

Abstract
Introduction
After several decades’ development, meta-analysis has become the pillar of evidence-based medicine. However, heterogeneity is still the threat to the validity and quality of such studies. Currently, Q and its descendant I2 (I square) tests are widely used as the tools for heterogeneity evaluation. The core mission of this kind of test is to identify data sets from similar populations and exclude those are from different populations. Although Q and I2 are used as the default tool for heterogeneity testing, the work we present here demonstrates that the robustness of these two tools is questionable.
Methods and Findings
We simulated a strictly normalized population S. The simulation successfully represents randomized control trial data sets, which fits perfectly with the theoretical distribution (experimental group: p = 0.37, control group: p = 0.88). And we randomly generate research samples Si that fits the population with tiny distributions. In short, these data sets are perfect and can be seen as completely homogeneous data from the exactly same population. If Q and I2 are truly robust tools, the Q and I2 testing results on our simulated data sets should not be positive. We then synthesized these trials by using fixed model. Pooled results indicated that the mean difference (MD) corresponds highly with the true values, and the 95% confidence interval (CI) is narrow. But, when the number of trials and sample size of trials enrolled in the meta-analysis are substantially increased; the Q and I2 values also increase steadily. This result indicates that I2 and Q are only suitable for testing heterogeneity amongst small sample size trials, and are not adoptable when the sample sizes and the number of trials increase substantially.
Conclusions
Every day, meta-analysis studies which contain flawed data analysis are emerging and passed on to clinical practitioners as “updated evidence”. Using this kind of evidence that contain heterogeneous data sets leads to wrong conclusion, makes chaos in clinical practice and weakens the foundation of evidence-based medicine. We suggest more strict applications of meta-analysis: it should only be applied to those synthesized trials with small sample sizes. We call upon that the tools of evidence-based medicine should keep up-to-dated with the cutting-edge technologies in data science. Clinical research data should be made available publicly when there is any relevant article published so the research community could conduct in-depth data mining, which is a better alternative for meta-analysis in many instances.
Introduction
Currently, Q and its descendent I2 tests are widely used, especially the I2 test, in meta-analysis [1–3]. Established in 2003 by Higgins et al, it is becoming the mainstay for testing heterogeneity [1]. Q and I2 tests have been integrated into Review Manager and almost all other meta-analysis software, and are used as the default tool to determine heterogeneity. In the past decade, along with the emergence of meta-analysis as a core technique for evidence-based approach in almost all branches of bio-medical research, Q and I2 make up an important methodological component of the enormous number of systematic reviews and clinical guidelines.
Unfortunately, despite the wide use and acceptance of Q and I2 tests, the work we present here demonstrates that the robustness of these two tools are questionable; and in many circumstances, relying solely on these tools to measure heterogeneity could lead to the wrong conclusion in meta-analysis, which forms the foundation of evidence-based medicine.
Materials and Methods
Theoretical Analysis and Simulation
Analyzing on the Structure of Q and I2
The structure of the equation of Q is the following:
| (1) |
| (2) |
Here, and represents the weight of the k-th study, n k is the sample size of the k–th study. It is assumed that the sample from any trial is independent and the distribution is normalized [3].
Q does not consider the influence from the number of enrolled trials (degree of freedom, df). We can understand this shortcoming of Q from its equation: Q is the weighted sum of the squares of deviations (WSSD) of data sets from the enrolled trials. Along with the increase of the number of trials (n), the non-negative term also increases. Therefore, the number of enrolled trials significantly influences the increase of Q value. Thus the increase of Q value cannot simply be attributed to the variants between enrolled trials. To overcome this shortcoming, Higgins et al constructed I2. It modifies Q and aims to balance the extra variant, which comes from the increase of the number of enrolled trials. Strictly speaking, I2 is not a test but a descriptive measure.
The equation of I2 is the following
| (3) |
Here df is the degree of freedom, df = n-1
Although I2 proposes to overcome quasi-heterogeneity from extra variants, a more serious influence is not considered, which is the sample size nk (Eq.2). We can easily find that is in proportion to n k. Along with the increase of the sample size, the corresponding deviation will also increase. Consequently, the Q value will increase.
