

Abstract
Epidemic outbreak detection is an important problem in public health and the development of reliable methods for outbreak detection remains an active research area. In this paper we introduce a Bayesian method to detect outbreaks of influenza-like illness from surveillance data. The rationale is that, during the early phase of the outbreak, surveillance data changes from autoregressive dynamics to a regime of exponential growth. Our method uses Bayesian model selection and Bayesian regression to identify the breakpoint. No free parameters need to be tuned. However, historical information regarding influenza-like illnesses needs to be incorporated into the model. In order to show and discuss the performance of our method we analyze synthetic, seasonal, and pandemic outbreak data.
1. Introduction
An important issue in public health is timely epidemic outbreak detection. Outbreak surveillance and monitoring are usually done by gathering official data reported by hospitals and clinics through medical consultation. One of the most frequent causes of medical consultation in all countries is influenza-like illness (ILI) or acute respiratory infection (ARI) [1–3]. ILI are responsible for substantial morbidity and mortality each year [3]. Seasonal influenza occurs throughout the world, and it is ranked as a leading cause of death for people below 4 and above 65 years of age and it is among the 10 top causes of death in almost all age groups [4, 5].
Early outbreak detection is necessary in order to take suitable control measures. Outbreaks correspond to breakpoints in surveillance data sets. Substantial research efforts have been devoted to this topic, inspired by a variety of statistical techniques including regression methods, time-series models, and statistical process control approaches and extensions to those fields that involve space-temporal studies and multivariate methods or techniques that include Bayesian inference [6, 7]. Comprehensive reviews of the field are presented by Unkel et al. [8], Sonesson and Bock [9], Brookmeyer and Stroup [10], and Watkins et al. [11]. Each of these papers presents a classification of methods used for outbreak detection. In general, outbreak methods use threshold values or threshold intervals to signal an alert, all based on historical data.
There are methods based on linear regression with model selection using criteria like AIC or BIC. However, outbreak detection is made under uncertainty, as noise is present in early signals of influenza surveillance [12]. Statistical methods that ignore this uncertainty may result in overconfident predictions. Bayesian methods provide a way to account for uncertainty in both data and model selection [13]. In this paper we introduce a Bayesian outbreak detection using regression models with model selection based on Bayes factors; see Hoeting et al. [13] for a review. Examples of Bayesian model comparison in linear models are [14, 15]. Smith and Spiegelhalter [16] present a review of selection criteria for linear models in terms of Bayes factors. Guo and Speckman [17] examine consistency of Bayes factors in the comparison problem for linear models. One key difference from most other methods is that the method introduced in this paper is not based on historical data alone, but rather on the exponential nature of an epidemic outbreak. For the purposes of this paper, prior information regarding influenza-like illnesses was used to build prior distributions which in turn are useful to estimate the Bayes factors for model selection.
The paper is organized as follows. Section 2 describes the results that lead to the outbreak detection method proposed in this paper. Section 3 applies the proposed method to synthetic and real data sets. Section 3.3 discusses the feasibility of our approach. Finally, Section 4 summarizes our findings and offers some perspectives.
2. Materials and Methods
Let us consider the epidemic process outlined in Figure 1. Let S(t), I(t), and R(t) denote the number of susceptible, infected, and recovered individuals at time t and the population size N(t) = S(t) + I(t) + R(t). The deterministic SIR model, without imported infections, that is, η = 0, is defined through the following ODE system [18]:
| (1) |
β is the per capita contact rate between susceptible and infected individuals and γ is the infection recovery rate. At the onset of an epidemic outbreak the number of infected individuals is small (relative to N); that is, I(t 0) = I 0 ≈ 0 and R(t 0) = 0 at initial time t 0. Therefore S(t 0) ≈ N and
| (2) |
for t ≈ t 0; consequently
| (3) |
Here R 0 = β/γ is the basic reproductive number, which is defined as the expected number of secondary infections caused by an infectious individual in a totally susceptible population during the time the individual spends in the infectious compartment. An epidemic may occur if R 0 is greater than one, while a basic reproductive number smaller than one will not sustain an epidemic; see [18]. Of note, the basic reproductive number does not change if η ≠ 0.
