

Abstract
Individuals with high spinal cord injuries are unable to operate a keyboard and mouse with their hands. In this experiment, we compared two systems using surface electromyography (sEMG) recorded from facial muscles to control an onscreen keyboard to type five-letter words. Both systems used five sEMG sensors to capture muscle activity during five distinct facial gestures that were mapped to five cursor commands: move left, move right, move up, move down, and “click”. One system used a discrete movement and feedback algorithm in which the user produced one quick facial gesture, causing a corresponding discrete movement to an adjacent letter. The other system was continuously updated and allowed the user to control the cursor’s velocity by relative activation between different sEMG channels. Participants were trained on one system for four sessions on consecutive days, followed by one crossover session on the untrained system. Information transfer rates (ITRs) were high for both systems compared to other potential input modalities, both initially and with training (Session 1: 62.1 bits/min, Session 4: 105.1 bits/min). Users of the continuous system showed significantly higher ITRs than the discrete users. Future development will focus on improvements to both systems, which may offer differential advantages for users with various motor impairments.
Index Terms: human-machine-interfaces, electromyography, communication rate
I. INTRODUCTION
There are an estimated 273,000 individuals in the U.S. [1] and 770,000 to 7.84 million [2] individuals worldwide with spinal cord injuries (SCI). The 54.1% of these individuals who have cervical injuries (e.g. C1–C7) are unable to use a typical mouse and keyboard [3], negatively affecting many aspects of their quality of life, including their ability to communicate their needs to caregivers and to maintain employment [4].
There are a variety of systems that allow these users to communicate. The most common classes of devices in use clinically are voice-activated designs, mouth sticks, machines that track head movement, eye-trackers, and sip-and-puff or other mechanical switch designs [4]. These systems can be physically or mentally fatiguing to the user, not appropriate for people with a wide range of physical capabilities, difficult to calibrate, or expensive [5]. Brain-controlled devices using electroencephalography (EEG) are accessible to individuals with a wide range of disabilities, but are very slow for practical use and not commercially available [6].
Advances in eye-tracking systems have enabled communication in some individuals with severe motor impairment, but have some disadvantages: performance is degraded with head movement or changes in ambient lighting, reports suggest that use is fatiguing to eye muscles, and these systems can interfere with the communication process due to the loss of directed gaze during conversations [7]. Further, eye-trackers have a limited communication rate, as selections are made by dwelling on a particular target for a set length of time. If the length of time a user must dwell on a target to select it (“dwell-time”) is lowered, there will be a subsequent increase in accidental selections. If dwell-time is increased, the time it takes to make each selection is increased. Although some clinical populations may be limited to eye-tracking devices or EEG-based devices, individuals with some intact motor control may be better served by surface electromyography (sEMG) based interfaces. sEMG is non-invasive, can offer excellent signal-to-noise ratios compared to EEG, and provides real-time information about muscle intent [8]. Individuals with high spinal cord injuries have unimpaired facial musculature, since these muscles are innervated by cranial nerves that are unaffected by the spinal cord injury. In this paper, we describe two systems that take advantage of this residual muscle function by using facial sEMG.
We tested the ability of healthy individuals to use facial sEMG to move a cursor to spell words on an on-screen keyboard using one of two systems. Both systems used the same facial gestures: left, right, up, down, blink, which caused corresponding movement of the cursor: left, right, up, down, or click (select). One system used a discrete algorithm for processing one facial gesture at a time, causing a corresponding discrete movement of the cursor to the center of an adjacent target. This system required minimal precision from the user: if the user produced activation above a threshold in one of the five channels of sEMG, the cursor moved to the center of an adjacent target; the magnitude of activation did not affect the cursor’s action. The second system used continuous cursor motions rather than the abrupt movements of the discrete system. This system processed the sEMG activation from each channel over very short time windows to recalculate cursor velocity, thus giving the user control over both the direction (relative activation of the different channels) and speed (based on magnitude of the activation) of the cursor. This system gave the user much more control over the cursor’s path, but required fine muscle control such that novice users may produce erratic cursor movements.
We evaluated user performance during four training sessions. The primary performance outcome of the systems over time was information transfer rate (ITR), a measure that includes speed and accuracy in one value [9]. We also evaluated the effects of training by calculating path efficiency, which indicates how directly the user moved the cursor to the intended target. We predicted that users of the discrete system would have higher ITRs than users of the continuous system in the early sessions, as the discrete system requires a lower degree of muscle control, presumably leading to increases in accuracy. We further hypothesized that the continuous users would have higher ITRs in the later sessions, as the continuous system gives users more control and flexibility. We also expected that the path efficiency in the later sessions should be higher as the users would learn to move directly to the target.
If these hypotheses were all supported, we anticipated that the discrete system could function as a training interface in future studies, introducing users to using facial gestures to control the cursor without requiring fine motor control. To that end, after the four training sessions, users also completed one crossover session in which they used the untrained system; that is, users who had trained on the discrete system exclusively completed one session with the continuous system, and vice versa. We hypothesized that the individuals who trained on the discrete system would have increased performance on the continuous system during this crossover session, and that the continuous users would have a decrease in performance.
II. Methods
A. Participants
Participants were 16 healthy adults who reported no history of speech, language, or hearing disorders and were fluent speakers of American English. Participants were pseudorandomly assigned to one of two experimental groups: “discrete” or “continuous”, which refer to the two different sEMG systems. The average age of the eight individuals (three males) in the discrete group was 20.4 years (SD = 1.3), and the average age of the eight individuals (two males) in the continuous group was 19.9 years (SD = 1.2). All participants completed written consent in compliance with the Boston University Institutional Review Board.
