

Abstract
The architecture and parameter initialization of wavelet neural network are discussed and a novel initialization method is proposed. The new approach can be regarded as a dynamic clustering procedure which will derive the neuron number as well as the initial value of translation and dilation parameters according to the input patterns and the activating wavelets functions. Three simulation examples are given to examine the performance of our method as well as Zhang's heuristic initialization approach. The results show that the new approach not only can decide the WNN structure automatically, but also provides superior initial parameter values that make the optimization process more stable and quickly.
1. Introduction
An artificial neural network (ANN) is a highly parallel distributed network of connected processing units called neurons. Due to their fascinating characteristics of robustness, fault tolerance, adaptive learning ability, and massive parallel processing capabilities, ANNs possess the capability of learning from examples with both linear and nonlinear relationships between the input and output signals, which makes them a popular tool for time series prediction [1, 2], feature extraction [3, 4], pattern recognition [5, 6], and classification [7, 8]. However, ANNs have limited ability to characterize local features, such as discontinuities in curvature, jumps in value, or other edges.
Instead of using common sigmoid activation functions, the wavelet neural network (WNN) employing nonlinear wavelet basis functions [9, 10], which are localized in both the time space and frequency space, has been developed as an alternative approach to nonlinear fitting problem. It has been proven that families of wavelet frames are universal approximators [11], which give a theoretical basis to their use in the framework of function approximation and process modeling.
There are two different WNN architectures: one type has fixed wavelet bases possessing fixed dilation and translation parameters (WNN-Type1). In this one only the output layer weights are adjustable. Another type has the variable wavelet base whose dilation and translation parameters and output layer weights are adjustable (WNN-Type2). Several WNN models have been proposed in the literatures. In [12], a four-layer self-constructing wavelet network (SCWN) controller for nonlinear systems control is described and the orthogonal wavelet functions are adopted as its node functions. In [13], a local linear wavelet neural network (LLWNN) is presented whose connection weights between the hidden layer and output layer of conventional WNN are replaced by a local linear model. In [14], a model of multiwavelet-based neural networks is proposed. The structure of this network is similar to that of the wavelet network, except that the orthonormal scaling functions are replaced by orthonormal multiscaling functions.
A time series is a sequence of observations taken sequentially in time [15]. Time series prediction is an important research and application area. Much effort has been devoted over the past several decades to the development and improvement of time series prediction models. Besides the well-known linear models such as moving average, exponential smoothing, and the autoregressive integrated moving average, nonlinear models including artificial neural network, wavelet neural network, and fuzzy system models also become the well-established time series models. In this paper, the wavelet neural network (WNN) is used as the time series predictor, and the detailed research works are described subsequently.
We adopt WNN-Type2 with adjustable translation and dilation parameters and multiplication form of multidimensional wavelets as the nonlinear model for time series prediction in this paper. Key problems in designing of this type of WNN consist of determining WNN architecture, initializing the translation and dilation vectors, and choosing learning algorithm that can be effectively used for training the WNN. This study mainly focuses on the first two points. In the practical applications, the number of hidden neurons which determines the structure of the network is often set by experience or the time-consuming trial-and-error tests, and the initial values of parameters are often set randomly. Due to the rapidly vanishing property of wavelet functions, the random initialization scheme to the dilation and translation parameters may cause the wavelets' effective response regions out of interest which makes the learning performance very instable. So it is inadvisable to adopt random initialization scheme for dilations and translations in WNN. In [9], Zhang proposes a heuristic initialization procedure which considers the interesting domain of input patterns. But, in its implementation, the wavelet functions used in WNN are not considered, and the resolution reduced gradually according to an established rule which does not take full consideration of sample distribution.
In the present paper, inspired by the localization character of wavelet functions and considering the multiplication form of multidimensional wavelets in the hidden neuron for multivariable inputs, we present a novel initialization approach by the help of a new clustering method for WNN. This approach can determine the unit number of hidden layer and initialize the translation and dilation vectors simultaneously. After performing the training process by gradient descent method, we can see that, besides the capability of neuron number determination, WNN with our initialization method gives more satisfactory and stable results for time series prediction compared to Zhang's heuristic initialization method which is used for this model in some literatures [9, 16, 17].
The paper is organized as follows. A brief review of wavelet and wavelet-based function approximation is given in Section 2, followed by the introduction of the architecture of wavelet neural network in Section 3. The detailed description of the clustering based initialization approach and the training algorithm are given in Sections 4 and 5. Three simulation experiments on time series prediction problems and the comparison results with Zhang's heuristic initialization method are presented in Section 6. Finally, some conclusions are drawn in the last section.
