

Abstract
Network graphs have become a popular tool to represent complex systems composed of many interacting subunits; especially in neuroscience, network graphs are increasingly used to represent and analyze functional interactions between multiple neural sources. Interactions are often reconstructed using pairwise bivariate analyses, overlooking the multivariate nature of interactions: it is neglected that investigating the effect of one source on a target necessitates to take all other sources as potential nuisance variables into account; also combinations of sources may act jointly on a given target. Bivariate analyses produce networks that may contain spurious interactions, which reduce the interpretability of the network and its graph metrics. A truly multivariate reconstruction, however, is computationally intractable because of the combinatorial explosion in the number of potential interactions. Thus, we have to resort to approximative methods to handle the intractability of multivariate interaction reconstruction, and thereby enable the use of networks in neuroscience. Here, we suggest such an approximative approach in the form of an algorithm that extends fast bivariate interaction reconstruction by identifying potentially spurious interactions post-hoc: the algorithm uses interaction delays reconstructed for directed bivariate interactions to tag potentially spurious edges on the basis of their timing signatures in the context of the surrounding network. Such tagged interactions may then be pruned, which produces a statistically conservative network approximation that is guaranteed to contain non-spurious interactions only. We describe the algorithm and present a reference implementation in MATLAB to test the algorithm’s performance on simulated networks as well as networks derived from magnetoencephalographic data. We discuss the algorithm in relation to other approximative multivariate methods and highlight suitable application scenarios. Our approach is a tractable and data-efficient way of reconstructing approximative networks of multivariate interactions. It is preferable if available data are limited or if fully multivariate approaches are computationally infeasible.
Introduction
Complex systems are often composed of many interacting simpler subunits. To summarize our knowledge about such a system in an accessible format we frequently draw on its representation as a network graph, where the subunits become nodes and the identified interactions become links. Indeed, this way of summarizing knowledge has become so successful that we witness a rapidly increasing interest in the graph-properties of such network depictions [1–4]. The use of networks as a tool to represent and analyze functional interactions has been gaining importance also in neuroscience [1, 5–9]. In neuroscience, however, it is often overlooked that all derived graph measures are only as good as the reconstruction of the underlying interactions. This reconstruction may suffer, because the identification of all interactions in a multi-node network is fundamentally intractable since it poses a problem in the complexity class of so called “NP-hard” problems [10, 11]. Thus, true network graphs of interactions must be recovered using approximations if we do not want to forgo the use of network representations altogether.
To see why the identification of all interactions in a multi-node network is fundamentally intractable, we have to consider that next to the interactions from one node simply to one other node (a bivariate or pairwise interaction), there may well be interactions from a set of two (or more) source nodes to a target node. Moreover, this multivariate nature of the interactions makes it necessary to control for a parallel influence from any other source in the network when trying to determine whether a particular set of source nodes interacts with the target node in question. It is the enormous number of combinations of potential sources and parallel influences that makes it impossible to search all possibilities in reasonable time for any but the smallest systems (e.g. n < 20, [10, 12]). In fact, it can be shown formally that the problem belongs to the class of NP-hard problems, which are believed to lack algorithms that produce solutions for arbitrary input sizes in polynomial time [13].
To nevertheless apply graph theory and network models in neuroscience we need to resort to approximate representations of the true multivariate interactions. Here, the term approximation implies that we will have to commit errors. These errors can be of two types—falsely identifying an interaction that is physically absent, or missing an interaction that is physically present. While both types of errors may have detrimental effects on interpretability of popular graph metrics, we may still ask which type of error to prefer, and how to build fast and efficient approximations that predominantly show the preferred type of error.
Here, we suggest that missing out on interactions instead of including spurious ones may be preferable because the nature of the obtained network becomes more ‘reliable’ in the sense that all the depicted links do exist. This knowledge can then be built upon in future work. Therefore we present an algorithm that can prune the most frequent spurious interactions from graphs obtained by a simple and efficient bivariate analysis of interactions (this idea was first proposed in [14] in abstract form).
Our focus here is specifically on corrections of graphs obtained from bivariate (i.e., pairwise) analysis methods as these have most often been used to overcome the intractability of the full network reconstruction described above. Despite their popularity, iterative bivariate analyses introduce well known methodological artifacts in the reconstructed interactions [12, 15, 16]: (1) Bivariate analysis may detect spurious interactions (false positives) whenever the dependency between two time series is caused or mediated by one or more additional nodes in the network; (2) bivariate analysis may miss synergistic effects [17, 18] that two or more time series have on a third. These two problems diminish not only the reliability of individual links in a network but also compromise graph metrics of the global network.
In this study we investigate a solution to the first problem above. Our solution builds on the possibility of reconstructing the delays of interactions (e.g. [19] and similar approaches), and on specific interaction-delay based fingerprints that potentially spurious interactions must leave even in a bivariate analysis. Our method allows to tag potentially spurious interactions for further testing (e.g. by a targeted multivariate analysis) or to remove them entirely from the graph to obtain its most reliable core. Our method thus keeps the advantages of bivariate methods in terms of data efficiency and computational tractability over approaches that are approximately or fully multivariate.
In the following we first provide the necessary background on delay reconstruction by information theoretic methods, and on graphs. Then we present our algorithm and a reference implementation as part of the open source toolbox TRENTOOL ([20], www.trentool.de). Subsequently, we characterize its properties and limitations based on theoretical considerations, simulations and application to magnetoencephalographic (MEG) data. We discuss the relative merits of our approach and other possible approximations to a fully multivariate analysis of networks, and close by outlining possible strategies to deal with the identified potentially spurious links in the network.
Background and Implementation
Before we outline the algorithm in more detail, we will provide some background information by reviewing the recovery of interaction delays in an information theoretic framework. We will also describe the coupling motifs leading to the detection of spurious interactions. Subsequently, we will formalize the network concept in mathematical terms and complement the common undirected and unweighted network representation used for neural data [1, 21] by introducing the weighting of network connections with their respective interaction delays (using the estimator provided in [19]). We will then describe the rationale underlying the algorithm and its implementation. We conclude this section with the validation of the algorithm using simulated as well as experimental data.
Background
Interaction delay reconstruction
Our algorithm is based on the availability of the interaction delays for bivariately reconstructed interactions. We will systematically use the term “bivariate interaction” to indicate that in the bivariate analysis setting there is no guarantee that a reconstructed interaction is actually present in the underlying data; nevertheless, even for a spurious interaction a meaningful delay can be assigned (see examples in [19]). One possibility to obtain the delays for bivariate interactions is to use delay-sensitive measures of information transfer, i.e. transfer entropy (TE) estimators. In [19] we presented a delay-sensitive TE functional:
| (1) |
which quantifies the mutual information between the past state x t − u of a source X and the present value y t of a target Y at a specific time delay u—conditional on the past state of the target, y t−1.
This functional can be used to recover the physical interaction delay δ X,Y by scanning over possible values for u, and by taking the value of u where TE reaches a maximum as the (bivariate) interaction delay:
| (2) |
A similar approach may be used for Granger causality as TE is equivalent to Granger causality for data with a jointly Gaussian distribution [22].
Note, that reconstructed interaction delays incorporate not only the mere transfer time between two neural processes, but also the time needed for local computation, if we only obtain one channel per subunit (see Fig 1 for further explanation). Thus, interaction delay reconstruction as proposed in [19], captures the total delay between two measurement points, which in a neural system may consist of transfer time along an axonal connection but also of time needed for information transfer within the local neural microcircuit.
Fig 1. Reconstructing delay times from electrophysiological recordings.

