

Abstract
Determining the appropriate dosage of warfarin is an important yet challenging task. Several prediction models have been proposed to estimate a therapeutic dose for patients. The models are either clinical models which contain clinical and demographic variables or pharmacogenetic models which additionally contain the genetic variables. In this paper, a new methodology for warfarin dosing is proposed. The patients are initially classified into two classes. The first class contains patients who require doses of >30 mg/wk and the second class contains patients who require doses of ≤30 mg/wk. This phase is performed using relevance vector machines. In the second phase, the optimal dose for each patient is predicted by two clinical regression models that are customized for each class of patients. The prediction accuracy of the model was 11.6 in terms of root mean squared error (RMSE) and 8.4 in terms of mean absolute error (MAE). This was 15% and 5% lower than IWPC and Gage models (which are the most widely used models in practice), respectively, in terms of RMSE. In addition, the proposed model was compared with fixed-dose approach of 35 mg/wk, and the model proposed by Sharabiani et al. and its outperformance were proved in terms of both MAE and RMSE.
1. Introduction
A great deal of effort has been dedicated to determine the optimal initial dose for warfarin. The challenge in estimating the right dose of warfarin for each patient arises from the fact that there is wide interpatient variability in dosing [1]. Over the past decade or so, a number of research groups have focused on developing models to predict the warfarin maintenance dose. Accurate warfarin dosing is critically important because of the drug's narrow therapeutic index, whereas there is an increased risk for thromboembolism or hemorrhage with sub- or supratherapeutic anticoagulation, respectively. In particular, the risk for bleeding increases when the international normalized ratio (INR) surpasses 3 [2], while the risk for thrombosis increases when the INR falls below 2 [3]. As a result, warfarin is the leading cause of drug-related hospitalizations among older adults in the United States of America [1]. The risks for bleeding or thrombosis with warfarin are greatest during the initial months of therapy [1]. Therefore, selecting an appropriate dose at the initiation of therapy is important to achieve optimal anticoagulation to reduce adverse effects. An additional challenge with warfarin dosing is the significant variability amongst patients in the dose required for therapeutic anticoagulation. Clinical factors, including age, body size, and use of medications that affect warfarin metabolism, contribute to warfarin dose requirements [4, 5]. In addition, genes involved in warfarin metabolism and determining warfarin sensitivity, namely, the cytochrome P450 2C9 (CYP2C9) and vitamin K epoxide reductase complex 1 (VKORC1) genes, significantly impact warfarin dose requirements. A recent clinical trial in a predominantly European population showed that the use of a pharmacogenetic model, containing genotype plus clinical factors, was superior to conventional warfarin dosing [6]. However, another trial in a more ethnically diverse population showed no benefit with a pharmacogenetic model versus a clinical model, containing just clinical factors [7]. Previous studies have shown better warfarin dose prediction with a clinical dosing algorithm versus convention dosing (e.g., fixed dose of 5 mg/day).
The proposed prediction models range from traditional methods such as linear regression modelling to more advance models which belong to the class of machine learning techniques.
In 2008 Gage et al. proposed 2 linear regression models involving pharmacogenetic and clinical factors to predict the therapeutic dose of warfarin. They applied BSA (body surface area) instead of height and weight, used the actual age values and not age categories, and also involved “Smokes,” “Target INR,” and “DVT/PE” (deep vein thrombosis or pulmonary embolism) in their models [4]. They trained their models in 1015 patients and tested them in 292 patients. In 2009, the IWPC (International Warfarin Pharmacogenetics Consortium) research team gathered patients' data of different ethnicities, 21 various research groups, 9 countries, and crossing 4 continents on warfarin-treated patients, totaling 5052 number of patients. After investigating several prediction models such as ordinary linear and polynomial regression, artificial neural networks (ANN), support vector regression with polynomial (including linear) and Gaussian kernels, regression trees, model trees, least angle regression, and Lasso and multivariate adaptive regression, they proposed 2 linear regression models (a clinical and one pharmacogenetic model). The variables involved in the proposed models differ from the Gage's models from different aspects. Instead of BSA, the actual values for height and weight were used. Instead of the real values for age, the age decade was used. “Smokes,” “Target INR,” and “DVT/PE” were not applied in the models. They claimed that the clinical model is well suited for patients requiring doses between 21 and 49 mg/week [5]. The abovementioned models are the most recommended models for determination of the initial warfarin dose according to the “Clinical Pharmacogenetics Implementation Consortium Guidelines for CYP2C9 and VKORC1 Genotypes and Warfarin Dosing” [8]. In 2014, Grossi et al. proposed a new prediction model using artificial neural network. Using the data of 377 patients, they selected 23 variables by TWIST system and derived an ANN model [9]. They proved that the proposed model outperformed those of IWPC [5], Gage et al. [4], and Zambon et al. [10] in terms of mean absolute error (MAE) and model's fitness (R 2). Furthermore, several models have been proposed for specific ethnicity groups, different age groups, or geographical areas. In 2011, Cosgun et al. proposed three pharmacogenetic prediction models using machine learning approaches for African-American patients. The models were random forest regression (RFR), boosted regression tree (BRT), and support vector regression (SVR) [11]. They used R 2 as the index for predictive accuracy and claimed that their model outperformed previously proposed pharmacogenetic models, namely, Limdi et al.'s [12, 13] and Schelleman et al.'s models [14, 15]. In 2013, Sharabiani et al. proposed a new clinical model for African-American patients. The proposed model outperforms IWPC and Gage models in terms of prediction accuracy [16]. Hernandez et al. also proposed a pharmacogenetic model customized for African-American patients. They compared their model with IWPC pharmacogenetic and clinical models and proved their model's outperformance [17].
