

Abstract
Objective. The aim of this study was to provide a definition of big data in healthcare. Methods. A systematic search of PubMed literature published until May 9, 2014, was conducted. We noted the number of statistical individuals (n) and the number of variables (p) for all papers describing a dataset. These papers were classified into fields of study. Characteristics attributed to big data by authors were also considered. Based on this analysis, a definition of big data was proposed. Results. A total of 196 papers were included. Big data can be defined as datasets with Log(n∗p) ≥ 7. Properties of big data are its great variety and high velocity. Big data raises challenges on veracity, on all aspects of the workflow, on extracting meaningful information, and on sharing information. Big data requires new computational methods that optimize data management. Related concepts are data reuse, false knowledge discovery, and privacy issues. Conclusion. Big data is defined by volume. Big data should not be confused with data reuse: data can be big without being reused for another purpose, for example, in omics. Inversely, data can be reused without being necessarily big, for example, secondary use of Electronic Medical Records (EMR) data.
1. Introduction
The 21st century is an era of big data involving all aspects of human life, including biology and medicine [1]. With the advance in genomics, proteomics, metabolomics, and other types of omics technologies during the past decades, a tremendous amount of data related to molecular biology has been produced [2]. In addition, the transition from paper medical records to EHR systems has led to an exponential growth of data [3]. As a result, big data provides a wonderful opportunity for physicians, epidemiologists, and health policy experts to make data-driven decisions that will ultimately improve patient care [3]. As Margolis stated, “Big data are not only a new reality for the biomedical scientist, but an imperative that must be understood and used effectively in the quest for new knowledge” [4].
To date, however, the term “big data” does not have a proper definition in the MeSH (Medical Subject Headings) database yet. A precise, well-formed, and unambiguous definition is a requirement for a shared understanding of the term big data. The objective of this work is to provide a definition of big data in healthcare through a review of the literature.
2. Material and Methods
2.1. Search Strategy
For this literature review, we conducted a systematic search of the PubMed database for all papers published until May 9, 2014, using the keywords “big data.” To be fully inclusive, we did not define a start date. We used the following PubMed query:
(big data[Title/Abstract]) AND (“1900/01/01”[Date - Publication]: “2014/05/09”[Date - Publication]).
Titles and abstracts were reviewed by a human for eligibility. Papers were excluded if they were not directly related to healthcare or if big data was not found to be the topic of the paper.
We then attempted to retrieve the full-text papers. We used online search facilities (the Free PMC database, Google, and Google Scholar), resources, and services of the Lille University library and tried to directly contact the first or corresponding author. Full-text papers were then read.
Each of the remaining papers was included in the analysis and classified either as a paper describing a dataset, a dissertation, or a review of the literature.
2.2. Data Collection Process
For each paper, we collected the following information: title, year of publication, journal title, specialty area, type of paper (paper using a dataset, dissertation, and literature review), the field of study, and characteristics given by authors to big data and to data reuse. In case the paper dealt with a dataset, we also collected the number of statistical individuals (n) and the number of variables (p). It should be noted that the number of statistical individuals n is not necessarily physical persons but can also be, for example, gene sequences. The number of variables p could be, for example, the number of physicochemical properties used to classify amino acids [5], the performance metrics adopted to evaluate model performance [6], or the number of features of medical claims. In this last case, the number of individuals n is represented by the number of records of medical claims [7].
2.3. Analysis and Classification
Statistical analyses were performed with R statistical computing software [8]. In this paper, the notation “Log” denotes the decimal (or common, or decadic) logarithm, and the notation “CI95” denotes 95% confidence intervals. CI95 of binary variables were computed using the binomial law.
2.3.1. Time Evolution of Publication about Big Data in Healthcare
To analyze the evolution of publication in healthcare, we draw a graph showing the annual publication of papers included in our review and a graph showing the annual publication of papers which were describing a dataset. We also noted the number of journals which published papers about big data in healthcare per year.
2.3.2. Time Evolution of the Size of Big Data in Healthcare
In order to see the evolution of what authors refer to as “big data,” from papers describing a dataset, we plotted the decimal logarithm of the product of the number of statistical individuals (n) and the number of variables (p), Log(n∗p), as a function of the year.
2.3.3. Number of Individuals and Variables in Each Field of Study
The numbers n and p were analyzed with respect to the field of study. To this end, the probability density functions of Log(n), Log(p), and Log(n∗p) were plotted with respect to fields of study. Finally, Log(p) as a function of Log(n) was plotted with respect to fields of study.
2.4. Characteristics of Big Data
Characteristics attributed to big data by the authors in free text were noted as reading all the papers included in the analysis and were then sorted out by categories.
2.5. Proposal of a Definition of Big Data
We then gathered to propose a definition of big data in healthcare. A difference was made between definition, properties, and related concepts. A dataset that matches the definition qualifies as “big data,” and thus has the properties that are proposed. Conversely, a dataset that has some or all of the listed properties does not necessarily qualify as “big data.” Finally, related concepts refer to properties that are not systematically related to big data.
We attempted to bring out a threshold of the volume of big data on the basis of findings from this literature review. The threshold resulted from a discussion between the authors of this paper, taking into account sizes of actual datasets, but also properties that are attributed to big data by the authors of the papers included in this literature review.
3. Results
3.1. Search Strategy
The search query yielded 330 papers. After reading titles and abstracts, 94 papers were excluded. A total of 236 papers were included for full-text review. Eighteen papers were unavailable. The full-texts of the remaining 218 papers were read. After applying the exclusion criteria, 22 papers were excluded, leaving 196 papers. Papers were excluded due to the following reasons: papers not directly related to healthcare (18 papers) and papers in which big data was not the topic of the paper (4 papers). Of the 196 papers left for inclusion, there were 48 papers describing a dataset, 121 dissertations, and 27 reviews of the literature. Figure 1 shows a detailed description of the search strategy and results.
Figure 1.

