

Abstract
Activated nuclear factor-κB (NF-κB) is associated with the pathogenesis of numerous cancers, such as gastric cancer (GC). Genetic polymorphisms in the genomic region containing nuclear factor-κB1 (NFKB1) have a plausible role in modulating the risk of GC.
To identify markers contributing to the genetic susceptibility to GC, we analyzed 15 single nucleotide polymorphisms (SNPs, rs28362491, rs3774932, rs1598856, rs230531, rs230530, rs230528, rs230521, rs230498, rs230539, rs1005819, rs3774956, rs4648055, rs3774964, rs4648068, and rs3774968) in the genomic region containing NFKB1. The participants included 401 patients with GC and 433 healthy controls.
The allelic or genotypic frequencies of the rs28362491 (located in the promoter region of NFKB1), rs230521 (NFKB1 intron 4), and rs4648068 (NFKB1 intron 12) polymorphisms in the patients with GC were significantly different from those in the healthy controls. Strong linkage disequilibrium was observed in 4 blocks (D′ > 0.9). Significantly more A-T haplotypes (block 1, P = 0.0005), A-C haplotypes (block 2, P = 0.0001) and G-A-A haplotypes (block 4, P = 0.016) were found in the patients with GC. Significantly more A-C haplotypes (block 1, P = 0.005) and A-G haplotypes (block 2, P = 0.0004) were found in the healthy controls.
These findings suggest a role for NFKB1 polymorphism in GC among a Han Chinese population and may be informative for future genetic studies on gastric cancer.
INTRODUCTION
The early diagnosis rate of gastric cancer (GC) is increasing, resulting in 10-year survival rates between 80% and 95% in the Far East.1 GC mortality is ranked the highest in Eastern Asia (China, Japan), Eastern Europe, and South America among all cancers.1 As with other types of cancer, genetic predisposition has been shown to be a potential risk factor in GC.2 Approximately 5% to 10% of all gastric cancers show familial clustering with 2 or more cases in the same family.2 Other studies have suggested that polymorphisms in nuclear factor-κB1 (NFKB1) may relate to GC.3,4
Nuclear factor-kappa B (NF-κB) is a critical transcription factor that regulates hundreds of genes involved in various biological functions, including immune response, apoptosis, and cell growth control.5 The NF-κB family contains 5 members in mammals: NFKB1 encoding p50, NFKB2 encoding p52, RELA encoding p65, REL encoding c-Rel, and RELB encoding Rel-B. The most common dimer is the p65/p50 heterodimer. NF-κB is persistently active in the pathogenesis of numerous cancers, including breast,6,7 prostate,8 pancreatic,9 colorectal,10 oral,11 and GC.4 NF-κB activation has been identified in GC and is a potential prognostic factor of GC.5,12
The NFKB1 gene is located on chromosome 4 and has a 15-kb coding region with 22 exons and 21 introns. A common insertion/deletion (single nucleotide polymorphism [SNP] rs28362491, −94 insertion/deletion ATTG) located between 2 putative key promoter regulatory elements in the NFKB1 gene has been identified and seems to be the first potential functional NFKB1 genetic variation.13 Although several NFKB1 SNPs, such as rs28362491, rs4648068, and rs12509517, were studied in patients with GC, discrepant results have been obtained.14,15 The limited number1–4 of SNPs may result in the inconsistency of these studies. In fact, a study of the limited number of SNPs may not effectively reveal the role of truly causative SNPs in the NFKB1 gene due to weak linkage disequilibrium among them. Thus, to exactly identify the association of NFKB1 SNPs with GC, it is necessary to use a more powerful technique that could identify biologically important SNPs.
In this study, we investigated 15 loci in a Chinese population from Shaanxi province (China) to verify the putative association between NFKB1 polymorphisms and GC.