B. Experimental Design
The participants had four training sessions and one crossover session. The first session lasted up to 1.5 hours and each of the subsequent sessions lasted 30–50 minutes. The four training sessions took place over four consecutive days and the crossover session immediately followed the final training session, on the fourth day. In the four training sessions, the participants used the sEMG system assigned to their group (i.e., the “discrete” group used an sEMG system that used facial gestures corresponding to discrete cursor movements, fully described in the Discrete System section; the “continuous” group used a sEMG system with continuous cursor movements, described in the Continuous System section). In the crossover session, the participants used the other, untrained system.
Each day began with skin preparation and sEMG sensor application, and each session consisted of calibration followed by 45 trials of interaction with a sEMG keyboard system. Trials began with the presentation of a common five-letter American English word and ended when the participant had selected five letters using the graphical user interface shown in Fig. 1. After each trial, the user was presented with a real-time estimate of their ITR from that trial as feedback and were encouraged to increase their values (see Performance Measures section).
Figure 1.

Left: Electrodes 1–5 were placed over the left risorius and orbicularis oris, right risorius and orbicularis oris, frontalis, mentalis, and orbicularis oculi. Right: Graphical user interface. Five letter stimulus is presented at the top of the screen and each letter the user types appears below. Example path for discrete user shown in dashed black line. Example path for continuous user shown in a solid red line.
C. Data Acquisition
Participants’ skin was prepared for electrode placement by first cleaning the skin surface with alcohol and then exfoliating the area with tape to reduce electrode-skin impedance, noise, and motion artifacts [8]. A ground electrode was placed on the skin of the left shoulder above the acromion. Five single differential sEMG sensors were placed with electrode bars roughly parallel to the underlying muscle fibers of the (1) left risorius and orbicularis oris, (2) right risorius and orbicularis oris, (3) frontalis, (4) mentalis, and (5) orbicularis oculi (see Fig. 1 and Table I). Electrodes were placed either on the left mentalis and right orbicularis oculi or the right mentalis and left orbicularis oculi according to each user’s preference. Each of these electrodes was placed over one or more muscles that are activated during particular facial gestures. The sEMG signals recorded during these gestures was then mapped to cursor movement (see Table I). We chose these muscles and movements because healthy individuals are able to activate them independently and concurrently at will, and because the spatial orientation of the electrodes nominally corresponds to the movement of the cursor. That is, when the user contracted muscles at the top of her face, the cursor moved up. When she contracted muscles on the left of her mouth, the cursor moved left.
TABLE I.
Electrode Placement
| Electrode Number | Electrode Placement | Muscle Group | Facial Gesture | Cursor Action | Threshold Multipliers
|
|
|---|---|---|---|---|---|---|
| Discrete | Continuous | |||||
| 1 | Left of mouth | Risorius and orbicularis oris | Left cheek movement, similar to half a smile | Move left | 0.6 | 0.3 |
| 2 | Right of mouth | Risorius and orbicularis oris | Right cheek movement, similar to half a smile | Move right | 0.6 | 0.3 |
| 3 | Above eyebrow | Frontalis | Eyebrow raise | Move up | 0.6 | 0.5 |
| 4 | Chin | Mentalis | Chin contraction | Move down | 0.6 | 0.3 |
| 5 | Side and slightly below eye | Orbicularis oculi | Hard wink or blink | Click | 0.7 | 0.7 |
This experiment used two different methods to translate sEMG signals to cursor movements. Both methods used the same facial gestures (shown in Table I): left, right, up, down, blink, which caused corresponding movement of the cursor: left, right, up, down, or click. The sEMG signals were preamplified and filtered using Bagnoli-2 EMG systems (Delsys, Boston, MA) set to a gain of 1000 with a band-pass filter with roll-off frequencies of 20 and 450 Hz. Simultaneous sEMG signals were recorded digitally with National Instruments hardware and custom MATLAB (Mathworks, Natick, MA) software at 1000 Hz.
D. Calibration
The system was calibrated for each user at the beginning of each session. The user was asked to make each facial gesture twice (i.e., “left” “left”, “right” “right”, “up” “up”, “down” “down”, “blink” “blink”; each sequence took approximately 5–20s to complete). Participants continued producing calibration sequences until four clear, consistent sequences were completed; clear calibrations were those in which the user had isolated each facial gesture with minimal coactivation noted in the sEMG from other sensors (see Fig. 2). Participants were trained to isolate facial gestures with verbal feedback from the experimenter, visual feedback from looking at a plot of the calibration sequence (as in Fig 2), and the use of a mirror if necessary. Participants required between 5 and 23 (mean: 13.1; SD: 5.6) calibration attempts on their first day in order to produce four clean calibrations. The entire calibration process took an average of 15 minutes during the first session. On their final day of training, participants required fewer calibrations (mean: 7.1, SD: 3.7), which took an average of 3.6 minutes.
Figure 2.
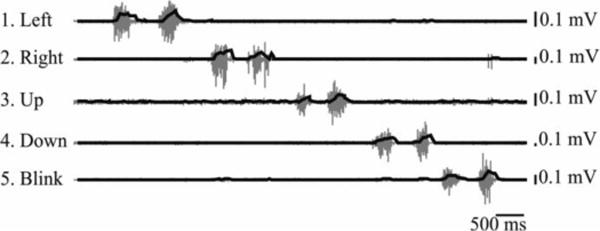
Example of calibration sequence. Raw signal plotted in gray with root-mean-square plotted in black. Numbers also correspond to electrodes and facial gestures from Fig. 1 and Table I.
