

Abstract
Background
The importance of studying associations between socio-economic position and health has often been highlighted. Previous studies have linked the prevalence and severity of lung disease with national wealth and with socio-economic position within some countries but there has been no systematic evaluation of the association between lung function and poverty at the individual level on a global scale. The BOLD study has collected data on lung function for individuals in a wide range of countries, however a barrier to relating this to personal socio-economic position is the need for a suitable measure to compare individuals within and between countries. In this paper we test a method for assessing socio-economic position based on the scalability of a set of durable assets (Mokken scaling), and compare its usefulness across countries of varying gross national income per capita.
Results
Ten out of 15 candidate asset questions included in the questionnaire were found to form a Mokken type scale closely associated with GNI per capita (Spearman’s rank rs = 0.91, p = 0.002). The same set of assets conformed to a scale in 7 out of the 8 countries, the remaining country being Saudi Arabia where most respondents owned most of the assets. There was good consistency in the rank ordering of ownership of the assets in the different countries (Cronbach’s alpha = 0.96). Scores on the Mokken scale were highly correlated with scores developed using principal component analysis (rs = 0.977).
Conclusions
Mokken scaling is a potentially valuable tool for uncovering links between disease and socio-economic position within and between countries. It provides an alternative to currently used methods such as principal component analysis for combining personal asset data to give an indication of individuals’ relative wealth. Relative strengths of the Mokken scale method were considered to be ease of interpretation, adaptability for comparison with other datasets, and reliability of imputation for even quite large proportions of missing values.
Keywords: Poverty, Measurement tool development, Socio-economic position, Developing countries, Respiratory diseases
Background
Studying associations between health outcomes and socio-economic position is an important aspect of health research [1]. A measure of socio-economic position may be useful to describe and monitor the social distribution of disease to inform health policy, to explain causal mechanisms through which socio-economic position generates health differences, or to statistically adjust for socio-economic circumstances when another exposure is the main focus of interest [2].
The Burden of Obstructive Lung Disease (BOLD) study is an international survey of ventilatory function [3] which has demonstrated a strong ecological association between “low” forced vital capacity, a measurement of the functional lung size, and gross national income (GNI) per capita, especially in poorer countries [4]. In the United Kingdom associations have been recorded between mortality rates from Chronic Obstructive Pulmonary Disease (COPD) and measures of social class, [5] and of childhood deprivation [6]. Other studies have also linked ventilatory function to different measures of socio-economic status within countries [7]. However, there has so far been no systematic evaluation of lung function and socio-economic position at the individual level on a global scale.
A barrier to achieving this is the lack of an easily applicable measure of socio-economic position that is broadly relevant to many countries and that discriminates between individuals as well as between regions or countries. No method will capture all aspects of socio-economic position but asset-based measures have been widely used in low and middle income countries because they provide an easily collected variable that is stable over short term economic fluctuations [8]. The usual method of analysing these measures is to use principal component analysis (PCA) to identify complex scores from correlated variables. An alternative is to use simpler approaches such as Mokken scale analysis, which is based on a count of assets selected and ranked for their ability to discriminate between different levels of affluence [9].
In order to establish a measurement of socio-economic position that could be used to compare individuals within and between countries, we used a Mokken scale approach to develop scores using an inventory of assets included in the BOLD study. This was comprised of commonly used items selected from a number of survey instruments and from experience in an attempt to cover a wide range of levels of affluence with relatively few items. In this analysis we examined whether the answers were scalable, i.e. whether the assets tend to be acquired in the same order by different people and all people with a given number of assets tend to have the same set of assets [10]. We compared the Mokken scale with PCA, and checked the scalability in different sites and for both current asset ownership and reported household asset ownership in early life (around 5 years of age). We also tested the face validity of the scale by comparing the mean values obtained in each centre against the GNI per capita associated with each centre and by comparison with other individual and household level variables expected to be associated with socio-economic position.
Methods
Overview of the data
The BOLD study has been described in detail elsewhere [3]. Briefly, this is a cross-sectional study of representative samples of adults aged over 40 years old living in centres selected in all the regions of the world defined by the Global Burden of Disease programme, with the exception of the Latin America and the Asian Pacific High Income regions. The current analysis includes only the eight centres, from eight different countries, entering the study after 2006 when new questionnaires were introduced that included 15-item asset inventories relating to the current time and to the time when the participant was 5 years old. Fourteen of the asset questions had binary (yes/no) responses. The respondents were asked whether their household has any of the following: electricity, flush toilet, fixed phone, cell phone, television, radio, refrigerator, car, moped/scooter/motorcycle, washing machine, owns their own home, indoor bath or shower, indoor tap, or an outdoor tap of their own. One further question, how often anyone in their household goes hungry due to lack of money, was recoded from a six point scale to a binary response (never or sometimes). Don’t know responses were considered as missing. Items included in this study were selected to cover a range of values from basic assets such as electricity and radios to luxury goods such as washing machines and cars, all of which were considered to be desirable to most people.
