

Abstract
A popular model of human sensorimotor learning suggests that a fast process and a slow process work in parallel to produce the canonical learning curve (Smith et al., 2006). Recent evidence supports the subdivision of sensorimotor learning into explicit and implicit processes that simultaneously subserve task performance (Taylor et al., 2014). We set out to test whether these two accounts of learning processes are homologous. Using a recently developed method to assay explicit and implicit learning directly in a sensorimotor task, along with a computational modeling analysis, we show that the fast process closely resembles explicit learning and the slow process approximates implicit learning. In addition, we provide evidence for a subdivision of the slow/implicit process into distinct manifestations of motor memory. We conclude that the two-state model of motor learning is a close approximation of sensorimotor learning, but it is unable to describe adequately the various implicit learning operations that forge the learning curve. Our results suggest that a wider net be cast in the search for the putative psychological mechanisms and neural substrates underlying the multiplicity of processes involved in motor learning.
Keywords: adaptation, cerebellum, explicit learning, motor control, motor learning, reaching
Introduction
Learning is rarely the result of a single process—it more often transpires by virtue of a chorus of distinct processes. Many studies have focused on dissociating various operations involved in learning and memory, such as model-based and model-free reinforcement learning (Daw et al., 2005; Gläscher et al., 2010), intentional and automatic forms of memory (Jacoby, 1991), and rule-based versus information-integration category learning (Ashby and Maddox, 2005). In fact, this multiple-process approach can be found in James' (1890) meditations on habit versus “volitional deliberation.”
A multiple-process framework also has appeared in the motor learning literature. In an influential demonstration, Smith et al. (2006) showed that there appear to be at least two processes with distinct timescales operating simultaneously while humans learn to counter a sensorimotor perturbation. Evidence for these processes was collected through an experimental design (Fig. 1A) in which participants first learned to counter a particular force field for a long period of time and then that force field reversed direction unexpectedly for a shorter period, after which they reached in a visually error-free “error-clamp” condition designed to probe motor memory without significantly altering it. Curiously, in the error-clamp condition, participants demonstrated spontaneous recovery of their memory of the first force field. Therefore, the memory of the first perturbation was not erased, but rather was masked by the second (Pekny et al., 2011). Smith et al. (2006) modeled two processes to explain this phenomenon: a “fast” process, which learns to reduce errors rapidly but also forgets rapidly, and a “slow” process, which learns to reduce errors slowly but forgets slowly (Fig. 1B).
Figure 1.
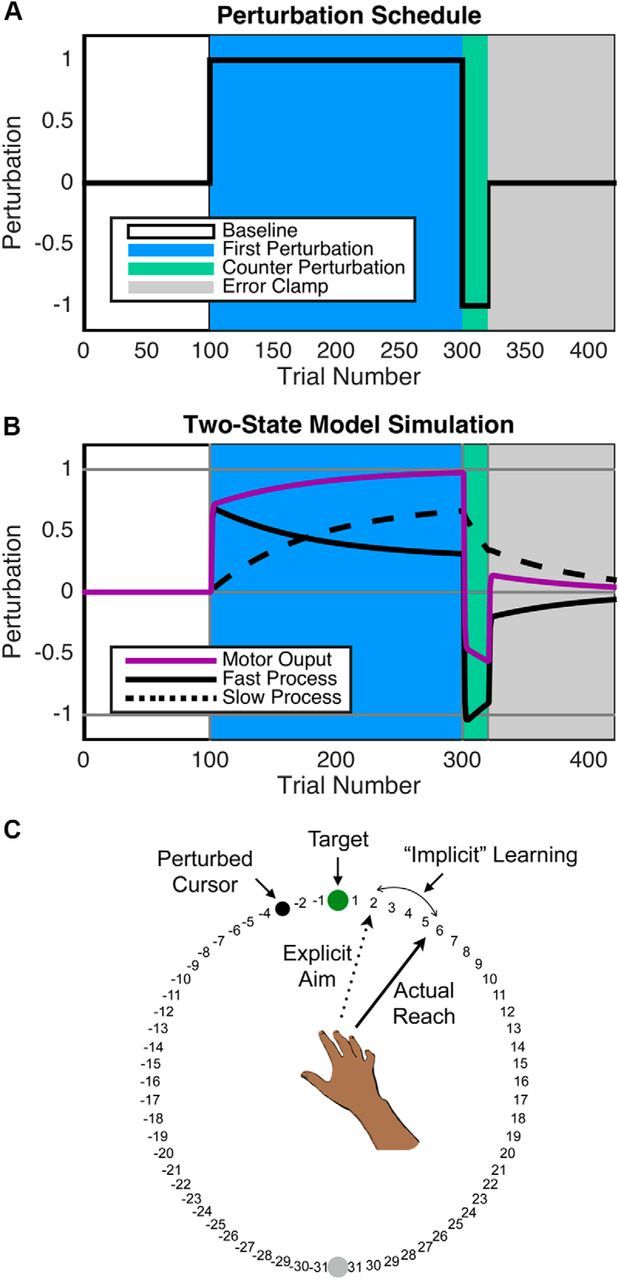
A, Perturbation schedule for all experiments, similar to Smith et al. (2006). Perturbations are normalized at 1/−1 for illustrative purposes. There were no perturbations in the baseline block (white), clockwise perturbations in the R1/F1 block (blue), counterclockwise perturbations in the R2/F2 block (green), and error clamp in the EC block (gray). B, Simulations of the two-state model of sensorimotor learning. Note that the fast process (solid black line) learns at a fast rate but has low retention and the slow process (dashed black line) learns at a slow rate but has high retention. Motor output was defined as the combination of the fast and slow process (purple line). C, Task display. In the Report conditions, participants verbally report, before each movement, where they planned to aim to make the cursor land on the target. In the Report condition of Experiment 1, the numbers are displayed in a 180° arc. In all experiments, participant's vision of their hand was occluded.
Although a number of studies have pointed to potential neural substrates corresponding to these processes (Smith et al., 2006; Galea et al., 2011; Choi et al., 2014; Yang and Lisberger, 2014), a mechanistic account of the psychological underpinnings of the fast and slow process remains elusive. Most accounts consider these processes to be facets of error-based adaptation, mapping onto forward and inverse models (Izawa et al., 2012) or environmental and body-based learning (Berniker and Kording, 2011).
Alternatively, our work suggests that explicit aiming strategies and implicit motor adaptation may underlie the fast and slow processes (Taylor et al., 2014). By having participants explicitly state an aiming direction toward visual landmarks during a visuomotor learning task (Fig. 1C), trial-by-trial shifts in aiming strategies can be measured. Subsequently, the direction of aim can be subtracted from participants' reach directions to quantify implicit learning. The time courses of explicit and implicit learning revealed by this methodology appeared to mirror the time courses of the fast and slow processes (Taylor et al., 2014).
We set out to confirm whether explicit and implicit learning correspond to the fast and slow processes. In Experiments 1 and 2, we tested this hypothesis in two common motor learning paradigms: force field learning and visuomotor rotations. In Experiments 3 and 4, we provide evidence for two separate, temporally insensitive facets of implicit sensorimotor learning.
Materials and Methods
Participants.
Ninety right-handed participants (mean age 21 years, range 18–33, 52 female) were recruited from the research participation pool maintained by the Department of Psychology at Princeton University in exchange for course credit. Handedness was verified using the Edinburgh handedness inventory (Oldfield, 1971). One participant was excluded for not complying with task instructions in Experiment 2. The protocol was approved by the Princeton University's Institutional Review Board and all participants provided informed consent.
Experimental apparatus and general procedures.
In Experiment 1, participants made center-out, horizontal reaching movements while holding onto the handle of a robotic manipulandum (KINARM; BKIN Technologies). Movement trajectories were sampled at 1000 Hz. At the beginning of each trial, the manipulandum guided the participant's hand to a starting position in the middle of the display. After maintaining this position for 250 ms, the participant was instructed to make a rapid horizontal reaching movement to land the cursor (3 mm radius, online feedback) inside a small circular target (5 mm radius; 10 cm from start point). If the cursor passed the invisible ring containing the target within 500 ms, the movement was deemed fast enough and the cursor turned red; otherwise, the cursor turned blue. If the center of the cursor landed within the target, the target filled in green; if not, the target remained empty.
In Experiments 2–4, participants made center-out, horizontal reaching movements to visually displayed targets (7 mm radius), moving their right hand across a digitizing tablet while holding onto a digitizing pen (Intuos Pro; Wacom). Movement trajectories were sampled at 100 Hz. The stimuli were displayed on a 17-inch LCD computer monitor (Dell) mounted horizontally 25 cm above the tablet. The monitor occluded vision of the hand and a small, circular cursor (3.5 mm radius) provided continuous online visual feedback during each reach. The task was controlled by custom software written in Python (http://www.python.org).