SUBJECTS AND METHODS
Subjects
A hospital-based case–control study was conducted in 401 patients with GC (mean ± SD age: 45.2 ± 4.6 years) and 433 healthy controls (mean ± SD age: 46.3 ± 5.6 years). The patients with confirmed pathological diagnosis in Tangdu Hospital, Fourth Military Medical University of China (Xi’an, China) between March 2008 and December 2012 were enrolled in the present study. Patients who had cardiac adenocarcinoma, secondary or recurrent tumors, a history of other malignant neoplasms, and previous eradication therapy for H pylori were excluded. The healthy control group consisted of patients who underwent health examinations in the Medical Examination Center of the Tangdu Hospital (Xi’an, China) between October 2010 and September 2012. Participants were excluded if they were taking other prescribed medications that could affect the central nervous system or had a history of seizures, hematological diseases, or severe liver or kidney impairment. No familial relationship was known between the study participants. Written informed consent was obtained from each participant in this study. The study protocol was approved by the Ethical Committee of the Tangdou hospital.
SNP Selection and Genotyping
SNPs in the promoter region, untranslated regions, exons, and introns of NFKB1 were systematically screened. 15 SNPs (rs28362491, rs3774932, rs1598856, rs230531, rs230530, rs230528, rs230521, rs230498, rs230539, rs1005819, rs3774956, rs4648055, rs3774964, rs4648068, and rs3774968) with minor allele frequencies (MAF) greater than 0.05 were selected from NFKB1 and nearby regions. Marker selection was based on the following criteria. We used the CHB data from the HapMap (release 27) to tag SNPs for NFKB1. We restricted our search for SNPs from base pair 102501329 to 102617302. We further limited the SNPs to tag to those with a MAF ≥0.2 in the CHB. Based on these restrictions, there were a total of 15 SNPs tagged. Using HAPLOVIEW with an r2 threshold ≥0.8, these 15 tagged SNPs were selected and used for subsequent analyses. Peripheral blood was collected from a vein into a sterile tube coated with ethylenediaminetetraacetic acid. Plasma samples were stored at −20 °C. Genomic DNA was extracted from peripheral blood leukocytes according to the manufacturer protocol (Genomic DNA kit, Axygen Scientific, Inc., Union City, CA, USA). DNA was stored at −80 °C for SNP analysis. Genotyping was carried out for all SNPs using the MassARRAY platform (Sequenom, San Diego, CA, USA). Briefly, SNPs were genotyped using high-throughput matrix-assisted laser desorption ionization time-of-flight (MALDI-TOF) mass spectrometry. Probes and primers were designed using the Assay Design Software (Sequenom, San Diego, CA, USA). The resulting spectra were processed with the Typer Analyzer software (Sequenom), and genotype data were generated for the samples. Genotype calling was performed in realtime with the MassARRAYRT software version 3.0.0.4 and analyzed using the MassARRAY Typer software version 3.4 (Sequenom). The final genotype call rate of each SNP was >98%, and the overall genotyping call rate was 98.6%, ensuring the reliability of further statistical analysis.
Statistical Analysis
All statistical analyses were carried out using SPSS 11.5 software (SPSS Inc, Chicago, IL, USA). Each SNP was tested for deviation from Hardy–Weinberg equilibrium (HWE) using the Pearson chi-squared (χ2) test or Fisher exact test. Differences between the cases and controls in the frequency of the alleles, genotypes, and haplotypes were evaluated using chi-squared tests. Unconditional logistic regression was used to calculate the odds ratio (OR) and 95% confidence interval (CI) in independent association between each locus and the presence of GC. The Bonferroni correction was used to adjust the test level when multiple comparisons were conducted, and the P value was divided by the total number of loci. Haplotype blocks were defined according to the criteria developed by Gabriel et al.16 Pair-wise LD statistics (D′ and r2) and haplotype frequency were calculated, and haplotype blocks were constructed using Haploview 4.0.17 To ensure that the LD blocks most closely reflect the population level LD patterns, the definitions of the blocks were based on the control samples alone. The haplotype frequencies were estimated using GENECOUNTING, which computes maximum-likelihood estimates of haplotype frequencies from unknown phase data by utilizing an expectation-maximization algorithm. The significance of any haplotypic association was evaluated using a likelihood ratio test followed by permutation testing that compared estimated haplotype frequencies in cases and controls.
