

Abstract
Researchers have begun to evaluate animals’ metacognitive capacities. Continuing this evaluation, the present authors asked whether monkeys could use the analog of a confidence-rating scale to judge retrospectively their accuracy in a psychophysical discrimination. Monkeys and human participants classified stimuli as dense or sparse without feedback. Then, they made a secondary confidence judgment by choosing responses that risked different levels of timeout but could earn different levels of reward. Human participants were instructed to use these responses to express levels of confidence. They used 2- and 3-level confidence-rating scales appropriately. Monkeys used the 2-level scale appropriately—especially one who performed almost identically to humans. Neither monkey used the 3-level scale as the humans did. These studies place humans and animals for the first time in the identical risk-taking situation that collects declarative confidence judgments from humans. They demonstrate the first retrospective reports of uncertainty by non-human primates while also suggesting their limits in this area.
Keywords: animal cognition, cognitive monitoring, confidence judgments, metacognition
Humans often experience feelings of certainty and doubt, of knowing and not knowing, and of remembering and not remembering. They often react adaptively to these by pausing, reflecting, and seeking hints or information. These coping responses ground the literatures on metacognition and uncertainty monitoring (A. L. Brown, Bransford, Ferrara, & Campione, 1983; A. S. Brown, 1991; Dunlosky & Nelson, 1992; Flavell, 1979; Hart, 1965; Koriat, 1993; Metcalfe & Shimamura, 1994; Nelson, 1992; Schwartz, 1994; S. M. Smith, Brown, & Balfour, 1991).
Metacognition is defined as thinking about thinking, or cognition about cognition. The idea is that the human mind (at least) contains a cognitive executive that monitors perception, memory, or problem solving to see how it is going and how it might be facilitated (e.g., when we realize we cannot recall someone’s name and undertake retrieval efforts to recover it). Nelson and Narens (1990) gave the literature on human metacognition a constructive theoretical framework by distinguishing between mental activities that occur at an overseeing, meta level and a lower, object level during cognitive processing. The meta level monitors the object-level processing to judge its progress and prospects. These monitoring functions are assessed by collecting metacognitive judgments (i.e., ease-of-learning judgments, feeling-of-knowing judgments, judgments of learning, and confidence judgments).
Researchers infer intriguing aspects of mind when humans behave metacognitively. Metacognition is taken to be about hierarchical tiers of cognitive oversight (i.e., the meta level and object level). It is taken to demonstrate humans’ awareness of the processes of mind. Researchers also link metacognitive states to subjective self-awareness because uncertainty and doubts are subjective and personal (i.e., we know that we are uncertain). Metacognitive states are even linked to declarative consciousness (Nelson, 1996) because humans easily introspect these states and communicate them to others. Thus, metacognition is taken to be one of humans’ most sophisticated cognitive capacities and possibly uniquely human. For these reasons, it is an important question whether animals have analogous cognitive capacities. Indeed, the sophistication of the metacognitive capacity could let it rival tool use and language for the potential to highlight continuities or discontinuities between human and animal minds.
Accordingly, researchers have initiated a new area of comparative inquiry that considers the capacity of nonhuman animals (hereafter animals) for cognitive monitoring (Shields, Smith, & Washburn, 1997; J. D. Smith et al., 1995; J. D. Smith, Shields, Allendoerfer, & Washburn, 1998; J. D. Smith, Shields, Schull, & Washburn, 1997; J. D. Smith, Shields, & Washburn, 2003a, 2003b). To address the metacognitive problem with animals, these researchers used cognitive tasks in which some trials were predictably more difficult than others. They also gave animal participants an uncertainty response that let them decline trials. The researchers posited that if the animal participants could monitor cognition accurately, then they would recognize difficult trials as problematic and error risking and choose the uncertainty response on these trials.
One line of research adopted the psychophysical uncertainty paradigm that has long intrigued psychophysicists (Watson, Kellogg, Kawanishi, & Lucas, 1973; Woodworth, 1938). This paradigm combines a psychophysical discrimination (providing a range of controlled trial difficulties) with the uncertainty response. In these studies, animals produced a data pattern (i.e., using the uncertainty response proactively to avoid errors on difficult trials) that was identical to that which humans produced when instructed to use the response to cope with uncertainty. Indeed, the graphs of the human and animal data from these studies show some of the strongest similarities between human and animal performance in the comparative literature. Shields et al. (1997) extended these results by showing that animals could make uncertainty responses identically to humans even when facing a difficult and abstract same–different task. J. D. Smith et al. (1998) used a serial-probe recognition task to show that animals could even make adaptive uncertainty responses when they judged that their memory traces were ambiguous or indeterminate. Other laboratories have followed up these results. Hampton (2001) replicated J. D. Smith et al.’s metamemory result with an alternative paradigm. Inman and Shettleworth (1999) found the interesting null result that pigeons show no evidence of a metacognitive capacity. The present research continues this exploration of the animal analogs of human metacognition.
Here, we focus on whether animals can make judgments that are the analog of humans’ retrospective confidence ratings (i.e., ratings of confidence in an answer already given). There were many motivations for this focus. First, retrospective confidence is a standard metacognitive judgment that has been important in cognitive research (e.g., Baranski & Petrusic, 2001; Jonsson & Allwood, 2003; Kunimoto, Miller, & Pashler, 2001; Nelson & Narens, 1990; Roebers, 2002).
Second, we thought that confidence judgments were a good candidate for comparative study. Confidence is a metacognitive signal that humans monitor easily and frequently in the real world. It also seemed to us that animals would have frequent need to evaluate their confidence (e.g., “Am I confident enough to try this leap through the canopy?”; see J. D. Smith et al., 2003a, 2003b, for discussion), making it plausible that they also might be able to express confidence judgments.
