

Abstract
Clinical risk prediction is one important problem in medical informatics, and logistic regression is one of the most widely used approaches for clinical risk prediction. In many cases, the number of potential risk factors is fairly large and the actual set of factors that contribute to the risk is small. Therefore sparse logistic regression is proposed, which can not only predict the clinical risk but also identify the set of relevant risk factors. The inputs of logistic regression and sparse logistic regression are required to be in vector form. This limits the applicability of these models in the problems when the data cannot be naturally represented vectors (e.g., medical images are two-dimensional matrices). To handle the cases when the data are in the form of multi-dimensional arrays, we propose HOSLR: High-Order Sparse Logistic Regression, which can be viewed as a high order extension of sparse logistic regression. Instead of solving one classification vector as in conventional logistic regression, we solve for K classification vectors in HOSLR (K is the number of modes in the data). A block proximal descent approach is proposed to solve the problem and its convergence is guaranteed. Finally we validate the effectiveness of HOSLR on predicting the onset risk of patients with Alzheimer’s disease and heart failure.
1. Introduction
Predictive modeling of clinical risk, such as disease onset [1] or hospitalization [2], is an important problem in medical informatics. Effective risk prediction can be very helpful for the physician to make proper decision and provide the right service at point-of-care.
Typically we need three steps to perform patient clinical risk prediction:
Collecting all potential risk factors from patient historical data and utilizing them to properly represent each patient (e.g., as a vector [1][3]).
Identifying important risk factors from the risk factor pool collected in the first step, such that the value change of the selected risk factors could generate big impact on the predicted risk.
Training a proper predictive model based on the patients represented with the selected risk factors from the second step. Such model will be used to score the clinical risk of new testing patients.
One representative clinical risk prediction work that follows those three steps is the work by Sun et al. [1], where the goal is to predict the onset risk for potential heart failure patients. The authors first collect all potential risk factors from the two year patient electronic health records, and then designed an scalable orthogonal regression method to identify important risk factors, which will be used to train a logistic regression model for risk prediction at last. The authors showed that they can achieve the state-of-the-art performance as well as identify clinically meaningful risk factors for heart failure.
Note that in practice, depending on the concrete risk factor identification method and predictive model, step 2 and 3 could be combined into one step, i.e., a unified model can be constructed for both prediction and risk factor identification (e.g., LASSO [4]). This will make the constructed model more integrative and interpretable. Sparse Logistic Regression [5] is one such model. As is known to all that logistic regression is a popular model for clinical risk prediction [6] [1][3]. However, the pool of potential risk factors is usually very large and noisy, which would affect the efficiency and performance of predictive modeling. The main difference between sparse and convectional logistic regression is it adds an one norm regularizer on the model coefficients to encourage the model sparsity, so that only those important risk factors will contribute to the final predictions. In recent years people have also been doing research on constructing different regularization terms to enforce different sparsity structures on the model coefficients, such as the lp norm [7], group sparsity [8] and elastic net regularization [9].
One limitation of the existing sparse logistic regression type of approaches is that they assume vector based inputs, which means that we need to have a vector based representation for each patient before we can use those methods to evaluate the patient’s clinical risk. However, we are in the era of big data with variety as one representative characteristic, so does medical data, i.e., there are many medical data are not naturally in vector form. For example, typical medical images (e.g., X-Ray and MRI) are two dimensional matrices, with some more advanced medical imaging technologies can even generate three-dimensional image sequences (e.g., functional Magnetic Resonance Imaging (fMRI)). In a recent paper, Ho et al. [10] proposed a tensor (which can be viewed as high order generalization of matrix) based representation of patient Electronic Health Records (EHRs) to capture the interactions between different modes in patient EHRs. For example, medication order information for every patient could be captured by a 2nd order tensor with 2 modes, where each mode is an aspect of a tensor: a) medication and b) diagnosis. With such a representation we can take into consideration the correlation between diagnosis and drugs when predicting the patient risk. If there are more inter-correlated modes in the data then we will need to represent the patient in higher order tensors. In these cases, if we still want to apply logistic regression one straightforward way is to stretch those matrices and tensors into vectors as people did in image processing, but this will lose the correlation information among different dimensions. Moreover, after stretching the dimensionality of the data objects will become very high, which will make traditional sparse logistic regression inefficient.
