

Abstract
Railway tunnel 3D clearance inspection is critical to guaranteeing railway operation safety. However, it is a challenge to inspect railway tunnel 3D clearance using a vision system, because both the spatial range and field of view (FOV) of such measurements are quite large. This paper summarizes our work on dynamic railway tunnel 3D clearance inspection based on a multi-camera and structured-light vision system (MSVS). First, the configuration of the MSVS is described. Then, the global calibration for the MSVS is discussed in detail. The onboard vision system is mounted on a dedicated vehicle and is expected to suffer from multiple degrees of freedom vibrations brought about by the running vehicle. Any small vibration can result in substantial measurement errors. In order to overcome this problem, a vehicle motion deviation rectifying method is investigated. Experiments using the vision inspection system are conducted with satisfactory online measurement results.
Keywords: railway tunnel, 3D clearance, dynamic inspection
1. Introduction
With the speed of trains increasing and the departure frequency improving, railway infrastructure quality requires a more proper and effective maintenance system to guarantee its operational security. Railway tunnels, as an important part of railway infrastructure, have critical dimension limitations regarding their 3D clearance. The physical dimensions of a railway tunnel must be in strict accordance with relevant standards [1]. In order to determine the effective clearance of operating trains and to ensure the safety of the railway system, regular monitoring of railway tunnel 3D clearance needs to be implemented. A slight deformation found just at an early stage allows for better scheduling of the maintenance, which can eliminate potential risks, avoid incidents and also reduce maintenance costs.
The existing techniques for railway tunnel 3D clearance inspection can roughly be divided into contact and non-contact measurements. In the former category, the 3D railway tunnel clearance metrics information is acquired by skilled workers utilizing a special mechanical gauge. This has the advantages of low-cost and simple implementation; however, this approach is extremely laborious and time consuming, and it can only satisfy the local static measurement demands and can hardly estimate any potential trends of railway tunnel deformation with time.
With the development of computer vision and image processing techniques, methods of on-line dynamic inspection for railway tunnel 3D clearance have appeared with the help of non-contact vision sensors mounted on dedicated vehicles. Methods of non-contact dynamic measurements for railway tunnel 3D clearance commonly in use include time of flight (TOF) inspection, stereoscopic vision (SV) inspection and laser triangulation (LT) inspection [2,3,4,5]. The TOF method refers to the time it takes for a pulse of energy to travel from its transmitter to the surface of an object and then back to the receiver. The emitted light is used as the energy source, and the relevant parameter involved in range finding is the speed of light. 3D clearance inspection for railway tunnels based on the TOF method has been used for many practical applications [6,7]. However, due to the intrinsic limitations of both the physical resolutions and sampling rates of TOF sensors, this method can hardly meet the expected demands of high-speed and high-accuracy dynamic inspection. The SV method is the approach to acquire 3D geometric information about an object’s surface according to two or more perspective images obtained by stereovision sensors. The operation of this kind of stereovision sensor mainly relies on the changes of the light reflection or radiation from the object surface. However, the smooth characteristics of railway tunnel surfaces make the extraction of the corresponding feature points from the perspective images results a challenge.
The LT method, by adopting a laser stripe modulated by the structured-light plane intersecting with the object, makes the extraction of feature points from the captured images facile and has the additional advantages of flexibility, fast on-site acquisition and high accuracy. Thus, it is quite suitable for quickly measuring objects’ surfaces. Recently, the strengths of vision sensing and computer vision have led to the development of the LT method for various surface detection applications. Examples include circuit board inspection [8], railway track profile inspection [9], seamless steel pipe straightness inspection [10,11], etc. Using the LT method to detect railway tunnel 3D clearance with a complete field of view (FOV), a multi-camera and structured-light vision system (MSVS) should be employed to capture the images of railway tunnel surfaces from different orientations, because the FOV of a single vision sensor is often too limited. When using the LT method to collect the 3D metric information of railway tunnels, other new problems arise, such as the lack of a common FOV and a wide distribution of the different cameras. These problems make the global calibration of MSVS a difficult task.
The vision principle of the LT method and global calibration for a multi-camera system has previously been presented in [5,12]. However, a detailed analysis of the imaging model of MSVS in railway tunnel 3D clearance dynamic inspection applications has not yet been performed, and the global calibration algorithm needs to be further explained in detail. Moreover, MSVSs for railway tunnel 3D clearance dynamic measurement are mounted on a dedicated vehicle. When the onboard vision sensing system begins to work, the vision sensors suffer from the multiple degrees of freedom vibrations caused by the running vehicle. In order to reduce the impact of vehicle vibrations on the measurement results, a compensation method to improve measurement accuracy should be employed and added to the software. In this paper, we focus on the two key issues in railway tunnel 3D clearance dynamic inspection: one is the global calibration of MSVS; the other is the compensation approach to reduce the measurement errors induced by vehicle vibrations.
The rest of this paper is organized as follows: Section 2 mainly describes the basic vision principle of MSVS for railway tunnel 3D clearance dynamic inspection and the MSVS parameters that need to be calibrated. Section 3 introduces the calibration approach in detail. The vehicle vibration compensation approach to improve the measurement accuracy is detailed in Section 4. Section 5 provides the experimental results performed by the proposed method. The conclusions are presented in Section 6.
