

Abstract
Magnetic resonance imaging (MRI) is the dominant modality for neuroimaging in clinical and research domains. The tremendous versatility of MRI as a modality can lead to large variability in terms of image contrast, resolution, noise, and artifacts. Variability can also manifest itself as missing or corrupt imaging data. Image synthesis has been recently proposed to homogenize and/or enhance the quality of existing imaging data in order to make them more suitable as consistent inputs for processing. We frame the image synthesis problem as an inference problem on a 3-D continuous-valued conditional random field (CRF). We model the conditional distribution as a Gaussian by defining quadratic association and interaction potentials encoded in leaves of a regression tree. The parameters of these quadratic potentials are learned by maximizing the pseudo-likelihood of the training data. Final synthesis is done by inference on this model. We applied this method to synthesize T2-weighted images from T1-weighted images, showing improved synthesis quality as compared to current image synthesis approaches. We also synthesized Fluid Attenuated Inversion Recovery (FLAIR) images, showing similar segmentations to those obtained from real FLAIRs. Additionally, we generated super-resolution FLAIRs showing improved segmentation.
Keywords: Magnetic resonance, Image synthesis, Conditional random field
1 Introduction
Image synthesis in MRI is a process in which the intensities of acquired MRI data are transformed in order to enhance the data quality or render them more suitable as input for further image processing. Image synthesis has been gaining traction in the medical image processing community in recent years [6,15], as a useful pre-processing tool for segmentation and registration. It is especially useful in MR brain imaging, where a staggering variety of pulse sequences like Magnetization Prepared Gradient Echo (MPRAGE), Dual Spin Echo (DSE), FLAIR etc. are used to interrogate the various aspects of neuroanatomy. Versatility of MRI is a boon for diagnosticians but can sometimes prove to be a handicap when performing analysis using image processing. Automated image processing algorithms are not always robust to variations in their input [13]. In large datasets, sometimes images are missing or corrupted during acquisition and cannot be used for further processing. Image synthesis can be used as a tool to supplement these datasets by creating artificial facsimiles of the missing images by using the available ones. An additional source of variability is the differing image quality between different pulse sequences for the same subject. An MPRAGE sequence can be quickly acquired at a resolution higher than 1 mm3, which is not possible for FLAIR. Image synthesis can be used to enhance the resolution of existing low resolution FLAIRs using the corresponding high resolution MPRAGE images, thus leading to improved tissue segmentation.
Previous work on image synthesis has proceeded along two lines, (1) registration-based, and (2) example-based. Registration-based [3,12] approaches register the training/atlas images to the given subject image and perform intensity fusion (in the case of multiple training/atlas pairs) to produce the final synthesis. These approaches are heavily dependent on the quality of registration, which is generally not accurate enough in the cortex and abnormal tissue regions. Example-based approaches involve learning an intensity transformation from known training data pairs/atlas images. A variety of example-based approaches [5,8,15] have been proposed. These methods treat the problem as a regression problem and estimate the synthetic image voxel-by-voxel from the given, available images. The voxel intensities in the synthetic image are assumed to be independent of each other, which is not entirely valid as intensities in a typical MR image are spatially correlated and vary smoothly from voxel-to-voxel.
In this work, we frame image synthesis as an inference problem in a probabilistic discriminative framework. Specifically, we model the posterior distribution p(y|x), where x is the collection of known images and y is the synthetic image we want to estimate, as a Gaussian CRF [10]. Markov random field (MRF) approaches lend themselves as a robust, popular way to model images. However in a typical MRF, the observed data x are assumed to be independent given the underlying latent variable y, which is a limiting assumption for typical images. A CRF, by directly modeling the posterior distribution allows us to side-step this problem. CRFs have been used in discrete labeling and segmentation problems [9]. A continuous-valued CRF, modeled as a Gaussian CRF, was first described in [17]. Efficient parameter learning and inference procedures of a Gaussian CRF were explored in the Regression Tree Fields concept in [7]. We also model the posterior distribution as a Gaussian CRF, the parameters of which are stored in the leaves of a single regression tree. We learn these parameters by maximizing a pseudo-likelihood objective function given training data. Given a subject image, we build the Gaussian distribution parameters from the learned tree and parameters. The prediction of the synthetic subject image is a maximum a posteriori (MAP) estimate of this distribution and is estimated efficiently using conjugate gradient descent.
