

Abstract
Agent-based modeling has become increasingly popular in recent years, but there is still no codified set of recommendations or practices for how to use these models within a program of empirical research. This article provides ideas and practical guidelines drawn from sociology, biology, computer science, epidemiology, and statistics. We first discuss the motivations for using agent-based models in both basic science and policy-oriented social research. Next, we provide an overview of methods and strategies for incorporating data on behavior and populations into agent-based models, and review techniques for validating and testing the sensitivity of agent-based models. We close with suggested directions for future research.
1. INTRODUCTION
Agent-based models are computer programs in which artificial agents interact based on a set of rules and within an environment specified by the researcher (Miller and Page 2007). While these rules and constraints describe predictable behavior at the micro-level, the interactions among agents and their environment often aggregate to create unexpected social patterns. It is such emergent patterns that sociologists want to understand or policy-makers want to change (e.g., patterns of residential segregation, the intergenerational reproduction of inequality, or the origin and persistence of disease epidemics). Because agent-based models explicitly link individuals’ characteristics and behavior with their collective consequences, they provide a powerful tool for exploring the social consequences of individual behavior.
While agent-based modeling is not new to sociology (see Macy and Willer 2002 for a comprehensive review of early work), these models tend to be highly stylized and—with the exception of Schelling’s (1971, 1978) seminal work on neighborhood tipping and Axelrod’s model of cooperation (Axelrod and Hamilton 1981; Axelrod and Dion 1988; Axelrod 1997) —have had minimal impact on mainstream sociological research. One reason for this lack of impact is the absence of dialogue between agent-based modeling and data-driven social research within the discipline.1 This is unfortunate, as agent-based models are very useful for sharpening one’s thinking about an empirical problem and identifying key explanatory mechanisms. Agent-based models help fill the gap between formal but restrictive models and rich but imprecise qualitative description (Holland and Miller 1991, cited in Page 2008). Moreover, agent-based models are especially amenable to incorporating detailed, multi-layered empirical data on human behavior and the social and physical environment, and can represent a granularity of information and faithfulness of detail that is not easily handled within statistical or mathematical models.
The goal of this paper is to provide a practical overview of how agent-based models can be used within a larger program of empirical research. We proceed as follows. First, we discuss reasons to use agent-based models in both basic science and more policy-driven research, and describe the kinds of substantive and methodological problems where agent-based models are particularly helpful. Next, we review the different ways in which agent-based models can be anchored to real-world information: “low-dimensional realism” in which there is empirical realism along one or two dimensions but the model remains simple and abstract; or “high dimensional realism” in which the goal is to accurately represent some phenomenon along many dimensions. We also provide concrete strategies for constructing agent-based models that correspond to real populations and incorporating empirical data on individual behavior into agent-based models. Finally, we discuss state-of-the-art techniques to assess both the goodness-of-fit of these models to data, and also their sensitivity to key assumptions. We close with some suggested directions for future research.
Modeling Interdependent Behavior
A key feature of agent-based modeling is that it explicitly links micro- and macro-levels of analysis. Sociology has a longstanding interest in the relationship between individuals’ motivations and decisions and large-scale patterns of social organization and change.2 The “micro-macro problem” concerns how to explicitly account for the ways in which actions of individuals give rise to social organization and dynamics, rather than assuming that macro-level phenomena are simply aggregates of individual characteristics and behavior (Coleman 1994, p.197; Granovetter 1978 p.1421; Hedström and Bearman 2009, pp. 9-14). The connection between individuals’ actions and their collective consequences would be transparent if one could simply sum over individuals’ intentions or behavior to generate expected population-level attributes.3 The problem is that nearly all human behavior is interdependent; individuals’ actions are contingent on the past, present, and predicted future behavior of others.4
Contingent behavior can take on a number of different forms. For example, people have preferences for the composition of social groups (e.g., friendship circles, neighborhoods, or churches), but their own characteristics also contribute to group composition. Accordingly, any decision to join or leave the group is both responding to and changing its composition. More generally, individuals’ actions are constrained by the social context (e.g., network structure, social institutions, and demographic composition) that shapes available opportunities for action. But this social context is produced (and reproduced) from the accumulation of people acting in the past. Thus, interdependent behavior implies feedback between micro and macro levels of analysis. In the short run, individuals respond to their environments; in the longer run, the accumulation of individuals’ choices or behavior changes the environment. This feature makes standard statistical models that assume independence of observations or unidirectional causality inappropriate for analyzing the relationship between micro- and macro levels of analysis. Feedback also often implies a non-linear relationship between individual behavior and its macro consequences. Models that seek to explain the social consequences of interdependent behavior must explicitly represent feedback between individuals’ actions and their decision-making environments.5
The explicit representation of how micro-level processes generate largerscale social dynamics is a hallmark of mechanism-based explanations (cf. Hedström and Udehn 2009; Elster 2007; Hedström and Ylikoski 2010). In essence, mechanisms explain some social phenomenon in terms of a dynamic and robust process through which individual interactions compose some social aggregate (Hedström and Swedberg 1998). In addition to various forms of feedback (e.g., tipping, contagion, diffusion, self-fulfilling prophecy, tragedy of the commons), other mechanisms in sociological research include selection (Hedström and Bearman 2009), offsetting (Bruch 2013), vacancy chains (e.g., White 1970), and network externalities (Dimaggio and Garip 2011). A good explanation of a social phenomenon specifies the conditions necessary for the social phenomenon to arise and how those conditions depend on both individuals’ behavior and the distribution of salient social attributes within the population. Agent-based models allow researchers to explicitly investigate how and why a given set of interactions among individuals generates some collective result. One can also explore how alternative assumptions regarding population constraints (e.g., the sex ratio of students within a classroom, or number or proportion of minority groups in a city) affect observed dynamics. In addition, because the models are usually built from the ground up, they bring into sharp relief our “implicit models,” that is, latent assumptions regarding individual traits and behavior, the nature of interaction among individuals, and the environment in which the interaction takes place.
Finally, when used iteratively within an empirical research program, an agent-based model can be a powerful tool to help guide specification of statistical models and data collection efforts. In many empirical research problems, we face one of two related dilemmas. On the one hand, we may have large amounts of data, but we do not know which statistical models to run. We make model specification decisions not knowing which decisions are truly consequential. On the other hand, often our ideas about human behavior are much richer than available data. In both instances, agent-based models can help. In the first instance, we can experiment with simulated data to see what difference our assumptions about individual behavior make for aggregate outcomes. In the second instance, individual-level data, combined with alternative behavioral assumptions and aggregate data, may be used to simulate aggregate outcomes that can be compared to observed data.6
Feedback Effects & Public Policy
Beyond pure academic interest, there is a practical need for models that allow for contingent behavior of individuals and feedback between micro- and macro-levels of analysis. Within a number of fields, most notably epidemiology and public health, there is an increasing acknowledgement that our current methods of designing, evaluating, and implementing policy do not work and may potentially even make things worse (e.g., Fenichel et al. 2011; Sterman 2006; Homer and Hirsch 2006; Mabry et al. 2008; Deaton 2010). A major roadblock in the development of more effective policy is that most social problems exhibit a dynamic complexity that hinders our ability to identify underlying causal relationships. Dynamic complexity does not imply many moving parts so much as the interconnectedness among parts (Forrester 1971). This is apparent in both self-reinforcing cycles for individuals (e.g., perceived job insecurity is associated with poorer health, and poor health affects labor market performance [Burgard, Brand, and House 2009]) and in neighborhood “spillover effects” where disadvantage along one dimension of neighborhoods (e.g., high vacancy rates and low property values) exacerbates inequalities along other neighborhood dimensions (e.g., school funding and school quality) thus contributing to the cycle of poverty (Durlauf 1993, 1995). Poverty traps and other self-reinforcing cycles of disadvantage can make it difficult to identify the most effective points of intervention.
Moreover, people may change their behavior in response to an intervention, and failure to anticipate this can lead to undesirable and unexpected outcomes.7 Within public health, there is evidence that low-fat foods may have contributed to the obesity epidemic as people ate larger quantities than they would have otherwise (La Berge 2008). Within criminology and sociology, there is some controversial evidence that Section 8 housing programs led to an increase in neighborhood violence in some cities, as the program moved people from high-poverty neighborhoods into moderately poor areas. It is in these areas where the number of social problems (e.g., neighborhood violence) increases nonlinearly with the poverty rate (Galster 2005; Rosin 2008). By keeping the total number of high-poverty neighborhoods fixed, but increasing the poverty rate in medium-poverty areas, the vouchers may have inadvertently led to a net increase in violent crime across all poor neighborhoods.
Agent-based models and other methods such as system dynamics may be able to identify potentially self-reinforcing behaviors or feedback loops, and suggest better designs for policies based on identification of major flaws in existing ones. More modestly, these models can allow for a relaxation of unrealistic assumptions made in more traditional models. For example, classical epidemiology models assume random mixing and relatively homogenous populations. Agent-based models allow for heterogeneous agents with more realistic behavioral responses and varying risk profiles. A key advantage is that agent-based models can integrate data and theories from many different sources and at many levels of analysis. Finally, agent-based models can demonstrate tradeoffs, efficiencies, or links between policies and theoretical concepts.
The most successful policy-driven agent-based modeling projects to date have come from epidemiology and urban planning. Within epidemiology, the Models of Infectious Disease Agent Study (MIDAS) draws together multiple interdisciplinary teams of researchers at different sites to investigate how to use computational and mathematical models of disease transmission to understand infectious diseases.8 The network of researchers developed a number of agent-based models that incorporate detailed geographic, demographic, social, biological, and epidemiological information to model the spread of disease. These models have been particularly influential in exploring potential response scenarios for disease outbreaks during the H5N1 and H1N1 flu scares. For example, the Global Scale Agent Model developed at Brookings played a key role in analyzing both the H1N1 and avian flu outbreaks, modeling both the predicted spread of the disease, and also the potential costs and benefits of specific interventions (e.g., school closures or the allocation of scarce vaccines) See Epstein (2009) for more details.9
In the area of urban planning, the UrbanSim model developed by Paul Waddell and his collaborators (Waddell 2002) represents the state of the art in agent-based models of urban policy, transportation, and development. UrbanSim was designed to be an experimental laboratory for the analysis of policies related to city infrastructure and investment (Borning, Waddell, and Forster 2008). The model blends empirically grounded modules describing processes at the person level (e.g., individuals’ decisions regarding place of work and residence, job choice, and transportation), organization level (e.g., business birth and death, relocation, and development), infrastructure level, and housing market (e.g., real estate prices) with a highly realistic geographic landscape. It has been influential in guiding decisions regarding urban transportation investments such as light rail, freeway extension, and changes in land use zoning (Borning and Waddell 2006).
