

Abstract
Within the class of memory-one strategies for the iterated Prisoner's Dilemma, we characterize partner strategies, competitive strategies and zero-determinant strategies. If a player uses a partner strategy, both players can fairly share the social optimum; but a co-player preferring an unfair solution will be penalized by obtaining a reduced payoff. A player using a competitive strategy never obtains less than the co-player. A player using a zero-determinant strategy unilaterally enforces a linear relation between the two players' payoffs. These properties hold for every strategy used by the co-player, whether memory-one or not.
Keywords: Repeated games, Zero-determinant strategies, Cooperation, Reciprocity, Extortion
Highlights
-
•
We consider 3 different strategy classes for the Iterated Prisoner's Dilemma.
-
•
With partner strategies, players ensure that mutual cooperation is a stable equilibrium.
-
•
A player using a competitive strategy never obtains less than the co-player
-
•
With a ZD strategy, a player can unilaterally enforce a linear relation between payoffs.
-
•
We characterize these 3 classes within the space of memory-one strategies.
1. Introduction
In a one-shot Prisoner's Dilemma (PD) game, the two players have to choose between C and D (to cooperate resp. to defect). Following the notation in Rapoport and Chammah (1965), the payoff matrix is given by
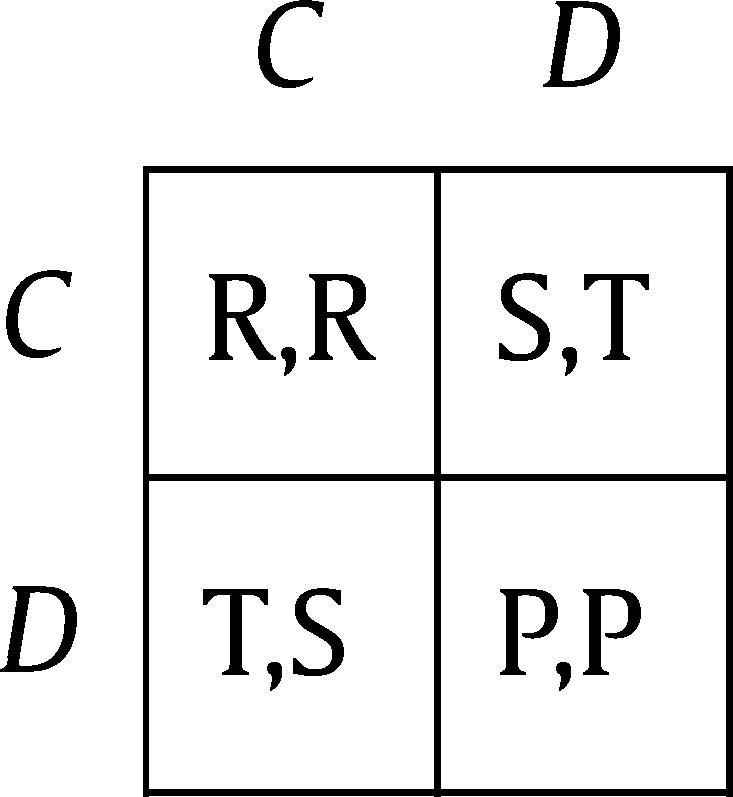 |
(1) |
in which the four payoff variables represent the reward for mutual cooperation R, the sucker's payoff S, the temptation to defect T, and the punishment for mutual defection P. Payoffs satisfy the inequalities , such that defection is a dominant strategy, but mutual cooperation is preferred over mutual defection. In addition to these inequalities, we shall also assume that
| (2) |
such that mutual cooperation is unanimously preferred from a group perspective.1 In such cases, experimental evidence suggests that many players want to achieve conditional cooperation. They are willing to play C, provided the co-player also plays C (see, e.g., Fehr and Fischbacher, 2003; Yamagishi et al., 2005). However, short of a commitment device, this cannot be ensured. Thus, players either have to trust their co-player, or else use their dominant strategy.
The situation is different for an iterated PD game (IPD). Diverse ‘folk theorems’ state that any feasible and individually rational outcome can be sustained as an equilibrium if the probability δ of a further round is sufficiently large. Such outcomes can be enforced in various ways, and under a wide range of circumstances (see, e.g., Friedman, 1971; Aumann, 1981; Aumann and Shapley, 1994; Fudenberg and Maskin, 1986; Kalai, 1990; Myerson, 1991; Mailath and Olszewski, 2011). If subjects can make binding commitments ahead of the game, then analogous results can be obtained even for one-shot games (Kalai et al., 2010).
Experimental research has uncovered considerable heterogeneity in human social preferences (Colman, 1995; Kagel and Roth, 1997; Camerer, 2003), and a similar variety can be found among the strategies that are played in the IPD (Milinski and Wedekind, 1998; Dal Bó and Fréchette, 2011; Fudenberg et al., 2012). Players who in the one-shot game would opt for conditional cooperation should be willing to engage in ‘partner’ strategies. Such strategies aim for an average payoff R per round, which necessarily provides the same payoff R for the co-player; should the co-player not go along, however, then the co-player's payoff will be less than R. Thus, a partner strategy appeals to the co-player's self-interest in order to further the own self-interest. It is fair, and provides an incentive for the co-player to also be fair. In contrast, some players tend to view their co-player as a rival, rather than a partner. The main purpose, for such competitive players, is to do better, or at least as well as the other player. A preference for dominating the co-player is particularly likely in the context of a game, which often has antagonistic connotations.
