

Abstract
We add a set of convex constraints to the lasso to produce sparse interaction models that honor the hierarchy restriction that an interaction only be included in a model if one or both variables are marginally important. We give a precise characterization of the effect of this hierarchy constraint, prove that hierarchy holds with probability one and derive an unbiased estimate for the degrees of freedom of our estimator. A bound on this estimate reveals the amount of fitting “saved” by the hierarchy constraint.
We distinguish between parameter sparsity—the number of nonzero coefficients—and practical sparsity—the number of raw variables one must measure to make a new prediction. Hierarchy focuses on the latter, which is more closely tied to important data collection concerns such as cost, time and effort. We develop an algorithm, available in the R package hierNet, and perform an empirical study of our method.
Key words and phrases: Regularized regression, lasso, interactions, hierarchical sparsity, convexity
1. Introduction
There are numerous situations in which additive (main effects) models are insufficient for predicting an outcome of interest. In medical diagnosis, the co-occurrence of two symptoms may lead a doctor to be confident that a patient has a certain disease whereas the presence of either symptom without the other would provide only a moderate indication of that disease. This situation corresponds to a positive (i.e., synergistic) interaction between symptom variables. On the other hand, suppose both symptoms convey redundant information to the doctor about the patient so that knowing both provides no more information about the disease status than either one on its own. This situation is again not additive, but this time there is a negative interaction between symptoms. Fitting regression models with interactions is challenging when one has even a moderate number, p, of measured variables, since there are interactions of order k. For this paper, we focus on the case of pairwise (k = 2) interaction models, although the ideas we develop generalize naturally to higher-order interaction models.
1.1. Two-way interaction model
We consider a regression model for an outcome variable Y and predictors X1, …, Xp, with pairwise interactions between these predictors. In particular our model has the form
| (1) |
where ε ~ N(0, σ6). Regardless of whether the predictors are continuous or discrete, we will refer to the additive part as the “main effect” terms and the quadratic part as the “interaction” terms. Our goal is to estimate β ∈ ℝp and Θ ∈ ℝp×p, where Θ = ΘT and Θjj = 0. The factor of one half before the interaction summation is a consequence of our notational decision to deal with a symmetric matrix Θ of interactions rather than a vector of length p(p − 1)/2. We take Θjj = 0 throughout this paper because it simplifies notation, but everything carries over if we remove this restriction. Indeed, we provide this as an option in the hierNet (pronounced “hair net”) package.
We observe a training sample, (x1, y1), …, (xn, yn), and our goal is to select a subset of the p + p(p − 1)/2 main effect and interaction variables that is predictive of the response, and to estimate the values for the nonzero parameters of the model.
1.2. Strong and weak hierarchy
It is a well-established practice among statisticians fitting (1) to only allow an interaction into the model if the corresponding main effects are also in the model. Such restrictions are known under various names, including “heredity,” “marginality,” and being “hierarchically well-formulated” [Hamada and Wu (1992), Chipman (1996), Nelder (1977), Peixoto (1987)]. There are two types of restrictions, which we will call strong and weak hierarchy:
Some statisticians argue that models violating strong hierarchy are not sensible. For example, according to McCullagh and Nelder (1983),
“[T]here is usually no reason to postulate a special position for the origin, so that the linear terms must be included with the cross-term.”
To see that violating strong hierarchy amounts to “postulating a special position for the origin,” consider writing an interaction model as Y = β0 + (β1 + Θ12X2)X1 + ···. First of all, we would only take β0 = 0 if we have special reason to believe that the regression surface must go through the origin. Likewise, taking β1 = 0 but Θ12 ≠ 0 would only be appropriate if we actually believe that X1’s effect on Y should only be present specifically when X2 is nonzero. In most situations, we do not think that the variable X2 that we measured is any more special than aX2 + b. Yet if our model with X2 violates strong hierarchy, then our model with aX2 + b (for any b ≠ 0) is strongly hierarchical. This argument suggests that violations to hierarchy occur in special situations whereas hierarchy is the default.
Another argument in favor of hierarchy has to do with statistical power. In the words of Cox (1984):
“[L]arge component main effects are more likely to lead to appreciable interactions than small components. Also, the interactions corresponding to larger main effects may be in some sense of more practical importance.”
In other words, rather than looking at all possible interactions, it may be useful to focus our search on those interactions that have large main effects. Indeed, the method we propose in this paper makes direct use of this principle.
As a final argument for hierarchy, it is useful to distinguish between two notions of sparsity, which we will call parameter sparsity and practical sparsity. Parameter sparsity is what most statisticians mean by “sparsity”: the number of nonzero coefficients in the model. Practical sparsity is what someone actually collecting data cares about: the number of variables one needs to measure to make predictions at a future time. The hierarchy restriction favors models that “reuse” measured variables whereas a nonhierarchical model does not. The top left panel of Figure 1 gives a small example where this difference is manifest. In fact, a simple calculation shows that this difference can be quite substantial: we can have a hierarchical and a nonhierarchical interaction model with the same parameter sparsity but with the nonhierarchical method having a practical sparsity of k(k + 1) whereas the hierarchical method’s practical sparsity is just k.
Fig. 1.

Olive oil data: (Top left) Parameter sparsity is the number of nonzero coefficients while practical sparsity is the number of measured variables in the model. Results from all 100 random train-test splits are shown as points; lines show the average performance over all 100 runs. (Top right) Misclassification error on test set versus practical sparsity. (Bottom) Wheel plots showing the sparsity pattern at 6 values of λ for the strong hierarchical lasso. Filled nodes correspond to nonzero main effects, and edges correspond to nonzero interactions.
While taking these arguments to the extreme leads to the use of strong hierarchy exclusively, we develop the case of weak hierarchy in parallel throughout this paper. Weak hierarchy, as the name suggests, can be thought of as a compromise between strong hierarchy and imposing no such structure and appears as a principle in certain statistical methods such as classification and regression trees [Breiman et al. (1984)] and multivariate additive regression splines [Friedman (1991)].
1.3. Sparsity, the lasso and structured sparsity
The lasso [Tibshirani (1996)] is a method that performs both model selection and estimation. It penalizes the squared loss of the data with an ℓ1-norm penalty on the parameter vector. This penalty has the property of producing estimates of the parameter vector that are sparse (corresponding to model selection). Given a design matrix X̃ ∈ ℝn×d and response vector y ∈ ℝn, the lasso is the solution to the convex optimization problem,
where 1 ∈ ℝn is the vector of ones. The penalty parameter, λ ≥ 0, controls the relative importance of fitting to the training data (sum-of-squares term) and of sparsity (ℓ1 penalty term). A natural extension of the lasso to our interaction model (1) would be to take ϕT = [βT, vec(Θ)T] and X̃ = (X:Z/2), where the columns of Z ∈ ℝn×p(p−1) correspond to elementwise products of the columns of X. We will refer to this method as the all-pairs lasso since it is simply the lasso applied to a data matrix which includes all pairs of interactions (as well as all main effects). It is common with the lasso to standardize the predictors so that they are on the same scale. In this paper, we standardize X so that its columns have mean 0 and standard deviation 1; we then form Z from these standardized predictors and, finally, center the resulting columns of Z. By centering y and X̃, we may take β̂0 = 0.
The lasso’s ℓ1 penalty is neutral to the pattern of sparsity, allowing any sparsity pattern to emerge. The notions of strong and weak hierarchy introduced in Section 1.2 represent situations in which we want to exclude certain sparsity patterns. There has been a growing literature focusing on methods that produce structured sparsity [Yuan and Lin (2006), Zhao, Rocha and Yu (2009), Jenatton et al. (2010), Jenatton, Audibert and Bach (2011), Bach (2011), Bach et al. (2012)]. These methods make use of the group lasso penalty (and generalizations thereof) which, given a predetermined grouping of the parameters, induces entire groups of parameters to be set to zero [Yuan and Lin (2006)]. Given a set of groups of variables,
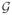 , these methods generalize the ℓ1 penalty by
, these methods generalize the ℓ1 penalty by
where γG > 1, ϕG is ϕ projected onto the coordinates in G, and dG is a nonnegative weight. Hierarchical structured sparsity is obtained by choosing
to have nested groups. For example, Zhao, Rocha and Yu (2009) consider the penalty
Likewise, the framework of Bach et al. (2012) if specialized to this paper’s focus would lead to a penalty of the form
| (2) |
for some q > 1 and dj > 0. In fact, Radchenko and James (2010) suggest a penalty for generalized additive models with interactions that reduces to (2) in the linear model case, with q = 2 and dj independent of j.
