

Abstract
We develop a stochastic, agent-based model to study how genetic traits and experiential changes in the state of agents and available resources influence individuals’ foraging and movement behaviors. These behaviors are manifest as decisions on when to stay and exploit a current resource patch or move to a particular neighboring patch, based on information of the resource qualities of the patches and the anticipated level of intraspecific competition within patches. We use a genetic algorithm approach and an individual’s biomass as a fitness surrogate to explore the foraging strategy diversity of evolving guilds under clonal versus hermaphroditic sexual reproduction. We first present the resource exploitation processes, movement on cellular arrays, and genetic algorithm components of the model. We then discuss their implementation on the Nova software platform. This platform seamlessly combines the dynamical systems modeling of consumer-resource interactions with agent-based modeling of individuals moving over a landscapes, using an architecture that lays transparent the following four hierarchical simulation levels: 1.) within-patch consumer-resource dynamics, 2.) within-generation movement and competition mitigation processes, 3.) across-generation evolutionary processes, and 4.) multiple runs to generate the statistics needed for comparative analyses. The focus of our analysis is on the question of how the biomass production efficiency and the diversity of guilds of foraging strategy types, exploiting resources over a patchy landscape, evolve under clonal versus random hermaphroditic sexual reproduction. Our results indicate greater biomass production efficiency under clonal reproduction only at higher population densities, and demonstrate that polymorphisms evolve and are maintained under random mating systems. The latter result questions the notion that some type of associative mating structure is needed to maintain genetic polymorphisms among individuals exploiting a common patchy resource on an otherwise spatially homogeneous landscape.
Introduction
Computational modeling of population interactions is a growing research endeavor [1] in the context of including behavioral, physiological or genetic heterogeneity among individuals living in spatiotemporally heterogenous stochastic environments [2]. This endeavor is facilitated by ever more powerful computational tools, both hardware (easier and more cost effective access to distributed computing resources) and software (more accessible and user friendly software interfaces for model prototyping, development and deployment) that overcome the limits of analytical and dynamical systems modeling frameworks for addressing both theoretical and applied problems. Access to computational technologies requires either strong coding fluency and skills, or modeling platforms that minimize the need for such fluency and skills.
The last decade has seen considerable progress in the development of user-friendly modeling software. Numerous platforms such as Vensim [3], Stella [3], Simile [3, 4], Insight Maker [5] and Berkeley Madonna [6] now provide flow-chart-like visual environments for modeling dynamical systems. Other platforms, such as NetLogo [7], Simile [4], Insight Maker [5], Repast Simphony [8] and AnyLogic [9] facilitate agent-based modeling (ABM). These platforms, with varying degrees of success, meet the following principles that have guided the development of the Nova platform [10, 11] used in the simulations presented here. Platforms should: 1.) be accessible to students with noncoding skills when it comes to developing didactic models that have either or both dynamical systems and ABM capabilities; 2.) emphasize model design principles by accessibly organizing and coordinating the details of model implementation; 3.) incorporate a versatile, “Turing complete” (i.e., computationally universal) language that facilitates model sharing online (e.g. as web applications); 4.) be powerful enough to build models able to address cutting-edge research questions in the basic and applied sciences.
In this paper, we discuss the characteristics of the Nova platform in the context of principles 1–4 articulated above, through the application of genetic (sometimes referred to as evolutionary) algorithms to addressing questions in population biology. Genetic algorithms have been applied to ecological problems for at least three decades, although it was not referred to as such or in terms of its alternative evolutionary algorithm designation, in its application by Poethke and Kaiser in 1985 to the evolution of time-sharing behavior in a Dragonfly mating system [12]. In the early 1990’s, Stockwell, Nobel and colleagues developed machine-learning methods, in particular a framework called GARP (Genetic Algorithms for Ruleset Production) [13], which since then has been frequently used to study species distributions [14–16]. Genetic algorithms have also been used inter alia to study the evolution of female preference as it relates to male age [17], dispersal in insects [18] including the potential impact of climate change on the geographical distribution of the Argentine ants [19], insect-plant [20], and prey-predator studies [21], as well as ecotoxicology [22], landuse change [23] and other challenging questions [24].
A discussion of genetic algorithms is included in a review by Olden et al. [25], while Holzkämper et al. [23] provide an informative diagram on the implementation of genetic algorithms in their study on managing landscapes to enhance species diversity. Here, for the sake of completeness, we provide a broad overview of GA terms and methods, focusing on the application of GAs to models of agents foraging on a patchy landscape. Specifically, following the lead of earlier work on the application of artificial intelligence methods to movement-related decision processes of animals in heterogeneous environments [26], we first provide details of the within-patch, consumer-resource interaction components and movement decisions components of our model, and then provide details of the GA component of our model, particularly as it relates to mutational and reproductive processes. Subsequently, we examine hypotheses regarding the evolution of movement-type polymorphisms in populations of individuals foraging on patchy landscapes and reproducing clonally versus hermaphroditically. Our model includes the ecological processes of competition among individuals and the dynamical response of exploited resources. The total biomass production over all individuals is recorded at the end of each generation, but only the most successful individuals (i.e. those experiencing the greatest increase in biomass), however, are involved in reproduction.
Methods
Simulation framework
Our simulation model was built using the Nova platform [10], which is highly modularized in terms of: 1.) first creating dynamic agent “capsules” that interact with their environments through input/output interfaces and 2.) the allowing these agents to move over a heterogeneous resource landscape. Movement can either be on a Cartesian plane or from one cell to another on a rectangular or hexagonal array of specifiable dimension (Fig 1; see S1 Text for more details of the platform). Our model moves agents over rectangular arrays of variable and dynamic resource cells and was designed to address questions regarding the efficiency of behavioral guilds of foragers. The model itself operates at three time scales: i) a within patch foraging scale (one tick of the intragenerational clock); ii) an intragenerational patch-to-patch movement scale (n ticks of the intrageneration clock equal to 1 tick of the intergenerational clock); and iii) an intergenerational evolutionary scale (G ticks of the epochal clock), as depicted in Fig 2. At the within-patch and intragenerational scales, a cohort of individuals of specified size is followed. During their lifespan, these individuals (i.e. agents) live on a cellular-array landscape where each cell has a single resource value. The agents consume resources at their current location, gain biomass (which serves as a proxy for evolutionary fitness), and make decisions about movement, based on their local resource environment and locations of neighboring competitors (see details below). Landscape cells grow in resource value when not consumed. At the end of each cohort’s pre-determined lifespan, intergenerational reproductive and evolutionary processes are simulated. The biomass of each individual is tallied as a proxy for fitness, and the most fit individuals (top half of the cohort) are allowed to reproduce. In our simulations involving clonal reproduction, a mutational process was included by allowing parameter values of progeny to be stochastic perturbed from those of their parent, using an approach elaborated below. In an initial set of ‘quick and dirty’ sexual reproduction simulations used to generate hypotheses, we allowed the fittest half of the population to choose partners at random and then set the parameter values of their progeny to be the average of the parameter values of the parents involved, subject to mutations of these values. In a subsequent set of sexual reproduction simulations, we made the process more realistic by incorporating diploid genetic structure, random segregation and codominant phenotypic expression of alleles. Once the new generation of individuals (progeny) was created in all three approaches to reproduction, we then assigned an initial location on the landscape at random, and the intragenerational simulation cycle began again. This cycle continued for a pre-determined number of generations, as indicated in Fig 2.
Fig 1. Stock-and-flow icons are used to graphically build systems of difference (lavender-pink square in cell capsule) and differential (lime-green square in agent capsule) equations that Nova encapsulates as chips with input output pins (pale blue squares) at higher levels of representation, through drag and drop construction.

Agent and cell capsules respectively dropped onto the clover and purple colored components of an aggregator that creates an array of agents able to move over either a rectangular or hexagonal cellular array, of specifiable dimensions with toroidal or non-toroidal topologies.
Fig 2.