Flowchart of the literature review.
3.2. Data Collection Process
The number of papers by field of study among the 48 papers describing a dataset is listed in Table 1.
Table 1.
Number of papers by field of study among the 48 papers describing a dataset.
| Field of study | Number of papers |
|---|---|
| Omics | |
| Genomics | 18 |
| Metabolomics | 1 |
| Proteomics | 4 |
| Medical specialties | |
| Endocrinology | 2 |
| Imaging | 3 |
| Immunology | 1 |
| Infectiology | 1 |
| Neurology | 8 |
| Pharmacovigilance | 1 |
| Public health | |
| Bioinformatics | 3 |
| EHR* | 1 |
| Epidemiology | 2 |
| Public health | 3 |
*EHR: Electronic Health Records.
Among the 48 papers describing a dataset, three main categories of studies were identified: omics, medical specialties, and public health. The term “omics” refers to biology fields of study ending in -omics, such as genomics, metabolomics, or proteomics. The main area represented is omics: 23 papers (48%, CI95 = [33; 63]). It is followed by medical specialties (endocrinology, infectology, immunology, neurology, and imaging): 15 papers (31%, CI95 = [19; 46]) and public health (bioinformatics, Electronic Health Records (EHR), epidemiology, pharmacovigilance, and public health): 10 papers (21%, CI95 = [10; 35]).
3.3. Analysis and Classification
3.3.1. Time Evolution of Publication about Big Data in Healthcare
Figure 2 shows the evolution of the publication of papers about big data in healthcare from 2003 to 2013. Annual publication of papers about big data in healthcare increased from 1 in 2003 to 79 in 2013. In the same way, an increase in the annual publication of papers describing a dataset can be observed (Figure 3). The 196 papers included in our review were published in 134 different journals. Among these journals, one journal published papers about big data in healthcare in 2008. There were 68 in 2013.
Figure 2.
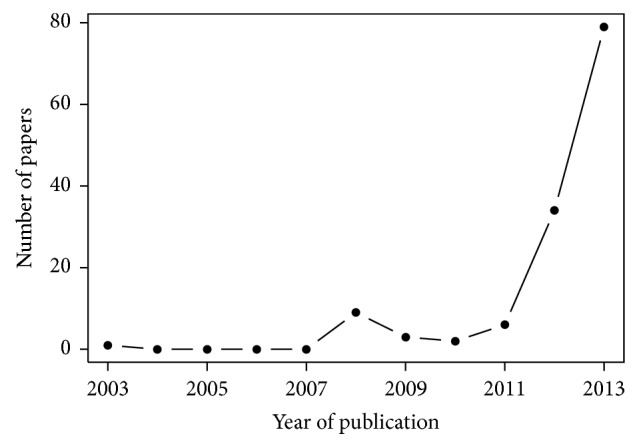
Number of papers about big data in healthcare published per year (full years only).
Figure 3.
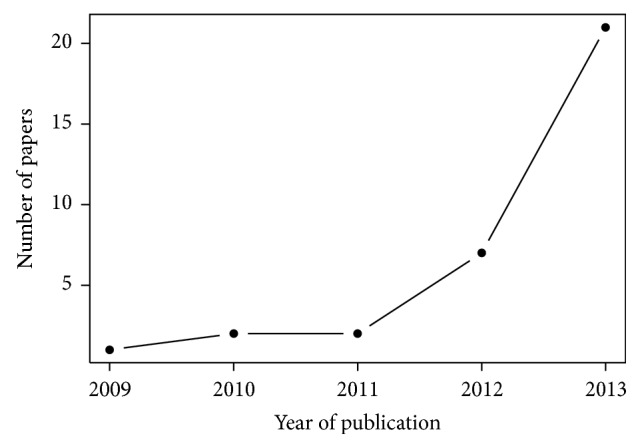
Number of papers about big data in healthcare describing a dataset per year (full years only).
3.3.2. Time Evolution of the Size of Big Data in Healthcare
Figure 4 illustrates the decimal logarithm of the number of statistical individuals multiplied by the number of variables (Log(n∗p)) for each year of publication of the papers that describe a dataset. We observe a nonsignificant increase of 0.43 per year (P value = 0.34).
Figure 4.
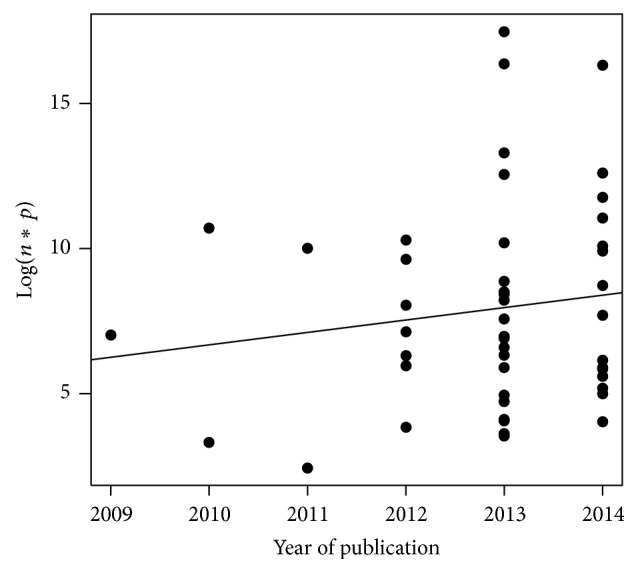
Log(n∗p) per year of publication. The continuous line represents the linear regression (P = 0.34).
3.3.3. Number of Individuals and Variables in Each Field of Study
Figures 5, 6, and 7 represent the probability density function of Log(n), Log(p), and Log(n∗p), respectively, for omics, medical specialties, public health, and all papers. It can be pointed out that Log(n∗p) is inferior to 7 in 23 studies out of 48 (48%, CI95 = [33; 63]).
Figure 5.
