

Abstract
Language and vision are highly interactive. Here we show that people activate language when they perceive the visual world, and that this language information impacts how speakers of different languages focus their attention. For example, when searching for an item (e.g., clock) in the same visual display, English and Spanish speakers look at different objects. Whereas English speakers searching for the clock also look at a cloud, Spanish speakers searching for the clock also look at a gift, because the Spanish names for gift (regalo) and clock (reloj) overlap phonologically. These different looking patterns emerge despite an absence of direct linguistic input, showing that language is automatically activated by visual scene processing. We conclude that the varying linguistic information available to speakers of different languages affects visual perception, leading to differences in how the visual world is processed.
Keywords: language, vision, perception, cognition, bilingualism
Language and vision are highly interactive – language input influences visual processing (e.g., Chiu & Spivey, 2014; Spivey & Marian, 1999; Tanenhaus, Spivey-Knowlton, Eberhard, & Sedivy, 1995), and visual input can influence language activation (e.g., Bles & Jansma, 2008; Görges, Oppermann, Jescheniak, & Schriefers, 2013; Meyer, Belke, Telling, & Humphreys, 2007; Morsella & Miozzo, 2002). Here, we show that language is automatically activated during picture processing, even when no linguistic input is present, which carries implications for how speakers of different languages process the same visual scene.
It is already known that visual input activates linguistic representations when it is processed as part of a language-based task. For example, during production, the phonological form of an un-named picture impacts naming times for other images (e.g., Meyer & Damian, 2007; Morsella & Miozzo, 2002; Navarrete & Costa, 2005), and during comprehension, visual objects compete for selection when their names sound similar to an aurally-received label (e.g., Allopenna, Magnuson, & Tanenhaus, 1998; Tanenhaus et al., 1995; see also McQueen & Huettig, 2014). Even when no linguistic information is provided, visual-search performance can be affected by phonological overlap between visual objects if those objects’ labels have been pre-activated by preceding tasks (Görges et al., 2013; Meyer et al., 2007). What is not understood, however, is the relationship between linguistic and visual processing when language is not explicitly introduced to the task in any way.
When visual objects must be committed to memory, there is evidence from eye-movements that some linguistic characteristics of those objects are implicitly accessed. For example, when instructed to memorize a visual display, people spend more time looking at objects with longer names (Noizet & Pynte, 1976; Zelinsky & Murphy, 2000). This phenomenon is not observed, however, during an object-finding task within the same display (Zelinsky & Murphy, 2000). Similarly, the length of an object’s name does not impact the speed with which that object can be recognized (Meyer, Roelofs, & Levelt, 2003). This suggests that the activation of linguistic features may be contingent upon the explicit need to meaningfully encode visual objects into memory. Effects of automatic language activation on un-encoded visual scenes have not been extensively explored.
If language is automatically activated during basic visual scene processing, people’s specific language experiences should affect how scenes are processed. Because speakers of different languages have different names for the same objects, linguistic connections between visual items vary across languages. Therefore, in the current study we include two groups of participants: English monolinguals and Spanish-English bilinguals. The inclusion of populations with varying linguistic backgrounds allows us to probe linguistic activation while simultaneously controlling for unintentional relationships between objects’ names and their visual features.
To test whether the names of visually-perceived objects become automatically activated, leading to differences in how speakers of different languages perceive those objects, we developed an eye-tracking paradigm devoid of linguistic input (e.g., spoken or written language) and output (e.g., production). We presented participants with a picture of an easily-recognizable visual object (e.g., clock) and asked them to locate and click on an identical image of that object in a subsequent search display. Critically, the search display contained an item whose name shared initial phonological overlap with the name of the target in either English (e.g., clock-cloud) or Spanish (e.g., reloj-regalo [clock-gift]). If participants access the linguistic forms of visual items, they should look more often at items whose names share phonology (clock-cloud) than to items that do not share phonology (clock-scissors). Moreover, looking patterns should vary for speakers of different languages. Spanish speakers should activate the Spanish labels of objects within the visual display, and should look more at objects whose names overlap phonologically in Spanish (reloj-regalo [clock-gift]). Therefore, while Spanish-English bilinguals should look more at objects whose names sound similar in both Spanish and English, English monolinguals should only look more at objects whose names overlap in English, even though no linguistic information is present in the task.
Method
Participants
Twenty monolingual English speakers and twenty Spanish-English bilinguals were recruited from Northwestern University and participated in the current study. Language group was determined by responses to the Language Experience and Proficiency Questionnaire (Marian, Blumenfeld, & Kaushanskaya, 2007). Bilinguals reported learning both English and Spanish by age 7 and reported a composite proficiency score in each language of at least 7 on a scale from 0 (none) to 10 (perfect). Monolinguals reported a proficiency of no greater than 3 in any non-English language, and reported being exposed to a language other than English no earlier than the age of 13. See Table 1 for group comparisons and demographics.
Table 1.
Cognitive and Linguistic Participant Demographics.
| Measure | Monolinguals | Bilinguals |
|---|---|---|
| N | 20 | 20 |
| Age | 22.95 (3.80) | 22.45 (5.35) |
| Performance IQ (Wechsler Abbreviated Scale of Intelligence; Wechsler, 1999) | 112.35 (9.44) | 110.30 (10.28) |
| Working Memory: Digit Span (Comprehensive Test of Phonological Processing; Wagner et al., 1999) | 12.30 (2.05) | 13.30 (2.20) |
| Working Memory: Non-word Repetition (Comprehensive Test of Phonological Processing; Wagner et al., 1999) | 9.55 (2.37) | 8.55 (1.39) |
| Simon Effect (ms; Weiss et al., 2010) | 45.48 (16.96) | 54.83 (16.44) |
| English Vocabulary Standard Score (Peabody Picture Vocabulary Test; Dunn, 1981) | 118.90 (9.08) | 114.00 (16.28) |
| English Proficiency (LEAP-Q; Marian et al., 2007)a | 9.75 (0.55) | 9.68 (0.56) |
| Spanish Proficiency (LEAP-Q; Marian et al., 2007)a | - | 8.73 (0.82) |
| Spanish Vocabulary (Testo de Vocabulario de Imagenes Peabody; Dunn et al., 1986) | - | 115.65 (4.58) |
Note. Values represent means. Those in parentheses represent standard deviations. Groups did not differ on any cognitive or linguistic factors (except Spanish Proficiency and Spanish Vocabulary performance; all p’s>0.05).
Composite proficiency measures were computed by averaging speaking, reading, and understanding proficiencies (on a scale from 0=none to 10=perfect).
