

Abstract
The problem of estimation of density functionals like entropy and mutual information has received much attention in the statistics and information theory communities. A large class of estimators of functionals of the probability density suffer from the curse of dimensionality, wherein the mean squared error (MSE) decays increasingly slowly as a function of the sample size T as the dimension d of the samples increases. In particular, the rate is often glacially slow of order O(T−γ/d), where γ > 0 is a rate parameter. Examples of such estimators include kernel density estimators, k-nearest neighbor (k-NN) density estimators, k-NN entropy estimators, intrinsic dimension estimators and other examples. In this paper, we propose a weighted affine combination of an ensemble of such estimators, where optimal weights can be chosen such that the weighted estimator converges at a much faster dimension invariant rate of O(T−1). Furthermore, we show that these optimal weights can be determined by solving a convex optimization problem which can be performed offline and does not require training data. We illustrate the superior performance of our weighted estimator for two important applications: (i) estimating the Panter-Dite distortion-rate factor and (ii) estimating the Shannon entropy for testing the probability distribution of a random sample.
1 Introduction
Non-linear functionals of probability densities f of the form G(f) = ∫g(f(x), x)f(x)dx arise in applications of information theory, machine learning, signal processing and statistical estimation. Important examples of such functionals include Shannon g(f, x) = −log(f) and Rényi g(f, x) = fα −1 entropy, and the quadratic functional g(f, x) = f2. In these applications, the functional of interest often must be estimated empirically from sample realizations of the underlying densities.
Functional estimation has received significant attention in the mathematical statistics community. However, estimators of functionals of multivariate probability densities f suffer from mean square error (MSE) rates which typically decrease with dimension d of the sample as O(T−γ/d), where T is the number of samples and γ is a positive rate parameter. Examples of such estimators include kernel density estimators [18], k-nearest neighbor (k-NN) density estimators [4], k-NN entropy functional estimators [9, 17, 13], intrinsic dimension estimators [17], divergence estimators [19], and mutual information estimators. This slow convergence is due to the curse of dimensionality. In this paper, we introduce a simple affine combination of an ensemble of such slowly convergent estimators and show that the weights in this combination can be chosen to significantly improve the rate of MSE convergence of the weighted estimator. In fact our ensemble averaging method can improve MSE convergence to the parametric rate O(T−1).
Specifically, for d-dimensional data, it has been observed that the variance of estimators of functionals G(f) decays as O(T−1) while the bias decays as O(T−1/(1+d)). To accelerate the slow rate of convergence of the bias in high dimensions, we propose a weighted ensemble estimator for ensembles of estimators that satisfy conditions
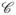 .1(2.1) and
.2(2.2) defined in Sec. II below. Optimal weights, which serve to lower the bias of the ensemble estimator to O(T
−1/2), can be determined by solving a convex optimization problem. Remarkably, this optimization problem does not involve any density-dependent parameters and can therefore be performed offline. This then ensures MSE convergence of the weighted estimator at the parametric rate of O(T−1).
.1(2.1) and
.2(2.2) defined in Sec. II below. Optimal weights, which serve to lower the bias of the ensemble estimator to O(T
−1/2), can be determined by solving a convex optimization problem. Remarkably, this optimization problem does not involve any density-dependent parameters and can therefore be performed offline. This then ensures MSE convergence of the weighted estimator at the parametric rate of O(T−1).
1.1 Related work
When the density f is s > d/4 times differentiable, certain estimators of functionals of the form ∫g(f(x), x)f(x)dx, proposed by Birge and Massart [2], Laurent [11] and Giné and Mason [5], can achieve the parametric MSE convergence rate of O(T −1). The key ideas in [2, 11, 5] are: (i) estimation of quadratic functionals ∫f2(x)dx with MSE convergence rate O(T −1); (ii) use of kernel density estimators with kernels that satisfy the following symmetry constraints:
| (1.1) |
for r = 1,.., s; and finally (iii) truncating the kernel density estimate so that it is bounded away from 0. By using these ideas, the estimators proposed by [2, 11, 5] are able to achieve parametric convergence rates.
In contrast, the estimators proposed in this paper require additional higher order smoothness conditions on the density, i. e. the density must be s > d times differentiable. However, our estimators are much simpler to implement in contrast to the estimators proposed in [2, 11, 5]. In particular, the estimators in [2, 11, 5] require separately estimating quadratic functionals of the form ∫f2(x)dx, and using truncated kernel density estimators with symmetric kernels (1.1), conditions that are not required in this paper. Our estimator is a simple affine combination of an ensemble of estimators, where the ensemble satisfies conditions
.1 and
.2. Such an ensemble can be trivial to implement. For instance, in this paper we show that simple uniform kernel plug-in estimators (3.3) satisfy conditions
.1 and
.2.
Ensemble based methods have been previously proposed in the context of classification. For example, in both boosting [16] and multiple kernel learning [10] algorithms, lower complexity weak learners are combined to produce classifiers with higher accuracy. Our work differs from these methods in several ways. First and foremost, our proposed method performs estimation rather than classification. An important consequence of this is that the weights we use are data independent, while the weights in boosting and multiple kernel learning must be estimated from training data since they depend on the unknown distribution.
1.2 Organization
The remainder of the paper is organized as follows. We formally describe the weighted ensemble estimator for a general ensemble of estimators in Section 2, and specify conditions
.1 and
.2 on the ensemble that ensure that the ensemble estimator has a faster rate of MSE convergence. Under the assumption that conditions
.1 and
.2 are satisfied, we provide an MSE optimal set of weights as the solution to a convex optimization(2.3). Next, we shift the focus to entropy estimation in Section 3, propose an ensemble of simple uniform kernel plug-in entropy estimators, and show that this ensemble satisfies conditions
.1 and
.2. Subsequently, we apply the ensemble estimator theory in Section 2 to the problem of entropy estimation using this ensemble of kernel plug-in estimators. We present simulation results in Section 4 that illustrate the superior performance of this ensemble entropy estimator in the context of (i) estimation of the Panter-Dite distortion-rate factor [6] and (ii) testing the probability distribution of a random sample. We conclude the paper in Section 5.