1.4. This paper
Here, we propose a lasso-like procedure that produces sparse estimates of β and Θ while satisfying the strong or weak hierarchy constraint. In contrast to much of the structured sparsity literature which is based on group lasso penalties, our approach, presented in Section 2, involves adding a set of convex constraints to the lasso. Although we find this form of constraint more naturally interpretable, we show (Remark 3) that this problem can be equivalently expressed in a form that relates it to penalties from the structured sparsity literature such as (2).
A key advantage of our specific choice of penalty structure is that it admits a simple interpretation of the effect of the hierarchy demand. Unlike other hierarchical sparsity methods, which do not pay much attention to the particular choice of norms (as long as γG > 1), our formulation is carefully tailored to allow it to be related directly back to the lasso, permitting one to understand specifically how hierarchy alters the solution (Section 3.1). This feature of our estimator gives it a transparency that exposes the effects (both positive and negative!) of the hierarchy constraint. Furthermore, our characterization suggests that the demand for hierarchy is—analogous to the demand for sparsity—a form of “regularization.” We develop an unbiased estimator of the degrees of freedom of our method (Section 3.3) and an interpretable upper bound on this quantity, which also points to hierarchy as regularization. In particular, we show that we do not “spend” in degrees of freedom for main effects that are forced into the model by the hierarchy constraint.
Another difference from much of the structured sparsity literature, which aims to develop a broad treatment of structured and hierarchical sparsity methods, is that our focus is narrowed to the problem of interaction models. Our restricted scope allows us to address specifically the performance of such a tool to this important problem. In Section 4, we review previous work on the problem of hierarchical interaction model fitting and selection. These methods fall into three categories: Multi-step procedures, which are defined by an algorithm [Peixoto (1987), Friedman (1991), Turlach (2004), Nardi and Rinaldo (2012), Bickel, Ritov and Tsybakov (2010), Park and Hastie (2008), Wu et al. (2010)]; Bayesian approaches, which specify the hierarchy requirement through a prior [Chipman (1996)]; and, most related to this paper’s proposal, regularized regression methods, which are defined by an optimization problem [Yuan, Joseph and Zou (2009), Zhao, Rocha and Yu (2009), Choi, Li and Zhu (2010), Jenatton et al. (2010), Radchenko and James (2010)]. In Section 5, we study via simulation the statistical implications of imposing hierarchy on an interactions-based estimator under various scenarios (in both the lasso and stepwise frameworks). In Section 6 we present an efficient algorithm for computing our estimator. Real data examples are used to illustrate a distinction we draw between “parameter sparsity” and “practical sparsity” and to discuss hierarchy’s role in promoting the latter.
2. Our proposed method
In Section 1.3, we introduced the all-pairs lasso, which can be written as
| (3) |
where ||Θ||1 = Σj≠k |Θjk| and q(β0, β, Θ) is the loss function, typically , but may also include a ridge penalty on the coefficients as discussed later or may be substituted for the binomial negative log-likelihood. The one-half factors in front of terms involving Θ are merely a consequence of the notational choice to represent Θ as a symmetric matrix (with Θjj = 0 for j = 1, …, p). In this paper, we propose a modification of the all-pairs lasso that produces models that are guaranteed to be hierarchical.
As motivation for our proposal, consider building hierarchy into the optimization problem as a constraint,
| (4) |
where Θj denotes the jth row (and column, by symmetry) of Θ. Notice that if Θ̂jk ≠ 0, then ||Θ̂j||1 > 0 and ||Θ̂k||1 > 0 and thus β̂j ≠ 0 and β̂k ≠ 0. While the added constraints enforce strong hierarchy, they are not convex, which makes (4) undesirable as a method. In this paper, we propose a straightforward convex relaxation of (4), which we call the strong hierarchical lasso,
| (5) |
where we have replaced the optimization variable β ∈ ℝp by two vectors β+, β− ∈ ℝp. After solving the above problem, our fitted model is of the form f̂(x) = β̂0 + xT (β̂+ − β̂−) + xT Θ̂x/2. While we might informally think of β+ and β− as positive and negative parts of a vector β = β+ − β−, that is, that β± = max{±β, 0}, this is not actually the case since at a solution we can have both and . Indeed, if we were to add the constraints for j = 1, …, p to (5), then these would be positive and negative parts and so , giving us precisely problem (4). This observation establishes that (5) is a convex relaxation of (4).
The hierarchy constraints can be seen as an embedding into our method of David Cox’s “principle” that “large component main effects are more likely to lead to appreciable interactions than small components.” The constraint
budgets the total amount of interactions involving variable Xj according to the relative importance of Xj as a main effect. One additional advantage of the convex relaxation is that the constraint is less restrictive. If the best fitting model would have ||Θj||1 large but |βj| only moderate, this can be accommodated by making and both large.
Remark 1
Another possibility for the hierarchy constraint that we have considered is ; however, we have found that this can lead to an overabundance of interactions relative to main effects.
Remark 2
It is desirable to include in the loss function q an elastic net term, , to ensure uniqueness of the solution [Zou and Hastie (2005)]. We think of ε > 0 as a fixed tiny fraction of λ, such as ε = 10−8λ, rather than as an additional tuning parameter. Such a modification does not complicate the algorithm, but simplifies the study of the estimator. In all numerical examples and in the hierNet package, we use this elastic net modification.
Remark 3
We prove in Section 2 of the supplementary materials [Bien, Taylor and Tibshirani (2013)] that (5) may equivalently be written as
| (6) |
This reparameterization of the problem shows its similarities to the group lasso based methods. In place of the more standard penalty ||(Θj, βj)||q of (2), we use max{||Θj||1, |βj|}. In Section 3.1, we show that this unusual choice of penalty admits a particularly simple interpretation for the effect of imposing hierarchy.
In Section 1.2, we also introduced the notion of weak hierarchy. By simply removing the symmetry constraint on Θ, we get what we call the weak hierarchical lasso,
| (7) |
Even though at a solution to this problem, Θ̂ is not symmetric, we should b think of the interaction coefficient as (Θ̂jk + Θ̂kj)/2 since this is what multiplies the interaction term xijxik when computing f̂(xi).
Remark 4
We can build further on the connection between (2) and (5) discussed in Remark 3. Our removal of the symmetry constraint in (7) is analogous to the technique of duplicating columns of the design matrix used in the overlap group lasso [Obozinski, Jacob and Vert (2011)].
A favorable property that distinguishes our method from previous approaches discussed in Section 4 is the relative transparency of the role that the hierarchy constraint plays in our estimator. This aspect is developed in Section 3.1.
Although our primary focus in this paper is on the Gaussian setting of (1), our proposal extends straightforwardly to other situations, such as the logistic regression setting in which the response is binary. In this case, we simply have q(β0, β, Θ) be the appropriate negative log-likelihood, , where . In Section 3 of the supplementary materials [Bien, Taylor and Tibshirani (2013)], we show that solving this problem requires only a minor modification to our primary algorithm. It should also be noted that our estimator (and the algorithms developed to compute it) is designed for both the p < n and p ≥ n setting.
As a preliminary example, consider predicting whether a sample of olive oil comes from Southern Apulia based on measurements of the concentration of p = 8 fatty acids [Forina et al. (1983)]. The dataset consists of n = 572 samples, and we average our results over 100 random equal-sized train-test splits. We compare three methods: (a) a standard lasso with main effects only (MEL), (b) the all-pairs lasso (APL), and (c) the strong hierarchical lasso (HL).
