

Abstract
Purpose
Brain vessels are among the most critical landmarks that need to be assessed for mitigating surgical risks in stereo-electroencephalography (SEEG) implantation. Intracranial haemorrhage is the most common complication associated with implantation, carrying significantly associated morbidity. SEEG planning is done pre-operatively to identify avascular trajectories for the electrodes. In current practice, neurosurgeons have no assistance in the planning of electrode trajectories. There is great interest in developing computer-assisted planning systems that can optimise the safety profile of electrode trajectories, maximising the distance to critical structures. This paper presents a method that integrates the concepts of scale, neighbourhood structure and feature stability with the aim of improving robustness and accuracy of vessel extraction within a SEEG planning system.
Methods
The developed method accounts for scale and vicinity of a voxel by formulating the problem within a multi-scale tensor voting framework. Feature stability is achieved through a similarity measure that evaluates the multi-modal consistency in vesselness responses. The proposed measurement allows the combination of multiple images modalities into a single image that is used within the planning system to visualise critical vessels.
Results
Twelve paired data sets from two image modalities available within the planning system were used for evaluation. The mean Dice similarity coefficient was , representing a statistically significantly improvement when compared to a semi-automated single human rater, single-modality segmentation protocol used in clinical practice ().
Conclusions
Multi-modal vessel extraction is superior to semi-automated single-modality segmentation, indicating the possibility of safer SEEG planning, with reduced patient morbidity.
Keywords: Computer-assisted planning system, Vessel extraction , Depth electrode insertion, Image-guided surgery, Multi-modal segmentation
Introduction
The primary goal of epilepsy surgery is to remove the epileptogenic zone, the minimum amount of cortex that must be resected to produce seizure freedom [3, 16]. As the epileptogenic zone may not be associated with a clear structural abnormality, intracranial electrodes must be used to record the area of the brain where seizures start, known as the seizure-onset zone (SOZ) [3]. Stereo-electroencephalography (SEEG) is the recording of the brain electrical activity by depth electrodes implanted into the brain parenchyma to precisely identify the SOZ. The major complication associated with SEEG implantation is intracranial haemorrhage with a risk that ranges from 0.6 to 2.7 % [13] and reported morbidity and mortality of 5.6 % [2] and 1 % (or less) [13], respectively. To reduce the risk of this and other associated complications, it is necessary to identify electrode trajectories with adequate cortical coverage that pass through safe avascular planes. This is done through pre-operative SEEG planning.
In recent years, there has been great interest in the development of computer-assisted planning systems for optimising intracranial depth electrode insertion [1, 4, 5, 18]. These methods require the effective extraction of critical brain landmarks (such as vessels, ventricles and sulci), with high accuracy and robustness. Despite this requirement, the techniques used to extract the landmarks are very general and may not be the best for this application. While some efforts have been made to improve them [1, 4], greater improvements yet may be obtained using domain-specific knowledge. Furthermore, as pointed by Du et al. [4], the evaluation or validation of the extraction of these brain landmarks is not included in these studies, which hinders the identification of potential problems of the currently used techniques. In this work, we specifically address the extraction of the intracranial vasculature within an SEEG planning system.
A key part of the landmark identification is the vessel extraction. This, despite years of research [9], remains a challenging problem. For this reason, Essert et al. [5], avoid dealing with it directly. Instead, they segment the cortical sulci under the hypothesis that vessels of interest are generally located there. Existing methods of vessel extraction still tend to suffer from discontinuities (caused by low intensity due to partial volume effects and noise) and false-positives; both of these are undesirable as they can lead to invalid or suboptimal trajectories. A common solution, adopted by Bériault et al. [1] and Du et al. [4], is the use of a vesselness filter [6, 10, 17] that enhances voxels within tubular structures. These filters have been very successful thanks to the inclusion of multiple spatial scales within their formulation, but lack information about the surrounding structures. Also, despite increased access to multi-modal images, particularly within computer-assisted planning systems, very few methods have exploited the information complementarity to improve vessel extraction. Passat et al. [15] combined multiple MR sequences to segment the superior sagittal sinus, but their vessel extraction was only performed on a single image, with a second modality used to provide a priori anatomical information of the brain. More recently, Bériault et al. [1] used susceptibility weighted imaging (SWI) and time-of-flight (TOF) images within a planning system to segment veins and arteries, but they do so in a separate fashion and leave it up to the human planner to combine the information from the two modalities. Elsewhere, Hu et al. [8] have proposed a bi-modal approach to 2D retinal vessel extraction using a k-NN classifier trained on features from both modalities.