2. HIGH VERSUS LOW DIMENSIONAL REALISM IN AGENT-BASED MODELS
A key issue for the analyst is the appropriate level of model complexity and empirical realism. These are by no means the same; a model may be relatively simple, but its few dimensions can be firmly grounded in empirical data, or complex phenomena may be modeled with only anecdotal evidence. The appropriate levels depend on the research question and intended use of the model. Agent-based models range from abstract worlds where agents are defined by a single attribute, have simple deterministic rules for interaction, and exist in a highly stylized environment (e.g., a grid or torus) to simple worlds where agents have only one or two attributes and behaviors anchored to as many empirical features as possible to high dimensional worlds where agents have many attributes, the environment contains a great deal of information and may even have its own dynamics, and agents engage in a variety of different behaviors.
The degree of empirical realism desired in the model depends on its analytical and empirical goals. Models should be designed with a specific question in mind. At one extreme, empirically validated agent-based models may be used as a virtual “laboratory” to test the implications of a policy intervention or predict future population dynamics. For example, the MIDAS study enlisted a team of subject matter experts to develop an empirically rich model of disease spread, and this model is used to anticipate the spread of epidemics and explore alternative disaster response scenarios (Epstein 2009). Similarly, the Artificial Anasazi project marshaled substantial archeological, anthropological, and ecological data to explore the rise and fall of the Anasazi culture in the Long House Valley in northeastern Arizona between 1800 B.C. and 1300 A.D (Dean et al. 2000). Both models were subject to intensive validation and testing.
At the other extreme, simple, abstract models allow for the clarification or development of new theories or mechanisms. Schelling’s (1978) famous tipping model, which allowed for two groups to sort themselves across a grid in accordance with their preferences about the composition of their neighborhoods, demonstrated how even seemingly tolerant agents can generate highly segregated neighborhoods. Axelrod’s prisoners’ dilemma tournament model pitted different strategies against one another to show how cooperation can emerge and even thrive in a world of self-interested agents (Axelrod and Hamilton 1981). More recently, the research program spearheaded by Michael Macy (e.g., Willer, Kuwabara, and Macy 2009; Centola, Willer, and Macy 2005; Centola and Macy 2007) uses simple agent-based models to illuminate theoretical properties of game theoretic and network models. In these examples, the goal is not to reproduce existing patterns or even to anchor agents’ behavior, characteristics, or environment in empirical knowledge. Rather, the models are generative; they develop new ways of thinking about a problem and provide a great deal of theoretical stimulation for existing empirical research.
Between these two extremes are models that incorporate one or more dimensions of realism but keep other aspects of the model abstract. Often these “low dimensional realism” models are aimed at exploring the implications of empirical research or testing the assumptions of formal theories. For example, Epstein et al. (2008) uses a relatively simple model to demonstrate that when one takes the traditional epidemic model, which assumes perfect mixing and fixed behavior, and adds adaptive behavior, whereby agents may hide from disease or flee to a safer area, this changes the dynamics in ways that more closely approximate the dynamics observed in the Spanish flu and other historical epidemics. Todd and Billari (2003) explore how empirically plausible mate-search heuristics give rise to population-wide patterns of age-at-marriage distributions. Hedström and Åberg (2005) take a somewhat empirically richer approach, in which they assign agents the social and demographic characteristics of Swedish youth in the Stockholm metropolitan area, and explore how empirically grounded rates of leaving unemployment vary under alternative assumptions about social interactions. The goal of in all cases, however, is not to reproduce empirical patterns or incorporate all aspects of reality so much as understand the implications for social dynamics of one or more empirical observations or stylized facts.
Coming from a conventional social research background, the most seductive approach often is to create agent-based models that incorporate as much empirical data and knowledge as possible in an attempt to create a highly realistic laboratory in which to conduct experiments. However, this approach is rarely the most fruitful line of inquiry. For one thing, our data and knowledge of human behavior are almost never up to the task. While social scientists are good at collecting demographic, biological, and social characteristics of discrete units such as individuals, families, or other social groupings, we are often missing data on key mechanisms governing interaction among those units. As mentioned above, one advantage of agent-based modeling is that it allows researchers to hypothesize about the importance of mechanisms for which there are no data (and assess the potential value of collecting these data). Second, layering on many dimensions of realism can make the model cumbersome, and it can be difficult to get clear analytic results. A model’s success is determined not by how realistic it is but by how useful it is for helping understand the problem at hand.10
One useful heuristic for determine the appropriate level of model complexity and realism is to consider what motivated the agent-based model in the first place. Simulations are useful in three different circumstances. First, when some micro-level behavior is known or strongly assumed, and simulation explores its aggregate consequences. In this case, a simple abstract model or a “low-dimensional” realism model is often most effective. Second, when some aggregate phenomenon is observed empirically, and the simulation investigates alternative mechanistic explanations. In this case, a low dimensional model may be illuminating but cannot rule out all alternative explanations. Finally, simulations are useful when the analyst must explore the behavior of a social system under some hypothesized conditions for predictive purposes. In this case, a “high dimensional” realism model is usually necessary to ensure that the model predictions are not based on some reduced form account of the social process. In the balance of this article, we focus on empirically grounded models aimed at addressing questions of the second or third type.
3. EMPIRICALLY GROUNDED AGENT-BASED MODELS
Agent-based models can incorporate a wide range of empirical measures, including but not limited to rates such as age-specific mortality, fertility, and disease risk; population size and demographic composition; geographic boundaries and spatial relationships; inputs into dynamical processes (e.g., estimated payoffs to educational investments); granularity of time (e.g., how often agents make decisions, and to what extent to agents act simultaneously or asynchronously); individuals’ preferences, behavior, memory, and/or ability to perceive and detect environmental change; the organization of labor, marriage, or housing markets; and social network structure. Of course, some features of the model are easier to anchor in data than others. The primary constraint is the availability of high quality data at the appropriate unit of analysis. To illustrate how one might incorporate empirical data into an agent-based model, we focus on two features of agent-based models that have been most frequently grounded in past work: individual behavior and population characteristics.
Incorporating Population Characteristics
The actors that populate agent-based models are typically assigned some set of attributes such as a sex, age, education, income, life expectancy, disease risk, or network position. The analyst may assume an arbitrary distribution of agent attributes, or he or she can import the joint distribution of agents’ attributes from an empirical data source.11 Survey data typically document the characteristics and attitudes of individuals, households, or families and thus it is relatively straightforward to assign agents characteristics from these data. However, survey data are a relatively small sample; more often scholars prefer to use population (Census) data to initialize agents. For U.S. populations one can initialize the agents using data from the United States Integrated Public Use Microdata Series (IPUMS), which is a five percent sample of all U.S. households. For United Kingdom populations, one can use the UK Sample of Anonymized Records (SAR) Census data. However, while these sources provide Census data at the individual, household, or family level, they do not contain detailed geographic identifiers. The smallest geographic identifier available for United States Census data is IPUMS’ Public Use Microdata Area (PUMA), which contains approximately 100,000 people each.
A key challenge in initializing agent-based models using Census data is adapting the aggregated or discrete nature of these data to a more finely grained context. Individual-level Census data are publicly available at smaller units of geography (i.e., blocks, block groups, tracts) only in the form of aggregated, multi-way tables. Thus, if the researcher wants to initialize her agent population with more than a single attribute (e.g., race/ethnicity or household income), these tables typically do not contain the full joint distribution of household or population traits.12 Also, continuous attributes are often collapsed into discrete categories. The smaller the geographic unit identified, the less information is available and the more collapsed the variable categories are. For example, one might know the marginal distribution of categorical household size and the marginal distribution of categorical household income within identified Census tracts, but not the joint distribution of household size and household income.
Fortunately, there are well-developed methods for converting a set of incomplete marginal tables into a full table when the joint distribution of variables is known from a separate source. The most common method for generating individual-level data from incomplete tables on populations is table standardization using iterative proportional fitting (e.g., Agresti 2002: 345-6; Deming and Stephan 1940; Fienberg 1970; Ireland and Kullback 1968; Beckman, Baggerly, and McKay 1996). This approach was used in the NIH funded Models of Infectious Disease Agent Study (MIDAS) to generate an agent-based model with a population that included every household and individual in the U.S. population in 2000, as well as schools and workplaces generated to match counts at the Census block level area of geography (Wheaton et al. 2009; Wheaton 2009).13 The MIDAS micro- population data are available by request from RTI International. However, the data were constructed using specific criteria to assign households to block groups, and thus the fit is optimal for only a narrow subset of Census variables (Wheaton et al. 2009:7).
Finally, agents can be assigned social networks that correspond to some data source; for example the sexual or friendship networks collected in the National Longitudinal Study of Adolescent Health (Add Health). This network information may be read into the agent-based model the same way that population characteristics are initialized. While networks may correspond to some empirical social structure at the beginning of the model, they can also evolve over time based on subsequent agent interactions. Realistic data on social networks have been used in policy-driven agent-based models of disease transmission and epidemics (e.g., Ferguson et al.2005; Eubank et al. 2004; Cauchemez et al. 2011; Germann et al. 2006), and this represents a potentially fruitful direction for future work.
Specifying Agent Behavior
Another rich area of investigation within agent-based modeling research is to explore the population dynamics implied by a given set of empirical preferences or behaviors (e.g., Schelling 1978; Bruch and Mare 2006, 2009; Benenson and Torrens 2004). Thus a key challenge is specifying appropriate activities for the individual actor. If the goal of the modeling exercise is to explore the macro-level consequences of some theorized preference or behavior, the analyst may prefer to assume a set of behaviors that correspond to the underlying theory. However, if the goal is to understand the aggregate consequences of real world phenomena, it is critical to specify agents’ actions in a way that is empirically defensible (Hedström andÅberg 2005: 118-199). Agents typically gather information about their environment, assess that information according to some set of criteria or ranking system, and then make decisions based on their assessment. They may also learn from past experiences and update their behavior. Empirical information can potentially enter into each stage of this process.
One useful strategy is to assume that agents’ preferences, strategies, or likelihood of making a particular choice or state transition are based on a statistical model. If the agent-based model is aimed at modeling discrete changes in agents’ attributes—for example entering or exiting a state of unemployment, getting married or divorced, or having a child—these state transitions can be defined based on coefficients from a discrete-time event history model (Allison 1982; see also Hedström and Åberg 2005). If the agent-based model is aimed at capturing agents’ decision-making process, discrete choice models provide one flexible framework for estimating the parameters of choice behavior (McFadden 1973; Louviere, Hensher, and Swait 2000; Train 2009).These models have become increasingly sophisticated in recent years, and can allow for variation in individuals knowledge of available options, strategies for learning about or evaluating available options; reactions to change in environmental conditions; reactions to past experiences; and susceptibility to social influence. Estimation of relevant coefficients requires information on either on revealed preferences (observed choices) or stated preferences (survey responses to hypothetical choice scenarios) for some population of interest. These data may be obtained from surveys, observational data, or administrative records. Multiple sources of data on behavior or preferences may be combined in specifying agents’ behavior.