Let
| (4) |
Remember that the default assumption behind the statistics of the t-test is that the distribution of all enrolled trials met and we therefore have T ∼ T (n k − 1) → N (0, 1). So Q is indeed the sum of the squares of Tk. Consequently, constructing Q is a process that is made up by the sum of the square of Tk. It is easy to infer that the sample size of each trial cannot be too big, otherwise the T value will surge.
To explore the evolutionary patterns between Q, I2 and nk, we herein introduce a simulation process to verify the influence of N and n to Q and I2.
Simulation Process
We illustrated the research flow and simulation process of the study in Fig 1.
Fig 1. Diagram of the simulation process.
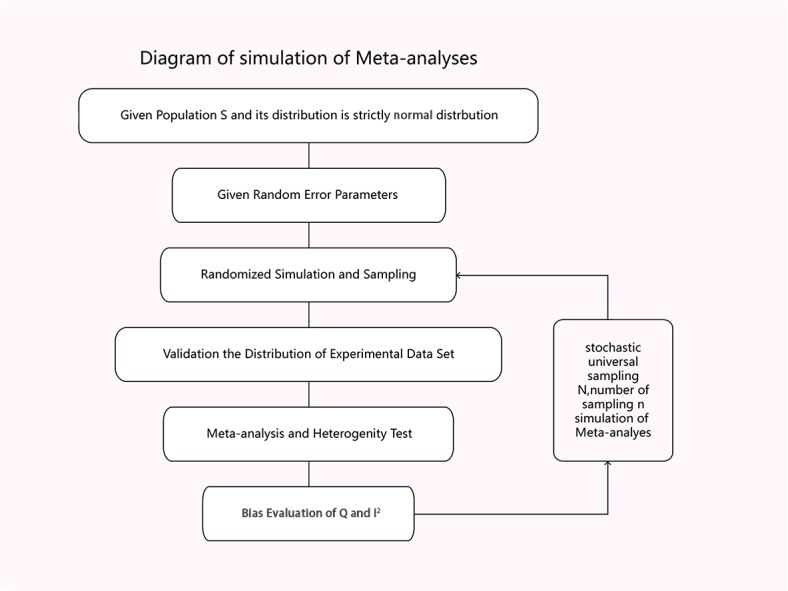
We simulated a population S and its distribution is strictly normalized, which means S∽N (μ, σ2) (Table A in S1 File). Now we have samples Si (i = 1, 2, 3…n) where each is a random sample from S (Table B in S1 File). Let Si∽(μi, σi 2). The variation between the samples is only made by random error ε, and ε∽N(0,σε).
The distribution parameters of Si can be descripted as following :
| (5) |
| (6) |
Let σε<<σ, then we have:
| (7) |
| (8) |
We know Si is a non-skewed sampling of the population. Therefore the simulated data sets are homogenous. We then synthesized these data sets by meta-analysis (fixed model, meta: meta-analysis with R was employed for data aggregating) and we calculated Q and I2 for each synthesis experiment (Tables C and D in S1 File). To each Si, sampling process will be repeated in 1000 times. Thus we get the distribution of I2 variations in synthesizing different number of trials (the sample size of each trial is the same). Finally we generated heat map to see the impact of I2, Q and the number of trials (n) and sample size N (Tables E, F and G in S1 File)
Distribution Test
We used Kolmogorov-Smirnov Tests to test the distribution of the samples,α = 0.05.
Simulation Algorithm
We employed Mersenne-Twister (Matsumoto and Nishimura, 1998) from RNG to simulate data sets [4, 5]. Simulation programming in R see Tables A-G in S1 File.
Environment and Setting of Computation
All computing processes were done using a high performance-computing platform at the Sichuan Academy of Medical Sciences, by using R (version 3.1.1 for win7 64bit) [4].