RESULTS
The distribution frequencies of the 15 genotyped SNPs were in agreement with HWE. LD analyses of the patient and control data revealed that 2 of the SNPs (rs3774932 and rs1598856) were located in the haplotype block 1, 2 (rs230528 and rs230521) were located in haplotype block 2, 2 (rs3774956 and rs4648055) were located in haplotype block 3, and 4 (rs4648068, rs3774964, and rs3774968) were located in haplotype block 4 (D′ > 0.9, Figure 1). The genotype distribution, allelic frequencies, and haplotypes in the patients with GC and healthy controls are shown in Tables 1 Tables 2–5.
FIGURE 1.
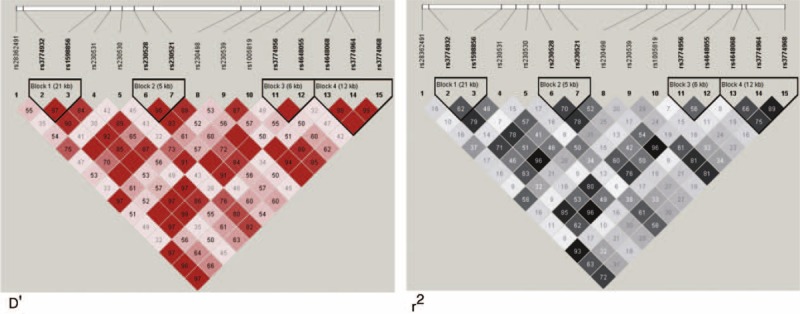
1 LD plot of the 15 SNPs in the NFKB1 gene. Values in squares were obtained by the pairwise calculations of D′ (left) or r2 (right).
