

Abstract
As previously reported, P. aeruginosa genes PA2077 and PA2078 code for 10S-DOX (10S-Dioxygenase) and 7,10-DS (7,10-Diol Synthase) enzymes involved in long-chain fatty acid oxygenation through the recently described oleate-diol synthase pathway. Analysis of the amino acid sequence of both enzymes revealed the presence of two heme-binding motifs (CXXCH) on each protein. Phylogenetic analysis showed the relation of both proteins to bacterial di-heme cytochrome c peroxidases (Ccps), similar to Xanthomonas sp. 35Y rubber oxidase RoxA. Structural homology modelling of PA2077 and PA2078 was achieved using RoxA (pdb 4b2n) as a template. From the 3D model obtained, presence of significant amino acid variations in the predicted heme-environment was found. Moreover, the presence of palindromic repeats located in enzyme-coding regions, acting as protein evolution elements, is reported here for the first time in P. aeruginosa genome. These observations and the constructed phylogenetic tree of the two proteins, allow the proposal of an evolutionary pathway for P. aeruginosa oleate-diol synthase operon. Taking together the in silico and in vivo results obtained we conclude that enzymes PA2077 and PA2078 are the first described members of a new subfamily of bacterial peroxidases, designated as Fatty acid-di-heme Cytochrome c peroxidases (FadCcp).
Introduction
P. aeruginosa is a gram-negative rod known for its metabolic versatility, which allows its distribution in numerous environmental niches, being host in higher plants, invertebrates and vertebrates [1,2]. P. aeruginosa can metabolize xenobiotics and also unsaturated long-chain fatty acids (LCFAs), widely spread in the environment, to convert them into hydroxylated derivatives (HFAs) known as oxylipins [3,4].
Hydroxylated fatty acids have a wide range of biological functions, being involved in inflammation, signaling, plant pest defense, germination or fungal reproduction [5–7]. Furthermore, the biotechnological applications of HFAs have extensively been studied, constituting important emulsifying agents in food and cosmetics industries, acting as antibacterial or antifungal substances, or being used as intermediate compounds for fine chemistry industry, with an important role in the pharmaceutical area [4,8,9]. However, the bottleneck of their chemical production is the low reactivity of the fatty acid hydrophobic chain [10]. This problem is solved in nature through several enzymatic strategies including LCFA biotransformation by diol synthases (DS), lipoxygenases (LOX), heme-containing fatty acid dioxygenases (DOX), cyclo-oxygenases (COX), hydratases, allene oxide synthases (AOS) or cytochromes P450 (CYP450) [11–15]. Moreover, these oxylipin-releasing enzymes are capable to generate products with high regio- and enantioselectivities from a broad range of substrates [16].
We previously described that a diol synthase activity is responsible for the conversion of oleic acid (OA) into oxylipins in P. aeruginosa [3,4]. Oleic acid is initially converted into hydroperoxide 10-H(P)OME ((10S)-hydroxy-(8E)-octadecenoic acid) by a dioxygenase (DOX), followed by conversion of the hydroperoxide intermediate into 7,10-DiHOME ((7S,10S)-dihydroxy-(8E)-octadecenoic acid) by an oleate-diol synthase (DS). We recently identified the genes coding for these activities, which are linked in a finely tuned operon. Gene PA2077 codes for the 10S-dioxygenase activity (10S-DOX) responsible for the first step of the reaction, whereas PA2078 encodes the (7S, 10S)-hydroperoxide diol synthase enzyme (7,10-DS), which allows conversion of 10-H(P)OME into 7,10-DiHOME, in a metabolic pathway unique for P. aeruginosa [3].
Here we report the results of a detailed in silico/in vivo study of the nucleotide and amino acid sequences of PA2077 and PA2078, including comprehensive insights into their functional and structural features, with rational mutagenesis analysis of important residues, identification of probable evolutionary elements and phylogenetic analysis. From the results obtained we conclude that proteins PA2077 and PA2078 would be the first described and functionally characterized members of a new di-heme cytochrome c peroxidase enzyme subfamily, acting on long-chain fatty acids.
Materials and Methods
Materials
Oleic acid 99% (Sigma) was used as a substrate for bioconversion assays in LC/MS analysis. (10S)-hydroperoxy-8E-octadecenoic acid (10S-H(P)OME), provided by Dr. Martín-Arjol, was purified from P. aeruginosa 42A2 culture supernatants as described previously [8,17].
Bacterial strains
Bacterial strains and plasmids used in this work are listed in S1 Table. All strains were routinely grown in TSB (17 g casein peptone, 3 g soymeal peptone, 2.5 g glucose, 5 g NaCl, and 2.5 g KH2PO4) at 37°C on a rotary shaker operated at 200 rpm. Antibiotics were added for P. aeruginosa mutant recombinant strains growth when required at the following concentrations: tetracycline 5 μg ml-1; chloramphenicol 200 μg ml-1, and ampicillin 100 μg ml-1 for E. coli DH5α recombinant strains.
Site-directed mutagenesis
Site-directed mutagenesis of selected amino acids in the heme binding or putative P450 regions of PA2077 and PA2078 (pGEMTe-77 and pGEMTe-78 variants) was carried out using a QuikChange Site-Directed Mutagenesis Kit (Stratagene), with Pfu/Phusion High-Fidelity DNA polymerase (New England BioLabs) and the primers stated in S2 Table. Amplification was performed at 98°C for 30 s followed by 25 cycles (98°C for 10 s, 60°C for 30 s, and 72°C for 3 min) in a thermocycler PTC200, MJ Research or GeneAMP PCR system 2400 (Perkin Elmer). The amplified products were digested with DpnI (Thermo Scientific) for 2 h and checked by agarose gel electrophoresis. DpnI–resistant plasmid molecules were confirmed by sequencing using plasmid internal primers (S2 Table). Sequencing was performed using an ABI PRISM BigDye Terminator v.3.1 Cycle Sequencing kit (Applied Biosystems), available at the Serveis Científics i Tecnològics of the University of Barcelona. Plasmids carrying the desired mutations were transformed into E. coli DH5α, as described [18].
Bioconversion assays
500 μl of 10x concentrated crude cell extracts were incubated with 100 μM oleic acid (OA) or 0.1% (v/v) 10S-H(P)OME in 0.5 M Tris-HCl buffer pH 7. Reactions were incubated for 2 h at 37ºC with occasional vortexing, and terminated by acidification to pH 2 with 0.5 M HCl. Released products were extracted with ethyl acetate (1:1; v:v), routinely analyzed by TLC (hexane:diethyl ether:acetic acid; 75:15:10), and further identified by LC–MS/MS analysis.
Protein expression in P. aeruginosa mutant strains
In order to obtain functional enzymes for purification, P. aeruginosa PA2078 and PA2077 genes, cloned into pMMB207 fused to the tac promoter [3] were over-expressed or co-expressed in mutants ∆PA2078 and ∆PA2077. Cultures were grown to exponential phase (D.O.600nm = 0.6), induced with 1 mM IPTG and incubated overnight at 37ºC. Bradford assay [19] was used to measure soluble protein concentration to determine the effect caused by expression of these genes on both mutant strains.
Computational analysis of ORFs PA2077 and PA2078
The nucleotide sequences of ORFs PA2077 and PA2078 and their respective orthologous genes were retrieved from Pseudomonas aeruginosa database (www.pseudomonas.com) [20]. The recently published nucleotide sequences of P. aeruginosa 42A2 oleate-diol synthase operon (GenBank #KJ372239) were also included in the analysis [3]. Nucleotide and amino acid sequences were submitted to the basic local alignment search tools BLASTn and BLASTp respectively, to identify possible homologues in the databases available at EMBL/EBI and NCBI (http://www.ncbi.nlm.nih.gov/), and to retrieve identity and similarity percentages by pairwise alignment [21].
