

Abstract
A fundamental problem in wildlife ecology and management is estimation of population size or density. The two dominant methods in this area are capture–recapture (CR) and distance sampling (DS), each with its own largely separate literature. We develop a class of models that synthesizes them. It accommodates a spectrum of models ranging from nonspatial CR models (with no information on animal locations) through to DS and mark-recapture distance sampling (MRDS) models, in which animal locations are observed without error. Between these lie spatially explicit capture–recapture (SECR) models that include only capture locations, and a variety of models with less location data than are typical of DS surveys but more than are normally used on SECR surveys. In addition to unifying CR and DS models, the class provides a means of improving inference from SECR models by adding supplementary location data, and a means of incorporating measurement error into DS and MRDS models. We illustrate their utility by comparing inference on acoustic surveys of gibbons and frogs using only capture locations, using estimated angles (gibbons) and combinations of received signal strength and time-of-arrival data (frogs), and on a visual MRDS survey of whales, comparing estimates with exact and estimated distances. Supplementary materials for this article are available online.
Keywords: Abundance estimation, Acoustic survey, Closed population, Measurement error, Visual survey
1. INTRODUCTION
Estimating animal population density is crucial for successful and efficient management and conservation of wildlife resources. As a complete census is rarely feasible, this usually requires survey sampling, most often using one of the two dominant survey methods: capture–recpature (CR) or distance sampling (DS; see Schwarz and Seber 1999; Borchers, Buckland, and Zucchini 2002; Williams, Nichols, and Conroy 2002; Royle and Dorazio 2008, for overviews of methods). In CR, a series of detectors (e.g., traps or cameras) are deployed on multiple sampling occasions. The resulting “capture history” of occasions on which each uniquely identified animal was detected is used to estimate the probability of detection, and hence account for undetected animals. DS requires only a single survey occasion and uses the distances of detected animals from detectors to estimate the detection probability and hence account for animals missed.
Both methods sample a subset of the area occupied by the population of interest and both require some measure of effective area sampled to estimate animal density. When detection is not certain, effective area sampled is obtained by integrating under an estimated detection probability surface. DS methods estimate the detection probability surface by using observed distances to detections to estimate detection probability as a function of distance from detector. CR methods have until recently had no statistically rigorous method for estimating density, but this changed with the advent of spatially explicit capture–recapture (SECR) methods (Efford 2004; Borchers and Efford 2008; Royle and Young 2008; Royle et al. 2013a). SECR data do not include distances to animal locations; instead SECR methods use the distances between detectors at which animals are (and are not) detected to estimate a distance-based detection probability surface.
As it involves a distance-based detection function, SECR is closer to DS than is traditional CR, and in fact SECR methods have borrowed detection function forms from DS. At the same time, there have been developments in DS that bring it closer to CR methods. For example, standard DS methods have been extended to use two independent observers, generating capture history as well as DS data—a method known as mark recapture distance sampling (MRDS; Manly, McDonald, and Garner 1996; Borchers, Zucchini, and Fewster 1998).
In this article, we unify DS and CR methods and in doing so create a class of model that includes a range of models that can be viewed as hybrids of them. Examples include MRDS surveys with distance measurement error and SECR surveys that contain additional information about animal location, such as received acoustic signal strength (SS), precise time of acoustic detection, or estimated bearing to detected animals. We demonstrate the new class through a series of applications to both real and simulated datasets.
2. MOTIVATING PROBLEMS
2.1. Gibbon Survey
Gibbons are difficult to detect visually in forest but can be detected quite easily acoustically when they make territorial calls. An acoustic survey with human detectors, of northern yellow-cheeked gibbon (Nomascus annamensis) was conducted in northeastern Cambodia by Conservation International in 2010. The design involved three people standing in a line spaced approximately 500 m apart, recording estimated angles to all gibbon groups they heard. Observers who detected a group comprise the group’s capture history, while the estimated angles to detected groups provide additional data on group location. Use of the additional data is shown to improve inference.
2.2. Frog Survey
An acoustic survey of Lightfoot’s moss frog (Arthroleptella lightfooti) in a water seepage on Table Mountain, South Africa, was conducted using six microphones in a roughly rectangular arrangement. The survey is similar to the gibbon survey in that spatial capture histories consist of the locations of detectors (microphones) at which each vocalization (frog click) was detected. The time difference of arrival (TDOA) of the same click at different detectors and the received SS at each detector provide additional data on animal location. Each of the additional data types improves inference in this case.
2.3. Minke Whale Survey
As part of the 2001 North Atlantic Sightings Survey (NASS 2001; see Pike et al. 2009, for details), two independent observers surveyed the same region of sea simultaneously from an aircraft, recording estimated distances to detected whale cues (blows). The detectors (the observers) were at the same location, and capture histories indicate which observer(s) detected each cue. Having the detectors at the same location has implications for SECR analysis that we expand upon below. Additional data on whale location are contained in the estimated distances to detected cues, even though they are subject to measurement error. Use of these data is shown to substantially reduce density estimation bias.
3. THE MODEL
3.1. Animal Location
We use a generic notion of animal location, specified via Cartesian coordinates . In DS surveys, is the actual location of an animal at the time of the survey. If an animal moves during the survey its location represents the average of its positions over the survey. In the context of trapping studies, these locations have variously been called, “home range centers,” “centroids,” and “activity centers” (Borchers and Efford 2008; Royle and Young 2008; Royle et al. 2009a). Ideally, we would like to observe , but this may not be possible. Below we derive a likelihood function that accommodates situations in which location is observed, in which it is partially observed or observed with error, and in which only locations of the detectors are observed. We develop the likelihood for SECR surveys without any information on animal locations other than the spatial capture history, and then extend this to include location observation data.