TABLE 1.
Genotype and Allele Frequencies of the NFKB1 Gene Polymorphisms in Controls (n = 433) and Gastric Cancer (n = 401) and Their Associated Risk
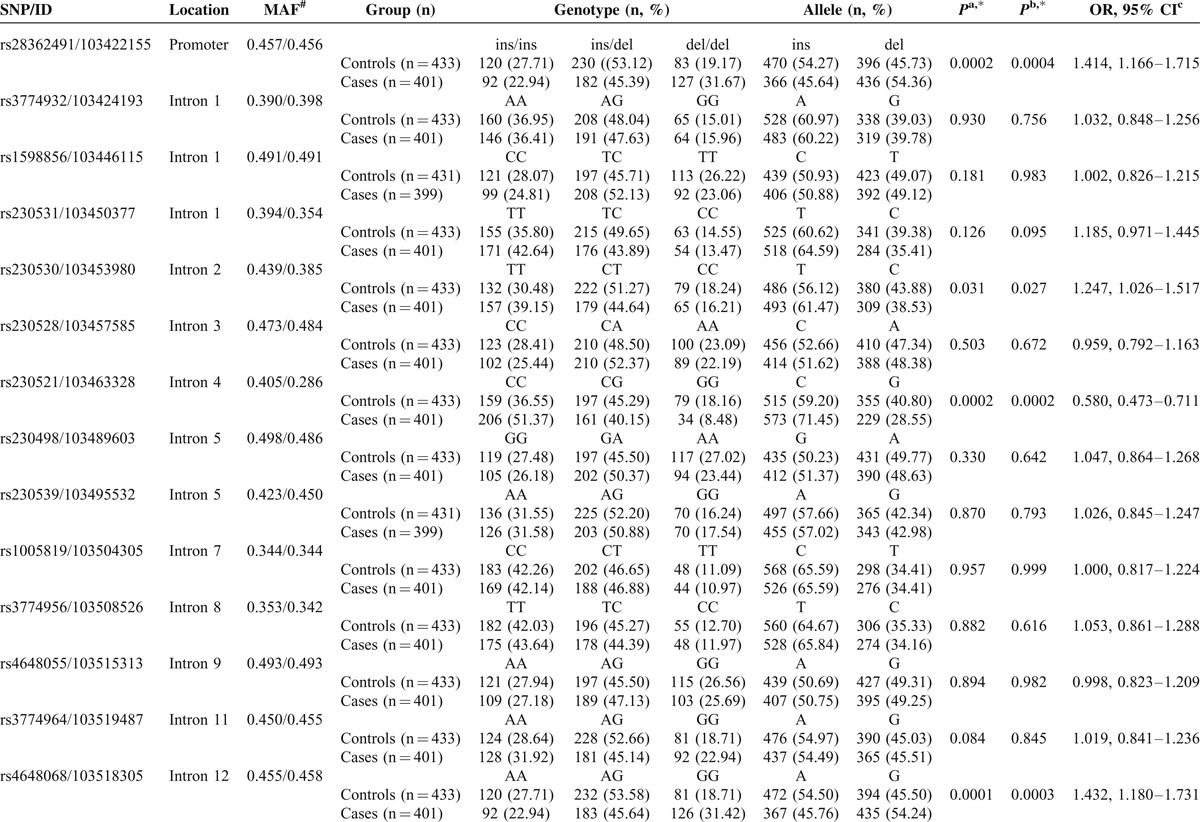
TABLE 1 (Continued).
Genotype and Allele Frequencies of the NFKB1 Gene Polymorphisms in Controls (n = 433) and Gastric Cancer (n = 401) and Their Associated Risk

TABLE 4.
NFKB1 Haplotype in Block 3 Frequencies and the Results of Their Associations with Risk of Gastric Cancer
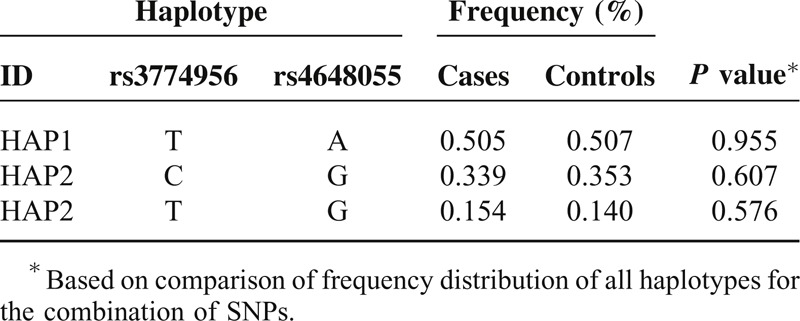
TABLE 2.
NFKB1 Haplotype in Block 1 Frequencies and the Results of Their Associations with Risk of Gastric Cancer
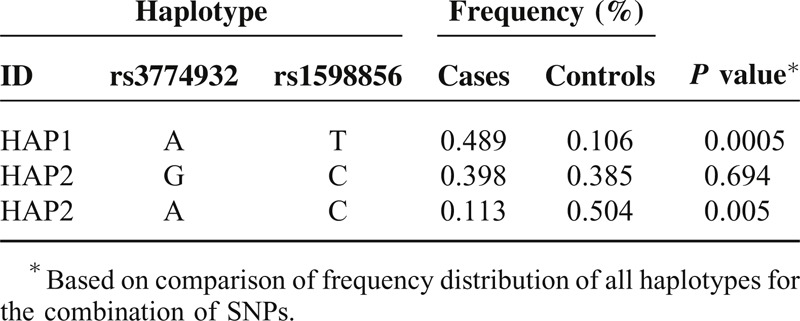
TABLE 3.