Notation
We will use bold face type to indicate random variables and random vectors and regular type face for constants. We denote the statistical expectation operator by the symbol
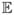 and the conditional expectation given random variable Z using the notation
and the conditional expectation given random variable Z using the notation
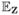 . We also define the variance operator as
. We also define the variance operator as
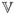 [X] =
[(X −
[X])2] and the covariance operator as Cov[X, Y] =
[(X −
[X])(Y −
[Y])]. We denote the bias of an estimator by
[X] =
[(X −
[X])2] and the covariance operator as Cov[X, Y] =
[(X −
[X])(Y −
[Y])]. We denote the bias of an estimator by
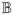 .
.
2 Ensemble estimators
Let l̄ = {l1, .., lL} denote a set of parameter values. For a parameterized ensemble of estimators {Êl}l∈l̄ of E, define the weighted ensemble estimator with respect to weights w = {w(l1), …, w(lL)} as
where the weights satisfy Σl∈l̄w(l) = 1. This latter sum-to-one condition guarantees that Êw is asymptotically unbiased if the component estimators {Êl}l∈l̄ are asymptotically unbiased. Let this ensemble of estimators {Êl}l∈l̄ satisfy the following two conditions:
-
.1 The bias is given by
(2.1) where ci are constants that depend on the underlying density,
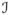 = {i1, .., iI} is a finite index set with cardinality I < L, min(
) = i0
> 0 and max(
) = id ≤ d, and ψi(l) are basis functions that depend only on the estimator parameter l.
= {i1, .., iI} is a finite index set with cardinality I < L, min(
) = i0
> 0 and max(
) = id ≤ d, and ψi(l) are basis functions that depend only on the estimator parameter l. - .2 The variance is given by
(2.2)
Theorem 1
For an ensemble of estimators {Êl}l∈l̄, assume that the conditions
.1 and
.2 hold. Then, there exists a weight vector wo such that
This weight vector can be found by solving the following convex optimization problem:
| (2.3) |
where ψi(l) is the basis defined in (2.1).
Proof
The bias of the ensemble estimator is given by
| (2.4) |
Denote the covariance matrix of {Êl; l ∈ l̄} by ΣL. Let Σ̄L = ΣLT. Observe that by (2.2) and the Cauchy-Schwarz inequality, the entries of Σ̄L are O(1). The variance of the weighted estimator Êw can then be bounded as follows:
| (2.5) |
We seek a weight vector w that (i) ensures that the bias of the weighted estimator is O(T−1/2) and (ii) has low ℓ2 norm ||w||2 in order to limit the contribution of the variance, and the higher order bias terms of the weighted estimator. To this end, let wo be the solution to the convex optimization problem defined in (2.3). The solution wo is the solution of
where A0 and b are defined below. Let a0 be the vector of ones: [1, 1…, 1]1×L; and let ai, for each i ∈
be given by ai = [ψi(l1), .., ψi(lL)]. Define
and b = [1; 0; 0; ..; 0](I+1)×1.
Since L > I, the system of equations A0w = b is guaranteed to have at least one solution (assuming linear independence of the rows ai). The minimum squared norm is then given by
Consequently, by (2.4), the bias
. By (2.5), the estimator variance
[Êw0] = O(LηL(d)/T). The overall MSE is also therefore of order O(LηL(d)/T).
For any fixed dimension d and fixed number of estimators L > I in the ensemble independent of sample size T, the value of ηL(d) is also independent of T. Stated mathematically, LηL(d) = Θ(1) for any fixed dimension d and fixed number of estimators L > I independent of sample size T. This concludes the proof.
In the next section, we will verify conditions
.1(2.1) and
.2(2.2) for plug-in estimators Ĝk(f) of entropy-like functionals G(f) = ∫g(f(x), x)f(x)dx.
3 Application to estimation of functionals of a density
Our focus is the estimation of general non-linear functionals G(f) of d-dimensional multivariate densities f with known finite support
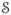 = [a, b]d, where G(f) has the form
= [a, b]d, where G(f) has the form
| (3.1) |
for some smooth function g(f, x). Let
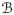 denote the boundary of
. Assume that T = N +M i.i.d realizations {X1, …, XN, XN+1, …, XN+M} are available from the density f.
denote the boundary of
. Assume that T = N +M i.i.d realizations {X1, …, XN, XN+1, …, XN+M} are available from the density f.
3.1 Plug-in estimators of entropy
The truncated uniform kernel density estimator is defined below. For any positive real number k ≤ M, define the distance dk to be: dk = (k/M)1/d. Define the truncated kernel region for each X ∈
to be Sk(X) = {Y ∈
: ||X − Y ||∞ ≤ dk/2}, and the volume of the truncated uniform kernel to be Vk(X) = ∫Sk(X)
dz. Note that when the smallest distance from X to
is greater than dk/2,
. Let lk(X) denote the number of samples falling in
. The truncated uniform kernel density estimator is defined as
| (3.2) |
The plug-in estimator of the density functional is constructed using a data splitting approach as follows. The data is randomly subdivided into two parts {X1, …, XN } and {XN+1, …, XN+M} of N and M points respectively. In the first stage, we form the kernel density estimate f̂k at the N points {X1, …, XN } using the M realizations {XN+1, …, XN+M}. Subsequently, we use the N samples {X1, …, XN} to approximate the functional G(f) and obtain the plug-in estimator:
| (3.3) |
Also define a standard kernel density estimator f̃k, which is identical to f̂k except that the volume Vk(X) is always set to the untruncated value Vk(X) = k/M. Define
| (3.4) |
The estimator G̃k is identical to the estimator of Györfi and van der Meulen [8]. Observe that the implementation of G̃k, unlike Ĝk, does not require knowledge about the support of the density.