In recent years, there has been a lot of research on extending traditional vector based approaches to 2nd (matrix based) or higher order (tensor based) settings. Two representative examples are two-dimensional Principal Component Analysis (PCA) [11] and Linear Discriminant Analysis [12], which have been found to be more effective on computer vision tasks compared to traditional vector based PCA and LDA. Recently, Huang and Wang [13] developed a matrix variate logistic regression model and applied it in electroencephalography data analysis. Tan et al. [14] further extended logistic regression to tensor inputs and achieved good performance in a video classification task.
In this paper, we propose HOSLR, a High-Order Sparse Logistic Regression method that can perform prediction based on matrix or tensor inputs. Our model learns a linear decision vector on every mode of the input, and we added an ℓ1 regularization term on each decision vector to encourage sparsity. We developed a Block Proximal Gradient (BPG) [15] method to solve the problem iteratively. The convergence of the proposed algorithm can be guaranteed by the Kurdyka–Lojasiewicz inequality [16] (for proof details please see a more technical version of this paper [17]). Finally we validate the effectiveness of our algorithm on two real world medical scenarios on the risk prediction of patients with Alzheimer’s Disease and Heart Failure.
The rest of this paper is organized as follows. Section 2 reviews some related works. The details along with the convergence analysis of HOSLR is introduced in Section 3. Section 4 presents the experimental results, followed by the conclusions in Section 5.
2. Related Work
Logistic regression [18] is a statistical prediction method that has widely been used in medical informatics [1][6][19]. Suppose we have a training data matrix X = [x1, x2, ⋯, xn] ∈ ℝd×n, where xi ∈ ℝd (1 ≤ i ≤ n) is the i-th training data vector with dimensionality d, and associated with each xi we also have its corresponding label yi ∈ {+1, −1}. The goal of logistic regression is to train a linear decision function f(x) = w⊤x + b to discriminate the data in class +1 from the data in class −1 by minimizing the following logistic loss
| (1) |
where w ∈ ℝd is the decision vector and b is the bias. They can be learned with gradient descent type of approaches.
In many medical informatics applications, the data vectors are sparse and high-dimensional (e.g., each patient could be a tens of thousands dimensional vector with bag-of-feature representation [1]). To enhance the interpretability of the model in these scenarios, we can minimize the following ℓ1-regularized logistic loss
| (2) |
where ||·||1 is the vector ℓ1 norm and λ > 0 is a factor trading off the prediction accuracy and model sparsity. The resultant model is usually referred to as sparse logistic regression model [5][20]. Compared with the conventional logistic regression model obtained by minimizing Jorg, the w obtained by minimizing Jsp is sparse thanks to the ℓ1 norm regularization. In this way, we can not only get a predictor, but also know what are the feature dimensions that are important to the prediction (which are the features with nonzero classification coefficients).
Sparse logistic regression has widely been used in health informatics because it can achieve a good balance between model accuracy and model interpretability. For example, sparse logistic regression has been used in the prediction of Leukemia [21], Alzheimer’s disease [22] and cancers [23]. In recent years people also designed different regularization terms [7][8][9] to enforce more complex sparsity patterns on the learned model. However, all these works require a vector based data representations. Under this framework, if the data naturally come as tensors (like medical imaging), we need to first stretch them into vectors before we can apply sparse logistic regression. This may lose the correlation structure among different modes in the original data, while for the HOSLR method proposed in this paper, we directly work with data in tensor representations. Fig. 1 provides a graphical illustration on the difference of traditional vector based logistic regression and high order logistic regression when working on multi-dimensional data.