At the start of each trial, participants were required to position their hand in a central starting position with the aid of a visual ring, which represented the distance between the hand and the starting position. After maintaining this position for 1 s, a green visual target appeared. After leaving the starting position, the participant's hand had to cross an invisible ring that contained the target in 500 ms to avoid a “too slow” warning delivered aurally to the participant automatically by the game software. If the center of the cursor landed within the target, a pleasant “chime” sounded; otherwise, a “buzz” sounded. Participants in all experiments were told to make sure to reach within the time limit on each trial and to try to land the cursor in the target on every attempt.
Experiment 1.
Participants (n = 20) learned to counter a viscous force field (curl field) to hit a single target positioned at 90°, 10 cm in front of the start point. Participants were placed in one of two conditions: a Control condition (n = 10) and a Report condition (n = 10). The trial design in both conditions was identical (Fig. 1A). The first 100 trials were baseline trials in which cursor feedback was veridical. On trials 101–300 (F1 epoch), a clockwise force field perturbation was applied to the manipulandum. On trials 301–320 (F2 epoch), a counterclockwise force field was applied to the manipulandum. In trials 321–420 (EC epoch), a physical error clamp was introduced, guiding participants' reaches to the target. In addition, a randomly chosen 10% of trials in the baseline and F1 epochs were error-clamp trials, matching similar conditions in Smith et al. (2006) except that we also included a single error-clamp trial in the F2 epoch.
During force field trials, the motors of the robotic manipulandum applied a force (f) to the hand. The strength of these forces was proportional to the velocity (V) of hand motion and force direction was perpendicular to hand motion as follows:
Where M is a force matrix applied to velocity vector V. In the first force epoch (F1, trials 101–300), the force field pushed the hand in a clockwise direction. In the second force epoch (F2, trials 301–320), the matrix M was multiplied by −1, producing a counterclockwise perturbation. During the error-clamp trials, a force channel was applied to the hand via a simulated spring (6 kN/m) and damper (20 N/s/m) perpendicular to the target direction, guiding the participant's hand to the target and limiting deviations from a straight path to the target (mean reach endpoint deviation from target during error-clamp trials = 0.22° ± 0.13°).
The task instructions in the Report condition were similar to that of Taylor et al. (2014). For the first 320 trials, the target was flanked by a 180° arc of numbered visual landmarks spaced 4.25° apart. Starting at trial 91 of the baseline epoch, participants were instructed to report verbally before each reach the landmark that they planned to push the manipulandum toward to make the cursor hit the target. The experimenter manually recorded the reported aiming directions and we refer to these data as explicit learning. The basic experimental procedure was identical in the Control condition, but landmarks were not present and no reporting was required.
Experiment 2.
A recent method from our laboratory has shown that, in visuomotor rotation tasks, explicit and implicit components of sensorimotor learning can be isolated (Taylor et al., 2014). Therefore, we designed an experiment with the same trial structure as Experiment 1, but used visuomotor rotations rather than force fields. Participants were placed in either a Control condition (n = 9, one participant excluded) or a Report condition (n = 10) and reached toward a single target located at 0°. The trial design in all conditions was identical (Fig. 1A). The first 100 trials were baseline trials in which cursor feedback was veridical. On trials 101–300 (R1 epoch), the cursor was rotated by 45° in the clockwise direction. On trials 301–320 (R2 epoch), the cursor was rotated by 45° in the counterclockwise direction. In trials 321–420 (EC epoch), a visual error clamp was placed on the cursor, making it move straight to the target regardless of the participant's hand trajectory orthogonal to the target. The instructions and visual display in the Report condition only differed from Experiment 1 in that the spacing constant between the visual landmarks was larger (5.625°) and the numbers were arranged in a 360° ring rather than a 180° arc (Fig. 1C). In contrast to Experiment 1, in this rotation task, participant's hand position and reported aiming direction were in comparable units; therefore, we could quantify implicit learning by subtracting the explicit component from participant's movement directions on each trial (Taylor et al., 2014; see “Movement analysis” section).
In all conditions, after the end of the second rotation epoch (trial 320), participants were told to stop using any potential aiming strategy that they had developed and reach directly for the green target for the remainder of the session (EC epoch). This allowed us to measure the size of aftereffects without an added aiming strategy, which conflate the size of aftereffects (Taylor et al., 2014).
Experiment 3.
It has been suggested that the amount of sensorimotor adaptation that occurs for movements to specific regions of space is sensitive to the time elapsed between consecutive movements (Brennan et al., 2012; Hadjiosif and Smith, 2013). In this experiment, we manipulated the duration of an experimentally forced intertrial interval (ITI) to test this theory. Participants were placed in one of three conditions: 0 s forced ITI (n = 10), 15 s forced ITI (n = 10), and 30 s forced ITI (n = 10). After each trial, the screen turned black and subjects waited for a fixed number of seconds (based on condition) before they were prompted to find the start point and begin the next trial.
The trial design in all conditions was identical and only a single target direction was used. However, to avoid unreasonably long sessions due to the added delays, the number of trials was reduced relative to Experiments 1 and 2, but the ratio of the number of trials in the two rotation blocks was maintained. The first 15 trials were baseline trials. On trials 16–115 (R1 epoch), the cursor was rotated by 45° in the clockwise direction. On trials 116–125 (R2 epoch), the cursor was rotated by 45° in the counterclockwise direction. Trials 126–145 were error-clamp trials (EC epoch). The instructions and visual display in this experiment were identical to that of the Report conditions of Experiment 2. Note that, because the forced ITIs differed between conditions, the total duration of the experiments differed between the 0, 15, and 30 s ITI conditions and were ∼15, 50, and 90 m, respectively.
Experiment 4.
Findings from Experiments 2 and 3 inspired a hypothesis that our measured implicit learning curve is composed of an additional process that is relatively time insensitive. This additional implicit process may be akin to an operant, use-dependent process that is driven by repeated movements to one area of space (Huang et al., 2011; Verstynen and Sabes, 2011). To test this idea, participants were exposed to several different target locations instead of a single location. Participants were equally divided between two conditions: a Full workspace condition (n = 10) and a Partial workspace condition (n = 10). In the Full condition, the target could appear at one of eight locations separated by 45° along an invisible ring with a radius of 7 cm (0°, 45°, 90°, 135°, 180°, −135°, −90°, and −45°). In the Partial condition, the target locations were restricted to 1/4 of the circular workspace along an invisible wedge centered at 0° (−45°, −32.1°, −19.3°, −6.4°, 6.4°, 19.3°, 32.1°, 45°). Importantly, both conditions had the same number of targets and only differed in the breadth of training across the workspace. In both conditions, the sequences of target locations were pseudorandomly presented within each epoch such that, in each “cycle” of eight trials, all eight targets were seen exactly once before being repeated. Each participant received a different randomized sequence of target locations. The pseudorandomized sequences were truncated at their ends in the three epochs with lengths that were not multiples of eight (baseline, R2, EC). The procedure was otherwise identical to that used in the Report condition of Experiment 2.
Movement analysis.
Kinematic and statistical analyses were performed using customized scripts in MATLAB (The MathWorks) and R (R Foundation for Statistical Computing). For Experiment 1, we focused on the lateral force produced by the hand during error clamp trials, which were interspersed throughout all the epochs of the task, since the error clamp minimizes inertial and reactionary forces. Lateral force was measured by the robot's force sensor throughout the movement. To quantity the degree of learning during the error clamp trials, we computed an adaptation index defined by regressing the lateral force profile produced by the hand (while hand speed exceeded 2.5 cm/s) onto the ideal force profile which would be required to move in a straight line during force field trials (see Smith et al., 2006 for details). An additional metric, hand heading angle, was measured by taking the angle of the hand midway through the movement (5 cm). Reaction time was calculated by measuring the time elapsed between the appearance of the target and the point at which the hand was moving at least 5 cm/s. For the error-clamp trials mentioned above, we analyzed participants' force trajectory profiles by plotting both the mean lateral force produced by participants for the first 6 cm of their movement, as well as the mean ideal velocity-dependent lateral force needed to counteract the force field for those same movements. The full movement was not used because marked between-subject differences in velocity during the second half of reaches adds noise to the calculation of full ideal force profiles.
To assess task performance in Experiments 2–4, we focused on the intermediate heading angle of the hand rather than final cursor locations to limit the role of corrective movements in our measure of learning. The average heading angle was computed as the angle midway along the trajectory (3.5 cm). All reach trajectories in the two eight-target conditions (Experiment 4) were rotated to a common axis with a target location of 0°. Reaction time was calculated by measuring the time elapsed between the appearance of the target and the point at which the hand was 1 cm from the starting region. To visualize movement trajectories in all experiments, we plotted the mean reach trajectory over the last two error-clamp trials in the baseline, the first two in R1/F1, the last two in R1/F1, the single error clamp in R2/F2, and the first two in EC.
