

Abstract
De-duplication of biometrics is not scalable when the number of people to be enrolled into the biometric system runs into billions, while creating a unique identity for every person. In this paper, we propose an iris classification based on sparse representation of log-gabor wavelet features using on-line dictionary learning (ODL) for large-scale de-duplication applications. Three different iris classes based on iris fiber structures, namely, stream, flower, jewel and shaker, are used for faster retrieval of identities. Also, an iris adjudication process is illustrated by comparing the matched iris-pair images side-by-side to make the decision on the identification score using color coding. Iris classification and adjudication are included in iris de-duplication architecture to speed-up the identification process and to reduce the identification errors. The efficacy of the proposed classification approach is demonstrated on the standard iris database, UPOL.
Keywords: De-duplication, Biometrics, Iris fibers, Iris classification, Iris adjudication, Sparse representation, On-line dictionary learning
Introduction
Various government sectors in the world provide welfare services like NREGS (national rural employment guarantee system), TPDS (targeted public distribution system), old age pensions, health insurance etc... for the benefit of the people. A unique identity (UID) number creation for every person removes the requirement of producing mutliple documentary proofs for availing the services. De-duplication of biometrics plays a key role in providing unique identity of a person. De-duplication means the elimination of duplicate enrollments of the same person using the biometric data. As the number of people enrolled into the biometric system runs into billions, the time complexity increases in the de-duplication process while creating a unique identity for every individual. There is a need for de-duplication architecture based on biometrics which are scalable in large-scale databases. Among all the biometrics, fingerprints and iris give more accurate results in uniquely identifying the people based on minutia features. The biometric recognition system allows few errors in the identification process. In order to reduce the errors, fingerprint experts look for possible fingerprint matches and enhance the fingerprints to compare the minutia features manually using fingerprint adjudication process. Fingerprint adjudication means, comparison of two fingerprints side-by-side to analyze the matched minutia features. Even though the iris biometric is more accurate than the fingerprints, there is a need for iris adjudication process to reduce the identification errors.
The complex iris texture provides the uniqueness for iris images. Daugman proposed an iris recognition system by using gabor filters and iris codes (Daugman 1993, 2001, 2003, 2004). Wildes 1997 has implemented a gradient iris segmentation using Laplacian pyramid construction. Few researchers already explored iris classification techniques based on hierarchical visual codebook (Sun et al. 2014), block-wise texture analysis (Ross and Sunder 2010) and color information (Zhang et al. 2012). There are no approaches for classification of iris images based on the pre-defined iris classes in the existing work. In this paper, we propose an iris classification based on sparse representation of log-gabor wavelet features using on-line dictionary learning (ODL). Three different iris classes based on iris fiber structures, namely, stream, flower, jewel and shaker, are used for faster retrieval of identities in large-scale de-duplication applications. Also, an iris adjudication process is proposed by comparing the matched iris-pair images side-by-side to make the decision on the identification score using color coding. The iris classification and adjudication framework is used to speed-up the identification process and to reduce the identification errors in iris de-duplication architecture.
The rest of the paper is organized as follows: Section 2, gives the details of sparse representation and on-line dictionary learning. Section 3, gives the motivation for the proposed iris classification approach by illustrating the complexity involved in de-duplication of large scale iris databases. In Section 4, the proposed iris classification and adjudication framework is presented. Experimental results of the proposed classification and adjudication framework are given in Section 5. Conclusions are explained in Section 6.
Sparse representation and on-line dictionary learning (ODL)
Sparse representation has received a lot of attention from researchers in signal and image processing. Sparse coding involves the representation of an image as a linear combination of some atoms in a dictionary (Ramirez et al. 2010). Several algorithms like on-line dictionary learning (ODL) (Mairal et al. 2009), K-SVD (Aharon et al. 2006) and method of optimal directions (MOD) (Engan et al. 1999) have been developed to process training data. Sparse representation is used to match the input query image with the appropriate class. Etemand and Chellappa (Etemad and Chellappa 1998) proposed a feature extraction method for classification using wavelet packets. In (Sprechmann and Sapiro 2010), a method presented for the learning of dictionaries simultaneously. Recently, similar algorithms for simultaneous sparse signal representation have also been proposed (Huang and Aviyente 2006; Rodriguez and Sapiro2008).