A total of 8910 subjects were randomly selected in the eight countries. Of these 1863 did not provide responses, mainly due to unavailability or untraceability (51 %). Other reasons were refusal to participate (22 %), deceased (0.5 %), ineligible due to age (7 %) or incomplete data collection (19 %). Sixty-one (0.9 %) out of the 7047 respondents had a missing response to at least one of the asset questions and were also excluded from the analyses. Characteristics of those included are given in Table 1. Four hundred and five (6 %) of the respondents had incomplete data for childhood ownership of the selected assets (excluding cell phone) and were also excluded from the comparison with asset ownership scores at the age of five.
Table 1.
Characteristics of the samples and GNI per capita for the countries included in the study
| Annaba (Algeria) | Fes (Morocco) | Ife (Nigeria) | Penang (Malaysia) | Riyadh (Saudi Arabia) | Sousse (Tunisia) | Srinagar (India) | Tirana (Albania) | Total | |
|---|---|---|---|---|---|---|---|---|---|
| Included in random selection (number) | 969 | 985 | 1704 | 1217 | 936 | 799 | 1100 | 1200 | 8910 |
| Included in this study (number) | 886 | 955 | 1083 | 693 | 758 | 716 | 927 | 968 | 6986 |
| Sex | |||||||||
| Male | 442 (49.9 %) | 412 (43.1 %) | 406 (37.5 %) | 355 (51.2 %) | 411 (54.2 %) | 331 (46.2 %) | 499 (53.8 %) | 486 (50.2 %) | 3342 (47.8 %) |
| Female | 444 (50.1 %) | 543 (56.9 %) | 677 (62.5 %) | 338 (48.8 %) | 347 (45.8 %) | 385 (53.8 %) | 428 (46.2 %) | 482 (49.8 %) | 3644 (52.2 %) |
| Age | |||||||||
| 40–54 years | 538 (60.7 %) | 474 (49.6 %) | 522 (48.2 %) | 347 (50.1 %) | 544 (71.8 %) | 416 (58.1 %) | 603 (65.0 %) | 503 (52.0 %) | 3947 (56.5 %) |
| 55–69 years | 295 (33.3 %) | 363 (38.0 %) | 369 (34.1 %) | 305 (44.0 %) | 206 (27.2 %) | 254 (35.5 %) | 248 (26.8 %) | 351 (36.3 %) | 2391 (34.2 %) |
| ≥70 years | 53 (6.0 %) | 118 (12.4 %) | 192 (17.7 %) | 41 (5.9 %) | 8 (1.1 %) | 46 (6.4 %) | 76 (8.2 %) | 114 (11.8 %) | 648 (9.3 %) |
| GNI per capita ($US) | 12,860 | 6160 | 4930 | 22,530 | 53,760 | 9680 | 4750 | 9950 | |
Mokken scaling
We first developed a scale using item response theory based on the idea that the items formed a hierarchy such that ownership of any of the assets implied ability to own all the items lower in the order. The method used was a non-parametric model attributed to Mokken [11] which differs from the earlier Guttman-type scale [12] in that it is probabilistic in nature, and from similar but parametric models (e.g. the Rasch scale [13]) in that it makes no assumptions about the shape of the relationship between the probability of item ownership and the trait being measured (such as socio-economic position).
Mokken scales are defined by three fundamental assumptions [14]: (1) unidimensionality (responses to all of the items are explained by a common trait); (2) local independence (ownership depends on the trait but not on ownership of other items in the scale); (3) monotonic increase (or decrease) in the probability of owning each of the assets with increases in the trait being measured. Scalability of a set of items is assessed using Loevinger’s H coefficients, which relate the number of times high-order assets are owned without ownership of all of the lower assets, to the frequency with which this would occur by chance. Loevinger’s coefficients can be calculated for the fit of each individual item in the scale (Hj) and for the scale as a whole (H). The usual interpretation is that 0.3 ≤ H<0.4 implies a weak scale, 0.4 ≤ H<0.5 a medium scale and ≥0.5 a strong scale, whilst scales with H < 0.3 do not satisfy a Mokken scale [14, 15].
Selection of items for the Mokken scale
Data from all of the countries combined and an automated item selection procedure (AISP) were used to select suitable items for inclusion in the scale. This procedure successively adds items to the scale such that the whole scale H coefficient and the individual item, Hj coefficients were ≥0.3. The procedure stops when no more items meeting these criteria could be added [14].
Applicability of the scale in different countries
To examine the scalabilty of the selected assets in different countries, item (Hi) and whole scale (H) coefficients were also calculated for each of the individual countries, using the same set of assets in each case. To assess the consistency of the scale across countries, the selected assets were ranked according to the proportion of respondents who owned them in each country. The consistency of the item ownership rankings between the eight countries was assessed using Cronbach’s alpha. Item rankings within countries were also plotted against the equivalent ranks for all of the countries combined.