Monagle et al. investigated the impact of pharmacogenetics-based warfarin dosing in children. Despite the presence of multiple prediction models for adults, not many models are available for children. The most simple dosing procedure for children is the weight-based dose model with initial dose of 0.2 mg/kg/day [18]. In addition, several models have been proposed in the literature which are solely designed for children, such as models proposed by Nowak-Göttl et al. [19], Moreau et al. [20], Biss et al. [21], Nguyen et al. [22], and Kato et al. [23]. The proposed models also took advantage of the pharmacogenetic factors along with the clinical factors.
Despite the application of pharmacogenetic factors in the proposed models, the application of pharmacogenetic factors in prediction models is still a controversial issue. Burmester et al. compared the time to reach the therapeutic dose on two patient cohorts. They established the initial dose solely by clinical factors for the first group and added the pharmacogenetic factors for the second cohort. They claimed that involving the pharmacogenetic factors did not make any significant difference in reaching the time to the therapeutic dose. This study is known as “Marshfield Clinic Research Foundation (MCRF)” [24]. Stergiopoulos and Brown also investigated the difference between genotype guided versus clinical dosing of warfarin. They also proved that, in meta-analysis of randomized clinical trials, a pharmacogenetic dosing method did not cause a superior percentage of time that the INR fell within the therapeutic range [25]. In spite of encouraging research outcomes and US FDA warfarin label adjustments, the Centers for Medicare and Medicaid Services (CMS) have not regularly enclosed clinical CYP2C9 and VKORC1 genotyping, and therefore it demands additional evidence to require the need for genotyping. In addition to MCRF, several European research teams also made inquiries on the impact of pharmacogenetic factors on warfarin dosing, such as CoumaGen [26], CoumaGen-II [7], European Pharmacogenetics of Anticoagulant Therapy (EU-PACT) [6], and Clarification of Optimal Anticoagulation Through Genetics (COAG) [27]. Most of the abovementioned studies do not claim a general conclusion on accepting or rejecting the pharmacogenetic models. For example, the EU-PACT demonstrates that “pharmacogenetic-guided dosing is superior to a fixed-dosing regimen for achieving therapeutic international normalized ratios in Caucasian patients initiated on warfarin.” For the detailed comparison on different studies or challenges on involving the pharmacogenetic factors on warfarin dosing, see [28, 29].
Considering the prevailing uncertainty of applying the pharmacogenetics-based models and the fact that, in practice, the availability of gene information may be limited, and hence not many clinicians have access to that data; in this paper we have concentrated on developing a dose prediction methodology using only clinical factors.
In this paper, a novel methodology towards warfarin dosing for adults is proposed using the clinical variables. In this methodology, initially, the patients get classified into two classes. The first class is the patients who require doses of >30 mg/wk and the second class contains the patients who require doses of ≤30 mg/wk. In the following phase, the optimal dose for each patient will be predicted by two regression clinical models which are customized for each class of patients. The proposed methodology is proven to outperform the existing popular clinical prediction models in terms of prediction accuracy.
2. Materials and Methods
2.1. The Dataset
The dataset that we have used in this paper is the IWPC dataset which is a well-known multiethnic warfarin dataset. This dataset is one of the most widely used and publically available warfarin datasets, as evident by its citations in the literature [30]. We handled the missing values in the dataset by imputation using the K-nearest neighbor (KNN) method with k = 1 [31]. The variables whose percentage of missing values was more than 50% were not involved in the model. The variables used in the modeling were only the clinical and demographic variables which are presented in Table 1. In order to develop a robust prediction model, we followed the CRISP-DM methodology in order to build our models [32]. We randomly selected 50% of the data points to comprise the training set (derivation cohort) and the remaining 50% were assigned to the testing set (validation cohort). The data in the test set was used for the models' performance in dealing with unseen data points.
Table 1.