In this paper, we present a novel method that integrates the concepts of scale, neighbourhood structure and feature stability with the aim of improving the robustness and accuracy of vessel extraction within a computer-assisted SEEG planning system [19]. The method accounts for both the scale and vicinity of a voxel by formulating the problem within a multi-scale tensor voting framework. Feature stability is achieved by introducing a similarity measure that accounts for the multi-modal consistency in the vesselness responses. The proposed measurement enables the combination of multiple responses into a single image that is used within the planning system to visualise critical vessels. This article is an extended version of Zuluaga et al. [20]; it explains the methodology in more detail, extends the original method to cope with an arbitrary number of images and proposes a new way to consider multiple scales within the tensor voting framework to improve the computational speed. A new set of validation experiments is also included.
Method
The tensor voting framework [11] is a robust technique for extracting structures from a cloud of points. It is based on the principle that a set of unconnected tokens (i.e. points) can exchange information within a neighbourhood that allows one to infer the geometric structure in which a token lies. In 3D, it provides a way to estimate the likelihood that a token lies on a surface, curve or junction (as opposed to being just noise).
Tensor voting consists of three stages: token initialisation, where token locations are identified and their tensors assigned; tensor voting, where tensors from a token and its neighbours are combined; and analysis of voting results. In order to give our method feature stability and scale invariance, we add a data fusion step and then embed the different components into a multi-scale framework. A diagram illustrating the proposed method is shown in Fig. 1.
Fig. 1.
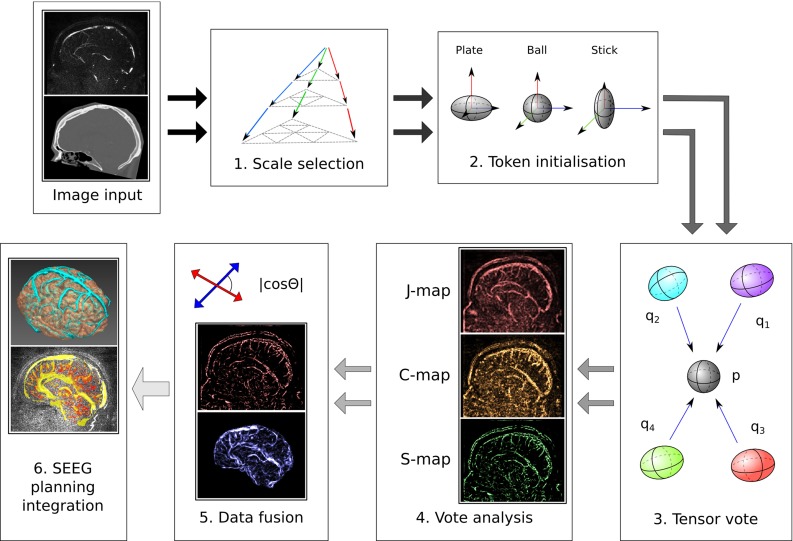
Vessel extraction diagram. After optimal scale selection, images are converted into tokens through analysis of the Hessian matrix. After voting, the resulting saliency maps are combined using the cosine between the vectors defining orientation. The resulting probability map is then visualised in the planning system
Multi-scale framework and voxel selection
In previous work [20], we formulated the tensor voting approach into a multi-scale framework by evaluating the response of different scales at the data fusion stage and retaining the maximum response through scales. This consists in performing steps 2–5 in Fig. 1 for every scale and image modality. As the tensor vote has to be computed every time, this can be very computationally intensive. To reduce the computational burden of the method, we now perform the multi-scale analysis before the tensor voting step, rather than at the final stage.
Let be an image and be the Hessian matrix at voxel at scale . By means of the eigenvalues and eigenvectors of , a vesselness function [10] is computed at a range of scales . An “optimal scale” image is constructed by finding the value of with the maximum vesselness response at each voxel:
| 1 |
While the Hessian and its eigensystem are computed across the full range of scales, all further calculations involving scale analysis are performed using the scale defined by . For simplicity, we denote the Hessian at the locally optimal scale as .
We derive from this eigensystem the information about which voxels are likely to belong to a vessel structure. The eigenvalues of are ordered by their absolute value, so that . For bright vessels on a dark background, a voxel is expected to belong to a vessel only if and [10]. Based on this information, voxels that do not satisfy this condition for at least one scale can be discounted in the further analysis. Voxels satisfying the condition go on to take part in the tensor voting, with their Hessian computed at the locally optimal scale. Under the voting formalism, a voxel considered for tensor voting is called a token and is denoted as .
Token initialisation
The information contained in a token is encoded on a 3D second-order, symmetric, nonnegative definite tensor . According to the spectrum theorem, can be expressed as the linear combination of three tensors:
| 2 |
where are the eigenvalues obtained from the eigendecomposition of , with , and are the corresponding eigenvectors.