3.2. Probability Model and Likelihood
Consider a survey of a region with surface area A in which K detectors are deployed on S occasions. Following Borchers and Efford (2008), we assume that animals are independently distributed in this region according to a nonhomogeneous Poisson process (NHPP) with parameter vector and intensity at . We denote the probability that an animal at is detected by at least one detector on the survey as , with unknown parameter vector . It follows that the locations of detected animals, , are realizations of a filtered NHPP with intensity at .
We construct a probability model for the outcomes of a survey via a product of conditional probabilities, which are developed below. The first component of the model is the probability of detecting n animals: . The second is the probability density function (pdf) of animal locations, , conditional on detection, which we write as .
The third component is the probability of observing the capture histories , conditional on detections and detected animal locations , which we write as . Here , where is the capture history of the ith animal. The joint pdf of n, , and is then
| (1) |
We now expand upon each of the terms on the RHS of this equation, after which we add a term for (possibly noisy) observations of animal locations.
Note that our model assumes that each animal has a single for the survey. This does not mean that animals do not move, just that is the center of activity over the whole survey if they do move. We discuss this further in Section 5.
3.2.1. Capture History Given Location.
We define an indicator variable ωiks that is 1 if animal i is detected by detector k on occasion s and is 0 otherwise, so that the capture history of animal i on occasion s is and its full capture history is . It is convenient to define two indicator variables derived from ωiks, as follows: let ωi · s = 1 if animal i was detected on occasion s and ωi · s = 0 otherwise, and ωi · · = 1 if animal i is detected at all and ωi · · = 0 otherwise. Letting B(ω, p) indicate a Bernoulli probability mass function for ω, with parameter p, we can write as
| (2) |
where is the probability that animal i at is detected on occasion s, is the probability that animal i is detected by detector k on occasion s, and is the inclusion probability for animal i, that is, the probability that it is detected at all. is the probability that on occasion s detected animal i has capture history . This probability is different for proximity detectors (which detect animals without detaining them) and detectors that hold animals until the end of the occasion. Appendix A contains the details for each of these cases. It is also shown in this Appendix that in the case of proximity detectors with a single occasion and any survey with a single detector and multiple occasions, is identical to the conditional likelihood of Huggins (1989).
So if the 's were observed, we could estimate abundance using the conditional likelihood approach of Huggins (1989), with as the observed covariate vector. This implies that (unlike conventional CR) estimation is possible from multiple detectors on one occasion with proximity detectors, as recaptures within occasion are possible. (Efford, Borchers, and Byrom 2009a, first noted this fact.)
Because animal location () is not observed on conventional CR studies (only locations of capture are observed), we cannot take the approach of Huggins (1989). But the location covariate is observed on MRDS surveys, which involve a single occasion (S = 1) and typically two observers (K = 2), acting as independent detectors, recording locations of detections. In this case, we could use the approach of Huggins (1989). This is, however, seldom done because on MRDS and other DS surveys with randomized sampler locations, animal locations in the vicinity of detectors can be treated as random variables with a known pdf determined by design (namely a uniform distribution in the plane) and Borchers (1996) showed that using this pdf of locations in estimation usually improves MRDS estimator properties. Hence, the estimator of Huggins (1989), which conditions on locations, is not optimal for MRDS estimation and is generally not used for MRDS data. Instead MRDS inference is based on likelihood functions that treat as random. These involve the conditional distribution of animal locations given detection, , which we now consider in more detail.
3.2.2. Animal Locations, Given Detection.
As noted above, MRDS methods assume an independent uniform distribution of animals within detectable range (Borchers, Zucchini, and Fewster 1998). This distribution is consistent with animals being distributed according to a homogeneous Poisson process (HPP) in the plane. We make the more general assumption that animals occur according to an NHPP, with intensity at . As an animal at is detected with probability , it follows that detected animals occur according to a filtered NHPP with intensity . The pdf of given detection is obtained using Bayes’ theorem as , where . Assuming independent detections, we have . The same is obtained if we treat the number of animals in the area as fixed at N and assume that these animals are located independently in space with probability density at .
3.2.3. Number of Detections.
If animals are independently distributed in the plane according to an NHPP with parameter vector and intensity at , and they are independently detected with probability , it follows that n, the number of detected animals, is a Poisson random variable with rate parameter . If the number of animals in the area is a fixed number N, then n is a binomial random variable with parameters N and .
3.2.4. Location Observation Given Capture History.
Suppose now that in addition to observing ωiks for animal i on occasion s, we also observe a vector containing M different kinds of data, each of which is a noisy observation of animal location. An example with M = 2 is an acoustic survey in which detectors are microphones and SS (y iks1) and time of arrival (y iks2) of the sound at a microphone are recorded. Writing the set of all observations as , we write the conditional pdf of given as , where is a vector of parameters to be estimated. In the models we consider, the 's are conditionally independent, given . In general, yiksm may affect detection probability, and in this case must be replaced by in all of the above, and , , become , , . (See Efford, Dawson, and Borchers 2009b, and below.)
Following Efford, Dawson, and Borchers (2009b), we model the expected value of the random variable ym (dropping the iks subscript for brevity here), given , as . Here gm is a link function, is a component of and the “proxy function” returns the component of location for which ym is a proxy, at detector k. For example, if ym is either the observed distance from detector to animal or the received SS, then is the true distance from detector k to the animal.