2. Wavelet-Based Function Approximation
Wavelets in the following form,
| (1) |
are a family of functions generated from one single function ψ(x) by the operation of dilation and translation. ψ(x) ∈ L 2(R) is called a mother wavelet function that satisfies the admissibility condition:
| (2) |
where is the Fourier transform of ψ(x) [11, 18].
Grossmann and Morlet [19] proved that any function f(x) in L 2(R) can be represented by
| (3) |
where Wf(a, b) given by
| (4) |
is the continuous wavelet transform of f(x).
Superior to conventional Fourier transform, the wavelet transform (WT) in its continuous form provides a flexible time-frequency window, which narrows when observing high frequency phenomena and widens when analyzing low frequency behavior. Thus, time resolution becomes arbitrarily good at high frequencies, while the frequency resolution becomes arbitrarily good at low frequencies. This kind of analysis is suitable for signals composed of high frequency components with short duration and low frequency components with long duration, which is often the case in practical situations.
As the parameters a and b are the continuous values, the resulting continuous wavelet transform (CWT) is a very redundant representation and impracticable also. This impracticability is the result of the redundancy. Therefore, the scale and shift parameters are evaluated on a discrete grid of time-scale leading to a discrete set of continuous wavelet functions:
| (5) |
The continuous inverse wavelet transform (3) is discretized as
| (6) |
If there exist two constants c > 0 and C < +∞ such that, for any f(x) in L 2(R), the following inequalities hold:
| (7) |
where ‖f‖ denotes the norm of function f(x) and 〈f, g〉 denotes the inner product of functions f and g, and the family {ψ ai,bi} is said to be a frame of L 2(R). It has been proved that families of wavelet frames of L 2(R) are universal approximators.
Inspired by the wavelet decomposition of f(x) ∈ L 2(R) in (6) and a single hidden layer network model, Zhang and Benveniste [9] had developed a new neural network model, namely, wavelet neural network (WNN).
3. Architecture of Wavelet Neural Network
A brief review of wavelet decomposition theory has been given in Section 2, where functions with univariable were concerned. For the modeling of multivariable processes, multidimensional wavelets must be defined. In the present work, multidimensional wavelets are defined as the multiplication of single-dimensional wavelet functions:
| (8) |
where x = (x 1, x 2,…, x n)T is the input vector and b j = (b j1, b j2,…, b jn) and a j = (a j1, a j2,…, a jn) are the translation and dilation vectors, respectively.
Generalized from radial basis function neural network, WNN is in fact a feed-forward neural network with one hidden layer, wavelet functions as activation functions in the hidden nodes, and a linear output layer. As a result, the network output y = (y 1, y 2,…, y q)T is computed as
| (9) |
where w = (w ij) and define the connecting weights and the bias terms between the hidden layer and the output layer, respectively. N is the number of units in hidden layer. These wavelet neurons are usually referred to as wavelons. The architecture of a WNN is illustrated in Figure 1.
Figure 1.
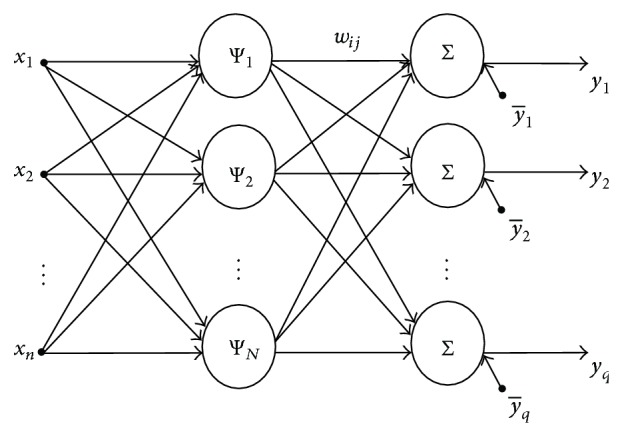
Architecture of wavelet neural network.
4. Initialization Approach of Wavelet Neural Network
Before training the WNN, some factors should be determined in advance, which are the number of wavelons and initial value of parameters (a jk, b jk, w ij, and ). The former is fixed once the structure of network was determined, while the latter is adjusted by the training algorithm. All these factors are crucial for the performance of network in simulating the real model. In this section, a brief description of wavelet window is presented firstly, and then a novel initialization method based on the dynamic clustering is proposed, which could provide the number of hidden neurons and the initial values of translation and dilation parameters at the same time.
