

Abstract
Psycholinguistic and electrophysiological studies of lexical processing show convergent evidence for morpheme-based lexical access for morphologically complex words that involves early decomposition into their constituent morphemes followed by some combinatorial operation. Considering that both semantically transparent (e.g., sailboat) and semantically opaque (e.g., bootleg) compounds undergo morphological decomposition during the earlier stages of lexical processing, subsequent combinatorial operations should account for the difference in the contribution of the constituent morphemes to the meaning of these different word types. In this study we use magnetoencephalography (MEG) to pinpoint the neural bases of this combinatorial stage in English compound word recognition. MEG data were acquired while participants performed a word naming task in which three word types, transparent compounds (e.g., roadside), opaque compounds (e.g., butterfly), and morphologically simple words (e.g., brothel) were contrasted in a partial-repetition priming paradigm where the word of interest was primed by one of its constituent morphemes. Analysis of onset latency revealed shorter latencies to name compound words than simplex words when primed, further supporting a stage of morphological decomposition in lexical access. An analysis of the associated MEG activity uncovered a region of interest implicated in morphological composition, the Left Anterior Temporal Lobe (LATL). Only transparent compounds showed increased activity in this area from 250 to 470 ms. Previous studies using sentences and phrases have highlighted the role of LATL in performing computations for basic combinatorial operations. Results are in tune with decomposition models for morpheme accessibility early in processing and suggest that semantics play a role in combining the meanings of morphemes when their composition is transparent to the overall word meaning.
Keywords: compounds, MEG, left anterior temporal lobe (LATL), word naming, morphology, semantic transparency, morphological decomposition, morphological composition
1. Introduction
Some words are simple and some words are not. This, at first, sounds like a very trivial tautology, but the controversy over whether multi-morphemic words are simply stored in whole word form (Butterworth, 1983; Giraudo and Grainger, 2001) or always constructed from their morphemic parts (Taft, 2004) has been entertaining, provocative, and contentious in the field of lexical processing for the last 40 years. A comprehensive model of how words are both stored and retrieved requires an understanding of how form and meaning are connected, and how this connection unfolds in time in natural speech.
The potential contrast between whole-word storage and morpheme storage was first discussed in the classic affix-stripping model (Taft and Forster, 1975), which proposed that lexical access involves access to the stem of morphologically complex words. This study demonstrated that pseudo-complex words with real stems (e.g., de-juvenate) took longer to reject in a lexical decision task (and were often selected incorrectly as words) than pseudo-complex words with real prefixes and non-existent stems (e.g., de-pertoire). This was taken as evidence that the morphemes were accessed prior to lexical access and they contribute the retrieval of the lexical item in memory. With various priming paradigms, evidence has accumulated in favor of morpheme accessibility during lexical access (Marslen-Wilson et al., 1994; Rastle and Davis, 2003; Taft, 2004). This has given rise to processing models where morphological decomposition is an automatic- and necessary stage in processing for complex words (Rastle et al., 2004). Recent studies (Fiorentino et al., 2014; Semenza and Luzzatti, 2014) have looked at the stages following decomposition to see how morpheme meaning is integrated into the meaning of the complex word. Results from electrophysiology (Fiorentino et al., 2014) revealed a greater negativity for lexicalized compounds (e.g., teacup) and novel compounds (e.g., tombnote) compared to mono-morphemic words in a time window of 275–400 ms, positing a stage where morpheme meanings are combined in English compounds. These psychological models make clear predictions as to the stages and time-course of lexical access, but currently, there is a lack of evidence for the anchoring of these stages to particular areas of the brain. This study seeks to identify an area responsible for the composition of morpheme meanings. Research from the picture naming literature (Dohmes et al., 2004) suggests that there should be greater activation at this stage in processing for semantically transparent complex words since they exhibit greater conceptual activation, and lemma competition in addition to the effect of morphological overlap. Therefore, this area should be sensitive only to the composition within complex words whose morpheme meaning have a semantically transparent relationship to the overall meaning as compared to complex words whose morphemes do not share a semantic relationship, opaque.
