

Abstract
Unlike the western medical approach where a drug is prescribed against specific symptoms of patients, traditional Chinese medicine (TCM) treatment has a unique step, which is called syndrome differentiation (SD). It is argued that SD is considered as patient classification because prior to the selection of the most appropriate formula from a set of relevant formulae for personalization, a practitioner has to label a patient belonging to a particular class (syndrome) first. Hence, to detect the patterns between herbs and symptoms via syndrome is a challenging problem; finding these patterns can help prepare a prescription that contributes to the efficacy of a treatment. In order to highlight this unique triangular relationship of symptom, syndrome, and herb, we propose a novel three-step mining approach. It first starts with the construction of a heterogeneous tripartite information network, which carries richer information. The second step is to systematically extract path-based topological features from this tripartite network. Finally, an unsupervised method is used to learn the best parameters associated with different features in deciding the symptom-herb relationships. Experiments have been carried out on four real-world patient records (Insomnia, Diabetes, Infertility, and Tourette syndrome) with comprehensive measurements. Interesting and insightful experimental results are noted and discussed.
1. Introduction
Traditional Chinese medicine (TCM) has a long history and has been accepted as one of the main medical approaches in China [1]. Many of the herbal medicines used in today's clinical practice and some of the traditional Chinese medicine preparation has been used in human patients for thousands of years, which has been successfully applied to the treatment of many diseases, such as insomnia, diabetes, infertility, and Tourette syndrome. Unlike the western medical approach where a drug is prescribed against specific symptoms of patients, TCM treatment has a unique step, which is called syndrome differentiation (SD). It is argued that SD is, in fact, patient classification because, prior to the personalization of the most appropriate formula, a practitioner has to label a patient belonging to a particular class (syndrome) for a set of relevant formulae. Hence, to detect the patterns between herbs and symptoms via syndrome is a challenging problem; finding these patterns can help prepare a prescription that contributes to the efficacy of a treatment.
In recent years, interest in TCM has increased globally and the application of data mining to TCM [2–4] is also getting more attention. However, most of the previous research was related to the extraction of core herbs or to mine herb-herb relationships [1, 5, 6] from a network of herbs. We term this kind of network as a homogeneous information network, that is, network consisting of only one type of objects (herb in this example). When a network contains different types of objects (such as herbs, symptoms, and syndromes), we refer to them as heterogeneous information networks. Since heterogeneous information networks are not well studied, this has become the motivation of our work.
In general, a homogeneous information network can be derived from a heterogeneous information network, for example, an herb-herb network can be derived from a symptom-syndrome-herb network by a projection on herbs only. A heterogeneous information network is different from a homogeneous information network because it carries richer information than its corresponding projected homogeneous information networks. Therefore, it aimed to discover herb-symptom patterns, via syndromes, from a heterogeneous information network, which contains different types of attribute values associated with objects. To the best of our knowledge, this is the first attempt towards mining herb-symptom patterns in TCM utilizing heterogeneous information networks.
In this research, we construct the heterogeneous information network leveraging the tripartite graph. Our heterogeneous information network contains multiple types of objects, such as herb, symptom, syndrome, and multiple types of links defining different relations among these objects, such as links existing between herbs and syndromes, between syndromes and symptoms, and between symptoms and herbs. Thus, the number of different types of objects there are in the network can be found out, as well as the identification of the possible links existing among objects. Furthermore, we can detect the patterns between herbs and symptoms.
The major contributions of this paper are summarized.
We construct the TCM heterogeneous information network utilizing the tripartite graph.
We study the problem of the symptom-herb relationship prediction in TCM heterogeneous information network.
We propose a novel three-step prediction approach based on the TCM heterogeneous information network to discover symptom-herb patterns.
Experiments on real TCM patient records indicate that our proposed method can mine symptom-herb relationships with high accuracy.
Treatments are proven to be more effective than a direct symptom-herb relationship; that is, classifying patients into different syndromes is a crucial step in TCM treatment.
The remaining of the paper is organized as follows. We first introduce the background and preliminaries on TCM heterogeneous information networks and denote the task of symptom-herb pattern prediction in Section 2. In Section 3, we obtain some interesting observations based on TCM heterogeneous information network. We next present a novel three-step mining approach to discover the symptom-herb patterns in Section 4. We report our experiments and results in Section 5, discuss related work in Section 6, and conclude the study in Section 7.
2. Preliminaries and Problem Definition
2.1. Notations Definitions
In this work, we need to consider three types of entities: a set of herbs H = {h 1, h 2,…, h n}, a set of syndromes D = {d 1, d 2,…, d m}, and a set of symptoms P = {p 1, p 2,…, p q}. We assume that there are n herbs, m syndromes, and q symptoms. Here, symptoms refer to something that can be observed and measured, such as fever, nausea, coughing, and weight loss. Syndrome is a special phenomenon in TCM. A TCM doctor will base upon the patient's symptoms and classify them into one or two syndromes. After that, formulas will be prescribed according to the syndrome.
2.2. Heterogeneous Information Network
We first introduce the definitions of heterogeneous information network [7, 8], tripartite graph [9], and tritype information network, so as to study the characteristic of TCM and discuss how to find or predict symptom-herb patterns in TCM information network.
Definition 1 (heterogeneous information network). —
A heterogeneous information network is denoted as a directed graph G = (V, E, W) with an entity type mapping function ϕ : V → 𝒜 and a link type mapping function ψ : E → ℛ, where each entity v⊆V belongs to one particular entity type ϕ(v)⊆𝒜, each link e⊆E belongs to a particular relation type ψ(e)⊆ℛ, and W : E → R + is a weight mapping from an edge e⊆E to a real number w⊆R +. Notice that, when the types of entities |𝒜| > 1 and also the types of relations |ℛ| > 1, the network is called heterogeneous information network.
Definition 2 (tripartite graph). —
A graph TG = 〈{V 1 ∪ V 2 ∪ V 3}, E〉 can be called as tripartite, if a set of graph nodes decomposed into three disjoint sets such that no two graph nodes within the same set are adjacent; that is, V 1∩V 2∩V 3 = ∅.