2. Measurement Principle and Calibration Parameters
2.1. Measurement Principle
The vision principle of railway tunnel 3D clearance dynamic inspection based on the LT method is illustrated in Figure 1. The measurement system includes MSVS, a high-speed image acquisition block, an odometer, a vibration compensation component (VCC) and an image processing computer:
-
(1)
MSVS: including multiple cameras and structured-light projectors. The FOV of the cameras and projectors are overlapping in the measurement range.
-
(2)
High-speed image acquisition block: used to collect images and send them to the computer.
-
(3)
Odometer: including an optical-electrical encoder on the train axle transforming the turning angle of the axle to pulse signals and a signal controller calculating mileage from the number of pulses.
-
(4)
VCC: including two line structured-light vision sensors installed at the bottom of the vehicle body to monitor the feature point of the railhead.
Figure 1.

The vision measurement principle. MSVS, multi-camera and structured-light vision system; VCC, vibration compensation component.
As shown in Figure 1, MSVSs are installed at the frontal-side of the vehicle body. The structured-light projectors emit laser planes from different orientations. The laser planes intersect with the surface of the railway tunnel and form laser stripes in the same cross-section with full FOV. When the train is running, the optical-electrical encoder emits pulse signals and sends them to the signal controller to calculate the mileage. Simultaneously, it generates trigger signals to control the different cameras of the MSVS working synchronously. The laser stripe images captured by the cameras are sent to the computer through the high-speed image acquisition block. Since the laser stripes are modulated by the depth of the tunnel surface, the image processing software can reconstruct the 3D metric information of the railway tunnel based on the optical triangulation principle.
For the railway tunnel 3D clearance dynamic inspection, one of the key issues is to extract the metric information of the railway tunnel from multiple 2D distorted stripe images. The high-accuracy global calibration of MSVS is the first step. The so-called global calibration of MSVS is the process of determining the mapping relationship between the 3D world coordinate frame and the 2D image coordinate frame based on the optical imaging model.
2.2. Calibration Approach
Due to the large range and complete FOV of MSVSs, traditional approaches [13,14,15,16,17,18,19,20,21,22,23] can hardly realize the global calibration of MSVSs. However, the intrinsic parameters of MSVSs are only determined by the sensors and lenses themselves, independent of their placement orientations and positions. According to this property, we can adopt a 2D chessboard as a calibration target to extract the intrinsic parameters of each camera off-line in advance. After the intrinsic parameters of each vision sensor have been obtained and the MSVS has been assembled, we then use a 1D target, which has the advantages of high accuracy, simple structure and easy manufacturing, to extract the extrinsic parameters of the MSVS on-line. Through the combination of a 2D planar target and a 1D target, we can ultimately realize the global calibration of the MSVS. In this paper, the proposed approach mainly contains the following four steps:
-
(1)
For each camera, the perspective projective matrix and lens distortion coefficients are calibrated off-line by the 2D planar target.
-
(2)
After, the MSVS is assembled, placing the 1D target to cover the FOV of two neighboring cameras and then computing the extrinsic parameters of each neighboring cameras on-line, including the rotation matrix and translation vector, according to the collinear property and known distances of feature points on the 1D target [24,25,26,27]. Then, an arbitrary camera coordinate frame is selected as the global coordinate frame. By utilizing the extrinsic parameters of each neighboring camera, we can transform the measurement results of the other cameras from their local coordinate frame to the global coordinate frame.
-
(3)
Using the same computation method in Step 2 and through at least three non-collinear feature points on the structured-light plane, the equation of the structured-light plane can also be determined.
-
(4)
With the help of the intrinsic parameters of each camera, the extrinsic parameters of the neighboring cameras and the structured-light plane equation, the global measurement model of the MSVS can ultimately be obtained.
3. The Global Calibration of the Vision System
This section briefly introduces the basic notations in the intrinsic parameter calibration process of each camera off-line by using a 2D planar target. Then, the extrinsic parameter calibration for the MSVS are detailed, starting with the rotation matrix and translation vector acquisition between the neighboring cameras, followed by the structured-light plane determination and ending with the global optimization for the vision system.
3.1. Basic Notations
Without loss of generality, a usual pinhole camera model is used. As shown in Figure 2, a 2D image point is denoted by and a 3D world coordinates point by .
Figure 2.

The intrinsic parameters calibration principle.
The corresponding homogeneous coordinates are written by and . Based on the pinhole model, the mapping of a 3D world coordinates point to a 2D image point is described by:
| (1) |
where s is an arbitrary scale factor that is not equal to zero. A is called the intrinsic matrix, which contains five parameters: and are the scale factors in the image axes and , is the principle point and is the skew of the two image axes, which in practice is almost always set to zero. , called the extrinsic matrix, is composed of a rotation matrix and a translation vector from the world coordinate frame to camera coordinates frame.