Elements involved in enzymatic processing like post-translational modifications were predicted using PSORTb v. 2.0 for bacterial sequences (http://www.psort.org/) [22]. SignalP 4.1 server (http://www.cbs.dtu.dk/services/SignalP) was used for prediction of protein subcellular location [23]. Transmembrane helices prediction was achieved using TMPred Server (http://www.ch.embnet.org/software/TMPRED_form.html) [24]. ExPASy proteomics server (http://us.expasy.org/tools/protparam.html) was used to analyze the protein physico-chemical parameters (ProtParam tool) and to predict isoelectric point and molecular mass of non-processed and mature proteins. GPMAW tool was used for detection of aromatic amino acids [25]. Nucleotide and amino acid sequence alignments were obtained using T-Coffee (http://tcoffee.crg.cat/) [26] or ClustalO (http://www.ebi.ac.uk/Tools/msa/clustalo/) [27] multiple sequence alignment software.
Search for functional similarity motifs
InterProScan 5.2 was used for domain identification [28]. HMMER (http://hmmer.janelia.org/) was used to create a Hidden Markov Model in order to visualize conserved protein motifs [29]. Amino acid sequences of both proteins were compared with protein sequences of functionally characterized enzymes bearing similar catalytic mechanisms: diol synthases, allene oxide synthases, cytochrome P450 monooxygenases, lipoxygenases, cyclooxygenases, heme-dioxygenases, cis-trans isomerases or catalase-peroxidases, available in the literature and in UniprotKB or Protein Data Bank (PDB) (http://www.rcsb.org/pdb/), always considering their catalytic residues [30,31].
Selected protein sequences were used to analyze the phylogenetic relationship between functionally related proteins using MEGA 6 software [32]. A phylogenetic study by maximum likelihood, employing WAG+G as the amino acid substitution model from MEGA 6 software [33] was performed to analyze specific relationships of proteins PA2077 and PA2078 with previously characterized di-heme Ccp enzymes.
3D homology model construction and optimization
PA2077 and PA2078 amino acid sequences were compared by BlastP PSI-BLAST (Position-Specific Iterated) using a BLOSUM 45 matrix with PDB database [21] in order to identify homologous proteins with available 3D structure. Template for 3D model construction was selected as that showing the highest identity score (RoxA, pdb 4b2n) compared with target proteins in multiple amino acid sequence alignments obtained by T-Coffee [26]. For alignment correction, secondary structure prediction was performed using the PSIPRED protein structure prediction server (http://bioinf.cs.ucl.ac.uk/psipred/) [34]. Alignment of conserved amino acid motifs and modeling corrections of the protein core were performed by comparison with the structure of the selected template sequence, using the visualization tool Pymol Molecular Graphics System, Version 1.5.0.4, Schrödinger, LLC (http://www.pymol.org).
A 3D homology model based on sequence alignment between proteins PA2077 and PA2078 and the template RoxA was obtained using Modeller 9.10 [35]. Both heme groups were included in the model generation but no other special restrictions were applied. The coordinate PDB files were used for structure comparison and overlapping structures were monitored using Pymol Molecular Graphics System, Version 1.5.0.4, Schrödinger, LLC.
Significant evolutionary elements
Presence of palindromic elements in both ORFs was confirmed with Emboss 6.2.0. (http://emboss.bioinformatics.nl/cgi-bin/emboss/palindrome) [36]. Further phylogenetic analysis were performed to establish a relationship pattern between the palindromic sequences found in PA2077 and PA2078 and orthologous nucleotide sequences, employing the JC model from MEGA 6 software [33].
Results and Discussion
Predicted parameters
P. aeruginosa ORFs PA2077 and PA2078 (UniProt Q9I238 and Q9I237) code for proteins of 634 and 624 amino acids with molecular masses of 68.6 and 67.3 kDa (66.5 and 65 kDa in mature form) and a theoretical pI of 5.37 and 5.38, respectively. As inferred from UniProt electronic annotation, the two proteins are described as putative heme-binding proteins with electron transport activity. In agreement with the periplasmic location of oleate-diol synthase activity [37], both proteins display type I signal export sequences that allow transport of the synthesized products to the periplasm, a fact experimentally confirmed by PhoA fusion screening [38]. According to SignalP, signal peptidase cleavage site is located at positions 21 and 23 in PA2077 and PA2078, respectively (Table 1). Despite being periplasmic proteins [4,37], presence of a transmembrane helix was predicted by TMpred for PA2077, but not for PA2078, suggesting that while PA2077 could be a periplasmic membrane-related protein, PA2078 would stay completely soluble in the periplasm. As observed before, PA2077 and PA2078 display very low homology to other proteins in the databases, except for those corresponding to their orthologues in other P. aeruginosa strains [3]. Moreover, PA2077 and PA2078 bear 43.4% identity (58% similarity) with respect to each other, probably pointing to a common predecessor during evolution, as previously suggested [3] (Fig 1).
Table 1. Features and attributes of PA2077 and PA20778 nucleotide and amino acid sequences.
| Attribute | PA2077 | PA2078 |
|---|---|---|
| ORFs (bp) | 1905 | 1875 |
| Molecular mass (KDa) | 68.6 | 67.3 |
| Mature protein | 66.5 | 65.0 |
| Mature protein + 2 hemes | 68.7 | 67.5 |
| Pi (theoretical) | 5.37 | 5.38 |
| % aromatic amino acids (nº of F, W and Y amino acids) | 8.2 (21/10/20) | 7.6 (23/10/15) |
| Heme attachment a (N terminus/C terminus) | CAGCH130/ CAACH375 | CAGCH130/ CAACH365 |
| Axial heme ligands a (N terminus/C terminus) | H130/H375 H611 | H130/H365 H603 |
| MauG motif | PYFH553NGSVP | PYFH543NGSVP |
| F317 equivalent | F269 | F260 |
| W302 equivalent | W251 | S243 |
| Signal Peptide cleavage site | 21 | 23 |
| IR in protein-coding sequence (+ strand) | GACGTCGGCG | CCATCTGCAA |
| IR length | 57 pb | 68 bp |
a: Numbering includes signal peptide.
Fig 1. Amino acid sequence alignment of PA2077 and PA2078 proteins, obtained by ClustalO.

Significant amino acid motifs are highlighted in squares and the functionally identified amino acids are shown in bold. Conserved heme sequences (CXXCH) are shown in red. The predicted motif for ferrous ion union is depicted in green (EGR or EYD). The signature of oxidases containing the essential histidine like in MauG is shown in blue. Predicted tyrosyl radical (YRQH in PA2077) appears in grey. P450 motifs (EXXR) are in yellow and the distal histidines are highlighted in light green. Peroxidase signature (GXHXCLPHD) is shown in pink, with the peroxidase motif (HD) in orange. A red star indicates the position of the mutated residues (underlined).
Functionally significant sequence motifs in PA2077 and PA2078
Rational comparison of amino acid sequences among previously characterized oxylipin-forming enzymes allowed identification in PA2077 and PA2078 of several significant motifs or specific residues (Fig 1) related to heme/iron-binding sites or relevant in oxygenation reactions. Thus, a sequence (YRQ H) similar to the tyrosil radical (YRWH) involved in dioxygenation of fungal linoleate-diol synthase activity [39] could be found in PA2077 but not in PA2078. The latter displays several consensus motifs like an EYD sequence presumably related to iron binding, the HD motif found in peroxidases, and a possible P450 sequence (ESQR), all of them located in the 22 C-terminal amino acid positions of the protein (Fig 1). PA2077 contains additional conserved amino acid motifs like three putative P450 sequences (EPTR, ELYR and EQQR), two HD peroxidase motifs, and a signature very close to the GSHFN LPHD peroxidase consensus sequence [40]. However, the sequence FXXGPHXCLG, responsible for hydroperoxide isomerase activity in Aspergillus fumigatus linoleate-diol synthase [41] could neither be found in PA2077 nor in PA2078. Interestingly, both proteins bear a leucine as the C-terminal residue (Fig 1), a hydrophobic amino acid close to the isoleucine shown to play an essential role in P. aeruginosa lipoxygenase (LOX) activity [42].