For primary statistical analyses in Experiment 1, we focused on the adaptation index and lateral force during four different epochs of the session as follows: F1 early (first error clamp trial), F1 late (last error clamp), F2 (single error clamp), and EC (average of the first five trials of the EC epoch). For Experiments 2–4, we focused on the same epochs, but binned the heading angle for each participant as follows: R1 early (the first five trials of R1), R1 late (the last five trials of R1), R2 (the last five trials of R2), and EC (the first five trials of the EC epoch). For aiming data, the EC epoch was not analyzed in Experiments 2–4 because participants were instructed to aim directly at the target during that epoch and ceased reporting. Further, in our analysis of aiming data, the R1/F1 early epoch started one trial after the first report because participants were abruptly presented with the perturbations and were thus not using any aiming strategy on the initial trial.
For all reported and depicted values, we report the mean and SEM. For statistical analyses that require pairwise multiple comparisons, we used the Bonferroni correction.
Model simulations and fitting.
In the standard state-space model of motor learning, the output (x) of the motor system is updated at each time point (t) according to a learning rule:
Where e is the error experienced at time t involving perturbation p, A is the retention factor of the previous state, and B is the learning rate.
Smith et al. (2006) outlined a “fast” process (F, Eq. 5) that allows for the rapid learning of each perturbation and a “slow” process (S, Eq. 6) that has not fully unlearned the first perturbation at the time of the error clamp. The two processes are combined to produce the final output x (Eq. 7). This two-state model postulates separate retention factors and learning rates for each process as follows:
Where AF < AS and BF > BS.
We simulated the output of the two-state model of motor learning described in Equations 5–7 with manually adjusted parameter values approximately corresponding to simulations performed in Smith et al. (2006) (Fig. 1B). Perturbations used in the error term (Eq. 3) were normalized values (−1/1). All updating of motor output (x) was clamped at zero in the EC epoch for all simulations.
For model fitting, we fit the two-state model to both the adaptation index and lateral force during error clamps for both the Report and Control conditions of Experiment 1. For Experiment 2, we fit the heading angles in both the Report and Control conditions. For the Report condition of Experiment 2 and all groups in Experiment 4, the outputs of the fast and slow processes were fit to the time series of explicit and implicit learning, respectively. For Experiment 4, the state x was assumed to be independent of target location.
The model was fit to minimize the rms between the model simulation and participant data using the fmincon function in MATLAB. For model fitting, the model was constrained such that AF < AS, and BF > BS (Smith et al., 2006) and, in Experiment 1, AS was constrained to be > 0.9. The stability of the model fits and the sensitivity of the initial conditions were tested using a grid search over different starting parameter values. We found that the model fits were consistently highly stable within our constraints. rms and correlation coefficients for all model fits are presented in Table 1.
Table 1.
Mean fit parameter values for the retention factors of the fast (AF) and slow (AS) processes and the learning rates of the fast (BF) and slow (BS) processes
| AF | AS | BF | BS | rms | R | |
|---|---|---|---|---|---|---|
| Experiment 1 (Control) | 0.52 ± 0.22 | 0.97 ± 0.02 | 0.22 ± 0.14 | 0.03 ± 0.02 | 0.11 ± 0.03 | 0.79 ± 0.14 |
| Experiment 1 (Report) | 0.56 ± 0.19 | 0.98 ± 0.01 | 0.38 ± 0.14 | 0.02 ± 0.02 | 0.14 ± 0.03 | 0.88 ± 0.02 |
| Experiment 2 (Control) | 0.85 ± 0.08 | 0.99 ± 0.00 | 0.44 ± 0.06 | 0.05 ± 0.02 | 8.85 ± 1.75 | 0.92 ± 0.04 |
| Experiment 2 (Report) | 0.83 ± 0.10 | 0.98 ± 0.04 | 0.61 ± 0.14 | 0.10 ± 0.10 | 11.07 ± 2.28 | 0.91 ± 0.03 |
| Experiment 4 (Full) | 0.96 ± 0.01 | 1.00 ± 0.00 | 0.53 ± 0.18 | 0.02 ± 0.01 | 11.01 ± 1.20 | 0.88 ± 0.06 |
| Experiment 4 (Partial) | 0.84 ± 0.12 | 0.98 ± 0.05 | 0.39 ± 0.10 | 0.09 ± 0.07 | 15.71 ± 2.65 | 0.80 ± 0.07 |
Quality of model fits are also shown, quantified by rms and the correlation coefficient R. See Materials and Methods for model details and fitting procedures. Averages of fit parameter values, rms of fits, and correlation coefficients of fits with 95% confidence interval.
Results
Experiment 1
Participants in Experiment 1 performed a force field learning task and were divided into a Report and Control condition. The average of participants' median reaction times over the experiment differed significantly between the Control (305 ± 23 ms) and Report (606 ± 90 ms) conditions (t(18) = 3.25, p < 0.005), as predicted. This difference was expected because participants in the Report condition were required to pause and state an aiming direction before moving on the majority of trials. Both groups performed similarly in the task and there was no significant difference in heading angle during the baseline epoch (t(18) = 0.25, p = 0.81). To measure task performance, we conducted a mixed factorial ANOVA on participants' mean hand heading angles only on the early and late first force epoch (F1) and the second force epoch (F2) because reaching path deviations were clamped near zero for the EC epoch. We found no significant main effect of condition (F(1,18) = 0.48, p = 0.50), a significant effect of trial epoch (F(2,37) = 27.85, p < 0.001), and no significant interaction (F(1,9) = 0.46, p = 0.64).
To get a more detailed measure of learning, we focused on the adaptation index between the two conditions (Fig. 2A). After observing the relatively long interval that it took for error-clamp rebound to occur in both conditions (Fig. 2A), we added, a posteriori, an additional time point consisting of the last five EC trials (EC late). We found no significant main effect of condition (F(1,18) = 0.68, p = 0.42), a significant effect of trial epoch (F(4,35) = 29.90, p < 0.001), and no significant interaction (F(4,18) = 0.81, p = 0.52). Rebound in the EC epoch did not show any clear decay back to zero and remained elevated relative to the baseline epoch. We also examined the pure lateral force midway through the movement (5 cm) in the error clamp trials over the same epochs and we found no significant main effect of condition (F(1,18) = 2.29, p = 0.15), a significant effect of trial epoch (F(4,35) = 25.68, p < 0.001), and no significant interaction (F(4,18) = 0.19, p = 0.94). Last, force trajectories in error clamp trials (Fig. 2C,D) showed that, whereas learning progressed in a similar fashion between groups, overall force magnitude appeared to be slightly larger in the Report group (Fig. 2D) compared with the Control group (Fig. 2C). We suspect that aim reporting encouraged the Report group to apply a wider range of forces to the robot than the Control group, but this difference did not affect the overall shape of the learning curve (Fig. 2A).
Figure 2.

Experiment 1 behavioral results. A, Adaptation index for the error clamp trials. Note that participants rapidly flip the sign of their applied force during F2 and show rebound of forces appropriate for F1 during the EC epochs. B, Participants in the Report condition report aiming directions that are appropriate to the applied forces in both the F1 and F2 epochs and quickly decay to 0° of aiming in the EC epoch. C, D, Averaged participant force profiles (blue) and ideal force profiles (red) for both the Control (C) and Report (D) conditions during selected error-clamp trials throughout the blocks of the task. The ideal force profile for a trial was computed by taking the participant's reach velocity at each time point and calculating the ideal force needed to counter perfectly the perturbation given that velocity. Shading represents SEM.
All participants in the Report condition aimed to locations other than the target during F1, F2, and the earliest portion of the EC epoch (Fig. 2B). We performed a repeated-measures ANOVA on five epochs of aiming data—early and late F1, late F2, and early and late EC. There was a main effect of trial epoch on aiming angle (F(4,36) = 10.38, p < 0.001) and post hoc t tests (Bonferroni-corrected) revealed significant differences between F1 early and F2 (p < 0.001), F1 early and EC early (p < 0.01), F1 late and F2 (p < 0.001), F1 late and EC early (p < 0.001), and F2 and EC late (p < 0.001). The average aiming time course (Fig. 2B) displays clear rapid early learning and a rapid flip in sign during the counter perturbation, suggesting that an explicit aiming process is at play during force field learning. Further, the rapid decay in aiming during early EC seen in this group approximately matches the decay of the simulated fast process shown in Figure 1B; in a force field learning task, participants appeared to stop aiming to locations other than the target rapidly when errors were removed (Fig. 2B).
In a previous study (Taylor et al., 2014), we quantified implicit learning by subtracting the reported aiming angle from the movement heading angle for each trial. Here, we could not conduct an assay of implicit learning because a subtraction measurement is abstruse: participants were not reporting where they planned to pass their hand through the target ring as they do in visuomotor rotation tasks; rather, they were asked to report where they thought they needed to push the robotic manipulandum to get their cursor on target. Critically, in the force field task, the hand must actually pass through the target position for task success on all trials, unlike in a rotation experiment, in which the cursor and hand are separated by an applied perturbation. Therefore, a subtraction to infer implicit learning is unreasonable because explicit learning and force are not along the same dimension. We will address this issue directly in Experiment 2, which is better suited to assay both explicit and implicit learning. Although our explicit metric could not be used in a subtraction, our results nonetheless show that participants are likely using some form of explicit strategy when counteracting a force (Fig. 2B).