We refer to our method as Synthesis with Conditional Random Field Tree or SyCRAFT. We applied SyCRAFT to synthesize T2-weighted (T2-w) images from T1-w (T1-w) images and showed a superior quality of synthesis compared to state-of-the-art methods. We also applied our method to synthesize FLAIRs from corresponding T1-w, T2-w, and PD-weighted (PD-w) images and showed that tissue segmentation on synthetic images is comparable to that achieved using real images. Finally, we used our method in an example-based super-resolution framework to estimate a super-resolution FLAIR image and showed improved tissue segmentation. In Sect. 2, we describe our method in detail, followed by experiments and results in Sect. 3 and discussion in Sect. 4.
2 Method
2.1 Model
We start with the definition of a CRF, initially proposed in [10]. A CRF is defined over a graph G = (V, E), V and E are the sets of vertices and edges respectively, of G. In an image synthesis context, the set of all voxels i in the image domain form the vertices of V. A pair of voxels (i, j), i, j ∈ V, that are neighbors according to a predefined neighborhood, form an edge in E. Let x = {x1, … ,
xm} be the observed data. Specifically, x represents the collection of available images from m pulse sequences from which we want to synthesize a new image. Let y be the continuous-valued random variable over V, representing the synthetic image we want to predict. In a CRF framework, p(y|x) is modeled and learned from training data of known pairs of (x,
y). Let y = {yi, i ∈ V}. Then (y,
x) is a CRF if, conditioned on x, yi exhibit the Markov property, i.e. p(yi|x,
yV\i) = p(yi|x,
y
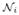 ), where
= {j | (i, j) ∈ E}, is the neighborhood of i.
), where
= {j | (i, j) ∈ E}, is the neighborhood of i.
Assuming p(y|x) > 0, ∀y, from the Hammersley-Clifford theorem, we can express the conditional probability as a Gibbs distribution. The factorization of p(y|x) in terms of association potentials and interaction potentials is given as,
| (1) |
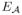 (yi,
x; θ) is called an association potential, defined using the parameter set θ,
(yi,
x; θ) is called an association potential, defined using the parameter set θ,
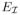 (yi, yj,
x; θ) is called an interaction potential, λ is a weighting factor, and Z is the partition function. If EA and EI are defined as quadratic functions of y, we can express this distribution as a multivariate Gaussian as below,
(yi, yj,
x; θ) is called an interaction potential, λ is a weighting factor, and Z is the partition function. If EA and EI are defined as quadratic functions of y, we can express this distribution as a multivariate Gaussian as below,
| (2) |
The parameters A(x) and b(x) are dependent on the association and interaction potential definitions. In most classification tasks involving CRF’s the association potential is defined as the local class probability as provided by a generic classifier or a regressor [9]. Image synthesis being a regression task, we chose to model and extract both association and interaction potentials from a single regressor, in our case a regression tree. We define a quadratic association potential as
| (3) |
where {aL(i), bL(i)} ∈ θ are the parameters defined at the leaf L(i). L(i) is the leaf where the feature vector fi(x) extracted for voxel i from the observed data x, lands after having been passed through successive nodes of a learned regression tree, Ψ. The features and regression tree construction are described in Sect. 2.2.
The interaction potential usually acts as a smoothing term, but can also be designed in a more general manner. We define interaction potentials for each type of neighbor. A ‘neighbor type’ r ∈ {1, … , |
|} is given by a voxel i and one of its n (= |
|) neighbors. For example, a neighborhood system with four neighbors (up, down, left, right) has four types of neighbors, and hence four types of edges. The complete set of edges E can be divided into non-intersecting subsets {E1, … , Er, … , En} of edges of different types. Let the voxel j be such that (i, j) ∈ E is a neighbor of type r, that is (i, j) ∈ Er. Let the corresponding feature vectors fi(x) and fj (x) land in leaves L(i) and L(j) of the trained tree Ψ, respectively. The interaction potential is modeled as
| (4) |
Let the set of leaves of the regression tree Ψ be
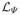 . Each leaf l ∈
stores the set of parameters θl = {al, bl, αl1, βl1, γl1, ωl11, ωl21, … , αln, βln, γln, ωl1n, ωl2n}. The complete set of parameters is thus, θ = {θl|l ∈
}. Our approach bears similarity to the regression tree fields concept introduced in [7], where the authors create a separate regression tree for each neighbor type. Thus with a single association potential and a typical 3D neighborhood of 26 neighbors, they would need 27 separate trees to learn the model parameters. Training a large number of trees with large training sets makes the regression tree fields approach computationally expensive. It was especially not feasible in our application with large 3D images, more neighbors, and high dimensional feature vectors. We can however train multiple trees using bagging to create an ensemble of models to create an average, improved prediction. The training of a single regression tree is described in the next section.