Results and Discussion
The simulation successfully represents randomized control trial data sets that meet normal distribution and generates S (Table 1 and Fig 2), which fits perfectly with the theoretical distribution (experimental group: p = 0.37, control group: p = 0.88). And we randomly generate research samples Si that fits the population with tiny distributions. In short, these data sets are perfect and can be seen as completely homogenous data from the exactly same population. If Q and I2 are truly robust tools, the Q and I2 test results on our simulated data sets here should not be positive. We then synthesized these trials by using fixed model. We exhibit here three meta-analyses that are selected from our simulation experiments (Figs 3–5). Pooled results indicated that the mean difference (MD) corresponds highly with the true values, and the 95% is narrow. But, along with the increase of the numbers of trials and sample size, the value of the I2 steadily increased (Figs 6 and 7A). Relatively, the influence of number of trials is relatively smaller. In terms of Q, we found that the value of Q increases along with the increase of the number of trials synthesized into the meta-analysis, and with the increase of the sample sizes of enrolled trials (Fig 7B).
Table 1. Distribution of simulated data sets.
| Parameters of Distribution | True value of S (population) | Estimation of simulated S | Error | P |
|---|---|---|---|---|
| Experimental Group | 0.37 | |||
| μe | 100 | 99.99 | 0.01 | |
| σe | 1 | 0.963 | 0.037 | |
| Control group | 0.88 | |||
| μc | 10 | 10.01 | 0.01 | |
| σc | 1 | 1.059 | 0.059 |
Fig 2. Distribution of simulated S, which is typical normal distribution.
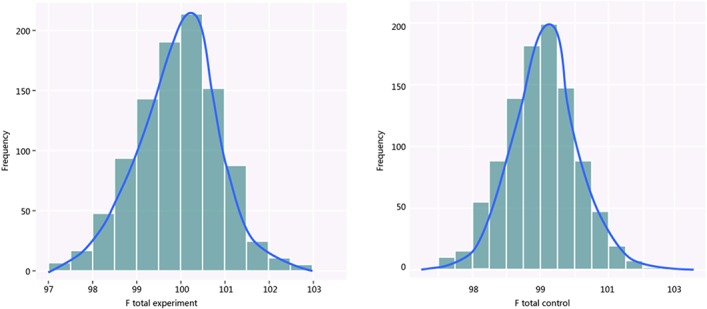
(A: Experimental group; B: control group).
Fig 3. Simulated Meta-analysis.
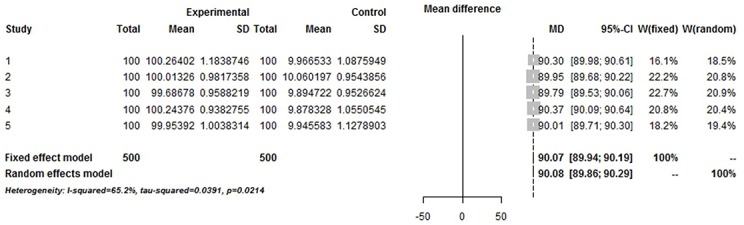
Enrolled 5 trials, total number 1000, pooled MD 90, I2 = 65.2%.
Fig 5. Simulated Meta-analysis.
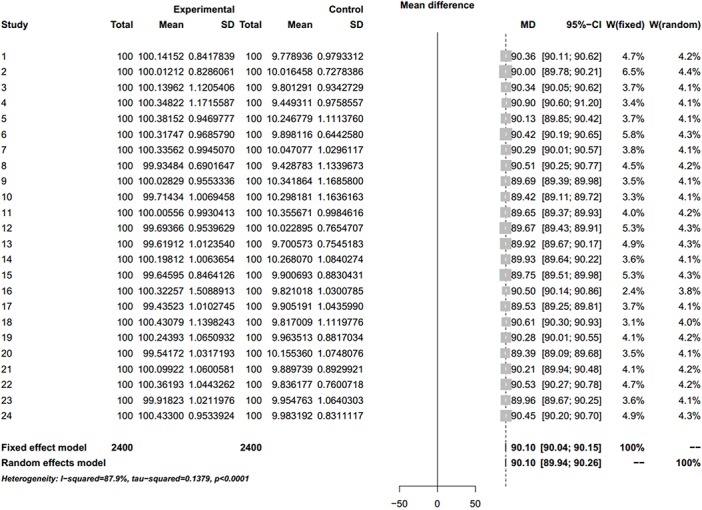
Enrolled 24 trials, total number 2400, pooled MD 90.1, I2 = 87.9%.