For each of the selected items an item response curve (IRC) was produced by plotting the probability of an individual owning the asset against the total number of these assets owned. If the total scores are related to an individual’s wealth this could be thought of as a plot of the probability of an individual owning an item against his/her overall wealth. In order to test for differences between the IRCs in different countries [known as differential item functioning (DIF)] each country’s IRC was compared with that for all other countries combined using the Mantel–Haenszel test [16], and the resulting eight p values were adjusted using a Bonferroni procedure. It was considered that there was significant DIF for that asset (i.e. inconsistency between countries) where the minimum of the adjusted p values was less than 0.05. This procedure was repeated for each of the selected items in the scale in turn.
Comparison with scores for childhood assets
Scores and Loevinger’s H coefficients were also calculated for the same selected set of assets when the respondent was 5 years old, excluding cell phones as these were not available at that time. Only individuals with complete data for childhood ownership of the remaining selected assets were included. Equivalent scores, excluding cell phone, were calculated for the current asset data for comparison. Scores for current and childhood ownership of the assets were compared graphically.
Comparison of scores with national wealth and variables related to socio-economic position
In order to check whether the scores given by our scale were related to wealth we plotted the individual and country mean scores against the GNI per capita [17] of the country where the respondent lived for the year the survey took place. We also assessed the strength of relationship between country mean scores and GNI per capita using Spearman’s rank correlation coefficient (rs). Whilst we did not have any direct measure of individual wealth we assessed the face validity of the scale by determining the direction of the rank correlation between the scores and a number of variables collected for each respondent which we expected to be broadly related to socio-economic position, particularly in low and middle income countries. The variables studied were the highest level of education completed by the respondent and his/her father and mother, height, body mass index (BMI), frequency of someone in the household going hungry for lack of money, and number of people per room in their household.
Sensitivity analysis
To compare socio-economic position using data collected in different surveys it may sometimes be necessary to exclude items from the scale. In some circumstances it may also be desirable to include the same set of items in all countries, even though they are not related to socio-economic position in all of the populations. To examine the robustness of the scale to these scenarios we plotted cumulative distribution curves for the scores when one of the questions (cell phone) was omitted and also when an additional random item [~Bernoulli (0.5)] was included. We also assessed the usefulness of an imputation procedure for missing values. This procedure first orders the items according to overall prevalence in the data. The algorithm then imputes a positive response for a missing value if the individual gave a positive response for the following (more common) item, else a negative response if he/she gave a negative response for the preceding (less common) item. If the value to be imputed cannot be determined in this way it is calculated from the relative numbers of positive and negative responses the individual gave for higher and lower items in the scale [18]. Five, 10 or 25 % of the responses were deleted at random and replaced by imputed values. In each case the scores in the resulting dataset were then compared with those in the original dataset.
Comparison with PCA
Finally we used PCA to develop scores from the assets, using both the full list of 15 assets and the 10 assets selected for the Mokken scale. We compared the individuals’ scores on the first principal component derived from these two PCA analyses with the individual Mokken scale scores, and country mean scores for all three methods with GNI per capita, using Spearman’s rank correlation coefficients.
All analyses were carried out using Stata v13.1, (StataCorp, College Station, TX, USA). Selection of items for inclusion in the Mokken scale and imputation of missing values were carried out using the user-written add-on commands in Stata, msp and imputemok [14, 18].
Results
From the original list of 15 assets thought to be related to socio-economic position, the AISP selected 10 assets for inclusion in the Mokken scale (Table 2). Loevinger’s item coefficients (Hj) were all greater than 0.44 and the overall H coefficient was 0.70, indicating that the items formed a strong scale. This is shown graphically for the selected assets in Fig. 1, which also confirms that the items all had virtually monotonic relationships with the trait being measured.
Table 2.
Assets selected for the Mokken scale and Loevinger’s H coefficients, ranked by prevalence of ownership
| Asset | Hj coeff | N | % | Rank |
|---|---|---|---|---|
| Electricity | 0.68 | 6907 | 98.9 | 1 |
| Television | 0.73 | 6678 | 95.6 | 2 |
| Cell phone | 0.44 | 6627 | 94.9 | 3 |
| Refrigerator | 0.70 | 5619 | 80.4 | 4 |
| Indoor bath | 0.71 | 5616 | 80.4 | 5 |
| Indoor tap | 0.69 | 5478 | 78.4 | 6 |
| Flush toilet | 0.72 | 4682 | 67.0 | 7 |
| Washing machine | 0.76 | 4466 | 63.9 | 8 |
| Car | 0.61 | 3128 | 44.8 | 9 |
| Fixed phone | 0.74 | 3109 | 44.5 | 10 |
| Overall (H) | 0.70 |
The number (N) and percentage of respondents who owned each of the assets are shown. Overall number of respondents = 6986
Fig. 1.

Item response curves for each of the assets included in the Mokken scale
All of the assets showed significant DIF when compared between countries (p < 0.001). Figure 2 shows the rank of each asset in each country plotted against the rank for that asset across all countries. On the whole, both the higher ranked assets (those least commonly owned) and the lowest ranked assets were similar in all countries. This suggests that despite statistically significant differences in individual item functioning, increasing scores on the scale as a whole would generally reflect increasing levels of wealth in all of the countries. Cronbach’s alpha for consistency of the item rankings between countries was 0.96; a very high level of overall consistency. Loevinger’s Hj coefficients were only >0.3 for all of the assets in two of the eight countries (Nigeria and Albania), suggesting that some items did not contribute useful information on socio-economic position in some countries. However, overall H coefficients for strength of the scale were >0.3 (i.e. acceptable) for all of the countries except Saudi Arabia.