If the world coordinates are established on a plane (-axis is the perpendicular), then the point on the plane is . Let us redefine as and denote the i-th column of the rotation matrix by . From Equation (1), we have:
| (2) |
According to the projective geometry, this plane to plane mapping can also be expressed by a projective transform:
| (3) |
where is a 3 × 3 homography matrix defined up to a scale factor. Let us denote the i-th column of by . From Equations (2) and (3), we have:
| (4) |
If and are known, then the extrinsic matrix is readily computed. From Equation (4), we have:
| (5) |
3.2. Extrinsic Parameters Calibration of Neighboring Cameras
The extrinsic parameter calibration principle of neighboring cameras using a 1D target is illustrated in Figure 3. The 1D target should have at least six collinear feature points guaranteeing that there are at least three feature points in the FOV of each vision sensor. The distance between different feature points was known previously.
Figure 3.

The extrinsic parameter calibration for neighboring cameras.
As shown in Figure 3, the feature points in the camera coordinate frame and are denoted as and , respectively. Their image coordinates are denoted as and . In addition, let , , and denote the augment vector by adding one as the last element of , , and .
Assuming that the infinite point coordinate of the 1D target in camera coordinate frame to be denoted as , according to the cross ratio definition [28,29], the cross ratio of feature points , , and can be computed by Equation (6):
| (6) |
The projective point of in the image coordinate frame is called the image vanishing point and is denoted as . According to the invariance of the cross ratio by the perspective projection rule, we have:
| (7) |
where , and denote the corresponding image point of 3D point . When the 1D target images are captured by each camera, the image coordinates of feature point and can be accurately determined by the sub-pixel extracting algorithm [30,31]. Because the distance of and are given, the coordinate of image vanishing point can be computed by Equation (7).
Assuming that the 1D target can be freely moved, when the 1D target is at the i-th position, the 1D target unit directional vector, in the k-th camera coordinate frame, is denoted as . The image vanishing point is denoted as . Through Equation (7), we can get the image coordinates of vanishing point [32,33,34].
| (8) |
When the 1D target is placed at the i-th position, the unit directional vectors determined by the 1D target in the camera coordinates , are denoted as and . The unit directional vector and can be easily computed through Equation (8) by the combination of image vanishing points , and intrinsic parameters and . Then, and can be related by the rotation matrix , i.e., . To extract the rotation matrix , the 1D target should be moved at least two times. Thus, there exists Equation (9):
| (9) |
If , we can get the rotation matrix through Equation (10):
| (10) |
When the 1D target is moved to the i-th position, the feature point is denoted as . The image coordinates of is denoted as , and the augment vector is denoted as . With the help of the intrinsic parameters matrix , we can get the following relation between and as Equation (11):
| (11) |
When the 1D target is at the i-th position, the coordinates of feature points , are denoted as and and can be expressed as Equations (12) and (13), respectively:
| (12) |
| (13) |
The unit directional vector in the camera coordinate frame is specified as . Thus, can be written as:
| (14) |
Since the distance of is known, we can obtain Equation (15).
| (15) |
From Equation (15), we can directly solve the unknown parameters and . Then, substituting and into Equations (12) and (13), the coordinates and can be accurately computed.
Similarly, we can get the coordinates of , and in the camera coordinate frame . Let us denote in the camera coordinate frame as . Thus, there exists the formula that transforms feature point from camera coordinate frame to . Therefore, the distance between and with reference to can be computed by Equation (16):
| (16) |
In Equation (16), is the known distance between the feature points and on the 1D target, and is the only unknown variable. Solving Equation (16), the translation vector can be accurately extracted.
3.3. Structured-Light Plane Equation Calibration
The principle of structured-light plane calibration in MSVS is illustrated as Figure 4. Let the 1D target, which contains at least three collinear points with known distance, be freely moved on the structured-light plane more than two times. The camera captures the laser stripe images generated by the line structured-light plane intersecting with the 1D target. Then, using the image sub-pixel processing algorithm extracts the center of the laser stripes with high-accuracy. By notation, we still use to denote the feature points on the structured-light plane. The coordinate of with reference to can be obtained by the method provided in Section 3.2.
Figure 4.
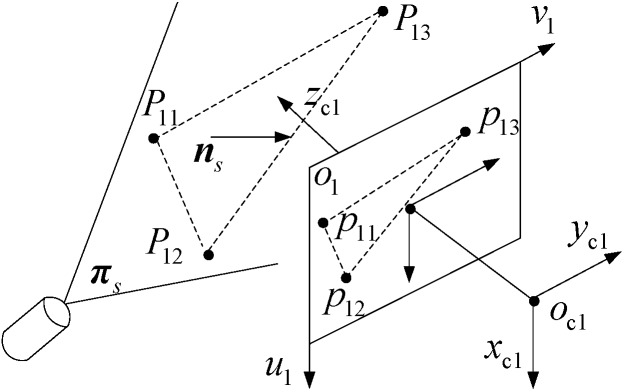
The calibration principle of the structured-light plane.
Assume that there exist three non-collinear feature points denoted as , and on the structured-light plane, and the normal unit vector of the structured-light plane is denoted as . Thus, we can compute as follow: . After is obtained, the structured-light plane equation can be uniquely determined by Equation (17):
| (17) |
where is an arbitrary point on the laser plane and is a feature point whose coordinates are known on the structured-light plane. If is denoted as , then Equation (17) can be rewritten as . If the number of feature points on the laser plane is more than three, the least squares method in [35,36] should be employed to get the optimization solution of .