NFKB1 Haplotype in Block 2 Frequencies and the Results of Their Associations with Risk of Gastric Cancer
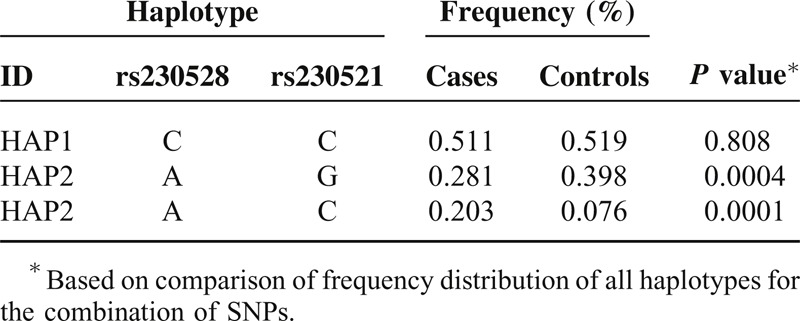
TABLE 5.
NFKB1 Haplotype in Block 4 Frequencies and the Results of Their Associations with Risk of Gastric Cancer

Comparison of genotype and allele frequency distribution revealed significant differences between the patients with GC and healthy controls for 3 SNPs: rs28362491, rs230521, and rs4648068. We found a strong linkage between the −94 ins/del ATTG (rs28362491) genotype distribution and GC (P = 0.0002 after Bonferroni correction). The frequency of the −94 del ATTG allele was significantly lower in the patients with GC than in the healthy controls (P = 0.0004, OR = 1.414, 95% CI = 1.166–1.715). The frequency of the C allele in rs230521 (P = 0.0002, OR = 0.580, 95% CI = 0.473–0.711) and G allele in rs4648068 (P = 0.0003, OR = 1.432, 95% CI = 1.180–1.731) in the patients with GC was significantly lower than in the controls, and these differences still remained statistically significant after Bonferroni corrections. There were no interactions among rs28362491, rs230521, and rs4648068 (P > 0.05).
Significantly more A-C haplotypes (block 1, P = 0.005) and A-G haplotypes (block 2, P = 0.0004) were found in the healthy controls than in GC patients. Significantly more A-T haplotypes (block 1, P = 0.0005), A-C haplotypes (block 2, P = 0.0001) and G-A-A haplotypes (block 4, P = 0.016) were found in the patients with GC than in healthy controls. These differences were still significant after Bonferroni corrections.
DISCUSSION
A key step in linkage and association studies is to identify common risk variants in different populations. To determine if common risk variants exist in distinct populations, 15 SNPs spanning approximately 14 kb of the NFKB1 gene were genotyped in samples from patients with GC and healthy controls in a Chinese Han population. In this study, we first conducted a large genetic association study of the NFKB1 gene in a Chinese Han population. The evidence of markers associated with GC is presented, and these markers were mapped to different locations in the NFKB1 gene (103422155–103531112). Association signals in the region were identified, and some significantly associated haplotypes also appeared this region. Our results provide direct evidence that a genetic change in NFKB1 is linked to human GC and extend the list of genetic variations in NFKB1 that may affect the development of GC.4,14
Genetic variations contribute to the differential disease susceptibility of individuals. The functional significances of several NFKB1 SNPs, particularly rs28362491, have been well elucidated.13 Previously findings regarding the role of the −94 ins/del ATTG (rs28362491) polymorphism in NFKB1 promoter activity strengthen the hypothesis that this risk allele of NFKB1 may cause aberrantly increased levels of p50/p105 NF-κB, which, in turn, transactivate anti-apoptosis genes that are important for cell survival.6,13 Indeed, previous studies have reported that the presence of the insertion allele is associated with increased cancer risk and aggressive cancer behavior.15,18,19 In this study, the frequency of the NFKB1 rs28362491 ins allele was significantly higher in the patients with GC than in the healthy controls. The “risk” effect of NFKB1 ins allele increased with the number of its copies in the genotype, which is consistent with the result obtained in the patients with GC in a Taiwanese population.18 The mechanism by which the rs28362491 SNP affects the susceptibility to GC may be through affecting the function of the NFKB1 protein. Karban et al first identified a functional polymorphism of the NFKB1 promoter and reported that an NFKB1 promoter containing the rs28362491 ins allele showed higher promoter activity than a promoter containing the del allele.13 However, Kim et al reported that this functional polymorphism was not a prognostic marker for Korean patients with surgically resected gastric adenocarcinoma.14 The discrepancy between studies could be due to regional and ethnic differences in genotypes and the sample size included in these studies. Population stratification and sample size are important issues to be considered in human genetic surveys.20