While the tensor is most commonly expressed as a matrix, it can be viewed as a 3D ellipsoid whose shape describes the contribution of its different components in Eq. 2. These components are known as the stick tensor , the plate tensor and the ball tensor . More precisely, through expansion of the second and third terms, they are defined as:
| 3 |
Each tensor component corresponds to a different type of structural information: the stick tensor represents an elongated ellipsoid encoding eccentricity with orientation , the plate tensor represents a disc-shaped structure with normal , and the ball tensor represents a round structure in which all orientations are equally probable. The scalar values associated with each tensor are the saliency measurements of “surfaceness” , “curveness” and “junctionness” . Points with very small eigenvalues are regarded as noise.
The scalar information contained in a greyscale image needs to be encoded into a tensor that satisfies Eqs. 2–3 before it can be used within the tensor voting framework. Depending on which tensor is assigned to the tokens in the token intitialisation step, different aspects of image will inform the final vessel segmentation. In this paper, we explore the three alternatives presented below.
No preferred orientation
A common approach is to assign an isotropic, ball-shaped tensor to each of the tokens [11, 12]. All three eigenvalues of a token’s tensor have the same value, . While the tensors at each token have the same shape, they can be given different magnitudes (values of ) according to their tokens’ vessel salience score. In this way, tokens that are most likely to be on the vessels are given greater importance in the final segmentation. In this work, we experiment with using both a token’s vesselness, , or its image intensity, , as salience score/weight.
Hessian matrix-based orientation
The analysis of the eigensystem of the Hessian matrix provides information about the orientations of structures within an image [6]. Let us recall , the eigenvectors of at the optimal scale, and , its eigenvectors. Tokens are initialised with a stick tensor that has orientation (the eigenvector associated with ), the direction along the vessel. The saliency of the stick tensor is obtained by assigning the to the corresponding . As with the ball tensor, it is possible to initialise the stick tensors with different weights reflecting an initial estimate of a token’s vesselness. Section “Experiments and results” compares the results obtained when varying these values.
Structure tensor-based initialisation. Given ,1 the image gradient at a given token position , Moreno et al. [12] showed that the tensorised gradient, , can be used to initialise a stick tensor at every token, giving a saliency measurement .
Table 1 summarises the values that are assigned to the tensor’s eigenvalues, , and eigenvectors, , depending on the type of used initialisation.
Table 1.
Eigenvalues and eigenvectors of for each initial orientation initialisation
| Initialisation | Eigenvalues | Eigenvectors |
|---|---|---|
| No preferred orientation | 1: | , |
| 2: | ||
| 3: | ||
| Hessian matrix | 1: | |
| 2: | ||
| Structure tensor | , | , |
Note that when no preferred orientation is used, three different saliency measurements can be used. Similarly, two different configurations of the initial eigenvalues are proposed when using Hessian matrix analysis
Tensor voting
After each token is encoded as a tensor in the form of Eq. 2, it propagates structural information to its neighbours in the form of a vote. Votes are combined through addition at every token to infer the type of structure going through it. More formally, the tensor voting at is given by [12]:
| 4 |
where denotes the neighbourhood of , a point belonging to , SV, PV and BV the stick, plate and ball votes cast to by each component , , of and . The strength of the vote will be dependent on the norm of , as the influence of a point should decay as its distance from increases. Here, is defined as the window of size at every token with
| 5 |
where is the “optimal scale” image defined in Eq. 1.
The derivation of SV, PV and BV in Eq. 4 is extensive and beyond the scope of this paper. We therefore only present their formulation (see Appendix 6), mentioning that the tensor voting procedure can be regarded as a tensor convolution with a voting kernel which itself produces a tensor. The interested reader is referred to [11, 12] for further details.
Voting analysis
As the result of the tensor voting is another tensor, it can be decomposed as in Eq. 2. From this decomposition, three feature vector maps, the surface (S-Map), the curve map (C-Map) and the junction map (J-Map), are constructed. A voxel of these maps contains a 2-tuple , where is a scalar indicating strength/saliency and is a unit vector indicating direction. Table 2 summarises the values for within the different feature maps.
Table 2.
Feature maps 2-tuple definition
| Map | ||
|---|---|---|
| S-Map | ||
| C-Map | ||
| J-Map | Arbitrary |
In the context of our problem, we are interested in the information provided by the S-map (first term of Eq. 2). For a given tuple, we interpret as a consensus measurement of vesselness between a voxel and its neighbours and as the direction along the vessel.
Data fusion
Given two -dimensional vectors, the cosine of the angle between them is an index on the extent to which they are aligned. As vessels are well-oriented structures, the cosine of the direction vectors is a surrogate of vesselness consistency between different images. Given two sets of tuples and from vesselness maps obtained from two different modalities after voting analysis, with , it is possible to fuse the maps into a single one through the following expression:
| 6 |
where denotes the dot product between the two vectors. By refactoring Eq. 6, the fusion can be extended to different image modalities through:
| 7 |
The fusion scheme is a measure that rewards consensus and punishes discord; the greater the angular distance between the different directions, the more the absolute value of the resulting output is reduced. When there is complete agreement between modalities, the output is simply the average. When their directions are perpendicular, the output drops to zero to reflect a complete lack of certainty.