Left hand panel: individual level processes controlling the replenishment of resource patches and the growth (biomass) of individuals, through extraction of resources from these patches, are depicted using graphical Nova elements. Central panel: ecological level process managed by a Nova simworld aggregator are graphically depicted, with consumers either foraging within patches or moving from patch-to-patch during each tick of the intragenerational clock. The progeny of the fittest individuals (i.e., greatest biomass at t = n) inherit perturbed (mutational process) parameter values from one (clonal reproduction) or two (sexual reproduction) parents at the end of each generation. Right panel: the evolutionary level process, represented by changes to the parameter values of individuals (i.e., genotypes and corresponding phenotypes), is monitored by the epochal clock that runs the evolutionary algorithm for G generations. (See S1 Text for discussion of Nova platform).
We first carried out a set of exploratory simulations, using parameters specified in S1 Table, with the interpretations of these parameters provided for clarity. Based on these results, we then formulated the hypothesis that movement behavioral guilds of foragers evolve to collectively be more efficient in exploiting resources (in the context of our model) under clonal than under random hermaphroditic reproduction. To explore this question, we modified the sexual reproduction process within our model to be a diploid co-dominant process in which the genotype of each individual’s parameter values (three parameters in our case) are each specified by two alleles. These alleles were subjected to mutations during each reproductive cycle, with each individual’s parameter phenotype being the average of the two allelic values. The results of this study are reported in the section following the presentation of the exploratory simulation results.
Genetic algorithms from a biological perspective
In the computer science field of artificial intelligence, a genetic algorithm (GA) is a search heuristic that mimics the process of natural selection [24]. In modeling in the applied sciences, a GA is a numerical method, mimicking evolution, to select agents (models) with sets of parameter values that optimize some measure associated with the performance of the agents [25]. For example, in the context developed here, the model deals with the efficiency of individual consumers in exploiting a landscape of patchily distributed resources. Much of the jargon, but not all, associated with GAs comes from evolutionary theory: some of it is summarized in Table 1.
Table 1. Terms and definitions used in genetic algorithms (GAs).
| Term | Definition |
|---|---|
| Phenotype | an agent of a particular behavioral, physiological, or morphological type |
| Fitness function | a measure associated with the agent that will be optimized |
| Genome | a set of parameter values associated with an agent |
| Genotype | a specific genome |
| Mutation | a perturbation of a parameter value in the genome |
| Simulated annealing* | mutational perturbations decrease in size over time |
| Cloning reproduction | duplication of a genotype (with mutations) |
| Sexual reproduction | genotype values generated from two parents (with mutations) |
| Codominant | phenotype is average of parental genotype for gene concerned |
| Hard selection | best group of individuals produce a fixed number of progeny |
| Soft selection | better than worse individuals more likely to reproduce |
| Generation time | the model run time over which fitness is assessed |
| Epoch | the number of generations over which the evolutionary process is assessed |
*see Eq 1
The seminal text on genetic algorithms (GA), formulated within a general adaptive systems framework, is Holland’s 1975 book: Adaptation in Natural and Artificial Systems (1992 Edition: [27]). More recently, the application of GAs is widely spread within the computer science and artificial intelligence communities, but has only occasionally been applied to economic systems [28], reviewed for a general audience from a bit-string coding point of view [29], reviewed for a chemistry audience [30], applied to evolutionary questions in ecology [20, 31, 32], used to assess the design of sensory systems in animals [33], and to asses the efficiency of decision processes in movement ecology [34, 35].
The essential features of a genetic algorithm is that it consists of at least two temporal frames (Fig 2): an intragenerational frame in which individuals are governed by processes that affect their life-time fitness; and an intergenerational frame in which generations of individuals succeed one another, with the fittest individuals in each generation being the most likely to pass on the traits promoting that fitness to future generations. The intragenerational frame itself may be further refined so that the processes determining the life-time fitness of individuals can be dynamically modeled over the life time of individuals. This integration across time scales is depicted in Fig 2 in the context of consumer-resource interactions, where our surrogate for a measure of fitness is individual biomass, as determined by growth processes dependent on resource extraction over the life time of individual consumers.
The genetic algorithm begins by initializing the system t = 0 (start of the intragenerational clock) and T = 1 (the first generation). In our exemplar, the initial state of agent A a, a = 1, …, N A, is its starting biomass B a(0), and is located at L a(0) = C i,j, where C i,j are cells on a rasterized two-dimensional landscape or cellular array (row i and column j). The initial state of each cell is R i,j(0) at the start of each intragenerational cycle. In moving the intragenerational clock forward from t to t + 1, t = 0, …, n, we query each agent as to whether it will move or stay to exploit the resources in its current cell. If it does move, we then determine to which cell it moves. The outcome of these calculations for agent A a is represented by the value of its movement designator , as discussed in the next section, where pa is a set of agent-specific parameter values. After computation, the state B a(t) and location L a(t) of agent A a, and the state R i,j(t) of all cells C i,j are updated, as elaborated In the intergenerational updating subsection below.
Once the updating process is completed, we continue for t = 1, …, n − 1, ultimately reaching a final state B a(n) for each of the agents A a. The agents A a are then sorted according to their final state values B a(n) from, say, largest to smallest. A number of different reproductive systems are possible including clonal (apomictic or automictic) versus sexual reproduction (hermaphroditic or distinct sexes, assortative or disassortative mating or different levels of inbreeding), as are patterns of inheritance (e.g. using co-dominant versus dominant-recessive relationships) and processes relating to linkage and genetic crossover. Most of our exploratory simulations use the following clonal reproduction process.
The N A agents simulated over each generation are ranked by biomass value B a(n) (the fitness measure) and the fittest half are selected to reproduce. Each of the selected agents is cloned by creating a copy with the same parameter set pa. Each of the cloned values within pa are then individually perturbed by differing amounts, each amount drawn at random on the interval [−μ, μ] for some suitably small value μ > 0. The fittest half of the current generation and their mutated clones constitute N A individuals used to start the next generation simulation. The maximum allowable perturbation μ to the values in pa decreases as the generations progress over T = 1, …, G (i.e. simulated annealing) so that μ is regarded as a decreasing function of T—i.e., μ ≡ μ(T), where : this allows for initial rapid progress towards the emergence of the fittest individuals, followed by smoother convergence to the fittest group of individuals. We note that further investigations are needed to evaluate how likely it is that solutions are local or global maxima. In our simulations, for perturbation parameter values μ 0 > > μ ∞ > 0 and time parameter values ψ > 0, we expressed μ(T) as
| (1) |
which satisfies μ(0) = μ 0, μ(ψ) = (μ 0 − μ ∞)/2 and limT → ∞ μ(T) = μ ∞. The intergeneration computations are then repeated for T = 1,2,…, until terminating at T = G, the end of the Epoch, at which point the genotypes (parameter values) are noted and the performance of the phenotypes evaluated.
The exploratory simulations were then followed by a comparison of clonal with random hermaphroditic sexual mating, and under an assumption of diploid genetics under codominance for the three trait parameters involved. Thus, for the diploid system, the progeny parameter values are averages of two alleles: one from each parent segregated at random during “meiosis.”
Landscape perception and movement computations
General Movement Process Algorithm
The movement process itself, as described in general terms in Nathan et al. [36], requires an agent to make movement decisions based both on its internal state and the state of its environment. The sequence of information considered as part of the general process of making the decision where and when to move, is follows.
- Evaluate environment: each agent A a, a = 1, ⋯, N A, computes a state vector E a(t) associated with its local environment, as it may pertain to the location of
-
-resources such as food, water or shelter
-
-conspecifics for either protection, social or antagonistic interactions, mitigation of competition, fear, or mating behavior
-
-location of heterospecifics that may be competitors, predators, prey items, etc.
-
-
Initiate movement decision computation: each agent feeds the environmental information computed above, along with its internal state—such as, degree of hunger, thirst, fear, states of internal diurnal and seasonal clocks, memory states—into its “brain.”
Complete movement decision computation: based on environmental input E a(t) and internal state B a(t), agent A a carries out a computation that yields a movement designator
Execute action: The designator will either specify that agent a should stay (i.e., L a(t + 1) = L a(t)) or move to new location L a(t + 1) (identified as a specific cell L a(t + 1) = C i,j).
The ability of individuals to quantify their local environment will depend on the sensory machinery they possess. For example, they may have visual capabilities with acuity reduced with distance and influenced by the local topography of the landscape; or, they may be able to process olfactory or auditory cues that depend on local wind direction and landscape features. This information, along with information on their current internal states, is then fed into a computational module that uses either a mathematical function or a dynamical systems computation to produce an answer to the questions being addressed.