We show here in a cohort of Han Chinese that the NFKB1 SNP rs4648068 (intron 12) appears to be relevant to GC. In particular, the frequency of the G allele is significantly higher in the patients with GC than in the healthy controls. Lu et al found that the rs4648068 polymorphism had a significantly different distribution in patients with GC and healthy control in a preliminary small-scale genotyping study.21 Lu et al investigated the role of the NFKB1 rs4648068 polymorphism in GC susceptibility in a Han Chinese population in a case–control study. The results showed that people with the homozygous G/G alleles in rs4648068 had increased risk of GC compared with people with other rs4648068 alleles.21 The region near rs4648068 in intron 12 of NFKB1 exhibited increased levels of incorporation of histones H3K9me1 and H3K4me1. Maps of chromatin state were generated by the Broad/MGH ENCODE group using chromatin immunoprecipitation coupled with sequencing (ChIPseq). The increased levels of chemomodification imply that rs4648408 may be located in a regulatory element such as an enhancer.21 Hence, the G allele of rs4648068 may alter the power of a potential enhancer, which may have an influence on disease in the host. The present study indicates that the frequency of the C allele in rs230521 in the patients with GC was significantly lower than that in the healthy controls. To our knowledge, this is the first report to evaluate the association between these genetic variants in NFKB1 and GC. The precise molecular mechanism underlying the association remains unclear and should be further investigated.
We further investigated the genetic interactions among polymorphisms, and strong linkage disequilibrium was observed. The haplotype analysis revealed that significantly more A-T haplotypes (block 1), A-C haplotypes (block 2) and G-A-A haplotypes (block 4) were found in the patients with GC than in healthy controls. Furthermore, significantly more A-C haplotypes (block 1) and A-G haplotypes (block 2) were found in the healthy controls than in the GC patients. Significant point-wise associations of these variants with GC were observed. These results indicate that the patients with A-T haplotypes (block 1), A-C haplotypes (block 2) and G-A-A haplotypes of the NFKB1 gene were more prone to develop GC. Significantly higher frequencies of A-C haplotypes (block 1) and A-G haplotypes (block 2) were detected in the healthy controls than in the patients with GC, suggesting that these variants may exert a protective effect against GC. To some extent, this finding further supports a role for NFKB1 polymorphisms in GC, although ethnic group differences may exist.
In conclusion, our study contributes to a better understanding of the pathogenesis of GC. Our study suggests a potential role for NFKB1 SNPs and their related haplotypes in the genetic susceptibility to GC. Further studies are needed to investigate how these SNPs could affect the function of NFKB1.
Acknowledgment
This research was supported by partially supported by the National Science Foundation of China (# NSFC30800515) and Shannxi Province National Science Foundation (2013JM4021).
Footnotes
Abbreviations: CI = confidence interval, EDTA = ethylenediaminetetraacetic acid, GC = gastric cancer, HWE = Hardy–Weinberg equilibrium, LD = linkage disequilibrium, MAF = minor allele frequencies, MALDI-TOF = matrix-assisted laser desorption ionization time-of-flight, NFKB1 = nuclear factor-kappa B1, OR = odds ratio, SNP = single nucleotide polymorphism, UTR = untranslated regions.
There are no conflicts of interest.
