

Abstract
We present an innovative framework for reconstructing high-spatial-resolution diffusion magnetic resonance imaging (dMRI) from multiple low-resolution (LR) images. Our approach combines the twin concepts of compressed sensing (CS) and classical super-resolution to reduce acquisition time while increasing spatial resolution. We use sub-pixel-shifted LR images with down-sampled and non-overlapping diffusion directions to reduce acquisition time. The diffusion signal in the high resolution (HR) image is represented in a sparsifying basis of spherical ridgelets to model complex fiber orientations with reduced number of measurements. The HR image is obtained as the solution of a convex optimization problem which can be solved using the proposed algorithm based on the alternating direction method of multipliers (ADMM). We qualitatively and quantitatively evaluate the performance of our method on two sets of in-vivo human brain data and show its effectiveness in accurately recovering very high resolution diffusion images.
1 Introduction
Diffusion-weighted MRI is a key technique in studying the neural architecture and connectivity of the brain. It can be utilized as imaging-based biomarkers for investigating several brain disorders such as Alzheimer’s disease, schizophrenia, mild traumatic brain injury, etc. [1]. In many clinical applications such as neurosurgical planning and deep brain stimulation, it is critically important to use high-spatial-resolution diffusion images to accurately localize brain structures, especially those that are very small (such as substantia nigra and sub-thalamic nucleus). Moreover, HR images are critical for tracing small white-matter fiber bundles and to reduce partial volume effects. Further, with high spatial resolution, gray-matter and white-matter structures can be better resolved, especially in neonate and infant brains. The typical voxel size of a dMRI image acquired from a clinical scanner is about 1.73 to 23 mm3 which is too large to study certain brain structures that are a few millimeters thick. Due to signal loss from T2 decay with longer echo times, reducing the voxel size leads to a proportionate decrease in the signal-to-noise ratio (SNR). Though SNR could be enhanced by averaging multiple acquisitions, the total acquisition time may be too long to apply this approach in clinical settings.
Existing techniques that obtain high-resolution (HR) dMRI can be classified into two categories based on their data acquisition scheme. The first group of methods obtain HR data using a single LR image via intelligent interpolations or regularizations. These types of methods have been investigated in structural MRI [2] and in dMRI to enhance anatomical details as in [3]. However, as pointed out in [3], the performance of some of these methods still largely relies on the information contained in the original LR image. The second group of methods require multiple LR images acquired according to a specific sampling scheme to reconstruct a HR image. Each of the LR image is modeled as the measurement of an underlying HR image via a down-sampling operator. Then the HR image is estimated by solving a linear inverse problem with suitable regularization. These methods use the classical concept of super-resolution reconstruction (SRR) [4]. In dMRI, these methods were used in [5, 6] to reconstruct each diffusion weighted volume independently. A different acquisition scheme with the LR images having orthogonal slice acquisition direction was proposed in [7]. However, the distortions from LR scans with different slice directions need to be corrected prior to applying the SRR algorithm, which involves complex non-linear spatial normalization. Moreover, each diffusion-weighted image (DWI) volume is reconstructed independently, requiring the LR images to be acquired or interpolated on the same dense set of gradient directions. Thus, these methods require the same number of measurements (e.g., 60 gradient directions) for each LR acquisition. To address this problem, more recently, [8] introduced a method that used the diffusion tensor imaging (DTI) technique to model the diffusion signal in q-space. However, a very simplistic diffusion tensor model was assumed, which is not appropriate for modeling more complex diffusion phenomena (crossing fibers). A similar method has been proposed in [9] to improve distortion corrections for DWI’s using interlaced q-space sampling.