Dataset description.
| Continuous variables | |||
|
| |||
| Target international normalized ratio | Mean | 2.5 | |
| Std. deviation | 0.1 | ||
| Minimum | 1.8 | ||
| Maximum | 3.5 | ||
|
| |||
| Body surface area | Mean | 1.94 | |
| Std. deviation | 0.3 | ||
| Minimum | 1.2 | ||
| Maximum | 3.4 | ||
|
| |||
| Categorical variables | |||
|
| |||
| Values | Frequency | Percent | |
|
| |||
| Gender | 0 | 1822 | 43.00% |
| 1 | 2415 | 57.00% | |
|
| |||
| Race | 1 | 2663 | 62.85% |
| 2 | 656 | 15.48% | |
| 3 | 918 | 21.67% | |
|
| |||
| Deep vein thrombosis and pulmonary embolism | 0 | 3846 | 90.77% |
| 1 | 391 | 9.23% | |
|
| |||
| Diabetes | 0 | 3500 | 82.61% |
| 1 | 737 | 17.39% | |
|
| |||
| Congestive heart failure | 0 | 3492 | 82.42% |
| 1 | 745 | 17.58% | |
|
| |||
| Valve replacement | 0 | 3243 | 76.54% |
| 1 | 994 | 23.46% | |
|
| |||
| Aspirin | 0 | 3199 | 75.50% |
| 1 | 1038 | 24.50% | |
|
| |||
| Simvastatin | 0 | 3608 | 85.15% |
| 1 | 629 | 14.85% | |
|
| |||
| Atorvastatin | 0 | 3810 | 89.92% |
| 1 | 427 | 10.08% | |
|
| |||
| Fluvastatin | 0 | 4220 | 99.60% |
| 1 | 17 | 0.40% | |
|
| |||
| Lovastatin | 0 | 4153 | 98.02% |
| 1 | 84 | 1.98% | |
|
| |||
| Pravastatin | 0 | 4121 | 97.26% |
| 1 | 116 | 2.74% | |
|
| |||
| Rosuvastatin | 0 | 4208 | 99.32% |
| 1 | 29 | 0.68% | |
|
| |||
| Amiodarone | 0 | 3984 | 94.03% |
| 1 | 253 | 5.97% | |
|
| |||
| Carbamazepine | 0 | 4195 | 99.01% |
| 1 | 42 | 0.99% | |
|
| |||
| Phenytoin | 0 | 4197 | 99.06% |
| 1 | 40 | 0.94% | |
|
| |||
| Rifampin | 0 | 4231 | 99.86% |
| 1 | 6 | 0.14% | |
|
| |||
| Sulfonamide Antibiotics | 0 | 4214 | 99.46% |
| 1 | 23 | 0.54% | |
|
| |||
| Macrolide antibiotics | 0 | 4225 | 99.72% |
| 1 | 12 | 0.28% | |
|
| |||
| Antifungal azoles | 0 | 4210 | 99.36% |
| 1 | 27 | 0.64% | |
|
| |||
| Smoker | 0 | 3733 | 88.10% |
| 1 | 504 | 11.90% | |
|
| |||
| Enzyme | 0 | 4150 | 97.95% |
| 1 | 87 | 2.05% | |
|
| |||
| Patient class | 0 | 2111 | 49.82% |
| 1 | 2126 | 50.18% | |
|
| |||
| Age | 1 | 9 | 0.21% |
| 2 | 94 | 2.22% | |
| 3 | 189 | 4.46% | |
| 4 | 444 | 10.48% | |
| 5 | 806 | 19.02% | |
| 6 | 1023 | 24.14% | |
| 7 | 1133 | 26.74% | |
| 8 | 511 | 12.06% | |
| 9 | 28 | 0.66% | |
2.2. The Proposed Methodology
The dose prediction method that is proposed in this paper contains two phases. In the first phase, the data points in the test will be assigned to two classes. The first class contains patients who require doses of >30 mg/wk (high required dose (HRD)) and the second class contains the patients who need doses of ≤30 mg/wk (low required dose (LRD)).
The selected cut-off point (30 mg/wk) was derived from the validation process in which the data in the learning set was divided randomly into training and validation sets. Different values (15, 20, 30, 35, 40, 45, and 50 mg/wk) were selected and examined to identify the threshold that maximized the classification accuracy. The optimal threshold, 30 mg/wk, from the validation process, was applied in the modelling procedure.
This phase is performed using a classification technique which incorporates relevance vector machines (RVM). In the second phase, the optimal dose for each patient will be predicted by two regression clinical models which are customized for each class of patients; see Figure 1.
Figure 1.
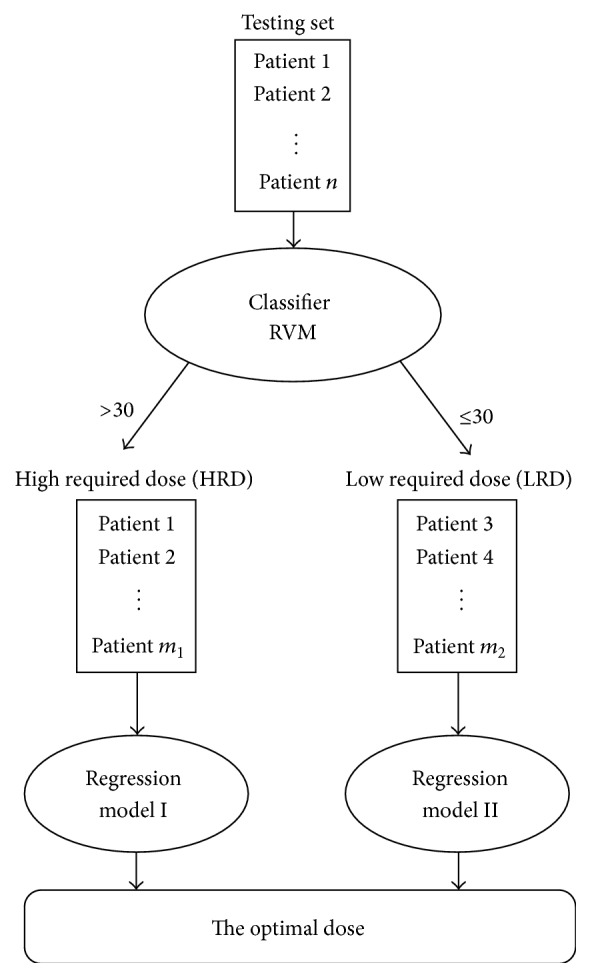
The proposed methodology.