The online dictionary learning algorithm alternates between sparse coding and dictionary update steps. Several efficient pursuit algorithms have been proposed in the literature for sparse coding (Engan et al. 1999; Mallat and Zhang 1993). The simplest one is the l1-lasso algorithm (Lee et al. 2007). Main advantage with ODL algorithm is its computational speed as it uses l1-lasso algorithm for sparse representation.
De-duplication architecture
De-duplication means the elimination of duplicate enrollments of the same person using the biometric data. During de-duplication process, matching the biometrics of a person is done against the biometrics of other persons to ensure that the same person is not enrolled more than once.
3.0.1 Motivation behind this work The state government of Andhrapradesh (Government of Andhra Pradesh, civil supplies department 2015) in India undertake the responsibility to identify the eligible households/beneficiaries and issue a ration card which enables them to avail the prescribed quantity of food grains and/or other commodities. The de-duplication was carried out for the ration cards using 52 million people iris codes to reduce the misuse of government subsidy. There are over 6.26 quadrillion (6,262,668,889,152,840) iris matches performed in de-centralized manner to remove duplicate enrollments in 61 days with high-end blade servers equipment which is not a scalable solution. This is the motivation for the proposed classification approach which reduces the search time drastically and provide the scalable de-duplication solutions.
The proposed de-duplication architecture is shown in Figure 1. In the processing stage, an iris image is segmented and normalized. Then iris templates are extracted using log-gabor wavelets. The de-duplication engine or iris matcher improves the speed of de-duplication by adding multiple blade servers. All the enrolled iris templates are loaded into each blade server and the iris templates are compared in "1:all" manner in N blade servers simultaneously. For example, if there are N query iris templates to be processed, then each query iris template goes to a blade server for de-duplication. If there are more than N query images, the delta of the iris templates keep on waiting in a queue till any of the blade servers are free. Increasing the blade servers is not an optimal solution, especially in large-scale iris databases. There should be another layer for iris classification to reduce the search space in the de-duplication engine. So, we propose an iris classification based on sparse representation of log-gabor wavelet features using on-line dictionary learning (ODL). Also, an iris adjudication process is done by comparing the matched iris-pair images side-by-side to know the confidence-level on the matching score based on color coding.
Figure 1.
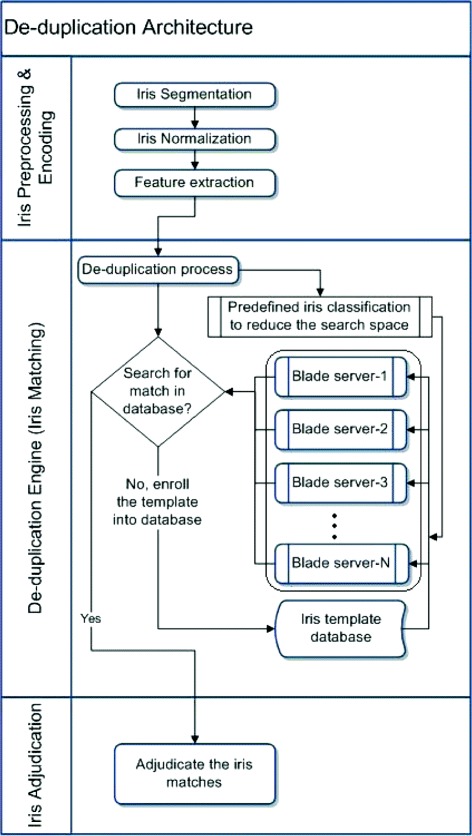
Iris de-duplication architecture.
Proposed iris classification and adjudication framework
The proposed iris classification approach uses three different classes of iris images (Unitree foundation the rayid model of iris interpretation 2009) namely, stream, flower, and jewel-shaker as illustrated in Figure 2. The iris structure can be determined by the arrangement of white fibers radiating from the pupil. In stream iris structure, these fibers are arranged in regular and uniform fashion. The arrangement of fibers is irregular in the flower iris structure. In jewel iris structure, the fibers have some dots. The shaker iris structure have both the characteristics of flower and jewel iris structures. The arrangement of fibers are illustrated in Figure 3.
Figure 2.
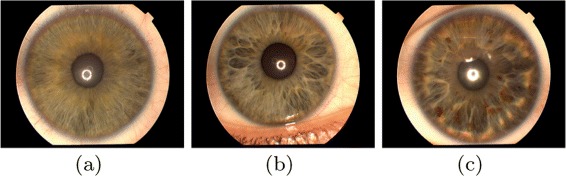
Iris classes: (a) stream, (b) flower and (c) jewel-shaker structures.