One way to look at the lexical processing of complex words is to see if activating morphological structure can modulate the accessibility of a complex word. Some cross-modal priming studies (Marslen-Wilson et al., 1994) have shown that priming in lexical decision between words that shared a stem only occurred when the prime and target had related meanings (e.g., departure primed depart but department did not) while other studies (Zwitserlood, 1994) using partial-repetition priming found that priming did not depend on a semantic relationship between the prime and target. However, studies using masked priming, a subliminal priming paradigm where a prime word is preceded by a forward mask and followed by the target word (Forster and Davis, 1984), found that when manipulating semantic transparency, facilitation effects occurred for complex words regardless of whether the prime and target share the same morphological root (Longtin et al., 2003; Rastle et al., 2004; Fiorentino and Poeppel, 2007; McCormick et al., 2008). These effects did not appear for the morphologically simple words (e.g., brothel). Faster lexical decision times were found for complex words that can be segmented into existing morphemes, which means that masked prime/unmasked target pairs with no semantic relationship like corner-corn and bootleg-boot speeded recognition showed of the target words with magnitudes indistinguishable from pairs with a semantic relationship like cleaner-clean and teacup-tea.
Since it is generally agreed that morphological decomposition is performed for every complex word that can be exhaustively parsed into existing morphemes, research on visual word recognition should shift its focus from decomposition to the subsequent mechanisms engaged to activate the actual meaning of a complex target word. Meunier and Longtin (2007) suggested that word activation comes into play in stages, which include at least one early stage for morphological decomposition and a later stage for semantic integration of the morphological pieces. Fiorentino et al. (2014) presented evidence for a morpheme-based route for word activation that includes decomposition into morphological constituents and combinatorial processes operating on these representations. Since previous studies have shown that early decomposition triggered by morphological structure happens automatically for transparent and opaque words, the difference between these two word types may manifest itself during a later stage of combinatorial operations.
Another way to look at lexical processing of complex words is to look at how form is mapped onto meaning. This is critical in processing morphologically complex words in order to disentangle how the brain perceives transparent ones from how it perceives opaque ones. This can be investigated by looking at how morpheme meanings are composed in the brain. There are models for a general binding mechanism in sentence building (Friederici et al., 2000) and in basic composition of noun phrases (Bemis and Pylkkänen, 2011) that implicate the left Anterior Temporal Lobe (LATL) in the composition of words into phrases. In a minimum composition paradigm, Bemis and Pylkkänen (2011) found that two composable items in an adjective-noun phrase (e.g., red boat) evoked more activation in the left anterior temporal lobe, LATL, at roughly 225 ms, than two non-composable items (e.g., xkq boat, a random letter string and word). This was taken as evidence that the most basic of combinatorial processing is supported by the LATL. Within complex words, there is a special subclass of words that have a parallel structure to noun phrases known as compound words. Compound words have the unique property of being composed of only free morphemes (stand-alone words). Compound words also vary along the dimension of semantic transparency, the degree to which the combination of morpheme meanings corresponds to the overall word meaning. This means we can vary the contribution of the morphemes to the composition of the meaning. These properties make compound words a great candidate for investigating morphological composition within complex words since they can provide an analogous structure to work done at the phrase level. These parallels give rise to the LATL as a candidate region for composition within a word and this provides an interesting basis for studying effects of intra-lexical semantic composition as an analog to composition at the phrase level.
Thus, semantically transparent compound words (e.g., mailbox) should elicit greater activity in this region than simple words since their meanings are derived from the composition of their morphemic parts, whereas semantically opaque compounds (e.g., bootleg) should not elicit greater activity since there is no relationship between their parts and meanings. In sum, a model of complex word recognition would require at least these two stages of processing: parsing into basic units (decomposition), and the composition of these word forms into a complex meaning. To unpack these stages, we propose using two types of priming paradigms: partial-repetition priming (e.g., ROAD-roadside), similar to the paradigms used in masked priming studies, which will be used to investigate the decomposition effects in compounds, and a full-repetition priming (e.g., ROADSIDE-roadside), which will be used to investigate the composition effects of their morphemes. The primes of the repetition priming condition were used to evaluate the composition effect in the absence of a behavioral response. In this respect, the method of analysis analogous to that adopted by Zweig and Pylkkänen (2009), in which the authors directly compare complex (derived) words, thus aiming to find decomposition effects that are not dependent on priming. This study uses a word naming production task to investigate these stages involved in lexical processing since it provides comparable effects to lexical decision tasks (Neely, 1991) and does not require filler trials. This task was done while brain activity was recorded using MEG to investigate whether there is an area within the left temporal lobe that is responsible for morphological composition. This study contributes to the work of characterizing the neural bases of lexical processing of complex words by providing evidence for composition within compound words, while linking it to their neural correlates. Given the prior literature, we expect to find evidence of decomposition for compound words but not for simplex words. This would be a finding that fits in with the visual word recognition literature, specifically the masked priming literature, where there are facilitatory effects when priming morphologically complex words but not morphologically simple words. However, we do not expect to find this overall benefit of morphological complexity in composition. Since composition of meaning is semantically governed, we expect to find composition effects on brain activity only for transparent compounds.