Search for conserved functional amino acid domains in discontinuous pattern mode allowed further identification of short, relevant elements shared by both proteins (Fig 1), such as the presence of two conserved cytochrome c-like domains of 19 amino acids (368–386) in PA2077 and 21 amino acids (349–370) in PA2078 that exhibit identity to cytochrome c oxydases (cbb3-type) [43]. Also, the two heme-binding motifs (CXXCH), used for covalent attachment of heme in bacterial di-heme cytochrome c peroxidases (Ccps) were found in both proteins. Moreover, the signature ‘PYLHNGSV’, containing the essential histidine of oxydases and described for MauG (methylamine dehydrogenase) as a cytochrome c peroxidase domain [44], was also found in PA2077 and PA2078 (Fig 1, Table 1). These findings suggest that the two proteins involved in P. aeruginosa oleate diol synthase activity are members of the cytochrome c peroxidase (Ccp) enzyme family.
Comparison of PA2077 and PA2078 with other bacterial Ccps
Known bacterial Ccp protein family is predominantly spread among proteobacteria (Fig 2), with an average molecular mass of 35–40 KDa, whose active form purifies as a homodimer [45–48]. However, like rubber oxygenase RoxA from Xanthomonas sp. 35Y and its orthologous genes [49], PA2077 and PA2078 show about double molecular size compared to other bacterial Ccps, and display activity as monomers. RoxA was previously classified as a Ccp protein showing homology to PA2078 [49], which allows inclusion of protein PA2078 in the same enzyme family. Moreover, PA2078 and PA2077, share a high degree of identity between them, indicating that PA2077 can also be assigned to the Ccp protein family, even if displaying different biochemical functions [3].
Fig 2. Phylogenetic relationship between amino acid sequences of bacterial di-heme cytochrome c peroxidases (Ccps).

NITEU–Nitrosomonas europaea, SHEON–Shewanella oneidensis, PSN–Pseudomonas nautica, PARDP–Paracoccus denitrificans, RHOCB–Rhodobacter capsulatus, PSEAE–Pseudomonas aeruginosa, GEOSL–Geobacter sulfurreducens. XANT–Xanthomonas sp. 35Y, DELT–Haliangium ochraceum, MYXFU–Myxococcus fulvus, CORCK–Corallococcus coralloides. Oleate-diol synthase enzymes (PA2077 and PA2078 orthologues) constitute the newly described subfamily of FadCcps (Fatty-acid di-heme cytochrome c peroxidases).
To further prove this preliminary assignment, PA2077 or PA2078 and their orthologs were aligned to obtain two phylogenetic join-trees with either other known oxylipin-forming proteins (not shown) or with the 13 known members of bacterial Ccps (Fig 2). In both cases, PA2077 and PA2078 appeared localized together in the same node of the phylogenetic tree. In the first tree they appeared far related to the other oxylipin-forming enzymes analyzed, which share less than 18% identity with PA2077 and PA2078. In the second phylogenetic tree, two well-differentiated groups of bacterial Ccps appeared (Fig 2). One group includes those proteins functionally characterized as cytochrome c peroxidases, together with MauG (methylamine dehydrogenase), whereas the second protein group includes Xanthomonas sp. 35Y RoxA with its orthologs, and P. aeruginosa PA2077, PA2078 homologous proteins (Fig 2). According to these results, protein PA2077 (10S-DOX) constitutes, together with RoxA and MauG, the third functionally characterized bacterial oxygenase-Ccp protein. These evidences further confirm that the proteins responsible for P. aeruginosa oleate-diol synthase activity are quite unique, not only among bacteria but also with respect to other oxylipin-forming enzymes previously reported like those of Aspergillus fumigatus [41,50] or linoleate diol synthase (LDS) from the rice blast fungus Gaeumannomyces graminis, which consist on a single protein bearing two domains [51].
Comparative 3D modeling of PA2077 and PA2078
Taking into consideration the difficulties found in purifying PA2077 and PA2078 proteins for crystallization purposes, a comparative homology 3D model was obtained here. Based on the results from multiple sequence alignment, pdb 4b2n from RoxA, the closest crystallographic structure related to PA2077 and PA2078 known so far, was selected as a template for modeling the 3D structure of the two proteins (S1 Fig). RoxA catalyzes the oxidative cleavage of natural rubber (poly-[cis-1,4-isoprene]), a complex hydrophobic biopolymer. As other Ccp proteins, RoxA bears di-heme binding domains, which act as low potential (LP; N-terminal domain; -65 mV) and high potential (HP; C-terminal domain; -130 mV to -160 mMV) hemes. Both heme domains are linked by W302, which provides an inter-heme electron bridge. RoxA active site is located in residue H195, acting as a proximal axial ligand to the heme iron. The closely located hydrophobic residues F317, A251, I252, F301, L254, I255, and A316 constitute the heme environment, being F317 essential for activity. Furthermore, the complex flexibility of three hydrophobic amino acid loops located in the distal active site possibly create a transient channel for substrate access and accommodation [52,53]. Although RoxA, PA2077 and PA2078 have a similar molecular mass (71.5, 66.5 and 65 KDa, respectively), they share low percentage of sequence identity (coverage 20% and 32%, identity 43% and 65%, PA2077 and PA2078 respectively in front of RoxA) and, as shown in the multiple sequence alignment (S2 Fig), insertions and deletions occur at different regions of their sequences, suggesting a different spatial loop arrangement. Heme-binding sites are separated by 245 and 235 amino acids in PA2077 and PA2078 respectively, further than the 199 amino acid distance found in RoxA [52], confirming this assumption. The low similarity and complex fold of RoxA, together with ubiquitous loops, made the global process of modeling difficult to validate. Although the surface loops were poorly modelled in the 3D-models obtained, the core region holding both heme groups, well conserved according to the sequence alignment (S2 Fig), provided enough confidence to trust this modelled region for analysis. Therefore, the conserved dual-heme environment core, constituting the common trait of Ccps [52], could be modeled with enough confidence to be studied in detail, providing insights into the catalytic preferences of both proteins. To obtain a reliable model, a multiple sequence alignment including PA2077, PA2078 and RoxA (S2 Fig) was used instead of pairwise alignment, to magnify similarities around the heme cavities. Important amino acid differences could be identified in the oxygen-binding axial heme cavity (His195 in RoxA), which might alter reactivity by modifying the heme active conformation and substrate-binding pocket. As shown in Fig 3, important, non-neutral variations with respect to RoxA were identified in PA2077 and PA2078 heme environments, where hydrophobic residues are mainly substituted by polar amino acids: F301Q in both proteins, L254S in PA2077, and I255S, I252T and L254Q in PA2078. Moreover, a drastic A316K substitution is predicted for PA2077 heme-binding site. Presence of this positive charge, partially stabilized by a serine residue sitting nearby, might be important in the catalytic mechanism of this protein (Fig 3).
Fig 3. A, B, C, Homology models of surrounding amino acids of the low potential heme environment in PA2077 and PA2078, obtained using rubber oxidase RoxA protein (pdb 4b2n) as a template (C191XXC194H195).

RoxA structure is shown in grey, PA2077 in green and PA2078 in pink. D, Amino acid relationships between both heme-binding motifs (H195, H641) in RoxA compared to those of PA2077 and PA2078. E, Heme environment changes observed in PA2077 (green) and PA2078 (pink/yellow) in comparison with those of RoxA (grey).