SEEG planning system integration
Similar to Bériault et al. [1] and Du et al. [4], the resulting vessel probability map, , is used as input of our computer-assisted planning system [19]. As the electrode-implanting trajectory needs to be further than a safety margin from the critical tissue (vessels in this case), the probability map serves as a measure of risk of crossing a vessel. Within the planning system, the probability map is converted into a 3D surface mesh object, coloured using a pre-defined landmark colour scheme [19] and displayed within the neuronavigation planning system along with other brain structures (Fig. 3).
Fig. 3.
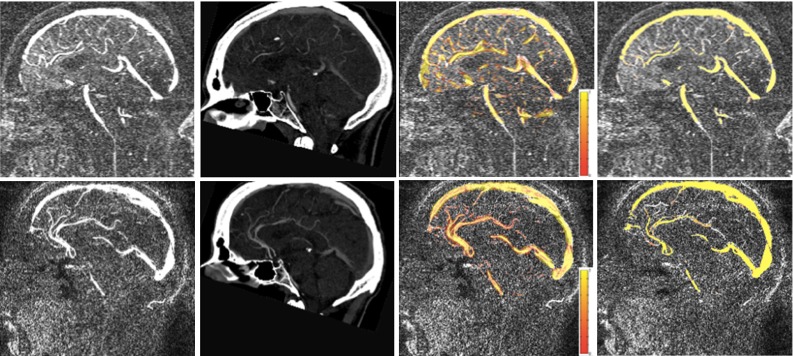
3DPC (first column) and CTA images (second column), superposed vesselness map generated by the proposed method over 3DPC (third column) and consensus for two subjects (fourth column)
Experiments and results
Data
Blood vessel images for the computer-assisted planning system [19] were acquired using 3D phase contrast MRI (3DPC) and CT angiograms (CTAs). For our experiments, we used twelve paired data sets of 3DPC and CTA available within the planning system (informed consent obtained from all the patients). The 3DPC data were acquired on a 1.5-T Siemens Avanto MR scanner with voxel size resolution and velocity encoding of 5 cm/s in each direction. CTA images were acquired on a Siemens SOMATOM Definition AS+ scanner with voxel size resolution . During image acquisition, the patient’s head was immobilised by placing a pad between the head and the coil.
Gold standard generation
Three different observers (a neurosurgical trainee, a physicist with 8-year experience in clinical neuroimaging and a master student trained for the task) segmented blood vessels structures following the protocol typically used in clinical practice for SEEG planning in the absence of a computer-assisted planning system. The semi-automated annotation procedure followed the steps described hereafter:
An intracranial space mask was applied to the CTA image to remove skull and to the 3DPC image to remove extracranial blood vessels.
Masked CTA and 3DPC were separately thresholded to give an initial estimate of the vessels. The threshold was defined by visually evaluating the resulting segmentation and determining whether noise and blood vessels were easy to distinguish and differentiate from each other with minimal manual cleaning.
Small isolated clusters were removed based on diameter size within MeshLab. The observers varied the threshold until they considered the segmented result satisfactory through visual inspection. Afterwards, large noise (e.g. calcifications) was removed by manually editing the images using MeshLab.
The six segmentations of the observers were combined into a consensus agreement through a voting strategy in a similar fashion as Hameeteman et al. [7].
Validation scheme
The proposed algorithm was evaluated on the twelve affinely co-registered [14] data sets using ten different scales between and distributed equally in a log space.
For a quantitative evaluation, each of the twelve vessel images was compared to the consensus agreement using the Dice similarity coefficient (DSC):
| 8 |
where the intersection operation is the voxel-wise minimum operation and is the integration of the voxel values over the complete image [7].
We used the DSC to assess the performance of our method and that one of each observer w.r.t the consensus when doing a semi-automated segmentation with a single modality as is done in clinical routine. We could then compare the accuracy of the proposed method to current practice.
Evaluation of different initialisation strategies
In Section “Token initialisation”, we presented different strategies to initialise the token’s tensors. Initialisation involves the definition of an initial orientation and the saliency of the tensors. In order to determine the effects of initialisation in vessel extraction, we evaluated the performance of the six different initialisation configurations (Table 1).
No preferred orientation
Three different saliency measurements were estimated to initialise ball tensors: a constant value for every tensor , the image intensity at each token, , and a vesselness measurement at each token . We chose the vesselness measurement proposed by Manniesing et al. [10] due to its smoothness properties. In order to compute the vesselness function, we followed the guidelines reported in the original publication [10].
Reported DSCs were , and for constant value, intensity-based and vesselness measurement initialisation, respectively. Not surprisingly, the use of a constant value to initialise the saliency gives the worst results. This shows that the use of a priori information to define initial saliency improves the vessel extraction quality.