2. Materials and methods
2.1 Participants
Eighteen right-handed native speakers of English ranging from 18 to 30, with normal or corrected vision, all gave informed consent and participated in this experiment. The study was approved by the University Committee on Activities Involving Human Subjects (UCAIHS) of New York University. The MEG data from three participants were excluded due to the large number of trial rejections caused by a noise interference (>25%). Details for rejection are described in the procedure.
2.2. Material
All stimuli consisted of English bi-morphemic compounds (e.g., teacup) and morphologically simple (e.g., spinach) nouns, matched for length and surface frequency. We manipulated semantic transparency, including fully semantically transparent (e.g., teacup) words, in which both constituent morphemes have a semantic relationship to the meaning of the whole compound, and fully semantically opaque words (e.g., hogwash), in which neither of the constituent morphemes have a semantic relationship to the compound meaning.
311 English compounds were compiled from previous studies (Juhasz et al., 2003; Fiorentino and Poeppel, 2007; Fiorentino and Fund-Reznicek, 2009; Drieghe et al., 2010) and categorized in terms of semantic transparency by means of a semantic relatedness task conducted using the Amazon Mechanical Turk tool. In this task, 20 participants were asked to judge, on a 1–7 scale, how much each constituent of the compounds related to the whole word. On the scale, 1 corresponded to unrelated and 7 corresponded to very related. Each participant was randomly presented with one of the constituents of each compound. Compounds were classified as semantically opaque (henceforth opaque) if the sum of the scores of their constituents was within the interval 2–6, and as semantically transparent (henceforth transparent) if the sum were within the interval 10–14. For example, the opaque compound deadline received a summed rating of 3.76 with dead contributing a transparency rating of 1.44 and line contributing a rating of 2.32. Similarly, the compound dollhouse received a summed rating of 11.79 with doll contributing a transparency rating of 6.47 and house contributing a rating of 5.32. Sixty compounds were selected for each word type. This method of semantic transparency norming was consistent with the methods used in the mentioned prior studies. The morphologically simple words (henceforth simplex: e.g., spinach) were pooled from Rastle et al. (2004) and the English Lexicon Project selecting the words coded for having only one morpheme (Balota et al., 2007). The simplex words (e.g., brothel) were selected to have a non-morphological form relationship to their primes (e.g., broth). Also, these words were constrained and selected such that the simple word could not be broken into smaller parts without creating illegal morphemes.
2.3. Design
The three different word types were contrasted in two priming conditions: full repetition and partial (constituent) repetition (See Table 1). For the repetition priming condition, the same compound was used as prime and target (e.g., TEACUP-teacup). For the partial-repetition priming, we used the first constituent of the compound as the prime (e.g., TEA-teacup). For the simplex condition, the non-morphological related form was used as the constituent in the partial-repetition priming condition (e.g., SPIN-spinach). These two priming conditions were paired to control conditions in which the prime had no semantic relationship to the target (e.g., DOORBELL-teacup; DOOR-teacup).
Table 1.
Design matrix.
| Transparent | Opaque | Simplex | ||||
|---|---|---|---|---|---|---|
| Prime | Target | Prime | Target | Prime | Target | |
| Control | Doorbell | Teacup | Heirloom | Hogwash | Brothel | Spinach |
| Repetition | Teacup | Teacup | Hogwash | Hogwash | Spinach | Spinach |
| Control | Door | Teacup | Heir | Hogwash | Broth | Spinach |
| Partial-repetition | Tea | Teacup | Hog | Hogwash | Spin | Spinach |
2.4. Procedure
All participants read all the items in all conditions (720 total), which were divided in three lists of 240 words and randomized within each list. The order of presentation of the lists was counterbalanced between subjects. The experimental task was word naming: subjects were presented with word pairs, and they were asked to read out loud the second word of each pair. Stimuli were presented in 30-point white Courier font on a gray background using PsychToolbox (Brainard, 1997). Each trial began with the presentation of a fixation cross, followed by the prime, then the target. Each of these visual presentations was presented for 300 ms followed by a 300 ms blank (see Figure 1). We recorded the onset latency to speech and the utterance from each subject for behavioral analysis.
Figure 1.
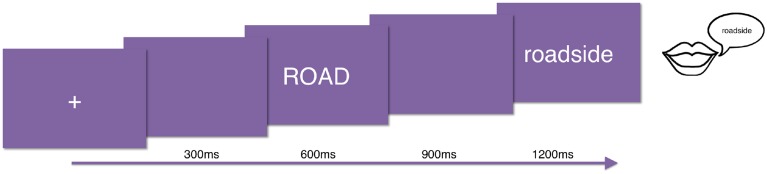
Experiment trial structure.