The top left panel of Figure 1 shows an interesting difference between HL and APL. We see that, on average, at a parameter sparsity level of five, the HL model uses four of the measured variables whereas APL uses six. Using the hierarchical model to classify a future olive oil, we only need to measure four rather than six of the fatty acids.
The top right panel of Figure 1 shows the predictive performance (versus the practical sparsity) of the three methods. It appears that HL enjoys the “best of both worlds,” matching the good performance of MEL for low practical sparsity levels (since it tends to pick out the main effects first) and the good performance of APL at high practical sparsity levels (since it can incorporate predictive interactions). Finally, the bottom panel of the figure provides a visual display of a sequence of HL’s solutions (by varying λ). Nonzero main effects are shown as filled nodes, and edges indicate nonzero interactions. Since all edges are incident to filled nodes, we see that strong hierarchy holds.
In the next section, we present several properties of our estimator that shed light on the effect of adding the convex hierarchy constraint to the lasso. Among these properties is an unbiased estimate of the degrees of freedom of our estimator. We view this degrees-of-freedom result as valuable primarily for the sake of understanding the effect of hierarchy. While such an estimate could be used for parameter selection, we prefer cross validation to select λ since this is more directly tied to the goal of prediction.
3. Properties
3.1. Effect of the constraint
A key advantage of formulating an estimator as a solution to a convex problem is that it can be completely characterized by a set of optimality conditions, known as the Karush–Kuhn–Tucker (KKT) conditions. These conditions are useful for understanding the effect that the hierarchy constraint in (5) and (7) has on our solutions. In this section, we will study the simplest case, taking q(β0, β, Θ) to be the quadratic loss function with no elastic net penalty. We let
denote partial residuals (where * denotes elementwise multiplication, ŷ the vector of fitted values and xj the jth predictor), and we assume that ||xj||2 = 1. For linear regression, the KKT conditions are known as the normal equations and can be written as
The all-pairs lasso solution satisfies
| (8) |
where
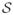 denotes the soft-thresholding operator defined by
(c, λ) = sign(c)(|c| − λ)+. Written this way, we see that the lasso is similar to linear regression, but all coefficients are shrunken toward 0, with some coefficients (those for which
) set to zero. It is instructive to examine the corresponding statements for the strong and weak hierarchical lasso methods.
denotes the soft-thresholding operator defined by
(c, λ) = sign(c)(|c| − λ)+. Written this way, we see that the lasso is similar to linear regression, but all coefficients are shrunken toward 0, with some coefficients (those for which
) set to zero. It is instructive to examine the corresponding statements for the strong and weak hierarchical lasso methods.
Property 1
The coefficients of the strong and weak hierarchical lassos with λ > 0 and taking q(β0, β, Θ) to be the quadratic loss (with no elastic net penalty) satisfy:
- Strong:
-
Weak:
for some α̂ ≥ 0, j = 1, …, p with α̂j = 0 when (and likewise for α̃j).
Proof
See Section 1 of the supplementary materials [Bien, Taylor and Tibshirani (2013)].
The α̂j, α̃j appearing in the above two properties are optimal dual variables corresponding to the jth hierarchy constraint for the strong and weak hierarchical lasso problems, respectively. When , we have α̂j = 0 (or α̃j = 0) by complementary slackness. Comparing these expressions to those of the all-pairs lasso gives insight into the effect of the constraint. Property 1 reveals that the overall form of the all-pairs lasso and hierarchical lasso methods is identical. The difference is that the hierarchy constraint leads to a reduction in the shrinkage of certain main effects and an increase in the shrinkage of certain interactions. In particular, we see that when the hierarchy constraints are loose at the solution, that is, , the weak hierarchical lasso’s optimality conditions become identical to the all-pairs lasso (since α̃j = 0) for all coefficients involving xj. For the strong hierarchical lasso, when both the jth and kth constraints are loose, the optimality conditions match those of the all-pairs lasso for the coefficients of xj, xk and xj * xk. The methods differ when constraints are active, that is, when , which allows α̂j (or α̃j) to be nonzero. Intuitively, this case corresponds to the situation in which hierarchy would not have held “naturally” (i.e., without the constraint), and the corresponding dual variable plays the role of reducing Θ̂j in ℓ1-norm and increasing until the constraint is satisfied. The way in which the weak and strong hierarchical lasso methods perform this shrinkage is different, but both are identical to the all-pairs lasso when all constraints are loose.
3.2. Hierarchy guarantee
In Section 2, we showed that adding the constraint ||Θj||1 ≤ |βj| would guarantee that hierarchy holds. However, we have not yet shown that the same is true of the convex relaxation’s constraint, . In particular, while , we could still have . This would correspond to a model in which XjXk is used in the model, but Xj is not. Intuitively, we would expect that if , then is analogous to getting an exact zero in linear regression (i.e., a zero probability event). In this section, we establish that this is in fact the case.
In particular, we study (5) and (7) where q(β0, β, Θ) includes an elastic net term. The importance of this modification is that it ensures uniqueness, simplifying the analysis. As noted in Remark 2, we think of ε as a small, fixed proportion of λ rather than as a separate tuning parameter.
Property 2
Suppose y is absolutely continuous with respect to the Lebesgue measure on ℝn. If (β̂+, β̂−, Θ̂) solves (5), where q(β0, β, Θ) is the quadratic loss with an ε > 0 ridge penalty, then strong hierarchy holds with probability 1, that is,
Proof
See Appendix A.
To understand how dropping the symmetry constraint leads to the “or” statement required of weak hierarchy, note that XjXk is in the weak hierarchical lasso model if and only if Θ̂jk + Θ̂kj ≠ 0. This holds only if Θ̂jk ≠ 0 or Θ̂kj ≠ 0.
Property 3
Suppose y is absolutely continuous with respect to the Lebesgue measure on ℝn. If (β̂+, β̂−, Θ̂) solves (7), where q(β0, β, Θ) is the quadratic loss with an ε > 0 ridge penalty, then weak hierarchy holds with probability 1, that is,
Proof
See Appendix A.
3.3. Degrees of freedom
In classical statistics, the degrees of freedom of a procedure refer to the dimension of the space over which its fitted values can vary. It is useful in that it provides a measure of how much “fitting” the procedure is doing. This notion can be generalized to adaptive procedures such as the lasso [Stein (1981), Efron (1986), Efron et al. (2004), Zou, Hastie and Tibshirani (2007)]. See (Ryan) Tibshirani and Taylor (2012) for a thorough discussion. If given data y ∈ ℝn, a procedure h produces fitted values ŷ = h(y) ∈ ℝn, the degrees of freedom of the procedure h is defined to be
| (9) |
Property 4
Suppose y ~ N(μ, σ6In). An unbiased estimate of the degrees of freedom of the strong hierarchical lasso, with quadratic loss and no ridge penalty, is given by
where X̃ = (X:−X:Z/2: −Z/2) with Z containing the interactions, and P is a projection matrix which depends on the sign pattern of (β̂+, β̂−, Θ̂) and on the set of hierarchy constraints that are tight.
Proof
See Appendix B.
Figure 2 provides a numerical evaluation of how well estimates dfλ. We fix X ∈ ℝn×p, β ∈ ℝp and Θ ∈ ℝp×p, and we generate B = 10,000 Monte Carlo replicates y(1), …, y(B) ∈ ℝn. For each replicate, we fit the strong hierarchical lasso along a grid of λ values to get ( ) and . From these values, we compute Monte Carlo estimates of dfλ from the definition in (9) and of .
Fig. 2.

Numerical evaluation of how well estimates dfλ. Monte Carlo estimates of (y-axis) versus Monte Carlo estimates of dfλ (x-axis) for a sequence of λ values (circular) are shown. One-standard-error bars are drawn and are hardly visible. Our bound on the unbiased estimate is plotted with diamonds.
While can be calculated from the data and is therefore useful as an unbiased way of calibrating the amount of fitting the strong hierarchical lasso is doing, this expression is difficult to interpret. However, it turns out that we can bound by a quantity that does make more sense:
Property 5
Let
and
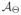 = {jk: Θ̂jk ≠ 0, j < k}. Then,
= {jk: Θ̂jk ≠ 0, j < k}. Then,
holds almost surely, where
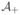 Δ
Δ
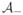 = (
\
) ∪ (
\
).