Fig. 2.
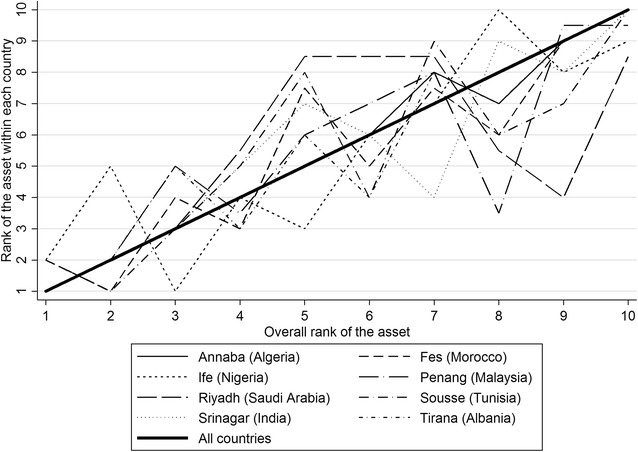
Assets ranked by percentage ownership within each country and overall. Higher ranks signify less commonly owned assets. For overall ownership the items were ranked in the order (1 most common) electricity, 2 television, 3 cell phone, 4 refrigerator, 5 indoor bath or shower, 6 indoor tap, 7 flush toilet, 8 washing machine, 9 car, (10 least common) fixed phone
Figure 3 shows the individual and mean scores plotted against the GNI per capita for the country in which the study was situated. There is a clear relation between the mean number of assets owned by individuals and GNI per capita (rs = 0.905, p = 0.002), but with a considerable range of scores in all but the richest countries. When compared with other variables collected for each individual which we expected to be associated with socio-economic position, highest level of schooling was positively and statistically significantly correlated with Mokken scale scores in all countries (p < 0.05) (Table 3). Mother and father’s highest level of education, respondent’s height and BMI were also positively correlated with the scores in most countries and not significantly negatively correlated in any countries. Frequency of someone in the household going hungry for lack of money and number of people per room in the house were negatively correlated with the Mokken scale scores in all of the countries as would be expected for a scale measuring socio-economic position (p < 0.05 in 13 out of these 16 tests).
Fig. 3.
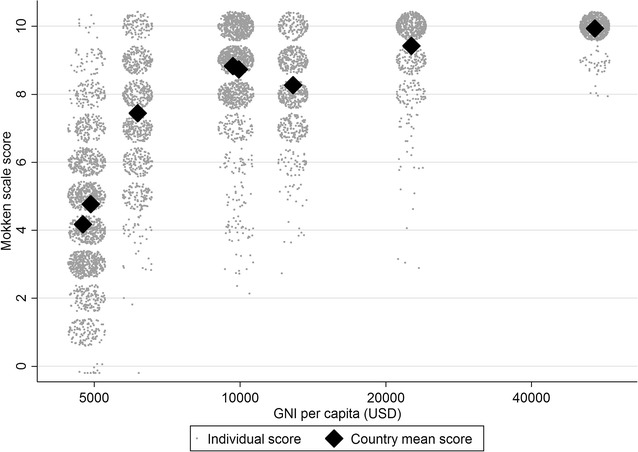
Mokken scale scores vs. GNI per capita for the country the respondent lived in. Some random noise has been added to the individual scores to prevent many points overlying each other
Table 3.
Spearman’s rank correlation coefficients (rs) for correlations between Mokken scale scores and the stated variables
| Annaba (Algeria) | Fes (Morocco) | Ife (Nigeria) | Penang (Malaysia) | Riyadh (Saudi Arabia) | Sousse (Tunisia) | Srinagar (India) | Tirana (Albania) | |
|---|---|---|---|---|---|---|---|---|
| Highest level of schoolinga | ||||||||
| Respondent | 0.251* | 0.388* | 0.411* | 0.176* | 0.114* | 0.301* | 0.246* | 0.524* |
| Father | 0.161* | 0.149* | 0.217* | 0.147* | 0.056 | 0.149* | 0.220* | 0.441* |
| Mother | 0.068* | 0.066* | 0.182* | 0.184* | –0.014 | 0.190* | – | 0.405* |
| Height | 0.023 | 0.038 | 0.139* | 0.123* | 0.073 | 0.050 | 0.212* | 0.197* |
| BMI | 0.120* | 0.141* | 0.247* | –0.043 | –0.062 | 0.091* | 0.153* | 0.001 |
| Frequency of going hungryb | –0.338* | –0.389* | –0.204* | –0.128* | –0.070 | –0.312* | –0.152* | –0.111* |
| Number of people per room in housec | –0.187* | –0.385* | –0.019 | –0.054 | –0.131* | –0.136* | –0.414* | –0.117* |
* Denotes a statistically significant correlation (p < 0.05)
aHighest level of schooling completed, categorised as 0 = none, 1 = primary, 2 = middle, 3 = high, 4 = college/technical, 5 = university. None of the mothers had been educated in Srinagar
bSelf reported frequency of someone in the household going hungry for lack of money, categorised as 0 = never, 1 = occasionally, 2 = certain times of year, 3 = most months, 4 = most weeks, 5 = most days
cNumber of people per room = number of people living in the house/number of rooms in the house [excluding kitchen and bathroom(s)]
Using the data on childhood ownership of the selected assets (excluding cell phone) the H coefficient was 0.70 indicating strong scalability also amongst these data. There was a general increase in the number of household assets owned in adulthood compared with childhood with only a small number of respondents having fewer assets in adulthood (Fig. 4). The number of assets in childhood decreased with increasing age of the respondent (Fig. 5), as would be expected.