Before the experiment, the head shape of each participant was digitized using the Polhemus Fastscan system, along with five head position indicator points, which are used to co-register the head position with respect to the MEG sensors during acquisition. Electromagnets attached to these points are localized after the participants are lying within the MEG sensor array, allowing for co-registration of head and sensor coordinate systems. The head shape is used during the analysis to co-register the head to participants MRIs. For half of the participants, MRIs were not provided; therefore, we scaled the common reference brain that is provided in FreeSurfer to fit the size of these participants' heads.
During the experiment, participants remained lying in a magnetically shielded room as their brain response was monitored by the MEG gradiometers. The experimental items were projected onto a screen so the participant could read and perform the task. The MEG data were collected using an axial whole-head gradiometer system with 157 channels and three reference channels (Kanazawa Institute of Technology, Nonoichi, Japan). The recording was conducted in direct current mode, that is, without a high-pass filter, and with a 300 Hz low-pass filter and a 60 Hz notch filter.
2.5. Analysis
We examined onset latency, the reaction time to naming the word, to evaluate the effects of morphological decomposition based on Fiorentino and Poeppel (2007). Since reaction time is sensitive to lexical properties of words (Fiorentino and Poeppel, 2007), compound words should be processed faster when primed than simplex words due to residual activation of previously activated morphemes. A non-decompositional account predicts no differences due to word structure, if the words are correctly matched for relevant whole word properties. Thus, onset latency can be used to disentangle whether or not there is a decomposition effect. The behavioral data were analyzed using traditional analysis of variance for the Word Type by Partial-Repetition priming interaction model. Partial-repetition priming in lexical decision tasks has been used to demonstrate the accessibility of morphemes within complex words (Rastle et al., 2004). Similar behavioral effects have also been found using word naming (see Neely, 1991 for a comparative review of lexical decision and word naming). Therefore, the evidence of decomposition effects can be observed in the reaction time to speak, onset latency. Prior research led to the prediction that there should be a facilitative effect of shorter onset latency due to priming for the compounds as compared to their simplex word counterparts since the segmentation into morphemes lead to faster access to the complex word.
After brain data acquisition, we applied a Continuously Adjusted Least-Squares Method (Adachi et al., 2001), a noise reduction procedure in the MEG160 software (Yokogawa Electric Corporation and Eagle Technology Corporation, Tokyo, Japan) that subtracts noise from the MEG gradiometers based on noise measurements at the reference channels positioned away from the head. The data were bandpass filtered between 1–40 Hz using an IIR filter. The recording of the whole experiment was segmented into epochs of interest, from −200 ms before to 600 ms after the visual display of the prime word. We rejected trials in which the maximal peak-to-peak amplitude exceeded the limit of 4000fT and we equalized the trials to have an equal number of trials per condition and per word type for proper comparison. The average percentage of all trials rejected across subjects was 1.9%, and per word type: 1.3% for opaque, 2.2% for simplex, 1.8% for transparent. Sensor channels were marked as bad and discarded for each subject if the channel's peak-to-peak rejection exceeded 10%.
A noise-covariance matrix was computed for each participant using an automated model selection procedure (Engemann and Gramfort, 2015) on a random selection of baseline epochs (120 epochs) from −200 ms to the onset of the presentation of the fixation cross. For participants with MRIs, cortical reconstructions were generated using FreeSurfer resulting in a source space of 5124 vertices (CorTechs Labs Inc., La Jolla, CA and MGH/HMS/MIT Athinoula A. Martinos Center for Biomedical Imaging, Charleston, MA). A boundary-element model (BEM) method was used to model activity at each vertex to calculate a forward solution. An inverse solution was generated using this forward model and noise-covariance matrix, and was computed with a fixed-orientation constraint requiring dipole sources to be normal to the cortical surface. The sensor data for each subject was then projected into their individual source space using a cortically-constrained minimum norm estimate (all analyses were conducted using MNE-Python: Gramfort et al., 2013, 2014) resulting in noise-normalized dynamic statistical parameter maps (dSPMs: Dale et al., 2000).
For this analysis, our design (Table 2) reduces to the simple comparison between compounds (e.g., TEACUP) and simplex words (e.g., SPINACH) of the same size that served as primes in the repetition condition (e.g., TEACUP-teacup) described above in the Design section. Since, for this analysis, we use neurophysiological data related to the silent reading of the words that served as primes, there is no behavioral data for these words. By these means we also avoid artifacts associated with voluntary movements that can compromise the analysis of the effects of interest to the study (Hansen et al., 2010).