As already mentioned, in the Nova platform agents can move over a landscape specified by a rectangular or hexagonal cellular array of any dimension. The two approaches are contrasted in S2 Text, though we use the Moore Neighborhood approach outlined below, where movement is formulated in terms of eight neighboring cells that occur on rectangular arrays (cf. Figure in S2 Text).
Moore Neighborhood Movement (resources and competitors)
The three-parameter model, presented here, is but one example of how to set up a movement decision process that considers tradeoffs among the relative values of obtaining resources, avoiding competition, and investing energy to move.
For all cells in the array, using a single index label k (e.g. C i,j, i = 1, …, n i, j = 1, …, n j can be labeled k = i + (j − 1)n i, for k = 1, …, n i n j), R k denotes the resources in cell k and denotes the average of the resources across all eight cells in the Moore neighborhood of cell k. Note that at an individual agent level a local neighbor labeling is more convenient (cf. left panel of Figure in S2 Text), in which case later translation to a global labeling of cells is required.
Similarly, for all cells in the array, J k denotes the number of agents in cell k and denotes the average number of agents in the eight cells of the Moore neighborhood of cell k.
For each agent A a, a = 1, …, N A, at time t, identify its current location L a(t).
- Then labeling L a(t) as cell 0, for agent generate the environmental vector introduced in the previous subsection.
which is then used to implement (in a series of logical statements) the movement designator . - Given parameters α ≥ 0 and δ ≥ 0, which we will respectively refer to as the neighbor-discount and competition-tradeoff parameters, assign the following values to each of the eight cells neighboring C k:
- Given parameter ρ ≥ 0, which we refer to as the movement-threshold parameter, apply the movement rule
Note, in this algorithm, if the element V 0 in the list is the largest, then the Move is to stay in the current cell, but the cost calculated in the updating section will be as though the individual moved. Of course, this can be modified in anyway we think appropriate. Also, note that the movement parameter vector p a = (α, δ, ρ)′ is agent specific.
Intragenerational updating
At the start of each generation, T = 1, …, G, the simworld aggregator (central green/purple chip in the middle panel in Fig 2) is initialized by assigning to each cell an initial resource value R k(0), k = 1, …, n i n j (i.e., using the single index convention mentioned in point 1 in the subsection above), that is chosen at random to be in the range [R min, R max]. Of course, more sophisticated approaches can assign the resource values in some aggregated or contagious way. The new group of agents A a, a = 1, …, N A, whose genotypes have been determined by the reproductive process outlined earlier, are then assigned to cells (the simplest is a random assignment), as well as assigned a set of initial state values B a(0), a = 1, …, N A, which in the simplest case may all be the same. Once these assignments have been made, the intragenerational ecological dynamics, in which cell resource values R k(t) and agent locations and values (L a(t), B a(t)) are updated, can be applied.
In formulating our updating equations, we confine ourselves to separately identifying the agent A a’s internal state B a(t) (i.e., its biomass) and location L a(t) at time t as scalar values. Also, in referring to the movement designator M a(t), we have dropped reference to the movement parameters p a; since, although they are agent specific, they are unchanging over each intragenerational simulation. For notational convenience, we use Agent k to represent the set of N k(t) agents remaining in cell C k after movement has been implemented at time t, and similarly use N a(t) to represent the number of agents occupying cell L a(t) at time t, after movement has occurred. We also consider the state of cell k only in terms of a scalar resource value R k(t), fully recognizing that a more general approach requires a vector description.
Since we are focusing on consumer-resource interactions [37–39], the key to specifying our updating equations at time t + 1 is first to evaluate the movement designators M a(t) for each agent, then to formulate the resources acquired by agent A a, if it stays within a cell to extract resources, and the resources extracted from cell C k by those agents that do not move during the interval [t, t + 1]. With these conventions the following equations are used.
- Intragenerational Updating Equations. After the initial agent state values B a(0), and agent cell locations L a(0) = C k (the initial cell k that agent a is placed in), for some k = 1, …, n i n j, have been selected for a + 1, …, N A, then for t = 1, …, n the following updating procedure is followed, employing the following parameters (which in more advanced applications can be made agent specific): the maximum resource extraction rate u, the extraction-efficiency parameter h, the competition parameter q, the biomass-conversion-rate parameter κ, the metabolic-loss-rate parameter c, the resource-intrinsic-growth-rate parameter r, reservoir parameter g and saturation parameter s:
We note that resource growth equation for R k(t + 1) is the same for each cell: that is, r, s and g, in the last equation above, are not cell specific. A thorough examination of the impacts of resource heterogeneity on the evolutionary ecology processes considered in this paper, requires these parameters to depend on k; and, also, u, h and q could be made patch specific. Considering this level of heterogeneity requires elaboration beyond the detail of this presentation.
Epochal implementation
At the completion of each intergenerational cycle, after implementation of the reproductive process, the clock T is advanced, and the cycle is repeated (cf. the right-hand panel of Fig 2). During each reproductive cycle, the progeny of the fittest agents’ parameters are mutated, so it might be useful to monitor the reproducing-population average of this fitness measure (i.e. biomass of an agent at the end of its intragenerational cycle), as the population evolves.
It is useful during the simulation to keep track of the values of selected parameters to see how they evolve, since analyses of these values provide insight into the evolving movement decision tradeoffs in response to resource heterogeneity levels, intensity of competition, and other ecological parameters in the model. In our illustrative simulation results presented in the next section, we focus on the evolution of the average final biomass of the upper 50th percentile of the agents (i.e., those that reproduce) in each generation. We also follow the evolving values of the neighbor-discount parameter α, the competition-tradeoff parameter δ and the movement-threshold parameter ρ in determining the movement decision making process of the fittest individuals, as the population evolves.
Exploratory Analysis
A primary source of heterogeneity in our model is the initial resource value of each patch. Since this initial patch heterogeneity, compounded with stochastic aspects of the model, creates considerable variability in the output, we explored the behavior of the model with this heterogeneity removed: viz. we made the initial resource conditions near homogeneous by setting the baseline initial range of patch values to [2.99,3.00] (Table 2: note the 0.01 difference between the lower and upper values creates a small amount of stochasticity that renders initial movements of agents stochastic rather than deterministic). We carried out a number of runs where the initial resource patch values were random, uniformly distributed on [0,5.99] (i.e., the same mean as above); and found that all our results were qualitatively the same as those presented below.
Table 2. Baseline Parameter Values.
| Parameter | Description | Value |
|---|---|---|
| [R min, R max] | patch initial resource range each generation | [2.99,3.00] |
| s | resource saturation in a patch | 20 |
| g | resource reservoir level | 0.1 |
| r | resource intrinsic growth rate | 0.1 |
| u | maximum extraction rate | 10 |
| h | half-saturation efficiency | 20 |
| q | intraspecific competition | 0.5 |
| c | cost of moving | 0.1 |
| κ | consumer biomass conversion | 0.1 |
| μ 0 | initial maximum mutation size* | 0.1 |
| μ ∞ | asymptotic maximum mutation size* | 0.001 |
| ψ | mutation-scaling* | 50 |
| n | length of intragenerational cycle | 100 |
| G | number of generations in epochal cycle | 200 |
| α | neighbor-discount | evolution |
| δ | competition-tradeoff | evolution |
| ρ | movement-threshold | evolution |
*see Eq 1
In our first set of simulations, we considered the simplest case of two agents (N A = 2) and executed three separate runs. The evolved parameter values and the average fitness values for the two agents at the final time T = 200 are provided in Table 3. The results suggest that the optimal movement-threshold value for parameter ρ is around the low 0.70s, while different combinations of values for the neighbor-discount and competition-tradeoff parameters α and δ respectively are possible. Some variation in fitness across runs occurs because the probability that two individuals get close to one another at any time during the simulation has a stochastic component, which then impacts individuals through competitive processes included in the resource extraction process and movement to patches previously visited by other consumers.