Materials
Fifteen stimuli sets were constructed, each containing a target object (e.g., clock, reloj in Spanish), an English competitor whose name in English overlapped with the English name of the target (e.g., cloud), a Spanish competitor whose name in Spanish overlapped with the Spanish name of the target (e.g., gift, regalo in Spanish), and three filler items (to replace the English competitor, Spanish competitor, and to fill the remaining quadrant of the four-item search display). On English competition trials, the target, English competitor, and two filler items were present on the display; on Spanish competition trials, the target, Spanish competitor, and two filler items were present. See Appendix for a full stimuli list. Target and English competitor pairs shared an average of 2.20 (SD=0.41) initial phonemes; target and Spanish competitor pairs shared an average of 2.27 (SD=0.46) initial phonemes; filler items did not overlap in either language with any item that was simultaneously presented. Stimuli were matched on the linguistic features listed in Table 2.
Table 2.
Comparisons between target, competitor, and filler stimuli.
| Log Frequencya | Orthographic Neighborsb | Phonological Neighborsb | Familiarityc | Concretenessc | Imageabilityc | |
|---|---|---|---|---|---|---|
| English Characteristics | ||||||
| Target | 3.12 (0.40) | 11.93 (10.52) | 26.27 (16.29) | 556.80 (44.81) | 589.00 (59.44) | 599.47 (44.07) |
| English Competitor | 2.79 (0.58) | 7.79 (5.87) | 13.64 (10.10) | 514.17 (35.76) | 529.08 (170.12) | 524.75 (170.82) |
| Spanish Competitor | 2.88 (0.58) | 9.87 (9.40) | 15.73 (15.28) | 531.29 (60.32) | 583.08 (50.23) | 585.38 (37.42) |
| Filler 1 | 2.84 (0.57) | 9.60 (8.60) | 17.47 (14.59) | 532.53 (72.68) | 596.08 (25.09) | 589.17 (23.90) |
| Filler 2 | 2.85 (0.41) | 8.00 (5.49) | 19.71 (15.52) | 530.21 (58.75) | 596.46 (13.79) | 599.38 (14.15) |
| Filler 3 | 2.73 (0.39) | 6.50 (8.24) | 12.29 (13.74) | 537.45 (27.25) | 57.73 (65.65) | 576.36 (41.64) |
| Comparisons | F(5,87) = 1.15, n.s. | F(5,86) = 0.78, n.s. | F(5,86) = 1.78, n.s. | F(5,80) = 0.90, n.s. | F(5,75) = 1.22, n.s. | F(5,75) = 1.75, n.s. |
| Spanish Characteristics | ||||||
| Target | 2.80 (0.43) | 3.07 (3.11) | 3.53 (4.64) | 6.17 (0.32) | 6.24 (0.54) | 6.32 (0.34) |
| English Competitor | 2.68 (0.52) | 3.13 (3.64) | 4.20 (5.83) | 5.83 (0.91) | 6.08 (0.24) | 5.68 (0.83) |
| Spanish Competitor | 2.65 (0.48) | 3.00 (3.51) | 4.20 (5.85) | 5.99 (0.58) | 6.05 (0.46) | 5.73 (0.62) |
| Filler 1 | 2.76 (0.77) | 2.67 (2.19) | 4.27 (4.59) | 5.80 (0.85) | 6.07 (0.30) | 5.71 (0.79) |
| Filler 2 | 2.43 (0.58) | 3.07 (2.63) | 3.47 (3.32) | 5.42 (1.24) | 5.98 (0.57) | 5.64 (0.75) |
| Filler 3 | 2.59 (0.44) | 2.93 (3.13) | 3.13 (3.34) | 5.70 (1.07) | 6.06 (0.25) | 5.71 (0.75) |
| Comparisons | F(5,89) = 0.90, n.s. | F(5,889) = 0.04, n.s. | F(5,89) = 0.16, n.s. | F(5,67) = 1.08, n.s. | F(5,67) = 0.38, n.s. | F(5,67) = 1.85, n.s. |
Note. Values represent means, those in parentheses represent standard deviations.
English: SUBTLEXUS (Brysbaert & New, 2009); Spanish: SUBTLEX-ESP (Cuetos, Glez-Nosti, Barbón, & Brysbaert, 2011)
CLEARPOND (Marian, Bartolotti, Chabal, & Shook, 2012)
English: MRC Psycholinguistic Database (Coltheart, 1981); Spanish: BuscaPalabras (Davis & Perea, 2005)
Stimuli were depicted by black and white line drawings, chosen from the International Picture Naming Project (IPNP) database (E. Bates et al., 2000). IPNP naming consistency was at least 75% for target and competitor objects in the critical language. Objects whose images were unavailable from the IPNP were chosen from Google Images and were independently normed by 20 English monolinguals and 20 Spanish-English bilinguals using Amazon Mechanical Turk (http://www.mturk.com)1.
Images were scaled to a maximum dimension of 343 pixels (8cm) and were viewed at a distance of 80cm. The four objects in each display were arranged in the outer four corners of the display, with a fixation cross in the center. Image locations were determined by creating a 3×3 grid matching the size of the monitor display (2560×1440 pixels) and centering the images in each of the four corner regions (search display images) and in the center region (fixation cross). Locations of target, competitor, and filler items were counterbalanced across trials, with targets and competitors always placed in adjacent quadrants (either horizontally or vertically) to ensure a consistent relationship between target/English competitor pairs and target/Spanish competitor pairs. Because the locations of objects within a visual display can impact looking patterns (e.g., because English speakers read from left to right and top to bottom), the locations of target and competitor items were balanced. Within a participant’s critical trials, the target appeared in the top left quadrant (Q1) eight times, the top right (Q2) eight times, the bottom left (Q3) six times, and the bottom right quadrant (Q4) eight times; the English competitor appeared four times in Q1, Q2, and Q3, and three times in Q4; the Spanish competitor appeared three times in Q1 and four times in the remaining three quadrants.
The experiment contained 30 critical trials (15 English phonological overlap, 15 Spanish phonological overlap) and 210 filler trials designed to mask the phonological manipulation. Timing of each trial matched that of Meyer et al., 2007, and is shown in Figure 1. On each trial, participants were presented with the target picture for 1000ms, followed by a fixation cross, which was replaced by the four-object search display after 1000ms. The search display remained on the screen until the participant provided a response. Each trial was preceded by an inter-stimulus interval of 1500ms.
Fig. 1.
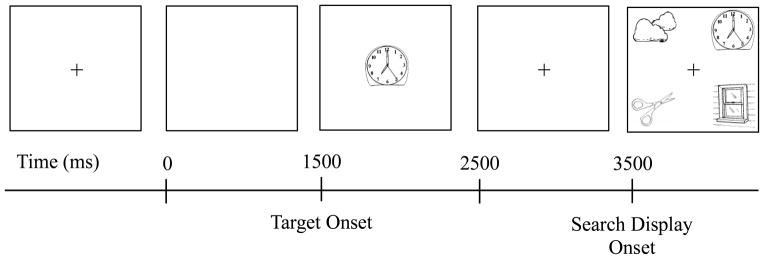
Sample trial structure for the English overlap condition. The target (e.g., clock) was present in the search display along with a phonological competitor (e.g., clouds) and two filler items whose names did not overlap phonologically (e.g., scissors, window); participants were instructed to click on the target object as quickly as possible.
