

Abstract
Background
Levels of inbreeding in cattle populations have increased in the past due to the use of a limited number of bulls for artificial insemination. High levels of inbreeding lead to reduced genetic diversity and inbreeding depression. Various estimators based on different sources, e.g., pedigree or genomic data, have been used to estimate inbreeding coefficients in cattle populations. However, the comparative advantage of using full sequence data to assess inbreeding is unknown. We used pedigree and genomic data at different densities from 50k to full sequence variants to compare how different methods performed for the estimation of inbreeding levels in three different cattle breeds.
Results
Five different estimates for inbreeding were calculated and compared in this study: pedigree based inbreeding coefficient (FPED); run of homozygosity (ROH)-based inbreeding coefficients (FROH); genomic relationship matrix (GRM)-based inbreeding coefficients (FGRM); inbreeding coefficients based on excess of homozygosity (FHOM) and correlation of uniting gametes (FUNI). Estimates using ROH provided the direct estimated levels of autozygosity in the current populations and are free effects of allele frequencies and incomplete pedigrees which may increase in inaccuracy in estimation of inbreeding. The highest correlations were observed between FROH estimated from the full sequence variants and the FROH estimated from 50k SNP (single nucleotide polymorphism) genotypes. The estimator based on the correlation between uniting gametes (FUNI) using full genome sequences was also strongly correlated with FROH detected from sequence data.
Conclusions
Estimates based on ROH directly reflected levels of homozygosity and were not influenced by allele frequencies, unlike the three other estimates evaluated (FGRM, FHOM and FUNI), which depended on estimated allele frequencies. FPED suffered from limited pedigree depth. Marker density affects ROH estimation. Detecting ROH based on 50k chip data was observed to give estimates similar to ROH from sequence data. In the absence of full sequence data ROH based on 50k can be used to access homozygosity levels in individuals. However, genotypes denser than 50k are required to accurately detect short ROH that are most likely identical by descent (IBD).
Keywords: Inbreeding, Cattle, Whole-genome sequence, Runs of homozygosity
Background
The definition of inbreeding coefficient (F) is the probability that two alleles in an individual are identical by descent (IBD) relative to a base population where all alleles are assumed unrelated [1]. Rates of inbreeding have increased as intensive selection was applied to the populations [2–7]. Increased levels of inbreeding result in increased probability that animals are homozygous for deleterious alleles [2, 8, 9]. Thus, inbred animals suffer from inbreeding depression with reduced fitness, and highly inbred animals may have considerably reduced lifespans [2, 6, 10–13]. Information on inbreeding is critical in the design of breeding program to control the increase in inbreeding levels and thereby controlling inbreeding depression in the progeny. Pedigree information has been used to calculate the estimated inbreeding coefficient as the expected probability that two alleles at a locus are IBD [14–16]. For example, Meuwissen and Luo proposed a method to estimate inbreeding coefficients based on pedigree data of large populations [17]. However, incomplete pedigrees result in erroneous estimates and an underestimation of levels of inbreeding [18]. VanRaden proposed a method to take into account unknown ancestors when estimating inbreeding coefficients, increasing the accuracy of inbreeding level estimates in incomplete pedigrees [19].
With the availability of Single Nucleotide Polymorphism (SNP) array genotyping technologies, long stretches of homozygous genotypes, known as runs of homozygosity (ROH) can be identified. ROH are believed to reflect an estimate of autozygosity on genomic level and generally identify genomic regions which are IBD [20, 21]. Theoretically, it is expected that ROH can be accurately estimated from the full sequence data, because these estimates do not suffer from sampling such as may be expected when subsets of loci, for instance 50k SNPs, are used [22–24]. The inbreeding coefficient can be calculated as the proportion of genome covered by ROH and has been shown to be more informative than the inbreeding coefficient estimated from pedigree data or other estimators because ROH strongly correlate with homozygous mutation load [25]. ROH have commonly been used to infer population history and to examine the effect of deleterious homozygotes caused by inbreeding in human populations [20, 26–29]. Long ROH reflect recent inbreeding, whereas short ROH reflect ancient inbreeding [26]. However, only a few studies have evaluated ROH in cattle populations. Ferenčaković et al. examined the effect of SNP density and genotyping errors when estimating autozygosity from high-throughput genomic data [24]. Estimates based on ROH also vary with different densities of genomic data. The minimum length of ROH that can be detected depends on SNP density [24, 30]. Recently, Purfield et al. detected ROH in a cattle population from SNP chip data to infer population history [31]. However, to estimate the “true” state of ROH, whole-genome sequences should be used rather than SNP chip data, but, to date, there are only few studies doing this in cattle [32]. With the advent of next-generation sequencing technology, whole-genome sequences have become available to examine the fine-scale genetic architecture of the cattle genome. It is now possible to investigate and compare how well different commonly used estimators of inbreeding level correlate with ROH estimated using next-generation sequence (NGS) data.
In recent years, widespread availability of genotype data enabled computation of inbreeding from the diagonals of genomic relationship matrices, i.e., the “GRM” method (FGRM), as a by-product of genomic selection. Similarly, using the genotypes, the inbreeding coefficient can be computed based on excess of homozygosity following Wright (1948) (FHOM) [33] and based on correlation between uniting gametes following Wright (1922) (FUNI) [1]. The objective of the present study was to compare different estimators for inbreeding coefficients calculated from pedigree, 50k SNP chip genotypes and full sequence data with estimates based on ROH, for three different dairy cattle breeds.
Methods
SNP genotyping and sequencing
A total of 89 bulls with a high genetic contribution to current Danish dairy cattle populations were selected for whole-genome resequencing. These included 32 Holstein (HOL), 27 Jersey (JER), and 30 Danish Red Cattle (RDC) bulls. RDC cattle are a composite breed with contributions from different red breeds, including Swedish Red, Finnish Ayrshire, and Brown Swiss [34]. Only bi-allelic variants SNPs with a phred-scaled quality score [35] higher than 100 were kept for analysis to ensure the quality of variants. Genotypes were extracted from whole-genome sequence (WGS) data using GATK [36] and a perl script. The sequence variants with read depth lower than 7 or higher than 30 were filtered out. In addition, 85 of the sequenced animals were genotyped with the Illumina 50k SNP assay (BovineSNP50 BeadChip version 1 or 2, Illumina, San Diego, CA). SNP genotyping and quality control were as described by Höglund et al. [37]. Among the whole genome sequenced animals, 4 animals were not genotyped with the 50k SNP chip. Their genotypes for the SNPs on the 50k chip were extracted from their whole-genome sequences. The quality of genotype calls from SNP chips is expected to be higher than that of whole-genome sequences; therefore, only sequence variants with a high quality score (phred score > 100) were included. The corresponding corrections for reverse strand calls in the sequence data were converted to Illumina calls by correcting locus calling from reverse strands in Illumina calls to maintain consistency of allele encoding between Illumina calls and sequence data. The concordance between the SNP chip and sequence data was ~97 %.
