

Abstract
Statistical learning may be central to lexical and grammatical development: The phonological and distributional properties of words provide probabilistic cues to their grammatical and semantic properties. Infants can capitalize on probabilistic cues to learn grammatical patterns in listening tasks. However, infants often struggle to learn labels when performance requires attending to less obvious cues, raising the question of whether probabilistic cues support word learning. The current experiment presented forty 22-month-olds with an artificial language containing probabilistic correlations between words’ statistical and semantic properties. Only infants with higher levels of grammatical development capitalized on statistical cues to support learning word-referent mappings. These findings suggest that infants’ sensitivity to correlations between sounds and meanings may support both word learning and grammatical development.
Gains in infants’ lexical and grammatical development are highly apparent during the latter part of the second year. For example, while early word learning is slow and effortful (Bloom, 2000), by 18 months infants can learn novel word-referent mappings after a single exposure (e.g., Halberda, 2003) and can also extend them to novel instances appropriately (Smith et al., 2002; Booth, Waxman, & Huang, 2005). At 18-months infants are also learning complex grammatical patterns such as nonadjacent dependencies (e.g., that “everybody is baking bread” and “everybody can baking bread” are not equally good sentences; Santelman & Jusczyk, 1998). By 21 months they are sensitive to the semantics of transitive and intransitive sentence constructions, correctly interpreting the difference in meaning between “The duck is gorping the bunny” and “The bunny is gorping the duck”, Gertner, Fisher, & Eisengart, 1996).
Infants’ ability to track statistical regularities in speech may be a key mechanism supporting these gains in lexical and grammatical development. In particular, statistical cues that mark words’ category membership are potentially relevant to learning both lexical items and grammatical structure. Many grammatical categories can be distinguished by their phonological properties (i.e., their forms or “covers”). For example, in English, nouns and verbs differ in their lexical stress patterns, syllable number, and phonotactics, (e.g., Christiansen, Onnis, & Hockema, 2009; Kelly, 1992; Monaghan, Chater, & Christiansen, 2005; Monaghan, Christiansen, & Chater, 2007). Nouns and verbs also differ in their distributional properties, or the sentence contexts in which they are likely to occur (i.e., the “company” they keep). For example, nouns are reliably preceded by determiners such as “a” and “the”, while verbs are preceded by pronouns and auxiliaries (Mintz, 2003). English nouns are further grouped into count nouns such as “flower”, and mass nouns such as “milk”, a distinction that is also marked by statistical cues (Yoshida, Colunga, & Smith, 2003):Count nouns follow definite articles and numbers, such as “a” “several”, and “one” and take the plural morphology (e.g., “those flowers”). In contrast, mass nouns occur after indefinite articles such as “some” and “more” (e.g., “some milk”, “more water”), but do not occur after definite articles and numerals or take plural markings.
Importantly, beyond sharing statistical properties, such as phonology and distributional characteristics, words within grammatical categories tend to have similar semantic properties. For example, in English nouns typically refer to objects and animals, and verbs are more likely to refer to actions. Likewise, count noun labels generally refer to an object’s shape, while mass nouns tend to refer to the substance of an entity (e.g., Yoshida, Colunga, & Smith, 2003).
Work with artificial languages suggests that infants’ experience with these cues promotes learning grammatical structure as well as word-referent associations. Evidence that these cues support learning grammatical patterns comes from the fact infants’ successfully form word categories and learn how they co-occur only when words within categories are reliably distinguished by both distributional and phonological cues (Gerken et al., 2005; Gomez & Lakusta, 2004; Lany & Gomez, 2008). Likewise, 22-month-old infants successfully learn the referents of words, and the semantic properties common to words within categories, when categories are marked by correlated distributional and phonological cues (Lany & Saffran, 2010). In contrast, when words’ category membership is not reliably marked by these cues, infants fail to learn anything about the semantic properties of words.
The findings from these artificial language studies suggest that infants’ experience with statistical cues promotes learning grammatical categories and their semantic correlates. However, it is unclear whether these cues support language development “in the wild”. Specifically, while words within categories tend to share statistical and semantic properties, these cues are often much more probabilistic in natural languages than in the artificial languages that have been studied. An analysis of frequent nouns and verbs in the CHILDES database suggests that approximately 67% of nouns and 72% of verbs can be classified correctly on the basis of their distributional and phonological properties (Monaghan Chater, & Christiansen, 2005). Several studies suggest that school-aged children are adept at learning patterns despite the presence of potentially misleading “noise”. For example, children use words’ phonological properties (e.g., syllable number) and distributional properties to determine word meanings, despite the fact that they are imperfect cues (Brown, 1957; Fitneva et al., 2009). Singleton & Newport (2004) investigated the effects of variable input by studying language development in a deaf child, Simon. Simon was primarily exposed to American Sign Language (ASL) by his hearing parents, who were not native signers and whose ASL production contained many inconsistencies and errors. Despite his experience with irregular input, Simon’s language production was highly consistent and paralleled that of a group of 8 same-aged peers who were learning ASL from native signers. Hudson Kam and Newport (2005) found that children are much more likely than adults to regularize inconsistent input when learning an artificial language. These findings suggest that children are able to cope with noisy language input.
Infants and toddlers, however, may not learn from probabilistic input as easily as older children. Gómez & Lakusta (2004) tested whether 12-month-olds can learn the grammatical categories and their co-occurrence relationships in an artificial language when distributional and phonological cues are probabilistic, rather than deterministic. Infants successfully learned this structure when the cues were highly reliable (i.e., when they accurately cued the words’ category membership 100% or 83% of the time). Infants failed to learn when the cues were reliable only 67% of the time, which is the level that more closely approximates the reliability of statistical cues in natural language. Gerken et al. (2005) found that 17-month-olds, but not 12-month-olds can learn similar structure when it is more probabilistic, but that they nonetheless rely on the presence of relatively robust correlations.
These findings suggest that infants can use probabilistic cues to group words into categories and learn co-occurrence relationships by about 18 months (Gomez & Lakusta, 2004; Gerken, Wilson, & Lewis, 2005), but it is unclear how far this ability can take in them in tasks that are more similar to real-word language learning. In particular, infants may struggle to use such cues when attempting to map words to referents, as speech sequences that don’t conform to predominant patterns may be harder to encode, remember, and map to referents.