Definition 3 (tritype information network). —
Given three types of objects sets X, Y, and Z, where X = {x 1, x 2,…, x m}, Y = {y 1, y 2,…, y n}, and Z = {z 1, z 2,…, z q}, graph G = 〈V, E〉 is called a tritype information network on types X, Y, and Z, if V(G) = X ∪ Y ∪ Z and E(G) = {〈o i, o j〉}, where o i, o j ∈ X ∪ Y ∪ Z.
Let W (m+n)∗(m+n) = {〈w oioj〉} (or W (n+q)∗(n+q) = {〈w oioj〉} or W (m+q)∗(m+q) = {〈w oioj〉}) be the adjacency matrix of links, where 〈w oioj〉 equals the weight of link 〈o i, o j〉, which is the observation number of the link, and we thus use G = 〈{X ∪ Y ∪ Z}, W〉 to define this tritype information network with weight. In the following, we use X, Y, and Z denoting the object set and their type name. For convenience, we decompose the link matrix into four blocks: W XX, W XY, W YX, and W YY (or W YY, W YZ, W ZY, and W ZZ or W XX, W XZ, W ZX, and W ZZ), each denoting a subnetwork of objects between types of the subscripts. W can be denoted as
| (1) |
This tritype information network, one of the heterogeneous information networks, denotes the rules of how entities exist and how links should be created. And, through analyzing this tritype information network, we can know how many types of objects there are in the network and where the possible links exist. In the following, we give an example of tritype information network, which is showed in Figure 1. Here, as an abbreviation, we utilize the special letters to define these entity types, namely, H representing herbs, P representing symptoms, and D representing syndromes. Notations and similarity relations used in definitions as well as the rest part of the paper can be found in Notation section.
Figure 1.
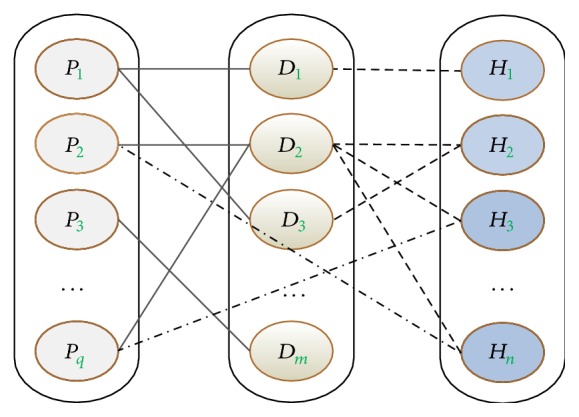
Tripartite graph structure of TCM. Here, instances of different objects are represented by different colour nodes and links among different objects are represented by different line styles. q, m, and n represent the number of symptom, the number of syndrome, and the number of herb, respectively.
2.3. Target Relationship Prediction
Based on the previous definitions, our goal of this work can be summarized as follows: given a tritype network G = 〈{H ∪ D ∪ P}, W〉, the target type P, and a set of herbs {H j}, our goal is to find or predict the most reasonable herbs for each symptom P i, that is, how to predict the target relationship E(G) = {〈P i, H j〉}, where P i, H j ∈ P ∪ H.
Different from symptom-syndrome patterns and syndrome-herb patterns, which are directed relationships (because patients' syndromes are derived from a set of patients symptoms and herbs are configured by doctors according to the patients' syndromes, symptom-syndrome patterns and syndrome-herb patterns are directed relationships.), symptom-herb patterns are undirected relationships. Intuitively, the herb-symptom relationship detection is an implicit relationship mining, which is more difficult to detect than an explicit relationship mining. However, if new herb-symptom relationships can be discovered, they are beneficial for doctors configuring the prescriptions.
2.4. Dataset
In this work, our experiments were performed on four real TCM datasets: Insomnia, Infertility, Diabetes, Tourette. These four datasets were provided by Guang'anmen Hospital, China Academy of Chinese Medical Sciences. These four datasets include the symptoms, the syndromes, and prescription information of outpatients. Here, edges are formed among objects belonging to the same prescription. Properties of these four datasets are shown in Table 1.
Table 1.
Properties of four TCM data sets. Here, “—” represents that this attribute can not be included in this data set.
| Insomnia | Infertility | Diabetes | Tourette | |
|---|---|---|---|---|
| Number of prescriptions | 460 | 852 | 1674 | 670 |
| Number of herbs | 111 | 251 | 204 | 189 |
| Number of symptoms | 155 | 389 | 186 | — |
| Number of syndromes | — | 106 | 178 | 98 |
| Symptoms per herb | 82.58 | 71.64 | 84.72 | — |
| Syndromes per herb | — | 24.34 | 29.56 | 20.56 |
| Herbs per symptom | 59.14 | 46.4 | 33.89 | — |
| Herbs per syndrome | — | 57.41 | 92.91 | 71.13 |
3. Observation
In this section, we conduct following observations based on the four TCM datasets in order to get a better understanding on the symptom-syndrome-herb patterns and structural properties of TCM tripartite network.
3.1. Entity Distribution
We first study the distribution of each entity frequency. Figure 2 plots the distribution in a log-log scale based on the Infertility dataset. In Figure 2(a), the x-axis represents the 251 unique herbs, ordered by descending herb frequency. The y-axis refers to the herb frequency. As reported by other authors [5, 10], we find the herb frequency to follow a power law distribution with few herbs being responsible for a high number of prescriptions. Here, the probability of a kind of herb having herb frequency x is proportional to x −0.843. It indicates that most herbs are rarely used, while only a small number of the herbs are frequently used. In other words, the head of the power law contains herbs that would be used more frequently and the very tail of the power law contains the infrequent herbs. The most frequent herbs were used more than 530 times by different prescriptions altogether. Similarly, same distributions can be found in Figures 2(b) and 2(c).
Figure 2.

Distribution of the entity frequency in Infertility Dataset. Here, in (a), the x-axis represents the 251 unique herbs, ordered by descending herb frequency. The y-axis refers to the herb frequency. In (b), the x-axis represents the 389 unique symptoms, ordered by descending symptom frequency. The y-axis refers to the symptom frequency. In (c), the x-axis represents the 106 unique syndromes, ordered by descending syndrome frequency. The y-axis refers to the syndrome frequency.
In addition to the infertility dataset, we carried on similar statistical analysis with other three datasets, and the same pattern is observed in the vast majority of cases.