Estimation of inbreeding
Using pedigree records (FPED)
Inbreeding coefficients for the 89 bulls were estimated using pedigree records (FPED). The average pedigree depth was ~8 generations ranging from 3 to 13. Average pedigree depth was 7, 8 and 9 for HOL, JER, and RDC, respectively. The method proposed by VanRaden [19] was used to compute inbreeding coefficients, which replaces unknown inbreeding coefficients by average inbreeding coefficients in the same generations. Inbreeding coefficients were calculated using the following formula [38]:
where is the ith diagonal element of the A matrix (pedigree relationship matrix), which is equal to the inbreeding coefficient of the ith animal plus 1. L is a lower triangular matrix containing the fraction of the genes that animals derive from their ancestors, and D is a diagonal matrix containing the within family additive genetic variances of animals [17]. The computation for matrix elements Lij and Djj follows the rule of computation of the A matrix [17]. The detailed decomposition for computing is explained by Meuwissen and Luo [17]. The analysis was conducted using Relax2 software [39].
Using genotypes (FROH, FGRM, FHOM, FUNI)
Sequence data
ROH were detected from sequence data using all bi-allelic variants according to the method of Bosse et al. [23]. This method was used to compute ROH for sequence data instead of PLINK because not all short ROH can be detected using PLINK for sequence data (the sliding window size in PLINK is fixed; therefore, ROH shorter than a certain length cannot be detected). The measure of homozygosity based on ROH (FROH) from genomic data is defined as the total length of genome covered by ROH divided by the overall length of genome covered by SNPs or sequences as follows [20]:
where LROH is the sum of ROH lengths and LAUTO is the total length of autosomes covered by reads. The inbreeding coefficient was calculated by extracting ROH from sequence data. Three ROH estimates based on lengths were calculated from sequence data. The ROH was calculated separately by summing the ROH in different length classes: 1) based on all ROH; 2) ROH >1 Mbp; 3) ROH >3 Mbp.
In addition, three other estimates of inbreeding coefficients were calculated using sequence data (FGRM, FHOM, FUNI). The FGRM estimate was calculated following VanRaden (2008) [40] based on the variance of the additive genotypes. FGRM was derived from
where pi is the observed fraction of the first allele at locus i, hi = 2pi(1 − pi) and xi is the number of copies of the reference allele (i.e., the allele whose homozygous genotype was coded as “0”) for the ith SNP [41]. This was equivalent to estimating an individual’s relationship to itself (diagonal of the SNP-derived GRM). The FHOM estimate was calculated based on the excess of homozygosity following Wright (1948) [33]:
where O (# hom) and E (# hom) are the observed and expected numbers of homozygous genotypes in the sample, respectively [41]. The FUNI estimate was calculated based on the correlation between uniting gametes following Wright (1922) [1]:
where hi and xi are the same as for FGRM [41]. The calculations for these three estimates FGRM, FHOM and FUNI were computed using the option –ibc from GCTA software [41].
50k SNP chip
ROH were detected from 50k SNP chip data using the software PLINK with adjusted parameters (–homozyg-density 1000, –homozyg-window-het 1, –homozyg-kb 10, –homozyg-window-snp 20) [23, 42]. These settings for PLINK to detect ROH in SNP data were chosen to make the detected ROH in SNP chip data and sequence data as similar as possible to enable comparisons of results when using different types of data. Genomic estimates of the inbreeding coefficient based on all ROH (FROH) were calculated using the same formula as was used for the sequence data. The other three types of estimates (FGRM, FHOM, FUNI) were also calculated for genotypes extracted from 50k SNP chip data using the same methods as for sequence data.
Pearson’s correlation coefficients were calculated between estimates of inbreeding coefficients from each of pedigree records, 50k SNP genotypes, and whole-genome sequence variants. All correlations between different inbreeding coefficient estimators were tested within breed to determine whether they were significantly different from 0 using the R (http://www.r-project.org/) cor and cor.test functions.
Impact of allele frequencies on estimators of inbreeding
As some estimators explicitly use allele frequencies to compute inbreeding coefficients, it is important to investigate how varying allele frequencies affect estimated inbreeding coefficients. Here, we investigated how the three different estimators change across the whole range of allele frequencies. For each genotype xi (homozygous for the reference allele; heterozygous for the reference and non-reference allele; homozygous for the non-reference allele), the values can be written as a function of allele frequency pi, as shown in Table 1.
Table 1.
Formula for calculating three estimators (FGRM, FHOM and FUNI) for each genotype (homozygous for reference allele; heterozygous for reference and non-reference allele; homozygous for non-reference allele)
| FGRM | FHOM | FUNI | |
|---|---|---|---|
| x i = 0 | FHOM = 1 | ||
| x i = 1 | FUNI = −1 | ||
| x i = 2 | FHOM = 1 |
x i is the number of reference allele
Results
We used five different approaches (FPED, FGRM, FHOM, FUNI, FROH) to estimate inbreeding coefficients using information from three different sources: pedigree, whole genome sequence and 50k SNP chip genotype data. There were total 11 estimates of inbreeding coefficients for each animal (Table 2). The average inbreeding coefficients estimated using different approaches and different data sets are presented in Table 2. The FPED and FROH estimated from 50k data for HOL and JER are significantly higher than for RDC (p < 0.05). For inbreeding coefficients estimated from sequence data, FROH, FROH>1Mb, FROH>3Mb, FHOM and FUNI differed significantly among breeds, being highest in JER and lowest in RDC. The mean FROH for 50k SNP chip data (0.066), and sequence data (0.19) are significantly higher than FPED (0.016) (p < 0.01).
Table 2.
