

Abstract
The neuromodulator dopamine has a well established role in reporting appetitive prediction errors that are widely considered in terms of learning. However, across a wide variety of contexts, both phasic and tonic aspects of dopamine are likely to exert more immediate effects that have been less well characterized. Of particular interest is dopamine's influence on economic risk taking and on subjective well-being, a quantity known to be substantially affected by prediction errors resulting from the outcomes of risky choices. By boosting dopamine levels using levodopa (l-DOPA) as human subjects made economic decisions and repeatedly reported their momentary happiness, we show here an effect on both choices and happiness. Boosting dopamine levels increased the number of risky options chosen in trials involving potential gains but not trials involving potential losses. This effect could be better captured as increased Pavlovian approach in an approach–avoidance decision model than as a change in risk preferences within an established prospect theory model. Boosting dopamine also increased happiness resulting from some rewards. Our findings thus identify specific novel influences of dopamine on decision making and emotion that are distinct from its established role in learning.
Keywords: decision making, dopamine, reward prediction error, subjective well-being
Introduction
Decision making under risk is an important area of investigation at the confluence of economics, psychology, and neuroscience. Although much is known about its neural underpinnings, the precise role of at least one major ingredient, the neuromodulator dopamine, remains unclear. Its importance is evident in the common clinical observation that dopaminergic drugs are linked to compulsive gambling in Parkinson's patients (Molina et al., 2000) and increased risk taking in both humans (Norbury et al., 2013) and animals (St Onge and Floresco, 2009; Stopper et al., 2014).
One influential explanatory framework for these findings is the established role of dopamine in representing reinforcement prediction errors (RPEs), which quantify the difference between experienced and predicted appetitive outcomes (Montague et al., 1996; Schultz et al., 1997; Bayer and Glimcher, 2005; Cohen et al., 2012; Hart et al., 2014). Such prediction errors can exert various effects that might relate to risk-taking behavior, including their role as a medium of reinforcement learning (Rutledge et al., 2009; Chowdhury et al., 2013; Piray et al., 2014). A second framework involves dopamine's more immediate effects on behavior (Frank et al., 2004; Niv et al., 2007; Robbins and Everitt, 2007; Salamone et al., 2007; Lex and Hauber, 2008; Palmiter, 2008; Sharot et al., 2009; Pine et al., 2010; Jocham et al., 2011; Guitart-Masip et al., 2012; Shiner et al., 2012; Norbury et al., 2013; Collins and Frank, 2014), which have been formalized through incentive salience (Berridge and Robinson, 1998; McClure et al., 2003; Robbins and Everitt, 2007; Salamone et al., 2007; Berridge and O'Doherty, 2013) as Pavlovian influences over appetitive choice. A third possibility is one suggested by our recent observation that RPEs influence momentary happiness via effects on task-related neural activity in the ventral striatum, a major target for dopamine neurons (Rutledge et al., 2014). This could increase the attractiveness of taking risks, although we acknowledge that dopamine's role in influencing feelings of either pleasure or happiness remains a subject of controversy (Wise et al., 1978; Drevets et al., 2001; Salamone et al., 2007; Smith et al., 2011; Berridge and O'Doherty, 2013).
To examine dopamine's causal influence more directly, we administered either placebo or 150 mg of levodopa (l-DOPA) to boost dopamine levels in 30 healthy subjects before performing an economic decision-making task. We also periodically asked subjects “how happy are you at this moment?” (Fig. 1A). We compared an established parametric decision model based on prospect theory, which operationalizes concepts of risk and loss aversion (Kahneman and Tversky, 1979; Tversky and Kahneman, 1992; Sokol-Hessner et al., 2009), with an alternative decision model that incorporates a Pavlovian approach–avoidance influence. Although subjective feelings relate to objective economic variables, including wealth (Diener et al., 1999; Layard, 2005; Oswald and Wu, 2010), the relationship between feelings and rewards remains murky (Kahneman and Deaton, 2010). Experience sampling methods are widely used in well-being research to relate subjective states to daily life events (Csikszentmihalyi and Larson, 1987; Killingsworth and Gilbert, 2010). Adapting these methods to the laboratory setting has allowed us to develop a model for momentary subjective well-being (Rutledge et al., 2014) and we employ that approach here.
Figure 1.

Task design and performance on placebo and l-DOPA. A, In each of 300 trials, subjects made choices between safe and risky options. In 100 gain trials, the worst gamble outcome was zero. In 100 loss trials, the best gamble outcome was zero. In 100 mixed trials, both gamble outcome gains and losses were possible. Chosen gambles were resolved after a brief delay period. Subjects were also asked after every 3–4 choice trials “how happy are you at this moment?” and indicated their responses by moving a slider. B, On average, subjects (n = 30) gambled most in gain trials, less in mixed trials, and least in loss trials on both placebo and l-DOPA. Error bars indicate SEM. C, Subjects did not gamble more in mixed and loss trials on l-DOPA compared with placebo, but did gamble more in gain trials. *p < 0.05. D, Subjects who received higher effective drug doses chose more gain gambles on l-DOPA than placebo (p < 0.01).
Based on previous literature, we predicted that l-DOPA would increase the number of risky options chosen (Molina et al., 2000; Cools et al., 2003; St Onge and Floresco, 2009; Stopper et al., 2014) and, given the relationship between prediction errors and momentary happiness, we expected that this manipulation would also influence its expression here. The design that we implement also enabled us to test the extent to which these effects depend on outcome valence, a pertinent question that speaks to reported asymmetries related to dopamine (Frank et al., 2004; Bayer and Glimcher, 2005; Pessiglione et al., 2006; Rutledge et al., 2009; Schmidt et al., 2014).
Materials and Methods
Subjects.
Thirty healthy, young adults (age = 23.4 ± 3.8 years, mean ± SD, 19 females) took part in the experiment. Subjects had a mean body weight of 66.3 kg (range, 47–96) and a mean body mass index of 23.0 (range, 17.0–29.8). Subjects were screened to ensure no history of neurological or psychiatric disorders and were not on any active medications. Subjects were endowed with £20 at the beginning of each experimental session and paid according to overall performance after completion of the entire study by bank transfer. The study was approved by the Research Ethics Committee of University College London and all subjects gave informed consent.
Study procedure.
This was a within-subject double-blind placebo-controlled study. Subjects participated on 2 occasions, typically 1 week apart at a similar time of day, performing the same task on both days, 60 min after ingestion of either l-DOPA (150 mg of l-DOPA and 37.5 mg of benserazide mixed in orange juice) or placebo (500 mg of ascorbic acid mixed in orange juice). The testing order was randomized and counterbalanced across subjects. Subjects were instructed not to eat for 2 h before the study to achieve an equivalent level of drug absorption across individuals. Subjective mood ratings were recorded at initiation of the protocol, after drug/placebo administration, and at the start of the experiment. Subjects were contacted 24 h after each session and asked to report on a scale of 0–100 how happy they remembered being during the session to evaluate possible drug effects on remembered happiness. Subjects were not informed as to their precise cumulative earnings in either session until 1 d after their final session, ensuring that remembered happiness measures were not confounded by precise information about earnings.
Experimental task.
Stimuli were presented in MATLAB (MathWorks) using Cogent 2000 (Wellcome Trust Centre for Neuroimaging). All subjects performed a 300-trial economic decision-making task with trials of three different types: gain trials, mixed trials, and loss trials. All trials were independent and all values were explicit, obviating any learning. It is important to note that preferences can differ in decision making from description compared with decision making from experience (Hertwig et al., 2004). In 100 gain trials, subjects chose between a certain gain (30–55 pence) and a gamble with equal probabilities of £0 or a larger gain determined by a multiplier on the certain amount that varied from 1.6 to 4 to accommodate a wide range of risk sensitivity, as in previous experiments (Sokol-Hessner et al., 2009; Rutledge et al., 2014). In 100 loss trials, subjects chose between a certain loss (30–55 pence) and a gamble with equal probabilities of £0 or a larger loss determined by the same multipliers as the gain trials. In 100 mixed trials, subjects chose between £0 and a gamble with equal probabilities of a gain (40–75 pence) or a loss determined by a multiplier on the gain amount that varied from 0.5–5 to accommodate a wide range of loss sensitivity.