Finally, we fit the adaptation index from the Control and Report conditions with the two-state model. The model fits were similar for both groups, capturing the rapid learning in R1, the sign change in force during R2, and the aftereffect in EC (Fig. 3). Note that the decay of the fast process in the model fit for the Report condition is similar to the decay of that group's reported aiming angles during the early portion of the EC epoch (Figs. 3B, 2B). There were no significant between-group differences in fitted parameter values for any of the four parameters (Table 1). Additionally, we also modeled the pure lateral force in the error clamp trials and found no group differences in parameter values.
Figure 3.
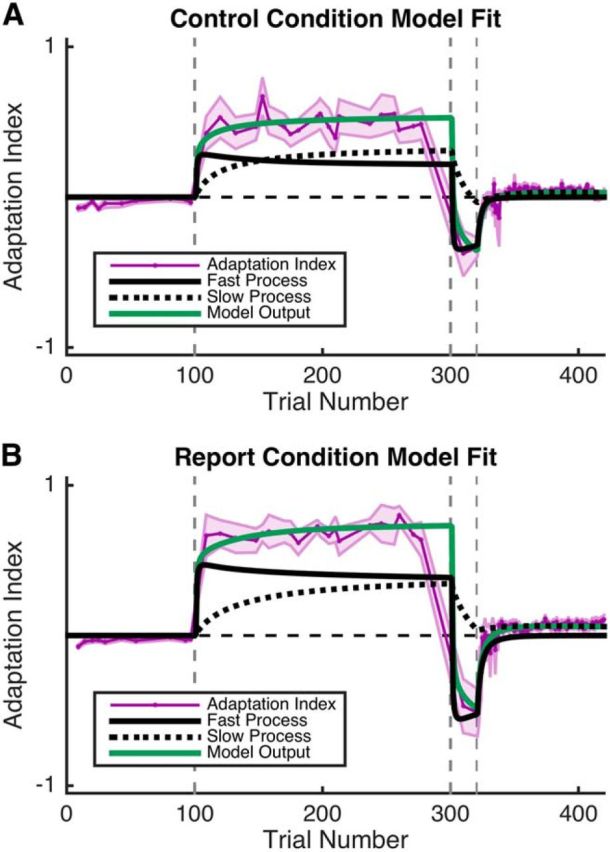
Experiment 1 model fitting. The two-state model was fit to each participant in both the Control (A) and Report (B) conditions. The output of the model (green line) was fit to each participant's adaptation index data (purple). Also depicted are the fast (solid black line) and slow (dashed black line) processes implied by the fits. Shading represents SEM.
Experiment 2
To quantify both explicit and implicit learning (Taylor et al., 2014), we conducted an experiment analogous to Experiment 1 using visuomotor rotations instead of force fields. Similar to Experiment 1, the mean of participants' median reaction times over the experiment differed significantly between the Control (332 ± 42 ms) and Report (590 ± 55 ms) conditions (t(17) = 3.66, p < 0.005), which can be attributed to the procedure of reporting the intended aiming location.
We first performed a direct comparison of baseline heading angle between the Report and Control conditions by comparing participants' mean heading angle over the last five trials of the baseline epoch. The conditions were not significantly different (t(17) = 1.05, p = 0.31).
Participants in both the Report and Control conditions learned to counter the rotation in the R1 epoch and the opposing rotation in the R2 epoch and showed a strong spontaneous recovery of the memory for the R1 epoch in the EC epoch (Fig. 4A). This general learning time course was echoed in participants' reach trajectories in the error-clamp trials dispersed throughout the task, both during learning and during the EC epoch (Fig. 4B). Participants' hand trajectories in these interspersed error-clamp trials were in the direction appropriate for countering the clockwise R1 rotation (Fig. 4B, blue), flipped to counter the counterclockwise R2 rotation (Fig. 4B, magenta), and, finally, in the EC epoch, rebounded back to the direction first used to counter the R1 rotation (Fig. 4B, red dashed line).
Figure 4.
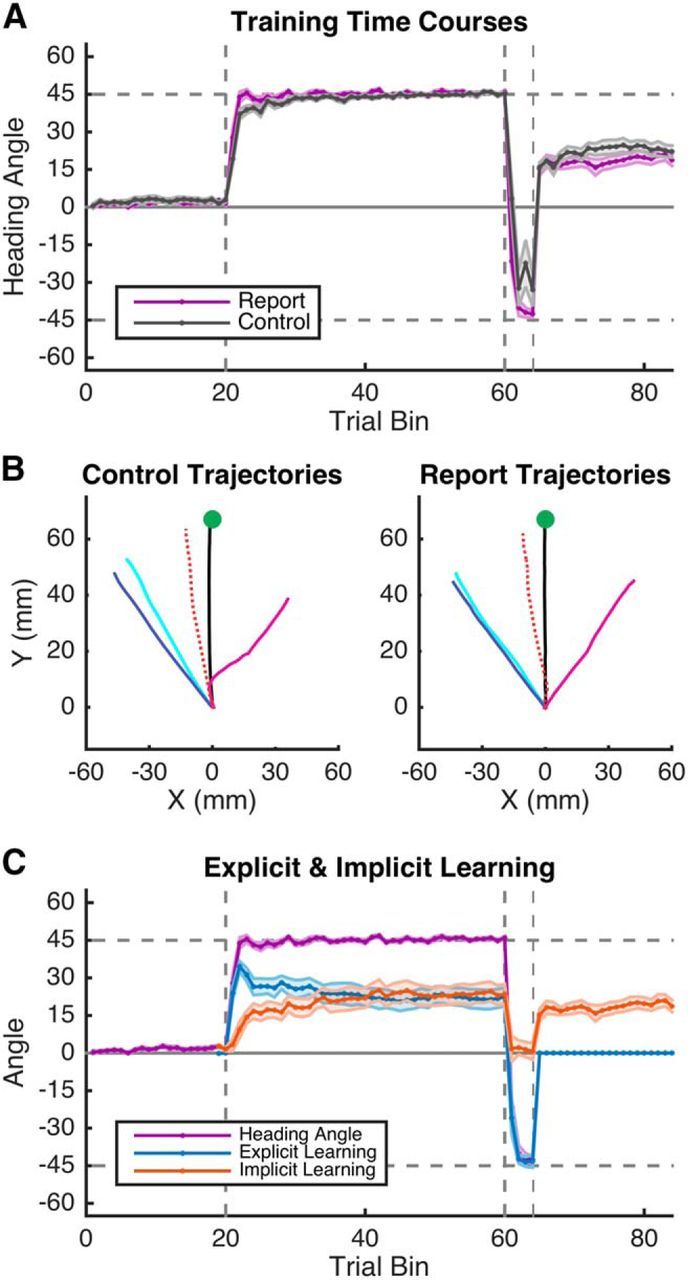
Experiment 2 behavioral results. A, Averaged hand heading angles for both groups binned by five trials. Participants in both the Report (purple) and Control (black) conditions learn the first 45° clockwise rotation (R1), then the 45° counterclockwise rotation (R2), and subsequently show rebound back to the first rotation during the error-clamp block (EC). B, Reach trajectories during interspersed error clamps. Participants in both conditions show accurate baseline performance (BL, black), robust early R1 learning (ER1, cyan), late R1 learning (LR1, blue), R2 learning (R2, magenta), and early EC epoch rebound (EC, red dashed). C, Explicit aiming and implicit learning in the Report condition. Participants showed both explicit (blue) and implicit (red) learning components of measured heading angles (purple). Implicit learning is estimated through a subtraction of aiming direction from heading angle. Participants are instructed to aim directly to the target for the EC epoch. Note that heading angle (purple) and implicit learning (red) are equivalent in the EC epoch. Shading represents SEM.
To evaluate learning, we performed a mixed factorial ANOVA with two factors, condition and trial epoch, with trial epoch treated as a repeated measure. The epochs analyzed consisted of four five-trial bins: R1 early (the first five trials of R1), R1 late (the last five trials of R1), R2 (the last five trials of R2), and EC (the first five trials of the EC epoch). There was no significant main effect of condition (F(1,17) = 0.17, p = 0.90), a significant effect of trial epoch (F(3,36) = 254.93, p < 0.001), and a marginally significant interaction (F(1,9) = 2.83, p = 0.05). Post hoc tests suggest that this interaction was largely driven by a marginally (uncorrected) significant difference in R1 learning between the two groups (t(17) = 1.05, p = 0.08). Note that participants in both conditions showed rapid learning of the second rotation and, at the start of the EC epoch, showed comparable and immediate rebound back to the heading angle that they used to counter the first rotation (Fig. 4A,B). Although there were qualitative group differences in early R1 learning and reaction time, the overall effect of instruction was relatively small, which was also observed in our previous experiment (Taylor et al., 2014).