A second reason that infants may fail to capitalize on probabilistic cues marking grammatical categories in word-learning tasks is that the relations between words’ statistical and semantic properties are themselves probabilistic, adding yet another level of complexity to the learning situation. For example, nouns frequently refer to objects and animals, but do not always (e.g., freedom, problem), and many verbs can be made into nouns (e.g., walk, kiss, hug). Infants are able to learn perfect correlations between words’ statistical and semantic properties, as evidenced by their ability to generalize to novel word-referent associations (Lany & Saffran, 2010), however capitalizing on probabilistic overlap between words’ statistical and semantic properties is likely to be much be more challenging. Gleitman (1990) pointed out that infants face a similar problem when learning mappings between individual words and referents, as words can refer to absent entities (e.g., a dog may rarely be present when an infant hears the word “dog”), and entities can have multiple labels (e.g., a dog may regularly be described with other words, such as Fido, puppy, and mutt). Vouloumanos and Werker (2009) found that 18 months infants readily learn word-referent mappings when they are 100% reliable, but their ability to learn probabilistic mappings is less robust. In particular, they found that when a label co-occurred with a particular object in 80% of the label’s occurrences during training, at test infants preferentially looked to that object over a foil object with which the label never co-occurred. However, when the label referred to one object 80% of the time and to the foil object the other 20% of the time, infants looked equally to both objects when hearing the label at test. Voloumanos and Werker’s findings suggest that infants struggle to learn the association between a word and its referent when they co-occur only probabilistically. Likewise, infants may fail to capitalize on higher-order correlations between statistics and semantics in word learning tasks when these associations are probabilistic, despite successfully capitalizing on deterministic relationships (Lany & Saffran, 2010).
In sum, preliminary evidence suggests that statistical cues marking grammatical categories can support word learning, but a more ecologically valid test of this ability would provide an opportunity to more stringently evaluate this hypothesis. Thus, the current study tested the extent to which infants can capitalize on probabilistic cues in a word-learning task, and whether this varies concurrently with their level of language development. The methods incorporated a three-phase design adapted from Lany and Saffran (2010; see Figure 1). In the first phase, Auditory Familiarization, 22-month-old infants listened to an artificial language containing two word-categories that were marked by correlated distributional and phonological cues at probabilistic levels comparable to those in natural languages. During the Referent Training phase, phrases from the language were paired with pictures of uncommon animals and vehicles. Across the miniature lexicon, the semantic properties of words were probabilistically related to their distributional and phonological properties, such that words within a categories were predominantly associated with either animals or vehicles. The Test phase assessed whether infants learned the trained labels.
Figure 1.
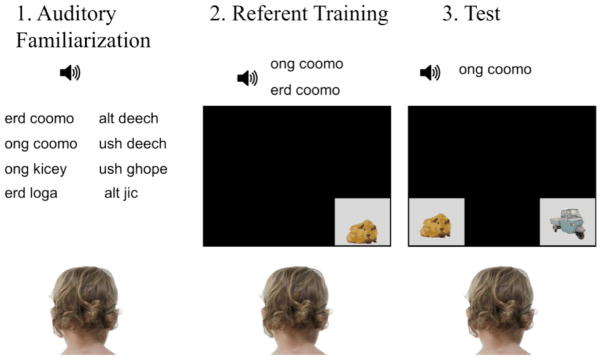
A schematic of the three phases of the experimental procedure.
Critically, Lany and Saffran (2010) found that experience with reliable distributional and phonological cues in the speech stream is key to word learning in this difficult task: When words’ distributional and phonological properties correctly indicated words’ membership 100% of the time, infants successfully learned label-referent pairings. In contrast, when distributional and phonological cues were not reliably correlated with category membership, infants failed to learn label-referent pairings. Thus, if infants learn the trained label-referent associations in the current experiment, it would provide evidence that probabilistic correlations among cues associated with category membership can support word learning.
Twenty-two months is an age at which infants’ lexical and grammatical learning is undergoing dramatic development (Bates et al., 1988; Fenson et al., 1994). If statistical learning ability supports such developments, then individual differences in performance on the statistical learning task should be related to measures of native language development at the same age. In particular, if tracking these cues supports learning grammatical patterns in speech, then infants who are better able to do so should be relatively advanced in their grammatical development. Likewise, sensitivity to these cues support learning the meanings of words, then infants who are better able to track them may have larger native language vocabularies. Thus, in addition to testing whether infants can use probabilistic cues to support word learning, this experiment will test the extent to which infants’ performance on a laboratory-based statistical-learning task is related to their vocabulary size and grammatical development.
Method
Participants
Forty 22-month-old monolingual English-speaking infants (mean age = 667 days, range = 643–690 days, 21 female) participated. All infants were born full term, and were free of problems with hearing, vision, or language development, according to parental report. Families were primarily Caucasian, and middle-to upper-middle-class. Expressive vocabulary on the MCDI Short Form: Level II (Fenson et al., 2000) ranged from 7 to 84 words (mean = 40), with percentile scores ranging from 5 to 90% (mean = 35%). Grammar scores ranged from 1 to 3. Data from additional infants were excluded for failure to complete the experiment (i.e., refusal to sit in the parent’s lap, or crying for longer than 30 seconds: N=18, or equipment failure; N=1).
Materials
Auditory Familiarization consisted of an artificial language that contained two a-words (ong, erd), two b-words (alt, ush), and eight each of the X- and Y-words (see Table 1). The X-words were disyllabic (e.g., coomo, loga), while the Y-words were monosyllabic (e.g., deech, skige). The words were combined into phrases such that 75% took the form of aX and bY, and the remaining 25% took the form of aY and bX. Thus, the correlations between words’ distributional and phonological properties were reliable but probabilistic: 75% of the time a-words were followed by disyllabic words (e.g., ongcoomo, erdcoomo) and b-words were followed by monosyllabic words (e.g., alt deech, ushdeech). This level of cue reliability is similar to that found in English (Monaghan et al., 2005; 2007)
Table 1.
Auditory Familiarization Materials
| a1X1–6 | a2X1–6 | b1Y1–6 | b2Y1–6 |
|---|---|---|---|
| ongcoomo | erdcoomo | alt deech | ushdeech |
| ongfengle | erdfengle | alt gope | ushgope |
| ongbevit | erdbevit | alt vot | ushvot |
| ongmeeper | erdmeeper | alt rud | ushrud |
| ongpaylig | erdpaylig | alt vabe | ushvabe |
| ongwazil | erdwazil | alt tam | ush tam |
|
| |||
| a1Y7–8 | a2Y7–8 | b1X7–8 | b2X7–8 |
|
| |||
| ongjic | erdjic | alt kicey | ushkicey |
| ongskige | erdskige | alt loga | ushloga |
An adult female was recorded speaking the materials in an animated voice. Materials were digitized for editing, and phrases were created by splicing word tokens together. The language contained 32 unique phrases (12 each aX and bY, and 4 each aY and bX; see Table 1). Within phrases, words were separated by 100 msec. Strings were created by combining two phrases separated by 300 msec, and strings were separated by 700 msec.