Estimated mean (min-max) of pedigree-based inbreeding coefficient (FPED), GRM-based inbreeding coefficient (FGRM), inbreeding coefficients based on excess of homozygosity (FHOM), inbreeding coefficients based on correlation between uniting gametes (FUNI), ROH-based inbreeding coefficients (FROH). FROH greater than 1 Mb, 3 Mb derived from sequence data were reported
| Mean | Range | ||||||
|---|---|---|---|---|---|---|---|
| Inbreeding coefficients | HOL | JER | RDC | HOL | JER | RDC | |
| FPED | 0.036A | 0.018B | 0.003C | 0-0.100 | 0–0.060 | 0–0.013 | |
| 50k SNP chip data | FROH | 0.066A | 0.070A | 0.038B | 0.011–0.160 | 0.015–0.140 | 0.006–0.088 |
| FGRM | 0.023A | −0.062A | 0.345B | −0.162–0.683 | −0.365–0.351 | −0.055–0.653 | |
| FHOM | −0.008A | −0.001A | −0.234B | −0.420–0.185 | −0.227–0.147 | −0.403–(−0.021) | |
| FUNI | 0.013A | −0.031B | 0.057C | −0.076–0.274 | −0.121–0.063 | −0.048–0.177 | |
| Sequence data | FROH | 0.187A | 0.242B | 0.118C | 0.087–0.271 | 0.193–0.294 | 0.043–0.177 |
| FROH> 1Mb | 0.113A | 0.162B | 0.055C | 0.060–0.205 | 0.104–0.225 | 0.009–0.110 | |
| FROH> 3Mb | 0.070A | 0.089B | 0.027C | 0.017–0.167 | 0.033–0.158 | 0–0.079 | |
| FGRM | −0.108A | −0.122A | 0.014B | −0.189–0.031 | −0.179–(−0.031) | −0.244–0.34 | |
| FHOM | 0.069A | 0.145B | −0.123C | −0.082–0.208 | 0.053–0.231 | −0.408–0.061 | |
| FUNI | 0.028A | 0.059B | −0.007C | −0.031–0.087 | 0.024–0.108 | −0.054–0.055 |
HOL Holstein, JER Jersey, RDC Danish Red cattle. Significantly different means within each breed are indicated by a different superscript letter, P-values < 0.05
FROH estimated from sequence data is a direct and accurate estimate of the levels of homozygosity. It mostly reflects regions which were IBD on the genome; therefore, we limited our comparisons to comparing between FROH from sequence data with other estimates of F. High correlations were observed between FROH estimated from the 50k and sequence data with FROH>1Mb and FROH>3Mb from the sequence data for all three breeds (Tables 3, 4 and 5). The correlation between FROH estimated from 50k data and FROH>3Mb was higher than FROH estimated from 50k data and FROH>1Mb in JER and RDC (Tables 4 and 5). FROH was consistently positively correlated with FHOM and FUNI, when both were computed from either 50k or sequence data in all three breeds (Tables 3, 4 and 5). A high correlation was found between FROH and FUNI, when both were computed from either 50k or sequence data in all three breeds (Tables 3, 4 and 5). However, for different breeds, FHOM and FUNI were correlated differently across different densities of genomic data. For HOL and RDC, the higher the density of genomic data used for FUNI, the higher the correlation was between FUNI and FROH from sequence data (Tables 3 and 5). For HOL, the correlation between FUNI and FROH from sequence data (0.95) was still higher than the correlation between FROH estimated from 50k SNP chip data and sequence data (0.87) (Table 3). In contrast to JER, FHOM and FUNI were most highly correlated with FROH estimated from sequence data (Table 5).
Table 3.
Correlation coefficients between different estimates for inbreeding from different data sets for HOL
| Correlation | FPED | 50k SNP chip data | Sequence data | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FROH | FGRM | FHOM | FUNI | FROH | FROH> 1Mb | FROH> 3Mb | FGRM | FHOM | FUNI | |||
| FPED | 1 | 0.82** | −0.20 | 0.58** | 0.20 | 0.73** | 0.83** | 0.84** | −0.26 | 0.78** | 0.68** | |
| 50k SNP chip data | FROH | 1 | −0.23 | 0.61** | 0.15 | 0.87** | 0.96** | 0.96** | 0.03 | 0.70** | 0.88** | |
| FGRM | 1 | −0.83** | 0.87** | −0.10 | −0.13 | −0.16 | 0.36* | −0.31 | −0.0005 | |||
| FHOM | 1 | −0.44* | 0.50** | 0.58** | 0.67** | −0.38* | 0.66** | 0.41* | ||||
| FUNI | 1 | 0.27 | 0.29 | 0.27 | 0.21 | 0.11 | 0.35 | |||||
| Sequence data | FROH | 1 | 0.96** | 0.91** | 0.09 | 0.71** | 0.95** | |||||
| FROH> 1Mb | 1 | 0.98** | 0.01 | 0.77** | 0.94** | |||||||
| FROH> 3Mb | 1 | −0.32 | 0.77** | 0.90** | ||||||||
| FGRM | 1 | −0.61** | 0.29 | |||||||||
| FHOM | 1 | 0.58** | ||||||||||
| FUNI | 1 | |||||||||||
*: significantly different from 0 at p < 0.05; **: significantly different from 0 at p < 0.01. FPED is the inbreeding coefficient estimated from pedigree data. FROH is inbreeding coefficient estimated based on ROH for 50k data and for sequence data FROH> 1Mb and FROH> 3Mb are also reported. FGRM is GRM-based inbreeding coefficient estimated from 50k and sequence data. FHOM is inbreeding coefficient estimated based on excess of homozygosity for 50k and sequence data. FUNI is the inbreeding coefficient estimated based on correlation of uniting gametes for 50k and sequence data
Table 4.
Correlation coefficients between different estimates for inbreeding from different data sets for JER
| Correlation | FPED | 50k SNP chip data | Sequence data | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FROH | FGRM | FHOM | FUNI | FROH | FROH> 1Mb | FROH> 3Mb | FGRM | FHOM | FUNI | |||
| FPED | 1 | 0.47* | −0.18 | 0.46* | 0.25 | 0.46* | 0.52* | 0.53* | −0.21 | 0.60** | 0.43* | |
| 50k SNP chip data | FROH | 1 | 0.36 | 0.06 | 0.79** | 0.92** | 0.93** | 0.96** | 0.29 | 0.67** | 0.96** | |
| FGRM | 1 | −0.89** | 0.80** | 0.19 | 0.16 | 0.22 | 0.86** | −0.34 | 0.44* | |||
| FHOM | 1 | 0.24 | 0.28 | 0.21 | −0.76** | 0.66** | −0.01 | 0.24 | ||||
| FUNI | 0.67** | 0.67** | 0.71** | 0.69** | 0.20 | 0.84** | 0.67** | |||||
| Sequence data | FROH | 1 | 0.99** | 0.96** | 0.14 | 0.76** | 0.92** | |||||
| FROH> 1Mb | 1 | 0.97** | 0.094 | 0.80** | 0.91** | |||||||
| FROH> 3Mb | 1 | 0.20 | 0.74** | 0.95** | ||||||||
| FGRM | 1 | −0.48* | 0.42* | |||||||||
| FHOM | 1 | 0.60** | ||||||||||
| FUNI | 1 | |||||||||||
*: significantly different from 0 at p < 0.05; **: significantly different from 0 at p < 0.01. FPED is the inbreeding coefficient estimated from pedigree data. FROH is inbreeding coefficient estimated based on ROH for 50k data and for sequence data FROH> 1Mb and FROH> 3Mb are also reported. FGRM is GRM-based inbreeding coefficient estimated from 50k and sequence data. FHOM is inbreeding coefficient estimated based on excess of homozygosity for 50k and sequence data. FUNI is the inbreeding coefficient estimated based on correlation of uniting gametes for 50k and sequence data
Table 5.