. Each leaf l ∈
stores the set of parameters θl = {al, bl, αl1, βl1, γl1, ωl11, ωl21, … , αln, βln, γln, ωl1n, ωl2n}. The complete set of parameters is thus, θ = {θl|l ∈
}. Our approach bears similarity to the regression tree fields concept introduced in [7], where the authors create a separate regression tree for each neighbor type. Thus with a single association potential and a typical 3D neighborhood of 26 neighbors, they would need 27 separate trees to learn the model parameters. Training a large number of trees with large training sets makes the regression tree fields approach computationally expensive. It was especially not feasible in our application with large 3D images, more neighbors, and high dimensional feature vectors. We can however train multiple trees using bagging to create an ensemble of models to create an average, improved prediction. The training of a single regression tree is described in the next section.
2.2 Learning a Regression Tree
As mentioned before, let x = {x1, x2, … , xm} be a collection of co-registered images, generated by modalities Φ1, … , Φm, respectively. The image synthesis task entails predicting the image y of a target modality Φt. The training data thus consists of known co-registered pair of {x, y}. At each voxel location i, we extract features fi(x), derived from x. For our experiments we use two types of features, (1) small, local patches, (2) context descriptors. A small 3D patch, denoted by pi(x) = [pi(x1), … , pi(xm)], where the size of the patch is typically 3 × 3 × 3 and provides us with local intensity information.
We construct the context descriptors as follows. The brain images are rigidly aligned to the MNI coordinate system [4] with the center of the brain approximately at the center of the image. Thus for each voxel we can find out the unit vector u from the voxel i to the origin. We can define 8 directions by rotating the component of u in the axial plane by angles {0,
}. In each of these directions, we select average intensities of cubic regions of cube-widths {w1, w2, w3, w4} at four different radii {r1, r2, r3, r4} respectively. This becomes a 32-dimensional descriptor of the spatial context surrounding voxel i. In our experiments we used w1 = 3, w2 = 5, w3 = 7, w4 = 9 and r1 = 4, r2 = 8, r3 = 16, r4 = 32. These values were chosen empirically. We denote this context descriptor by ci(x). The final feature vector is thus fi(x) = [pi(x),
ci(x)]. fi(x) is paired with the voxel intensity yi at i in the target modality image y to create training data pairs (fi(x), yi). We train the regression tree Ψ on this training data using the algorithm described in [2]. Once the tree is constructed, we initialize θl at each of the leaves l ∈
. θl is estimated by a pseudo-likelihood maximization approach.
2.3 Parameter Learning
An ideal approach to learn parameters would be to perform maximum likelihood using the distribution in Eq. 2. However as mentioned in [7], estimation of the mean parameters Σ and μ, requires calculation of A−1 (see Eq. 2). The size of A is |V × V| where |V| is the number of voxels in y and for large 3D images, |V| is of the order of ~106, which makes the computation practically infeasible. We follow [7] and implement a pseudo-likelihood maximization-based parameter learning.
Pseudo-likelihood is defined as the product of local conditional likelihoods,
| (5) |
The local conditional likelihood can be expanded as
| (6) |
where Zi =
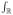 p(yi,
y
, x; θ)dyi. Using the CRF definition in Eq. 1, we can write − log p(yi,
y
, x; θ) as
p(yi,
y
, x; θ)dyi. Using the CRF definition in Eq. 1, we can write − log p(yi,
y
, x; θ) as
| (7) |
where we can find aCi(Eq. 8) and bCi,(Eq. 9) by matching quadratic and linear terms. Equations 8 and 9 show the contribution of interaction potentials induced by the neighbors of voxel i. The r̃ denotes the type of edge which is symmetric to type r. For example, if edges of type r are between voxel i and its right neighbor, then r̃ denotes the type that is between a voxel and its left neighbor.