Referent Training materials consisted of phrases from Auditory Familiarization paired with realistic pictures of animals and vehicles that are unlikely to be familiar to infants of this age (Dale & Fenson, 1996). The relationships between words’ distributional, phonological, and semantic properties were reliable but probabilistic: 75% of Xs referred to pictures from one semantic category (e.g., animals), and likewise, as preceded 75% of the labels for animal pictures (Table 2). The picture-phrase pairings were counterbalanced such that for half of the infants aX phrases predominantly referred to animals and bY phrases predominantly referred to vehicles, and vice versa for the remaining infants. The pairings between specific Xs and Ys and referents were also counterbalanced.
Table 2.
Referent Training Materials
| Trial Type | Labeling Phrases | Picture Referents |
|---|---|---|
| Double Cue | ongcoomo erdcoomo |

|
| Double Cue | ongfengle erdfengle |

|
| Phonological Cue | alt loga ushloga |

|
| Distributional Cue | ongjic erdjic |

|
| Double Cue | alt deech ushdeech |

|
| Double Cue | alt gope ushgope |

|
| Phonological Cue | ongskige erdskige |

|
| Distributional Cue | alt kicey ushkicey |

|
This artificial language strongly parallels structure found in natural languages in which animate and inanimate nouns are used with different determiners (e.g., Algonquin; Corbett, 1991) or classifiers (e.g., Chinese, Korean, Japanese, and ASL; Aikhenvald, 2000). Likewise, the artificial language contained two word clusters that differed as a function of their statistical properties, and those clusters mapped onto a conceptual-semantic distinction that parallels both noun/verb distinctions and the count/mass-distinction within nouns. Importantly, while this linguistic distinction between animates and in animates is present in many natural languages, it would be unfamiliar to infants learning English.
The relationships between the distributional, phonological, and semantic properties of words were manipulated to create three label types: Double-Cue, Distributional-Cue, and Phonological-Cue labels; see Table 2). In the 4 Double -Cue labels, familiar phrases containing the predominant associations between distributional and phonological cues (i.e., aX and bY phrases) were associated with referents. Specifically, two aX phrases were paired with pictures of animals, and two bY phrases were paired with pictures of vehicles (e.g., ongcoomo and erdcoomo labeled a guinea pig, while alt deech and ushdeech labeled a Vespa truck). In the Distributional-Cue labels and Phonological-Cue labels, the phrases took the form aY and bX. Thus, the phrases were familiar to infants, but they did not conform to the predominant co-occurrence pattern. Moreover, for these mappings, the semantic properties of words aligned with either the predominant distributional-semantic or the phonological-semantic associations, but not both. The 2 Distributional-Cue labels consisted of an aY phrase paired with an animal picture and a bX phrase paired with a vehicle picture (e.g., ongjic and erdjic labeled a ram, while alt kicey and ushkicey labeled a golf cart). Thus, in these trials, the distributional properties of the words were consistent with the predominant semantic mappings (e.g., words following ong and jic typically referred to animals), but their phonological properties were more typically associated with the other semantic category. Likewise, the 2 Phonological-Cue labels consisted of an aY phrase paired with a vehicle and a bX phrase was paired with an animal, such that only the phonological properties of the words were consistent with the predominant mappings.
These three label types were used to shed light on how statistical cues promote word learning. In Double-Cue labels, the strongest level of support was available to infants: The phrases containing the labels followed the predominant co-occurrence patterns, and both their distributional and phonological properties were most often associated with referents from that category. Moreover, these trials were equivalent to the Familiar trials in Lany and Saffran (2010, 2011) in that trained pairings between aX phrases and animal pictures, and between and bY phrases and vehicle pictures, were tested. The key difference is that in the current study the category-level correlations within the miniature lexicon were probabilistic. The Distributional- and Phonological-Cue labeling phrases, while familiar, did not conform to the predominant patterns. Moreover, only one cue in the labeling phrase supported forming the mappings, while the other cue was more strongly associated with the other semantic category. Thus, these labels may be more difficult to learn and remember. In particular, if benefits to word learning arise solely from facilitated processing of phrases that follow the predominant co-occurrence patterns, then infants should successfully learn Double-Cue labels, but fail to learn Distributional- and Phonological-Cue labels.
The Test materials consisted of pictures from referent training and the phrases that labeled them. On each trial, infants saw a pair of pictures from the same semantic category (two animals or two vehicles), and heard a phrase that had been associated with one of them (see Figure 2). Infants were tested on Double Cue, Distributional Cue, and Phonological Cue labels.
Figure 2.

An example of a test trial containing a guinea pig and a Vespa truck. Two seconds after the appearance of the pictures, the auditory stimulus began to play.
Procedure
Infants were tested individually in a sound-attenuated booth (see Figure 1 for a schematic). During the Auditory Familiarization phase, the artificial language strings were played from a speaker mounted in the booth using Quicktime software. Each of the 32 unique phrases occurred 4 times during the randomized sequence. During this phase infants could move around in the booth and play quietly.
The remainder of the experiment was controlled by Habit X software (Cohen, Atkinson, & Chaput, 2004). Infants were seated on the parent’s lap approximately 1m from a projector screen, and parents wore opaque glasses. During Referent Training, each trial consisted of a single picture presented on the lower left or right corner of the screen for 6.5 sec via an LCD projector. To maintain infants’ attention, the picture moved up and down once over the course of the trial. Two labeling phrases (e.g., “ongcoomo, erdcoomo,” separated by 300 msec of silence) were played from a speaker below the screen beginning 1.5-sec after the picture appeared. Labels were presented in these two “sentence contexts” within training trials, similar to labeling practices in natural language (e.g, It’s a book! Look at the book”). Each of the 8 pictures was presented 4 times, with position on the screen and order of the labeling phrases counterbalanced across trials. A 7 sec cartoon was presented after every 4th trial to keep infants engaged.