Images used in critical trials were repeated in filler trials (in different combinations; i.e., target-competitor pairs were never included in the same filler trial) to ensure that every experimental image was seen an equal number of times. The 240 trials were arranged in a pseudo-randomized order (no image appeared in two consecutive trials), which was fixed between participants; half of the participants received the stimuli in reverse order.
Apparatus
The experiment was controlled by a 3.1 GHz Intel Core i5 running MATLAB 2010. Stimuli were presented using MATLAB Psychtoolbox and were displayed on a 27-inch monitor, with a screen resolution of 2560×1440. Eye movements were recorded using a desk-mounted eye-tracker (EyeLink 1000 Version 1.5.2, SR Research Ltd.) at a sampling rate of 1000Hz.
Procedure
Participants were familiarized with the eye-tracker and given written instructions for the procedure. Eye-tracker calibration was obtained using a 9-point calibration and validation procedure including drift correction at the onset of the experiment and again halfway through the experimental procedure. Participants were instructed to click on a central fixation cross to begin each trial, and to click on the target item as quickly and accurately as possible.
Following the eye-tracking procedure, participants provided names, in both English and Spanish, for each of the target and competitor items seen throughout the experiment. To maintain the intended phonological overlap between critical items, incorrectly-named or unnamed images were discarded individually for each participant on a trial-by-trial basis; trials in which Spanish images were named correctly by monolingual participants were also discarded. Trials were discarded (21.03% of trials; consistent with Görges et al., 2013) only if the incorrect naming of an item removed the intended phonological overlap between target-competitor pairs or added phonological overlap between control items; items whose incorrect naming did not impact the desired trial structure were retained.
Data Analysis
Mouse movements were sampled at 100Hz to collect accuracy and response time measures. Trials were considered accurate if the mouse was clicked in the region of the target image. Response time was only computed for accurate trials (2.14% of trials excluded) and was measured from the onset of the search array to the point of the mouse-click response; outliers were removed at two standard deviations above and below the response time mean (5.64% of trials).
Eye movements were sampled at 1000Hz and were coded for looks to each picture on the display. Only eye movements resulting in a fixation of at least 80ms were included in analyses. Within each trial, we calculated the total number of looks made to each object and the total amount of time spent looking at each object (ms). We converted these values into proportions by dividing by the total number of looks or the total amount of time spent looking at objects within that trial. Logit transformations of the total number of looks were computed to eliminate spurious effects resulting from bounded proportion data (Barr, 2007; Jaeger, 2008). These empirical logit values were used for all analyses of number of looks. To facilitate post-hoc between-trial comparisons, filler analyses were based on looks to the object that was present during both English and Spanish competition trials (within-trial analyses were comparable when looks to filler items were averaged together to obtain a composite filler score).
Data analyses for the number and duration of looks employed multi-level modeling (MLM; Jaeger, 2008) with language group (monolinguals vs. bilinguals; between-subjects) and item type (competitors vs. fillers; within-subjects) as fixed effects. Fixed effects were sum-coded. Constructed models included maximum slopes and intercepts (Barr, Levy, Scheepers, & Tily, 2012) with subjects and items as random effects, including slope terms of item type (competitors vs. fillers) on the subjects effect and of group (monolinguals vs. bilinguals) on the items effect. P-values were computed using Satterthwaite’s approximation for degrees of freedom derived from the lmerTest package in R.
To account for changes over the duration of a trial, a timecourse of fixations was created by sampling the logit-transformed number of looks to each item type every millisecond beginning with the onset of the search display and terminating with the participant’s mouse click. Resultant timecourse curves were analyzed using growth-curve analysis (GCA; Mirman, Dixon, & Magnuson, 2008) to compare the number of looks to competitor and filler items from 200ms post-display-onset (the time required to plan and execute an eye-movement; Viviani, 1990) to the average click response time. Timecourses included fixed effects of item type (competitors vs. fillers; within-subjects), group (monolinguals vs. bilinguals; between-subjects), and the polynomial time terms; and random effects of participant and participant-by-item type. Orthogonal time terms were also treated as random slopes in the model. The best-fitting orthogonal polynomial time terms were determined by constructing models including linear, quadratic, cubic, and quartic time terms, and comparing the models using chi-square model comparisons. In the English condition, the quartic model failed to converge. Model comparisons confirmed that the maximally-converging cubic model was a better fit than the linear (X2(22)=49063, p<0.001) and quadratic (X2(12)=30937, p<0.001) models. In the Spanish condition, the quartic model was found to be a better fit than the linear (X2(36)=65191, p<0.001), quadratic (X2(26)=48359, p<0.001), and cubic (X2(14)=16970, p<0.001) models. P-values resulting from all GCA models were computed by assuming that the t-values converged to a normal distribution given the large number of observations present in time course data (Mirman, 2014).
MLM and GCA models were constructed separately for English and Spanish competitor trials to ensure that all competitor-filler comparisons were conducted on a within-trial basis.
Results
Accuracy and Reaction Time
Accuracy on the search task reached 97.50% (SD=6.59%), and did not differ across groups (β=−0.52, SE=0.65, z=−0.80, p=0.43) or competitor conditions (β =−0.45, SE=0.51, z=−0.88, p=0.37). Analyses of reaction time yielded no main effects of group (β =48.10, SE=39.33, t(37.12)=1.22, p=0.23) or condition (β =−23.57, SE=15.72, t(128.55)=−1.50, p=0.14), and no significant interaction (β =−54.81, SE=31.42, t(129.44)=−1.74, p=0.09).
Number and Duration of Looks: Multi-Level Modeling
English competition
Our first analyses examined English competition by assessing the effects of item type and group on the number and duration of fixations. MLM analyses revealed that all participants made more looks to objects whose labels overlapped phonologically with the target in English than to objects whose names shared no phonological overlap (main effect of item type: β =−0.09, SE=0.05, t(31.40)=−2.03, p=0.052; no main effects of group: β =0.01, SE=0.06, t(39.01)=−0.22, p=0.83; no item type by group interactions: β =−0.09, SE=0.07, t(27.92)=−1.22, p=0.23) (Figure 2A). Similarly, participants spent more time looking at objects whose names overlapped in English (main effect of item type: β =−0.36, SE=0.17, t(32.59)=−2.10, p=0.04; no main effects of group: β =0.09, SE=0.17, t(32.04)=0.51, p=0.62; no item type by group interactions: β =−0.36, SE=0.25, t(30.13)=−1.42, p=0.16).
Fig. 2.