Table 2.
Primes analysis.
| Word types | Examples |
|---|---|
| Opaque | Hogwash |
| Transparent | Teacup |
| Simplex (control) | Brothel |
We examined the neural activity localized in the entire left temporal lobe. This region was selected based on composition effects found with sentences (Friederici et al., 2000) or adjective-noun phrases (Bemis and Pylkkänen, 2011). In order to verify if there was increased activity for compounds in this area, a t-test was performed on the residual activation of a compound word type (opaque, transparent) after removing the activation from the simplex control word from 100 to 600 ms after the stimulus onset. The p-value map of the brain was generated for the time series and spatiotemporal clusters were identified for contiguous space-time clusters that had a p-value of less than 0.05 and a duration of at least 10 ms. The t-values were summed for those points within the cluster that met these criteria. Then, a non-parametric permutation test was performed first by shuffling the word type labels, then calculating clusters formed by the new labels. A distribution generated from 10,000 permutations was computed from calculating significant levels of the observed cluster. The corrected p-value was determined from the percentage of clusters that were larger than the original computed cluster (Maris and Oostenveld, 2007). These tests were computed using the statistical analysis package for MEG data, Eelbrain, (https://pythonhosted.org/eelbrain/).
3. Results
3.1. Morphological decomposition
Behaviorally, we found a significant effect of partial-repetition priming [F(1, 17) = 25.91, p < 0.001], but most critically an interaction of word type by priming [F(2, 17) = 9.24, p < 0.001] (Figure 2). This effect shows that there is a greater facilitation in word naming for compound words than for morphologically simple words when primed. In the planned comparisons, reliable differences were found between opaque compounds and simplex words [F(1, 17) = 5.93, p < 0.03], and transparent compounds and simplex words [F(1, 17) = 14.46, p < 0.005] but not between transparent and opaque compounds [F(1, 17) = 2.84, p > 0.1]. These results show that even in word production, there is sensitivity to morphological structure above and beyond orthographic and phonological overlap, but this stage of processing is not sensitive to the meaning of the morphemes in relationship to the compound word, which is consistent with the prior literature on morphological decomposition (Rastle et al., 2004; McCormick et al., 2008).
Figure 2.
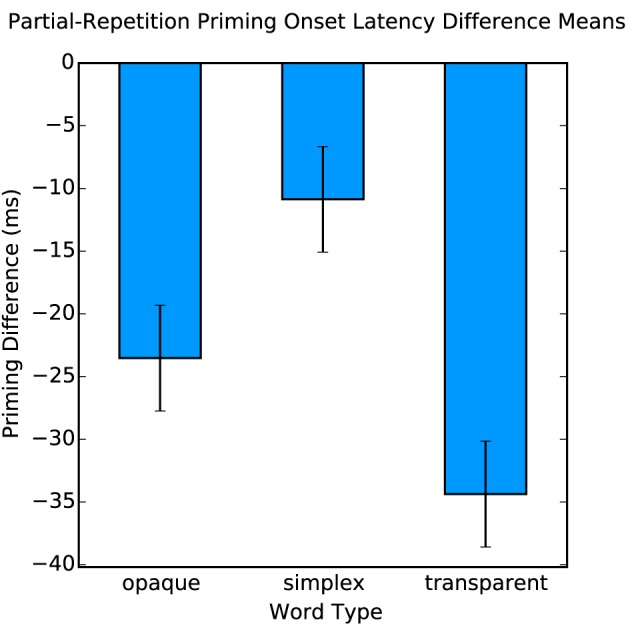
Partial-repetition priming onset latency difference means.
3.2. Morphological composition
Results reveal reliable effects of greater activation for transparent compounds when compared with their simplex controls within the temporal lobe. There were two significant clusters associated with this difference: the first cluster was localized to the anterior middle temporal gyrus from 250 to 470ms (∑ t = 4552.3, p < 0.05, Figure 3), and a second cluster of activity was localized to the posterior superior temporal gyrus from 430 to 600 ms (∑ t = 5654, p < 0.05, Figure 4). However, there were no reliable clusters found for the difference of opaque compounds and simplex words within the temporal lobe.
Figure 3.