Our contributions
We propose a compressed-sensing-based super-resolution reconstruction (CS-SRR) approach for reconstructing HR diffusion images from multiple sub-pixel-shifted thick-slice acquisitions. As illustrated in Figure 1, we use three LR images with anisotropic voxel sizes that are shifted in the slice acquisition direction. Each LR image is acquired with a different (unique) set of gradient directions to construct a single HR image with isotropic voxel size and a combined set of gradient directions. This is in contrast to classical SRR techniques which require each LR scan to have the same set of gradient directions. In the proposed framework, only a subset (one-third) of the total number of gradient directions are acquired for each LR scan, which reduces scan time significantly while making the technique robust to head motion. To account for the correlation between diffusion signal along different gradients, we represent the signal in the HR image in a sparsifying basis of spherical ridgelets. To obtain the HR image, we propose a framework based on the ADMM algorithm, where we enforce sparsity in the spherical-ridgelet domain and spatial consistency using total variation regularization. We perform quantitative validation of our technique using very high resolution data acquired on a clinical 3T scanner.
Fig. 1.
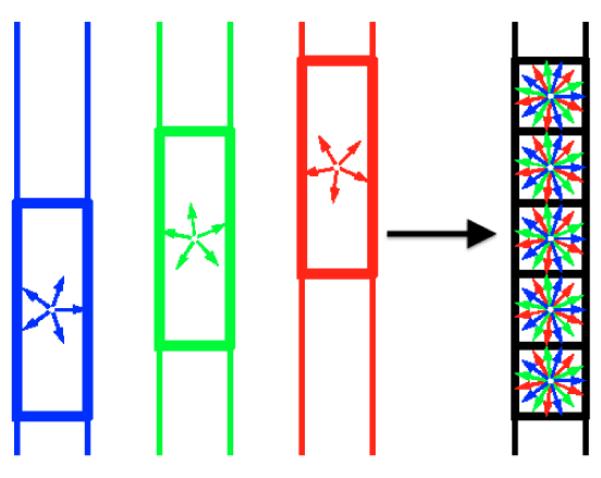
An illustration of the CS-SRR scheme: a high-resolution image is reconstructed using three overlapping thick-slice volumes with down-sampled diffusion directions.
2 Background
We consider diffusion images acquired on single spherical shell in q-space [10]. Hence, the problem of super resolution reduces to that of reconstructing the spherical signal at each voxel of the HR image. Before introducing the proposed method, we provide a brief note on the concepts of compressed sensing and spherical ridgelets that are used to model and estimate the diffusion signals.
Compressed Sensing
The theory of compressed sensing provides the mathematical foundation for accurate recovery of signals from set of measurements far fewer than that required by the Nyquist criteria [11]. In the CS framework, a signal of interest s ∈ ℝn is represented in an over-complete basis Φ ∈ ℝn×m with n << m such that s = Φc with c ∈ ℝm being a sparse vector, i.e. c only has few non-zero elements. Let y ∈ ℝp denote a measurement vector given by y = Ψ s + µ = Ψ Φc + µ where µ is the noise component and Ψ ∈ ℝp×n is a downsampling operator. If the matrix Ψ Φ satisfies certain incoherent properties, then the CS theory [11] asserts that the sparse vector c can be robustly recovered by solving the ℓ1-norm regularized problem
| (1) |
for a suitable λ ≥ 0. Hence, the signal s can be accurately recovered as Φc using the lower dimensional measurement y. This CS methodology has been used to estimate the dMRI signal from reduced number of measurements [12–14] with the basis given by the spherical ridgelets.
Spherical ridgelets
Spherical ridgelet functions were introduced in [12] as a frame to represent L2 functions on the sphere. Each spherical ridgelet function is specially designed to represent diffusion signals with a particular orientation and certain degree of anisotropy. A sparse combination of such basis functions is suitable to model the diffusion data with complex fiber orientations [13, 14]. Specifically, the spherical ridgelets are constructed as follows: For x ∈ ℝ+ and be a Gaussian function. Further, we let
Then the spherical ridgelets with their energy spread around the great circle supported by a unit vector is given by
| (2) |
where Pn denotes the Legendre polynomial of order n, κ−1(n) = 0, ∀n and if n is even, otherwise λn = 0.