The proportions of gambling in each domain will depend on the exact multipliers used to construct the design matrix. Because the same multipliers were used for gain and loss trials, including more small multipliers should increase gambling in loss trials at the same time that it decreases gambling in gain trials. The maximum gain or loss in a single trial was £2.75. There was no time limit for choices. Unchosen options disappeared after a choice and outcomes from chosen gambles were revealed after a 2 s delay. Economic paradigms typically do not reveal the outcome of every trial (Frydman et al., 2011; Symmonds et al., 2013) and this may have important consequences for decision making in our task. Each trial was followed by a 1 s intertrial interval. After every 3–4 trials, subjects were asked “how happy are you at this moment?” and made their responses by moving a slider to indicate a point on a line. There was no time limit to make these responses. The experiment started and ended with a happiness question.
Behavioral analysis.
Changes in the frequency of gambling and in model parameters within placebo and l-DOPA sessions were not normally distributed (Shapiro–Wilk, p < 0.05). Therefore, we used two-tailed Wilcoxon signed-rank tests to evaluate the significance of differences and also used two-tailed Spearman's correlations. For each comparison involving data that passed tests of normality (Shapiro–Wilk, p > 0.05), we also performed analyses using paired t tests and Pearson's correlations. All findings reported as being significant at the 5% level with nonparametric statistical tests remained so when we used Gaussian-based tests.
To test for a value dependence of l-DOPA effects in gain trials, we split the 100 gain trials according to the average objective return compared with the safe option. In 70 high-value gain trials, gambling is advantageous and the average return exceeds that of the safe alternative. In 30 low-value gain trials, the average return does not exceed that of the safe alternative. Because the potential gains vary as a ratio of the certain gain, this means that the potential gains, and therefore also the RPEs, are on average larger for high- than low-value gain trials.
To test whether l-DOPA increased risk taking more in trials with potential gains compared with trials with potential losses, we used a permutation test, which is a nonparametric test that allows multiple hypotheses to be tested simultaneously. In 10,000 random samples, we randomly shuffled the condition (drug or placebo) for every subject and computed the difference between the increase in gambling in gain trials on l-DOPA compared with placebo and the increase in gambling for mixed trials or loss trials. The permutation p-value is equal to the fraction of samples for which the actual gambling-increase difference is not greater than the resampled gambling-increase difference for gain trials compared with either mixed trials or loss trials. Two comparisons were performed for each resample, thus testing both hypotheses simultaneously.
Parametric decision model based on prospect theory.
We fitted choice behavior using an established parametric decision model (Sokol-Hessner et al., 2009) based on prospect theory (Kahneman and Tversky, 1979) that describes choice behavior using four parameters. The subjective values or expected utility of gambles and certain options were determined using the following equations:
 |
Where Vgain and Vloss are the values of the potential gain and loss from a gamble, respectively, and Vcertain is the value of the certain option. Potential losses in the gain trials were equal to zero (Vloss = 0), as were potential gains in the loss trials (Vgain = 0). The degree of curvature in the utility function in the gain domain is determined by αgain and thus the degree of risk aversion. An individual that is risk-neutral in gain trials has αgain = 1 and would be indifferent between a certain gain and a gain gamble with the same expected value. A risk-seeking subject would have αgain > 1 and a risk-averse subject would have αgain < 1. The degree of risk aversion in the loss domain is determined by αloss. A risk-seeking subject would have αloss < 1 and a risk-averse subject would have αloss > 1. The parameter λ determines the degree of loss aversion. A gain-loss neutral subject would have λ = 1. A loss-averse subject would have λ > 1. A gain-seeking subject would have λ < 1. We used the softmax rule to determine the probability of selecting the gamble as follows:
 |
Where the inverse temperature parameter μ quantifies the degree of stochasticity in choice behavior. We fitted parameters from both l-DOPA and placebo sessions simultaneously with a shared inverse temperature parameter in each individual. Parameters were constrained to the range of parameters that could be identified based on our design matrix (λ: 0.5–5, αgain: 0.3–1.3, αloss: 0.3–1.3).
We used model comparison techniques (Schwarz, 1978; Burnham and Anderson, 1998) to compare model fits. For each model fit in individual subjects, we computed the Bayesian information criterion (BIC), which penalizes for parameter number, and then summed BIC across subjects. The model with the lowest BIC is the preferred model.
Parametric approach–avoidance decision model.
We fitted choice behavior with an alternative parametric decision model that allowed for value-independent tendencies to select or not select gambles. This had no effect on the computation of subjective values for the risky or safe option. Instead, we modified the softmax rule by which subjective values determine choice probabilities. We included separate parameters for gain trials and loss trials. For gain trials, the probability of gambling depended on βgain as follows:
 |
For loss trials, the probability of gambling depended on βloss as follows:
 
|
The softmax rule requires the function that relates subjective values and choice probabilities to map subjective value differences to probabilities from (0, 1). If either β parameter is positive, the function maps choice probabilities in that domain from (β, 1). If either β parameter is negative, the function maps choice probabilities in that domain from (0, 1+β). The parameter β acts as a value-independent influence on the probability of choosing the option with the largest potential gain or loss (always a gamble in our design) that could be thought of as an approach–avoidance bias term. This model differs substantially from prospect theory in being discontinuous around the origin, such that the worst gain gamble can be chosen a substantial fraction of the time and the best loss gamble can be rejected a substantial fraction of the time.
Because mixed gambles included both potential gains and losses, we did not apply bias parameters in those trials. To determine whether including a β parameter for mixed trials would affect our main findings, we fitted an additional model with a βmixed parameter. For mixed trials, the probability of gambling was determined in the same manner as for the other two β parameters as follows:
 |
The present task design does not permit testing a more general form of our proposal, which is that there may be valence-dependent, but value-independent, tendencies to choose options with the largest potential gain and avoid options with the largest potential loss. When two options, each with one or more possible prizes, do not include potential losses, the probability of choosing the option with the largest available reward (with subjective value or expected utility Ularge) instead of the alternative (with subjective value or expected utility Usmall, where Usmall can be larger than Ularge) is equal to:
 |
It is a limitation of our present task design that the gamble always had the largest potential gain in gain trials and these equations are therefore equivalent to the notation we use above. Therefore, we cannot determine whether any effects of l-DOPA will be specific for risky options or, as we believe, options with the largest available reward. This more general model (and the corresponding equations for trials with potential losses) can be applied in situations in which the safe option has the largest available reward or both options are risky and can have more than two potential outcomes with different probabilities.
Dual-inverse-temperature decision model.
We also fitted choice behavior with an alternate decision model used in a previous study (Frydman et al., 2011) that allowed for an asymmetric stochastic choice function with separate inverse temperature parameters when the subjective value of the gamble is higher or lower that the subjective value of the safe alternative. This had no effect on the computation of option subjective values, which were the same as in the prospect theory model. The probability of gambling was determined by the following equations:
 |
Gain-loss learning model.
To determine whether the outcome of previous gamble choices has an impact on subsequent choices, we fitted an alternative model that allowed for the subjective value of a gain gamble to be increased or decreased according to a gain-specific parameter depending on whether the most recently chosen gain gamble resulted in a win or loss. It also included an equivalent parameter for loss trials. These parameters would capture influences of previous trials related to a learning effect and allow testing for an effect of l-DOPA on that relationship. For example, subjects might be more likely to gamble in a gain trial after a win from a gain gamble. The subjective values or expected utility of gambles were determined using the following equations:
 |
The variable Ogainprevious was equal to 1 if the most recently chosen gain gamble resulted in a win and −1 if a loss. The variable Olossprevious was similarly equal to 1 or −1 depending on the outcome of the most recently chosen loss gamble.
Happiness computational models.
We modeled momentary happiness using a model (Rutledge et al., 2014) that includes terms for certain rewards (CR, in £), gamble expected values (EV, average of the two possible outcomes), and RPEs (the difference between the gamble outcome and gamble EV). According to the model, happiness ratings are as follows:
 |
Where t is trial number, w0 is a constant term, and other weights w capture the influence of different event types. These influences are assumed to decay exponentially over time with a forgetting factor 0 ≤ γ ≤ 1 that renders recent events more influential than earlier events. CRj is the certain reward if chosen instead of a gamble on trial j, EVj is the expected value of a gamble (average reward for the gamble) if chosen on trial j, and RPEj is the RPE on trial j contingent on choice of the gamble. Terms for unchosen options were set to zero.