2.3. Training the Models
The classification and the regression models are created using the data points in the learning set. Each data point in the learning set got labeled as 0 (LRD patients) or 1 (HRD patients) depending on the value of the therapeutic dose. Now by considering the generated labels as the new response variable, the nature of the problem transforms to classification. A classification model (RVM) is trained using the data in the learning set. Additionally, the points in the learning set are assigned to two groups according to their label and a regression model for each group gets generated.
As it is shown in Figure 1, when the points are labeled as 1 or 0 by the classification model, they will get entered into the second phase which is the prediction phase. A comprehensive review on machine learning methods and, specifically, support vector machines and relevance vector machines are presented in the next section.
2.4. Machine Learning
Machine learning (ML) is known as a branch of artificial intelligence. The major goal in ML is developing models and techniques that enable the computers to learn. The methods in ML can be categorized into two broad categories: supervised and unsupervised techniques. The difference between these techniques is the presence of response variables in the dataset. Therefore, once the response variable is unknown, the nature of the problem calls for unsupervised methods such as clustering. Subsequently, when the response variable is known, supervised methods will come into practice. If the response variable is known and takes numerical values, prediction models will be used, such as regression, and when it takes categorical values, classification models will be applied [31]. Several powerful classification models have been developed in the last 6 decades, namely, decision tree [33], artificial neural network [34], support vector machines [35], logistic regression [36], and so forth.
2.5. Support Vector Machines
As discussed above, since we aim to classify patients to either class HRD or class LRD in the initial phase of the modeling, our problem is a classification problem. Among numerous classifiers that are proposed in machine learning literature, support vector machine (SVM) is one of the most popular classification techniques. This model was first introduced by Vapnik in 1998 [37]. SVMs use a simple linear method applied to the data but in a high-dimensional feature space which is nonlinearly associated with the input space [30].
In a typical classification problem, the dataset consists of several features X 1, X 2,…, X L and one or several variables for labels C 1, C 2,…, C p. The goal is to develop a model to assign the objects (data points) to their classes. The classification model that was used in this paper is relevance vector machines (RVM) which is a special form of support vector machines (SVM). In a two-class classification problem (C 1 and C 2), the objective is to develop a classifier using the N data points in the training set. Therefore for each point in the training set {x n}n=1 N a label z n ∈ {−1,1}, n = 1,…, N should be estimated. The classifier is defined as
| (1) |
where w ∈ R M is the weight vector, b ∈ R is the constant, and ϕ(·) is the transformation function. The predicted labels are computed using the sgn(·) function, sgn(y(x)). Assuming the data is linearly separable, there exist vectors w(w ∗) and b(b ∗) which yield a hyperplane that completely separates the data to two disjoint areas. This hyperplane is called the decision boundary (D) and the predicted labels for the data points and the value of y(x n) have the same sign (z n y(x n) > 0; ∀x n ∈ R D and z n ∈ {−1,1}). The minimum distance of the points in the training set to D is called the margin (see Figure 2) which is computed using minn∈{1,…,N}(z n y(x n)/‖w‖); ‖·‖ is the L 2-norm. The objective in SVM is choosing the values for W and b which maximizes the margin. The values for w ∗ and b ∗ are yielded by solving the following optimization problem:
| (2) |
The w ∗ and b ∗ which resulted from (2) are also the solutions to the following minimization problem:
| (3) |
where x n ∈ ℝ D, z n ∈ {−1,1}, and n = 1,…, N.
Figure 2.
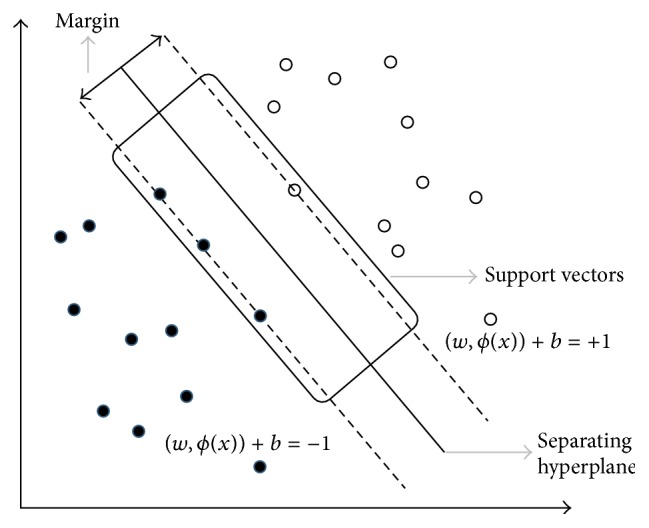
The separating hyperplane.