Fig. 4.

Mokken scale scores for current asset ownership vs. scores for aged 5 years. Some random noise has been added to the data to prevent many points overlying each other. 1:1 line is also shown. Note—cell phone was excluded from the current assets to make the scores more directly comparable with the scores for age 5
Fig. 5.

Association between respondents’ current age and their Mokken scale score for age 5 years. The figure relates the number of Mokken scale assets the respondent reported owning in their household when they were 5 years old to their age at the time of the survey. The mean scores for all respondents in each 1 year age group are also shown
Sensitivity analyses showed that removing an item from the scale or adding an item uncorrelated to socio-economic position had little effect on the cumulative distribution of scores (Fig. 6). Individuals’ scores could only be decreased or increased by one point by these actions so despite inevitable differences in individual scores such changes would be unlikely to have a major effect on any apparent relationships between the scores and health outcomes. The Mokken scale scores were also robust to deleting and re-imputing some of the values. Even with 25 % of the data imputed, 67 % of individual scores were unchanged and 95 % were within ±1 of the original score (Table 4).
Fig. 6.
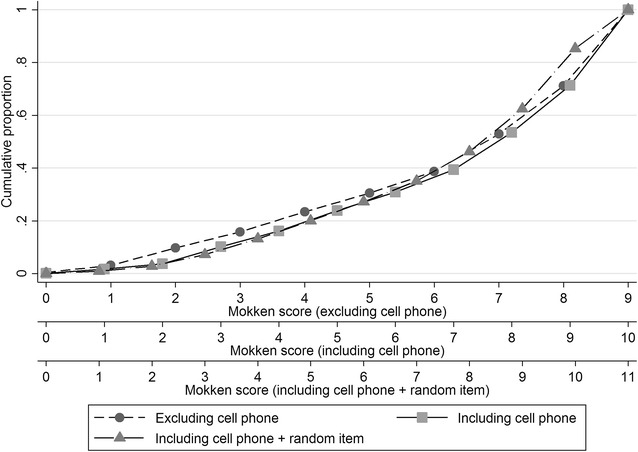
Cumulative distributions of scores for the current asset ownership data compared to the distributions when one item (cell phone) was omitted or and additional, random item was included
Table 4.
Effects of imputing missing data
| Error | 5 % imputed | 10 % imputed | 25 % imputed |
|---|---|---|---|
| N (%) | N (%) | N (%) | |
| −4 | 0 (0.0) | 0 (0.0) | 1 (0.0) |
| −3 | 0 (0.0) | 0 (0.0) | 17 (0.2) |
| −2 | 6 (0.1) | 27 (0.4) | 126 (1.8) |
| −1 | 225 (3.2) | 437 (6.3) | 893 (12.8) |
| 0 | 6423 (91.9) | 5920 (84.7) | 4691 (67.1) |
| 1 | 316 (4.5) | 560 (8.0) | 1042 (14.9) |
| 2 | 16 (0.2) | 36 (0.5) | 178 (2.5) |
| 3 | 0 (0.0) | 6 (0.1) | 32 (0.5) |
| 4 | 0 (0.0) | 0 (0.0) | 6 (0.1) |
| Total | 6986 (100.0) | 6986 (100.0) | 6986 (100.0) |
| Number of respondents with ≥1 imputed response | 2869 (41.1) | 4621 (66.1) | 6583 (94.2) |
| Number of respondents with error within ±1 | 6964 (99.7) | 6917 (99.0) | 6626 (94.8) |
Errors in Mokken scale scores after removing a percentage of the responses for each asset at random and then re-imputing the data
Error was defined as the difference between the score using imputed data and the score using the original, observed data. The number and percentage of respondents with different magnitudes and directions of error are shown
Scores on the Mokken scale comprised of 10 assets were compared with scores on the first principal component obtained from PCA using either all 15 of the original assets, or just the 10 assets included in the Mokken scale. In both cases the PCA scores were very highly correlated with the Mokken scale scores (15 items, rs = 0.977; 10 items, rs = 0.996). As for the Mokken scale scores, mean PCA scores for each country showed strong rank correlation with GNI per capita (15 items, rs = 0.929; 10 items, rs = 0.905). The association between the gross national wealth and the mean participant asset index measured by either the Mokken Scale or by PCA was essentially the same.
