

Abstract
Since introduced in early 2000, multiscale entropy (MSE) has found many applications in biosignal analysis, and been extended to multivariate MSE. So far, however, no analytic results for MSE or multivariate MSE have been reported. This has severely limited our basic understanding of MSE. For example, it has not been studied whether MSE estimated using default parameter values and short data set is meaningful or not. Nor is it known whether MSE has any relation with other complexity measures, such as the Hurst parameter, which characterizes the correlation structure of the data. To overcome this limitation, and more importantly, to guide more fruitful applications of MSE in various areas of life sciences, we derive a fundamental bi-scaling law for fractal time series, one for the scale in phase space, the other for the block size used for smoothing. We illustrate the usefulness of the approach by examining two types of physiological data. One is heart rate variability (HRV) data, for the purpose of distinguishing healthy subjects from patients with congestive heart failure, a life-threatening condition. The other is electroencephalogram (EEG) data, for the purpose of distinguishing epileptic seizure EEG from normal healthy EEG.
Keywords: scaling law, multiscale entropy analysis, fractal signal, heart rate variability (HRV), adaptive filtering
1. Introduction
Biological systems provide the definitive examples of highly integrated systems functioning at multiple time scales. Neurons function on a time scale of milliseconds. Circadian rhythms operate on time scale of hours, reproductive cycles occur on a time scale of weeks, and bone remodeling involves time scales of months. As an integrated system, each process interacts with faster and slower processes. Consequently, biosignals often are multiscaled (Gao et al., 2007)—depending upon the scale at which the signals are examined, they may exhibit different behaviors (e.g., nonlinearity, sensitive dependence on small disturbances, long memory, extreme variations, and nonstationarity), just as a great painting may exhibit various details and arouse a multitude of aesthetic feelings when appreciated at different distances, from different angles, under different illuminations, and under different moods.
With the rapid advance of sensing technology, complex data have been accumulating exponentially in all areas of life sciences. To better cope with such complex data, recently, Costa et al. (2005) have introduced an interesting method, the multiscale entropy (MSE) analysis. MSE has found numerous applications in various types of biosignal analysis, including fetal heart rate monitoring (Cao et al., 2006), assessment of EEG dynamical complexity in Alzheimer's disease (Mizuno et al., 2010), classification of surface EMG of neuromuscular disorders (Istenic et al., 2010), heart rate analysis for predicting hospital mortality (Norris et al., 2008), and analysis of hear beat interval and blood flow for characterizing psychological dimensions in non-pathological subjects (Nardelli et al., 2015). MSE has also been extended to multivariate MSE (Ahmed and Mandic, 2011) and multiscale permutation entropy (Li et al., 2010). So far, however, no analytic analyses about MSE or multivariate MSE have been carried out. This has severely limited our basic understanding of MSE. For example, it has not been known whether MSE estimated using default parameter values and short data set is meaningful or not. Nor is it known whether MSE has any relation with other complexity measures, such as the Hurst parameter, which characterizes the correlation structure of the data.
To help gain insights into the above questions, and to guide more fruitful applications of MSE in diverse fields of life sciences, in this work, we report a fundamental bi-scaling law for MSE of the most popular model of biosignals, the fractal 1/f type time series. As example applications, we will analyze heart rate variability (HRV) and electroencephalogram (EEG) data. With HRV, we will focus on distinguishing healthy subjects from patients with congestive heart failure (CHF), a life-threatening condition, as well as resolving an interesting debate (Wessel et al., 2003; Nikulin and Brismar, 2004) regarding the usefulness of MSE in distinguishing HRV of healthy subjects from that of patients with certain cardiac disease. With EEG, we will focus on distinguishing epileptic seizure EEG from normal healthy EEG.
2. Materials and methods
2.1. Data
To illustrate the use of scaling analysis of MSE, in this paper, we analyze two types of data, heart rate variability (HRV), for the purpose of distinguishing healthy subjects from patients with congestive heart failure (CHF), and EEG, for the detection of epileptic seizures.
We downloaded two types of HRV data from the PhysioNet (MIT-BIH Normal Sinus Rhythm Database and BIDMC Congestive Heart Failure Database available at http://www.physionet.org/physiobank/database/#ecg), one for healthy subjects, and the other for subjects with CHF. The latter includes long-term ECG recordings from 15 subjects (11 men, aged 22 to 71, and 4 women, aged 54 to 63) with severe CHF (NYHA class 3–4). This group of subjects was part of a larger study group receiving conventional medical therapy prior to receiving the oral inotropic agent, milrinone. Further details about the larger study group can be found at the PhysioNet. The individual recordings of ECG are each about 20 h in duration, and contain two ECG signals each sampled at 250 samples per second with 12-bit resolution over a range of ±10 millivolts. The other database are for 18 normal subjects. The individual recordings are each about 25 h in duration, each sampled at 128 samples per second. The HRV data analyzed here are the R-R intervals (in unit of second) derived from the ECG recordings.
The EEG database is downloaded at http://www.meb.unibonn.de/epileptologie/science/physik/eegdata.html. The database consists of three groups, H (healthy), E (epileptic subjects during a seizure-free interval), and S (epileptic subjects during seizure); each group contains 100 data segments, whose length is 4097 data points with a sampling frequency of 173.61 Hz. These data have been carefully examined by adaptive fractal analysis (Gao et al., 2011c) and scale-dependent Lyapunov exponent (Gao et al., 2006b, 2011b, 2012), for the same purpose of distinguishing epileptic seizure EEG from normal healthy EEG.