Figure 3.
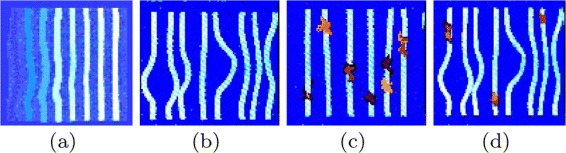
Iris fibers: (a) stream, (b) flower, (c) jewel and (d) shaker.
The following are the steps involved in the proposed iris classification and adjudication framework: Step 1.Iris segmentation and normalization : The pupillary and limbic boundaries (Masek 2003) of an iris image are approximated as circles using three parameters: the radius r, and the coordinates of the center of the circle, x0 and y0. The integrodifferential operator (Daugman 1993) used for iris segmentation is:
| (1) |
where Gσ(r) is a smoothing function and I(x,y) is the image of the eye.
After applying the operator, the resultant segmented iris image is as shown in Figure 4. The segmented iris image is then converted to a dimensionless polar coordinate system based on the Daugman Rubber Sheet model (Daugman 1993) as shown in Figure 5.
Figure 4.
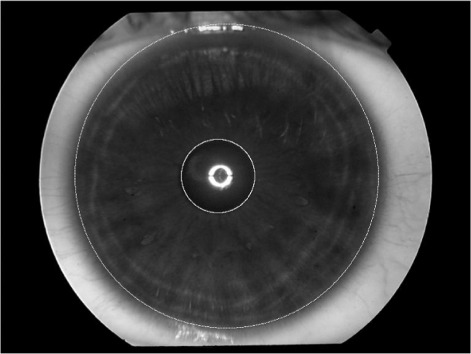
Iris image segmentation.
Figure 5.

Normalized iris image.
Step 2.Feature extraction(Masek 2003): The log-gabor wavelet feature vector of size 720 × 40 is extracted from the normalized iris image of size 360 × 40. The resultant feature vector is converted to a single column vector by column major ordering. From each class, some of the iris images are selected to express as a linear weighted sum of the feature vectors in a dictionary belonging to three different classes of iris.Step 3.Iris classification using ODL: An on-line dictionary learning (ODL) algorithm is used to classify the iris data into three different classes to reduce the search space. The weights associated with feature vectors in the dictionary are evaluated using ODL algorithm, which is a solution to l1 optimization for over-determined system of equations. The feature vectors which belong to a particular iris class carry significant weights which are non-zero maximum values. The class C=[C1,…,CN] consists of training samples collected directly from the image of interest. In the proposed sparsity model, images belonging to the same class are assumed to lie approximately in a low dimensional subspace. Given N training classes, the pth class has Kp training images =1,…, Kp. Let b be an image belonging to the pth class, and it is represented as a linear combination of these training samples:
| (2) |
where Dp is a dictionary of size m×Kp, whose columns are the training samples in the pth class and Φp is a sparse vector.
The following are the steps involved in the proposed classification method:
-
Dictionary Construction: Construct the dictionary for each class of training images using on-line dictionary learning algorithm (Mairal et al. 2009). Then, the dictionaries D=[D1,…,DN] are computed using the equation:
satisfying
-
Classification: In this classification process, the sparse vector Φ for given test image is found in the test dataset B=[b1,…,bl]. Using the dictionaries of training samples D=[D1,…,DN], the sparse representation Φ satisfying DΦ= B is obtained by solving the following optimization problem:
(3)
where δi is a characteristic function that selects the coefficients. Then bj is assigned to Ci associated with the ith dictionary. It means, finding the sparsest dictionary for a given test data using l1 -lasso algorithm. Then, test data is assigned to the class associated with this sparsest dictionary. Step 4.Iris Adjudication: The matched iris pairs are compared using the adjudication process to illustrate the match-ability of iris images based on the similarity of iris regions marked with three different colors, namely, green, yellow and red. The green, yellow and red colors indicate good, poor and bad match, respectively. The normalized iris image is divided into different regions and the confidence-level of matching for each region is verifed and assigned a color code using the dissimilarity measurement.