= (
\
) ∪ (
\
).
Proof
See Appendix B.
By contrast, for the all-pairs lasso in the case that
and the design matrix is full rank, we have dfλ(APL) = E[|
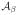 | + |
|] [Zou, Hastie and Tibshirani (2007)]. In other words, the strong hierarchical lasso does not “pay” (in terms of fitting) for those main effects,
, that are forced into the model by the hierarchy constraint to accommodate a strong interaction. Notice that we do pay for a nonzero main effect if both
and
are nonzero. This makes sense since the constraint could be satisfied with just one of these variables nonzero, but in this case it is advantageous to the fit to make both nonzero. In Figure 2, we find that this bound is in expectation visually indistinguishable from
.
| + |
|] [Zou, Hastie and Tibshirani (2007)]. In other words, the strong hierarchical lasso does not “pay” (in terms of fitting) for those main effects,
, that are forced into the model by the hierarchy constraint to accommodate a strong interaction. Notice that we do pay for a nonzero main effect if both
and
are nonzero. This makes sense since the constraint could be satisfied with just one of these variables nonzero, but in this case it is advantageous to the fit to make both nonzero. In Figure 2, we find that this bound is in expectation visually indistinguishable from
.
4. Related work
There has been considerable interest in fitting interaction models in statistics and related fields. We focus here on an overview of methods that aim at forming predictive models that satisfy the hierarchical interactions restriction.
4.1. Multi-step procedures
Many statistics textbooks discuss a simple stepwise procedure in which one iteratively considers adding or removing the “best” variable (whether it be main effect or interaction); they add that one should only consider including an interaction if its main effects are in the model [e.g., see backward elimination in Agresti (2002), Section 6.1.3]. In doing so, they are enforcing the strong hierarchy restriction. Such procedures are ubiquitous [Nelder (1997), Peixoto (1987)] as are more recent versions [Friedman (1991), Bickel, Ritov and Tsybakov (2010), Park and Hastie (2008), Wu et al. (2010)]. Another approach is to perform model selection first without considering hierarchy and then to include any lower-order terms necessary to satisfy hierarchy as a post-processing step [Nardi and Rinaldo (2012)]. Finally, Turlach (2004) and Yuan, Joseph and Lin (2007) consider modifying the LARS algorithm [Efron et al. (2004)] so that hierarchy is enforced.
4.2. Bayesian approaches
Another set of procedures for building hierarchical interaction models comes from a Bayesian viewpoint. Chipman (1996) adapts the stochastic search variable selection (SSVS) approach of George and McCulloch (1993) to produce strong or weak hierarchical interaction models. SSVS makes use of a hierarchical normal mixture model to perform variable selection in regression. Every variable has a latent binary variable indicating whether it is “active.” Conditional on this latent variable, each coefficient is a 0-mean normal with variance determined by the latent importance of the coefficient. The original SSVS paper chooses a prior in which the importance of each variable is an independent Bernoulli. Chipman (1996) introduces dependence into the prior so that Θjk is important only if βj and/or βk is important as well.
4.3. Optimization-based approaches
Choi, Li and Zhu (2010) formulate a nonconvex optimization problem to get sparse hierarchical interaction models. They write Θjk = Γjkβjβk, where β are the main effect coefficients and then apply ℓ1 penalties on β and Γ. Notice that Θjk ≠ 0 implies βj ≠ 0 and βk ≠ 0. The nonconvexity arises in writing Θjk as the product of optimization variables.
Most similar to this paper’s proposal is a series of methods which formulate convex optimization problems to give sparse hierarchical interaction models. Yuan, Joseph and Zou (2009) modify the nonnegative garrote [Breiman (1995)] by adding linear inequality constraints to enforce hierarchy. In this sense, our method can be seen as the adaption of their approach to the lasso.
Finally, as discussed in Section 1.3, another set of convex methods makes use of the group lasso penalty [Yuan and Lin (2006)]. Zhao, Rocha and Yu (2009) [and, relatedly, Jenatton, Audibert and Bach (2011)] describe composite absolute penalties (CAP), a very broad class of penalties that can achieve group and hierarchical sparsity. To achieve “hierarchical selection,” they put forward the principle that a penalty of the form ||(ϕ1, ϕ2)||γ + |ϕ1|, with γ > 1, induces ϕ2 to be zero only when ϕ1 is zero as well. For hierarchical interaction models, they suggest a penalty of the form λ Σj<k[|Θjk| + ||(βj, βk, Θjk)||γj,k]. This framework has been developed in the structured sparsity literature [e.g., Bach et al. (2012)]. Radchenko and James (2010) introduce VANISH, which uses this nested-group principle to achieve hierarchical sparsity in the context of nonlinear interactions. Their penalty in the setting of (1) is Σj[λ1||(βj, Θj)||2 + λ2||Θj||1]. As noted in Remark 3, our proposal is closer to CAP and VANISH than it may first appear. Our problem can be rewritten to have a penalty of the form λ Σj[max{|βj|, ||Θj||1} + (1/2)||Θj||1]. In this sense, the penalty is in the spirit of CAP and related methods although it does not quite fall into the class of CAP (since ours involves a sum of norms of norms). It is most similar to VANISH in that it combines all of Θj into the term involving βj.
5. Empirical study
5.1. Simulations
Our main interest in this section is to study the advantages and disadvantages of restricting one’s interaction models to those that honor hierarchy. Clearly, the effectiveness of such a strategy depends on the true model generating the data. We take n = 100 and p = 30 (435 two-way interactions) and consider four scenarios:
Truth is hierarchical: Θjk ≠ 0 ⇒ βj ≠ 0, βk ≠ 0;
Truth is anti-hierarchical: Θjk ≠ 0 ⇒ βj = 0, βk = 0;
Truth only has interactions: βj = 0 for all j;
Truth only has main effects: Θjk = 0 for all jk.
In cases (I), (II), (IV), we set 10 elements of β to be nonzero (with random sign), and, in cases (I), (II), (III), we set 20 elements of the submatrix of Θ = ΘT to be nonzero. The signal-to-noise ratio (SNR) for the main effects part of the signal is about 1.5 whereas the SNR for the interactions part is about 1.
We study the effectiveness of the hierarchy constraint in the context of both the lasso and forward stepwise regression. Forward stepwise regression refers to a greedy strategy for generating a sequence of linear regression models in which we start with an intercept-only model and then at each step add the variable that leads to the greatest decrease in the residual sum of squares. We choose forward stepwise as a basis of comparison since it has a simple modification that we think may be the hierarchical interactions approach most commonly used by statisticians. The modification is to restrict the set of interactions that could be added at a given step to only those between main effect variables currently in the model. A backward stepwise version of this approach is suggested in Peixoto (1987).
We compare six methods, corresponding to each cell of the following table:
| Hierarchical | All-pairs | Main effects only | |
|---|---|---|---|
| Lasso | HL (our method) | APL | MEL |
| Fwd stepwise | HF | APF | MEF |
Each method has a single tuning parameter: for the lasso methods, the penalty parameter, λ, and for the forward stepwise methods, the number of variables, k. We fit each method along a grid of tuning parameter values and select the model with the smallest mean squared error, E||ŷ − μ||6. Note that such an operation is only possible in simulation since it requires knowing μ; however, doing so avoids the added variance of cross validation without being biased in favor of any particular method. The results presented are based on 100 simulations from the underlying model. Figure 3 shows the expected prediction error, σ6 + E[(ŷ − μ)6]. Panel (I) shows that when the truth is hierarchical, methods that assume hierarchy (HL, HF) do better than the rest. These methods have “concentrated” their power on the correct set of models and therefore receive the biggest payoff for being correct. APL does better than MEL and MEF since it succeeds in incorporating some of the correct interactions (recall that interactions make up one quarter of the signal). In panel (II), we notice our first surprise—that HL predicts well relative to the others even when the truth is not hierarchical! We would have expected APL (or APF) to be the clear winner in this situation since surely the hierarchy assumption can only be detrimental in this “anti-hierarchical” scenario. The reason APL does not outperform HL in this scenario is because APL has trouble identifying the main effects (it gets swamped by the 435 interaction variables). In light of Section 3.1, this is where the hierarchy constraint helps—main effects are penalized by less and interactions by more. Even though APL is better able to find the correct interactions than HL, as seen in panel (II) of Figure 4, APL does not predict as well as HL because it fails to find the main effects, which constitute three quarters of the signal. Relatedly, in a “hierarchical truth” scenario similar to (I) but with p > n (not presented here), we have in fact observed MEL doing better than APL (though not as well as HL) since APL is not able to detect interactions accurately enough to make up for its inferior ability to detect main effects. By contrast, HL does best in that scenario, aided by hierarchy to capture both the main effect and interaction components of the signal.