Given some defined set of alternatives, discrete choice models specify a ranked ordering of these choice outcomes, which can be converted into predicted probabilities. However, in order for agents to make a realized choice, these probabilities must be transformed into actual decisions. One method of doing this is to sample from a multinomial distribution with probabilities given by those computed by the agent. Sampling from predicted probabilities incorporates a random component into the choice process, consistent with the specification of discrete choice models. The random component maybe interpreted as the fact that agents may make mistakes or that the choice model does not reflect all dimensions of a choice that affect its desirability. Alternatively, one can assume that the probabilities computed from the choice model accurately reflect the underlying desirability of alternatives, and agents make decisions without error. In this case, one might specify that agents always “take the best” outcome, that is, they choose the outcome with the highest calculated utility.
A different strategy for modeling decision-making is to specify that agents’ behavior follow some set of rules, for example heuristics that update behavioral rules according to the accumulation of experience (Todd, Billari, and Simao 2005). Heuristics are “rules of thumb” for making decisions under conditions of uncertainty (Kahneman, Tversky, and Slovic 1982). Heuristics are used both in the information-gathering stage of decision-making, and also when making the final choice. Typically heuristic decision-making strategies must be used in conjunction with a set of assumed or revealed preferences for agents to rank order-outcomes by desirability. For example, in marriage market models one concern is how to best choose a marriage partner when potential mates can only be explored one at a time, and there is uncertainty about whether the next person down the pipeline will be better than what is currently available. One strategy is to use a “satisficing” heuristic; give agents only a preference for members of the opposite sex, and then let the initial period of interaction be one of learning about the market (e.g., treat the first dozen or so encounters or “dates” agents have with the opposite sex as a learning experience). Agents pick the next agent who comes along whose quality is equal to the best agent observed during the learning period (Todd 1997; Todd and Miller 1999).
Finally, agents may also be assigned beliefs, values, or world-views that correspond to observations from ethnographic or participant observation, or in accordance with stakeholders’ assessments. For example, agents in a model of the intergenerational reproduction of inequality may vary in their beliefs about the degree to which education can lead to social mobility, or their understanding of how to go about getting a job. In practice, these beliefs or worldviews would be programmed as a set of rules governing action. For example, an agent who believes that networks are most important for job seekers may spend its time attempting to develop ties with other agents whereas an agent that believes credentials are key to success may focus on education. Unlike in the statistical model of behavior based on quantitative data, the qualitative data is incorporated into the agent-based model loosely as a set of rules governing behavior, or alternatively as a set of rules for interpreting information. However, agent beliefs, world-views, or values may be coupled with a statistical or heuristic model of decision-making. For example, if qualitative data were available on how the time horizon an individual uses to make a decision varies with their degree of uncertainty about outcomes and perception that things are improving or deteriorating, the appropriate time horizon could be used to adjust the inputs to a statistical model of behavior. See Yang and Gilbert (2008) for more on qualitative data and agent-based models and Geller and Moss (2008) for an example of agent behavior that is empirically grounded using a stakeholder approach.
4. ASSESSING MODEL OUTPUT: UNCERTAINTY, VARIABILITY, & SENSITIVITY
After specifying an agent-based model and providing inputs, one needs to produce and make sense of the model outputs. At the lowest level of granularity, agent-based models can output the distribution of agents and their associated states at every time point. This is often an unwieldy amount of data and its granularity can outstrip the theoretical and empirical knowledge that was used to create the model.14 It is often more useful to summarize output as population level or sub-group statistics or as a modal experimental trajectory taken by an agent who fits a given profile. For example, the spatial distribution of agents can be summarized into a single measure of segregation (e.g., the index of dissimilarity) or a set of local neighborhood composition measures. Alternatively one could track the trajectory of neighborhoods a typical agent experiences over the duration of the model. In applications of crime dynamics, one might capture overall crime rates within a stylized city, or look at neighborhood specific rates. At the micro level, one might examine the modal criminal career for an agent. Regardless of what types of output one chooses, variability in those measures needs to be considered in light of uncertainty about model inputs. Empirical measures and knowledge of key parameters or processes are often vaguely defined, measured with error, or completely unknown. This uncertainty generates statistical variability in model outputs. In the remainder of the section, we discuss different forms of uncertainty in agent-based models, and how to assess them via uncertainty and sensitivity analyses.
There are two sources of uncertainty and variability in agent-based models: input uncertainty and model uncertainty (McKay, Morrison, and Upton 1999). Input uncertainty—also known as epistemic uncertainty (see Helton et al. 2006)—arises due to incomplete knowledge of model input parameters; for example, the parameter estimates from a behavioral model estimated from survey data will represent point estimates with associated standard errors. Alternatively, the data used to initialize the model may have some uncertainty due to sampling variability. Model uncertainty arises because the model typically requires some set of unverifiable assumptions about key parameters, processes, or social interactions. Thus, this source of uncertainty is associated with the architecture of the model. Model uncertainty and input uncertainty imply that there are a number of alternative specifications of the model possible, and these alternatives may generate variability in the outcome of interest (which may be one or more of the outputs discussed in the previous section). Agent-based models also have a third source of variability due to the stochastic elements of the model. Stochastic variability refers to the variation in model estimates that occurs from randomness within the model. For example, if agents’ choices are realized from probabilities, there will be fluctuation from model run to model run due to random sampling.
Input Uncertainty
There is a well-developed literature aimed at assessing the implications of input uncertainty (see Helton et al. 2006; Saltelli et al. 2004; Saltelli et al. 2008; Marino et al. 2008). The overarching goal is to assess what inputs and initial conditions are critical for the model results. This approach breaks down into two types of analyses. Uncertainty analyses examine the total variability in the model output that can be attributed to uncertainty in model inputs. Sensitivity analyses explore how uncertainty in the output of a model can be allocated across different sources of model input (Saltelli et al. 2004, 2008). The setup is the same for both and typically one first does an overall uncertainty analysis and then focuses on key parameters via sensitivity analyses.
Input uncertainty is most commonly assessed via Monte Carlo sampling procedures whereby the analyst varies input values systematically, re-runs the model, and then examines how the distribution of model outputs vary with model inputs. The first step is to specify the known or assumed joint distribution of parameters of interest. If nothing is known about the distribution, it is best to assume that each parameter follows a uniform distribution. If the analyst believes a parameter tends to take on a specific value, a normal distribution may be more appropriate (Marino et al. 2008). The actual sampling may be done via random sampling, importance sampling, or—as is most common—Latin Hypercube sampling (Helton and Davis 2003; Saltelli et al. 2008:76-78; Mease and Bingham 2006). Latin Hypercube sampling allows for an unbiased estimate of model output uncertainty, and requires fewer samples to accomplish this task than random sampling of input parameters (McKay, Beckman, and Conover 1979). Latin Hypercube sampling first requires the analyst to partition the distributions of relevant model parameters into s > 2 non-overlapping regions (where each region has the same density), and then sample one value from within each region without replacement. If k is the number of parameters, than s should be of value at least k + 1, but generally is much larger to allow the analyst to examine the influence of each parameter separately. Typically this method assumes that sampling is performed independently for each parameter, although there are methods for imposing correlations across the sampled values (Iman and Conover 1982; Iman and Davenport 1982, cited in Marino et al. 2008).
An illustrative example is interest shown in Figure 1. Let us say that we have three input parameters of interest, where a~N (μa, σa) and b~N (μb, σb) are parameter estimates from a discrete choice model, and c~Unif (cmin, cmax) is the assumed distribution of agents’ consumption thresholds. Let y be some model outcome of interest. Figure 1 shows the partitioning of the parameters into s = 5 regions, and we randomly sample a value from within each region. We then combine randomly sampled values to generate our s by k (in this example, a 5 × 3) input matrix X, where. Xj = {aj,bj, cj}. We then run the agent-based model for j = 1,2, … 5, each time using a set of parameters Xj. We record the model outputs yj for each of the five runs to generate y = {y1, y2, y3, y4, y5}. This distribution of outputs reveals the impact of input uncertainty on model estimates because variation in the yi‘s shows the model to be sensitive to which parameter combinations we are starting with. The simplest way to examine the distribution of output values is via a histogram, which provides an overall measure of model uncertainty, or scatterplots where the distribution of model output is plotted against the distributions for each of the input variables (which provides a qualitative assessment of model sensitivity to a particular input value). For a more rigorous quantitative assessment, a variety of statistical techniques can be used, including correlation coefficients and decomposition of model output variance. Details and discussion of these techniques can be found in Saltelli (2002); Saltelli et al. (2004, 2008); and Marino et al. (2008).
Figure 1. Latin Hypercube Sampling for Uniform and Normal PDFs*.
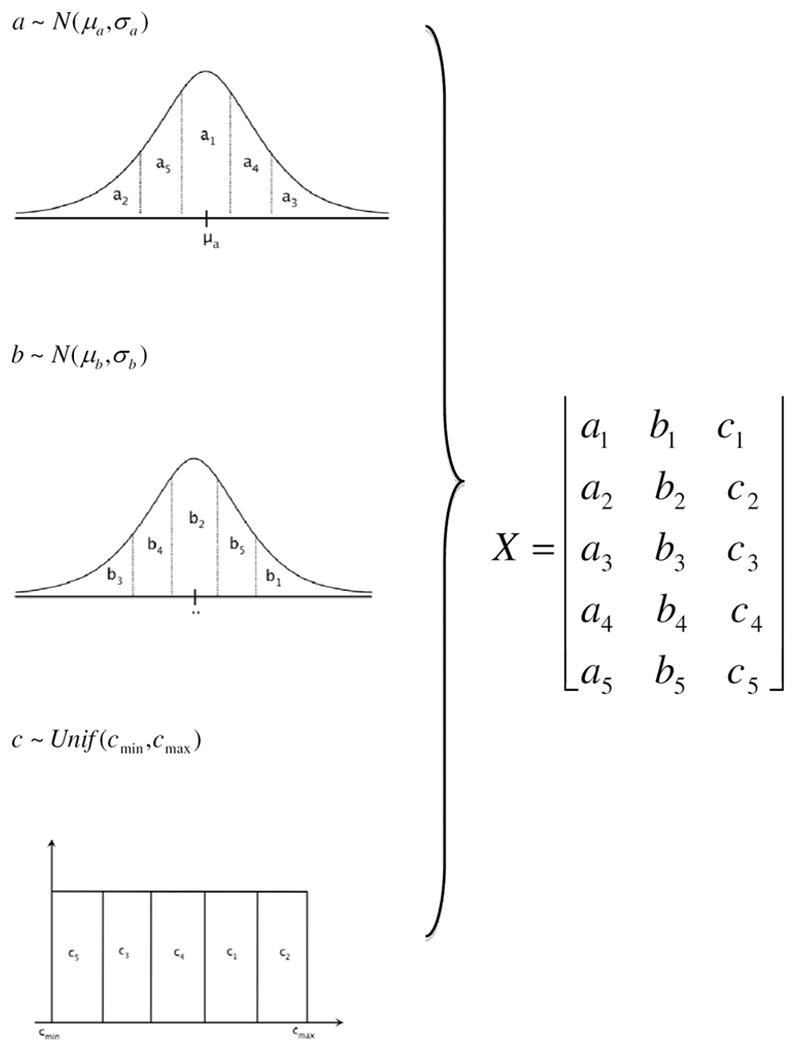
* Note: This figure is adapted from Marino et al. (2008).