3.3. The Likelihood Function
The joint density of n, , and is
| (3) |
where is the product of , and . In general, is not observed and this density cannot therefore be evaluated. We obtain our likelihood by marginalizing over in Equation (3):
| (4) |
and we estimate by maximizing this equation with respect to . We obtain interval estimates using the inverse of the negative Hessian matrix, which is obtained from numerical maximization of the likelihood. Model selection can be done using AIC or any other likelihood-based method.
3.3.1. Estimating Animal Location
Given estimates , and , animal locations can be estimated from by application of Bayes’ Theorem as follows (omitting , , and for brevity and indicating estimates by “hats” on functions):
| (5) |
Besides being of possible inherent interest, the pdf of animal locations, , is useful for illustrating the effect of the location observation data on the precision of location estimation, and we use it primarily for this purpose below.
4. ANALYSES OF MOTIVATING PROBLEMS
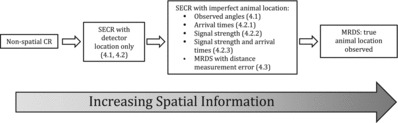
The continuum of increasingly spatially resolved spatial sampling models covered in this article is illustrated in Figure 1. SECR models without location observations are obtained by omitting from the model. Detection probability of an animal at distance zero from detectors (denoted , with being the location of the kth detector) may be constrained to be 1 or not, depending on the application. DS and MRDS models are obtained by defining to be unity at and zero elsewhere. MRDS models generally have K = 2 and S = 1 and allow while conventional DS models have K = 1, S = 1 and define .
Figure 1 . A continuum of increasingly spatially resolved capture–recapture models. Numbers in brackets correspond to subsections of the article.
All the case studies below involve proximity detectors and a single occasion (so we omit subscript s), but the methods apply equally to multi-catch traps and multiple occasions. We do not include any covariates or individual random effects (other than ) in our applications for brevity and because our emphasis is on illustration of the effects of adding supplementary data. See Discussion for more on covariates.
All analyses and plots were done with the R library admbsecr, written by authors of this article (see online supplementary material).
4.1. Gibbon Survey: SECR With Estimated Angles
4.1.1. The Model
Recall that the detectors are observers standing in a line spaced approximately 500 m apart (see Figure 2), recording estimated angles to gibbon groups they heard. We use SECR methods to estimate the density of calling groups from the locations of the observers who detected the group, both with and without the angle data.
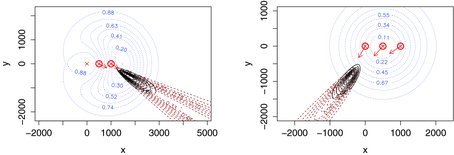
Figure 2 . Example location estimates, given capture, of two different gibbons. Detectors are crosses; circled detectors are those that detected the gibbon call. Arrows show estimated angles to detections. Dotted lines are the contours of the estimated probability of the group being contained within the contour, given only the spatial capture history data Ω. Dashed lines are estimated contours, given only observed angles to detections. Solid lines are estimated contours, given capture history and angles.
Here S = 1 and we model the probability of detecting animal i with location in trap k on this occasion as , where , is the distance from observer k (located at coordinates ) to animal i at : . We assume an HPP for animal locations with .
Supplementary data comprise recorded angles to animals, so M = 1 and, dropping subscripts s and m for brevity, we let yik denote the recorded angle between animal i and detector k, with respect to some reference direction. The proxy function is the inverse tangent of (z k2 − x i2)/(z k1 − x i1)). We assume an identity link in the expectation function so that , and we assume angles are estimated without bias at all distances so that β0 = 0 and β1 = 1. A von Mises distribution with concentration parameter γ is used to model the angle observation error (). With independent angle observation errors,
| (6) |
where I 0( ) is the modified Bessel function of order 0.
4.1.2. Results
A total of 123 detections of 77 calls were made. Using only capture histories (), the density of calling gibbon groups is estimated to be 0.83 groups per square kilometer, with a coefficient of variation (CV) of 44%, while using and it is estimated to be 0.32 with CV of 23%. The differences arise as a consequence of the estimated detection function scale parameter θ being much smaller when only is used ( = 754 m; CV = 23%) than when is also used ( = 1248 m; CV = 11%).
To investigate the cause of the differences we plotted estimated locations of calling groups using Equation (5), and we conducted a simulation study (with 500 simulations) in which true parameter values were equal to those estimated using and . Illustrative examples of location contours are shown in Figure 2 and the simulated sampling distributions of the two estimators is shown in Figure 3.
Figure 3 . Smoothed simulated sampling distributions of estimated gibbon call density when only spatial capture history is used in estimation (“simple”) and when capture history and observed angles are used (“angle”). The down arrow marks true (simulated) density, the horizontal axis is percentage deviation from true density, and the up arrows are the means of the sampling distributions.
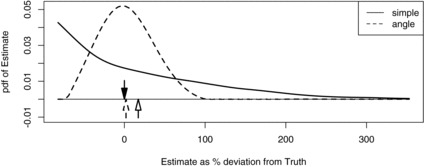
The utility of angle data is apparent in Figure 2 in the form of much tighter contours when and are used than for alone. It is also apparent in Figure 3, which shows the “simple” estimator using only to be biased (by about 15%), very much more dispersed and with a mode far below truth (“truth” being the density used in simulating). (Note that with three detectors there are only seven possible capture histories and hence the simple SECR model will estimate all animals to be at one of only seven locations, while with the angle data, an infinite number of locations is possible.)