4.1. Wavelet Window in Time Domain
A mother wavelet function ψ(x) defined by (2) will have sufficient decay, which can be considered as “local response.” In other words, ψ(x) is a window with center in μ and radius σ in time domain, which can be computed by [20]
| (10) |
As a result, its translated and dilated version ψ a,b = ψ((x − b)/a) will be concentrated in the region of [b + aμ − aσ, b + aμ + aσ] in the time domain.
In this paper, the Mexican Hat wavelet function with symmetric graph (Figure 2) is employed, which is given by the following equation:
| (11) |
Figure 2.
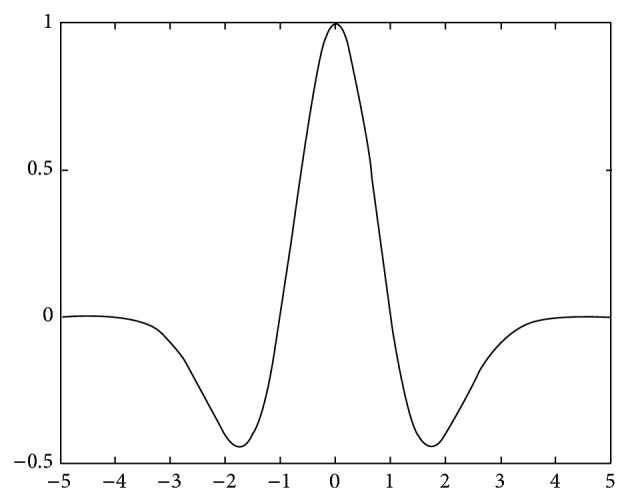
Mexican Hat wavelet.
From (10), the center and radius of Mexican Hat wavelet window in the time domain can be derived as
| (12) |
4.2. Initialization by a Novel Clustering Approach for WNN
The structure of our network is illustrated in Figure 1. Suppose the input data for network training are M vectors with n components: {x l = (x l1, x l2,…, x ln)T, l = 1,2,…, M}. The procedure comprises the following steps:
Create the first cluster C 1 = {x 1} with cluster mean m 1 = x 1 and dimensional radius r 1 = 0. Set the number of clusters J = 1.
Put l = 2.
Compute the distance vectors D i = |x l − m i| = (d i1, d i2,…, d in)T, i = 1,2,…, J.
If there are some D is ∈ {D i}i=1 J (s = 1,2,…, S), such that, ∀j ∈ {1,2,…, n}, d isj ≤ max(r isj, thj) and Arg mink(∑j=1 n d kj) = K, then x l ∈ C K. The vector t h = (th1, th2,…, thn)T is a threshold vector which is set in advance of executing the algorithm. The cluster mean will be reset as
| (13) |
and dimensional radius r K = (r K1, r K2,…, r Kn) will be reset as
| (14) |
where |C K| is the cardinal number of C K and x k = (x k1, x k2,…, x kn)T are the patterns that belong to C K.
Else, the number of clusters becomes J = J + 1; create the Jth cluster C J = {x l} with cluster mean m J = x l and dimensional radius r J = 0.
-
(4)
Put l = l + 1. If l > M, then stop; otherwise go to step (3).
Remark 1 . —
(i) Vector t h = (th1, th2,…, thn)T in the above procedure is crucial to the clustering result. Large elements of t h will lead to a coarse partition, namely, a small J, whereas t h with small value will lead to a large J. In practice, a reasonable t h should be determined by the input patterns. In our experiments, we prefer to adopt vector t h as in formula (15) to control the cluster scale, which offers moderate results in most times. Consider
(15) where .
(ii) The conditions “there are some D is ∈ {D i}i=1 J (s = 1,2,…, S) such that, ∀j ∈ {1,2,…, n}, d isj ≤ max(r isj, thj)” in step (3) are derived from “local response” property of activation wavelet functions Ψ(x) = ∏k=1 n ψ((x k − b k)/a k) in the wavelons. As a result, patterns satisfying that each feature activates corresponding 1-D wavelet function will be identified as a class.
(iii) After the clustering procedure of (1)–(4), the corresponding results help us to determine the number of wavelons in WNN as N = J and the initial value of translation and dilation vectors as
(16)
(17) β in (17) is a relaxation parameter which satisfies β ≥ 1; σ is the window radius of wavelet function ψ(x).