Correlation coefficients between different estimates for inbreeding from different data sets for RDC
| Correlation | FPED | 50k SNP chip data | Sequence data | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FROH | FGRM | FHOM | FUNI | FROH | FROH> 1Mb | FROH> 3Mb | FGRM | FHOM | FUNI | |||
| FPED | 1 | 0.54** | 0.36* | −0.31 | 0.45* | 0.49** | 0.54** | 0.51** | −0.21 | 0.37* | 0.32 | |
| 50k SNP chip data | FROH | 1 | 0.41* | 0.35 | 0.80** | 0.85** | 0.96** | 0.98** | 0.08 | 0.21 | 0.77** | |
| FGRM | 1 | −0.66** | 0.82** | 0.22 | 0.34 | 0.38* | −0.36 | 0.43* | 0.05 | |||
| FHOM | 1 | −0.10 | 0.40* | 0.40* | 0.38* | 0.38* | −0.23 | 0.52 | ||||
| FUNI | 1 | 0.60** | 0.76** | 0.79** | −0.20 | 0.40* | 0.46* | |||||
| Sequence data | FROH | 1 | 0.93** | 0.87** | 0.003 | 0.31 | 0.81** | |||||
| FROH> 1Mb | 1 | 0.97** | 0.010 | 0.29 | 0.79** | |||||||
| FROH> 3Mb | 1 | 0.038 | 0.25 | 0.76** | ||||||||
| FGRM | 1 | −0.95** | 0.54** | |||||||||
| FHOM | 1 | −0.24 | ||||||||||
| FUNI | 1 | |||||||||||
*: significantly different from 0 at p < 0.05; **: significantly different from 0 at p < 0.01. FPED is the inbreeding coefficient estimated from pedigree data. FROH is inbreeding coefficient estimated based on ROH for 50k data and for sequence data FROH> 1Mb and FROH> 3Mb are also reported. FGRM is GRM-based inbreeding coefficient estimated from 50k and sequence data. FHOM is inbreeding coefficient estimated based on excess of homozygosity for 50k and sequence data. FUNI is the inbreeding coefficient estimated based on correlation of uniting gametes for 50k and sequence data
FPED was mostly intermediately correlated with FHOM and FROH estimated from 50k and sequence data. The highest correlation between FPED and FROH estimated from 50k and sequence data was found in HOL (Table 3). The strongest correlation among estimators of FROH (FROH from 50k or sequence data or FROH>3Mb or FROH>1Mb from sequence data) and FPED was observed between FPED and FROH>3Mb from sequence data in HOL (Table 3). A moderate correlation was found between FPED and FROH estimated from 50k and sequence data for JER and RDC (Tables 4 and 5).
The estimate FGRM from both 50k and sequence data and FPED had a correlation close to zero in all three breeds and the values were often negative (Tables 3, 4 and 5). At the same time, FGRM estimated from 50k and sequence data generally showed a low correlation with other estimates except between two estimates FGRM estimated from 50k and sequence data in HOL and JER, and between FGRM and FUNI estimated from 50k data (Tables 3 and 4).
Discussion
Pedigree has been used to estimate inbreeding coefficients in animal breeding for over 50 years [1, 17]. Recently, researchers have utilized runs of homozygosity (ROH) estimated from medium density genotype data such as 50k SNP chip data to estimate inbreeding coefficients in livestock populations [22–24, 30]. ROH were initially used to explore regions of inbreeding in the genome and further investigate the fitness effect of these regions on different traits [2, 9, 11, 43]. Population subdivision and either inbreeding or inbreeding avoidance affects the whole genome composition, whereas selection and assortative mating will affect only those loci associated with particular phenotypes. However, we observed that inbreeding coefficient FROH estimated from sequence data were relatively higher for chromosome 1 and 10 for all four breeds (Fig. 1). This is most likely because the local recombination rate is relatively lower than average, which results in high levels of homozygosity on average [23, 44].
Fig. 1.
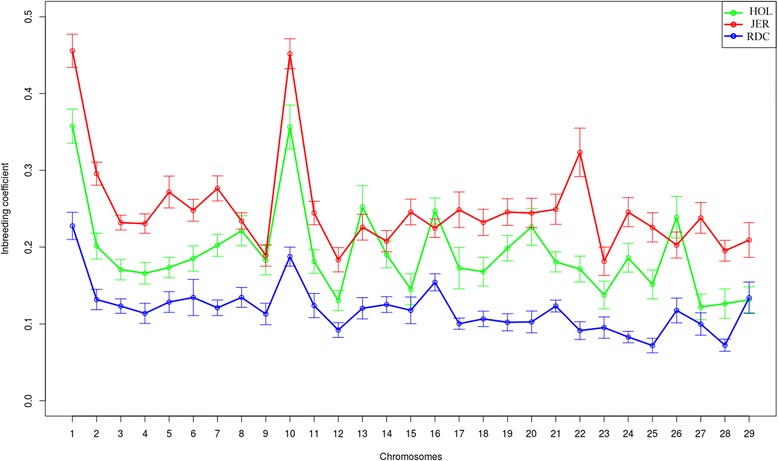
Distribution of inbreeding coefficients FROH estimated from sequence data using ROH for each chromosome in three breeds. Inbreeding coefficients FROH estimated from sequence data versus chromosomes 1–29 in HOL. JER and RDC. Standard error bars were computed among individuals within HOL, JER and RDC
Our study is the first to calculate inbreeding coefficient based on ROH from full sequence data in cattle. The objective of this study was to compare estimates of inbreeding calculated from different methods and different data sources (pedigree, 50k SNP chip genotypes and full sequence data).