3.2. Link Distribution
So far, there is some existing work that explicitly addresses herb-herb patterns [5, 6]. They indicated that there are common herb pairs frequently used in the regular TCM herb prescriptions. However, few works focus on studying symptom-herb, symptom-syndrome, and syndrome-herb patterns. In this work, we extract these patterns and analyze what distribution they obey.
Figure 3 shows that the distribution of these patterns (symptom-herb, symptom-syndrome, and syndrome-herb patterns) also follows a power law distribution. In Figure 3(a), the x-axis represents the 17,910 symptom-herb patterns, ordered by their cooccurrence frequency (descending). The y-axis refers to the symptom-herb frequency. Furthermore, we find that 80% of all symptom-herb patterns appear only 1–3 times in the infertility dataset. Here, the probability of a kind of symptom-herb pattern having symptom-herb pattern frequency x is proportional to x −0.945. This indicates that there are common herb-symptom pairs frequently used in the regular TCM herb prescriptions. If we can predict these common herb-symptom pairs, it is very useful for a doctor configuring a formulae. Again, the same law distributions can be found in Figures 3(b) and 3(c).
Figure 3.

Distribution of the link frequency in Infertility Dataset. Here, in (a), the x-axis represents the 17,910 symptom-herb patterns, ordered by descending symptom-herb frequency. The y-axis refers to the symptom-herb frequency. In (b), the x-axis represents the 6,085 syndrome-herb patterns, ordered by descending syndrome-herb frequency. The y-axis refers to the syndrome-herb frequency. In (c), the x-axis represents the 7,897 symptom-syndrome patterns, ordered by descending symptom-syndrome frequency. The y-axis refers to the symptom-syndrome frequency.
3.3. Relationship Distribution
Furthermore, we study the relationship among symptom, syndrome, and herb. Here, the relationship also exists among symptom, syndrome, and herb. It is a one-to-many relationship, that is, the number of herbs each symptom is associated with, the number of syndromes each herb is associated with, and so forth. Figure 4 shows that the distribution of the number of herbs per symptom (syndromes per herb or syndromes per symptom) also follows a power law distribution. In Figure 4(a), the x-axis represents the 389 unique symptoms, ordered by the number of herbs per symptom (descending). The y-axis refers to the number of herbs per symptom. The probability of having x herbs per symptom is proportional to x −0.51. We can find each symptom to be labeled with 46.4 herbs on average. Also, it can be found for the occurrence frequencies of herbs per symptom where 23.2% of all herbs link to the Top 1% of symptoms. Similarly, the same law distributions can be found in Figures 4(b) and 4(c).
Figure 4.

Distribution of relationship of objects in Infertility Dataset. Here, in (a), the x-axis represents the 389 unique symptoms, ordered by the descending number of herbs per symptom. The y-axis refers to the number of herbs per symptom. In (b), the x-axis represents 251 unique herbs, ordered by descending number of syndromes per herb. The y-axis refers to the number of syndromes per herb. In (c), the x-axis represents the 389 unique symptoms, ordered by the descending number of syndromes per symptom. The y-axis refers to the number of syndromes per symptom.
4. Prediction Method Based on Tripartite Graph
In this section, we will introduce a novel three-step prediction approach based on the tripartite graph (Tri-TSPA). First, we extract two types of paths, which carry different semantic meanings. In terms of these two paths, we draw three matrices, which represent different cooccurrence relationship. And then, we propose an unsupervised prediction method in order to discover symptom-herb patterns.
4.1. Extracting Paths
In a tripartite network, two entities can be connected by different paths, which carry different semantic meanings. In this work, we choose two kinds of paths in order to find the reasonable symptom-herb patterns. These two kinds of paths are taken as follows:
| (2) |
Path PH_Path extracts the direct target relationship; it looks like the way western medicine often adopts. In western medicine, medical doctors and other healthcare professionals (such as nurses, pharmacists, and therapists) treat diseases using drugs, radiation, or surgery according to symptoms [11]. Path PDH_Path extracts the indirect target relationship, it is a common way TCM often adopts. In TCM, doctors first choose a series of syndromes in terms of patients' symptoms, and, then, configure herbs on the basis of syndromes.
4.2. Constructing Matrix
After extracting paths from the tripartite graph, we can further construct matrices describing the relationship among different entities, such as symptom-herb, symptom-syndrome, and syndrome-herb. In this work, we build the three matrices, namely, symptom-herb matrix based on the path PH_Path, symptom-syndrome matrix, and syndrome-herb matrix based on the path PDH_Path.
In addition, we also build matrices depicting the relationship among same entities, such as herb-herb, symptom-symptom, and syndrome-syndrome, in order to promote the similarity measure and find some useful symptom-herb patterns. These three matrices can be extracted based on the homogeneous information networks (here, if two herbs (or symptoms, syndromes) belong to the same prescription and they produce the positive effect when used together, we can connect these two herbs. According to this rule, the homogeneous information networks can be constructed), including herb, symptom, and syndrome homogeneous information networks.
In order to build aforementioned matrices, we define and implement multiple measurement strategies in this work. These strategies can be introduced as follows.
-
(i)Frequency (F). Frequency is a basic strategy, which is an observation number of cooccurrence of two entities (A x and A y), such as symptom-herb, symptom-syndrome, and syndrome-herb. It can be defined as F(A x, A y):
(3) -
(ii)Jaccard Coefficient (JC). According to the Jaccard coefficient [12], we can normalise the cooccurrence of two entities A x and A y by calculating
(4) -
The coefficient takes the number of intersections between the two entities, divided by the union of the two entities. The Jaccard coefficient is known to be useful to measure the relevance between two objects or sets. In general, we can use symmetric measures, like Jaccard, to induce whether two entities have a related meaning.
- (iii)
-
AM captures how often the entity A y cooccurs with entity A x normalised by the total frequency of entity A y. We can interpret this as the probability of a patient being diagnosed with entity A x given entity A y occuring.
-
(iv)TfIdf. It is often used as a weighting factor in information retrieval and text mining [16]. In this work, we denote Tf(A x, A y) = F(A x, A y), which is the frequency of two entities (A x and A y) cooccurrence and define Idf(A x, A y) = log(N/F(A x, A y)), which measures the importance of A x-A y patterns for the entity A x (or A y). Thus, TfIdf(A x, A y) can be denoted as follows:
(6) -
where N is the frequency of A x (or A y).