Third, the use of behavioral confidence judgments offered the most direct way to solve a critical question in comparative metacognition research. There is sharp interest in knowing whether participants (human or animal) make accurate metacognitive judgments. To know this, one must assess whether strong and weak reports of knowing, respectively, tend to be paired with accurate and inaccurate performance on the primary task. This assessment is a constant feature of human metacognition research (e.g., Hart, 1966; Metcalfe & Shimamura, 1994; Nelson, 1992; Nelson & Narens, 1980). But the primary method in animal metacognition research has been to let animals decline and avoid difficult trials. Thus, one does not measure performance following these weak reports of knowing. Accuracy is measured only after strong reports (i.e., trials that are not declined). One solution to this problem has been to use forced trials that cannot be declined. The idea is that performance on forced trials should be a composite of performance on trials the participant would have accepted and declined. The metacognitive hypothesis is then that performance on forced trials will be lower than performance on accepted trials that presumably are accepted because a favorable metacognitive signal was monitored on them. But this solution has problems, too. It may affect performance by jarring or distracting animals when their response repertory suddenly changes from trial to trial. It only lets one estimate indirectly (through algebra and assumptions) what performance would have been given weak metacognitive judgments. It has also involved wasting 33% of all trials to fill out the design with trials (i.e., forced-decline trials to balance the forced-accept trials) that are theoretically uninteresting and unanalyzed (Hampton, 2001; Inman & Shettleworth, 1999; Teller, 1989). In addition, this approach can be insensitive—that is, the difference between performance on forced and chosen trials is expected to be small and may be difficult to discern statistically. In contrast, by using confidence ratings as in the present study, one can integrate strong and weak metacognitive judgments seamlessly, unjarringly, and efficiently into ongoing task performance, while also assessing performance directly for every weak and strong judgment of knowing.
Fourth, we focused on confidence judgments because we were interested in getting animals to respond in a way that verged on the use of a rating scale. The potential for scientific knowledge is vast if animals can rate things in their world (e.g., the level of threat in a conspecific, their preferences, or even moods). We thought that the exploration of the rating-scale approach could lay the groundwork for many future lines of research. Research of this kind could eventually break down the introspection/self-report barrier that makes it so difficult to query animal minds.
As a result, the present research evaluates comparatively the capacity of humans and monkeys to make retrospective judgments of their confidence in answers just given. To communicate this idea to the monkeys, we instituted a betting procedure to let them accept higher reward or penalty stakes for the trials they felt they knew more strongly. They could gain large rewards for a high-confidence response but risked longer penalty timeouts for an error in this case. They could gain small rewards for a low-confidence response and risked shorter penalty timeouts for an error in this case. In Experiment 1, we compared the results from humans and monkeys who used the analog of a 2-level confidence scale (high and low confidence expressed for both discriminative responses). In Experiment 2, we compared the results from humans and one monkey who used the analog of a 3-level confidence scale (high, medium, and low confidence expressed for both discriminative responses).
EXPERIMENT 1
A: Humans’ Retrospective Confidence (2-Level Rating Scale)
Method
Participants
Ninety-two undergraduates from the University at Buffalo, State University of New York, participated in a single, 45-min session to fulfill a course requirement.
Apparatus
An IBM-compatible computer generated stimuli on a color monitor. The participants were seated in front of the monitor and used a standard analog joystick to move a cursor to indicate their responses and confidence ratings.
Primary Discrimination Response
Each trial consisted of a primary discrimination response and a secondary confidence rating. The task was a psychophysical density discrimination in which participants judged whether a 200– ×100-pixel rectangle on the screen (hereafter the Box) was sparsely or densely filled with illuminated pixels. This task followed that described in J. D. Smith et al. (1997) and modified into a same–different task by Shields et al. (1997). If the Box contained less or more than 1,164 pixels, it was defined to be a sparse or dense stimulus, respectively. The correct response was then to move the cursor to the letter S (presented below and to the right of the Box) or to the letter D (presented below and to the left). Thirty density levels between 864 and 1,152 pixels (Levels 1–30) were designated as sparse stimuli, and 30 density levels between 1,176 and 1,569 pixels (Levels 32–61) were designated as dense stimuli. To be fair, the box holding 1,164 pixels (Level 31) was never presented. Pixel counts were determined by the formula: 855 × 1.01level. The participants made discrimination responses by moving the cursor to the D or S but received no feedback.
Secondary Confidence Rating
One second after the discrimination response, the unselected response icon (S or D) disappeared and two colored bars appeared under the selected icon. If the D was selected, then pink and blue bars appeared below the D to the left and right, respectively. If the S was selected, then pink and blue bars appeared below the S to the right and left, respectively. The participants used the pink and blue bars, respectively, to express high and low confidence about the discrimination response they had just given. After they made correct discrimination responses, the pink bar earned the participants 2 points, signaled by two computer-generated whooping sounds and the addition of 2 points to their score. The blue bar earned one point that was signaled by one whooping sound and the addition of 1 point to their score. After they made incorrect discrimination responses, the pink bar cost participants 2 points and two 10-s timeout penalties. The blue bar cost participants 1 point and one 6-s timeout penalty. Timeouts were accompanied by a low buzzing sound. The screen cleared and a new trial began after reward or timeout.
Trial Difficulty Adjustment
Sparse and dense trials occurred with equal probability. Early in the session, the easiest sparse and dense stimuli were presented (Level 1 vs. Level 61, 864 vs. 1,569 pixels). When participants achieved 80% accuracy, the computer program increased the difficulty of the task by presenting levels that gradually telescoped toward the center of the sparse–dense continuum. When trial difficulty reached Levels 19 and 43 (1,033 vs. 1,312 pixels), a dual-rectangular trial distribution was instituted to evaluate participants’ mature performance. Half the trials in this phase sampled carefully the five most difficult levels of sparse and dense stimuli that surrounded the discrimination’s breakpoint (Levels 26–30; 32–36), and the other half sampled the entire stimulus range (Levels 1–30; 32–61). Only the trials in this mature phase of testing were analyzed (about 150 per participant).