Model Uncertainty
If the goal is to assess the degree to which uncertainty in the architecture of the model (e.g., assumptions about functional forms, sequencing of events, and definition of units of analysis like neighbors) generates uncertainty in model output, model uncertainty can be handled in ways similar to input uncertainty. However, rather than simply sampling values from a known or assumed distribution, the analyst will run the model under alternative assumptions about model architecture. For example, the analyst can run the model under varying assumptions about population size or the shape of neighborhoods to assess the extent to which these factors affect conclusions about residential segregation (Fossett and Dietrich 2009; Laurie and Jaggi 2003). An alternative approach is to use Bayesian model averaging (Raftery 1995; Hoeting et al. 1999) to average over all possible values of parameters and model specifications based on their likelihood of generating the data. Bayesian model averaging was originally developed as a method of accounting for uncertainty in statistical models, but it could be adapted to agent-based models by replacing the likelihood function with a comparison between simulated and observed data. This procedure is called approximate Bayesian computation. The technical details are beyond the scope of this essay, but more information can be found in Toni et al. (2009); also see Sisson, Fan, and Tanaka. (2007).
Stochastic Variability
Most uncertainty and sensitivity analysis techniques were developed for deterministic models. Because agent-based models often contain a stochastic element—for example, the initial distribution of agents across the landscape may vary over model runs, or probabilities may be sampled randomly from a multinomial distribution—there is often fluctuation in model output across model runs. Sometimes this fluctuation is a property of the phenomenon being studied; path dependence within the model may result in meaningful output variability and is interesting in its own right. In other instances, fluctuation is not meaningful and merely the result of stochastic elements of the model. In our experience, this fluctuation will be less apparent if the agent population size is sufficiently large and if the model output is summarized into aggregate summary measures. However, if the population is small or the analyst is interested in individual- or locally-based measures, this stochastic variation will lead to a distribution of output measures even with the same input values. The simplest way to account for this is to run each model setting multiple times and then analyze the resulting model trajectories. To reduce variability from random fluctuation, one can average over the distribution of estimated output values for a given set of input values (Marino et al. 2008).While it is common for agent-based modelers to explore how model output changes under a few alternative assumptions about key model inputs, only a handful of researchers have done rigorous sensitivity analyses. All of these are biological or epidemiological models. See Marino et al. (2008), Segovia-Juarez et al. (2004), Dancik, Jones, and Dorman (2010), and Riggs et al. (2008) for details.
6. MODEL VALIDATION IN HIGH AND LOW DIMENSIONAL AGENT-BASED MODELS
Agent-based models, like laboratory experiments, have strong internal validity. Since the modeler is aware of all aspects of model design, and since agent-based models make it easy to manipulate different parameters of the model, one can usually trace the causes of some observed aggregate process to one or more specific assumptions within the model. Insofar as one or more model parameters are grounded in empirical knowledge, this means that the analyst can rigorously explore how realistic assumptions about behavior, populations, or their environment affect an outcome of interest under highly controlled conditions. However, all these inferences are made internal to the model. External validity—the ability to generalize conclusions from the model to real- world processes—requires substantially more effort.
Of course, many agent-based models are not designed to reproduce real-world patterns. Indeed, in a world where theories are poorly developed and at best only weakly linked to empirical results and statistical models often stand in for analytic modeling, simple low-dimensional agent-based models can have substantial payoffs. However, if the aim of the agent-based model is to make some policy recommendation—even if the goal is just to identify one or two potentially useful mechanisms for manipulation and not make predictions—researchers need to trust that the inferences made from the model reflect actual mechanisms operating in the world. In the case of low dimensional, more abstract models, this may require conducting an analysis external to the agent-based model to assess whether there is empirical evidence for the mechanisms observed within the model. In the case of highly realistic models, the goal is typically to compare output from the model with empirical data to evaluate overall goodness of fit.
Evaluating Highly Realistic Models
A few requirements must be in place for an agent-based model to be feasibly evaluated by comparing model output to real world data. First, the model must be initialized with a population of agents that correspond to some known population. Second, the model output must be able to be mapped into real units of time. If spatial comparisons are desired, then the model environment must be linked to real space (e.g., using GIS data as discussed earlier). Finally, of course, the analyst must have access to field data at the appropriate level with which to do the evaluation. Typically some statistic is computed from the model and compared with its real world analogue. Highly aggregated summary statistics are the lowest bar of validation criteria. Because of the high level of data aggregation, a wide range of local conditions may give rise to the same aggregate statistic. One can compare either the final statistic after some specified time span or the evolution of that statistic over some time period. For validation at the micro level, the observed behavior of individual agents in the model can be compared with the behavior of individuals drawn from a comparable population. For example, if the researcher initialized the agents using a discrete choice model to describe their behavior, he could re-estimate this model from the agent decisions, and see if the coefficient estimates line up. Alternatively, one can look at trajectories for different types of agents to see if their average trajectory corresponds with observed human behavior.
Between the micro and macro levels of analysis, one can also compare information about local area statistics; for example, the proportion poor in a neighborhood or the average test scores in a school. The less stringent test would be to compare distributions from the agent-based model with data; for example, the number of high-poverty neighborhoods estimated in the model and the number of high-poverty neighborhoods observed in the data. Unfortunately, this ignores the spatial distribution of outcomes. The more stringent criterion would be to go area-by-area and compare the degree to which the agent-based model predicted outcomes consistent with the attributes of real places. Again, one can compare the trajectories of units over time, or merely record their start and end points. Maps may be useful to show geographic areas where the model did and did not perform well.15
Over the past five years, a number of simulation researchers have offered detailed, programmatic recommendations for data-based model evaluation (Richiardi et al. 2006; Troitzsch 2004; Windrum, Fagiolo, and Moneta 2007; an older discussion is available in Carley 1996). However, there is a fairly well developed methodology in the atmospheric and physical sciences aimed at evaluating the results of computer experiments (e.g., Sacks et al. 1989; Bayarri et al. 2007a, Bayarri et al. 2007b). This approach has been suggested for agent-based research (see Berk 2008), but is not widely known or utilized within the agent-based modeling community. It provides a solid statistical foundation for the validation exercise and represents the state of the art (Berk 2008: 294). We briefly summarize their suggested method below, and provide relevant references for readers who want to pursue more technical details. See Bayarri et al. (2007) and especially Berk (2008) for more details. Figure 2 provides a summary of the steps involved.
Figure 2. Process of Model Evaluation.

The first step of model evaluation is to specify model inputs and parameters with associated uncertainties or ranges. Ideally the modeler has already done a sensitivity analysis (see Section 7), so she is aware of how the model responds to fluctuations in key parameters. In particular, she knows the distribution of model results given the degree of empirical uncertainty in model inputs. (Note that model inputs can include parameter estimates as well as any key modeling decisions [for example, assumptions about the structure of the housing or labor markets or the extent to which an agent has incomplete information about its environment]). The sensitivity analysis will help determine which modeling decisions are most critical in explaining variation in model results. The model evaluation then takes into account uncertainty in inputs, and compares the distribution of model output to the observed data.
The second step is to determine the evaluation criteria. Researchers will generally want to include multiple measures of fit at multiple levels of granularity, and these measures will likely be adapted and refined as the evaluation process proceeds (Bayarri et al. 2007: 143). At least one measure will likely include an overall goodness-of-fit between the model and the data. Mean-squared error is one possible statistic, although it is sensitive to outliers (Berk 2008: 296). Summary measures are useful for assessing overall fit, but they do not provide detailed diagnostic information. For this, more detailed measures are useful. For example, residuals can be constructed from differences in expected versus observed characteristics of local areas, specific agents, or agent types. Note that these statistics may display substantial spatial or temporal autocorrelation, which can be handled via standard statistical techniques (Cressie 1991).
The third step is to identify real-world data suitable for the model evaluation. The data will preferably be at the same geographic level and time scale of the model output. Decennial Census data are one likely candidate for comparing populations, though these are only available at ten-year intervals. School enrollment data are available annually, but provide information only on children’s characteristics. However, these might be used to get some sense of population distributions within school districts. Other possible data sources include police reports and other crime data, hospital admissions records, births and deaths, and of course surveys on relevant populations. Ideally the data used to assess the model are not the same as those used to initialize it, but that is not always possible.
The fourth step is to generate the agent-based modeling estimates for comparison with real-world data. If the analyst has done a sensitivity analysis, he should already have collected data on how the distribution of model outcomes varies with uncertainty in model inputs. Note that obtaining this distribution of model outcomes may require a substantial number of model runs. When model runs are computationally expensive and the researcher lacks access to high performance computing, this approach may not be feasible. One option is to estimate Statistically Equivalent Models (SEMs) using nonparametric statistical techniques that reply on algorithms designed to link model inputs to model outputs without trying to represent the underlying causal mechanisms (Brieman 2001; see also Berk 2008: 304-5).Finally, the researcher compares the distribution of model output to the real world data. Of course, we would expect the model to do an imperfect job of predicting real world outcomes. However, the ways in which the model estimates depart from real world processes may be highly informative and useful for highlighting parts of the model that might be usefully revised, or point to data required to improve model fidelity. The process is iterative. The agent-based model and any associated empirical estimates may be refined based on conclusions from the evaluation, and the whole process repeats again.
Evaluating Low-Dimensional or Abstract Agent-based Models
While highly realistic models have been widely used in urban studies, epidemiology, and public health, this approach is less common in sociological research. Most agent-based models aimed at solving concrete empirical problems in sociology are not designed to replicate real-world situations, or predict expected outcomes under alternative policy scenarios. Rather, the goal is to explore the systems implications of behavioral mechanisms and the robustness of those mechanisms to changes in the key parameters. Even when much of the agent-based modeling architecture is informed by empirics, the purpose of the analysis is not to recreate the process of interest so much as identify key relationships among the parameters. In this case, one should resist the temptation to “validate” the model by comparing its output to empirical, aggregate patterns. Since multiple assumptions at the individual level can give rise to the same aggregate social dynamics, an agent-based model has not “explained” some process of interest merely by reproducing it (Grimm et al. 2005; Jones 2007).16 However, the model can show what might be expected under a set of empirically plausible assumptions. Rather than directly comparing model output to empirical data, researchers should try to determine whether the key relationships or mechanisms highlighted in the agent-based model seem to be plausible explanations of real-world phenomena. This often involves an analysis of empirical data that is completely separate from the agent-based model. In this case, the agent-based model is more of a theoretical tool used for the generation of hypotheses.