In addition to the 16 participants included in this study, 3 were unable to satisfactorily complete the calibration task and were excluded. One participant was unable to isolate the left and right gestures even with encouragement and training, due to coactivation of the left and right risorius and orbicularis. The experimenter stopped the session after the participant had attempted 24 calibrations without improvement. Another participant was unable to isolate the left/right gestures from the blink gesture. The experimenter stopped the session after the participant completed 22 calibrations without improvement. The final excluded participant had varying coactivations between sequences. Further, she would produce two e.g. “down” movements in a row that were different both visually and in sEMG activation, but reported that the two movements felt the same and therefore could not reliably reproduce the correct movement. Nonetheless, she produced four clear calibrations after 23 calibration sequences, and was allowed to complete the first session. Her performance during this session was very similar to other users in her experimental group (her mean ITR: 54.7; group mean ITR: 54.5). During the second session, however, the participant completed 29 calibration runs without having 4 clean calibration sequences and chose to stop participating. The participant reported practicing the movements in the mirror after the first session, likely causing the decrease in performance, given that she could not reliably identify or reproduce the correct movement with expert feedback during the session. Subsequent participants were specifically instructed not to practice between sessions.
The root mean square (RMS) was calculated over 60 ms windows from each channel of sEMG. The maximum RMS from each channel was averaged across the four clean calibrations and was then used to calculate thresholds that determined the minimum activation required for the system to recognize a particular facial gesture as representing an intentional action by the user. Thresholds were a set percentage (“threshold multiplier”) of the maximum RMS averaged over the calibrations. These multipliers (see Table I) were determined during pilot testing and represented how much activation was required for the system to recognize muscle activation as indicating a deliberate gesture. For example, the threshold multiplier for the blink electrode was 0.7; each participant was therefore required to produce an activation that was at least 70% of the average maximum blink RMS from her own four calibrations in order for the system to register a blink, thus allowing the participant to otherwise blink normally without unintentionally making selections.
E. Discrete System
The discrete system allowed the user to move from the center of one target directly to the center of the next using only one quick facial movement, analogous to using the arrow keys on a keyboard. The maximum RMS from the signal from each electrode during a user-specific movement interval was compared to thresholds in order to determine whether the user intended to click or move the cursor.
Personalized movement intervals were calculated from the calibration files. The personalized movement interval was calculated by applying a Butterworth filter (order: 5, cutoff frequency: 9Hz) to lowpass filter the full-wave rectified sEMG signal from each channel. The length of time that the filtered signal remained above 20% of the maximum activation (“gesture duration”) was calculated for each sEMG channel, and the maximum of these gesture durations were found for each calibration sequence. The personalized movement interval was set to the mean of these four maximum gesture durations. Participants had movement intervals ranging from 213 ms to 1217 ms (mean = 576 ms, SD = 243 ms), and the personalized movement intervals allowed participants with quicker facial movements, either due to inherent skill or training, to move more quickly, but prevented those with slower facial movements from overshooting targets.
During a trial, if the RMS of the signal from the blink electrode went over threshold at any point during the personalized movement interval, the cursor was ”clicked” to select a letter and then returned to the center of the keyboard. If the RMS of the signal from the blink electrode did not go over threshold, the algorithm next checked if the RMS of the signal from one of the other electrodes went over threshold. If the signal from only one electrode went over threshold in that length of time, the cursor was moved from the center of one target to the center of the next in the direction of the active electrode (see Fig. 1). However, if the maximum RMS in more than one of the channels went above threshold, the cursor was not moved and the user was informed that there was an error by a red box appearing around the keyboard. The discrete system therefore required minimal precision from the user: if the user produced activation above threshold in one channel, the cursor moved over one target. The magnitude of the activation above the threshold did not affect the cursor’s action. Further, the thresholds for the discrete system were relatively high (60% of the maximum RMS from the calibrations) in order to promote higher accuracy: the cursor only moved when a user made an obviously intentional gesture, leading to fewer accidental movements. An example showing how the discrete system translated sEMG to cursor movements is shown in Fig. 3A.
Figure 3.
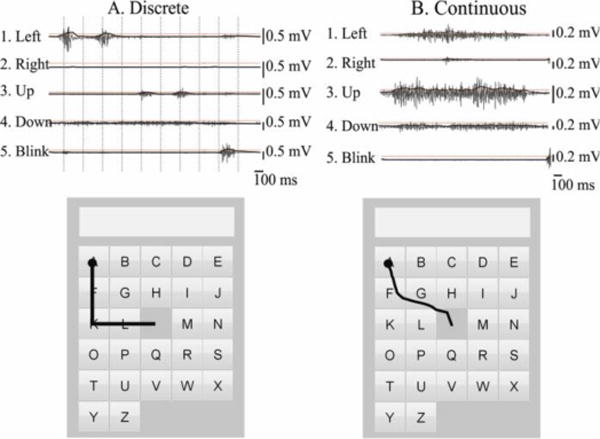
Example of translating the sEMG signal into cursor movements. The raw signal is shown in gray and the RMS is in black. Subject-specific thresholds are shown by horizontal dotted red lines. Cursor paths are shown on the lower figures in black, with clicks represented by circles. The discrete method is shown in (A); vertical dotted lines indicate the subject-specific movement intervals over which the maximum RMS is compared to thresholds. The continuous method is shown in (B); RMS is compared to thresholds every 60ms, and the magnitude of the activation above threshold determines the speed of the cursor.