3.1.1 Assumptions
We make a number of technical assumptions that will allow us to obtain tight MSE convergence rates for the kernel density estimators defined above. (
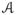 .0) : Assume that k = k0Mβ for some rate constant 0 < β < 1, and assume that M, N and T are linearly related through the proportionality constant αfrac with: 0 < αfrac < 1, M = αfracT and N = (1 − αfrac)T. (
.1) : Let the density f be uniformly bounded away from 0 and upper bounded on the set
, i.e., there exist constants ε0, ε∞ such that 0 < ε0 ≤ f(x) ≤ ε∞
< ∞ ∀x ∈
. (
.2): Assume that the density f has continuous partial derivatives of order d in the interior of the set
, and that these derivatives are upper bounded. (
.3): Assume that the function g(f, x) has max{λ, d} partial derivatives w.r.t. the argument f, where λ satisfies the condition λβ > 1. Denote the n-th partial derivative of g(f, x) wrt x by g(n)(f, x). (
.4): Assume that the absolute value of the functional g(f, x) and its partial derivatives are strictly upper bounded in the range ε0 ≤ f ≤ ε∞ for all x. (
.5): Let ε ∈ (0, 1) and δ ∈ (2/3, 1). Let
.0) : Assume that k = k0Mβ for some rate constant 0 < β < 1, and assume that M, N and T are linearly related through the proportionality constant αfrac with: 0 < αfrac < 1, M = αfracT and N = (1 − αfrac)T. (
.1) : Let the density f be uniformly bounded away from 0 and upper bounded on the set
, i.e., there exist constants ε0, ε∞ such that 0 < ε0 ≤ f(x) ≤ ε∞
< ∞ ∀x ∈
. (
.2): Assume that the density f has continuous partial derivatives of order d in the interior of the set
, and that these derivatives are upper bounded. (
.3): Assume that the function g(f, x) has max{λ, d} partial derivatives w.r.t. the argument f, where λ satisfies the condition λβ > 1. Denote the n-th partial derivative of g(f, x) wrt x by g(n)(f, x). (
.4): Assume that the absolute value of the functional g(f, x) and its partial derivatives are strictly upper bounded in the range ε0 ≤ f ≤ ε∞ for all x. (
.5): Let ε ∈ (0, 1) and δ ∈ (2/3, 1). Let
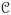 (M) be a positive function satisfying the condition
(M) = Θ(exp(−Mβ(1 −
δ))). For some fixed 0 < ε < 1, define pl = (1 − ε)ε0 and pu = (1 + ε)ε∞. Assume that the conditions
(M) be a positive function satisfying the condition
(M) = Θ(exp(−Mβ(1 −
δ))). For some fixed 0 < ε < 1, define pl = (1 − ε)ε0 and pu = (1 + ε)ε∞. Assume that the conditions
,
,
,
-
,
are satisfied by h(f, x) = g(f, x), g(3)(f, x) and g(λ)(f, x), for some constants G1, G2, G3 and G4.
These assumptions are comparable to other rigorous treatments of entropy estimation. The assumption (
.0) is equivalent to choosing the bandwidth of the kernel to be a fractional power of the sample size [15]. The rest of the above assumptions can be divided into two categories: (i) assumptions on the density f, and (ii) assumptions on the functional g. The assumptions on the smoothness, boundedness away from 0 and ∞ of the density f are similar to the assumptions made by other estimators of entropy as listed in Section II, [1]. The assumptions on the functional g ensure that g is sufficiently smooth and that the estimator is bounded. These assumptions on the functional are readily satisfied by the common functionals that are of interest in literature: Shannon g(f, x) = −log(f)I(f > 0) + I(f = 0) and Rényi g(f, x) = fα−1I(f > 0) + I(f = 0) entropy, where I(.) is the indicator function, and the quadratic functional g(f, x) = f2.
3.1.2 Analysis of MSE
Under the assumptions stated above, we have shown the following in the Appendix:
Theorem 2
The biases of the plug-in estimators Ĝk, G̃k are given by
where c1,i, c1 and c2 are constants that depend on g and f.
Theorem 3
The variances of the plug-in estimators Ĝk, G̃k are identical up to leading terms, and are given by
where c4 and c5 are constants that depend on g and f.
3.1.3 Optimal MSE rate
From Theorem 2, observe that the conditions k → ∞ and k/M → 0 are necessary for the estimators Ĝk and G̃k to be unbiased. Likewise from Theorem 3, the conditions N → ∞ and M → ∞ are necessary for the variance of the estimator to converge to 0. Below, we optimize the choice of bandwidth k for minimum MSE, and also show that the optimal MSE rate is invariant to the choice of αfrac.
Optimal choice of k
Minimizing the MSE over k is equivalent to minimizing the square of the bias over k. The optimal choice of k is given by
| (3.5) |
and the bias evaluated at kopt is Θ(M−1/1+d).
Choice of αfrac
Observe that the MSE of Ĝk and G̃k are dominated by the squared bias (Θ(M−2/1+d)) as contrasted to the variance (Θ(1/N + 1/M)). This implies that the asymptotic MSE rate of convergence is invariant to the selected proportionality constant αfrac.
In view of (a) and (b) above, the optimal MSE for the estimators Ĝk and G̃k is therefore achieved for the choice of k = Θ(M1/(1+d)), and is given by Θ(T−2/(1+d)). Our goal is to reduce the estimator MSE to O(T−1). We do so by applying the method of weighted ensembles described in Section 2.
3.2 Weighted ensemble entropy estimator
For a positive integer L > I = d−1, choose l̄ = {l1, …, lL} to be positive real numbers. Define the mapping and let k̄ = {k(l); l ∈ l̄}. Define the weighted ensemble estimator
| (3.6) |
From Theorems 2 and 3, we see that the biases of the ensemble of estimators {Ĝk(l); l ∈ l̄} satisfy
.1(2.1) when we set ψi(l) = li/d and
= {1, .., d−1}. Furthermore, the general form of the variance of Ĝk(l) follows
.2(2.2) because N, M = Θ(T). This implies that we can use the weighted ensemble estimator Ĝw to estimate entropy at O(LηL(d)/T) convergence rate by setting w equal to the optimal weight wo given by (2.3).