The number of looks made to English phonological competitors (e.g., clock-cloud) and fillers (e.g., clock-scissors) (a) and Spanish phonological competitors (e.g., reloj-regalo [clock-gift]) and fillers (e.g., reloj-tijeras [clock-scissors]) (b). Values are plotted in empirical logits, where a more negative number represents fewer looks. Error bars represent the standard error of the mean.
Because the spatial relationships between objects within a visual display may affect looking patterns, we wanted to ensure that our observed competition was not attributed to spurious effects arising from object placement. We therefore assessed the effects of item type and group on the number and duration of fixations when considering the filler item that shared the same spatial location to the target as the competitor (the target-adjacent competitor versus the target-adjacent filler). In the English competition condition, we observed a main effect of item type on the overall proportion of looks (β =−0.09, SE=0.04, t(30.77)=−2.03, p=0.05), but no effect of group (β =0.01, SE=0.06, t(35.69)=−0.19, p=0.85) or group by item type interaction (β =−0.04, SE=0.07, t(27.79)=−0.64, p=0.53). Similarly, when exploring the duration of looks, a main effect of item type (β =−0.35, SE=0.16, t(31.83)=−2.14, p=0.04) emerged, but there was no effect of group (β =0.18, SE=0.18, t(32.23)=1.00, p=0.33) and no interaction (β =−0.17, SE=0.26, t(29.52)=−0.65, p=0.52). Therefore, regardless of the relative position of the filler item used in analyses, all participants looked more often and for a longer duration of time at the English competitor than they did at the filler.
Spanish competition
We examined Spanish competition by again assessing the effects of item type and group on the number and duration of fixations. In trials containing Spanish competition, a group by item type interaction emerged on the number of looks (β =−0.11, SE=0.06, t(415.80)=−1.93, p=0.052; no main effects of item type: β =−0.04, SE=0.05, t(29.50)=−0.77, p=0.45 no main effects of group: β =0.06, SE=0.06, t(37.30)=1.04, p=0.30) (Figure 2B). Follow-up analyses revealed that bilinguals looked more at the Spanish competitor than did monolinguals (β =0.12, SE=0.06, t(36.13)=2.03, p=0.05) but that the groups did not differ in looks to the filler (β =0.01, SE=0.06, t(37.53)=0.19, p=0.85). Similarly, when considering the amount of time spent looking at each object in Spanish trials, only bilinguals looked marginally longer at objects whose names overlapped in Spanish (item type by group interaction: β =−0.48, SE=0.26, t(26.13)=−1.84, p=0.078; no main effects of item type: β =−0.17, SE=0.21, t(30.76)=−0.82, p=0.42; no main effects of group: β =0.03, SE=0.15, t(29.26)=0.17, p=0.89).
Just as with the English trials, we wanted to ensure that our observed Spanish competition was not due to unintentional location biases. We therefore conducted additional MLM analyses comparing looks to the target-adjacent competitor versus the target-adjacent filler. The group by item type interaction (β =−0.10, SE=0.06, t(565.30)=−1.60, p=0.11) reached marginal significance with a one-tailed statistical approach (p=0.055), and no main effects of item type (β =−0.01, SE=0.05, t(29.50)=−0.29, p=0.78) or group (β =0.07, SE=0.06, t(38.00)=1.19, p=0.24) emerged. Analyses of the duration of looks revealed no group by item type interaction (β =−0.37, SE=0.30, t(27.36)=−1.20, p=0.24), no effects of group (β =0.09, SE=0.17, t(30.75)=0.51, p=0.62), and no effects of item type (β =−0.07, SE=0.19, t(30.19)=−0.34, p=0.74).
Additional between-trial analyses compared the relative amount of competition experienced in Spanish versus English. In order to account for the nonindependence of eye movements, we computed individual within-trial difference scores by subtracting the logit-transformed number of looks to the filler item from the logit-transformed looks to the competitor item. These difference scores were then compared within groups using Welch two-sample t-tests. Results confirmed that bilinguals did not differ in the competition experienced between English and Spanish (t(19.28)=0.84, p=0.41; a two-tailed statistical approach was used given that bilinguals knew both languages), but that monolinguals experienced greater competition in English than in Spanish (t(21.73)=1.71, p=0.05; a one-tailed statistical approach was used given monolinguals’ lack of Spanish knowledge).
Timecourse of Fixations: Growth Curve Analyses
English competition
In order to determine the role of time in fixations to phonologically-related objects, we first compared the effects of item type and language group during English competition trials using growth-curve analysis (see Figure 3 for English GCA model fits). We observed more overall fixations to English competitors than to fillers (main effect of item type on the intercept term: β =−0.03, SE=0.01, t=−3.91, p<0.005) and a steeper curvature of fixations to English competitors relative to fillers (main effect of item type on the quadratic term: β =0.44, SE=0.21, t=2.26, p=0.02). No main effects of group or item type by group interactions emerged on any time terms (see Table 3), indicating that both monolinguals and bilinguals looked more at objects whose names overlapped in English (Figure 4A).
Fig. 3.

Timecourse of fixations to the English competitor (e.g., clock-cloud) and filler (e.g., clock-scissors) items plotted in empirical logits. Thick lines represent mean fixations, thin lines represent GCA model fits. Graphs are plotted collapsed across both groups (a) and separately for monolinguals and bilinguals (b) ranging from 200 ms post-display onset to the average click response time.
Table 3.
Parameter estimates for English growth curve analysis of object fixations.
| β | Std. Error | t | p | |
|---|---|---|---|---|
| Group: Intercept | 0.022 | 0.046 | 0.473 | 0.64 |
| Group: Linear | 0.350 | 0.866 | 0.405 | 0.69 |
| Group: Quadratic | −0.740 | 0.626 | −1.182 | 0.24 |
| Group: Cubic | −0.586 | 0.361 | −1.622 | 0.10 |
| Item Type: Intercept | −0.028 | 0.007 | −3.907 | <0.005 |
| Item Type: Linear | −0.151 | 0.202 | −0.748 | 0.45 |
| Item Type: Quadratic | 0.465 | 0.206 | 2.257 | 0.02 |
| Item Type: Cubic | 0.071 | 0.227 | 0.312 | 0.76 |
| Group*Item Type: Intercept | −0.020 | 0.014 | −1.382 | 0.17 |
| Group*Item Type: Linear | 0.426 | 0.404 | 1.055 | 0.29 |
| Group*Item Type: Quadratic | 0.394 | 0.412 | 0.955 | 0.34 |
| Group*Item Type: Cubic | 0.178 | 0.454 | 0.392 | 0.69 |
Note. P-values estimated using the normal approximation for the t-values.
Fig. 4.