(iv) In order to avoid the dilation parameters being zeros, the radius vector of the cluster with single element should be redefined. The minimum value strategy is employed which can be described as r l′j = minl(r lj), (|C l′| = 1, |C l| > 1).
(v) The connecting weights w = (w ij) between the hidden layer and the output layer will be randomly initialized in the region [−1,1], and the bias term initialized as the mean vector of input patterns.
5. Training Algorithm
Gradient descent method is implemented for training the WNN in this paper. Parameters are adjusted in the opposite direction of the gradient such that the objective function in (18) of the model should be minimized. Consider
| (18) |
where y l is the output of network and f l is the desired output.
The corrections applied to parameters a jk, b jk, w ij, and are shown as follows:
| (19) |
where Ψj(x l) = ∏k=1 n ψ((x lk − m jk)/d jk), ∂Ψj(x l)/∂a jk = F(x l)(x lk − b jk)(−1/a jk 2), ∂Ψj(x l)/∂b jk = F(x l)(−1/a jk), and F(x l) = ψ′((x lk − b jk)/a jk)∏i=1,i≠k n ψ((x li − b ji)/a ji). γ 1, γ 2, γ 3, γ 4 are the learning rates which should be set on the basis of specific experiment.
6. Simulation Examples
In this section, WNN model with two different initialization schemes is applied to three time series prediction problems, namely, the prediction of Mackey-Glass, Box-Jenkins, and traffic volume time series. The performance of WNN with the clustering based initialization approach (WNN-CIA) described in Section 4 is compared to Zhang's heuristic initialization approach (WNN-HIA) in each simulation.
Because the architecture of WNN-HIA must be decided in advance, in order to compare directly, we adopt the same architecture with WNN-CIA in the experiments. Relaxation parameter β in (17) of WNN-CIA is set as 2.5 in all simulations and the Mexican Hat function defined in (11) is employed as the wavelet function in the hidden neurons of all models. Root mean square error (RMSE) given by (20) of the training/testing set is used as index for comparing performances of WNN with different initialization schemes. Consider
| (20) |
6.1. Prediction of Mackey-Glass Time Series
The Mackey-Glass chaotic time series is generated from the following delay differential equation:
| (21) |
Here we predict the x(t + 6) using the input variables x(t), x(t − 6), x(t − 12), and x(t − 18). Parameters in (21) are set as a = 0.2, b = 0.1, τ = 17, and x(0) = 1.2 which make the equation show chaotic behavior. One thousand input-output data points are extracted from the Mackey-Glass time series x(t), where t = 118 to t = 1117. The first 500 data pairs of the series are used as training data, while the remaining 500 data pairs are used to validate the proposed network. After performing the proposed clustering based initialization method proposed in Section 4.2, we get that the number of wavelons is N = 9.
For the performance comparison of WNN-CIA with WNN-HIA, some different architectures are employed for WNN-HIA. Table 1 shows the mean and standard deviation (std.) of RMSE for training and testing data obtained when 100 runs were performed by each model. The models are trained for 500 epochs in each run. Some results of different models for testing set are shown in Table 2. The RMSE reduction curve during training and testing of gradient descent algorithm corresponding to the best WNN-CIA model is drawn in Figure 3. Figures 4 and 5 show the prediction output of the best WNN-CIA model and the corresponding prediction error for training and testing data with the training and testing RMSE as 0.0080 and 0.0078.
Table 1.
Comparison results of WNN with two initialization methods for Mackey-Glass time series.
| Model | Structure | Number of parameters | Mean of RMSE | Std. of RMSE | ||
|---|---|---|---|---|---|---|
| Training | Testing | Training | Testing | |||
| WNN-CIA | 4-9-1 | 82 | 0.01398 | 0.01377 | 0.00188 | 0.00203 |
|
| ||||||
| WNN-HIA [9] | 4-8-1 | 73 | 0.02915 | 0.03073 | 0.00976 | 0.01079 |
| 4-9-1 | 82 | 0.02789 | 0.02912 | 0.00899 | 0.00953 | |
| 4-10-1 | 91 | 0.02906 | 0.03059 | 0.01097 | 0.01174 | |
| 4-11-1 | 100 | 0.02700 | 0.02819 | 0.00871 | 0.00940 | |
Table 2.
Some test results of different models for Mackey-Glass time series.
Figure 3.

RMSE values obtained during training and testing for Mackey-Glass time series.
Figure 4.