The trick is to figure out what empirical patterns would be consistent with a given mechanism. This is especially difficult when the focal mechanism is unobserved. For example, network externalities are rarely observed explicitly (e.g., Hedström and Åberg 2005; DiMaggio and Garip 2011). However, one can still specify hypotheses about what empirical relationships would be consistent with the observed mechanism. In quantitative models, fixed effects or statistical controls can help rule out alternative explanations. This strategy of model validation is useful in situations in which there is good aggregate data to test the theoretical relationships implied by the agent-based model. For example, Bruch (2013) uses both abstract and empirically grounded agent-based models to explore how between- and within-race income inequality shapes racial segregation dynamics. She finds that when there is a sufficiently high level of within-race income inequality, an increase in between-race income inequality has offsetting effects at the high and low ends of the income distribution. These offsetting effects attenuate the total change in segregation resulting from a decrease in between-race income inequality. To evaluate whether such offsetting effects are operating in real world settings, she uses fixed-effects models applied to three decades of decennial Census data to estimate the relationships among between-race income inequality, within-race income inequality, and the relative size of minority groups. While this approach shares the same drawbacks as any observational study, it does establish some empirical support for the underlying relationships observed in the agent-based model.
An alternative approach for testing the validity of mechanisms identified in the agent-based model is to design an experiment aimed at capturing the mechanism of interest. This is the strategy used by Todd and colleagues (Todd and Miller 1999; Lenton, Fasolo, and Todd 2009; Todd 2007) in their analyses of mate search strategies and marriage market outcomes. They first use an agent-based model to simulate outcomes under alternative assumptions about the degree of competition. They assume individuals update beliefs about their own marketability after sequential encounters with potential mates. They find that when there is greater indirect competition among same sex mate-seekers, individuals are quicker to make their choice, and shorten the initial learning period. To test whether this same result holds in the real world, they organize a series of speed-dating experiments to see how differences in levels of competition (e.g., the sex ratio and total number of participants) affects individuals’ mate choice behavior.
7. FUTURE DIRECTIONS AND CHALLENGES
Agent-based models are increasingly recognized as valuable tools within an empirical research program. However, there is no codified set of recommendations for or practices for using these models in empirical research programs. This paper offers a set of suggestions and practical guidelines for how to conceptualize, develop, and evaluate empirically grounded agent-based models. Our goal is to bring together literature across a wide range of fields—including transportation research, epidemiology, biology, atmospheric sciences, and statistics—representing “best practices” in this line of work.
There are several promising directions for future research. One is to make use of the emerging insights from behavioral economics and cognitive science on how people make collect, analyze, and act upon information to develop agents with more plausible and nuanced human behavior (c.f. Payne, Bettman, and Johnson 1993). Much of our work in sociology has focused solely on the role of preferences in individual choices and assumed people have infinite cognitive resources; we have not paid much attention to how people actually gather information and make decisions. For example, how do systematic biases in perception of things with near versus far time horizons affect choice behavior and to what extent do individuals learn from experience or past mistakes? One might specify agents that not only have tastes but also strategies for action under limited information or learning mechanisms, and then exploring how these features of human decision- making matter for social dynamics. Allowing for a more empirical realism in individual behavior would open up a whole set of interesting theoretical questions concerning how individuals’ cognitive biases and heuristic strategies for gathering information and making decisions shapes opportunity structure and the social environment. This topic is especially well suited to agent-based modeling given its natural ability to model the co-evolution of individual behavior and social environments.
Another promising application of empirical agent-based models is in studies aimed at understanding the development and evolution of social networks. Structural sociologists argue that the social environment formalized as networks constrains individual actions and defines the implications of those actions. Accordingly the majority of research treats an existing network as an independent variable, rather than an endogenous outcome of social interaction. However, agent-based models can be used to specify dynamic networks that explore how social outcomes and structure evolve given agents’ preferences and opportunities to create ties.17 To date, the most systematic and ambitious treatment of network change is work by Padgett and Powell (2012) that uses a simple agent-based model of autocatalysis and a multiple networks perspective to make sense of emergent phenomena ranging from partnership systems to high-tech clusters.
Another potential research direction is to couple detailed geographic data with quantitative and qualitative accounts of how people interact with space to better understand how physical proximity and the layout of cities and other social environments hinder or facilitate interaction and interdependence among individuals and groups, and how this process aggregates up to result in cooperation or conflict among communities. Space remains an under theorized aspect of social life: we often take spatial relationships as proxies for social relationships but we know very little about how individuals’ orientation to their physical environment affects social life. Geography may be especially relevant in applications where agents’ opportunities are constrained or defined by geography. This includes studies of residential mobility, but also marriage markets, employment opportunities, and school choice. Moreover there is evidence that geographic barriers such as freeways, train tracks, busy intersections, and other features play important roles in neighboring relationships, social networks, and community dynamics (e.g., Noonan 2005; Grannis 2009). Agent-based models historically have represented the agents’ environment as abstract and aspatial; a continuous space or a discrete space composed of cells arrayed on a grid. However, modelers are increasingly using explicit geography for a specific city or region (e.g., Crooks, Castle, and Batty 2008; Robinson et al.2007). In addition, detailed sensor data available from cell phones provides rich information on individuals’ movement in space, which can be also be incorporated into agent-based models (Osgood and Stanley 2012). Capturing how geographic barriers constrain or enhance interaction patterns may shed further light on how space conditions social life.
We close with a few words about software, documentation and replicable science. There are many software platforms and programming languages that support the construction of agent-based models. Well established platforms like Repast, Netlogo, MASON, and Swarm speed up development time by taking care of messy background details, but it is also relatively easy it is to construct a model in environments like R or Matlab. For empirically grounded models, especially those that realistic geography and populations, languages Python and R can make the handling and analysis of data easier. Regardless of what language one chooses, there are several practical introductions to the modeling process to consult before you begin (cf. Macal and North 2010, Railsback and Grimm 2011).
A key part of model development is documenting the code. Good documentation abstracts away from the code and makes the model’s structure and assumptions apparent. There have been calls for standardization of documentation (cf. Grimm et al. 2006, Richiardi et el. 2006), and one promising candidate is the Unified Model Language (UML). UML lays out a series of well-defined and standardized schematics—independent of any specific programming language—for representing the underlying logic of the model. This technique has become the gold standard for describing object oriented programming code (Fowler 2003), and agent-based modelers have begun to incorporate these diagrams into documentation and publications (Bersini 2012). In addition, the OpenABM repository is an excellent vehicle for sharing code and supporting documents.18 However, the adoption of these “best practices” has been slow and there remains great variation in how models are documented and shared. All methods would benefit from more peer validation of data and coding, but because agent-based models have more opportunities for coding error it is all the more important to allow others to explore and test models.19 Good practices around documenting and sharing models will help broaden the appeal and acceptance of agent-based models.
APPENDIX A
AGGREGATE VERSUS INDIVIDUAL-LEVEL MODELS
In this appendix, we provide an overview of how agent-based modeling compares to other methods for analyzing interdependent behavior, feedback effects, and social dynamics. These include systems dynamics and various forms of mathematical modeling. A full discussion of the relative advantages of these approaches is beyond the scope of this appendix (see Osgood 2008 for detailed discussions of model tradeoffs), but it is important to highlight the key methodological distinction between dynamic models that represent aggregated or expected behavior (e.g., general equilibrium models, interactive Markov models and other forms of population projection, and systems of differential equations) and models specified at the individual level, where each agent represents an autonomous actor (Osgood 2008; Bruch and Mare 2012; section 8).20 In sociology, nearly all individual-based models are agent-based models, so we use the terms interchangeably.
Aggregate models typically represent the distribution of a population across some discrete set of “states” at time t, where states denote the proportion of the population with a given value of an attribute at a given time point. For example, in the classic “SIR” epidemiologic model, states reflect the number or proportion of people who are susceptible to, infected by, or recovered from some disease (Brauer,van den Driessche and Wu 2008). In a neighborhood dynamics model, states may reflect the population distribution across specific neighborhoods or areas (e.g. Mare and Bruch 2003). A matrix of transition values describes the probability of transitioning from one state to another, either as constants or as a function of the population distribution at time t, so that the probabilities are endogenous to the underlying population dynamics (Conlisk 1976). The observed dynamics or expected equilibrium can be computed by iteratively multiplying over matrices, or the system may be solved analytically.21
There are two key differences between aggregate and individual-level models: (1) their ability to handle population heterogeneity (which includes not just variation in individual attributes but also local interactions and network topology); and (2) whether decisions are represented as discrete choices or continuous transition probabilities or realized decisions. The former difference is due to the computational limits of aggregate models and the latter is the chief methodological innovation of agent-based modeling. First, agent-based models allow for a significantly more robust representation of population heterogeneity than do aggregate models because, as the analyst subdivides the population into detailed categories based on one or more key attributes, the complexity of the aggregate model grows geometrically whereas the complexity of the agent-based model grow only linearly (Osgood 2008). Thus, typically the number of subgroups represented in aggregate models is small even while there may still be considerable heterogeneity within subgroup categories. Furthermore, if there is heterogeneity within the population subgroups defined by the aggregate model, and those heterogeneous individuals have different transition probabilities, this can lead to a biased set of inferences regarding population dynamics due to selection effects (Vaupel and Yashin 1985)22
The second difference between models at the aggregate and individual levels is that aggregate models simulate dynamics based on continuous or “smoothed” probabilities while agent-based models simulate the dynamics of realized decisions (that may be generated probabilistically). Simulating based on smoothed probabilities is tantamount to assuming an infinitely large population, as it implies that people can be subdivided into arbitrarily fractional units without changing the underlying dynamics. When the population under investigation is small or the units in which individuals influence one another is small (e.g., networks, neighborhoods, contact areas for disease), individual and aggregate models can generate different observed macro dynamics (Green, Kiss, and Kao 2006). For example, in residential mobility models an agent’s decision to move or stay will change neighborhood composition by 1 unit. Contrast this with an aggregate model of neighborhood change, in which probabilities may take on any value between 0 and 1. When neighborhoods are small, a 1-unit change may have very different implications for neighborhood desirability than a unit change for a given individual response behavior. Similarly, if total population size is small, agent-based models may generate different predictions about the emergence of pandemics than a model that assumes an infinite population (Keeling and Grenfell 2000).
In spite of these limitations, aggregate models do have certain advantages over agent-based models. They are more straightforward to construct and understand, they take less time and computational power to run,23 and it may be easier to find empirical data for anchoring them. Also, if one wants to simulate the dynamics of a very large population (e.g., the population of the United States), agent- based models may become unwieldy. Accordingly, researchers have to weigh the tradeoffs. Both aggregate and individual models can incorporate feedback, stocks and flows, and other properties of dynamic systems. A few factors that can motivate using an agent-based model include the amount of individual heterogeneity desired in the model, the size of the population and relevant units, and the extent to which the problem at hand has the features outlined in the section below.
Footnotes
Gianluca Manzo provided helpful comments on this paper. We are also grateful for the suggestions and constructive criticisms provided by two anonymous reviewers.
A few notable exceptions include Hedström and Åberg’s (2005) “Empirically Calibrated Agent-Based Models” (ECA); Manzo’s (2007) discussion of the role of agent-based modeling in theoretically engaged, quantitative research; and Boero and Squazzoni’s (2005) discussion of the role of empirical data into agent-based models.