F. Continuous System
The continuous system allowed the user to move in any 360° direction by using isolated facial gestures as in the discrete condition or by combining facial gestures together. In this system, the cursor moved smoothly in small increments, rather than moving directly from the center of one target to the center of an adjacent target as in the discrete case. In addition, the magnitude of the activation was used to determine the cursor’s speed, therefore giving the user more control over the cursor’s movement, but requiring more precision.
If the RMS of the signal from the blink electrode was higher than the blink threshold, the cursor was “clicked” to select a letter and then returned to the center of the keyboard. If the RMS of any of the four electrodes associated with direction (left, right, up, down) were above threshold, the x (horizontal) and y (vertical) movements of the cursor were calculated using (1) and (2). The RMS values from the left, right, up, and down electrodes (RMSL, RMSR, RMSU, RMSD) were divided by their respective thresholds from calibrations, and then squared to define the magnitude of the cursor movement, as in Williams and Kirsch [10]. Then the magnitude of the left was subtracted from the right, and the up was subtracted from down. These values were then multiplied by a scalar (speed in (1) and (2); identical for all participants), to convert the magnitude to a change in cursor position in both the x and y directions. If the signals from all five electrodes were below their respective thresholds, the cursor remained stationary. An example showing how the continuous system translated sEMG to cursor movements is shown in Fig. 3B.
| (1) |
| (2) |
G. Performance Measures
The information transfer rate was calculated for each trial in bits per minute using Wolpaw’s method [9]. This method uses bits per selection (3), in which N is 26, the number of potential targets on the screen, and A is accuracy (0 – 1). The result of (3) in bits/selection is converted to ITR in bits/min by multiplying (3) by the selection rate: the number of selections (5 letters) divided by the time the user took to spell the word. In this way, ITR incorporates both accuracy and speed into one measure.
| (3) |
In addition, path efficiency was calculated as in (4) [10]. In this equation, the beginning coordinates (here, the center of the screen) are represented by (x1,y1) and the location that the user clicked (the letter selected) is (xn,yn). The Euclidean distance between these two points is divided by the actual distance travelled, calculated by adding the distance from each coordinate (xi,yi) to the previous cursor location (xi−1,yi−1). This path efficiency is then multiplied by 100, so that an ideal path would have an efficiency of 100. The path efficiency was used to estimate how directly the user moved the cursor to the intended target.
| (4) |
H. Data Analysis
Statistical analysis was performed using Minitab Statistical Software (Minitab Inc, State College, PA) and MATLAB (Mathworks, Natick, MA). Two two-factor mixed model analyses of variance (ANOVAs) were used to examine the effect of training group (discrete versus continuous) and session (training sessions 1–4, crossover session) and group × session on the outcome measures of mean ITR and path efficiency. An α level of 0.05 was considered statistically significant for ANOVAs and post hoc testing when appropriate. Eleven post-hoc Student’s t-tests were run on ITR for a subset of group and session combinations, and the α for significance was Bonferroni-corrected.
III. Results
A. ITRs
Fig. 4 shows mean ITRs per group across sessions. The mean ITR over all users and all sessions was 85.8 bits/min (SD = 23.2). Continuous users had higher ITRs (mean over all trials = 94.6 bits/min, SD = 23.2) than discrete users (mean over all trials = 77.0 bits/min, SD = 20.0). The mixed model ANOVA on ITR showed large significant main effects for both condition and session as well as a large significant interaction of session and condition ( ; see Table II).
Figure 4.
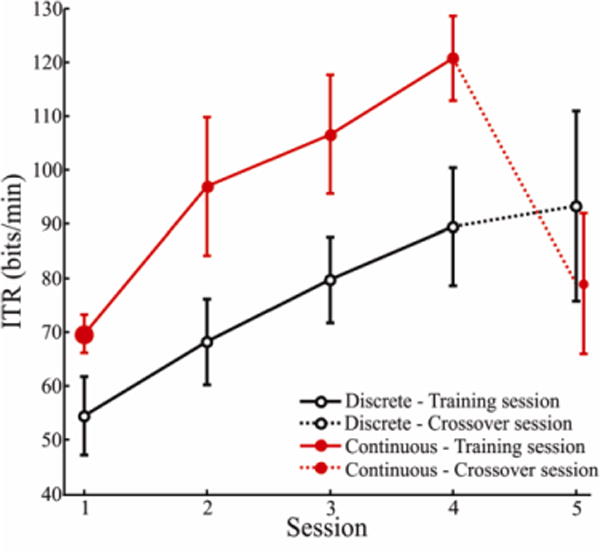
Mean information transfer rate (ITR) as a function of group and session. Sessions 1–4 were training sessions on the system indicated, and Session 5 was the crossover session in which participants used the non-trained system. Error bars are 95% confidence intervals. The mean of all discrete users is shown in black open circles and continuous is shown in red solid circles.
TABLE II.