Prediction results for Mackey-Glass time series by WNN-CIA.
Figure 5.
Prediction errors for Mackey-Glass time series by WNN-CIA.
From Table 1, it can be seen that the performance of WNN with structure and initial parameters derived by the proposed initialization approach is much better than that of WNN-HIA, even when more parameters are employed in the model.
6.2. Prediction of Box-Jenkins Time Series
The gas furnace data of Box and Jenkins (1970), that is, Box-Jenkins time series, was recorded from a combustion process of a methane-air mixture. It is well known and frequently used as a benchmark example for testing identification algorithms. During the process, the portion of methane was randomly changed, keeping a constant gas flow rate. The data set consists of 296 pairs of input-output measurements. The input u(t) is the gas flow into the furnace and the output y(t) is the CO2 concentration in outlet gas. The sampling interval is 9 s.
In this section, the data set used consists of 292 consecutive values of methane at time (t − 4) and CO2 produced in a furnace at time (t − 1) as input variables, with the produced CO2 at time (t) as an output variable. Namely, variables u(t − 4) and y(t − 1) are used to predict y(t). The data are partitioned in 200 data points as a training set and the remaining 92 points as a testing set for testing the performance of the proposed network. After performing the initialization method of WNN proposed in Section 4.2, we get the number of wavelons N = 8.
As is done in Section 6.1, different architectures are employed for WNN-HIA for comparison with WNN-CIA whose structure and initial parameters are derived by the proposed approach. Table 3 shows the mean and standard deviation of RMSE for training and testing data obtained when 100 runs were performed by each model. The models are also trained for 500 epochs in each run. Table 4 shows some test results of different models. The RMSE reduction curve during training and testing of gradient descent algorithm corresponding to the best WNN-CIA model is drawn in Figure 6. Figures 7 and 8 show the prediction output of the best WNN-CIA model and the corresponding prediction error for training and testing data with the training and testing RMSE as 0.0186 and 0.0348.
Table 3.
Comparison results of WNN with two initialization methods for Box-Jenkins time series.
| Model | Structure | Number of parameters | Mean of RMSE | Std. of RMSE | ||
|---|---|---|---|---|---|---|
| Training | Testing | Training | Testing | |||
| WNN-CIA | 2-8-1 | 41 | 0.02023 | 0.05900 | 0.00086 | 0.00952 |
|
| ||||||
| WNN-HIA [9] | 2-7-1 | 36 | 0.02108 | 0.06220 | 0.00121 | 0.01516 |
| 2-8-1 | 41 | 0.02110 | 0.05964 | 0.00172 | 0.01420 | |
| 2-9-1 | 46 | 0.02068 | 0.05616 | 0.00099 | 0.01339 | |
| 2-10-1 | 51 | 0.02064 | 0.05579 | 0.00115 | 0.01064 | |
Table 4.
Some test results of different models for Box-Jenkins time series.
Figure 6.

RMSE values obtained during training and testing for Box-Jenkins time series.
Figure 7.
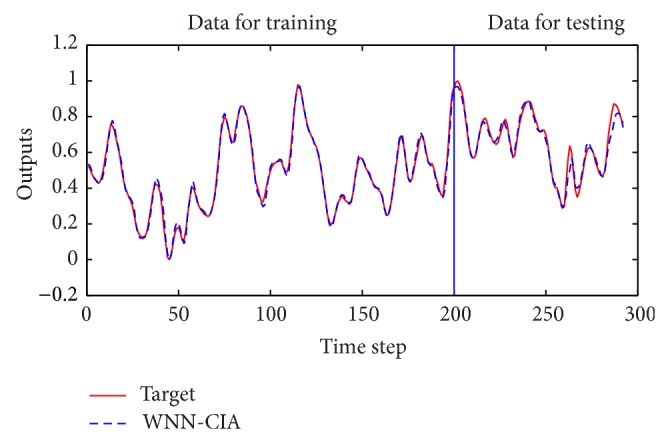
Prediction results for Box-Jenkins time series by WNN-CIA.
Figure 8.