Part of the problem is poor design: with detectors spaced only 500 m apart and scale parameter θ = 1248 the simple estimator has no information on how detection probability varies at distances greater than 1000 m—because detections are never more than 1000 m apart. The angle data overcome this limitation: use of improves estimation.
4.2. Frog Survey: SECR With Arrival Times and Signal Strength
In this case, we have multivariate location data , comprising the TDOA and SS of detected frog clicks. We have one occasion (S = 1) and the arrangement of the six microphones (K = 6) is shown in Figure 4.
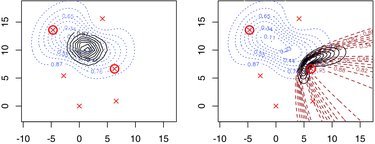
Figure 4 . Estimated location contours given capture history and SS (left) and capture history and TDOA (right), of a click. Detectors are crosses; circled detectors are those that detected the frog click. Dotted lines are the contours of the probability density of frog location given only spatial capture history data Ω. Dashed lines in the right plot are contours given only TDOA. Solid lines are contours of location given capture history and SS (left) or capture history and TDOA (right).
We compare estimators using SECR methods with no location observations, using TDOA data, using SS data, and using both. We use the same forms for , , and as were used in the gibbon survey. Models for TDOA data and SS are specified below, followed by analysis and simulation results for each case.
4.2.1. TDOA Observation
As we have only one kind of supplementary location data (M = 1), we omit the m subscript and we let yik denote the time of arrival of the ith clicks at detector k. The proxy function is the distance function (in meters) used above. We assume normal errors in time of arrival, and constant variance σ2 t of this error at all microphones, which is consistent with randomness in time of arrival being dominated by measurement error. We use an identity link so that , where β0i is the time the ith sound was generated and β1 is the inverse of the speed of sound in air (in meters per second).
The time clicks are made is uninformative about location, as a click made at distance at time β0 has the same expected arrival time as one made at distance at time β0 − c, for any c. The β0i's are what (Millar 2011, pp. 188–189) called incidental parameters, and to eliminate them we can base inference on the likelihood of time differences of arrival (TDOAs) from the mean arrival time, conditional on the mean arrival time:
| (7) |
where n + is the number of clicks detected on more than one microphone, mi is the number of microphones on which the ith of these was detected, , , and . The same likelihood can be obtained using a marginal approach, treating the β0s as random effects (see online supplementary material). For this reason, and for brevity, we do not explicitly show the conditioning on s on the LHS of the equation.
4.2.2. Signal Strength (SS) Observation
The ideas of this section are taken from Efford, Dawson, and Borchers (2009b). M = 1 and we let yik denote the received SS at detector k. The proxy function is as above and we model the expectation as , where β0 is the mean SS of clicks and β1 is a parameter quantifying SS loss with propagation distance. (We also tried a log link, , but this was found to be inferior in terms of AIC: ΔAIC = 18.) As with the time of arrival model, we assume that yik is normally distributed with constant variance, σ2 s, but unlike the time of arrival model, we estimate β0 and β1 in addition to σ2 s, so that . In addition, because signals weaker than some specified strength c are filtered out at the acoustic processing stage, detection probability depends on received SS. We can write the probability of microphone k detecting signal i made at a distance from it as , where is the cumulative distribution function (CDF) of a normal random variable with mean and variance σ2 s, evaluated at c. Then,
| (8) |
where mi is as before, the number of microphones on which click i was detected and is a normal pdf with mean and variance σ2 s, evaluated at yik.
4.2.3. TDOA and Signal Strength (SS) Observation
In this case, M = 2 and we let where y ik1 is the time of arrival and y ik2 is the received SS of click i at detector k. Both and are the distance function and we assume the same models as above so that , , and assuming y ik1, y ik2 to be independent we have
| (9) |
4.2.4. Comparison of Estimates With and Without TDOA, SS
A total of 590 detections of 345 frog clicks were made. Using SECR only, the click density is estimated to be 152.1 clicks per hectare per minute, with standard error 10.6 (CV = 7.0%). When SS is used these are reduced to 148.9 and 8.9 (CV = 6.0%), when TDOA is used they are reduced to 134.5 and 9.5 (CV=7.1%), and when both SS and TDOA are used, they reduce to 125.7 and 8.0 (CV = 6.4%). While both SS and TDOA reduce the point estimate of density and its standard error, the effect of SS on the point estimate is weaker. Investigation at the individual click level revealed that point estimates of click locations from the TDOA+SS model tended to agree well with those from the simple SECR model (but were more precise), while those from SECR+TDOA often differed substantially. Figure 4 shows an example for a specific click. The average difference in received SS for individual clicks was less than 2% of its mean value and it may be that the distances between microphones were too small for the contrast in received SS to be very informative about location. The same is not true of TDOA.
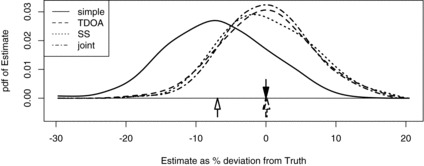
We investigate estimator properties by simulation (500 simulations), using the parameter estimates from the SECR+SS+TDOA model as truth and mean sample size equal to that observed on the survey. Simulated sampling distributions are shown in Figure 5. As expected, the addition of SS or TDOA reduces bias and improves precision, and there is a further small improvement in precision when both SS and TDOA data are used: the CVs for the SECR, SECR+SS, SECR+TDOA, and SECR+SS+TDOA models are 7.9%, 6.8%, 6.8%, and 6.1%, respectively.