The optimization problem in (3) can also be solved by applying Lagrange multipliers (λ n ∈ R, n = 1,…, N). The Lagrangian formation of (3) is
| (4) |
The first-order conditions for optimality in (4) are ∑n=1 N λ n z n ϕ(x n) = w and ∑n=1 N λ n z n = 0. After applying the conditions, the dual form of (3) will result in
| (5) |
where ℒ(λ)≜∑n=1 N λ n − (1/2)∑n=1 N∑m=1 N λ n λ m z n z m k(x n, x m) and k(x, x′) = ϕ T(x)ϕ(x′) are called the kernel function. The KKT (Karush-Kuhn-Tucker) conditions for optimality for optimization problems in (3) and (5) are λ n ≥ 0, z n y(x n) − 1 ≥ 0, and λ n(z n y(x n) − 1) = 0, where n = 1,…, N. Those data points for which the corresponding λ n is nonzero are called support vectors. These points play a crucial role in classifying new points.
If the points in the dataset are not linearly separable, by using slack variables (ξ n ≥ 0) the concept of soft-margin classifiers will be defined. In this family of classifiers, by assigning a penalty to the points that lay on the wrong side of the boundary, the optimization problem in 3 will be rewritten as follows:
| (6) |
C > 0 is called the complexity parameter. The Lagrangian method can again be applied for solving (6) which has the form ℒ(w, b, λ, ξ) = (1/2)‖w‖2 + C∑n=1 N ξ n − ∑n=1 N λ n(z n y(x n) − 1 + ξ n) − ∑n=1 N μ n ξ n, where w = ∑n=1 N λ n z n ϕ(x n), 0 = ∑n=1 N λ n z n, λ n = C − μ n, n = 1,…, N, and λ n ≥ 0. The dual form of this optimization problem is presented in
| (7) |
The major drawbacks of SVM are as follows.
The linear growth of the number of support vectors is with the number of data points in the training set.
Providing a hard binary decision, in most applications it would be much more useful when the level of certainty is addressed when classifying new objects.
It is necessary to estimate the C (complexity parameter) which requires the cross-validation.
To overcome the abovementioned shortcomings, in the next section the relevance vector machines (RVM) will be introduced.
2.6. Relevance Vector Machines
Relevance vector machines (RVM) belong to the family of sparse Bayesian learners. This method, which can be used for both classification and regression, was introduced by Tipping [38]. One of the most important advantages of RVMs is its ability for handling classification problem when the cost of misclassification includes different classes. In a classification problem, RVM assigns a class membership probability for a given point (x): p(C k∣x, X, Z), where X is the feature set and Z is the set of labels in the training set. Assuming that the posterior probability of a target variable in C 1 is calculated by
| (8) |
we will configure the likelihood function (LF). Using σ(·) for the logit function, the right side of (8) can be denoted as σ(y(x n)). Therefore, in our binary classification problem, the LF is
| (9) |
The weight parameters (w) in (9) have a Gaussian distribution with a mean of zero. However the variance of each w i i = 1,…, M could be different. So, the prior distribution of the weight vector will be
| (10) |
where α i, i = 1,…, M is known as hyperparameters and is the inverse of the Gaussian distribution variance. For any new point (x) the posterior probability can be calculated as p(z∣x, X, Z). This probability is computed by marginalizing the p(z, x, X, Z, w, α):
| (11) |
Solving (11) can be done by using approximation, in which for the vector of α we will use a constant (α ∗). α ∗ is the value which maximizes the p(Z∣X, α). Therefore, (11) will be equal to
| (12) |
Furthermore, p(w∣x, X, Z, α) = p(Z∣x, X, w, α)p(w∣x, X, α)/p(Z∣x, X, α) = p(Z∣X, w)p(w∣α)/p(Z∣X, α). This probability should also get approximated. The approximation process aims to detect the vector of w which maximizes p(w∣x, X, Z, α). The maximization problem (w ∗) is
| (13) |
and the marginal LF p(Z∣X, α) will be
| (14) |
which, using the Laplace approximation method, is equivalent to
| (15) |
The Σ in (15) is the covariance matrix of the Gaussian approximation. Using the approximation method, the vector of α and w will be estimated. Surprisingly enough, the value of α for most weights goes to infinity which will result in minimizing w to zero. Therefore, this process will yield a much sparser model. The points in the training set for which the corresponding w is nonzero are called the relevance vectors.
3. Evaluation Methods
There are several methods to evaluate a classification method. In Table 2, the fundamental definitions for a confusion matrix are presented. A confusion matrix is a tabulated presentation of correctly or incorrectly classified points in the dataset. The definition of the cell values in the confusion matrix is presented below:
true positives (TP): the number of positive examples that were predicted correctly,
false positives (FP): the number of positive examples that were predicted incorrectly,
true negatives (TN): the number of negative examples that were predicted correctly,
false negatives (FN): the number of negative examples that were predicted incorrectly.