Fig. 3.

Prediction error: Dashed line shows Bayes error (i.e., σ2), and the base rate refers to the prediction error of ȳtrain. Green, red and blue colors indicate hierarchy, all-pairs, and main effect only, respectively; solid and striped indicate lasso and forward stepwise, respectively.
Fig. 4.

Plots show the ability of various methods to correctly recover the nonzero interactions. This is the sensitivity (i.e., proportion of Θjk ≠ 0 for which Θ●jk ≠ 0) and specificity (i.e., proportion of Θjk ≠ 0 for which Θ●jk ≠ 0) corresponding to the lowest prediction error model of each method.
In panel (III), we see a situation where APL does dominate HL. Since there are no main effects in the signal, all that is relevant is a method’s ability to find the interactions. HL identifies fewer correct interactions than APL since any main effect “information” that HL is using is spurious. Finally in panel (IV), we see a situation where MEF, HF, MEL do better than the rest. Here again we find that the hierarchy methods beat the all-pairs methods since they favor main effects.
It is particularly illuminating to note the difference in performance between HL and HF. HF in scenarios (II), (III) and (IV) performs very similarly to the main effect only models. In (II) and (III), HL does much better than HF both in terms of prediction error and in ability to correctly identify interactions. HL appears to be far less sensitive to violations of hierarchy than HF. This difference is attributable to the joint nature in which HL acts: the decision to include a main effect is made at the same time as decisions about interactions. This allows a strong interaction to “pull” itself into the model. By contrast, HF selects main effects with no regard to the information contained in the interactions.
5.2. Data examples
Rhee et al. (2006) study six nucleoside reverse tran-scriptase inhibitors (NRTIs) that are used to treat HIV-1. The target of these drugs can become resistant through mutation, and Rhee et al. (2006) compare a collection of models for predicting these drug’s (log) susceptibility—a measure of drug resistance—based on the location of mutations. In the six cases, there are between p = 211 and p = 218 sites with mutations occurring in the n = 784 to n = 1073 samples. While they focus on main effect only models, we consider here the all-pairs lasso (APL) and weak hierarchical lasso (HL) in addition to the standard main effects lasso (MEL). We train on half of the samples and test on the remaining samples. To reduce the dependence of the results on the particular random training-test split, we repeat this process twenty times and average the results. Figure 5 shows the average test RMSE versus the average practical sparsity for each of the six drugs. In all cases but ABC, we find that HL achieves a better test error at most levels of practical sparsity than APL. That said, if the number of mutations one has to measure is not of concern (so that we can choose for each method the minimum RMSE model), then no method dominates in all the situations. It is worth conceding—since this is a paper on interactions—that in several of the cases a pure main effects model appears to be the best option.
Fig. 5.

HIV drug data: Test-set RMSE versus practical sparsity (i.e., number of measured variables required for prediction) for six different drugs. For each method, the data from all 20 runs are displayed in faint colors; the thick lines are averages over these runs.
6. Algorithmics
Some of the fastest lasso solvers rely on coordinate descent, which amounts to iteratively applying (8) until convergence [Friedman, Hastie and Tibshirani (2010)]. Tseng (2001) proves that blockwise coordinate descent converges to the global minimum for a convex problem specifically when the nondifferentiable part of the problem is blockwise separable. In the case of the strong hierarchical lasso, the hierarchy constraints combined with the symmetry constraint couple all the parameters together, meaning that coordinate descent is prone to getting stuck at sub-optimal points. To see this, note that Θjk = Θkj appears in two constraints and . By contrast, the constraints in the weak hierarchical lasso problem are blockwise separable so that blockwise coordinate descent on blocks of the form (Θj, ) for j = 1, …, p does work. We begin by discussing our approach to solving the weak hierarchical lasso problem. In Section 6.2 we discuss how we can solve a sequence of weak hierarchical lasso problems that converges to a solution of the strong hierarchical lasso.
6.1. Solving the weak hierarchical lasso
While blockwise coordinate descent would work for solving the weak hierarchical lasso problem, we instead describe a generalized gradient descent approach. Given a problem of the form
| (10) |
in which g is convex and differentiable with a Lipschitz gradient and h is convex, generalized gradient descent works by solving a sequence of problems of the form 1
where t is a suitably chosen step size [Beck and Teboulle (2009)]. These subproblems are easier to solve than (10) since they replace g by a spherical quadratic. Under the previously stated conditions, generalized gradient descent is guaranteed to get within O(1/k) of the optimal value after k steps; in fact, with a simple modification to the algorithm, this rate improves to O(1/k6) [Beck and Teboulle (2009)]. Looking back at (7), we take g to be the differentiable part, q(β0, β+ − β−, Θ) + λ1T (β+ + β−) and h to be the ℓ1 penalty on Θ and the set of constraints. The subproblem is of the form
where (β̃+, β̃−, Θ̃) depends on the previous iteration’s solution and the data, X, Z and y. The exact form of (β̃+, β̃−, Θ̃) is given in Algorithm for solving (7), where q(β0, β, Θ) includes an elastic net penalty as described in Remark 2 of Section 2. The above problem decouples into p separate pieces involving (Θj, ) that could be solved in parallel:
| (11) |
Algorithm 1.
WEAK–HIERNET: Generalized gradient descent to solve weak hierarchical lasso, (7), with elastic net penalty ε.
| Inputs: X ∈ ℝn×p, Z ∈ ℝn×p(p−1), λ > 0. Initialize (β̂+(0), β̂−(0), Θ̂(0)). | |
| For k = 1, 2, … until convergence: | |
| Compute residual: r̂(k−1) ← y − X(β̂+(k−1) − β̂− (k−1)) − ZΘ̂(k−1)/2. | |
| For j = 1, …, p:
| |
| where ONEROW is given in Algorithm 3, δ = 1 − tε, and Z(j, ·) ∈ ℝn×(p−1) denotes the columns of Z involving Xj. |
In Appendix C, we derive an algorithm, ONEROW, that solves (11) based on the observation that, in terms of an optimal dual variable α̂, a solution is simply Θ̂j =
[Θ̃j, t(λ/2 + α̂)] and
.
We solve (7) along a sequence of λ values, from large to small, using the solution from the previous λ as a warm start for the next. The WEAK-HIERNET algorithm gets within ε of the optimal value of (7) in O(p6 max{n, p}/ε) time.
6.2. Solving the strong hierarchical lasso
In Section 6.1, we noted that each step of generalized gradient descent conveniently decouples into p single-variable optimization problems. However, for the strong hierarchical lasso, (5), the symmetry constraint ties all variables together. We therefore make use of Alternating Direction Method of Multipliers (ADMM), which is a very widely applicable framework that allows convex problems to be split apart into separate easier subproblems [Boyd et al. (2011)].
Given a convex problem of the form Minimizeϕf(ϕ) + g(ϕ), we rewrite it equivalently as Minimizeϕ, φf(ϕ) + g(φ) s.t. ϕ = φ, and then the ADMM algorithm repeats the following three steps until convergence:
ϕ̂ = argminϕ[f(ϕ) + (ρ/2)||ϕ − φ̂ + û/ρ||6].