Timecourse of fixations to the English competitor (e.g., clock-cloud) and filler (e.g., clock-scissors) items (a) and Spanish competitor (e.g., reloj-regalo [clock-gift]) and filler (e.g., reloj-tijeras [clock-scissors] items (b) ranging from 200 ms post-display onset to the average click response time. Although analyses were conducted based on empirical logit transformations, timecourses are plotted in proportions to facilitate visual interpretation.
Spanish competition
We next used GCA to compare effects of item type and language group during Spanish competition trials (see Figure 5 for Spanish GCA model fits), and found that bilinguals – but not monolinguals – made marginally more overall fixations to Spanish competitors relative to fillers (item type x group interaction on the intercept term: β =−0.02, SE=0.01, t=1.86, p=0.06) (Figure 4B). Additionally, a main effect of item type emerged on the quartic time term (β =−0.40, SE=0.12, t=−3.26, p<0.005). However, effects on time terms higher than the quadratic are difficult to interpret (Mirman, 2014) in the absence of overt visual differences between models fitted with and without the relevant (quartic) term; plotted data fits appeared visually identical, rendering the quartic effect uninterpretable. No further main effects or interactions emerged on any time terms (see Table 4).
Fig. 5.

Timecourse of fixations to the Spanish competitor (e.g., reloj-regalo [clock-gift]) and filler (e.g., reloj-tijeras [clock-scissors] items plotted in empirical logits. Thick lines represent mean fixations, thin lines represent GCA model fits. Graphs are plotted collapsed across both groups (a) and separately for monolinguals and bilinguals (b) ranging from 200 ms post-display onset to the average click response time.
Table 4.
Parameter estimates for Spanish growth curve analysis of object fixations.
| β | Std. Error | t | p | |
|---|---|---|---|---|
| Group: Intercept | −0.001 | 0.042 | −0.030 | 0.98 |
| Group: Linear | 0.894 | 0.770 | 1.161 | 0.25 |
| Group: Quadratic | 0.308 | 0.608 | 0.506 | 0.61 |
| Group: Cubic | −0.690 | 0.437 | −1.5781 | 0.11 |
| Group: Quartic | −0.180 | −0.398 | −0.452 | 0.65 |
| Item Type: Intercept | −0.002 | 0.005 | −0.303 | 0.76 |
| Item Type: Linear | −0.069 | 0.136 | −0.509 | 0.61 |
| Item Type: Quadratic | 0.108 | 0.174 | 0.622 | 0.53 |
| Item Type: Cubic | 0.118 | 0.164 | 0.719 | 0.47 |
| Item Type: Quartic | −0.397 | 0.122 | −3.257 | <0.005 |
| Group*Item Type: Intercept | −0.020 | 0.011 | −1.863 | 0.06 |
| Group*Item Type: Linear | −0.062 | 0.271 | −0.227 | 0.82 |
| Group*Item Type: Quadratic | 0.466 | 0.348 | 1.340 | 0.18 |
| Group*Item Type: Cubic | −0.084 | 0.328 | −0.257 | 0.80 |
| Group*ItemType: Quartic | −0.163 | 0.244 | −0.670 | 0.50 |
Note. P-values estimated using the normal approximation for the t-values.
Discussion
When processing a visual scene, language is automatically activated and causes speakers of different languages to perceive the world differently. Specifically, while viewing visual scenes without linguistic information, people attend to objects whose names sound similar in a language that they know. In the current study, monolingual English speakers and Spanish-English bilinguals completed a visual search task that did not require the use of language. While they searched for a target image (e.g., clock), all participants looked more at objects whose names overlapped phonologically in English (e.g., clock-cloud), but only Spanish speakers looked more at objects whose names overlapped in Spanish (e.g., reloj-regalo [clock-gift]).
Participants’ preference for looking at phonologically similar items reveals that the linguistic forms of visually-presented objects were automatically activated, even though language was irrelevant to the task and even though participants did not hear or see the names of the objects. Importantly, because English monolinguals did not make looks to objects whose names overlapped only in Spanish in spite of both groups viewing identical visual displays, our observed effects can be attributed to specific language knowledge and not to unintentional item or location effects. This claim is further bolstered by our demonstration that, regardless of the spatial location of the filler item used for analysis, all participants looked more at objects whose names overlapped phonologically. Thus, looks to competitors are driven by specific stimuli characteristics (i.e., phonological overlap) and not by spatial relationships between items. We therefore show that language experience biases attentional processing, causing speakers of different languages to attend to different items within a visual scene (see Boroditsky, 2011 and Regier & Kay, 2009 for discussions of other ways language shapes perception).
Our findings support a growing body of literature suggesting that visual search can be influenced in a top-down manner by non-visual features. For example, objects that are associatively related to a target (e.g., grapes-wine) attract more looks than unrelated objects (e.g., grapes-lock) in a language task (Huettig & Altmann, 2005; Moores, Laiti, & Chelazzi, 2003; Yee, Overton, & Thompson-Schill, 2009). Soto and Humphreys (2007) propose that these top-down effects on visual attention arise when objects are conceptually encoded into working memory: stimuli within the search display are rapidly processed at an abstract, semantic level and then matched with conceptual information provided by the initial cue (often the target). Here, we demonstrate that not only is top-down processing driven by conceptual links between objects, but that linguistic features also impact the processing of visual scenes.
As with semantically-mediated eye-movements, the linguistic effects observed in our current study are likely attributed to long-term mental representations of the objects that are temporarily encoded into working memory. Huettig, Olivers, and Hartsuiker (2011) propose a model in which objects within a visual display are encoded into visual working memory (e.g., Baddeley & Hitch, 1974; Logie, 1995). These visual features activate long-term memory codes, which lead to the cascaded activation of semantic and phonological information (see Huettig et al., 2011 for full discussion). Competition arises and can be measured within the traditional visual world paradigm when spoken input partially matches activated phonological information from more than one image, leading to fixations of phonologically-competing items (e.g., Allopenna et al., 1998). In our study, however, auditory input never provides a bottom-up phonological code. Instead, the cascaded activation of phonological codes is sufficient to direct attention to objects whose names sound similar to one another, even when language is completely absent from the surrounding task.
Critically, phonological activation is not limited to a single code mapped to a single item, but instead occurs simultaneously across multiple languages. For bilinguals, the presentation of a single stimulus image (e.g., clock) led to activation of more than one language, as evidenced by looks to objects whose names overlapped in both English (clock-cloud) and Spanish (reloj-regalo [clock-gift]). We therefore demonstrate that bilinguals simultaneously access both of their languages (e.g., Marian & Spivey, 2003a, 2003b), even in circumstances devoid of direct linguistic input.
It might be argued that our observed effects reflect intentional encoding and rehearsal of the target’s name to enhance task performance. This rehearsal, in turn, could serve as an auditory cue which would lead to bottom-up connections between the rehearsed name of the target and the names of items in the subsequent search display. However, because verbal cues lead to less efficient search than do visual cues (e.g., Vickery, King, & Jiang, 2005; Wolfe, Horowitz, Kenner, Hyle, & Vasan, 2004), it is unlikely that participants adopted this strategy. Post-experimental debriefing confirmed this, as most participants reported basing their search on gross visual features (and many reported being distracted by objects with similar visual form; e.g., clock-orange in filler trials).