Table 2.
The confusion matrix.
| Total accuracy | Actual values | |||
|---|---|---|---|---|
| Actual positive | Actual negative | |||
| Predicted values | Predicted positive | True positives (TP) | False negatives (FN) | Precision+ |
| Predicted negative | False positives (FP) | True negative (TN) | Precision− | |
| Sensitivity | Specificity | |||
The measures that were considered to pick the best model are as follows:
| (16) |
In the next section, the experimental results for applying the proposed methodology on the dataset will be presented.
4. Results and Discussion
Using the RVM model, the data points in the testing set were classified to HRD and LRD classes and two regression models were developed for each class separately. The models are presented below.
Model for HRD class (Model I):
| (17) |
Model for HRD class (Model II):
| (18) |
In the cross-validation phase, the trained models were applied on the data points in the testing set. The classification results for the two models are presented in Table 3.
Table 3.
Classification results for RVM.
| Method | Accuracy | Sensitivity | Specificity | Precision+ | Precision− |
|---|---|---|---|---|---|
| RVM | 66% | 63% | 73% | 81% | 50% |
After classifying the points in the test set, 49% of the points were assigned to HRD class and 51% to LRD class. The proposed method's prediction accuracy got evaluated based on RMSE (root mean squared error): and MAE (mean absolute error): mean (|Actual Value − Predicted Value|). The prediction results are presented in Table 4.
Table 4.
Comparing the prediction accuracy of the proposed methodology with IWPC Cl and Gage Cl models.
| Methods | RMSE | MAE |
|---|---|---|
| The proposed methodology | 11.6 | 8.4 |
| IWPC Cl | 13.8 | 9.1 |
| Gage Cl | 12.2 | 9.9 |
| Sharabiani | 18.1 | 12.7 |
| Fixed-dose approach | 18.7 | 12.3 |
As it is evident in Table 4, the proposed methodology for predicting the warfarin dose outperforms the IWPC cl model for 16% in terms of RMSE and 8% in terms of MAE. It also outperforms the Gage Cl model for 5% in terms of RMSE and 16% in terms of MAE. The proposed method was also compared with fixed-dose approach (35 mg/wk) and the prediction model proposed in [16]. The method resulted in significantly lower RMSE and MAE than both models (37%, 31% less than the fixed-dose approach and 35%, 33% less than the method in [16] in terms of RMSE and MAE, resp.). In Table 4, we have compared our methods with four other clinical methods that are either widely used or have outperformed other widely used models. We were not able to find any other clinical model in the literature that has an advantage (either in terms of popularity or in terms of prediction accuracy) over these selected methods. Therefore, our conclusion is that our proposed method outperforms all available clinical models for initial warfarin dosing in the literature.
We have not compared our model with any existing pharmacogenetic model (e.g., the models proposed in [9, 11]). As we mentioned in the Introduction section, there is no general consensus in the literature that pharmacogenetic models outperform clinical models. Even if pharmacogenetic models had generally a higher accuracy of warfarin dose prediction, such a comparison would have not been absolutely required due to the differences in the application domains of these classes of models. In practice, for some patients, it is impossible to use a pharmacogenetic model. Pharmacogenetic models rely on patients' gene information. In some cases (especially in clinics and hospitals who serve underrepresented populations), obtaining these information is impossible due to the lack of necessary equipment and lab tests. In such cases, clinical models and fixed-dose approaches are the only solutions for warfarin dosing. In other instances, even when it is possible to obtain the gene information from patients, the use of pharmacogenetic models might be questionable due to time constraints. For example, when a patient, whose gene information is not available, is involved in an accident and needs an immediate dose of warfarin, it might be unsafe to wait for the gene information to become available. It could take several hours before one can obtain the gene information by performing the required laboratory tests. For a patient involved in an accident this wait might result in death or serious blood clot complications.
5. Conclusions
The significance of prescribing an accurate initial dose for warfarin is undeniably important. Therefore several mathematical models have been proposed in order to predict the optimal dose for each patient. In this paper, a novel methodology for predicting the initial dose is proposed, which only relies on patients' clinical and demographic data. In this method, the patients are assigned to either one of two classes in the first phase. The patients who require doses of >30 mg/wk belong to the first class and the second class contains the patients who require doses of ≤30 mg/wk. This phase is implemented using relevance vector machines (RVM). Then, the optimal dose for each patient will be predicted using one of the two regression clinical models which are customized for each class. The proposed methodology outperformed two popular existing clinical prediction models (IWPC Cl and Gage Cl models), the method in [16], and the fixed-dose approach in terms of prediction accuracy. The methodology which is proposed in this work can be extended by investigating the best classifiers for patients of specific ethnicities.