Discussion
Using an automated selection procedure it was found that the majority (10) of the 15 assets included in the questionnaire could be incorporated into a single scale such that the mean number of items owned was closely related to wealth as shown by the GNI per capita of the country. There was a high degree of consistency in the rank ordering of percent ownership of these items across countries, and the same set of assets was found to be at least weakly scalable in all of the study countries except the richest, Saudi Arabia, where most people owned most of the assets. Ownership of the set of assets also demonstrated an appreciable improvement in living standards for most people since the time they were aged five, as one might expect.
The set of assets used in this study were similar to those used in many other studies [1]. Although not all items were clearly related to socio-economic position in all of the countries, sensitivity analysis suggested that use of the scale would not be greatly affected by inclusion of items which were uncorrelated with socio-economic position in some countries or by dropping items to maintain comparability. Missing values could be imputed with reasonable accuracy suggesting the technique may be useful where missing data would require the exclusion of many individuals in other forms of multivariate analysis.
PCA has become a widely used method for estimating people’s socio-economic position rankings from an asset based inventory [1, 19–22]. However there have been criticisms about its applicability to binary data, leading some authors to propose using polychoric correlations in the calculations [23]. In this study we found this made negligible difference to the scores (Pearson’s correlation coefficient between scores calculated with and without using polychoric correlations was 0.999). Multiple correspondence analysis (MCA) has also been proposed [24] although the results are highly correlated with those from PCA [25]. More practical difficulties with using PCA are that the relationship between scores and asset ownership is usually unclear (for example different numbers of assets can sometimes lead to the same score) and comparison of scores between countries is complex [26, 27].
Zinn et al. [15] applied the Mokken scaling method to asset data in Indonesia in 1992 and found that a scale could be made up from selected assets. They argued that the technique was attractive because it was easy to see the relationship between wealth scores and the list of assets. Much later the method has also been tested in Vietnam [9]. The authors found it simple to apply and very similar in the way it ranks individuals to PCA, as we also observed.
In this study we found statistically significant differences in item functioning (DIF) implying that for people with the same score (which we considered to be a proxy for socio-economic position) the probability of owning any particular asset differed to some extent between countries. Whist this would preclude reliable comparisons of socio-economic position based on any particular asset, the score as a whole is a function of ownership of a set of assets which were acquired with a similar order of ability or preference in all of the countries.
We did not have any direct measure of socio-economic position at the individual or household level with which to compare the range of scores within countries. However we found positive correlations in most countries between the individuals’ scores and other variables collected for each respondent that might be expected to increase with increasing socio-economic positon (education, height and BMI). Conversely negative correlations were found between Mokken scale scores and the number of people per room in the house and the frequency of going hungry for lack of money as might be expected for a scale related to socio-economic position.
Despite the simplicity of Mokken scales, their ease of interpretation and apparent near equivalence to PCA, their uptake may have been hindered by a lack of familiarity or availability of suitable software. However routines are now readily available for Stata, R, SAS and other specialist software. The Mokken scaling software includes an automated item selection procedure and tests for goodness of fit so that a suitable set of assets can be chosen from amongst a longer list of candidate questions. For maximum efficiency, therefore, a list of potential questions might be included in a pilot survey and the list shortened accordingly before the main survey. Specialist software is only required for the development and testing of scales. Scoring an individual on an established scale is simply a matter of counting the number of the items that they own.
Mokken scaling provides a potentially useful way of assessing wealth on an ordinal scale and hence of testing whether health outcomes are related to socio-economic position. It could be used to distinguish rich from poor across a wide range of settings and therefore to help target healthcare where it is most needed. Reidpath and Ahmadi [9] highlighted the need for further studies to assess the method’s applicability across a range of countries. The BOLD study provided one such opportunity and we believe our results extend the evidence in support of the widespread usefulness of this method.
Since previous work had shown that GNI per capita had the greatest effect on lung function amongst the poorest countries [4], the assets included in our questionnaires were focussed on discriminating between levels of poverty mainly within developing countries. In the richer countries in our study most people owned most of the assets but this was not considered to be a significant limitation because we did not expect the level of wealth within rich countries to be a major influence on our outcomes of interest. For other types of study, however, it may also be useful to include questions about assets such as internet use and leisure activities to discriminate between people within the richer countries.
Conclusions
Use of a Mokken scale appears to be very similar to PCA in its ability to discriminate between people of different socio-economic position but may have advantages in interpretability, adaptability and robustness to variations in the scale or missing data. Now that appropriate software is readily available its use should be considered as a possible alternative to other methods where it is required to rank individuals’ socio-economic position on the basis of an asset inventory.
Authors’ contributions
JT carried out the data analysis and drafted the manuscript. PB and CM conceived the study, PB also drafted some parts of the text. JP managed the data and contributed to data analysis. IH, DO and KE-R contributed to data collection. All authors critically reviewed the manuscript. All authors read and approved the final manuscript.