Figure 1.
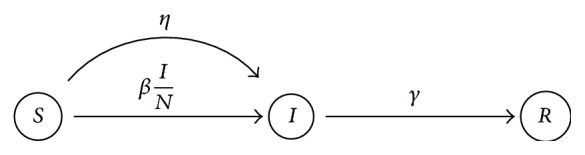
SIR epidemic model. Parameter β is the contact rate, γ is the recovery rate, and η accounts for infections due to imported cases. No births or deaths are taken into account given the time frame of an epidemic outbreak (few months for ILI).
In the remainder of the paper we write ΔR 0 = R 0 − 1. Thus I(t) ≈ I 0exp(γΔR 0 t) and therefore
| (4) |
That is, the logarithm of the number of infected individuals is linear in t during an epidemic outbreak.
On the other hand, outside epidemic outbreaks we expect that the number of infected reported cases varies around a background level, either around zero or an average number of reports as it is the case in influenza-like illnesses (ILI reports, examples to be analyzed in Section 3). By chance, the number of infected persons reports may vary around the average, with temporary runs going up (or down). In such a case we may fit a linear model in the original scale; namely,
| (5) |
The basis for our approach is to compare models (4) and (5), with a short run of reports, using the machinery of Bayesian model selection (see Section 2.1). If the exponential (i.e., linear in log scale) model is selected, it will signal the possible start of an epidemic outbreak. It will be crucial to properly code in the prior distribution for ΔR 0 and b a clear separation between the two models, since for small values of ΔR 0 both models may be quite similar (since e x ≈ 1 + x, for small x). We explain the model selection and prior selection in the following sections.
2.1. Bayesian Model Comparison
Given a data set of reported cases I(t i), i = 1,2,…, k at times t i, we consider a sliding window of n consecutive reports I(t i) to compare the statistical models defined by expressions (4) and (5). Before the outbreak, a linear model explains better the reported cases. On the other hand, during the early phase of the epidemic outbreak the number of infected individuals grows exponentially; thus the exponential model should be selected by the Bayes factors and the onset of the outbreak detected. Next we present an outline of Bayes factors and Bayesian model comparison and the basis for our approach.
Given two hypotheses H 1 and H 2 corresponding to the alternative models M 1 and M 2 for data D and parameters θ 1 and θ 2, the posterior distribution in each case is f(θ j∣D) = p(θ∣H i)p(D∣θ, H i)/p(D∣H i), j = 1,2. Here p(θ j∣H i) and p(y∣θ j, H i) are the prior and likelihood for model i and
| (6) |
is the normalization constant in each case. The basis of Bayesian model selection is that we can calculate the posterior distribution that each model, or each hypothesis, H i, is true. Namely, from Bayes's theorem we have
| (7) |
where p(H i) is the prior probability assigned for model i. The Bayes factor (B 1,2) comparing these two models is given by the odds ratio of model M 1 versus model M 2; that is,
| (8) |
Intuitively, the Bayes factor provides a measure of whether data D have increased or decreased the odds on H 1 versus H 2. Thus B 1,2 > 1 signifies that H 1 (or M 1) is relatively more probable than H 2 (or M 2) given D [19]. The optimal decision is therefore to choose the model with the highest posterior probability, that is, model 1 if B 1,2 > 1 and model 2 otherwise.
Note that Bayes factors do not make sense when using improper priors (due to unspecified constants) and are sensitive to vague or default a priori distributions; see [20]. However, in this paper we use strong and informative (and indeed proper) priors aimed at distinguishing both models. Therefore the mentioned issues, thoroughly discussed in the Bayesian literature, should be of no concern in the current setting.
Let us denote by M 1 the exponential model in (4) and M 2 the linear model given in (5). Let D be the data at hand, either I(t i) for model 1 or logI(t i) for model 2, i = 1,2,…, k. Then we assume
| (9) |
Thats is, D ∈ ℝ n follows a normal distribution with mean Xθ and covariance matrix σ 2 I n, where I n is the identity matrix; X ∈ ℝ n×2 and θ ∈ ℝ 2 are the design matrix and the parameter vector, respectively. We will require a different design matrix X and prior distributions, for each model M i.