The aim of the present manuscript is two-fold: first, we are going to characterize all memory-one strategies which are either competitive, or partner strategies in the sense above. We emphasize that players using such strategies can enforce their preferences against all comers, since we impose no restrictions on the strategies used by the co-players. For partner strategies, the corresponding results in the limiting case of an IPD without discounting have been obtained within the last two years (Akin, 2013; Stewart and Plotkin, 2013, 2014). Here, we are going to extend the theory by allowing for discount factors (which may either be interpreted as the constant continuation probability of having another round, or as the players' common discount rate on future payoff streams). The recent progress was stimulated by the unexpected discovery of so-called zero-determinant (ZD) strategies, a class of memory-one strategies enforcing a linear relationship between the payoffs of the two players, irrespective of the co-player's strategy (Press and Dyson, 2012). In particular, ZD strategies can fix the co-player's payoff to an arbitrary value between P and R; or ensure that the own ‘surplus’ (over the maximin value P) is twice as large as the co-player's surplus; etc. Also for ZD strategies, we are going to extend the theory to the case when future payoffs are discounted, and .
The nature of our results is somewhat different from usual treatments of repeated games. Our article does not focus on equilibrium behavior (in particular, we do not aim to explore which payoffs rational players can achieve). Instead, we define some interesting properties that a player's strategy may have (e.g., being competitive); and then we are going to characterize all memory-one strategies that have the respective property (independent of whether such a strategy can be sustained as an equilibrium). Thereby, we do not make any assumptions on the behaviors of the co-players (e.g., we do not require them to play best responses, or to follow a predefined equilibrium path). Nevertheless, there are natural connections between several of the described strategy classes and equilibrium behavior, and in that case we will discuss these connections in detail.
In the discussion, we will briefly review the previous development, and in particular the relevant findings in evolutionary game theory (Stewart and Plotkin, 2012, 2013, 2014; Adami and Hintze, 2013; Hilbe et al., 2013a, 2013b; Akin, 2013; Szolnoki and Perc, 2014a, 2014b; Wu and Rong, 2014). In a nutshell, these findings say that in the context of populations of adapting players, partner strategies do well, whereas competitive strategies fare poorly.
2. A fundamental lemma on mean distributions
We consider the standard setup of an IPD with perfect monitoring. In each round, the two players choose whether to cooperate or to defect. That is, they choose an action from their respective action set , with . The outcome of a given round t can then be described by an action profile . After each round, both players observe the chosen action profile, and they receive the respective payoffs as specified in the payoff matrix (1). The round t history is a vector , and the set of possible histories is the union , with the initial history being defined as the null set . A strategy for player i is a rule that tells the player how to act after any possible history; that is, a strategy is a map , where denotes the set of probability distributions over the action set .2
For given strategies of the two players, let denote the probability that the resulting action profile played in round t is . For convenience, we use the following vector notation:
| (3) |
Using this notation, we can write the players' expected payoffs in round t as and . For a discount factor , the expected payoffs of the repeated game can then be defined by the Abelian means
| (4) |
and similarly , where refers to the (Abelian) mean distribution
| (5) |
In the limiting case , the payoff per round is given by the Cesaro mean
| (6) |
(if this limit exists), and a similar expression for .3 A theorem by Frobenius states that if the Cesaro mean exists, it is the limit of the Abelian mean, for .
In the following, we will sometimes focus on players who only take the decisions in the previous round into account.
Definition 1
A strategy σ is a memory-one strategy if for all histories and with and .
For rounds , the move of a memory-one player is therefore solely determined by the action profile played in the previous round (in particular, we note that such players do not condition their behavior on the round number, as sometimes considered in models of bounded recall, e.g. Mailath and Olszewski, 2011). Such memory-one strategies can be written as a 5-tuple . The element denotes the probability to cooperate in the initial round. The continuation vector denotes the conditional probabilities to cooperate in rounds , depending on the outcome of the previous round (slightly abusing notation, we let the first letter in the subscript refer to the player's own action in the previous round, and the second letter to the co-player's action. Using this convention, we ensure that the interpretation of a memory-one strategy does not depend on whether the player acts as player I or as player II, see Nowak and Sigmund, 1995). Examples of memory-one strategies include , Tit For Tat , or Win-Stay, Lose-Shift , see Sigmund (2010) for a comprehensive discussion.
When both players apply a memory-one strategy, the resulting mean distribution v can be calculated explicitly (Nowak and Sigmund, 1995): if player I uses the memory-one strategy against a player II with memory-one strategy , then
| (7) |
where is the initial distribution, is the identity matrix, and M is the transition matrix of the Markov chain,
| (8) |
But even if only one of the players is using a memory-one strategy p, there is still a powerful relationship between p and the resulting mean distribution v.
Lemma 1
Suppose player I applies a memory-one strategy p, and let the strategy of player II be arbitrary, but fixed.
- (i)
In the case with discounting , let v denote the mean distribution of the repeated game. Thenor in vector notation, , where .
(9) - (ii)
In the case without discounting, we haveIn particular, if the Cesaro mean distribution v exists, .
(10)
Proof
Suppose , and let denote the probability that player I cooperates in round t. Then and . It follows that is given by
(11) Multiplying each by and summing up over yields
(12) On the other hand, due to Eq. (11),
(13) As both limits need to coincide, we have confirmed Eq. (9). For the case without discounting, an analogous calculation as in Eq. (12) yields
(14) whereas Eq. (13) becomes
(15) It follows that the limit of for exists and equals zero. □
It is worthwhile to stress the generality of Lemma 1: it neither makes any assumption on the strategy used by the co-player, nor does it depend on the specific payoff constraints of a prisoner's dilemma. In the limiting case , Lemma 1 allows a geometric interpretation: the mean distribution v (if it exists) is orthogonal to (see Akin, 2013).
3. Partner strategies and competitive strategies
Definition 2
A player's strategy is nice, if the player is never the first to defect. A player's strategy is cautious if the player is never the first to cooperate.
For memory-one strategies, nice strategies fulfill , and cautious strategies . As an example, the strategy TFT is nice, whereas the defector's strategy AllD is cautious.
Lemma 2
If , then payoffs satisfy if and only if (which for holds if and only if both players are nice). Similarly, if , then if and only if (which for is equivalent to both players being cautious).