φ̂ = argminφ[g(φ) + (ρ/2)||φ − ϕ̂ − û/ρ||6].
û ← û + ρ(ϕ̂ − φ̂).
Thus the ADMM algorithm separates the two difficult parts of the problem, f and g, into separate optimization problems. The dual variable û serves to pull these two problems together, resulting in an algorithm that is guaranteed to converge to a solution as long as ρ > 0. In practice, the value of ρ affects the speed of convergence.
In our case, we use ADMM to separate the hierarchy constraints, involving (β+, β−, Θ) from the symmetry constraint, which will involve a symmetric version of Θ, which we call Ω:
| (12) |
The resulting ADMM algorithm is given in Algorithm 2, which is explained in greater detail in Section 4 of the supplementary materials [Bien, Taylor and Tibshirani (2013)]. Conceptually, the algorithm alternately updates two matrices, Θ and Ω. Throughout the algorithm, we update Θ by solving a version of problem (7), and we update Ω by symmetrizing a version of Θ. At convergence, Θ̂ = Ω̂, and thus Θ̂ is both symmetric and satisfies the hierarchy constraints.
Algorithm 2.
STRONG-HIERNET: Solve (5) via ADMM.
| Inputs: X ∈ ℝn×p, Z ∈ ℝn×p(p−1), λ > 0, ρ > 0. |
| Initialize (β̂+, β̂−, Θ̂), Ω̂, Û. |
Repeat until convergence:
|
7. Discussion
In this paper, we have proposed a modification to the lasso for fitting strong and weak hierarchical interaction models. These two approaches are closely tied, and our algorithms to solve the two exploit their similar structure. A key advantage of our framework is that it admits a simple characterization of the effect of imposing hierarchy. We compare our hierarchical methods to the lasso and to stepwise procedures to understand the implications of demanding hierarchy. We introduce a distinction between models that have a small number of parameters and those that require measuring only a small number of variables. The hierarchical interaction requirement favors models with the latter type of sparsity, a feature that is desirable when performing measurements is costly, time consuming, or otherwise inconvenient. The R package hierNet provides implementations of our strong and weak methods, both for Gaussian and logistic losses. This work has potential applications to genomewide association studies. In future work, we intend to extend this framework to contexts in which only certain interactions should be considered such as in gene-environment interaction models.
Supplementary Material
Acknowledgments
We thank Will Fithian, Max Grazier-G’Sell, Brad Klingenberg, Balasubramanian Narasimhan and Ryan Tibshirani for useful conversations and two referees and an Associate Editor for helpful comments.
APPENDIX A: PROOFS OF STRONG AND WEAK HIERARCHY
We begin by proving Lemma 1, which characterizes all solutions to (5) as a relatively simple function of y. The structure of our proof is based on (Ryan) Tibshirani and Taylor (2011, 2012).
A.1. Characterizing the solution
For ease of analysis, we write (5) equivalently in terms of Θ+ and Θ−. Also, for notational simplicity, we write ϕ = (β+, β−, Θ+, Θ−) and X̃ = (X; −X;Z/2; −Z/2). The strong hierarchical lasso problem is the following:
In introducing Θ±, we are not in fact changing the problem since at a solution Θ̂± = max{±Θ̂, 0} (for λ2 > 0). To see this, note that given any feasible point with and , we can produce a feasible point with strictly lower objective by reducing all by equal amounts.
We will try to make this as close as possible in form and notation to (Ryan) Tibshirani and Taylor’s (2012) treatment of the generalized lasso problem. Our optimization problem is of the form
| (13) |
The Lagrangian of this problem is
where μ ≥ 0 and ν are dual variables. The KKT conditions for (ϕ̂(y), (μ̂(y), ν̂(y))) to be an optimal primal-dual pair are the following:
Now, define the “boundary” and “active” sets as
These are not necessarily unique since (ϕ̂, (μ̂, ν̂)) may not be unique. In terms of the active set
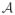 (ϕ̂), the KKT conditions become
(ϕ̂), the KKT conditions become
Solving for ϕ̂, we get the following characterization of a strong hierarchical lasso solution:
Lemma 1
Suppose ϕ̂ is a solution to the strong hierarchical lasso problem (5) [taking q(β0, β, Θ) to be the quadratic loss] with
(ϕ̂) = {i : [Dϕ̂]i > 0}. Then, ϕ̂ can be written in terms of
(ϕ̂) and y as
where b ∈ null(X̃) ∩ null(L) ∩ null(
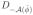 ) satisfies
) satisfies
for all i ∈
(ϕ̂).
Proof
Defining
and P = Pnull(D̃) =
 , we solve for ϕ̂ in the same manner as is done in (Ryan) Tibshirani and Taylor (2012). Since D̃ϕ̂ = 0 is equivalent to Pϕ̂ = ϕ̂, we have PX̃T (y − X̃Pϕ̂) = Pw. We see that Pw ∈ col(PX̃T) and thus Pw = (PX̃T)(PX̃T)+Pw. Thus, PX̃TX̃Pϕ̂ = PX̃T(y − (PX̃T)+Pw) from which we get
, we solve for ϕ̂ in the same manner as is done in (Ryan) Tibshirani and Taylor (2012). Since D̃ϕ̂ = 0 is equivalent to Pϕ̂ = ϕ̂, we have PX̃T (y − X̃Pϕ̂) = Pw. We see that Pw ∈ col(PX̃T) and thus Pw = (PX̃T)(PX̃T)+Pw. Thus, PX̃TX̃Pϕ̂ = PX̃T(y − (PX̃T)+Pw) from which we get
for b ∈ null(X̃P) and such that D̃b = 0 and Diϕ̂ > 0 for i ∈
(ϕ̂). To complete the result, we observe that the first two conditions reduce to b ∈ null(X̃) ∩ null(L) ∩ null(
).
We will use this characterization of a solution both to prove that the hierarchy property holds with probability one under weak assumptions and to derive an unbiased estimate of the degrees of freedom.
Before we do so, we write out more explicitly and introduce a little notation that will be useful later. Every row of D corresponds to an inequality constraint, and we can describe these rows in terms of ten subsets,
| (14) |
The set
(ϕ̂)c is made up of
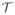 ,
,
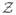 (β̂+),
(β̂−),
(Θ̂+) and
(Θ̂−). The matrix D̃ has 2p+2p6 columns that can be partitioned as (D̃β+ : D̃β− : D̃Θ +: D̃Θ−) and a row for every constraint. The rows of this matrix are the following (where ej and 1p are row vectors):
(β̂+),
(β̂−),
(Θ̂+) and
(Θ̂−). The matrix D̃ has 2p+2p6 columns that can be partitioned as (D̃β+ : D̃β− : D̃Θ +: D̃Θ−) and a row for every constraint. The rows of this matrix are the following (where ej and 1p are row vectors):
We will refer to this in the proofs that follow.
A.2. Proof of strong hierarchy (Property 2)
Including the elastic net penalty, , is equivalent to replacing X̃ and y in (13) by
Suppose we solve (13) with the above design matrix. By Lemma 1,
for some b ∈ null(X̃ε) ∩ null(L) ∩ null(
) satisfying
for all i ∈
(ϕ̂). Let Sv :ℝ2p+2p2 → ℝ|v| be the linear operator that selects the part of a vector corresponding to the variable v. Now, b ∈ null(X̃ε) implies that Sβ+ (b) = Sβ− (b) = 0 and SΘ+ (b) = − SΘ− (b). We showed earlier that we cannot have
and
. This means that for any jk, there must be an i ∉
(ϕ̂) for which Diϕ̂ = 0 corresponds to
or
. Thus,
b = 0 means that
or
for each jk. This implies that null(X̃ε) ∩ null(
) = {0} and thus b = 0.