Table 3. Results for two agents.
| Run | α | δ | ρ | Fitness Value |
|---|---|---|---|---|
| competition tradeoff | neighbor discount | movement threshold | ||
| 1 | 0.73 | 0.14 | 0.75 | 32.6 |
| 2 | 0.33 | 0.22 | 0.76 | 32.8 |
| 3 | 0.46 | 0.54 | 0.72 | 33.1 |
In our second set of simulations, we considered the low-density case of ten agents (ten agents on 400 patches is a density of 0.025 individuals per patch). In two different runs, the population evolved to a particular movement type rather than to a coalition or guild of movement types (i.e., a movement-type monomorphism versus a polymorphism); but, again, the types differed from run to run, as illustrated in Fig 3 (note: fitness is on the horizontal axis in this figure but on the vertical axes in subsequent figures). In these two cases, the average fitness values were 31.0 and 28.5 respectively, which is around 6 to 14% less than in the two-agent case, the difference being explained by the stochastic variations in the cost of avoiding competition and the slightly lower availability of resources when individuals have 9 rather than just one other agent to avoid (as discussed below).
Fig 3. Evolved values of parameters (introduced in the Moore neighborhood movement section above).
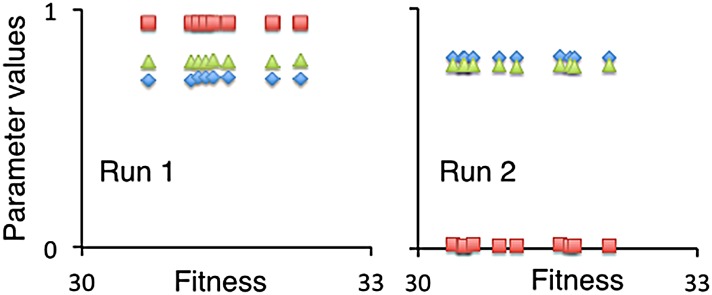
The left and right panels are the result from two different 10-agent runs using the same baseline data (Table 2). Parameter values for each of the ten agents in the final generation (T = 200) are plotted as a function of their fitnesses (ranging from 30 to 33). The evolved neighbor-discount parameter α (green triangles), competition-tradeoff parameter δ (red squares), and movement-threshold parameter ρ (blue diamonds), across the 10 agents differ, in the two runs; but yield similar fitness distributions, although the left panel shows a little more chance variance than the right.
In our third set of simulations, we increased the density of agents to 50 agents and in a fourth set of runs to 100 agents (i.e., densities of 0.125 and 0.25 individuals per patch respectively). Now the evolved outcomes after 200 generations become more interesting and structured than the low density 10-agent case. In two runs of 50 agents, the populations evolved into a 2–3 movement type polymorphism. For example, in Run 1 of the 50 agent case (top panel of Fig 4), we see a phenotype around ρ = 0.5 that actually appears to be two phenotypes with similar ρ values, and a phenotype with ρ = 0.7. In two runs of 100 agents, the populations evolved into around six different phenotypes in each case, (bottom two panels of Fig 4), though a couple of these phenotypes appear to have very similar ρ values.
Fig 4. Evolved values of the movement-threshold parameter ρ.

The four panels provide snapshots of the final values of ρ (T = 200), which range between just under 0.3 and just over 0.70 for the two 50-agent (two upper panels) and two 100-agent (two lower panels) runs, using the same baseline parameter values listed in Table 2.
Of course, evolution is an ongoing process, so we cannot be sure how the movement polymorphisms, illustrated in Fig 4, may continue to evolve after T = 200. To investigate this question, we took a detailed look at the evolutionary process over time by conducting a third run of the 100-agent case and taking snapshots of the evolving values of ρ at times T = 1, 50, 100, 150 and 200 (Fig 5). In this case, we see in the top left panel of Fig 5 that initially (T = 1) all values of ρ ∈ [0, 1] are evident (due to distributed selection of initial values of ρ), with low values of ρ (on the interval [0,0.25]) and values around 1 exhibiting low or even zero fitness. By the 50th generation, the value of ρ for most agents lies between 0.3 and 0.8, with the upper threshold dropping below 0.7 by the 100th generation. Beyond generation 100, a polymorphism of several movement types begins to emerge with all values of ρ roughly between 0.25, and 0.6. The heterogeneity in fitness across each morph (i.e., the vertical spread for each of the ρ values) is due primarily to chance events in which some individuals find themselves initially distributed over the landscape in denser areas than others. We note for the lowest panel in Fig 5, which depicts the average fitness plus/minus one standard deviation, in the value of ρ over the full 200-generation evolutionary epoch. We see that, initially, the high level of variance settles down and reaches a minimum around T = 70, when all the unfit individuals (i.e., those possessing low (< 0.25) and high (> 0.65) values of ρ) have been purged from the population. After that the variance begins to rise as the population organizes itself in polymorphism of around a half-dozen movement types on the interval ρ ∈ [0.25,0.65].
Fig 5. Evolution of the movement-threshold value ρ.

The five scatter graphs (top two rows) represents snapshots over a particular 200-generation (T), 100-agent run of the parameter values ρ at times T = 1,50,100,150 and 200. The lower panel depicts the mean plus/minus the standard deviation of the values of ρ for the 100 agents over the interval 0 ≤ T ≤ 200.
The trend of increasing diversity in movement-type polymorphisms that evolves with increasing numbers of individuals is seen in a simulation with 150-agents. In Fig 6, we see that eight movement types emerge, as indicated by the 8 different colored arrows pointing to parameter triplets, (α, δ, ρ), where each color represents the parameter values associated with one type. These eight types are clearly indicated with regard to parameters ρ and δ, but three of the types that all have small ρ values (i.e., resist moving unless their current patch has relatively few resources) also have α values that are close to zero. This latter situation indicates an indifference to the resource and competitor values of second-tier neighbors (cells that are distance one removed for each individual’s immediate neighbors). For those individuals that are most likely to move out of their current cells (i.e., the green arrow, which corresponds to ρ ≈ 0.5), second-tier neighbors are relatively important (i.e., α = 0.9 for the green arrow type: see extreme left of upper left panel of Fig 6). We note that δ values can be both below and above 1, with the former weighting resources over competition and the latter associated with highly competition averse movement types. It is not surprising to see a high degree of polymorphism in the competition avoidance parameter δ since, if some individuals avoid competitors others can be more lax about avoiding competitors; in the extreme situation of all but one individual avoiding competitors, this individual can ignore the competition issue that is being taken care of by the others.
Fig 6. Evolved parameter values of different movement types in the 150-agent case.

The final values (T = 200) of the three parameters ρ (blue diamonds), α (green triangles) and δ (red squares) are plotted for 150 individuals agents in the simulation, which we see have self-organized into eight different movement types (movement polymorphism), identified by the eight variously colored arrows: same colored arrows identify three parameter values that define each of the eight movement types.
Our final simulation in our exploratory series of clonally reproducing agent guilds was for the high density case of 200 agents. We then plotted the average 200-generation fitness trajectory obtain from this simulation along with representative runs for 2, 10, 50, 100, and 150-agent cases, as well as an exploratory run (see Figure in S3 Text) of 100 sexually reproducing hermaphroditic agents. In all cases, except the 2-agent case, the population rises within a few generations to reach the highest average fitness levels (Fig 7), with selection over time then having little effect on average fitness and, in some cases, even declining slightly (notice the slight downward trend in the 50, 100, and 150 agent cases in Fig 7). The reason for this slight downward trend is that as agents evolve to behave optimally so competition for resources stiffens to compensate for more effective movement decisions evolving at the individual level. Also losing diversity over time, as selection produces just a few movement types, leads to less efficient exploitation of resources from a population point of view—a phenomenon that is accentuated under sexual reproduction, as explored further in the study reported in the next section. The reason for the drop in biomass as the population evolved over time is that, from a population point of view, it is more efficient to have several different behavioral morphs exploiting a heterogeneous landscape, than just one type. Sexual reproduction, under the unrealistic assumption that we can ignore allelic structure when determining phenotype (i.e. by just assuming progeny are an average of their parents phenotype), results in a “fittest” behavioral type that may have locally maximized individual fitness in each generation, but has not maximized the collective biomass production rates of the evolved guild. This result suggests that it might be useful to undertake, as reported in the next section, a more detailed study of differences between the evolution of foraging guilds under clonal versus sexual reproduction, using a more realistic model of sexual reproduction that accounts for allelic structure in diploid organisms. This increase in realism leads to dramatically different conclusions regarding the emergent phenotypic structure of the evolved guild, thereby providing a cautionary tail against oversimplification.