Fig 6. Impact of I2 and the sample size.

Lateral axis represents the sample size; vertical axis represents the I2 value. Boxes represent the distribution of I2 variations in synthesizing different number of trials (the sample size of each trial is the same). To each Si, sampling process will be repeated in 1000 times.
Fig 7. Heat maps of the impact of two heterogeneity test tools.

A: Heat map of I2 and the number of trials (n) and sample size N; B: Heat map of Q and the number of trials (n) and sample size N;.
Fig 4. Simulated Meta-analysis.
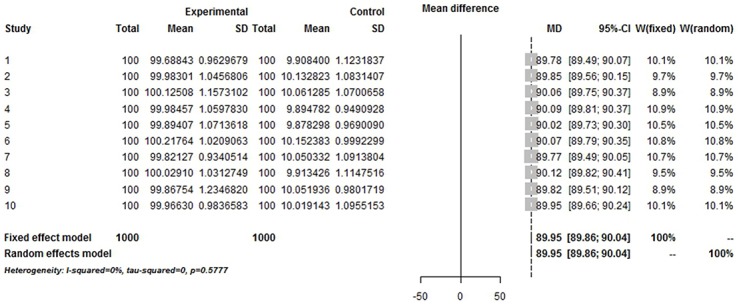
Enrolled 10 trials, total number 2000, pooled MD 89.95, I2 = 0%.
Forest plots of Simulated Meta-analysis
We demonstrate here that the validity of Q and I2 test is questionable and unstable to evaluate heterogeneity for meta-analysis. The purpose of the heterogeneity test is to determine whether the included trials are sampled from similar populations. If the samples of included trials are from similar populations, then the expected mean of the samples should equal the mean of the populations (true data). If it is not, then the mean of the samples does not equal the mean of the populations (false data). The core philosophy of meta-analysis is to include those trials from populations that are de facto the same. The mission of any heterogeneity test is to detect the trials that are de facto not the same. A good heterogeneity-testing tool therefore should not make the mistake to classify a homogenous trial as heterogeneous.
Because all the data sets of the simulated enrolled trials in our study are from the sample population, there could be no heterogeneity between them. When the sample size is small, the bias from sampling will increase with the frequency of sampling. When sampling increases in frequency, the theoretical true bias will decrease, thus heterogeneity should decrease. The mean and variance tend to stabilize when the sampling frequency continues to increase. In this scenario, the I2 and Q value will increase proportionally along with the sample size nk, thus causing the quasi-heterogeneity. In summary, both Q and I2 are sensitive and dependent on sample size nk (Fig 6 and Fig 7).
Gerta Rücker et al have published an article in 2008 also tried to address the I2 problem [6]. The result of Rücker’s study seemed similar to ours: we both reached the conclusion that the I2 will increase to 100% along with the sample size increasing in a meta-analysis. But, there was a major methodological flaw in Rücker’s study, which it was the fact that they did not test the homogeneity and distribution of the data sets included in their simulation. As is well known, most people performing meta-analysis do not conduct distribution tests on their data set from the original trials, and heterogeneity is quite real in most circumstances. Because the data sets of Rücker’s study are from real meta-analysis which quite possibly contains high heterogeneous trials, it is impossible to get rid of the heterogeneity risk by directly and randomly sampling from these data sets. In other words, when the sample size is large enough and the heterogeneity is de facto existent, the increase of I2 is most likely expected. But, such a simulation cannot be seen as a strict mathematic proof. What we did in our study was to give the complete proof in full generality. In short, we simulated a pure homogenous population S and strictly normalized its distribution, and then we repeated the sampling in 1000 times and proved the I2 was unstable in any case when sample size increased. To our best knowledge, the study we presented here is the very first one that generally proved that using I2 test can lead erroneous results in any case when sample size of a meta-analysis is large.