Figure 1:
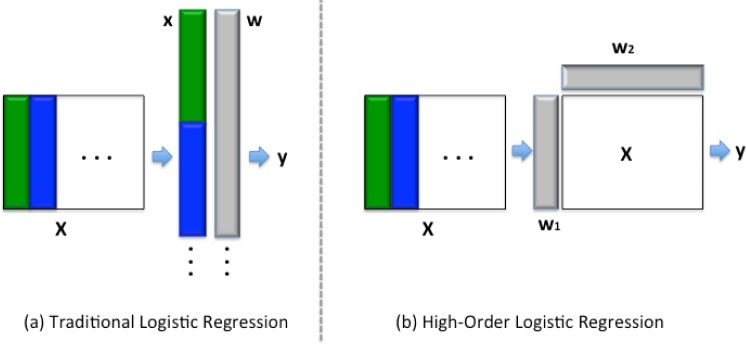
Traditional vector based logistic regression and high-order logistic regression work on multi-dimensional data.
3. Methodology
We introduce the details of HOSLR in this section. First we will formally define the problem.
3.1. Problem Statement
Without the loss of generality, we assume each observation is a tensor , suppose its corresponding response is yi ∈ {0, 1}, then HOSLR assumes
| (3) |
where ×k is the mode-k product, and is the prediction coefficients on the k-th dimension. Then
| (4) |
Let W = {w1, w2, ⋯, wK} be the set of prediction coefficient vectors. The loss we want to minimize is
where for notational convince, we denote
| (5) |
The loss function we considered in this paper is Logistic Loss:
| (6) |
We also introduce the regularization term
| (7) |
which is usually referred to as elastic net regularization [24]. This regularizer is a combination of ℓ1 and ℓ2 norm regularizations, thus it can achieve better numerical stability and reliability [24]. Then the optimization problem we want to solve is
| (8) |
We adopt a Block Coordinate Descent (BCD) procedure to solve the problem. Starting from some initialization (W(0), b(0)), at the i-th step of the t-th round of updates, we update by
where and .
Algorithm 1.
Block Coordinate Descent Procedure

|
3.2. Proximal Gradient Descent
Algorithm 2 summarized the whole algorithmic flow of our algorithm, where and is the component-wise shrinkage operator defined as
| (9) |
At each iteration the most time consuming part is evaluating the gradient, which takes time, that is linear with respect to data set size and data dimension. The detailed algorithm derivation can be referred to [17].
Algorithm 2.
Block Proximal Gradient Descent for Multilinear Sparse Logistic Regression

|
4. Experiments
In this section we will present the experimental results on applying HOSLR to predict the onset risk of potential Alzheimer’s Disease patients from their fMRI images, and the onset risk of potential heart failure patients from their EHR data.
4.1. Experiments on Predicting the Onset Risk of Alzheimer’s Disease
Alzheimer’s disease (AD) is the most common form of dementia. It worsens as it progresses and eventually leads to death. There is no cure for the disease. AD is usually diagnosed in elder people (typically over 65 years of age), although the less-prevalent early-onset Alzheimer’s can occur much earlier. There are currently more than 5 million Americans living with Alzheimer’s disease and that number is poised to grow to as many as 16 million by 2050. The care for has been the country’s most expensive condition, which costs the nation $203 billion annually with projections to reach $1.2 trillion by 2050 [25].
Early detection of AD is of key importance for its effective intervention and treatment, where functional magnetic resonance imaging or functional MRI (fMRI) [26] is an effective approach to investigate alterations in brain function related to the earliest symptoms of Alzheimer’s disease, possibly before development of significant irreversible structural damage.