2.2. Methods
Entropy characterizes creation of information in a dynamical system. To facilitate derivation of a fundamental scaling law for MSE, we first rigorously define MSE and all related concepts.
Suppose that the F-dimensional phase space is partitioned into boxes of size εF. Suppose that there is an attractor in phase space and consider a transient-free trajectory . The state of the system is now measured at intervals of time τ. Let p(i1, i2, … ,id) be the joint probability that = τ) is in box i1, = 2τ) is in box i2, …, and = dτ) is in box id. Let us now introduce the block entropy,
| (1) |
take the difference between Hd + 1 (ε, τ) and Hd (ε, τ), and normalize it by τ,
| (2) |
Let
| (3) |
It is called the (ε, τ)-entropy (Gaspard and Wang, 1993). Taking limits, we obtain the Kolmogorov-Sinai (K-S) entropy,
| (4) |
We now consider computation of the (ε, τ)-entropy from a time series of length N, x1, x2, …, xN. As is well-known, the first step is to use the time delay embedding to construct vectors of the form:
| (5) |
where m, the embedding dimension, and L, the delay time, can be chosen according to certain optimization criterion (Gao et al., 2007). Then one can employ the Cohen-Procaccia algorithm (Cohen and Procaccia, 1985) to estimate the (ε, τ)-entropy. In particular, when it is evaluated at a fixed finite scale , the resulting entropy is called the approximate entropy. To get better statistics from a finite time series, one may compute K2(ε) using the Grassberger-Procaccia’s algorithm (Grassberger and Procaccia, 1983):
| (6) |
where δt is the sampling time, C(m)(ε) is the correlation integral based on the m − dimensional reconstructed vectors Vi and Vj,
| (7) |
where Nv = N − (m − 1)L is the number of reconstructed vectors, H(y) is the Heaviside function (1 if y ≥ 0 and 0 if y < 0). C(m+1)(ε) can be computed similarly based on the m + 1 − dimensional reconstructed vectors. When we evaluate K2 (ε) at a finite fixed scale , we obtain the sample entropy Se (Richman and Moorman, 2000).
MSE analysis is based on the sample entropy Se. The procedure is as follows. Let X = {xt: t = 1, 2,…} be a covariance stationary stochastic process with mean μ, variance σ2, and autocorrelation function r(k), k ≥ 0. Construct a new covariance stationary time series
by averaging the original series X over non-overlapping blocks of size bs,
| (8) |
MSE analysis involves (i) choosing a finite scale in phase space, and (ii) computing Se from the original and the smoothed data X and X(bs) at the chosen scale . For convenience of later discussion, we denote K2 (bs) (ε) for the correlation entropy of the smoothed data. When bs = 1, it is the correlation entropy of the original data, and can be simply denoted as K2 (ε).
We emphasize that the length of the smoothed time series is only 1/bs of the original one. To fully resolve the scaling behavior of K2 (ε), the requirement on data length is quite stringent. A fundamental question is whether MSE calculated from short noisy data is meaningful or not.
3. Results
3.1. Scaling for the MSE of fractal time series
Among the most widely used models for biological signals, including HRV, EEG, and posture (Gao et al., 2011a), is the fractal time series with long memory, the so-called 1/fα, or 1/f2H − 1, α = 2H − 1 processes, where 0 < H < 1 is called the Hurst parameter, whose value determines the correlation structure of the data (Gao et al., 2006a, 2007): when H = 1/2, the process is like the independent steps of the standard Brownian-motion; when H < 1/2, the process has anti-persistent correlations; when H > 1/2, the process has persistent correlations. Two special cases, white noise with H = 0.5 and 1/f process with H = 1, have been extensively used for the development of multivariate MSE (Ahmed and Mandic, 2011). In this subsection, we derive fundamental scalings for MSE of the ubiquitous 1/f2H − 1 noise.
A covariance stationary stochastic process X = {Xt: t = 0, 1, 2, …}, with mean μ, variance σ2, and autocorrelation function r(w), w ≥ 0, is said to have long range correlation if r(w) is of the form Cox (1984)
| (9) |
where 0 < H < 1 is the Hurst parameter. When 1/2 < H < 1, ∑w r(w) = ∞, leading to the term long range correlation. Note the X time series has a power spectral density 1/f2H−1. Its integration, {yt}, where yt = ∑ti = 1 xi, is called a random walk process which is nonstationary with power-spectral density (PSD) 1/f2H+1. Being 1/f processes, they cannot be aptly modeled by Markov processes or ARIMA models (Box and Jenkins, 1976), since the PSD for those processes are distinctly different from 1/f. To adequately model 1/f processes, fractional order processes has to be used. The most popular is the fractional Brownian motion model Mandelbrot (1982), whose increment process is called the fractional Gaussian noise (fGn). The importance and popularity of fGn in modeling various types of noises in science and engineering motivates us to focus our analysis on it when deriving the bi-scaling law.
1/f2H−1 noises are self-similar, with the autocorrelation for the original data and the smoothed data (defined by Equation 8) being the same (Gao et al., 2006a, 2007). This signifies that there must exist a simple relation between K2 (bs) (ε) and K2 (ε). To find this relation, we note that the variance, var(X(bs)), of the smoothed data, and the variance, σ2, of the original data, are related by the following simple and elegant scaling law (Gao et al., 2006a, 2007),
| (10) |
Equation (10) states that the scale ε for the original data is transformed to a smaller scale bs H−1ε for the smoothed data. Using the self-similarity property of the 1/f2H−1 noise, we therefore obtain,
| (11) |
Since for stationary random processes, K2 (ε) diverges when ε → 0, Equation (11) states that can be obtained from K2 (ε) by shifting downward the curve for K2 (ε). How much K2 (ε) should be shifted depends on the functional form for K2 (ε), which we shall find out momentarily.