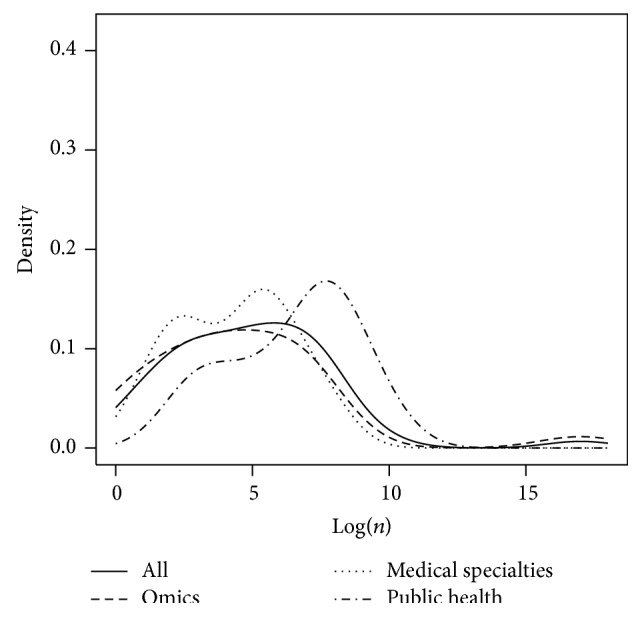
Representation of the probability density function of Log(n) for omics, medical specialties, public health, and all fields together.
Figure 6.
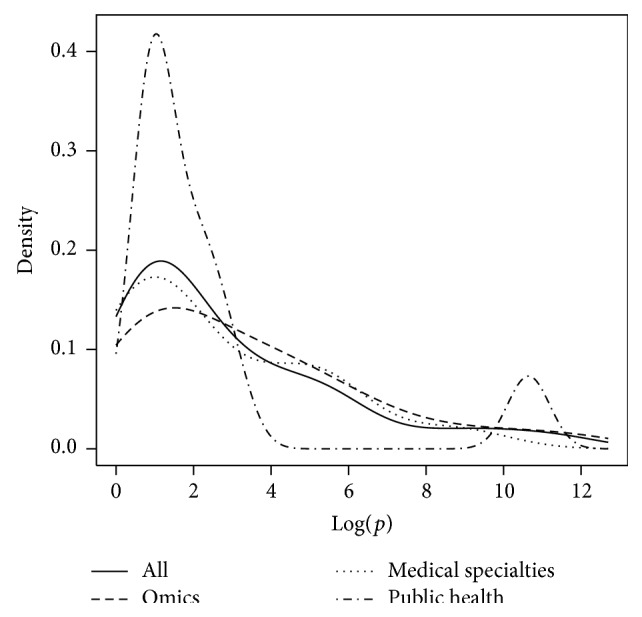
Representation of the probability density function of Log(p) for omics, medical specialties, public health, and all fields together.
Figure 7.
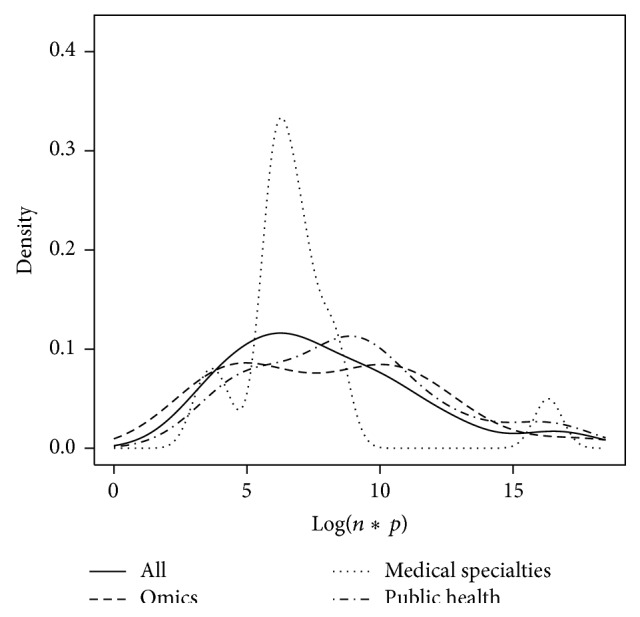
Representation of the probability density function of Log(n∗p) for omics, medical specialties, public health, and all fields together.
Figure 8 shows Log(p) as a function of Log(n) for omics, medical specialties, and public health. This figure suggests the following differences between omics, medical specialties, and public health categories:
big data in omics concern massive data collected on a limited number of individuals: small n, high p;
public health studies concern an important number of individuals and a low number of variables: high n, small p;
medical specialties are characterized by an important number of individuals and variables: high n, high p.
Figure 8.
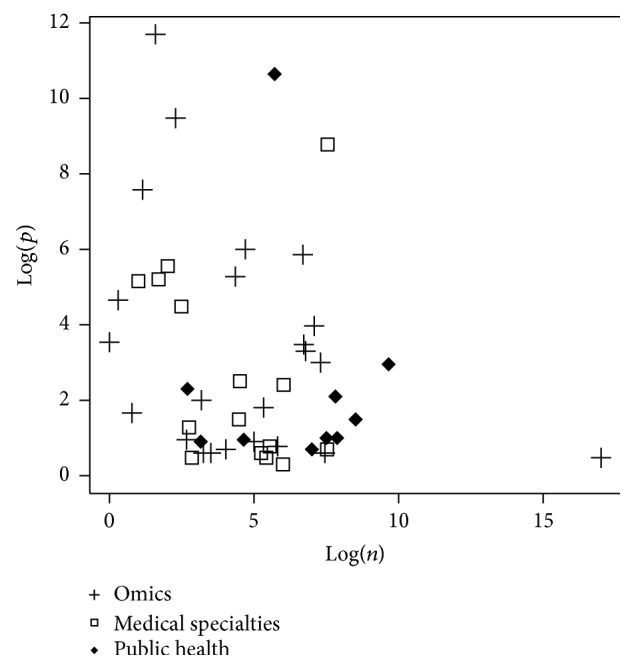
Log(p) as a function of Log(n) for omics, medical specialties, and public health. Each pictogram stands for one paper.
