning strategies, have been successfully applied to AFP [78] as well as to disease gene prioritization [79] and drug repositioning problems [80, 81].
Reference [82] showed that different graph-based algorithms can be cast into a common framework where a quadratic cost objective function is minimized. In this framework, closed form solutions can be derived by solving a linear system of size equal to the cardinality of nodes (proteins) or using fast iterative procedures such as the Jacobi method [83]. A network-based approach, alternative to label propagation and exhibiting strong theoretical predictive guarantees in the so-called mistake bound model, has been recently proposed by [84].
2.3. Kernel Methods for Structured Output Spaces
By extending kernels to the output space, the multilabel hierarchical classification problem is solved globally: the multilabels are viewed as elements of a structured space modeled by suitable kernel functions [85–87], and structured predictions are viewed as a maximum a posteriori prediction problem [88].
Given a feature space 𝒳 and a space of structured labels 𝒴, the task is to learn a mapping f : 𝒳 → 𝒴 by an induced joint kernel function k that computes the “compatibility” of a given input-output pair (x, y): for each test example x ∈ 𝒳, we need to determine the label such that , for any x ∈ 𝒳. By modeling probabilities by a log-linear model, and using a suitable feature map ϕ(x, y), we can define an induced joint kernel function that uses both inputs and outputs to compute the “compatibility” of a given input-output pair [88]
| (1) |
Structured output methods infer a label by finding the maximum of a function g that uses the previously defined joint kernel (1)
| (2) |
The GOstruct system implemented a structured perceptron and a variant of the structured support vector machine [85]. This approach has been successfully applied to the prediction of GO terms in mouse and other model organisms [19]. Structured output maximum-margin algorithms have been also applied to the tree-structured prediction of enzyme functions [50, 86].
2.4. Hierarchical Ensemble Methods
Other approaches take explicitly into account the hierarchical relationships between functional terms [26, 29, 53, 54, 89, 90]. Usually, they modify the “flat” predictions (i.e., predictions made independently of the hierarchical structure of the classes) and correct them improving accuracy and consistency of the multilabel annotations of proteins [24].
The flat approach makes predictions for each term independently and, consequently, the predictor may assign to a single protein a set of terms that are inconsistent with one another. A possible solution for this problem is to train a classifier for each term of the reference ontology to produce a set of prediction at each term and, finally, to reconcile the predictions by taking into account the relationships between the classes of the ontology. Different ensemble based algorithms have been proposed ranging from methods restricted to multilabels with single and no partial paths [91] to methods extended to multiple and also partial paths [92]. Many recent published works clearly demonstrated that this approach ensures an increment in precision, but this comes at expenses of the overall recall [2, 30].
In the next section, we discuss in detail hierarchical ensemble methods, since they constitute the main topic of this review.
3. Hierarchical Ensemble Methods: Exploiting the Hierarchy to Improve Protein Function Prediction
Ensemble methods are one of the main research areas of machine learning [52, 93–95]. From a general standpoint, ensembles of classifiers are sets of learning machines that work together to solve a classification problem (Figure 1). Empirical studies showed that in both classification and regression problems ensembles improve on single learning machines, and, moreover, large experimental studies compared the effectiveness of different ensemble methods on benchmark data sets [96–99], and they have been successfully applied to several computational biology problems [100–104]. Ensemble methods have been also successfully applied in an unsupervised setting [105, 106]. Several theories have been proposed to explain the characteristics and the successful application of ensembles to different application domains. For instance, Allwein, Schapire, and Singer interpreted the improved generalization capabilities of ensembles of learning machines in the framework of large margin classifiers [107, 108]; Kleinberg, in the context of Stochastic Discrimination Theory [109], and Breiman and Friedman in the light of the bias-variance analysis borrowed from classical statistics [110, 111]. The interest in this research area is motivated also by the availability of very fast computers and networks of workstations at a relatively low cost that allow the implementation and the experimentation of complex ensemble methods using off-the-shelf computer platforms.
Figure 1.
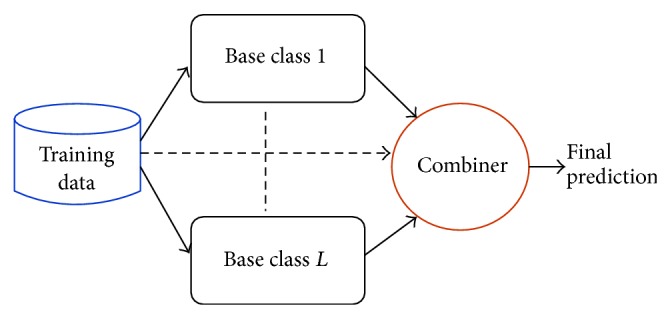
Ensemble of classifiers.
Constraints between labels and, more in general, the issue of label dependence have been recognized to play a central role in multilabel learning [112]. Protein function prediction can be regarded as a paradigmatic multilabel classification problem, where the exploitation of a priori knowledge about the hierarchical relationships between the labels can dramatically improve classification performance [24, 27, 113].
In the context of AFP problems, ensemble methods reflect the hierarchy of functional terms in the structure of the ensemble itself: each base learner is associated with a node of the graph representing the functional hierarchy and learns a specific GO term or FunCat category. The predictions provided by the trained classifiers are then combined by exploiting the hierarchical relationships of the taxonomy.
In their more general form, hierarchical ensemble methods adopt a two-step learning strategy.
In the first step, each base learner separately or interacting with connected base learners learns the protein functional category on a per term basis. In most cases, this yields a set of independent classification problems, where each base learning machine is trained to learn a specific functional term, independently of the other base learners.
In the second step, the predictions provided by the trained classifiers are combined by considering the hierarchical relationships between the base classifiers modeled according to the hierarchy of the functional classes.
Figure 2 depicts the two learning steps of hierarchical ensemble methods. In the first step, a learning algorithm (a square object in Figure 2(a)) is applied to train the base classifiers associated with each class (represented with numbers from 1 to 9). Then, the resulting base classifiers (circles) in the prediction phase exploit the hierarchical relationships between classes to combine its predictions with those provided by the other base classifiers (Figure 2(b)). Note that the dummy 0 node is added to obtain a rooted hierarchy. Up and down arrows represent the possibility of combining predictions by exploiting those provided, respectively, by children and parents classifiers, according to a bottom-up or top-down learning strategy. Note that both “local” combinations are possible (e.g., the prediction of node 5 may depend only on the prediction of node 1), but also “global” combinations can be considered, by taking into account the predictions across the overall structure of the graph (e.g., predictions for node 9 can depend on all the predictions made by all the other base classifiers from 1 to 8). Moreover, both top-down propagation of the predictions (down arrows, Figure 2(b)) and bottom-up propagation (up arrows) can be considered, depending on the specific design of the hierarchical ensemble algorithm.
Figure 2.
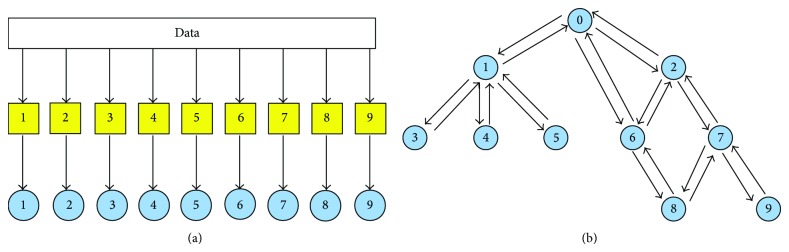
Schematic representation of the two main learning steps of hierarchical ensemble methods. (a) Training of base classifiers; (b) top-down and/or bottom-up propagation of the predictions.
This ensemble approach is highly modular: in principle, any learning algorithm can be used to train the classifiers in the first step, and both annotation decisions, probabilities, or whatever scores provided by each base learner can be combined, depending on the characteristics of the specific hierarchical ensemble method.
In this section, we provide some basic notations and an ensemble taxonomy that will be used to introduce the different hierarchical ensemble methods for AFP.
3.1. Basic Notation
A gene/gene product g can be represented through a vector x ∈ ℝd having d different features (e.g., gene expression levels across d different conditions, sequence similarities with other genes/proteins, or presence or absence of a given domain in the corresponding protein or genetic or physical interaction with other proteins). Note that we, for the sake of simplicity and with a certain approximation, refer in the same way to genes and proteins, even if it is well known that a given gene may correspond to multiple proteins. A gene g is assigned to one or more functional classes in the set C = {c 1, c 2,…, c m} structured according to a FunCat forest of trees T or a directed acyclic graph G of the Gene Ontology (usually a dummy root class c 0, which every gene belongs to, is added to T or G to facilitate the processing). The assignments are coded through a vector of multilabels y = (y 1, y 2,…, y m)∈{0,1}m, where g belongs to class c i if and only if y i = 1.
In both the Gene Ontology(GO) and FunCat taxonomies, the functional classes are structured according to a hierarchy and can be represented by a directed graph, where nodes correspond to classes and edges correspond to relationships between classes. Hence, the node corresponding to the class c i can be simply denoted by i. We represent the set of children nodes of i by child(i), and the set of its parents by par(i). Moreover, y child(i) denotes the labels of the children classes of node i and analogously y par(i) denotes the labels of the parent classes of i. Note that in FunCat only one parent is permitted, since the overall hierarchy is a tree forest, while, in the GO, more parents are allowed, because the relationships are structured according to a directed acyclic graph.
Hierarchical ensemble methods train a set of calibrated classifiers, one for each node of the taxonomy T. These classifiers are used to derive estimates of the probabilities p i(g) = ℙ(V i = 1∣V par(i) = 1, g) for all g and i, where (V 1,…, V m)∈{0,1}m is the vector random variable modeling the unknown multilabel of a gene g, and V par(i) denotes the random variables associated with the parents of node i. Note that p i(g) are probabilities conditioned to V par(i) = 1, that is, the probability that a gene is annotated to a given term i, given that the gene is just annotated to its parent terms, thus respecting the true path rule. Ensemble methods infer a multilabel assignment based on estimates .
3.2. A Taxonomy of Hierarchical Ensemble Methods
Hierarchical ensemble methods for AFP share several characteristics, from the two-step learning approach to the exploitation of the hierarchical relationships between classes. For these reasons, it is quite difficult to clearly and univocally individuate taxonomy of hierarchical ensemble methods. Here, we show taxonomy useful mainly to describe and discuss existing methods for AFP. For a recent review and taxonomy of hierarchical ensemble methods, not specific for AFP problems, we refer the reader to the comprehensive Silla and others' review [44].
In the following sections, we discuss the following groups of hierarchical ensemble methods:
top-down ensemble methods. These methods are characterized by a simple top-down approach in the second step: only the output of the parent node/base classifier influences the output of the children, thus resulting in a top-down propagation of the decisions;
Bayesian ensemble methods. These are a class of methods theoretically well founded and in some cases they are optimal from a Bayesian standpoint;
Reconciliation methods. This is a heterogeneous class of heuristics by which we can combine the predictions of the base learners, by adopting different “local” or “global” combination strategies;
true path rule ensembles. These methods adopt a heuristic approach based on the “true path rule” that governs both the GO and FunCat ontologies;
decision tree-based ensembles. These methods are characterized by the application of decision trees as base learners or by adopting decision tree-like learning strategies to combine predictions of the base learners.
Despite this general characterization, several methods could be assigned to different groups, and for several hierarchical ensemble methods it is difficult to assign them to any the introduced classes of methods.
For instance, in [114–116] the authors used the hierarchy only to construct training sets different for each term of the Gene Ontology, by determining positive and negative examples on the basis of the relationships between functional terms. In [89] for each classifier associated with a node, a gene is labeled as positive (i.e., belonging to the term associated with that node) if it actually belongs to that node or as negative if it does not belong to that node or to the ancestors or descendants of the node.
Other approaches exploited the correlation between nearby classes [32, 53, 117]. Shahbaba and Neal [53] take into account the hierarchy to introduce correlation between functional classes, using a multinomial logit model with Bayesian priors in the context of E. coli functional classification with Riley's hierarchies [118]. Bogdanov and Singh incorporated functional interrelationships between terms during the extraction of features based on annotations of neighboring genes and then applied a nearest-neighbor classifier to predict protein functions [117]. The HiBLADE method (hierarchical multilabel boosting with label dependency) [32] not only takes advantage of the preestablished hierarchical taxonomy of the classes but also effectively exploits the hidden correlation among the classes that is not shown through the class hierarchy, thereby improving the quality of the predictions. In particular, the dependencies of the children for each label in the hierarchy are captured and analyzed using the Bayes method and instance-based similarity. Experiments using the FunCat taxonomy and the yeast model organism show that the proposed method is competitive with TPR-W (Section 7.2) and HABYES-CS (Section 5.3) hierarchical ensemble methods.
An adaptation of a classical multiclass boosting algorithm [119] has been adapted to fit the hierarchical structure of the FunCat taxonomy [120]: the method is relatively simple and straightforward to be implemented and achieves competitive results for the AFP in the yeast model organism.
Finally, other hierarchical approaches have been proposed in the context of competitive networks learning framework. Competitive networks are well-known unsupervised and supervised methods able to map the input space into a structured output space where clusters or classes are usually arranged according to a grid topology and where learning adopts at the same way a competition, cooperation, and adaptation strategy [121]. Interestingly enough, in [122], the authors adopted this approach to predict the hierarchy of gene annotations in the yeast model organism, by using a tree-topology according to the FunCat taxonomy: each neuron is connected with its parent or with its children. Moreover, each neuron in tree-structured output layer is connected to all neurons of the input layer, representing the instances, that is, the set of genomic features associated with each gene to be classified. Results obtained with the hierarchy of enzyme commission codes showed that this approach is competitive with those obtained with hierarchical decision trees ensembles [29] (Section 8).
To provide a general picture of the methods discussed in the following sections, Table 1 summarizes their main characteristics. The first two columns report the name and a reference to the method, the third whether multiple or single paths across the taxonomy are allowed, and the next whether partial paths are considered (i.e., paths that do not end with a leaf). The successive columns refer to the class structure (a tree or a DAG), to the adoption or not of cost-sensitive (i.e., unbalance-aware) classification approaches, and to the adoption of strategies to properly select negative examples in the training phase. Finally, the last three columns summarize the type of the base learner used (“spec” means that only a specific type of base learner is allowed and “any” means that any type of learner can be used within the method), whether the method improves or not with respect to the flat approach, and the mode of processing of the nodes (“TD”: top-down approach, and “TD&BUP”: adopting both top-down and bottom-up strategies). Of course methods having more checkmarks are more flexible and in general methods that can process a DAG can also process tree-structured ontologies, but the opposite is not guaranteed, while the type of node processing relies on the way the information is propagated across the ontology. It is worth noting that all the considered methods improve on baseline “flat” classification methods.
Table 1.
Characteristics of some of the main hierarchical ensemble methods for AFP.
| Methods | References | Multipath | Partial path | Class structure | Cost sens. | Sel neg. | Base learn | Improves on flat | Node process |
|---|---|---|---|---|---|---|---|---|---|
| HMC-LMLP | [124, 125] | √ | √ | TREE | any | √ | TD | ||
| HTD-CS | [27] | √ | √ | TREE | √ | any | √ | TD | |
| HTD-MULTI | [127] | √ | TREE | any | √ | TD | |||
| HTD-PERLEV | [128] | TREE | spec | √ | TD | ||||
| HTD-NET | [26] | √ | √ | DAG | any | √ | TD | ||
| BAYES NET-ENS | [20] | √ | √ | DAG | √ | spec | √ | TD & BUP | |
| HIER-MB and BFS | [30] | √ | √ | DAG | any | √ | TD & BUP | ||
| HBAYES | [92, 135] | √ | √ | TREE | √ | any | √ | TD & BUP | |
| HBAYES-CS | [123] | √ | √ | TREE | √ | √ | any | √ | TD & BUP |
| Reconc-heuristic | [24] | √ | √ | DAG | any | √ | TD | ||
| Cascaded log | [24] | √ | √ | DAG | any | √ | TD | ||
| Projection-based | [24] | √ | √ | DAG | any | √ | TD & BUP | ||
| TPR | [31, 142] | √ | √ | TREE | √ | any | √ | TD & BUP | |
| TPR-W | [31] | √ | √ | TREE | √ | √ | any | √ | TD & BUP |
| TPR-W weighted | [145] | √ | √ | TREE | √ | any | √ | TD & BUP | |
| Decision-tree-ens | [29] | √ | √ | DAG | spec | √ | TD & BUP |
4. Hierarchical Top-Down (HTD) Ensembles
These ensemble methods exploit the hierarchical relationships between functional terms in a top-to-bottom fashion, that is, considering only the relationships denoted by the down arrows in Figure 2(b). The basic hierarchical top-down ensemble method (HTD) algorithm is straightforward: for each gene g, starting from the set of nodes at the first level of the graph G (denoted by root(G)), the classifier associated with the node i ∈ G computes whether the gene belongs to the class c i. If yes, the classification process continues recursively on the nodes j ∈ child(i); otherwise, it stops at node i, and the nodes belonging to the descendants rooted at i are all set to 0. To introduce the method, we use probabilistic classifiers as base learners trained to predict class c i associated with the node i of the hierarchical taxonomy. Their estimates of ℙ(V i = 1∣V par(i) = 1, g) are used by the HTD ensemble to classify a gene g as follows:
| (3) |
where {x} = 1 if x > 0; otherwise, {x} = 0 and is the probability predicted for the parent of the term i. It is easy to see that this procedure ensures that the predicted multilabels are consistent with the hierarchy. We can apply the same top-down procedure also using nonprobabilistic classifiers, that is, base learners generating continuous scores, or also discrete decisions, by slightly modifying (3).