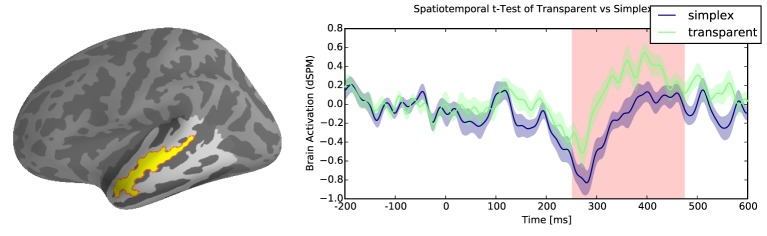
Transparent vs. simplex difference in Left Anterior Temporal Lobe (LATL).
Figure 4.
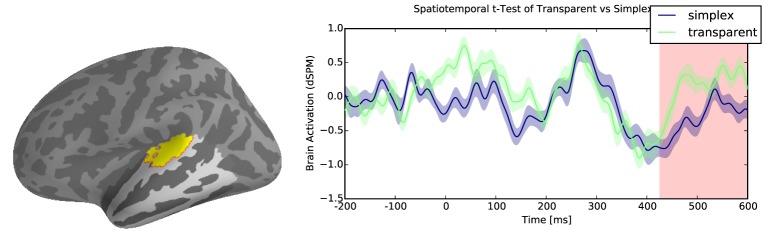
Transparent vs. simplex difference in Posterior Superior Temporal Gyrus (pSTG).
4. Discussion
Analyses of the different word types in isolation revealed very consistent evidence that there is a difference in how simplex and complex words are processed in the brain. The behavioral results confirmed that there is a stage in lexical access that is sensitive to the morphological forms within complex words and demonstrated that these effects could also be observed in other testing modalities, namely, word naming. The onset latency interaction effect where compound words were faster to produce than morphologically simple words when primed by their constituent morpheme is largely consistent with the results within the masked priming literature on word recognition, and gives further evidence that there is a decomposition stage in lexical access where complex words are parsed into their morphemes (Rastle et al., 2004; Taft, 2004; Morris et al., 2007; McCormick et al., 2008; Fiorentino and Fund-Reznicek, 2009). The parsing operation occurs independent of the semantic relationship between constituent morphemes and their complex word. Since early activation of constituents via morphological decomposition happens irrespective of semantic transparency, what differentiates transparent and opaque compound must happen, thus, during a later stage of morphemic composition. The increased activity found for transparent compounds in anterior temporal lobe from 250 to 470ms provides evidence for a stage in lexical access where meanings of the morpheme play a part in accessing the overall meaning of the word. Bemis and Pylkkänen (2011) show combinatorial effects in the LATL for adjectival words at around 225 ms after the critical word is presented. The difference in timing could be explained by the different time points at which we time lock the onset of the stimulus. In Bemis and Pylkkänen (2011), the onset coincides with the onset of the noun boat in the phrase red boat, whereas in our study the critical stimulus is the entire compound sailboat.
The increased activation in the posterior temporal lobe for transparent compounds from 430 to 600 ms that follows the activity in the LATL is consistent with the fact that this region is involved in lexical retrieval (Hickok and Poeppel, 2007; Lau et al., 2008). Lau et al. (2008) proposed that the posterior region of the temporal lobe is the best candidate for the lexical storage of words. Since the LATL is responsible for composing the meaning of the constituent morphemes, the posterior temporal lobe would be responsible for retrieving information from its stored lexico-semantic representation. This region is also engaged in sound-to-meaning transformation (Binder et al., 2000), which would include the retrieval of phonological information. This study is in tune with decomposition models from visual word recognition literature and provides the neural basis for a stage in lexical access involved in the composition of meaning within compound words, thus helping to disentangle cognitive processes that are indistinct when reaction time is the only measure. Bridging results from psycholinguistic research with MEG recordings of brain activity, the emerging results suggest that the recognition of compounds involves distinct stages: a decomposition stage that is independent of semantics, and a composition stage that is governed by semantics. We showed that the course of activation varies in terms of word complexity and semantic transparency.
Author contributions
Authors TB and DC share first-authorship as they have both equally contributed to the paper.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We would like to thank Alec Marantz for his support and guidance with this project. We would also like to thank Masha Westerlund and Phoebe Gaston for providing critical feedback for this paper. We would also like to thank Jeff Walker of the NYU MEG Lab for his help while running participants.
Footnotes
Funding. This work is supported by the National Science Foundation under Grant No. BCS-0843969, and by the NYU Abu Dhabi Research Council under Grant No. G1001 from the NYUAD Institute, New York University Abu Dhabi. The work of TB was supported by the National Science Foundation Graduate Research Fellowship under DGE-1342536. The work of DC was supported by the Coordination for the Improvement of Higher Education Personnel and the Fulbright Commission under the Mutual Educational Exchange Act, sponsored by The United States of America Department of State, Bureau of Educational and Cultural Affairs.