4.3. Symptom-Herb Patterns Prediction Method
In this subsection, we first show two similarity measures. And then, we introduce a relevance function. Finally, we proposed an unsupervised prediction method.
4.3.1. Similarity Measures
A similarity measure is a real-valued function that quantifies the similarity between two objects. In this work, taking the symptom as an example, if two symptoms are similar, they are likely to have similar frequency of symptom-herb patterns. Given symptom p 1, p 2, and herb h 1, if p 1 is similar to p 2, and there exists the p 1-h 1 pattern, we can infer that there exists the pattern p 2-h 1.
As mentioned previously, we have extracted two kinds of paths and built three matrices. Also, we have built other three homogeneous matrices. Based on them, we proposed two strategies measuring the similarity of entities of the same type.
-
(i)PH_Path based similarity: On basis of the symptom-herb matrix and symptom-symptom matrix, we use cosine similarity simPH and simPP to compute symptoms similarity, respectively. By combining simPH and simPP, we can get PH_Path based similarity. It can be denoted as
(7) -
where λ 0, λ 1 > 0 and λ 0 + λ 1 = 1. simPH reflects the frequency similarity of symptom-herb patterns. In other words, if two symptoms are similar, they are likely to have similar frequency of symptom-herb patterns. simPP reflects the frequency similarity of symptom-symptom patterns. In other words, if two symptoms belong to the same prescription, they are likely to be similar.
-
(ii)PDH_Path based on similarity: In terms of the symptom-syndrome matrix, syndrome-herb matrix, and syndrome-syndrome matrix, we can obtain two syncretic syndrome similarities, simPDH 1(d x, d y) and simPDH 2(d x, d y). Furthermore, through combining these two syncretic syndrome similarities, PDH_Path based on similarity can be formalized as
(8) -
where the definition of simPDH 1 and simPDH 2 is simlar to simPH_Path, but their only difference is that simPDH 1 and simPDH 2 are based on the symptom-syndrome matrix, syndrome-herb matrix, and syndrome-syndrome matrix. Here, simPDH 1(d x, d y) = α 0simPD(d x, d y) + α 1simDD(d x, d y) and simPDH 2(d x, d y) = β 0simDH(d x, d y) + β 1simDD(d x, d y). Note that, α, α 0, α 1, β, β 0, β 1 > 0 and α + β = 1 and α 0 + α 1 = 1, β 0 + β 1 = 1.
4.3.2. Relevance Function
In our datasets, the outcomes of all the prescriptions are classified into two categories: good and bad. When a treatment was effective, which means that if the patient recovered completely or partly from diseases in the next encounter, then the prescription of the current encounter would be categorized as “good”; otherwise, the prescription would be categorized as “bad.” In other words, when the outcome of a prescription is good, the patterns in this prescription, such as symptom-herb, symptom-syndrome, herb-herb, and others, make the positive role; otherwise, the patterns make a negative role.
In this work, relevance function is used to filter out the patterns with bad outcome. Here, the relevance function is parameterized with “relevance threshold” θ ∈ [0,1] to provide a range of tolerance to bad outcomes. In particular, given a relevance function R(〈A x, A y〉∣θ), the relevance threshold θ is used for creating the parameterized version of this relevance function, R(〈A x, A y〉∣θ), that is formalized as
| (9) |
where θ changes over different datasets. A x, A y ∈ X ∪ Y ∪ Z and ratio = Good_Outcome(Pattern)/(Good_Outcome(Pattern) + Bad_Outcome(Pattern)). Here, Good_Outcome(Pattern) refers to the total number of this pattern working effectively, and Bad_Outcome(Pattern) is the total number of this pattern having no effect on patients. In the next section, patterns of symptom-herb that are predicted above relevance threshold θ (i.e., R(〈A x, A y〉∣θ) = 1) are sorted according to predicted rating, while patterns of symptom-herb that are below θ (i.e., R(〈A x, A y〉∣θ) = 0) are ignored.
4.3.3. Proposed Method
Up to now, we have given a systematic way to extract and build the topological features in the tripartite networks. In this subsection, we will introduce our prediction algorithm (Tri-TSPA). Our prediction method is as follows: first, we discover K nearest entities according to the similarity measures, simPH_Path(A x, A y) or simPDH_Path(A x, A y); then, we predict rating for each potential entity pair; subsequently, we get Top-n predicted patterns by ranking prediction rating; lastly, we get Top-N list by filtering the patterns of bad outcome using relevance function. The pseudocode of Tri-TSPA is shown in Algorithm 1.
Algorithm 1.

Tri-TSPA.
In Algorithm 1, we only show the F measurement strategy to calculate the rating. Actually, we can replace F(·, ·) with JC(·, ·), AW(·, ·), and TfIdf(·, ·), respectively. In addition, PH_Path based on symptom-herb patterns mining is shown in Line 4–line 7, and PDH_Path based on symptom-herb patterns mining is shown in Line 8–Line 11.
5. Experiments
In this section, we conduct many experiments to evaluate the effectiveness of the proposed algorithm. We show that our proposed three step prediction approach can mine a reasonable set for each symptom on the TCM networks.
5.1. Experiment Setup
We first convert these datasets into heterogeneous tripartite information networks. We construct four TCM networks from TCM datasets, which consist of three types of objects: symptoms, syndromes, and herbs. Links exist between symptoms and syndromes, syndromes and herbs, and herbs and symptoms.
In order to effectively mine symptoms-herbs patterns, we adopt two kinds of strategies: PH_Path based strategy and PDH_Path based strategy. For each strategy, we apply four different measurement methods to set each term of each matrix related to this PH_Path (or PDH_Path). By combining these two kinds of strategies and four measurement methods together, we get total 8 different predicted methods. In the following section, a series of experiments will be carried on in order to find which predicted method can get the best performance.
In this work, we adopt twofold cross-validation (i.e., half training and half testing) to evaluate the performance of the prediction for each TCM network. In the training stage, we first extract two kinds of paths, symptom-herb path and symptom-syndrome-herb path. In terms of these two paths, we further build five matrices (in Section 4) according to the measurement method aforementioned (F, JC, AM, and TfIdf). After collecting all associated features, a training model is then built to learn the best coefficients associated with different features in deciding the symptom-herb patterns by performing multiple experiments. In the test stage, we utilize the learned coefficients to predict the potential patterns between symptoms and herbs and record whether this pattern is to appear in the test dataset.