Acknowledgment
The authors would like to acknowledge the Research Open Access Publishing (ROAAP) Fund of the University of Illinois at Chicago for financial support regarding the open access publishing fee for this paper.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
References
- 1.Hirsh J., Fuster V., Ansell J., Halperin J. L. American Heart Association/American College of Cardiology foundation guide to warfarin therapy. Journal of the American College of Cardiology. 2003;41(9):1633–1652. doi: 10.1016/s0735-1097(03)00416-9. [DOI] [PubMed] [Google Scholar]
- 2.Hylek E. M., Evans-Molina C., Shea C., Henault L. E., Regan S. Major hemorrhage and tolerability of warfarin in the first year of therapy among elderly patients with atrial fibrillation. Circulation. 2007;115(21):2689–2696. doi: 10.1161/circulationaha.106.653048. [DOI] [PubMed] [Google Scholar]
- 3.Hylek E. M., Go A. S., Chang Y., et al. Effect of intensity of oral anticoagulation on stroke severity and mortality in atrial fibrillation. The New England Journal of Medicine. 2003;349(11):1019–1026. doi: 10.1056/nejmoa022913. [DOI] [PubMed] [Google Scholar]
- 4.Gage B. F., Eby C., Johnson J. A., et al. Use of pharmacogenetic and clinical factors to predict the therapeutic dose of warfarin. Clinical Pharmacology and Therapeutics. 2008;84(3):326–331. doi: 10.1038/clpt.2008.10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.International Warfarin Pharmacogenetics Consortium. Estimation of the warfarin dose with clinical and pharmacogenetic data. The New England Journal of Medicine. 2009;360(8):753-–764. doi: 10.1056/NEJMoa0809329. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Pirmohamed M., Burnside G., Eriksson N., et al. A randomized trial of genotype-guided dosing of warfarin. The New England Journal of Medicine. 2013;369(24):2294–2303. doi: 10.1056/nejmoa1311386. [DOI] [PubMed] [Google Scholar]
- 7.Anderson J. L., Horne B. D., Stevens S. M., et al. A randomized and clinical effectiveness trial comparing two pharmacogenetic algorithms and standard care for individualizing warfarin dosing (CoumaGen-II) Circulation. 2012;125(16):1997–2005. doi: 10.1161/CIRCULATIONAHA.111.070920. [DOI] [PubMed] [Google Scholar]
- 8.Johnson J. A., Gong L., Whirl-Carrillo M., et al. Clinical pharmacogenetics implementation consortium guidelines for CYP2C9 and VKORC1 genotypes and warfarin dosing. Clinical Pharmacology and Therapeutics. 2011;90(4):625–629. doi: 10.1038/clpt.2011.185. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Grossi E., Podda G. M., Pugliano M., et al. Prediction of optimal warfarin maintenance dose using advanced artificial neural networks. Pharmacogenomics. 2014;15(1):29–37. doi: 10.2217/pgs.13.212. [DOI] [PubMed] [Google Scholar]
- 10.Zambon C.-F., Pengo V., Padrini R., et al. VKORC1, CYP2C9 and CYP4F2 genetic-based algorithm for warfarin dosing: an Italian retrospective study. Pharmacogenomics. 2011;12(1):15–25. doi: 10.2217/pgs.10.162. [DOI] [PubMed] [Google Scholar]
- 11.Cosgun E., Limdi N. A., Duarte C. W. High-dimensional pharmacogenetic prediction of a continuous trait using machine learning techniques with application to warfarin dose prediction in African Americans. Bioinformatics. 2011;27(10):1384–1389. doi: 10.1093/bioinformatics/btr159. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Limdi N. A., Veenstra D. L. Warfarin pharmacogenetics. Pharmacotherapy. 2008;28(9):1084–1097. doi: 10.1592/phco.28.9.1084. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Limdi N. A., Beasley T. M., Crowley M. R., et al. VKORC1 polymorphisms, haplotypes and haplotype groups on warfarin dose among African-Americans and European-Americans. Pharmacogenomics. 2008;9(10):1445–1458. doi: 10.2217/14622416.9.10.1445. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Schelleman H., Chen J., Chen Z., et al. Dosing algorithms to predict warfarin maintenance dose in Caucasians and African Americans. Clinical Pharmacology & Therapeutics. 2008;84(3):332–339. doi: 10.1038/clpt.2008.101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Schelleman H., Limdi N. A., Kimmel S. E. Ethnic differences in warfarin maintenance dose requirement and its relationship with genetics. Pharmacogenomics. 2008;9(9):1331–1346. doi: 10.2217/14622416.9.9.1331. [DOI] [PubMed] [Google Scholar]
- 16.Sharabiani A., Darabi H., Bress A., Cavallari L., Nutescu E., Drozda K. Machine learning based prediction of warfarin optimal dosing for African American patients. Proceedings of the IEEE International Conference on Automation Science and Engineering (CASE ’13); August 2013; Madison, Wis, USA. pp. 623–628. [DOI] [Google Scholar]