Proof
Due to Eq. (4), . As , the inequality implies . For , this requires both players to cooperate in every round (if , it only requires the players to cooperate in almost every round). Similarly, for a prisoner's dilemma with , the inequality implies . □
Definition 3
- (i)
A partner strategy for player I is a nice strategy such that, irrespective of the co-player's strategy,
(16) - (ii)
A competitive strategy for player I is a strategy such that, irrespective of the co-player's strategy,
(17)
Fig. 1 gives a schematic illustration of these two strategy classes. The definition of partner strategies implies that these strategies are best replies to themselves, and thus they are Nash equilibria. Even more, because condition (16) is equivalent to , we can conclude due to Lemma 2 that . Thus, no matter which best reply the co-player applies, a player with a partner strategy will always obtain the mutual cooperation payoff R.
Fig. 1.
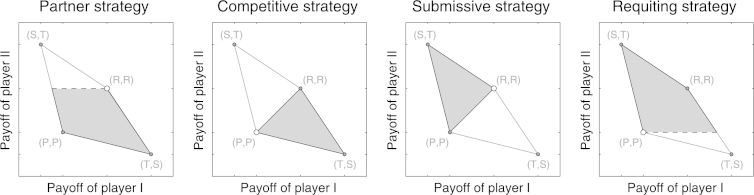
Schematic representation of partner strategies, competitive strategies, submissive strategies and requiting strategies. The grey-shaded area depicts the set of possible payoff pairs when player I adopts a strategy of the respective strategy class. The white dot represents the payoff that player I gets against a co-player using the same strategy.
On the other hand, players with a competitive strategy always obtain at least the co-player's payoff. It is easy to see that for a competitive strategy needs to be cautious (otherwise the focal player would be outcompeted by an AllD-player). In the limiting case , competitiveness is closely related to the concept of being unbeatable, as introduced by Duersch et al. (2012). A strategy for player I is unbeatable, if against any co-player and for any number of rounds, the payoff differential is bounded from above (in particular, if the average payoffs per round converge to and , then ).
Proposition 1
For a player I with a nice memory-one strategy p, the following are equivalent:
- (i)
p is a partner strategy;
- (ii)
If the co-player uses either AllD or the strategy , then ;
- (iii)
The two inequalities and hold, with
(18)
Proof
- (i) ⇒ (ii)
Assume to the contrary that . Then the definition of partner strategies implies that . Since all players use memory-one strategies, this would require that everyone cooperates after mutual cooperation, which is neither true for nor for the strategy .
- (ii) ⇒ (iii)
We note that this payoff is also defined when , because (otherwise p would satisfy , and player I would always cooperate. In that case, an AllD co-player would receive , which is ruled out by (ii)). Elementary algebra yields
(19) In particular, has the same sign as . On the other hand, if the co-player uses the strategy (0,1,1,1;0), the co-player's payoff is
(20) and
(21) Therefore, has the same sign as .
(22) - (iii) ⇒ (i)
Using the linear equations and (Lemma 1 with , since the memory-one strategy is nice), we calculate as a function of and :
(23) The denominator of is positive, as implies . Plugging (24) into (23) and multiplying both sides with shows that if and only if
(24) with and as defined in (18). Thus, the assumptions and indicate that , and by (24) that . We conclude that , and therefore , i.e., p is a partner strategy.
(25) □
For example, TFT is a partner strategy if and only if and , whereas WSLS is a partner strategy if and only if and , which is a sharper condition. In analogy to the definition of partner strategies, one may define a mild partner strategy for player I as a nice strategy such that implies , irrespective of the co-player's strategy.4 For memory-one strategies, the characterization of mild partner strategies is analogous to the characterization of partner strategies (only the strict inequalities in Proposition 1 need to be replaced by weak inequalities).
Proposition 1 also provides an interesting connection to the folk theorems. The existence of an equilibrium with individually rational payoffs () in the IPD is typically shown by applying trigger strategies – any deviation from the equilibrium path is punished with relentless defection (as for example in Friedman, 1971).5 The following Corollary states that trigger strategies are, in some sense, the most effective means to enforce a cooperative equilibrium in the IPD.
Corollary 1
For a given prisoner's dilemma and a given continuation probability δ, there exists a memory-one partner strategy if and only if the trigger strategy Grim is a partner strategy.
Proof
The two quantities and in Proposition 1 are minimal for . Thus, if there is a memory-one strategy that meets the inequalities and , then the corresponding inequalities are also met by Grim. □
From Corollary 1, we may also conclude that partner strategies exist if and only if (this condition for the existence of fully cooperative equilibria has been previously derived by Roth and Murnighan, 1978; Stahl, 1991).
Let us next give a characterization of competitive memory-one strategies:
Proposition 2
Suppose player I applies the memory-one strategy p. Then the following are equivalent:
- (i)
p is competitive.
- (ii)
If the co-player uses either AllD or the strategy , then .
- (iii)
The entries of p satisfy and .
Proof
- (i) ⇒ (ii)
Follows immediately from the definition, a competitive strategy yields against any co-player.
- (ii) ⇒ (iii)
and thus implies . Similarly, if player II applies the strategy , we obtain (using ):
(26) This is non-negative if and only if .
(27) - (iii) ⇒ (i)
Using the inequality , this leads to
(28) or equivalently . This implies . As a consequence, .
(29) □
Fig. 2 shows the space of partner strategies (and the space of competitive strategies) as subsets of the nice memory-one strategies (cautious memory-one strategies), respectively. One can also define the dual properties, and derive the corresponding characterizations: a strategy for player I is said to be submissive if payoffs always satisfy , irrespective of the strategy of player II; and a cautious strategy for player I is said to be requiting if implies (see Fig. 1 for a schematic representation of these strategy classes). The corresponding characterizations are:
Fig. 2.