Participants in the Report condition aimed to locations other than the target throughout the majority of the R1 and R2 epochs (Fig. 4C, blue). During the R1 epoch, the aiming locations followed a nonmonotonic time course, rising quickly during the early stages of learning and falling slowly over continued training. When the counter rotation was imposed in the R2 epoch, the aiming direction abruptly changed sign and appeared to account for nearly all of the learning associated with the counter rotation. This aiming behavior was assessed by performing a repeated-measures ANOVA on three epochs of aiming data—R1 early, R1 late, and R2 late. There was a main effect of epoch on aiming angle (F(2,27) = 160.8, p < 0.001) and post hoc t tests (Bonferroni-corrected) revealed significant differences between R1 early and R2 (p < 0.001) and R1 late and R2 (p < 0.001), but not R1 early and R1 late (p = 0.19). Therefore, explicit learning was significantly different between the R1 and R2 epochs, but the change during the R1 epoch was not statistically reliable.
We quantified implicit learning in the Report condition by subtracting the reported aiming angle from the movement heading angle on each trial. As shown in Figure 4C, implicit learning proceeds in an exponential-like fashion in the R1 epoch, sharply descends in the R2 epoch, and rebounds in the EC epoch. We assessed this pattern by performing a repeated-measures ANOVA on four epochs of implicit learning: R1 early, R1 late, R2 late, and EC early. There was a significant main effect of trial epoch on implicit learning (F(3,36) = 10.13, p < 0.001) and post hoc t tests revealed significant differences between R1 early and R1 late (p < 0.01), R1 late and R2 (p < 0.001), and R2 and EC (p < 0.05), but not R1 early and EC (p = 0.13), or R1 late and EC (p = 0.74). Overall, implicit learning increased during the first rotation, significantly reversed direction during the second rotation, and rebounded to a value equivalent to the late period of the first rotation when the error clamp was introduced (Fig. 4C, red).
To determine how well the time courses of explicit and implicit learning matched the time courses of the fast and slow processes, we fit the two-state model (Smith et al., 2006) to each participant in the Control and Report conditions. Crucially, we compared the conditions by fitting the models to different sources of participant data. For the Control condition, we fit the total motor output of the model to participant's actual motor output (heading angle) and, for the Report condition, we fit the individual fast and slow processes to, respectively, participant's explicit and implicit learning data. For participants in the Control condition, the two-state model provides a good fit to the time series of heading angles during all phases of the experiment (Fig. 5A). In particular, it predicts a nonmonotonic fast process, which increases abruptly then drops gradually, and a monotonically increasing slow process during the R1 epoch. It also predicts the rapid flip in motor output during the R2 epoch and approximates the rebound during the EC epoch.
Figure 5.
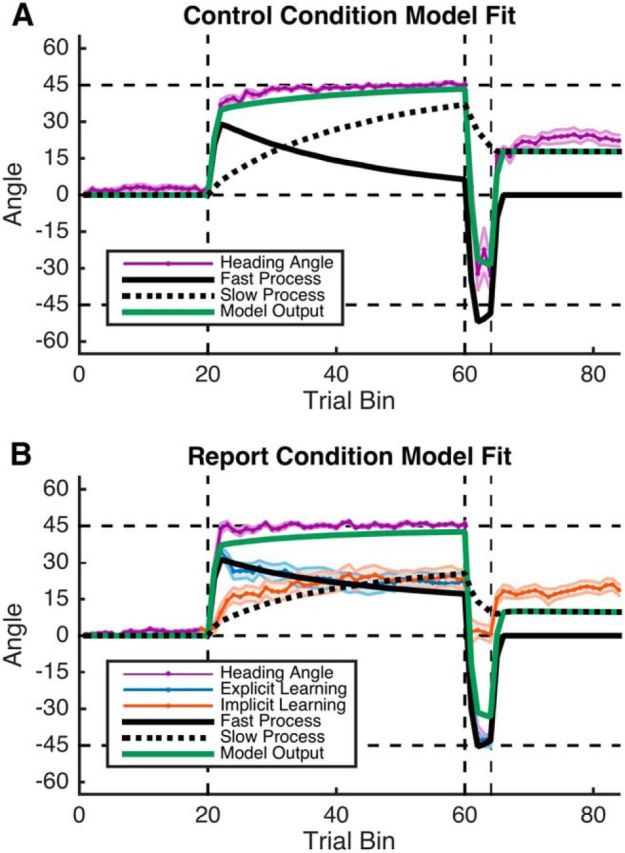
Experiment 2 model fitting. The two-state model (see Materials and Methods) was fit to both conditions. A, In the Control condition, the total model output (green line) was fit to participant's mean heading angle data (purple). Implied fast (solid black line) and slow processes (dashed black line) of the model fit are also depicted. B, In the Report condition, the fast and slow processes of the model were fit individually to each participant's respective explicit (blue) and implicit (red) learning data. Here, the model captures R1 behavior but fails to capture all implicit learning in the R2 epoch and undershoots the rebound in the EC epoch. Shading represents SEM.
For the Report group, the shape of the fast and slow processes of the model produced good fits to the explicit and implicit data (Fig. 5B). The fast process of the two-state model fits the time course of explicit learning remarkably well throughout the R1 and R2 epoch before being clamped at zero in the EC epoch. Although the slow process fits the time course of implicit learning throughout the R1 epoch, it underestimates the decrease in implicit learning observed during the R2 epoch and underestimates the large rebound during the EC epoch.
To justify using different fitting procedures for the Control versus Report condition, we compared both the rms and correlation coefficients produced by fitting the Report condition using either the heading angle data alone or both the explicit and implicit learning data, as reported above. We found no significant differences between the two fitting procedures in either the rms (t(18) = 1.18, p = 0.26) or the correlation coefficients (t(18) = 0.74, p = 0.47).
We performed t tests on the fitted values of the four parameters, AF, AS, BF, and BS. There were no statistically reliable group differences in the four parameters, although there was a marginally significant difference in the learning rates of the fast process BF (t(17) = 1.81, p = 0.09). This result was expected, given that the qualitative difference found in early R1 learning between the conditions is better explained by the rate of the fast process, not the slow process. This suggests that the subtle effect of aim reporting (Taylor et al., 2014) relates to the explicit/fast process, not implicit adaptation. Aside from noticeable differences in the fast process, there is also a qualitative difference between the two fits (Fig. 5A,B) in terms of the slow process. The fit in the Control condition (Fig. 5A) implies a more robust slow process than the fit in the Report condition (Fig. 5B). Although a diminished slow process in the Report condition would be expected given a possible boost to the fast process brought about by the aiming task (according to the model, the two processes interact), it should be noted that the fast and slow processes in the Control condition model fit (Fig. 5A) are only implied and thus offer an imperfect comparison to the Report condition fits.
Although the two-state model does a suitable job of fitting the explicit and implicit components of learning, the fit to the implicit learning trace is imprecise during the R2 and EC epochs due to discontinuities in the observed behavior—EC rebound is not continuous with R2 implicit learning and is larger than the slow process predicts. This led us to hypothesize that implicit learning itself has distinct components.
It has been suggested that the amount of time elapsed between movements to specific locations modulates the amount of sensorimotor adaptation that occurs in the motor system (Brennan et al., 2012; Hadjiosif and Smith, 2013). Furthermore, this hypothesis suggests that implicit adaptation is itself multifaceted, with a component that is temporally sensitive and another that is temporally stable (Brennan et al., 2012; Hadjiosif and Smith, 2013). The amount of adaptation accounted for by the temporally sensitive component peaks at 0 s of intertrial time and decays exponentially until ∼40 s (Hadjiosif and Smith, 2013). If the discontinuities seen in the implicit adaptation curve of our single-target condition could be explained within this framework, then the flexible implicit learning in the counter perturbation phase may represent the contribution of a temporally sensitive component of adaptation and the large rebound in the error-clamp phase may reflect an unmasking of a pure temporally stable component. In Experiment 3, we tested this hypothesis systematically by manipulating the ITI directly in three separate single-target reporting conditions.
Experiment 3
We hypothesized that the time elapsed between reaches to unique locations could affect the time course of implicit learning (Fig. 4C, red). To test this, we titrated the duration of a forced ITI over three separate conditions: 0, 15, and 30 s ITI. Recent work has suggested that, with an ∼35 s ITI, the temporally sensitive component of adaptation is essentially abolished and only a temporally stable component remains (Hadjiosif and Smith, 2013). Including reaction time and reporting time, the mean ITIs for each condition were 5.83 ± 0.32, 20.43 ± 0.42, and 37.15 ± 0.27 s, respectively.
We conducted three separate mixed factorial ANOVAs with two factors, condition and trial epoch, on participants' heading angles, explicit learning, and implicit learning. The epochs analyzed consisted of four five-trial bins: R1 early (the first five trials of R1), R1 late (the last five trials of R1), R2 (the last five trials of R2), and EC (the first five trials of the EC epoch). Note that the number of trials (145 trials) was ∼1/3 of the number used in Experiments 1 and 2 (420 trials).