- 17.Hernandez W., Gamazon E. R., Aquino-Michaels K., et al. Ethnicity-specific pharmacogenetics: the case of warfarin in African Americans. Pharmacogenomics Journal. 2014;14(3):223–228. doi: 10.1038/tpj.2013.34. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Monagle P., Chan A. K. C., Goldenberg N. A., et al. Antithrombotic therapy in neonates and children: antithrombotic therapy and prevention of thrombosis, 9th ed: american college of chest physicians evidence-based clinical practice guidelines. Chest. 2012;141(2):e737–e801. doi: 10.1378/chest.11-2308. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Nowak-Göttl U., Dietrich K., Schaffranek D., et al. In pediatric patients, age has more impact on dosing of vitamin K antagonists than VKORC1 or CYP2C9 genotypes. Blood. 2010;116(26):6101–6105. doi: 10.1182/blood-2010-05-283861. [DOI] [PubMed] [Google Scholar]
- 20.Moreau C., Bajolle F., Siguret V., et al. Vitamin K antagonists in children with heart disease: height and VKORC1 genotype are the main determinants of the warfarin dose requirement. Blood. 2012;119(3):861–867. doi: 10.1182/blood-2011-07-365502. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Biss T. T., Avery P. J., Brandão L. R., et al. VKORC1 and CYP2C9 genotype and patient characteristics explain a large proportion of the variability in warfarin dose requirement among children. Blood. 2012;119(3):868–873. doi: 10.1182/blood-2011-08-372722. [DOI] [PubMed] [Google Scholar]
- 22.Nguyen N., Anley P., Yu M. Y., Zhang G., Thompson A. A., Jennings L. J. Genetic and clinical determinants influencing warfarin dosing in children with heart disease. Pediatric Cardiology. 2013;34(4):984–990. doi: 10.1007/s00246-012-0592-1. [DOI] [PubMed] [Google Scholar]
- 23.Kato Y., Ichida F., Saito K., et al. Effect of the VKORC1 genotype on warfarin dose requirements in Japanese pediatric patients. Drug Metabolism and Pharmacokinetics. 2011;26(3):295–299. doi: 10.2133/dmpk.DMPK-10-NT-082. [DOI] [PubMed] [Google Scholar]
- 24.Burmester J. K., Berg R. L., Yale S. H., et al. A randomized controlled trial of genotype-based Coumadin initiation. Genetics in Medicine. 2011;13(6):509–518. doi: 10.1097/gim.0b013e31820ad77d. [DOI] [PubMed] [Google Scholar]
- 25.Stergiopoulos K., Brown D. L. Genotype-guided vs clinical dosing of warfarin and its analogues: meta-analysis of randomized clinical trials. JAMA Internal Medicine. 2014;174(8):1330–1338. doi: 10.1001/jamainternmed.2014.2368. [DOI] [PubMed] [Google Scholar]
- 26.Anderson J. L., Horne B. D., Stevens S. M., et al. Randomized trial of genotype-guided versus standard warfarin dosing in patients initiating oral anticoagulation. Circulation. 2007;116(22):2563–2570. doi: 10.1161/circulationaha.107.737312. [DOI] [PubMed] [Google Scholar]
- 27.Kimmel S. E., French B., Kasner S. E., et al. A pharmacogenetic versus a clinical algorithm for warfarin dosing. The New England Journal of Medicine. 2013;369(24):2283–2293. doi: 10.1056/nejmoa1310669. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Scott S. A., Lubitz S. A. Warfarin pharmacogenetic trials: is there a future for pharmacogenetic-guided dosing? Pharmacogenomics. 2014;15(6):719–722. doi: 10.2217/pgs.14.18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Cavallari L. H., Nutescu E. A. Warfarin pharmacogenetics: to genotype or not to genotype, that is the question. Clinical Pharmacology & Therapeutics. 2014;96(1):22–24. doi: 10.1038/clpt.2014.78. [DOI] [PubMed] [Google Scholar]
- 30.Oztaner S., Taskaya Temizel T., Erdem S., Ozer M. A Bayesian estimation framework for pharmacogenomics driven warfarin dosing: a comparative study. IEEE Journal of Biomedical and Health Informatics. 2014 doi: 10.1109/jbhi.2014.2336974. [DOI] [PubMed] [Google Scholar]
- 31.Hastie T., Tibshirani R., Friedman J. The Elements of Statistical Learning. Vol. 2. Springer; 2009. [Google Scholar]
- 32.Wirth R., Hipp J. CRISP-DM: towards a standard process model for data mining. Proceedings of the 4th International Conference on the Practical Application of Knowledge Discovery and Data Mining; 2000; pp. 29–39. [Google Scholar]
- 33.Quinlan J. R. Induction of decision trees. Machine Learning. 1986;1(1):81–106. doi: 10.1007/BF00116251. [DOI] [Google Scholar]
- 34.Yegnanarayana B. Artificial Neural Networks. New Delhi, India: Phi Learning Private Limited; 2009. [Google Scholar]
- 35.Steinwart I., Christmann A. Support Vector Machines. Springer; 2008. [Google Scholar]
- 36.Hosmer D. W., Lemeshow S., Sturdivant R. X. Introduction to the Logistic Regression Model. Wiley; 2000. [Google Scholar]
- 37.Vapnik V. N. Statistical Learning Theory. New York, NY, USA: John Wiley & Sons; 1998. [Google Scholar]
- 38.Tipping M. E. Sparse Bayesian learning and the relevance vector machine. Journal of Machine Learning Research. 2001;1(3):211–244. doi: 10.1162/15324430152748236. [DOI] [Google Scholar]