3.4. Global Optimization
The MSVS for railway tunnel 3D clearance dynamic inspection consists of multiple vision sensors. After implementing the aforementioned calibration procedures, we have obtained the intrinsic parameters of each camera, the extrinsic parameters of the neighboring camera and the laser plane structured parameters. The global measurement model of the MSVS is still not established. The task of this section is to unify the local coordinate frames of each camera to be under one global coordinate frame and to achieve the establishment of the MSVS global measurement model for railway tunnel 3D clearance dynamic inspection.
The global optimization principle of the MSVS is shown in Figure 5. Selecting as the global coordinate frame, the local coordinate frames of other cameras should be transformed into . The coordinate frame of the n-th camera is denoted as and the corresponding image coordinate frame as . The extrinsic parameters of the neighboring cameras are denoted as . The extrinsic parameters between the n-th camera coordinate frame and the global coordinate frame are denoted as .
Figure 5.

The global calibration principle of the MSVS.
In Section 3.2, the extrinsic parameters of the neighboring cameras have been obtained. The same approach can also be put into the extraction of . Thus, the n-th camera local coordinate frame can be converted into the global coordinate frame , through thefollowing transformations:
| (18) |
If we add the perspective imaging model into Equation (18), we can get Equation (19):
| (19) |
where and are the scale factor and camera perspective matrix of the n-th camera. From Equation (19), it can be seen that if arbitrary image coordinates from the MSVS are given, its 3D coordinates in the global coordinate frame can be accurately computed.
4. Vehicle Vibration Compensation
Due to the fact that the MSVS is mounted on a running vehicle, the onboard vision sensors should suffer from multiple degrees of freedom vibrations brought about by the running vehicle. Any slight vibration can result in substantial measurement errors. If the dynamic inspection is implemented in curved railway lines, the measurement performance should be degraded much more severely. In order to reduce the measurement errors caused by the vehicle vibrations, an appropriate compensation method for vehicle vibrations should be adopted and added to the software to improve accuracy.
The compensation principle of vehicle vibrations is shown in Figure 6. It can be seen that the VCC consists of two line structured-light vision sensors installed at the bottom of the vehicle body.
Figure 6.

(a) The vehicle vibrations compensation principle; (b) the detailed computation sketch diagram.
The structured-light vision sensors project line structured-light on the rails, ensuring that light sheds on the rail waist and rail head. The laser strip images are acquired by the high-speed image acquisition block and stored in the computer memory unit. The inspection software processes the laser stripe images and extracts rail feature points on-line. The rail feature point extraction algorithm can be found in [13,14]. The varied results of the rails’ features draws attention to the vision sensors’ local calibration coordinate frame, which can be obtained according to the laser triangulation principle.
When the dedicated inspection vehicle is running, the rolling vibration, pitching vibration and heading vibration are created simultaneously from the vehicle damping springs. Since these three types of vibrations are orthogonal to one another and the structured-light planes emitted by the projectors are perpendicular to the vehicle running direction, only the rolling vibration has a significant impact on the railway tunnel 3D clearance dynamic inspection measurement results. In this paper, the rolling angle is denoted as in Figure 6a. In the rest of this paper, we only consider the influence of the rolling vibration on the measurement results.
The compensation principle of vehicle vibrations is illustrated in Figure 6b. The definition of different notations is listed in Table 1. The parameters in Table 1 can be divided into three categories. The first category indicates the ranging results that can be directly obtained by the vision sensors of the VCC and MSVS, including , , , and , . The second is the constants that are determined by the VCC and MSVS on-site installation, including and . The third is the unknown parameters that need to be determined, including rolling angle , and . If we do not add the vehicle vibration compensation algorithm to the measurement results, the detected values of the feature point are . In fact, the real measurement coordinates in reference to the track central coordinate frame are . Vehicle vibration compensation is the goal of acquiring the coordinates of the feature points, i.e., , based on the parameters from the first and second category.
Table 1.
The definitions of different notations.
| Notation | Parameters |
|---|---|
| The feature point of the left rail | |
| The intersection point of the vehicle central line and the rail top surface | |
| The middle point of | |
| The vertical intersection point of and the line through | |
| The feature point of the right rail | |
| The vertical intersection point of and the line through | |
| The vertical intersection point of and the line through | |
| The vertical intersection point of and the line through | |
| The left calibration center of the VCC | |
| The middle point of | |
| The right calibration center of the VCC | |
| The vertical intersection point of and the line through | |
| The calibration center of the MSVS | |
| An arbitrary feature point on the surface of the railway tunnel | |
| The central line of the track | |
| The central line of the vehicle body | |
| The vertical ranging result of VCC for the left rail | |
| The horizontal ranging result of VCC for the left rail | |
| The vertical ranging result of VCC for the right rail | |
| The horizontal ranging result of VCC for the right rail | |
| The vertical ranging result of the MSVS for the railway tunnel | |
| The horizontal ranging result of the MSVS for the railway tunnel | |
| The vehicle rolling vibration angle |
In Section 3, the calibration approach for the intrinsic and extrinsic parameters of the MSVS has been detailed. Similarly, this approach is also suitable for the calibration of the VCC. Therefore, we can establish the imaging model for the two compensation vision sensors through Equations (20) and (21):
| (20) |
| (21) |
where denotes the image coordinates of the rail feature points and . The coordinates of and in their local measurement coordinate frame are denoted as and , which are illustrated in Figure 6b.