To construct a finite over-complete dictionary, we follow the method in [13, 14] and restrict the values for the resolution index j to the set {−1, 0, 1}. For each resolution index j, the set of all possible orientations is discretized to a set of Mj directions on the unit sphere with M−1 = 25, M0 = 81 and M1 = 289. To this end, the set of over-complete spherical ridgelets is given by . Since the spherical ridgelets are anisotropic, the isotropic diffusion signal in the CSF areas is not efficiently modeled as a sparse combination of the basis functions. To resolve this issue, we expand the basis functions by adding one isotropic element as Ψ := {ψiso, ΨSR} where ψiso denotes a constant function on the unit sphere. For convenience, we denote the functions in Ψ as ψ1, ψ2, … , ψM with ψ1 = ψiso. Given the diffusion signal measured along N diffusion directions , we construct a basis matrix A with Anm = ψm(un) for m = 1, … , M and n = 1, … , N.
3 Method
Let Lk, k = 1, … , K, denote the K low-resolution diffusion weighted imaging (DWI) volumes. For each Lk , the diffusion signal is acquired along a set of gradient directions at the same b-value. The set of gradient directions for each LR image Lk is assumed to be different, i.e. Uk ∩ Uℓ = ∅ for k ≠ ℓ. The HR image that has nx × ny × nz voxels and gradient directions is denoted by a matrix H of size nxny nz × N . Then, each LR image Lk is given by
| (3) |
where Dk denotes the down-sampling matrix that averages neighboring slices, Bk denotes the blurring (or point-spread function) and Qk is the sub-sampling matrix in q-space. The main difference between the above model and the one used in [15, 6] is given by the Qk ’s that allow the LR images to have different sets of gradient directions. Further, we use the spherical ridgelets basis to model the diffusion signal at each voxel of H. To this end, H is assumed to satisfy H = V AT with A being the basis matrix of spherical ridgelets (SR) constructed along the set of gradient directions {U1, … , UK } and each row vector of V being the SR coefficients at the corresponding voxel. Since each basis function is designed to model a diffusion signal with certain degree of anisotropy, a non-negative combination of spherical ridgelets provides more robust representation for diffusion signals especially when the SNR is low. Hence, the coefficients V are restricted to be non-negative. Following (1), we estimate H by solving
| (4) |
where denotes the element-wise multiplication, ∥M∥2 is the squared Frobenius norm of a matrix M and ∥M∥1 is the summation of the absolute values of all the entries of M . W is the weighting matrix with each row having the form [w, 1, … , 1] where w is used to adjust the penalty for choosing the isotropic basis function in a voxel. The value of w can be obtained a-priori from a probabilistic segmentation of the T1-weighted image of the brain. Thus, w is small in the CSF and large in white and gray-matter areas.
3.1 Total-variation (TV) regularization
Let hr (un) denote the diffusion signal along the direction un at the voxel r ∈ Ω with Ω being the set of all voxels of the HR image. The diffusion signal along the gradient un in all voxels forms a 3D image volume denoted by Hn. The correlation of the diffusion signal in neighboring voxels implies that Hn is spatially smooth. A standard technique to utilize this fact is to minimize the TV seminorm of Hn defined as where N (r) denotes a set of neighbors around r. For a collection of image volumes , the TV semi-norm of H is defined as the sum of the TV semi-norm of each image volume Hn, i.e. . By adding a regularization term for lHlTV in (4), we rewrite the optimization problem as
| (5) |
where the positive parameters λ1, λ2 determine the relative importance of the data fitting terms versus the sparsity and the total regularization terms. Next, we introduce an efficient algorithm for solving (5) based on the alternating directions method of multipliers (ADMM) [16].
3.2 Optimization algorithm
The optimization problem (5) typically involves high dimensional optimization variables. A suitable implementation of the ADMM algorithm may distribute the computational cost and decompose the optimization into a sequence of simpler problems. First, we note that (5) can be equivalently written as
where Z is an auxiliary variable that equals to H, and the augmented terms with do not change the optimal value. Let Λ1, Λ2 be the multipliers for H −V AT = 0 and H − Z = 0, respectively. Then, each iteration of the ADMM algorithm consists of several steps of alternately minimizing the augmented Lagrangian over H, V, Z and one step of updating Λ1, Λ2. More specifically, let V t, Ht, Zt and denote the values of these variables at iteration t. Then, iteration (t + 1) consists of two steps of estimating {V t+1, Zt+1} and Ht+1 by solving
| (6) |
| (7) |
and one step of updating the multipliers as
A typical stopping criteria is to check if have “stopped changing”, i.e. for some user defined choice of E1, E2.