First we note that for 1-D independent random variables, which correspond to H = 1/2, h(ε,τ) ~ − ln ε (Gaspard and Wang, 1993). Therefore, K2 (ε) ~ −ln ε. In fact, for any stationary noise process, irrespective of its correlation structure, we always have C(m)(ε) ~ ε −m, ε → 0, therefore,
| (12) |
Equation (12) is, however, not adequate for us to understand the scaling of K2 (ε) on finite scales. To gain more insights, we resort to the rate distortion function or the Shannon-Kolmogorov (SK) entropy (Berger, 1971; Gaspard and Wang, 1993). It is thought to diverge with ε in the same way as the (ε,τ)-entropy and K2 (ε) (Gaspard and Wang, 1993).
Suppose we wish to approximate the random signal X(t) by Z(t) according to
| (13) |
where < > denotes averaging. Equation (13) may be considered a partition of the phase space containing the random signal X(t) by centering around X(t). Denote the conditional probability density for Z given x by q(z|x). The mutual information I(q) between X and Z is a functional of q(z|x),
| (14) |
The SK (ε,τ)-entropy is
| (15) |
where Q(ε) is the set of all conditional probabilities q(z|x) such that Condition (13) is satisfied. The SK (ε,τ)-entropy per unit time is then
| (16) |
For stationary Gaussian processes, hSK (ε,τ) can be readily computed by the Kolmogorov formula (Berger, 1971; Kolmogorov, 1956). In the case of a discrete-time process, it reads
| (17) |
| (18) |
where Φ(ω) is the PSD of the process and θ is an intermediate variable.
We now evaluate the SK entropy for a popular model of 1/f2H−1 noise, the fractional Gaussian noise (fGn). It is a stationary Gaussian process with PSD 1/ ω2H−1. Since we are primarily interested in small ε, we may choose the intermediate variable θ ≤ Φ(ω). Let us denote Φ(ω) = B(H) ω1−2H, where B(H) is a factor depending on H. When H = 1/2, it equals the variance of the noise σ 2H = 1/2. Using Equations (17) and (18), we immediately have
| (19) |
where
| (20) |
If we assume fGn of different H to have the same variance, then is a constant independent of H. A(H) can then be written as
| (21) |
A(H) is maximal when H = 1/2. However, when H is not close to 0 or 1, the term [ln (2 − 2H) − (1 − 2H)] is negligibly small, signifying that hSK (ε) cannot readily classify fGn of different H.
Since hSK (ε) and K2 (ε) diverge in the same fashion (Gaspard and Wang, 1993), using Equation (12) to determine the prefactor, we have a scaling for finite ε
| (22) |
Combining Equations (22) and (11), we arrive at a fundamental bi-scaling law for K(bs)2 (ε) for fractal time series:
| (23) |
To verify the above bi-scaling law, and more importantly, to gain insights into the relative importance of the two scale parameters bs and ε in MSE analysis, we numerically perform MSE analysis of fGn processes with different H. A few examples are shown in Figures 1, 2. The computations are done with 214 points and m = 2. We observe excellent bi-scaling relations, thus verifying Equation (23). Recalling our earlier comment that K2 (ε) itself is not very useful for distinguishing fGn of different H, Figure 2 clearly shows that the scaling K(bs)2 (ε) ~ (H − 1) ln bs can aptly separate fGn processes of different H. In fact, H values estimated from Figure 2 are fully consistent the values of H chosen in simulating the fGn processes. This analysis thus has demonstrated the major advantage of the scale parameter bs over ε for the study of fGn processes using MSE. It has also made it clear that MSE is a highly non-trivial extension of the sample entropy, and more generally, the correlation entropy K2(ε).
Figure 1.
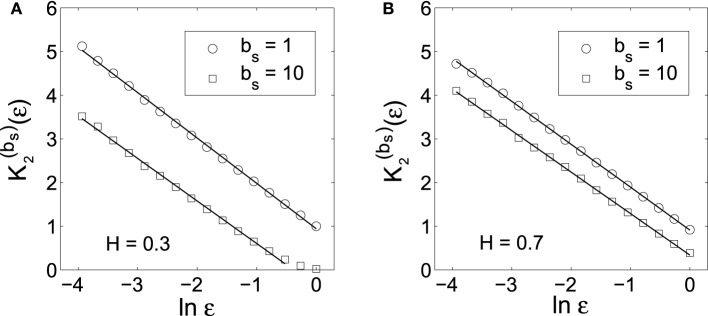
K(bs)2 (ε) vs. ln ε curves corresponding to the original data (bs = 1) and the smoothed data (bs = 10) for fGn processes with (A) H = 0.3 and (B) H = 0.7. The slopes of the linear regression lines are very close to 1.
Figure 2.