Because some studies have suggested that dopamine might differentially represent positive and negative RPEs, we fitted a second model that separates RPEs into positive and negative terms and weights w3 and w4 capture their distinct influences as follows:
 |
Because some subjects rarely gambled in the low-value gain trials, we included in non-model-based analyses the 21 subjects who experienced at least two gamble wins and two gamble losses from low-value gain trials in placebo and l-DOPA sessions.
Results
Overall earnings did not differ between placebo (£33.40 ± 7.65, mean ± SD) and l-DOPA sessions (£35.94 ± 6.47, Wilcoxon signed-rank test, Z = 1.31, p = 0.19). Because subjects were presented with each set of options twice in a randomized order in each experimental session, we could assess consistency of preferences while avoiding confounds related to learning. We observed that subjects made the same choice when presented with each set of options on 82.8 ± 9.6% of trials on placebo and 84.1 ± 8.1% on l-DOPA (Z = 0.99, p = 0.32), indicating similar degrees of consistency across conditions.
The percentages of gambles chosen in placebo and l-DOPA sessions were similar in mixed (Z = −1.33, p = 0.18) and loss trials (Z = −0.83, p = 0.41). However, in gain trials, subjects chose more gambles under l-DOPA compared with placebo (Z = 2.07, p = 0.04; Fig. 1). Using a permutation test allowing multiple hypotheses to be tested simultaneously, we found that l-DOPA increased the number of risky options chosen more in trials with only potential gains compared with trials with potential losses (p = 0.02). We also found a significant effect of drug dosage (which varied between 1.6 and 3.2 mg/kg according to body weight). Subjects with larger effective doses showed a greater increase in the number of risky options chosen in gain trials on l-DOPA compared with placebo (Spearman's ρ = 0.47, p < 0.01; Fig. 1D), a relationship also present in females alone (Spearman's ρ = 0.67, p < 0.01), suggesting that the effect is related to dosage and not sex. To test for a value dependence of l-DOPA effects, we split the trials according to average objective return into high-value (gambling is advantageous) and low-value (gambling is disadvantageous) trials. Subjects gambled more on l-DOPA than placebo in low-value trials (Z = 2.15, p = 0.03), but the increase was not significant in high-value trials alone (Z = 1.43, p = 0.15).
Parametric decision model based on prospect theory
Prospect theory offers a canonical account of decision making under risk (Kahneman and Tversky, 1979). Therefore, we first considered whether the effect of l-DOPA could be characterized by a change in prospect theory model parameters (Tversky and Kahneman, 1992; Sokol-Hessner et al., 2009). This identifies four quantities, namely the weighting of losses relative to equivalent gains (loss aversion, λ), risk aversion in the gain domain (αgain), risk aversion in the loss domain (αloss), and stochasticity in choice (inverse temperature, μ). By design, the options presented allow these parameters to be estimated over a wide range of values.
Generally, the parametric prospect theory model offered a good account of subject choices under placebo and l-DOPA (Fig. 2A). On average, the model fit choice data with a pseudo-r2 = 0.51 ± 0.19 (mean ± SD), with a similar low degree of loss aversion to previous results using a similar design in which every trial counts (see Sokol-Hessner et al., 2009 for a discussion of loss aversion in previous studies). Parameter estimates were correlated across placebo and l-DOPA sessions (all parameters, Spearman's ρ > 0.6, p < 0.001), suggesting that our paradigm allows measurement of stable differences in choice preferences between subjects. However, there was no difference in αgain between placebo and l-DOPA sessions (Z = 0.96, p = 0.34; Fig. 2B) despite a clear change in behavior. To examine this further, we plotted the propensity to gamble for each decile of gamble value (indexed as the ratio of the gamble gain amount to the certain gain amount; Fig. 2C). The decision model based on prospect theory is notably unable to account for key effects evident in the data (Fig. 2D).
Figure 2.

Choice behavior and economic decision model fits. A, Parametric model based on prospect theory explained choice behavior. Error bars indicate SEM. B, Parameter estimates were similar on placebo and l-DOPA. C, Gain gamble value was determined relative to the value of the certain option. Deciles 1–2 corresponded to lower expected reward for the gamble than the certain option. Decile 3 corresponded to equal expected reward for the gamble and certain option. Deciles 4–10 corresponded to higher expected reward for the gamble than the certain option. As gain gamble value increased, subjects gambled more on both placebo and l-DOPA, as expected. D, Average model fit across subjects for the prospect theory model, which cannot account for the observed difference in choice behavior on l-DOPA compared with placebo.
Parametric approach–avoidance decision model
In prospect theory, the propensity to choose risky options depends on the value of available options. However, the data shown in Figure 2C suggest that the l-DOPA effect in gain trials is independent of value: subjects choose more risky options on l-DOPA for all gamble value levels. We therefore developed a model that allows for value-independent influences, thought of in terms of approach or avoidance, in addition to the value-dependent influences captured by parametric models based on prospect theory. Given the link between dopamine and appetitive processing, we allowed for the possibility that this effect would depend on valence. Therefore, we included parameters βgain for gain trials and βloss for loss trials and performed model comparison to verify that the additional model complexity compared with the parametric prospect theory model was justified. Positive or negative values of these parameters correspond respectively to an increased or decreased probability of gambling without regard to the value of the gamble. Strikingly, the parameter βgain was positive in both placebo and l-DOPA sessions (both Z > 2.2, p < 0.05) and the parameter βloss was negative in both sessions (both Z < −2.2, p < 0.05). Our new model was preferred by Bayesian model comparison with the benchmark parametric prospect theory model, an alternative decision model (Frydman et al., 2011) and a model that allowed for, but failed to find, an effect of previous outcomes on choice (Table 1).
Table 1.
Decision model comparison results
| Model | Parameters per subject | Mean r2 | Median r2 | Model BIC | BIC- BICa-a |
|---|---|---|---|---|---|
| Prospect theory | 7 | 0.51 | 0.50 | 13620 | 883 |
| Approach–avoidance | 11 | 0.57 | 0.58 | 12737 | 0 |
| Dual-inverse-temperature | 10 | 0.54 | 0.52 | 13363 | 626 |
| Gain-loss learning | 11 | 0.52 | 0.51 | 14160 | 1423 |
| Approach–avoidance-mixed | 13 | 0.60 | 0.59 | 12596 | −141 |
BIC measures are summed across the 30 subjects. Parameters per subject are across both placebo and l-DOPA sessions. All models include separate parameters for placebo and l-DOPA sessions that capture the weighting of losses relative to equivalent gains (loss aversion, λ), risk aversion in the gain domain (αgain), and risk aversion in the loss domain (αloss). All models except the dual-inverse-temperature model included a shared parameter across sessions for stochasticity in choice (inverse temperature, μ). The final column is the difference between the model BIC and BICa-a, the BIC for the approach–avoidance model. The approach–avoidance model was preferred (lower BIC) to the prospect theory model, dual-inverse-temperature model, and gain-loss learning model. The more complex approach-avoidance-mixed model included additional approach–avoidance parameters for the mixed trials and had the lowest BIC of the models tested.
We found that βgain was significantly greater under l-DOPA than placebo (Z = 2.14, p = 0.03; Fig. 3). In comparison, there was no difference in λ, αgain, and αloss between placebo and l-DOPA sessions (all |Z| < 1, p > 0.3). Parameter estimates were correlated across sessions (all parameters, Spearman's ρ > 0.5, p < 0.01). Furthermore, the predictions of this model qualitatively captured the increase in gain gambling on l-DOPA across gamble value levels (Fig. 3A). Consistent with a causal effect, subjects who received higher effective doses had a greater increase in βgain (Spearman's ρ = 0.42, p = 0.02; Fig. 3D). As expected, dose and change in αgain were uncorrelated (Spearman's ρ = 0.13, p = 0.49). The change in the number of gain gambles chosen on l-DOPA and placebo was highly correlated with the change in βgain (Spearman's ρ = 0.87, p < 0.001), but not the change in αgain (Spearman's ρ = 0.27, p = 0.15). There was no difference in βloss between sessions (Z = −1.03, p = 0.30).