The pedigree-based inbreeding coefficient, FPED, was moderately correlated with FHOM and FROH in all breeds. These moderate correlations (~0.47 to 0.56) may be partly explained by the relatively shallow depth of the pedigree records (~8–9) for these bulls. Another difference between FROH and FPED is that short ROH capture ancient inbreeding while long ROH capture recent inbreeding whereas pedigree captures only relatively recent inbreeding. Pedigree accounts only for inbreeding that occurred since pedigree recording began. Therefore, after excluding ROH smaller than 1 or 3 Mbp, the correlation between FPED and FROH from sequence data increased slightly for all breeds. We should also point out that a very long stretch of homozygosity using marker data might not actually be completely homozygous and therefore, higher density data was suggested to be used to detect selective sweeps through runs of homozygosity [45]. Sørensen et al. [7] has estimated inbreeding in Danish Dairy Cattle Breeds and our estimates FPED are lower than theirs. This is because our sampled animals for sequencing are founder and older animals compare to the other study where they used all animals [7].
Estimates of inbreeding coefficients differed with methods. Inbreeding coefficients estimates from methods using allele frequencies, i.e., FGRM, FHOM and FUNI, showed considerable variation across data type and breeds. These estimators were sensitive to allele frequencies compared to ROH estimators, especially for populations with divergent allele frequencies (e.g., Fig. 2; RDC population). The estimates of genomic inbreeding coefficients are dependent on the allele frequencies in the base population [40].
Fig. 2.
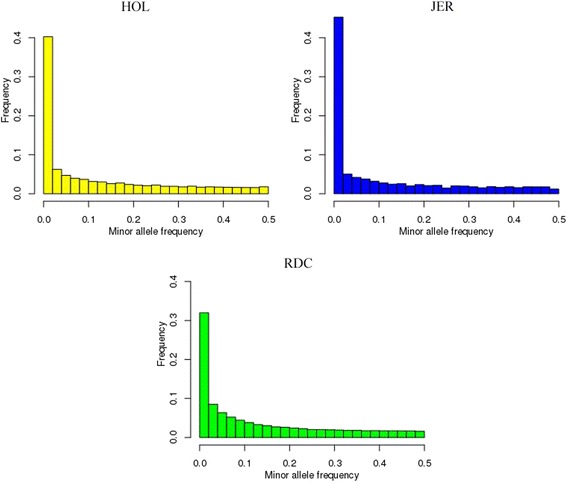
Minor allele frequency distribution for HOL, JER, and RDC bulls from sequence data. Minor allele frequency in HOL (yellow), JER (blue), and RDC (green) bulls against the minor allele frequency among all loci
In order to explore the reasons about the various correlations between inbreeding coefficients estimates using allele frequencies, FGRM, FHOM and FUNI were plotted against the allele frequency changing from 0 to 1 when the number of copies of reference alleles for ith SNP is 0, 1 or 2 (Figs. 3, 4 and 5). When a locus is homozygous for either the reference alleles or the non-reference alleles with the allele frequency ranging from 0 to 1, FGRM ranged from -1 to infinity, FHOM has a constant value of 1 and FUNI ranged from 0 to infinity (Figs. 3 and 5). FHOM gave constant estimates for homozygous genotypes, regardless of the allele frequency (Figs. 3 and 5). When the allele frequency of the non-reference alleles is smaller than 0.2 or larger than 0.8, FGRM was less than 0 (Figs. 3 and 5). When the allele frequency of the non-reference allele was between 0.2 and 0.5 or when the allele frequency of the reference allele was between 0.5 and 0.8, FGRM become positive and ranges from 0 to 1 (Figs. 3 and 5).
Fig. 3.
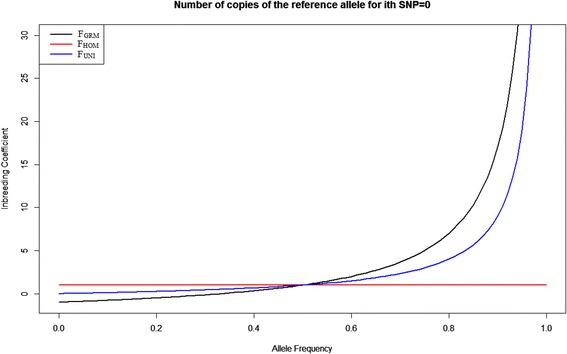
Inbreeding coefficients FGRM, FHOM and FUNI against the reference allele frequency changing from 0 to 1 when the number of copies of reference alleles for the ith SNP is 0. Black line represents FGRM; red line represents FHOM and blue line represents FUNI
Fig. 4.
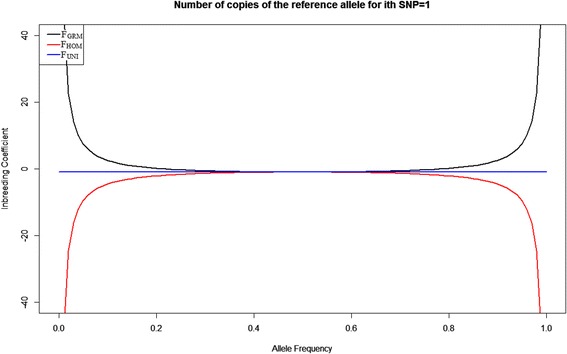
Inbreeding coefficients FGRM, FHOM and FUNI against the reference allele frequency changing from 0 to 1 when the number of copies of reference alleles for the ith SNP is 1. Black line represents FGRM; red line represents FHOM and blue line represents FUNI
Fig. 5.
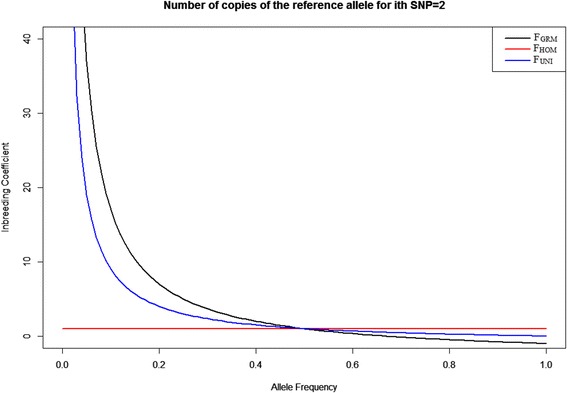
Inbreeding coefficients FGRM, FHOM and FUNI against the reference allele frequency changing from 0 to 1 when the number of copies of reference alleles for the ith SNP is 2. Black line represents FGRM; red line represents FHOM and blue line represents FUNI
For a heterozygous locus with an allele frequency ranging from 0 to 1, FGRM and FHOM ranged from minus infinity to plus infinity, and FUNI has a constant value of 0 (Fig. 4). If the allele frequency was smaller than 0.2 or larger than 0.8 FGRM become very large positive whereas FHOM become a large negative. FHOM was always negative, and FGRM was always positive (Fig. 4). Thus, when a population has a high level of heterozygosity and some rare alleles with small frequency, FGRM would yield large positive inbreeding coefficients, which can be misleading. This result explains why FGRM was positive in the RDC breed (Table 2): this population had a higher level of heterozygosity than HOL and JER. FUNI gave a stable value of 0 when the locus was heterozygous and therefore was robust to allele frequency (Fig. 4).