In addition, the Insomnia and Tourette dataset lacks the object of syndrome and symptom, respectively. In this case, we assume some virtual objects (representing syndromes or symptoms) which can be constructed according to the next method. Here, we take the Insomnia dataset as an example to explain how to construct the virtual objects, namely, syndromes. First, we can get the existing patterns based on the PDH_Path from Infertility and Diabetes datasets, such as p 1-d 1-h 1, p 2-d 1-h 1; meanwhile, we can obtain the existing patterns based on the PH_Path from Insomnia dataset, such as p 1-h 1, p 2-h 1. Second, we can further check whether the patterns based on the PH_Path from Insomnia dataset exist in the dataset Insomnia or Tourette. If they exist (i.e., p 1-h 1, p 2-h 1), we can assume a virtual syndrome d and construct the edge between d and p 1 and the edge between d and h 1 (or the edge between d and p 2). Otherwise, we only assume a virtual syndrome d and produce the edges between d and other symptoms (or the edges between d and other herbs). Similarly, we can construct the tripartite graph based on the Tourette dataset.
5.2. Evaluation Metrics
Our proposed algorithm computes a ranking score for each candidate herb and returns the top-N highest ranked herbs as the predicted list for a target symptom. To evaluate the prediction accuracy, we focus on how many symptoms-herbs patterns previously removed in the preprocessing step reappear in the predicted results. Therefore, we apply two popular performance metrics, namely, Precision@N and Recall@N [17–20], to capture the performance of our proposed algorithm.
Precision@N is the ratio of recovered symptoms-herbs patterns to the N predicted symptoms-herbs patterns. Recall@N is the ratio of recovered symptoms-herbs patterns to the set of symptoms-herbs patterns deleted in preprocessing. We divide the symptoms-herbs patterns into two sets: the test set T h and the Top-N set R h. Symptoms-herbs patterns that appear in both sets are members of the hit set. Precision and Recall are defined as follows:
| (10) |
5.3. Parameter Tuning
In our experiments, we divide each dataset into two parts: training set and test set. We further split the training data to validation data to optimize the parameters λ 0, λ 1, α, α 0, α 1, β, β 0, β 1, θ, and K. We have varied the neighborhood size from 10 to 50 by an interval of 10 and the other nine parameters from 0 to 1 by an interval of 0.1. Using the validation data (in Infertility dataset), we have found the best λ 0 to be 0.8, λ 1 to be 0.2, α to be 0.7, α 0 to be 0.8, α 1 to be 0.2, β to be 0.3, β 0 to be 0.8, β 1 to be 0.2, θ to be 0.5, and K to be 30. In addition, we have different values for these parameters in the other three datasets, but we get the similar experimental results. Here, we do not list all the values for these parameters because of the limitation of space.
In Figure 5, we take the neighborhood size K as an example to explain how to install optimal value for each parameter. From Figure 5(a), we can see that for each Top-N list the Precision changes over the neighborhood size K. We can further observe that when the neighborhood size K equals 30, our proposed method gets the best performance. Also, from Figure 5(b), we have the similar results. Therefore, we set the neighborhood size K as 30.
Figure 5.

Selecting the optimal neighborhood size in Infertility Dataset. Here, in (a), the x-axis represents Top-N prediction. The y-axis refers to Precision. In (b), the x-axis represents Top-N prediction. The y-axis refers to Recall. These two figures can be obtained by using PH_Path based strategy, which applies the measurement method AM. In this experiment, we set λ 0, λ 1, and θ as 0.8, 0.2, and 0.5, respectively.
5.4. Result and Analysis
In this section, we first evaluate the performance of four different measurement methods for two kinds of paths. And then, we compare the performance of PH_Path based strategy and PDH_Path based strategy by using the optimal measurement method.
5.4.1. The Optimal Measurement Method
It is worth noting that a comprehensive set of experiments was conducted using every measurement method in conjunction with every evaluation metric on every dataset, and the results are very consistent across all experiments. Because of the space limitations, we show the results based on the Infertility dataset in the Figures 6 and 7. From Figure 6(a), we can see that the measurement method TfIdf apparently beats all the other three measures and produces the best prediction performance in terms of Precision. Specifically speaking, TfIdf has its average Precision 13%, 21.6%, and 30.8% better than AM, F, and JC, respectively. From Figure 6(b), according to Recall, TfIdf also significantly outperforms other three measures. TfIdf, respectively, achieves a 38%, a 61%, and a 116% improvement over AM, F, and JC. Here, an interesting result is observed that JC gets the worst performance. Contrary to JC being known to be more useful to measure the similarity between two same type of objects, it may be due to the existence of different type of objects. Similarly, from Figure 7, we can also observe that TfIdf is the best measurement method. Therefore, we should use TfIdf to help choose the best value for each term in each matrix so that the mining of symptoms-herbs patterns can produce the best results.
Figure 6.
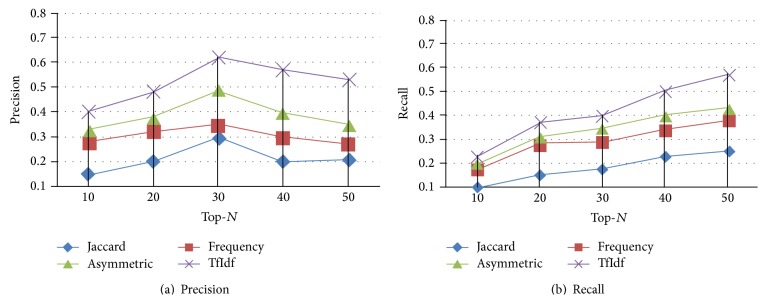
Selecting the optimal measurement method in Infertility Dataset. Here, in (a), the x-axis represents Top-N prediction. The y-axis refers to Precision. In (b), the x-axis represents Top-N prediction. The y-axis refers to Recall. These two figures can be obtained by using PH_Path based strategy.
Figure 7.