In this set of experiment, we adopted a set of fMRI scans collected from real clinic cases of 1,005 patients [27], whose cognitive function scores (semantic, episodic, executive and spatial - ranges between −2.8258 and 2.5123) were also acquired at the same time using a cognitive function test. There are three types of MRI scans that were collected from the subjects: (1) FA, the fractional anisotropy MRI gives information about the shape of the diffusion tensor at each voxel, which reflects the differences between an isotropic diffusion and a linear diffusion; (2) FLAIR, Fluid attenuated inversion recovery is a pulse sequence used in MRI, which uncovers the white matter hyperintensity of the brain; (3)
GRAY, gray MRI images revealing the gray matter of the brain. In the raw scans, each voxel has a value from 0 to 1, where 1 indicates that the structural integrity of the axon tracts at that location is perfect, while 0 implies either there are no axon tracts or they are shot (not working). The raw scans are preprocessed (including normalization, denoising and alignment) and then restructured to 3D tensors with a size of 134 × 102 × 134. Associated with each sample we have a label, which could be either normal, Mild Cognitive Impairment (MCI) or demented.
We constructed three binary classification problems to test the effectiveness of our HOSLR method, i.e., Normal vs. Rest (MCI and Demented), MCI vs. Rest (Normal and Demented), Demented vs. Rest (Normal and MCI). For HOSLR, because the input fMRI images are three dimensional tensors, we set the ℓ1 term regularization parameters on all three dimensions equal, i.e., λ1 = λ2 = λ3 and tune it from the grid {10−3, 10−2, 10−1, 1, 10, 102, 103} with five fold cross validation. The ℓ2 term regularization parameters are set to μ1 = μ2 = μ3 = 10−4. For comparison purpose, we also implemented the following baseline algorithms:
Nearest Neighbor (NN). This is the one nearest neighbor classifier with standard Euclidean distance.
Support Vector Machine (SVM). This is the regular vector based SVM method.
Logistic Regression (LR). This is the traditional vector based logistic regression method.
Sparse Logistic Regression (SLR). This is the vector based sparse logistic regression.
Multilinear Logistic Regression (MLR). This is equivalent to HOSLR with all ℓ1 regularization parameters setting to 0.
We use LIBLINEAR [28] for the implementation of LR and SLR, and LIBSVM [29] for the implementation of SVM. Note that in order to test those vector based approaches, we need to stretch those fMRI tensors into very long vectors (with dimensionality 1,831,512). Fig. 2 summarized the average performance over 5-fold cross validation in terms of Areas Under the receiver operating characteristics Curve (AUC) values. The data we used are the FLAIR images. From the figure we can observe that HOSLR beats all other competitors in all three tasks. This is because HOSLR can not only take into consideration the spatial correlation between three different dimensions in those fMRI images, but also exploring their joint sparsity structures (the FLAIR images are sparse in nature).
Figure 2:
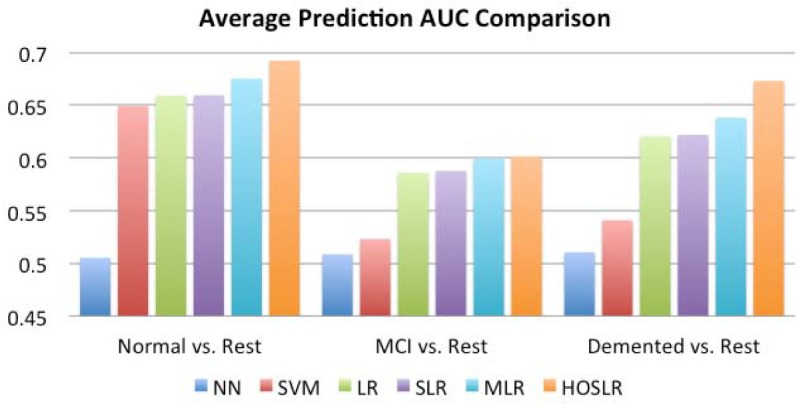
Average prediction AUC over 5-fold cross validation comparison for different methods.