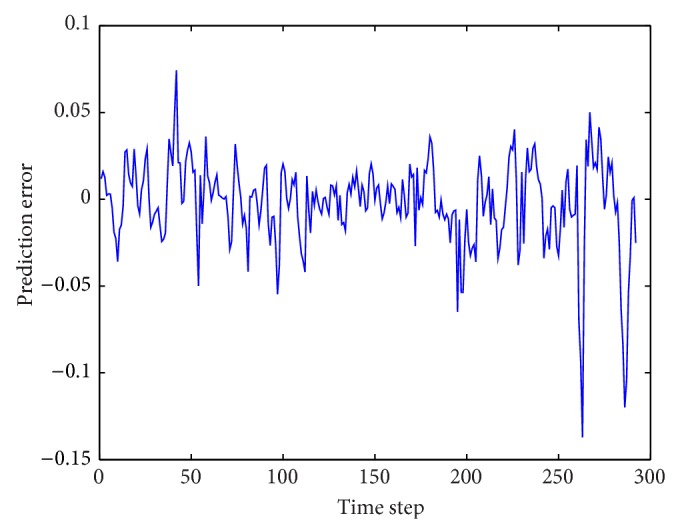
Prediction errors for Box-Jenkins time series by WNN-CIA.
From the data in Table 3, we can see that WNN-CIA outperforms WNN-HIA when the same architectures are employed. When more parameters are employed to WNN-HIA, the performances of WNN-HIA gradually improve. However, WNN-CIA model can make a more stable performance than all WNN-HIA models in the experiments. In order to further examine the effectiveness of the proposed method, simulation experiments of a real-word example, traffic volume time series prediction, are carried out.
6.3. Prediction of the Traffic Volume Time Series (A Real-Word Example)
Chen in [21] implemented the neural network time series models for traffic volume forecasting. In this section, the data of hourly traffic volume for station 5 from [21], which were collected on IR 271 and IR 90 in Cuyahoga County, are used as the real-word time series to examine the performance of WNN-CIA as well as WNN-HIA. There are 105 volume data points collected from June 4, 4:00 pm, to June 8, 12:00 pm, for training purposes, with the remaining 9 data points collected from 1:00 am to 9:00 am on June 9 reserved for model accuracy checking. This is a one-step forecasting with 6 anterior data points as input vector. Data normalizing is done to transfer values of the raw time series into the numbers in interval [0,1]. After performing the initialization method of WNN proposed in Section 4.1, we get the number of wavelons N = 17.
Some same and different architectures are employed for WNN-HIA for comparison with WNN-CIA. After 100 experiments with 500 epochs in each run, Table 5 shows the mean and standard deviation of RMSE for training and testing data for two WNN models with different initialization methods. Test results of different models are shown in Table 6. The RMSE reduction curve during training and testing of gradient descent algorithm corresponding to the best WNN-CIA model is drawn in Figure 9. Figures 10 and 11 show the prediction output of the best WNN-CIA model and the corresponding prediction error for training and testing data with the training and testing RMSE as 0.0233 and 0.0335.
Table 5.
Comparison results of WNN with two initialization methods for traffic volume time series.
| Model | Structure | Number of parameters | Mean of RMSE | Std. of RMSE | ||
|---|---|---|---|---|---|---|
| Training | Testing | Training | Testing | |||
| WNN-CIA | 6-17-1 | 222 | 0.03201 | 0.05343 | 0.00462 | 0.01237 |
|
| ||||||
| WNN-HIA [9] | 6-16-1 | 209 | 0.03996 | 0.05692 | 0.01162 | 0.02125 |
| 6-17-1 | 222 | 0.03868 | 0.05561 | 0.01109 | 0.02266 | |
| 6-18-1 | 235 | 0.03761 | 0.05373 | 0.01065 | 0.02035 | |
| 6-19-1 | 248 | 0.03796 | 0.05567 | 0.01248 | 0.02312 | |
Table 6.
Some test results of different models for traffic volume time series.
Figure 9.
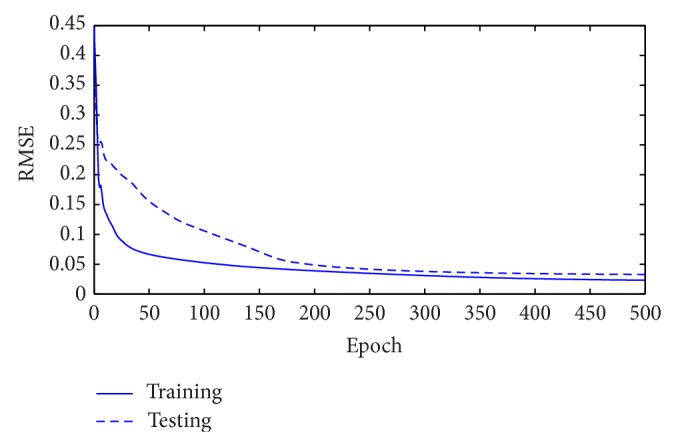
RMSE values obtained during training and testing for traffic volume time series.