We point out some important notes for the above iterative algorithm: (1) Problem (6) can be decomposed into two independent optimization problems on V and Z, respectively. The update for V t is obtained by solving an ℓ1-minimization problem. In particular, the solution for each voxel can be obtained independently (parallely). We have also developed an ADMM-based algorithm for solving the non-negative weighted ℓ1-regularization problem, which is not presented here due to page limitations. (2) The update for Zt is a standard TV denoising problem. (3) Problem (7) is a least-squared problem which needs a matrix inversion to compute the closed-form solution. Though, in general a huge matrix needs to be inverted, in this particular situation where the LR images are sub-pixel-shifted scans with Bk ’s representing a blurring operation along the slice-selection direction and is a permutation matrix, the computation reduces to inverting K matrices of size nz × nz , i.e. for k = 1, … , K, which can be easily done on standard workstations. We also note that in extreme situations, when the matrix size is too large, the steepest descent iterative method in [6] or the conjugate gradient method can be used alternatively.
4 Experiments
We tested the performance of the proposed method using two experiments. In the first one, we used artificially generated thick-slice acquisitions based on the high resolution data set from the Human Connectome Project (HCP) while the second experiment consisted of an actual validation setup where both the LR and HR images were acquired on a 3T Siemens clinical scanner. We compared the recovered CS-SRR result with the corresponding gold-standard (GS) HR data using the following metrics:
– FA and Trace difference: Whole brain multi-tensor tractography [17] was computed on the GS and the reconstructed data, and several fiber bundles were extracted. The average fractional anisotropy (FA) and trace for tensors along the fiber bundles were computed.
– Fiber-bundle overlap: The Bhattacharyya coefficient described in [18] was used to compare the fiber bundle overlap. This measure ranges between [0, 1], with 0 being no overlap, while 1 being complete overlap of fibers.
4.1 Evaluation on HCP data
In this experiment, we used HCP data, which has spatial resolution of 1.25 × 1.25 × 1.25 mm3 with 90 gradient directions at b = 2000 s/mm2. To construct LR images, we first artificially blurred the DWI volumes along the slice direction using a Gaussian kernel with full width at half maximum (FWHM) of 1.25 mm. Then the data was down-sampled by averaging three contiguous slices to obtain a single thick-slice volume with spatial resolution of 1.25 × 1.25 × 3.75 mm3. Similarly, two additional LR volumes were obtained so that all the three LR volumes were slice-shifted in physical space (see Figure 1). The thick-slice volumes were also sub-sampled in q-space so that each set had 30 unique gradient directions. We also obtained a segmentation of the brain into three tissue types, namely, gray, white and CSF, from the T1-weighted MR images. This tissue classification was used as a prior to set w = 10−4 in CSF and w = 1 in gray and white matter areas. The auxiliary parameter ρ1 was set to ρ1 = 1.
To compare the tractography results, we first obtained the whole-brain tractography using the method in [17] for the GS and the reconstructed data sets, respectively. Next, we extracted the cingulum bundle (CB), the corticospinal tract (CST), the superior longitudinal fasiculus II (SLF-II) and a sub-part of the corpus callosum called caudal middle frontal bundle (CC-CMF), respectively, using the white matter query language (WMQL) [19] which uses Freesurfer cortical parcellations. The four pairs of fiber bundles are shown in Figure 2a to 2d, respectively. The fiber-bundle overlap measure is very close to one, indicating a significant overlap between the fiber bundles obtained using the GS and CS-SRR data. Further, the estimated average FA and trace are very similar for both data sets.
Fig. 2.

(a), (b) (c) and (d) are the tractography results for the cingulum bundle (CB), the corticospinal tract (CST), the superior longitudinal fasciculus II (SLF-II) and the corpus callosum caudal middle frontal (CC-CMF) bundle (with red and yellow tracts obtained using the GS and CS-SRR data sets respectively). The comparison metrics for the tractography results are shown in the following table.