During Testing, all trials consisted of two pictures presented simultaneously for 6.25 sec on the lower left and right sides of the screen. After 2 seconds, a label for one picture (the target) was played. Two labels of each type (Double Cue, Distributional Cue, and Phonological Cue) were tested. Each label was tested 4 times, yielding a total of 24 test trials. Test-trial order was randomized, and a 7 sec cartoon was again presented after every 4th trial to maintain infants’ attention. Each picture appeared with equal frequency and served as the target equally often, with side of presentation counterbalanced. Infants’ looking behavior during the test was recorded onto a DVD at 30 frames/sec.
After the Test Phase, caregivers filled out the MacArthur Short Form: Level II (Fenson et al., 2001). The short-form version of the MCDI includes a parent-report measure of expressive vocabulary size, or the number of items from a 100-word inventory spoken by the infant. This inventory includes a subset of the words included on the full-length version of the MCDI: Words and Sentences. The Short Form was designed to maximize measurement accuracy while minimizing administration time, and thus does not also include a comprehension measure. Infants’ scores on the short form are strongly correlated with those on the long form, confirming the validity of the measure. Reliability as measured by Chronbach’s alpha is also high (Fenson et al., 2000).
The short form also contains an index of grammatical development, specifically a measure of the frequency with which infants produce multi-word utterances. Possible responses are “not yet”, “sometimes”, or “often”. A normative study of 1, 803 infants suggests that that the median age of attainment of the “often” designation is 22 months(Fenson et al., 1993). Consistent with these norms, approximately half of the 22-month-olds in this sample (23 of 40) fell into this category. The onset of word combinations is widely considered to be a sign of emerging grammatical skill. Infants’ scores on this measure track other measures of grammatical proficiency on the longer form of the MCDI. For example, like the Maximum Sentence Length and Sentence Complexity measures of grammatical level on the Words and Sentences version, combination scores correlate highly with vocabulary size (Fenson et al., 1993; Dale et al., 2000). The onset of word combinations is reliably predicted by children’s ability to combine speech and gestures (Iverson & Goldin-Meadow, 2005), a development that also predicts measures of grammatical competence at 42 months (Rowe & Goldin-Meadow, 2009). Altogether, these data suggest that the measure reflects something meaningful about early grammatical development.
Data Analysis Procedure
Recordings of the test phase were viewed by trained observers who coded whether the infant was looking to the picture on the left, on the right, transitioning between pictures, or off-task for each frame (see Fernald, Zangl, Portillo, & Marchman, 2008). Coders were blind to the hypotheses of the current experiment, to infants’ MCDI scores, and to the stimuli presented and location of the Target picture on any given trial. Agreement between coders within a single frame was greater than 99%. Each trial was divided into two time windows for the purposes of statistical analysis. The Baseline window included the 2000 ms of silence at the start of each trial. The Target window began 1000ms after the onset of the X or Y, and ended 2000 ms after the word onset. These windows were chosen based on previous studies using this paradigm (e.g., Fernald et al., 2008; Lany & Saffran, 2010; 2011). In previous work with this artificial language, infants sometimes show increased looking to the target beginning 367ms after the onset of the labeling phrase (Lany & Saffran, 2010). However, for harder test trials, such as ones that require generalization, increases in looking to the target emerge later. Consistent with the fact that the labels in this artificial language may be more difficult to learn, infants in the current study show increased looking to the target picture only after hearing the entire label. Infants did not show increased target-looking for any trials during the time window prior to label offset, regardless of their native language scores or the label type tested.
Trials during which infants were not attending for at least half of both the Baseline and Target Windows were not included in the analyses. The proportion of trials an infant was looking to the target at each 33 ms interval was calculated. A word-learning score was created for each infant by subtracting the mean proportion of looking to the target during the Baseline window from the mean proportion of looking to the target during the Target window (Table 3). Word-learning scores above zero indicate greater looking to the target in response to the label.
Table 3.
Mean Proportion Looking to the Target Picture on Trials, with Standard Errors in Parentheses, as a Function of Grammatical Proficiency
| Proportion Looking to Target | Increase in Proportion Looking to Target | ||
|---|---|---|---|
|
|
|
||
| Baseline | Target | ||
|
|
|
||
| High Grammar | |||
| Double Cue | .50(.02) | .61(.03) | .11(.03)** |
| Phonological Cue | .53(.02) | .60(.03) | .06(.04) |
| Distributional Cue | .48(.02) | .59(.04) | .11(.05)* |
| Overall | .50(.01) | .60(.02) | .09(.02) |
|
| |||
| Low Grammar | |||
| Double Cue | .52(.02) | .52(.03) | −.001(.03) |
| Phonological Cue | .52(.02) | .50(.04) | −.03(.04) |
| Distributional Cue | .51(.02) | .51(.05) | .01(.06) |
| Overall | .52(.01) | .51(.02) | −.01 (.03) |
Note: The mean proportion of trials on which infants were looking to the target picture across the Baseline and Late Target windows is shown on the left panel. Word-learning scores, or increases in looking to the target picture during the Target windows relative to Baseline, are shown on the right panel. One sample t tests comparing increase in proportion looking to target to chance (no difference): p≤.01 = **, p≤.05 = *.
Results
Preliminary analyses revealed no effects of sex on word-learning scores, and thus this factor was not included in subsequent analyses. The first set of analyses were designed to test whether infants learned the trained words successfully, and whether learning varied as a function of language proficiency. Infants were classified as High- or Low-Vocabulary, and High- or Low-Grammar, based on their MCDI scores. The primary function of these classifications was to form groups of roughly equal sizes whose performance could be compared to each other and to chance. High-Vocabulary infants (N=21) produced 37 or more words, and Low-Vocabulary infants (N=19) produced fewer. This cut-off was also used in previous research with this artificial language with infants of this age (Lany & Saffran, 2011). Infants were classified as High-Grammar (N=23) if they combined words often, and as Low-Grammar (N=17) if they did so sometimes or not at all. Because 22 months is the median age at which children reach this level, using it as a cut-off distinguishes infants who are developing at an average or better-than-average pace from infants who are slower than average. The majority of High-Grammar infants (17 of 23) were also in the High-Vocabulary group, and vice versa (13 of 17 infants with Low-Grammar scores were also in the Low-Vocabulary group). A logistic regression confirmed that this distribution was not random (χ2 = 10.4, p = .001, B = −2.22, SE = .74).