Using the imaging model provide by Equations (20) and (21), we can carry out the vehicle vibration compensation algorithm as the following four steps:
-
(1)Computing the rolling vibration angle and the auxiliary angles:
-
(2)Decomposing orthogonally in the track central coordinate frame:
-
(3)Computing the ranging variables and :
-
(4)Computing the coordinates of an arbitrary feature point on the surface of the railway tunnel reference to the track central coordinate frame:
After the four transformations, the real coordinate values of an arbitrary point on the surface of the railway tunnel are accurately obtained, and the measurement errors caused by the vehicle vibrations can be ultimately eliminated.
5. Experimental Section
In this section, the experiments consist of two parts: one is the calibration of the vision sensors from the MSVS; the other is the railway 3D clearance dynamic measurement. The details are presented in Section 5.1 and Section 5.2, respectively.
5.1. Calibration Experiments
In this section, a MICROVIEW camera Model MVC1000SAM_GE60 with 1280 × 1024 resolution, a KOWA 5-mm focal length lens Model LM5NCL and a Z_Laser Model ZM18 are selected to establish the vision system for railway tunnel 3D clearance dynamic inspection. The MSVS, consisting of seven CCD cameras and seven line structured-light projectors, and the VCC, consisting of two CCD cameras and two line structured-light projectors, are calibrated by the proposed approach.
Before implementing the MSVS assembly procedure, the intrinsic parameter calibration of each camera should be performed first. As shown in Figure 7a, a chessboard, which contains 25 × 20 squares with a distance between the near square corners of 10 mm, is applied in the off-line calibration of the camera intrinsic parameters. In the FOV of each camera, it is only required for the camera to observe the planar target pattern shown at different orientations. In this paper, each camera captures eight images of the planar pattern. Then, with the help of the Harris corner extraction [37] and Zhang’s calibration [18] algorithms, the intrinsic parameters of each camera can be accurately obtained. Due to paper space limitations, the planar pattern images applied in the intrinsic parameters calibration are not carried out, and we only present the acquisition results of the intrinsic parameters in Table 2, where and are the scale factors in the image axes and , is the principle point and is the skew factor of the two image axes.
Figure 7.

(a) The intrinsic parameter calibration using the 2D planar target off-line; (b) the extrinsic parameter calibration using the 1D target on-line.
Table 2.
The intrinsic parameter calibration results.
| Parameters | Camera 1 | Camera 2 | Camera 3 | Camera 4 | Camera 5 | Camera 6 | Camera 7 |
|---|---|---|---|---|---|---|---|
| 2265.17 | 2268.45 | 2262.75 | 2267.32 | 2268.89 | 2260.77 | 2269.53 | |
| 2268.23 | 2269.23 | 2266.91 | 2265.41 | 2265.42 | 2265.92 | 2267.48 | |
| −0.81 | 1.08 | −1.34 | −0.88 | 1.07 | −1.14 | −0.56 | |
| 639.24 | 645.32 | 640.25 | 639.45 | 637.46 | 637.55 | 643.55 | |
| 518.05 | 516.41 | 513.25 | 511.90 | 514.12 | 513.51 | 516.02 |
In Table 2, we have found that the results are very consistent with each other. In order to further investigate the stability of the proposed calibration algorithm, we have presented the nominal values of this type of camera, where = 2264.1, = 2264.1, = 0, = 640 and = 512, as provided by the manufacturer. Comparing the nominal values with the calibration results of Table 2, it can be seen that the sample deviations for all parameters are quite small, which implies that the proposed algorithm is quite stable. The value of the skew parameters is not significant from 0, since the coefficients of variation, from −1.34–1.08, are quite large. Indeed, the maximum value = −1.34 with = 2262.75 corresponds to 89.97 degrees, which is very close to 90 degrees, for the angle between the two image axes. We have also computed the aspect ratio . It is very close to 1, i.e., the pixels are square.
After finishing the intrinsic parameter extraction of each vision sensor, the extrinsic parameters of the MSVS can be obtained according to the acquisition results of Table 2, and the next step is to calibrate the extrinsic parameters of the MSVS. The setup for the extrinsic parameter calibration is shown in Figure 7b. Without loss of generality, multiple cameras can be disassembled into several couples, and the neighboring cameras are calibrated individually.
As shown in Figure 8a, on the surface of the 1D target, there is a total of 20 feature points. In the calibration of each camera couple, the 1D target is fixed and crosses through the FOV of the neighboring cameras. Then, each camera captures part of the 1D target, and the same 1D target imaged by the neighboring cameras is used in the extrinsic parameters’ extraction. In Figure 8a, it can be seen that the left vision sensor captures feature Points 1–10, and the right vision sensor captures feature Points 11–20.
Figure 8.

(a) The 1D target for the camera extrinsic parameter calibration; (b) the 1D target image for a one-camera calibration; (c) the 1D target image for a one-camera calibration.