To perform a standard conjugate Bayesian analysis on this linear model [19, 21, 22] we proceed as follows; please see Appendix A for more details. We use the Normal-Inverse Gamma (NIG) prior distribution:
| (10) |
θ 0 corresponds to the location parameter, Σ0 is the covariance matrix (for θ∣σ 2 ~ N 2(θ 0, σ 2Σ0)), and α 0 and β 0 denote the parameters of the Inverse-Gamma distribution (for σ 2 ~ InvGa(α 0, β 0)), in the usual way. The posterior distribution results in a NIG(θ n, Σn, α n, β n), where
| (11a) |
| (11b) |
| (11c) |
| (11d) |
The normalization constant in (6), required by the Bayes factor, is
| (12) |
(see Appendix A for more details).
From (4) and (5) it is clear that the design matrices X are
| (13) |
for the log-linear (exponential) and linear models, with θ T equal to (log(I 0), ΔR 0) and (a, b), respectively.
Other relevant parameters are explained and set in Table 1. In the following section we discuss and establish prior distributions for each model, setting the hyperparameters of the prior NIG distribution.
Table 1.
Model parameters summary of parameters used for both synthetic data generation and outbreak detection method.
| Parameter | Value | Dimension | Description |
|---|---|---|---|
| η | 100 | Days | Infection importation rate |
| γ | 7 | Days | Infection recovery time |
| n | 3 | Reporting interval | Length of the window used to compare the models |
| p | 2 | Parameter index |
2.2. Prior Distributions
As mentioned in Section 2.1, it is crucial to separate both models through a prior distribution that distinguishes clearly the exponential growth from a linear fluctuation. The basic reproduction number R 0 plays a central role in the prior information. Here, prior information of our approach is set for influenza-like illnesses; other prior specifications could be attempted for another type of epidemic outbreaks. It is known that for seasonal influenza R 0 is approximately 1.5 [23]; therefore prior expectation for ΔR 0 will be centered at 0.5. Moreover, in calibrating our models we have found that the bigger the population size N the sharper the prior needed, where the prior variance should decrease as 1/N. This rule is in agreement with standard hypothesis in physics; in a well mixed system the amplitude of fluctuations scales like the square root of the system size [24].
For each data window, we first subtract its corresponding mean, for either the logged or the original data, and center the prior linear model around 0. Consequently, the hyperparameters θ 0 and Σ0 for the NIG prior are set to
| (14) |
for the log-linear (exponential) and linear models, respectively. The outbreak detection method introduced here is robust to other reasonable settings for these hyperparameters. The only critical value is the variance for ΔR 0, which, as mentioned above, needs to be adjusted with the population size as 1/N.
The remaining hyperparameters are set to α 0 = (1/2)(n − p) and , where is the observed variance in the data window, for either the logged or the original data. Thus, the prior variance is centered near the observed variance for each model.
Indeed, in a pure inference scenario it is questionable to use data driven prior distributions. However, in the current setting it is desired to distinguish between the linear and exponential models and not in fact the estimation of the regression parameters themselves, which are regarded as nuisance. By subtracting the mean and centering the prior of θ 1 (either to ΔR 0 or to b) to 0 and by setting a priori we are helping the inference of the regression parameters in each case (and equally for both models). This is a key feature of the proposed approach, since we will use a small window of three consecutive reports, and uncentered priors would blur the relative weight of each model, rendering the model comparison useless. Overall, the prior distribution selection at this stage should be regarded as a pragmatic approach to making the outbreak detection procedure work.
Once the outbreak is detected we may then try to estimate R 0 using the data window at hand. Again, since the data set is very small, we will use a noninformative prior (see [19]) and use the marginal posterior for the regression parameters of the log-linear (exponential) model to estimate R 0. The corresponding marginal posterior for the whole θ = (log(I 0), ΔR 0)T parameter is , where and (indeed, D is the logged data). The marginal distribution of any one of the entries of θ is a univariate Student t distribution. We are interested in θ 2 (corresponding to ΔR 0); thus . We will use the posterior expected value, , of this posterior marginal to estimate R 0; namely, . Also, since γ is fixed an estimator for β can be produced with .