Hessian-based analysis initialisation
Two different initialisation schemes based on the analysis of the Hessian matrix were evaluated: the use of the eigenvalues of , and a modified scheme to reflect a token’s vesselness. For this second approach, we assigned the response of vesselness filter [10], i.e. , while the other two values were set to zero. The DSC obtained using the response of vesselness filter () was higher than the one obtained by directly using the of the Hessian matrix ().
Structure tensor-based initialisation
Tokens initialised through the tensorised image gradient were assigned a saliency measurement equal to the squared gradient magnitude . The value used for the Gaussian kernel size involved in the computation of the structure tensor was obtained from the multi-scale analysis. A DSC of was reported.
Summary
Table 3 summarises the mean Dice score coefficients obtained when comparing the proposed method, using the three different initialisation strategies (no preferred orientation, Hessian-based and structure tensor-based), to the consensus . For no preferred orientation and Hessian-based initialisation schemes, only the best performing configuration is reported (i.e. using the vesselness filter result). The obtained DSCs using no orientation () and Hessian-based initialisation () indicate similar performance. Performance using structure tensor initialisation, on the other hand, appears to be worse (). A visual inspection of the probability maps obtained through each strategy (Fig. 2) showed that structure tensor-based initialisation tends to extract big vessels, but fails in the extraction of the small ones, explaining its lower DSC.
Table 3.
Dice score coefficients obtained using the three different initialisation strategies: no preferred orientation, Hessian-based analysis and structure tensor-based initialisation
| No orientation | Hessian analysis | Structure tensor | |
|---|---|---|---|
| DSC |
Fig. 2.
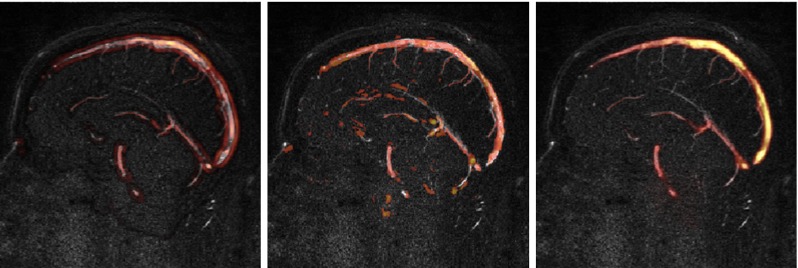
Probability maps obtained using, from left to right, no preferred orientation, Hessian-based analysis and structure tensor-based initialisation. The response of a vesselness filter [10] was used as initial saliency measurement for the first two cases. The approaches using the response of the vesselness filter are more sensible to fine structures. The structure tensor approach fails to detect small vessels, but has a strong response in large vessels
Multi-modal versus single-modality extraction
To evaluate the relevance of the multi-modal approach, we compared the proposed method with the results obtained when using a single modality. We evaluate the results obtained when combining the two modalities through:
| 9 |
It should be noted that the and operations are used instead of the logical AND and OR operators, since the images are probabilistic, rather than binary maps.
Results show that when using a single image modality, CTA tends to perform better than 3DPC (Fig. 4). By combining the modalities through the and operations, the performance w.r.t 3DPC is improved, but it degrades performance of CTA. To understand this behaviour, we visually inspected the maps obtained through both methods. When using , weak vesselness responses and discontinuities are propagated into the final map. On the other hand, favours continuity, but at the cost of increasing the number of false-positives mainly close to boundaries. As a result of this, the DSC can drop dramatically in some cases (see outliers for max in Fig. 4). The proposed method offers a productive balance between the two: False-positives diminish where there is no directionality agreement and weak vesselness responses are not suppressed.
Fig. 4.

Boxplots displaying the DSC for the proposed method, the single-modality results (without data fusion) using CTA and 3DPC, and data fusion through and operators. The red cross represents an outlier
Multi-modal extraction versus single-modality observers
The mean Dice coefficients obtained when comparing our method and the observer’s annotations to the consensus are summarised in Table 4. The DSC of the proposed multi-modal approach is superior to the one obtained by the best performing rater using a single modality. Although CTA images have richer vessel content that is reflected in better rater segmentations, 3DPC contains complementary information that is exploited by the proposed algorithm. A visual comparison of obtained vesselness maps with a consensus map is given in Fig. 3 to further illustrate the performance of our method w.r.t. the current semi-automated approach (Fig. 4).
Table 4.
Mean standard deviation of the Dice similarity coefficient (DSC) when comparing our method and the observers annotations to the consensus agreement
| Our method | Observer 1 | Observer 2 | Observer 3 | ||||
|---|---|---|---|---|---|---|---|
| 3DPC | CTA | 3DPC | CTA | 3DPC | CTA | ||
| DSC | |||||||
Computational time
To demonstrate the improvement in computational time due to the modification of the multi-scale analysis, we compared the execution times of the current method and the original one [20] as a function of the number of scales. Both methods were executed on a PC with a quad-core processor (2.13 GHz). Figure 5 shows the reported execution times along with the Dice score coefficients obtained by each method. Results show that the computational time of the new approach decreases at no cost to the method’s accuracy, which remains unchanged.