Forced Trials
Participants are often given trials on which their metacognitive options are eliminated, and they are forced to perform in a certain way. We incorporated this trial type. On 8% and 8% of trials, respectively, participants were forced to complete the trial using the high- and low-confidence options. These trials are useful to ensure that participants experience the contingencies relating to all the confidence choices in the task. However, we discuss the results from these forced trials only briefly because the trials on which participants chose to express high or low confidence are more directly informative.
Instructions
The participants read these instructions: This experiment is about perception. You will see boxes that are DENSE or SPARSE with dots. When the Box is Dense, use the joystick to move the cursor (+) to touch the D. When the Box is Sparse, use the joystick to move the cursor (+) to touch the S. Then, if you have HIGH confidence in your answer, touch the PINK bar to possibly win 2 points. Or, if you have LOW confidence in your answer, touch the BLUE bar to possibly win 1 point. Sometimes the computer will decide for you which bar you should touch. For correct D or S responses, you will hear whooping sounds and GAIN points. For incorrect D or S responses, you will hear buzzing sounds and LOSE points. So, just choose the D for DENSE trials, the S for SPARSE trials and rate your confidence using the colored bars so you can maximize your points.
Results
Overall Performance
The 92 participants completed 13,168 mature, nonforced trials with an overall sparse–dense discrimination accuracy of 73%.
Use of High- and Low-Confidence/Risk Choices
We expected that if the participants knew when they knew, they would tend to use the high-confidence/risk choice (henceforth high-risk choice) after classifying easy (very sparse or very dense) stimuli and the low-confidence/risk choice (henceforth low-risk choice) after classifying difficult stimuli near the discrimination’s breakpoint. The data conformed to this pattern. Figure 1A shows the composite data from 92 human participants. High-risk choices (filled circles) were dominant for easy stimuli (those toward the edges of the stimulus continuum), whereas low-risk choices (open circles) reached their peak toward the center of the stimulus continuum near the sparse–dense boundary. One may also be interested in the performance of individual human participants, because we will report the results from individual monkey participants hereinafter. Figures 1B and 1C show two single-participant graphs. These graphs illustrate the extremes of relative use of the high-and low-risk options. Yet, in both cases, the use of the low-risk option clearly peaked for the boundary stimuli. (In Figures 1B and 1C, the data were binned more coarsely than in the composite graph, so that individual humans, who received only about 150 mature trials each, would have data in each performance bin.)
FIGURE 1.

The performance of human participants in the confidence-rating density-discrimination task of Experiment 1A. A. The use of the two risk choices (high- and low-confidence) by 92 humans. In this and all graphs to follow, the x-axis represents density Levels 1 to 61, of which Levels 1 to 30 were designated as sparse trials and Levels 32 to 61 as dense trials. Level 31 was never presented. The filled and open circles show humans’ use of the high-risk and low-risk choices, respectively, for stimuli at different density levels. B. Human 1’s use of the two risk choices (high- and low-confidence) depicted as just described. C. Human 2’s use of the two risk choices. D. The percentage of correct dense–sparse responses at each density level when these responses were followed by high-risk choices (filled circles) or low-risk choices (open circles).
Discrimination Accuracy Given High- and Low-Risk Responses
If the participants knew when they knew, then we expected they would show better performance when they chose a high-risk option than when they chose a low-risk option. Figure 1D shows that the data conformed to this pattern. Performance was lower on the low-risk trials (open circles) than on the high-risk trials (filled circles). This was true overall—the accuracy associated with high- and low-risk responses averaged across performance levels was 77% and 63%, respectively—a difference worth monitoring and responding to. This was also true at different performance levels taken separately—the average accuracy advantage for high-risk trials over low-risk trials was 11.2% with density level controlled. The human participants did respond to a sense of confidence that was veridical. Their high- and low-risk responses were justified.
Forced Trials
The confidence level expressed on forced trials had no meaning. Thus, these responses simply summarize the overall performance of participants combining both strong and weak metacognitive judgments (because either might have been true on a forced trial). This is the function that forced trials serve in other paradigms (Hampton, 2001; Inman & Shettleworth, 1999; Teller, 1989). The discrimination performance associated with forced trials was worse than performance associated with voluntary high-risk responses. For different performance levels taken separately (thus with density level controlled), the average accuracy advantage for high-risk trials over forced trials was 3.0%. This is the standard result in the literature—it confirms that participants know when they know and voluntarily choose high-risk responses on those occasions. However, the present approach of confidence ratings more than triples the metacognitive effect to 11.2% because it allows one to compare directly the performance associated with strong and weak metacognitive judgments (i.e., high and low confidence ratings). The directness and sensitivity of the confidence-rating approach are important strengths that will let it serve well the area of comparative metacognition research. In the remainder of the article, we consider the direct measures of performance on low- and high-risk trials and omit the forced trials from consideration as less sensitive and interesting.
Perhaps it is not surprising that human participants produce a data pattern confirming their ability to make accurate and adaptive confidence judgments. In Experiment 1B, we asked whether monkeys could do the same by using the same task and a highly similar procedure. The two procedural differences were that monkeys, of course, could not be given instructions, and that each monkey performed in the experiment for many long sessions, producing many more trials.
B: Monkeys’ Retrospective Confidence (2-Level Rating Scale)
Method
Participants
Two male rhesus monkeys (Macaca mulatta) were tested. Murph and Lou were 8 years old at the time of testing. They had been previously trained and tested on a variety of computerized tasks by using procedures described elsewhere (Rumbaugh, Richardson, Washburn, Savage-Rumbaugh, & Hopkins, 1989; Washburn & Rumbaugh, 1992) to respond to computer-graphic stimuli by manipulating a joystick. The monkeys were tested in their home cages, with free access to the test apparatus and working or resting as they chose. They were not deprived of food or reduced in weight for the purposes of testing, and they had continuous access to water.