For heading angle, there was no significant main effect of condition (F(1,28) = 2.88, p = 0.10), a significant effect of trial epoch (F(3,84) = 16.36, p < 0.001), and no significant interaction (F(1,9) = 0.44, p = 0.72). For explicit learning, there was no significant main effect of condition (F(1,28) = 1.08, p = 0.31), a significant effect of trial epoch (F(2,56) = 109.3, p < 0.001), and no significant interaction (F(1,9) = 0.11, p = 0.90). Last, for implicit learning, there was no significant main effect of condition (F(1,28) = 0.11, p = 0.74), a significant effect of trial epoch (F(3,84) = 16.36, p < 0.001), and no significant interaction (F(1,9) = 0.74, p = 0.53). As shown in Figure 6, explicit (Fig. 6B) and implicit (Fig. 6C) learning across the three conditions were strikingly similar.
Figure 6.
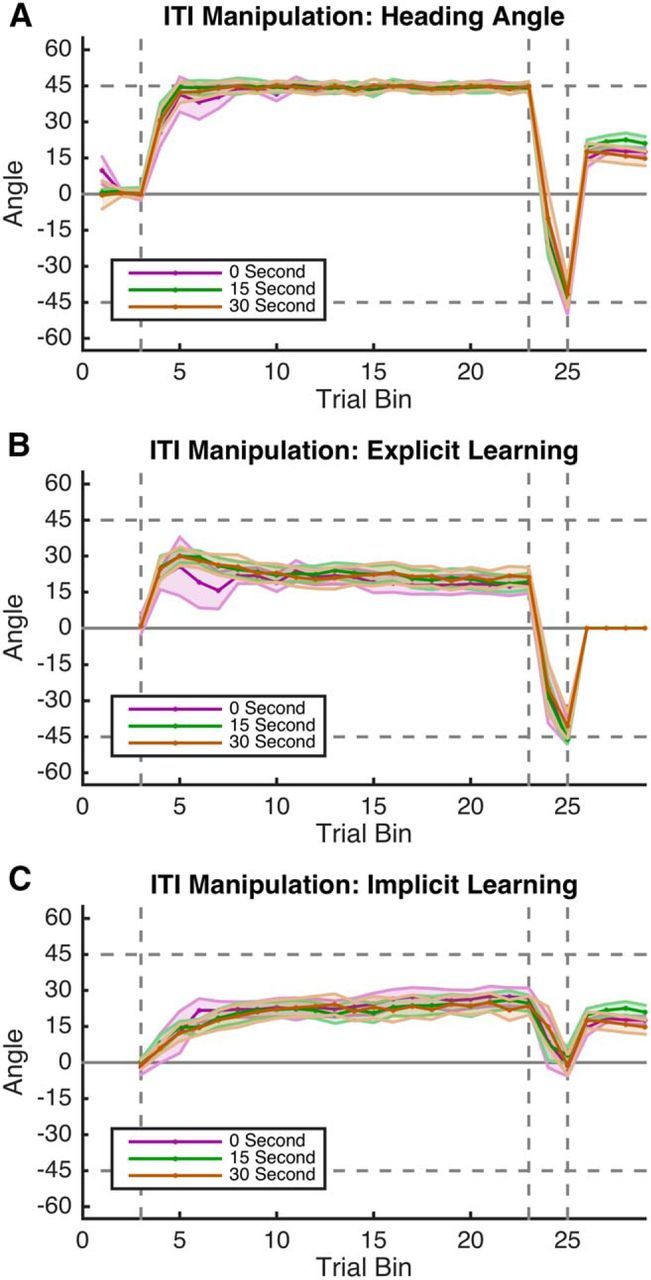
Experiment 3 behavior. A, Averaged hand heading angles, B, C, Explicit aiming (blue; B) and implicit learning (red; C) for the three conditions of Experiment 3. All three ITI conditions show remarkably similar learning. Shading represents SEM.
Our results indicate that the amount of time elapsed between consecutive movements to specific regions of space had no appreciable effect on implicit learning. Therefore, we believe that the stark discontinuities observed between the end of the R2 block and the EC rebound (Figs. 4C, 6C) reflect contributions from a third process of motor learning that is implicit, but distinct from the monotonic, trial-by-trial learning predicted by the slow process of the two-state model.
Experiment 4
Recent work in sensorimotor learning has revealed implicit learning processes distinct from adaptation, such as reinforcement learning (Huang et al., 2011; Galea et al., 2015; Nikooyan and Ahmed, 2015), hand-path priming (Jax and Rosenbaum, 2007), and use-dependent plasticity (Diedrichson et al., 2010; Verstynen and Sabes, 2011). All of these processes show that directional biases can form as a result of repeated movements to a specific region of space.
Experiment 4 was designed to manipulate those biases by having participants reach to multiple target locations distributed over different regions of the task environment. Participants in the Full condition reached to targets around the entirety of the workspace, whereas those in the Partial condition were only presented with targets in 1/4 of the workspace. We suggest that directional biases caused by repeated movements to one target direction are the source of the inflated rebound we observed in implicit learning in Experiments 2 and 3 (Figs. 4C, 6C). In the Full condition, such biases could “cancel out” due to the even spread of reach directions across the workspace, resulting in error-clamp rebound that is contiguous with the implicit learning trace during R2. However, assuming that this putative additional implicit process can narrowly generalize, directional biases could be recovered if the same number of targets were restricted to a small region of the workspace. This prediction was tested in the Partial condition.
We conducted three separate mixed factorial ANOVAs with two factors, condition and trial epoch, on participants' heading angles, explicit learning, and implicit learning. For heading angle, there was a marginally significant main effect of condition (F(1,18) = 4.33, p = 0.05), a significant effect of trial epoch (F(3,38) = 43.94, p < 0.001), and no significant interaction (F(1,9) = 0.14, p = 0.94). For explicit learning, there was no main effect of condition (F(1,28) = 0.01, p = 0.93), a significant effect of trial epoch (F(2,37) = 53.96, p < 0.001), and a significant interaction (F(1,9) = 4.72, p < 0.05). Last, for implicit learning, there was a significant main effect of condition (F(1,18) = 13.08, p < 0.01), a significant effect of trial epoch (F(3,38) = 15.47, p < 0.001), and a significant interaction (F(1,9) = 5.36, p < 0.01).
Differences in the magnitude of implicit learning between the conditions were predicted due to the role of generalization in sensorimotor adaptation—adaptation in the Partial condition should generalize more than the Full condition due to the close proximity of the target locations, leading to greater implicit learning (Krakauer et al., 2000; Taylor and Ivry, 2013). Furthermore, if trial-by-trial learning generalizes more in the Partial condition, then the rate of adaptation should appear to be faster as well.
These predictions were supported by the results. Our ANOVA revealed a significant main effect of condition on implicit learning, which is reflected by heightened implicit learning in the Partial condition relative to the Full condition (Fig. 7). Furthermore, differences in the rate of implicit learning are supported by two findings. In the Partial condition, implicit learning dropped precipitously in the R2 epoch compared with the end of the R1 epoch (t(9) = 2.80, p < 0.05), but remained stable in the Full condition (t(9) = 1.36, p = 0.21), suggesting a faster learning rate in the Partial condition. Second, fitting the two-state model to the data in both conditions revealed that the slow process learning rates (BS) tended to be higher in the Partial condition, although this difference was only of marginal significance (t(18) = 1.85, p < 0.10). There were no significant group differences in the fast process learning rate (t(18) = 1.28, p = 0.22).
Figure 7.

Experiment 4 behavior and model fitting. A, In the Full condition, implicit learning (red) was low relative to the Partial condition, but rebound was continuous with R2 learning. The fast and slow processes of the model were fit individually to explicit (blue) and implicit (red) learning data. B, In the Partial condition, implicit learning (red) echoed that of the various single-target groups of Experiments 2 and 3, with a higher rebound than predicted by a single monotonic implicit learning process. The fast and slow processes of the model were fit individually to explicit (blue) and implicit (red) learning data. C, Superimposed implicit learning curves from the Partial (green) and Full (brown) conditions. Shading represents SEM.
We compared the rms of each fit of the two-state model and found that the quality of fit in the Full condition was significantly better than the Partial condition (t(18) = 3.17, p < 0.01). This can be seen in Figure 7; the slow process fit in the Full condition accurately captures all stages of implicit learning and does not underestimate the magnitude of rebound, contrasting with both the Partial condition and all model fits in Experiments 1 and 2.
To capture differences between the full operation of rebound and implicit learning during the counter perturbation epoch, we conducted a final analysis, a posteriori, comparing learning in the last five trials of the EC epoch to the last five trials of the R2 epoch. Rebound in the EC epoch was significantly higher than late R2 learning in the Partial condition (t(9) = 2.28, p < 0.05) and, conversely, was significantly lower than late R2 learning in the Full condition (t(9) = 2.44, p < 0.05). Intriguingly, there was virtually no decay of the adaptation rebound seen in the EC epoch across the majority of our data, contrasting with results reported by Smith et al. (2006), in which a subtle early decay of rebound was observed. We believe that our lack of observed rebound decay may be due to the fact that we used a longer R1 training session relative to Smith et al. (2006) and this extra training could act to buoy adaptation rebound, perhaps due to the directional biases mentioned above. In addition, nonzero rebound in Smith et al. (2006) did persist throughout the entire EC epoch, similar to our current findings.