In order to guarantee the measurement accuracy of the vision system, all of the vision sensors collect the calibration images from multiple views. In the actual calibration experiment, the 1D target is firstly placed in front of each neighboring vision sensor 12 times with different states, and each vision sensor captures 12 images with the same 1D target at different orientations. Then, selecting the coordinate frame of Camera 1 as the global coordinate frame, the 1D target is also moved 12 times in the FOV of the global camera. At each pose, the structured-light plane intersects with the 1D target and formats a laser stripe on its surface, while the global camera captures a total of 12 images with laser stripes.
Due to the limitation space, we only show the images captured by one vision sensor when the 1D target is placed at two different poses. The obtained images are shown in Figure 8b and Figure 8c. By use of the total images and the proposed global calibration method of Section 3, the extrinsic parameters of each neighboring camera and the structured-light plane equation with reference to the global coordinate frame can be directly obtained. The obtained result is calculated as follows:
Finally, we can use the global optimization method provided by Section 3.4 to compute the camera extrinsic parameter matrix and transform the coordinates of an arbitrary feature point from its local coordinate frame to the global coordinate frame. Then, by utilizing of the intrinsic parameters of each camera and the structured-light plane equation, the global measurement model of the MSVS for the railway tunnel 3D clearance dynamic inspection can ultimately be obtained.
5.2. Dynamic Inspection Experiments
In order to validate the effectiveness of the proposed approach in the MSVS calibration, experiments were conducted in the field on a metro line. The dedicated vehicle with the installed MSVS and VCC for railway tunnel 3D clearance dynamic inspection is shown in Figure 9. In the dynamic measurement, the inspection software collects each full cross-sectional profile of the railway tunnel with an interval of 250 mm at a speed of about 60 km/h. There mainly exist three clearance shapes of metro tunnels in China, e.g., circle tunnels, half-circle tunnels and rectangular tunnels.
Figure 9.

(a) The circle tunnel; (b) the half-circle tunnel; (c) the dedicated vehicle installed with the MSVS and VCC; (d) the manual static measurement.
The experiments are implemented in the region between People’s Square Station and Jiansheyi Road Station of Hangzhou Metro Line 2. In this region, the investigated tunnels include two different types, such as circle tunnels and rectangular tunnels.
Since the tunnel of this metro line is designed according to Chinese construction standards, the corresponding drawings showing the geometric dimensions of circle and rectangle tunnels can be separately carried out in Figure 10a,b according to [1]. The drawing of each type of railway tunnel contains vehicle static and dynamic geometric gauges, railway equipment and construction geometric gauges, which are all plotted and labeled individually.
Figure 10.

(a) The circle tunnel actual drawing; (b) the rectangle tunnel actual drawing; (c) the circle tunnel dynamic measurement results; (d) the rectangle tunnel dynamic measurement results.
In one complete cross-sectional profiling dataset of the railway tunnel, there is a total of 8960 feature points, which are collected by the vision sensors of the MSVS simultaneously. In the experiments for railway tunnel 3D clearance dynamic measurements, the continuous records consisting of circle and rectangle tunnels within a 20-m distance are acquired by the inspection software automatically and are shown in Figure 10c,d, respectively. Based on the results shown in Figure 10c,d, we can directly get the dimensional information of the railway tunnel’s 3D clearance. Furthermore, if we compared the measurement results of Figure 10c,d with the drawings of Figure 10a,b, a slight deformation on the surface of the railway tunnel can be found over time, which can eliminate potential risks, avoid incidents and also reduce maintenance costs.
From Figure 10c,d, it can be seen that the surfaces of the 3D images are smooth and without any foreign objects on them. After the comparison of the measurement results of Figure 10c,d and the design drawings of Figure 10a,b, we find that there is no obvious deformation on the surfaces, and the railway tunnels in these areas are in good order.
Furthermore, in order to determine the measurement accuracy of the vision system, 50 feature points, evenly distributed over 50 different cross-sections of railway tunnel along a 20 m section, are selected as testing feature points. Through Figure 10c, the coordinates of these feature points measured by the dynamic vision system are obtained. Then, with the help of a manually-operated theodolite, we can get the coordinates of these feature points under the static state with 0.5-mm accuracy. Selecting the manual measurement results as the basic data and comparing the dynamic measurement results with them, the dynamic measurement errors of these feature points in the horizontal and vertical directions can be easily obtained. The coordinate measurement errors of these feature points in the horizontal and vertical directions are calculated in Figure 11a,b, respectively.
Figure 11.

(a) The horizontal coordinate measurement errors; (b) the vertical coordinate measurement errors.
According to the results shown in Figure 11a,b, it is clear that the measurement errors are not completely eliminated, although the vehicle vibration compensation algorithm is added to the measurement results. From Figure 11a,b, it is not difficult to find that both of the errors in the horizontal and vertical directions conform to a random distribution, and the centers of the random distributions are approximately zero. Since the mean values of the measurement results approach zero, we can conclude that the systemic errors of the dynamic measurement results are almost eliminated, and the current errors are mainly increased by the random errors, which may be brought about by the noises in the procedures of vision sensor calibration and dynamic measurements.
In order to quantitatively analyze the measurement errors of the vision system, the minimum measurement errors, the maximum measurement errors and the root mean square (RMS) measurement errors from the 50 sample feature point error results of Figure 11 in the horizontal and vertical directions are computed. Let , and denote the minimum error, maximum error and RMS error, respectively. The statistical results of the measurement errors based on Figure 11b are detailed in Table 3.