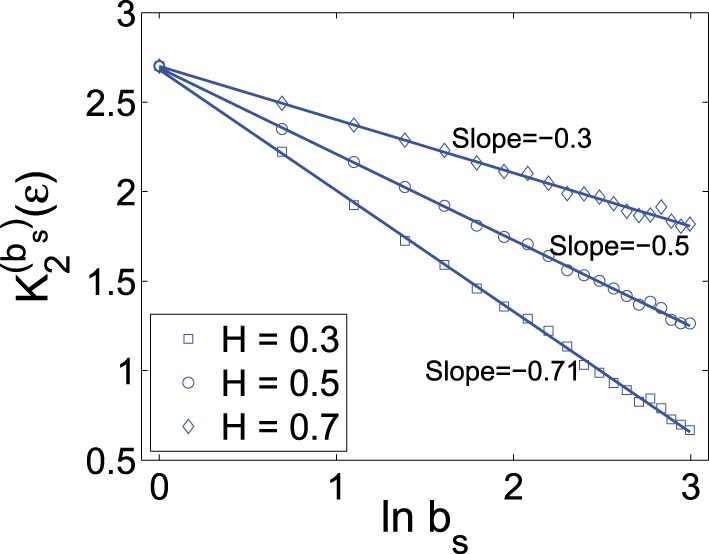
K(bs)2 (ε) vs. ln bs curves for fGn processes with different H values. The scale ε is chosen as 20% of the standard deviation of the corresponding fGn process. H value is estimated as 1 plus the slope of the curve.
While Equation (23) is fundamental for MSE, it can also help us better understand the behavior of multivariate MSE, which is shown in numerical simulations to be almost constant for 1/f processes with H=1, and decays in a well-defined fashion for white noise, where H=1/2, and some randomized data derived from experimental data possibly with correlations (Ahmed and Mandic, 2011). The reason is very clear. For 1/f process, H=1, and therefore, MSE or multivariate MSE does not vary with the scale parameter bs. For white noise or some derived randomized data, H=1/2, and therefore, MSE or multivariate MSE decays with the scale parameter bs in a well-defined fashion,
| (24) |
One can readily check that the MSE curve for white noise shown in Ahmed and Mandic (2011) is fully consistent with the formula derived here.
3.2. Heart rate variability data analysis
As an important application of MSE, we analyze HRV data for the purpose of distinguishing healthy subjects from patients with CHF, a life-threatening condition. This is an important issue. We refer to (Hu et al., 2009, 2010) and references therein for the background. Note that part of the data examined here were analyzed in prior work (Ivanov et al., 1999; Barbieri and Brown, 2006), for the same purpose. We analyze all 33 datasets here. For ease of comparison, we take the first 3 × 104 points of both groups of HRV data for analysis. Note that based on different bs parameter, MSE was not very good at separating the two groups (Hu et al., 2010). This instigated a debate on whether MSE was useful or not for analyzing HRV (Wessel et al., 2003; Nikulin and Brismar, 2004). To resolve this interesting debate, and more importantly, to satisfactorily separate the two groups of HRV data, we shall focus on the dependence of MSE on the scale parameter ε in the following discussions.
Since earlier studies find HRV data to be nonstationary, having 1/f spectrum with anti-persistent long-range correlations and multifractality (see Ivanov et al., 1999 and references therein), we analyze the increment processes of the HRV data. Figure 3 shows K2 (ε) vs. ln ε curves for the two groups of HRV data. We observe: (i) On small scales, K2 (ε) vs. ln ε curves for both groups of HRV data show good scaling behavior. As a consequence, one can expect a scaling relation between K(bs)2 (ε) and ln bs (Equation 23). This is indeed so. The results, being very similar to that shown in Figure 2, are not shown here, however. (ii) The scaling of K2 (ε) vs. ln ε is better and longer for the normal HRV data. (iii) As indicated by ε* in the figure, the smallest scale resolvable by the HRV data of the healthy subjects is much larger than that of the diseased subjects.
Figure 3.
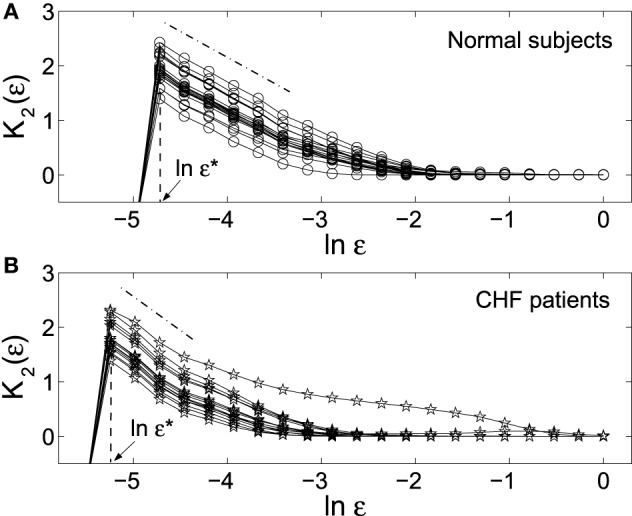
K2 (ε) vs. ln ε curves for the HRV data of (A) 18 normal subjects and (B) 15 patients with CHF. Each curve corresponds to one subject. The computations were done with 3 × 104 points and m = 5. ε* indicates the smallest scale resolvable by the data.