A general heme-binding site scheme for RoxA, PA2077 and PA2078 is depicted in Fig 4. The catalytic N-terminal heme environment of RoxA and PA2077, where the monomeric assembly of the oxygen molecule is produced, is mainly constituted by hydrophobic amino acids (excluding the lysine change in PA2077 previously described). However, a more hydrophilic environment was found in PA2078 model (Fig 4). These features can explain the polar nature of the substrate preferred by each enzyme, as RoxA transforms natural rubber, a highly hydrophobic polymer, and PA2077 substrates are mainly monounsaturated LCFAs with a polar head, whereas PA2078 acts on more polar hydroperoxide fatty acids [3,54]. Supporting the higher substrate specificity similarity of RoxA and PA2077, both proteins conserve a tryptophan located between the two heme groups (W302 in RoxA and W251 in PA2077), which can act as a linker of the redox reaction between the two hemes (Fig 3D; Table 1). On the contrary, presence of a serine instead of a tryptophan at this position in PA2078 (S243) may alter the electron transfer process between the two hemes, which would thus function as a mono-heme enzyme like cytochrome CYP450, AOS or cis-trans isomerase (Cti) enzymes [55]. Therefore, the amino acid variations found in the heme-binding structures of the analyzed proteins may explain the catalytic differences in behavior found between these three enzymes.
Fig 4. Heme environment hydrophobicity is shown for RoxA (A), PA2077 (B) and PA2078 (C).
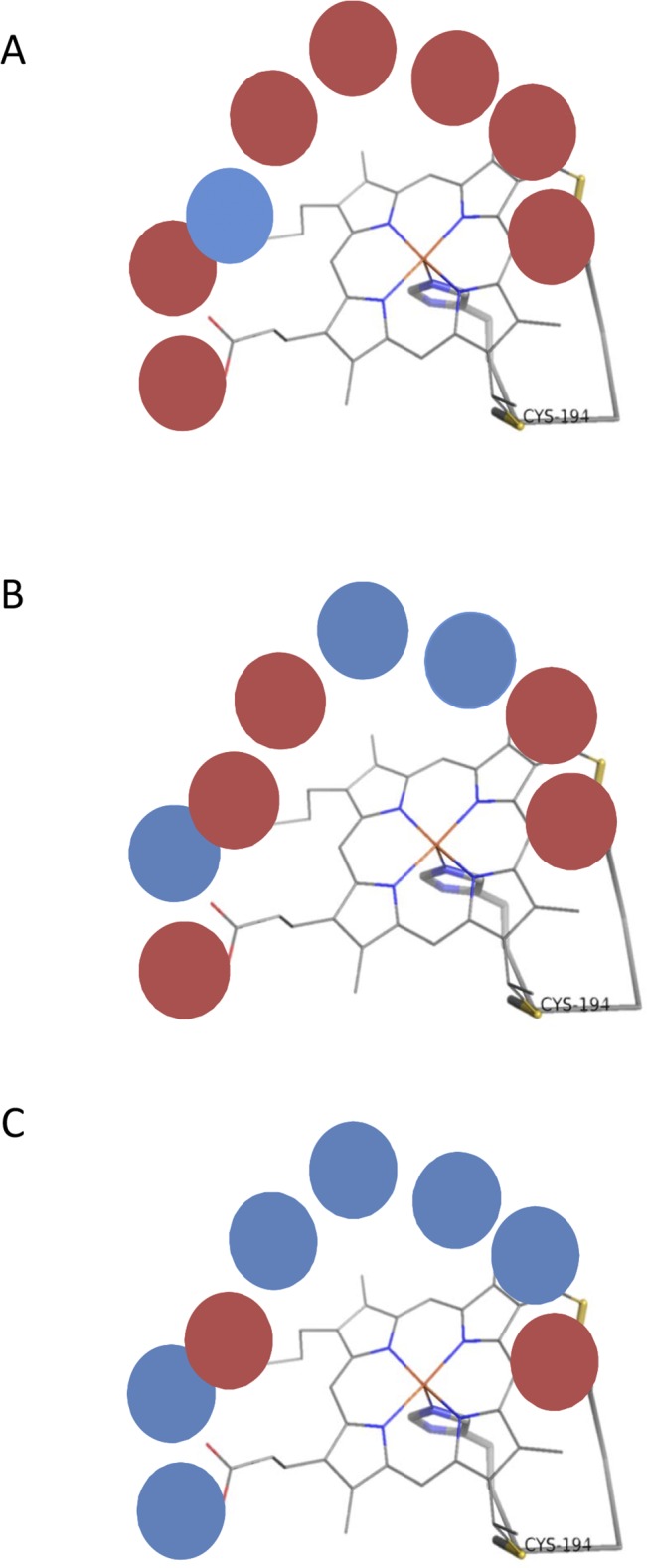
Polar amino acids are shown as blue circles and hydrophobic amino acids appear in red.
Protein evolution elements found in genes PA2077 and PA2078
Analysis of the nucleotide sequence of ORFs PA2077 and PA2078 revealed the presence of short inverted repeats (IR) of 19 and 22 amino acids, inserted at positions 716 and 870, respectively (Table 1). On the contrary, no IR insertions were found in roxA nucleotide sequence. In silico removal of the IR insertions from the original nucleotide sequence of PA2077 and PA2078 produced a frame-readout from amino acid 240 in PA2078, which would result in loss of the C-terminal heme-binding motif CAACH, supporting the previous idea that PA2078 might not use the distal heme-binding site for activity, acting as a mono-heme enzyme. On the other hand, when the same procedure was applied to PA2077, the two CXXCH motifs were maintained, suggesting that they are required for activity. To prove this hypothesis, mutants of PA2077 and PA2078 at the proximal and distal heme motifs (Fig 1) were experimentally constructed and tested for activity on their corresponding substrates. Mutants at either position H130 or H375 (residue numbering with signal peptide) in protein PA2077 failed to convert oleic acid into 10-H(P)OME (Fig 5), definitely showing that both histidines (the two hemes) are required by PA2077 to display activity. However, mutants H130Q, H365Q and C518S constructed for PA2078 (numbering includes signal peptide) produced the same pattern as wild type PA2078 when assayed for conversion of 10-H(P)OME into 7,10-DiHOME (S3 Fig). These results indicate that neither the proximal or distal heme groups, nor the cysteine putatively related to P450 enzymes are involved in the catalytic activity of PA2078. Thus, despite being a di-heme enzyme, none of the heme groups of PA2078 seems to be involved in 10-H(P)OME conversion. Further mutagenesis approaches are required to completely elucidate the catalytic environment of PA2078, which must be located elsewhere in the protein sequence, out from the heme region.
Fig 5. Products released from oleic acid by wild type PA2077 (A) and mutant PA2077 H130Q (B).

Hydroperoxide 10-H(P)OME (RT = 11) could only be detected for wild type PA2077, whereas no conversion of oleic acid occurred when both mutants, PA2077 H130Q and PA2077 H375Q, were assayed.
The lack of activity of the heme groups in PA2078 supports the previous hypothesis that these motifs might have been inherited from an ancestor di-heme protein and maintained during evolution independently of the present activity of the enzyme (3). In fact, the in-frame repeat insertions found in protein-coding regions like those of PA2077 and PA2078 have been proposed to constitute evolutionary mechanisms for enrichment of protein diversity in other proteobacteria genomes [56,57], and could be responsible for the loss of functionality of the heme groups in PA2078, thus contributing to the high metabolic versatility and adaptability shown by P. aeruginosa strains.