In [123], a cost-sensitive version of the basic top-down hierarchical ensemble method HTD has been proposed: by assigning before the label of any j in the subtree rooted at i, the following rule is used:
| (4) |
for i = 1,…, m (note that the guessed label of the root of G is always 1). Then, the cost-sensitive variant HTD-CS introduces a single cost-sensitive parameter τ > 0 which replaces the threshold 1/2. The resulting rule for HTD-CS is then
| (5) |
By tuning τ, we may obtain ensembles with different precision/recall characteristics. Despite the simplicity of the hierarchical top-down methods, several works showed their effectiveness for AFP problems [28, 31].
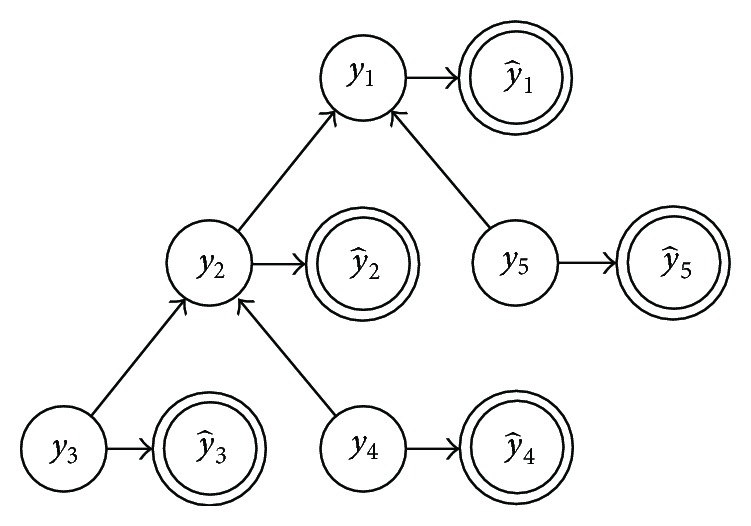
For instance, Cerri and De Carvalho experimented different variants of top-down hierarchical ensemble methods for AFP [28, 124, 125]. The HMC-LMLP (hierarchical multilabel classification with local multilayer perceptron) successively trains a local MLP network for each hierarchical level, using the classical backpropagation algorithm [126]. Then, the output of the MLP for the first layer is used as input to train the MLP that learns the classes of the second level and so on (Figure 3). A gene is annotated to a class if its corresponding output in the MLP is larger than a predefined threshold; then, in a postprocessing phase (second-step of the hierarchical classification), inconsistent predictions are removed (i.e., classes predicted without the prediction of their superclasses) [125]. In practice, instead of using a dichotomic classifier for each node, the HMC-LMLP algorithm applies a single multiclass multilayer perceptron for each level of the hierarchy.
Figure 3.

HMC-LMLP: outputs of the MLP responsible for the predictions in the first level are used as input to another MLP for the predictions in the second level (adapted from [125]).
A related approach adopts multiclass classifiers (HTD-MULTI) for each node, instead of a simple binary classifier, and tries to find the most likely path from the root to the leaves of the hierarchy, considering simple techniques, such as the multiplication or the sum of the probabilities estimated at each node along the path [127]. The method has been applied to the cell cycle branch of the FunCat hierarchy with the yeast model organism, showing improvements with respect to classical hierarchical top-down methods, even if the proposed approach can only predict classes along a single “most likely path,” thus not considering that in AFP we may have annotations involving multiple and partial paths.
Another method that introduces multiclass classifiers instead of simple dichotomic classifiers has been proposed by Paes et al. [128]: local per level multiclass classifiers (HTD-PERLEV) are trained to distinguish between the classes of a specific level of the hierarchy, and two different strategies to remove inconsistencies are introduced. The method has been applied to the hierarchical classification of enzymes using the EC taxonomy for the hierarchical classification of enzymes, but unfortunately this algorithm is not well suited to AFP, since leaf nodes are mandatory (that is partial path annotations are not allowed) and multilabel annotations along multiple paths are not allowed.
Another interesting top-down hierarchical approach proposed by the same authors is HMC-LP (hierarchical multilabel classification label-powerset), a hierarchical variation of the label-powerset nonhierarchical multilabel method [129], that has been applied to the prediction of gene function of the yeast model organism using 10 different data sets and the FunCat taxonomy [124]. According to the label-powerset approach, the method is based on a first label-combination step by which, for each example (gene), all classes assigned to the example are combined into a new and unique class, and this process is repeated for each level of the hierarchy. In this way, the original problem is transformed into a hierarchical single-label problem. In both the training and test phases, the top-down approach is applied, and at the end of the classification phase the original classes can be easily reconstructed [124]. In an experimental comparison using the FunCat taxonomy for S. cerevisiae, results showed that hierarchical top-down ensemble methods significantly outperform decision trees-based hierarchical methods, but no significant difference between different flavors of top-down hierarchical ensembles has been detected [28].
Top-down algorithms can be conceived also in the context of network-based methods (HTD-NET). For instance, in [26], a probabilistic model that combines relational protein-protein interaction data and the hierarchical structure of GO to predict true-path consistent function labels obeys the true path rule by setting the descendants of a node as negative whenever that node is set to negative. More precisely, the authors at first compute a local hierarchical conditional probability, in the sense that, for any nonroot GO term, only the parents affect its labeling. This probability is computed within a network-based framework assuming that the labeling of a gene is independent of any other genes given that of its neighbors (a sort of the Markov property with respect to gene functional interaction networks) and assuming also a binomial distribution for the number of neighbors labeled with child terms with respect to those labeled with the parent term. These assumptions are quite stringent but are necessary to make the model tractable. Then, a global hierarchical conditional probability is computed by recursively applying the previously computed local hierarchical conditional probability by considering all the ancestors. More precisely, by assuming that , that is, the probability that a gene g is annotated for a a node i, given the status of the annotations of its neighborhood N(g) in the functional networks, the global hierarchical conditional probability factorizes according to the GO graph as follows:
| (6) |
where N loc(g) represents the local hierarchical neighborhood information on the parent-child GO term pair par(j) and j [26]. This approach guarantees to produce GO term label assignments consistent with the hierarchy, without the need of a postprocessing step.
Finally in [130], the author applied a hierarchical method to the classification of yeast FunCat categories. Despite its well-founded theoretical properties based on large margin methods, this approach is conceived for one path hierarchical classification, and hence it results to be unsuited for hierarchical AFP, where usually multiple paths in the hierarchy should be considered, since in most cases genes can play different functional roles in the cell.
5. Ensemble Based Bayesian Approaches for Hierarchical Classification
These methods introduce a Bayesian approach to the hierarchical classification of proteins, by using the classical Bayes theorem or Bayesian networks to obtain tractable factorizations of the joint conditional probabilities from the original “full Bayesian” setting of the hierarchical AFP problem [20, 30] or to achieve “Bayes-optimal” solutions with respect to loss functions well suited to hierarchical problems [27, 92].
5.1. The Solution Based on Bayesian Networks
One of the first approaches addressing the issue of inconsistent predictions in the Gene Ontology is represented by the Bayesian approach proposed in [20] (BAYES NET-ENS). According to the general scheme of hierarchical ensemble methods, two main steps characterize the algorithm:
flat prediction of each term/class (possibly inconsistent);
Bayesian hierarchical combination scheme to allow collaborative error-correction over all nodes.
After training a set of base classifiers on each of the considered GO terms (in their work, the authors applied the method to 105 selected GO terms), we may have a set of (possibly inconsistent) predictions. The goal consists in finding a set of consistent y predictions, by maximizing the following equation derived from the Bayes theorem:
| (7) |
where n is the number of GO nodes/terms and Z is a constant normalization factor.
Since the direct solution of (7) is too hard, that is, exponential in time with respect to the number of nodes, the authors proposed a Bayesian network structure to solve this difficult problem, in order to exploit the relationships between the GO terms. More precisely, to reduce the complexity of the problem, the authors imposed the following constraints:
y i nodes conditioned to their children (GO structure constraints);
nodes conditioned on their label y i (the Bayes rule);
are independent from both , i ≠ j, and y j, i ≠ j, given y i.
In other words, we can ensure that a label is 1 (positive) when any one of its children is 1 and the edges from y i to assure that a classifier output is a random variable independent of all other classifier outputs and labels y j, given its true label y i (Figure 4).
Figure 4.
Bayesian network involved in the hierarchical classification (adapted from [20]).
More precisely, from the previous constraints we can derive the following equations:
| (8) |
| (9) |
Note that (8) can be inferred from training labels simply by counting, while (9) can be inferred by validation during training, by modeling the distribution of outputs over positive and negative examples, by assuming a parametric model (e.g., Gaussian distribution; see Figure 5).
Figure 5.
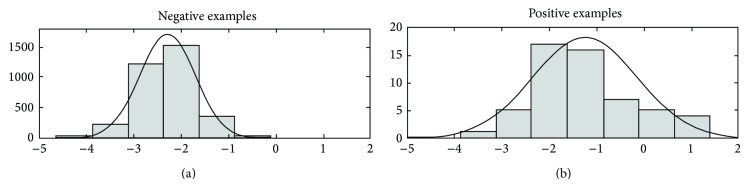
Distribution of positive and negative validation examples (a Gaussian distribution is assumed). Adapted from [20].
For the implementation of their method, the authors adopted bagged ensemble of SVMs [131] to make their predictions more robust and reliable at each node of the GO hierarchy, and median values of their outputs on out-of-bag examples have been used to estimate means and variances for each class. Finally, means and variances have been used as parameters of the Gaussian models used to estimate the conditional probabilities of (9).
Results with the 105 terms/nodes of the GO BP (model organism S. cerevisiae) showed substantial improvements with respect to nonhierarchical “flat” predictions: the hierarchical approach improves AUC results on 93 of the 105 GO terms (Figure 6).
Figure 6.
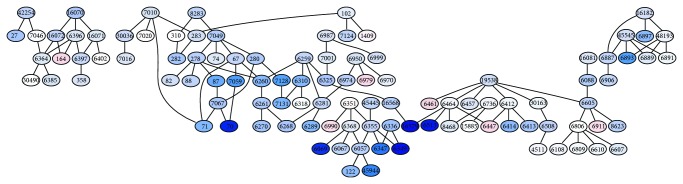
Improvements induced by the hierarchical prediction of the GO terms. Darker shades of blue indicate largest improvements, and darker shades of red indicate largest deterioration; white means no change (adapted from [20]).
5.2. The Markov Blanket and Approximated Breadth First Solution
In [30], the authors proposed an alternative approximated solution to the complex equation (7) by introducing the following two variants of the Bayesian integration:
HIER-MB: hierarchical Bayesian combination involving nodes in the Markov blanket.
HIER-BFS: hierarchical Bayesian combination involving the 30 first nodes visited through a breadth-first-search (BFS) in the GO graph.
The method has been applied to the prediction of more than 2000 GO terms for the mouse model organism and performed among the top methods in the MouseFunc challenge [2].
The first approach (HIER-MB) modifies the output of the base learners (SVMs in the Guan et al. paper) taking into account the Bayesian network constructed using the Markov blanket surrounding the GO term of interest (Figure 7). In a Bayesian network, the Markov blanket of a node i is represented by its parents (par(i)), its children (child(i)), and its children's other parents. The Bayesian network involving the Markov blanket of node i is used to provide the prediction of the ensemble, thus leveraging the local relationships of node i and the predictions for the nodes included in its Markov blanket.
Figure 7.
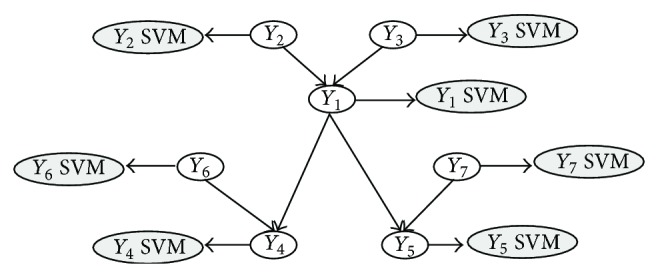
Markov blanket surrounding the GO term Y 1. Each GO term is represented as a blank node, while the SVM classifier output is represented as a gray node (adapted from [30]).
To enlarge the size of the Bayesian subnetwork involved in the prediction of the node of interest, a variant based on the Bayesian networks constructed by applying a classical breadth-first search is the basis of the HIER-BFS algorithm. To reduce the complexity at most, 30 terms are included (i.e., the first 30 nodes reached by the breadth-first algorithm; see Figure 8). In the implementation, ensembles of 25 SVMs have been trained for each node, using vector space integration techniques [132] to integrate multiple sources of data.
Figure 8.
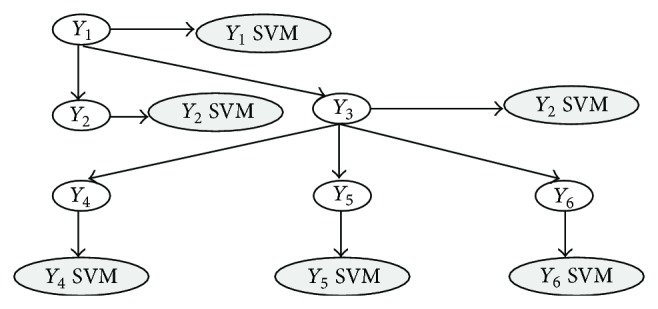
The breadth-first subnetwork stemming from Y 1. Each GO term is represented through a blank node and the SVM outputs are represented as gray nodes (adapted from [30]).
Note that with both HIER-MB and HIER-BFS methods we do not take into account the overall topology of the GO network but only the terms related to the node for which we perform the prediction. Even if this general approach is reasonable and achieves good results, its main drawback is represented by the locality of the hierarchical integration (limited to the Markov blanket and the first 30 BFS nodes). Moreover, in previous works, it has been shown that the adopted integration strategy (vector space integration) is in most cases worse than kernel fusion [11] and ensemble methods for data integration [23].
In the same work [30], the authors propose also a sort of “test and select” method [133], by which three different classification approaches (a) single flat SVMs, (b) Bayesian hierarchical correction, and (c) Naive Bayes combination are applied, and for each GO term the best one is selected by internal cross-validation (Figure 9).
Figure 9.

Integration of diverse methods and diverse sources of data in an ensemble framework for AFP prediction. The best classifier for each GO term is selected through held-out set validation (adapted from [30]).
It is worth noting that other approaches adopted Bayesian networks to resolve the hierarchical constraints underlying the GO taxonomy. For instance, in the FALCON algorithm the GO is modeled as a Bayesian network and for any given input the algorithm returns the most probable GO term assignment in accordance with the GO structure, by using an evolutionary-based optimization algorithm [134].
5.3. HBAYES: An “Optimal” Hierarchical Bayesian Ensemble Approach
The HBAYES ensemble method [92, 135] is a general technique for solving hierarchical classification problems on generic taxonomies G structured according to forest of trees. The method consists in training a calibrated classifier at each node of the taxonomy. In principle, any algorithm (e.g., support vector machines or artificial neural networks) whose classifications are obtained by thresholding a real prediction , for example, , can be used as base learner. The real-valued outputs of the calibrated classifier for node i on the gene g are viewed as estimates of the probabilities p i(g) = ℙ(y i = 1∣y par(i) = 1, g). The distribution of the random Boolean vector Y is assumed to be
| (10) |
where, in order to enforce that only multilabels Y that respect the hierarchy have nonzero probability, it is imposed that ℙ(Y i = 1∣Y par(i) = 0, g) = 0 for all nodes i = 1,…, m and all g. This implies that the base learner at node i is only trained on the subset of the training set including all examples (g, y) such that y par(i) = 1.
5.3.1. HBAYES Ensembles for Protein Function Prediction
H-loss is a measure of discrepancy between multilabels based on a simple intuition: if a parent class has been predicted wrongly, then errors in its descendants should not be taken into account. Given fixed cost coefficients θ 1,…, θ m > 0, the H-loss between multilabels and v is computed as follows: all paths in the taxonomy T from the root down to each leaf are examined and whenever a node i ∈ {1,…, m} is encountered such that , θ i is added to the loss, while all the other loss contributions from the subtree rooted at i are discarded. This method assumes that, given a gene g, the distribution of the labels V = (V 1,…, V m) is ℙ(V = v) = ∏i=1 m p i(g) for all v ∈ {0,1}m, where p i(g) = ℙ(V i = v i∣V par(i) = 1, g). According to the true path rule, it is imposed that ℙ(V i = 1∣V par(i) = 0, g) = 0 for all nodes i and all genes g.
In the evaluation phase, HBAYES predicts the Bayes-optimal multilabel for a gene g based on the estimates for i = 1,…, m. By definition of Bayes-optimality, the optimal multilabel for g is the one that minimizes the loss when the true multilabel V is drawn from the joint distribution computed from the estimated conditionals . That is,
| (11) |
In other words, the ensemble method HBAYES provides an approximation of the optimal Bayesian classifier with respect to the H-loss [135]. More precisely, as shown in [27] the following theorem holds.
Theorem 1 . —
For any tree T and gene g the multilabel generated according to the HBAYES prediction rule is the Bayes-optimal classification of g for the H-loss.
In the evaluation phase, the uniform cost coefficients θ i = 1, for i = 1,…, m, are used. However, since with uniform coefficients the H-loss can be made small simply by predicting sparse multilabels (i.e., multilabels such that is small), in the training phase the cost coefficients are set to θ i = 1/|root(G)|, if i ∈ root(G), and to θ i = θ j/|child(j)| with j = par(i), if otherwise. This normalizes the H-loss, in the sense that the maximal H-loss contribution of all nodes in a subtree excluding its root equals that of its root.