A mixed ANOVA including label type as a within-participant factor, and grammatical development and vocabulary size as between-participant factors revealed that High-Grammar infants had better word-learning scores (M=.08, SE=.02) than Low-Grammar infants (M=−.02, SE=.023); F(1, 36)=10.2, p=.003 (see also Table 3). In this and all subsequent analyses, α was set to .05. No other main effects or interactions reached significance. One-sample t tests comparing word-learning scores for each label type to chance (i.e., a score of zero, or no increase in looking to the target picture) revealed that High-Grammar infants learned Double-Cue and Distributional-Cue labels, while failing to learn Phonological-Cue labels (Table 3 and Figure 3a). Low-Grammar infants showed no evidence of learning for any of the label types (Table 3 and Figure 3b). In sum, infants with higher levels of grammatical development successfully learned Double- and Distributional-Cue labels, while infants with lower levels of grammatical development showed no evidence of learning for any of the label types.
Figure 3.

Figures 3A and B. Mean proportion of trials on which infants in were looking to the target picture across the three trial types. Chance is .5. The Target Window boundaries are demarcated by solid lines, with the onset and offset of target words marked by dashed lines.
Given that there was a high degree of overlap in infants’ Vocabulary and Grammar scores, the effect of grammatical development in the ANOVA may in part reflect an effect of vocabulary size on the statistical learning task. Two additional analyses tested the extent to which infants’ grammar scores were specifically related to performance on the statistical learning task. In the first analysis, infants’ were divided into four groups; High-Grammar and High-Vocabulary (N=17), High-Grammar and Low-Vocabulary (N=6), Low-Grammar and High-Vocabulary (N=4), and Low-Grammar and Low-Vocabulary (N=13). The mean word-learning score for the High-Grammar and High-Vocabulary infants was .09 (SE = .026), which did not differ from word learning in infants with High-Grammar and Low-Vocabulary scores (M = .10, SE = .044), p = .79. However, it did differ from performance of infants with Low-Grammar and High-Vocabulary scores, (M = −.08, SE = .054), p = .007. Thus, infants with High-Grammar but Low-Vocabulary scores evidenced high levels of learning, similar to infants with High-Grammar and High-Vocabulary scores. In contrast, the 13 infants with Low-Grammar and High-Vocabulary scores did not appear to learn, performing no differently from infants with Low-Grammar and Low-Vocabulary (M = .02, SE = .03), p = .12.
These findings suggest that infants’ ability to capitalize on statistical regularities marking grammatical categories in a word learning task is related to language development, and to grammatical development in particular. If this is the case, then a similar relation should emerge using correlational analyses in which the full range of native language scores and the shared variance in infants’ grammatical development and vocabulary size can be taken into account. Because there were no reliable differences in performance as a function of label type, word-learning scores were collapsed across this factor, and the results of these analyses did not differ when using only Double- and Distributional-Cue trials. Consistent with previous research (see Bates & Goodman, 1997 for a review), infants’ vocabulary size and grammar scores were positively correlated, r(40) =.61, p<.001. Infants’ grammar scores were related to performance on the statistical learning task, r(40)=.45, p=.004, however vocabulary size was not, r(40)=.12, p=.45. A hierarchical regression regression in which vocabulary size was entered first, and grammar scores were entered second, revealed that grammar accounted for significant variance in performance even when controlling for vocabulary size; ΔR2(37) = .215. p< .01 (see Table 4). These findings, combined with the lack of significant correlation between vocabulary size and statistical learning, suggest that infants’ grammatical development, was selectively related to performance on the statistical learning task.
Table 4.
Blocked Hierarchical Regression Analysis for Infant Language Measures and Performance on the Statistical Learning Task
| B | SE B | β | t | p-value | |
|---|---|---|---|---|---|
|
|
|||||
| Model 1 | |||||
| Vocabulary Size | 0.001 | 0.001 | 0.162 | 1.01 | 0.8 |
| Model 2 | |||||
| Vocabulary Size | −0.001 | 0.001 | −0.199 | −1.1 | 0.28 |
| Grammatical Development | 0.1 | 0.03 | 0.59 | 3.24 | 0.003 |
Note: Model 1 R2 = .026, p = .32; Model 2 R2=.241, p< .01
In sum, infants with higher levels of grammatical development showed evidence of word learning when the distributional, phonological, and semantic properties of words were probabilistically correlated, while infants with lower levels of grammatical development did not. High-Grammar infants’ ability to learn labels did not differ as a function of label type (i.e., the extent to which the distributional, phonological, and semantic cues aligned with the predominant associations), though they showed significant evidence of learning only for Double-Cue and Distributional-Cue labels. In contrast, infants’ performance did not differ as a function of whether they were classified as High- or Low-Vocabulary. A regression confirmed that while vocabulary size and grammatical development were related to each other, only grammatical development was strongly related to performance on the statistical learning task.
Discussion
The current study tested whether infants can use probabilistic cues to learn the meanings associated with words and word categories, and whether their ability to do so is related to concurrent levels of native language development. Infants first listened to an artificial language in which two word categories were distinguished by probabilistic distributional and phonological cues. They were then trained on a set of word-referent associations in which correlations between the distributional, phonological, and semantic properties of words were probabilistic. We found that only infants with higher levels of grammatical development successfully learned the trained associations between words and referents. Moreover, infants’ grammatical development, but not their vocabulary size, was related to their performance.
In previous work with this artificial language, infants successful learned word-referent associations when distributional and phonological cues were perfectly correlated, but failed to do so when these cues were uncorrelated, regardless of their level of native language development (Lany & Saffran, 2010). This suggests that the probabilistic correlations among distributional and phonological properties played a critical role in the High-Grammar infants’ ability to learn word-referent associations. In particular, it is not the case that High-Grammar infants are simply better at memorizing words or phrases and learning their associated referents, regardless of their distributional and phonological properties. If so, the High-Grammar infants in Lany and Saffran (2010) would have shown a similar advantage when cues were uncorrelated. Thus, the current findings, together with those of Lany and Saffran (2010), provide strong evidence that the presence of correlations among words’ distributional, phonological, and semantic properties enhances infants’ ability to learn word-referent mappings.
The fact that only infants with more advanced grammatical development performed better on this task may suggest that they were more successful at learning the statistical regularities during Auditory Familiarization, and thus had a foundation for learning semantic information. In particular, sensitivity to these statistical regularities may facilitate word learning by promoting infants’ ability to encode the speech sequences. Hearing a word in a predictable context promotes its identification, as infants more readily encode a novel noun when it follows a determiner vs. an adjective, particularly if it conforms to typical noun phonology (Farmer, Christiansen, & Monaghan, 2006). Facility with encoding would in turn make it easier to determine the referent of the novel word, and to form a robust mapping between them.