Insights into the evolutionary pathway of PA2077 and PA2078
As suggested in a previous work [3] and confirmed here after site directed mutagenesis, genes PA2077 and PA2078 would derive from a common phylogenetic ancestor, involving a gene duplication event followed by functional divergence into two different catalytic activities. Moreover, no functionally characterized orthologues exist in the databases or in the literature, thus constituting the first reported elements for oleic acid metabolism in P. aeruginosa strains [3]. Here we further analyzed the nature of this ancestor and the probable evolutionary model of such a process. From the results obtained above, we can conclude that protein PA2077 conserved the two heme-binding functional domains for dioxygenase activity even after the IR insertions, so it can be assumed that it is more closely related to the ancestral enzyme than PA2078, where the CXXCH motifs can be abolished without losing activity. Moreover, the IR sequence GACGTCGGCG is conserved in most PA2077 homologous genes, whereas the IR sequence found in PA2078 varies among the corresponding orthologous genes, which means that they have suffered a higher rate of mutations (Table 1). From both, the experimental and the in silico data obtained, we can conclude that the enzymes responsible for P. aeruginosa oleate diol synthase activity are inparalogs, where the activity of PA2078 would have been more recently acquired than the dioxygenase activity of PA2077, which seems to be much closer than PA2078 to the antecessor protein.
Evolutionary conservation of diol synthase operon
The evolutionary significance of P. aeruginosa diol synthase operon was tested by in vivo plasmid-based expression of gene PA2077, the hydroperoxide-forming enzyme, in the genetic context of mutant ∆PA2078 where the whole operon expression is blocked and there is no conversion of oleic acid at all [3]. However, this construction demonstrated to be lethal and no growth could be obtained (Fig 6A). Moreover, when gene PA2077 was expressed in mutant ∆PA2077, where protein PA2078 is functional, a similar toxic effect was found, with an overall 66% decrease in soluble protein production (Fig 6A). These results show that overexpression of gene PA2077 has a toxic effect due to the properties of the hydroperoxide product released by the encoded functional PA2077 (10(S)-DOX). On the contrary, overexpression of gene PA2078 in either mutant under the same conditions caused no decrease of soluble protein concentration compared to the wild type strain. As described before [3], the 10(S)-DOX encoded by gene PA2077 produces oxygenation of OA and could possibly act on other cellular unsaturated fatty acids, leading to accumulation of high concentrations of organic hydroperoxides, which could damage DNA, proteins and membrane phospholipids [42,58] thus causing cell lysis and a concomitant soluble protein reduction. In fact, although conversion of several unsaturated fatty acids has already been explored with the operon PA2078-PA2077 [4], the physiological range of PA2077 substrates, as for other novel dioxygenases, remains still to be elucidated. Taking into consideration these observations, the tandem disposition of genes PA2078-PA2077 in the diol synthase operon, and its genetic regulation as a dis-coordinated operon (gene PA2078 is expressed to a double extent than gene PA2077), probably allows enzymatic control of organic hydroperoxide production, thus avoiding the cellular damage caused by organic hydroperoxide accumulation. Therefore, the operon nature and disposition of oleate-diol synthase genes (transcribed PA2078 (2X)→PA2077) would have evolved to acquire the differentiated functions of the two encoded enzymes, probably addressed to long chain fatty acid oxygenation (PA2077) and further detoxification/control mechanism (PA2078) to avoid the intracellular effects of hydroperoxide accumulation. This was further confirmed after expression of the complete operon in either a ∆PA2077 or a ∆PA2078 background. Normal growth rates and full activity were achieved in both mutants, indicating that when the two enzymes are co-expressed in trans, both maintain their respective functions, with PA2078 abolishing toxicity. These results strengthen the idea that presence of the diol synthase operon represents an evolutionary advantage for bacterial strains, constituting a non-essential metabolic pathway which, nevertheless, can provide benefits to the cell when present [3]. This fact is supported by the recently isolated P. aeruginosa KK-related strains which contain a non-phagic insertion of 57.2 Kb located upstream PA2077 (Fig 6B), a phenomenon occurred later after gene duplication, which involves mercuric resistant coding-proteins [59]. These strains constitute the first P. aeruginosa cells reported so far in which oleate-diol synthase activity was absent when we tested them for bioconversion of oleic acid (Fig 6C). Therefore, interruption of the oleate-diol synthase operon does not affect the viability of the KK-related strains in the environment but prevents them from long-chain fatty acid oxygenation.
Fig 6. (A) Effect of gene PA2077 overexpression on cell viability of mutant ∆PA2078, measured as soluble protein and culture cell density.

Non IPTG-induced (right tube; 1.21 mg mL-1 soluble protein) and IPTG-induced (left tube; 0.8 mg mL-1 soluble protein) cultures of mutant ∆PA2078 carrying gene PA2077, shown as example of cell lysis caused by overexpression of gene PA2077. An overall 66% decrease in soluble protein was found in mutants overexpressing gene PA2077, suggesting a toxic effect of the products released by the encoded functional 10(S)-DOX. (B) Schematic representation of the PA2078-PA2077 operon showing the 57 Kbp DNA insertion affecting the operon architecture. (C) Thin layer chromatography analysis showing lack of oleic acid conversion by KK strains (1,2: KK1; 3,4: KK14; 5,6: KK72) incubated for 2 [1,3,5] or 4 hours [2,4,6] with oleic acid. Oleic acid and 10-H(P)OME are shown as control markers.
PA2077 and PA2078 constitute a unique, new subfamily of di-heme peroxidases
According to the previous functional, structural and phylogenetic results, we conclude that PA2077 and PA2078 are di-heme proteins that can be classified as bacterial Ccps, analogous to the well-characterized and heterogeneous group of fungal and bacterial diol synthases. They show low homology to other proteins in different databases, preventing construction of a valid complete 3D homology model. However, the 3D model structure of the heme environment allowed identification of relevant differences in residue composition that might justify the substrate specificity of each enzyme. Both proteins have different but complementary enzymatic functions, constituting a set of metabolic elements for fatty acid or fatty acid-derivatives metabolism in the cell periplasm. Nevertheless, the phylogenetic results obtained here indicate that PA2077 and PA2078 do not group in the main phylogenetic branch described so far for functionally characterized Ccps, constituting thus a new cluster of functional and structural enzymes. Therefore, we propose the inclusion of proteins PA2077 and PA2078 as the first functionally characterized members of a new subfamily of enzymes of the Ccp family, for which we suggest the designation of Fatty acid di-heme Cytochrome c peroxidases (FadCcps).
Supporting Information
The structure of RoxA (B), used as a template, is shown as a reference. Conserved di-heme core is colored in each model.
(TIF)
The amino acids shown in the model of Fig 3 are highlighted by green boxes.
(TIF)
The same conversion pattern was obtained for all PA2078 mutants (H130Q, H365Q and C518S), indicating that the mutated residues are not involved in activity.
(TIF)
(DOCX)
(DOCX)
Acknowledgments
ME acknowledges a fellowship from the “Comissionat per a Universitats i Recerca” (CUR) of “Departament d'Innovació, Universitats i Empresa” (DIUE) from Generalitat de Catalunya and European Social Source (FI-DGR2011). P. aeruginosa KK-related strains were kindly provided by Prof. Dr. Bordi. We thank Dr. Martín-Arjol and lab technician Laura Lorenzo for 10S-H(P)OME purification. Dr. E. Oliw is acknowledged for kindly providing research facilities and scientific advice.
Data Availability
All relevant data are within the paper and its Supporting Information files.