Table 3.
The measurement errors.
| Notation | (mm) | (mm) | (mm) |
|---|---|---|---|
| Horizontal measurement errors | 0.12 | −1.47 | 0.81 |
| Vertical measurement errors | −0.10 | 1.43 | 0.82 |
From Table 3, it can be seen that the maximum measurement error is −1.47 mm. In the railway tunnel field dynamic measurement, the required accuracy is 5 mm. The results of Figure 11a,b show that the dynamic measurement errors are within the allowed range and also demonstrate that the vision system can fully satisfy railway tunnel 3D clearance field measurement.
6. Conclusions
In this paper, a global calibration method for an MSVS is presented. The use of a 2D planar target to calibrate the intrinsic parameters of each camera off-line and the 1D target to calibrate the extrinsic parameters of the neighboring cameras, as well as the equation for the on-line structured-light plane, respectively, is proposed. By integration of the intrinsic parameters to each camera, the extrinsic parameters of each neighboring camera and the structured-light plane equation, the global measurement model can be successfully established. The onboard vision system is mounted on a dedicated vehicle, and it is expected to suffer from multiple degrees of vibrations caused by the running vehicle. In order to overcome this problem, a vehicle motion deviation rectifying method is proposed. The minimum errors, maximum errors and RMS errors based on the railway tunnel 3D clearance dynamic inspection results are calculated, which demonstrate the effectiveness of the proposed vision system.
Acknowledgments
This work was supported by the National High Technology Research and Development Program of China through the 863 Program (No. 2011AA11A102) and the National Natural Science Foundation of China (Nos. 61134001, 51177137, U1234203).
Author Contributions
Tanglong Chen designed the project and instructed the research. Dong Zhan and Long Yu performed the detailed experiments. Jian Xiao analyzed the data and examined the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- 1.Ministry of Construction of the People’s Republic of China . Stand of Metro Gauge, CJJ96–2003. Ministry of Construction of the People’s Republic of China Press; Beijing, China: 2003. [Google Scholar]
- 2.Höfler H., Baulig C., Blug A. Optical high-speed 3D metrology in harsh environments recording structural data of railway lines. Proc. SPIE. 2005;5856:296–306. [Google Scholar]
- 3.John Laurent M.S., Richard F.I. Use of 3D Scanning Technology for Automated Inspection of Tunnels; Proceedings of the World Tunnel Congress; Foz do Iguaçu, Brazil. 9–15 May 2014; pp. 1–10. [Google Scholar]
- 4.Hu Q.W., Chen Z.Y., Wu S. Fast and automatic railway building structure clearance detection technique based on mobile binocular stereo vision. J. China Railw. Soc. 2012;34:65–71. [Google Scholar]
- 5.Mark E. Television measurement for railway structure gauging. Proc. SPIE. 1986;654:35–42. [Google Scholar]
- 6.Markus A., Thierry B., Marc L. Laser ranging: A critical review of usual techniques for distance measurement. Opt. Eng. 2001;40:10–19. doi: 10.1117/1.1330700. [DOI] [Google Scholar]
- 7.Richard S., Peter T., Michael S. Distance measurement of moving objects by frequency modulated laser radar. Opt. Eng. 2001;40:33–37. doi: 10.1117/1.1332772. [DOI] [Google Scholar]
- 8.Dar I.M., Newman K.E., Vachtsevanos G. On-line inspection of surface mount devices using vision and infrared sensors; Proceedings of the AUTOTESTCON ’95. Systems Readiness: Test Technology for the 21st Century. Conference Record; Atlanta, GA, USA. 8–10 August 1995; pp. 376–384. [Google Scholar]
- 9.Alippi C., Casagrande E., Scotti F. Composite real-time processing for railways track profile measurement. IEEE Trans. Instrum. Meas. 2000;49:559–564. doi: 10.1109/19.850395. [DOI] [Google Scholar]
- 10.Lu R.S., Li Y.F., Yu Q. On-line measurement of straightness of seamless steel pipe using machine vision technique. Sens. Actuators A: Phys. 2001;74:95–101. doi: 10.1016/S0924-4247(01)00683-5. [DOI] [Google Scholar]
- 11.Lu R.S., Li Y.F. A global calibration technique for high-accuracy 3D measurement systems. Sens. Actuators A: Phys. 2004;116:384–393. doi: 10.1016/j.sna.2004.05.019. [DOI] [Google Scholar]
- 12.Guo Y.S., Shi H.M., Yu Z.J. Research on tunnel complete profile measurement based on digital photogrammetric technology. Proc. SPIE. 2011:521–526. [Google Scholar]