Another possibility is that High-Grammar infants were better able to capitalize on statistical-semantic correlations amongst words. Sensitivity to statistical-semantic correlations may promote lexical organization, or the formation of links or associations between words with similar properties. For example, words that occur after “a” and contain the diminutive marker “y’ tend to refer to objects and animals. Forming links between weak or fragile representations may have the effect of strengthening them and promoting their retention. Moreover, such organization within the lexicon could support more efficient learning of novel words with these distributional, phonological, or semantic properties. Specifically, strengthening links among words that share context, phonology and meaning may heighten attention to relevant properties and support forming memories for the mappings (e.g., Sandhofer & Smith, 2004; Smith et al., 2002; Yoshida & Smith, 2005).
These explanations for the benefits of sensitivity to statistical cues in language development are consistent with the fact that there are major developments in both speech processing and lexical organization in the second year. For example, infants’ ability to process speech improves dramatically between 15 and 24 months (Fernald et al., 1998), and that increases in speech processing efficiency are linked to gains in language proficiency, including grammatical development (Fernald, Perfors, & Marchman, 2006). Likewise, lexical organization increases as children approach 24 months of age. For example, by 18 months infants exhibit phonological priming, such that activating the word “cat” speeds processing of words sharing an onset, such as “cup” (Mani & Plunkett, 2010). By 21 months of age, infants show priming for semantically related words, such that presenting the word “cat” facilitates finding the referent of “dog” (Arias-Trejo & Plunkett, 2009).
The current findings also shed light on to the extent to which infants use words’ covers (i.e. their phonological properties) and the company they keep (i.e., their distributional properties) to support word learning. The fact that infants with higher levels of grammatical development were more likely to use distributional cues than infants with lower levels suggests that learning distributional regularities and using them in online speech processing may be quite demanding. Words providing distributional cues could become associated with semantic information through the irreliable co-occurrence with the specific labels for those referents (e.g., nouns in English are often preceded by determiners, such as “a” and “the”). Distributional cues could also become linked to semantic information through direct co-occurrence with individual referents: Because determiners reliably precede nouns, they also often occur with the referents themselves. In either case, tracking distributional cues to category membership is likely to place heavy demands on encoding and memory, and is consistent with the fact that infants with more advanced language skills are better able to capitalize on these cues.
In contrast, High-Grammar infants failed to show significant learning of Phonological-Cue labels in the current study. In these labels, phonological and distributional cues were both present, but they conflicted: A two-syllable word was associated with an animal, and across the lexicon most animals were labeled by two-syllable words, but the distributional properties were more often linked to words from other semantic category. In other words, infants had a difficult time learning the association between a two-syllable word and animal referent when that word is preceded by a word that typically precedes vehicle labels. In contrast, they successfully learned the association between a 1-syllable word and an animal referent when it is preceded by a word that typically precedes animal labels (i.e., they learned Distributional-Cue labels). This pattern of findings may suggest that infants weigh distributional cues more heavily, or that they are more sensitive to violations of distributional-semantic relationships than phonological-semantic ones. This could reflect carry-over from their experience with English, in which highly frequent functional elements like “a” and “the” are relatively strong cues to category membership and semantics, while individual phonological cues are relatively weakly associated with category membership. These results should be interpreted cautiously given that there is some suggestion of more modest learning of these labels, and because previous work suggests that infants can use phonological cues in word-learning under some circumstances (Lany & Saffran, 2011).
More broadly, the current findings suggest that statistical learning plays an important role in both word learning and grammatical development. Previous research indicated that infants’ experience listening to speech containing statistical cues marking grammatical categories facilitates grouping words into grammatical categories and learning simple grammatical patterns (Gerken et al., 2005; Gomez & Lakusta, 2004). The current study revealed that infants’ can capitalize on such probabilistic cues in a word learning task, and that this ability is related to their concurrent grammatical development. Infants with lower levels of grammatical development may fail to capitalize on these cues because tracking them is highly demanding: It requires encoding subtle phonological properties as well as learning distributional regularities, and tracking the correlations among them and associated semantic information.
The fact that infants’ ability to use statistical cues marking grammatical categories in a laboratory task was associated with their native-language grammatical development is consistent with the hypothesis that statistical learning ability supports language acquisition “in the wild”. In particular, it suggests that tracking these cues in speech supports learning grammatical structure. Interestingly, while vocabulary size and grammatical development were correlated with each other, only grammatical development was related to word-learning on the statistical learning task. Given that the use of these cues in word-learning primarily driven by infants’ use of grammatical knowledge to learn words in their native language, it may take longer for such learning to be evidenced by gains in vocabulary size. Thus, while performance on this task was unrelated to concurrent measures of vocabulary size, it may be related to vocabulary size at later points in development.
It is important to note the measure of grammatical development used in the current study is relatively coarse, and does not provide nuanced information about what aspects of grammar are known by these infants. In addition, our findings on statistical learning and grammatical development are correlational, and it is impossible to rule out the possibility that increases in statistical learning and grammatical development may both be driven by a third, unmeasured factor. Thus, while these data are consistent with the hypothesis that the ability to track correlations among words’ distributional and phonological properties, and to use such cues to support word-learning, is related to grammatical development, stronger claims must await further testing.
Overall the current findings make two important contributions to our understanding of the role of statistical learning in language development. First, they demonstrate that infants can capitalize on probabilistic associations between distributional, phonological, and semantic cues. These findings provide key support for the hypothesis that infants’ sensitivity to statistical properties of words marking grammatical categories is an important mechanism driving developments in both lexical and grammatical learning. Second, they provide an important link between controlled tests of statistical learning ability and native language proficiency, suggesting that statistical learning is relevant outside the laboratory. Continued study of how statistical learning supports these developments may shed light on the acceleration in both lexical and grammatical development in the second year, and sources of difficulty for infants who are delayed in achieving these milestones.
Acknowledgments
I thank the members of the Infant Learning Lab at the University of Wisconsin–Madison for their contributions to this work, Anne Fernald and the Center for Infant Studies at Stanford University for providing the customized coding software, and Jessica Hay, Jenny Saffran, Alexa Romberg, and three anonymous reviewers for comments on an earlier draft. I am also grateful to the families whose participation made this research possible. This research was funded by National Institute of Child Health and Human Development Grants F32 HD057698 to J.L. and R01HD37466 to J.R.S., by a James S. McDonnell Foundation Scholar Award to J.R.S, and by National Institutes of Health Grant P30 HD03352 to the Waisman Center, University of Wisconsin–Madison. The content is solely the responsibility of the author and does not necessarily represent the official views of the Eunice Kennedy Shriver National Institute of Child Health and Human Development or the National Institutes of Health.