In Section 3 we compute B 12 over a moving window of four consecutive data points, that is, N = 4, to decide whether changes are due to data oscillations (linear model is selected and B 12 < 1), or the onset of exponential growth occurs (the exponential model is selected and B 12 > 1) and an epidemic outbreak is expected.
3. Results
We have tested the predictive capacity of the outbreak detection method proposed in this paper with real and synthetic data sets. The real data sets used are from the Spanish influenza outbreak in San Francisco, USA, in 1918 (see [25]) and data of the acute respiratory illnesses (ARI) from San Luis Potosí, México (see Noyola and Arteaga-Domínguez [26]).
Outbreak information and model relevant parameters like the infection rate (β), the basic reproductive number (R 0), and the week of outbreak were estimated. In each figure, red dots indicate three consecutive points in which the exponential model is selected over the linear model; that is, B 12 > 1. Grey points indicate one single four-point window in which B 12 > 1. As explained in the previous section, once the outbreak is detected we use the log-linear model, with a noninformative prior, to produce estimators for both R 0 and β.
3.1. Synthetic Data Analysis
To create synthetic data we have avoided committing an “Inverse Crime” [27]. Synthetic data was produced with a closely related but different model to the one assumed in (4) or (5) to be producing the infectious reports. Namely, we use the Gillespie algorithm to make a realization of the SIR epidemic model with demographic stochasticity [28]. Initially all individuals are susceptible and the epidemic outbreak is due to imported cases. The frequency of imported cases is controlled with parameter η; see Figure 1. Of note, the deterministic model (1) is the mean field equation of this stochastic SIR model. Moreover, in a real scenario data is accumulated over the reporting time frame (daily, weekly, etc., reports for infected persons). We then accumulate the simulated data over the reported time frame to produce the synthetic infectious reports I(t i). Also, a linear autoregressive process is added to the synthetic data to simulate a background of diseases caused by other agents, as it is the case of influenza-like illness. Simulations have R 0 = 1.5, γ = 1/7 (days); the rate of imported cases is η ∈ [10−7, 10−4] depending on the population size N. Reports are accumulated weekly. Some examples are presented in Figure 2 and the estimates for R 0 and γ are presented in Table 2.
Figure 2.

Outbreak detection for population sizes of (a) N = 5,000, (b) N = 10,000, (c) N = 500,000, and (d) N = 1,000,000. Data was generated with a realization of a SIR model with demographic stochasticity and imported cases. Outbreaks detection improves as the population size grows.
Table 2.
Estimates obtained for the detected outbreak.
| N | Week of outbreak | ||
|---|---|---|---|
| 5000 | 1.23 | 2 | 0.17 |
| 10000 | 1.36 | 7 | 0.19 |
| 500000 | 1.91 | 8 | 0.27 |
| 1000000 | 1.35 | 14 | 0.19 |
3.2. Real Data Analysis
Real surveillance data sets account for medical consultation cases. These numbers represent infected persons seeking medical attention at health centers. For influenza, it is estimated that as low as 17% of the infected population seek medical consultation and approximately 75% of people with seasonal or pandemic influenza do not exhibit symptoms [29]. However, under normal circumstances reports are proportional to the actual number of infected people and exponential growth in the number of infected people will be shown as such in the reported cases. In the following examples we do not explicitly model subreporting, obtaining good results in all cases.
The Spanish influenza of 1917-18 was a pandemic considered among the most devastating ones in history [30, 31]. Figure 3 shows a data set corresponding to San Francisco, USA, spanning from September 24th to November 24th.
Figure 3.