Fig 7. Time course of average fitness.

(i.e., final biomass B a(n) among N A agents). The average fitness is plotted over T = 1,…,200 generations for illustrative runs with the following number of clonal reproducing individuals, except for one sexually reproducing group, as indicated: 2 (blue), 10 (red), 50 (green), 100 (purple), 100 with sexual reproduction (turquoise), 150 (orange) and 200 (grey) agents.
Clonal versus Sexual Reproduction
Our exploratory results support the hypothesis that the evolving collective biomass production efficiencies of clonally and sexually reproducing guilds of foragers, exploiting resources over patchy landscapes, are likely to differ considerably over time. To further address this hypothesis, we modified the sexual component of the simulation model discussed above to incorporate diploid genetics in which the behavioral phenotype of individuals (i.e. the expressed values of the trait parameters α, δ and ρ) is computed by averaging across two allelic values for each of the three phenotypic traits (i.e. codominent genes), where one allelic value for each trait is inherited from each parent following Mendelian rules for diploid genetic systems (random mating, random assortment of alleles, no linkage among traits). We did not assign a sex to agents, so the interpretation is that we are dealing with hermaphroditic (or monoecious) systems.
We compared simulations (i.e. runs) using our hermaphroditic mating version of our model with the clonal version used in the exploratory phase for the cases of 60, 100 and 140 agents (note: we selected agent numbers divisible by four since each pair of parents produces 4 progeny). Output from initial simulations suggested that we should extend the 200 generation simulation interval used in our exploratory studies to 250 generations to obtain a better perspective on the long term behavior of our system. We repeated each simulation 50 times for the two reproduction modes (clonal and random) and the three agent densities (60, 100, 140). The total biomass produced (i.e. accumulated by each individual and summed across all individuals) each generation by each guild of agents for each of the different cases, was averaged over all the runs undertaken. The means and standard deviations over these fifty runs are plotted in Fig 8.
Fig 8. Evolving biomass production efficiency of guilds.
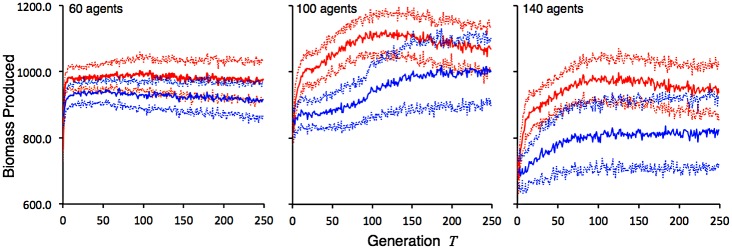
Total biomass produced per generation (solid lines are averages over n runs, dotted lines are plus and minus one standard deviation) under clonal reproduction (red) and random mating (blue), by evolving guilds over 250 generations of, respectively from left to right, 60 (n = 50), 100 (n = 50), and 140 agent (n = 50) guilds of foragers. For a reference to these data see S4 Text.
As expected, based on our exploratory results, the total amount of biomass produced by each guild of foragers in each generation was highly compensatory in terms of the number of agents, with both clonally and sexually reproducing guilds of 60 agents able to collectively produce almost as much each generation as guilds of 100 agents. As the number of agents increases, though, biomass production is hindered by competition, which we see in terms of a noticeable drop in total biomass produced by the 140-agent guild compareds with the corresponding (with regard to reproductive system) 100-agent guilds. Thus, guild exploitation is, in fact, overcompensatory. To formally test the significance of our results, we divided our simulations into two phases: an initial 125-generation “burn in” phase, and the subsequent 125-generation “approach to equilibrium” phase. From Fig 8 though, it appears in some cases that an equilibrium has been reached, while in others (e.g. the 60 agent random and 100 agent clonal cases) the amount produced over generations 126 to 250 appears to be declining slightly over time. The results of this analysis are tabulated in Table 4, where we see clonally evolving guilds of foragers produce more biomass in total over both phases of the evolutionary process than randomly mating guilds of foragers. We also expected greater levels of variation associated with the randomly mating guilds, but this was only true (i.e. highly significant) for the 100-agent and 140-agent cases. In the 60-agent case, the reverse was true, with randomly mating guilds showing significantly less variation than clonally mating guilds. The major difference between the 60-agent versus the 100 and 140-agent cases is that in the latter two interspecific competition becomes a much more important factor, as seen from the compensatory behavior of the total biomass produced by the guild in the 60-agent, 100-agent, and 140-agent comparisons (Fig 8).
Table 4. Foraging guild biomass extraction efficiency: total produced over the two labeled 125-generation periods.
| Period | Clonal | Random mating | Two-sided T-test* | |||
|---|---|---|---|---|---|---|
| Biomass | Biomass | Significance | Var1 ≠ Var2 | |||
| 60 Agents | n = 50 | |||||
| 1–125 | 122829 | 1769 | 116409 | 1067 | p < 0.0001 | p ≈ 0.0006 |
| 126–250 | 122286 | 41272 | 115044 | 2644 | p < 0.000 | p ≈ 0.0022 |
| 100 Agents | n = 50 | |||||
| 1–125 | 131857 | 1739 | 112606 | 3440 | p < 0.0001 | p < 0.0001 |
| 126–250 | 136228 | 2958 | 124074 | 10136 | p < 0.0001 | p < 0.0001 |
| 140 Agents | n = 50 | |||||
| 1–125 | 116017 | 1764 | 96895 | 7645 | p < 0.0001 | p < 0.0001 |
| 126–250 | 119859 | 3129 | 101711 | 10854 | p < 0.0001 | p < 0.0001 |
* Tests run at URL: http://www.quantitativeskills.com/sisa/statistics/t-test.htm
To understand in more detail the genetic structure of the foraging guilds that evolve under random mating, we plotted the parameter values that emerged in the first two runs of our 50-run, 140-agent simulations (Fig 9), and tabulated (Table 5) the allelic aspects of the first of these runs (left panel in Fig 9). For comparative purposes, we also tabulated (Table 5) the phenotypic trait values for the first of our 50-run, 140-agent clonal reproduction simulations. In Table 5, we see for the clonal case that seven foraging phenotypes evolved from a random mating configuration during the 250-generation evolutionary epoch. The neighbor-discount parameter α exhibits the widest range of variation (around 0.06 to 1.52, noting that the values in Table 5 are the evolved values multiplied by 103), while the competition-tradeoff δ and movement-threshold parameter ρ exhibit considerably less variation (around -0.03 to 0.04, and 0.12 to 0.21, respectively). For the random mating case, the phenotypic trait values can be unpacked according to underlying diploid genotypes. In Run 1 (left panel of Fig 9), as with the first clonal run, we see that the neighbor-discount parameter α exhibits the widest range of variation compared with competition-tradeoff δ and movement-threshold ρ parameter values. The results of Run 2 (right panel of Fig 9) are different, though, in that the movement-threshold parameter ρ now exhibits the widest range of variation, but noticeable variation in the other two parameters is still evident. In Run 1, the underlying genetic basis of the the six neighbor-discount α phenotypes are three distinct alleles (also the values of the homozygote phenotypes because of codominant averaging), as indicated in the Table 5, that have the approximate (because of mutational variation) values 0.045, 0.645 and 1.03 respectively, with the three possible heterozygote phenotypes being the intermediate to these values. In Run 2, we see a number of phenotypes that have evolved, with the underlying genetic structure, as evident in the right panel of Fig 9 that the phenotypes are based on two alleles (one close to 0.7 and one to 0.8) for the competition-tradeoff trait, three alleles (all three relatively close in value, lying between 0.40 and 0.55) for the neighbor-discount trait, and three alleles (more spread out in value between 0.1 and 0.8) for the movement-threshold trait. We note in Table 5 that the 140-agents are in Hardy-Weinberg equilibrium, which is expected since this equilibrium arises in the progeny due to random mating and random segregation of alleles. Selection only acts at the end of each generation, when individuals are sorted according to how much biomass they have produced. We hypothesize that evolved random mating guilds are less efficient than evolved clonally reproducing guilds, as evident in Fig 9, because heterozygotes are constrained to be intermediate to homozygotes in the random mating case, while clonal phenotype strategy guilds are not under such constraints, allowing them to be optimally spaced by the evolutionary process. Such an analysis, however, is beyond the scope of this paper, particularly since other factors in our model (such as hard versus soft selection) need to be modified to make our simulations more realistic, as discussed in the next section.