| (8) |
| (9) |
The integral of exponential terms Zi in Eq. 6, is also known as the log partition term. To optimize objective functions with log partition terms, we express Zi in its variational representation using the mean parameters μi = [μi, σi] [18]. The parameter set θCi = {bCi, aCi} that defines the exponential distribution is known as the canonical parameter set. The conjugate dual function of Zi is defined as follows,
| (10) |
where 〈〉 denotes inner product. Substituting θCi and the expression for − log p(yi,
y
, x; θ) from Eq. 7, we get the negative pseudo-likelihood contributed by voxel i to be,
| (11) |
where the mean parameters are given by and .
Equation 11 is similar to the one in [7], as the overall model is a Gaussian CRF. The objective function is linearly related to θ and is thus convex [7,18]. We minimize Σi∈V NPLi(θ) using gradient descent. The weighting factor λ = 0.1, was chosen empirically in our experiments. The regression tree fields concept performed a constrained, projected gradient descent on the parameters to ensure positive definiteness of the final precision matrix (A(x) in Eq. 1) [7]. We observed that unconstrained optimization in our model and applications generated a positive definite A(x). Training in our experiments takes about 20–30 min with ~106 samples of dimensionality of the order of ~102 and neighborhood size of 26, on a 12 core 3.42 GHz machine.
2.4 Inference
Given a test image set x̂ = {x̂1, … , x̂m}, which are co-registered, we first extract features fi(x̂) from all voxel locations i. Next, we apply the learned regression tree Ψ to each of fi(x̂) to determine the leaf node L(i) in Ψ. Using the learned parameters at these leaves, we construct the matrix A(x̂) and the vector b(x̂), (see Eq. 2). The diagonal and off-diagonal elements of A(x̂) are populated by matching the linear and quadratic terms from Eq. 2. The MAP estimate for p(y|x̂) as well as the conditional expectation E[y|x̂] is the mean of the multivariate Gaussian described in Eq. 2. The expression for the mean and hence the estimate ŷ is given by,
| (12) |
A(x̂) is a large (~106×106), sparse (~27×106 non-zero entries), symmetric positive definite matrix. Thus, we use an iterative preconditioned conjugate gradient descent method to solve the linear system in Eq. 12. The estimate ŷ is our synthetic image. Estimates from multiple (5 in our experiments) trained models using bagging can also be averaged to produce a final result.
3 Results
3.1 Synthesis of T2-w Images from T1-w Images
In this experiment, we used MPRAGE images from the publicly available multimodal reproducibility (MMRR) data [11] and synthesized the T2-w images of the DSE sequence. The multimodal reproducibility data consists of 21 subjects, each with two imaging sessions, acquired within an hour of each other. Thus there are 42 MPRAGE images. We excluded data of five subjects (ten images), which were used for training and synthesized the remaining 32. We compared SyCRAFT to MIMECS [15] and multi-atlas registration and intensity fusion (FUSION) [3]. We used five subjects as the atlases for FUSION with the parameters β = 0.5 and κ = 4 (fuse the four best patch matches).
We used PSNR (peak signal to noise ratio), universal quality index (UQI) [19], and structural similarity (SSIM) [20] as metrics. UQI and SSIM take into account image degradation as observed by a human visual system. Both have values that lie between 0 and 1, with 1 implying that the images are equal to each other. SyCRAFT performs significantly better than both the methods for all metrics except PSNR. Figure 1 shows the results for all three methods along with the true T2-w image. FUSION results (Fig. 1(b)) have the highest PSNR, but produce anatomically incorrect images, especially in the presence of abnormal tissue anatomy (lesions for example) and the cortex. Overall, SyCRAFT produces an image that is visually closest to the true T2-w image (Table 1).
Fig. 1.
Shown are (a) the input MPRAGE image, (b) the true T2-w image, and the synthesis results from the MPRAGE for each of (c) FUSION, (d) MIMECS, and (e) SyCRAFT (our method). The lesion (green circle) and the cortex (yellow circle) in the true image are synthesized by MIMECS and SyCRAFT, but not by FUSION (Colour figure online).
Table 1.