Funding Statement
This work was partially funded by the Ministerio de Economía y Competitividad (MINECO, projects CTQ2010-21183-CO2-01/02 and CTQ2014-59632), by the IV Pla de Recerca de Catalunya (Generalitat de Catalunya), grant 2009SGR-819, to the “Xarxa de Referència en Biotecnologia” (XRB). ME acknowledges a fellowship from the “Comissionat per a Universitats i Recerca” (CUR) of “Departament d'Innovació, Universitats i Empresa” (DIUE) from Generalitat de Catalunya and European Social Source (FI-DGR2011). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript
References
- 1. Frimmersdorf E, Horatzek S, Pelnikevich A, Wiehlmann L, Schomburg D. How Pseudomonas aeruginosa adapts to various environments: a metabolomic approach. Environ Microbiol [Internet]. 2010. June [cited 2014 Sep 18];12(6):1734–47. Available: http://www.ncbi.nlm.nih.gov/pubmed/20553553 10.1111/j.1462-2920.2010.02253.x [DOI] [PubMed] [Google Scholar]
- 2. Folkesson A, Jelsbak L, Yang L, Johansen HK, Ciofu O, Hoiby N, et al. Adaptation of Pseudomonas aeruginosa to the cystic fibrosis airway: an evolutionary perspective. Nat Rev Microbiol. London: Nature Publishing Group; Macmillan Publishers Limited; 2012;10(12):841–51. 10.1038/nrmicro2907 [DOI] [PubMed] [Google Scholar]
- 3. Estupiñán M, Diaz P, Manresa A. Unveiling the genes responsible for the unique Pseudomonas aeruginosa oleate-diol synthase activity. Biochim Biophys Acta. 2014. June;1841(10):1360–71. [DOI] [PubMed] [Google Scholar]
- 4. Martínez E, Hamberg M, Busquets M, Diaz P, Manresa A, Oliw EH. Biochemical Characterization of the Oxygenation of Unsaturated Fatty Acids by the Dioxygenase and Hydroperoxide Isomerase of Pseudomonas aeruginosa 42A2. J Biol Chem. 2010;285(13):9339–45. 10.1074/jbc.M109.078147 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Noverr MC, Erb-Downward JR, Huffnagle GB. Production of Eicosanoids and Other Oxylipins by Pathogenic Eukaryotic Microbes. Clin Microbiol Rev [Internet]. 2003. July 1 [cited 2014 Sep 18];16(3):517–33. Available: http://cmr.asm.org/content/16/3/517.full [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Mosblech A, Feussner I, Heilmann I. Oxylipins: structurally diverse metabolites from fatty acid oxidation. Plant Physiol Biochem [Internet]. 2009. June [cited 2014 Jul 15];47(6):511–7. Available: http://www.sciencedirect.com/science/article/pii/S0981942808002404 10.1016/j.plaphy.2008.12.011 [DOI] [PubMed] [Google Scholar]
- 7. Brodhun F, Feussner I. Oxylipins in fungi. FEBS J [Internet]. 2011. April [cited 2013 Nov 7];278(7):1047–63. Available: http://www.ncbi.nlm.nih.gov/pubmed/21281447 [DOI] [PubMed] [Google Scholar]
- 8. Martín-Arjol I, Bassas-Galia M, Bermudo E, García F, Manresa A. Identification of oxylipins with antifungal activity by LC-MS/MS from the supernatant of Pseudomonas 42A2. Chem Phys Lipids. Laboratori de Microbiologia, Facultat de Farmacia, Universitat de Barcelona, Joan XXIII s/n, Barcelona, Spain.: Elsevier Ireland Ltd; 2010. May;163(4–5):341–6. 10.1016/j.chemphyslip.2010.02.003 [DOI] [PubMed] [Google Scholar]
- 9. Hou CT. Biotechnology for fats and oils: new oxygenated fatty acids. N Biotechnol [Internet]. 2009. October 1 [cited 2013 Nov 12];26(1–2):2–10. Available: http://www.ncbi.nlm.nih.gov/pubmed/19447212 10.1016/j.nbt.2009.05.001 [DOI] [PubMed] [Google Scholar]
- 10.Cao Y, Zhang X. Production of long-chain hydroxy fatty acids by microbial conversion. 2013;3323–31. [DOI] [PubMed]
- 11. Hiseni A, Medici R, Arends IWCE, Otten LG. Enzymatic hydration activity assessed by selective spectrophotometric detection of alcohols: a novel screening assay using oleate hydratase as a model enzyme. Biotechnol J [Internet]. 2014. June [cited 2014 Sep 18];9(6):814–21. Available: http://www.ncbi.nlm.nih.gov/pubmed/24449561 10.1002/biot.201300412 [DOI] [PubMed] [Google Scholar]
- 12. Hoffmann I, Hamberg M, Lindh R, Oliw EH. Novel insights into cyclooxygenases, linoleate diol synthases, and lipoxygenases from deuterium kinetic isotope effects and oxidation of substrate analogs. Biochim Biophys Acta-Molecular Cell Biol Lipids [Internet]. [Hoffmann, Inga; Oliw, Ernst H.] Uppsala Univ, Div Biochem Pharmacol, Dept Pharmaceut Biosci, Biomed Ctr, SE-75124 Uppsala, Sweden. [Hamberg, Mats] Karolinska Inst, Dept Med Biochem & Biophys, Div Physiol Chem 2, SE-17177 Solna, Sweden. [Lindh, Roland] Up; 2012. December;1821(12):1508–17. Available: <Go to ISI>://WOS:000310100900007 [DOI] [PubMed] [Google Scholar]
- 13. Massey KA, Nicolaou A. Lipidomics of polyunsaturated-fatty-acid-derived oxygenated metabolites. Biochem Soc Trans [Internet]. 2011;39:1240–6. Available: <Go to ISI>://WOS:000295745200023 10.1042/BST0391240 [DOI] [PubMed] [Google Scholar]
- 14. Andreou A, Brodhun F, Feussner I. Biosynthesis of oxylipins in non-mammals. Prog Lipid Res. Elsevier Ltd; 2009. May;48(3–4):148–70. 10.1016/j.plipres.2009.02.002 [DOI] [PubMed] [Google Scholar]
- 15. Garscha U, Jernerén F, Chung D, Keller NP, Hamberg M, Oliw EH. Identification of dioxygenases required for Aspergillus development. Studies of products, stereochemistry, and the reaction mechanism. J Biol Chem. Uppsala Biomed Ctr, Dept Pharmaceut Biosci, SE-75124 Uppsala, Sweden. Univ Wisconsin, Dept Med & Microbiol Immunobiol, Madison, WI 53706 USA. Univ Wisconsin, Dept Plant Pathol, Madison, WI 53706 USA. Karolinska Inst, Dept Med Biochem & Biophys, SE-17177 S; 2007. November;282(48):34707–18. [DOI] [PubMed] [Google Scholar]
- 16. Oliw EH, Wennman A, Hoffmann I, Garscha U, Hamberg M, Jernerén F. Stereoselective oxidation of regioisomeric octadecenoic acids by fatty acid dioxygenases. J Lipid Res [Internet]. 2011. November 1 [cited 2013 Nov 20];52(11):1995–2004. Available: http://www.jlr.org/content/52/11/1995.long [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Martin-Arjol I, Llacuna JL, Manresa A. Yield and kinetic constants estimation in the production of hydroxy fatty acids from oleic acid in a bioreactor by Pseudomonas aeruginosa 42A2. Appl Microbiol Biotechnol. 2014 Sep; [DOI] [PubMed]
- 18. Sambrook J, Russell DW. Molecular cloning: A laboratory manual [Internet]. Molecular cloning: A laboratory manual. Sambrook, Joseph; University of Melbourne, Melbourne, Australia: Cold Spring Harbor Laboratory Press; {a}, 10 Skyline Drive, Plainview, NY, 11803–2500, USA; 2001. Available: http://books.google.it/books?id=Bosc5JVxNpkC [Google Scholar]
- 19. Bradford MM. Rapid and sensitive method for quantitation of microgram quantities of protein utilizing principle of protein dye binding. Anal Biochem. 1976;72(1–2):248–54. [DOI] [PubMed] [Google Scholar]