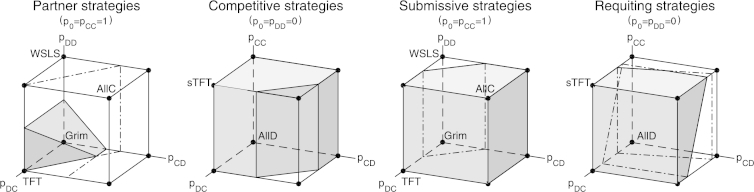
The space of partner strategies, competitive strategies, submissive strategies and requiting strategies. Each grey block represents the set of strategies that fulfill the respective constraints in Propositions 1–4. For this representation, the continuation probability was set to δ = 2/3, using the payoff values in Axelrod (1984), i.e. T = 5, R = 3, P = 1, S = 0. The depicted pure strategies are: TFT = (1,0,1,0;1), Grim = (1,0,0,0;1), Win-stay lose-shift: WSLS = (1,0,0,1;1), AllC = (1,1,1,1;1), AllD = (0,0,0,0;0) and suspicious Tit For Tat: sTFT = (1,0,1,0;0).
Proposition 3
Suppose player I applies the memory-one strategy p. Then the following are equivalent:
- (i)
p is submissive;
- (ii)
If the co-player uses either AllC or the strategy , then ;
- (iii)
The entries of p satisfy and .
Proposition 4
Suppose the game payoffs satisfy . Then, for a player I with a cautious memory-one strategy p, the following are equivalent:
- (i)
p is requiting;
- (ii)
If the co-player uses either AllC or the strategy , then ;
- (iii)
The two inequalities and hold, with
(30)
4. ZD-strategies
The previous results have highlighted how Lemma 1 can be used to characterize several interesting strategy classes within the space of memory-one strategies (for example, the strategies that allow a player to outcompete the opponent, or the strategies that provide incentives to reach the social optimum). In the following, we present another application of Lemma 1: there are strategies with which a player can unilaterally enforce a linear relationship between the players' payoffs.
Definition 4
A memory-one strategy p is said to be a ZD strategy if there exist constants such that
(31)
Proposition 5
Let , and suppose player I applies a memory-one strategy p satisfying Eq. (31). Then, irrespective of the strategy of the co-player,
(32) The same relation holds for , provided that the payoffs and exist.6
Proof
This follows directly from Lemma 1, using the identities , , and . □
In the following, let . We proceed with a slightly different representation of ZD strategies, using the parameter transformation , , and .7 Under this transformation, ZD strategies take the form
| (33) |
and the enforced payoff relationship according to (32) becomes
| (34) |
Eq. (34) implies that the payoffs lie on a line segment intersecting the diagonal at some value κ (the payoff for the ZD-strategy against itself) and having a slope χ (see Fig. 3).
Fig. 3.
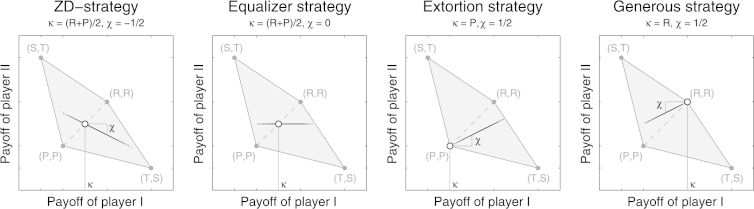
Characteristic payoff relations for ZD strategies, equalizer strategies, extortion strategies and generous strategies. The grey-shaded area represents the set of feasible payoffs. In each graph, the strategy of player I was fixed, whereas for the strategy of player II we sampled 1000 random memory-one strategies. The resulting payoffs were drawn as black dots. For general ZD-strategies, these dots are on a line (intersecting the diagonal at κ, and having slope χ). Equalizer strategies have the additional property that the slope χ is zero, i.e. the payoff of co-player II is fixed to κ, independent of the co-player's strategy. Extortion strategies are ZD-strategies with κ = P and 0 < χ < 1, and generous strategies fulfill κ = R and 0 < χ < 1. For this figure, we have used the payoff values in Axelrod (1984), T = 5, R = 3, P = 1, S = 0, and continuation probability δ = 4/5. For the strategy of player I we have used: (i) ZD-strategy p = (0.85,0.725,0.1,0.35;0.1); (ii) Equalizer strategy p = (0.875,0.375,0.375,0.125;0.5); (iii) Extortion strategy p = (1,0.125,0.75,0;0); (iv) Generous strategy p = (1,0.125,0.75,0;1).
Players cannot use ZD strategies to enforce arbitrary payoff relationships of the form (34): since the entries of the continuation vector correspond to conditional probabilities (and hence need to be in the unit interval), the parameters κ, χ and ϕ need to obey certain restrictions. This gives rise to the following definition.
Definition 5
For a given δ, we call a payoff relationship enforceable if there are and such that each entry of the continuation vector according to Eq. (33) is in [0,1]. We refer to the set of all enforceable payoff relationships as .
Proposition 6
- (i)
The set of enforceable payoff relationships is monotonically increasing in the discount factor: if , then .
- (ii)
There is a such that if and only if andwith at least one inequality in (35) being strict.
(35)
Proof
- (i)
According to the definition, if and only if one can find and , such that the corresponding continuation vector according to Eq. (33) satisfies , or equivalently,
(36a)
(36b)
(36c) We note that in (36a)–(36d), the left hand side is monotonically decreasing in δ, whereas the right hand side is monotonically increasing in δ. In particular, if the conditions (36) are satisfied for some they are also satisfied for any .
(36d) - (ii)
- (⇒)
Suppose , and therefore the conditions (36) hold for appropriate parameters ϕ and . Summing up the first inequality in (36a) and the first inequality in (36d) showsSimilarly, by taking the inequalities in (36b) and (36c), we get
(37) In particular, and , and therefore and . Moreover, the conditions (36) imply
(38) Since and , these conditions are equivalent to condition (35). If none of the inequalities in (35) was strict, then (36a) or (36b) would require , whereas (36c) or (36d) would require .
(39) - (⇐)
Conversely, let , and suppose . Then the inequalities (39) hold for any choice of , with the first two inequalities being strict. In particular, we can choose a ϕ sufficiently small such that each term on the right hand's side of (39) is bounded from above by 1/2. By setting and choosing a δ sufficiently close to one, it thus follows that all inequalities in (36) can be satisfied. An analogous argument holds when , in which case one needs to set .□
The first part of Proposition 6 shows that a given linear payoff relationship of the form (34) is easier to enforce when players are sufficiently patient. As , the limiting set of enforceable payoff relationships () is characterized by Proposition 6(ii); Fig. 4 provides an illustration.