After several decades’ development, meta-analysis has become a pillar of evidence-based medicine. But heterogeneity is still the threat to the validity and quality of meta-analysis. The core issue is to distinguish data sets from similar populations and exclude the others. First of all, currently meta-analysis researchers accept the data expressed as mean±sd by default as normal distribution, without any further analysis to test whether this distribution hypothesis is correct or not. Thus the heterogeneity challenge is quite real.
Secondly, almost none of the clinical researchers are aware that Q and I2 are tools that can only be applicable to test heterogeneity between small sample size trials, and will lost their robustness when the sample sizes and the number of trials are substantially increased (as demonstrated by our study presented here).
This represents a dilemma: the purpose of meta-analysis is to enlarge the sample size, in order to expand and validate the implication of the result. New meta-analysis researches including these flaws are emerging and passed on to clinical practitioners as “updated evidence”, but they are actually not strong as they assumed.
Conclusions
In summary, the validity of widely used Q and I2 test in current meta-analysis is questionable and unstable on heterogeneity evaluation. Before new heterogeneity evaluation tool which is developed and its robustness are demonstrated, we will suggest more strict applications of meta-analysis. The meta-analysis may only be applied to those synthesized trials with small sample sizes. We call upon that the tools of evidence-based medicine should keep up-to-dated with the cutting-edge technologies in data science. Clinical research data should be made available publically when there is any relevant article published so the research community could conduct in-depth data mining, which is a better alternative for meta-analysis in many instances.
Supporting Information
Code of simulation algorithm and graphics plot in R.
(DOCX)
Acknowledgments
The authors would thank Mr. Lu He of University of Waikato, for his generous help on proofreading of the manuscript. We appreciate Dr. Kai Wang of Metabolomics and Multidisciplinary Laboratory of Sichuan Provincial People’s Hospital, Sichuan Academy of Medical Sciences, for his help on manuscript editing.
Data Availability
The work we present in this manuscript is based on a simulation study, all data are generated in R and we provide all details of the simulation process in our supplementary information section. Anyone may repeat our study when the codes are executed in R.
Funding Statement
This work was partially supported by Sichuan Provincial Department of Science and Technology (to Hua Jiang, No. 2014FZ0125 and Jun Zeng, No. 15ZC0656), and Chengdu Municipality Department of Science and Technology (to Hua Jiang, No. 11PPYB099SF) and Sichuan Academy of Medical Sciences (to Hao Yang). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Higgins J, Thompson S, Deeks J, Altman D. Measuring inconsistency in meta-analysis. BMJ. 2003; 327: 557–560. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Borenstein M. Fixed-Effect versus Random-Effects Models In: Borenstein M, Hedges L, Higgins J, Rothstein H, editors. Introduction to Meta-Analysis. U.S.: John Wiley & Sons, Ltd; 2009. pp. 79–94. [Google Scholar]
- 3. Kulinskaya E. Evidence in Cochran’s Q for heterogeneity of effects In: Kulinskaya E, Morgenthaler S, Staudte R, editors. Meta-Analysis: A Guide to Calibrating and Combining Statistical Evidence. U.S.:, John Wiley & Sons, Ltd; 2008. pp. 209–220. [Google Scholar]
- 4.Schwarzer G. meta: Meta-Analysis with R. R package version 3.2–1. 2014; Available: http://CRAN.R-project.org/package=meta
- 5. Kabacoff R. Generalized linear models In: Kabacoff R, editors. R in Action: Data Analysis and Graphics with R. U.S., Manning Publications; 2011. pp. 158–197. [Google Scholar]
- 6. Rücker G, Schwarzer G, Carpenter JR, Schumacher M. Undue reliance on I2 in assessing heterogeneity may mislead. BMC Med Res Methodol. 2008; 8:79 doi: 10.1186/1471-2288-8-79 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Code of simulation algorithm and graphics plot in R.
(DOCX)
Data Availability Statement
The work we present in this manuscript is based on a simulation study, all data are generated in R and we provide all details of the simulation process in our supplementary information section. Anyone may repeat our study when the codes are executed in R.