Experimental results
To enable the effective test of the proposed classification strategy, three standard iris image databases are used, namely, CASIA1 database (Casia-irisv1 chinese academy of sciencesinstitute of automation iris database 2015), IITD iris database (Kumar and Passi 2010, 2015), and UPOL iris database (Dobe and Machala 2004; Dobes̆ et al. 2006, 2004).
The CASIA database consists of 108 subjects, three instances of left iris and four instances of right iris are collected from each subject. So there is a total of 756 iris images in the database, all are having the image dimensions 320 × 280 gray-scale images. For testing, 216 iris images are used and the remaining iris images are used for training.
The IITD iris database consists of 224 subjects iris data, both left and right iris images. For each subject there are 10 instances of each iris image. So there is a total of 2232 iris images in the database, all are having the image dimensions 320 x 280 gray-scale images.
The UPOL iris data is collected from 64 subjects, with three samples of left and right eyes from each subject resulting in a total of 384 iris images. Each iris image is of 24 bit RGB color space with a high resolution image size, 768x576. The images were captured using the optical device (TOPCON TRC50IA) which is connected to a Sony DXC-950p 3CCD camera.
Experiments are performed using the following iris classification approaches: Approach-1: SVM-4Class-PCA-Kmeans Approach-2: ODL-4Class-PCA-Kmeans Approach-3: SVM-3Class-IrisFibers Approach-4: ODL-3Class-IrisFibers
The results are compared to demonstrate the efficacy of the proposed classification approach in the iris de-duplication architecture. The details are given below:
SVM-4Class-PCA-Kmeans classification approach:This classification approach uses the support vector machine (SVM) as a classifier. The classes are defined by applying the k-means clustering on the iris feature vectors whose dimensions are reduced to 100 features by considering the 100 principle components using principle component analysis (PCA). The correlation similarity measure is used for clustering the iris data into four different iris categories. This approach is applied on three standard iris databases, where 2/3 of the each database is used for training and remaining data is used for testing.
ODL-4Class-PCA-Kmeans classification approachIn this classification approach, the sparsity-based on-line dictionary learning (ODL) is used as a classifier. The k-means clustering is applied to define the classes on the iris feature vectors whose dimensions are reduced to 100 features by considering the 100 principle components using PCA. The correlation similarity measure is used for clustering the iris data into four different iris categories. This approach is applied on three standard iris databases, where 2/3 of the each database is used for training and remaining data is used for testing.
SVM-3Class-IrisFibers classification approachThis classification approach uses SVM as a classifier. The classes are defined by manual labeling of three iris categories (Unitree foundation the rayid model of iris interpretation 2009) using the iris fiber structures. This approach is applied on UPOL standard iris database, where 2/3 of the database is used for training and remaining data is used for testing.
ODL-3Class-IrisFibers classification approachSparsity-based on-line dictionary learning (ODL) is used in this iris classification approach. The proposed iris de-duplication architecture include this classification to reduce the search space. The classes are defined by manual labeling of three iris categories using the iris fiber structures. This approach is applied on UPOL standard iris database, where 2/3 of the database is used for training and remaining data is used for testing.
5.1 Description of the experiments
5.1.1 Experiment-1
In iris classification approaches 1 and 2, the experiments are conducted using the three databases, namely, CASIA1, IITD and UPOL iris dabases with template sizes 480 by 20. Four classes are identified using k-means clustering algorithm using the correlation-based distance metric. Table 1 describes the details of the number of images in each class and in three different databases.
Table 1.
Iris classes defined based on k-means clustering and PCA
| # of Images in | CASIA1 | IITD | UPOL |
|---|---|---|---|
| Class-1 | 196 | 525 | 81 |
| Class-2 | 203 | 500 | 114 |
| Class-3 | 196 | 595 | 69 |
| Class-4 | 161 | 580 | 120 |
The experimental results are illustrated as shown in Figure 6. It is observed that the ODL-4Class-PCA-Kmeans classification approach gives better classification performance due to the effectiveness of sparsity.
Figure 6.

Experimental results for the classification approaches SVM-4Class-PCA-Kmeans and ODL-4Class-PCA-Kmeans for the three iris databases namely, CASIA1, IITD and UPOL.
5.1.2 Experiment-2
In iris classification approaches 3 and 4, the experiments are conducted using the UPOL iris database with template sizes 720 by 40. Three classes are manually identified in these proposed iris classification approaches using the iris patterns stream, flower and jewel-shaker as shown in Table 2. In this experiment, the other two databases are excluded as it was difficult to mark the class labels due to the less clarity to manually identify the iris fiber structures.