Let {E} be the indicator function of event E. Given g and the estimates for i = 1,…, m, the HBAYES prediction rule can be formulated as follows.
HBAYES Prediction Rule. Initially, set the labels of each node i to
| (12) |
where
| (13) |
is recursively defined over the nodes j in the subtree rooted at i with each set according to (12).
Then, if is set to zero, set all nodes in the subtree rooted at i to zero as well.
It is worth noting that can be computed for a given g via a simple bottom-up message-passing procedure. It can be shown that if all child nodes k of i have close to a half, then the Bayes-optimal label of i tends to be 0 irrespective of the value of . On the contrary, if i's children all have close to either 0 or 1, then the Bayes-optimal label of i is based on only, ignoring the children. This behaviour can be intuitively explained in the following way: the estimate is built based only on the examples on which the parent i of k is positive; hence, a “neutral” estimate signals that the current instance is a negative example for the parent i. Experimental results show that this approach achieves comparable results with the TPR method (Section 7), an ensemble approach based on the “true path rule” [136].
5.3.2. HBAYES-CS: The Cost-Sensitive Version
The HBAYES-CS is the cost-sensitive version of HBAYES proposed in [27]. By this approach, the misclassification cost coefficient θ i for node i is split into two terms θ i + and θ i − for taking into account misclassifications, respectively, for positive and negative examples. By considering separately these two terms, (12) can be rewritten as
| (14) |
where the expression of gets changed correspondingly. By introducing a factor α ≥ 0 such that θ i − = αθ i + while keeping θ i + + θ i − = 2θ i, the relative costs of false positives and false negatives can be parameterized, thus allowing us to further rewrite the hierarchical Bayesian rule (Section 5.3.1) as follows:
| (15) |
By setting α = 1, we obtain the original version of the hierarchical Bayesian ensemble and by incrementing α we introduce progressively lower costs for positive predictions. In this way, we can obtain that the recall of the ensemble tends to increase, eventually at the expenses of the precision, and by tuning the α parameter we can obtain different combinations of precision/recall values.
In principle, a cost factor α i can be set for each node i to explicitly take into account the unbalance between the number of positive n i + and negative n i − examples, estimated from the training data
| (16) |
The decision rule (15) at each node then becomes
| (17) |
Results obtained with the yeast model organism showed that HBAYES-CS significantly outperform HTD methods [27, 136].
6. Reconciliation Methods
Hierarchical ensemble methods are basically two-step methods, since at first provide predictions for the single classes and then arrange these predictions to take into account the functional relationships between GO terms. Noble and colleagues name this general approach reconciliation methods [24]: they proposed methods for calibrating and combining independent predictions to obtain a set of probabilistic predictions that are consistent with the topology of the ontology. They applied their ensemble methods to the genome-wide and ontology-wide function prediction with M. musculus, involving about 3000 GO terms.
Their goal consists in providing consistent predictions, that is, predictions whose confidence (e.g., posterior probability) increases as we ascend from more specific to more general terms in the GO. Moreover, another important issue of these methods is the availability of confidence values associated with the predictions that can be interpreted as probabilities that a protein has a certain function given the information provided by the data.
The overall reconciliation approach can be summarized in the following four basic steps (Figure 10):
Kernel computation: at first a set of kernels is computed from the available data. We may choose kernel specific for each source of data (e.g., diffusion kernels for protein-protein interaction data [137], linear or Gaussian kernel for expression data, and string kernel for sequence data [138]). Multiple kernels for the same type of data can also be constructed [24].
SVM learning: SVMs are used as base learners using the kernels selected at the previous step; the training is performed by internal cross-validation to avoid overfitting, and a local cost-sensitive strategy is applied, by tuning separately the C regularization factor for positive and negative examples. Note that the authors in their experiments used SVMs as base learners but any meaningful classifier could be used at this step.
Calibration: to produce individual probabilistic outputs from the set of SVM outputs corresponding to one GO term, a logistic regression approach is applied. In this way, a calibration of the individual SVM outputs is obtained, resulting in a probabilistic prediction of the random variable Y i, for each node/term i of the hierarchy, given the outputs of the SVM classifiers.
Reconciliation: the first three steps generate unreconciled outputs; that is, in practice a “flat” ensemble is applied that may generate inconsistent predictions with respect to the given taxonomy. In this step, the outputs of step three are processed by a “reconciliation method.” The goal of this stage is to combine predictions for each term to produce predictions that are consistent with the ontology, meaning that all the probabilities assigned to the ancestors of a GO term are larger than the probability assigned to that term.
Figure 10.
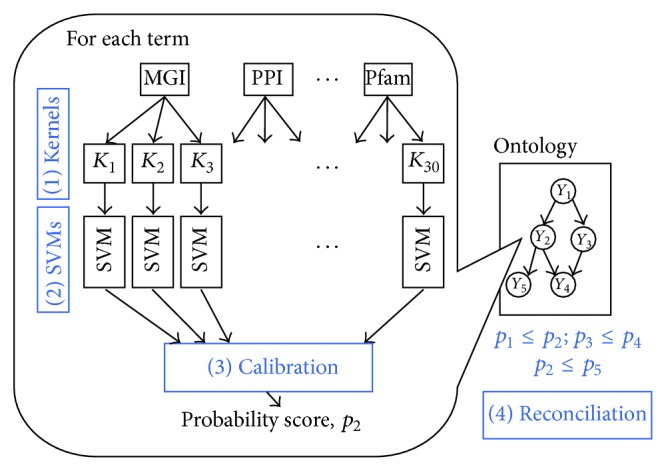
The overall scheme of reconciliation methods (adapted from [24]).
The first three steps are basically the same for (or very similar to) each reconciliation ensemble method. The crucial step is represented by the fourth, that is, the reconciliation step, and different ensemble algorithms can be designed to implement it. The authors proposed 11 different ensemble methods for the reconciliation of the base classifier outputs. Schematically, they can be subdivided into the following four main classes of ensembles:
heuristic methods;
Bayesian network-based methods;
cascaded logistic regression;
projection-based methods.
6.1. Heuristic Methods
These approaches preserve the “reconciliation property”
| (18) |
through simple heuristic modifications of the probabilities computed at step 3 of the overall reconciliation scheme.
- The MAX method simply chooses the largest logistic regression value for the node i and all its descendants desc
(19) - The AND method implements the notion that the probability of all ancestral GO terms anc(i) of a given term/node i is large, assuming that, conditional on the data, all predictions are independent
(20) - OR estimates the probability that the node i is annotated at least for one of the descendant GO terms, assuming again that, conditional on the data, all predictions are independent
(21)
6.2. Cascaded Logistic Regression
Instead of modeling class-conditional probabilities, as required by the Bayesian approach, logistic regression can be used instead to directly model posterior probabilities. Considering that modeling conditional densities are in most cases difficult (also using strong independence assumptions as shown in Section 5.1), the choice of logistic regression could be a reasonable one. In [24], the authors embedded in the logistic regression setting the hierarchical dependencies between terms. By assuming that a random variable X whose values represent the features of the gene g of interest is associated to a given gene g and assuming that ℙ(Y = y∣X = x) factorizes according to the GO graph, then it follows
| (22) |
with ℙ(Y i = 1∣∀ j ∈ par(i) Y j = 0, X i = x i) = 0. The authors estimated ℙ(Y i = 1∣∀ j ∈ par(i)Y j = 1, X i = x i) with logistic regression. This approach is quite similar to fitting independent logistic regressions, but note that in this case only examples of proteins having all parents GO terms are used to fit the model, thus implicitly taking into account the hierarchical relationships between GO terms.
6.3. Bayesian Network-Based Methods
These methods are variants of the Bayesian network approach proposed in [20] (Section 5.1): the GO is viewed as a graphical model where a joint Bayesian prior is put on the binary GO term variables y i. The authors proposed four variants that can be summarized as follows:
the BPAL is a belief propagation approach with asymmetric Laplace likelihoods. The graphical model has edges directed from more general terms to more specific terms. Differently from [20], the distribution of each SVM output is modeled as an asymmetric Laplace distribution, and a variational inference algorithm that solves an optimization problem whose minimizer is the set of marginal probabilities of the distribution is used to estimate the posterior probabilities of the ensemble [139];
the BPALF approach is similar to BPAL but with edges inverted and directed from more specific terms to more general terms;
the BPLR is a heuristic variant of BPAL, where, in the inference algorithm, the Bayesian log posterior ratio for Y i is replaced by the marginal log posterior ratio obtained from the logistic regression (LR);
The BPLRF is equal to BPLR but with reversed edges.
6.4. Projection-Based Methods
A different approach is represented by methods that directly use the calibrated values obtained from logistic regression (step 3 of the overall scheme of the reconciliation methods) to find the closest set of values that are consistent with the ontology. This approach leads to a constrained optimization problem. The main contribution of the Obozinski et al. work [24] is represented by the introduction of projection reconciliation techniques based on isotonic regression [140] and the Kullback-Leibler divergence.
The isotonic regression method tries to find a set of marginal probabilities p i that are close to the set of calibrated values obtained from the logistic regression. The Euclidean distance is used as a measure of closeness. Hence, considering that the “reconciliation property” requires that p i ≥ p j when (i, j) ∈ E, this approach yields the following quadratic program:
| (23) |
This problem is the classical isotonic regression problems that can be solved using an interior point solver or also approximated algorithm when the number of edges of the graph is too large [141].
Considering that we deal with probabilities, a natural measure of distance between probability density functions f(x) and g(x) defined with respect to a random variable x is represented by the Kullback-Leibler divergence D fx||gx as follows:
| (24) |
In the context of reconciliation methods, we need to consider a discrete version of the Kullback-Leibler divergence, yielding the following optimization problem:
| (25) |
The algorithm finds the probabilities closest to the probabilities obtained from logistic regression according to the Kullback-Leibler divergence and obeying the constraints that probabilities cannot increase while descending on the hierarchy underlying the ontology.
The extensive experiments exploited in [24] show that, among the reconciliation methods, isotonic regression is the most generally useful. Across a range of evaluation modes, term sizes, ontologies, and recall levels, isotonic regression yields consistently high precision. On the other hand, isotonic regression is not always the “best method,” and a biologist with a particular goal in mind may apply other reconciliation methods. For instance, with small terms usually Kullback-Leibler projections achieve the best results, but considering average “per term” results heuristic methods yield precision at a given recall comparable with projection methods and better than that achieved with Bayes-net methods.
This ensemble approach achieved excellent results in the prediction of protein function in the mouse model organism, demonstrating that hierarchical multilabel methods can play a crucial role for the improvement of protein function prediction performances [24]. Nevertheless, the approach suffers from some drawbacks. Indeed, the paper focuses on the comparison of hierarchical multilabel methods, but it does not analyze impact of the concurrent use of data integration and hierarchical multilabel methods on the overall classification performances. Moreover, potential improvements could be introduced by applying cost-sensitive variants of hierarchical multilabel predictors, able to effectively calibrate the precision/recall trade-off at different levels of the functional ontology.
7. True Path Rule Hierarchical Ensembles
These ensemble methods exploit at the same time the downward and upward relationships between classes, thus considering both the parent-to-child and child-to-parent functional links (Figure 2(b)).
The true path rule (TPR) ensemble method [31, 142] is directly inspired by the true path rule that governs both GO and FunCat taxonomies. Citing the curators of the Gene Ontology is as follows [143]: “An annotation for a class in the hierarchy is automatically transferred to its ancestors, while genes unannotated for a class cannot be annotated for its descendants.” Considering the parents of a given node i, a classifier that respects the true path rule needs to obey the following rules:
| (26) |
On the other hand, considering the children of a given node i, a classifier that respects the true path rule needs to obey the following rules:
| (27) |
From (26) and (27), we observe an asymmetry in the rules that govern the assignments of positive and negative labels. Indeed, we have a propagation of positive predictions from bottom to top of the hierarchy in (26) and a propagation of negative labels from top to bottom in (27). Conversely, negative labels cannot propagate from bottom to top, and positive predictions cannot propagate from top to bottom.
The “true path rule” suggests algorithms able to propagate “positive” decisions from bottom to top of the hierarchy and negative decisions from top to bottom (Figure 11).
Figure 11.

The asymmetric flow of information suggested by the true path rule.
7.1. The True Path Rule Ensemble Algorithm
The TPR algorithm puts together the predictions made at each node by local “base” classifiers to realize an ensemble that obeys the “true path rule.”
The basic ideas behind the method can be summarized as follows:
training of the base learners: for each node of the hierarchy, a suitable learning algorithm (e.g., a multilayer perceptron or a support vector machine) provides a classifier for the associated functional class;
in the evaluation phase, the trained classifiers associated with each class/node of the graph provide a local decision about the assignment of a given example to a given node;
positive decisions, that is, annotations to a specific functional class, may propagate from bottom to top across the graph: they influence the decisions of the parent nodes and of their ancestors in a recursive way, by traversing the graph towards higher level nodes/classes. Conversely, negative decisions do not affect decisions of the parent node;that is, they do not propagate from bottom to top (26);
negative predictions for a given node (taking into account the local decision of its descendants) are propagated to the descendants, to preserve the consistency of the hierarchy according to the true path rule, while positive decisions do not influence decisions of child nodes (27).
The ensemble combines the local predictions of the base learners associated with each node with the positive decisions that come from the bottom of the hierarchy, and with the negative decisions that spring from the higher level nodes. More precisely, base classifiers estimate local probabilities that a given example g belongs to class θ i, but the core of the algorithm is represented by the evaluation phase, where the ensemble provides an estimate of the “consensus” global probability .
It is worth noting that instead of a probability, may represent a score associated with the likelihood that a given gene/gene product belongs to the functional class i.
Let us consider the set ϕ i(g) of the children of node i for which we have a positive prediction for a given gene g
| (28) |
The global consensus probability of the ensemble depends both on the local prediction and on the prediction of the nodes belonging to ϕ i(g)
| (29) |
The decision at node/class i is set to 1 if and to 0, if otherwise (a natural choice for t is 0.5), and only children nodes for which we have a positive prediction can influence their parent. In the leaf nodes, the sum of (29) disappears and (29) becomes . In this way, positive predictions propagate from bottom to top, and negative decisions are propagated to their descendants when for a given node .
The bottom-up per level traversal of the tree assures that all the offsprings of a given node i are taken into account for the ensemble prediction. For the same reason, we can safely set the classes belonging to the subtree rooted at i to negative, when is set to 0. It is worth noting that we have a two-way asymmetric flow of information across the tree: positive predictions for a node influence its ancestors, while negative predictions influence its offsprings.
The algorithm provides both the multilabels and an estimate of the probabilities that a given example g belongs to the class i = 1,…, m.
7.2. The Cost-Sensitive Variant
Note that in the TPR algorithm there is no way to explicitly balance the local prediction at node i with the positive predictions coming from its offsprings (29). By balancing the local predictions with the positive predictions coming from the ensemble, we can explicitly modulate the interplay between local and descendant predictors. To this end, a weight w, 0 ≤ w ≤ 1, is introduced, such that if w = 1 the decision at node i depends only by the local predictor; otherwise, the prediction is shared proportionally to w and 1 − w between, respectively, the local parent predictor and the set of its children
| (30) |
This variant of the TPR algorithm is the weighted true path rule (TPR-W) hierarchical ensemble algorithm. By tuning the w parameter, we can modulate the precision/recall characteristics of the resulting ensemble. More precisely, for w → 0, the weight of the parent local predictor is small, and the ensemble decision mainly depends on the positive predictions of the offsprings nodes (classifiers). Conversely, w → 1 corresponds to a higher weight of the parent predictor; then, less weight is given to possible positive predictions of the children, and the decision depends mainly on the local/parent base classifier. In case of a negative decision, all the subtree is set to 0, causing the precision to increase. Note that for w → 1 the behaviour of TPR-W becomes similar to that of HTD (Section 4).
A specific advantage of the TPR-W ensembles is the capability of tuning precision and recall rates, through the parameter w (30). For small values of w, the weight of the decision of the parent local predictor is small, and the ensemble decision depends mainly by the positive predictions of the offsprings nodes (classifiers), and higher values of w correspond to a higher weight of the “parent” local predictor, with a resulting higher precision. In [31], the author shows that the w parameter highly influences the precision/recall characteristics of the ensemble: low w values yield a higher recall, while high values improve the precision of the TPR-W ensemble.
Recently, Chen and Hu proposed a method that applies the TPR-W hierarchical strategy, but using composite kernel SVMs as base classifiers, and a supervised clustering with oversampling strategy to solve the imbalance data set learning problem, showed that the proper selection of base learners, and unbalance-aware learning strategies can further improve the results in terms of hierarchical precision and recall [144].
The same authors proposed also an enhanced version of the TPR-W strategy to overcome a limitation of this bottom-up hierarchical method for AFP. Indeed, for some classes at the lower levels of the hierarchy, the classifier performances are sometimes quite poor, due to both noisy data and the relatively low number of available annotations. More precisely, in the basic TPR ensemble, the probabilities computed by the children of the node i (30) contribute in equal way to the probability computed by the ensemble at node i, independently of the accuracy of the predictions made by its children classifiers. This “unweighted” mechanism may generate error propagation of the errors across the hierarchy: a poor performance child classifier may, for instance, with high probability, predict a negative example as positive and this error may propagate to its parent node and recursively to its ancestor nodes. To try to alleviate this possible bottom-up error propagation in [145], Chen and Hu proposed an improved TPR ensemble (TPR-W weighted), based on classifier performance. To this end, they weighted the contribution of each child classifier on the basis of their performance evaluated on a validation data set, by adding to (30) another weight ν j
| (31) |
where ν j is computed on the basis of some accuracy metric A j (e.g., the F-score) estimated for the child classifiers associated with node j as follows:
| (32) |
In this way, the contribution of “poor” classifier is reduced, while “good” classifiers weight more in the final computation of (31). Experiments with the “Protein Fate” subtree of the FunCat taxonomy with the yeast model organism show that this approach improves prediction with respect to the “vanilla” TPR-W hierarchical strategy [145].