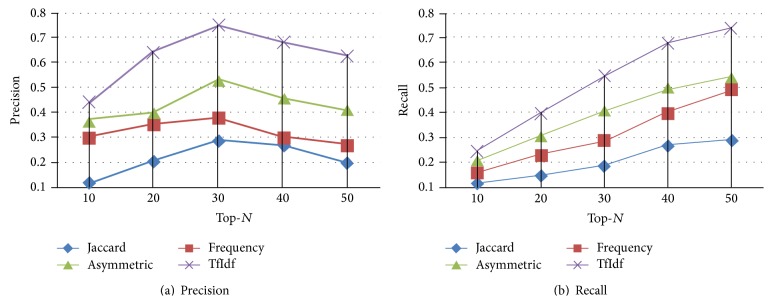
Selecting the optimal measurement method in Infertility Dataset. Here, in (a), the x-axis represents Top-N prediction. The y-axis refers to Precision. In (b), the x-axis represents Top-N prediction. The y-axis refers to Recall. These two figures can be obtained by using PDH_Path based strategy.
5.4.2. The Performance of Proposed Method
In this section, we will estimate the performance of our presented Tri-TSPA based on two kinds of paths.
First, we illustrate how our Tri-TSPA can serve as a powerful model for predicting potential symptom-herb relationships. The prediction processing performance results can be found in Figures 8(a) and 8(b). We use two prediction processing measures to evaluate the performance of each method on four TCM datasets, which are Precision at top 30 prediction results and Recall at top 30 prediction results, denoted as Precision@30 and Recall@30, respectively. In terms of these two measurements, one can observe that our proposed Tri-TSPA based on PDH_Path can find more symptom-herb relations than the one based on PH_Path, in general.
Figure 8.
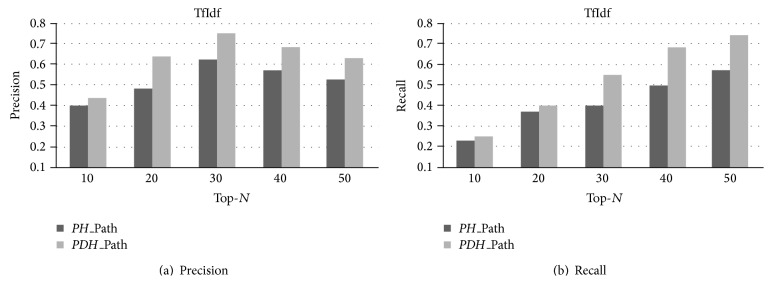
Prediction performance of our proposed method Tri-TSPA. Here, in (a), the x-axis represents Top-N prediction. The y-axis refers to Precision. In (b), the x-axis represents Top-N prediction. The y-axis refers to recall. Tri-TSPA adopts TfIdf to install the reasonable value to each term for each matrix.
From Figure 8(a), we notice that our proposed method Tri-TSPA based on PDH_Path improves Precision@30 by 10.8% compared with the one based on PH_Path. In addition, from Figure 8(b), we also see that our proposed method Tri-TSPA based on PDH_Path improves Recall@30 by 11% when compared with PH_Path. Therefore, we can conclude that PDH_Path based prediction method gives a good performance overall. Here, we can see that when N reaches 30, the precision of both algorithms is optimal. Meanwhile, although Recall@50 of both algorithms reaches optimal value, the gap between Recall@30 of both algorithms and Recall@50 of both algorithms is very small. So we take N = 30 as an optimal value to achieve optimal prediction power for the Infertility dataset.
In addition to the Infertility dataset, we tested the proposed algorithm with other three datasets, and the same pattern is observed in the vast majority of cases.
5.4.3. Discussion
The symptoms in TCM are related to the body as a whole. A certain subset of symptoms belongs to a certain syndrome, and the typical treatment of a syndrome usually follows a therapeutic principle, which refers to the use of a certain combination of herbs [21].
So far, we have mined a Top-N list of herbs for each symptom (see Table 2). However, our aim is to discover an effective combination of interacting herbs for each symptom, which is useful for healing the sick. In this section, we will introduce a matching function (MF) in order to achieve our aim.
Table 2.
An Example of Top-30 List. This table can be obtained by using PDH_Path based strategy. Here, the third column represents symptom-herb ranking rating produced by Algorithm 1.
| Symptom | Herb | Rating |
|---|---|---|
| Stomachache | Chiretta | 7.567 |
| Radix Paeoniae Rubra | 6.765 | |
| Bupleurum | 6.70 | |
| Ligustrum Japonium | 6.43 | |
| Epimedium Herb | 6.397 | |
| Paeonia sterniana Fletcher in Journ | 6.396 | |
| Radix Polygoni Multiflori | 6.167 | |
| Rhizoma Atractylodis Macrocephalae | 6.0 | |
| Salvia | 5.989 | |
| Astragali Radix | 5.973 | |
| Tuckahoe | 5.915 | |
| Licorice Roots Northwest Origin | 5.899 | |
| Dioscoreae | 5.659 | |
| Homo sapiens | 5.549 | |
| Rehmannia root | 5.438 | |
| Motherwort Fruit | 5.357 | |
| Tortoise Shell | 5.347 | |
| Himalayan Teasel Root | 5.327 | |
| Tangerine Peel | 5.209 | |
| Nutgrass Galingale Rhizome | 5.176 | |
| Palmleaf Raspberry Fruit | 5.165 | |
| Diverse Wormwood Herb | 4.97 | |
| Plantain Seed | 4.934 | |
| Bitter Orange | 4.92 | |
| Safflower | 4.905 | |
| Hyacinth Bean | 4.876 | |
| Finger Citron | 4.844 | |
| Towel Gourd Vegetable Sponge | 4.819 | |
| Common Macrocarpium Fruit | 4.736 | |
| Zedoary | 4.736 |
Our matching function is as follows: first, we find all the patterns of good outcome in the dataset and then, we match the Top-N list with each existed pattern, and find a longest chain, namely, a maximum effective set of interacting herbs. Our matching function is described in Algorithm 2. Here, the differences between the relevant function and the matching function are as follows: the relevant function is used for filtering the bad patterns (i.e., symptom-herb); the matching function is used for finding a maximum effective set of interacting herbs for each symptom. By using MF, we get an effective combination of interacting herbs for each symptom (see Table 3). Stomachache is a manifestation of various syndromes according to Chinese medicine diagnosis. The aim of Chinese medicine is to address the root cause of disease that is a syndrome rather than a single symptom; as a result, multiple herbs are used to treat a particular syndrome. According to the assessment from a TCM practitioner, the herbs in Table 3 are appropriate to stomachache and they have the properties of relieving pain or stomach-related problems. Each of these herbs has different functions, including Regulate Qi (Nutgrass Galingale Rhizome, Tangerine Peel, Dioscoreae, Rhizoma Atractylodis Macrocephalae, Bupleurum), Regulate fluid (Plantain Seed, Tuckahoe), Clear heat (Radix Paeoniae Rubra, Chiretta), Regulate blood (Motherwort Fruit, Salvia), and Nourish Yin (Himalayan Teasel Root). Here, we think our approach works in view of TCM, because when we check the original Infertility dataset, we find that most of the combinations of our Top-N list of herbs exist in the original dataset.