Acknowledgements
We are grateful to the following who provided data from the different sites: Parvaiz A Koul (PI), Sajjad Malik, Nissar A Hakim, Umar Hafiz Khan (Sher-i-Kashmir Institute of Medical Sciences, Srinagar, J&K, India); Myriam Denguezli, Zouhair Tabka, Hager Daldoul, Zaki Boukheroufa, Firas Chouikha, Wahbi Belhaj Khalifa (Faculté de Médecine, Sousse, Tunisia); Mohamed C Benjelloun (PI), Chakib Nejjari, Mohamed Elbiaze (Laboratoire d’épidémiologie, Recherche Clinique et Santé Communautaire, Fès, Morroco); Gregory Erhabor, Olayemi Awopeju, Olufemi Adewole (Obafemi Awolowo University, Ile-Ife, Nigeria), Al Ghobain M (PI), Alorainy H (PI), El-Hamad E, Al Hajjaj M, Ayan H, Rowena D, Rofel F, Elizabeth E, Imelda I, Safia H, Lyla (Saudi Thoracic Society, Saudi Arabia), Hasan Hafizi (PI), Anila Aliko, Donika Bardhi, Holta Tafa, Natasha Thanasi, Arian Mezini, Alma Teferici, Dafina Todri, Jolanda Nikolla, Rezarta Kazasi (Tirana University Hospital “Shefqet Ndroqi, Albania), Hamid Hacene Cherkaski (PI), Amira Bengrait, Tabarek Haddad, Ibtissem Zgaoula, Maamar Ghit, Abdelhamid Roubhia, Soumaya Boudra, Feryal Atoui, Randa Yakoubi, Rachid Benali, Abdelghani Bencheikh, Nadia Ait-Khaled (Faculté de Médecine Annaba, SEMEP Elhadjar, Algérie), Abdul Rashid Khan, Prof Richard Loh (PI) (Department of Medicine, Penang Medical College, Penang, Malaysia). The BOLD Study is currently funded by a grant from The Wellcome Trust (085790/Z/08/Z) which supports the London, UK Co-ordinating Centre. The initial BOLD program was funded in part by unrestricted educational grants to the Co-Ordinating Centre in Portland, USA from Aventis, AstraZeneca, Boehringer-Ingelheim, Chiesi, GlaxoSmithKline, Merck, Novartis, Pfizer, Schering-Plough, Sepracor and University of Kentucky. Additional local support for BOLD sites was provided by: Sher-i-Kashmir Institute of Medical Sciences, Srinagar, J&K (Srinagar, India); Boehringer Ingelheim (Sousse, Tunisia); Boehringer Ingelheim, Faculty of Medicine and Hassan II University Hospital Center of Fez (Fes, Morocco); The Wellcome Trust, National Population Commission, Ile-Ife, Osun State, Nigeria (Ile-Ife, Nigeria), GlaxoSmithKline (Tirana, Albania), The Saudi Thoracic Society, King Abdullah International Medical Research Center KAIMRC (Riyadh, Saudi Arabia), Boehringer Ingelheim (Annaba, Algérie), GlaxoSmithKline Pharmaceutical Sdn. Bhd. (Penang, Malaysia). The funders played no part in influencing the scientific direction of this study or its conclusions nor in the decision to publish.
Compliance with ethical guidelines
Competing interests The authors declare that they have no competing interests.
Contributor Information
John Townend, Email: j.townend@imperial.ac.uk.
Cosetta Minelli, Email: cosetta.minelli1@imperial.ac.uk.
Imed Harrabi, Email: imed_harrabi@yahoo.fr.
Daniel O. Obaseki, Email: danseki@yahoo.com
Karima El-Rhazi, Email: elrhazikarima@gmail.com.
Jaymini Patel, Email: j.patel@imperial.ac.uk.
Peter Burney, Email: p.burney@imperial.ac.uk.
References
- 1.Gwatkin DR, Rutstein S, Johnson K, Suliman E, Wagstaff A, Amouzou A. Socio-economic differences in health, nutrition and population within developing countries—an overview. Washington DC: The World Bank; 2007. [PubMed] [Google Scholar]
- 2.Galobardes B, Lynch J, Smith GD. Measuring socioeconomic position in health research. Br Med Bull. 2007;81:21–37. doi: 10.1093/bmb/ldm001. [DOI] [PubMed] [Google Scholar]
- 3.Buist AS, Vollmer WM, Sullivan SD, Weiss KB, Lee TA, Menezes A, et al. The burden of obstructive lung disease initiative (BOLD): rationale and design. COPD. 2005;2:277–283. doi: 10.1081/COPD-57610. [DOI] [PubMed] [Google Scholar]
- 4.Burney P, Jithoo A, Kato B, Janson C, Mannino D, Niżankowska-Mogilnicka E, et al. Chronic obstructive pulmonary disease mortality and prevalence: the associations with smoking and poverty—a BOLD analysis. Thorax. 2014;69:465–473. doi: 10.1136/thoraxjnl-2013-204460. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Registrar General. Anon. Occupational mortality: the registrar general’s decennial supplement for Great Britain, 1979–80, 1982–83. Office of Population Censuses and Surveys, London: H.M. Stationery Office; 1986.