ANOVA Results on ITR and Path Efficiency
| Effect | DF | ITR |
Path Efficiency |
||||
|---|---|---|---|---|---|---|---|
| F | P | F | P | ||||
| Condition (Discrete, Continuous) | 1 | 0.43 | 12.9 | 0.003 | 0.01 | 0.3 | 0.586 |
| Session (1–5) | 4 | 0.66 | 27.7 | <0.001 | 0.28 | 5.4 | 0.001 |
| Condition × Session | 4 | 0.41 | 9.8 | <0.001 | 0.13 | 2.1 | 0.096 |
Four unpaired, two-tailed Student’s t-tests (Table III) between groups indicated that continuous users had consistently higher ITRs in each of the training sessions (Sessions 1 – 4; significant for all four sessions). Two paired, two-tailed t-tests (Table III) showed that both continuous and discrete participants had significantly higher ITRs in Session 4 compared to Session 1; discrete users increased from a mean ITR of 54.5 bits/min to 89.5 bits/min, and continuous users increased from 69.6 bits/min to 120.7 bits/min. When continuous users switched to the discrete system in the crossover session (Session 5), they had significantly lower ITRs compared to the immediately preceding training session, Session 4 (paired t-test; Table IV), decreasing from a mean ITR of 120.7 bits/min (SD = 12.2) to a mean ITR of 79.0 bits/min (SD = 13.9). Discrete users switching to continuous did not show a significant change in their ITRs compared to their final training session (paired t-test; Table IV).
TABLE III.
Post-hoc tests on ITR – Training and Group Effects
| Comparison | Type of Test | Results |
|---|---|---|
| Discrete: Session 1 vs Session 4 | Paired, within groups | Session 4 higher* |
| Continuous: Session 1 vs Session 4 | Paired, within groups | Session 4 higher* |
| Discrete vs. Continuous, Session 1 | Two sample, across groups | Continuous higher* |
| Discrete vs. Continuous, Session 2 | Two sample, across groups | Continuous higher* |
| Discrete vs. Continuous, Session 3 | Two sample, across groups | Continuous higher* |
| Discrete vs. Continuous, Session 4 | Two sample, across groups | Continuous higher* |
Significant (α = 0.05, Bonferroni corrected)
TABLE IV.
Post-hoc tests on ITR – Crossover Effects
| Comparison | Type of Test | Results |
|---|---|---|
| Discrete vs. Continuous, Session 5 | Two sample, across groups | Not significant |
| Discrete: Session 4 vs Session 5 | Paired, within groups | Not significant |
| Continuous: Session 4 vs Session 5 | Paired, within groups | Crossover (Session 5) lower* |
| Discrete Session 1 vs. Continuous Session 5 | Two sample, across groups | Session 5 higher* |
| Continuous Session 1 vs. Discrete Session 5 | Two sample, across groups | Session 5 higher* |
Significant (α = 0.05, Bonferroni corrected)
The two components that contribute to ITR are accuracy and selection rate. As shown in Fig. 5A, all users had high accuracy throughout the sessions (mean: 96.4%, SD = 2.8%). However, users in both groups tended to improve accuracy through training (discrete Session 1: 95.0%, discrete Session 4: 98.4%; continuous Session 1: 95.1%, continuous Session 4: 98.2%). Fig. 5B shows that both groups also tended to increase the selection rate through training (discrete Session 1: 14.8 letters/min, discrete Session 4: 22.2 letters/min; continuous Session 1: 18.4 letters/min, continuous Session 4: 29.3 letters/min).
Figure 5.
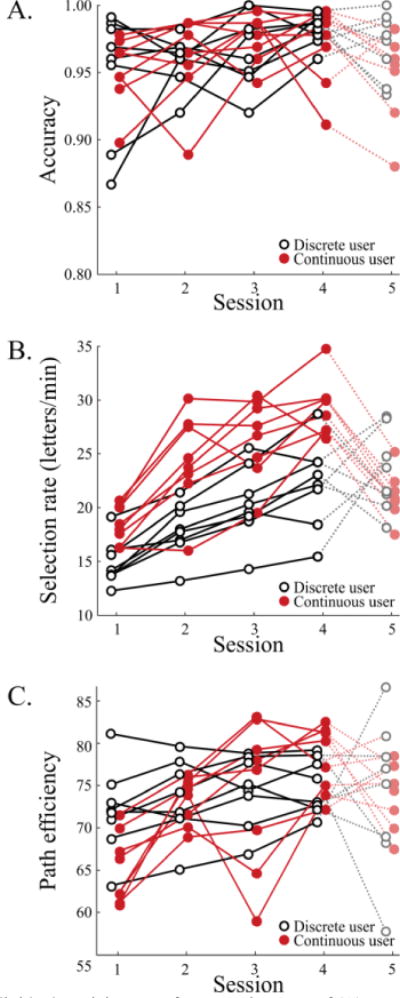
Individual participant performance in terms of (A) percent accuracy, (B) selection rate in letters per minute, and (C) path efficiency. Discrete users are shown in black open circles and continuous users are shown in red solid circles.
B. Path Efficiency
Fig. 5C shows path efficiency for each participant. An ANOVA on the effects of condition, session, and session × condition on path efficiency showed that session had a large significant effect ( ; see Table II), with more efficient paths in later sessions. However, there was not a significant effect of condition, nor a significant interaction of condition and session.
IV. Discussion
A. Performance and Training Effects in the Continuous and Discrete Systems
Users in the continuous group achieved higher ITRs than those in the discrete group, both in the first session and in all subsequent training sessions. When the continuous users switched to the discrete system in the crossover session, their ITRs decreased significantly from their final training session (Session 4). When the discrete users switched to the continuous system, however, their ITRs did not show a statistically significant change from their final training session, although the group variability increased.