References
- Aikenvhald AY. Classifiers: A Typology of Noun Categorization Devices. Oxford: Oxford University Press; 2000. [Google Scholar]
- Arias-Trejo N, Plunkett K. Lexical-semantic priming effects during infancy. Philosophical Transactions of the Royal Society B: Biological Sciences. 2009;364:3633–3647. doi: 10.1098/rstb.2009.0146. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bates E, Bretherton I, Snyder L. From First Words to Grammar: Individual Differences and Dissociable Mechanisms. New York: Cambridge University Press; 1988. [Google Scholar]
- Bates E, Goodman JC. On the inseparability of grammar and the lexicon: evidence from acquisition, aphasia, and real-time processing. Language and Cognitive Processes, 1997. 1997;12:507–584. [Google Scholar]
- Bloom P. How Children Learn the Meanings of Words. Cambridge, MA: MIT Press; 2000. [Google Scholar]
- Booth AE, Waxman SR, Huang Y. Conceptual information permeates word learning in infancy. Developmental Psychology. 2005;41:491–505. doi: 10.1037/0012-1649.41.3.491. [DOI] [PubMed] [Google Scholar]
- Brown R. Linguistic determinism and the part of speech. The Journal of Abnormal and Social Psychology. 1957;55:1–5. doi: 10.1037/h0041199. [DOI] [PubMed] [Google Scholar]
- Christiansen MH, Onnis L, Hockema SA. The secret is in the sound: from unsegmented speech to lexical categories. Developmental Science. 2009;12:388–395. doi: 10.1111/j.1467-7687.2009.00824.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cohen LB, Atkinson DJ, Chaput HH. Habit X: A new program for obtaining and organizing data in infant perception and cognition studies (Version 1.0) Austin: University of Texas; 2004. [Google Scholar]
- Corbett GG. Gender. New York: Cambridge University Press; 1991. [Google Scholar]
- Dale PS, Fenson L. Lexical development norms for young children. Behavioral Research Methods, Instruments, & Computers. 1996;28:125–127. [Google Scholar]
- Dixon JA, Marchman V. Grammar and the lexicon: Developmental ordering in language acquisition. Child Development. 2007;78:190–212. doi: 10.1111/j.1467-8624.2007.00992.x. [DOI] [PubMed] [Google Scholar]
- Farmer TA, Christiansen MH, Monaghan P. Phonological typicality influences on-line sentence comprehension. Proceedings of the National Academy of Sciences. 2006;103:12203–12208. doi: 10.1073/pnas.0602173103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fenson L, Dale P, Reznick JS, Bates E, Thal D, Pethick S. Variability in early communicative development. 1993;59(5) Monographs of the Society for Research in Child Development, Serial No. 242. [PubMed] [Google Scholar]
- Fenson L, Pethick S, Renda C, Cox J, Dale PS, Reznick JS. Short-form versions of the MacArthur Communicative Development Inventories. Applied Psycholinguistics. 2000;21:95–116. [Google Scholar]
- Fernald A, Hurtado N. Names in frames: Infants interpret words in sentence frames faster than words in isolation. Developmental Science. 2006;9:F33–F40. doi: 10.1111/j.1467-7687.2006.00482.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fernald A, Marchman VA. Individual differences in lexical processing at 18 months predict vocabulary growth in typically developing and late-talking toddlers. Children Development. 2012;83:203–222. doi: 10.1111/j.1467-8624.2011.01692.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fernald A, Perfors A, Marchman VA. Picking up speed in understanding: Speech processing efficiency and vocabulary growth across the 2nd year. Developmental Psychology. 2006;42:98–116. doi: 10.1037/0012-1649.42.1.98. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fernald A, Zangl R, Portillo A, Marchman VA. Looking while listening: Using eye movements to monitor spoken language comprehension by infants and young children. In: Sekerina IA, Fernández EM, Clahsen H, editors. Developmental psycholinguistics: On-line methods in children’s language processing. Amsterdam: John Benjamins; 2008. pp. 97–135. [Google Scholar]
- Fisher C, Klinger SL, Song H. What does syntax say about space? 2-year-olds use sentence structure to learn new prepositions. Cognition. 2006;101:B19–B29. doi: 10.1016/j.cognition.2005.10.002. [DOI] [PubMed] [Google Scholar]
- Fitneva SA, Christiansen MH, Monaghan P. From sound to syntax: phonological constraints on children’s lexical categorization of new words. Journal of Child Language. 2009;36:967–997. doi: 10.1017/S0305000908009252. [DOI] [PubMed] [Google Scholar]
- Gerken LA, Wilson R, Lewis W. Seventeen-month-olds can use distributional cues to form syntactic categories. Journal of Child Language. 2005;32:249–268. doi: 10.1017/s0305000904006786. [DOI] [PubMed] [Google Scholar]
- Gertner Y, Fisher C, Eisengart J. Learning words and rules: Abstract knowledge of word order in early sentence comprehension. Psychological Science. 2006;17:684–691. doi: 10.1111/j.1467-9280.2006.01767.x. [DOI] [PubMed] [Google Scholar]
- Gleitman L. The structural sources of verb meanings. Language Acquisition. 1990;1:3–55. [Google Scholar]
- Gleitman LR, Cassidy K, Nappa R, Papafragou A, rueswell JC. Hard Words. Language Learning and Development. 2005;1:23–64. [Google Scholar]
- Gómez RL, Lakusta L. A first step in form-based category abstraction in 12-month-old infants. Developmental Science. 2004;7:567–580. doi: 10.1111/j.1467-7687.2004.00381.x. [DOI] [PubMed] [Google Scholar]
- Graf Estes K, Edwards J, Saffran JR. Phonotactic constraints on infant word learning. Infancy. 2011;16:180–197. doi: 10.1111/j.1532-7078.2010.00046.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Halberda J. The development of a word-learning strategy. Cognition. 2003;87:B23–B34. doi: 10.1016/s0010-0277(02)00186-5. [DOI] [PubMed] [Google Scholar]
- Hirsh-Pasek Kemler Nelson, Jusczyk Wright, Druss, Kennedy 1987 doi: 10.1016/s0010-0277(87)80002-1. [DOI] [PubMed] [Google Scholar]
- Hudson Kam CL, Newport EL. Regularizing unpredictable variation: The roles of adult and child learners in language formation and change. Language Learning and Development. 2005;1:151–195. [Google Scholar]