Fig 9. Evolved values of parameters under random mating.

Parameter phenotype values for each of the 140 agents in the final generation (T = 250) of the first two of 50 simulations are plotted as a function of their fitnesses (ranging from 0 to 12). The evolved neighbor-discount parameter α (green triangles), competition-tradeoff parameter δ (red squares), and movement-threshold parameter ρ (blue diamonds), across the 140 agents differ in the two runs and show different degrees of dispersion, but reflect both heterogeneous and homogeneous phenotypes: viz. in Run 1 we see six α phenotypes that arise from the emergence of three alleles, as discussed in Table 5.
Table 5. Foraging guild phenotypes at the end of 140 agent exemplar runs.
| Clonal reproduction | Parameter phenotype values | ||||
| Type | Number | α × 103 | δ × 103 | ρ × 103 | Biomass |
| 1 | 52 | 67 ± 3 | 23 ± 2 | 192 ± 5 | 6.3 ± 2.2 |
| 2 | 12 | 209 ± 2 | 37 ± 1 | 206 ± 2 | 6.8 ± 1.2 |
| 3 | 18 | 240 ± 1 | 9 ± 5 | 204 ± 3 | 7.0 ± 2.0 |
| 4 | 22 | 758 ± 2 | 7 ± 2 | 156 ± 5 | 7.3 ± 2.5 |
| 5 | 4 | 808 ± 1 | 42 ± 1 | 180 ± 3 | 7.1 ± 1.6 |
| 6 | 20 | 1191 ± 2 | 26 ± 3 | 157 ± 2 | 6.8 ± 2.7 |
| 7 | 12 | 1520 ± 01 | −31 ± 1 | 124 ± 2 | 5.8 ± 3.7 |
| Total | 140 | 6.6 ± 2.4 | |||
| Random mating | Parameter phenotype values | ||||
| Type | Obs (Exp ‡ ) | α × 103 | δ × 103 | ρ × 103 | Biomass |
| Genotypes † | |||||
| α 1 α 1 δδρρ | 22 (20.8) | 45 ± 5 | 9 ± 13 | 188 ± 9 | 7.3 ± 1.8 |
| α 1 α 2 δδρρ | 38 (37.0) | 345 ± 5 | 18 ± 14 | 189 ± 9 | 7.1 ± 1.5 |
| α 2 α 2 δδρρ | 18 (16.5) | 645 ± 4 | 18 ± 9 | 188 ± 8 | 7.2 ± 2.1 |
| α 2 α 3 δδρρ | 22 (26.1) | 864 ± 3 | 19 ± 11 | 187 ± 7 | 5.9 ± 2.4 |
| α 3 α 3 δδρρ | 14 (10.3) | 1031 ± 4 | 18 ± 15 | 188 ± 7 | 7.05 ± 2.5 |
| α 1 α 3 δδρρ | 26 (29.3) | 562 ± 5 | 19 ± 8 | 1928 ± 8 | 6.8 ± 2.4 |
| Total | 140 | 6.9 ± 2.1 | |||
† Although more than one allele is evident for δ and ρ that variation is low (cf. left panel in Fig 9): so we only sort on α
‡ Hardy-Weinberg equilibrium theory: differences between observed and expected not significant
Discussion and Conclusion
Analyses of hierarchical, multi-scale ecological systems have long been of concern to ecologists [40]. It is only in the last decade, however, that it has become reasonable to simulate such systems in terms of access to adequate, inexpensive computational power. Methodologies for evaluating the output of complex systems have been discussed for nearly two decades [41–43], but our ability to communicate the structure of complex ecological models remains hampered by the lack of facility to visually understand the structure of modules at different hierarchical levels (but see Fig 2). Frameworks have been proposed for modeling complex systems (e.g. complex adaptive landscape (CAL) framework for modeling complex adaptive systems occurring on heterogeneously structured landscapes [44]), particularly across multiples scales when spatial structure is included (cf. [45] in the context of epidemiological systems). Increasingly, scientists are making their code available to others to build upon; but this code typically does not help in visualizing the underlying model structure. For example, a recent, agent-based modeling study to assess the impact of landscape fragmentation on diseases transmission [46], included details of the model written in Java; but, as such, the code is only accessible to experienced Java programmers as a basis for building more elaborate models.
In the model developed here, we have endeavored to make the underlying architecture of our code as transparent as possible, by providing figures of the Nova model components at each hierarchical level of the four nested computational clocks employed in our analysis (individuals in cells, intragenerational, evolutionary epoch, repeated simulations to obtain statistical data). This level of visualization of model design is a departure from our previous agent-based studies, written in MATLAB [47]. These earlier MATLAB models were used to address questions regarding the evolution of specialization among individuals exploiting a mix of resource types (the leitmotif being insects selecting different plant types on which to lay their eggs—see [20]), and provide insight into the emergence of Batesian mimicry among vulnerable “resource-individuals” trying to mimic the aposematic signals of individuals protected from exploitation [32]. In the first of these earlier studies, we modeled a mix of generalists and specialist exploiters, in terms of how these exploiters use several versus only one type of plant. In these systems, a guild of exploiter types typically emerged, much as in our results reported here. These new results reveal the following characteristics that we could not a priori infer or anticipate: i) the number of foraging strategy types emerging as a result of clonal reproduction varied and increased with the density of agents per unit cell; ii) the foraging strategy types that constituted an emerging polymorphism under clonal reproduction varied with runs, but showed some repeatable and some variable characteristics (e.g. at the very low densities of 2 to 10 agents, the movement-threshold parameter ρ evolved each time to a value in the range 0.7 to 0.8, though the other two parameters could vary greatly, as in the neighbor-discount parameter α evolving to 0 or to 1); iii.) under random mating, foraging strategy polymorphisms evolve and create several distinct alleles per trait.
The existence of polymorphisms is a necessary but not sufficient precursor for the occurrence of sympatric speciation ([31, 48, 49]). Holmgren and colleagues studied the process of speciation among individuals specializing in exploiting particular resource types by, first, replacing clonal reproduction with sexual reproduction and then studying the divergence of specialists in the context of assortative mating within particular exploiter types [32]. In the study reported here, we found that it was not necessary to have assortative mating for the maintenance of strategy polymorphisms or, more surprisingly, even more than one resource type. Such polymorphisms are a precursor for the occurrence of sympatric speciation on patchy landscapes: i.e. a precursor for heteropatric speciation, as defined by Getz and Kaitala [50]. The inclusion of assortative mating in future studies, facilitated say through the inclusion of metapopulation structures or genes for mate selection linked to genes for strategy type (as discussed by Norrstrom et al. in the context of habitat selection [31]), is likely to enhance the emergence and maintenance of diverse foraging strategy guilds and, ultimately, sympatric speciation.
Computational methods have been used to address questions relating to the behavior of populations in the context of complex systems theory, with the emergence of collective behavior of biological populations being a case in point. In the past, such questions have typically been of a rather general or theoretical nature [51–53], as are the questions addressed here regarding the emergence of polymorphisms of foraging strategy types and how such polymorphisms may be affected by sexual reproduction. This work could easily be extended by, say, including a more sophisticated treatment of patch heterogeneity in terms of growth and recovery rates of resources within patches, the effects of patch aggregation and landscape structure on movement behavior [54], and the effects of assortative or disassortative mating structures on the emergence of behavioral (forging strategy in our case) polymorphisms (e.g. see [31, 55]). Also, the assumption of hard selection (i.e. a fixed number of progeny are produced each generation) could be replaced with a soft selection assumption (i.e. the fecundity of individuals depends on the amount of biomass they produce each generation) to make the models ecologically more realistic [56]. Within such an extended framework, a host of interesting evolutionary questions can be investigated as they may relate to the emergence or existence of dominant/recessive allelic relationships, recognition systems, sex-ratio dynamics, sexual selection and so on. Since the options appear to be innumerable, beyond purely theoretical questions the development and application of models is best executed with specific systems in mind. Cases in point are computationally intensive models used to investigate the carrion finding strategies of griffon vultures [57] or predict the movement of banana stem weevils in the banana plantations [58].