Another important goal of this work is to demonstrate the advantage of using high-resolution DWI image in studying small white-matter fascicles. For this purpose, we generated a low-resolution DWI volume by averaging every 2 × 2 × 2 neighboring voxels from the GS data to obtain a LR dMRI data with isotropic voxel size of 2.53 mm3. Figure 3a-3c shows the single tensor glyphs color coded by the direction of the dominant eigenvector for the GS, LR and SRR data sets in the same brain region from a coronal slice. Linear interpolations were used to increase the spatial resolution of the LR image. The background of the glyphs is the corresponding T1 weighted image. As pointed out in the rectangular area in Figure 3b, due to partial-volume effects, the LR image was not able to capture the fine curvature of of fiber bundles near the gray matter areas. Figure 3d-3f show the tractography results for tracts originating from the sub-thalamic nucleus with fibers being color-coded by orientation. While the tracts obtained from the GS and CS-SRR data are very similar, as pointed out by the arrow in Figure 3e, most of the green fibers are missing in the LR image, though the number of seeds in the LR image is 8 times higher than the HR images.
Fig. 3.

(a), (b) and (c) show the single tensor glyphs for the GS, LR and CS-SRR HCP data sets, respectively. The rectangle in (b) shows the partial-volume effects in the LR image where the orientations of the glyphs are not estimated correctly. (d), (e) and (f) are the fiber tracts, color-coded with tract orientation for the three data sets with seeds in sub-thalamic nucleus. The arrow points out some missing fiber tracts in the LR image.
4.2 True CS-SRR scenario
The second experiment was based on a data set acquired on a 3T Siemens clinical scanner. We acquired three overlapping thick-slice scans with spatial resolution 1.2×1.2×3.6 mm3. The DWI volumes were sub-pixel shifted by 1.2 mm along the slice-selection direction. Each LR DWI had a set of 30 unique gradient directions with b = 1000. For comparison, we also acquired 9 acquisitions (with 90 gradient directions each) of the same subject with a spatial resolution of 1.2 × 1.2 × 1.2 mm3, which was used as the “gold standard” data. Due to time limitations, these high resolution scans had partial brain coverage (it took about 1.5 hours to obtain these 9 scans). The average of these 9 scans (after motion correction) was considered as the gold standard. We also acquired a high resolution B0 image, i.e. the b = 0 image with no diffusion encoding, and a T1-weighted image to obtain tissue classifications for prior-information used in our algorithm. To ensure that the LR DWI’s were in the same spatial co-ordinate system, we first down-sampled the whole-brain B0 image to produce three thick-slice volumes which were considered as the reference images. These images were only used for spatial normalization and not in the actual reconstruction algorithm. Then, the three acquired thick-slice LR DWI scans were registered to the corresponding reference volumes. The T1 image was registered to the whole-brain B0 image using a nonlinear transformation. From the registered T1 image, the tissue brain segmentation was used for adjusting the parameters of the algorithm in different tissue types. We set the FWHM of the blurring kernel to 1.2 mm, λ1 = 0.005, λ2 = 0.05, and w = 0.01 in CSF area and w = 1 in gray and white matters. These parameters were learned using exhaustive search experiments based on one slice of the image so that the reconstruction error was small compared with the gold-standard. For computing quantitative metrics, we registered the reconstructed whole-brain data to the partial-brain GS data set.
We first obtained the tractography results from the reconstructed (CS-SRR) and GS partial-brain data sets using the method in [17]. Since whole-brain Freesurfer cortical parcellation was not available, we could not employ WMQL for tract extraction. Consequently, we use manually selected ROI’s to extract fiber bundles in the corpus callosum (CC) and the corticospinal tract (CST), respectively. The extracted fiber bundles are shown in Figure 4a and 4b, respectively. We note that there is minor difference between FA and Trace obtained from both the data sets. The value of the Bhattacharyya coefficient also indicates a significant overlap between the fiber bundles.