Table 2.
Iris classes defined based on the iris fibers stream, flower and jewel-shaker
| Class | # of Images | Subject Ids |
|---|---|---|
| (%) | ||
| Class-1 | 192 (50%) | 001,006,007,008,011, 013,014,016,018,019, |
| (Stream) | 020,021,023,024,026, 027,028,033,041,042, | |
| 044,045,050,051,052, 053,058,059,060,061, | ||
| 062,064 | ||
| Class-2 | 102 (26.56%) | 002,009,010,015,017, 022,031,036,037,040, |
| (Flower) | 043,047,048,049,054, | |
| 056,063 | ||
| Class-3 | 90 (23.44%) | 003,004,005,012,025, 029,030,032,034,035, |
| (Jewel-Shaker) | 038,039,046,055,057 |
The experimental results for the UPOL database are compared using SVM and ODL and illustrated as shown in Figure 7. It is observed that the classification accuracy is better in the ODL-related classification approaches.
Figure 7.
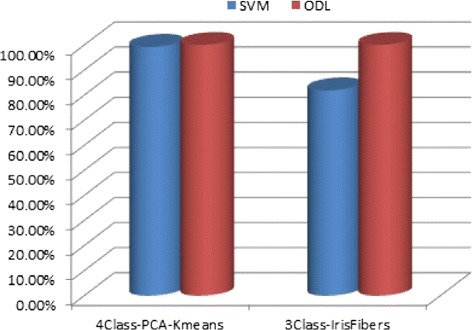
Experimental results for all the proposed classification approaches on UPOL iris database.
5.1.3 Detailed analysis on the proposed classification approach : ODL-3Class-IrisFibers
In order to evaluate the performance of proposed classification approach using on-line dictionary learning, the database is split into three sets: training set, testing set and validation set. The distribution of all the three sets are taken in such a way that the 2 samples of each iris image is allotted to the training set and validation set, and the remaining iris sample is given to the test set. The training set consists of 224 images where 112 images are from Class-1 (Stream), 60 images are from Class-2 (Flower) and 52 images are from Class-3 (Jewel-Shaker). The number of test images selected from Class-1, Class-2 and Class-3 are 64, 34 and 30, respectively. A set of 32 iris images is assigned to validation set where 16 images belong to Class-1, 8 images belong to Class-2 and 8 images belong to Class-3.
The experiments were conducted in three different ways of choosing test sets (systematically selecting first, second or third samples of each iris) where the performance is almost similar. The classification performance is shown for the test data set with different dictionary sizes 60, 90 and 120, in Tables 3, 4 and 5, respectively.
Table 3.
Classification performance on test data set for dictionary size = 60
| Class | Residual parameter | ||
|---|---|---|---|
| 0.5 | 0.05 | 0.005 | |
| Class-1 (Stream) | 90.5 | 97 | 93.83 |
| Class-2 (Flower) | 91.18 | 94.12 | 88.2 |
| Class-3 (Jewel-Shaker) | 100 | 100 | 100 |
Boldface data represents the best performance.
Table 4.
Classification performance on test data set for dictionary size = 90
| Class | Residual parameter | ||
|---|---|---|---|
| 0.5 | 0.05 | 0.005 | |
| Class-1 (Stream) | 95 | 100 | 98.5 |
| Class-2 (Flower) | 94.12 | 100 | 97.06 |
| Class-3 (Jewel-Shaker) | 100 | 100 | 100 |
Boldface data represents the best performance.
Table 5.
Classification performance on test data set for dictionary size = 120
| Class | Residual parameter | ||
|---|---|---|---|
| 0.5 | 0.05 | 0.005 | |
| Class-1 (Stream) | 95 | 100 | 98.5 |
| Class-2 (Flower) | 91.18 | 100 | 96.06 |
| Class-3 (Jewel-Shaker) | 100 | 100 | 100 |
Boldface data represents the best performance.
In Table 6, the classification accuracy for the validation data set is given. It is observed that 100% classification accuracy is achieved for the dictionary sizes, 90 and 120 with residual error value 0.05 as shown in Figure 8. The confusion matrix for both test data and validation data sets are shown in Table 7.
Table 6.