Mean and standard deviation (Std. Dev.) of the PSNR, UQI, and SSIM values for synthesis of T2-w images from 32 MPRAGE scans.
| PSNR Mean (Std) |
UQI Mean (Std.) |
SSIM Mean (Std) |
|
|---|---|---|---|
| FUSION | 52.73 (2.78)a | 0.78 (0.02) | 0.82 (0.02) |
| MIMECS | 36.13 (2.23) | 0.78 (0.02) | 0.77 (0.02) |
| SyCRAFT | 49.73 (1.99) | 0.86 (0.01)a | 0.84 (0.01)a |
Statistically significantly better than either of the other two methods (α level of 0.01) using a right-tailed test.
3.2 Synthesis for FLAIR Images
In this experiment, given atlas PD-w, T2-w, T1-w, and FLAIR images, we trained SyCRAFT and applied it to subject PD-w, T2-w, and T1-w images, to predict the subject synthetic FLAIR image. We used our in-house multiple sclerosis (MS) patient image dataset with 49 subject images, with four training subjects and testing on the remaining 45. We computed average PSNR (20.81, std = 1.19), UQI (0.81, std = 0.03) and SSIM (0.78, std = 0.03), over these 45 subjects. These values indicate that the synthetic FLAIRs are structurally and visually similar to their corresponding real FLAIRs. Figure 2 shows the input images and the synthetic FLAIR image along side the real FLAIR image.
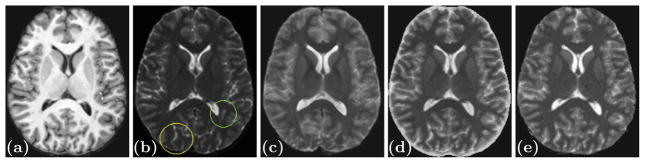
Fig. 2.
Subject input images along with the SyCRAFT FLAIR and true FLAIR images.
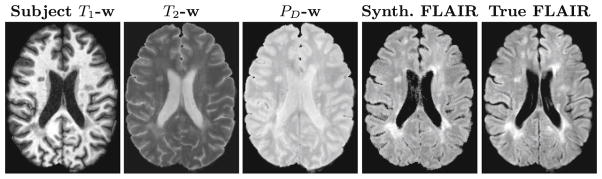
Next, we investigated the segmentations acquired from these synthetic FLAIRs. We would like the segmentation algorithm, LesionTOADS [16], to behave identically for real and synthetic images. LesionTOADS uses a T1-w and a corresponding FLAIR to generate a multi-class, topologically correct segmentation in the presence of lesions. We compared the overlap of segmentations obtained using synthetic FLAIRs to those obtained using real FLAIRs in terms of Dice coefficients (averaged over 45 subjects) for white matter (0.97, std = 0.01) (WM), gray matter (0.99, std = 0.01) (GM), cerebrospinal fluid (0.97, std = 0.01) (CSF) and white matter lesions (0.52, std = 0.17) (WML). Figure 3 shows the segmentations by LesionTOADS on real and synthetic FLAIRs. The overlap is very good for WM, GM, and CSF, however it is low for the WML class. The lesions being small and diffuse, even a small difference in the overlap can cause a low value for the Dice coefficient. So, we looked at the overall lesion volumes as provided by the algorithm for real and synthetic FLAIRs. To understand how different the lesion volumes are for the synthetic images as compared to the real images, we created a Bland-Altman [1] plot shown in Fig. 4. Let RFlv be the lesion volumes given by LesionTOADS using real FLAIRs as input. Let SFlv be the lesion volumes using synthetic FLAIRs as input. Bland-Altman plot is a scatter plot of (RFlv − SFlv)/2 (y axis) vs. RFlv + SFlv (x axis). The measurements are considered to be interchangeable if 0 lies within ±1.96σ where σ is the standard deviation of (RFlv − SFlv)/2. There is a small bias between RFlv and SFlv (mean = 0.88 × 103) however, 0 does lie between the prescribed limits and hence based on this plot we can say that these two measurements are interchangeable.
Fig. 3.
LesionTOADS segmentations for real and synthetic FLAIRs.
Fig. 4.

A Bland-Altman plot of lesion volumes for synthetic FLAIRs vs real FLAIRs.