Fig. 5.

Average execution times of the proposed approach (fast) and our original formulation Zuluaga et al. [20] as a function of the number of scales. Dice score coefficients (DSCs) for both methods are also displayed to show that speedup of the method is not at the cost of accuracy
Integration into the SEEG planning system: visual assessment
Figure 6 presents different examples of the visualisation within the SEEG planning system. Furthermore, we compare the results obtained with the proposed method (Fig. 6 bottom, left) with the extracted vessels when 3DPC and CTA are processed separately (Fig. 6, bottom, right). The images show how the developed method combines the information coming from both modalities while remaining robust to noise.
Fig. 6.

Integration into the computer-assisted planning system. On top, examples of displayed extracted vessels using different colour schemes. On bottom left, display of a segmented vascular tree contrasted with the combined single-modality segmentation, right, from 3DPC (blue) and CTA (gold). The results obtained with the proposed method contain less noise
Discussion
Brain vessels are among the most critical landmarks that need to be assessed in order to mitigate surgical risks [4]. Traditionally, the procedure of extracting vessels (and other structures) is performed in a semi-automated manner by an expert inspecting an image. This is time-consuming, difficult and prone to errors due to the complexity of the vessel network. The development of fully automated and robust methods that can reduce the workload is highly desirable. Here, we have presented a fully automated method that integrates scale, neighbouring structure and feature stability within a single framework to improve vessel extraction within an SEEG planning system.
The proposed method is built upon the tensor voting framework [11]. We have extended it by introducing the evaluation of multiple scales and by using complementary sources of information to reduce noisy structures and to improve the connectivity of voxels. Although we have evaluated the proposed framework with two image modalities in this work, its formulation is generic enough that it can be applied to any number of modalities.
The tensor voting framework requires encoding of greyscale information into a tensorised form. We have evaluated a set of different alternatives for tensor initialisation, which include the use of no priors, zero-order (intensity), first-order (the structure tensor) and second-order information (Hessian-based). Our results have shown that the information derived from the analysis of the Hessian matrix, when used to initialise saliency, provides the best results. Results also show that the selection of optimal saliency measures is more critical than initial tensor orientations. The Dice score coefficients obtained when using vesselness measures as saliency were the highest, independently of the tensor orientation used (no orientation or Hessian-based). On the other hand, changes in the type of saliency measurement used for initialisation did greatly influence the extraction accuracy.
By comparing our method with its single-modality equivalent (e.g. tensor voting without data fusion), we have shown that the use of multiple image types increases performance. This is simply explained by the complementary information offered by the different images. We have also found that the way the information from all sources is combined influences the algorithmic performance. Through the use of a priori knowledge on tubular structures, we favour the fusion of well-aligned objects. Many of the previously seen false-positives are absent form the final probability map as a result, particularly along the brain boundaries.
It is common to find weak vesselness responses in different regions of the vessel tree in both 3DPC and CTA, and discontinuities are likely to appear there if a single modality is used for visualisation. By combining several modalities, the response of weak vessels increases, improving the continuity of the vessel tree and its visualisation within the planning system. The improvement in the continuity of the vessel tree, combined with a decrease in false-positives detected, should lead to a better path planning.
The comparison of the proposed method with human raters has shown that the use of combined image modalities represents an advantage w.r.t current practice. The presented results are more accurate than a human observer using a single modality. However, the method has some limitations that need to be solved before it can be deployed in clinical practice. While discontinuities are reduced w.r.t single-modality segmentation, they can still appear in small branches. Following the principle of using complementary sources of information (i.e. different image modalities of the same object/anatomical structure), a natural extension of the presented approach to solve this limitation is to combine the outputs obtained when processing different sources of information (e.g. zero-, first- and second-order information or S-,C- and J-maps) into a single probability map. As an example, the structure tensor provides the best results on larger vessels but not performs poorly on small vessels (Fig. 2). Under this scenario, the best features of each source of information would be exploited instead of just keeping the one that overall performs best.
Regarding computational time, which is a key feature if an algorithm is to be translated into the clinic, we have reformulated the multi-scale analysis to reduce the time required to extract the vessel tree. The results show that the new formulation is nearly four times faster than the original one [20] at no cost for the vessel extraction accuracy.
Conclusions
In this paper, we have presented a vessel extraction method for the identification of critical landmarks within a computer-assisted SEEG planning system. The main feature of this method is that it integrates scale, neighbouring structure and feature stability within a single framework. The introduction of a voting neighbourhood within the well-established multi-scale approach and the use of complimentary sources of information reduces noisy structures and improves the connectivity of the voxels belonging to vessels. The results presented here demonstrate the superiority of our method to the semi-automated single-modality segmentation, indicating the possibility of safer SEEG planning with reduced patient morbidity.