Figure 3.

Approach–avoidance model fits. A, Our approach–avoidance model incorporates an additional value-independent, valence-dependent effect on choice probability that accounts for the increased gambling on l-DOPA across gamble value deciles. B, Risk aversion parameters αgain and αloss for both placebo and l-DOPA sessions were <1, indicating risk aversion in the gain domain and risk seeking in the loss domain. Approach–avoidance parameter βgain was positive (“approach”) and βloss was negative (“avoid”) in placebo and l-DOPA sessions. Error bars indicate SEM. *p < 0.05. C, βgain was higher on l-DOPA than placebo, indicating an increased tendency to choose gain gambles independent of value. D, Subjects that received higher effective drug doses had a greater increase in βgain on l-DOPA than placebo (p < 0.05).
Because the gambles in mixed trials include both potential gains and losses, these trials were not allocated to either βgain or βloss. The data suggest that the best mixed gambles are usually chosen and the worst mixed gambles rarely chosen (Fig. 4), consistent with there being little approach or avoidance influence on those trials in our task. To determine whether including a β parameter for mixed trials would affect our main findings, we fitted an additional model that included a βmixed parameter. This model actually fit best overall; however, importantly, βgain was again greater under l-DOPA (βgain: Z = 2.01, p = 0.04) and subjects who received higher effective doses had a greater increase in βgain on l-DOPA (Spearman's ρ = 0.37, p = 0.045). There was no difference between βmixed on l-DOPA and placebo (Z = −0.11, p = 0.91), parameters that were positive in both sessions (placebo: Z = 2.21, p = 0.03; l-DOPA: Z = 1.84, p = 0.07).
Figure 4.

Choice behavior and approach–avoidance model fits for mixed and loss trials. A, Mixed gamble value was determined by the ratio of the potential gain to the potential loss. As mixed gamble value increased, subjects gambled more, as expected. B, Average model fit across subjects for the approach–avoidance model. C, Subjects who received higher effective doses did not have a larger change in the number of mixed gambles chosen on l-DOPA than placebo (Spearman's ρ = 0.02, p = 0.91), a relationship that would be negative if l-DOPA decreased risk taking. D, Loss gamble value was determined relative to the value of the certain option. As loss gamble value increased, subjects gambled more, as expected. E, Average model fit across subjects for the approach–avoidance model, which can account for the low probability of gambling for even the highest gamble values in placebo and l-DOPA sessions. F, Subjects who received higher effective doses did not have a larger change in the number of loss gambles chosen on l-DOPA than placebo (Spearman's ρ = 0.19, p = 0.32), a relationship that would be negative if l-DOPA decreased risk taking.
We tested two additional decision models (Table 1). The dual-inverse-temperature model (Frydman et al., 2011) allowed for an asymmetric stochastic choice function with separate inverse temperature parameters when the subjective value of the gamble is higher or lower that the subjective value of the certain alternative. There was no difference between sessions for the inverse temperature parameter when the gamble subjective value was higher than the certain alternative (a+: placebo, 0.88; l-DOPA, 0.74; Z = −0.92, p = 0.36) or when the gamble subjective value was lower (a−: placebo, 0.74; l-DOPA, 0.66; Z = −0.48, p = 0.63). There was no relationship between the change in a+ in l-DOPA compared with placebo sessions and effective dosage (Spearman's ρ = 0.10, p = 0.61).
We also tested a decision model that tested for an effect of previous outcomes on choice. There was no difference between placebo and l-DOPA sessions for the parameter for gain trials (θgain: placebo, 0.15; l-DOPA, 0.19; Z = 0.83, p = 0.41) or the parameter for loss trials (θloss: placebo, 0.01; l-DOPA, −0.07; Z = −0.57, p = 0.57). There was also no relationship between effective dosage and the increase in θgain on l-DOPA compared with placebo (Spearman's ρ = −0.14, p = 0.45). To further test for possible learning effects, we also examined the frequency with which subjects chose to gamble depending on the outcome of previously chosen gambles. Subjects were similarly likely to gamble when the most recently chosen gamble resulted in a win or loss (placebo, 50.7% after win, 51.0% after loss; l-DOPA, 51.0% after win, 51.0% after loss). Subjects were also similarly likely to gamble when the mostly recently chosen gamble in the same domain resulted in a win or a loss (placebo, 51.1% after win, 52.4% after loss; l-DOPA, 53.8% after win, 52.4% after loss). In both cases, the probability of gambling after a win was not greater on l-DOPA than placebo (both |Z| < 1, p > 0.3).
Dopamine and subjective emotional state
We measured subjective feelings over various time scales, finding no difference on average between placebo and l-DOPA sessions in ratings or the SD of ratings (Fig. 5). We note that the latter measure was highly correlated across placebo and l-DOPA sessions (Spearman's ρ = 0.79, p < 0.001), suggesting that it represents a stable trait in individuals. Three other model-free measures also failed to capture an effect of l-DOPA. First, subjective feeling reports on 16 dimensions before and after the task did not show any difference between l-DOPA and placebo sessions (Table 2). Second, after each session, subjects rated their overall feelings about the task on 12 dimensions using the day reconstruction method (Kahneman et al., 2004). Positive and negative affect scores computed from these responses did not differ between sessions (average positive affect: 3.2 for placebo, 3.0 for l-DOPA; average negative affect: 2.0 for placebo, 2.1 for l-DOPA; both |Z| < 1, p > 0.3). Finally, we contacted subjects the day after each session, but before they knew their earnings from the experiment, and asked them how happy they remembered being during the task. Their remembered states of happiness did not differ between sessions (Z = −0.26, p = 0.79; Fig. 5).
Figure 5.

Happiness ratings across sessions. A, l-DOPA did not affect the mean or SD of happiness ratings. Error bars indicate SEM. B, Mean happiness ratings were uncorrelated across placebo and l-DOPA sessions (p = 0.27). C, SD of happiness ratings was correlated across placebo and l-DOPA sessions (p < 0.001). D, l-DOPA did not affect initial or final happiness ratings or how happy subjects remembered being the day after the session (all p > 0.2). Error bars indicate SEM. E, Mean happiness ratings were correlated with how happy subjects remembered being the day after the session (both Spearman's ρ > 0.5, p < 0.01). F, Remembered happiness was uncorrelated between placebo and l-DOPA sessions (Spearman's ρ = −0.21, p = 0.27).
Table 2.
Subjective state questionnaire results
| Subjective state questionnaire | Placebo start | l-DOPA start | p-value | Placebo end | l-DOPA end | p-value |
|---|---|---|---|---|---|---|
| Alert to drowsy | 0.18 | 1.20 | 0.15 | 0.12 | 0.82 | 0.62 |
| Calm to excited | −0.29 | −0.22 | 0.42 | −0.36 | −0.06 | 0.72 |
| Strong to feeble | −0.17 | 0.68 | 0.06 | 0.06 | 0.51 | 0.96 |
| Muzzy to clear headed | 0.04 | −0.94 | 0.12 | −0.60 | −1.12 | 0.86 |
| Coordinated to clumsy | −0.75 | 0.25 | 0.11 | −0.34 | 0.33 | 0.78 |
| Lethargic to energetic | −0.15 | −0.67 | 0.19 | −0.17 | −0.91 | 0.21 |
| Contented to discontented | −0.05 | 0.65 | 0.20 | 0.40 | 0.51 | 0.85 |
| Troubled to tranquil | −0.23 | 0.05 | 0.70 | −0.71 | −0.32 | 0.62 |
| Slow to quick witted | −0.05 | −0.64 | 0.04 | −0.44 | −0.68 | 0.40 |
| Tense to relaxed | −0.04 | −0.54 | 0.22 | −0.74 | −0.93 | 0.44 |
| Attentive to dreamy | 0.11 | 0.83 | 0.14 | 0.01 | 0.94 | 0.09 |
| Incompetent to proficient | −0.26 | −0.32 | 0.67 | −0.48 | −0.71 | 0.95 |
| Happy to sad | −0.08 | 0.06 | 0.87 | 0.28 | 0.16 | 0.62 |
| Antagonistic to friendly | −0.09 | −0.24 | 0.95 | −0.64 | −1.04 | 0.26 |
| Interested to bored | 0.14 | 0.40 | 0.53 | 0.52 | 0.64 | 1.00 |
| Withdrawn to sociable | 0.52 | 0.41 | 0.75 | −0.06 | −0.02 | 0.88 |
Scores represent differences in ratings in a subjective state questionnaire between baseline (before placebo or l-DOPA administration) and the start of the task or the end of the task. Questions were answered by marking a point on a line and responses were converted to a 0–10 scale. We used a Wilcoxon signed-rank test and the p-values listed are not corrected for multiple comparisons. We found no evidence for an overall effect of l-DOPA on any subjective state report because no test would survive any correction for multiple comparisons. However, many such corrections might be considered too conservative. For three variables, we identified trends at the 10% significance level (uncorrected) for a difference in subjective ratings between placebo and l-DOPA. For those three cases, we then tested for a dose-dependent relationship between l-DOPA and the size of the change in subjective responses because heavier subjects may not be affected and lighter subjects would be. We found no evidence for a relationship at the 10% significance level for these three tests, and therefore found no evidence supporting a dose-dependent effect of l-DOPA on these subjective state reports.