Figure 10.
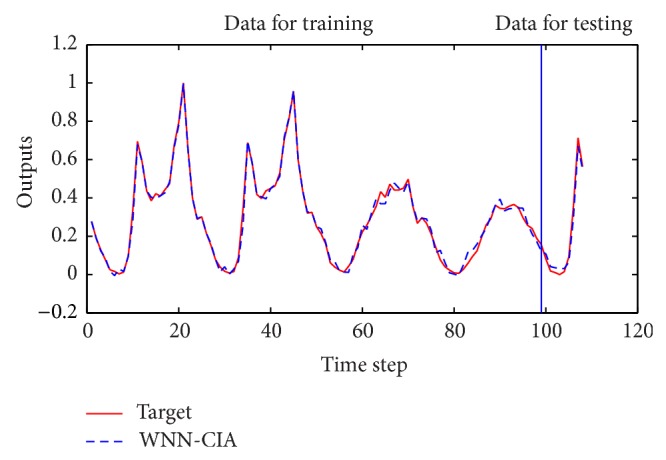
Prediction results for traffic volume time series by WNN-CIA.
Figure 11.

Prediction errors for traffic volume time series by WNN-CIA.
From Table 5, we can see that the performance of WNN with the proposed clustering based initialization procedure is also superior to that with heuristic initialization approach even when more parameters are employed in WNN-HIA. It demonstrates again the validity of our methods.
7. Conclusion
In this paper, a novel initialization procedure for WNN as time series predictor is proposed, which behaves as a dimensional clustering procession. Taking account of the distribution of input patterns and the local response property of wavelet functions, the input patterns can be dynamically classified by the proposed approach. And then the architecture as well as the initial values of translation and dilation parameters of WNN model can be determined accordingly. Simulation results demonstrate that, besides the capability of neuron number determination, WNN with our initialization method can provide satisfactory and stable results for time series prediction.
Acknowledgments
The authors are thankful that the research is supported by the National Science Foundation of China (61275120) and Tian Yuan Special Foundation (11426207).
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
References
- 1.Frank R. J., Davey N., Hunt S. P. Time series prediction and neural networks. Journal of Intelligent and Robotic Systems: Theory and Applications. 2001;31(1–3):91–103. doi: 10.1023/a:1012074215150. [DOI] [Google Scholar]
- 2.Lotric U., Dobnikar A. Predicting time series using neural networks with wavelet-based denoising layers. Neural Computing and Applications. 2005;14(1):11–17. doi: 10.1007/s00521-004-0434-z. [DOI] [Google Scholar]
- 3.Setiono R., Liu H. Feature Extraction, Construction and Selection. Springer US; 1998. Feature extraction via neural networks; pp. 191–204. [Google Scholar]
- 4.Egmont-Petersen M., de Ridder D., Handels H. Image processing with neural networks—a review. Pattern Recognition. 2002;35(10):2279–2301. doi: 10.1016/s0031-3203(01)00178-9. [DOI] [Google Scholar]
- 5.Bishop C. M. Neural Networks for Pattern Recognition. Oxford, UK: The Clarendon Press; 1995. [Google Scholar]
- 6.Balasubramanian M., Palanivel S., Ramalingam V. Real time face and mouth recognition using radial basis function neural networks. Expert Systems with Applications. 2009;36(3):6879–6888. doi: 10.1016/j.eswa.2008.08.001. [DOI] [Google Scholar]
- 7.Zhang G. P. Neural networks for classification: a survey. IEEE Transactions on Systems, Man and Cybernetics Part C: Applications and Reviews. 2000;30(4):451–462. doi: 10.1109/5326.897072. [DOI] [Google Scholar]
- 8.Ghate V. N., Dudul S. V. Optimal MLP neural network classifier for fault detection of three phase induction motor. Expert Systems with Applications. 2010;37(4):3468–3481. doi: 10.1016/j.eswa.2009.10.041. [DOI] [Google Scholar]
- 9.Zhang Q., Benveniste A. Wavelet networks. IEEE Transactions on Neural Networks. 1992;3(6):889–898. doi: 10.1109/72.165591. [DOI] [PubMed] [Google Scholar]
- 10.Zhang J., Walter G. G., Miao Y., Lee W. N. W. Wavelet neural networks for function learning. IEEE Transactions on Signal Processing. 1995;43(6):1485–1497. doi: 10.1109/78.388860. [DOI] [Google Scholar]
- 11.Daubechies I. Ten Lectures on Wavelets. Vol. 61. Philadelphia, Pa, USA: Society for Industrial and Applied Mathematics; 1992. (CBMS-NSF Regional Conference Series in Applied Mathematics). [DOI] [Google Scholar]