We had initially considered that the discrete system may be useful as a training interface, as it requires less precision from the user: the discrete system’s classifier is essentially a “go/no-go” system, and therefore moves the cursor identically whether the user produces activation at the threshold or two times the threshold. Conversely, the continuous system uses the magnitude of the activations to determine the velocity of the cursor, which therefore may lead to erratic cursor movements if the user does not have complete, graded control over their muscle activation. In addition, the discrete system produces an error when activation is observed above threshold in more than one channel, thus training the users to isolate all facial gestures and theoretically increasing accuracy when moving to the continuous system. However, our experimental data showed mixed results when the discrete users switched to continuous, which does not support the explicit use of the discrete system to train for the continuous system. In fact, path efficiency increased with training in the continuous group. Williams and Kirsch found that users of a similar sEMG system did not use coordinated gestures, and instead moved the cursor e.g. left and then up [10]. We found that in the initial sessions, when path efficiency was low, continuous users were using the system in this way (see Fig. 6A for an example). However, as users trained, they were able to increase path efficiency by using facial gestures in concert to move smoothly directly to the target (see Fig. 6B for an example). Therefore, it may not be necessary to have a separate discrete interface for training purposes: those users who find the coordinated movements initially difficult can simply use the continuous system “discretely” (e.g. by going only left and then up) until they are comfortable with combining the movements.
Figure 6.

Example cursor paths for an entire session (225 letters). (A) is Session 1 from one continuous participant; (B) shows Session 4 from the same participant. Circles indicate selections.
The discrete system may still be of use for certain classes of users. For example, the systems described here require the user to have independent control over five distinct facial muscle groups, which may not be possible for all users. If users have control over a different set of five muscle groups, they could use either the discrete or continuous systems without any change to the software. If a user has less graded control of five muscle groups and/or any control over as few as three muscle groups, the continuous system could not be used; however, the discrete system could be modified for his/her use. For example, the “classifier” in the discrete system relies entirely on the user to independently activate different muscle groups. A more sophisticated classifying algorithm could analyze patterns of activation across multiple electrodes, allowing the use of fewer electrodes and users who have coactivations across gestures. In this hypothetical discrete system, users could produce any gestures during calibration that represented left, right, up, down, and click, and then the system could use machine-learning techniques (e.g. support vector machines) to discriminate between the gestures. This would reduce the amount of training and calibration time, as users would be making gestures natural to them, rather than learning a new set of gestures that may or may not seem intuitive. Reducing the training time may be vital in the eventual target population, both to ensure rapid user buy-in and to reduce fatigue. Finally, the lower precision requirement of the discrete system would make it more usable by users with motor impairments: users who lack enough fine motor control for the continuous system may still have enough volitional gross motor control to use the discrete system, as it requires only that the user produce volitional movement above a threshold rather than requiring graded muscle control.
B. Comparisons to Other Communication Systems
Novice users in both groups had higher ITRs than users of non-invasive and invasive brain-computer interfaces (BCIs) and other sEMG systems that require continuous muscle activation (see Table V for ITRs) [11]. For comparison, continuous users in this experiment had a mean selection rate of 18 letters/min during the first session and 29 letters/min on the last training session. Users of non-invasive EEG-based BCIs can achieve 1 to 5 letters/min [12–14]. Invasive BCIs using electrocortography (ECoG) can reach 3 to 15 letters/min [15, 16]. These systems also outperformed other published sEMG systems, which reach rates of 1–11 letters/min [10, 17–19].
TABLE V.
Comparisons to other communication systems
| System | ITR Range (bits/min) | Example References |
|---|---|---|
| Computer Keyboard | 1800 | [20] |
| Computer Mouse | 300–600 | [10, 21] |
| Eye-tracking (includes predictive methods) | 60–222 | [7, 22–24] |
| Mechanical Switch (includes predictive methods) | 96–198 | [7] |
| Head tracking and orientation devices | 78 | [10] |
| Other sEMG systems (continuous muscle control) | 5.4–51 | [10, 17–19] |
| Invasive BCIs | 5.4–69 | [15, 16, 25, 26] |
| Non-invasive BCIs | 1.8–24 | [12–14] |
The two main communication systems in use clinically for this population are eye-tracking and mechanical switch systems. Eye-trackers that include predictive methods have achieved typing speeds of 12 to 35 letters/minute [7, 22–24], and mechanical switch systems with prediction have achieved typing speeds of 28 letters/minute [27]. With training, users of the sEMG systems in this study showed ITRs in the upper range of ITRs achieved with eye-tracking and mechanical switch systems that include prediction. sEMG may provide advantages over eye-tracking and mechanical switch options aside from purely ITR-based measures. For example, eye-tracking requires high illumination, stable head positions, complete control over eye movements, and users cannot look away from the screen without an error [28]. Some head-tracking systems do not require specific lighting or position [10], but users with very high spinal cord injuries may not be able to control their head position well enough to use these systems, as some required muscles (e.g. sternocleidomastoid) are innervated by cervical nerves. Mechanical switch options (like shoulder switch or sip-and-puff devices) are popular and simple to use, but require multiple choices/selections to be made before one letter is selected, which leads to increased cognitive and physical effort. sEMG systems do not require any particular lighting, and the user need not be directly in front of the computer screen, as in many eye and head tracking systems. The systems described in this paper use visual feedback and therefore also require some intact vision, but alternate systems could easily be adapted for users with visual impairments [29]. Further, reports have suggested that eye-tracking use is fatiguing to eye muscles [7]; our qualitative data show that these sEMG systems are not fatiguing during 1–1.5 hour sessions, but further research will examine the effects of longer usage sessions.