Alexander and Giesen (1987, Chapter 1) provide a comprehensive overview of the “macro-micro” problem within sociology, from its early manifestations in the foundational writings of Marx, Weber, and Durkheim to more recent work. See also Sawyer’s (2001) historical account of the idea of emergence in sociology and philosophy.
For example, the decision to wear purple socks on any given day is relatively independent of what other people are doing. Thus the expected number of people wearing purple socks is simply the sum of the probabilities for each person.
The idea of a self-fulfilling prophecy (Merton [1948] 1968) provides a mechanism to explain how beliefs about future events can bring them about via interdependent behavior. See Biggs (2009) for an overview of this model.
While our essay focuses on agent-based models, there are other methods for analyzing interdependent behavior, feedback effects, and social dynamics, namely systems dynamics and various forms of mathematical modeling. We highlight the key differences among these approaches in Appendix A.
See Manzo (2013) for an example of this approach with regard to the effect of unobserved social interactions on individuals’ educational decisions and resulting aggregate patterns of educational inequality.
Sterman (2006: 506) discusses more examples of policies that failed or were greatly limited due to a failure to anticipate systematic response.
For more information about MIDAS, see http://www.nigms.nih.gov/Research/FeaturedPrograms/MIDAS/Background/Factsheet.htm.
The goal of this model was not to generate a specific prediction from a given run of the model, but rather to allow the analysts to explore potential consequences of alternative scenarios or assumptions.
It can be useful to contrast agent-based modeling with statistical regression models. We can add as many variables as we like to a regression model, but we make the simplifying assumption that the errors are independent and identically distributed. Agent-based models allow us to relax this major assumption, but this introduces enormous model complexity with respect to social interaction that can make results difficult to interpret. To keep things tractable, one must simplify on some dimensions.
Note that multiple agent types may be present within the same model. In addition to representing individuals, families, or households, agents can also represent institutions and other more aggregated social structures. For example, one can specify a “school” agent that has a set of characteristics as well as a list of associated pupils, all agents themselves. National Center for Educational Statistics (NCES) data on school attributes may be used to assign the simulated schools initial distributions of resources, safety levels, and student-teacher ratios corresponding to the schools in a given district.
In the United States, the Summary Tape Files (STF) contains selected 2- and 3-way tables of attributes describing housing units, households, populations, and families. Similarly, the Small Area Statistics (SAS) for the United Kingdom have limited one- two-way and three-way tables.
These data will eventually be updated using the demographic data from the American Community Survey.
Less aggregated measures are often more sensitive to path dependence; for example, overall levels of residential or school segregation, patterns of assortative mating, or incidence of disease may be constant from run to run but the actual distribution of agents in space may vary widely due to random variation in initial distributions of agents or a sequence of decisions that unfolded within the model.
Keep in mind that the process may be path dependent. Small differences in initial conditions or seemingly trivial decisions at one point in the model may propagate into substantive divergence in results later on. This one reason to study trajectories: if the model departs from reality, one would like to know whether at what point in time it departed and what accounted for this departure.
For example, two very different assumptions about mate preferences—that people desire a mate with the highest mate value (e.g., as measured by attractiveness or income) or that people desire a mate with a mate value most similar to their own—will generate the same patterns of assortative mating.
Snijders, van de Bunt, and Steglich (2010) introduce a useful computational model employing a Markov process, howevr decisions are by definition “memoryless” and there is limited opportunity to include environmental constraints and heterogeneity among agents.
One promising tool for replicating scientific computing is the IPython notebook. It embeds live code (written in Python, R, Java and C++ [both via extensions] and many other languages) alongside documentation such as written descriptions, graphs and other figures. The end result is a portable “notebook” document that can be easily run on a local machine or a server. An introduction to this continually improving project can be found at www.ipython.org
“Actor” usually means an individual but can also be schools, households, and other units.
See Otto and Day (2007) for a more detailed discussion of analytical solutions and Bruch and Mare (2012, pp.142-45) for a discussion of computational solutions.
Consider, for example, residential mobility based on the racial composition of neighborhoods, where states denote the proportion black within the jth neighborhood category at time t. Within race groups some people are more tolerant of members of other races than others. The calculated transition probability represents the average tolerance of this non-homogenous population. As less tolerant people move away from areas with substantial black populations first, the underlying transition probabilities associated with each neighborhood will change, as selection leads to a population in black neighborhoods composed of more tolerant or diversity-seeking individuals. However, this will not be reflected in the observed dynamics based on the initial calculated average probability ( Xie and Zhou 2012; Rahmandad and Sterman 2009; Brown and Robinson 2006). See Osgood (2008) for a more detailed discussion of representing heterogeneity in aggregate versus individual-based models
Although this may be a nonissue as processing power and infrastructure continue to improve.
References
- Agresti Alan. Categorical Data Analysis. second edition. Hoboken: John Wiley and Sons; 2002. [Google Scholar]
- Alexander Jeffrey, Giesen Bernhard. From Reduction to Linkage: The Long View of the Micro-Macro Link. In: Alexanders Jeffrey, Giesen Bernhard, Münch Richard, Smelser Neil J., editors. The Micro-Macro Link. Chapter 1. Berkeley: University of California Press; 1987. [Google Scholar]
- Allison Paul. Discrete-Time Methods for the Analysis of Event Histories. Sociological Methodology. 1982;13:61–98. [Google Scholar]
- Axelrod Robert. The Complexity of Cooperation:Agent-Based Models of Competition and Collaboration. Princeton, NJ: Princeton University Press; 1997. [Google Scholar]
- Axelrod Robert, Dion Douglas. The Further Evolution of Cooperation. Science. 1988;242:1385–90. doi: 10.1126/science.242.4884.1385. [DOI] [PubMed] [Google Scholar]
- Axelrod Robert, Hamilton William. The Evolution of Cooperation. Science. 1981;211:1390–96. doi: 10.1126/science.7466396. [DOI] [PubMed] [Google Scholar]
- Bayarri Maria, Berger James, Paolo Rui, Sacks Jerry, Cafeo John, Cavendish James, Lin Chin-Hsu, Tu Jian. A Framework for Validation of Computer Models. Technometrics. 2007a;49:138–54. [Google Scholar]
- Bayarri Maria, Berger James, Cafeo John, Garcia-Donato G, Liu F, Palomo J, Parthasarathy R, Paolo R, Sacks Jerry, Walsh D. Computer Model Validation with Functional Input. The Annals of Statistics. 2007b;35:1874–1906. [Google Scholar]
- Beckman Richard, Baggerly Keith, McKay Michael. Creating Synthetic Baseline Populations. Transportation Research. 1996;30:415–29. [Google Scholar]
- Benenson Itzhak, Torrens Paul. Geosimulation: Automata-Based Modeling of Urban Phenomena. Chichester, West Sussex: John Wiley and Sons; 2004. [Google Scholar]
- Berk Richard. How Can You Tell If The Simulations in Computational Criminology Are Any Good? Journal of Experimental Criminology. 2008;4:289–308. [Google Scholar]
- Bersini Hugues. UML for ABM. Journal of Artificial Societies and Social Simulation. 2012;15:9. [Google Scholar]
- Biggs Michael. Self-Fulfilling Prosphesies. In: Hedström P, Bearman P, editors. Oxford Handbook of Analytic Sociology. Chapter 13. Oxford: Oxford University Press; 2009. [Google Scholar]
- Boero Riccardo, Squazzoni Flaminio. Does Empirical Embeddedness Matter? Methodological Issues on Agent-Based Models in Analytical Social Science. Journal of Artificial Societies and Social Simulations. 2005;8(4) [Google Scholar]
- Borning Alan, Waddell Paul. UrbanSim: Interaction and Participation in Integrated Urban Land Use, Transportation, and Environment Modeling. Association for Computing Machinery International Conference Proceeding Series; 2006. pp. 133–134. [Google Scholar]
- Borning Alan, Waddell Paul, Förster Ruth. UrbanSim: Using Simulation to Inform Public Deliberation and Decision-Making. Digital Government: Integrated Series in Information Systems. 2008;17:439–464. [Google Scholar]
- Brauer Fred, van den Driessche Pauline, Wu Jianhong., editors. Mathematical Epidemiology. Berlin: Springer-Verlag; 2008. [Google Scholar]
- Breiman Leo. Statistical Modeling: the Two Cultures. Statistical Science. 2001;16:199–231. [Google Scholar]
- Brown Daniel, Robinson Derek. Effects of Heterogeneity in Residential Preferences on an Agent-Based Model of Urban Sprawl. Ecology and Society. 2006;11:46. [Google Scholar]
- Bruch Elizabeth. Residential Sorting by Race and Income. 2013 Unpublished Manuscript. [Google Scholar]
- Bruch Elizabeth, Mare Robert. Neighborhood Choice and Neighborhood Change. American Journal of Sociology. 2006;112:667–709. [Google Scholar]
- Bruch Elizabeth, Mare Robert. Preferences and Pathways to Segregation: Reply to Van De Rijt, Siegel, and Macy. American Journal of Sociology. 2009;114:1181–98. doi: 10.1086/597599. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bruch Elizabeth, Mare Robert. Methodological Issues in the Analysis of Residential Preferences, Residential Mobility and Neighborhood Change. Sociological Methodology. 2012;42:103–154. doi: 10.1177/0081175012444105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Burgard Sarah, Brand Jennie, House James. Preceived Job Insecurity and Worker Health in the United States. Social Science & Medicine. 2009;69:777–85. doi: 10.1016/j.socscimed.2009.06.029. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cauchemez Simon, Bhattarai Achuyt, Marchbanks Tiffany, Fagan Ryan, Ostroff Stephen, Ferguson Neil, Swerdlow David the Penn H1N1 Working Group. Role of Social Networks in Shaping Disease Transmission During a Community Outbreak of 2009 H1N1 Pandemic Influenza. Proceedings of the National Academy of Sciences. 2011;108:2825–30. doi: 10.1073/pnas.1008895108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carley KM. Validating computational models. Carnegie Mellon University; Pittsburgh, PA: 1996. Working paper. [Google Scholar]