Fig. 4.
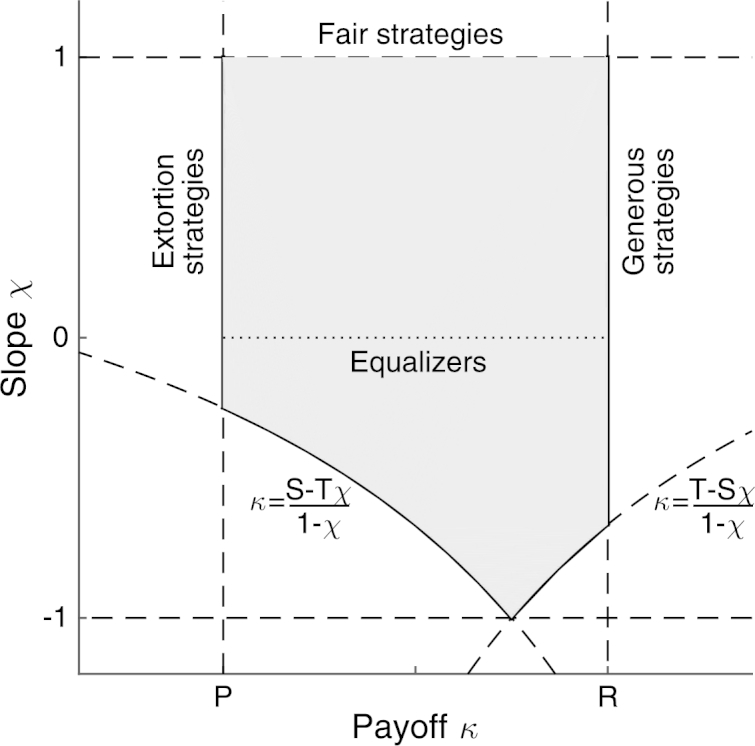
Enforceable payoff relationships for players with a ZD strategy. The grey area depicts all pairs (κ,χ) that are enforceable when the discount factor δ is sufficiently close to one, as characterized in Proposition 6. The graph also depicts some particular subclasses of ZD strategies: equalizer strategies (χ = 0), extortion strategies (κ = P, χ > 0), and generous strategies (κ = R, χ > 0). The so-called fair strategies (with χ = 1) do only exist in the limit of no discounting, δ = 1. For the illustration, we have taken the payoff values in Axelrod (1984), i.e. T = 5, R = 3, P = 1, S = 0.
There are various remarkable subclasses of ZD strategies (as depicted in Fig. 3 and Fig. 4). For , we encounter so-called equalizer strategies (see Boerlijst et al., 1997; Press and Dyson, 2012). By Eq. (34), player I can make use of such strategies to prescribe κ as payoff for player II. A player can thus determine the opponent's payoff (however, player I cannot fix the own payoff, since this would require χ to be unbounded, which is ruled out by Proposition 6). Press and Dyson (2012) also highlighted the class of extortion strategies (with and ). Extortion strategies guarantee that the own ‘surplus’ over the minimax payoff P exceeds the opponent's surplus by a factor of . Moreover, since , the payoffs of the two players are positively related. Hence, to maximize the own payoff, player II needs to maximize player I's payoff: the best response against an extortioner is to cooperate unconditionally. As a counterpart to extortioners, Stewart and Plotkin (2012) defined the class of generous strategies, which satisfy Eq. (34) with and . Players using a generous strategy shoulder a larger burden of the loss (with respect to the social optimum R) than their co-player. Since , they also ensure that the payoffs of the two players are aligned, thereby motivating the co-player to cooperate. Finally, for games without discounting it was noted that strategies with enforce (for , TFT is an example of such a fair strategy, see Press and Dyson, 2012; Hilbe et al., 2014b). However, as Proposition 6 shows, fair strategies cease to exist when future payoffs are discounted, and only approximately fair strategies (with χ close to one) may be feasible.
ZD strategies can also be connected to the strategy classes discussed in the previous section. Generous strategies, for example, are exactly the ZD strategies which are submissive partner strategies (in particular it follows that every generous strategy is a Nash equilibrium of the IPD). On the other hand, for stage games with (which ensures ), extortion strategies are precisely those ZD strategies which are requiting and competitive.
We note that herein, we have entirely focused on the repeated prisoner's dilemma, due to the central role that this simple game situation takes in the literature on the evolution of cooperation (Rapoport and Chammah, 1965; Trivers, 1971; Sugden, 1986; Axelrod, 1984; Sigmund, 2010). However, the proofs of Lemma 1 and Proposition 5 did not require any assumptions on the payoff values (and in the proof of Proposition 6, we have only made use of the assumptions and ). Moreover, for , it was recently shown that similar results can also be obtained for stage games with 2 actions but players (Hilbe et al., 2014b). Thus, while we believe that our results are most intuitive in the context of a prisoner's dilemma, the mathematics can be extended to more general strategic situations.
5. Discussion
The recent development began with the paper of Press and Dyson (2012) introducing ZD strategies for repeated games without discounting. In this context, Press and Dyson derived the linear relation (32). Their proof was based on a neat formula for the payoffs achieved if both players use memory-one strategies. This formula only involves vanishing determinants, which explains the name ZD. Press and Dyson highlighted those ZD strategies that fix the co-player's payoff to a given value between P and R, as well as the sinister properties of extortion strategies. They also stressed the fact that more complex strategies (based on larger memories, for instance) are not able to profit from their sophistication to gain the upper hand. The intriguing aspects of ZD strategies raised considerable attention (see, e.g., Ball, 2012). In the News section of the American Mathematical Society, it was stated that 'the world of game theory is currently on fire.' A more skeptical view could be found among economists. The well-known folk theorem for repeated games states that trigger strategies can induce a rational co-player to agree to any feasible payoff pair above the minimax level P, by threatening to switch to relentless defection otherwise (see Aumann, 1981; Kalai, 1990; Fudenberg and Maskin, 1986, 1990). Seen from this angle, the progress consisted merely in displaying memory-one strategies with a similar power to enforce specific payoff pairs. However, there is a subtle difference: whereas the Folk theorems are based on the assumption that players wish to maximize their payoffs, the results presented herein are independent of such an assumption. Interpreted in this way, we have explored how much control player I can exert on the resulting payoffs without being sure about the motives of player II.