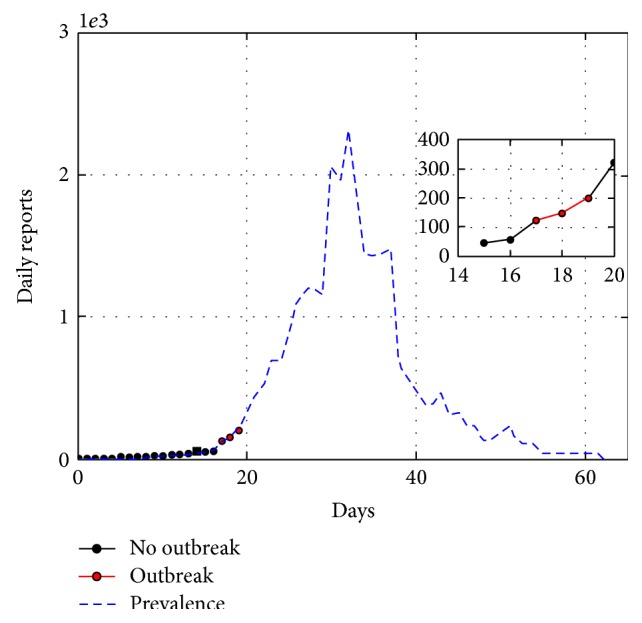
Spanish influenza in San Francisco, USA, 1918. Population 550000. Outbreak spanned from September 24th to November 24th. Method detected outbreak on the 17th day of the outbreak (October 10th). Estimated parameters are β = 0.53 and R 0 = 3.7.
Our detection method identifies an outbreak on October 10th. The estimated parameters associated with this epidemic are and . Both the estimated R 0 and outbreak day are comparable with the values calculated by Chowell et al. [23].
Data of acute respiratory infections (ARI) in San Luis Potosí, México, are available in Noyola and Arteaga-Domínguez [26]. Here, we analyze ARI weekly reports from the winter seasons of 2000 to 2008. Reports refer to epidemiological weeks, for which week 1 is week 25 of the calendar year (i.e., mid June). Data for 2002-2003 and 2003-2004 winter seasons are plotted in Figure 4 along with outbreak detection results. In this series of data sets the seasonal outbreak is consistently detected between epidemiological weeks 13 and 15 with R 0 between 1.3 and 2.5; see Table 3.
Figure 4.

ARI reports from SLP, Mexico, winter seasons of (a) 2000-2001, , , outbreak detected at epidemiological week 8, and (b) 2003-2004, , , outbreak detected at epidemiological week 8.
Table 3.
Parameters of acute respiratory infection records from San Luis Potosí 2000–2009. Population is approximately 2,000,000.
| Year | Week of outbreak | ||
|---|---|---|---|
| 2000-2001 | 1.57 | 8 | 0.22 |
| 2001-2002 | 1.29 | 7 | 0.18 |
| 2002-2003 | 1.34 | 7 | 0.19 |
| 2003-2004 | 1.37 | 8 | 0.19 |
| 2004-2005 | 1.59 | 8 | 0.23 |
| 2005-2006 | 1.32 | 8 | 0.19 |
| 2006-2007 | 1.42 | 8 | 0.20 |
| 2007-2008 | 2.5 | 11 | 0.36 |
Of note, other questions from ARI surveillance may be addressed; for instance, when do the weekly reports of ARI exceed the historical mean? However, in this paper we limit ourselves to the introduction of the detection method and leave other questions of disease surveillance for future research.
3.3. Discussion
We have introduced an outbreak detection method based on Bayesian linear regression and Bayes factors. Our method performs correctly in real and synthetic examples. Undoubtedly a key component of this method is the structure of the prior information used to distinguish the exponential from the linear model. In the above examples we have focused on influenza-like illness (ILI) or acute respiratory infection (ARI). Consequently, the prior expectation for R 0 was set equal to 1.5. We anticipate that other diseases may be modeled correctly using previous reports of the expected value of the basic reproductive number. We have learned that the prior variance for ΔR 0 needs to reduce as 1/N, where N is the population size. This choice may be justified recalling that in a well mixed physical system fluctuations scale like the square root of the system size.