Acknowledgments
The authors thank Dr. Mark White from the National Hospital for Neurology and Neurosurgery (London, UK) for the provided support and Ninon Burgos and Carole Sudre for their help in the revision of this text.
Conflict of interest
M.A. Zuluaga, R. Rodionov, M. Nowell, S. Achhala, G. Zombori, A.F. Mendelson, M.J. Cardoso, A. Miserocchi, A.W. McEvoy, J.S. Duncan and S. Ourselin declare they have no conflict of interest. This publication presents independent research supported by the Health Innovation Challenge Fund (HICF-T4-275), a parallel funding partnership between the Department of Health and Wellcome Trust. The views expressed in this publication are those of the authors and not necessarily those of the Department of Health or Wellcome Trust.
Appendix: Stick, plate and ball tensor voting
For the sake of completeness, we present in this section the expressions for SV, PV and BV, the stick, plate and ball votes. Further details on the mathematical derivation of the three expressions can be found in [11, 12].
Stick tensor vote
Given , which encodes the orientation of the normal at point , a vote casted from to can be defined as:
| 10 |
where represents the angle defining the orientation of , is a rotation w.r.t the axis , and is a decaying function used to weight the vote and defined as:
| 11 |
where denotes the arc length, the curvature, is a scale parameter associated with the window size , and is a parameter that can be adjusted to give more importance to the curvature (, [12]).
Plate tensor vote
Given , a stick inside a plate , a plate vote is defined as the aggregation of stick votes cast by all the stick tensors that constitute . It is defined as:
| 12 |
Ball tensor vote
Let be a unitary stick tensor expressed in spherical coordinates with orientation . Similar to the plate tensor vote, a ball vote can be obtained through the aggregation of the stick votes within the surface of the unitary sphere:
| 13 |
Footnotes
For the sake of simplicity, we will drop the index term and the image gradient at a given token position will be expressed as for the remaining of this article.
This work is supported by the Department of Health and Wellcome Trust through the Health Innovation Challenge Fund (HICF-T4-275), the EPSRC (EP/ H046410/1, EP/J020990/1, EP/K005278), the MRC (MR/ J01107 X/1), the EU-FP7 project VPH-DARE@ IT (FP7-ICT-2011-9-601055), the National Institute for Health Research Biomedical Research Unit (NIHR BRU) in Dementia at University College London Hospitals NHS Foundation Trust and University College London, and the NIHR University College London Hospitals Biomedical Research Centre (BRC) (UCLH/ UCL High Impact Initiative).
References
- 1.Bériault S, Al Subaie F, Collins D, Sadikot A, Pike G. A multi-modal approach to computer-assisted deep brain stimulation trajectory planning. Int J Comput Assist Radiol Surg. 2012;7:687–704. doi: 10.1007/s11548-012-0768-4. [DOI] [PubMed] [Google Scholar]
- 2.Cossu M, Cardinale F, Castana L, Citterio A, Francione S, Tassi L, Benabid ALM, Lo Russo G. Stereoelectroencephalography in the presurgical evaluation of focal epilepsy: a retrospective analysis of 215 procedures. Neurosurgery. 2005;57(4):706–718. doi: 10.1227/01.NEU.0000176656.33523.1e. [DOI] [PubMed] [Google Scholar]
- 3.David O, Blauwblomme T, Job AS, C S, Hoffmann D, Minotti L, Kahane P. Imaging the seizure onset zone with stereo-electroencephalography. Brain. 2011;134:2898–2911. doi: 10.1093/brain/awr238. [DOI] [PubMed] [Google Scholar]
- 4.Du X, Ding H, Zhou W, Zhang G, Wang G. Cerebrovascular segmentation and planning of depth electrode insertion for epilepsy surgery. Int J Comput Assist Radiol Surg. 2013;8:905–916. doi: 10.1007/s11548-013-0843-5. [DOI] [PubMed] [Google Scholar]
- 5.Essert C, Haegelen C, Lalys F, Abadie A, Jannin P. Automatic computation of electrode trajectories for deep brain stimulation: a hybrid symbolic and numerical approach. Int J Comput Assist Radiol Surg. 2012;7(4):517–532. doi: 10.1007/s11548-011-0651-8. [DOI] [PubMed] [Google Scholar]