4.2. Experiments on Predicting the Onset Risk of Congestive Heart Failure Patients
Congestive heart failure (CHF), occurs when the heart is unable to pump sufficiently to maintain blood flow to meet the needs of the body, is a major chronic illness in the U.S. affecting more than five million patients. It is estimated CHF costs the nation an estimated $32 billion each year [30]. Effective prediction of the onset risk of potential CHF patients would help identify the patient at risk in time, and thus the decision makers can provide the proper treatment. This can also help save huge amount of unnecessary costs.
The data set we use in this set of experiments is from a real world Electronic Health Record (EHR) data warehouse including the longitudinal EHR of 319,650 patients over 4 years. On this data set, we identified 1,000 CHF case patients according to the diagnostic criteria in [3]. Then we obtained 2,000 group matched controls according to patient demographics, comorbidities and primary care physicians similar as in [3]. We use the medication orders of those patients within two years from their operational criteria date (for case patients, their operational criteria dates are just their CHF confirmation date; for control patients that date is just the date of their last records in the database). On each medication order we use the corresponding pharmacy class according to the United States Pharmacopeial (USP) convention1 and the primary diagnosis in terms of Hierarchical Condition Category (HCC) codes [31] for the medication prescription. In total there are 92 unique pharmacy classes and 195 distinct HCC codes appeared in those medication orders. Therefore each patient can be represented as a 92 × 195 matrix, where the (i, j)-th entry indicates the frequency that the i-th drug was prescribed during the two years with the j-th diagnosis code as primary diagnosis.
The parameters for HOSLR are set in the same manner as the experiments in last subsection. For comparison purpose, we also implemented NN, SVM, LR, SLR, MLR and reported the averaged AUC value over 5-fold cross validation along with their standard deviations on Fig. 3. From the figure we can get similar observations as we saw in Fig. 2.
Figure 3:
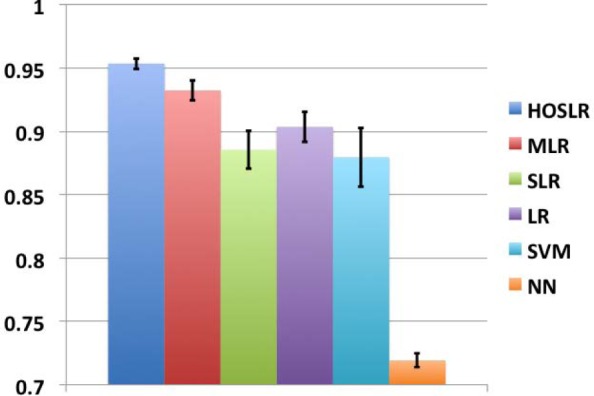
Prediction performance for different methods on the CHF onset prediction task in terms of averaged AUC value with 5-fold cross validation along with their standard deviations.
Another interesting thing to check is which medications and diagnosis play key roles during the decision. Because in this set of experiments we have two feature modes: medications and diagnosis, we will get two decision vectors wmed and wdiag, one on each mode. The bilinear decision function in this case can be written as
| (10) |
where 1 denotes all-one vector of appropriate dimension, ⊙ is element-wise matrix product. The importance of the (i, j)-th feature Xij to the decision can be evaluated as wmed(i)wdiag(j). Therefore if both the magnitudes of wmed(i) and wdiag(j) are large, then the feature pair (medication i, diagnosis j) will definitely be important. We list in Table 1 the top diagnoses and medications according to their coefficient magnitudes in wdiag and wmed. From the table we can see that the diagnoses are mainly hypertension, heart disease and some common comorbidities of heart failure including chronic lung disease (e.g., Chronic Obstructive Pulmonary Disease (COPD) [32]) and chronic kidney disease [33]. The top medications include drugs for treating heart disease such as Beta blockers and calcium blockers, and medicine for treating lung disease such as Corticosteroids. There are also medicine for treating heart failure related symptom, such as Gout, which is a well-known Framingham symptom [34]. Vaccine is also an important treatment for reducing the stress on heart [35].