Figure 5 . Smoothed simulated sampling distributions of estimated frog click density using only spatial capture history (“simple”), using capture history and time of arrival (“TDOA”), using capture history and signal strength (“SS”), and using capture history, time of arrival and signal strength (“joint”). The down arrow marks true density, the horizontal axis is percentage deviation from true density, and the up arrows are the means of the sampling distributions, expressed as percentage deviation from truth (some are almost coincident).
4.3. Whale Survey: MRDS With Estimated Distances
4.3.1. The Model
We estimate the number of minke whale cues per hectare over the sampling period from 71 detections obtained on the aerial cue-counting component of the NASS 2001 survey. K = 2 as there were two detectors and S = 1 as they made one pass over animals. Standard SECR methods cannot be applied in this case because a distance-dependent detection function cannot be estimated from detectors at a single location. But with the addition of estimated distances to detections (yik for observer k’s estimate of distance to cue i), estimation is possible.
MRDS survey models treat distances as being observed without error (see Borchers et al. 2009; Laake et al. 2011, for cue counting and point transect examples); our model readily allows distance measurement error to be incorporated in MRDS inference, estimating measurement error from the pairs of recorded distances of the two observers to recaptures, simultaneously with density and detection function parameters. In this survey, measurement error is substantial, as can be seen from Figure 6. We estimate cue density allowing probability of detection at distance zero to be less than unity, both with and without the assumption of no measurement error. Were we to enforce certain detection at distance zero, we would have conventional distance sampling (CDS) models with and without measurement error. (See Borchers et al. 2010, for references to CDS models with measurement error.)
Figure 6 . Estimated location contours (dotted) given capture history and recorded location (solid) of a whale detected by one of the two detectors. Contours are such that 100α% of the density falls between the two contours marked α. The left plot shows locations in perpendicular and forward distance space, the right curve shows it in radial distance space. Detectors are crosses.
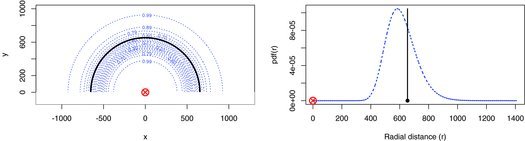
Following standard practice for DS surveys, we assume an independent uniform distribution of animals in the plane (Buckland et al. 2001) and hence use a HPP for animal locations with . This leads to the usual cue-counting pdf for radial distances of detected animals (see online supplementary material). We found it necessary to introduce detector-specific detection function parameters as one detector was far more efficient than the other. We use , where (k = 1, 2) and . The proxy function is the distance function . Following Borchers et al. (2009), we assume unbiased distance estimation with gamma errors, that is, and
| (10) |
where yik is the radial distance measurement from observer j to cue i.
For the case without measurement error, we define to be 1 if , and zero otherwise.
4.3.2. Results
When distance measurement error is accommodated using an SECR model with estimated distance data, density is estimated to be 1.72 whale cues per hectare over the duration of the survey (CV = 18%), and detection probability at distance zero for the two detectors (, k = 1, 2) to be 1.0 (CV = 0.01%) and 0.30 (CV = 25%). When using an MRDS estimator in which distances are assumed to be error-free (as is the norm for such analyses), density is estimated to be 1.61 (CV = 17%) and , k = 1, 2 to be 1.0 (CV = 0.01%) and 0.30 (CV = 23%). Figure 6 shows the contours of estimated location of a whale detected only by detector 2, when observed distance is assumed error free and when it is estimated with measurement error.
Formulating the MRDS survey as an SECR estimation problem with distance measurement error provides a ready means of accommodating both measurement error and estimation of —something that has to date not been done in analyses of DS data, with the exception of a model developed by Hiby and Lovell (1998) which used distance interval data rather than continuous distance measurements.
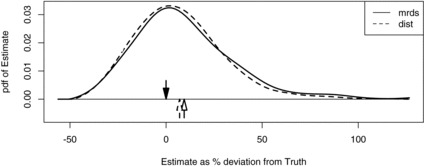
We conducted a simulation study (500 simulations) to investigate the effect of neglecting measurement error on density estimates, using the parameters estimated from the model that incorporates measurement error, with mean sample size of 70, and with error CVs of 12%, 32%, and 50%. Results for the 32% case are shown in Figure 7. On the 1987 NASS survey measurement error CV was estimated to be 32% compared to 12% on the 2001 survey—see Borchers et al. (2009). All estimators were found to be positively biased but those from the MRDS model were (in order of increasing measurement error CVs) larger by 14%, 34%, and 68%, respectively. Biases using the SECR model with measurement error were 7.7%, 7.0%, and 8.2%. As the model estimates six parameters from only 70 observations, we believe this to be small-sample bias.
Figure 7 . Smoothed simulated sampling distributions of estimated whale cue density when capture history and exact distances are observed (“mrds”) and when capture history and estimated distances are used (“dist”). The down arrow marks true density, the horizontal axis is percentage deviation from true density, and the up arrows are the means of the sampling distributions.