Memory-one strategies able to fix the co-player's payoff had already been derived in Boerlijst et al. (1997) and Sigmund (2010), based on an approach different from that of Press and Dyson (2012). This method was used in Hilbe et al. (2013a) to provide another derivation of (32), not involving any determinants. It was substantially extended by Akin (2013) to yield a general equation for the mean distribution of memory-one strategies when . In this case, the mean distribution is understood in the sense of Cesaro, and need not always exist. In Lemma 1, we have extended this approach to cover the case , from which Akin's result for immediately follows. Lemma 1 offers a geometric tool for the investigation of memory-one strategies. The vector consists of the conditional probabilities to play C in the next round (δ is the probability that there is a next round), whereas can be viewed as 'conditional probability' to play C in the current round. In the limit of no discounting, Lemma 1 states that no matter which strategy player II is using, the limiting distribution v (if it exists) is on a hyperplane orthogonal to the difference of these two conditional probabilities. It was also Akin (2013) who extended the investigations beyond the case of ZD-strategies, to characterize partner strategies for (calling them 'good' strategies, a term we feel is too general).
In a comments article, Stewart and Plotkin (2012) introduced an example of a generous strategy, and showed that in a round robin tournament conducted after the fashion of Axelrod (1984), this generous strategy emerged as winner. Stewart and Plotkin also asked whether ZD strategies were relevant for evolutionary game theory. In this context, one considers a population of players, each equipped with a strategy. The players are then allowed to imitate other strategies, preferentially those with a higher payoff (see, e.g., Weibull, 1995; Samuelson, 1997; Hofbauer and Sigmund, 1998; Nowak, 2006; Sandholm, 2010).
It is obvious that extortion strategies cannot spread too much in such an evolutionary context; if they become too common, they are likely to encounter their own, which bides ill. If player I obtains twice the surplus of II, and II twice the surplus of I, each surplus is zero. However, Hilbe et al. (2013a) showed that extortion strategies can pave the way for the emergence of cooperative strategies, similar to TFT (which, for , can be regarded as a limiting case of an extortion strategy, Press and Dyson, 2012). This catalytic role of extortion strategies has also been confirmed for games on networks, in which players only interact within a small neighborhood (Szolnoki and Perc, 2014a, 2014b; Wu and Rong, 2014). Overall, these studies confirm that extortionate strategies have problems to succeed within a population. However, if the games are played between members of two distinct populations – for instance, between hosts organisms and their symbionts – then extortion strategies can emerge in whichever population is slower to adapt (Hilbe et al., 2013a). The slower rate of evolution acts as a commitment device. In effect, the slowly evolving organism becomes the Stackelberg leader in a sequential game, in which the slow player learns to adopt extortion strategies, whereas the faster evolving player learns to play the best response, and to cooperate unconditionally (Bergstrom and Lachmann, 2003; Damore and Gore, 2011; Gokhale and Traulsen, 2012).
But even in a one-population setup, certain ZD strategies prove successful: Stewart and Plotkin showed that evolutionary trajectories often visit the vicinity of generous strategies. The dynamics leads ‘from extortion to generosity’ (the title of Stewart and Plotkin, 2013). This is also confirmed, by analytical means based on adaptive dynamics, by Hilbe et al. (2013b). Remarkably, Stewart and Plotkin (2013, 2014) derived a characterization of all memory-one strategies which are robust in an evolutionary sense, for given population size N. This means that the replacement probability, as a resident strategy, is at most (which is the probability to be replaced if the mutant is neutral). In the limit of weak selection, which roughly means that the choice between two strategies is only marginally influenced by payoff (see Nowak et al., 2004), all robust ZD strategies need to be generous (Stewart and Plotkin, 2013). These predictions have also been tested in a recent behavior experiment, in which human subjects played against various computer opponents (Hilbe et al., 2014a). Although extortionate programs outcompeted their human co-players in every game, generous programs received, on average, higher payoffs against the human subjects than extortionate programs. Humans were hesitant to give in to extortion; although unconditional cooperation would have been their best response in all treatments, they only became more cooperative over time if their co-player was generous.
Intriguingly, if a player uses a generous strategy and the co-player does not go along, then the focal player will always shoulder a larger part of the loss (with respect to the mutual cooperation payoff R). Despite their forbearance, generous strategies do very well – which is not the least of the surprises offered by the Iterated Prisoner's Dilemma game.
Footnotes
We would like to thank the advisory editor and two anonymous referees for their thoughtful comments, which significantly improved the paper. Karl Sigmund acknowledges Grant RFP 12-21 from Foundational Questions in Evolutionary Biology Fund, and Christian Hilbe acknowledges generous funding from the Schrödinger scholarship of the Austrian Science Fund (FWF), J3475.
Whereas this additional constraint is rather uncommon in economics, it is fairly common in psychology and in the evolutionary game theory literature (e.g., Rapoport and Chammah, 1965; Axelrod, 1984). Inequality (2) rules out some additional complications that arise when players need to coordinate on different actions to obtain the social optimum. The difficulties become more apparent in the repeated game. As part of our analysis, we wish to characterize strategies which only depend on the decisions of the last round (so-called memory-one strategies), and which enforce a fair and efficient outcome (which will be referred to as partner strategies). When , efficiency requires players to alternate between cooperation and defection, and to establish an equilibrium path (CD, DC, CD, DC, …). Now problems can arise when players observe a round with mutual defection, since a memory-one player is unable to determine who of the two players deviated from the equilibrium path (or in which stage of a possible punishment phase the players are). These issues can be circumvented when players are allowed to have longer memory (Mailath and Olszewski, 2011), or when the action space is rich (e.g., when the action space is a convex set, see Barlo et al., 2009). Herein, we will neglect these additional complications by focusing on games that satisfy the constraint (2). However, we note that inequality (2) is only used in proofs of results pertaining to partner strategies (Lemma 2 and Proposition 1). All other results presented in this manuscript (Lemma 1 and the Propositions 2–6) are independent of this condition.