We now discuss how to use MSE to distinguish the healthy subjects from patients with CHF. We have found (i) The curves K(bs)2 (ε) vs. bs averaged over all the subjects within the two groups are different, just as reported in Costa et al. (2005). However, such curves are not very useful for separating the two groups as a diagnostic tool, as pointed out in Nikulin and Brismar (2004). The fundamental reason is of course that the Hurst parameter H is not very effective in distinguishing healthy subjects from patients with HRV, as quantitatively analyzed in Hu et al. (2010). (ii) The smallest resolvable scale, ε*, completely separates the healthy subjects from patients with CHF, as shown by Figure 3. Note the scale parameter ε is a generalization of the concept variance (or standard deviation). The observation made by Nikulin and Brismar (2004) that a variance-like parameter is better than MSE with varying block size parameter bs in distinguishing healthy subjects from patients with HRV is most appropriately interpreted as the following: the parameter bs is less important than the scale parameter ε. This is somewhat the opposite of the case for 1/f noise analyzed in the last section.
To more clearly see how much more advantageous ε is over bs in distinguishing healthy subjects from patients with HRV, we examine how the scaling K2(ε) ~ − ln ε can be used for this purpose. We have found that the errors obtained by linearly fitting the K2(ε) vs. ln ε curves of Figure 3 are much smaller for the normal HRV data than for those of CHF patients and also can completely separate the healthy subjects from patients with CHF. This is shown in Figure 4. Therefore, the scale parameter ε is indeed more important than bs.
Figure 4.
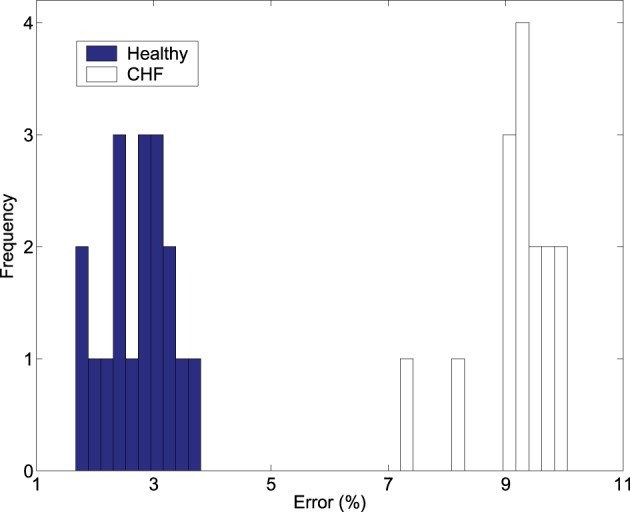
The frequency of the percentage of errors obtained by linearly fitting the K2 (ε) vs. ln ε curves in Figure 3 with 6 points starting from ε * for the healthy and diseased subjects.
3.3. Epileptic seizure detection through MSE of EEG
Epilepsy is a common and debilitating brain disorder. It is characterized by intermittent seizures. During a seizure, the normal activity of the central nervous system is disrupted. The concrete symptoms include abnormal running/bouncing fits, clonus of face and forelimbs, or tonic rearing movement as well as simultaneous occurrence of transient EEG signals such as spikes, spike and slow wave complexes or rhythmic slow wave bursts. Clinical effects may include motor, sensory, affective, cognitive, automatic and physical symptomatology. To make medications effective, timely detection of seizure is very important. In the past several decades, considerable efforts have been made to detect/predict seizures through nonlinear analysis of EEGs. For a list of the major nonlinear methods proposed for seizure detection, we refer to Gao and Hu (2013) and references therein. In particular, the three groups of EEG data analyzed here, H (healthy), E (epileptic subjects during a seizure-free interval), and S (epileptic subjects during seizure), were examined by adaptive fractal analysis (Gao et al., 2011c) and scale-dependent Lyapunov exponent (Gao et al., 2012), and excellent classification was achieved.
To examine how well MSE characterizes the three groups of EEG data, we have plotted in Figure 5 the mean MSE curves for the three groups, for two parameter values of the phase space scale, ε. We observe that they separate very well. Indeed, statistical test shows that the separations are significant. In particular, for the scale parameter in the phase space ε = 0.2, the MSE curve for the S group lies well below the other 2 curves. One may be tempted to equate this as smaller complexity of the seizure EEG. However, such an interpretation is informative only relative to the specific ε chosen here, which is 0.2. When ε = 0.05, the red curve for seizure EEG actually lie above the other 2 curves for larger bs. In fact, if one can pause a moment and think twice, one would realize that such interpretations are not too helpful for clinical applications, since MSE can vary substantially within and across the groups.
Figure 5.
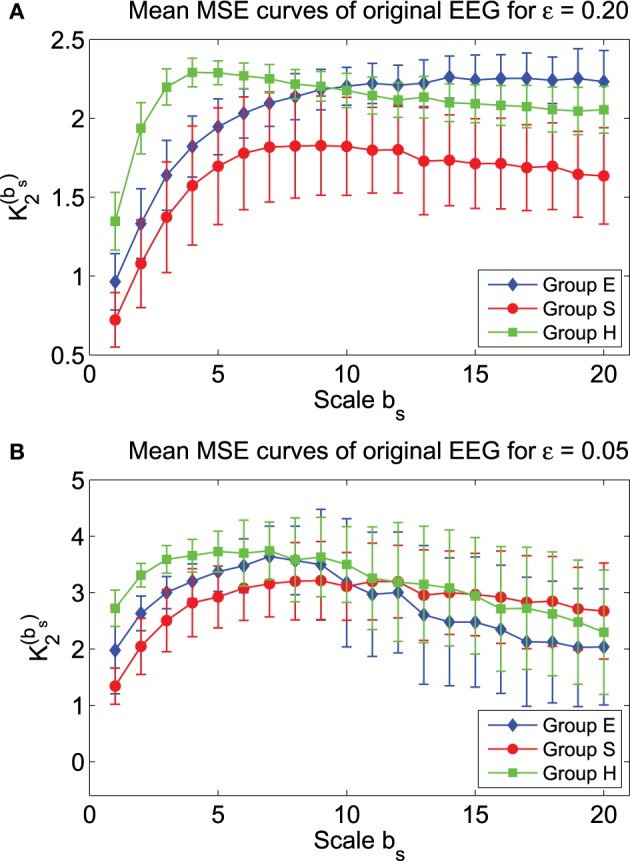
Mean MSE curves for the 3 EEG groups with (A) ε = 0.2 and (B) ε = 0.05.