Although it has been easier in the past to use agent-based models to address general rather than specific-systems questions, because the latter generally have “many more moving parts” and involve landscape specific data handled by GIS software, we have no doubt that the field of systems-specific computational biology will burgeon, as the capabilities of software grow to easily code and handle such models. We have demonstrated here that the Nova platform is moving us towards these desired software capabilities. As a result of reducing the considerable burden of coding complex agent-based models and casting them within a genetic algorithmic framework that now is easily implemented using the Nova platform, in the future we should be able to study evolutionary process with much greater ease. We anticipate that such studies will lead to a plethora of now insights, with the study reported here providing a taste of things to come. In particular, we provide incontrovertible evidence here that a population of randomly mating foragers, exploiting a single, randomly-distributed set of resource patches can (and may well be likely to) evolve into and be maintained as a polymorphic foraging-strategy guild.
Supporting Information
(PDF)
(PDF)
(PDF)
(PDF)
(PDF)
Acknowledgments
We thank John Pataki of Logical Labs for considerable help in creating and supporting the ‘Nova Modeler’ website (URL: http://novamodeler.com/). We thank two anonymous reviewers for extensive comments and suggestions that resulted in considerable improvements to this paper.
Data Availability
Data are available from: http://dx.doi.org/10.6084/m9.figshare.1477998.
Funding Statement
The development of Nova has been supported by the National Science Foundation grant CNS-0939153 to Oberlin College with Richard Salter as PI.
References
- 1. Smith M. Using massively-parallel supercomputers to model stochastic spatial predator-prey systems. Ecological Modelling. 1991;58:347–367. 10.1016/0304-3800(91)90045-3 [DOI] [Google Scholar]
- 2. Getz WM. Computational population biology: linking the inner and outer worlds of organisms. Israel Journal of Ecology and Evolution. 2013;59(1):2–16. 10.1080/15659801.2013.797676 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Smith FP, Holzworth DP, Robertson MJ. Linking icon-based models to code-based models: a case study with the agricultural production systems simulator. Agricultural Systems. 2005;83(2):135–151. 10.1016/j.agsy.2004.03.004 [DOI] [Google Scholar]
- 4. Morales JM, Fortin D, Frair JL, Merrill EH. The Simile visual modelling environment. European Journal of Agronomy. 2003;18(3–4):345–358. 10.1016/S1161-0301(02)00112-0 [DOI] [Google Scholar]
- 5. Fortmann-Roe S. Insight Maker: A general-purpose tool for web-based modeling and simulation. Simulation Modelling Practice and Theory. 2014;47(September):28–45. 10.1016/j.simpat.2014.03.013 [DOI] [Google Scholar]
- 6. Krause A, Lowe P. Visualization and Communication of Pharmacometric Models With Berkeley Madonna. CPT: Pharmacometrics and Systems Pharmacology. 2014;3(5):1–20. Available from: 10.1038/psp.2014.13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Railsback SF, Lytinen SL, Jackson SK. Agent-based simulation platforms: Review and development recommendations. Simulation-Transactions of the Society for Modeling and Simulation International. 2006;82(9):609–623. 10.1177/0037549706073695 [DOI] [Google Scholar]
- 8. North MJN, Collier T, Ozik J, Tatara ER, Macal CM, Bragen M, et al. Complex adaptive systems modeling with Repast Simphony. Complex Adaptive Systems Modeling. 2013;1(3):1–26. [Google Scholar]
- 9. Borshchev A, Karpov Y, Kharitonov V. Distributed simulation of hybrid systems with AnyLogic and HLA. Future Generation Computer Systems. 2002;18(6):829–839. 10.1016/S0167-739X(02)00055-9 [DOI] [Google Scholar]
- 10. Salter RM. Nova: A modern platform for system dynamics, spatial, and agent-based modeling. Procedia Computer Science. 2013;18:1784–1793. 10.1016/j.procs.2013.05.347 [DOI] [Google Scholar]
- 11. Getz WM, Gonzalez JP, Salter R, Bangura J, Carlson CJ, Coomber M, et al. Tactics and Strategies for Managing Ebola Outbreaks and the Salience of Immunization. Computational and Mathematical Methods in Medicine. 2015;2015:9 pages. 10.1155/2015/736507 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Poethke HJ, Kaiser H. A Simulation Approach to Evolutionary Game Theory: The Evolution of Time-Sharing Behaviour in a Dragonfly Mating System. Behavioral Ecology and Sociobiology. 1985;18(2):pp. 155–163. Available from: http://www.jstor.org/stable/4599874. 10.1007/BF00299044 [DOI] [Google Scholar]
- 13. Stockwell DRB, Noble IR. Induction of sets of rules from animal distribution data: A robust and informative method of data analysis. Mathematics and Computers in Simulation. 1992;33(56):385–390. 10.1016/0378-4754(92)90126-2 [DOI] [Google Scholar]
- 14. Snchez-Cordero V, Martnez-Meyer E. Museum specimen data predict crop damage by tropical rodents. Proceedings of the National Academy of Sciences. 2000;97(13):7074–7077. Available from: http://www.pnas.org/content/97/13/7074.abstract. 10.1073/pnas.110489897 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15. Saupe EE, Papes M, Selden PA, Vetter RS. Tracking a Medically Important Spider: Climate Change, Ecological Niche Modeling, and the Brown Recluse (Loxosceles reclusa). PLoS ONE. 2011. 03;6(3):e17731 10.1371/journal.pone.0017731 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Bond JE, Beamer DA, Lamb T, Hedin M. Combining genetic and geospatial analyses to infer population extinction in mygalomorph spiders endemic to the Los Angeles region. Animal Conservation. 2006;9(2):145–157. 10.1111/j.1469-1795.2006.00024.x [DOI] [Google Scholar]
- 17. Beck CW, Shapiro B, Choksi S, Promislow DE. A genetic algorithm approach to study the evolution of female preference based on male age. Evolutionary Ecology Research. 2002;4(2):275–292. [Google Scholar]
- 18. Ezoe H, Iwasa Y. Evolution of condition-dependent dispersal: A genetic-algorithm search for the ESS reaction norm. Researches on population ecology. 1997;39(2):127–137. 10.1007/BF02765258 [DOI] [Google Scholar]
- 19. Roura-Pascual N, Suarez AV, Gómez C, Pons P, Touyama Y, Wild AL, et al. Geographical potential of Argentine ants (Linepithema humile Mayr) in the face of global climate change. Proceedings of the Royal Society of London B: Biological Sciences. 2004;271(1557):2527–2535. 10.1098/rspb.2004.2898 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Holmgren NMA, Getz WM. Evolution of host plant selection in insects under perceptual constraints: A simulation study. Evolutionary Ecology Research. 2000;2(1):81–106. [Google Scholar]
- 21. Bond AB, Kamil AC. Visual predators select for crypticity and polymorphism in virtual prey. Nature. 2002;415(6872):609–613. 10.1038/415609a [DOI] [PubMed] [Google Scholar]
- 22. Drew MG, Lumley JA, Price NR. Predicting ecotoxicology of organophosphorous insecticides: Successful parameter selection with the genetic function algorithm. Quantitative Structure-Activity Relationships. 1999;18(6):573–583. [DOI] [Google Scholar]
- 23. Holzkämper A, Lausch A, Seppelt R. Optimizing landscape configuration to enhance habitat suitability for species with contrasting habitat requirements. ecological modelling. 2006;198(3):277–292. [Google Scholar]
- 24. Hamblin S. On the practical usage of genetic algorithms in ecology and evolution. Methods in Ecology and Evolution. 2013;4(2):184–194. 10.1111/2041-210X.12000 [DOI] [Google Scholar]