Table 1:
Top diagnosis and medications according to the magnitude of their corresponding decision coefficient
| Diagnosis | |
|---|---|
| Heart Disease | Congestive Heart Failure |
| Acute Myocardial Infarction | |
| Specified Heart Arrhythmias | |
| Ischemic or Unspecified Stroke | |
| Hypertension | Hypertension |
| Hypertensive Heart Disease | |
| Lung Disease | Fibrosis of Lung and Other Chronic Lung Disorders |
| Asthma | |
| Chronic Obstructive Pulmonary Disease (COPD) | |
| Kidney Disease | Chronic Kidney Disease, Very Severe (Stage 5) |
| Chronic Kidney Disease, Mild or Unspecified (Stage 1–2 or Unspecified) | |
| Medication |
|---|
| Antihyperlipidemic |
| Antihypertensive |
| Beta Blockers |
| Calcium Blockers |
| Cardiotonics |
| Cardiovascular |
| Corticosteriods |
| Diuretics |
| General Anesthetics |
| Gout |
| Vaccines |
5. Conclusions
We propose a high order sparse logistic regression method called HOSLR in this paper, which can directly take data matrices or tensors as inputs and do prediction on that. HOSLR is formulated as an optimization problem and we propose an effective BCD strategy to solve it. We validate the effectiveness of HOSLR on two real world medical scenarios on predicting the onset risk of Alzheimer’s disease and heart failure. We demonstrate that HOSLR can not only achieve good performance, but also discover interesting predictive patterns.
Footnotes
References
- [1].Sun Jimeng, Hu Jianying, Luo Dijun, Markatou Marianthi, Wang Fei, Edabollahi Shahram, Steinhubl Steven E, Daar Zahra, Stewart Walter F. AMIA Annual Symposium Proceedings. Vol. 2012. American Medical Informatics Association; 2012. Combining knowledge and data driven insights for identifying risk factors using electronic health records; p. 901. [PMC free article] [PubMed] [Google Scholar]
- [2].Philbin Edward F, DiSalvo Thomas G. Prediction of hospital readmission for heart failure: development of a simple risk score based on administrative data. Journal of the American College of Cardiology. 1999;33(6):1560–1566. doi: 10.1016/s0735-1097(99)00059-5. [DOI] [PubMed] [Google Scholar]
- [3].Wu Jionglin, Roy Jason, Stewart Walter F. Prediction modeling using EHR data: challenges, strategies, and a comparison of machine learning approaches. Medical care. 2010;48(6):S106–S113. doi: 10.1097/MLR.0b013e3181de9e17. [DOI] [PubMed] [Google Scholar]
- [4].Tibshirani Robert. Journal of the Royal Statistical Society. 1996. Regression shrinkage and selection via the lasso; pp. 267–288. (Series B (Methodological)). [Google Scholar]
- [5].Shevade Shirish Krishnaj, Keerthi S Sathiya. A simple and efficient algorithm for gene selection using sparse logistic regression. Bioinformatics. 2003;19(17):2246–2253. doi: 10.1093/bioinformatics/btg308. [DOI] [PubMed] [Google Scholar]
- [6].Miravitlles Marc, Guerrero Tina, Mayordomo Cristina, Sánchez-Agudo Leopoldo, Nicolau Felip, Segú José Luis. Factors associated with increased risk of exacerbation and hospital admission in a cohort of ambulatory COPD patients: a multiple logistic regression analysis. Respiration. 2000;67(5):495–501. doi: 10.1159/000067462. [DOI] [PubMed] [Google Scholar]
- [7].Liu Zhenqiu, Jiang Feng, Tian Guoliang, Wang Suna, Sato Fumiaki, Meltzer Stephen J, Tan Ming. Sparse logistic regression with Lp penalty for biomarker identification. Statistical Applications in Genetics and Molecular Biology. 2007;6(1) doi: 10.2202/1544-6115.1248. [DOI] [PubMed] [Google Scholar]