3.3 Super-Resolution of FLAIR
Next, we applied SyCRAFT to synthesize super-resolution (SR) FLAIRs using corresponding high resolution (HR) MPRAGE and low resolution (LR) FLAIRs. During a clinical or a research scan, not all the pulse sequences acquired are acquired at the same fixed resolution. Sequences like the T1-w MPRAGE can be acquired very fast and hence are easy to image at a high resolution–usually higher than 1 mm3 isotropic. However sequence like DSE and FLAIR have long repetition times (TR) and inversion times (TI), which limits the amount of scan time, and therefore, are acquired at a low (2–5 mm) through plane resolution.
Our approach can be described as an example-based super-resolution [14] technique. Example-based methods leverage the high resolution information extracted from a HR image—an MPRAGE, for example—in conjunction with a LR input image—corresponding FLAIR image—to generate a SR version of the LR image. We used HR (1 × 1 × 1 mm3) MPRAGE and FLAIR data, and downsampled the HR FLAIR to create a LR (1 × 1 × 4 mm3) FLAIR. The atlas data included an HR MPRAGE + LR FLAIR and we trained SyCRAFT to predict the HR FLAIR. Given a test HR MPRAGE and LR FLAIR, we applied SyCRAFT to synthesize a SR FLAIR. We ran the LesionTOADS [16] segmentation algorithm on three scenarios for each subject: (a) HR MPRAGE + LR FLAIR (b) HR MPRAGE + SR FLAIR (c) HR MPRAGE + HR FLAIR. The last case acting as the ground truth for how the segmentation algorithm should behave on best case data. We aim to show that the tissue segmentation using SR FLAIR is closer to that achieved using HR FLAIR, than using LR FLAIR. Figure 5(d) shows the super-resolution results, the LR FLAIR image is shown in Fig. 5(b), and the HR FLAIR image in Fig. 5(c). The corresponding LesionTOADS segmentations are shown in Figs. 5(e, f, g), respectively. The lesion boundaries as well as the cortex is overestimated when a LR FLAIR is used. Shown in Fig. 6 are the lesion volumes on 13 subjects for each of the three scenarios.
Fig. 5.

Coronal slices of LR, HR, and SR FLAIRs along with their corresponding LesionTOADS segmentation are shown. It is evident that using a LR FLAIR affects the segmentation of the lesions and even the cortex.
Fig. 6.

Shown are the lesion volumes acquired by LesionTOADS on HR FLAIR+HR MPRAGE (black), LR FLAIR+HR MPRAGE (blue), and SR FLAIR+HR MPRAGE (red). Note that the black plot is closer to the red plot than the blue plot for all but one of the subjects (Colour figure online).
4 Conclusion
We have described an image synthesis framework, SyCRAFT, as a learning and inference problem on a Gaussian CRF. The parameters of the Gaussian CRF are built from parameters stored at the leaves of a single regression tree. Parameter learning is done by maximizing a pseudo-likelihood objective function. Our approach is extremely flexible in terms of features it can use to create the initial regression tree. It is also general enough to add larger neighborhoods and long-range relationships among voxels. Adding more neighbors leads to additional parameters, but these can be stored in the same initial tree and we do not need to create any more trees. Our approach is also computationally efficient, training from millions of samples in 20–30 min, and inference taking less than five minutes. We compared SyCRAFT to competitive image synthesis algorithms and showed that the image quality is superior. We also demonstrated practical benefits of using our algorithm to synthesize FLAIRs and validated the synthesis by showing tissue segmentation equivalent to that obtained using real FLAIRs. This shows that our image synthesis algorithm can be used in realistic scenarios, where imaging data is missing and needs to be replaced by a feasible alternative. Finally we also applied our algorithm to enhance the resolution of low resolution FLAIRs and showed improved tissue segmentation as a result.