We have tried to use MSE at specific bs values to classify the three groups of EEG. Guided by the mean MSE curves in Figure 5, we have found that when ε = 0.2, if only two bs can be used, then b2 = 2 and 15 are the optimal values. The result of the classification is shown in Figure 6A. We observe that there are some overlaps between groups H (healthy) and E (epileptic subjects during a seizure-free interval), as well as E and S (epileptic subjects during seizure). Intuitively, this is reasonable. Overall, the classification is not very satisfactory. How may we improve the accuracy of the classification?
Figure 6.
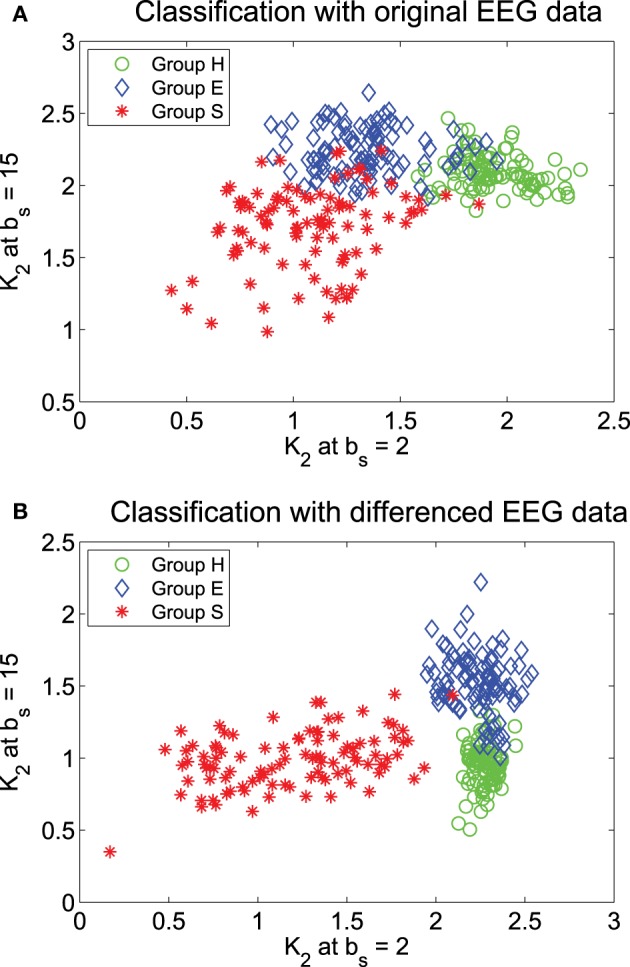
Classification of the 3 EEG groups using features from the MSE curves: (A) the original data and (B) the differenced data.
Recall that in fractal scaling analysis of EEG, EEG data are found to be equivalent to random walk processes, but not noise or increment processes (Gao et al., 2011c). The latter amounts to a differentiation of the random walk processes. Since the basic scaling law derived here is for noise or increment process, but not for random walk processes, it suggests us to try to compute MSE from the differenced data of EEG, defined by yi = xi − xi − 1, where xi is the original EEG signal. The mean MSE curves for the differenced data of EEG are shown in Figure 7, again for two ε values. We observe that the separation between the mean MSE curves becomes wider. Indeed, classification of the 3 EEG groups now is much improved, as shown in Figure 6B. It should be noted however that the accuracy of the classification is still slightly worse than using other methods, such as adaptive fractal analysis (Gao et al., 2011c) and scale-dependent Lyapunov exponent (Gao et al., 2012).
Figure 7.
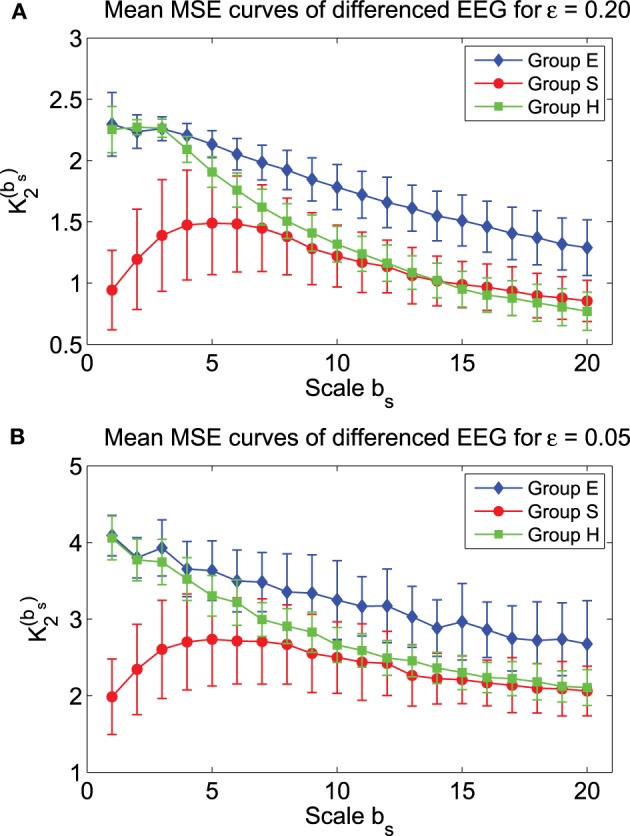
Mean MSE curves for the differenced data of the 3 EEG groups with (A) ε = 0.2 and (B) ε = 0.05.