- [8].Meier Lukas, Van De Geer Sara, Bühlmann Peter. The group LASSO for logistic regression. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 2008;70(1):53–71. [Google Scholar]
- [9].Ryali Srikanth, Supekar Kaustubh, Abrams Daniel A, Menon Vinod. Sparse logistic regression for whole-brain classification of fMRI data. NeuroImage. 2010;51(2):752–764. doi: 10.1016/j.neuroimage.2010.02.040. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Ho Joyce C, Ghosh Joydeep, Steinhubl Steve, Stewart Walter, Denny Joshua C, Malin Bradley A, Sun Jimeng. Limestone: High-throughput candidate phenotype generation via tensor factorization. Journal of Biomedical Informatics. 2014 doi: 10.1016/j.jbi.2014.07.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [11].Yang Jian, Zhang David, Frangi Alejandro F, Yang Jing-yu. Two-dimensional PCA: a new approach to appearance-based face representation and recognition. Pattern Analysis and Machine Intelligence, IEEE Transactions on. 2004;26(1):131–137. doi: 10.1109/tpami.2004.1261097. [DOI] [PubMed] [Google Scholar]
- [12].Ye Jieping, Janardan Ravi, Li Qi, et al. Two-dimensional linear discriminant analysis. Advances in Neural Information Processing Systems. 2004;17 [Google Scholar]
- [13].Hung Hung, Wang Chen-Chien. Matrix variate logistic regression model with application to EEG data. Biostatistics. 2013;14(1):189–202. doi: 10.1093/biostatistics/kxs023. [DOI] [PubMed] [Google Scholar]
- [14].Tan Xu, Zhang Yin, Tang Siliang, Shao Jian, Wu Fei, Zhuang Yueting. Intelligent Science and Intelligent Data Engineering. Springer; 2013. Logistic tensor regression for classification; pp. 573–581. [Google Scholar]
- [15].Xu Yangyang. Alternating proximal gradient method for sparse nonnegative Tucker decomposition. Mathematical Programming Computation. 2013:1–32. [Google Scholar]
- [16].Bolte Jérôme, Daniilidis Aris, Lewis Adrian. The Lojasiewicz inequality for nonsmooth subanalytic functions with applications to subgradient dynamical systems. SIAM Journal on Optimization. 2007;17(4):1205–1223. [Google Scholar]
- [17].Wang Fei, Zhang Ping, Qian Buyue, Wang Xiang, Davidson Ian. Clinical risk prediction with multilinear sparse logistic regression; Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining; ACM. 2014. [Google Scholar]
- [18].Hosmer David W, Jr, Lemeshow Stanley. Applied logistic regression. John Wiley & Sons; 2004. [Google Scholar]
- [19].Xiang Shuo, Yuan Lei, Fan Wei, Wang Yalin, Thompson Paul M, Ye Jieping. Multi-source learning with block-wise missing data for Alzheimer’s disease prediction; Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining; ACM. 2013. pp. 185–193. [Google Scholar]
- [20].Liu Jun, Chen Jianhui, Ye Jieping. Large-scale sparse logistic regression; Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining; ACM. 2009. pp. 547–556. [Google Scholar]
- [21].Manninen Tapio, Huttunen Heikki, Ruusuvuori Pekka, Nykter Matti. Leukemia prediction using sparse logistic regression. PloS one. 2013;8(8) doi: 10.1371/journal.pone.0072932. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Rao Anil, Lee Ying, Gass Achim, Monsch Andreas. Classification of Alzheimer’s disease from structural MRI using sparse logistic regression with optional spatial regularization; Engineering in Medicine and Biology Society, EMBC, 2011 Annual International Conference of the IEEE; IEEE. 2011. pp. 4499–4502. [DOI] [PubMed] [Google Scholar]