Typical mouse use in individuals without motor impairments can reach ITRs of 300–600 bits/min or 60–130 words/min, substantially higher than the ITRs achieved with these sEMG systems. However, our experimental data suggest that individuals using both systems continued to improve between all training sessions, and therefore likely did not reach optimal performance by Session 4. Initial performance on both systems was high, at 16 letters/min, so ideally users will be highly motivated to continue training on the systems. Future study, especially in disordered populations, should include additional training sessions in order to fully benchmark the potential performance with these systems. Furthermore, addition of predictive methods such as those employed by Frey [22] and Koester and Levine [30] could reduce the level of effort required by users and could additionally improve ITRs by as much as 100% [23].
One limitation to the sEMG systems described is in the setup. Many eye-trackers do not require any specialized equipment aside from the eye-tracker and computer, which means that an independent user could theoretically approach the computer with an eye-tracker and begin and stop using the eye-tracker without intervention from family or nursing staff. However, the target population here is likely reliant on regular nursing care, so as long as the electrode application was streamlined, it could easily be accomplished with minimal time and training.
V. Conclusion
In this paper, we have presented two systems utilizing facial sEMG to control a cursor and on-screen keyboard: continuous and discrete. Both systems used facial gestures that mapped to cursor commands. Users of both systems had high performance, both initially and with training, and achieved ITRs higher than invasive BCIs, non-invasive BCIs, and other sEMG systems. Although users of the continuous system had higher ITRs throughout, further development will focus on improving both systems, as both provided high performance and may be beneficial for different types of users. Future development will ideally lead to advancements in HMIs and eventually transform the lives of severely paralyzed individuals through improving communication and enabling greater independence.
Acknowledgments
This work was supported by CELEST, a NSF Science of Learning Center (SMA-0835976) and the National Institute on Deafness and Other Communication Disorders (DC012651). Thanks to Carolyn Michener for assistance with data recording.
References
- 1.Spinal Cord Injury Facts and Figures at a Glance. The National SCI Statistical Center. 2013 Feb; [Google Scholar]
- 2.Wyndaele M, Wyndaele JJ. Incidence, prevalence and epidemiology of spinal cord injury: what learns a worldwide literature survey? Spinal Cord. 2006 Sep;44:523–9. doi: 10.1038/sj.sc.3101893. [DOI] [PubMed] [Google Scholar]
- 3.Jackson AB, Dijkers M, Devivo MJ, Poczatek RB. A demographic profile of new traumatic spinal cord injuries: change and stability over 30 years. Arch Phys Med Rehabil. 2004 Nov;85:1740–8. doi: 10.1016/j.apmr.2004.04.035. [DOI] [PubMed] [Google Scholar]
- 4.Drainoni ML, Houlihan B, Williams S, Vedrani M, Esch D, Lee-Hood E, Weiner C. Patterns of Internet use by persons with spinal cord injuries and relationship to health-related quality of life. Arch Phys Med Rehabil. 2004 Nov;85:1872–9. doi: 10.1016/j.apmr.2004.07.350. [DOI] [PubMed] [Google Scholar]
- 5.Barreto AB, Scargle SD, Adjouadi M. A practical EMG-based human-computer interface for users with motor disabilities. J Rehabil Res Dev. 2000 Jan-Feb;37:53–63. [PubMed] [Google Scholar]
- 6.Tonet O, Marinelli M, Citi L, Rossini PM, Rossini L, Megali G, Dario P. Defining brain–machine interface applications by matching interface performance with device requirements. J Neurosci Methods. 2008;167:91–104. doi: 10.1016/j.jneumeth.2007.03.015. [DOI] [PubMed] [Google Scholar]
- 7.Higginbotham DJ, Shane H, Russell S, Cave K. Access to AAC: present, past, and future. Augment Altern Commun. 2007 Sep;23:243–57. doi: 10.1080/07434610701571058. [DOI] [PubMed] [Google Scholar]
- 8.Stepp CE. Surface electromyography for speech and swallowing systems: measurement, analysis, and interpretation. J Speech Lang Hear Res. 2012 Aug;55:1232–46. doi: 10.1044/1092-4388(2011/11-0214). [DOI] [PubMed] [Google Scholar]
- 9.Wolpaw JR, Birbaumer N, Heetderks WJ, McFarland DJ, Peckham PH, Schalk G, Donchin E, Quatrano LA, Robinson CJ, Vaughan TM. Brain-computer interface technology: a review of the first international meeting. IEEE Trans Rehabil Eng. 2000 Jun;8:164–73. doi: 10.1109/tre.2000.847807. [DOI] [PubMed] [Google Scholar]
- 10.Williams MR, Kirsch RF. Evaluation of head orientation and neck muscle EMG signals as command inputs to a human-computer interface for individuals with high tetraplegia. IEEE Trans Neural Syst Rehabil Eng. 2008 Oct;16:485–96. doi: 10.1109/TNSRE.2008.2006216. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Cler MJ, Michener CM, Stepp CE. Discrete vs. continuous surface electromyographic interface control. presented at the Proceedings of the 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society; 26 – 30 August; Chicago, IL. 2014. [DOI] [PubMed] [Google Scholar]