4 Experiments
We illustrate the superior performance of the proposed weighted ensemble estimator for two applications: (i) estimation of the Panter-Dite rate distortion factor, and (ii) estimation of entropy to test for randomness of a random sample.
For finite T direct use of Theorem 1 can lead to excessively high variance. This is because forcing the condition (2.3) that γw(i) = 0 is too strong and, in fact, not necessary. The careful reader may notice that to obtain O(T−1) MSE convergence rate in Theorem 1 it is sufficient that γw(i) be of order O(T−1/2+i/2d). Therefore, in practice we determine the optimal weights according to the optimization:
| (4.1) |
The optimization (4.1) is also convex. Note that, as contrasted to (2.3), the norm of the weight vector w is bounded instead of being minimized. By relaxing the constraints γw(i) = 0 in (2.3) to the softer constraints in (4.1), the upper bound η on
can be reduced from the value ηL(d) obtained by solving (2.3). This results in a more favorable trade-off between bias and variance for moderate sample sizes. In our experiments, we find that setting η = 3d yields good MSE performance. Note that as T → ∞, we must have γw(i) → 0 for i ∈
in order to keep ε finite, thus recovering the strict constraints in (2.3).
For fixed sample size T and dimension d, observe that increasing L increases the number of degrees of freedom in the convex problem (4.1), and therefore will result in a smaller value of ε and in turn improved estimator performance. In our simulations, we choose l̄ to be L = 50 equally spaced values between 0.3 and 3, ie the li are uniformly spaced as
with scale and range parameters a = 10 and x = 3 respectively. We limit L to 50 because we find that the gains beyond L = 50 are negligible. The reason for this diminishing return is a direct result of the increasing similarity among the entries in l̄, which translates to increasingly similar basis functions ψi(l) = li/d.
4.1 Panter-Dite factor estimation
For a d-dimensional source with underlying density f, the Panter-Dite distortion-rate function [6] for a q-dimensional vector quantizer with n levels of quantization is given by δ(n) = n−2/q ∫ fq/(q+2)(x)dx. The Panter-Dite factor corresponds to the functional G(f) with g(f, x) = n−2/qf−2/(q+2)I(f > 0) + I(f = 0). The Panter-Dite factor is directly related to the Rényi α-entropy, for which several other estimators have been proposed [7, 3, 14, 12].
In our simulations we compare six different choices of functional estimators - the three estimators previously introduced: (i) the standard kernel plug-in estimator G̃k, (ii) the boundary truncated plug-in estimator Ĝk and (iii) the weighted estimator Ĝw with optimal weight w = w* given by (4.1), and in addition the following popular entropy estimators: (iv) histogram plug-in estimator [7], (v) k-nearest neighbor (k-NN) entropy estimator [12] and (vi) entropic k-NN graph estimator [3, 14]. For both G̃k and Ĝk, we select the bandwidth parameter k as a function of M according to the optimal proportionality k = M1/(1+d) and N = M = T/2.
We choose f to be the d dimensional mixture density f(a, b, p, d) = pfβ(a, b, d) + (1−p)fu(d); where d = 6, fβ(a, b, d) is a d-dimensional Beta density with parameters a = 6, b = 6, fu(d) is a d-dimensional uniform density and the mixing ratio p is 0.8. The reason we choose the beta-uniform mixture for our experiments is because it trivially satisfies all the assumptions on the density f listed in Section 3.1, including the assumptions of finite support and strict boundedness away from 0 on the support. The true value of the Panter-Dite factor δ(n) for the beta-uniform mixture is calculated using numerical integration methods via the ‘Mathematica’ software (http://www.wolfram.com/mathematica/). Numerical integration is used because evaluating the entropy in closed form for the beta-uniform mixture is not tractable.
The MSE values for each of the six estimators are calculated by averaging the squared error [δ̂i(n) − δ(n)]2, i = 1, .., m over m = 1000 Monte-Carlo trials, where each δ̂i(n) corresponds to an independent instance of the estimator.
4.1.1 Variation of MSE with sample size T
The MSE results of the different estimators are shown in Fig. 1(a) as a function of sample size T, for fixed dimension d = 6. It is clear from the figure that the proposed ensemble estimator Ĝw has significantly faster rate of convergence while the MSE of the rest of the estimators, including the truncated kernel plug-in estimator, have similar, slow rates of convergence. It is therefore clear that the proposed optimal ensemble averaging significantly accelerates the MSE convergence rate.
Figure 1.

Variation of MSE of Panter-Dite factor estimates using standard kernel plug-in estimator [14], truncated kernel plug-in estimator (3.3), histogram plug-in estimator[17], k-NN estimator [20], entropic graph estimator [18] and the weighted ensemble estimator (3.6).
(a) Variation of MSE of Panter-Dite factor estimates as a function of sample size T. From the figure, we see that the proposed weighted estimator has the fastest MSE rate of convergence wrt sample size T (d = 6).
(b) Variation of MSE of Panter-Dite factor estimates as a function of dimension d. From the figure, we see that the MSE of the proposed weighted estimator has the slowest rate of growth with increasing dimension d (T = 3000).
4.1.2 Variation of MSE with dimension d
For fixed sample size T and fixed number of estimators L, it can be seen that ε increases monotonically with d. This follows from the fact that the number of constraints in the convex problem 4.1 is equal to d + 1 and each of the basis functions ψi(l) = li/d monotonically approaches 1 as d grows, . This in turn implies that for a fixed sample size T and number of estimators L, the overall MSE of the ensemble estimator should increase monotonically with the dimension d.
The MSE results of the different estimators are shown in Fig. 1(b) as a function of dimension d, for fixed sample size T = 3000. For the standard kernel plug-in estimator and truncated kernel plug-in estimator, the MSE increases rapidly with d as expected. The MSE of the histogram and k-NN estimators increase at a similar rate, indicating that these estimators suffer from the curse of dimensionality as well. On the other hand, the MSE of the weighted estimator also increases with the dimension as predicted, but at a slower rate. Also observe that the MSE of the weighted estimator is smaller than the MSE of the other estimators for all dimensions d > 3.