Fig. 4.

(a), (b) are the tractography results with manually selected seeds in corpus callosum (CC) and the corticospinal tract (CST) (with red and yellow tracts obtained using the GS and CS-SRR data sets respectively). The comparison metrics for the tractography results are shown in the following table.
To demonstrate the difference between HR and LR images, we also generated a LR image by averaging every 2 × 2 × 2 neighboring voxel in the GS data set to obtain a LR dMRI data set with isotropic voxel size of 2.43 mm3. Figure 5 shows the single tensor glyphs color coded by direction for the GS, LR and the CS-SRR data sets in the same brain region from a coronal slice. The background of the glyphs is the corresponding T1 weighted image. As pointed out in the rectangular region in Figure 5b, due to partial-volume effects, the LR image was not able to capture the correct fiber orientations near the gray matter areas. Figure 5c is similar to Figure 5a, indicating that the proposed method was able to correctly reconstruct the fiber orientations near gray-matter areas.
Fig. 5.

(a), (b) and (c) show the single tensor glyphs colored coded by fiber orientation for the GS, LR and CS-SRR data sets, respectively. The rectangle in (b) points out the partial-volume effects in the LR image where the directions of the glyphs are not estimated correctly (shown by different colors from the GS glyphs).
5 Conclusion
We introduced a novel method for reconstructing very high-resolution diffusion data on a standard clinical scanner. By combining the concepts of compressed sensing and super-resolution, we were able to with significantly reduce scan time while increasing the spatial resolution. Preliminary results show that the our method is capable of accurately recovering complex fiber orientations in white and gray matter regions at a high spatial resolution, similar to a physically acquired gold-standard data. Future work involves doing extensive validation on several subjects in different brain regions.
| GS FA | CS-SRR FA | GS Trace | CS-SRR Trace | Fiber-bundle overlap | |
|---|---|---|---|---|---|
| CB | 0.54 | 0.52 | 2.1 × 10−3 | 2.0 × 10−3 | 0.97 |
| CST | 0.69 | 0.66 | 2.0 × 10−3 | 2.0 × 10−3 | 0.97 |
| SLF-II | 0.63 | 0.60 | 2.0 × 10−3 | 2.0 × 10−3 | 0.95 |
| CC-CMF | 0.63 | 0.61 | 2.2 × 10−3 | 2.1 × 10−3 | 0.95 |
| GS FA | CS-SRR FA | GS Trace | CS-SRR Trace | Fiber-bundle overlap | |
|---|---|---|---|---|---|
| CC | 0.64 | 0.65 | 2.2 × 10−3 | 2.4 × 10−3 | 0.96 |
| CST | 0.62 | 0.64 | 2.0 × 10−3 | 2.2 × 10−3 | 0.94 |
Acknowledgments
The authors would like to acknowledge the following grants which supported this work: R01MH099797 (PI: Rathi), R00EB012107(PI: Setsompop), P41RR14075 (PI: Rosen), R01MH074794 (PI: Westin), P41EB015902 (PI: Kikinis) and Swedish Research Council (VR) grant 2012-3682.