5. DISCUSSION
We have shown that DS and CR are special cases of a more general class of spatial sampling model that uses detection locations to assist in estimating detection probability, and hence density. We have also shown that in the case of CR surveys, supplementing data on locations of captures with data on animal location (albeit noisy or incomplete) can substantially improve inference, particularly when designs are not optimal. Indeed, when MRDS surveys are considered as SECR surveys, most have the worst possible design (detectors at the same location) and inference about density from them would be impossible without the additional location data.
In the case of DS surveys, the new class of model provides a ready means for incorporating measurement error into inference, with or without the conventional DS assumption of certain detection at distance zero. The general model also provides a framework for incorporating into SECR surveys the point independence (Laake 1999; Innes et al. 2002; Borchers et al. 2006) and limiting independence (Buckland, Laake, and Borchers 2009) methods developed in the DS literature, as a means of reducing bias due to unmodeled heterogeneity.
5.1. Model Extensions
One topic that we have skirted, for lack of space, is how covariate data is incorporated into the models. Covariates can be incorporated in the density model most naturally via a log link function, in the scale parameter of detection functions using a log link, and in the intercept parameter of detection functions using a logit link. Borchers and Efford (2008) and Royle et al. (2013b) contained SECR examples with a variety of explanatory variables and the former includes individual random effects. Marques and Buckland (2003) dealt with explanatory variables for DS models, and Borchers, Zucchini, and Fewster (1998) dealt with them for MRDS models.
We have also not covered any detail of how NHPP or other models that involve nonuniform animal distribution might be implemented. Although animal distribution is typically not homogeneous in space, it is usual to assume uniform spatial distribution in DS analyses (as a consequence of random placement of detectors), but DS estimators usually use this assumption only to estimate detection probability (estimating density conditional on detection probability using design-based methods). They have been found to be relatively robust to violation of the assumption at this level (see Buckland et al. 2001). Other methods may not be. Johnson, Laake, and Hoef (2010) implemented DS with an NHPP and Royle et al. (2013b) implemented a Bayesian version of SECR with an NHPP, with log-linear dependence on environmental covariates in both cases. We believe there is a need for more flexible models that are not necessarily monotonic in their dependence on explanatory variables, and expect that these will be developed in the near future. This could be achieved using penalized regression splines, in a similar way to that in which Gimenez et al. (2006) used them to model nonmonotonic dependence of survival probability in an open-population capture–recapture model.
Bayesian and frequentist versions of SECR have been developed in parallel by different authors. Bayesian inference tends to be particularly useful in the presence of latent variables or random effects—and animal locations are latent variables in SECR models. However, marginalization over locations involves a simple two-dimensional integral when locations are independent, making maximum likelihood inference straightforward. In this case, both approaches work well and it is largely a matter of personal preference which is used. Maximum likelihood estimation has to date proved to be much faster than the MCMC methods used for Bayesian inference, even when a random effect for unmodeled heterogeneity in detection probability is incorporated in the model. It seems likely that the Bayesian approach will come into its own when there is a more complicated latent variable structure—when there is dependence between latent variables, for example. In such cases, the marginalization required for maximum likelihood inference may become infeasible. We expect that models that do not involve independent distribution of animal locations (as NHPPs do) will soon be developed, as animals are often not independently distributed. A simple but common case is when animals occur in groups; in this case, animals within the group may not be detected independently of one another. This can often be dealt with by treating the group as the detection unit while simultaneously estimating mean group size if individual animal density is of interest, but in other cases models for spatial dependence may be required.
5.2. Robustness and Diagnostics
The robustness of estimators within the class of models developed in this article to failures of assumptions is likely to be case-specific. DS point estimators of density tend to be robust to failure of the assumption of independent uniform animal distribution (see Buckland et al. 2001, p. 36), although interval estimators are not. Efford, Borchers, and Byrom (2009a) found SECR point and interval estimators with multi catch traps to be robust to failure of assumptions of independence and uniformity (see Table 4, p. 266), and also found density estimates to be little affected by the form assumed for the detection function.
Goodness-of-fit diagnostics are well developed for DS detection function estimators, using observed locations (see Buckland et al. 2004, pp. 385–389). Similar diagnostics when locations are not observed remain to be developed (for both DS and SECR estimators). Borchers and Efford (2008) proposed a Monte Carlo goodness-of-fit test based on scaled deviance for the overall fit of SECR models but this does not distinguish between lack of fit of the animal density model and lack of fit of the detection model. This is an area that would benefit from further research.
5.3. Animal Movement
The methods of this article assume a single location (activity center) for each animal over the whole survey, but this does not imply or require that animals do not move during the survey. Nor does it require that movement between occasions on a multi occasion survey (S > 1) be modeled; providing that either (a) single- or multi-catch traps are used, or (b) occasions are long enough that the distribution of points that an animal visits over the duration of an occasion is the same as that over the duration of the whole survey. In the former case, there is no information on animal movement within occasions and the location is by definition the center of activity across occasions. In the latter case, the center of activity across occasions is identical to that within occasions. If proximity detectors are used and (b) above does not hold, then the detection functions within occasion will differ from those across occasions (typically having shorter ranges for shorter occasions). Models that do not allow for this are misspecified and may produce biased estimates. This problem can usually be avoided by having a design with occasions that are sufficiently long.
When activity centers move between occasions, an additional model layer for activity center movement will be required in general. The simplest such model is probably one in which the activity centers on each occasion are independent random effects with mean equal to an animal’s activity center across all occasions. But we believe that this will not be an adequate model in many applications, because activity centers on consecutive occasions are likely to be correlated. If activity centers are observed on some (but not all) occasions, the methods of Langrock and King (2013) and of references therein may be useful for modeling activity centers that were not observed, conditional on those that were. (If animal activity centers are the same for all occasions and some but not all are observed, the likelihood is like Equation (4), but with integration over only those centers that were not observed.)