- Centola Damon, Macy Michael. Complex Contagions and the Weakness of Long Ties. American Journal of Sociology. 2007;113:702–34. [Google Scholar]
- Centola Damon, Willer Robb, Macy Michael. The Emperor’s Dilemma: A Computational Model of Self-Enforcing Norms. American Journal of Sociology. 2005;110:1009–1040. [Google Scholar]
- Coleman James. Foundations of Social Theory. Cambridge, MA: Harvard University Press; 1994. [Google Scholar]
- Conlisk John. Interactive Markov Chains. The Journal of Mathematical Sociology. 1976;4:157–85. [Google Scholar]
- Cressie Noel. Statistic for Spatial Data. New York: Wiley; 1991. [Google Scholar]
- Crooks Andrew, Castle Christian, Batty Michael. Key Challenges in Agent-Based Modeling for Geo-Spatial Simulation. Computers, Environment and Urban Systems. 2008;32:417–30. [Google Scholar]
- Dancik Garrett, Jones Douglas, Dorman Karin. Parameter Estimation and Sensitivity Analysis in an Agent-Based Model of Leishmania major Infection. Journal of Theoretical Biology. 2010;262:398–412. doi: 10.1016/j.jtbi.2009.10.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dean Jeffrey, Gumerman George, Epstein Joshua, Axtell Robert, Swedlund Alan, Parker Miles, McCarrol Stephen. Understanding Anasazi Culture Change Through Agent-Based Modeling. In: Kohler Timothy, Gumerman George., editors. Dynamics in Human and Primate Societies: Agent-Based Modeling of Social and Spatial Processes. Oxford: Oxford University Press; 2000. pp. 179–205. [Google Scholar]
- Deaton Angus. Instruments, Randomization, and Learning about Development. Journal of Economic Literature. 2010;48:424–55. [Google Scholar]
- Deming W Edwards, Stephan Frederick. On a Least Squares Adjustment of a Sampled Frequency Table When the Expected Marginal Totals are Known. The Annals of Mathematical Statistics. 1940;11:427–44. [Google Scholar]
- Dimaggio Paul, Garip Feliz. How Network Externalities Can Exacerbate Intergroup Inequality. American Journal of Sociology. 2011;116:1887–1933. [Google Scholar]
- Durlauf Steven. Spillovers, Stratification, and Inequality. European Economic Review. 1993;38:836–45. [Google Scholar]
- Durlauf Steven. Neighborhood Feedbacks, Endogenous Stratification and Income Inequality. Santa Fe Institute working paper 95-07-061 1995 [Google Scholar]
- Elster Jon. Explaining Social Behavior: More Nuts and Bolts for the Social Sciences. Cambridge UK: Cambridge University Press; 2007. [Google Scholar]
- Epstein Joshua. Modeling to Contain Pandemics. Nature. 2009;460:687. doi: 10.1038/460687a. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Epstein Joshua, Parker Jon, Cummings Derek, Hammond Ross. Coupled Contagion Dynamics of Fear and Disease: Mathematical and Computational Explorations. Public Library of Science ONE. 2008;3:e3955. doi: 10.1371/journal.pone.0003955. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eubank Stephen, Guclu Hasan, Anil Kumar VS, Marathe Madhav, Srinivasan Aravind, Toroczkai Zoltan, Wang Nan. Modeling Disease Outbreaks in Realistic Urban Social Networks. Nature. 2004;429:180–4. doi: 10.1038/nature02541. [DOI] [PubMed] [Google Scholar]
- Fenichel Eli, Castillo-Chavez Carlos, Ceddia M, Chowell Gerardo, Gonzalez Parra Paula, Hickling Grapham, Holloway Garth, Horan Richard, Morin Benjamin, Perrings Charles, Springborn Michael, Velazquez Leticia, Villabos Cristina. Adaptive Human Behavior in Epidemiological Models. Proceedings of the National Academy of Sciences. 2011;108:6303–11. doi: 10.1073/pnas.1011250108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ferguson Neil, Cummings Derek, Cauchemez Simon, Fraser Christophe, Riley Steven, Meeyai Arorag, Iamsirithaworn Sopon, Burke Donald S. Strategies for Containing an Emerging Influenza Pandemic in Southeast Asia. Nature. 2005;437:209–14. doi: 10.1038/nature04017. [DOI] [PubMed] [Google Scholar]
- Fienberg Stephen. An Iterative Procedure for Estimation in Contingency Tables. The Annals of Mathematical Statistics. 1970;41:907–17. [Google Scholar]
- Forrester Jay. World Dynamics. Cambridge, MA: Wright-Allen Press; 1971. [Google Scholar]
- Fossett Mark, Dietrich David. Effects of City Size, Shape, and Form and Neighborhood Size and Shape in Agent-Based Models of residential Segregation: Are Schelling-style Preference Effects Robust? Environment and Planning B: Planning and Design. 2009;36:149–69. [Google Scholar]
- Galster George. Consequences From the Redistribution of Urban Poverty During the 1990s: A Cautionary Tale. Economic Development Quarterly. 2005;19:119–25. [Google Scholar]
- Geller Armando, Moss Scott. Growing Qawm: An Evidence-driven Declarative Model of Afghan Power Structure. Advances of Complex Systems. 2008;11:321–335. [Google Scholar]
- Germann Timothy, Kadau Kai, Longini Ira, Macken Catherine. Mitigation Strategies for Pandemic Influenza in the United States. Proceedings of the National Academy of Sciences. 2006;103:5935–40. doi: 10.1073/pnas.0601266103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Grannis Rick. From the Ground Up: Translating Geography into Community through Neighbor Networks. Princeton: Princeton University Press; 2009. [Google Scholar]
- Granovetter Mark. Threshold Models of Collective Behavior. American Journal of Sociology. 1978;83:1420–43. [Google Scholar]
- Grimm Volker, Revilla Eloy, Berger Uta, Jeltsch Florian, Grannis Wolf, Railsback Steven, Thulke Hans-Hermann, Weiner Jacob, Wiegand Thorsten, DeAngelis Donald. Pattern-Oriented Modeling of Agent-Based Complex Systems: Lessons from Ecology. Science. 2005;310:987–91. doi: 10.1126/science.1116681. [DOI] [PubMed] [Google Scholar]
- Grimm Volker, Berger Uta, Bastiansen Finn, Eliassen Singrunn, Ginot Vincent, Giske Jarl, Gross-Custard John, Grand Tamara, Heinz Simone, Huse Geir, Huth Andreas, Jepsen Jane, Jørgensen Christian, Mooij Wolf, Müller Birgit, Pe’er Guy, Piou Cyril, Railsback Steven, Robbins Andrew, Robbins Martha, Rossmanith Eva, Rüger Nadja, Strand Espen, Souissi Sami, Stillman Richard, Vabø Rune, Visser Uta, DeAngelis Donald. A Standard Protocol for Describing Individual-Based and Agent-Based Models. Ecological Modelling. 2006;198:115–26. [Google Scholar]
- Green Darren, Kiss Istvan, Kao Rowland. Modeling the Initial Spread of Foot-and-Mouth Disease through Animal Movements. Proceedings of the Royal Society B: Biological Sciences. 2006;272:2729–35. doi: 10.1098/rspb.2006.3648. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hedström Peter, Åberg Yvonne. Dissecting the Social: On the Principles of Analytical Sociology. Cambridge: Cambridge University Press; 2005. Quantitative Research, Agent-Based Modeling, and Theories of the Social; pp. 114–144. [Google Scholar]
- Hedström Peter, Bearman Peter., editors. Oxford Handbook of Analytical Sociology. Oxford: Oxford University Press; 2009. [Google Scholar]
- Hedström Peter, Swedberg Richard. Social Mechanisms: An Introductory Essay. In: Hedström Peter, Swedberg Richard., editors. Social Mechanisms: An Analytical Approach to Social Theory. Chapter 1. Cambridge, UK: Cambridge University Press; 1998. [Google Scholar]
- Hedström Peter, Udehn Lars. Analytical Sociology and Theories of the Middle Range. In: Hedström P, Bearman P, editors. Oxford Handbook of Analytic Sociology. Chapter 2. Oxford: Oxford University Press; 2009. [Google Scholar]
- Hedström Peter, Ylikoski Petri. Causal Mechanisms in the Social Sciences. Annual Review of Sociology. 2010;36:49–67. [Google Scholar]
- Helton J, Davis F. Latin Hypercube Sampling and the Propagation of Uncertainty in the Analyses of Complex Systems. Reliability Engineering and Systems Safety. 2003;81:23–69. [Google Scholar]
- Helton JC, Johnson JD, Sallaberry CJ, Storlie CB. Survey of sample-based methods for uncertainty and sensitivity analysis. Reliability Engineering and System Safety. 2006;91:1175–1209. [Google Scholar]
- Hoeting Jennifer, Madigan David, Raftery Adrian, Volinsky Chris. Bayesian Model Averaging: A Tutorial. Statistical Science. 1999;14:382–401. [Google Scholar]
- Holland John, Miller John. Artificial Adaptive Agents in Economic Theory. American Economic Review. 1991;81:365–70. [Google Scholar]
- Homer Jack, Hirsch Gary. Systems Dynamics Modeling for Public Health: Background and Opportunities. American Journal of Public Health. 2006;96:19–25. doi: 10.2105/AJPH.2005.062059. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iman Ronald, Conover WJ. A Distribution-Free Approach to Inducing Rank Correlation Among Input Variables. Communications in Statistics-Simulation and Computation. 1982;11:311–34. [Google Scholar]
- Iman Ronald, Davenport JM. Rank Correlation Plots for Use with Correlated Input Variables. Communications in Statistic-Simulation and Computation. 1982;11:335–60. [Google Scholar]
- Ireland CT, Kullback S. Contingency Tables with Given Marginals. Biometrika. 1968;55:179–88. [PubMed] [Google Scholar]
- Jones Gregory. Agent-Based Modeling: Use with Necessary Caution. American Journal of Public Health. 2007;97:780–1. doi: 10.2105/AJPH.2006.109058. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kahneman Daniel, Tversky Amos, Slovic Paul. Judgment under Uncertainty: Heuristics & Biases. Cambridge: Cambridge University Press; 1982. [Google Scholar]
- Keeling Matt, Grenfell Bryan. Individual-Based Perspectives on R0. Journal of Theoretical Biology. 2000;203:51–61. doi: 10.1006/jtbi.1999.1064. [DOI] [PubMed] [Google Scholar]
- La Berge Ann. How the Ideology of Low Fat Conquered America. Journal of the History of Medicine and Allied Sciences. 2008;63:139–77. doi: 10.1093/jhmas/jrn001. [DOI] [PubMed] [Google Scholar]
- Laurie Alexander, Jaggi Narendra. Role of ‘Vision’ in Neighbourhood Racial Segregation: A Variant of the Schelling Segregation Model. Urban Studies. 2003;40:2687–2704. [Google Scholar]
- Lenton Alison, Fasolo Barbara, Todd Peter. The Relationship between Number of Potential Mates and Mating Skew in Humans. Animal Behavior. 2009;77:55–60. [Google Scholar]
- Louviere Jordan, Hensher David, Swait Joffre. Stated Choice Methods: Analysis and Application. Cambridge: Cambridge University Press; 2000. [Google Scholar]