In the examples presented above the outbreak is detected in the presence of underreporting. The good performance of the method is explained considering the fact that the method is based on detecting a qualitative feature of the surveillance data instead of a quantitative threshold. Methods based on historical thresholds may have difficulties in detecting an outbreak happening within or below average historical report levels. Of note, our method uses historical data to calibrate prior distributions; for example, historical data is used to model how much we allow surveillance data to oscillate while in the autoregressive regime. Moreover, the method introduced in this paper allows us to estimate important parameters like infection rate (β) and the basic reproductive number (R 0) which provide valuable information regarding outbreak behavior. The estimation of these quantities was made using a sliding window of three consecutive reports.
Bayesian outbreak detection was applied to two types of real data sets. It consistently succeeded in making an early detection and the estimated R 0 and β values were in agreement with values reported in the literature.
A Python-Scipy implementation of our approach may be downloaded from http://www.cimat.mx/jac/software; a user friendly interphase is available at request from the authors.
4. Conclusions
Outbreak detection is an important problem in surveillance of infectious diseases. The development of robust methods of early outbreak detection remains an active research area.
In this paper we use Bayes factors to detect a breakpoint that characterizes the onset of an epidemic outbreak in influenza-like illness surveillance data. The breakpoint characterizes the change from an autoregressive regime to exponential behavior of reported cases at the beginning of an epidemic outbreak. The detection method was successfully used on synthetic and real data sets. The resulting algorithm is straightforwardly implemented. The mathematical methods behind the algorithm are simple but contrast with other proposed methods which are based on calculating thresholds and control charts. Of note, our approach has no free parameters to tune.
The prior distributions used arise from coding information available for influenza-like illness. It is apparent that the method may be applied to surveillance data of other infectious diseases, for example, acute diarrheal diseases, provided enough prior information about the disease of interest is available.
Certainly, it is important to detect outbreaks before they have fully developed, that is, when the number of cases is still low. Our outbreak detection method seems to be able to achieve an early detection of influenza-like illness outbreaks, when synthetic and real data are analyzed. Furthermore, it allows us to make quantitative estimations for important parameters regarding the epidemic. The estimated parameters in the data sets analyzed are in agreement with previously published values.
Some features like the optimal number of reports required to identify an outbreak, optimal number of consecutive Bayes factors required to call an outbreak, and so forth are left as subject of further research.
Appendix
A. Details on the Prior and Posterior Distributions and Obtaining the Normalizing Constants
Let us denote by M 1 the linear model I(t) = a + bt, modeling the background data, and M 2 the exponential model given by log(I(t)) = log(I 0) + γΔR 0 t, modeling the early outbreak. Let D be the data, either I(t i) for model 1 or log(I(t i)) for model 2. Then, we assume
| (A.1) |
that is, D ∈ R n, follows a normal distribution with mean Xθ and covariance matrix σ 2 I n, where I n is the identity matrix, and X ∈ R n and θ ∈ R 2 are the design matrix and the parameter vector, respectively. The following details may also be found in [22].
A.1. The NIG Prior
To perform a standard conjugate Bayesian analysis on this linear model, we use the Normal-Inverse Gamma (NIG) prior distribution as follows:
| (A.2) |
This two-dimensional NIG distribution signifies that
| (A.3) |
where θ 0 correspond to the a priori location parameter and Σ0 the a priori covariance matrix for θ and α 0 and β 0 denote the hyperparameters for the a priori Inverse-Gamma distribution for σ 2; consider
| (A.4) |
The functional form of this prior distribution is given by
| (A.5) |
where Γ(·) represents the Gamma function and the IG(α 0, β 0) prior density for σ 2 is given by
| (A.6) |
A.2. The Likelihood
The likelihood function for each model is defined as the joint probability of observing the data viewed as a function of the parameters; consequently
| (A.7) |
viewed as a function of θ and σ 2 and fixing D.
A.3. The Posterior NIG Distribution
The posterior distribution is defined as p(θ, σ 2∣D) = p(θ, σ 2)p(D∣θ, σ 2)/p(D), where p(D) = ∫p(θ, σ 2)p(D∣θ, σ 2)dθ dσ 2 is the marginal distribution of the data.