3.4. Characteristics of Big Data
The main characteristic about big data found in the papers is its massive size and complexity [7, 9–17]. Big data concern “not only the sheer scale and breadth of the new data sets but also their increasing complexity” [15]. Widely used notions to describe the complexity of big data are the three “Vs”: volume, variety, and velocity [7, 18–25]. “Big Data is a term used to describe information assemblages that make conventional data, or database, processing problematic due to any combination of their size (volume), frequency of update (velocity), or diversity (variety)” [18]. Veracity is a fourth “V” sometimes added to describe big data challenge [17, 23, 26–28]. Some authors mention a fifth “V”: valorization [26, 29].
3.4.1. Volume
Volume is the main characteristic mentioned by authors [7, 12, 16, 21, 23, 26, 30, 31]. “These correspond to the well-accepted notions of volume (breadth and/or depth) (…) recognized as the hallmarks of big data” [21]. “For volume, this translates today into terabytes (1012 bytes), petabytes (1015 bytes) or exabytes (1018 bytes)” [7]. “Volume - much greater amounts of rapidly multiplying data than were ever previously available” [25]. Some authors mention a big data threshold without clearly defining it [7, 32]: “How big is ‘Big'? (…) size is a relative term when it comes to data” [32]. “Those data are unquestionably ‘big' (order 1017)” [21]. Data sets used “in epidemiology (…) in fact barely pass the ‘big data' threshold” [7].
3.4.2. Variety
Variety is another important characteristic of big data [7, 25, 26, 30, 31, 33–35]. Indeed, big data comes from various sources [23, 36]. Variety translates into “aggregation of widely disparate sources of data or mash-ups of data derived from independent sources” [7]. Unstructured data, for example, free text data [7, 12, 37] and images [32, 38–40], are particularly a big challenge. In healthcare, “data take many forms including numbers, text, coded data, graphics, images, physiological measures (signals), and sound. Healthcare professionals rely on all their senses, including smell, to collect assessment data from individuals” [12]. In this area, “unstructured data is expected to exponentially outpace structured data” [34]. “Electronic Medical Records (EMR) generate massive data sets, offering the challenge of how to convert largely unstructured by-products of healthcare delivery into useful assets for patients' insight” [41]. Big data “can deviate from traditional structured data (organized in rows and columns) and can be represented as semi-structured data such as XML, or unstructured data including flat files which are not compliant with traditional database methods” [33]. These data are “unstructured for analysis using conventional relational database techniques” [31].
Moreover, big data can be “volatile, that is, changing, and available only for a limited amount of time” [23].
3.4.3. Velocity
Accelerated increase of data is another attribute of big data [7, 21, 23, 25, 26, 31, 42]. It is “data at or near real-time” [25]. “Velocity refers to the enormous frequency with which today's data is generated, delivered, and processed” [31].
3.4.4. Challenge on Veracity
Veracity comes next: big data can be difficult to validate [17, 26–28]. “Big data must be interpreted with caution, and in context, if it is to be clinically useful” [27]. It has a low veracity. Big data can never “be 100% accurate” [28].
3.4.5. Challenges on All Aspects of the Workflow
Big data raises challenges on all aspects of the workflow: from amassing [32], capturing [7, 37, 43–45], collecting [20, 46], storing [7, 20, 32, 43, 44, 47–53], data management [20, 43, 45, 54, 55], processing [9, 12, 19, 26, 47, 48, 51, 52, 56, 57], and analyzing [7, 20, 31–33, 39, 43–45, 49–55, 58–60], to peer-reviewed publications of results [45]. Big data “creates difficulties in data capture, storage, cleaning, analytics, visualization and sharing” [43]. Big data is also difficult to valorize [26, 29]: big data “is not merely large in volume; it also moves rapidly, is difficult to validate and valorize” [26].
3.4.6. Challenges on Statistical and Computational Methods
Finding new statistical and computational methods is another challenge raised by big data [33, 43, 50, 51, 59, 61, 62]. Big data requires “a change of perspective, infrastructure, and methods for data collection and analyses” [62]. Visualization methods that allow us to understand the data need to be created [32, 43, 44, 57]. To make sense of big data, “the further creation of new tools and services for data discovery, integration, analysis, and visualization” [32] will be required.
3.4.7. Challenges on Extracting Meaningful Information
Several authors emphasize the fact that it is necessary to derive useful information of these data [30, 44, 63, 64] and raise the question of how the data could be meaningfully interpreted: big data creates “challenges around how to meaningfully interpret the data - much of it not described using consistent standards or metadata - into information and recommendations while eliminating noise and erroneous data” [19].
3.4.8. Challenges on Facilitating Information Access and Sharing
Many authors highlight the necessity of identifying ways to facilitate information access and sharing [7, 15, 30, 34, 43–46, 49, 50, 53, 62, 63, 65–67]. It is necessary to promote “collaboration among scientists” [46]. Data must be made more readily available from more open sources to better compare data.
3.4.9. Not Enough Human Experts
Some authors mention the fact that the number of available human experts who have both clinical and analytic knowledge is not sufficient yet [30, 68]: “the role needs some sort of hybrid person that has clinical knowledge and analytic knowledge. We are experiencing a drought in terms of analytic experience. We don't have enough of those people in place yet” [30].
3.4.10. Data Reuse
Some authors mention the fact that big data can be data that are commonly collected without an immediate use: “Massive amounts of data are commonly collected without an immediate business case, but simply because it is affordable. This data, so it is hoped, will later answer questions, most of which yet have to arise” [20]. They put into light the fact that big data are often a secondary use of data, which we can call data reuse [14, 20, 21, 41, 65, 69–72].