- 12.Lin C. J. Nonlinear systems control using self-constructing wavelet networks. Applied Soft Computing Journal. 2009;9(1):71–79. doi: 10.1016/j.asoc.2008.03.014. [DOI] [Google Scholar]
- 13.Chen Y., Yang B., Dong J. Time-series prediction using a local linear wavelet neural network. Neurocomputing. 2006;69(4–6):449–465. doi: 10.1016/j.neucom.2005.02.006. [DOI] [Google Scholar]
- 14.Jiao L., Pan J., Fang Y. Multiwavelet neural network and its approximation properties. IEEE Transactions on Neural Networks. 2001;12(5):1060–1066. doi: 10.1109/72.950135. [DOI] [PubMed] [Google Scholar]
- 15.Box G. E. P., Jenkins G. M., Reinsel G. C. Time Series Analysis: Forecasting and Control. John Wiley & Sons; 2013. [Google Scholar]
- 16.Veitch D. Wavelet Neural Networks and Their Application in the Study of Dynamical Systems. University of York; 2005. [Google Scholar]
- 17.Liu R. Research on Computational Intelligence-Based Strctural Reliability Design Optimization. Jilin University; 2006. [Google Scholar]
- 18.Mallat S. G. A theory for multiresolution signal decomposition: the wavelet representation. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1989;11(7):674–693. doi: 10.1109/34.192463. [DOI] [Google Scholar]
- 19.Grossmann A., Morlet J. Decomposition of Hardy functions into square integrable wavelets of constant shape. SIAM Journal on Mathematical Analysis. 1984;15(4):723–736. doi: 10.1137/0515056. [DOI] [Google Scholar]
- 20.Mallat S. A Wavelet Tour of Signal Processing. Academic Press; 1999. [Google Scholar]
- 21.Chen J. Characterization and Implementation of Neural Network Time Series Models for Traffic Volume Forecasting. Toledo, Ohio, USA: University of Toledo; 1997. [Google Scholar]
- 22.Wang L. X., Mendel J. M. Generating fuzzy rules by learning from examples. IEEE Transactions on Systems, Man, and Cybernetics. 1992;22(6):1414–1427. doi: 10.1109/21.199466. [DOI] [Google Scholar]
- 23.Kim D., Kim C. Forecasting time series with genetic fuzzy predictor ensemble. IEEE Transactions on Fuzzy Systems. 1997;5(4):523–535. doi: 10.1109/91.649903. [DOI] [Google Scholar]
- 24.Surmann H., Kanstein A., Goser K. Self-organizing and genetic algorithms for an automatic design of fuzzy control and decision systems. Proceedings of the 1st European Congress on Fuzzy and Intelligent Technologies (EUFIT '93); 1993; Aachen, Germany. [Google Scholar]
- 25.Lee Y. C., Hwang C., Shih Y. P. A combined approach to fuzzy model identification. IEEE Transactions on Systems, Man, and Cybernetics. 1994;24(5):736–744. doi: 10.1109/21.293487. [DOI] [Google Scholar]
- 26.Lin Y., Cunningham G. A., III A new approach to fuzzy-neural system modeling. IEEE Transactions on Fuzzy Systems. 1995;3(2):190–198. doi: 10.1109/91.388173. [DOI] [Google Scholar]
- 27.Nie J. Constructing fuzzy model by self-organizing counterpropagation network. IEEE Transactions on Systems, Man and Cybernetics. 1995;25(6):963–970. doi: 10.1109/21.384258. [DOI] [Google Scholar]
- 28.Jang J. S. R., Sun C. T. Neuro-Fuzzy and Soft Computing: A Computational Approach to Learning and Machine Intelligence. Prentice-Hall; 1996. [Google Scholar]
- 29.Kasabov N. K., Kim J., Watts M. J., Gray A. R. FuNN/2—a fuzzy neural network architecture for adaptive learning and knowledge acquisition. Information Sciences. 1997;101(3-4):155–175. doi: 10.1016/s0020-0255(97)00007-8. [DOI] [Google Scholar]