The correlation between the three estimators FGRM, FHOM and FUNI was computed for each of the three genotypes (i.e., homozygotes for allele 1, homozygotes for allele 2 and heterozygotes) for comparison between FGRM, FHOM and FUNI when the allele frequency was varied between 0 and 1 (Fig. 6). Correlations reached the maximal value (i.e., 1) when the allele frequencies were 0.5. When the allele frequencies were extremely high or low, correlations between estimators became low, especially the correlation between FGRM and FHOM (0.27). The correlation plot (Fig. 6) reflected a similar result as those in Figs. 3, 4 and 5. Therefore, when computing inbreeding coefficients using allele frequencies, populations with different allele frequencies might have very different inbreeding coefficients and the correlations between those inbreeding coefficients might be very low, with different allele frequencies.
Fig. 6.
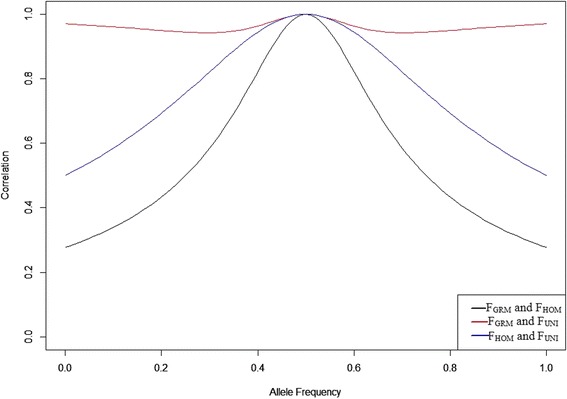
Correlations between FGRM and FHOM, FGRM and FUNI, and FHOM and FUNI when reference allele frequency changes between 0 and 1. Black line represents correlation between FGRM and FHOM against reference allele frequencies; red line represents correlation between FGRM and FUNI against reference allele frequencies and blue line represents correlation between FHOM and FUNI against reference allele frequencies
The comparison between FGRM and other estimators showed a very low correlation and FGRM was mostly negatively correlated with other estimators. FHOM based on excess of homozygosity was positively correlated with other estimators and was relatively highly correlated with FROH detected from 50k and sequence data. FUNI based on correlations between uniting gametes estimated from 50k data generally was negatively correlated with other estimators. However, with increasing marker density, the correlation between FUNI and other estimators became positive for the HOL and RDC populations. Surprisingly, when using sequence data, FUNI was highly correlated with other estimators, especially FROH, detected from sequence data (~0.95) for HOL. This correlation may have resulted from the nature of the estimators: FROH uses only runs of homozygosity, whereas the other estimators (to some extent) capture all of the homozygosity. This high correlation for FUNI and FROH compared with low correlation between FGRM and FROH might also be explained by the algorithms: FGRM = (1 + F)-1 and F is the correlation between uniting gametes. This estimator has only sampling on the F-term, whereas in the FGRM estimator there is also sampling variance on the “1”, which creates additional sampling variance.
It is known that RDC is an admixed breed with introgressed haplotypes from Old Danish Red, Holstein and Brown Swiss breeds. HOL and JER are relatively pure breeds and more inbred than RDC (Zhang Q, Guldbrandtsen B, Bosse M, Lund MS, Sahana G. Runs of homozygosity and distribution of functional variants in the cattle genome. BMC Genomics (in press)). Therefore, minor allele frequencies tend to be lower in HOL and JER breeds than in RDC. FGRM is negatively correlated with other estimators for all three breeds. FHOM becomes negative for RDC, which is likely due to the admixture present in RDC. Therefore, it appears that FGRM tends to be less accurate for populations with a low minor allele frequency and that FHOM tends to be less accurate for populations with a higher level of heterozygosity. This argument is supported by our results that the three inbreeding estimators FGRM, FHOM and FUNI were most closely correlated with each other when the allele frequency is approximately 0.5 (Figs. 3, 4 and 5). Therefore, the three estimators FGRM, FHOM and FUNI depend strongly on the estimation of allele frequencies in the population, unlike FROH. However, here we only took one locus as an example to study the impact of allele frequencies on three estimators FGRM, FHOM and FUNI.
Conclusion
In this study, we compared different estimators of inbreeding coefficient with different types of data (pedigree, 50k SNP chip genotypes and full sequence data). Methods based on GRM, excess of homozygosity and the correlation between uniting gametes were observed to be sensitive to allele frequencies in the base population. The estimator based on pedigree data was moderately correlated with estimators based on ROH when a pedigree is relatively complete. Estimators based on ROH from SNP chip genotypes and full sequence directly reflect homozygosity on the genome, and have the advantage of not being affected by estimates of allele frequency or incompleteness of the pedigree. Inbreeding estimated from ROH was shown to be affected by the marker density used. Using sequence data, we obtained a full picture of the distribution of ROH on the genome, including short and medium length ROH that reflect ancient inbreeding regions which are possibly IBD. Detecting ROH based on high-density or 50k chip data was shown to give estimates most closely related to ROH from sequence data. However, more than 50k genotypes are required to accurately detect short ROH that are most likely identical by descent (IBD).
Availability of supporting data
Data used in this study are from the 1000 Bull Genome Project (Daetwyler et al. 2014 Nature Genet. 46:858–865). Whole genome sequence data of individual bulls of the 1000 Bull Genomes Project are already available at NCBI using SRA no. SRP039339 (http://www.ncbi.nlm.nih.gov/bioproject/PRJNA238491).
Acknowledgement
Q. Zhang benefited from a joint grant from the European Commission within the framework of the Erasmus-Mundus joint doctorate “EGS-ABG”. This research was supported by the Center for Genomic Selection in Animals and Plants (GenSAP) funded by The Danish Council for Strategic Research.