- 25. Olden JD, Lawler JJ, Poff NL. Machine learning methods without tears: A primer for ecologists. Quarterly Review of Biology. 2008;83(2):171–193. 10.1086/587826 [DOI] [PubMed] [Google Scholar]
- 26. Folse LJ, Packard JM, Grant WE. AI modelling of animal movements in a heterogeneous habitat. Ecological Modelling. 1989;46:57–72. 10.1016/0304-3800(89)90069-0 [DOI] [Google Scholar]
- 27. Holland J. Adaptation in natural and artificial systems. MIT Press, Cambridge, MA; 1992. [Google Scholar]
- 28. Holland JH, Miller JH. Artificial Adaptive Agents in Economic-Theory. American Economic Review. 1991;81(2):365–370. Fj364 Times Cited:171 Cited References Count:12. [Google Scholar]
- 29. Forrest S. Genetic Algorithms—Principles of Natural-Selection Applied to Computation. Science. 1993;261(5123):872–878. Lr897 Times Cited:385 Cited References Count:63. 10.1126/science.8346439 [DOI] [PubMed] [Google Scholar]
- 30. Leardi R. Genetic algorithms in chemometrics and chemistry: a review. Journal of Chemometrics. 2001;15(7):559–569. 10.1002/cem.651.abs [DOI] [Google Scholar]
- 31. Norrström N, Getz WM, Holmgren NMA. Selection against accumulating mutations in niche-preference genes can drive speciation. PLoS One. 2011;6(12):e29487 10.1371/journal.pone.0029487 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Norrström N, Getz WM, Holmgren NMA. Coevolution of exploiter specialization and victim mimicry can be cyclic and saltational. Evolutionary bioinformatics online. 2006;2:35. [PMC free article] [PubMed] [Google Scholar]
- 33. Phelps SM. Sensory ecology and perceptual allocation: new prospects for neural networks. Philosophical Transactions of the Royal Society B-Biological Sciences. 2007;362(1479):355–367. 10.1098/rstb.2006.1963 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Morales JM, Fortin D, Frair JL, Merrill EH. Adaptive models for large herbivore movements in heterogeneous landscapes. Landscape Ecology. 2005;20(3):301–316. 10.1007/s10980-005-0061-9 [DOI] [Google Scholar]
- 35. Mueller T, Fagan WF, Grimm V. Integrating individual search and navigation behaviors in mechanistic movement models. Theoretical Ecology. 2011;4(3):341–355. 10.1007/s12080-010-0081-1 [DOI] [Google Scholar]
- 36. Nathan R, Getz WM, Revilla E, Holyoak M, Kadmon R, Saltz D, et al. A movement ecology paradigm for unifying organismal movement research. Proceedings of the National Academy of Sciences of the United States of America. 2008;105:19052–19059. 10.1073/pnas.0800375105 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Abrams P, Ginzburg L. The nature of predation: prey dependent, ratio dependent or neither? Trends in Ecology and Evolution. 2000;15:337–341. 10.1016/S0169-5347(00)01908-X [DOI] [PubMed] [Google Scholar]
- 38. Abrams PA. Determining the Functional Form of Density Dependence: Deductive Approaches for Consumer-Resource Systems Having a Single Resource. American Naturalist. 2009;174:321–330. 10.1086/603627 [DOI] [PubMed] [Google Scholar]
- 39. Getz WM. Biomass transformation webs provide a unified approach to consumer-resource modelling. Ecology Letters. 2011;14(2):113–124. 10.1111/j.1461-0248.2010.01566.x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Levin SA. The Problem of Pattern and Scale in Ecology. Ecology. 1992;73(6):1943–1967. 10.2307/1941447 [DOI] [Google Scholar]
- 41. Grimm V, Frank K, Jeltsch F, Brandl R, Uchmanski J, Wissel C. Pattern-oriented modelling in population ecology. Science of the Total Environment. 1996;183(1–2):151–166. 10.1016/0048-9697(95)04966-5 [DOI] [Google Scholar]
- 42. Grimm V, Berger U, Bastiansen F, Eliassen S, Ginot V, Giske J, et al. A standard protocol for describing individual-based and agent-based models. Ecological Modelling. 2006;198(1-2):115–126. 10.1016/j.ecolmodel.2006.04.023 [DOI] [Google Scholar]
- 43. Grimm V, Berger U, DeAngelis DL, Polhill JG, Giske J, Railsback SF. The ODD protocol: A review and first update. Ecological Modelling. 2010;221(23):2760–2768. 10.1016/j.ecolmodel.2010.08.019 [DOI] [Google Scholar]
- 44. Ryan JG, Ludwig JA, Mcalpine CA. Complex adaptive landscapes (CAL): A conceptual framework of multi-functional, non-linear ecohydrological feedback systems. Ecological Complexity. 2007;4(3):113–127. 10.1016/j.ecocom.2007.03.004 [DOI] [Google Scholar]
- 45. Gosme M, Lucas P. Cascade: An epidemiological model to simulate disease spread and aggregation across multiple scales in a spatial hierarchy. Phytopathology. 2009;89(7):823–832. 10.1094/PHYTO-99-7-0823 [DOI] [PubMed] [Google Scholar]
- 46. Tracey JA, Bevins SN, VandeWoude S, Crooks KR. An agent-based movement model to assess the impact of landscape fragmentation on disease transmission. Ecosphere. 2014;5(9):art119 10.1890/ES13-00376.1 [DOI] [Google Scholar]
- 47. Hahn BD, Valentine DT. Essential MATLAB for engineers and scientists. 5th ed Elsevier; 2013. [Google Scholar]
- 48. Dieckmann U, Doebeli M. On the origin of species by sympatric speciation. Nature. 1999. 07;400(6742):354–357. 10.1038/22521 [DOI] [PubMed] [Google Scholar]
- 49. Corl A, Davis AR, Kuchta SR, Sinervo B. Selective loss of polymorphic mating types is associated with rapid phenotypic evolution during morphic speciation. Proceedings of the National Academy of Sciences. 2010;107(9):4254–4259. 10.1073/pnas.0909480107 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50. Getz WM, Kaitala V. Ecogenetic models, competition, and heteropatry. Theoretical Population Biology. 1989;36(1):34–58. 10.1016/0040-5809(89)90022-1 [DOI] [Google Scholar]
- 51. Couzin ID, Krause J, Franks NR, Levin SA. Effective leadership and decision making in animal groups on the move. Nature. 2005;433:513–516. 10.1038/nature03236 [DOI] [PubMed] [Google Scholar]
- 52. Krause J, Ruxton GD. Living in Groups. Oxford University Press, Oxford; 2002. [Google Scholar]
- 53. Giuggioli L, Potts JR, Harris S. Animal Interactions and the Emergence of Territoriality. PLoS Computational BIology. 2009;7:e1002008 10.1371/journal.pcbi.1002008 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54. Revilla E, Wiegand T. Individual movement behavior, matrix heterogeneity, and the dynamics of spatially structured populations. Proceedings of the National Academy of Sciences of the United States of America. 2008;105:19120–19125. 10.1073/pnas.0801725105 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55. Edelsparre AH, Vesterberg A, Lim JH, Anwari M, Fitzpatrick MJ. Alleles underlying larval foraging behaviour influence adult dispersal in nature. Ecology Letters. 2014;17(3):333–339. 10.1111/ele.12234 [DOI] [PubMed] [Google Scholar]
- 56. Saccheri I, Hanski I. Natural selection and population dynamics. Trends in Ecology and Evolution. 2006;21(6):341–347. Twenty years of {TREE}—part I. Available from: http://www.sciencedirect.com/science/article/pii/S0169534706001054. 10.1016/j.tree.2006.03.018 [DOI] [PubMed] [Google Scholar]
- 57. Cortés-Avizanda A, Jovani R, Donázar JA, Grimm V. Bird sky networks: How do avian scavengers use social information to find carrion? Ecology. 2014;95:1799–1808. 10.1890/13-0574.1 [DOI] [PubMed] [Google Scholar]
- 58. Vinatier F, Lescourret F, Duyck PF, Martin O, Senoussi R, Tixier P. Should I stay or should I go? A habitat-dependent dispersal kernel improves prediction of movement. PLoS One. 2011;6(7):e21115 10.1371/journal.pone.0021115 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
(PDF)
(PDF)
(PDF)
(PDF)
(PDF)
Data Availability Statement
Data are available from: http://dx.doi.org/10.6084/m9.figshare.1477998.