References
- Adachi Y., Shimogawara M., Higuchi M., Haruta Y., Ochiai M. (2001). Reduction of non-periodic environmental magnetic noise in MEG measurement by continuously adjusted least squares method. Appl. Superconduct. IEEE Trans. 11:669–672 10.1109/77.919433 [DOI] [Google Scholar]
- Balota D. A., Yap M. J., Cortese M. J., Hutchison K. A., Kessler B., Loftis B., et al. (2007). The english lexicon project. Behav. Res. Methods 39, 445–459. 10.3758/BF03193014 [DOI] [PubMed] [Google Scholar]
- Bemis D. K., Pylkkänen L. (2011). Simple composition: a magnetoencephalography investigation into the comprehension of minimal linguistic phrases. J. Neurosci. 31, 2801–2814. 10.1523/JNEUROSCI.5003-10.2011 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Binder J. R., Frost J. A., Hammeke T. A., Bellgowan P. S., Springer J. A., Kaufman J. N., et al. (2000). Human temporal lobe activation by speech and nonspeech sounds. Cereb. Cortex 10, 512–528. 10.1093/cercor/10.5.512 [DOI] [PubMed] [Google Scholar]
- Brainard D. H. (1997). The psychophysics toolbox. Spat. Vis. 10, 433–436. 10.1163/156856897X00357 [DOI] [PubMed] [Google Scholar]
- Butterworth B. (1983). Lexical representation, in Language Production, Vol. 2, ed Butterworth B. (London: Academic Press; ), 257–294. [Google Scholar]
- Dale A. M., Liu A. K., Fischl B. R., Buckner R. L., Belliveau J. W., Lewine J. D., et al. (2000). Dynamic statistical parametric mapping: combining fmri and MEG for high-resolution imaging of cortical activity. Neuron 26, 55–67. 10.1016/S0896-6273(00)81138-1 [DOI] [PubMed] [Google Scholar]
- Dohmes P., Zwitserlood P., Bölte J. (2004). The impact of semantic transparency of morphologically complex words on picture naming. Brain Lang. 90, 203–212. 10.1016/S0093-934X(03)00433-4 [DOI] [PubMed] [Google Scholar]
- Drieghe D., Pollatsek A., Juhasz B. J., Rayner K. (2010). Parafoveal processing during reading is reduced across a morphological boundary. Cognition 116, 136–142. 10.1016/j.cognition.2010.03.016 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Engemann D. A., Gramfort A. (2015). Automated model selection in covariance estimation and spatial whitening of MEG and EEG signals. Neuroimage 108, 328–342. 10.1016/j.neuroimage.2014.12.040 [DOI] [PubMed] [Google Scholar]
- Fiorentino R., Fund-Reznicek E. (2009). Masked morphological priming of compound constituents. Ment. Lexicon 4, 159–193 10.1075/ml.4.2.01fio [DOI] [Google Scholar]
- Fiorentino R., Naito-Billen Y., Bost J., Fund-Reznicek E. (2014). Electrophysiological evidence for the morpheme-based combinatoric processing of english compounds. Cogn. Neuropsychol. 31, 123–146. 10.1080/02643294.2013.855633 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fiorentino R., Poeppel D. (2007). Compound words and structure in the lexicon. Lang. Cogn. Process. 22, 953–1000 10.1080/01690960701190215 [DOI] [Google Scholar]
- Forster K. I., Davis C. (1984). Repetition priming and frequency attenuation in lexical access. J. Exp. Psychol. Learn. Mem. Cogn. 10, 680–698 10.1037/0278-7393.10.4.680 [DOI] [Google Scholar]
- Friederici A. D., Wang Y., Herrmann C. S., Maess B., Oertel U. (2000). Localization of early syntactic processes in frontal and temporal cortical areas: a magnetoencephalographic study. Hum. Brain Mapp. 11, 1–11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Giraudo H., Grainger J. (2001). Priming complex words: evidence for supralexical representation of morphology. Psychon. Bull. Rev. 8, 127–131. 10.3758/BF03196148 [DOI] [PubMed] [Google Scholar]