References
- 1.Bland JM, Altman DG. Statistical Methods For Assessing Agreement Between Two Methods Of Clinical Measurement. The Lancet. 1986;327(8476):307–310. [PubMed] [Google Scholar]
- 2.Breiman L, Friedman JH, Olshen RA, Stone CJ. Classification and Regression Trees. Wadsworth Publishing Company; U.S.A: 1984. [Google Scholar]
- 3.Burgos N, Cardoso MJ, Modat M, Pedemonte S, Dickson J, Barnes A, Duncan JS, Atkinson D, Arridge SR, Hutton BF, Ourselin S. Attenuation correction synthesis for hybrid PET-MR scanners. In: Mori K, Sakuma I, Sato Y, Barillot C, Navab N, editors. MICCAI 2013, Part I. LNCS. Vol. 8149. Springer; Heidelberg: 2013. pp. 147–154. [DOI] [PubMed] [Google Scholar]
- 4.Evans A, Collins D, Mills S, Brown E, Kelly R, Peters T. 3D Statistical Neuroanatomical Models from 305 MRI volumes. Nuclear Science Symposium and Medical Imaging Conference; 1993. pp. 1813–1817. [Google Scholar]
- 5.Hertzmann A, Jacobs CE, Oliver N, Curless B, Salesin DH. Image Analogies. Proceedings of SIGGRAPH. 2001;2001:327–340. [Google Scholar]
- 6.Iglesias JE, Konukoglu E, Zikic D, Glocker B, Van Leemput K, Fischl B. Is synthesizing MRI contrast useful for inter-modality analysis? In: Mori K, Sakuma I, Sato Y, Barillot C, Navab N, editors. MICCAI 2013, Part I. LNCS. Vol. 8149. Springer; Heidelberg: 2013. pp. 631–638. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Jancsary J, Nowozin S, Sharp T, Rother C. Regression Tree Fields; An Efficient, Non-parametric Approach to Image Labeling Problems. CVPR. 2012:2376–2383. [Google Scholar]
- 8.Jog A, Roy S, Carass A, Prince JL. Magnetic Resonance Image Synthesis through Patch Regression. 10th International Symposium on Biomedical Imaging (ISBI 2013); 2013. pp. 350–353. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Kumar S, Hebert M. Discriminative random fields. Int J Comput Vision. 2006;68(2):179–201. [Google Scholar]
- 10.Lafferty JD, McCallum A, Pereira FCN. Conditional random fields: probabilistic models for segmenting and labeling sequence data. ICML 2001. 2001:282–289. [Google Scholar]
- 11.Landman BA, Huang AJ, Gifford A, Vikram DS, Lim IAL, Farrell JAD, Bogovic JA, Hua J, Chen M, Jarso S, Smith SA, Joel S, Mori S, Pekar JJ, Barker PB, Prince JL, van Zijl P. Multi-parametric neuroimaging reproducibility: a 3-T resource study. NeuroImage. 2011;54(4):2854–2866. doi: 10.1016/j.neuroimage.2010.11.047. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Miller MI, Christensen GE, Amit Y, Grenander U. Mathematical textbook of deformable neuroanatomies. Proc Natl Acad Sci. 1993;90(24):11944–11948. doi: 10.1073/pnas.90.24.11944. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Nyúl LG, Udupa JK, Zhang X. New variants of a method of MRI scale standardization. IEEE Trans Med Imag. 2000;19(2):143–150. doi: 10.1109/42.836373. [DOI] [PubMed] [Google Scholar]
- 14.Rousseau F. Brain hallucination. In: Forsyth D, Torr P, Zisserman A, editors. ECCV 2008, Part I. LNCS. Vol. 5302. Springer; Heidelberg: 2008. pp. 497–508. [Google Scholar]
- 15.Roy S, Carass A, Prince JL. Magnetic resonance image example based contrast synthesis. IEEE Trans Med Imag. 2013;32(12):2348–2363. doi: 10.1109/TMI.2013.2282126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Shiee N, Bazin PL, Ozturk A, Reich DS, Calabresi PA, Pham DL. A topology-preserving approach to the segmentation of brain images with multiple sclerosis lesions. NeuroImage. 2010;49(2):1524–1535. doi: 10.1016/j.neuroimage.2009.09.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Tappen M, Liu C, Adelson E, Freeman W. Learning gaussian conditional random fields for low-level vision. CVPR. 2007:1–8. [Google Scholar]
- 18.Wainwright MJ, Jordan MI. Graphical models, exponential families, and variational inference. Found Trends Mach Learn. 2008;1(1–2):1–305. [Google Scholar]
- 19.Wang Z, Bovik AC. A universal image quality index. IEEE Signal Proc Letters. 2002;9 (3):81–84. [Google Scholar]
- 20.Wang Z, Bovik AC, Sheikh HR, Member S, Simoncelli EP. Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Proc. 2004;13:600–612. doi: 10.1109/tip.2003.819861. [DOI] [PubMed] [Google Scholar]