We show now that . In terms of our above notation, this is
| (15) |
where
is the vector with all zeros except for
. Let P =
 , and consider the set
, and consider the set
In light of (14), fixing
automatically specifies
,
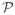 (β̂±),
(Θ̂±). The outer union is restricted to those subsets
of 2p +2p6 elements that would have
(Θ̂+) ∩
(Θ̂−) = Ø and
(β̂+) ∩
(β̂−) ⊆
. The event in (15) is contained in {yε ∈
(β̂±),
(Θ̂±). The outer union is restricted to those subsets
of 2p +2p6 elements that would have
(Θ̂+) ∩
(Θ̂−) = Ø and
(β̂+) ∩
(β̂−) ⊆
. The event in (15) is contained in {yε ∈
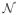 } since it corresponds to the case in which
is
(ϕ̂). We begin by showing that
(ϕ̂) is in this restricted union with probability one. We have already argued that at a solution we must have
for all jk. Now,
and
together imply that
since otherwise we could lower the objective by reducing
and
without leaving the feasible set. Therefore, it would be sufficient to show that P(yε ∈
) = 0. We do so by observing that {yε ∈
} is a finite union of zero probability sets.
} since it corresponds to the case in which
is
(ϕ̂). We begin by showing that
(ϕ̂) is in this restricted union with probability one. We have already argued that at a solution we must have
for all jk. Now,
and
together imply that
since otherwise we could lower the objective by reducing
and
without leaving the feasible set. Therefore, it would be sufficient to show that P(yε ∈
) = 0. We do so by observing that {yε ∈
} is a finite union of zero probability sets.
We begin by establishing that . To do so, we write P = UUT for some UTU = I. Now, row(X̃P) ⊆ row(P) = col(U), so we can write U = (U1 : U2), where row(X̃P) = col(U1) and thus X̃PU2 = 0. Since PU2 = U2, it follows that X̃U2 = 0. Write for i = 1, 2, and observe that so that
Now, for each jk we must have jk ∈
(Θ+) ∪
(Θ−) since
(Θ+) ∩
(Θ−) = Ø. Thus, for each jk, there is a R4 or R5 row in
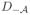 and thus
(U1 : U2) = 0 implies that
or
for each jk and likewise
or
. Therefore,
. Now,
and thus
(U1 : U2) = 0 implies that
or
for each jk and likewise
or
. Therefore,
. Now,
Now, since and ⪰ 0 and X̃U1 has full column rank. Thus, . This completes the first part of the proof.
Next, we show that
as long as
. Now, since j ∈ ∩
(β+) ∩
(β−) ⊆
, the only row of D̃ that has
is the R1 row; but clearly
. Thus,
and
. It follows that
Putting these two parts of the proof together establishes that
. Thus, {yε ∈
} is a finite union of Lebesgue measure 0 sets. This shows that P(yε ∈
) = 0 as long as y is absolutely continuous with respect to the Lebesgue measure on ℝn.
A.3. Proof of weak hierarchy (Property 3)
An argument nearly identical to that of the previous section establishes that with probability one. Thus, if and , then both Θ̂jk = 0 and Θ̂kj = 0. It follows then that (Θ̂jk + Θ̂kj)/2 = 0. This establishes weak hierarchy.
APPENDIX B: DEGREES OF FREEDOM
B.1. Proof of unbiased estimate (Property 4)
The fit in terms of the active set is given by
where P =
. Of course,
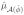 = 0, and we can solve the KKT conditions to get the rest of the optimal dual variables in terms of the active set
= 0, and we can solve the KKT conditions to get the rest of the optimal dual variables in terms of the active set
where c ∈ null(D̃) satisfies D̃T+[w − X̃T (y − X̃ ϕ̂)] + c ≥ 0.
Note that ϕ̂ = ϕ̂(y) and thus
(ϕ̂) and b depend on y even though we do not write this explicitly. We will continue writing ϕ̂ to mean specifically ϕ̂(y). For y′ in a neighborhood of y, we might guess that ϕ̂(y′) = f(y′) and (μ̂(y′), ν̂(y′)) = (g(y′),h(y′)), where
To verify this guess, we need to check that the pair (f(y′), (g(y′),h(y′))) satisfies the optimality conditions at y′,
First of all, Lf(y′) = 0 holds since L(X̃
)+ = 0 and Lb = 0. Likewise,
f(y′) = 0. Now
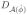 f(y) > 0, so by continuity of f, we have
f(y′) > 0 for all y′ in a small enough neighborhood, U1, of y. This establishes that
(f(y′)) =
(ϕ̂). Now
f(y) > 0, so by continuity of f, we have
f(y′) > 0 for all y′ in a small enough neighborhood, U1, of y. This establishes that
(f(y′)) =
(ϕ̂). Now
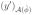 = 0, so complementary slackness holds. To see that the first optimality condition holds, we can simply plug (g(y′),h(y′)) into the left-hand side. All that remains is to show that
= 0, so complementary slackness holds. To see that the first optimality condition holds, we can simply plug (g(y′),h(y′)) into the left-hand side. All that remains is to show that
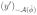 ≥ 0. If we knew that
≥ 0. If we knew that
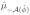 > 0, then by continuity of g we could argue that over a small enough neighborhood, U2,
> 0. However, it could be the case that μ̂i = 0 for some i ∉
(ϕ̂), that is, i ∈
> 0, then by continuity of g we could argue that over a small enough neighborhood, U2,
> 0. However, it could be the case that μ̂i = 0 for some i ∉
(ϕ̂), that is, i ∈
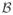 (ϕ̂) \
(ϕ̂). Nonetheless, one can show that there is a set
of measure 0 for which y ∉
implies that
(ϕ̂(y)) =
(ϕ̂(y′)) and
(ϕ̂(y)) =
(ϕ̂(y′)) for all y′ in a neighborhood of y. Lemma 9 of (Ryan) Tibshirani and Taylor (2012) proves this result for a nearly identical situation.
(ϕ̂) \
(ϕ̂). Nonetheless, one can show that there is a set
of measure 0 for which y ∉
implies that
(ϕ̂(y)) =
(ϕ̂(y′)) and
(ϕ̂(y)) =
(ϕ̂(y′)) for all y′ in a neighborhood of y. Lemma 9 of (Ryan) Tibshirani and Taylor (2012) proves this result for a nearly identical situation.
The fit X̃ϕ̂(y) is a piecewise affine function of y. Using Stein’s formula for the degrees of freedom [as described in Ryan, Tibshirani and Taylor (2012)], we get that
where P =
.
B.2. Proof of bound on estimate (Property 5)
We bound this by an estimate that is more interpretable: .
Clearly, R2–R7 are linearly independent rows. Thus, the rank of D̃ is at least |
(β+)| + |
(β−)| + |
(Θ+)| + |
(Θ−)| + 2p. Now, an R1 row is linearly independent of R2–R8 precisely when j ∈
has j ∈
(β+)Δ
(β−). To see this, note that if j ∈
(β+) \
(β−), then R1 is certainly linearly independent of R2–R8 and likewise for j ∈
(β−) \
(β+); however if j ∈
(β+) ∩
(β−), then jk ∈
(Θ+) ∩
(Θ−) for all k ∈ {1, …, p} \ {j}, and therefore this row of R1 lies in the span of R3–R7. Thus, this means there are |
\ (
(β+)Δ
(β−))| additional linearly independent rows. Finally, we consider R8. Clearly, R8 lies in the span of R4–R5 for jk ∈
(Θ+) ∩
(Θ−) since jk ∈
(Θ+) =⇒ kj ∈
(Θ+) at a solution. But if jk ∈
(Θ+) ∪
(Θ−), then it is linearly independent of R1–R8. Therefore, R8 adds |
(Θ+)|/2 + |
(Θ−)|/2 to the rank where we have used that
(Θ+) ∩
(Θ−) = Ø at a solution (since λ6 > 0) and recalling that j < k for the rows of R8. In summary, we have shown that the row-rank is
Recalling that there are 2p +2p6 columns, we get that
APPENDIX C: SOLVING THE PROX FUNCTION
The Lagrangian of (11) is given by
where α is the dual variable corresponding to the hierarchy constraints and γ± are the dual variables corresponding to the nonnegativity constraints. For notational convenience, we have written θ for Θj, and we have dropped the subscripts on β±. The KKT conditions are
where uj is a subgradient of the absolute value function evaluated at θ̂j. The three conditions involving γ± implies that β̂± = [β̃± + tα̂]+. The stationarity condition involving θ̂ implies that θ̂ = S(θ̃, t(λ/2+ α̂)). Now, define f(α) = ||S(θ̃, t(λ/2 + α))||1 − [β̃+ + tα]+ − [β̃− + tα]+. The remaining KKT conditions involve α̂ alone: α̂f(α̂) = 0, f(α̂) ≤ 0, α̂ ≥ 0. Observing that f is nonincreasing in α and piecewise linear suggests finding α̂ as done in Algorithm 3.