Apparatus
The monkeys were tested with the use of the Language Research Center’s Computerized Test System (LRC–CTS; Washburn & Rumbaugh, 1992). This system consisted of an IBM-compatible computer, an analog joystick, a color monitor, and a pellet dispenser. Each monkey sat unrestrained on a perch in his home cage to view the video display on the monitor outside the cage. Each could reach through the cage mesh (while continuing to view the monitor) to manipulate a joystick that protruded horizontally toward the cage from the bottom of the monitor. Movement of the joystick resulted in isomorphic movements of a computer-graphic cursor on the screen. Bringing the cursor into contact with appropriate computer-generated stimuli resulted in the automatic delivery of a 97-mg fruit-flavored chow pellet (Research Diets, New Brunswick, NJ) by a Gerbrands 5120 dispenser interfaced to the computer using a relay box and output board (PIO-12 and ERA-01; Keithley Instruments, Cleveland, OH).
Procedure
The procedure for the monkeys basically followed that used with humans in Experiment 1A, including the primary discrimination, the secondary confidence rating, and so forth. For the monkeys, the symbols X and O replaced D and S as the primary responses. Murph and Lou received 2 or 1 food rewards for correct responses that were followed by high- or low-risk responses, respectively. Murph received either two 16-s timeouts or one 1-s timeout for incorrect responses. Lou received either two 20-s timeouts or one 1-s timeout. We did not use a ramp for an initial adjustment of trial difficulty with these animals because they had experienced a dense–sparse discrimination before (during an earlier, unsuccessful attempt to collect their confidence judgments). For Murph, the stimulus distribution was set to deliver 50% of stimuli at density Levels 26–30 and 32–36 (the 10 most difficult stimulus levels). The remaining 50% of stimuli were chosen randomly from the whole range of the discrimination (density Levels 1–30 and 32–61). Lou was given 70% of stimuli at the 10 most difficult levels (Levels 26–30, 32–36) and 30% of stimuli drawn from the easier density levels (Levels 1–25, 37–61). Lou’s trial regimen was designed to give us more control over his trial difficulty and to let us increase that difficulty to encourage his use of the low-risk response. As with humans, Murph received 8% forced low-risk responses and 8% forced high-risk responses. Lou received only 8% forced low-risk responses (once again trying to overcome his bias against this response). Murph and Lou completed about 700 and 400 trials per day, respectively, of which about 600 and 300 nonforced trials, respectively, were analyzed.
Results
Overall Performance
Murph and Lou completed 8,601 and 5,718 nonforced trials, respectively, with overall respective accuracies of 84% and 79%.
Use of High- and Low-Risk Responses
Murph (Figure 2A) showed the human data pattern, with high-risk responses (filled circles) decreasing toward the difficult center of the distribution as low-risk responses (open circles) increased. Lou (Figure 2B) showed the same pattern but weakly. Whereas Murph’s performance was similar to that of the human participant shown in Figure 1B, Lou’s was more similar to that of the human participant shown in Figure 1C.
FIGURE 2.

The performance of monkey participants in the confidence-rating density-discrimination task of Experiment 1B. A. Monkey Murph’s use of the two risk choices. The filled and open circles show his use of the high-risk choice and low-risk choice, respectively, for stimuli at different density levels. B. Monkey Lou’s use of the two risk choices. C. Monkey Murph’s percentage of correct dense–sparse responses at each density level when these responses were followed by high-risk choices (filled circles) or low-risk choices (open circles). D. Monkey Lou’s percentage of correct dense–sparse responses at each density level when these responses were followed by high-risk choices (filled circles) or low-risk choices (open circles).
Discrimination Accuracy for High- and Low-Risk Responses
We expected that if the monkeys knew when they knew, then they would show better performance when they selected the high- rather than the low-risk choice. This was true overall for Murph—he was 91% accurate when he made high-risk choices (filled circles) and 71% accurate when he made low-risk choices (open circles; see Figure 2C). This was also true for Murph at different performance levels taken separately (i.e., with stimulus density controlled)—the average accuracy advantage for high- over low-risk trials was 8.6%. Lou produced the same pattern, but much more weakly (see Figure 2D). Overall, he was 81% and 73.5% correct when he made high- or low-risk responses, respectively. However, for different performance levels taken separately, the average accuracy advantage for high- over low-risk trials was only 1.5%.
Thus, Murph seems clearly to have succeeded at the 2-level rating-scale task. His data pattern is very similar to that of human participants in Experiment 1A. In contrast, even in comparison to a poorly performing human participant (Figure 1C), Lou’s performance is weak, especially given the large number of trials he completed. Given the success of the 2-level confidence-rating results for both human participants and Monkey Murph, it seemed reasonable to challenge participants’ capabilities further with a 3-level confidence-rating task.
EXPERIMENT 2
A: Humans’ Retrospective Confidence (3-Level Rating Scale)
Method
Participants
Forty-five undergraduates from the University at Buffalo, State University of New York, participated in a single, 45-min session to fulfill a course requirement.