4.2 Distribution testing
In this section, we illustrate the weighted ensemble estimator for non-parametric estimation of Shannon differential entropy. The Shannon differential entropy is given by G(f) where g(f, x) = −log(f)I(f > 0) + I(f = 0). The improved accuracy of the weighted ensemble estimator is demonstrated in the context of hypothesis testing using estimated entropy as a statistic to test for the underlying probability distribution of a random sample. Specifically, the samples under the null and alternate hypotheses H0 and H1 are drawn from the probability distribution f(a, b, p, d), described in Section IV.A, with fixed d = 6, p = 0.75 and two sets of values of a, b under the null and alternate hypothesis, H0 : a = a0, b = b0 versus H1 : a = a1, b = b1.
First, we fix a0 = b0 = 6 and a1 = b1 = 5. The density under the null hypothesis f(6, 6, 0.75, 6) has greater curvature relative to f(5, 5, 0.75, 6) and therefore has smaller entropy. Five hundred (500) experiments are performed under each hypothesis with each experiment consisting of 1000 samples drawn from the corresponding distribution. The true entropy and estimates G̃k, Ĝk and Ĝw obtained from each instance of 103 samples are shown in Fig. 2(a) for the 1000 experiments. This figure suggests that the ensemble weighted estimator provides better discrimination ability by suppressing the bias, at the cost of some additional variance.
Figure 2.

Entropy estimates using standard kernel plug-in estimator, truncated kernel plug-in estimator and the weighted estimator, for random samples corresponding to hypothesis H0 and H1. The weighted estimator provides better discrimination ability by suppressing the bias, at the cost of some additional variance.
(a) Entropy estimates for random samples corresponding to hypothesis H0 (experiments 1–500) and H1 (experiments 501–1000).
(b) Histogram envelopes of entropy estimates for random samples corresponding to hypothesis H0 (blue) and H1 (red).
To demonstrate that the weighted estimator provides better discrimination, we plot the histogram envelope of the entropy estimates using standard kernel plug-in estimator, truncated kernel plug-in estimator and the weighted estimator for the cases corresponding to the hypothesis H0 (color coded blue) and H1 (color coded red) in Fig. 2(b). Furthermore, we quantitatively measure the discriminative ability of the different estimators using the deflection statistic , where μ0 and σ0 (respectively μ1 and σ1) are the sample mean and standard deviation of the entropy estimates. The deflection statistic was found to be 1.49, 1.60 and 1.89 for the standard kernel plug-in estimator, truncated kernel plug-in estimator and the weighted estimator respectively. The receiver operating curves (ROC) for this entropy-based test using the three different estimators are shown in Fig. 3(a). The corresponding areas under the ROC curves (AUC) are given by 0.9271, 0.9459 and 0.9619.
Figure 3.

Comparison of performance in terms of ROC for the distribution testing problem. The weighted estimator uniformly outperforms the individual plug-in estimators.
In our final experiment, we fix a0 = b0 = 10 and set a1 = b1 = 10 − δ, perform 500 experiments each under the null and alternate hypotheses with samples of size 5000, and plot the AUC as δ varies from 0 to 1 in Fig. 3(b). For comparison, we also plot the AUC for the Neyman-Pearson likelihood ratio test. The Neyman-Pearson likelihood ratio test, unlike the Shannon entropy based tests, is an omniscient test that assumes knowledge of both the underlying beta-uniform mixture parametric model of the density and the parameter values a0, b0 and a1, b1 under the null and alternate hypothesis respectively. Figure 4 shows that the weighted estimator uniformly and significantly outperforms the individual plug-in estimators and comes closest to the performance of the omniscient Neyman-Pearson likelihood test. The relatively superior performance of the Neyman-Pearson likelihood test is due to the fact that the weighted estimator is a nonparametric estimator that has marginally higher variance (proportional to ) as compared to the underlying parametric model for which the Neyman-Pearson test statistic provides the most powerful test.
Figure 4.

Illustration for the proof of Lemma 4.
5 Conclusions
We have proposed a new estimator of functionals of a multivariate density based on weighted ensembles of kernel density estimators. For ensembles of estimators that satisfy general conditions on bias and variance as specified by
.1(2.1) and
.2(2.2) respectively, the weight optimized ensemble estimator has parametric O(T−1) MSE convergence rate that can be much faster than the rate of convergence of any of the individual estimators in the ensemble. The optimal weights are determined as a solution to a convex optimization problem that can be performed offline and does not require training data. We illustrated this estimator for uniform kernel plug-in estimators and demonstrated the superior performance of the weighted ensemble entropy estimator for (i) estimation of the Panter-Dite factor and (ii) non-parametric hypothesis testing.
Several extensions of the framework of this paper are being pursued: (i) using k-nearest neighbor (k-NN) estimators in place of kernel estimators; (ii) extending the framework to the case where support
is not known, but for which conditions
.1 and
.2 hold; (iii) using ensemble estimators for estimation of other functionals of probability densities including divergence, mutual information and intrinsic dimension; and (iv) using an l1 norm ||w||1 in place of the l2 norm ||w||2 in the weight optimization algorithm (2.3) so as to introduce sparsity into the weighted ensemble.
Acknowledgments
This work was partially supported by (i) ARO grant W911NF-12-1-0443 and (ii) NIH grant 2P01CA087634-06A2.
Appendices: Outline of appendix
We first establish moment properties for uniform kernel density estimates in Appendix A. Subsequently, we prove theorems 2 and 3 in Appendix B.
A Moment properties of boundary compensated uniform kernel density estimates
Throughout this section, we assume without loss of generality that the support
= [−1, 1]d. Observe that lk(X) is a binomial random variable with parameters M and Uk(X) = Pr(Z ∈ Sk(X)). The probability mass function of the binomial random variable lk(X) is given by
Define the error function of the truncated uniform kernel density,
| (A.1) |
Also define the error function of the standard uniform kernel density,
and note that when X ∈
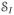 (k), ẽk(X) = êk(X).
(k), ẽk(X) = êk(X).