Moreover, an intentional verbalization account is inconsistent with the pattern of results observed in bilinguals. Because bilinguals experienced competition arising from the activation of both English and Spanish, sub-vocalization would require that bilinguals rehearsed the object names in both languages (or rehearsed the names in Spanish on some trials and in English on other trials). However, this interpretation is inconsistent with the finding that bilinguals did not differ in the amount of competition they experienced in English and the amount of competition they experienced in Spanish. This result suggests that if both Spanish and English rehearsal were occurring, they must have been in approximately equal proportions (i.e., 50% of trials in English, 50% of trials in Spanish). Had bilinguals adopted that strategy, however, we would expect them to experience less English competition than the monolinguals (because on some instances in which items overlapped in English, Spanish rehearsal would eliminate this overlap). Instead, monolinguals and bilinguals did not differ in the number of looks they made to English competitors. We therefore believe that our data are incompatible with a sub-vocalization account. Instead, we propose that linguistic information stored in long-term memory is automatically activated for visually-presented objects.
In the context of our task, such an account assumes linguistic activation for all objects within the visual display. This interpretation is, in fact, consistent with previous research using the spoken word visual world paradigm. Although often not discussed, it is not uncommon for studies to find looks to target and competitor items before the target word has been announced or processed (e.g., Bartolotti & Marian, 2012; Shook & Marian, 2012; Weber & Cutler, 2004). In other words, before an auditory token is received, “first the visual display is processed up to a high level, including the creation of conceptual and linguistic representations” (Huettig et al., 2011, p. 142). In line with previous evidence that visually-presented objects are processed at a linguistic level (Huettig & McQueen, 2007; McQueen & Huettig, 2014; Meyer et al., 2007; Noizet & Pynte, 1976; Zelinsky & Murphy, 2000), we propose that our observed results are indicative of pervasive and automatic language activation during visual processing.
Our results provide compelling support for an interactive view of cognitive and perceptual processing, in which information flows in both bottom-up (basic percepts affect higher levels of cognition) and top-down (higher-order linguistic processes affect perception) directions. Linguistic and perceptual systems are highly interconnected – language is automatically activated by the processing of visual scenes, causing speakers of different languages to perceive the visual world differently.
Acknowledgments
This research was funded by grant NICHD RO1 HD059858-01A to Viorica Marian. The authors thank the members of the Northwestern Bilingualism and Psycholinguistics Research Group, Dr. James Booth, and Dr. Steven Franconeri for comments on this work. We also thank the Editor and two anonymous reviewers for their helpful suggestions on earlier versions of this manuscript.
Appendix
| Set | Target | English Competitor | Spanish Competitor | Filler 1 | Filler 2 | Filler 3 |
|---|---|---|---|---|---|---|
| 1 | cat (gato) | cast (yeso) | hanger (gancho) | magnet (imán) | jar (frasco) | broom (escoba) |
| 2 | clock (reloj) | cloud (nube) | gift (regalo) | ax (hacha) | window (ventana) | scissors (tijeras) |
| 3 | bell (campana) | belt (cinturón) | shirt (camisa) | fan (ventilador) | rain (lluvia) | glasses (lentes) |
| 4 | fly (mosca) | flag (bandera) | windmill (molino) | ring (anillo) | leaf (hoja) | drawer (cajón) |
| 5 | chair (silla) | chain (cadena) | whistle (silbato) | octopus (pulpo) | grapes (uvas) | bone (hueso) |
| 6 | butterfly (mariposa) | bus (autobús) | hammer (martillo) | envelope (sobre) | whip (látigo) | toys (juguetes) |
| 7 | lighter (encendedor) | lightning (rayo) | plug (enchufe) | spoon (cuchara) | heel (tacón) | net (red) |
| 8 | mouse (ratón) | mouth (boca) | frog (rana) | desk (escritorio) | arrow (flecha) | sock (calcetín) |
| 9 | glass (vaso) | glue (pegamento) | cow (vaca) | book (drum) | fence (cerco) | drum (tambor) |
| 10 | bat (murciélago) | basket (canasta) | doll (muñeca) | feather (pluma) | rollingpin (rodillo) | onion (cebolla) |
| 11 | knee (rodilla) | needle (aguja) | puzzle (rompecabezas) | helmet (casco) | fork (tenedor) | balloon (globo) |
| 12 | rabbit (conejo) | raft (balsa) | tie (corbata) | deer (venado) | glove (guante) | mushroom (hongo) |
| 13 | beach (playa) | beaver (castor) | iron (plancha) | egg (huevo) | roof (techo) | vacuum (aspiradora) |
| 14 | ant (hormiga) | antler (cuerno) | ear (oreja) | mop (trapeador) | bridge (puente) | church (iglesia) |
| 15 | butter (mantequilla) | bucket (cubeta) | apple (manzana) | shoe (zapato) | umbrella (paraguas) | lightbulb (foco) |
Footnotes
Like objects selected from the IPNP (E. Bates et al., 2000), objects chosen from Google Images were black and white line drawings. Twenty English monolinguals and twenty Spanish-English bilinguals (who were not participants in the current study) were recruited from Amazon Mechanical Turk (http://www.mturk.com). Participants were shown the images and were asked to provide each object’s name in English (all participants) and Spanish (bilingual participants only). Images were selected for inclusion if they were named with at least 75% reliability in both English and Spanish.
The computation of p-values from multi-level regression models is not trivial and cannot be precisely determined, due to variations in how degrees of freedom may be calculated (for a discussion see “DRAFT r-sig-mixed-models FAQ,” 2014). In its original implementation, the lme4 package did not provide a built-in method for calculating p-values and creator Douglas Bates recommended using Markov Chain Monte Carlo (MCMC) samples as the closest approximation (Bates, 2006; see also “DRAFT r-sig-mixed-models FAQ,” 2014). Earlier versions of this manuscript used MCMC sampling to obtain p-values by constructing simple random intercepts models and running MCMC sampling using the pvals.fnc function in the languageR package (chi-square tests of model comparisons revealed no differences between the simple and maximal models). During English competition, the main effect of item type was significant for both the number (p=0.04) and duration of looks (p=0.03), and was consistent when considering the filler item located adjacent to the target (number: p=0.04; duration: p=0.03). During Spanish competition, the item type by group interaction reached significance for both the number (p=0.045) and duration (p=0.04) of looks; when considering target-adjacent fillers, significance was reached with a one-tailed statistical approach (number: p=0.05; duration: p=0.05). The current manuscript calculates degrees of freedom using the Satterthwaite approximation in the lmerTest package in conjunction with lme4, as degrees of freedom can be computed using maximally-structured models (as recommended by Barr, Levy, Scheepers, & Tily, 2013) and therefore provides a more conservative estimate of p-values. For a discussion of why conventional p-values should be cautiously interpreted, see Johansson, 2011.