Algorithm 2.

MF.
Table 3.
An effective combination of interacting herbs for symptom Stomachache. Based on Table 2, this table can be obtained by using Algorithm 2.
| Symptom | Herb | Rating |
|---|---|---|
| Stomachache | Chiretta | 7.567 |
| Radix Paeoniae Rubra | 6.765 | |
| Bupleurum | 6.70 | |
| Ligustrum Japonium | 6.43 | |
| Epimedium Herb | 6.397 | |
| Paeonia sterniana Fletcher in Journ | 6.396 | |
| Rhizoma Atractylodis Macrocephalae | 6.0 | |
| Salvia | 5.989 | |
| Tuckahoe | 5.915 | |
| Licorice Roots Northwest Origin | 5.899 | |
| Dioscoreae | 5.659 | |
| Motherwort Fruit | 5.357 | |
| Himalayan Teasel Root | 5.327 | |
| Tangerine Peel | 5.209 | |
| Nutgrass Galingale Rhizome | 5.176 | |
| Palmleaf Raspberry Fruit | 5.165 | |
| Plantain Seed | 4.934 | |
| Hyacinth Bean | 4.876 | |
| Common Macrocarpium Fruit | 4.736 |
6. Related Work
TCM network and its properties are researched in many fields. One of these fields is how to explore the complex relationships amongst different components of TCM clinical prescriptions. So far, there are some attempts that explicitly address this aspect.
In [22], authors proposed a new methodology of clinical decision of pulmonary tuberculosis, which can adapt the features of TCM and can be applied to other contagious diseases. This method increased the possibility and accuracy of online diagnosis and treatment especially on contagious diseases. In [23], they presented a new approach to systematically generate combinations of interacting herbs that might lead to good outcome. Their approach was tested on a dataset of prescriptions for diabetic patients to verify the effectiveness of detected combinations of herbs. Their approach is able to detect effective higher orders of herb-herb interactions with statistical validation. In this work, we also consider the factor of good outcome, but we focus on how to improve the algorithm accuracy using good outcome. In [24], they introduced a framework to explore the complex relationships amongst herbs in TCM clinical prescriptions using Boolean logic. In [25], authors put forward a framework which can be used to extract synergistic herbal combinations in a variety of clinical situations. They found that not only the herbs (present herbs) necessary for a positive outcome, but the choice of some other herbs (absent herbs) may have a negative impact on the outcome. In [5], they introduced a two-stage analytical approach. This method first uses hierarchical core subnetwork analysis to preselect the subset of herbs that have high probability in participating in herb-herb interactions and, then, detects strong attribute interactions in the preselected subset by applying MDR. In [26], a new parameter-free algorithm was designed to systematically generate a set of combinations of interacting herbs that leads to good outcome. So far, most of these researches were related to how to extract core herbs or mine herb-herb relationships, which focused on the homogeneous information networks consisting of only one type of objects. In this work, we try to extract the symptom-herb relationships based on the heterogeneous information network.
Another line similar to our research problem is the relationship mining task in heterogeneous information network [27, 28], which involves different types of objects and relations. However, these studies have a different focus compared with our work. In [27], they constructed a heterogeneous biological information network by combining multiple different databases and interaction information in order to find multidrug prescriptions that are effective and safe. In [28], they proposed MedRank, a new network-based algorithm that ranks heterogeneous objects in a medical information network. In this work, we aim at mining symptom-herb patterns in the TCM heterogeneous information network.
7. Conclusion
In this work, we put forward a novel three-step prediction approach to mine symptom-herb relationships effectively and efficiently. Experiments on the TCM network show that our method can find symptom-herb relationships with much higher accuracy using heterogeneous topological features. The results have shown that the performance is indeed superior when the symptoms are mapped to herbs via syndromes, rather than a direct mapping between symptoms and herbs. In other words, syndrome differentiation (patient classification) is a crucial step to a successful treatment in TCM. In the future, we intend to extend our work in the following three directions. Firstly, a new measure to estimate the performance in the proposed method should be explored. Secondly, another novel similarity measure method should be studied to capture the rich topological features. Thirdly, a new matching function to improve the predictive performance should be sought.
Acknowledgments
This work was done when the first author was a visiting student in the University of Sydney. This work is supported by the project of National Natural Science Fund (no. 81173226), National Natural Science Foundation of China under Grant no. 61202238, the Graduate School of Beihang University Scholarship Fund, and the award from the China Scholarship Council (student no. is 201406020044). The assessment of the effective set of herbs was also contributed by Dr. Diana Jun.