We used our recently developed model that parameterizes how ratings of momentary happiness relate to past rewards and expectations (Rutledge et al., 2014). Note that quantities in the model are linked to phasic dopamine release (Schultz et al., 1997), providing a substrate for an interaction with the drug. Parameters were fit to happiness ratings in individual subjects (Fig. 6). CR, EV, and RPE weights were, on average, positive in both sessions (all Z > 3.3, p < 0.001; Fig. 6C), with EV weights lower than RPE weights in both placebo and l-DOPA sessions (both Z < −3.8, p < 0.001), replicating previous results (Rutledge et al., 2014). There was no significant difference in CR, EV, or RPE weights between placebo and l-DOPA sessions (all |Z| < 1, p > 0.3). The forgetting factor also did not differ between sessions (placebo: 0.79 ± 0.24; l-DOPA: 0.71 ± 0.32; Z = −0.87, p = 0.38). One obvious complicating factor is the possibility that the release and impact of dopamine after positive and negative prediction errors may be asymmetric (Frank et al., 2004; Bayer and Glimcher, 2005; Rutledge et al., 2009; Cockburn et al., 2014). We therefore split the RPE term into separate terms for positive and negative RPEs. Weights were lower for positive than negative RPEs, although not significantly so in either session (placebo: Z = −1.66, p = 0.10; l-DOPA: Z = −1.18, p = 0.24; Fig. 6D). The model with a single RPE term was preferred by Bayesian model comparison (lower BIC) for both sessions (placebo: BIC = −13,163 versus −13,085; l-DOPA: BIC = −12,275 versus −12,251). There was no difference for either parameter between sessions (both |Z| < 1, p > 0.3). Therefore, we found no support for the hypothesis that l-DOPA affects happiness by modulating all positive RPEs.
Figure 6.
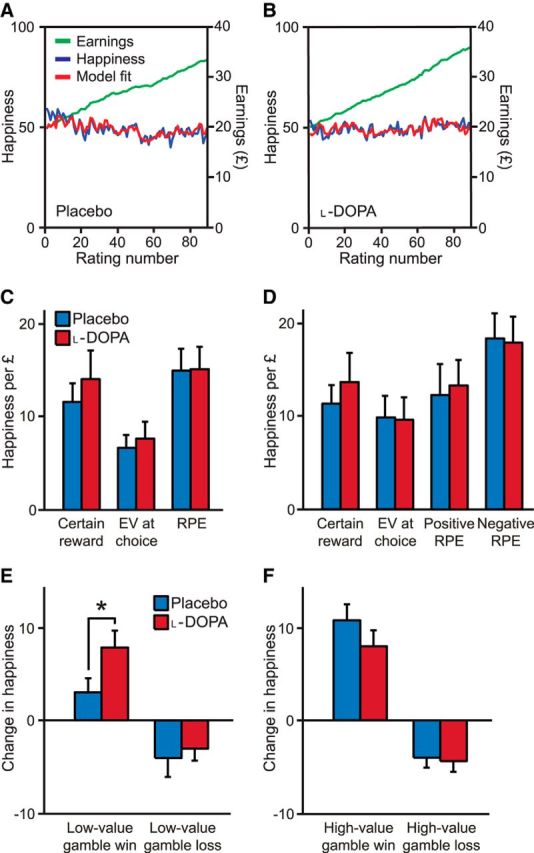
Rewards and expectations explain momentary subjective well-being. A, B, Happiness ratings and cumulative task earnings across subjects (n = 30) on placebo (A) and l-DOPA (B) (placebo: r2 = 0.49 ± 0.25; l-DOPA: r2 = 0.45 ± 0.25). Happiness model fits are displayed for the model in C. Subjects completed 300 choice trials and made a rating after every 3–4 trials for a total of 90 ratings. C, The computational model that best explained momentary happiness had positive weights for certain rewards, gamble EVs, and gamble RPEs. Error bars indicate SEM. D, An alternative computational model included separate positive and negative RPE terms. E, F, In trials with potential gains but not losses, happiness was higher after gamble wins than losses on both placebo and l-DOPA (both p < 0.05). Happiness was higher after the small rewards from low-value gain gambles on l-DOPA compared with placebo (E), but not for the large rewards from high-value gain gambles (F). Error bars indicate SEM. *p < 0.05.
As with the failure of the parametric prospect theory model to capture the effect of l-DOPA on risk taking, the happiness model failed to capture any effect of l-DOPA on happiness ratings. We tested an additional hypothesis that l-DOPA might influence the subset of trials with potential gains but not potential losses (Pessiglione et al., 2006; Schmidt et al., 2014), a hypothesis also motivated by our finding that the influence of l-DOPA on choice was confined to gain trials. We considered gain trials based upon a split into high- and low-value gain gambles, as described previously. As expected, subjects were happier after gamble wins than losses for both high- and low-value gamble trials on both placebo and l-DOPA (all Z > 2.3, p < 0.05; Fig. 6). In placebo sessions, happiness was greater after the larger rewards in high- compared with low-value gamble wins (Z = 3.70, p < 0.001). In contrast, happiness did not differ after wins from high- and low-value gambles on l-DOPA (Z = 0.33, p = 0.74). Despite equivalent objective rewards, subjects were happier after winning the small rewards from low-value gambles while on l-DOPA than they were after winning those same rewards while on placebo (Z = 2.17, p = 0.03; Fig. 6E). That is, for the same actions and same rewards, happiness was higher on l-DOPA than placebo with the interaction between drug condition and value being significant (two-way ANOVA, p = 0.03). Happiness after losses from low-value gambles was unaffected (Z = 0.54, p = 0.59). One explanation for our results is that on l-DOPA all reward magnitudes are associated with similar dopamine release and therefore similar resulting happiness. Consistent with this idea, we used a Spearman correlation to determine the strength of relationships between happiness and gamble value decile in each subject and found lower reward discriminability on l-DOPA compared with placebo (Z = −2.33, p = 0.02).
Discussion
We investigated the role of dopamine in value-based decision making by considering both choices and the subjective feelings elicited by rewards resulting from those choices. Boosting dopamine levels pharmacologically using l-DOPA dose-dependently increased the number of gambles chosen in trials with potential gains, but not in trials in which losses were possible. Furthermore, self-reports of subjective well-being were explained by the recent history of expectations and RPEs resulting from those expectations, as we showed previously (Rutledge et al., 2014). l-DOPA boosted the increase in happiness that followed small rewards, outcomes that on placebo increased happiness by only a small amount.