The effect of an implicit directional bias on the magnitude of rebound can be seen clearly when the implicit learning curves of both the Partial condition and the Report condition are superimposed (Fig. 7C). Interestingly, whereas both groups show similar implicit learning by the end of the R2 phase of learning, the rebound in the EC phase for the Partial condition is much higher than the Full condition (Fig. 7C). This discontinuity in the Partial condition suggests that an additional implicit process is at play. We suggest that having participants move in opposing radial directions an equal number of times (Full condition) effectively cancels out the implicit directional biases, which in turn unmasks a pure monotonic implicit learning signal. It is this learning signal that is best captured by the slow process of the two-state model (Fig. 7A).
Discussion
This study aimed to provide a more mechanistic explanation of the oft-cited fast and slow processes of human motor learning put forth by Smith et al. (2006). To do this, we examined explicit and implicit components of sensorimotor learning using a recently developed method that measures verbally reported, goal-driven learning in addition to the physical markers of implicit learning (Taylor et al., 2014). We used this novel method across the two common paradigms of human sensorimotor learning: force field and visuomotor rotation tasks. We found striking similarities between the purported fast process and explicit learning and also between the slow process and implicit learning. In addition, we confirmed the presence of multiple components within the slow/implicit process itself. These results provide evidence for at least three processes of sensorimotor learning that evolve over time in unique ways—indeed, there are likely more such processes. For example, there is evidence that adaptation also operates on a timescale across days in addition to single sessions (Albert et al., 2012). Ultimately, our findings argue for a wider consideration of the diversity of psychological and neural mechanisms that subserve sensorimotor learning (Huberdeau et al., 2015).
Our behavioral results and model fits show that the fast and slow processes introduced by Smith et al. (2006) are captured by explicit and implicit components of learning, respectively. In Experiment 1, participants' explicit reports of aiming directions closely reflect the time course of the fast process. Furthermore, the fast process of the two-state model easily captures the explicit aiming data of both Experiments 2 and 4 (Figs. 5, 7). These data jointly suggest that the fast process and explicit learning may reflect the same underlying mechanism.
Until now, the gradual decay of the fast process seen clearly during the first perturbation epoch in Experiments 2–4 (Figs. 4C, 6, 7) has been characterized as rapid “forgetting” (Trewartha et al., 2014). Our results offer an alternative to this interpretation, suggesting that the decay of the fast process is actually compensation for simultaneous implicit learning. Participants are not slowly forgetting an explicit solution to the task; rather, they are attenuating their aim magnitude as an implicit process adapts to the environmental perturbation.
There is evidence that the fast component of motor learning relies on declarative memory resources (Keisler and Shadmehr, 2010) and requires high preparation times (Haith et al., 2015a). Our results here confirm this notion. “Fast” learning is explicit. Furthermore, recent evidence shows that explicit learning processes are responsible for savings in sensorimotor learning (Haith et al., 2015a).
The slow process resembles implicit learning, with an important caveat: implicit learning itself is composed of at least two components. Although the magnitude of adaptation has been thought to be attenuated by long delays between successive reaches in similar regions of space (Brennan et al., 2012; Hadjiosif and Smith, 2013), our data do not support this interpretation (Fig. 6). Instead, we suggest that the discontinuities in implicit learning between the end of the counter perturbation epoch and the error-clamp epoch, seen in all the conditions in which training was limited to a particular region of the workspace (Figs. 4C, 6, 7B), reflect a third implicit learning process distinct from what we expect is conventional cerebellar-based adaptation (Izawa et al., 2012).
In our one-target design, the exact solution for countering the first rotation is the same on every trial of that epoch. Therefore, a single reach direction is reinforced over many successive trials. Previous research has revealed that repetition of an adapted movement induces directional biases via a process of “use-dependent plasticity” (Huang et al., 2011; Verstynen and Sabes, 2011). Furthermore, such biases are reinforced when the repeated movement yields reward (task success), which is consistent with a fully adapted reach in the perturbation blocks of our task (Huang et al., 2011). These previous findings support our results—robust rebound in the EC epoch of the one-target conditions appears to be larger than predicted by implicit adaptation alone and is likely augmented by a directional bias induced by the repeated adapted movements of the first perturbation block. The counter-perturbation block is only 1/10 the length of the first perturbation block, so the original bias persists at the onset of error clamp.
Such biases should effectively be canceled out in the Full condition of Experiment 4 because movement directions are spread out equally in a circle. Indeed, this is what we found—EC rebound in the Full condition was relatively small and was contiguous with the implicit learning trace, suggesting that rebound in that condition is composed of only monotonic implicit adaptation (Fig. 7A). In contrast, in the Partial condition, in which the reach locations were restricted to a small area of space, rebound was enhanced (relative to adaptation alone), potentially due to a use-dependent/operant directional bias (Huang et al., 2011; Verstynen and Sabes, 2011) that also operates in Experiments 2 and 3. We contend that tasks involving a single movement direction are likely to elicit these biases and this fact should be taken into account when observed motor behaviors are interpreted mechanistically; methodologically speaking, the diversity of movement directions in a motor learning task is a vital variable. Further research is needed to explore these forms of learning, especially as they relate to reward, which was shown recently to have a complex relationship with implicit sensorimotor learning (Galea et al., 2015).
Importantly, the relatively low level of implicit learning in the eight-target Full condition versus the various one-target conditions is not just a reflection of the different components of implicit learning: adaptation in general shows narrow generalization (Krakauer et al., 2000; Taylor and Ivry, 2013) and participants in the Full condition had a fewer number of reaches toward each general reach direction, leading to less overall adaptation. Indeed, there appear to be strong differences in generalization between explicit and implicit components of learning (Heuer and Hegele, 2011). We note that the overall level of implicit learning in our Full condition was lower than that reported in a previous experiment with a similar eight-target design (Taylor et al., 2014). However, it matches the degree of implicit learning reported in more recent work from our laboratory (Bond and Taylor, 2015). This discrepancy across experiments may be due to differing numbers of training trials, the use of different experimental setups (e.g., viewing angle), and subtle differences in task procedures such as clockwise versus counterclockwise rotations. Future work should further elucidate what determines the magnitude of implicit learning.
Direct comparisons between results in Experiment 1 versus Experiments 2–4 are difficult because we do not have a comparable measurement of implicit learning in Experiment 1 and thus have to rely on the implied fast and slow process from the model-fitting analysis. Participants in the Report condition of Experiment 1 did aim in a manner similar to those in the other experiments, displaying both the characteristic rapid learning of the first perturbation and the rapid change in sign at the onset of the second (Fig. 2B). However, their aim reports did not show the identical full time course of explicit learning, a rapid rise followed by slow decay, as seen in Experiments 2–4. An alternative method of probing explicit and implicit learning in a dimension more relevant to force field learning tasks has yet to be developed. Nonetheless, the results reported here suggest that investigators should consider the significant role of explicit processes in future force field experiments. It is clear that explicit strategies are present across methodologies in the field of motor learning.
Although significant effects of explicit reporting on overall task performance were not found, learning was qualitatively slightly better in the Report group of Experiment 2 (Fig. 4A). Even though these effects are not statistically reliable, we suggest that a modest improvement to learning is brought about by the act of reporting, the presence of visual landmarks, or both. This subtle improvement could be explained by attentional and motivational features of task goals; indeed, dual-task manipulations, which divide attention between the motor task and a secondary distracting task, attenuate the rate of overall learning (Taylor and Thoroughman, 2007, 2008; Galea et al., 2011; Malone and Bastian, 2010). Therefore, it is possible that the converse of this may be true: drawing attention to the task via explicit reporting could speed the rate of learning. In addition, higher RTs in the Report groups give those participants more preparation time, during which an explicit/declarative learning process may select a movement plan (Haith et al., 2015a; Haith et al., 2015b; Huberdeau et al., 2015).
The fast and slow process model (Smith et al., 2006) is cited often in the motor learning literature and recent hypotheses concerning the physiological mechanisms driving each process are far-ranging, including muscle synergy patterns versus descending commands (Ting and McKay, 2007), M1 activity versus subcortical activity (Galea et al., 2011; Choi et al., 2014), declarative memory versus adaptation (Keisler and Shadmehr, 2010; Trewartha et al., 2014), and, in its original conception, two unique sites of plasticity in the cerebellum (Medina et al., 2001; Smith et al., 2006; Yang and Lisberger, 2014). Our results suggest that the fast process, being explicit, likely relies on a wide network of attentional, executive, and motor areas (Taylor and Ivry, 2014; Huberdeau et al., 2015). Furthermore, the multifaceted implicit process could be supported by both subcortical and neocortical substrates, with unique regions contributing to error-driven adaptation, use-dependent plasticity, and operant learning. Future experiments are required to disentangle the variety of processes that toil in parallel to produce the canonical learning curve.