5.4. Recapture Uncertainty
A final important issue that remains to be resolved for this class of model, and indeed for many CR models of any sort, is how to deal with uncertain recapture identification, as this can be fraught with uncertainty when animals are not physically tagged. This general problem was addressed by Link et al. (2010) for example, while Bonner (2013) and work referenced therein addressed the issue when there are multiple sources of individual identification. None of these methods explicitly use location information and we expect that methods that use location data to quantify the probability that detections are recaptures will be useful, as they were in the MRDS analysis of Hiby and Lovell (1998).
APPENDIX A: VARIETIES OF P Ω ∣ X; θ
Multi-catch traps detain animals until the end of the sampling occasion in which they are trapped (and do not fill up). Proximity detectors are detectors that do not detain animals and therefore allow captures of the same animal on different traps within occasions. In some proximity detector applications, it is possible to detect the same animal more than once at the same detector. In this case, either binary capture histories of the sort used in the body of this article can be used or the capture frequency of each animal at each trap on each occasion can be recorded.
In the case of multi catch traps, all but one of ωi1s, …, ωiKs are zero and Pr is a multinomial distribution with index 1 and probabilities (k = 1, …, K). Modeling using a competing hazard formulation (see Borchers and Efford 2008), , where is defined as , the relative hazard of detection at trap k on occasion s for an animal at , is the detection hazard at trap k and is the total hazard on the occasion. Hence, and the multinomial probabilities are .
In the case of proximity detectors with binary ωiks, Pr is written as . In the case of proximity detectors with frequency data in which ωiks is the frequency of detection on detector k on occasion s, Royle et al. (2009b) proposed a Poisson model for ωi · s, such that Pr is , where Po(x, λ) is a Poisson distribution with parameter λ.
With binary capture histories, Equation (2) reduces to Equation (A.1) below for proximity detectors when K = 1 and it reduces to Equation (A.2) with either kind of detector when S = 1.
| (11) |
These equations have the same form as the conditional likelihood of Huggins (1989). Equation (A.1) corresponds to the conventional CR case—in which there is usually more than one trap but all traps together are treated as a single composite trap, effectively with one location.
SUPPLEMENTARY MATERIALS
Conventional point transect likelihood as a special case; Derivation of random effect TDOA distribution; Details of the R library admbsecr.
REFERENCES
- Bonner S. Response to: A New Method for Estimating Animal Abundance With Two Sources of Data in Capture-Recapture Studies. Methods in Ecology and Evolution. 2013;4:585–588. [Google Scholar]
- Borchers D.L. Line Transect Abundance Estimation With Uncertain Detection on the Trackline. 1996 PhD Thesis, University of Cape Town, Cape Town. [Google Scholar]
- Borchers D.L. Buckland S.T. Zucchini W. Estimating Animal Abundance: Closed Populations. London: Springer; 2002. [Google Scholar]
- Borchers D.L. Efford M.G. Spatially Explicit Maximum Likelihood Methods for Capture-Recapture Studies. Biometrics. 2008;64:377–385. doi: 10.1111/j.1541-0420.2007.00927.x. [DOI] [PubMed] [Google Scholar]
- Borchers D.L. Laake J.L. Southwell C. Paxton C. G.M. Accommodating Unmodelled Heterogeneity in Double-Observer Distance Sampling Surveys. Biometrics. 2006;62:372–378. doi: 10.1111/j.1541-0420.2005.00493.x. [DOI] [PubMed] [Google Scholar]
- Borchers D.L. Marques T.A. Gunlaugsson Th. Jupp P. Estimating Distance Sampling Detection Functions When Distances are Measured With Errors. Journal of Agricultural, Biological and Environmental Statistics. 2010;15:346–361. [Google Scholar]
- Borchers D.L. Pike D. Gunlaugsson Th. Vikingson G. Minke Whale Abundance Estimation From the NASS 1987 and 2001 cue Counting Surveys Taking Account of Distance Estimation Errors. North Atlantic Marine Mammal Commission Publications. 2009;7:201–220. [Google Scholar]
- Borchers D.L. Zucchini W. Fewster R. Mark-Recapture Models for Line Transect Surveys. Biometrics. 1998;54:1207–1220. [Google Scholar]
- Buckland S.T. Anderson D.R. Burnham K.P. Laake J.L. Borchers D.L. Thomas L.J. Introduction to Distance Sampling. Oxford: Oxford University Press; 2001. [Google Scholar]
- Buckland S.T. Anderson D.R. Burnham K.P. Laake J.L. Borchers D.L. Thomas L.J. Advanced Distance Sampling. Oxford: Oxford University Press; 2004. [Google Scholar]