It is natural to consider the effects as relating to an influence of l-DOPA on phasic dopamine release (Pessiglione et al., 2006), which is associated with RPEs (Schultz et al., 1997). The same specificity for gain over loss trials has been observed in contexts in which phasic dopamine is associated with learning (Pessiglione et al., 2006; Schmidt et al., 2014), although our task was designed to obviate learning to allow testing of other roles for dopamine. That l-DOPA effects are specific to gain trials (and not also to mixed trials) suggests that RPEs associated with the trial type may be critical for the effect; in this task design, even the worst gain trial is better than the average trial and so likely inspires dopamine release. Our model proposes that l-DOPA amplifies approach toward potential gains but does not affect avoidance of potential losses. We had no prediction as to how approach and avoidance influences would combine when options are associated with both potential gains and losses, as in the mixed trials. Our results suggest that these influences do not combine linearly and that the presence of a potential loss negates any tendency to approach mixed gambles that might be amplified under l-DOPA. Our results do not support a proposal that modulating dopaminergic transmission should affect loss aversion (Clark and Dagher, 2014), although it is possible that another drug that affects the valuation process might increase gambling in mixed trials.
One possible interpretation of the valence-dependent but value-independent terms in the model is that they represent forms of Pavlovian approach (Dayan et al., 2006; Bushong et al., 2010) and withdrawal (Huys et al., 2011; Wright et al., 2012) in the face of gains and losses, respectively. Such Pavlovian actions are elicited without regard to their actual contingent benefits. The modulation of βgain by l-DOPA is consistent with an association between dopaminergic RPEs and incentive salience (Berridge and Robinson, 1998; McClure et al., 2003), which can, in principle, provide an account of dopaminergic drug effects on pathological gambling and impulsive behavior in humans (Molina et al., 2000; Cools et al., 2003) and rodents (St Onge and Floresco, 2009; Stopper et al., 2014). Under this Pavlovian interpretation, one might have expected βgain and βloss to depend on some aspect of gamble value. Our design was not optimized to investigate this possibility. Our model should generalize to noneconomic tasks such as instrumental learning paradigms, where we would predict that boosting dopamine should increase approach toward the option associated with the largest available reward even if the expected value of that option is lower than alternative options.
Our approach–avoidance model accounted for effects of l-DOPA that eluded prospect theory. Our model also outperformed a model with multiple inverse temperature parameters used to explain choice in MAOA-L carriers (Frydman et al., 2011). Because MAOA is an enzyme involved in prefrontal dopamine catabolism, it may be that the two studies identify distinct contributors to choice that both relate to dopamine, neither of which is easily explained by changes to the utility function. That our effect is Pavlovian might also account for the absence of an influence of a lower dose of l-DOPA in a previous study (Symmonds et al., 2013) that involved a mandatory 5 s waiting period before decisions, which might reduce the impact of cue-evoked dopamine release on Pavlovian approach.
Neural activity measured in ventral striatum and medial frontal cortex, areas innervated by dopamine afferents, is reported to correlate with the magnitude of potential gains and losses (Tom et al., 2007). Electrophysiological recording experiments report neuronal populations in the medial frontal cortex that represent appetitive and aversive stimuli (Amemori and Graybiel, 2012; Monosov and Hikosaka, 2012). How these and other areas contribute to choice is the subject of intense ongoing investigation (for review, see Levy and Glimcher, 2012; Bissonette et al., 2014). Dopamine neurons have been suggested to be insensitive to the aversiveness of a stimulus (Fiorillo, 2013), an observation consistent with our finding that boosting dopamine does not affect decisions with potential losses. Our results suggest that approach–avoidance influences play an important role in choice, adding to our growing quantitative understanding of dopaminergic contributions to asymmetries in learning (Piray et al., 2014) and choice (Collins and Frank, 2014).
The incentive salience model also permits choice asymmetries unrelated to learning (Zhang et al., 2009), but does not predict, as our model does, that l-DOPA will increase choice to risky options that have a larger potential reward but a lower expected value than the safe alternative. In the opponent actor learning model, an agent learns separate weights for how good and how bad an option is (Collins and Frank, 2014), corresponding to the D1-direct and D2-indirect striatal pathways, respectively, consistent with effects of optogenetic stimulation of D1 and D2 receptor-expressing striatal projection neurons on learning (Kravitz et al., 2012) and choice (Tai et al., 2012). In this model, dopaminergic drugs can, during choice, boost D1 weights representing how good options are. Although the opponent actor learning model focuses on experienced-based decisions, that model could in principle be adapted based on the results presented here to account for the increase in risk taking that we observe in gain trials. Our results suggest that l-DOPA increases dopamine release during trials with potential gains but not losses. This finding is consistent with l-DOPA increasing D1 activity in gain trials and in this way enhancing the probability of risky choice, but not similarly increasing D1 activity during trials with potential losses.
The role of dopamine in happiness remains controversial. Dopamine drugs do not affect the hedonic “liking” responses that animals make in response to sucrose reward (although opioid drugs do; see Smith et al., 2011; Castro and Berridge, 2014). Equally, l-DOPA does not affect overall mood (Liggins et al., 2012). However, l-DOPA can increase the expected pleasure of imagined future rewards (Sharot et al., 2009). The relationship is not firmly established between the happiness that we characterize, with its sensitivity to secondary reinforcers such as money, and the “liking” evident in low-level motor actions such as appetitive gapes that is sensitive to primary reinforcers such as food.
In our task, we would predict a role for dopamine in momentary happiness from the observation that this subjective state is explained by the recent history of RPEs (Rutledge et al., 2014), a finding replicated here. We would predict a specific influence in gain trials based on the inference from the l-DOPA effect on choice that the drug modulated RPEs in gain trials. We indeed found such an influence. Notably, the l-DOPA effect was present for the smaller rewards received from low-value gain gambles, but not the larger rewards received from high-value gain gambles, suggesting that there may be a ceiling effect that future research could examine. The observation that subjects experienced increased happiness after small rewards suggests that their increased willingness to take these apparently deleterious risks might actually have maximized their expected happiness. Unfortunately, the small number of low-value gain gamble wins precluded the development of an alternative happiness model that parameterizes a role for dopamine, but such a model is an important goal. Previous studies that involved learning have suggested that dopamine drugs boost the effects of RPEs on subsequent choice (Pessiglione et al., 2006; Schmidt et al., 2014). Our finding that l-DOPA boosts the effects of rewards on happiness is consistent with that result.
In summary, our findings suggest that dopamine plays a role in both decision making under uncertainty and the subjective feelings of happiness related to receipt of reward. These results are consistent with l-DOPA modulating positive prediction errors both at the time of option and outcome presentation when there are potential gains but not losses, affecting both the probability of a gamble decision and the subjective feelings that accrue from receipt of rewards. We note that anhedonia (reduced pleasure in response to the occurrence of rewarding events) is a major symptom of depression and that a link between dopamine and depression has been suggested (Nestler and Carlezon, 2006; Lemos et al., 2012; Tye et al., 2013). Our finding of a specific causal link between dopamine and subjective feelings suggests potential therapeutic approaches for mood disorders.
Footnotes
R.B.R. and R.J.D. are supported by funding from the Max Planck Society. P.D. is supported by the Gatsby Charitable Foundation. R.J.D. is supported by the Wellcome Trust (Grant 078865/Z/05/Z). The Wellcome Trust Centre for Neuroimaging is supported by core funding from the Wellcome Trust (Grant 091593/Z/10/Z). We thank Kent Berridge, Archy de Berker, Molly Crockett, Stephanie Lazzaro, Zeb Kurth-Nelson, and Marc Guitart-Masip for helpful comments.
The authors declare no competing financial interests.
This is an Open Access article distributed under the terms of the Creative Commons Attribution License Creative Commons Attribution 4.0 International, which permits unrestricted use, distribution and reproduction in any medium provided that the original work is properly attributed.