Classification performance on validation data set for dictionary sizes 60, 90 and 120
| Class | Dictionary sizes | ||
|---|---|---|---|
| 60 | 90 | 120 | |
| Class-1 (Stream) | 91.66 | 100 | 100 |
| Class-2 (Flower) | 100 | 100 | 100 |
| Class-3 (Jewel-Shaker) | 100 | 100 | 100 |
Boldface data represents the best performance.
Figure 8.
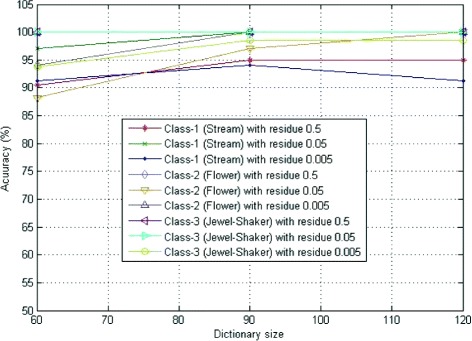
Classification accuracy for three different dictionary sizes 60, 90 and 120.
Table 7.
Confusion matrix
| Class | Testing set | Validation set | ||||
|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C1 | C2 | C3 | |
| C1 | 64 | 0 | 0 | 16 | 0 | 0 |
| C2 | 0 | 34 | 0 | 0 | 8 | 0 |
| C3 | 0 | 0 | 30 | 0 | 0 | 8 |
The adjudication results for genuine iris matches are illustrated in Figure 9 and for the impostor iris matches are given in Figure 10. The normalized images shown on these figures are taken from CASIA database for better illustration of adjudication process.
Figure 9.

Iris adjudication: genuine iris matches with hamming distances (a) 0.21, (b) 0.19, (c) 0.16, (d) 0.15, (e) 0.19.
Figure 10.

Iris adjudication: impostor iris matches with hamming distances (a) 0.48, (b) 0.46, (c) 0.43, (d) 0.51, (e) 0.37.
Conclusion
In this paper, an iris classification is proposed based on sparse representation of log-gabor wavelet features using on-line dictionary learning (ODL) for large-scale de-duplication applications. Three different iris classes based on iris fiber structures, namely, stream, flower, jewel and shaker, are used for faster retrieval of identities. Also, an iris adjudication process is illustrated by comparing the matched iris-pair images side-by-side to make the decision on the identification score using color coding. The efficacy of the proposed classification approach is demonstrated on the standard iris database, UPOL, and it is achieved 100% classification accuracy with dictionary size 90 and residual error 0.05. The proposed iris de-duplication architecture improves the speed of identification process and reduces the identification errors in large-scale de-duplication applications.
Footnotes
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
We propose an approach for classification of iris images based on sparse representation of Gabor features using dictionary learning for large-scale de-duplication applications. Sparse coding involves the representation of an image as a linear combination of some atoms in a dictionary.The signals and images of interest tend to enjoy the property of being sparse in some dictionary. These dictionaries are often learned directly from the training data. Iris classification and adjudication framework is proposed in iris de-duplication architecture to speed-up the identification process and to reduce the identification errors. All authors read and approved the final manuscript.
Contributor Information
Pattabhi Ramaiah Nalla, Email: ramaiah.iith@gmail.com.
Krishna Mohan Chalavadi, Email: cs10p005@iith.ac.in.
References
- Aharon M, Elad M, Bruckstein A. The k-svd: An algorithm for designing overcomplete dictionaries for sparse representation. Signal Process IEEE Trans. 2006;54(11):4311–4322. doi: 10.1109/TSP.2006.881199. [DOI] [Google Scholar]
- Casia-irisv1 chinese academy of sciencesinstitute of automation iris database (2015). http://biometrics.idealtest.org/.
- Daugman JG. High confidence visual recognition of persons by a test of statistical independence. Pattern Anal Mach Intell IEEE Trans. 1993;15(11):1148–1161. doi: 10.1109/34.244676. [DOI] [Google Scholar]
- Daugman J. Statistical richness of visual phase information: update on recognizing persons by iris patterns. Int J Comput Vis. 2001;45(1):25–38. doi: 10.1023/A:1012365806338. [DOI] [Google Scholar]
- Daugman J. Demodulation by complex-valued wavelets for stochastic pattern recognition. Int J Wavelets, Multiresolution Inform Process. 2003;1(01):1–17. doi: 10.1142/S0219691303000025. [DOI] [Google Scholar]
- Daugman, J How iris recognition works. Circuits Syst Video Technol IEEE Trans. 2004;14(1):21–30. doi: 10.1109/TCSVT.2003.818350. [DOI] [Google Scholar]
- Dobe M, Machala L (2004) Upol iris database. http://www.inf.upol.cz/iris/.