Notations
- P:
Symptom
- D:
Syndrome
- H:
Herb
- PH_Path:
The path of symptom-herb
- PDH_Path:
The path of symptom-syndrome-herb
- SimPH_Path:
The similarity based on PH_Path
- SimPP:
The similarity based on P-P matrix
- SimPH:
The similarity based on P-H matrix
- SimPDH_Path:
The similarity based on PDH_Path
- SimPD:
The similarity based on P-D matrix
- SimDH:
The similarity based on D-H matrix
- SimDD:
The similarity based on D-D matrix.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
References
- 1.Tang J.-L., Liu B.-Y., Ma K.-W. Traditional Chinese medicine. The Lancet. 2008;372(9654):1938–1940. doi: 10.1016/s0140-6736(08)61354-9. [DOI] [PubMed] [Google Scholar]
- 2.Zhu J., Ju S., Xin Y. Data mining based approach to preprocessing TCM data set. Computer Engineering. 2006;15(article 98) [Google Scholar]
- 3.Yang H., Chen J., Tang S., et al. New drug R&D of traditional chinese medicine: role of data mining approaches. Journal of Biological Systems. 2009;17(3):329–347. doi: 10.1142/s0218339009002971. [DOI] [Google Scholar]
- 4.Wang X. W., Qu H. B., Wang J. A quantitative diagnostic method based on data-mining approach in TCM. Journal of Beijing University of Traditional Chinese Medicine. 2005;28(1):4–7. [Google Scholar]
- 5.Zhou X., Josiah P., Kwan P., et al. Medical Biometrics. Berlin, Germany: Springer; 2010. Novel two-stage analytic approach in extraction of strong herb-herb interactions in TCM clinical treatment of insomnia; pp. 258–267. [Google Scholar]
- 6.Poon J., Poon S., Yin D., et al. Studying herb-herb interaction for insomnia through the theory of complementarities. Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine Workshops (BIBMW '10); December 2010; IEEE; pp. 722–726. [DOI] [Google Scholar]
- 7.Sun Y., Barber R., Gupta M., Aggarwal C. C., Han J. Co-author relationship prediction in heterogeneous bibliographic networks. Proceedings of the International Conference on Advances in Social Networks Analysis and Mining (ASONAM '11); July 2011; IEEE; pp. 121–128. [DOI] [Google Scholar]
- 8.Sun Y., Han J., Yan X., Yu P. S., Wu T. Pathsim: meta path-based top-k similarity search in heterogeneous information networks. PVLDB. 2011;4(11):992–1003. [Google Scholar]
- 9.Sani A., Coussy P., Chavet C., Martin E. An approach based on edge coloring of tripartite graph for designing parallel LDPC interleaver architecture. Proceedings of the IEEE International Symposium of Circuits and Systems (ISCAS '11); May 2011; IEEE; pp. 1720–1723. [DOI] [Google Scholar]
- 10.Barabási A.-L., Albert R. Emergence of scaling in random networks. Science. 1999;286(5439):509–512. doi: 10.1126/science.286.5439.509. [DOI] [PubMed] [Google Scholar]
- 11. http://www.cancer.gov/dictionary?cdrid=454743.
- 12.Thormann C. E., Ferreira M. E., Camargo L. E. A., Tivang J. G., Osborn T. C. Comparison of RFLP and RAPD markers to estimating genetic relationships within and among cruciferous species. Theoretical and Applied Genetics. 1994;88(8):973–980. doi: 10.1007/BF00220804. [DOI] [PubMed] [Google Scholar]
- 13.Mika P. The Semantic Web—ISWC 2005: 4th International Semantic Web Conference, ISWC 2005, Galway, Ireland, November 6–10, 2005. Vol. 3729. Berlin, Germany: Springer; 2005. Ontologies are us: a unified model of social networks and semantics; pp. 522–536. (Lecture Notes in Computer Science). [DOI] [Google Scholar]
- 14.Sanderson M., Croft B. Deriving concept hierarchies from text. Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR '99); 1999; ACM Press; pp. 206–213. [Google Scholar]
- 15.Schmitz P. Inducing ontology from Flickr tags. Proceedings of the Collaborative Web Tagging Workshop (WWW ’06); 2006. [Google Scholar]
- 16. http://www.tfidf.com/
- 17.Shardanand U., Maes P. Social information filtering: algorithms for automating ‘word of mouth’. Proceedings of the ACM CHI Conference on Human Factors in Computing Systems; May 1995; Denver, Colo, USA. ACM Press; pp. 210–217. [Google Scholar]
- 18.Chen J., Gao H., Wu Z., Li D. Tag co-occurrence relationship prediction in heterogeneous information networks. Proceedings of the 19th IEEE International Conference on Parallel and Distributed Systems (ICPADS '13); December 2013; IEEE; pp. 528–533. [DOI] [Google Scholar]
- 19.Chen J., Liu Y., Wu Z., Zou M., Li D. Recommending interesting landmarks in photo sharing sites. Neural Network World. 2014;24(3):285–308. doi: 10.14311/nnw.2014.24.017. [DOI] [Google Scholar]
- 20.Chen J., Liu Y., Hu J., He W., Li D. A novel framework for improving recommender diversity. International Workshop on Behavior and Social Informatics (BSI '13), Conjunction with Pacific-Asia Conference on Data Mining and Knowledge Discovery (PAKDD '13); April 2013; Brisbane , Australia. [Google Scholar]
- 21.Poon J., Luo Z., Zhang R.-S. Feature representation in the biclustering of symptom-herb relationship in Chinese medicine. Chinese Journal of Integrative Medicine. 2011;17(9):663–668. doi: 10.1007/s11655-011-0842-8. [DOI] [PubMed] [Google Scholar]
- 22.Yang Y. Data mining on prescription, herbal pairs, and pattern identification of pulmonary tuberculosis cases. Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine Workshops (BIBMW '12); October 2012; IEEE; pp. 332–335. [DOI] [Google Scholar]
- 23.Poon S. K., Poon J., McGrane M., et al. A novel approach in discovering significant interactions from TCM patient prescription data. International Journal of Data Mining and Bioinformatics. 2011;5(4):353–368. doi: 10.1504/ijdmb.2011.041553. [DOI] [PubMed] [Google Scholar]
- 24.Su A., Poon S. K., Poon J. Discovering causal patterns in TCM clinical prescription data using set-theoretic approach. Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM '13); December 2013; Shanghai, China. pp. 242–247. [DOI] [Google Scholar]
- 25.Poon S. K., Fan K., Poon J., et al. Analysis of herbal formulation in TCM: infertility as a case study. Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine Workshops (BIBMW '11); 2011; Atlanta, Ga, USA. IEEE; pp. 868–872. [DOI] [Google Scholar]
- 26.Poon J., Poon S., Yin D., et al. Studying herb-herb interaction for insomnia through the theory of complementarities. Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine Workshops (BIBMW '10); December 2010; IEEE; pp. 722–726. [DOI] [Google Scholar]
- 27.Lee K., Lee S., Jeon M., Choi J., Kang J. Drug-drug interaction analysis using heterogeneous biological information network. Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM '12); October 2012; pp. 1–5. [DOI] [Google Scholar]
- 28.Chen L., Li X., Han H. MedRank: discovering influential medical treatments from literature by information network analysis. Proceedings of the Australasian Database Conference (ADC '13); 2013. [Google Scholar]