7.3. Advantages and Drawbacks of TPR Methods
While the propagation of negative decisions from top to bottom nodes is quite straightforward and common to the hierarchical top-down algorithm, the propagation of positive decisions from bottom to top nodes of the hierarchy is specific to the TPR algorithm. For a discussion of this item, see Appendix C.
Experimental results show that TPR-W achieves equal or better results than the TPR and top-down hierarchical strategy, and both hierarchical strategies achieve significantly better results than flat classification methods [55, 123]. The analysis of the per level classification performances shows that TPR-W, by exploiting a global strategy of classification, is able to achieve a good compromise between precision and recall, enhancing the F-measure at each level of the taxonomy [31].
Another advantage of TPR-W consists in the possibility of tuning precision and recall by using a global strategy: large values of the w parameter improve the precision, and small values improve the recall.
Moreover, TPR and TPR-W ensembles provide also a probabilistic estimate of the prediction reliability for each functional class of the overall taxonomy.
The decisions performed at each node of the hierarchical ensemble are influenced by the positive decisions of its descendants. More precisely, the analyses performed in [31] showed the following:
weights of descendants decrease exponentially with respect to their depth. As a consequence the influence of descendant, nodes decay quickly with their depth;
the parameter w plays a central role in balancing the weight of the parent classifier associated with a given node with the weights of its positive offsprings: small values of w increase the weight of descendant nodes, and large values increase the weight of the local parent predictor associated with that node;
the effect on the overall probability predicted by the ensemble is the result of the choice of the w parameter, the strength of the prediction of the local learners and of its descendants.
These characteristics of TPR-W ensembles are well suited for the hierarchical classification of protein functions, considering that annotations of deeper nodes are likely to have less experimental evidence than higher nodes. Moreover, by enforcing the strength of the descendant nodes through low w values, we can improve the recall characteristics of the overall system (at the expense of a possible reduction in precision).
Unfortunately, the method has been conceived and applied only to the FunCat taxonomy, structured according to a tree forest (Section 11), while no applications have been performed using the GO, structured according to a directed acyclic graph (Section 11).
8. Ensembles Based on Decision Trees
Another interesting research line is represented by hierarchical methods base on inductive decision trees [146]. The first attempts to exploit the hierarchical structure of functional ontologies for AFP simply used different decision tree models for each level of the hierarchy [147] or investigated a modified decision tree model, in which the assignment to a node is propagated toward the parent nodes [9], by extending the classical C4.5 decision tree algorithm for multiclass classification.
In the context of the predictive clustering tree framework [148], Blockeel et al. proposed an improved version which they applied to the prediction of gene function in the yeast [149].
More recent approaches, always based on modified decision trees, used distance measure derived from the hierarchy and significantly improved previous methods [54]. The authors showed that separate decision tree models are less accurate than a single decision tree trained to predict all classes at once, even when they are built taking into account the hierarchy.
Nevertheless, the previously proposed decision tree-base methods often achieve results not comparable with state-of-the-art hierarchical ensemble methods. To overcome this limitation, Schietgat et al. showed that ensembles of hierarchical multilabel decision trees are competitive with state-of-the-art statistical learning methods for DAG-structured prediction of protein function in S. cerevisiae, A. thaliana, and M. musculus model organisms [29]. A further work explored the suitability of different ensemble methods based on predictive clustering trees, ranging from global ensembles that learn ensembles of predictive models, each able to predict the entire structure of the hierarchy (i.e., all the GO terms for a given gene), to local ensembles that train an entire ensemble as a classifier for each branch of the taxonomy. Recently, a novel approach used PPI network autocorrelation in hierarchical multilabel classification trees to improve gene function prediction [150].
In [151], methods related to decision trees, in the sense that interpretable classification rules to predict all functions at all levels of the GO hierarchy, have been proposed, using an ant colony optimization classification algorithm to discover classification rules.
Finally, bagging and random forest ensembles [152] have been applied to the AFP in yeast, showing that both local and global hierarchical ensemble approaches perform better than the single model counterparts in terms of predictive power [153].
9. The Hierarchical Classification Alone Is Not Enough
Several works showed that in protein function prediction problems we need to consider several learning issues [1, 16, 18]. In particular, in [80], the authors showed that even if hierarchical ensemble methods are fundamental to improve the accuracy of the predictions, their mere application is not enough to assure state-of-the-art results if we at the same time do not consider other important learning issues related to AFP. Indeed, in [123], it has been shown a significant synergy between hierarchical classification, data integration methods, and cost-sensitive techniques, highlighting that hierarchical ensemble methods should be designed taking into account different learning issues essential for the AFP problem.
9.1. Hierarchical Methods and Data Integration
Several works and the recently published results of the CAFA 2011 (Critical Assessment of Functional Annotation) challenge showed that data integration plays a central role to improve the predictions of protein functions [16, 25, 154–156].
Indeed, high-throughput biotechnologies make increasing quantities of biomolecular data of different types available, and several works pointed out that data integration is fundamental to improve the accuracy in AFP [1].
According to [154], we may subdivide the main approaches to data integration for AFP in four groups as follows:
vector subspace integration;
functional association networks integration;
kernel fusion;
ensemble methods.
Vector Space Integration. This approach consists in concatenating vectorial data to combine different sources of biomolecular data [132]. For instance, [22] concatenates different vectors, each one corresponding to a different source of genomic data, in order to obtain a larger vector that is used to train a standard SVM. A similar approach has been proposed by [30], but each data source is separately normalized in order to take into account the data distribution in each individual vector space.
Functional Association Networks Integration. In functional association networks, different graphs are combined to obtain the composite resulting network [21, 48]. The simplest approaches adopt conjunctive/disjunctive techniques [63], that is, respectively, adding an edge when in all the networks two genes are linked together or when a link between the two genes is present in at least one functional network or probabilistic evidence integration schemes [45].
Other methods differentially weight each data source using techniques ranging from Gaussian random fields [46] to the naive-Bayes integration [157] and constrained linear regression [14], or by merging data taking into account the GO hierarchy [158], or by applying XML-based techniques [159].
Kernel Fusion. These techniques at first construct a separated Gram matrix for each available data source using appropriate kernels representing similarities between genes/gene products. Then, by exploiting the closure property with respect to the sum and other algebraic operators, the Gram matrices are combined to obtain a “consensus” global integrated matrix.
Besides combining kernels linearly with fixed coefficients [22], one may also use semidefinite programming to learn the coefficients [11]. As methods based on semidefinite programming do not scale well to multiple data sources, more efficient methods for multiple kernel learning have been recently proposed [160, 161]. Kernel fusion methods, both with and without weighting the data sources, have been successfully applied to the classification of protein functions [162–165]. Recently, a novel method proposed an enhanced kernel integration approach by which the weights are iteratively optimized by reducing the empirical loss of a multilabel classifier for each of the labels simultaneously, using a combined objective function [165].
Ensemble Methods. Genomic data fusion can be realized by means of an ensemble system composed by learners trained on different “views” of the data and then combining the outputs of the component learners. Each type of data may capture different and complementary characteristics of the objects to be classified and the resulting ensemble may obtain better prediction capabilities through the diversity and the anticorrelation of the base learner responses.
Some examples of ensemble methods for data combination include “late integration” of kernels trained on different sources [22], the naive-Bayes integration [166] of the outputs of SVMs trained with multiple sources [30], and logistic regression for combining the output of several SVMs trained with different biomolecular data and kernels [24].
Recently, in [23], the authors showed that simple ensemble methods, such as weighted voting [167, 168] or decision templates [169], give results comparable to state-of-the-art data integration methods, exploiting at the same time the modularity and scalability that characterize most ensemble algorithms. Another work showed that ensemble methods are also resistant to noise [170].
Using an ensemble approach, biomolecular data differing in their structural characteristics (e.g., sequences, vectors, and graphs) can be easily integrated, because with ensemble methods the integration is performed at the decision level, combining the outputs produced by classifiers trained on different datasets [171–173].
As an example of the effectiveness of the integration of hierarchical ensemble methods with data fusion techniques, in [123], six different sources of yeast biomolecular data have been integrated, ranging from protein domain data (PFAM BINARY and PFAM LOGE) [174], gene expression measures (EXPR) [175], predicted and experimentally supported protein-protein interaction data (STRING and BIOGRID) [176, 177] to pairwise sequence similarity data (SEQ. SIM.). Kernel fusion integration (sum of the Gram matrices) has been applied, and preprocessing has been performed using the the HCGene R package [178].
Table 2 summarizes the results of the comparison across about two hundreds of FunCat classes, including single-source and data integration approaches together with both flat and hierarchical ensembles.
Table 2.
Comparison of the results (average per class F-scores) achieved with single sources and multisource (data fusion) techniques. FLAT, HTD, HTD-CS, HB (HBAYES), HB-CS (HBAYES-CS), TPR, and TPR-W ensemble methods are compared with and without data integration. In the last row, the number in parentheses refers to the percentage relative increment in F-score performance achieved with data fusion techniques with respect to the best single source of evidence (BIOGRID).
| Methods | FLAT | HTD | HTD-CS | HB | HB-CS | TPR | TPR-W |
|---|---|---|---|---|---|---|---|
| Single-source | |||||||
| BIOGRID | 0.2643 | 0.3759 | 0.4160 | 0.3385 | 0.4183 | 0.3902 | 0.4367 |
| String | 0.2203 | 0.2677 | 0.3135 | 0.2138 | 0.3007 | 0.2801 | 0.3048 |
| PFAM BINARY | 0.1756 | 0.2003 | 0.2482 | 0.1468 | 0.2407 | 0.2532 | 0.2738 |
| PFAM LOGE | 0.2044 | 0.1567 | 0.2541 | 0.0997 | 0.2847 | 0.3005 | 0.3160 |
| Expr. | 0.1884 | 0.2506 | 0.2889 | 0.2006 | 0.2781 | 0.2723 | 0.3053 |
| Seq. sim. | 0.1870 | 0.2532 | 0.2899 | 0.2017 | 0.2825 | 0.2742 | 0.3088 |
|
| |||||||
| Multisource (data fusion) | |||||||
| Kernel fusion | 0.3220(22) | 0.5401(44) | 0.5492(32) | 0.5181(53) | 0.5505(32) | 0.5034(29) | 0.5592(28) |
Data fusion techniques improve average per class F-score across classes in flat ensembles (first column of Table 2) and significantly boost multilabel hierarchical methods (columns HTD, HTD-CS, HB, HB-CS, TPR, and TPR-W of Table 2).
Figure 12 depicts the classes (black nodes) where kernel fusion achieves better results than the best single-source data set (BIOGRID). It is worth noting that the number of black nodes is significantly larger in TPR-W (Figure 12(b)) with respect to FLAT methods (Figure 12(a)).
Figure 12.

FunCat trees to compare F-scores achieved with data integration (KF) to the best single-source classifiers trained on BIOGRID data. Black nodes depict functional classes for which KF achieves better F-scores. (a) FLAT and (b) TPR-W ensembles.
Hierarchical multilabel ensembles largely outperform FLAT approaches [24, 30], but Table 2 and Figure 12 also reveal a synergy between hierarchical ensemble methods and data fusion techniques.
9.2. Hierarchical Methods and Cost-Sensitive Techniques
According to [27, 142], cost-sensitive approaches boost predictions of hierarchical methods when single-sources of data are used to train the base learners. These results are confirmed when cost-sensitive methods (HBAYES-CS, Section 5.3.2; HTD-CS, Section 4; and TPR-W, Section 7.2) are integrated with data fusion techniques, showing a synergy between multilabel hierarchical, data fusion (in particular, kernel fusion), and cost-sensitive approaches (Figure 13) [123].
Figure 13.

Comparison of hierarchical precision, recall, and F-score among different hierarchical ensemble methods using the best source of biomolecular data (BIOGRID), kernel fusion (KF), and weighted voting (WVOTE) data integration techniques. HB stands for HBAYES.
Perlevel analysis of the F-score in HBAYES-CS, HTD-CS, and TPR-W ensembles shows a certain degradation of performance with respect to the depth of nodes, but this degradation is significantly lower when data fusion is applied. Indeed, the per-level F-score achieved by HBAYES-CS and HTD-CS when a single source is used consistently decreases from the top to the bottom level, and it is halved at level 5 with respect to the first level. On the other hand, in the experiments with Kernel Fusion the average F-score at level 2, 3 and 4 is comparable, and the decrement at level 5 with respect to level 1 is only about 15% (Figure 14). Similar results are reported also with TPR-W ensembles.
Figure 14.
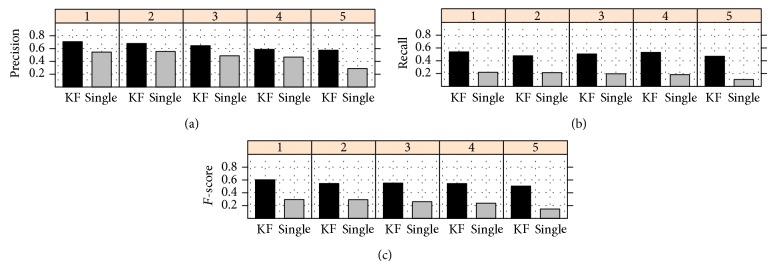
Comparison of per level average precision, recall, and F-score across the five levels of the FunCat taxonomy in HBAYES-CS using single data sets (single) and kernel fusion techniques (KF). Performance of “single” is computed by averaging across all the single data sources.
In conclusion, the synergic effects of hierarchical multilabel ensembles, cost-sensitive, and data fusion techniques significantly improve the performance of AFP. Moreover, these enhancements allow obtaining better and more homogeneous results at each level of the hierarchy. This is of paramount importance, because more specific annotations are more informative and can get more biological insights into the functions of genes.
9.3. Different Strategies to Select “Negative” Genes
In both GO and FunCat, only positive annotations are usually available, while negative annotations are much reduced. More precisely, in the GO, only about 2500 negative annotations are available, and surely this amount does not allow a sufficient coverage of negative examples.
Moreover, some seminal works in functional genomics pointed out that the strategy of choosing negative training examples does affect the classifier performance [8, 163, 179, 180].
In [123], two strategies for choosing negative examples have been compared: the basic (B) and the parent only (PO) strategy.
According to the B strategy, the set of negative examples are simply those genes g that are not annotated for class c i; that is,
| (33) |
The PO selection strategy chooses as negatives for the class c i only those examples that are nonannotated to c i but are annotated for a parent class. More precisely, for a given class c i corresponding to node i in the taxonomy, the set of negative examples is
| (34) |
Hence, this strategy selects negative examples for training that are in a certain sense “close” to positives. It is easy to see that N PO⊆N B; hence, this strategy selects for training a large set of generic negative examples, possibly annotated with classes that are associated with faraway nodes in the taxonomy. Of course, the set of positive examples is the same for both strategies.
The B strategy worsens the performance of hierarchical multilabel methods, while for FLAT ensembles there is no clear trend. Indeed, in Figure 15, we compare the F-scores obtained with B to those obtained with PO, using both hierarchical cost-sensitive (Figure 15(a)) and FLAT (Figure 15(b)) methods. Each point represents the F-score for a specific FunCat class achieved by a specific method with B (abscissa) and PO (ordinate) strategy for the selection of negative examples. In Figure 15(a), most points lie above the bisector independently of the hierarchical cost-sensitive method being used. This shows that hierarchical methods gain in performance when using the PO strategy as opposed to the B strategy (P-value = 2.2 × 10−16 according to the Wilcoxon signed-ranks test). This is not the case for FLAT methods (Figure 15(b)).
Figure 15.

Comparison of average per class F-score between basic and PO strategies. (a) FLAT ensembles; (b) hierarchical cost-sensitive strategies: HTD-CS (squares), TPR-W (triangles), and HBAYES-CS (filled circles). Abscissa: per class F-score with base learners trained according to the basic strategy; ordinate: per class F-score with base learners trained according to the PO strategy.
These results can be explained by considering that the PO strategy takes into account the hierarchy to select negatives, while the B strategy does not. More precisely, FLAT methods having no information about the hierarchical structure of classes may fail to distinguish negative examples belonging to very distant classes, thus resulting in a high false positive rate, while hierarchical methods, which know the taxonomy, can use the information coming from other base classifiers to prevent a local base learner from incorrectly classifying “distant” negative examples.
In conclusion, these seminal works show that the strategy to choose negative examples exerts a significant impact on the accuracy of the predictions of hierarchical ensemble methods, and more research work is needed to explore this topic.
10. Open Problems and Future Trends
In the previous section, we showed that different learning issues should be considered to improve the effectiveness and the reliability of hierarchical ensemble methods. Most of these issues and others related to hierarchical ensemble methods and to AFP represent challenging problems that have been only partially considered by previous work. For these reasons, we try to delineate some of the open problem and research trends in the context of this research area.
For instance, the selection strategies for negative examples have been only partially explored, even if some seminal works show that this item exerts a significant impact on the accuracy of the predictions [123, 163, 179, 180]. Theoretical and experimental comparison of different strategies should be performed in a systematic way, to assess the impact of the different strategies on different hierarchical methods, considering also the characteristics of the learning machines used as base learners.