Footnotes
This work was supported by the National Science Foundation (Graduate Research Fellowship to S.D.M.), the National Institute of Neurological Disorders and Stroke–National Institutes of Health (Grant R01NS084948 to K.M.B. and J.A.T.), and the Princeton Neuroscience Institute's Innovation Fund (K.M.B. and J.A.T.). We thank Alyssa Bangel for help with data collection; Ryan Morehead for helpful comments on the manuscript; and Jon Berliner, Judy Fan, and Peter Butcher for insightful discussions.
The authors declare no competing financial interests.
References
- Albert MV, Catz N, Thier P, Kording K. Saccadic gain adaptation is predicted by the statistics of natural fluctuations in oculomotor function. Front Comput Neurosci. 2012;6:96. doi: 10.3389/fncom.2012.00096. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ashby FG, Maddox WT. Human category learning. Annu Rev Psychol. 2005;56:149–178. doi: 10.1146/annurev.psych.56.091103.070217. [DOI] [PubMed] [Google Scholar]
- Berniker M, Kording KP. Estimating the relevance of world disturbances to explain savings, interference and long-term motor adaptation effects. PLoS Comput Biol. 2011;7:e1002210. doi: 10.1371/journal.pcbi.1002210. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bond KM, Taylor JA. Flexible explicit but rigid implicit learning in a visuomotor adaptation task. J Neurophysiol. 2015 doi: 10.1152/jn.00009.2015. In press. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brennan AE, Wu HG, Smith MA. Translational and Computational Motor Control, 2012. New Orleans: 2012. The identification of a rapidly-decaying, high-precision proprioceptive sensory memory and its effects on motor adaptation. [Google Scholar]
- Choi JT, Bouyer LJ, Nielsen JB. Disruption of locomotor adaptation with repetitive transcranial magnetic stimulation over the motor cortex. Cereb Cortex. 2014 doi: 10.1093/cercor/bhu015. In press. [DOI] [PubMed] [Google Scholar]
- Daw ND, Niv Y, Dayan P. Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control. Nat Neurosci. 2005;8:1704–1711. doi: 10.1038/nn1560. [DOI] [PubMed] [Google Scholar]
- Diedrichsen J, White O, Newman D, Lally N. Use-dependent and error-based learning of motor behaviors. J Neurosci. 2010;30:5159–5166. doi: 10.1523/JNEUROSCI.5406-09.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Galea JM, Vazquez A, Pasricha N, de Xivry JJ, Celnik P. Dissociating the roles of the cerebellum and motor cortex during adaptive learning: the motor cortex retains what the cerebellum learns. Cereb Cortex. 2011;21:1761–1770. doi: 10.1093/cercor/bhq246. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Galea JM, Mallia E, Rothwell J, Diedrichsen J. The dissociable effects of punishment and reward on motor learning. Nat Neurosci. 2015;18:597–602. doi: 10.1038/nn.3956. [DOI] [PubMed] [Google Scholar]
- Gläscher J, Daw N, Dayan P, O'Doherty JP. States versus rewards: dissociable neural prediction error signals underlying model-based and model-free reinforcement learning. Neuron. 2010;66:585–595. doi: 10.1016/j.neuron.2010.04.016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hadjiosif A, Smith MA. Translational and Computational Motor Control, 2013. San Diego: 2013. Savings is restricted to the temporally labile component of motor adaptation. [Google Scholar]
- Haith AM, Huberdeau DM, Krakauer JW. The influence of movement preparation time on the expression of visuomotor learning and savings. J Neurosci. 2015a;35:5109–5117. doi: 10.1523/JNEUROSCI.3869-14.2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haith AM, Huberdeau DM, Krakauer JW. Hedging your bets: intermediate movements as optimal behavior in the context of an incomplete decision. PLoS Comput Biol. 2015b;11:e1004171. doi: 10.1371/journal.pcbi.1004171. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heuer H, Hegele M. Generalization of implicit and explicit adjustments to visuomotor rotations across the workspace in younger and older adults. J Neurophysiol. 2011;106:2078–2085. doi: 10.1152/jn.00043.2011. [DOI] [PubMed] [Google Scholar]
- Huang VS, Haith A, Mazzoni P, Krakauer JW. Rethinking motor learning and savings in adaptation paradigms: model-free memory for successful actions combines with internal models. Neuron. 2011;70:787–801. doi: 10.1016/j.neuron.2011.04.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huberdeau DM, Krakauer JW, Haith AM. Dual-process decomposition in human sensorimotor adaptation. Curr Opin Neurobiol. 2015;33:71–77. doi: 10.1016/j.conb.2015.03.003. [DOI] [PubMed] [Google Scholar]
- Izawa J, Criscimagna-Hemminger SE, Shadmehr R. Cerebellar contributions to reach adaptation and learning sensory consequences of action. J Neurosci. 2012;32:4230–4239. doi: 10.1523/JNEUROSCI.6353-11.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jacoby LL. A process dissociation framework: separating automatic from intentional uses of memory. Journal of Memory and Language. 1991;30:513–541. doi: 10.1016/0749-596X(91)90025-F. [DOI] [Google Scholar]
- James W. The principles of psychology. New York: Holt; 1890. [Google Scholar]
- Jax SA, Rosenbaum DA. Hand path priming in manual obstacle avoidance: evidence that the dorsal stream does not only control visually guided actions in real time. J Exp Psychol Hum Percept Perform. 2007;33:425–441. doi: 10.1037/0096-1523.33.2.425. [DOI] [PubMed] [Google Scholar]
- Keisler A, Shadmehr R. A shared resource between declarative memory and motor memory. J Neurosci. 2010;30:14817–14823. doi: 10.1523/JNEUROSCI.4160-10.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krakauer JW, Pine ZM, Ghilardi MF, Ghez C. Learning of visuomotor transformations for vectorial planning of reaching trajectories. J Neurosci. 2000;20:8916–8924. doi: 10.1523/JNEUROSCI.20-23-08916.2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Malone LA, Bastian AJ. Thinking about walking: effects of conscious correction versus distraction on locomotor adaptation. J Neurophysiol. 2010;103:1954–1962. doi: 10.1152/jn.00832.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Medina JF, Garcia KS, Mauk MD. A mechanism for savings in the cerebellum. J Neurosci. 2001;21:4081–4089. doi: 10.1523/JNEUROSCI.21-11-04081.2001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nikooyan AA, Ahmed AA. Reward feedback accelerates motor learning. J Neurophysiol. 2015;113:633–646. doi: 10.1152/jn.00032.2014. [DOI] [PubMed] [Google Scholar]
- Oldfield RC. The assessment and analysis of handedness: the Edinburgh inventory. Neuropsychologia. 1971;9:97–113. doi: 10.1016/0028-3932(71)90067-4. [DOI] [PubMed] [Google Scholar]
- Pekny SE, Criscimagna-Hemminger SE, Shadmehr R. Protection and expression of human motor memories. J Neurosci. 2011;31:13829–13839. doi: 10.1523/JNEUROSCI.1704-11.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith MA, Ghazizadeh A, Shadmehr R. Interacting adaptive processes with different timescales underlie short-term motor learning. PLoS Biol. 2006;4:e179. doi: 10.1371/journal.pbio.0040179. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor JA, Ivry RB. Context-dependent generalization. Front Hum Neurosci. 2013;7:171. doi: 10.3389/fnhum.2013.00171. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor JA, Ivry RB. Cerebellar and prefrontal cortex contributions to adaptation, strategies, and reinforcement learning. Prog Brain Res. 2014;210:217–253. doi: 10.1016/B978-0-444-63356-9.00009-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor JA, Thoroughman KA. Divided attention impairs human motor adaptation but not feedback control. J Neurophysiol. 2007;98:317–326. doi: 10.1152/jn.01070.2006. [DOI] [PubMed] [Google Scholar]
- Taylor JA, Thoroughman KA. Motor adaptation scaled by the difficulty of a secondary cognitive task. PLoS One. 2008;3:e2485. doi: 10.1371/journal.pone.0002485. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor JA, Krakauer JW, Ivry RB. Explicit and implicit contributions to learning in a sensorimotor adaptation task. J Neurosci. 2014;34:3023–3032. doi: 10.1523/JNEUROSCI.3619-13.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ting LH, McKay JL. Neuromechanics of muscle synergies for posture and movement. Curr Opin Neurobiol. 2007;17:622–628. doi: 10.1016/j.conb.2008.01.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Trewartha KM, Garcia A, Wolpert DM, Flanagan JR. Fast but fleeting: adaptive motor learning processes associated with aging and cognitive decline. J Neurosci. 2014;34:13411–13421. doi: 10.1523/JNEUROSCI.1489-14.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Verstynen T, Sabes PN. How each movement changes the next: an experimental and theoretical study of fast adaptive priors in reaching. J Neurosci. 2011;31:10050–10059. doi: 10.1523/JNEUROSCI.6525-10.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang Y, Lisberger SG. Role of plasticity at different sites across the time course of cerebellar motor learning. J Neurosci. 2014;34:7077–7090. doi: 10.1523/JNEUROSCI.0017-14.2014. [DOI] [PMC free article] [PubMed] [Google Scholar]