- Gramfort A., Luessi M., Larson E., Engemann D. A., Strohmeier D., Brodbeck C., et al. (2013). MEG and EEG data analysis with MNE-python. Front. Neurosci. 7:267. 10.3389/fnins.2013.00267 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gramfort A., Luessi M., Larson E., Engemann D. A., Strohmeier D., Brodbeck C., et al. (2014). MNE software for processing MEG and EEG data. Neuroimage 86, 446–460. 10.1016/j.neuroimage.2013.10.027 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hansen P. C., Kringelbach M. L., Salmelin R. (2010). MEG: An Introduction to Methods. New York, NY: Oxford University Press. [Google Scholar]
- Hickok G., Poeppel D. (2007). The cortical organization of speech processing. Nat. Rev. Neurosci. 8, 393–402. 10.1038/nrn2113 [DOI] [PubMed] [Google Scholar]
- Juhasz B. J., Starr M. S., Inhoff A. W., Placke L. (2003). The effects of morphology on the processing of compound words: evidence from naming, lexical decisions and eye fixations. Br. J. Psychol. 94, 223–244. 10.1348/000712603321661903 [DOI] [PubMed] [Google Scholar]
- Lau E. F., Phillips C., Poeppel D. (2008). A cortical network for semantics: (de)constructing the n400. Nat. Rev. Neurosci. 9, 920–933. 10.1038/nrn2532 [DOI] [PubMed] [Google Scholar]
- Longtin C.-M., Segui J., Hallé P. A. (2003). Morphological priming without morphological relationship. Lang. Cogn. Process. 18, 313–334 10.1080/01690960244000036 [DOI] [Google Scholar]
- Maris E., Oostenveld R. (2007). Nonparametric statistical testing of EEG- and MEG-data. J. Neurosci. Methods 164, 177–190. 10.1016/j.jneumeth.2007.03.024 [DOI] [PubMed] [Google Scholar]
- Marslen-Wilson W., Tyler L. K., Waksler R., Older L. (1994). Morphology and meaning in the english mental lexicon. Psychol. Rev. 101, 3–33 10.1037/0033-295X.101.1.3 [DOI] [Google Scholar]
- McCormick S. F., Rastle K., Davis M. H. (2008). Is there a ‘fete’ in ‘fetish’? effects of orthographic opacity on morpho-orthographic segmentation in visual word recognition. J. Mem. Lang. 58, 307–326. 10.1016/j.jml.2007.05.00615875981 [DOI] [Google Scholar]
- Meunier F., Longtin C.-M. (2007). Morphological decomposition and semantic integration in word processing. J. Mem. Lang. 56, 457–471. 10.1016/j.jml.2006.11.00516725189 [DOI] [Google Scholar]
- Morris J., Frank T., Grainger J., Holcomb P. J. (2007). Semantic transparency and masked morphological priming: an erp investigation. Psychophysiology 44, 506–521. 10.1111/j.1469-8986.2007.00538.x [DOI] [PMC free article] [PubMed] [Google Scholar]
- Neely J. H. (1991). Semantic priming effects in visual word recognition: a selective review of current findings and theories, in Basic Processes in Reading: Visual Word Recognition, eds Besner D., Humphreys G. W. (Hillsdale, NJ: L. Erlbaum Associates; ), 264–336. [Google Scholar]
- Rastle K., Davis M. H. (2003). Reading Morphologically Complex Words. New York, NY: Psychology Press. [Google Scholar]
- Rastle K., Davis M. H., New B. (2004). The broth in my brother's brothel: morpho-orthographic segmentation in visual word recognition. Psychon. Bull. Rev. 11, 1090–1098. 10.3758/BF03196742 [DOI] [PubMed] [Google Scholar]
- Semenza C., Luzzatti C. (2014). Combining words in the brain: the processing of compound words. introduction to the special issue. Cogn. Neuropsychol. 31, 1–7. 10.1080/02643294.2014.898922 [DOI] [PubMed] [Google Scholar]
- Taft M. (2004). Morphological decomposition and the reverse base frequency effect. Q. J. Exp. Psychol. A 57, 745–765. 10.1080/02724980343000477 [DOI] [PubMed] [Google Scholar]
- Taft M., Forster K. I. (1975). Lexical storage and retrieval of prefixed words. J. Verb. Learn. Verb. Behav. 14, 638–647 10.1016/S0022-5371(75)80051-X [DOI] [Google Scholar]
- Zweig E., Pylkkänen L. (2009). A visual m170 effect of morphological complexity. Lang. Cogn. Process. 24, 412–439 10.1080/01690960802180420 [DOI] [Google Scholar]
- Zwitserlood P. (1994). The role of semantic transparency in the processing and representation of dutch compounds. Lang. Cogn. Process. 9, 341–368 10.1080/01690969408402123 [DOI] [Google Scholar]