A.1 Taylor series expansion of coverage
For any X ∈
, the coverage function Uk(X) can be represented by using a d order Taylor series expansion of f about X as follows. Because the density f has continuous partial derivatives of order d in
, for any X ∈
,
| (A.2) |
where ci,k are functions which depend on k and the unknown density f. This implies that the expectation of the density estimate is given by
| (A.3) |
A.2 Concentration inequalities for uniform kernel density estimator
Because lk(X) is a binomial random variable, standard Chernoff inequalities can be applied to obtain concentration bounds on lk(X). In particular, for 0 < p < 1/2,
| (A.4) |
Let
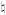 (X) denote the event (1 − pk)MUk(X) < lk(X) < (1+ pk)MUk(X), where pk = 1/(kδ/2) for some fixed δ ∈ (2/3, 1). Then, for k = O(Mβ),
(X) denote the event (1 − pk)MUk(X) < lk(X) < (1+ pk)MUk(X), where pk = 1/(kδ/2) for some fixed δ ∈ (2/3, 1). Then, for k = O(Mβ),
| (A.5) |
where
(M) satisfies the condition limM→∞
Ma/
(M) = 0 for any a > 0. Also observe that under the event
(X),
| (A.6) |
A.3 Bounds on uniform kernel density estimator
Let Br(X) be an Euclidean ball of radius r centered at X. Let X be a Lebesgue point of f, i.e., an X for which
Because f is an density, we know that almost all X ∈
satisfy the above property. Now, fix ε ∈ (0, 1) and find εr > 0 such that
For small values of k/M, Bεr(X) ⊂ Sk(X) and therefore
| (A.7) |
This implies that under the event
(X) defined in the previous subsection,
| (A.8) |
Let
 (X) denote the event that f̂k(X) = 0. Let
(X) denote the event that f̂k(X) = 0. Let
 (X) denote the event 1 <= lk(X) <= (1 − pk)MUk(X) and
(X) denote the event 1 <= lk(X) <= (1 − pk)MUk(X) and
 (X) denote lk(X) >= (1 + pk)MUk(X). Then conditioned on the event
(X)
(X) denote lk(X) >= (1 + pk)MUk(X). Then conditioned on the event
(X)
| (A.9) |
and conditioned on the event
(X)
| (A.10) |
Observe that
(X),
(X),
(X) and
(X) form a disjoint partition of the event space.
A.4 Bias
Lemma 4
Let γ(x, y) be an arbitrary function with d partial derivatives wrt x and supx,y |γ(x, y)| < ∞. Let X1, .., XM, X denote M + 1 i.i.d realizations of the density f. Then,
| (A.11) |
where c1,i(γ(x, y)) are functionals of γ and f.
Proof
To analyze the bias, first extend the density function f as follows. In particular, extend the definition of f to the domain
 = [−2, 2]d while ensuring that the extended function fe is differentiable d times on this extended domain. Let sk(X) = {Y : ||X − Y||1 ≤ dk/2} be the natural un-truncated ball. Let uk(X) = ∫z∈sk(X)
fe(z)dz. Define the function f̄k(X) = uk(X)/(k/M). For any X ∈
, using this extended definition,
= [−2, 2]d while ensuring that the extended function fe is differentiable d times on this extended domain. Let sk(X) = {Y : ||X − Y||1 ≤ dk/2} be the natural un-truncated ball. Let uk(X) = ∫z∈sk(X)
fe(z)dz. Define the function f̄k(X) = uk(X)/(k/M). For any X ∈
, using this extended definition,
| (A.12) |
where ci are only functions of the unknown density fe. Also define f̌k(X) =
[f̂k(X)|X]. Define the interior region
(k) = {X ∈
: sk(X) ∩
 = ϕ}. Note that f̄k(X) = f̌k(X) for all X ∈
(k). Now,
= ϕ}. Note that f̄k(X) = f̌k(X) for all X ∈
(k). Now,
| (A.13) |
A.4.1 Evaluation of I
| (A.14) |
where c11,i(γ(x, y)) are functionals of γ(x, y) and its derivatives.
A.4.2 Evaluation of II
Let m = M/2, kM = k/M and km = (k/m)1/d. Define mappings
 ,
,
 and
and
 :
−
(k) →
as follows. Let u(X) denote the unit vector from the origin to X, and define
(X) = u(X) ∩
. Let
(m) be a reference set. Define
(X) = u(X) ∩
(m). Let lb(X) = ||
(X) − X||. Finally define
(X) = n(X)u(X), where n(X) satisfies ||
(X) −
(X)|| = (m/k)1/dlb(X). For each X ∈
−
(k), let lr(X) = ||
(X) −
(X)|| and lmax(X) = ||
(X) −
(X)||. Let
:
−
(k) →
as follows. Let u(X) denote the unit vector from the origin to X, and define
(X) = u(X) ∩
. Let
(m) be a reference set. Define
(X) = u(X) ∩
(m). Let lb(X) = ||
(X) − X||. Finally define
(X) = n(X)u(X), where n(X) satisfies ||
(X) −
(X)|| = (m/k)1/dlb(X). For each X ∈
−
(k), let lr(X) = ||
(X) −
(X)|| and lmax(X) = ||
(X) −
(X)||. Let
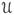 denote the set of all unit vectors:
=
denote the set of all unit vectors:
=
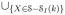 u(X). Observe that, by definition, the shape of the regions Sk(X) and Sm(
(X)) is identical. This is illustrated in Fig. 4.
u(X). Observe that, by definition, the shape of the regions Sk(X) and Sm(
(X)) is identical. This is illustrated in Fig. 4.
Analysis of f̄m(
(X)), f̌m(
(X))
(X) can represented in terms of
(X) as
(X) =
(X)+ls(X)u(X). Using Taylor series around
(X), f̌m(
(X)) can then be evaluated as
| (A.15) |
where the functionals
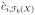 depend only on the shape of the regions Sk(X) or Sm(
(X)) and therefore only on
(X). Similarly,
depend only on the shape of the regions Sk(X) or Sm(
(X)) and therefore only on
(X). Similarly,
| (A.16) |
where the functionals
again depend only on
(X). This implies that for any fixed u ∈
and corresponding Xb ∈
, for any function η(x) and positive integer q ∈ {1, .., d}, integration over the line l(Xb) = {Xb − cu(Xb); c ∈ (0, lmax(Xb))}
| (A.17) |
and
| (A.18) |
where the functions c`i,q,η (Xb) and c`i,q,η (Xb) depend only on Xb, q, η and are independent of Z and k.