Procedure
The procedure was almost identical to that described in Experiment 1A, except that in the confidence-rating phase (after the primary discrimination response), three colored bars were presented (for high-, medium-, and low-confidence choices). If the D icon was selected in the discrimination, turquoise, pink, and blue bars appeared below the D and to its left, at its midline, or to its right. If the S icon was selected, turquoise, pink, and blue bars appeared below the S and to its right, at its midline, or to its left. The participants expressed high, medium, or low confidence, respectively, by using the turquoise, pink, or blue bar. For correct sparse–dense responses, they gained 3, 2, or 1 point(s), announced with successive whooping sounds. For incorrect dense–sparse responses, they lost 3, 2, or 1 point(s) and experienced three 15-s timeouts, or two 10-s timeouts, or one 6-s timeout. These were accompanied by a low buzzing sound. The next trial followed the feedback. Once again, only the trials from the final testing phase were analyzed (i.e., the phase with a dual-rectangular trial distribution that allowed a special emphasis on the 10 most difficult trial levels).
Results
Overall Performance
The 45 participants completed 4,842 mature, nonforced trials with an overall dense–sparse discrimination accuracy of 73%.
Use of High-, Medium-, and Low-Risk Responses
In accordance with the previous findings, one would expect that human participants would use the high-, medium-, and low-risk options for the low-, medium-, and high-difficulty trials, respectively. Figure 3A shows the composite graph of risk use for the 45 participants. Figures 3B and 3C show the use of the different risk options for Participants 3 and 4 in the experiment. In each case, the use of the high-risk option (filled circles) was predictably high for the easiest regions of the density continuum but decreased toward the center, where discrimination was poorest and errors most likely. In each case, the use of the low-risk option (open circles) was predictably highest for the most difficult, central regions of the stimulus continuum.
FIGURE 3.

The performance of a second group of human participants in the confidence-rating density-discrimination task of Experiment 2A. A. The use of the three risk choices (high, medium, or low confidence) by 45 humans. The filled circles, triangles, and open circles, respectively, show humans’ use of the high-, medium-, or low-risk choices for stimuli at different density levels. B. Human 3’s use of the three risk choices depicted as just described. C. Human 4’s use of the three risk choices. D. The percentage of correct dense–sparse responses at each density level when these responses were followed by high-risk choices (filled circles), medium-risk choices (triangles) or low-risk choices (open circles).
The interpretation of the medium-risk response is more complex. It seems to be a broader, more diffuse version of the low-risk response, peaking at the difficult center of the continuum and tailing off slowly to the sides. One could conclude that humans did not defend three separable levels of confidence in this task but instead treated the medium-risk response as a coarser version of the low-risk response. This is not what the participants were instructed to do. Moreover, in many cases in the psychophysics literature, participants have seemed able to treat several levels of confidence reliably and separately. So we do not think this conclusion is correct.
Another conclusion is probably correct. Suppose that the participants had perceived the pixel box and used the subjective impression it made on them to classify it into one of six response regions (high-, medium-, and low-risk sparse; low-, medium-, and high-risk dense). We know that the participants would have had a substantial perceptual error in this task—as they do in all psychophysical tasks. That is, from trial to trial, the subjective impression that an objective stimulus produced would have varied over a fairly wide interval. This would have had important effects on the shapes of the response curves. For one thing, it would have meant that objective medium-confidence stimuli would often be scattered (i.e., misperceived) into the high- or low-risk response regions, thus reducing the number of medium-risk responses these stimuli actually received. For another thing, it would have meant that the most difficult stimuli (i.e., Levels 26–30 and Levels 32–36) could sometimes be perceived as either medium-confidence sparse trials or medium-confidence dense trials, thus increasing through a doubling effect the number of medium-risk responses these stimuli received. The combined result of both things would have been that it was possible for medium-risk responses to be fairly constant over a wide central range of the continuum and even to be slightly higher for the most difficult trial levels. In fact, in simulations that model humans’ performance mathematically, we can reproduce the human graph almost perfectly. Humans were able to defend three separable levels of confidence in this task, and they did proceed by setting up six response regions corresponding to three levels of confidence for dense and sparse responses.
Discrimination Accuracy Given Responses of Different Confidence
This interpretation of the medium-risk response is supported if one examines the performance levels associated with the three risk responses (Figure 3D). If the participants knew how well they knew, they should have shown better performance when they made a high- compared with a medium- compared with a low-risk response. This was true overall—the accuracy associated with high-, medium-, and low-risk responses averaged across performance levels was 82.4%, 69.4%, and 59.4%, respectively—all differences worth monitoring and responding to. This was also true at different performance levels taken separately (i.e., with stimulus density controlled)—the average accuracy advantage for high- over medium-risk trials was 8.4%; the average accuracy advantage for medium- over low-risk trials was 6.2%. Again, humans were responding to a veridical sense of confidence and evidently one that can be partitioned somewhat finely, at least into three confidence regions for each of the two discrimination responses.
B: A Monkey’s Retrospective Confidence (3-Level Rating Scale)
Participant
Monkey Murph, who showed a strong metacognitive performance in Experiment 1, continued on into Experiment 2. Unfortunately, Monkey Lou’s response bias toward the high-risk option grew stronger as time went on, so his data were excluded from presentation here.
Procedure
Monkey Murph experienced Experiment 1B’s situation, including the use of the LRC–CTS (Washburn & Rumbaugh, 1992), but Experiment 2’s task, with high-, medium-, and low-risk bars available after each primary discrimination response. For correct dense–sparse answers, he gained 3, 2, or 1 food rewards, respectively, following high-, medium-, or low-risk responses, and these were announced with successive whooping sounds. For incorrect answers, he received three 10-s timeouts, two 5-s timeouts, or one 1-s timeout. The stimulus density distribution was set to deliver 67% of stimuli at density Levels 26–30 and 32–36 (the 10 most difficult stimulus levels). The remaining 33% of stimuli were chosen from among the easier density levels (Levels 1–25 and 37–61). Murph received 5%, 5%, and 5% forced high-, medium, and low-risk responses. He completed about 700 trials per day, of which about 600 nonforced trials were analyzed.
Results
Overall Performance
Monkey Murph completed 16,235 analyzable trials with an overall dense–sparse discrimination accuracy of 81%.