We have that
| (A.8) |
Using the identity
| (A.9) |
we may write
| (A.10) |
where
| (A.11) |
Therefore,
| (A.12) |
A.4. The Normalization Constant
This is the constant required by the Bayes factor. We need to compute the distribution p(D∣σ 2) by integrating out β and subsequently integrate out σ 2 to obtain p(D). Accordingly,
| (A.13) |
Here the matrix identity |A + BDC| = |A||D||D −1 + CA −1 B| was applied to obtain
| (A.14) |
Now, the marginal distribution of p(D) is obtained as follows:
| (A.15) |
In more detail, we have
| (A.16) |
Thus, the posterior distribution is
| (A.17) |
which indeed reduces (after some algebraic manipulation) to the NIG(θ n, Σn, α n, β n) density.
The marginal distribution of any one of the entries of θ n is a univariate Student t distribution. This is used and the correct parameters are described in Section 2.2 to estimate R 0 and infection rate (β).
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
References
- 1.Thompson W. W., Comanor L., Shay D. K. Epidemiology of seasonal influenza: use of surveillance data and statistical models to estimate the burden of disease. Journal of Infectious Diseases. 2006;194(supplement 2):S82–S91. doi: 10.1086/507558. [DOI] [PubMed] [Google Scholar]
- 2.Simonsen L. The global impact of influenza on morbidity and mortality. Vaccine. 1999;17(1):S3–S10. doi: 10.1016/s0264-410x(99)00099-7. [DOI] [PubMed] [Google Scholar]
- 3.Zhou H., Thompson W. W., Viboud C. G., et al. Hospitalizations associated with influenza and respiratory syncytial virus in the United States, 1993–2008. Clinical Infectious Diseases. 2012;54(10):1427–1436. doi: 10.1093/cid/cis211. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Murphy S. L., Xu J., Kochanek K. D. Deaths: final data for 2010. National Vital Statistics Reports. 2013;61(4):1–117. [PubMed] [Google Scholar]
- 5.Centers for Disease Control and Prevention. Seasonal Influenza (Flu) Centers for Disease Control and Prevention; 2014. http://www.cdc.gov/flu/weekly/summary.htm. [Google Scholar]
- 6. Martínez-Beneito M. A., Conesa D., López-Quílez A., López-Maside A. Bayesian Markov switching models for the early detection of influenza epidemics. Statistics in Medicine. 2008;27(22):4455–4468. doi: 10.1002/sim.3320. [DOI] [PubMed] [Google Scholar]
- 7.Pelat C., Boëlle P.-Y., Cowling B. J., et al. Online detection and quantification of epidemics. BMC Medical Informatics and Decision Making. 2007;7(1, article 29) doi: 10.1186/1472-6947-7-29. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Unkel S., Farrington C. P., Garthwaite P. H., Robertson C., Andrews N. Statistical methods for the prospective detection of infectious disease outbreaks: a review. Journal of the Royal Statistical Society Series A: Statistics in Society. 2012;175(1):49–82. doi: 10.1111/j.1467-985x.2011.00714.x. [DOI] [Google Scholar]
- 9.Sonesson C., Bock D. A review and discussion of prospective statistical surveillance in public health. Journal of the Royal Statistical Society. Series A. Statistics in Society. 2003;166(1):5–21. doi: 10.1111/1467-985X.00256. [DOI] [Google Scholar]
- 10.Brookmeyer R., Stroup D. F. Monitoring the Health of Populations: Statistical Principles and Methods for Public Health Surveillance. Oxford University Press; 2004. [Google Scholar]
- 11.Watkins R. E., Eagleson S., Hall R. G., Dailey L., Plant A. J. Approaches to the evaluation of outbreak detection methods. BMC Public Health. 2006;6(1, article 263) doi: 10.1186/1471-2458-6-263. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Cooper G. F., Dash D. H., Levander J. D., Wong W.-K., Hogan W. R., Wagner M. M. Bayesian biosurveillance of disease outbreaks. Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence; 2004; AUAI Press; pp. 94–103. [Google Scholar]