Some works showed also that the cost-sensitive strategies are needed to significantly improve predictions, especially in a hierarchical context [123], but new research could be considered for both applying and designing cost-sensitive base learners and to develop novel hierarchical ensemble unbalance-aware. Cost-sensitive methods have been applied to both the single base learners and also to the overall hierarchical ensemble strategy [31, 123], and recently a hierarchical variant of SMOTE (synthetic minority oversampling technique) [181] has been applied to hierarchical protein function prediction, showing very promising results [145]. In principle classical “balancing” strategies should be explored to improve the accuracy and the reliability of the base learners and hence of the overall hierarchical classification process. For instance, random undersampling or oversampling techniques could be applied: the former augments the annotations by exactly duplicating the annotated proteins, whereas the latter randomly takes away some unannotated examples [182]. Other approaches could be considered such as heuristic resampling methods [183] or embedding resampling methods into data mining algorithms [184] or ensemble methods tailored to imbalanced classification problems [185–187].
Since functional classes are unbalanced, precision/recall analysis plays a central role in AFP problems and often drives “in vitro” experiments that provide biological insights into specific functional genomics problems [1]. Only a few hierarchical ensemble methods, such as HBAYES-CS [27] and TPR-W [31], can tune their precision/recall characteristics through a single global parameter. In HBAYES-CS, by incrementing the cost factor α = θ i −/θ i +, we introduce progressively lower costs for positive predictions, thus resulting in an increment of the recall (at the expenses of a possibly lower precision). In TPR-W, by incrementing w, we can reduce the recall and enhance the precision. Parametric versions of other hierarchical ensemble methods could be developed, in order to design ensemble methods with “tunable” precision/recall characteristics.
Another important issue that should be considered in the design of novel hierarchical ensemble methods is the incompleteness of the available annotations and its impact on the performance of computational methods for AFP. Indeed, the successful application of supervised and semisupervised machine learning methods to these tasks requires a gold standard for protein function, that is, a trusted set of correct examples, but unfortunately the annotations is incomplete and undergoes frequent updates, and also the GO is frequently updated. Some seminal works showed that, on the one hand, current machine learning approaches are able to generalize and predict novel biology from an incomplete gold standard and, on the other hand, incomplete functional annotations adversely affect the evaluation of machine learning performance [188]. A very recent work addressed these items by proposing methods based on weak-label learning specifically designed to replenish the functions of proteins under the assumption that proteins are partially annotated. More precisely, two new algorithms have been proposed: ProWL, protein function prediction with weak-label learning, which can recover missing annotations by using the available relevant annotations, that is, a set of trusted annotations for a given protein, and ProWL-IF, protein function prediction with weak-label learning and knowledge of irrelevant function, by which also irrelevant functions, that is, functions that cannot be associated with the protein of interest, are exploited to replenish the missing functions [189, 190]. The results show that these items should be considered in future works for hierarchical multilabel predictions of protein functions in model organisms.
Another issue is represented by the reliability of the annotations. Usually, only experimental evidence is used to annotate the proteins for training AFP methods, but most of the available annotations are computationally predicted annotations without any experimental validation [191]. To at least partially exploit this huge amount of information, computational methods able to take into account the different reliability of the available annotations should be developed and integrated into hierarchical ensemble algorithms.
A quite neglected item is the interpretability of the hierarchical models. Nevertheless, the generation of comprehensible classification models is of paramount importance for biologists in order to provide new insights into the correlation of protein features and their functions [192]. A first step in this direction is represented by the work of Cerri et al. that exploits the advantages of grammar-based evolutionary algorithms to incorporate prior knowledge with the simplicity of genetic algorithms for optimization problems in order to produce interpretable rules for hierarchical multilabel classification [193].
Other issues depend on “strength” or the general rule that relates the predictions made by the base learner at a given term/node of the hierarchy with the predictions made by the other base learners of the hierarchical ensemble. For instance, the TPR algorithm (Section 7) weights the positive predictions of deeper nodes with an exponential decrement with respect to their depth (Section 11), but other rules (e.g., linear or polynomial) could be considered as the basis for the development of new algorithms that put more weight on the decisions of deep nodes of the hierarchy. Other enhancements could be introduced with the TPR-W algorithm (Section 7.2); indeed, we can note that positive children of a node at level i of the hierarchy have the same weight, independently of the size of their hanging subtree. In some cases, this could be useful, but in other cases it could be desirable to directly take into account the fact that a positive prediction is maintained along a path of the tree; indeed, this witnesses for a positive annotation of the node at level i.
More in general, in the spirit of a work recently proposed [123], the analysis of the synergy between the issues introduced above could be of great interest to better understand the behaviour of hierarchical ensemble methods.
Finally, we introduce some problems that could open new and interesting research lines in the context of hierarchical ensemble methods.
At first, an important issue could be represented by the design and development of multitask learning strategies [194] able to exploit the relationships between functional classes just during the learning phase, in order to establish a functional connection between learning processes associated with hierarchically related classes of the functional taxonomy. In this way, just during the training of the base learners, the learning processes will be dependent on each other (at least for nearby nodes/classes), enabling “mutual learning” of related classes in the taxonomy.
A second, to my knowledge, not explored learning issue is represented by the metaintegration of hierarchical predictions. Considering that there is no “killer” hierarchical ensemble method, a metacombination of the hierarchical predictions could be explored to enhance the overall performances.
A last issue is represented by multispecies predictions in a hierarchical context. By exploiting homology relationships between proteins of different species, we could enhance the prediction for a particular species by using predictions or data available for other species. This is a common practice with, for example, sequence-based methods, but novel research is needed to extend this homology-based approach in the context of hierarchical ensemble methods for multispecies prediction. It is worth noting that this multispecies approach yields to big-data analysis with the associated problems of scalability of existing algorithms. A possible solution to this last problem could be represented by distributed parallel computation [195] or by the adoption of secondary memory-based computational techniques [196].
11. Conclusions
Hierarchical ensemble methods represent one of the main research lines for AFP. Their two-step learning strategy introduces a high modularity in the prediction system: in the first step, different base learners can be trained to individually learn the functional classes, and in the second step different algorithms can be chosen to hierarchically combine the predictions provided by the base classifiers. The best results can be obtained when the global topology of the ontology is exploited and when both top-down and bottom-up learning strategies are applied [24, 27, 30, 31].
Nevertheless, a hierarchical learning strategy alone is not enough to achieve state-of-the-art results for AFP. Indeed, we need to design hierarchical ensemble methods in the context of the learning issues strictly related to the AFP problem.
The first one is represented by data fusion, since each source of biomolecular data may provide different and often complementary information about a protein and an integration of data fusion methods with hierarchical ensembles is mandatory to improve AFP results.
The second one is represented by the cost-sensitive techniques needed to take into account the usually small number of positive annotations: data unbalance-aware methods should be embedded in hierarchical methods to avoid solutions biased toward low sensitivity predictions.
Other issues, ranging from the proper choice of negative examples to the reliability and the incompleteness of the available annotation, the balance between local and global learning strategies, and the metaintegration of hierarchical predictions have been only partially addressed in previous work. More in general, the synergy between hierarchical ensemble methods, data integration algorithms, cost-sensitive techniques, and other related issues is the key to improve AFP methods and to drive experiments aimed at discovering previously unannotated or partially annotated protein functions [123].
Indeed, despite their successful application to protein function prediction in different model organisms, as outlined in Section 9, there is large room for future research in this challenging area of computational biology.
In particular, the development of multitask learning methods to jointly learn related GO terms in a hierarchical context and the design of multispecies hierarchical algorithms, able to scale with millions of proteins, represent a compelling challenge for the computational biology and bioinformatics community.
Acknowledgments
The author thanks the reviewers for their comments and suggestions and acknowledges partial support from the PRIN project “Automi e Linguaggi Formali: aspetti matematici e applicative,” funded by the Italian Ministry of University.
Appendices
A. Gene Ontology and FunCat
The two main taxonomies of gene functional classes are represented by the Gene Ontology (GO) [6] and the functional catalogue (FunCat) [5]. In the former, the functional classes are structured according to a directed acyclic graph, that is, a DAG (Figure 16), while in the latter, the functional classes are structured through a forest of trees (Figure 17). The GO is composed of thousands of functional classes, and it is set out in three separated ontologies: “biological processes,” “molecular function,” and “cellular component”. Indeed, a gene can participate to specific biological processes (e.g., cell cycle, metabolism, and nucleotide biosynthesis) and at the same time can perform specific molecular functions (e.g., catalytic or binding activities that occur at the molecular level) in specific cellular components (e.g., mitochondrion or rough endoplasmic reticulum).
Figure 16.

GO BP DAG for the yeast model organism (realized through the HCGene software [178]), involving more than 1000 terms and more than 2000 edges.
Figure 17.

FunCat tree for the yeast model organism (realized through the HCGene software) [178]. A “dummy” root node has been added to obtain a single tree from the tree forest.
A.1. GO: The Gene Ontology
The Gene Ontology (GO) project began as collaboration between three model organism databases, FlyBase (Drosophila), the Saccharomyces genome database (SGD), and the mouse genome database (MGD), in 1998. Now, it includes several of the world's major repositories for plant, animal, and microbial genomes. The GO project has developed three structured controlled vocabularies (ontologies) that describe gene products in terms of their associated biological processes, cellular components, and molecular functions in a species-independent manner (Figure 16). Biological process (BP) represents series of events accomplished by one or more ordered assemblies of molecular functions that exploit a specific biological function. for instance, lipid metabolic process or tricarboxylic acid cycle. Molecular function (MF) describes activities that occur at the molecular level, such as catalytic or binding activities. An example of MF is glycine dehydrogenase activity or glucose transporter activity. Cellular component (CC) represents just parts or components of a cell, such as organelles or physical places or compartments in which a specific gene product is located. An example is the endoplasmic reticulum or the ribosome.
The ontologies of the GO are structured as a directed acyclic graph (DAG) G = 〈V, E〉, where V = {t∣terms of the GO} and E = {(t, u)∣t, u ∈ V}. Relations between GO terms are also categorized in the following three main groups:
is-a (subtype relations): if we say the term/node A is a B, we mean that node A is a subtype of node B. For example, mitotic cell cycle is a cell cycle, or lyase activity is a catalytic activity;
part-of (part-whole relations): A is part of B which means that whenever A exists, it is part of B, and the presence of A implies the presence of B. For instance, mitochondrion is part of cytoplasm;
regulates (control relations): if we say that A regulates B we mean that A directly affects the manifestation of B; that is, the former regulates the latter.
While is-a and part-of are transitive, “regulates” is not. Moreover, in some cases, regulatory proteins are not expected to have the same properties as the proteins they regulate and hence predicting regulation may require other data and assumptions than predicting function similarity. For these reasons, usually in AFP, regulates relations (that however are a minority of the existing relations) are usually not used.
Each annotation is labeled with an evidence code that indicates how the annotation to a particular term is supported. They are subdivided in several categories ranging from experimental evidence codes, used when experimental assays have been applied for the annotation, for example, inferred from physical interaction (IPI) or inferred from mutant phenotype (IMP) or inferred from genetic interaction (IGI), to author statement codes, such as traceable author statement (TAS), that indicate that the annotation was made on the basis of a statement made by the author(s) in the cited reference, to computational analysis evidence codes, based on an in silico analyses manually reviewed (e.g., inferred from sequence or structural similarity (ISS)). For the full set of available evidence codes, please see the GO website (http://www.geneontology.org/).
A GO graph for the yeast model organism is represented in Figure 16. It is worth noting that, despite the complexity of the represented graph, Figure 16 does not show all the available terms and the relationships involved in the GO BP ontology with the yeast model organism.
A.2. FunCat: The Functional Catalogue
The FunCat taxonomy started with Saccharomyces cerevisiae genome project at MIPS (http://mips.gsf.de/): at the beginning, FunCat contained only those categories required to describe yeast biology [197, 198], but successively its content has been extended to plants to annotate genes from the Arabidopsis thaliana genome project and furthermore to cover prokaryotic organisms and finally animals too [5].
The FunCat represents a relatively simple and concise set of gene functional classes: it consists of 28 main functional categories (or branches) that cover general fields like cellular transport, metabolism, and cellular communication/signal transduction. These main functional classes are divided into a set of subclasses with up to six levels of increasing specificity, according to a tree-like structure that accounts for different functional characteristics of genes and gene products. Genes may belong at the same time to multiple functional classes, since several classes are subclasses of more general ones, and because a gene may participate in different biological processes and may perform different biological functions.
Taking into account the broad and highly diverse spectrum of known protein functions, the FunCat annotation scheme covers general features, like cellular transport, metabolism, and protein activity regulation. Each of its main 28 functional branches is organized as a hierarchical, tree-like structure, thus leading to a tree forest with hundreds of functional categories.
Differently from the GO, the FunCat is more compact and does not intend to classify protein functions down to the most specific level. From a general standpoint, it can be compared to parts of the molecular function and biological process terms of the GO system.
One of the main advantages of FunCat is its intuitive category structure. For instance, the annotation of yeast uses only 18 of the main categories and less than 300 distinct categories (Figure 17), while the Saccharomyces genome database (SGD) [199] uses more than 1500 GO terms in its yeast annotation. Indeed, FunCat focuses on the functional process and in part on the molecular function, while GO aims at representing a fine granular description of proteins that provides annotations with a wealth of detailed information. However, to achieve this goal, the detailed description offered by GO leads to a large number of terms (e.g., the ontology for biological processes alone contains more than 10000 terms), and such a huge amount of terms is very difficult to be handled for annotators. Moreover, we may have a very large number of possible assignments that may lead to erroneous or inconsistent annotations. FunCat is simpler: its tree structure, compared with the DAG structure of the GO, leads to both simple procedures for annotation and less difficult computational-based classification tasks. In other words, it represents a well-balanced compromise between extensive depth, breadth, and resolution but without being too granular and specific.
It is worth noting that both FunCat and GO ontologies undergo modifications between different releases, and at the same time the annotations are also subjected to changes, since they represent the results of the knowledge of the scientific community at a given time. As a consequence, predictions resulting, for example, in false positives for a given release of the GO, may become true positive in future releases, and more in general we should keep in mind that the available annotations are always partial and incomplete and depend on the knowledge available for the species under study. Nevertheless, even if some works pointed out the inconsistency of current GO taxonomies through the analysis of violations of terms univocality [200], GO and FunCat are considered the ground truth to evaluate AFP methods, since they represent the main effort of the scientific community to organize commonly accepted taxonomy of protein functions [191].
B. AFP Performance Assessment in a Hierarchical Context
In the context of ontology-wide protein function prediction problems, where negative examples are usually a lot more than positive ones, accuracy is not a reliable measure to assess the classification performance. For this reason, the classical F-score is used instead, to take into account the unbalance of functional classes. If TP represents the positive examples correctly predicted as positive, FN, the positive examples incorrectly predicted as negative, and, FP, the negatives incorrectly predicted as positives, then the precision P, and the recall R are
| (B.1) |
The F-score F is the harmonic mean between precision and recall
| (B.2) |
If we need to evaluate the correct ranking of annotated proteins with respect to a specific functional class, a valuable measure is represented by the area under the receiving operating characteristic curve (AUC). A random ranking corresponds to AUC≃0.5, while values close to 1 correspond to near optimal ranking; that is, AUC = 1, if all the annotated genes are ranked before the unannotated ones.
In order to better capture the hierarchical and sparse nature of the protein function prediction problem, we also need specific measures that estimate how far a predicted structured annotation is from the correct one. Indeed, functional classes are structured according to a direct acyclic graph (Gene Ontology) or to a tree (FunCat), and we need measures to accommodate not just “exact matches” but also “near misses” of different sorts.
For instance, correctly predicting a parent or ancestor annotation, while failing to predict the most specific available annotation, should be “partially correct,” in the sense that we can gain information about the more general functional characteristics of a gene, missing only its most specific functions.
More precisely, given a general taxonomy G representing the graph of the functional classes, for a given gene/gene product x, consider the graph P(x) ⊂ G of the predicted classes and the graph C(x) of the correct classes associated with x, and let l(P) be the set of the leaves (nodes without children) of the graph P. Given a leaf p ∈ P(x), let ↑p be the set of ancestors of the node p that belong to P(x), and, given a leaf c ∈ C(x), let ↑c be the set of ancestors of the node c that belong to C(x); the hierarchical precision (HP), hierarchical recall (HR), and hierarchical F-score (HF) are defined as follows [201]:
| (B.3) |
In the case of the FunCat taxonomy, since it is structured as a tree, we can simplify HP, HR, and HF as follows:
| (B.4) |
An overall high hierarchical precision is indicating that the predictor is able to detect the most general functions of genes/gene products. On the other hand, a high average hierarchical recall indicates that the predictors are able to detect the most specific functions of the genes. The hierarchical F-measure expresses the correctness of the structured prediction of the functional classes, taking into account also partially correct paths in the overall hierarchical taxonomy, thus providing in a synthetic way the effectiveness of the structured hierarchical prediction.