Use of High-, Medium-, and Low-Risk Responses
As predicted, Murph’s use of the high-risk response was high at the easy edges of the stimulus continuum and decreased toward the center, where discrimination was poorest and errors most likely (Figure 4A). The use of the low-risk option was highest for these difficult stimuli. This is what Murph did in Experiment 1B. However, the medium-risk response was not functionally connected to density level as it was for humans. Instead, that response occurred at a constant low rate across the stimulus continuum. This suggests that Murph was not using the medium-risk response as human participants did.
FIGURE 4.
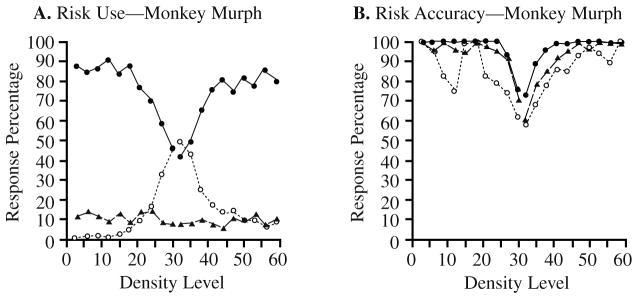
The performance of Monkey Murph in the confidence-rating density-discrimination task of Experiment 2B. A. Monkey Murph’s use of the three risk choices. The filled circles, triangles, and open circles show Murph’s use of the high-risk choice, the medium-risk choice, and the low-risk choice, respectively, for stimuli at different density levels. B. Monkey Murph’s percentage of correct dense–sparse responses at each density level when these responses were followed by high-risk choices (filled circles), medium-risk choices (triangles), or low-risk choices (open circles).
Discrimination Accuracy Given Responses of Different Confidence
Murph’s performance was consistently lower when he made the low- rather than the high-risk response (Figure 4B). This was true overall—the accuracy associated with high- and low-risk responses averaged across density levels was 89.7% and 66%, respectively. This was also true at different density levels taken separately—the average accuracy advantage for high-risk trials over low-risk trials was 10.9% with density level controlled. With regard to these two responses, Murph was responding to a veridical sense of something like confidence. The figure also shows that Murph’s medium-risk responses were associated with intermediate levels of performance (with density level controlled, his high-risk responses had a 3.6% performance advantage over his medium-risk responses). However, our interpretation of this, given the shape of his medium-risk response-use curve and the small size of this advantage, is that he used this response randomly on about 10% of trials, so that these present a composite of performance on low- and high-confidence trials (because either state might have been in effect when the medium-risk response was chosen for some unknown reason).
GENERAL DISCUSSION
Human participants in a psychophysical dense–sparse discrimination made secondary confidence ratings and used appropriately 2- and 3-level confidence scales retrospectively to report on the discrimination responses they had made. One monkey (Murph) performed as humans did with the 2-level scale. The other (Lou) did so only faintly but was mainly subject to a general response tendency to choose the highest level of confidence/risk. Monkey Murph sustained his appropriate use of high- and low-risk responses given a 3-level rating scale. But he used the third, medium rating indifferently across the stimulus continuum and not in a confidence-based way. These studies placed humans and animals for the first time in the identical confidence-rating or risk-taking situation. They showed that a monkey can produce identical performance to humans in an experimental setting that elicits declarative judgments of confidence from humans. They demonstrated the first retrospective reports of uncertainty by a nonhuman primate.
In other articles, researchers have explained why lower level, associative mechanisms are not sufficient to explain animals’ behavior in cognitive monitoring tasks of this kind (Shields et al., 1997; Smith, Schull, et al., 1995; Smith, Shields, Allendorfer, et al., 1998; J. D. Smith et al., 1997; J. D. Smith et al., 2003a, 2003b). We briefly reprise this explanation here. First, in a psychophysical task of this kind, the perceptual information is highly ambiguous and uncertain—on successive trials the same objective stimulus can create sparse or dense impressions in the mind—and thus the impression offers poor guidance as to what response the organism should choose. The situation is far different in the usual operant discrimination with qualitatively distinct, unambiguous stimulus inputs that can be reliably, consistently mapped to behavioral outputs. Therefore, the confidence-rating task is inconsistently mapped in the sense intended by Shiffrin and Schneider (1977). Shiffrin and Schneider explained why inconsistently mapped situations benefit from controlled and attentional cognitive processing that resolve the uncertain perceptual information in support of adaptive response selection. Thus, as a first step in psychological interpretation, we conclude that the ratings of human participants and Murph deserve an upgrade to the level of the aforementioned controlled and attentional processing. In fact, the performance by Monkey Murph in Experiment 1B represents one of the most sophisticated decision-making performances by an animal.
Another issue concerns participants’ consciousness during the confidence-rating task. One could take the results to indicate that choice and decision making were neither explicitly conscious nor metacognitive (if one’s construct of metacognition requires explicit consciousness). It would still be interesting that a monkey’s confidence-rating strategy was so similar to that of humans—producing one of the strongest performance similarities between humans and animals in the literature. But one could scale back the claims of consciousness and emphasize instead the functional similarities between humans and monkeys in decision making and risk taking.
To whom would this scaling back apply? It would be theoretically coherent to apply this scaling back both to human and animal performance. What we know is that human participants see the explicit instructions about confidence as they begin the task, and that they can describe their performance in a general metacognitive way after the fact. But we do not really know that humans are consciously metacognitive on each trial, or whether these states are integral to performance as opposed to just an optional experiential window on performance. As a general matter, the construct of confidence is incompletely specified psychologically, so that questions like this remain unanswered for humans as well as for animals. But the controlled and attentional processes that serve these judgments might be able to occur absent full consciousness or self-awareness of the underlying processes.