Abbreviations
- F
Inbreeding coefficient
- FPED
Pedigree based inbreeding coefficient
- ROH
Run of homozygosity
- FROH
Runs of homozygosity-based inbreeding coefficients
- GRM
Genomic relationship matrix
- FGRM
Genomic relationship matrix-based inbreeding coefficients
- FHOM
Inbreeding coefficients based on excess of homozygosity
- FUNI
Inbreeding coefficients based on correlation of uniting gametes
- IBD
Identity by descent
- SNP
Single nucleotide polymorphism
- NGS
Next-generation sequence
- HOL
Holstein
- JER
Jersey
- RDC
Danish Red Cattle
- WGS
Whole-genome sequence
Footnotes
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
QZ developed and planned the study design, coordinated the study, recruited the participants, performed data analyses and drafted the manuscript. MC participated in the study design, analyses of data, and drafting the manuscript. BG participated in the study design, analyses of data, and drafting the manuscript. MSL participated in study design and drafting the manuscript. GS participated in the study design, analyses of data, and drafting the manuscript. All authors read and approved the final manuscript.
Contributor Information
Qianqian Zhang, Email: Qianqian.zhang@mbg.au.dk.
Mario PL Calus, Email: Mario.calus@wur.nl.
Bernt Guldbrandtsen, Email: Bernt.guldbrandtsen@mbg.au.dk.
Mogens S Lund, Email: Mogens.Lund@mbg.au.dk.
Goutam Sahana, Email: Goutam.sahana@mbg.au.dk.
References
- 1.Wright S. Coefficients of inbreeding and relationship. Am Nat. 1922;56:330–338. doi: 10.1086/279872. [DOI] [Google Scholar]
- 2.Gonzalez-Recio O, de Maturana EL, Gutierrez JP. Inbreeding depression on female fertility and calving ease in Spanish dairy cattle. J Dairy Sci. 2007;90(12):5744–5752. doi: 10.3168/jds.2007-0203. [DOI] [PubMed] [Google Scholar]
- 3.Margolin S, Bartlett JW. The influence of inbreeding upon the weight and size of dairy cattle. J Anim Sci. 1945;4(1):3–12. [Google Scholar]
- 4.Miglior F, Szkotnicki B, Burnside EB. Analysis of levels of inbreeding and inbreeding depression in Jersey cattle. J Dairy Sci. 1992;75(4):1112–1118. doi: 10.3168/jds.S0022-0302(92)77856-4. [DOI] [PubMed] [Google Scholar]
- 5.Nomura T, Honda T, Mukai F. Inbreeding and effective population size of Japanese black cattle. J Anim Sci. 2001;79(2):366–370. doi: 10.2527/2001.792366x. [DOI] [PubMed] [Google Scholar]
- 6.Smith LA, Cassell BG, Pearson RE. The effects of inbreeding on the lifetime performance of dairy cattle. J Dairy Sci. 1998;81(10):2729–2737. doi: 10.3168/jds.S0022-0302(98)75830-8. [DOI] [PubMed] [Google Scholar]
- 7.Sorensen AC, Sorensen MK, Berg P. Inbreeding in Danish dairy cattle breeds. J Dairy Sci. 2005;88(5):1865–1872. doi: 10.3168/jds.S0022-0302(05)72861-7. [DOI] [PubMed] [Google Scholar]
- 8.Szpiech ZA, Xu JS, Pemberton TJ, Peng WP, Zollner S, Rosenberg NA, Li JZ. Long runs of homozygosity are enriched for deleterious variation. Am J Hum Genet. 2013;93(1):90–102. doi: 10.1016/j.ajhg.2013.05.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Bjelland DW, Weigel KA, Vukasinovic N, Nkrumah JD. Evaluation of inbreeding depression in Holstein cattle using whole-genome SNP markers and alternative measures of genomic inbreeding. J Dairy Sci. 2013;96(7):4697–4706. doi: 10.3168/jds.2012-6435. [DOI] [PubMed] [Google Scholar]
- 10.Leroy G. Inbreeding depression in livestock species: review and meta-analysis. Anim Genet. 2014;45(5):618–628. doi: 10.1111/age.12178. [DOI] [PubMed] [Google Scholar]
- 11.Charlesworth D, Charlesworth B. Inbreeding depression and its evolutionary consequences. Annu Rev Ecol Syst. 1987;18:237–268. doi: 10.1146/annurev.es.18.110187.001321. [DOI] [Google Scholar]
- 12.Wright S. Systems of mating. II. The effects of inbreeding on the genetic composition of a population. Genetics. 1921;6(2):124–143. doi: 10.1093/genetics/6.2.124. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Pusey A, Wolf M. Inbreeding avoidance in animals. Trends Ecol Evol. 1996;11(5):201–206. doi: 10.1016/0169-5347(96)10028-8. [DOI] [PubMed] [Google Scholar]
- 14.Weigel K. Controlling inbreeding in modern dairy breeding programs. Adv Dairy Technol. 2006;18:263–274. [Google Scholar]
- 15.Mc Parland S, Kearney JF, Rath M, Berry DP. Inbreeding trends and pedigree analysis of Irish dairy and beef cattle populations. J Anim Sci. 2007;85(2):322–331. doi: 10.2527/jas.2006-367. [DOI] [PubMed] [Google Scholar]
- 16.Blackwell BF, Doerr PD, Reed JM, Walter JR. Inbreeding rate and effective population-size - a comparison of estimates from pedigree analysis and a demographic-model (Vol 71, Pg 299, 1995) Biol Conserv. 1995;72(3):407. [Google Scholar]
- 17.Meuwissen THE, Luo Z. Computing inbreeding coefficients in large populations. Genet Sel Evol. 1992;24(4):305–313. doi: 10.1186/1297-9686-24-4-305. [DOI] [Google Scholar]
- 18.Cassell BG, Adamec V, Pearson RE. Effect of incomplete pedigrees on estimates of inbreeding and inbreeding depression for days to first service and summit milk yield in Holsteins and Jerseys. J Dairy Sci. 2003;86(9):2967–2976. doi: 10.3168/jds.S0022-0302(03)73894-6. [DOI] [PubMed] [Google Scholar]
- 19.Vanraden PM. Accounting for inbreeding and crossbreeding in genetic evaluation of large populations. J Dairy Sci. 1992;75(11):3136–3144. doi: 10.3168/jds.S0022-0302(92)78077-1. [DOI] [Google Scholar]
- 20.McQuillan R, Leutenegger AL, Abdel-Rahman R, Franklin CS, Pericic M, Barac-Lauc L, Smolej-Narancic N, Janicijevic B, Polasek O, Tenesa A, et al. Runs of homozygosity in European populations. Am J Hum Genet. 2008;83(3):359–372. doi: 10.1016/j.ajhg.2008.08.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Broman KW, Weber JL. Long homozygous chromosomal segments in reference families from the Centre d’Etude du polymorphisme humain. Am J Hum Genet. 1999;65(6):1493–1500. doi: 10.1086/302661. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Marras G, Gaspa G, Sorbolini S, Dimauro C, Ajmone-Marsan P, Valentini A, et al: Analysis of runs of homozygosity and their relationship with inbreeding in five cattle breeds farmed in Italy. Anim Genet. 2015;46(2):110-121. [DOI] [PubMed]