Analysis of f̄k(X), f̌k(X)
(X) can be represented in terms of X as
(X) = X + kmlr(X)u(X). Identically, this gives,
| (A.19) |
and
| (A.20) |
This implies that for any fixed u ∈
and corresponding Xb ∈
, integration over the line l(Xb) = {Xb − cu(Xb); c ∈ (0, kmlmax(Xb))}
| (A.21) |
and
| (A.22) |
Analysis of II
| (A.23) |
where c12,i(γ(x, y)) are functionals of γ(x, y) and its derivatives. This implies that
| (A.24) |
where the functionals c1,i(γ(x, y)) are independent of k.
A.5 Central Moments
Since lk(X) is a binomial random variable, we can easily obtain moments of the uniform kernel density estimate in terms of Uk(X). These are listed below.
Lemma 5
Let γ(x) be an arbitrary function satisfying supx |γ(x)| < ∞. Let X1, .., XM, X denote M + 1 i.i.d realizations of the density f. Then,
| (A.25) |
| (A.26) |
where c2(γ(x)) is a functional of γ and f.
Proof
When r = 2,
| (A.27) |
For any integer r ≥ 3,
| (A.28) |
Observe that Vk(X) = Θ(k/M) and therefore . This implies,
When X ∈
(k), ẽk(X) = êk(X). Also Pr(X ∈
(k)) = o(1). This result in conjunction with the fact that ẽk(X) = (MVk(X)/k) êk(X), and Vk(X) = Θ(k/M) gives
A.6 Cross moments
Let X and Y be two distinct points. Clearly the density estimates at X and Y are not independent. Observe that the uniform kernel regions Sk(X), Sk(Y) are disjoint for the set of points given by Ψk:= {X, Y}: ||X − Y||1 ≥ 2(k/M)1/d, and have finite intersection on the complement of Ψk.
Intersecting balls
Lemma 6
For a fixed pair of points {X, Y} ∈ Ψk, and positive integers q, r,
Proof
For a fixed pair of points {X, Y} ∈ ΨK, the joint probability mass function of the functions lk(X),lk(Y) is given by
Denote the high probability event
(X)∩
(Y) by
(X, Y). Define l̂k(X), l̂k(Y) to be binomial random variables with parameters {Uk(X), M − q} and {Uk(Y), M − r} respectively. The covariance between powers of density estimates is then given by
Then, the covariance between the powers of the error function is given by
Disjoint balls
For , there is no closed form expression for the covariance. However we have the following lemma by applying the Cauchy-Schwartz inequality:
Lemma 7
For a fixed pair of points ,
Proof
Joint expression
Lemma 8
Let γ1(x), γ2(x) be arbitrary functions with 1 partial derivative wrt x and supx |γ1(x)| < ∞, supx |γ2(x)| < ∞. Let X1, .., XM,X, Y denote M + 2 i.i.d realizations of the density f. Then,
| (A.29) |
| (A.30) |
where c5(γ1(x), γ2(x)) is a functional of γ1(x), γ2(x) and f.
Proof
Let the indicator function 1Δk(X, Y) denote the event . Then
where ‘I’ stands for the contribution form the intersecting balls and ‘D’ for the contribution from the dis-joint balls. I and D are given by
When 1Δk(X, Y) ≠= 0, we have . Then,
where the bound is obtained using the Cauchy-Schwarz inequality and using Eq.A.28. Also,
| (A.31) |
This gives
Again, since X ∈
(k) implies ẽk(X) = êk(X) and Pr(X ∈
I(k)) = o(1),
This concludes the proof.
B Bias and variance results
Lemma 9
Assume that U(x, y) is any arbitrary functional which satisfies
,
,
,
.
Let Z denote Xi for some fixed i ∈ {1, ..,N}. Let ζZ be any random variable which almost surely lies in the range (f(Z), f̂k(Z)). Then,
Proof
We will show that the conditional expectation
[|U(ζZ, Z)| |
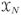 ] < ∞. Because 0 < ε0 < f(X) < ε∞ < ∞ by (
.1), it immediately follows that
] < ∞. Because 0 < ε0 < f(X) < ε∞ < ∞ by (
.1), it immediately follows that
Also observe that ε0 < f(Z) < ε∞ and therefore pl < f(Z) < pu. Finally observe that the events
(Z) and
(Z) occur with probability O(
(M)). Using (A.8), (A.9), (A.10), conditioned on
,
| (B.1) |
Proof of Theorem 2
Proof
Using the continuity of g‴(x, y), construct the following third order Taylor series of g(f̂k(Z), Z) around the conditional expected value f̌k(Z) =
[f̂k(Z) | Z].
where ζZ ∈ (f̌k(Z), f̂k(Z)) is defined by the mean value theorem. This gives
Let
. Direct application of Lemma 9 in conjunction with assumption (
.5) implies that
[Δ2(Z)] = O(1). By Cauchy-Schwarz and applying Lemma 5 for the choice q = 6,
By observing that the density estimates {f̂k(Xi)}, i = 1, …, N are identical, we therefore have
By Lemma 4 and Lemma 5 for the choice q = 2, in conjunction with assumptions (
.3) and (
.4), this implies that
where the last but one step follows because, by (A.3), we know f̌k(Z) = f(Z) + o(1). This in turn implies c2(f2(x)g″(f̌k(x), x)) = c2(f2(x)g″(f(x), x)) + o(1). Finally, by assumptions (
.2) and (
.4), the leading constants c1,i and c2 are bounded.
Note that the natural density estimate f̃k(X) is identical to the truncated kernel density estimate f̂k(X) on the set X ∈
(k). From the definition of set
(k), Pr(Z ∉ =
 ) = O((k/M)1/d) = o(1).