- Mabry Patricia, Olster Deborah, Morgan Glen, Abrams David. Interdisciplinarity and Systems Science to Improve Population Health: A View from the NIH Office of Behavioral and Social Sciences Research. American Journal of Preventive Medicine. 2008;35:S211–24. doi: 10.1016/j.amepre.2008.05.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Macal C, North Michael. Tutorial on Agent-based Modeling and Simulation. Journal of Simulation. 2010;4:151–62. [Google Scholar]
- Macy Michael, Willer Robert. From Factors to Actors:Computational Sociology and Agent-Based Modeling. Annual Review of Sociology. 2002;28:143–66. [Google Scholar]
- Manzo Gianluca. Educational Choices and Social Interactions: A Formal Model and A Computational Test. Forthcoming in Class and Stratification Analysis. 2013;30:47–100. [Google Scholar]
- Manzo Gianluca. Variables, Mechanisms, and Simulations: Can the Three Methods be Synthesized? A Critical Analysis of the Literature. R Franc Sociol. 2007;48:35–71. [Google Scholar]
- Mare Robert, Bruch Elizabeth. Spatial Inequality, Neighborhood Mobility, and Residential Segregation. California Center for Population Research, UCLA; 2003. Online Working Paper Series. [Google Scholar]
- Marino Simeone, Hogue Ian, Ray Christian, Kirschner Denise. A Methodology for Performing Global Uncertainty and Sensitivity Analysis in Systems Biology. Journal of Theoretical Biology. 2008;254:178–96. doi: 10.1016/j.jtbi.2008.04.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McKay Michael, Beckman R, Conover W. A Comparison of Three Methods for Selecting Values if Input Variable in the Analysis of Output from a Computer Code. Technometrics. 1979;21:239–45. [Google Scholar]
- McKay Michael, Morrison John, Upton Stephen. Evaluating Prediction Uncertainty in Simulation Models. Computer Physics Communications. 1999;117:44–51. [Google Scholar]
- McFadden Daniel. Conditional Logit Analysis of Qualitative Choice Behavior. In: Zarembka P, editor. Frontiers of Economics. New York: Academic Press; 1973. [Google Scholar]
- Mease David, Bingham Derek. Latin Hyperrectangle Sampling for Computer Experiments. Technometrics. 2006;48:467–77. [Google Scholar]
- Merton Robert K. The Self-Fulfilling Prophecy. The Antioch Review. 1948;8:193–210. [Google Scholar]
- Miller John, Page Scott. Complex Adaptive Systems: An Introduction to Computational Models of Social Life. Princeton: Princeton University Press; 2007. [Google Scholar]
- Noonan Douglas. Neighbours, Barriers and Urban Environments: Are Things ‘Different on the Other Side of the Tracks’? Urban Studies. 2005;42:1817–35. [Google Scholar]
- Otto Sarah, Day Troy. A Biologist’s Guide to Mathematical Modeling in Ecology and Evolution. Princeton: Princeton University Press; 2007. [Google Scholar]
- Osgood Nathanial. Individual Based Models: Technicalities and Tradeoffs. 2008 Working Paper. [Google Scholar]
- Osgood Nathanial, Stanley Kevin. Sensing and Feedback for Epidemiological Models. Presentation made to the Network on Inequality, Complexity, and Health 2012 [Google Scholar]
- Padgett John F, Powell Walter W., editors. The Emergence of Organizations and Markets. Princeton, NJ: Princeton University Press; 2012. [Google Scholar]
- Page Scott. Uncertainty, Difficulty, and Complexity. Journal of Theoretical Politics. 2008;20:115–49. [Google Scholar]
- Payne John, Bettman James, Johnson Eric. The Adaptive Decision Maker. Cambridge: Cambridge University Press; 1993. [Google Scholar]
- Raftery Adrian. Bayesian Model Selection in Social Research. Sociological Methodology. 1995;25:111–63. [Google Scholar]
- Rahmandad Hazhir, Sterman John. Heterogeneity and Network Structure in the Dynamics of Diffusion: Comparing Agent-based and Differential Equation Models. Management Science. 2009;54:998–1014. [Google Scholar]
- Railsback Steven, Grimm Volker. Agent-Based and Individual-Based Modeling: A Practical Introduction. Princeton, NJ: Princeton University Press; 2011. [Google Scholar]
- Richiardi M, Leombruni R, Saam N, Sonnessa M. A Common Protocal for Agent-Based Social Simulation. Journal of Artificial Societies and Social Simulation. 2006;9 [Google Scholar]
- Riggs Thomas, Walts Adrienne, Perry Nicolas, Bickle Laura, Lynch Jennifer, Myers Amy, Flynn Joanne, Linderman Jennifer, Miller Mark, Kirschner Denise. A Comparison of Random vs. Chemotaxis-driven Contacts of Tcells with Dendritic Cells During Repertoire Scanning. Journal of Theoretical Biology. 2008;250:732–51. doi: 10.1016/j.jtbi.2007.10.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robinson Derek, Brown Daniel, Parker Dawn, Schreinemachers Pepijn, Janssen Marco, Huigen Marco, Wittmer Heidi, Gotts Nick, Promburom Panomsak, Irwin Elema, Berger Thomas, Gatzweiler Franz, Barnaud Cécile. Comparison of Empirical Methods for Building Agent-Based Models in Land Use Science. Journal of Land Use Science. 2007;2:31–55. [Google Scholar]
- Rosin Hanna. American Murder Mystery. Atlantic Monthly. 2008:50–54. [Google Scholar]
- Sacks Jerome, Welch William, Mitchell Toby, Wynn Henry. Design and Analysis of Computer Experiments. Statistical Science. 1989;4:409–23. [Google Scholar]
- Saltelli Andrea. Making Best Use of Model Evaluations to Compute Sensitivity Indices. Computer Physics Communications. 2002;145:280–297. [Google Scholar]
- Saltelli Andrea, Tarantola Stefano, Campolongo Francesca, Ratto Marco. Sensitivity Analysis in Practice: A Guide for Assessing Scientific Models. Sussex: John Wiley and Sons; 2004. [Google Scholar]
- Saltelli Andrea, Ratto Marco, Andres Terry, Campolongo Francesca, Cariboni Jessica, Gatelli Debora, Saisana Michaela, Tarantola Stefano. Global Sensitivity Analysis: The Primer. Chichester: John Wiley and Sons; 2008. [Google Scholar]
- Sawyer R Keith. Emergence in Sociology: Contemporary Philosophy of Mind and Some Implications for Sociological Theory. American Journal of Sociology. 2001;107:551–85. [Google Scholar]
- Schelling Thomas. Dynamic Models of Segregation. Journal of Mathematical Sociology. 1971;1:143–86. [Google Scholar]
- Schelling Thomas. Micromotives and Macrobehavior. New York: W.W Norton & Company; 1978. [Google Scholar]
- Segovia-Juarez Jose, Ganguli Suman, Kirschner Denise. Identifying Control Mechanisms of Granuloma Formation During M. tuberculosis Infection Using an Agent-Based Model. Journal f Theoretical Biology. 2004;231:357–76. doi: 10.1016/j.jtbi.2004.06.031. [DOI] [PubMed] [Google Scholar]
- Sisson S, Fan Y, Tanaka M. Sequential Monte Carlo without Likelihoods. Proceedings of the National Academy of Sciences. 2007;104:1760–65. doi: 10.1073/pnas.0607208104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Snijders Tom AB, van de Bunt Gerhard G, Steglich Christian EG. An Introduction to Stochastic Actor-Based Models for Network Dynamics. Social Networks. 2010;32:44–60. [Google Scholar]
- Sterman John. Learning from Evidence in a Complex World. American Journal of Public Health. 2006;96:505–14. doi: 10.2105/AJPH.2005.066043. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Suri Siddharth, Watts Duncan. Cooperation and Contagion in Web-based, Networked Public Goods Experiments. PLoS ONE. 2011;6(3) doi: 10.1371/journal.pone.0016836. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Todd Peter. Searching for the Next Best Mate. In: Conte R, Hegselmann R, Terna P, editors. Simulating Social Phenomenon. Berlin: Springer; 1997. pp. 419–36 . [Google Scholar]
- Todd Peter, Miller G. the ABC Research Group. From Pride and Prejudice to Persuasion: Satisficing in Mate Search. In: Gigerenzer G, Todd P, editors. Simple Heuristics that Make Us Smart. New York: Oxford University Press; 1999. pp. 286–308. [Google Scholar]
- Todd Peter M, Billari Francesco. Population-Wide Marriage Patterns Produced by Individual Mate-Search Heuristics. In: Billari F, Prskawetz A, editors. Agent-Based Computational Demography: Using Simulation to Improve Our Understanding of Demographic Behavior. Berlin: Springer-Verlag; 2003. pp. 117–137. [Google Scholar]
- Todd Peter, Billari Francesco, Simao Jorge. Aggregate Age-At Marriage Patterns from Individual Mate-Search Heuristics. Demography. 2005;42:559–74. doi: 10.1353/dem.2005.0027. [DOI] [PubMed] [Google Scholar]
- Todd Peter. Coevolved Cognitive Mechanisms in Mate Search: Making Decisions in a Decision-shaped World. In: Forgas J, Haselton MG, von Hippel W, editors. Evolution and the Social Mind: Evolutionary Psychology and Social Cognition. New York: Taylor & Francis Group; 2007. [Google Scholar]
- Toni Tina, Welch David, Strelkowa Natalja, Ipsen Andreas, Stumpf Michael. Approximate Bayesian Computation Scheme for Paramter Inference and Model Selection in Dynamical Systems. Journal of the Royal Society Interface. 2009;6:187–202. doi: 10.1098/rsif.2008.0172. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Train Kenneth. Discrete Choice Methods with Simulation. Cambridge University Press; 2009. [Google Scholar]
- Troitzsch Klaus. Validating Simulation Models. Proceedings of the 18th European Simulation Multiconference; Graham Horton; 2004. [Google Scholar]
- Vaupel James, Yashin Anatoli. Heterogeneity’s Ruses: Some Surprising Effects of Selection on Population Dynamics. The American Statistician. 1985;39:176–85. [PubMed] [Google Scholar]
- Waddell Paul. UrbanSim: Modeling Urban Development for Land Use, Transportation and Environmental Planning. Journal of the American Planning Association. 2002;68(3):297–314. [Google Scholar]
- Willer Robb, Kuwabara Ko, Macy Michael W. The False Enforcement of Unpopular Norms. American Journal of Sociology. 2009;115:451–490. doi: 10.1086/599250. [DOI] [PubMed] [Google Scholar]
- Windrum Paul, Fagiolo Giorgio, Moneta Alessio. Empirical Validation of Agent- Based Models: Alternatives and Prospects. Journal of Artificial Societies and Social Simulation. 2007;10 [Google Scholar]
- Wheaton William, Cajka James, Chasteen Bernadette, Wagener Diane, Cooley Philip, Ganapathi Laxminarayana, Roberts Douglas, Allpress Justine. Synthesized Population Databases: A US Geospatial Database for Agent-Based Models. Methods Rep RTI Press. 2009;10:905. doi: 10.3768/rtipress.2009.mr.0010.0905. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wheaton William. U.S. Synthesized Population Quick Start Guide. RTI International. 2009 Unpublished Manuscript. [Google Scholar]
- White Harrison. Matching, Vacancies, and Mobility. The Journal of Political Economy. 1970;78:97–105. [Google Scholar]
- Xie Yu, Zhou Xiang. Modeling Individual-level Heterogeneity in Racial Residential Segregation. Proceedings of the National Academy of Sciences. 2012;29:11646–51. doi: 10.1073/pnas.1202218109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang Lu, Gilbert Nigel. Getting Away From Numbers: Using Qualitative Observation For Agent-based Modeling. Advances in Complex Systems. 2008;11:175–185. [Google Scholar]