Another theoretical position would be less coherent and parsimonious. One could demote animals’ performance to a sophisticated form of choice and decision making while promoting humans’ performance to the level of conscious metacognition. The problem with this description is that the humans and Murph in Experiments 1A and 1B produced strikingly similar data patterns in nearly identical task preparations. Therefore, there is no suggestion in these data that necessitates interpreting the two performances in qualitatively different ways. This does not mean that qualitative differences do not exist, as similar data patterns do not necessarily entail similar underlying mechanisms. What we object to are a priori assumptions that there must be differences in underlying mechanisms between human and animal performances that are very similar. The tendency to demote animals and promote humans has not served psychology well. It has led to prejudgment and prerejection of behavioral phenomena. While researchers should continue to probe the capabilities of different species by designing ever more sensitive tests that will reveal processing differences when they exist, the focus in the present case should be on the strong similarity between the performances and on the possibly common mechanisms of choice and decision making that allow risk to be assessed and assumed appropriately.
Yet the present data also place limits on the commonality of explanation. One monkey only faintly showed the confidence-based strategy given the 2-level scale. The strongly performing monkey did not fully express this strategy given the 3-level scale. So there may be a quantitative difference in the robustness with which humans and monkeys make ratings or judgments like these. Perhaps the necessary processes are cognitively effortful and avoided if reward-efficient alternative response strategies are available. Perhaps the psychological signals of confidence are subtler and drowned out by stimulus or response cues that have greater salience in animals’ psychological systems. In fact, individual differences such as those between Murph and Lou occur commonly. J. D. Smith et al. (1997) found a psychophysical task in which one monkey showed the uncertainty-monitoring data pattern but one did not (Figure 4, p. 87). Hampton (2001), in his crucial third experiment, found that one monkey showed the metacognitive data pattern but one did not. These results suggest that animals are limited in the flexible access they have to the processes or states that allow metacognitive judgments.
This suggestion is supported by the fact that pigeons and rats have thus far shown no capacity to be metacognitive in the way that cognitively sophisticated species such as humans, monkeys, and dolphins have (Inman & Shettleworth, 1999; J. D. Smith & Schull, 1989; Teller, 1989). From the theoretical perspective of constraints and limitations, the failure of particular animal species is interesting as part of the whole empirical picture. It might, in the long run, let one draw a comparative map of metacognitive capacities across species and trace phylogenetically the emergence of this aspect of mind. Such failures also underscore the cognitive sophistication of the underlying performances. For if uncertainty-monitoring tasks such as the confidence-rating task only required low-level associative processes, then rats and pigeons would show the appropriate data pattern naturally and easily. So would monkeys generally, without striking individual differences. But they do not.
However, this discussion makes it clear that a burden falls on the experimenter to arrange carefully the methods of a confidence-monitoring experiment so that animal participants will be strongly motivated to adopt a metacognitive strategy if they are able. This can be a complex matter to judge in planning an experiment, and it may be a common problem for task grammars to motivate a metacognitive strategy too weakly for the animal to struggle to adopt it. In the present case, we might have been able to adjust the contingencies to make it worthwhile to Murph to use all three confidence levels more appropriately (e.g., if food was taken away for incorrect answers as points were taken away for humans). As another example, the range of forgetting intervals used by Inman & Shettleworth (1999) happened to cause only a mild decrement in performance by pigeons, who only showed a 7% increase in the number of trials declined at longer forgetting intervals (insignificant by a parametric test). Perhaps the motivation of the birds to escape trials was just not sufficient. This point is not meant critically. It is only meant to emphasize that the methods one uses in this area need to be crafted to promote the most sophisticated performances from animals that they can achieve. This is important because these capacities may be near the animal’s limits, and they may tend to fall back to associative behavioral solutions if the easier strategy is profitable. This is also important so that negative findings, as in the case of pigeons and rats, will have the best chance to be conclusive and maximally informative.
Acknowledgments
The preparation of this article was supported by the National Institute of Child Health and Human Development (HD-38051). The authors thank Heide Deditius-Island for her assistance with this research.
Contributor Information
WENDY E. SHIELDS, Department of Psychology, University of Montana
J. DAVID SMITH, Department of Psychology and Center for Cognitive Science, University at Buffalo, State University of New York.
KATARINA GUTTMANNOVA, Department of Psychology, University of Montana.