References
- Amemori K, Graybiel AM. Localized microstimulation of primate pregenual cingulate cortex induces negative decision-making. Nat Neurosci. 2012;15:776–785. doi: 10.1038/nn.3088. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bayer HM, Glimcher PW. Midbrain dopamine neurons encode a quantitative reward prediction error signal. Neuron. 2005;47:129–141. doi: 10.1016/j.neuron.2005.05.020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Berridge KC, O'Doherty JP. From experienced utility to decision utility. In: Glimcher PW, Fehr E, editors. Neuroeconomics: decision making and the brain. Ed 2. London: Academic; 2013. pp. 335–354. [Google Scholar]
- Berridge KC, Robinson TE. What is the role of dopamine in reward: hedonic impact, reward learning, or incentive salience? Brain Res Rev. 1998;28:309–369. doi: 10.1016/S0165-0173(98)00019-8. [DOI] [PubMed] [Google Scholar]
- Bissonette GB, Gentry RN, Padmala S, Pessoa L, Roesch MR. Impact of appetitive and aversive outcomes on brain responses: linking the animal and human literatures. Front Syst Neurosci. 2014;8:24. doi: 10.3389/fnsys.2014.00024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Burnham KP, Anderson DR. Model selection and inference. New York: Springer; 1998. [Google Scholar]
- Bushong B, King LM, Camerer CF, Rangel A. Pavlovian processes in consumer choice: the physical presence of a good increases willingness-to-pay. Am Econ Rev. 2010;100:1556–1571. doi: 10.1257/aer.100.4.1556. [DOI] [Google Scholar]
- Castro DC, Berridge KC. Opioid hedonic hotspot in nucleus accumbens shell: mu, delta, and kappa maps for enhancement of sweetness “liking” and “wanting.”. J Neurosci. 2014;34:4239–4250. doi: 10.1523/JNEUROSCI.4458-13.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chowdhury R, Guitart-Masip M, Lambert C, Dayan P, Huys Q, Düzel E, Dolan RJ. Dopamine restores reward prediction errors in old age. Nat Neurosci. 2013;16:648–653. doi: 10.1038/nn.3364. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Clark CA, Dagher A. The role of dopamine in risk taking: a specific look at Parkinson's disease and gambling. Front Behav Neurosci. 2014;8:196. doi: 10.3389/fnbeh.2014.00196. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cockburn J, Collins AG, Frank MJ. A reinforcement learning mechanism responsible for the valuation of free choice. Neuron. 2014;83:551–557. doi: 10.1016/j.neuron.2014.06.035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cohen JY, Haesler S, Vong L, Lowell BB, Uchida N. Neuron-type-specific signals for reward and punishment in the ventral tegmental area. Nature. 2012;482:85–88. doi: 10.1038/nature10754. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Collins AG, Frank MJ. Opponent actor learning (OpAL): modeling interactive effects of striatal dopamine on reinforcement learning and choice incentive. Psychol Rev. 2014;121:337–366. doi: 10.1037/a0037015. [DOI] [PubMed] [Google Scholar]
- Cools R, Barker RA, Sahakian BJ, Robbins TW. l-Dopa medication remediates cognitive inflexibility, but increases impulsivity in patients with Parkinson's disease. Neuropsychologia. 2003;41:1431–1441. doi: 10.1016/S0028-3932(03)00117-9. [DOI] [PubMed] [Google Scholar]
- Csikszentmihalyi M, Larson R. Validity and reliability of the Experience-Sampling Method. J Nerv Ment Dis. 1987;175:526–536. doi: 10.1097/00005053-198709000-00004. [DOI] [PubMed] [Google Scholar]
- Dayan P, Niv Y, Seymour B, Daw ND. The misbehavior of value and the discipline of the will. Neural Netw. 2006;19:1153–1160. doi: 10.1016/j.neunet.2006.03.002. [DOI] [PubMed] [Google Scholar]
- Diener E, Suh EM, Lucas RE, Smith HL. Subjective well-being: three decades of progress. Psychol Bull. 1999;125:276–302. doi: 10.1037/0033-2909.125.2.276. [DOI] [Google Scholar]
- Drevets WC, Gautier C, Price JC, Kupfer DJ, Kinahan PE, Grace AA, Price JL, Mathis CA. Amphetamine-induced dopamine release in human ventral striatum correlates with euphoria. Biol Psychiatry. 2001;49:81–96. doi: 10.1016/S0006-3223(00)01038-6. [DOI] [PubMed] [Google Scholar]
- Fiorillo CD. Two dimensions of value: dopamine neurons represent reward but not aversiveness. Science. 2013;341:546–549. doi: 10.1126/science.1238699. [DOI] [PubMed] [Google Scholar]
- Frank MJ, Seeberger LC, O'Reilly RC. By carrot or by stick: cognitive reinforcement learning in parkinsonism. Science. 2004;306:1940–1943. doi: 10.1126/science.1102941. [DOI] [PubMed] [Google Scholar]
- Frydman C, Camerer C, Bossaerts P, Rangel A. MAOA-L carriers are better at making optimal financial decisions under risk. Proc R Soc Lond B Biol Sci. 2011;278:2053–2059. doi: 10.1098/rspb.2010.2304. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Guitart-Masip M, Chowdhury R, Sharot T, Dayan P, Duzel E, Dolan RJ. Action controls dopaminergic enhancement of reward representations. Proc Natl Acad Sci U S A. 2012;109:7511–7516. doi: 10.1073/pnas.1202229109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hart AS, Rutledge RB, Glimcher PW, Phillips PE. Phasic dopamine release in the rat nucleus accumbens symmetrically encodes a reward prediction error term. J Neurosci. 2014;34:698–704. doi: 10.1523/JNEUROSCI.2489-13.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hertwig R, Barron G, Weber EU, Erev I. Decisions from experience and the effect of rare events in risky choice. Psychol Sci. 2004;15:534–539. doi: 10.1111/j.0956-7976.2004.00715.x. [DOI] [PubMed] [Google Scholar]
- Huys QJ, Cools R, Gölzer M, Friedel E, Heinz A, Dolan RJ, Dayan P. Disentangling the roles of approach, activation and valence in instrumental and Pavlovian responding. PLoS Comput Biol. 2011;7:e1002028. doi: 10.1371/journal.pcbi.1002028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jocham G, Klein TA, Ullsperger M. Dopamine-mediated reinforcement learning signals in the striatum and ventromedial prefrontal cortex underlie value-based choices. J Neurosci. 2011;31:1606–1613. doi: 10.1523/JNEUROSCI.3904-10.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kahneman D, Deaton A. High income improves evaluation of life but not emotional well-being. Proc Natl Acad Sci U S A. 2010;107:16489–16493. doi: 10.1073/pnas.1011492107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kahneman D, Tversky A. Prospect theory: an analysis of decision under risk. Econometrica. 1979;47:263–291. doi: 10.2307/1914185. [DOI] [Google Scholar]
- Kahneman D, Krueger AB, Schkade DA, Schwarz N, Stone AA. A survey method for characterizing daily life experience: the day reconstruction method. Science. 2004;306:1776–1780. doi: 10.1126/science.1103572. [DOI] [PubMed] [Google Scholar]
- Killingsworth MA, Gilbert DT. A wandering mind is an unhappy mind. Science. 2010;330:932. doi: 10.1126/science.1192439. [DOI] [PubMed] [Google Scholar]
- Kravitz AV, Tye LD, Kreitzer AC. Distinct roles for direct and indirect pathway striatal neurons in reinforcement. Nat Neurosci. 2012;15:816–818. doi: 10.1038/nn.3100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Layard R. Happiness: lessons from a new science. London: Allen Lane; 2005. [Google Scholar]
- Lemos JC, Wanat MJ, Smith JS, Reyes BA, Hollon NG, Van Bockstaele EJ, Chavkin C, Phillips PE. Severe stress switches CRF action in the nucleus accumbens from appetitive to aversive. Nature. 2012;490:402–406. doi: 10.1038/nature11436. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Levy DJ, Glimcher PW. The root of all value: a neural common currency for choice. Curr Opin Neurobiol. 2012;22:1027–1038. doi: 10.1016/j.conb.2012.06.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lex A, Hauber W. Dopamine D1 and D2 receptors in the nucleus accumbens core and shell mediate Pavlovian-instrumental transfer. Learn Mem. 2008;15:483–491. doi: 10.1101/lm.978708. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liggins J, Pihl RO, Benkelfat C, Leyton M. The dopamine augmenter l-DOPA does not affect positive mood in healthy human volunteers. PLoS One. 2012;7:e28370. doi: 10.1371/journal.pone.0028370. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McClure SM, Daw ND, Montague PR. A computational substrate for incentive salience. Trends Neurosci. 2003;26:423–428. doi: 10.1016/S0166-2236(03)00177-2. [DOI] [PubMed] [Google Scholar]