- 20. Winsor GL, Lam DKW, Fleming L, Lo R, Whiteside MD, Yu NY, et al. Pseudomonas Genome Database: improved comparative analysis and population genomics capability for Pseudomonas genomes. Nucleic Acids Res [Internet]. 2011. January [cited 2013 Nov 13];39(Database issue):596–600. Available: http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=3013766&tool=pmcentrez&rendertype=abstract [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Altschul SF, Madden TL, Schaffer AA, Zhang JH, Zhang Z, Miller W, et al. Gapped BLAST and PSI-BLAST: a new generation of protein database search programs. Nucleic Acids Res. 1997;25(17):3389–402. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Gardy JL, Laird MR, Chen F, Rey S, Walsh CJ, Ester M. et al. PSORTb v.2.0: expanded prediction of bacterial protein subcellular localization and insights gained from comparative proteome analysis. Bioinformatics. 2005;21:617–23. [DOI] [PubMed] [Google Scholar]
- 23. Emanuelsson O, Brunak S, von Heijne G, Nielsen H. Locating proteins in the cell using TargetP, SignalP and related tools. Nat Protoc [Internet]. [Brunak, Soren; Nielsen, Henrik] Tech Univ Denmark, Ctr Biol Sequence Analys, DK-2800 Lyngby, Denmark. [Emanuelsson, Olof] Albanova Stockholm Univ, Stockholm Bioinformat Ctr, SE-10691 Stockholm, Sweden. [von Heijne, Gunnar] Ctr Biomembrane Res, Dept Bioch; 2007. January [cited 2013 Nov 15];2(4):953–71. Available: http://www.ncbi.nlm.nih.gov/pubmed/17446895 [DOI] [PubMed] [Google Scholar]
- 24. Hofmann. TMbase—A database of membrane spanning proteins segments. Biol Chem Hoppe-Seyler. 1993;374(166). [Google Scholar]
- 25. Gasteiger E, Gattiker A, Hoogland C, Ivanyi I, Appel RD, Bairoch A. ExPASy: The proteomics server for in-depth protein knowledge and analysis. Nucleic Acids Res [Internet]. 2003. July 1 [cited 2014 Sep 18];31(13):3784–8. Available: http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=168970&tool=pmcentrez&rendertype=abstract [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Notredame C, Higgins DG, Heringa J. T-Coffee: A novel method for fast and accurate multiple sequence alignment. J Mol Biol [Internet]. 2000. September 8 [cited 2014 Jul 11];302(1):205–17. Available: http://www.ncbi.nlm.nih.gov/pubmed/10964570 [DOI] [PubMed] [Google Scholar]
- 27. Sievers F, Wilm A, Dineen D, Gibson TJ, Karplus K, Li W, et al. Fast, scalable generation of high-quality protein multiple sequence alignments using Clustal Omega. Mol Syst Biol. 2011. January;7:539 10.1038/msb.2011.75 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Quevillon E, Silventoinen V, Pillai S, Harte N, Mulder N, Apweiler R, et al. InterProScan: protein domains identifier. Nucleic Acids Res [Internet]. 2005. July 1 [cited 2014 Jul 17];33(Web Server issue):W116–20. Available: http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=1160203&tool=pmcentrez&rendertype=abstract [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Finn RD, Clements J, Eddy SR. HMMER web server: interactive sequence similarity searching. Nucleic Acids Res [Internet]. 2011. July 1 [cited 2014 Jul 15];39(Web Server issue):W29–37. Available: http://nar.oxfordjournals.org/content/39/suppl_2/W29 10.1093/nar/gkr367 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Magrane M, Consortium U. UniProt Knowledgebase: a hub of integrated protein data. Database (Oxford) [Internet]. 2011. January 9 [cited 2014 Jul 9];2011(0):bar009 Available: http://database.oxfordjournals.org/content/2011/bar009 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Bernstein FC, Koetzle TF, Williams GJB, Meyer EF, Brice MD, Rodgers JR, et al. The protein data bank: A computer-based archival file for macromolecular structures. Arch Biochem Biophys [Internet]. 1978. January [cited 2014 Aug 28];185(2):584–91. Available: http://www.sciencedirect.com/science/article/pii/0003986178902047 [DOI] [PubMed] [Google Scholar]
- 32. Tamura K, Stecher G, Peterson D, Filipski A, Kumar S. MEGA6: Molecular Evolutionary Genetics Analysis version 6.0. Mol Biol Evol [Internet]. 2013. December 1 [cited 2014 Jan 21];30(12):2725–9. Available: http://mbe.oxfordjournals.org/content/30/12/2725.abstract.html?etoc 10.1093/molbev/mst197 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Tamura K, Stecher G, Peterson D, Filipski A, Kumar S. MEGA6: Molecular Evolutionary Genetics Analysis version 6.0. Mol Biol Evol. 2013. December;30(12):2725–9. 10.1093/molbev/mst197 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Bryson K, McGuffin LJ, Marsden RL, Ward JJ, Sodhi JS, Jones DT. Protein structure prediction servers at University College London. Nucleic Acids Res. 2005;33:W36–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35. Martí-Renom MA, Stuart AC, Fiser A, Sánchez R, Melo F, Sali A. Comparative protein structure modeling of genes and genomes. Annu Rev Biophys Biomol Struct [Internet]. 2000. January [cited 2014 Sep 9];29:291–325. Available: http://www.ncbi.nlm.nih.gov/pubmed/10940251 [DOI] [PubMed] [Google Scholar]
- 36. Pearson CE, Zorbas H, Price GB, Zannis-Hadjopoulos M. Inverted repeats, stem-loops, and cruciforms: significance for initiation of DNA replication. J Cell Biochem. 1996. October;63(1):1–22. [DOI] [PubMed] [Google Scholar]
- 37. Martínez E, Estupiñán M, Pastor FIJ, Busquets M, Díaz P, Manresa A. Functional characterization of ExFadLO, an outer membrane protein required for exporting oxygenated long-chain fatty acids in Pseudomonas aeruginosa. Biochimie. 2013;95(2):290–8. 10.1016/j.biochi.2012.09.032 [DOI] [PubMed] [Google Scholar]
- 38. Lewenza S, Gardy JL, Brinkman FSL, Hancock REW. Genome-wide identification of Pseudomonas aeruginosa exported proteins using a consensus computational strategy combined with a laboratory-based PhoA fusion screen. Genome Res [Internet]. 2005. February [cited 2014 Jan 28];15(2):321–9. Available: http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=546534&tool=pmcentrez&rendertype=abstract [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39. Jernerén F, Garscha U, Hoffmann I, Hamberg M, Oliw EH. Reaction mechanism of 5,8-linoleate diol synthase, 10R-dioxygenase, and 8,11-hydroperoxide isomerase of Aspergillus clavatus. Biochim Biophys Acta—Mol Cell Biol Lipids [Internet]. 2010. [cited 2013 Dec 2];1801(4):503–7. Available: http://www.sciencedirect.com/science/article/pii/S1388198109002923 [DOI] [PubMed] [Google Scholar]
- 40. Ravichandran KG, Boddupalli SS, Hasermann CA, Peterson JA, Deisenhofer J. Crystal structure of hemoprotein domain of P450BM-3, a prototype for microsomal P450’s. Science [Internet]. 1993. August 6 [cited 2014 Sep 21];261(5122):731–6. Available: http://www.ncbi.nlm.nih.gov/pubmed/8342039 [DOI] [PubMed] [Google Scholar]