- 23.Bosse M, Megens HJ, Madsen O, Paudel Y, Frantz LA, Schook LB, Crooijmans RP, Groenen MA. Regions of homozygosity in the porcine genome: consequence of demography and the recombination landscape. PLoS Genet. 2012;8(11):e1003100. doi: 10.1371/journal.pgen.1003100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Ferencakovic M, Solkner J, Curik I. Estimating autozygosity from high-throughput information: effects of SNP density and genotyping errors. Genet Sel Evol. 2013;45:42. doi: 10.1186/1297-9686-45-42. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Keller MC, Visscher PM, Goddard ME. Quantification of inbreeding due to distant ancestors and its detection using dense single nucleotide polymorphism data (vol 189, pg 237, 2011) Genetics. 2012;190(1):283. doi: 10.1534/genetics.111.130922. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Kirin M, McQuillan R, Franklin CS, Campbell H, McKeigue PM, Wilson JF. Genomic runs of homozygosity record population history and consanguinity. Plos One. 2010;5(11):e13996. doi: 10.1371/journal.pone.0013996. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Ku CS, Naidoo N, Teo SM, Pawitan Y. Regions of homozygosity and their impact on complex diseases and traits. Hum Genet. 2011;129(1):1–15. doi: 10.1007/s00439-010-0920-6. [DOI] [PubMed] [Google Scholar]
- 28.Li JZ, Absher DM, Tang H, Southwick AM, Casto AM, Ramachandran S, Cann HM, Barsh GS, Feldman M, Cavalli-Sforza LL, et al. Worldwide human relationships inferred from genome-wide patterns of variation. Science. 2008;319(5866):1100–1104. doi: 10.1126/science.1153717. [DOI] [PubMed] [Google Scholar]
- 29.Charlesworth B, Morgan MT, Charlesworth D. The effect of deleterious mutations on neutral molecular variation. Genetics. 1993;134(4):1289–1303. doi: 10.1093/genetics/134.4.1289. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Ferencakovic M, Hamzic E, Gredler B, Solberg TR, Klemetsdal G, Curik I, Solkner J. Estimates of autozygosity derived from runs of homozygosity: empirical evidence from selected cattle populations. J Anim Breed Genet. 2013;130(4):286–293. doi: 10.1111/jbg.12012. [DOI] [PubMed] [Google Scholar]
- 31.Purfield DC, Berry DP, McParland S, Bradley DG. Runs of homozygosity and population history in cattle. BMC Genet. 2012;13:70. doi: 10.1186/1471-2156-13-70. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.MacLeod IM, Larkin DM, Lewin HA, Hayes BJ, Goddard ME. Inferring demography from runs of homozygosity in whole-genome sequence, with correction for sequence errors. Mol Biol Evol. 2013;30(9):2209–2223. doi: 10.1093/molbev/mst125. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Wright S. Genetics of populations. Encyclopaedia Britannica. 1948;10:111-A-D-112. [Google Scholar]
- 34.Andersen B, Jensen B, Nielsen A, Christensen LG, Liboriussen T. Rød Dansk Malkerace-avlsmæssigt of kulturhistorisk belyst. Denmark: Danmarks HordbrugsForskning; 2003.
- 35.Ewing B, Hillier L, Wendl MC, Green P. Base-calling of automated sequencer traces using phred. I. Accuracy assessment. Genome Res. 1998;8(3):175–185. doi: 10.1101/gr.8.3.175. [DOI] [PubMed] [Google Scholar]
- 36.McKenna A, Hanna M, Banks E, Sivachenko A, Cibulskis K, Kernytsky A, Garimella K, Altshuler D, Gabriel S, Daly M, et al. The genome analysis toolkit: a mapreduce framework for analyzing next-generation DNA sequencing data. Genome Res. 2010;20:1297–1303. doi: 10.1101/gr.107524.110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Hoglund JK, Sahana G, Guldbrandtsen B, Lund MS. Validation of associations for female fertility traits in Nordic Holstein, Nordic Red and Jersey dairy cattle. BMC Genet. 2014;15:8. doi: 10.1186/1471-2156-15-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Quaas RL. Computing the diagonal elements and inverse of a large numerator relationship matrix. Biometrics. 1976;32:949–953.
- 39.Strandén I, Vuori K: Relax2: pedigree analyses program. Proceedings of the 8th WCGALP. Belo Horizonte, MG, Brazil: Instituto Prociência; 2006.
- 40.VanRaden PM. Efficient methods to compute genomic predictions. J Dairy Sci. 2008;91(11):4414–4423. doi: 10.3168/jds.2007-0980. [DOI] [PubMed] [Google Scholar]
- 41.Yang JA, Lee SH, Goddard ME, Visscher PM. GCTA: a tool for genome-wide complex trait analysis. Am J Hum Genet. 2011;88(1):76–82. doi: 10.1016/j.ajhg.2010.11.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Purcell S, Neale B, Todd-Brown K, Thomas L, Ferreira MAR, Bender D, Maller J, Sklar P, de Bakker PIW, Daly MJ, et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am J Hum Genet. 2007;81(3):559–575. doi: 10.1086/519795. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Pryce JE, Haile-Mariam M, Goddard ME, Hayes BJ. Identification of genomic regions associated with inbreeding depression in Holstein and Jersey dairy cattle. Genet Sel Evol. 2014;46(1):71. doi: 10.1186/s12711-014-0071-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Arias JA, Keehan M, Fisher P, Coppieters W, Spelman R. A high density linkage map of the bovine genome. BMC Genet. 2009;10:18. doi: 10.1186/1471-2156-10-18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Ramey HR, Decker JE, McKay SD, Rolf MM, Schnabel RD, Taylor JF. Detection of selective sweeps in cattle using genome-wide SNP data. BMC Genomics. 2013;14:382. doi: 10.1186/1471-2164-14-382. [DOI] [PMC free article] [PubMed] [Google Scholar]