4. Conclusion and discussion
To better understand MSE, we have derived a fundamental bi-scaling relation for the MSE analysis. While MSE analysis normally only focuses on the scale parameter bs with ε more or less arbitrarily chosen, our analysis of fGn and HRV data clearly demonstrates that both scale parameters are important—in the case of HRV analysis, the ε is more important, while in the case of 1/f noise, the bs parameter is more important. In fact, we have shown (Hu et al., 2010) that MSE, when used with ε fixed, is not very effective in distinguishing healthy subjects from patients with HRV. The accuracy achieved when we focus on the scaling of K2(ε) ~ −ln ε is not only much higher, but also comparable to that using the scale-dependent Lyapunov exponent (SDLE) (Gao et al., 2006a, 2007, 2013), as reported by Hu et al. (Hu et al., 2010). The fundamental reason of course is that SDLE has a similar scaling as K2(ε) ~ −ln ε.
We have also computed MSE for the original as well as the differenced data of the three EEG groups, H (healthy), E (epileptic subjects during a seizure-free interval), and S (epileptic subjects during seizure), and found that mean MSE curves for the three groups are well separated. The classification of the 3 EEG groups using MSE at two specific scale parameters bs is reasonably good, and is better for the differenced data than for the original EEG data. This strongly suggests that EEG data are like random walk processes. However, even with the differenced data of EEG, the classification is still not as accurate as using adaptive fractal analysis (Gao et al., 2011c) and scale-dependent Lyapunov exponent (Gao et al., 2011a). One of the reasons for this inferiority lies in the difference in the range of scales covered by these three multiscale methods. Adaptive fractal analysis and scale-dependent Lyapunov exponent both cover the entire range of scales presented in the EEG data. However, with the length of the EEG data, which is only 4097 points for each data set, MSE can only cover a moderate range of scales, with the largest bs only around 20, since with bs = 20, the smoothed data is already only 200 points long. Our analysis here has raised an important question: how do we use MSE to analyze short data? We conjecture that it may be beneficial to focus on the scaling of K2(ε) ~ −ln ε, or develop new smoothing schemes, by introducing a parameter equivalent to 1/bs but without sacrificing the length of the smoothed data.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
One of the authors (JG) is grateful for the generous support by National Institute for Mathematical and Biological Synthesis (NIMBIOS) at the University of Tennessee to attend Heart Rhythm Disorders Investigative Workshop.
References
- Ahmed M. U., Mandic D. P. (2011). Multivariate multiscale entropy: a tool for complexity analysis of multichannel data. Phys. Rev. E 84:061918. 10.1103/PhysRevE.84.061918 [DOI] [PubMed] [Google Scholar]
- Barbieri R., Brown E. N. (2006). Analysis of heartbeat dynamics by point process adaptive filtering. IEEE Trans. Biomed. Eng. 53, 4–12. 10.1109/TBME.2005.859779 [DOI] [PubMed] [Google Scholar]
- Berger T. (1971). Rate Distortion Theory. Englewood Cliffs, NJ: Prentice-Hall. [Google Scholar]
- Box G. E. P., Jenkins G. M. (1976). Time Series Analysis: Forecasting and Control, 2nd Edn. San Francisco, CA: Holden-Day. [Google Scholar]
- Cao H. Q., Lake D. E., Ferguson J. E., Chisholm C. A., Griffin M. P., Moorman J. R. (2006). Toward quantitative fetal heart rate monitoring. IEEE Trans. Biomed. Eng. 53, 111–118. 10.1109/tbme.2005.859807 [DOI] [PubMed] [Google Scholar]
- Cohen A., Procaccia I. (1985). Computing the Kolmogorov entropy from time series of dissipative and conservative dynamical systems. Phys. Rev. A 31, 1872–1882. 10.1103/PhysRevA.31.1872 [DOI] [PubMed] [Google Scholar]
- Costa M., Goldberger A. L., Peng C. K. (2005). Multiscale entropy analysis of biological signals. Phys. Rev. E 71:021906. 10.1103/PhysRevE.71.021906 [DOI] [PubMed] [Google Scholar]
- Cox D. R. (1984). Long-range dependence: a review. in Statistics: An Appraisal, eds David H. A., Davis H. T. (Ames: The Iowa State University Press; ), 55–74. [Google Scholar]
- Gao J. B., Cao Y. H., Tung W. W., Hu J. (2007). Multiscale Analysis of Complex Time Series — Integration of Chaos and Random Fractal Theory, and Beyond. Hoboken, NJ: Wiley. [Google Scholar]
- Gao J. B., Hu J., Tung W. W., Cao Y. H., Sarshar N., Roychowdhury V. P. (2006a). Assessment of long range correlation in time series: how to avoid pitfalls. Phys. Rev. E 73:016117. 10.1103/PhysRevE.73.016117 [DOI] [PubMed] [Google Scholar]