- 41. Hoffmann I, Jerneren F, Garscha U, Oliw EH. Expression of 5,8-LDS of Aspergillus fumigatus and its dioxygenase domain. A comparison with 7,8-LDS, 10-dioxygenase, and cyclooxygenase. Arch Biochem Biophys [Internet]. [Hoffmann, Inga; Jerneren, Fredrik; Garscha, Ulrike; Oliw, Ernst H.] Uppsala Univ, Sect Biochem Pharmacol, Dept Pharmaceut Sci, Biomed Ctr, SE-75124 Uppsala, Sweden. Oliw, EH, Uppsala Univ, Sect Biochem Pharmacol, Dept Pharmaceut Sci, Biomed Ctr, POB 591,; 2010. February;506(2):216–22. Available: <Go to ISI>://000286961600014 10.1016/j.abb.2010.11.022 [DOI] [PubMed] [Google Scholar]
- 42.Garreta A, Val-moraes SP, García-fernández Q, Busquets M, Juan C, Oliver A, et al. Structure and interaction with phospholipids of a prokaryotic lipoxygenase from Pseudomonas aeruginosa. FASEB J. 2013 Aug;1–11. [DOI] [PMC free article] [PubMed]
- 43. Marchler-Bauer A, Lu S, Anderson JB, Chitsaz F, Derbyshire MK, DeWeese-Scott C, et al. CDD: a Conserved Domain Database for the functional annotation of proteins. Nucleic Acids Res [Internet]. 2011. January [cited 2013 Nov 10];39(Database issue):D225–9. Available: http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=3013737&tool=pmcentrez&rendertype=abstract 10.1093/nar/gkq1189 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44. Wang Y, Graichen ME, Liu A, Pearson AR, Wilmot CM, Davidson VL. MauG, a novel diheme protein required for tryptophan tryptophylquinone biogenesis. Biochemistry. American Chemical Society; 2003. June;42(24):7318–25. [DOI] [PubMed] [Google Scholar]
- 45.Atack JM, Kelly DJ. Structure, mechanism and physiological roles of bacterial cytochrome c peroxidases. [Internet]. Advances in microbial physiology. 2007 [cited 2013 Nov 25]. 73–106 p. Available: http://www.ncbi.nlm.nih.gov/pubmed/17027371 [DOI] [PubMed]
- 46. Gilmour R, Goodhew CF, Pettigrew GW, Prazeres S, Moura JJ, Moura I. The kinetics of the oxidation of cytochrome c by Paracoccus cytochrome c peroxidase. Biochem J. 1994. June;300 (Pt 3:907–14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47. Alves T, Besson S, Duarte LC, Pettigrew GW, Girio FM, Devreese B, et al. A cytochrome c peroxidase from Pseudomonas nautica 617 active at high ionic strength: expression, purification and characterization. Biochim Biophys Acta. 1999. October;1434(2):248–59. [DOI] [PubMed] [Google Scholar]
- 48. De Smet L, Savvides SN, Van Horen E, Pettigrew G, Van Beeumen JJ. Structural and mutagenesis studies on the cytochrome c peroxidase from Rhodobacter capsulatus provide new insights into structure-function relationships of bacterial di-heme peroxidases. J Biol Chem. 2006. February;281(7):4371–9. [DOI] [PubMed] [Google Scholar]
- 49. Jendrossek D, Reinhardt S. Sequence analysis of a gene product synthesized by Xanthomonas sp. during growth on natural rubber latex. FEMS Microbiol Lett [Internet]. 2003. July [cited 2013 Dec 1];224(1):61–5. Available: http://doi.wiley.com/10.1016/S0378-1097(03)00424-5 [DOI] [PubMed] [Google Scholar]
- 50. Jernerén F, Oliw EH. The Fatty Acid 8,11-Diol Synthase of Aspergillus fumigatus is Inhibited by Imidazole Derivatives and Unrelated to PpoB. Lipids [Internet]. [Jerneren, Fredrik; Oliw, Ernst H.] Uppsala Univ, Dept Pharmaceut Biosci, Uppsala Biomed Ctr, S-75124 Uppsala, Sweden. Oliw, EH (reprint author), Uppsala Univ, Dept Pharmaceut Biosci, Uppsala Biomed Ctr, S-75124 Uppsala, Sweden. Ernst.Oliw@farmbio.uu.se; 2012. July;47(7):707–17. Available: <Go to ISI>://WOS:000306789400007 10.1007/s11745-012-3673-2 [DOI] [PubMed] [Google Scholar]
- 51. Jernerén F, Sesma A, Franceschetti M, Francheschetti M, Hamberg M, Oliw EH. Gene deletion of 7,8-linoleate diol synthase of the rice blast fungus: studies on pathogenicity, stereochemistry, and oxygenation mechanisms. J Biol Chem [Internet]. 2010. March 19 [cited 2015 Jan 31];285(8):5308–16. Available: http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=2820759&tool=pmcentrez&rendertype=abstract 10.1074/jbc.M109.062810 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52. Seidel J, Schmitt G, Hoffmann M, Jendrossek D, Einsle O. Structure of the processive rubber oxygenase RoxA from Xanthomonas sp. Proc Natl Acad Sci U S A [Internet]. 2013. August 20 [cited 2013 Dec 1];110(34):13833–8. Available: http://www.ncbi.nlm.nih.gov/pubmed/23922395 10.1073/pnas.1305560110 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53. Birke J, Hambsch N, Schmitt G, Altenbuchner J, Jendrossek D. Phe317 is essential for rubber oxygenase RoxA activity. Appl Environ Microbiol [Internet]. 2012. November [cited 2013 Dec 1];78(22):7876–83. Available: http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=3485939&tool=pmcentrez&rendertype=abstract 10.1128/AEM.02385-12 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54. Hambsch N, Schmitt G, Jendrossek D. Development of a homologous expression system for rubber oxygenase RoxA from Xanthomonas sp. J Appl Microbiol [Internet]. 2010. September [cited 2013 Dec 1];109(3):1067–75. Available: http://www.ncbi.nlm.nih.gov/pubmed/20408935 10.1111/j.1365-2672.2010.04732.x [DOI] [PubMed] [Google Scholar]
- 55. Heipieper HJ, Meinhardt F, Segura A. The cis-trans isomerase of unsaturated fatty acids in Pseudomonas and Vibrio: biochemistry, molecular biology and physiological function of a unique stress adaptive mechanism. FEMS Microbiol Lett. 2003;229:1–7. [DOI] [PubMed] [Google Scholar]
- 56. Claverie J-M, Ogata H. The insertion of palindromic repeats in the evolution of proteins. Trends Biochem Sci. 2003. February;28(2):75–80. [DOI] [PubMed] [Google Scholar]
- 57. Ogata H, Suhre K, Claverie J-M. Discovery of protein-coding palindromic repeats in Wolbachia. Trends Microbiol. 2005. June;13(6):253–5. [DOI] [PubMed] [Google Scholar]
- 58. Imlay JA. Cellular defenses against superoxide and hydrogen peroxide. Annu Rev Biochem. 2008. January;77:755–76. 10.1146/annurev.biochem.77.061606.161055 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59. Lucchetti-Miganeh C, Redelberger D, Chambonnier G, Rechenmann F, Elsen S, Bordi C, et al. Pseudomonas aeruginosa Genome Evolution in Patients and under the Hospital Environment. Pathogens. Multidisciplinary Digital Publishing Institute; 2014. April;3(2):309–40. 10.3390/pathogens3020309 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
The structure of RoxA (B), used as a template, is shown as a reference. Conserved di-heme core is colored in each model.
(TIF)
The amino acids shown in the model of Fig 3 are highlighted by green boxes.
(TIF)
The same conversion pattern was obtained for all PA2078 mutants (H130Q, H365Q and C518S), indicating that the mutated residues are not involved in activity.
(TIF)
(DOCX)
(DOCX)
Data Availability Statement
All relevant data are within the paper and its Supporting Information files.