References
- 1.Shenton M, Hamoda H, Schneiderman J, Bouix S, Pasternak O, Rathi Y, Vu MA, Purohit M, Helmer K, Koerte I, et al. A review of magnetic resonance imaging and diffusion tensor imaging findings in mild traumatic brain injury. Brain imaging and behavior. 2012;6:137–192. doi: 10.1007/s11682-012-9156-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Manjón JV, Coupé P, Buades A, Fonov V, Louis Collins D, Robles M. Non-local MRI upsampling. Medical image analysis. 2010;14:784–792. doi: 10.1016/j.media.2010.05.010. [DOI] [PubMed] [Google Scholar]
- 3.Dyrby TB, Lundell H, Burke MW, Reislev NL, Paulson OB, Ptito M, Siebner HR. Interpolation of diffusion weighted imaging datasets. NeuroImage. 2014;103:202–213. doi: 10.1016/j.neuroimage.2014.09.005. [DOI] [PubMed] [Google Scholar]
- 4.Irani M, Peleg S. Motion analysis for image enhancement: resolution, occlusion, and transparency. Journal of Visual Communication and Image Representation. 1993;4:324–335. [Google Scholar]
- 5.Peled S, Yeshurun Y. Superresolution in MRI: application to human white matter fiber tract visualization by diffusion tensor imaging. Magnetic Resonance in Medicine. 2001;45:29–35. doi: 10.1002/1522-2594(200101)45:1<29::aid-mrm1005>3.0.co;2-z. [DOI] [PubMed] [Google Scholar]
- 6.Scherrer B, Gholipour A, Warfield SK. Super-resolution reconstruction to increase the spatial resolution of diffusion weighted images from orthogonal anisotropic acquisitions. Medical image analysis. 2012;16:1465–1476. doi: 10.1016/j.media.2012.05.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Gholipour A, Estroff JA, Warfield SK. Robust super-resolution volume reconstruction from slice acquisitions: application to fetal brain MRI. IEEE Transactions on Medical Imaging. 2010;29:1739–1758. doi: 10.1109/TMI.2010.2051680. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Steenkiste G, Jeurissen B, Veraart J, den Dekker AJ, Parizel PM, Poot DH, Sijbers J. Super-resolution reconstruction of diffusion parameters from diffusion-weighted images with different slice orientations. Magnetic Resonance in Medicine. 2015 doi: 10.1002/mrm.25597. [DOI] [PubMed] [Google Scholar]
- 9.Bhushan C, Joshi AA, Leahy RM, Haldar JP. Improved b0-distortion correction in diffusion MRI using interlaced q-space sampling and constrained reconstruction. Magnetic Resonance in Medicine. 2014;72:1218–1232. doi: 10.1002/mrm.25026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Tuch D, Reese T, Wiegell M, Makris N, Belliveau J, Wedeen V. High angular resolution diffusion imaging reveals intravoxel white matter fiber heterogeneity. Magnetic Resonance in Medicine. 2002;48:577–582. doi: 10.1002/mrm.10268. [DOI] [PubMed] [Google Scholar]
- 11.Cand`es EJ, Romberg J, Tao T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Transactions on Information Theory. 2006;52:489–509. [Google Scholar]
- 12.Michailovich O, Rathi Y. On approximation of orientation distributions by means of spherical ridgelets. IEEE Transactions on Image Processing. 2010;19:461–477. doi: 10.1109/TIP.2009.2035886. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Michailovich O, Rathi Y, Dolui S. Spatially regularized compressed sensing for high angular resolution diffusion imaging. IEEE Transactions on Medical Imaging. 2011;30:1100–1115. doi: 10.1109/TMI.2011.2142189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Rathi Y, Michailovich O, Setsompop K, Bouix S, Shenton ME, Westin CF. MICCAI 2011. Springer; 2011. Sparse multi-shell diffusion imaging; pp. 58–65. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Greenspan H, Oz G, Kiryati N, Peled S. MRI inter-slice reconstruction using super-resolution. Magnetic Resonance Imaging. 2002;20:437–446. doi: 10.1016/s0730-725x(02)00511-8. [DOI] [PubMed] [Google Scholar]
- 16.Boyd S, Parikh N, Chu E, Peleato B, Eckstein J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trend. 2011;3:1–122. [Google Scholar]
- 17.Malcolm JG, Shenton ME, Rathi Y. Filtered multi-tensor tractography. IEEE Trans. on Medical Imaging. 2010;29:1664–1675. doi: 10.1109/TMI.2010.2048121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Rathi Y, Gagoski B, Setsompop K, Michailovich O, Grant PE, Westin CF. MICCAI 2013. Vol. 510. Springer; 2013. Diffusion propagator estimation from sparse measurements in a tractography framework; p. 517. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Wassermann D, Makris N, Rathi Y, Shenton M, Kikinis R, Kubicki M, Westin CF. MICCAI 2013. Springer; 2013. On describing human white matter anatomy: The white matter query language; pp. 647–654. [DOI] [PMC free article] [PubMed] [Google Scholar]