DAVID A. WASHBURN, Department of Psychology and Language Research Center, Georgia State University
References
- Baranski JV, Petrusic WM. Testing architectures of the decision-confidence relation. Canadian Journal of Experimental Psychology. 2001;55:195–206. doi: 10.1037/h0087366. [DOI] [PubMed] [Google Scholar]
- Brown AL, Bransford JD, Ferrara RA, Campione JC. Learning, remembering, and understanding. In: Mussen PH, Flavell JH, Markman EM, editors. Handbook of child psychology: Vol. 3. Cognitive development. 4. New York: Wiley; 1983. pp. 77–166. [Google Scholar]
- Brown AS. A review of the tip-of-the-tongue experience. Psychological Bulletin. 1991;109:204–223. doi: 10.1037/0033-2909.109.2.204. [DOI] [PubMed] [Google Scholar]
- Dunlosky J, Nelson TO. Importance of the kind of cue for judgments of learning (JOL) and the delayed JOL effect. Memory & Cognition. 1992;20:374–380. doi: 10.3758/bf03210921. [DOI] [PubMed] [Google Scholar]
- Flavell JH. Metacognition and cognitive monitoring: A new area of cognitive-developmental inquiry. American Psychologist. 1979;34:906–911. [Google Scholar]
- Hampton RR. Rhesus monkeys know when they remember. Proceedings of the National Academy of Sciences, USA. 2001;98(9):5359–5362. doi: 10.1073/pnas.071600998. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hart JT. Memory and the feeling-of-knowing experience. Journal of Educational Psychology. 1965;56:208–216. doi: 10.1037/h0022263. [DOI] [PubMed] [Google Scholar]
- Hart JT. Methodological note on feeling-of-knowing experiments. Journal of Educational Psychology. 1966;57:347–349. doi: 10.1037/h0023915. [DOI] [PubMed] [Google Scholar]
- Inman A, Shettleworth SJ. Detecting metamemory in nonverbal subjects: A test with pigeons. Journal of Experimental Psychology: Animal Behavior Processes. 1999;25:389–395. [Google Scholar]
- Jonsson A, Allwood CM. Stability and variability in the realism of confidence judgments over time, content domain, and gender. Personality and Individual Differences. 2003;34:559–574. [Google Scholar]
- Koriat A. How do we know that we know? The accessibility model of the feeling of knowing. Psychological Review. 1993;100:609–639. doi: 10.1037/0033-295x.100.4.609. [DOI] [PubMed] [Google Scholar]
- Kunimoto C, Miller J, Pashler H. Confidence and accuracy of near-threshold discrimination responses. Consciousness and Cognition. 2001;10:294–340. doi: 10.1006/ccog.2000.0494. [DOI] [PubMed] [Google Scholar]
- Metcalfe J, Shimamura A. Metacognition: Knowing about knowing. Cambridge, MA: Bradford Books; 1994. [Google Scholar]
- Nelson TO, editor. Metacognition: Core readings. Toronto: Allyn & Bacon; 1992. [Google Scholar]
- Nelson TO. Consciousness and metacognition. American Psychologist. 1996;51:102–116. [Google Scholar]
- Nelson TO, Narens L. A new technique for investigating the feeling of knowing. Acta Psychologica. 1980;46:69–80. [Google Scholar]
- Nelson TO, Narens L. Metamemory: A theoretical framework and new findings. In: Bower GH, editor. The psychology of learning and motivation. New York: Academic Press; 1990. pp. 125–173. [Google Scholar]
- Roebers CM. Confidence judgments in children’s and adults’ event recall and suggestibility. Developmental Psychology. 2002;38:1052–1067. doi: 10.1037//0012-1649.38.6.1052. [DOI] [PubMed] [Google Scholar]
- Rumbaugh DM, Richardson WK, Washburn DA, Savage-Rumbaugh ES, Hopkins WD. Rhesus monkeys (Macaca mulatta), video tasks, and implications for stimulus–response spatial contiguity. Journal of Comparative Psychology. 1989;103:32–38. doi: 10.1037/0735-7036.103.1.32. [DOI] [PubMed] [Google Scholar]
- Schwartz BL. Sources of information in metamemory: Judgments of learning and feelings of knowing. Psychonomic Bulletin and Review. 1994;1:357–375. doi: 10.3758/BF03213977. [DOI] [PubMed] [Google Scholar]
- Shields WE, Smith JD, Washburn DA. Uncertain responses by humans and rhesus monkeys (Macaca mulatta) in a psychophysical same–different task. Journal of Experimental Psychology: General. 1997;126:147–164. doi: 10.1037//0096-3445.126.2.147. [DOI] [PubMed] [Google Scholar]
- Shiffrin RM, Schneider W. Controlled and automatic human information processing: II. Perceptual learning, automatic attending, and a general theory. Psychological Review. 1977;84:127–190. [Google Scholar]
- Smith JD, Schull J. A failure of uncertainty monitoring in the rat. 1989 Unpublished raw data. [Google Scholar]
- Smith JD, Schull J, Strote J, McGee K, Egnor R, Erb L. The uncertain response in the bottlenosed dolphin (Tursiops truncatus) Journal of Experimental Psychology: General. 1995;124:391–408. doi: 10.1037//0096-3445.124.4.391. [DOI] [PubMed] [Google Scholar]
- Smith JD, Shields WE, Allendoerfer KR, Washburn DA. Memory monitoring by animals and humans. Journal of Experimental Psychology: General. 1998;127:227–250. doi: 10.1037//0096-3445.127.3.227. [DOI] [PubMed] [Google Scholar]
- Smith JD, Shields WE, Schull J, Washburn DA. The uncertain response in humans and animals. Cognition. 1997;62:75–97. doi: 10.1016/s0010-0277(96)00726-3. [DOI] [PubMed] [Google Scholar]
- Smith JD, Shields WE, Washburn DA. The comparative psychology of uncertainty monitoring and metacognition. The Behavioral and Brain Sciences. 2003a;26:317–339. doi: 10.1017/s0140525x03000086. [DOI] [PubMed] [Google Scholar]
- Smith JD, Shields WE, Washburn DA. Inaugurating a new area of comparative cognition research. The Behavioral and Brain Sciences. 2003b;26:358–373. doi: 10.1017/S0140525X03430082. [DOI] [PubMed] [Google Scholar]
- Smith SM, Brown JM, Balfour SP. TOTimals: A controlled experimental method for studying tip-of-the-tongue states. Bulletin of the Psychonomic Society. 1991;29:445–447. [Google Scholar]
- Teller SA. Unpublished baccalaureate thesis. Reed College; Portland, OR: 1989. Metamemory in the pigeon: Prediction of performance on a delayed matching to sample task. [Google Scholar]
- Washburn DA, Rumbaugh DM. Testing primates with joystick-based automated apparatus: Lessons from the Language Research Center’s Computerized Test System. Behavior Research Methods, Instruments, and Computers. 1992;24:157–164. doi: 10.3758/bf03203490. [DOI] [PubMed] [Google Scholar]
- Watson CS, Kellogg SC, Kawanishi DT, Lucas PA. The uncertain response in detection-oriented psychophysics. Journal of Experimental Psychology. 1973;99:180–185. [Google Scholar]
- Woodworth RS. Experimental psychology. New York: Holt; 1938. [DOI] [PubMed] [Google Scholar]