Another variant of hierarchical classification measure is represented by the hierarchical F-measure proposed by Kiritchenko et al. [202]. Let P(x) be the set of classes predicted in the overall hierarchy for a given gene/gene product x, and let C(x) be the corresponding set of “true” classes. Then, the hierarchical precision HPK and the hierarchical recall HRK according to Kiritchenko are defined as
| (B.5) |
Note that these definitions do not explicitly consider the paths included in the predicted subgraphs but simply the ratio between the number of common classes and, respectively, the predicted (HPK) and the true classes (HRK). The hierarchical F-measure HFK is the harmonic mean between HPK and HRK
| (B.6) |
C. Effect of the Propagation of the Positive Decisions in TPR Ensembles
In TPR ensembles, a generic node at level k is any node whose distance from the root is equal to k. The posterior probability computed by the ensemble for a generic node at level k is denoted by q k. More precisely, q k denotes the probability computed by the ensemble and denotes the probability computed by the base learner local to a node at level k. Moreover, we define q k+1 j as the probability of a child j of a node at level k, where the index j ≥ 1 refers to different children of a node at level k. From (30), we can derive the following expression for the probability q k computed for a generic node at level k of the hierarchy [31]:
| (C.1) |
To simplify the notation, we can introduce the following expression to indicate the average of the probabilities computed by the positive children nodes of a generic node at level k:
| (C.2) |
and we can introduce similar notations for a k+2 (average of the probabilities of the grandchildren) and more in general for a k+j (descendants at level j of a generic node). By extending these definitions across levels, we can obtain the following theorem.
Theorem 2 (influence of positive descendant nodes). —
In a TPR-W ensemble, for a generic node at level k, with a given parameter w, 0 ≤ w ≤ 1, balancing the weight between parent and children predictors, and having a variable number larger than or equal to 1 of positive descendants for each of the m lower levels below, the following equality holds for each m ≥ 1:
(C.3)
For the full proof, see [31].
Theorem 2 shows that the contribution of the descendant nodes decays exponentially with their depth and depends critically on the choice of the w parameter. To get more insights into the relationships between w and its effect on the influence of positive decisions on a generic node at level k (Theorem 1), Figure 18(a) shows the function that governs the decay of the influence of leaf nodes at different depths m, and Figure 18(b) shows the function responsible of the influence of nodes above the leaves.
Figure 18.

(a) Plot of f(w) = (1 − w)m, while varying m from 1 to 10. (b) Plot of g(w) = w(1 − w)j, while varying j from 1 to 10. The integers j refer to internal nodes at distance j from the reference node at level k.
Conflict of Interests
The author has no direct financial relations that might lead to a conflict of interests associated with this paper.
References
- 1.Friedberg I. Automated protein function prediction—the genomic challenge. Briefings in Bioinformatics. 2006;7(3):225–242. doi: 10.1093/bib/bbl004. [DOI] [PubMed] [Google Scholar]
- 2.Pena-Castillo L., Tasan M., Myers C. L., et al. A critical assessment of Mus musculus gene function prediction using integrated genomic evidence. Genome Biology. 2008;9(supplement 1, article S2) doi: 10.1186/gb-2008-9-s1-s2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Valentini G. Mosclust: a software library for discovering significant structures in bio-molecular data. Bioinformatics. 2007;23(3):387–389. doi: 10.1093/bioinformatics/btl600. [DOI] [PubMed] [Google Scholar]
- 4.Bertoni A., Valentini G. Discovering multi-level structures in bio-molecular data through the Bernstein inequality. BMC Bioinformatics. 2008;9(2, article S4) doi: 10.1186/1471-2105-9-S2-S4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Ruepp A., Zollner A., Maier D., et al. The FunCat, a functional annotation scheme for systematic classification of proteins from whole genomes. Nucleic Acids Research. 2004;32(18):5539–5545. doi: 10.1093/nar/gkh894. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Ashburner M., Ball C. A., Blake J. A., et al. Gene ontology: tool for the unification of biology. Nature Genetics. 2000;25(1):25–29. doi: 10.1038/75556. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Valencia A. Automatic annotation of protein function. Current Opinion in Structural Biology. 2005;15(3):267–274. doi: 10.1016/j.sbi.2005.05.010. [DOI] [PubMed] [Google Scholar]
- 8.Youngs N., Penfold-Brown D., Drew K., Shasha D., Bonneau R. Parametric bayesian priors and better choice of negative examples improve protein function prediction. Bioinformatics. 2013;29(9):1190–1198. doi: 10.1093/bioinformatics/btt110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Clare A., King R. D. Predicting gene function in Saccharomyces cerevisiae . Bioinformatics. 2003;19(2):II42–II49. doi: 10.1093/bioinformatics/btg1058. [DOI] [PubMed] [Google Scholar]
- 10.Bilu Y., Linial M. The advantage of functional prediction based on clustering of yeast genes and its correlation with non-sequence based classifications. Journal of Computational Biology. 2002;9(2):193–210. doi: 10.1089/10665270252935412. [DOI] [PubMed] [Google Scholar]
- 11.Lanckriet G. R. G., De Bie T., Cristianini N., Jordan M. I., Noble S. A statistical framework for genomic data fusion. Bioinformatics. 2004;20(16):2626–2635. doi: 10.1093/bioinformatics/bth294. [DOI] [PubMed] [Google Scholar]
- 12.Tian W., Zhang L. V., Taşan M., et al. Combining guilt-by-association and guilt-by-profiling to predict Saccharomyces cerevisiae gene function. Genome Biology. 2008;9(1, article S7) doi: 10.1186/gb-2008-9-s1-s7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Kim W. K., Krumpelman C., Marcotte E. M. Inferring mouse gene functions from genomic-scale data using a combined functional network/classification strategy. Genome Biology. 2008;9(1, article S5) doi: 10.1186/gb-2008-9-s1-s5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Mostafavi S., Ray D., Warde-Farley D., Grouios C., Morris Q. GeneMANIA: a real-time multiple association network integration algorithm for predicting gene function. Genome Biology. 2008;9(1, article S4) doi: 10.1186/gb-2008-9-s1-s4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Lee I., Ambaru B., Thakkar P., Marcotte E. M., Rhee S. Y. Rational association of genes with traits using a genome-scale gene network for Arabidopsis thaliana. Nature Biotechnology. 2010;28(2):149–156. doi: 10.1038/nbt.1603. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Radivojac P., Clark W. T., Oron T. R., et al. A large-scale evaluation of computational protein function prediction. Nature Methods. 2013;10(3):221–227. doi: 10.1038/nmeth.2340. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Juncker A. S., Jensen L. J., Pierleoni A., et al. Sequence-based feature prediction and annotation of proteins. Genome Biology. 2009;10(2):p. 206. doi: 10.1186/gb-2009-10-2-206. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Sharan R., Ulitsky I., Shamir R. Network-based prediction of protein function. Molecular Systems Biology. 2007;3:p. 88. doi: 10.1038/msb4100129. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Sokolov A., Ben-Hur A. Hierarchical classification of gene ontology terms using the GOstruct method. Journal of Bioinformatics and Computational Biology. 2010;8(2):357–376. doi: 10.1142/S0219720010004744. [DOI] [PubMed] [Google Scholar]
- 20.Barutcuoglu Z., Schapire R. E., Troyanskaya O. G. Hierarchical multi-label prediction of gene function. Bioinformatics. 2006;22(7):830–836. doi: 10.1093/bioinformatics/btk048. [DOI] [PubMed] [Google Scholar]
- 21.Chua H. N., Sung W.-K., Wong L. An efficient strategy for extensive integration of diverse biological data for protein function prediction. Bioinformatics. 2007;23(24):3364–3373. doi: 10.1093/bioinformatics/btm520. [DOI] [PubMed] [Google Scholar]
- 22.Pavlidis P., Weston J., Cai J., Noble W. S. Learning gene functional classifications from multiple data types. Journal of Computational Biology. 2002;9(2):401–411. doi: 10.1089/10665270252935539. [DOI] [PubMed] [Google Scholar]
- 23.Re M., Valentini G. Simple ensemble methods are competitive with stateof- the-art data integration methods for gene function prediction. Journal of Machine Learning Research, W&C Proceedings, Machine Learning in Systems Biology. 2010;8:98–111. [Google Scholar]
- 24.Obozinski G., Lanckriet G., Grant C., Jordan M. I., Noble W. S. Consistent probabilistic outputs for protein function prediction. Genome Biology. 2008;9(1, article S6) doi: 10.1186/gb-2008-9-s1-s6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Cozzetto D., Buchan D., Bryson K., Jones D. Protein function prediction by massive integration of evolutionary analyses and multiple data sources. BMC Bioinformatics. 2013;14(supplement 3, article S1) doi: 10.1186/1471-2105-14-S3-S1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Jiang X., Nariai N., Steffen M., Kasif S., Kolaczyk E. D. Integration of relational and hierarchical network information for protein function prediction. BMC Bioinformatics. 2008;9, article 350 doi: 10.1186/1471-2105-9-350. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Cesa-Bianchi N., Valentini G. Hierarchical cost-sensitive algorithms for genome-wide gene function prediction. Journal of Machine Learning Research, W&C Proceedings, Machine Learning in Systems Biology. 2010;8:14–29. [Google Scholar]
- 28.Cerri R., De Carvalho A. C. P. L. F. New top-down methods using SVMs for hierarchical multilabel classification problems. Proceedings of the International Joint Conference on Neural Networks (IJCNN '10); July 2010; IEEE Computer Society; pp. 1–8. [DOI] [Google Scholar]
- 29.Schietgat L., Vens C., Struyf J., Blockeel H., Kocev D., Džeroski S. Predicting gene function using hierarchical multi-label decision tree ensembles. BMC Bioinformatics. 2010;11, article 2 doi: 10.1186/1471-2105-11-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Guan Y., Myers C. L., Hess D. C., Barutcuoglu Z., Caudy A. A., Troyanskaya O. G. Predicting gene function in a hierarchical context with an ensemble of classifiers. Genome Biology. 2008;9(1, article S3) doi: 10.1186/gb-2008-9-s1-s3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Valentini G. True path rule hierarchical ensembles for genome-wide gene function prediction. IEEE/ACM Transactions on Computational Biology and Bioinformatics. 2011;8(3):832–847. doi: 10.1109/TCBB.2010.38. [DOI] [PubMed] [Google Scholar]
- 32.Alaydie N., Reddy C. K., Fotouhi F. Advances in Knowledge Discovery and Data Mining. Vol. 7301. Springer; 2012. Exploiting label dependency for hierarchical multi-label classification; pp. 294–305. (Lecture Notes in Computer Science). [Google Scholar]
- 33.Koller D., Sahami M. Hierarchically classifying documents using very few words. Proceedings of the 14th International Conference on Machine Learning; 1997; pp. 170–178. [Google Scholar]
- 34.Chakrabarti S., Dom B., Agrawal R., Raghavan P. Scalable feature selection, classification and signature generation for organizing large text databases into hierarchical topic taxonomies. VLDB Journal. 1998;7(3):163–178. [Google Scholar]
- 35.Zhang M.-L., Zhou Z.-H. Multilabel neural networks with applications to functional genomics and text categorization. IEEE Transactions on Knowledge and Data Engineering. 2006;18(10):1338–1351. doi: 10.1109/TKDE.2006.162. [DOI] [Google Scholar]
- 36.Burred A., Lerch J. A hierarchical approach to automatic musical genre classification. Proceedings of the 6th International Conference on Digital Audio Effects; 2003; pp. 8–11. [Google Scholar]
- 37.DeCoro C., Barutcuoglu Z., Fiebrink R. Bayesian aggregation for hierarchical genre classification. Proceedings of the 8th International Conference on Music Information Retrieval; 2007; pp. 77–80. [Google Scholar]
- 38.Trohidis K., Tsoumahas G., Kalliris G., Vlahavas I. P. Multilabel classification of music into emotions. Proceedings of the 9th International Conference on Music Information Retrieval; 2008; pp. 325–330. [Google Scholar]
- 39.Binder A., Kawanabe M., Brefeld U. Bayesian aggregation for hierarchical genre classification. Proceedings of the 9th Asian Conference on Computer Vision; 2009. [Google Scholar]
- 40.Barutcuoglu Z., DeCoro C. Hierarchical shape classification using Bayesian aggregation. Proceedings of the IEEE International Conference on Shape Modeling and Applications (SMI '06); June 2006; p. p. 44. [DOI] [Google Scholar]
- 41.Dimou A., Tsoumakas G., Mezaris V., Kompatsiaris I., Vlahavas I. An empirical study of multi-label learning methods for video annotation. Proceedings of the 7th International Workshop on Content-Based Multimedia Indexing (CBMI '09); June 2009; Chania, Greece. pp. 19–24. [DOI] [Google Scholar]
- 42.Punera K., Ghosh J. Enhanced hierarchical classification via isotonic smoothing. Proceedings of the 17th International Conference on World Wide Web (WWW '08); April 2008; Beijing, China. ACM; pp. 151–160. [DOI] [Google Scholar]
- 43.Ceci M., Malerba D. Classifying web documents in a hierarchy of categories: a comprehensive study. Journal of Intelligent Information Systems. 2007;28(1):37–78. doi: 10.1007/s10844-006-0003-2. [DOI] [Google Scholar]
- 44.Silla C. N., Jr., Freitas A. A. A survey of hierarchical classification across different application domains. Data Mining and Knowledge Discovery. 2011;22(1-2):31–72. doi: 10.1007/s10618-010-0175-9. [DOI] [Google Scholar]
- 45.Troyanskaya O. G., Dolinski K., Owen A. B., Altman R. B., Botstein D. A Bayesian framework for combining heterogeneous data sources for gene function prediction (in Saccharomyces cerevisiae) Proceedings of the National Academy of Sciences of the United States of America. 2003;100(14):8348–8353. doi: 10.1073/pnas.0832373100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Tsuda K., Shin H., Schölkopf B. Fast protein classification with multiple networks. Bioinformatics. 2005;21(supplement 2):ii59–ii65. doi: 10.1093/bioinformatics/bti1110. [DOI] [PubMed] [Google Scholar]
- 47.Xiong J., Rayner S., Luo K., Li Y., Chen S. Genome wide prediction of protein function via a generic knowledge discovery approach based on evidence integration. BMC Bioinformatics. 2006;7, article 268 doi: 10.1186/1471-2105-7-268. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Karaoz U., Murali T. M., Letovsky S., et al. Whole-genome annotation by using evidence integration in functional-linkage networks. Proceedings of the National Academy of Sciences of the United States of America. 2004;101(9):2888–2893. doi: 10.1073/pnas.0307326101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Sokolov A., Ben-Hur A. A structured-outputs method for prediction of protein function. Proceedings of the 2nd International Workshop on Machine Learning in Systems Biology (MLSB '08); 2008. [Google Scholar]
- 50.Astikainen K., Holm L., Pitkanen E., Szedmak S., Rousu J. Towards structured output prediction of enzyme function. BMC Proceedings. 2008;2(supplement 4, article S2) doi: 10.1186/1753-6561-2-s4-s2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Done B., Khatri P., Done A., Drǎghici S. Predicting novel human gene ontology annotations using semantic analysis. IEEE/ACM Transactions on Computational Biology and Bioinformatics. 2010;7(1):91–99. doi: 10.1109/TCBB.2008.29. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Valentini G., Masulli F. Neural Nets WIRN-02. Vol. 2486. Springer; 2002. Ensembles of learning machines; pp. 3–19. (Lecture Notes in Computer Science). [Google Scholar]
- 53.Shahbaba B., Neal R. M. Gene function classification using Bayesian models with hierarchy-based priors. BMC Bioinformatics. 2006;7, article 448 doi: 10.1186/1471-2105-7-448. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Vens C., Struyf J., Schietgat L., Džeroski S., Blockeel H. Decision trees for hierarchical multi-label classification. Machine Learning. 2008;73(2):185–214. doi: 10.1007/s10994-008-5077-3. [DOI] [Google Scholar]
- 55.Valentini G. True path rule hierarchical ensembles. In: Kittler J., Benediktsson J., Roli F., editors. Multiple Classifier Systems. Eighth InternationalWorkshop, MCS, 2009, Reykjavik, Iceland. Vol. 5519. Springer; 2009. pp. 232–241. (Lecture Notes in Computer Science). [Google Scholar]
- 56.Altschul S. F., Gish W., Miller W., Myers E. W., Lipman D. J. Basic local alignment search tool. Journal of Molecular Biology. 1990;215(3):403–410. doi: 10.1006/jmbi.1990.9999. [DOI] [PubMed] [Google Scholar]
- 57.Altschul S. F., Madden T. L., Schäffer A. A., et al. Gapped blast and psi-blast: a new generation of protein database search programs. Nucleic Acids Research. 1997;25(17):3389–3402. doi: 10.1093/nar/25.17.3389. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Conesa A., Götz S., García-Gómez J. M., Terol J., Talón M., Robles M. Blast2GO: a universal tool for annotation, visualization and analysis in functional genomics research. Bioinformatics. 2005;21(18):3674–3676. doi: 10.1093/bioinformatics/bti610. [DOI] [PubMed] [Google Scholar]
- 59.Loewenstein Y., Raimondo D., Redfern O. C., et al. Protein function annotation by homology-based inference. Genome biology. 2009;10(2):p. 207. doi: 10.1186/gb-2009-10-2-207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Prlić A., Down T. A., Kulesha E., Finn R. D., Kähäri A., Hubbard T. J. P. Integrating sequence and structural biology with DAS. BMC Bioinformatics. 2007;8, article 333 doi: 10.1186/1471-2105-8-333. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Falda M., Toppo S., Pescarolo A., et al. Argot2: a large scale function prediction tool relying on semantic similarity of weighted Gene Ontology terms. BMC Bioinformatics. 2012;13(supplement 4, article S14) doi: 10.1186/1471-2105-13-S4-S14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Hamp T., Kassner R., Seemayer S., et al. Homology-based inference sets the bar high for protein function prediction. BMC Bioinformatics. 2013;14(supplement 3, article S7) doi: 10.1186/1471-2105-14-S3-S7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Marcotte E. M., Pellegrini M., Thompson M. J., Yeates T. O., Eisenberg D. A combined algorithm for genome-wide prediction of protein function. Nature. 1999;402(6757):83–86. doi: 10.1038/47048. [DOI] [PubMed] [Google Scholar]