Strictly speaking, this means that we are considering behavior strategies, see Section 2.1.3 of Mailath and Samuelson (2006).
This definition of payoffs for is common in evolutionary game theory (e.g. Sigmund, 2010), whereas the equilibrium literature usually takes the of average payoffs to ensure that payoffs are always defined. Obviously, if the limit in (6) exists, the two definitions coincide. In the evolutionary literature, the strategy space is typically restricted (for example to memory-one strategies), which often guarantees the existence of the limit. Here, we have chosen the definition (6) to be consistent with the previous literature on ZD strategies in repeated games without discounting, e.g. Press and Dyson (2012) and Akin (2013).
Equivalently, one may define mild partner strategies as nice strategies such that implies . We note that if the premise was true and , then total payoffs would exceed 2R, which is ruled out by Lemma 2. We conclude that mild partner strategies enforce . That is, mild partner strategies are exactly those nice strategies that support mutual cooperation in a Nash equilibrium.
For arbitrary stage games, trigger strategies support all outcomes that Pareto dominate a Nash equilibrium of the stage game. To support any individually rational outcome in a perfect equilibrium, players may have to use “stick and carrot” strategies instead, which punish deviations only for a finite number of rounds, see Fudenberg and Maskin (1986).
For , the proof of Proposition 6 shows that ZD strategies require and (and hence and ). This allows us to conclude that the given parameter transformation is in fact bijective: the inverse is given by , , and .
Contributor Information
Christian Hilbe, Email: hilbe@fas.harvard.edu.
Arne Traulsen, Email: traulsen@evolbio.mpg.de.
Karl Sigmund, Email: karl.sigmund@univie.ac.at.
References
- Adami Christoph, Hintze Arend. Winning isn't everything: evolutionary stability of zero determinant strategies. Nat. Commun. 2013;4:2193. doi: 10.1038/ncomms3193. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Akin Ethan. The iterated prisoner's dilemma: good strategies and their dynamics. 2013. arXiv:1211.0969 Working paper.
- Aumann Robert J. Survey of repeated games. In: Henn R., Moeschlin O., editors. Essays in Game Theory and Mathematical Economics in Honor of Oskar Morgenstern. Wissenschaftsverlag; Mannheim: 1981. [Google Scholar]
- Aumann Robert J., Shapley Lloyd S. Long-term competition: a game-theoretic analysis. In: Meggido N., editor. Essays in Game Theory in Honor of Michael Maschler. Springer; New York: 1994. pp. 1–15. [Google Scholar]
- Axelrod Robert. Basic Books; New York: 1984. The Evolution of Cooperation. [Google Scholar]
- Ball Philip. Physicists suggest selfishness can pay. Nature. 2012 [Google Scholar]
- Barlo Mehmet, Carmona Guilherme, Sabourian Hamid. Repeated games with one-memory. J. Econ. Theory. 2009;144:312–336. [Google Scholar]
- Bergstrom Carl T., Lachmann Michael. The red king effect: when the slowest runner wins the coevolutionary race. Proc. Natl. Acad. Sci. USA. 2003;100:593–598. doi: 10.1073/pnas.0134966100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boerlijst Maarten C., Nowak Martin A., Sigmund Karl. Equal pay for all prisoners. Am. Math. Mon. 1997;104:303–307. [Google Scholar]
- Camerer Colin F. Princeton University Press; Princeton: 2003. Behavioral Game Theory. Experiments in Strategic Interactions. [Google Scholar]
- Colman Andrew M. Butterworth–Heinemann; Oxford: 1995. Game Theory and Its Applications in the Social and Biological Sciences. [Google Scholar]
- Dal Bó Pedro, Fréchette Guillaume R. The evolution of cooperation in infinitely repeated games: experimental evidence. Amer. Econ. Rev. 2011;101:411–429. [Google Scholar]
- Damore James, Gore Jeff. A slowly evolving host moves first in symbiotic interactions. Evolution. 2011;65:2391–2398. doi: 10.1111/j.1558-5646.2011.01299.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Duersch Peter, Oechssler Jörg, Schipper Burkhard C. Unbeatable imitation. Games Econ. Behav. 2012;76:88–96. [Google Scholar]
- Fehr Ernst, Fischbacher Urs. The nature of human altruism. Nature. 2003;425:785–791. doi: 10.1038/nature02043. [DOI] [PubMed] [Google Scholar]
- Friedman James W. A non-cooperative equilibrium for supergames. Rev. Econ. Stud. 1971;38:1–12. [Google Scholar]
- Fudenberg Drew, Maskin Eric. The folk theorem in repeated games with discounting or with incomplete information. Econometrica. 1986;50:533–554. [Google Scholar]
- Fudenberg Drew, Maskin Eric. Evolution and cooperation in noisy repeated games. Amer. Econ. Rev. 1990;80:274–279. [Google Scholar]
- Fudenberg Drew, Dreber Anna, Rand David G. Slow to anger and fast to forgive: cooperation in an uncertain world. Amer. Econ. Rev. 2012;102:720–749. [Google Scholar]