Algorithm 3.
ONEROW: Solve (11) via dual.
Inputs:
, Θ̃j ∈ ℝp−1, λ ≥ 0.
|
 =
=
Footnotes
Supplement to “A lasso for hierarchical interactions” (DOI: 10.1214/13-AOS1096SUPP;.pdf). We include proofs of Property 1 and of the statement in Remark 3. Additionally, we show that the algorithm for the logistic regression case is nearly identical and give more detail on Algorithm 2.
References
- Agresti A. Categorical Data Analysis. 2. Wiley-Interscience; New York: 2002. [Google Scholar]
- Bach F. Optimization with sparsity-inducing penalties. Foundations and Trends in Machine Learning. 2011;4:1–106. [Google Scholar]
- Bach F, Jenatton R, Mairal J, Obozinski G. Structured sparsity through convex optimization. Statist Sci. 2012;27:450–468. [Google Scholar]
- Beck A, Teboulle M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J Imaging Sci. 2009;2:183–202. [Google Scholar]
- Bickel P, Ritov Y, Tsybakov A. Inst Math Stat Collect. Vol. 6. Inst. Math. Statist; Beachwood, OH: 2010. Hierarchical selection of variables in sparse high-dimensional regression. Borrowing Strength: Theory Powering Applications—A Festschrift for Lawrence D. Brown; pp. 56–69. [Google Scholar]
- Bien J, Taylor J, Tibshirani R. Supplement to “A lasso for hierarchical interactions”. 2013 doi: 10.1214/13-AOS1096SUPP. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boyd S, Parikh N, Chu E, Peleato B, Eckstein J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning. 2011;3:1–124. [Google Scholar]
- Breiman L. Better subset regression using the nonnegative garrote. Technometrics. 1995;37:373–384. [Google Scholar]
- Breiman L, Friedman JH, Olshen RA, Stone CJ. Classification and Regression Trees. Wadsworth Advanced Books and Software; Belmont, CA: 1984. [Google Scholar]
- Chipman H. Bayesian variable selection with related predictors. Canad J Statist. 1996;24:17–36. [Google Scholar]
- Choi NH, Li W, Zhu J. Variable selection with the strong heredity constraint and its oracle property. J Amer Statist Assoc. 2010;105:354–364. [Google Scholar]
- Cox DR. Interaction. Internat Statist Rev. 1984;52:1–31. [Google Scholar]
- Efron B. How biased is the apparent error rate of a prediction rule? J Amer Statist Assoc. 1986;81:461–470. [Google Scholar]
- Efron B, Hastie T, Johnstone I, Tibshirani R. Least angle regression. Ann Statist. 2004;32:407–499. [Google Scholar]
- Forina M, Armanino C, Lanteri S, Tiscornia E. Food Research and Data Analysis. Applied Science Publishers; London: 1983. Classification of olive oils from their fatty acid composition; pp. 189–214. [Google Scholar]
- Friedman JH. Multivariate adaptive regression splines (with discussion) Ann Statist. 1991;19:1–141. [Google Scholar]
- Friedman JH, Hastie T, Tibshirani R. Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software. 2010;33:1–22. [PMC free article] [PubMed] [Google Scholar]
- George E, McCulloch R. Variable selection via gibbs sampling. J Amer Statist Assoc. 1993;88:884–889. [Google Scholar]
- Hamada M, Wu C. Analysis of designed experiments with complex aliasing. Journal of Quality Technology. 1992;24:130–137. [Google Scholar]
- Jenatton R, Audibert J-Y, Bach F. Structured variable selection with sparsity-inducing norms. J Mach Learn Res. 2011;12:2777–2824. [Google Scholar]
- Jenatton R, Mairal J, Obozinski G, Bach F. Proximal methods for sparse hierarchical dictionary learning. In. Proceedings of the International Conference on Machine Learning (ICML) 2010 [Google Scholar]
- McCullagh P, Nelder JA. Generalized Linear Models. Chapman & Hall; London: 1983. [Google Scholar]
- Nardi Y, Rinaldo A. The log-linear group-lasso estimator and its asymptotic properties. Bernoulli. 2012;18:945–974. [Google Scholar]
- Nelder JA. A reformulation of linear models. J Roy Statist Soc Ser A. 1977;140:48–76. [Google Scholar]
- Nelder JA. Letters to the editors: Functional marginality is important. J R Stat Soc Ser C Appl Stat. 1997;46:281–286. [Google Scholar]
- Obozinski G, Jacob L, Vert J. Group lasso with overlaps: The latent group lasso approach. 2011 Available at arXiv:1110.0413. [Google Scholar]
- Park M, Hastie T. Penalized logistic regression for detecting gene interactions. Biostatistics. 2008;9:30–50. doi: 10.1093/biostatistics/kxm010. [DOI] [PubMed] [Google Scholar]
- Peixoto J. Hierarchical variable selection in polynomial regression models. Amer Statist. 1987;41:311–313. [Google Scholar]
- Radchenko P, James GM. Variable selection using adaptive nonlinear interaction structures in high dimensions. J Amer Statist Assoc. 2010;105:1541–1553. [Google Scholar]
- Rhee S, Taylor J, Wadhera G, Ben-Hur A, Brutlag D, Shafer R. Genotypic predictors of human immunodeficiency virus type 1 drug resistance. Proc Natl Acad Sci USA. 2006;103:17355. doi: 10.1073/pnas.0607274103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stein CM. Estimation of the mean of a multivariate normal distribution. Ann Statist. 1981;9:1135–1151. [Google Scholar]
- Tibshirani R. Regression shrinkage and selection via the lasso. J Roy Statist Soc Ser B. 1996;58:267–288. [Google Scholar]
- Tibshirani RJ, Taylor J. The solution path of the generalized lasso. Ann Statist. 2011;39:1335–1371. [Google Scholar]
- Tibshirani RJ, Taylor J. Degrees of freedom in lasso problems. Ann Statist. 2012;40:1198–1232. [Google Scholar]
- Tseng P. Convergence of a block coordinate descent method for nondifferentiable minimization. J Optim Theory Appl. 2001;109:475–494. [Google Scholar]
- Turlach B. Discussion of “Least angle regression”. Ann Statist. 2004;32:481–490. [Google Scholar]
- Wu J, Devlin B, Ringquist S, Trucco M, Roeder K. Screen and clean: A tool for identifying interactions in genome-wide association studies. Genetic Epidemiology. 2010;34:275–285. doi: 10.1002/gepi.20459. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yuan M, Joseph VR, Lin Y. An efficient variable selection approach for analyzing designed experiments. Technometrics. 2007;49:430–439. [Google Scholar]
- Yuan M, Joseph VR, Zou H. Structured variable selection and estimation. Ann Appl Stat. 2009;3:1738–1757. [Google Scholar]
- Yuan M, Lin Y. Model selection and estimation in regression with grouped variables. J R Stat Soc Ser B Stat Methodol. 2006;68:49–67. [Google Scholar]
- Zhao P, Rocha G, Yu B. The composite absolute penalties family for grouped and hierarchical variable selection. Ann Statist. 2009;37:3468–3497. [Google Scholar]
- Zou H, Hastie T. Regularization and variable selection via the elastic net. J R Stat Soc Ser B Stat Methodol. 2005;67:301–320. [Google Scholar]
- Zou H, Hastie T, Tibshirani R. On the “degrees of freedom” of the lasso. Ann Statist. 2007;35:2173–2192. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.