- [23].Kim Yongdai, Kwon Sunghoon, Song Seuck Heun. Multiclass sparse logistic regression for classification of multiple cancer types using gene expression data. Computational Statistics & Data Analysis. 2006;51(3):1643–1655. [Google Scholar]
- [24].Zou Hui, Hastie Trevor. Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 2005;67(2):301–320. [Google Scholar]
- [25].Thies William, Bleiler Laura. Alzheimer’s disease facts and figures. Alzheimer’s & dementia: the journal of the Alzheimer’s Association. 2013;2013;9(2):208–245. doi: 10.1016/j.jalz.2013.02.003. [DOI] [PubMed] [Google Scholar]
- [26].Huettel Scott A, Song Allen W, McCarthy Gregory. Functional magnetic resonance imaging. Vol. 1. Sinauer Associates; Sunderland, MA: 2004. [Google Scholar]
- [27].Qian Buyue, Wang Xiang, Wang Fei, Li Hongfei, Ye Jieping, Davidson Ian. Active learning from relative queries; Proceedings of International Joint Conference on Artificial Intelligence; 2013. pp. 1614–1620. [Google Scholar]
- [28].Fan Rong-En, Chang Kai-Wei, Hsieh Cho-Jui, Wang Xiang-Rui, Lin Chih-Jen. LIBLINEAR: A library for large linear classification. The Journal of Machine Learning Research. 2008;9:1871–1874. [Google Scholar]
- [29].Chang Chih-Chung, Lin Chih-Jen. LIBSVM: a library for support vector machines. ACM Transactions on Intelligent Systems and Technology (TIST) 2011;2(3):27. [Google Scholar]
- [30].Heidenreich Paul A, Trogdon Justin G, Khavjou Olga A, Butler Javed, Dracup Kathleen, Ezekowitz Michael D, Finkelstein Eric Andrew, S Yuling Hong, Johnston Claiborne, Khera Amit, et al. Forecasting the future of cardiovascular disease in the United States a policy statement from the American heart association. Circulation. 2011;123(8):933–944. doi: 10.1161/CIR.0b013e31820a55f5. [DOI] [PubMed] [Google Scholar]
- [31].Pope Gregory C, Ellis Randall P, Ash Arlene S, Ayanian JZ, Bates DW, Burstin H, Iezzoni LI, arcantonio E, Wu B. Diagnostic cost group hierarchical condition category models for Medicare risk adjustment. Health Economics Research, Inc Waltham, MA. 2000 [PMC free article] [PubMed] [Google Scholar]
- [32].Rutten Frans H, Cramer Maarten-Jan M, Lammers Jan-Willem J, Grobbee Diederick E, Hoes Arno W. Heart failure and chronic obstructive pulmonary disease: an ignored combination? European journal of heart failure. 2006;8(7):706–711. doi: 10.1016/j.ejheart.2006.01.010. [DOI] [PubMed] [Google Scholar]
- [33].Ahmed Ali, Rich Michael W, Sanders Paul W, Perry Gilbert J, Bakris George L, Zile Michael R, Love Thomas E, Aban Inmaculada B, Shlipak Michael G. Chronic kidney disease associated mortality in diastolic versus systolic heart failure: a propensity matched study. The American journal of cardiology. 2007;99(3):393–398. doi: 10.1016/j.amjcard.2006.08.042. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [34].McKee Patrick A, Castelli William P, McNamara Patricia M, Kannel William B. The natural history of congestive heart failure: the Framingham study. New England Journal of Medicine. 1971;285(26):1441–1446. doi: 10.1056/NEJM197112232852601. [DOI] [PubMed] [Google Scholar]
- [35].Davis Matthew M, Taubert Kathryn, Benin Andrea L, Brown David W, Mensah George A, Baddour Larry M, Dunbar Sandra, Krumholz Harlan M. Influenza vaccination as secondary prevention for cardiovascular disease: a science advisory from the american heart association/american college of cardiology. Journal of the American College of Cardiology. 2006;48(7):1498–1502. doi: 10.1016/j.jacc.2006.09.004. [DOI] [PubMed] [Google Scholar]