- 13.Hoeting J. A., Madigan D., Raftery A. E., Volinsky C. T. Bayesian model averaging: a tutorial. Statistical Science. 1999;14(4):382–417. doi: 10.1214/ss/1009212519. [DOI] [Google Scholar]
- 14.Dickey J. M. The weighted likelihood ratio, linear hypotheses on normal location parameters. Annals of Mathematical Statistics. 1971;42:204–223. doi: 10.1214/aoms/1177693507. [DOI] [Google Scholar]
- 15.Spiegelhalter D. J., Smith A. F. Bayes factors for linear and Log-Linear models with vague prior information. Journal of the Royal Statistical Society Series B (Methodological) 1982;44(3):377–387. [Google Scholar]
- 16.Smith A. F., Spiegelhalter D. J. Bayes factors and choice criteria for linear models. Journal of the Royal Statistical Society. Series B (Methodological) 1980;42(2):213–220. [Google Scholar]
- 17.Guo R., Speckman P. L. Bayes factor consistency in linear models. Proceedings of the International Workshop on Objective Bayes Methodology; June 2009; Valencia, Spain. [Google Scholar]
- 18.Hethcote H. W. The mathematics of infectious diseases. SIAM Review. 2000;42(4):599–653. doi: 10.1137/S0036144500371907. [DOI] [Google Scholar]
- 19.Bernardo J. M., Smith A. F. Bayesian Theory. Vol. 405. John Wiley & Sons; 2009. [Google Scholar]
- 20.Berger J. O., Pericchi L. R. The intrinsic Bayes factor for model selection and prediction. Journal of the American Statistical Association. 1996;91(433):109–122. doi: 10.2307/2291387. [DOI] [Google Scholar]
- 21.Kunz S. New York, NY, USA: Mimeo; 2009. The bayesian linear model with unknown variance. [Google Scholar]
- 22.Banerjee S. Bayesian linear model: Gory details 1 the nig conjugate prior family, 2014, http://www.biostat.umn.edu/~ph7440/pubh7440/BayesianLinearModelGoryDetails.pdf.
- 23.Chowell G., Nishiura H., Bettencourt L. M. A. Comparative estimation of the reproduction number for pandemic influenza from daily case notification data. Journal of the Royal Society Interface. 2007;4(12):155–166. doi: 10.1098/rsif.2006.0161. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.van Kampen N. G. Stochastic Processes in Physics and Chemistry, Volume 1. Elsevier; 1992. [Google Scholar]
- 25.Bootsma M. C. J., Ferguson N. M. The effect of public health measures on the 1918 influenza pandemic in U.S. cities. Proceedings of the National Academy of Sciences of the United States of America. 2007;104(18):7588–7593. doi: 10.1073/pnas.0611071104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Noyola D. E., Arteaga-Domínguez G. Contribution of respiratory syncytial virus, influenza and parainfluenza viruses to acute respiratory infections in San Luis Potosí, Mexico. Pediatric Infectious Disease Journal. 2005;24(12):1049–1052. doi: 10.1097/01.inf.0000190026.58557.93. [DOI] [PubMed] [Google Scholar]
- 27.Kaipio J., Somersalo E. Statistical and Computational Inverse Problems. Vol. 160. Springer Science & Business Media; 2006. [Google Scholar]
- 28.Keeling M. J., Rohani P. Modeling Infectious Diseases in Humans and Animals. Princeton, NJ, USA: Princeton University Press; 2008. [Google Scholar]
- 29.Hayward A. C., Fragaszy E. B., Bermingham A., et al. Comparative community burden and severity of seasonal and pandemic influenza: results of the Flu Watch Cohort Study. The Lancet Respiratory Medicine. 2014;2(6):445–454. doi: 10.1016/s2213-2600(14)70034-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Taubenberger J. K., Morens D. M. 1918 influenza: the mother of all pandemics. Revista Biomédica. 2006;17:69–79. doi: 10.3201/eid1201.050979. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Crosby A. W. America's Forgotten Pandemic: The Influenza of 1918. Cambridge, UK: Cambridge University Press; 2003. [DOI] [Google Scholar]