3.4.11. False Knowledge Discovery
Some authors highlight the fact that deriving knowledge from big data can lead to false results and to conclusions that are wrong [73–75]: “Exploratory results emerging from Big Data are no less likely to be false” [75]. We cannot extract knowledge from big data without knowing the context in which data sets were collected: “big size is not enough for credible epidemiology” [74].
3.4.12. Privacy Issues
One concern mentioned by several authors is privacy issues: “the increasing ease with which data may be used and reused has increased concerns about privacy and informed consent” [76]. The ability “to protect individual privacy in the era of big data has become limited” [39]. Even if large databases use pseudonymised personal confidential data that have been anonymised, they retain a residual risk of reidentification. Indeed, the identity of individuals can be determined by manipulating databases through data linkage techniques [28, 39, 66, 77]. The data torrent poses ethical challenges [15]. “The widespread implementation of EHRs and the need to share data to measure quality and manage accountable care organizations (ACOs) brings to light all of the privacy issues surrounding sharing patient data” [66]. “The ability to derive DNA-based information from non-DNA-based sources generalizes the issue of data de-identification beyond the area of genotypic data privacy and has thus potentially important consequences for privacy rules in scientific research” [39].
3.5. Proposal of a Definition of Big Data
A definition of big data was established on the basis of findings from the literature review. We consider that big data should exclusively be defined by volume, and we propose that a dataset could be qualified as “big dataset” only if Log(n∗p) is superior or equal to 7.
Properties of big data can be listed as follows:
great variety,
high velocity,
challenge on veracity,
challenge on all aspects of the workflow,
challenge on computational methods,
challenge on extracting meaningful information,
challenge on sharing data,
challenge on finding human experts.
Related concepts of big data are as follows:
data reuse,
false knowledge discovery,
privacy issues.
The definition of big data is summed up in Table 2.
Table 2.
Definition of big data in healthcare.
| Definition | Volume: Log(n∗p) ≥ 7 |
|---|---|
| Properties | Great variety |
| High velocity | |
| Challenge on veracity | |
| Challenge on all aspects of the workflow | |
| Challenge on computational methods | |
| Challenge on extracting meaningful information | |
| Challenge on sharing data | |
| Challenge on finding human experts | |
|
| |
| Related concepts | Data reuse |
| False knowledge discovery | |
| Privacy issues | |
4. Discussion
In this work, through a detailed literature review, we tried to provide a current and quantitative definition of big data. We performed a literature review of 196 papers published until May 2014. Finally, we proposed a definition of big data in healthcare.
This systematic search should ensure that we accumulate a relatively complete census of relevant literature of big data in healthcare. However, we may have missed papers that do use big data in the research but were not included in our query because the term was not mentioned in the abstract or keywords of the paper. Those papers could be less and less frequent in the future.
Nevertheless, as there is no definition of big data, the literature can itself be wrong. It is a limitation of this inductive approach: we use observations to build a definition. The problem of defining a threshold illustrates this difficulty: the threshold of 107 may appear in disagreement with the results of Figure 7. This definition of big data is simply the result of a discussion between the authors of this literature review. It has been decided based on the results of the number of individuals and of variables found in the studies describing a dataset, but it has also taken into account the characteristics of big data mentioned by the authors of all the papers included in this literature review. Thus, for example, we can consider that the problems related to computational methods do not exist for Log(n∗p) inferior to 7, even when the analysis is performed with a simple spreadsheet instead of statistical software calling for high computational capacities. However, this proposal suggests that half of the studies describing a dataset in this literature review wrongly call their dataset big data. As everyone talks about the challenges of computing and data processing, considering what we know today in practice about software and computers, it would have been difficult to admit a threshold of Log(n∗p) superior or equal to 6 (although such a threshold already excludes 35% of the studies of our review), because we know that, nowadays, such size of data is easy to deal with.
It should also be pointed out that there is an undeniable current trend of big data, which leads to the fact that the term “big data” is now used to qualify datasets that, in the past, would not have been called this way. Moreover, we can consider that the size of datasets that qualify as big data may keep on increasing due to the main property of big data, which is the challenge on data processing and the fact that computational infrastructure that is required to process these large-scale datasets may progress with time.
Data reuse has been defined as a related concept of big data because we think that there might be some confusion between these two terms: data reuse is the fact of using for decisional purposes data that were collected routinely for transactional purposes, whereas big data is related to the size of the data collection. Indeed, data can be big without being reused for another purpose: this is the case of omics, for example. Inversely, data can be reused without being necessarily big, such as secondary use of data from Electronic Medical Records (EMR).
Big data presents many opportunities for translational studies, and informatics will be the key for successful translational research [78]. As Shah stated, “translational informatics is ready to revolutionize human health and healthcare using large-scale measurements on individuals. Data-centric approaches that compute on massive amounts of data to discover patterns and to make clinically relevant predictions will gain adoption” [79]. Cloud computing could be an enabling tool to facilitate translational bioinformatics research [67].