References
- Allopenna P, Magnuson JS, Tanenhaus MK. Tracking the time course of spoken word recognition using eye movements: Evidence for continuous mapping models. Journal of Memory and Language. 1998;38(4):419–439. http://doi.org/10.1006/jmla.1997.2558. [Google Scholar]
- Baddeley AD, Hitch G. Working memory. In: Bower GA, editor. Recent advances in learning and motivation. New York: Academic Press; 1974. pp. 47–90. [Google Scholar]
- Barr DJ. Analyzing “visual world” eyetracking data using multilevel logistic regression. Journal of Memory and Language. 2007;59(4):457–474. http://dx.doi.org/10.1016/j.jml.2007.09.002. [Google Scholar]
- Barr DJ, Levy R, Scheepers C, Tily HJ. Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language. 2012;68(3):1–51. doi: 10.1016/j.jml.2012.11.001. http://doi.org/10.1016/j.jml.2012.11.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barr DJ, Levy R, Scheepers C, Tily HJ. Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language. 2013;68(3):255–278. doi: 10.1016/j.jml.2012.11.001. http://doi.org/10.1016/j.jml.2012.11.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bartolotti J, Marian V. Language learning and control in monolinguals and bilinguals. Cognitive Science. 2012;36:1129–1147. doi: 10.1111/j.1551-6709.2012.01243.x. http://doi.org/10.1111/j.1551-6709.2012.01243.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bates D. [R] lmer, p-values and all that. 2006 Retrieved from https://stat.ethz.ch/pipermail/r-help/2006-May/094765.html.
- Bates E, Andonova E, D’Amico S, Jacobsen T, Kohnert K, Lu C, Pleh C. Introducing the CRL international picture naming project (CRL-IPNP) Center for Research in Language Newsletter. 2000;12(1) [Google Scholar]
- Bles M, Jansma BM. Phonological processing of ignored distractor pictures, an fMRI investigation. BMC Neuroscience. 2008;9:20. doi: 10.1186/1471-2202-9-20. http://doi.org/10.1186/1471-2202-9-20. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boroditsky L. How language shapes thought. Scientific American. 2011 Feb;304:62–65. doi: 10.1038/scientificamerican0211-62. http://doi.org/10.1038/scientificamerican0211-62. [DOI] [PubMed] [Google Scholar]
- Brysbaert M, New B. Moving beyond Kucera and Francis: A critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English. Behavior Research Methods. 2009;41(4):977–90. doi: 10.3758/BRM.41.4.977. http://dx.doi.org/10.3758/BRM.41.4.977. [DOI] [PubMed] [Google Scholar]
- Chiu EM, Spivey MJ. Timing of speech and display affects the linguistic mediation of visual search. Perception. 2014;43(6):527–548. doi: 10.1068/p7593. http://doi.org/10.1068/p7593. [DOI] [PubMed] [Google Scholar]
- Coltheart M. The MRC psycholinguistic database. Human Experimental Psychology. 1981;33(4):497–505. http://dx.doi.org/10.1080/14640748108400805. [Google Scholar]
- Cuetos F, Glez-Nosti M, Barbón A, Brysbaert M. SUBTLEX-ESP: Spanish word frequencies based on film subtitles. Psicologica. 2011;32:133–143. [Google Scholar]
- Davis CJ, Perea M. BuscaPalabras: A program for deriving orthographic and phonological neighborhood statistics and other psycholinguistic indices in Spanish. Behavior Research Methods. 2005;37(4):665–71. doi: 10.3758/bf03192738. http://dx.doi.org/10.3758/BF03192738. [DOI] [PubMed] [Google Scholar]
- DRAFT r-sig-mixed-models FAQ. 2014 Retrieved from http://glmm.wikidot.com/faq#df.
- Dunn L. The Peabody Picture Vocabulary Test. Circle Pines, MN: American Guidance Service; 1981. [Google Scholar]
- Dunn L, Dunn L. Test de vocabulario en imagenes Peabody (TVIP) Circle Pines, MN: American Guidance Service; 1986. [Google Scholar]
- Görges F, Oppermann F, Jescheniak JD, Schriefers H. Activation of phonological competitors in visual search. Acta Psychologica. 2013;143:168–175. doi: 10.1016/j.actpsy.2013.03.006. http://doi.org/10.1016/j.actpsy.2013.03.006. [DOI] [PubMed] [Google Scholar]
- Huettig F, Altmann GTM. Word meaning and the control of eye fixation: Semantic competitor effects and the visual world paradigm. Cognition. 2005;96(1):B23–32. doi: 10.1016/j.cognition.2004.10.003. http://doi.org/10.1016/j.cognition.2004.10.003. [DOI] [PubMed] [Google Scholar]
- Huettig F, McQueen JM. The tug of war between phonological, semantic and shape information in language-mediated visual search. Journal of Memory and Language. 2007;57(4):460–482. http://doi.org/10.1016/j.jml.2007.02.001. [Google Scholar]
- Huettig F, Olivers CNL, Hartsuiker RJ. Looking, language, and memory: Bridging research from the visual world and visual search paradigms. Acta Psychologica. 2011;137(2):138–50. doi: 10.1016/j.actpsy.2010.07.013. http://doi.org/10.1016/j.actpsy.2010.07.013. [DOI] [PubMed] [Google Scholar]
- Jaeger TF. Categorical data analysis: Away from ANOVAs (transformation or not) and towards logit mixed models. Journal of Memory and Language. 2008;59(4):434–446. doi: 10.1016/j.jml.2007.11.007. http://doi.org/10.1016/j.jml.2007.11.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Johansson T. Hail the impossible: P-values, evidence, and likelihood. Scandinavian Journal of Psychology. 2011;52:113–125. doi: 10.1111/j.1467-9450.2010.00852.x. http://doi.org/10.1111/j.1467-9450.2010.00852.x. [DOI] [PubMed] [Google Scholar]
- Logie RH. Visuo-spatial working memory. Hove, UK: Lawrence Erlbaum; 1995. [Google Scholar]
- Marian V, Bartolotti J, Chabal S, Shook A. CLEARPOND: Cross-linguistic easy-access resource for phonological and orthographic neighborhood densities. PloS One. 2012;7(8):e43230. doi: 10.1371/journal.pone.0043230. http://dx.doi.org/journal.pone.0043230. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marian V, Blumenfeld HK, Kaushanskaya M. The language experience and proficiency questionnaire (LEAP-Q): Assessing language profiles in bilinguals and multilinguals. Journal of Speech, Language, and Hearing Research. 2007;50(4):940. doi: 10.1044/1092-4388(2007/067). http://doi.org/10.1044/1092-4388(2007/067) [DOI] [PubMed] [Google Scholar]