- 64.Vazquez A., Flammini A., Maritan A., Vespignani A. Global protein function prediction from protein-protein interaction networks. Nature Biotechnology. 2003;21(6):697–700. doi: 10.1038/nbt825. [DOI] [PubMed] [Google Scholar]
- 65.Wang J. Z., Du R., Payattakil R. S., Yu P. S., Chen C. F. Improving GO semantic similarity measures by exploring the ontology beneath the terms and modelling uncertainty. Bioinformatics. 2007;23(10):1274–1281. doi: 10.1093/bioinformatics/btm087. [DOI] [PubMed] [Google Scholar]
- 66.Yang H., Nepusz T., Paccanaro A. Improving GO semantic similarity measures by exploring the ontology beneath the terms and modelling uncertainty. Bioinformatics. 2012;28(10):1383–1389. doi: 10.1093/bioinformatics/bts129. [DOI] [PubMed] [Google Scholar]
- 67.Yu H., Gao L., Tu K., Guo Z. Broadly predicting specific gene functions with expression similarity and taxonomy similarity. Gene. 2005;352(1-2):75–81. doi: 10.1016/j.gene.2005.03.033. [DOI] [PubMed] [Google Scholar]
- 68.Tao Y., Sam L., Li J., Friedman C., Lussier Y. A. Information theory applied to the sparse gene ontology annotation network to predict novel gene function. Bioinformatics. 2007;23(13):i529–i538. doi: 10.1093/bioinformatics/btm195. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Pandey G., Myers C. L., Kumar V. Incorporating functional inter-relationships into protein function prediction algorithms. BMC Bioinformatics. 2009;10, article 142 doi: 10.1186/1471-2105-10-142. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Zhang X.-F., Dai D.-Q. A framework for incorporating functional interrelationships into protein function prediction algorithms. IEEE/ACM Transactions on Computational Biology and Bioinformatics. 2012;9(3):740–753. doi: 10.1109/TCBB.2011.148. [DOI] [PubMed] [Google Scholar]
- 71.Nabieva E., Jim K., Agarwal A., Chazelle B., Singh M. Whole-proteome prediction of protein function via graph-theoretic analysis of interaction maps. Bioinformatics. 2005;21(1):302–310. doi: 10.1093/bioinformatics/bti1054. [DOI] [PubMed] [Google Scholar]
- 72.Bertoni A., Frasca M., Valentini G. European Conference on Machine Learning, ECML PKDD 2011. Vol. 6911. Springer; 2011. COSNet: a cost sensitive neural network for semi-supervised learning in graphs; pp. 219–234. (Lecture Notes on Artificial Intelligence). [Google Scholar]
- 73.Frasca M., Bertoni A., Re M., Valentini G. A neural network algorithm for semi-supervised node label learning from unbalanced data. Neural Networks. 2013;43:84–98. doi: 10.1016/j.neunet.2013.01.021. [DOI] [PubMed] [Google Scholar]
- 74.Deng M., Chen T., Sun F. An integrated probabilistic model for functional prediction of proteins. Journal of Computational Biology. 2004;11(2-3):463–475. doi: 10.1089/1066527041410346. [DOI] [PubMed] [Google Scholar]
- 75.Kourmpetis Y. A. I., Van Dijk A. D. J., Bink M. C. A. M., Van Ham R. C. H. J., Ter Braak C. J. F. Bayesian markov random field analysis for protein function prediction based on network data. PLoS ONE. 2010;5(2) doi: 10.1371/journal.pone.0009293.e9293 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Oliver S. Guilt-by-association goes global. Nature. 2000;403(6770):601–603. doi: 10.1038/35001165. [DOI] [PubMed] [Google Scholar]
- 77.McDermott J., Bumgarner R., Samudrala R. Functional annotation from predicted protein interaction networks. Bioinformatics. 2005;21(15):3217–3226. doi: 10.1093/bioinformatics/bti514. [DOI] [PubMed] [Google Scholar]
- 78.Re M., Mesiti M., Valentini G. A fast ranking algorithm for predicting gene functions in biomolecular networks. IEEE ACM Transactions on Computational Biology and Bioinformatics. 2012;9(6):1812–1818. doi: 10.1109/TCBB.2012.114. [DOI] [PubMed] [Google Scholar]
- 79.Re M., Valentini G. Cancer module genes ranking using kernelized score functions. BMC Bioinformatics. 2012;13(supplement 14, article S3) doi: 10.1186/1471-2105-13-S14-S3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Re M., Valentini G. International Symposium on Bioinformatics Research and Applications (ISBRA 2012) Vol. 7292. Springer; 2012. Large scale ranking and repositioning of drugs with respect to DrugBank therapeutic categories; pp. 225–236. (Lecture Notes in Computer Science). [DOI] [Google Scholar]
- 81.Re M., Valentini G. Network-based drug ranking and repositioning with respect to drugbank therapeutic categories. IEEE/ACM Transactions on Computational Biology and Bioinformatics. 2014;10(6):1359–1371. doi: 10.1109/TCBB.2013.62. [DOI] [PubMed] [Google Scholar]
- 82.Bengio Y., Delalleau O., Le Roux N. Label propagation and quadratic criterion. In: Chapelle O., Scholkopf B., Zien A., editors. Semi-Supervised Learning. MIT Press; 2006. pp. 193–216. [Google Scholar]
- 83.Saad Y. Iterative Methods For Sparse Linear Systems. Boston, Mass, USA: PWS Publishing Company; 1996. [Google Scholar]
- 84.Cesa-Bianchi N., Gentile C., Vitale F., Zappella G. Random spanning trees and the prediction of weighted graphs. Proceedings of the 27th International Conference on Machine Learning (ICML '10); June 2010; Haifa, Israel. pp. 175–182. [Google Scholar]
- 85.Tsochantaridis I., Joachims T., Hofmann T., Altun Y. Large margin methods for structured and interdependent output variables. Journal of Machine Learning Research. 2005;6:1453–1484. [Google Scholar]
- 86.Rousu J., Saunders C., Szedmak S., Shawe-Taylor J. Kernel-based learning of hierarchical multilabel classification models. Journal of Machine Learning Research. 2006;7:1601–1626. [Google Scholar]
- 87.Lampert C. H., Blaschko M. B. Structured prediction by joint kernel support estimation. Machine Learning. 2009;77(2-3):249–269. doi: 10.1007/s10994-009-5111-0. [DOI] [Google Scholar]
- 88.Bakir G., Hoffman T., Scholkopf B., Smola B., Taskar A. J., Vishwanathan S. V. N. Predicting Structured Data. Cambridge, Mass, USA: MIT Press; 2007. [Google Scholar]
- 89.Eisner R., Poulin B., Szafron D., Lu P., Greiner R. Improving protein function prediction using the hierarchical structure of the gene ontology. Proceedings of the IEEE Symposium on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB '05); November 2005; [Google Scholar]
- 90.Blockeel H., Schietgat L., Clare A. Hierarchical multilabel classification trees for gene function prediction. In: Rousu J., Kaski S., Ukkonen E., editors. Probabilistic Modeling and Machine Learning in Structural and Systems Biology. Tuusula, Finland: Helsinki University Printing House; 2006. [Google Scholar]
- 91.Dekel O., Keshet J., Singer Y. Large margin hierarchical classification. Proceedings of the 21th International Conference on Machine Learning (ICML '04); July 2004; Omnipress; pp. 209–216. [Google Scholar]
- 92.Cesa-Bianchi N., Gentile C., Zaniboni L. Hierarchical classifications combining bayes with SVM. Proceedings of the 23rd International Conference on Machine Learning (ICML '06); June 2006; ACM Press; pp. 177–184. [Google Scholar]
- 93.Dietterich T. G. Ensemble methods in machine learning. In: Kittler J., Roli F., editors. Multiple Classifier Systems. First International Workshop, MCS, 2000, Cagliari, Italy. Vol. 1857. Springer; 2000. pp. 1–15. (Lecture Notes in Computer Science). [Google Scholar]
- 94.Okun O., Valentini G., Re M. Ensembles in Machine Learning Applications. Vol. 373. Berlin, Germany: Springer; 2011. (Studies in Computational Intelligence). [Google Scholar]
- 95.Re M., Valentini G. Advances in Machine Learning and Data Mining for Astronomy. Chapman & Hall; 2012. Ensemble methods: a review; pp. 563–594. (Data Mining and Knowledge Discovery). [Google Scholar]
- 96.Bauer E., Kohavi R. Empirical comparison of voting classification algorithms: bagging, boosting, and variants. Machine Learning. 1999;36(1):105–139. [Google Scholar]
- 97.Dietterich T. G. Experimental comparison of three methods for constructing ensembles of decision trees: bagging, boosting, and randomization. Machine Learning. 2000;40(2):139–157. doi: 10.1023/A:1007607513941. [DOI] [Google Scholar]
- 98.Banfield R. E., Hall L. O., Lawrence O., Bowyer K. W., Kevin W., Kegelmeyer W. P. A comparison of decision tree ensemble creation techniques. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2007;29(1):173–180. doi: 10.1109/TPAMI.2007.250609. [DOI] [PubMed] [Google Scholar]
- 99.Sohn S. Y., Shin H. W. Experimental study for the comparison of classifier combination methods. Pattern Recognition. 2007;40(1):33–40. doi: 10.1016/j.patcog.2006.06.027. [DOI] [Google Scholar]
- 100.Dettling M., Bühlmann P. Boosting for tumor classification with gene expression data. Bioinformatics. 2003;19(9):1061–1069. doi: 10.1093/bioinformatics/btf867. [DOI] [PubMed] [Google Scholar]
- 101.Robles V., Larrañaga P., Peña J. M., et al. Bayesian network multi-classifiers for protein secondary structure prediction. Artificial Intelligence in Medicine. 2004;31(2):117–136. doi: 10.1016/j.artmed.2004.01.009. [DOI] [PubMed] [Google Scholar]
- 102.Valentini G., Muselli M., Ruffino F. Cancer recognition with bagged ensembles of support vector machines. Neurocomputing. 2004;56(1–4):461–466. doi: 10.1016/j.neucom.2003.09.001. [DOI] [Google Scholar]
- 103.Abeel T., Helleputte T., Van de Peer Y., Dupont P., Saeys Y. Robust biomarker identification for cancer diagnosis with ensemble feature selection methods. Bioinformatics. 2009;26(3):392–398. doi: 10.1093/bioinformatics/btp630.btp630 [DOI] [PubMed] [Google Scholar]
- 104.Rozza A., Lombardi G., Re M., Casiraghi E., Valentini G., Campadelli P. Ensembles in Machine Learning Applications. Vol. 373. Berlin, Germany: Springer; 2011. A novel ensemble technique for protein subcellular location prediction; pp. 151–177. (Studies in Computational Intelligence). [Google Scholar]
- 105.Topchy A., Jain A. K., Punch W. Clustering ensembles: models of consensus and weak partitions. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2005;27(12):1866–1881. doi: 10.1109/TPAMI.2005.237. [DOI] [PubMed] [Google Scholar]
- 106.Bertoni A., Valentini G. Neural Nets, WIRN 2005. Vol. 3931. Springer; 2006. Ensembles based on random projections to improve the accuracy of clustering algorithms; pp. 31–37. (Lecture Notes in Computer Science). [Google Scholar]
- 107.Schapire R. E., Freund Y., Bartlett P., Lee W. S. Boosting the margin: a new explanation for the effectiveness of voting methods. Annals of Statistics. 1998;26(5):1651–1686. [Google Scholar]
- 108.Allwein E. L., Schapire R. E., Singer Y. Reducing multiclass to binary: a unifying approach for margin classifiers. Journal of Machine Learning Research. 2001;1(2):113–141. [Google Scholar]
- 109.Kleinberg E. M. On the algorithmic implementation of stochastic discrimination. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2000;22(5):473–490. doi: 10.1109/34.857004. [DOI] [Google Scholar]
- 110.Breiman L. TR 460. Berkeley, Calif, USA: Statistics Department, University of California; 1996. Bias, variance and arcing classifiers. [Google Scholar]
- 111.Friedman J., Hall P. Stanford, Calif, USA: Statistics Department, University of Stanford; 2000. On bagging and nonlinear estimation. [Google Scholar]
- 112.Dembczynski K., Waegeman W., Cheng W., Hullermeier E. On label dependence in multi-label classification. Proceedings of the 2nd International Workshop on learning from Multi-Label Data (ICML-MLD '10); 2010; Haifa, Israel. pp. 5–12. [Google Scholar]
- 113.Mostafavi S., Morris Q. Using the Gene Ontology hierarchy when predicting gene function. Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence (UAI '09); June 2009; Corvallis, Ore, USA. AUAI Press; pp. 419–427. [Google Scholar]
- 114.Jensen L. J., Gupta R., Stærfeldt H.-H., Brunak S. Prediction of human protein function according to Gene Ontology categories. Bioinformatics. 2003;19(5):635–642. doi: 10.1093/bioinformatics/btg036. [DOI] [PubMed] [Google Scholar]
- 115.Lægreid A., Hvidsten T. R., Midelfart H., Komorowski J., Sandvik A. K. Predicting gene ontology biological process from temporal gene expression patterns. Genome Research. 2003;13(5):965–979. doi: 10.1101/gr.1144503. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 116.Bi R., Zhou Y., Lu F., Wang W. Predicting Gene Ontology functions based on support vector machines and statistical significance estimation. Neurocomputing. 2007;70(4–6):718–725. doi: 10.1016/j.neucom.2006.10.006. [DOI] [Google Scholar]
- 117.Bogdanov P., Singh A. K. Molecular function prediction using neighborhood features. IEEE/ACM Transactions on Computational Biology and Bioinformatics. 2010;7(2):208–217. doi: 10.1109/TCBB.2009.81. [DOI] [PubMed] [Google Scholar]
- 118.Riley M. Functions of the gene products of Escherichia coli . Microbiological Reviews. 1993;57(4):862–952. doi: 10.1128/mr.57.4.862-952.1993. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 119.Schapire R. E., Singer Y. BoosTexter: a boosting-based system for text categorization. Machine Learning. 2000;39(2):135–168. [Google Scholar]
- 120.Alaydie N., Reddy C. K., Fotouhi F. Hierarchical multi-label boosting for gene function prediction. Proceedings of the International Conference on Computational Systems Bioinformatics (CSB '10); 2010; Stanford, Calif, USA. [Google Scholar]
- 121.Kohonen T. The self-organizing map. Neurocomputing. 1998;21(1–3):1–6. doi: 10.1016/S0925-2312(98)00030-7. [DOI] [Google Scholar]
- 122.Borges H., Nievola J. Hierarchical classification using a competitive neural network. Proceedings of the International Conference on Computing, Networking and Communications (ICNC '12); 2012; pp. 172–177. [Google Scholar]
- 123.Cesa-Bianchi N., Re M., Valentini G. Synergy of multi-label hierarchical ensembles, data fusion, and cost-sensitive methods for gene functional inference. Machine Learning. 2012;88(1):209–241. doi: 10.1007/s10994-011-5271-6. [DOI] [Google Scholar]
- 124.Cerri R., De Carvalho A. C. P. L. F. Hierarchical multilabel classification using Top-Down label combination and Artificial Neural Networks. Proceedings of the 11th Brazilian Symposium on Neural Networks (SBRN '10); October 2010; IEEE Computer Society; pp. 253–258. [DOI] [Google Scholar]
- 125.Cerri R., de Carvalho A. Advances in Bioinformatics and Computational Biology. Vol. 6832. Springer; 2011. Hierarchical multilabel protein function prediction using local neural networks; pp. 10–17. (Lecture Notes in Computer Science). [Google Scholar]
- 126.Rumelhart D. E., Durbin R., Chauvin Y. Backpropagation: the basic theory. In: Rumelhart D. E., Chauvin Y., editors. Backpropagation: Theory, Architectures and Applications. Hillsdale, NJ, USA: Lawrence Erlbaum; 1995. pp. 1–34. [Google Scholar]
- 127.Hernandez J., Sucar L. E., Morales E. A hybrid global-local approach forhierarchcial classification. Proceedings of the 26th International Florida Artificial Intelligence Research Society Conference; 2013; pp. 432–437. [Google Scholar]
- 128.Paes B., Plastion A., Freitas A. Improving loacal per level hierarchical classification. Journal of Information and Data Management. 2012;3(3):394–409. [Google Scholar]
- 129.Tsoumakas G., Katakis I., Vlahavas I. Random k-labelsets for multilabel classification. IEEE Transactions on Knowledge and Data Engineering. 2011;23(7):1079–1089. doi: 10.1109/TKDE.2010.164. [DOI] [Google Scholar]
- 130.Wang H., Shen X., Pan W. Large margin hierarchical classification with mutually exclusive class membership. Journal of Machine Learning Research. 2011;12:2721–2748. [Google Scholar]
- 131.Breiman L. Bagging predictors. Machine Learning. 1996;24(2):123–140. [Google Scholar]
- 132.des Jardins M., Karp P., Krummenacker M., Lee T. J., Ouzounis C. A. Prediction of enzyme classification from protein sequence without the use of sequence similarity. Proceedings of the 5th International Conference on Intelligent Systems for Molecular Biology (ISMB '97); 1997; AAAI Press; pp. 92–99. [PubMed] [Google Scholar]
- 133.Sharkey A., Sharkey N., Gerecke U., Chandroth G. The test and select approach to ensemble combination. In: Kittler J., Roli F., editors. Multiple Classifier Systems. First International Workshop, MCS 2000, Cagliari, Italy. Vol. 1857. Springer; 2000. pp. 30–44. (Lecture Notes in Computer Science). [Google Scholar]
- 134.Kourmpetis Y., van Dijk A., ter Braak C. Gene Ontology consistent protein function prediction: the FALCON algorithm applied to six eukaryotic genomes. Algorithms for Molecular Biology. 2013;8, article 10 doi: 10.1186/1748-7188-8-10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 135.Cesa-Bianchi N., Gentile C., Tironi A., Zaniboni L. Advances in Neural Information Processing Systems. Vol. 17. MIT Press; 2005. Incremental algorithms for hierarchical classification; pp. 233–240. [Google Scholar]
- 136.Re M., Valentini G. An experimental comparison of Hierarchical Bayes and True Path Rule ensembles for protein function prediction. In: El-Gayar N., editor. Multiple Classifier Systems. Nineth International Workshop, MCS, 2010, Cairo, Egypt. Vol. 5997. Springer; 2010. pp. 294–303. (Lecture Notes in Computer Science). [Google Scholar]
- 137.Smola A. J., Kondor R. Kernels and regularization on graphs. In: Scholkopf B., Warmuth M. K., editors. Proceedings of the 16th Annual Conference on Learning Theory; August 2003; Springer; pp. 144–158. [Google Scholar]
- 138.Leslie C., Eskin E., Cohen A., Weston J., Noble W. S. Advances in Neural Information Processing Systems. Cambridge, Mass, USA: MIT Press; 2003. Mismatch string kernels for svm protein classification; pp. 1441–1448. [Google Scholar]
- 139.Wainwright M. J., Jordan M. I. Graphical models, exponential families, and variational inference. Foundations and Trends in Machine Learning. 2008;1(1-2):1–305. [Google Scholar]
- 140.Barlow R. E., Brunk H. D. The isotonic regression problem and its dual. Journal of the American Statistical Association. 1972;67(337):140–147. doi: 10.1080/01621459.1972.10481216. [DOI] [Google Scholar]
- 141.Burdakov O., Sysoev O., Grimvall A., Hussian M. Large-Scale Nonlinear Optimization. Vol. 83. Springer; 2006. An O(n 2) algorithm for isotonic regression; pp. 25–33. (Nonconvex Optimization and Its Applications). [DOI] [Google Scholar]
- 142.Valentini G., Re M. Weighted True Path Rule: a multilabel hierarchical algorithm for gene function prediction. Proceedings of the 1st International Workshop on learning from Multi-Label Data (MLD-ECML '09); 2009; Bled, Slovenia. pp. 133–146. [Google Scholar]
- 143. Gene Ontology Consortium. True path rule, 2010, http://www.geneontology.org/GO.usage.shtml#truePathRule.