Informatics is needed to fully harness the potential of health data and new tools are emerging to translate health data into knowledge for improved healthcare.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
References
- 1.Zhang Z. Big data and clinical research: focusing on the area of critical care medicine in mainland China. Quantitative Imaging in Medicine and Surgery. 2014;4(5):426–429. doi: 10.3978/j.issn.2223-4292.2014.09.03. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Li S., Kang L., Zhao X.-M. A survey on evolutionary algorithm based hybrid intelligence in bioinformatics. BioMed Research International. 2014;2014:8. doi: 10.1155/2014/362738.362738 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Sessler D. I. Big Data—and its contributions to peri-operative medicine. Anaesthesia. 2014;69(2):100–105. doi: 10.1111/anae.12537. [DOI] [PubMed] [Google Scholar]
- 4.Margolis R., Derr L., Dunn M., et al. The National Institutes of Health's Big Data to Knowledge (BD2K) initiative: capitalizing on biomedical big data. Journal of the American Medical Informatics Association. 2014;21(6):957–958. doi: 10.1136/amiajnl-2014-002974. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Zou Q., Wang Z., Guan X., Liu B., Wu Y., Lin Z. An approach for identifying cytokines based on a novel ensemble classifier. BioMed Research International. 2013;2013:11. doi: 10.1155/2013/686090.686090 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Zhao L., Wong L., Lu L., Hoi S. C. H., Li J. B-cell epitope prediction through a graph model. BMC Bioinformatics. 2012;13(supplement 17):p. S20. doi: 10.1186/1471-2105-13-S17-S20. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Berger M. L., Doban V. Big data, advanced analytics and the future of comparative effectiveness research. Journal of Comparative Effectiveness Research. 2014;3(2):167–176. doi: 10.2217/cer.14.2. [DOI] [PubMed] [Google Scholar]
- 8.R Development Core Team. R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing; 2012. http://www.r-project.org/ [Google Scholar]
- 9.Mallon W. J. Big data. Journal of Shoulder and Elbow Surgery. 2013;22(9, article 1153) doi: 10.1016/j.jse.2013.07.034. [DOI] [PubMed] [Google Scholar]
- 10.Salcido R. S. Big data and disruptive innovation in wound care. Advances in Skin and Wound Care. 2013;26(8, article 344) doi: 10.1097/01.asw.0000432244.36301.fc. [DOI] [PubMed] [Google Scholar]
- 11.Ketchersid T. Big data in nephrology: friend or foe? Blood Purification. 2014;36(3-4):160–164. doi: 10.1159/000356751. [DOI] [PubMed] [Google Scholar]
- 12.Hovenga E. J. S., Grain H. Health data and data governance. Studies in Health Technology and Informatics. 2013;193:67–92. [PubMed] [Google Scholar]
- 13.Müller H., Hanbury A., Al Shorbaji N. Health information search to deal with the exploding amount of health information produced. Methods of Information in Medicine. 2012;51(6):516–518. [PubMed] [Google Scholar]
- 14.Porche D. J. Men's health big data. American Journal of Men's Health. 2014;8(3):p. 189. doi: 10.1177/1557988314529838. [DOI] [PubMed] [Google Scholar]
- 15.Callebaut W. Scientific perspectivism: a philosopher of science's response to the challenge of big data biology. Studies in History and Philosophy of Science Part C :Studies in History and Philosophy of Biological and Biomedical Sciences. 2012;43(1):69–80. doi: 10.1016/j.shpsc.2011.10.007. [DOI] [PubMed] [Google Scholar]
- 16.Fan J., Liu H. Statistical analysis of big data on pharmacogenomics. Advanced Drug Delivery Reviews. 2013;65(7):987–1000. doi: 10.1016/j.addr.2013.04.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Lupşe O.-S., Crisan-Vida M., Stoicu-Tivadar L., Bernard E. Supporting diagnosis and treatment in medical care based on big data processing. Studies in Health Technology and Informatics. 2014;197:65–69. [PubMed] [Google Scholar]
- 18.Hay S. I., George D. B., Moyes C. L., Brownstein J. S. Big data opportunities for global infectious disease surveillance. PLoS Medicine. 2013;10(4) doi: 10.1371/journal.pmed.1001413.e1001413 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Hamilton B. Impacts of big data. Potential is huge, so are challenges. Health Management Technology. 2013;34(8):12–13. [PubMed] [Google Scholar]
- 20.Markowetz A., Błaszkiewicz K., Montag C., Switala C., Schlaepfer T. E. Psycho-informatics: big data shaping modern psychometrics. Medical Hypotheses. 2014;82(4):405–411. doi: 10.1016/j.mehy.2013.11.030. [DOI] [PubMed] [Google Scholar]
- 21.Chute C. G., Ullman-Cullere M., Wood G. M., Lin S. M., He M., Pathak J. Some experiences and opportunities for big data in translational research. Genetics in Medicine. 2013;15(10):802–809. doi: 10.1038/gim.2013.121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Kao R. R., Haydon D. T., Lycett S. J., Murcia P. R. Supersize me: how whole-genome sequencing and big data are transforming epidemiology. Trends in Microbiology. 2014;22(5):282–291. doi: 10.1016/j.tim.2014.02.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Sedig K., Ola O. The challenge of big data in public health: an opportunity for visual analytics. Online Journal of Public Health Informatics. 2014;5(3, article 223) doi: 10.5210/ojphi.v5i3.4933. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Gardner E. The HIT approach to big data. Health data management. 2013;21(3):34–38. [PubMed] [Google Scholar]
- 25.Moore K. D., Eyestone K., Coddington D. C. The big deal about big data. Healthcare Financial Management. 2013;67(8):60–68. [PubMed] [Google Scholar]
- 26.Dereli T., Coşkun Y., Kolker E., Güner Ö., Ağirbaşli M., Özdemir V. Big data and ethics review for health systems research in LMICs: understanding risk, uncertainty and ignorance-and catching the black swans? American Journal of Bioethics. 2014;14(2):48–50. doi: 10.1080/15265161.2013.868955. [DOI] [PubMed] [Google Scholar]