- 6.Frangi AF, Niessen WJ, Vincken KL, Viergever MA (1998) Multiscale vessel enhancement filtering. In: Wells W, Colchester A, Delp SL (eds) Medical Image Computing and Computer-Assisted Intervention—MICCAI, LNCS, vol 1496. Springer, Berlin, pp 130–137
- 7.Hameeteman K, Zuluaga MA, Freiman M, Joskowicz L, Cuisenaire O, Valencia LF, Gülsün M, Krissian K, Mille J, Wong W, Orkisz M, Tek H, Hoyos MH, Benmansour F, Chung A, Rozie S, van Gils M, van den Borne L, Sosnam J, Berman P, Cohen N, Douek P, Sánchez I, Aissat M, Schaap M, Metz C, Krestin G, van der Lugt A, Niessen W, van Walsum T. Evaluation framework for carotid bifurcation lumen segmentation and stenosis grading. Med Image Anal. 2011;15:477–488. doi: 10.1016/j.media.2011.02.004. [DOI] [PubMed] [Google Scholar]
- 8.Hu Z, Niemeijer M, Abràmoff MD, Garvin MK. Multimodal retinal vessel segmentation from spectral-domain optical coherence tomography and fundus photography. IEEE Trans Med Imaging. 2012;31:1900–1911. doi: 10.1109/TMI.2012.2206822. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Lesage D, Angelini ED, Bloch I, Funka-Lea G. A review of 3D vessel lumen segmentation techniques: models, features and extraction schemes. Med Image Anal. 2009;13(6):819–845. doi: 10.1016/j.media.2009.07.011. [DOI] [PubMed] [Google Scholar]
- 10.Manniesing R, Viergever MA, Niessen WJ. Vessel enhancing diffusion: a scale space representation of vessel structures. Med Image Anal. 2006;10(6):815–825. doi: 10.1016/j.media.2006.06.003. [DOI] [PubMed] [Google Scholar]
- 11.Medioni G, Lee MS, Tang CK. A computational framework for segmentation and grouping. Amsterdam: elsevier Science; 2000. [Google Scholar]
- 12.Moreno R, Garcia MA, Puig D, Pizarro L, Burgeth B, Weickert J. On improving the efficiency of tensor voting. IEEE Trans Patt Anal Mach Intell. 2011;33(11):2215–2228. doi: 10.1109/TPAMI.2011.23. [DOI] [PubMed] [Google Scholar]
- 13.Olivier A, Boling W, Tanriverdi T. Techniques in epilepsy surgery: the MNI approach. Cambridge: Cambridge University Press; 2012. [Google Scholar]
- 14.Ourselin S, Roche S, Subsol G, Pennec X, Ayache N. Reconstructing a 3D structure from serial histological sections. Image Vis Comput. 2001;19(1–2):25–31. doi: 10.1016/S0262-8856(00)00052-4. [DOI] [Google Scholar]
- 15.Passat N, Ronse C, Baruthio J, Armspach JP, Foucher J. Watershed and multimodal data for brain vessel segmentation: application to the superior sagittal sinus. Image Vis Comput. 2007;25:512–521. doi: 10.1016/j.imavis.2006.03.008. [DOI] [Google Scholar]
- 16.Rosenow F, Lüders H. Presurgical evaluation of epilepsy. Brain. 2001;124:1683–1700. doi: 10.1093/brain/124.9.1683. [DOI] [PubMed] [Google Scholar]
- 17.Sato Y, Nakajima S, Shiraga N, Atsumi H, Yoshida S, Koller T, Gerig G, Kikinis R. Three-dimensional multi-scale line filter for segmentation and visualization of curvilinear structures in medical images. Med Image Anal. 1998;2(2):143–168. doi: 10.1016/S1361-8415(98)80009-1. [DOI] [PubMed] [Google Scholar]
- 18.Shamir RR, Joskowicz L, Tamir I, Dabool E, Pertman L, Ben-Ami A, Shoshan Y. Reduced risk trajectory planning in image-guided keyhole neurosurgery. Med Phys. 2012;39:2885–2895. doi: 10.1118/1.4704643. [DOI] [PubMed] [Google Scholar]
- 19.Zombori G, Rodionov R, Nowell M, Zuluaga MA, Clarkson M, Micallef C, Diehl B, Wehner T, Miserochi A, McEvoy A, Duncan J, Ourselin S. A computer assisted planning system for the placement of seeg electrodes in the treatment of epilepsy. Inform Process Comput-Assist Interv Lect Notes Comput Sci. 2014;8498:118–127. doi: 10.1007/978-3-319-07521-1_13. [DOI] [Google Scholar]
- 20.Zuluaga MA, Rodionov R, Nowell M, Achhala S, Zombori G, Cardoso MJ, Miserocchi A, McEvoy AW, Duncan JS, Ourselin S (2014) SEEG trajectory planning: Combining stability, structure and scale in vessel extraction. In: Golland P, Hata N, Barillot C, Hornegger J, Howe R (eds) Medical Image Computing and Computer-Assisted Intervention - MICCAI 2014. Lecture Notes in Computer Science, vol 8674. Springer, Berlin, pp 651–658 [DOI] [PubMed]