) = O((k/M)1/d) = o(1).
| (B.2) |
Using the exact same method as in the Proof of Theorem 2, using (A.3) and (A.25), and the fact that Pr(Z ∉ =
(k)) = O((k/M)1/d) = o(1), we have
Because we assume that g satisfies assumption (
.5), from the proof of Lemma 9, for Z ∈
−
(k), we have
[g(f̃k(Z), Z) − g(f(Z), Z)] = O(1). This implies that,
| (B.3) |
This implies that
Proof of Theorem 3
Proof
By the continuity of g(λ)(x, y), we can construct the following Taylor series of g(f̌k(Z), Z) around the conditional expected value f̌k(Z).
where ξZ ∈ (g(
[f̌k(Z)], g(f̌k(Z))). Denote (gλ(ξZ, Z))/λ! by Ψ(Z). Further define the operator
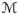 (Z) = Z −
[Z] and
(Z) = Z −
[Z] and
The variance of the estimator ĜN(f̂k) is given by
Because X1, X2 are independent, we have
[(p1)(p2 + q2 + r2 + s2)] = 0. Furthermore,
Applying Lemma 5 and Lemma 8, in conjunction with assumptions (
.3) and (
.4), it follows that
- [p12] =
[g(f̌k(Z), Z)] = c4(g(f̌k(x), x))
Since q1 and s2 are 0 mean random variables
Direct application of Lemma 9 in conjunction with assumptions (
.5) implies that
[Ψ2(Z)] = O(1). Note that from assumption (
.3),
. In a similar manner, it can be shown that
and
. This implies that
where the last but one step follows because, by (A.3), we know f̌k(Z) = f(Z) + o(1). This in turn implies c4(g(f̌k(x), x)) = c4(g(f(x), x)) + o(1) and c5(g′(f̌k(x), x), g′(f̌k(x), x)) = c5(g′(f(x), x), g′(f(x), x)) + o(1). Finally, by assumptions (
.2) and (
.4), the leading constants c4 and c5 are bounded.
Because of the identical nature of the expressions of êk(X) and ẽk(X) in Lemma 5 and Lemma 8, it immediately follows that
This concludes the proof of Theorem 3.
Contributor Information
Kumar Sricharan, Email: kksreddy@umich.edu.
Dennis Wei, Email: dlwei@umich.edu.
Alfred O. Hero, III, Email: hero@umich.edu.
References
- 1.Beirlant J, Dudewicz EJ, Györfi L, Van der Meulen EC. Nonparametric entropy estimation: An overview. Intl Journal of Mathematical and Statistical Sciences. 1997;6:17–40. [Google Scholar]
- 2.Birge L, Massart P. Estimation of integral functions of a density. The Annals of Statistics. 1995;23(1):11–29. [Google Scholar]
- 3.Costa JA, Hero AO. Geodesic entropic graphs for dimension and entropy estimation in manifold learning. Signal Processing, IEEE Transactions on. 2004;52(8):2210–2221. [Google Scholar]
- 4.Fukunaga K, Hostetler LD. IEEE Transactions on Information Theory. 1973. Optimization of k-nearest-neighbor density estimates. [Google Scholar]
- 5.Giné E, Mason DM. Uniform in bandwidth estimation of integral functionals of the density function. Scandinavian Journal of Statistics. 2008;35:739761. [Google Scholar]
- 6.Gupta R. PhD thesis. University of Michigan; Ann Arbor: 2001. Quantization Strategies for Low-Power Communications. [Google Scholar]
- 7.Györfi L, van der Meulen EC. Density-free convergence properties of various estimators of entropy. Comput Statist Data Anal. 1987:425–436. [Google Scholar]
- 8.Györfi L, van der Meulen EC. An entropy estimate based on a kernel density estimation. Limit Theorems in Probability and Statistics. 1989:229–240. [Google Scholar]
- 9.Hero AO, Costa J, Ma B. Technical Report, Communications and Signal Processing Laboratory. The University of Michigan; Mar, 2003. Asymptotic relations between minimal graphs and alpha-entropy. [Google Scholar]
- 10.Lanckriet G, Cristianini N, Bartlett P, El Ghaoui L. Learning the kernel matrix with semi-definite programming. Journal of Machine Learning Research. 2002;5:2004. [Google Scholar]
- 11.Laurent B. Efficient estimation of integral functionals of a density. The Annals of Statistics. 1996;24(2):659–681. [Google Scholar]
- 12.Leonenko N, Prozanto L, Savani V. A class of Rényi information estimators for multidimensional densities. Annals of Statistics. 2008;36:2153–2182. [Google Scholar]
- 13.Liitiäinen E, Lendasse A, Corona F. On the statistical estimation of rényi entropies. Proceedings of IEEE/MLSP 2009 International Workshop on Machine Learning for Signal Processing; Grenoble (France). September 2–4 2009. [Google Scholar]
- 14.Pal D, Poczos B, Szepesvari C. Proc Advances in Neural Information Processing Systems (NIPS) MIT Press; 2010. Estimation of Rényi entropy and mutual information based on generalized nearest-neighbor graphs. [Google Scholar]
- 15.Raykar VC, Duraiswami R. Fast optimal bandwidth selection for kernel density estimation. In: Ghosh J, Lambert D, Skillicorn D, Srivastava J, editors. Proceedings of the sixth SIAM International Conference on Data Mining; 2006. pp. 524–528. [Google Scholar]
- 16.Schapire Robert E. The strength of weak learnability. Machine Learning. 1990 Jun;5(2):197, 227–227. [Google Scholar]
- 17.Sricharan K, Raich R, Hero AO. Empirical estimation of entropy functionals with confidence. Dec, 2010. ArXiv e-prints. [Google Scholar]
- 18.Turlach B. Bandwidth selection in kernel density estimation: A review. [Google Scholar]
- 19.Wang Q, Kulkarni SR, Verdú S. Divergence estimation of continuous distributions based on data-dependent partitions. Information Theory, IEEE Transactions on. 2005;51(9):3064–3074. [Google Scholar]