- 27.Litman R. S. Complications of laryngeal masks in children: big data comes to pediatric anesthesia. Anesthesiology. 2013;119(6):1239–1240. doi: 10.1097/aln.0000000000000016. [DOI] [PubMed] [Google Scholar]
- 28.Ward J. C. Oncology reimbursement in the era of personalized medicine and big data. Journal of Oncology Practice. 2014;10(2):83–86. doi: 10.1200/JOP.2014.001308. [DOI] [PubMed] [Google Scholar]
- 29.Özdemir V., Badr K. F., Dove E. S., et al. Crowd-funded micro-grants for genomics and ‘big data’: an actionable idea connecting small (Artisan) science, infrastructure science, and citizen philanthropy. OMICS. 2013;17(4):161–172. doi: 10.1089/omi.2013.0034. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.AHA. Harnessing big data: how to achieve value. Hospitals & Health Networks. 2014;88(2):61–71. [PubMed] [Google Scholar]
- 31.Jee K., Kim G.-H. Potentiality of big data in the medical sector: focus on how to reshape the healthcare system. Healthcare Informatics Research. 2013;19(2):79–85. doi: 10.4258/hir.2013.19.2.79. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.van Horn J. D., Toga A. W. Human neuroimaging as a ‘Big Data’ science. Brain Imaging and Behavior. 2014;8(2):323–331. doi: 10.1007/s11682-013-9255-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.O'Driscoll A., Daugelaite J., Sleator R. D. ‘Big data’, Hadoop and cloud computing in genomics. Journal of Biomedical Informatics. 2013;46(5):774–781. doi: 10.1016/j.jbi.2013.07.001. [DOI] [PubMed] [Google Scholar]
- 34.Buyer’s brief: cognitive computing in the age of big data. Healthcare Financial Management. 2014;68(4):35–36. [PubMed] [Google Scholar]
- 35.Davenport T. H., Patil D. J. Data scientist: the sexiest job of the 21st century. Harvard Business Review. 2012;90(10):70–128. [PubMed] [Google Scholar]
- 36.Khoury M. J., Lam T. K., Ioannidis J. P. A., et al. Transforming epidemiology for 21st century medicine and public health. Cancer Epidemiology, Biomarkers & Prevention. 2013;22(4):508–516. doi: 10.1158/1055-9965.EPI-13-0146. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Bonney S. HIM’s role in managing big data: turning data collected by an EHR into information. Journal of American Health Information Management Association. 2013;84(9):62–64. [PubMed] [Google Scholar]
- 38.Jayapandian C. P., Chen C.-H., Bozorgi A., Lhatoo S. D., Zhang G.-Q., Sahoo S. S. Cloudwave: distributed processing of ‘big data’ from electrophysiological recordings for epilepsy clinical research using hadoop. AMIA Annual Symposium Proceedings. 2013;2013:691–700. [PMC free article] [PubMed] [Google Scholar]
- 39.Schadt E. E. The changing privacy landscape in the era of big data. Molecular Systems Biology. 2012;8, article 612 doi: 10.1038/msb.2012.47. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Aji A., Wang F., Saltz J. H. Towards building a high performance spatial query system for large scale medical imaging data. Proceedings of the 20th International Conference on Advances in Geographic Information Systems (SIGSPATIAL '12); 2012; pp. 309–318. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Matheson G. O., Klügl M., Engebretsen L., et al. Prevention and management of noncommunicable disease: the IOC consensus statement, lausanne 2013. Clinical Journal of Sport Medicine. 2013;23(6):419–429. doi: 10.1097/jsm.0000000000000038. [DOI] [PubMed] [Google Scholar]
- 42.Afendi F. M., Ono N., Nakamura Y., et al. Data mining methods for omics and knowledge of crude medicinal plants toward big data biology. Computational and Structural Biotechnology Journal. 2013;4(5):1–14. doi: 10.5936/csbj.201301010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Mohr D. C., Burns M. N., Schueller S. M., Clarke G., Klinkman M. Behavioral intervention technologies: evidence review and recommendations for future research in mental health. General Hospital Psychiatry. 2013;35(4):332–338. doi: 10.1016/j.genhosppsych.2013.03.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Ansermino J. M. From the journal archives: improving patient outcomes in the era of big data. Canadian Journal of Anesthesia. 2014;61(10):959–962. doi: 10.1007/s12630-014-0146-5. [DOI] [PubMed] [Google Scholar]
- 45.Klingström T., Soldatova L., Stevens R., et al. Workshop on laboratory protocol standards for the molecular methods database. New Biotechnology. 2013;30(2):109–113. doi: 10.1016/j.nbt.2012.05.019. [DOI] [PubMed] [Google Scholar]
- 46.Mervis J. U.S. Science policy: agencies rally to tackle big data. Science. 2012;335(6077):p. 22. doi: 10.1126/science.336.6077.22. [DOI] [PubMed] [Google Scholar]
- 47.Mohammed Y., Mostovenko E., Henneman A. A., Marissen R. J., Deelder A. M., Palmblad M. Cloud parallel processing of tandem mass spectrometry based proteomics data. Journal of Proteome Research. 2012;11(10):5101–5108. doi: 10.1021/pr300561q. [DOI] [PubMed] [Google Scholar]
- 48.Karlsson J., Trelles O. MAPI: a software framework for distributed biomedical applications. Journal of Biomedical Semantics. 2013;4(1, article 4) doi: 10.1186/2041-1480-4-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Bower M. R., Stead M., Brinkmann B. H., Dufendach K., Worrell G. A. Metadata and annotations for multi-scale electrophysiological data. Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society Conference. 2009;2009:2811–2814. doi: 10.1109/IEMBS.2009.5333570. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Ranganathan S., Schönbach C., Kelso J., Rost B., Nathan S., Tan T. W. Towards big data science in the decade ahead from ten years of InCoB and the 1st ISCB-Asia Joint Conference. BMC Bioinformatics. 2011;12(supplement 13):p. S1. doi: 10.1186/1471-2105-12-s13-s1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.DiLeo M. V., Strahan G. D., den Bakker M., Hoekenga O. A. Weighted correlation network analysis (WGCNA) applied to the tomato fruit metabolome. PLoS ONE. 2011;6(10) doi: 10.1371/journal.pone.0026683.e26683 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Greene C. S., Tan J., Ung M., Moore J. H., Cheng C. Big data bioinformatics. Journal of Cellular Physiology. 2014;229(12):1896–1900. doi: 10.1002/jcp.24662. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Dai L., Gao X., Guo Y., Xiao J., Zhang Z. Bioinformatics clouds for big data manipulation. Biology direct. 2012;7, article 43 doi: 10.1186/1745-6150-7-43. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.MacLean D., Kamoun S. Big data in small places. Nature Biotechnology. 2012;30(1):33–34. doi: 10.1038/nbt.2079. [DOI] [PubMed] [Google Scholar]