- Molina JA, Sáinz-Artiga MJ, Fraile A, Jiménez-Jiménez FJ, Villanueva C, Ortí-Pareja M, Bermejo F. Pathologic gambling in Parkinson's disease: a behavioral manifestation of pharmacologic treatment? Mov Disord. 2000;15:869–872. doi: 10.1002/1531-8257(200009)15:5<869::AID-MDS1016>3.0.CO%3B2-I. [DOI] [PubMed] [Google Scholar]
- Monosov IE, Hikosaka O. Regionally distinct processing of rewards and punishments by the primate ventromedial prefrontal cortex. J Neurosci. 2012;32:10318–10330. doi: 10.1523/JNEUROSCI.1801-12.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Montague PR, Dayan P, Sejnowski TJ. A framework for mesencephalic dopamine systems based on predictive Hebbian learning. J Neurosci. 1996;16:1936–1947. doi: 10.1523/JNEUROSCI.16-05-01936.1996. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nestler EJ, Carlezon WA., Jr The mesolimbic dopamine reward circuit in depression. Biol Psychiatry. 2006;59:1151–1159. doi: 10.1016/j.biopsych.2005.09.018. [DOI] [PubMed] [Google Scholar]
- Niv Y, Daw ND, Joel D, Dayan P. Tonic dopamine: opportunity costs and the control of response vigor. Psychopharmacology (Berl) 2007;191:507–520. doi: 10.1007/s00213-006-0502-4. [DOI] [PubMed] [Google Scholar]
- Norbury A, Manohar S, Rogers RD, Husain M. Dopamine modulates risk-taking as a function of baseline sensation-seeking trait. J Neurosci. 2013;33:12982–12986. doi: 10.1523/JNEUROSCI.5587-12.2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Oswald AJ, Wu S. Objective confirmation of subjective measures of human well-being: evidence from the U.S.A. Science. 2010;327:576–579. doi: 10.1126/science.1180606. [DOI] [PubMed] [Google Scholar]
- Palmiter RD. Dopamine signaling in the dorsal striatum is essential for motivated behaviors: lessons from dopamine-deficient mice. Ann N Y Acad Sci. 2008;1129:35–46. doi: 10.1196/annals.1417.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pessiglione M, Seymour B, Flandin G, Dolan RJ, Frith CD. Dopamine-dependent prediction errors underpin reward-seeking behaviour in humans. Nature. 2006;442:1042–1045. doi: 10.1038/nature05051. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pine A, Shiner T, Seymour B, Dolan RJ. Dopamine, time, and impulsivity in humans. J Neurosci. 2010;30:8888–8896. doi: 10.1523/JNEUROSCI.6028-09.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Piray P, Zeighami Y, Bahrami F, Eissa AM, Hewedi DH, Moustafa AA. Impulse control disorders in Parkinson's disease are associated with dysfunction in stimulus valuation but not action valuation. J Neurosci. 2014;34:7814–7824. doi: 10.1523/JNEUROSCI.4063-13.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robbins TW, Everitt BJ. A role for mesencephalic dopamine in activation: commentary on Berridge (2006) Psychopharmacology (Berl) 2007;191:433–437. doi: 10.1007/s00213-006-0528-7. [DOI] [PubMed] [Google Scholar]
- Rutledge RB, Lazzaro SC, Lau B, Myers CE, Gluck MA, Glimcher PW. Dopaminergic drugs modulate learning rates and perseveration in Parkinson's patients in a dynamic foraging task. J Neurosci. 2009;29:15104–15114. doi: 10.1523/JNEUROSCI.3524-09.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rutledge RB, Skandali N, Dayan P, Dolan RJ. A computational and neural model of momentary subjective well-being. Proc Natl Acad Sci U S A. 2014;111:12252–12257. doi: 10.1073/pnas.1407535111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Salamone JD, Correa M, Farrar A, Mingote SM. Effort-related functions of nucleus accumbens dopamine and associated forebrain circuits. Psychopharmacology (Berl) 2007;191:461–482. doi: 10.1007/s00213-006-0668-9. [DOI] [PubMed] [Google Scholar]
- Schmidt L, Braun EK, Wager TD, Shohamy D. Mind matters: placebo enhances reward learning in Parkinson's disease. Nat Neurosci. 2014;17:1793–1797. doi: 10.1038/nn.3842. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schultz W, Dayan P, Montague PR. A neural substrate of prediction and reward. Science. 1997;275:1593–1599. doi: 10.1126/science.275.5306.1593. [DOI] [PubMed] [Google Scholar]
- Schwarz G. Estimating the dimension of a model. Ann Stat. 1978;6:461–464. doi: 10.1214/aos/1176344136. [DOI] [Google Scholar]
- Sharot T, Shiner T, Brown AC, Fan J, Dolan RJ. Dopamine enhances expectation of pleasure in humans. Curr Biol. 2009;19:2077–2080. doi: 10.1016/j.cub.2009.10.025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shiner T, Seymour B, Wunderlich K, Hill C, Bhatia KP, Dayan P, Dolan RJ. Dopamine and performance in a reinforcement learning task: evidence from Parkinson's disease. Brain. 2012;135:1871–1883. doi: 10.1093/brain/aws083. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith KS, Berridge KC, Aldridge JW. Disentangling pleasure from incentive salience and learning signals in brain reward circuitry. Proc Natl Acad Sci U S A. 2011;108:E255–E264. doi: 10.1073/pnas.1101920108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sokol-Hessner P, Hsu M, Curley NG, Delgado MR, Camerer CF, Phelps EA. Thinking like a trader selectively reduces individuals' loss aversion. Proc Natl Acad Sci U S A. 2009;106:5035–5040. doi: 10.1073/pnas.0806761106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- St Onge JR, Floresco SB. Dopaminergic modulation of risk-based decision making. Neuropsychopharmacology. 2009;34:681–697. doi: 10.1038/npp.2008.121. [DOI] [PubMed] [Google Scholar]
- Stopper CM, Tse MT, Montes DR, Wiedman CR, Floresco SB. Overriding phasic dopamine signals redirects action selection during risk/reward decision making. Neuron. 2014;84:177–189. doi: 10.1016/j.neuron.2014.08.033. [DOI] [PubMed] [Google Scholar]
- Symmonds M, Wright ND, Fagan E, Dolan RJ. Assaying the effect of levodopa on the evaluation of risk in healthy humans. PLoS One. 2013;8:e68177. doi: 10.1371/journal.pone.0068177. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tai LH, Lee AM, Benavidez N, Bonci A, Wilbrecht L. Transient stimulation of distinct subpopulations of striatal neurons mimics changes in action value. Nat Neurosci. 2012;15:1281–1289. doi: 10.1038/nn.3188. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tom SM, Fox CR, Trepel C, Poldrack RA. The neural basis of loss aversion in decision-making under risk. Science. 2007;315:515–518. doi: 10.1126/science.1134239. [DOI] [PubMed] [Google Scholar]
- Tversky A, Kahneman D. Advances in prospect theory: cumulative representations of uncertainty. J Risk Uncertainty. 1992;5:297–323. doi: 10.1007/BF00122574. [DOI] [Google Scholar]
- Tye KM, Mirzabekov JJ, Warden MR, Ferenczi EA, Tsai HC, Finkelstein J, Kim SY, Adhikari A, Thompson KR, Andalman AS, Gunaydin LA, Witten IB, Deisseroth K. Dopamine neurons modulate neural encoding and expression of depression-related behaviour. Nature. 2013;493:537–541. doi: 10.1038/nature11740. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wise RA, Spindler J, deWit H, Gerberg GJ. Neuroleptic-induced “anhedonia” in rats: pimozide blocks reward quality of food. Science. 1978;201:262–264. doi: 10.1126/science.566469. [DOI] [PubMed] [Google Scholar]
- Wright ND, Symmonds M, Hodgson K, Fitzgerald TH, Crawford B, Dolan RJ. Approach–avoidance processes contribute to dissociable impacts of risk and loss on choice. J Neurosci. 2012;32:7009–7020. doi: 10.1523/JNEUROSCI.0049-12.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang J, Berridge KC, Tindell AJ, Smith KS, Aldridge JW. A neural computational model of incentive salience. PLoS Comput Biol. 2009;5:e1000437. doi: 10.1371/journal.pcbi.1000437. [DOI] [PMC free article] [PubMed] [Google Scholar]