- 144.Chen B., Duan L., Hu J. Composite kernel based svm for hierarchical multilabel gene function classification. Proceedings of the 26th International Florida Artificial Intelligence Research Society Conference; 2012; pp. 1380–1385. [Google Scholar]
- 145.Chen B., Hu J. Hierarchical multi-label classification based on over-sampling and hierarchy constraint for gene function prediction. IEEJ Transactions on Electrical and Electronic Engineering. 2012;7(2):183–189. doi: 10.1002/tee.21714. [DOI] [Google Scholar]
- 146.Quinlan J. R. Induction of decision trees. Machine Learning. 1986;1(1):81–106. doi: 10.1007/BF00116251. [DOI] [Google Scholar]
- 147.King R. D., Karwath A., Clare A., Dehaspe L. The utility of different representations of protein sequence for predicting functional class. Bioinformatics. 2001;17(5):445–454. doi: 10.1093/bioinformatics/17.5.445. [DOI] [PubMed] [Google Scholar]
- 148.Blockeel H., Bruynooghe M., Dzeroski S., Ramon J., Struyf J. Top-down induction of clustering trees. Proceedings of the 15th International Conference on Machine Learning; 1998; pp. 55–63. [Google Scholar]
- 149.Blockeel H., Schietgat L., Dzeroski S., Clare A. Proc. of the 10th European Conference on Principles and Practice of Knowledge Discovery in Databases. Vol. 4213. Springer; 2006. Decision trees for hierarchical multilabel classification: a case study in functional genomics; pp. 18–29. (Lecture Notes in Artificial Intelligence). [Google Scholar]
- 150.Stojanova D., Ceci M., Malerba D., Deroski S. Using PPI network autocorrelation in hierarchical multi-label classification trees for gene function prediction. BMC Bioinformatics. 2013;14, article 285 doi: 10.1186/1471-2105-14-285. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 151.Otero F., Freitas A., Johnson C. Evolutionary Computation, Machine Learning and Data Mining in Bioinformatics. Vol. 5483. Springer; 2009. A hierarchical classification ant colony algorithm for predicting gene ontology terms; pp. 68–79. (Lecture Notes in Computer Science). [Google Scholar]
- 152.Breiman L. Random forests. Machine Learning. 2001;45(1):5–32. doi: 10.1023/A:1010933404324. [DOI] [Google Scholar]
- 153.Kocev D., Vens C., Struyf J., Dzeroski S. Tree ensembles for predicting structured outputs. Pattern Recognition. 2013;46(3):817–833. doi: 10.1016/j.patcog.2012.09.023. [DOI] [Google Scholar]
- 154.Noble W. S., Ben-Hur A. Integrating information for protein function prediction. In: Lengauer T., editor. Bioinformatics—from Genomes To Therapies. Vol. 3. Wiley-VCH; 2007. pp. 1297–1314. [Google Scholar]
- 155.Lan L., Djuric N., Guo Y., Vucetic S. MS-kNN: protein function prediction by integrating multiple data sources. BMC Bioinformatics. 2013;14(supplement 3, article S8) doi: 10.1186/1471-2105-14-S3-S8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 156.Sokolov A., Funk C., Graim K., Verspoor K., Ben-Hur A. Combining heterogeneous data sources for accurate functional annotation of proteins. BMC Bioinformatics. 2013;14(supplement 3, article S10) doi: 10.1186/1471-2105-14-S3-S10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 157.Myers C. L., Troyanskaya O. G. Context-sensitive data integration and prediction of biological networks. Bioinformatics. 2007;23(17):2322–2330. doi: 10.1093/bioinformatics/btm332. [DOI] [PubMed] [Google Scholar]
- 158.Mostafavi S., Morris Q. Fast integration of heterogeneous data sources for predicting gene function with limited annotation. Bioinformatics. 2010;26(14):1759–1765. doi: 10.1093/bioinformatics/btq262.btq262 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 159.Mesiti M., Jiménez-Ruiz E., Sanz I., et al. XML-based approaches for the integration of heterogeneous bio-molecular data. BMC Bioinformatics. 2009;10(12, article 1471):p. S7. doi: 10.1186/1471-2105-10-S12-S7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 160.Sonnenburg S., Rätsch G., Schäfer C., Schölkopf B. Large scale multiple kernel learning. Journal of Machine Learning Research. 2006;7:1531–1565. [Google Scholar]
- 161.Rakotomamonjy A., Bach F., Canu S., Grandvalet Y. More efficiency in multiple kernel learning. Proceedings of the 24th International Conference on Machine Learning (ICML '07); June 2007; New York, NY, USA. ACM; pp. 775–782. [DOI] [Google Scholar]
- 162.Lanckriet G. R., Deng M., Cristianini N., Jordan M. I., Noble W. S. Kernel-based data fusion and its application to protein function prediction in yeast. Proceedings of the Pacific Symposium on Biocomputing. 2004:300–311. doi: 10.1142/9789812704856_0029. [DOI] [PubMed] [Google Scholar]
- 163.Lewis D. P., Jebara T., Noble W. S. Support vector machine learning from heterogeneous data: an empirical analysis using protein sequence and structure. Bioinformatics. 2006;22(22):2753–2760. doi: 10.1093/bioinformatics/btl475. [DOI] [PubMed] [Google Scholar]
- 164.Cesa-Bianchi N., Re M., Valentini G. Functional inference in FunCat through the combination of hierarchical ensembles with data fusion methods. Proceedings of the 2nd International Workshop on learning from Multi-Label Data (MLD '10); 2010; Haifa, Israel. pp. 13–20. [Google Scholar]
- 165.Yu G., Rangwala H., Domeniconi C., Zhang G., Zhang Z. Protein function prediction by integrating multiple kernels. Proceedings of the 23rd International Joint Conference on Artificial Intelligence (IJCAI '13); 2013; Beijing, China. [Google Scholar]
- 166.Titterington D. M., Murray G. D., Murray L. S., et al. Comparison of discrimination techniques applied to a complex data set of head injured patients. Journal of the Royal Statistical Society A. 1981;144(2):145–175. doi: 10.2307/2981918. [DOI] [Google Scholar]
- 167.de Condorcet N. C. Essai sur l'Application de l'Analyse a la Probabilité des Décisions Rendues à la Pluralité des Voix. Paris, France: Imprimerie Royale; 1785. [Google Scholar]
- 168.Kittler J., Hatef M., Duin R. P. W., Matas J. On combining classifiers. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1998;20(3):226–239. doi: 10.1109/34.667881. [DOI] [Google Scholar]
- 169.Kuncheva L. I., Bezdek J. C., Duin R. P. W. Decision templates for multiple classifier fusion: an experimental comparison. Pattern Recognition. 2001;34(2):299–314. doi: 10.1016/S0031-3203(99)00223-X. [DOI] [Google Scholar]
- 170.Rè M., Valentini G. Noise tolerance of multiple classifier systems in data integration-based gene function prediction. Journal of Integrative Bioinformatics. 2010;7(3, article 139) doi: 10.2390/biecoll-jib-2010-139. [DOI] [PubMed] [Google Scholar]
- 171.Re M., Valentini G. Ensemble based data fusion for gene function prediction. In: Kittler J., Benediktsson J., Roli F., editors. Multiple Classifier Systems. Eighth InternationalWorkshop, MCS, 2009, Reykjavik, Iceland. Vol. 5519. Springer; 2009. pp. 448–457. (Lecture Notes in Computer Science). [Google Scholar]
- 172.Re M., Valentini G. Applications of Supervised and Unsupervised Ensemble Methods. Vol. 245. Springer; 2009. Prediction of gene function using ensembles of SVMs and heterogeneous data sources; pp. 79–91. (Computational Intelligence Series). [Google Scholar]
- 173.Re M., Valentini G. Integration of heterogeneous data sources for gene function prediction using decision templates and ensembles of learning machines. Neurocomputing. 2010;73(7-9):1533–1537. doi: 10.1016/j.neucom.2009.12.012. [DOI] [Google Scholar]
- 174.Finn R. D., Tate J., Mistry J., et al. The Pfam protein families database. Nucleic Acids Research. 2008;36(1):D281–D288. doi: 10.1093/nar/gkm960. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 175.Gasch A. P., Spellman P. T., Kao C. M., et al. Genomic expression programs in the response of yeast cells to environmental changes. Molecular Biology of the Cell. 2000;11(12):4241–4257. doi: 10.1091/mbc.11.12.4241. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 176.Stark C., Breitkreutz B.-J., Reguly T., Boucher L., Breitkreutz A., Tyers M. BioGRID: a general repository for interaction datasets. Nucleic Acids Research. 2006;34:D535–D539. doi: 10.1093/nar/gkj109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 177.Von Mering C., Krause R., Snel B., et al. Comparative assessment of large-scale data sets of protein-protein interactions. Nature. 2002;417(6887):399–403. doi: 10.1038/nature750. [DOI] [PubMed] [Google Scholar]
- 178.Valentini G., Cesa-Bianchi N. HCGene: a software tool to support the hierarchical classification of genes. Bioinformatics. 2008;24(5):729–731. doi: 10.1093/bioinformatics/btn015. [DOI] [PubMed] [Google Scholar]
- 179.Ben-Hur A., Noble W. S. Choosing negative examples for the prediction of protein-protein interactions. BMC Bioinformatics. 2006;7(supplement 1, article S2) doi: 10.1186/1471-2105-7-S1-S2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 180.Skunca N., Altenhoff A., Dessimoz C. Quality of computationally inferred gene ontology annotations. PLoS Computational Biology. 2012;8(5) doi: 10.1371/journal.pcbi.1002533.e1002533 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 181.Chawla N. V., Bowyer K. W., Hall L. O., Kegelmeyer W. P. SMOTE: synthetic minority over-sampling technique. Journal of Artificial Intelligence Research. 2002;16:321–357. [Google Scholar]
- 182.Batista G., Prati R., Monard M. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explorations Newsletter. 2004;6(1):20–29. doi: 10.1145/1007730.1007735. [DOI] [Google Scholar]
- 183.Kubat M., Matwin S. Addressing the curse of imbalanced training sets: one-sided selection. Proceedings of the 14th International Conference on Machine Learning (ICML '97); 1997; Nashville, Tenn, USA. pp. 179–187. [Google Scholar]
- 184.Guo H., Viktor H. Learning from imbalanced data sets with boosting and data generation: the Databoost-IM approach. ACM SIGKDD Explorations Newsletter. 2004;6(1):30–39. doi: 10.1145/1007730.1007736. [DOI] [Google Scholar]
- 185.Sun Y., Kamel M. S., Wong A. K. C., Wang Y. Cost-sensitive boosting for classification of imbalanced data. Pattern Recognition. 2007;40(12):3358–3378. doi: 10.1016/j.patcog.2007.04.009. [DOI] [Google Scholar]
- 186.Zhang Y., Wang D. Cost-sensitive ensemble method for class-imbalanced datasets. Abstract and Applied Analysis. 2013;2013:6. doi: 10.1155/2013/196256.196256 [DOI] [Google Scholar]
- 187.Galar M., Fernandez A., Barrenechea E., Bustince H., Herrera F. A review on ensembles for the class imbalance problem: bagging-. boosting-, and hybrid-based approaches. IEEE Transactions on Systems, Man and Cybernetics Part C: Applications and Reviews. 2012;42(4):463–484. doi: 10.1109/TSMCC.2011.2161285. [DOI] [Google Scholar]
- 188.Huttenhower C., Hibbs M. A., Myers C. L., Caudy A. A., Hess D. C., Troyanskaya O. G. The impact of incomplete knowledge on evaluation: an experimental benchmark for protein function prediction. Bioinformatics. 2009;25(18):2404–2410. doi: 10.1093/bioinformatics/btp397. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 189.Yu G., Domeniconi C., Rangwala H., Zhang G., Yu Z. Transductive multilabel ensemble classification for protein function prediction. Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; 2012; pp. 1077–1085. [Google Scholar]
- 190.Yu G., Rangwala H., Domeniconi C., Zhang G., Yu Z. Protein function prediction with incomplete annotations. IEEE Transactions on Computational Biology and Bioinformatics. 2013 doi: 10.1109/TCBB.2013.142. [DOI] [PubMed] [Google Scholar]
- 191.Gene Ontology Consortium. Gene Ontology annotations and resources. Nucleic Acids Research. 2013;41:D530–D535. doi: 10.1093/nar/gks1050. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 192.Freitas A. A., Wieser D. C., Apweiler R. On the importance of comprehensible classification models for protein function prediction. IEEE/ACM Transactions on Computational Biology and Bioinformatics. 2010;7(1):172–182. doi: 10.1109/TCBB.2008.47. [DOI] [PubMed] [Google Scholar]
- 193.Cerri R., Barros R., de Carvalho A., Freitas A. A grammatical evolution algorithm for generation of hierarchical multi-label classification rules. Proceedings of the IEEE Congress on Evolutionary Computation; 2013. [Google Scholar]
- 194.Widmer C., Ratsch G. Multitask learning in computational biology. Journal of Machine Learning Research, W&P. 2012;27:207–216. [Google Scholar]
- 195.Gonzalez J., Low Y., Gu H., Bickson D., Guestrin C. PowerGraph: distributed graph-parallel computation on natural graphs. Proceedings of the 10th USENIX conference on Operating Systems Design and Implementation (OSDI '12); 2012; Hollywood, Calif, USA. pp. 17–30. [Google Scholar]
- 196.Mesiti M., Re M., Valentini G. Scalable network-based learning methods for automated function prediction based on the neo4j graph-database. Proceedings of the Automated Function Prediction SIG 2013—ISMB Special Interest Group Meeting; 2013; Berlin, Germany. pp. 6–7. [Google Scholar]
- 197.Mewes H. W., Albermann K., Bähr M., et al. Overview of the yeast genome. Nature. 1997;387(6632):7–8. doi: 10.1038/42755. [DOI] [PubMed] [Google Scholar]
- 198.Mewes H. W., Frishman D., Gruber C., et al. MIPS: a database for genomes and protein sequences. Nucleic Acids Research. 2000;28(1):37–40. doi: 10.1093/nar/28.1.37. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 199.Christie K. R., Weng S., Balakrishnan R., et al. Saccharomyces Genome Database (SGD) provides tools to identify and analyze sequences from Saccharomyces cerevisiae and related sequences from other organisms. Nucleic Acids Research. 2004;32:D311–D314. doi: 10.1093/nar/gkh033. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 200.Verspoor K., Dvorkin D., Cohen K. B., Hunter L. Ontology quality assurance through analysis of term transformations. Bioinformatics. 2009;25(12):i77–i84. doi: 10.1093/bioinformatics/btp195. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 201.Verspoor K., Cohn J., Mniszewski S., Joslyn C. A categorization approach to automated ontological function annotation. Protein Science. 2006;15(6):1544–1549. doi: 10.1110/ps.062184006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 202.Kiritchenko S., Matwin S., Famili A. Hierarchical text categorization as a tool of associating genes with Gene Ontology codes. Proceedings of the 2nd European Workshop on Data Mining and Text Mining for Bioinformatics; 2004; pp. 26–30. [Google Scholar]