- Iverson JM, Goldin-Meadow S. Gesture paves the way for language development. Psychological Science. 2005;16:367–371. doi: 10.1111/j.0956-7976.2005.01542.x. [DOI] [PubMed] [Google Scholar]
- Landau B, Gleitman LR. Language and experience: Evidence from the blind child. Cambridge, MA: Harvard University Press; 1985. [Google Scholar]
- Lany J, Gómez RL. Twelve-month-old infants benefit from prior experience in statistical learning. Psychological Science. 2008;19:1247–1252. doi: 10.1111/j.1467-9280.2008.02233.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lany J, Saffran JR. From statistics to meaning: Infant acquisition of lexical categories. Psychological Science. 2010;21:284–291. doi: 10.1177/0956797609358570. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lany J, Saffran JR. Interactions between statistical and semantic information in infant language acquisition. Developmental Science. 2011;14:1207–1219. doi: 10.1111/j.1467-7687.2011.01073.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ma W, Golinkoff RM, Houston DM, Hirsh-Pasek K. Word learning in infant- and adult-directed speech. Langauge Learning and Development. 2011;7:185–201. doi: 10.1080/15475441.2011.579839. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mani N, Plunkett K. In the infant’s mind’s ear: Evidence for implicit naming in 18-Month-Olds. Psychological Science. 2010;21:908–913. doi: 10.1177/0956797610373371. [DOI] [PubMed] [Google Scholar]
- Mintz TH, Newport EL, Bever TG. The distributional structure of grammatical categories in speech to young children. Cognitive Science. 2002;26:393–424. [Google Scholar]
- Mintz TH. Frequent frames as a cue for grammatical categories in child directed speech. Cognition. 2003;9:91–117. doi: 10.1016/s0010-0277(03)00140-9. [DOI] [PubMed] [Google Scholar]
- Monaghan P, Chater N, Christiansen MH. The differential role of phonological and distributional cues in grammatical categorization. Cognition. 2005;96:143–182. doi: 10.1016/j.cognition.2004.09.001. [DOI] [PubMed] [Google Scholar]
- Monaghan P, Christiansen MH, Chater N. The phonological-distributional coherence hypothesis: Cross-linguistic evidence in language acquisition. Cognitive Psychology. 2007;55:259–305. doi: 10.1016/j.cogpsych.2006.12.001. [DOI] [PubMed] [Google Scholar]
- Naigles L. Children use syntax to learn verb meanings. Journal of Child Language. 1990;17:357–374. doi: 10.1017/s0305000900013817. [DOI] [PubMed] [Google Scholar]
- Pinker S. Learnability and Cognition: The Acquisition of Argument Structure. Cambridge, MA: MIT Press; 1989. [Google Scholar]
- Rowe M, Goldin-Meadow S. Early gesture selectively predicts later language learning. Developmental Science. 2009;12:182–187. doi: 10.1111/j.1467-7687.2008.00764.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sandhofer C, Smith LB. Perceptual complexity and form class cued in novel word extension tasks: how 4-year-old children interpret adjectives and count nouns. Developmental Science. 2004;7:378–388. doi: 10.1111/j.1467-7687.2004.00354.x. [DOI] [PubMed] [Google Scholar]
- Shi R, Werker JF, Morgan JL. Newborn infants’ sensitivity to perceptual cues to lexical and grammatical words. Cognition. 1999;72:B11–B21. doi: 10.1016/s0010-0277(99)00047-5. [DOI] [PubMed] [Google Scholar]
- Singleton JL, Newport EL. When learners surpass their models: The acquisition of American Sign Language form inconsistent input. Cognitive Psychology. 2004;49:370–407. doi: 10.1016/j.cogpsych.2004.05.001. [DOI] [PubMed] [Google Scholar]
- Smith LB, Jones SS, Landau B, Gershkoff-Stowe L, Samuelson L. Object name learning provides on-the-job training for attention. Psychological Science. 2002;13:13–19. doi: 10.1111/1467-9280.00403. [DOI] [PubMed] [Google Scholar]
- Soderstrom M, Seidl A, Kemler Nelson DG, Juscyk PW. The prosodic bootstrapping of phrases: Evidence from prelinguistic infants. Journal of Memory and Language. 2003;49:249–267. [Google Scholar]
- Stager CL, Werker JF. Infants listen for more phonetic detail in speech perception than in word-learning tasks. Nature. 1997;388:381–382. doi: 10.1038/41102. [DOI] [PubMed] [Google Scholar]
- Tincoff R, Jusczyk PW. Some beginnings of word comprehension in 6-month-olds. Psychological Science. 1999;10:172–175. [Google Scholar]
- Tincoff R, Jusczyk PW. Six-month-olds comprehend words that refer to parts of the body. Infancy. 2012;17:432–444. doi: 10.1111/j.1532-7078.2011.00084.x. [DOI] [PubMed] [Google Scholar]
- Tomasello M. Constructing a language: A usage-based theory of language acquisition. Cambridge, MA: Harvard University Press; 2003. [Google Scholar]
- Voloumanos A, Werker JF. Infants’ learning of novel words in a stochastic environment. Developmental Psychology. 2009;45:1611–1617. doi: 10.1037/a0016134. [DOI] [PubMed] [Google Scholar]
- Waxman SR, Booth AE. Seeing pink elephants: Fourteen-month-olds’ interpretations of novel nouns and adjectives. Cognitive Psychology. 2000;43:217–242. doi: 10.1006/cogp.2001.0764. [DOI] [PubMed] [Google Scholar]
- Werker JF, Fennell CT, Corcoran KM, Stager CL. Infants’ ability to learn phonetically similar words: Effects of age and vocabulary size. Infancy. 2002;3:1–30. [Google Scholar]
- Yoshida H, Smith LB. Linguistic cues enhance the learning of perceptual cues. Psychological Science. 2005;16:90–95. doi: 10.1111/j.0956-7976.2005.00787.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yuan S, Fisher C. “Really? She Blicked the Baby?”: Two-Year-Olds Learn Combinatorial Facts About Verbs by Listening. Psychological Science. 2009;20:619–626. doi: 10.1111/j.1467-9280.2009.02341.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zangl R, Fernald A. Increasingly flexibility in children’s online processing of grammatical and nonce determiners in fluent speech. Language Learning and Development. 2007;3:199–231. doi: 10.1080/15475440701360564. [DOI] [PMC free article] [PubMed] [Google Scholar]