- 12.Sellers EW, Krusienski DJ, McFarland DJ, Vaughan TM, Wolpaw JR. A P300 event-related potential brain-computer interface (BCI): the effects of matrix size and inter stimulus interval on performance. Biol Psychol. 2006 Oct;73:242–52. doi: 10.1016/j.biopsycho.2006.04.007. [DOI] [PubMed] [Google Scholar]
- 13.Nijboer F, Sellers EW, Mellinger J, Jordan MA, Matuz T, Furdea A, Halder S, Mochty U, Krusienski DJ, Vaughan TM, Wolpaw JR, Birbaumer N, Kuble A. A P300-based brain-computer interface for people with amyotrophic lateral sclerosis. Clin Neurophysiol. 2008 Aug;119:1909–16. doi: 10.1016/j.clinph.2008.03.034. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Wolpaw JR, Birbaumer N, McFarland DJ, Pfurtscheller G, Vaughan TM. Brain-computer interfaces for communication and control. Clin Neurophysiol. 2002 Jun;113:767–91. doi: 10.1016/s1388-2457(02)00057-3. [DOI] [PubMed] [Google Scholar]
- 15.Simeral JD, Kim SP, Black MJ, Donoghue JP, Hochberg LR. Neural control of cursor trajectory and click by a human with tetraplegia 1000 days after implant of an intracortical microelectrode array. J Neural Eng. 2011 Apr;8:025027. doi: 10.1088/1741-2560/8/2/025027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Brunner P, Ritaccio AL, Emrich JF, Bischof H, Schal G. Rapid Communication with a “P300” Matrix Speller Using Electrocorticographic Signals (ECoG) Front Neurosci. 2011;5:5. doi: 10.3389/fnins.2011.00005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Larson E, Terry HP, Canevari MM, Stepp CE. Categorical vowel perception enhances the effectiveness and generalization of auditory feedback in human-machine-interfaces. PLoS One. 2013;8:e59860. doi: 10.1371/journal.pone.0059860. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Vernonand S, Joshi SS. Brain-muscle-computer interface: mobile-phone prototype development and testing. IEEE Trans Inf Technol Biomed. 2011 Jul;15:531–8. doi: 10.1109/TITB.2011.2153208. [DOI] [PubMed] [Google Scholar]
- 19.Choi C, Rim BC, Ki J. Development and Evaluation of a Assistive Computer Interface by sEMG for Individuals with Spinal Cord Injuries. presented at the IEEE International Conference on Rehabilitation Robotics; Zurich. 2011. [DOI] [PubMed] [Google Scholar]
- 20.Roeber H, Bacus J, Tomas C. Typing in thin air: the canesta projection keyboard – a new method of interaction with electronic devices. presented at the CHI EA ’03 Extended Abstracts on Human Factors in Computing Systems. 2003 [Google Scholar]
- 21.Card SK, English WK, Burr BJ. Evaluation of mouse, rate-controlled isometric joystick, step keys, and text keys for text selection on a CRT. Ergonomics. 1978;21:601–613. [Google Scholar]
- 22.Frey LA, White KP, Hutchinson TE. Eye-Gaze Word Processing. IEEE Trans Systems Man Cybernetics. 1990;20:944–950. [Google Scholar]
- 23.Liu SS, Rawicz A, Rezaei S, Ma T, Zhang C, Lin K, Wu E. An Eye-Gaze Tracking and Human Computer Interface System for People with ALS and Other Locked-in Diseases. J Med Biol Eng. 2012;32:111–116. [Google Scholar]
- 24.Majaranta P, MacKenzie IS, Aula A, Raih K. Effects of feedback and dwell time on eye typing speed and accuracy. Univ Access Inf Soc. 2006;5:199–208. [Google Scholar]
- 25.Hill NJ, Lal TN, Schroder M, Hinterberger T, Wilhelm B, Nijboer F, Mochty U, Widman G, Elger C, Scholkopf B, Kubler A, Birbaume N. Classifying EEG and ECoG signals without subject training for fast BCI implementation: comparison of nonparalyzed and completely paralyzed subjects. IEEE Trans Neural Syst Rehabil Eng. 2006 Jun;14:183–6. doi: 10.1109/TNSRE.2006.875548. [DOI] [PubMed] [Google Scholar]
- 26.Guenther FH, Brumberg JS. Brain-machine interfaces for real-time speech synthesis. Conf Proc IEEE Eng Med Biol Soc. 2011 Aug;2011:5360–3. doi: 10.1109/IEMBS.2011.6091326. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Koester HH, Levine SP. Learning and performance of able-bodied individuals using scanning systems with and without word prediction. Assist Technol. 1994;6:42–53. doi: 10.1080/10400435.1994.10132226. [DOI] [PubMed] [Google Scholar]
- 28.Beukelman DR, Fager S, Ball L, Diet A. AAC for adults with acquired neurological conditions: a review. Augment Altern Commun. 2007 Sep;23:230–42. doi: 10.1080/07434610701553668. [DOI] [PubMed] [Google Scholar]
- 29.Thorp E, Larson E, Step C. Combined Auditory and Vibrotactile Feedback for Human-Machine-Interface Control. IEEE Trans Neural Syst Rehabil Eng. 2013 Jul 31; doi: 10.1109/TNSRE.2013.2273177. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Koester HH, Levin S. Keystroke-level models for user performance with word prediction. Augment Altern Commun. 1997;13:239–257. [Google Scholar]