- Dobeš M, Machala L, Tichavskỳ P, Pospíšil J. Human eye iris recognition using the mutual information. Optik-Int J Light Electron Optics, Elsevier J. 2004;115(9):399–404. doi: 10.1078/0030-4026-00388. [DOI] [Google Scholar]
- Dobeš M, Martinek J, Skoupil D, Dobešová Z, Pospíšil J. Human eye localization using the modified hough transform. Optik-Int J Light Electron Optics, Elsevier J. 2006;117(10):468–473. doi: 10.1016/j.ijleo.2005.11.008. [DOI] [Google Scholar]
- Engan, K, Aase SO, Hakon Husoy J (1999) Acoustics, Speech, Signal Process 1999 IEEE Int Conf5: 2443–2446.
- Etemad K, Chellappa R. Separability-based multiscale basis selection and feature extraction for signal and image classification. Image Process IEEE Trans. 1998;7(10):1453–1465. doi: 10.1109/83.718485. [DOI] [PubMed] [Google Scholar]
- (2015) Government of India, national rural employment garantee act (nrega). http://nrega.nic.in/netnrega/home.aspx.
- (2015) Government of india, targeted public distribution system (tpds). http://dfpd.nic.in/?q=node/101.
- Government of Andhra Pradesh, civilsuppliesdepartment (2015). http://www.apcivilsupplies.gov.in/.
- Huang, K, Aviyente S (2006) Sparse representation for signal classification. NIPS. pp. 609–616 DTIC Document.
- Kumar A, Passi A. Comparison and combination of iris matchers for reliable personal authentication. Pattern Recognit. 2010;43(3):1016–1026. doi: 10.1016/j.patcog.2009.08.016. [DOI] [Google Scholar]
- Kumar A, Passi A (2015) Indian institute of technology delhi (iitd) iris database. http://www4.comp.polyu.edu.hk/~csajaykr/IITD/Database_Iris.htm.
- Lee H, Battle A, Raina R, Ng AY. Efficient sparse coding algorithms. Adv Neural Inform Process Syst 2007 MIT Trans. 2007;19:801. [Google Scholar]
- Mairal, J, Bach F, Ponce J, Sapiro G (2009) Online dictionary learning for sparse coding In: Machine Learning, 2009 ACM Conference on, 689–696.. ACM.
- Mallat SG, Zhang Z. Matching pursuits with time-frequency dictionaries. Signal Process IEEE Trans. 1993;41(12):3397–3415. doi: 10.1109/78.258082. [DOI] [Google Scholar]
- Masek, L (2003) Recognition of human iris patterns for biometric identification. Master?s thesis, University of Western Australia.
- Ramirez, I, Sprechmann P, Sapiro G (2010) Classification and clustering via dictionary learning with structured incoherence and shared features In: Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, 3501–3508.. IEEE.
- Rodriguez, F, Sapiro G (2008) Sparse representations for image classification: Learning discriminative and reconstructive non-parametric dictionaries.
- Ross, A, Sunder MS (2010) Block based texture analysis for iris classification and matching In: Computer Vision and Pattern Recognition Workshops (CVPRW), 2010 IEEE Computer Society Conference on, 30–37.. IEEE.
- Sprechmann, P, Sapiro G (2010) Dictionary learning and sparse coding for unsupervised clustering In: Acoustics Speech and Signal Processing (ICASSP), 2010 IEEE International Conference on, 2042–2045.. IEEE.
- Sun Z, Zhang H, Tan T, Wang J. Iris image classification based on hierarchical visual codebook. Pattern Anal Mach Intell IEEE Trans. 2014;36(6):1120–1133. doi: 10.1109/TPAMI.2013.234. [DOI] [PubMed] [Google Scholar]
- Unitree foundation the rayid model of iris interpretation (2009). http://rayid.com/main/structures.asp.
- Wildes RP. Iris recognition: an emerging biometric technology. Proc IEEE. 1997;85(9):1348–1363. doi: 10.1109/5.628669. [DOI] [Google Scholar]
- Zhang, H, Sun Z, Tan T, Wang J (2012) Iris image classification based on color information. Pattern Recognition (ICPR), 2012 21st International Conference on. IEEE.