- Buckland S.T. Laake J.L. Borchers D.L. Double-Observer Line Transect Methods: Levels of Independence. Biometrics. 2009;66:169–177. doi: 10.1111/j.1541-0420.2009.01239.x. [DOI] [PubMed] [Google Scholar]
- Efford M.G. Density Estimation in Live-Trapping Studies. Oikos. 2004;106:598–610. [Google Scholar]
- Efford M.G. Borchers D.L. Byrom A.E. Density Estimation by Spatially Explicit Capture-Recapture: Likelihood-Based Methods. In: Thompson D. L., editor; Cooch E. G., editor; Conroy M. J., editor. Modeling Demographic Processes in Marked Populations. New York: Springer; 2009a. pp. 255–269. [Google Scholar]
- Efford M.G. Dawson D.K. Borchers D.L. Population Density Estimated From Locations of Individuals on a Passive Detector Array. Ecology. 2009b;90:2676–2682. doi: 10.1890/08-1735.1. [DOI] [PubMed] [Google Scholar]
- Gimenez O. Crainiceanu C. Barbraud C. Jenouvrier S. Morgan B. J. T. Semiparametric Regression in Capture–Recapture Modelling. Biometrics. 2006;62:691–698. doi: 10.1111/j.1541-0420.2005.00514.x. [DOI] [PubMed] [Google Scholar]
- Hiby L. Lovell P. Using Aircraft in Tandem Formation to Estimate Abundance of Harbour Porpoise. Biometrics. 1998;54:1280–1289. [Google Scholar]
- Huggins R.M. On the Statistical Analysis of Capture Experiments. Biometrika. 1989;76:133–140. [Google Scholar]
- Innes S. Heide-Jorgensen M.P. Laake J.L. Laidre K.L. Cleator H.J. Richard P. Stewart R. E.A. Surveys of Belugas and Narwhals in the Canadian High Arctic in 1996. NAMMCO Scientific Publications. 2002;4:169–190. [Google Scholar]
- Johnson D.S. Laake J.L. Hoef J. M. Ver. A Model-Based Approach for Making Ecological Inference From Distance Sampling Data. Biometrics. 2010;66:310–318. doi: 10.1111/j.1541-0420.2009.01265.x. [DOI] [PubMed] [Google Scholar]
- Laake J.L. Distance Sampling With Independent Observers: Reducing Bias From Heterogeneity by Weakening the Conditional Independence Assumption. In: Amstrup G. W., editor; Garner S. C., editor; Laake J. L., editor; Manly B. F. J., editor; McDonald L. L., editor; Robertson D. G., editor. Marine Mammal Survey and Assessment Methods. Rotterdam: Balkema; 1999. pp. 137–148. [Google Scholar]
- Laake J.L. Collier B.A. Morrison M.L. Wilkins R.N. Point-Based Mark-Recapture Distance Sampling. Journal of Agricultural, Biological and Environmental Statistics. 2011;16:389–408. [Google Scholar]
- Langrock R. King R. Maximum Likelihood Estimation of Mark-Recapture-Recovery Models in the Presence of Continuous Covariates. Annals of Applied Statistics. 2013;7:1709–1732. [Google Scholar]
- Link W.A. Yoshizaki J. Bailey L.L. Pollock K.H. Uncovering a Latent Multi-Nomial: Analysis of Mark-Recapture Data With Misidentification. Biometrics. 2010;66:178–185. doi: 10.1111/j.1541-0420.2009.01244.x. [DOI] [PubMed] [Google Scholar]
- Manly B. F. J. McDonald L.L. Garner G.W. Maximum Likelihood Estimation for the Double-Count Method With Independent Observers. Journal of Agricultural, Biological and Environmental Statistics. 1996;1:170–189. [Google Scholar]
- Marques F. F.C. Buckland S.T. Incorporating Covariates Into Standard Line Transect Analyses. Biometrics. 2003;59:924–935. doi: 10.1111/j.0006-341x.2003.00107.x. [DOI] [PubMed] [Google Scholar]
- Millar R.B. Maximum Likelihood Estimation and Inference. Chichester, UK: Wiley; 2011. [Google Scholar]
- Pike D.G. Paxton C. G.M. Gunnlaugsson Th. Vikingsson G.A. Trends in the Distribution and Abundance of Cetaceans From Aerial Surveys in Icelandic Coastal Waters, 1986–2001. NAMMCO Scientific Publications. 2009;7:117–142. [Google Scholar]
- Royle J.A. Chandler R.B. Sollman R. Gardner B. Spatial Capture-Recapture. Boston: Academic Press; 2013a. [Google Scholar]
- Royle J.A. Chandler R.B. Sun C.C. Fuller A.K. Integrating Resource Selection Information With Spatial Capture-Recpature. Methods in Ecology and Evolution. 2013b;4:520–530. [Google Scholar]
- Royle J.A. Dorazio R.M. Hierarchical Modeling and Inference in Ecology. London: Academic Press; 2008. [Google Scholar]
- Royle J.A. Karanth K.U. Gopalaswamy A.M. Kumar N.S. Bayesian Inference in Camera-Trapping Studies for a Class of Spatial Capture-Recapture Models. Ecology. 2009a;90:3233–3244. doi: 10.1890/08-1481.1. [DOI] [PubMed] [Google Scholar]
- Royle J.A. Nichols J.D. Karanth K.U. Gopalaswamy A.M. “A Hierarchical Model for Estimating Density in Camera-Trap Studies. Journal of Applied Ecology. 2009b;46:118–127. [Google Scholar]
- Royle J.A. Young K.V. A Hierarchical Model for Spatial Capture–Recapture Data. Ecology. 2008;89:2281–2289. doi: 10.1890/07-0601.1. [DOI] [PubMed] [Google Scholar]
- Schwarz C.J. Seber G. A.F. Estimating Animal Abundance: Review III. Statistical Science. 1999;14:427–456. [Google Scholar]
- Williams B.K. Nichols J.D. Conroy M.J. Analysis and Management of Animal Populations. London: Academic Press; 2002. [Google Scholar]