- 55.Murdoch T. B., Detsky A. S. The inevitable application of big data to health care. The Journal of the American Medical Association. 2013;309(13):1351–1352. doi: 10.1001/jama.2013.393. [DOI] [PubMed] [Google Scholar]
- 56.Marx V. Biology: the big challenges of big data. Nature. 2013;498(7453):255–260. doi: 10.1038/498255a. [DOI] [PubMed] [Google Scholar]
- 57.Schadt E. E., Linderman M. D., Sorenson J., Lee L., Nolan G. P. Computational solutions to large-scale data management and analysis. Nature Reviews Genetics. 2010;11(9):647–657. doi: 10.1038/nrg2857. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Cole J. B., Newman S., Foertter F., Aguilar I., Coffey M. Breeding and genetics symposium: really big data: processing and analysis of very large data sets. Journal of Animal Science. 2012;90(3):723–733. doi: 10.2527/jas.2011-4584. [DOI] [PubMed] [Google Scholar]
- 59.Finding correlations in big data. Nature Biotechnology. 2012;30(4):334–335. doi: 10.1038/nbt.2182. [DOI] [PubMed] [Google Scholar]
- 60.Kolker E., Stewart E., Ozdemir V. Opportunities and challenges for the life sciences community. OMICS: A Journal of Integrative Biology. 2012;16(3):138–147. doi: 10.1089/omi.2011.0152. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Troiano R. P., McClain J. J., Brychta R. J., Chen K. Y. Evolution of accelerometer methods for physical activity research. British Journal of Sports Medicine. 2014;48:1019–1023. doi: 10.1136/bjsports-2014-093546. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Feldmann E., Liebeskind D. S. Developing precision stroke imaging. Frontiers in Neurology. 2014;5, article 29 doi: 10.3389/fneur.2014.00029. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Green D. E., Rapp E. J. Can big data lead us to big savings? Radiographics. 2013;33(3):859–860. doi: 10.1148/rg.333135035. [DOI] [PubMed] [Google Scholar]
- 64.Huberman B. A. Sociology of science: big data deserve a bigger audience. Nature. 2012;482(7385):p. 308. doi: 10.1038/482308d. [DOI] [PubMed] [Google Scholar]
- 65.Lynch C. Big data: how do your data grow? Nature. 2008;455(7209):28–29. doi: 10.1038/455028a. [DOI] [PubMed] [Google Scholar]
- 66.White S. E. De-identification and the sharing of big data. Journal of American Health Information Management Association. 2013;84(4):44–47. [PubMed] [Google Scholar]
- 67.Chen J., Qian F., Yan W., Shen B. Translational biomedical informatics in the cloud: present and future. BioMed Research International. 2013;2013:8. doi: 10.1155/2013/658925.658925 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Mavandadi S., Dimitrov S., Feng S., et al. Crowd-sourced BioGames: managing the big data problem for next-generation lab-on-a-chip platforms. Lab on a Chip. 2012;12(20):4102–4106. doi: 10.1039/c2lc40614d. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Riley D., Mittelman M. Maps, 'big data,' and case reports. Global Advances in Health and Medicine: Improving Healthcare Outcomes Worldwide. 2012;1(3):5–7. doi: 10.7453/gahmj.2012.1.3.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Hoffman S., Podgurski A. Big bad data: law, public health, and biomedical databases. Journal of Law, Medicine and Ethics. 2013;41(1):56–60. doi: 10.1111/jlme.12040. [DOI] [PubMed] [Google Scholar]
- 71.Cockfield J., Su K., Robbins K. A. MOBBED: a computational data infrastructure for handling large collections of event-rich time series datasets in MATLAB. Frontiers in Neuroinformatics. 2013;7, article 20 doi: 10.3389/fninf.2013.00020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Martin S. F., Falkenberg H., Dyrlund T. F., Khoudoli G. A., Mageean C. J., Linding R. PROTEINCHALLENGE: crowd sourcing in proteomics analysis and software development. Journal of Proteomics. 2013;88:41–46. doi: 10.1016/j.jprot.2012.11.014. [DOI] [PubMed] [Google Scholar]
- 73.Lindenmayer D. B., Likens G. E. Analysis: don’t do big-data science backwards. Nature. 2013;499(7458, article 284) doi: 10.1038/499284d. [DOI] [PubMed] [Google Scholar]
- 74.Toh S., Platt R. Big data in epidemiology: too big to fail? Epidemiology. 2013;24(6, article 939) doi: 10.1097/EDE.0b013e3182a71390. [DOI] [PubMed] [Google Scholar]
- 75.Castellanos F. X., Di Martino A., Craddock R. C., Mehta A. D., Milham M. P. Clinical applications of the functional connectome. NeuroImage. 2013;80:527–540. doi: 10.1016/j.neuroimage.2013.04.083. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Currie J. ‘Big data’ versus ‘Big brother’: on the appropriate use of large-scale data collections in pediatrics. Pediatrics. 2013;131(supplement 2):S127–S132. doi: 10.1542/peds.2013-0252c. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Docherty A. Big data—ethical perspectives. Anaesthesia. 2014;69(4):390–391. doi: 10.1111/anae.12656. [DOI] [PubMed] [Google Scholar]
- 78.Shen B., Teschendorff A. E., Zhi D., Xia J. Biomedical data integration, modeling, and simulation in the era of big data and translational medicine. BioMed Research International. 2014;2014:1. doi: 10.1155/2014/731546.731546 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Shah N. H. Translational bioinformatics embraces big data. Yearbook of Medical Informatics. 2012;7(1):130–134. [PMC free article] [PubMed] [Google Scholar]