- Gao J. B., Hu J., Tung W. W., Cao Y. H. (2006b). Distinguishing chaos from noise by scale-dependent Lyapunov exponent. Phys. Rev. E 74:066204. 10.1103/PhysRevE.74.066204 [DOI] [PubMed] [Google Scholar]
- Gao J. B., Hu J., Buckley T., White K., Hass C. (2011a). Shannon and Renyi entropies To classify effects of mild traumatic brain injury on postural sway. PLoS ONE 6:e24446. 10.1371/journal.pone.0024446 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gao J. B., Hu J., Tung W. W. (2011b). Complexity measures of brain wave dynamics. Cogn. Neurodynamics 5, 171–182. 10.1007/s11571-011-9151-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gao J. B., Hu J., Tung W. W. (2011c). Facilitating joint chaos and fractal analysis of biosignals through nonlinear adaptive filtering. PLoS ONE 6:e24331. 10.1371/journal.pone.0024331 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gao J. B., Hu J., Tung W. W. (2012). Entropy measures for biological signal analysis. Nonlin. Dynamics 68, 431–444. 10.1007/s11071-011-0281-2 [DOI] [Google Scholar]
- Gao J. B., Gurbaxani B. M., Hu J., Heilman K. J., Emauele V. A., Lewis G. F., et al. (2013). Multiscale analysis of heart rate variability in nonstationary environments. Front. Comput. Physiol. Med. 4:119. 10.3389/fphys.2013.00119 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gao J. B., Hu J. (2013). Fast monitoring of epileptic seizures using recurrence time statistics of electroencephalography. Front. Comput. Neurosci. 7:122 10.3389/fncom.2013.00122 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gaspard P., Wang X. J. (1993). Noise, chaos, and (ε, τ)-entropy per unit time. Phys. Rep. 235, 291–343. 10.1016/0370-1573(93)90012-3 [DOI] [Google Scholar]
- Grassberger P., Procaccia I. (1983). Estimation of the Kolmogorov entropy from a chaotic signal. Phys. Rev. A 28, 2591–2593. 10.1103/PhysRevA.28.2591 [DOI] [Google Scholar]
- Hu J., Gao J. B., Tung W. W. (2009). Characterizing heart rate variability by scale-dependent Lyapunov exponent. Chaos 19, 028506. 10.1063/1.3152007 [DOI] [PubMed] [Google Scholar]
- Hu J., Gao J. B., Tung W. W., Cao Y. H. (2010). Multiscale analysis of heart rate variability: a comparison of different complexity measures. Ann. Biom. Eng. 38, 854–864. 10.1007/s10439-009-9863-2 [DOI] [PubMed] [Google Scholar]
- Istenic R., Kaplanis P. A., Pattichis C. S., Zazula D. (2010). Multiscale entropy-based approach to automated surface EMG classification of neuromuscular disorders. Medi. Biol. Eng. Comput. 48, 773–781. 10.1007/s11517-010-0629-7 [DOI] [PubMed] [Google Scholar]
- Ivanov P. C., Amaral L. A. N., Goldberger A. L., Havlin S., Rosenblum M. G., Struzik Z. R. (1999). Multifractality in human heartbeat dynamics. Nature 399, 461–465. 10.1038/20924 [DOI] [PubMed] [Google Scholar]
- Kolmogorov A. N. (1956). On the Shannon theory of information transmission in the case of continuous signals. IRE Trans. Inf. Theory 2, 102–108. 10.1109/TIT.1956.1056823 [DOI] [Google Scholar]
- Li D. A., Li X. L., Liang Z. H., Voss L. J., Sleigh J. W. (2010). Multiscale permutation entropy analysis of EEG recordings during sevoflurane anesthesia. J. Neural Eng. 7:046010. 10.1088/1741-2560/7/4/046010 [DOI] [PubMed] [Google Scholar]
- Mandelbrot B. B. (1982). The Fractal Geometry of Nature. San Francisco, CA: Freeman. [Google Scholar]
- Mizuno T., Takahashi T., Cho R. Y., Kikuchi M., Murata T., Takahashi K., et al. (2010). Assessment of EEG dynamical complexity in Alzheimer's disease using multiscale entropy Clin. Neurophysil. 121, 1438–1446. 10.1016/j.clinph.2010.03.025 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nardelli M., Valenza G., Cristea I. A., Gentili C., Cotet C., David D., et al. (2015). Characterizing psychological dimensions in non-pathological subjects through autonomic nervous system dynamics. Front. Comput. Neurosci. 9:37. 10.3389/fncom.2015.00037 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nikulin V. V., Brismar T. (2004). Comment on “Multiscale entropy analysis of complex physiologic time series.” Phys. Rev. Lett. 92:089803. 10.1103/PhysRevLett.92.089803 [DOI] [PubMed] [Google Scholar]
- Norris P. R., Anderson S. M., Jenkins J. M., Williams A. E., Morris J. A., Jr. (2008). Heart rate multiscale entropy at three hours predicts hospital mortality in 3,154 Trauma patients. Shock 30 17–22. 10.1097/SHK.0b013e318164e4d0 [DOI] [PubMed] [Google Scholar]
- Richman J. S., Moorman J. R. (2000). Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Physiol. 278, H2039–H2049. Available online at: http://ajpheart.physiology.org/content/278/6/H2039 [DOI] [PubMed] [Google Scholar]
- Wessel N., Schirdewan A., Kurths J. (2003). Intermittently decreased beat-to-beat variability in congestive heart failure Phys. Rev. Lett. 91:119801. 10.1103/PhysRevLett.91.119801 [DOI] [PubMed] [Google Scholar]