- Gokhale Chaitanya, Traulsen Arne. Mutualism and evolutionary multiplayer games: revisiting the Red King. Proc. - Royal Soc., Biol. Sci. 2012;279:4611–4616. doi: 10.1098/rspb.2012.1697. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hilbe Christian, Nowak Martin A., Sigmund Karl. The evolution of extortion in iterated prisoner's dilemma games. Proc. Natl. Acad. Sci. USA. 2013;110:6913–6918. doi: 10.1073/pnas.1214834110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hilbe Christian, Nowak Martin A., Traulsen Arne. Adaptive dynamics of extortion and compliance. PLoS ONE. 2013;8:e77886. doi: 10.1371/journal.pone.0077886. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hilbe Christian, Röhl Torsten, Milinski Manfred. Extortion subdues human players but is finally punished in the prisoner's dilemma. Nat. Commun. 2014;5:3976. doi: 10.1038/ncomms4976. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hilbe Christian, Wu Bin, Traulsen Arne, Nowak Martin A. Cooperation and control in multiplayer social dilemmas. Proc. Natl. Acad. Sci. USA. 2014;111:16425–16430. doi: 10.1073/pnas.1407887111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hofbauer Josef, Sigmund Karl. Cambridge University Press; Cambridge: 1998. Evolutionary Games and Population Dynamics. [Google Scholar]
- Kagel John H., Roth Alvin E. Princeton University Press; Princeton: 1997. The Handbook of Experimental Economics. [Google Scholar]
- Kalai Ehud. Bounded rationality and strategic complexity in repeated games. In: Ichiishi T., Neyman A., Tauman Y., editors. Game Theory and Applications. Academic Press; San Diego: 1990. pp. 131–157. [Google Scholar]
- Kalai Adam T., Kalai Ehud, Lehrer Ehud, Samet Dov. A commitment folk theorem. Games Econ. Behav. 2010;69:127–137. [Google Scholar]
- Mailath George J., Olszewski Wojciech. Folk theorems with bounded recall under (almost) perfect monitoring. Games Econ. Behav. 2011;71:174–192. [Google Scholar]
- Mailath George J., Samuelson Larry. Oxford University Press; Oxford: 2006. Repeated Games and Reputations. [Google Scholar]
- Milinski Manfred, Wedekind Claus. Working memory constrains human cooperation in the prisoner's dilemma. Proc. Natl. Acad. Sci. USA. 1998;95:13755–13758. doi: 10.1073/pnas.95.23.13755. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Myerson Roger B. Harvard University Press; Cambridge, MA: 1991. Game Theory: Analysis of Conflict. [Google Scholar]
- Nowak Martin A. Harvard University Press; Cambridge, MA: 2006. Evolutionary Dynamics. [Google Scholar]
- Nowak Martin A., Sigmund Karl. Invasion dynamics of the finitely repeated prisoner's dilemma. Games Econ. Behav. 1995;11:364–390. [Google Scholar]
- Nowak Martin, Sasaki Akira, Taylor Christine, Fudenberg Drew. Emergence of cooperation and evolutionary stability in finite populations. Nature. 2004;428:646–650. doi: 10.1038/nature02414. [DOI] [PubMed] [Google Scholar]
- Press William H., Dyson Freeman J. Iterated prisoner's dilemma contains strategies that dominate any evolutionary opponent. Proc. Natl. Acad. Sci. USA. 2012;109:10409–10413. doi: 10.1073/pnas.1206569109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rapoport Anatol, Chammah Albert M. University Michigan Press; Ann Arbor: 1965. The Prisoner's Dilemma. [Google Scholar]
- Roth Alvin E., Murnighan J. Keith. Equilibrium behavior and repeated play of the prisoner's dilemma. J. Math. Psychol. 1978;17:189–198. [Google Scholar]
- Samuelson Larry. MIT Press; Cambridge, MA: 1997. Evolutionary Games and Equilibrium Selection. [Google Scholar]
- Sandholm William H. MIT Press; Cambridge MA: 2010. Population Games and Evolutionary Dynamics. [Google Scholar]
- Sigmund Karl. Princeton University Press; Princeton: 2010. The Calculus of Selfishness. [Google Scholar]
- Stahl Dale O. The graph of prisoners' dilemma supergame payoffs as a function of the discount factor. Games Econ. Behav. 1991;3:368–384. [Google Scholar]
- Stewart Alexander J., Plotkin Joshua B. Extortion and cooperation in the prisoner's dilemma. Proc. Natl. Acad. Sci. USA. 2012;109:10134–10135. doi: 10.1073/pnas.1208087109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stewart Alexander J., Plotkin Joshua B. From extortion to generosity, evolution in the iterated prisoner's dilemma. Proc. Natl. Acad. Sci. USA. 2013;110:15348–15353. doi: 10.1073/pnas.1306246110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stewart Alexander J., Plotkin Joshua B. Collapse of cooperation in evolving games. Proc. Natl. Acad. Sci. USA. 2014;111:17558–17563. doi: 10.1073/pnas.1408618111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sugden Robert. Blackwell; Oxford: 1986. The Economics of Rights, Co-Operation and Welfare. [Google Scholar]
- Szolnoki Attila, Perc Matjaz. Evolution of extortion in structured populations. Phys. Rev. E. 2014;89:022804. doi: 10.1103/PhysRevE.89.022804. [DOI] [PubMed] [Google Scholar]
- Szolnoki Attila, Perc Matjaz. Defection and extortion as unexpected catalysts of unconditional cooperation in structured populations. Sci. Rep. 2014;4:5496. doi: 10.1038/srep05496. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Trivers Robert L. The evolution of reciprocal altruism. Q. Rev. Biol. 1971;46:35–57. [Google Scholar]
- Weibull Jorgen W. MIT Press; Cambridge, MA: 1995. Evolutionary Game Theory. [Google Scholar]
- Wu Zhi-Xi, Rong Zhihai. Boosting cooperation by involving extortion in spatial prisoner's dilemma games. Phys. Rev. E. 2014;90:062102. doi: 10.1103/PhysRevE.90.062102. [DOI] [PubMed] [Google Scholar]
- Yamagishi Toshio, Kanazawa Satoshi, Mashima Rie, Terai Shigeru. Separating trust from cooperation in a dynamic relationship: prisoner's dilemma with variable dependence. Ration. Soc. 2005;17:275–308. [Google Scholar]