- 6.Barker DJP, Osmond C. Childhood respiratory infection and adult chronic bronchitis in England and Wales. Br Med J. 1986;293:1271–1275. doi: 10.1136/bmj.293.6557.1271. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Hegewald M, Crapo R. Socioeconomic status and lung function. Chest. 2007;132:1608–1614. doi: 10.1378/chest.07-1405. [DOI] [PubMed] [Google Scholar]
- 8.Howe LD, Galobardes B, Matijasevich A, Gordon D, Johnston D, Onwujekwe O, et al. Measuring socio-economic position for epidemiological studies in low- and middle-income countries: a methods of measurement in epidemiology paper. Int J Epidemiol. 2012;41:871–886. doi: 10.1093/ije/dys037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Reidpath DD, Ahmadi K. A novel nonparametric item response theory approach to measuring socioeconomic position: a comparison using household expenditure data from a Vietnam health survey, 2003. Emerg Themes Epidemiol. 2014;11:9. doi: 10.1186/1742-7622-11-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Gillespie M, Tenvergert EM, Kingma J. Using Mokken scale analysis to develop unidimensional scales: do the six abortion items in the NORC GSS form one or two scales? Qual Quant. 1987;21:393–408. doi: 10.1007/BF00172565. [DOI] [Google Scholar]
- 11.Mokken RJ. A theory and procedure for scale analysis: with applications in political research. Berlin: de Gruyter; 1971. [Google Scholar]
- 12.Guttman L. A basis for scaling qualitative data. Am Social Rev. 1944;9:139–150. doi: 10.2307/2086306. [DOI] [Google Scholar]
- 13.Wright BD, Masters GN. Rating scale analysis. Chicago: Mesa Press; 1982. [Google Scholar]
- 14.Hardouin J, Bonnaud-Antignac A, Bille V. Nonparametric item response theory using Stata. Stata J. 2011;11:30–51. [Google Scholar]
- 15.Zinn F, Henderson D, Nystuen J, Drake WD. A stochastic cumulative scaling method applied to measuring wealth in Indonesian villages. Environ Plan A. 1992;24:1155–1166. doi: 10.1068/a241155. [DOI] [Google Scholar]
- 16.Karami H. An introduction to differential item functioning. Int J Educ Psychol Assess. 2012;11:59–76. [Google Scholar]
- 17.GNI per capita, PPP (current international $). The World Bank. 2014. http://data.worldbank.org/indicator/NY.GNP.PCAP.PP.CD. Accessed 13 July 2015.
- 18.Hardouin J. Imputation of missing item responses with the Mokken scaling (help file for Stata add-in command Imputemok). http://fmwww.bc.edu/repec/bocode/i/imputemok.html. Accessed 16 July 2015.
- 19.Filmer D, Pritchett L. The effect of household wealth on educational attainment: evidence from 35 countries. Popul Dev Rev. 1999;25:85–120. doi: 10.1111/j.1728-4457.1999.00085.x. [DOI] [Google Scholar]
- 20.Filmer D, Pritchett L. Estimating wealth effects without expenditure data—or tears: an application to educational enrollments in states of India. Demography. 2001;38:115–132. doi: 10.1353/dem.2001.0003. [DOI] [PubMed] [Google Scholar]
- 21.Rutstein SO, Johnson K. The DHS wealth index. DHS comparative reports 6. Calverton: ORC Macro; 2004.
- 22.Vyas S, Kumaranayake L. Constructing socio-economic status indices: how to use principal components analysis. Health Policy Plan. 2006;21:459–468. doi: 10.1093/heapol/czl029. [DOI] [PubMed] [Google Scholar]
- 23.Kolenikov S, Angeles G. Socioeconomic status measurement with discrete proxy variables: is principal component analysis a reliable answer? Rev Income Wealth. 2009;55:128–165. doi: 10.1111/j.1475-4991.2008.00309.x. [DOI] [Google Scholar]
- 24.Traissac P, Martin-Prevel Y. Alternatives to principal components analysis to derive asset-based indices to measure socio-economic position in low- and middle-income countries: the case for multiple correspondence analysis. Int J Epidemiol. 2012;41:1207–1208. doi: 10.1093/ije/dys122. [DOI] [PubMed] [Google Scholar]
- 25.Howe LD, Hargreaves JR, Huttly SRA. Issues in the construction of wealth indices for the measurement of socio-economic position in low-income countries. Emerg Themes Epidemiol. 2008;5:3. doi: 10.1186/1742-7622-5-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Rutstein SO, Staveteig S. Making the Demographic and Health Surveys Wealth Index comparable. DHS methodological reports 9. Rockville: ICF International; 2014.
- 27.Smits J, Steendijk R. The International Wealth Index (IWI). NiCE working paper 12-107. Nijmegen: Nijmegen Centre for Economics; 2013.