- Marian V, Spivey MJ. Bilingual and monolingual processing of competing lexical items. Applied Psycholinguistics. 2003a;24(02):173–193. http://doi.org/10.1017/S0142716403000092. [Google Scholar]
- Marian V, Spivey MJ. Competing activation in bilingual language processing: Within- and between-language. Bilingualism: Language and Cognition. 2003b;6(2):97–115. http://doi.org/10.1017/S1366728903001068. [Google Scholar]
- McQueen JM, Huettig F. Interference of spoken word recognition through phonological priming from visual objects and printed words. Attention, Perception & Psychophysics. 2014;76(1):190–200. doi: 10.3758/s13414-013-0560-8. http://doi.org/10.3758/s13414-013-0560-8. [DOI] [PubMed] [Google Scholar]
- Meyer AS, Belke E, Telling AL, Humphreys GW. Early activation of object names in visual search. Psychonomic Bulletin & Review. 2007;14(4):710–6. doi: 10.3758/bf03196826. http://doi.org/10.3758/BF03196826. [DOI] [PubMed] [Google Scholar]
- Meyer AS, Damian MF. Activation of distractor names in the picture-picture interference paradigm. Memory & Cognition. 2007;35(3):494–503. doi: 10.3758/bf03193289. http://doi.org/10.3758/BF03193289. [DOI] [PubMed] [Google Scholar]
- Meyer AS, Roelofs A, Levelt WJM. Word length effects in object naming: The role of a response criterion. Journal of Memory and Language. 2003;48:131–147. http://doi.org/10.1016/S0749-596X(02)00509-0. [Google Scholar]
- Mirman D. Growth curve analysis and visualization using R. New York: CRC Press; 2014. [Google Scholar]
- Mirman D, Dixon JA, Magnuson JS. Statistical and computational models of the visual world paradigm: Growth curves and individual differences. Journal of Memory and Language. 2008;59(4):475–494. doi: 10.1016/j.jml.2007.11.006. http://doi.org/10.1016/j.jml.2007.11.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moores E, Laiti L, Chelazzi L. Associative knowledge controls deployment of visual selective attention. Nature Neuroscience. 2003;6(2):182–9. doi: 10.1038/nn996. http://doi.org/10.1038/nn996. [DOI] [PubMed] [Google Scholar]
- Morsella E, Miozzo M. Evidence for a cascade model of lexical access in speech production. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2002;28(3):555–563. http://doi.org/10.1037//0278-7393.28.3.555. [PubMed] [Google Scholar]
- Navarrete E, Costa A. Phonological activation of ignored pictures: Further evidence for a cascade model of lexical access. Journal of Memory and Language. 2005;53(3):359–377. http://doi.org/10.1016/j.jml.2005.05.001. [Google Scholar]
- Noizet G, Pynte J. Implicit labelling and readiness for pronunciation during the perceptual process. Perception. 1976;5(2):217–223. doi: 10.1068/p050217. http://doi.org/10.1068/p050217. [DOI] [PubMed] [Google Scholar]
- Regier T, Kay P. Language, thought, and color: Whorf was half right. Trends in Cognitive Sciences. 2009;13(10):439–46. doi: 10.1016/j.tics.2009.07.001. http://doi.org/10.1016/j.tics.2009.07.001. [DOI] [PubMed] [Google Scholar]
- Shook A, Marian V. Bimodal bilinguals co-activate both languages during spoken comprehension. Cognition. 2012;124(3):314–324. doi: 10.1016/j.cognition.2012.05.014. http://doi.org/10.1016/j.cognition.2012.05.014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Soto D, Humphreys GW. Automatic guidance of visual attention from verbal working memory. Journal of Experimental Psychology: Human Perception and Performance. 2007;33(3):730–7. doi: 10.1037/0096-1523.33.3.730. http://doi.org/10.1037/0096-1523.33.3.730. [DOI] [PubMed] [Google Scholar]
- Spivey MJ, Marian V. Cross talk between native and second languages: Partial activation of an irrelevant lexicon. Psychological Science. 1999;10(3):281. http://doi.org/10.1111/1467-9280.00151. [Google Scholar]
- Tanenhaus MK, Spivey-Knowlton M, Eberhard KM, Sedivy JC. Integration of visual and linguistic information in spoken language comprehension. Science. 1995;268(5217):1632–1634. doi: 10.1126/science.7777863. http://doi.org/10.1126/science.7777863. [DOI] [PubMed] [Google Scholar]
- Vickery TJ, King L, Jiang Setting up the target template in visual search. Journal of Vision. 2005;5:81–92. doi: 10.1167/5.1.8. http://doi.org/10.1167/5.1.8. [DOI] [PubMed] [Google Scholar]
- Viviani P. Eye movements in visual search: Cognitive, perceptual and motor control aspects. Reviews of Oculomotor Research. 1990;4:353. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/7492533. [PubMed] [Google Scholar]
- Wagner R, Torgesen J, Rashotte C. Comprehensive test of phonological processing. Auston, TX: Pro-Ed; 1999. [Google Scholar]
- Weber A, Cutler A. Lexical competition in non-native spoken-word recognition. Journal of Memory and Language. 2004;50(1):1–25. http://doi.org/10.1016/S0749-596X(03)00105-0. [Google Scholar]
- Wechsler D. Wechsler Abbreviated scale of intelligence. New York, NY: The Psychological Corporation: Harcourt Brace and Company; 1999. [Google Scholar]
- Weiss DJ, Gerfen C, Mitchel AD. Colliding cues in word segmentation: The role of cue strength and general cognitive processes. Language and Cognitive Processes. 2010;25(3):402–422. http://dx.doi.org/10.1080/01690960903212254. [Google Scholar]
- Wolfe JM, Horowitz TS, Kenner N, Hyle M, Vasan N. How fast can you change your mind? The speed of top-down guidance in visual search. Vision Research. 2004;44(12):1411–26. doi: 10.1016/j.visres.2003.11.024. http://doi.org/10.1016/j.visres.2003.11.024. [DOI] [PubMed] [Google Scholar]
- Yee E, Overton E, Thompson-Schill SL. Looking for meaning: Eye movements are sensitive to overlapping semantic features, not association. Psychonomic Bulletin & Review. 2009;16(5):869–74. doi: 10.3758/PBR.16.5.869. http://doi.org/10.3758/PBR.16.5.869. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zelinsky GJ, Murphy GL. Synchronizing visual and language processing: An effect of object name length on eye movements. Psychological Science. 2000;11(2):125–131. doi: 10.1111/1467-9280.00227. http://doi.org/10.1111/1467-9280.00227. [DOI] [PubMed] [Google Scholar]