REFERENCES
- 1.Hertz-Picciotto I, Samuels SJ. Incidence of early loss of pregnancy. N Engl J Med 1988; 319:1483–1484. [DOI] [PubMed] [Google Scholar]
- 2.Wilcox AJ, Weinberg CR, O’Connor JF, et al. Incidence of early loss of pregnancy. N Engl J Med 1988; 319:189–194. [DOI] [PubMed] [Google Scholar]
- 3.Chard T. Frequency of implantation and early pregnancy loss in natural cycles. Baillieres Best Pract Res Clin Obstet Gynaecol 1991; 5:179–189. [DOI] [PubMed] [Google Scholar]
- 4.Stirrat GM. Recurrent miscarriage. II: Clinical associations, causes, and management. Lancet 1990; 336:728–733. [DOI] [PubMed] [Google Scholar]
- 5.Stirrat GM. Recurrent miscarriage. Lancet 1990; 336:673–675. [DOI] [PubMed] [Google Scholar]
- 6.Zhang YX, Zhang YP, Gu Y, et al. Genetic analysis of first-trimester miscarriages with a combination of cytogenetic karyotyping, microsatellite genotyping and array CGH. Clin Genet 2009; 75:133–140. [DOI] [PubMed] [Google Scholar]
- 7.Stephenson MD, Awartani KA, Robinson WP. Cytogenetic analysis of miscarriages from couples with recurrent miscarriage: a case–control study. Hum Reprod 2002; 17:446–451. [DOI] [PubMed] [Google Scholar]
- 8.Greenwold N, Jauniaux E. Collection of villous tissue under ultrasound guidance to improve the cytogenetic study of early pregnancy failure. Hum Reprod 2002; 17:452–456. [DOI] [PubMed] [Google Scholar]
- 9.Regan L, Rai R. Epidemiology and the medical causes of miscarriage. Baillieres Best Pract Res Clin Obstet Gynaecol 2000; 14:839–854. [DOI] [PubMed] [Google Scholar]
- 10.Lind DS, Hochwald SN, Malaty J, et al. Nuclear factor-kappa B is upregulated in colorectal cancer. Surgery 2001; 130:363–369. [DOI] [PubMed] [Google Scholar]
- 11.Rueda B, Nunez C, Lopez-Nevot MA, et al. Functional polymorphism of the NFKB1 gene promoter is not relevant in predisposition to celiac disease. Scand J Gastroenterol 2006; 41:420–423. [DOI] [PubMed] [Google Scholar]
- 12.Houwert-de Jong MH, Bruinse HW, Eskes TK, et al. Early recurrent miscarriage: histology of conception products. Brit J Obstet Gynaecol 1990; 97:533–535. [DOI] [PubMed] [Google Scholar]
- 13.Hogan JI. The etch-retained metal restoration in hospital clinical use. Br Dent J 1988; 164:6–7. [DOI] [PubMed] [Google Scholar]
- 14.Gladen B. Re: “Risk factors for spontaneous abortion and its recurrence”. Am J Epidemiol 1990; 131:570–573. [DOI] [PubMed] [Google Scholar]
- 15.Risch HA, Weiss NS, Clarke EA, Miller AB. Risk factors for spontaneous abortion and its recurrence. Am J Epidemiol 1988; 128:420–430. [DOI] [PubMed] [Google Scholar]
- 16.Regan L, Braude PR, Trembath PL. Influence of past reproductive performance on risk of spontaneous abortion. BMJ 1989; 299:541–545. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Knudsen UB, Hansen V, Juul S, Secher NJ. Prognosis of a new pregnancy following previous spontaneous abortions. Eur J Obstet Gynecol Reprod Biol 1991; 39:31–36. [DOI] [PubMed] [Google Scholar]
- 18.Nybo Andersen AM, Wohlfahrt J, Christens P, et al. Maternal age and fetal loss: population based register linkage study. BMJ 2000; 320:1708–1712. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Liddell HS, Pattison NS, Zanderigo A. Recurrent miscarriage–outcome after supportive care in early pregnancy. Aust J Publ Health 1991; 31:320–322. [DOI] [PubMed] [Google Scholar]
- 20.Lewis PJ. Recurrent miscarriage. BMJ 1991; 302:1078. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Regan L. Recurrent miscarriage. BMJ 1991; 302:543–544. [DOI] [PMC free article] [PubMed] [Google Scholar]