- 13.Wang J.H., Shi F.H., Zhang J. A new calibration model of camera lens distortion. Pattern Recognit. 2008;41:607–615. doi: 10.1016/j.patcog.2007.06.012. [DOI] [Google Scholar]
- 14.Xu K., Yang C.L., Zhou P. 3D detection technique of surface defects for steel rails based on linear lasers. J. Mech. Eng. 2010;46:1–5. [Google Scholar]
- 15.Xu G.Y., Liu L.F., Zeng J.C. A new method of calibration in 3D vision system based on structured-light. Chin. J. Comput. 1995;18:450–456. [Google Scholar]
- 16.Duan F.J., Liu F.M., Ye S.H. A new accurate method for the calibration of line structured light sensor. Chin. J. Sci. Instrum. 2002;21:108–110. [Google Scholar]
- 17.Liu Z., Zhang G.J., Wei Z.Z. Global calibration of multi-sensor vision system based on two planar targets. J. Mech. Eng. 2009;45:228–232. doi: 10.3901/JME.2009.07.228. [DOI] [Google Scholar]
- 18.Zhang Z.Y. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000;22:1330–1334. doi: 10.1109/34.888718. [DOI] [Google Scholar]
- 19.Zhang Z.Y. Camera calibration with one-dimensional objects. IEEE Trans. Pattern Anal. Mach. Intell. 2004;26:892–899. doi: 10.1109/TPAMI.2004.21. [DOI] [PubMed] [Google Scholar]
- 20.Zhou F.Q., Cai F.H. Calibrating structured-light vision sensor with one-dimensional target. J. Mech. Eng. 2010;46:7–11. doi: 10.3901/JME.2010.18.007. [DOI] [Google Scholar]
- 21.Wang L., Wu F.C. Multi-camera calibration based on 1D calibration object. Acta Autom. Sin. 2007;33:225–231. doi: 10.1360/aas-007-0225. [DOI] [Google Scholar]
- 22.Zhou F.Q., Zhang G.J., Wei Z.Z. Calibrating binocular vision sensor with one- dimensional target of unknown motion. J. Mech. Eng. 2006;42:92–96. doi: 10.3901/JME.2006.06.092. [DOI] [Google Scholar]
- 23.Maybank S.J., Faugeras O.D. A theory of self-calibration of a moving camera. Int. J. Comput. Vis. 1992;8:123–151. doi: 10.1007/BF00127171. [DOI] [Google Scholar]
- 24.Liu Z., Wei X.G., Zhang G.J. External parameter calibration of widely distributed vision sensors with non-overlapping fields of view. Opt. Lasers Eng. 2013;51:643–650. doi: 10.1016/j.optlaseng.2012.11.009. [DOI] [Google Scholar]
- 25.Liu Z., Zhang G.J., Wei Z.Z. Novel calibration method for non-overlapping multiple vision sensors based on 1D target. Opt. Lasers Eng. 2011;49:570–577. doi: 10.1016/j.optlaseng.2010.11.002. [DOI] [Google Scholar]
- 26.Weng J.Y., Paul C., Marc H. Camera calibration with distortion models and accuracy evaluation. IEEE Trans. Pattern Anal. Mach. Intell. 1992;14:965–980. doi: 10.1109/34.159901. [DOI] [Google Scholar]
- 27.Zhan D., Yu L., Xiao J. Calibration approach study for the laser camera transducer of track inspection. J. Mech. Eng. 2013;49:39–47. doi: 10.3901/JME.2013.16.039. [DOI] [Google Scholar]
- 28.Zhang G.J., He J.J., Yang X.M. Calibrating camera radial distortion with cross-ratio invariability. Opt. Laser Technol. 2003;35:457–461. doi: 10.1016/S0030-3992(03)00053-7. [DOI] [Google Scholar]
- 29.Huynh D.Q. Calibration a structured light stripe system: A novel approach. Int. J. Comput. Vis. 1999;33:73–86. doi: 10.1023/A:1008117315311. [DOI] [Google Scholar]
- 30.Hu K., Zhou F.Q., Zhang G.J. Fast extrication method for subpixel of structured-light stripe. Chin. J. Sci. Instrum. 2006;27:1326–1329. [Google Scholar]
- 31.Edward P.L., Owen R.M., Mark L.A. Subpixel Measurement Using a Moment-Based Edge Operator. IEEE Trans. Pattern Anal. Mach. Intell. 1989;11:1293–1309. doi: 10.1109/34.41367. [DOI] [Google Scholar]
- 32.Hartley R., Zisserman A. Multiple View Geometric in Computer Vision. 2nd ed. Cambridge University Press; Cambridge, UK: 2003. [Google Scholar]
- 33.Caprile B., Torre V. Using vanishing points for camera calibration. Int. J. Comput. Vis. 1990;4:127–140. doi: 10.1007/BF00127813. [DOI] [Google Scholar]
- 34.He B.W., Li Y.F. Camera calibration from vanishing points in a vision system. Opt. Laser Technol. 2008;40:555–561. doi: 10.1016/j.optlastec.2007.09.001. [DOI] [Google Scholar]
- 35.Zhou F.Q., Zhang G.J., Jiang J. Field calibration method for line structured light vision sensor. J. Mech. Eng. 2004;40:169–173. doi: 10.3901/JME.2004.06.169. [DOI] [Google Scholar]
- 36.Zhou F.Q., Zhang G.J. Complete calibration of a structured light stripe vision sensor through planar target of unknown orientations. Image Vis. Comput. 2005;23:59–67. doi: 10.1016/j.imavis.2004.07.006. [DOI] [Google Scholar]
- 37.Harris C., Stephens M. A combined corner and edge detector; Proceedings of the Alvey Vision Conference; Manchester, UK. 31 August–2 September 1988; pp. 147–152. [Google Scholar]