The physiological delay between two measurement points v s, v t consists of the time needed for information transfer via axonal connections (δ s,t′) and internal computation within populations of neurons (), such that in a network representation of reconstructed interactions we find . Black arrows represent information transfer within the neural microcircuits.
Spurious interactions in bivariate analysis of multivariate data sets
Spurious interactions may arise in bivariate analysis from one of two distinct coupling motifs: In the first coupling motif (Fig 2A) the dynamics of two or more nodes, representing neural sources, are simultaneously driven by processes in a third node. A bivariate analysis may detect an interaction between the two driven nodes. We term this a common drive (CD, also “common cause” [12]). In the second coupling motif (Fig 2B) an interaction between two nodes is mediated by one or more intermediate nodes in the network and information transfer from source node to target node is routed via these intermediate nodes. A bivariate analysis may detect an interaction between the source and target node. We term this a cascade effect (CE, also “pathway effect” [12] or “indirect causal pathways” [15]). The detection of spurious interactions by bivariate analysis have been demonstrated for simulated data as well as in neural recordings [15, 16, 23–25].
Fig 2. Spurious Interactions.
(A) Common drive effect: A spurious interaction due to common drive may be potentially present if the processes at vertices v s and v t are driven by v 0 with differential delays, such that the bivariate information transfer between v s and v t is a result of the common input from v 0; (B) Cascade effect: Spurious interaction due to cascade effects may be potentially present for all cascades of information transfer in a “chain” of sources. In the example here, the bivariate information transfer between v s and v t (edge (s, t)) can be explained by an alternative routing of information via vertices v 1 and v 2. The summed weight of the alternative routing is equal to w (s,t); (C) “Triangle” motif: This is the most simple motif potentially giving rise to either of the above spurious interactions: (v s, v t) could be a result of a cascade effect with respect to the path 〈v s, v 1, v t〉, and (v 1, v t) could be the result of a common drive of v 1 and v t by v s. At most one of these interactions can be spurious.
Coupling motifs leading to spurious interactions due to CD and CE exhibit a specific timing signature in the network of bivariately reconstructed interactions. We found an example for such a timing signature in experimental data recorded from the turtle (Fig 3C) [19]). Here, a spurious interaction was detected between the light source and the optic tectum. This spurious interactions resulted from a CE, i.e., an actual routing of information from light source to tectum via an intermediate node, namely the retina. Information transfer delays reconstructed with the TE estimator proposed in [19], revealed this CE: The summed interaction delays in the actual routing of information equaled the delay of the spurious information transfer.
Fig 3. Directed interactions in the turtle brain during visual stimulation with random light pulses (modified from [19], creative common attribution license CC BY).

(A) Raw traces recorded in the tectum (blue) and from the retina (green) overlaid on the light pulses (yellow). (B) Turtle brain explant with eyes attached. Transfer entropy was found from the retina of the right eye to the left tectum, as well as from the light source (yellow) to the retina and to the tectum (***** denotes p < 10(−5)). P-values for the opposite directions were not significant (n.s.). Note, that the interaction between light source and optic tectum shows a interaction delay roughly equal to the summed interaction delay between light source and retina and retina and optic tectum (deviation ≤ 5%).
Graph representation of neural data and notation
As a last preliminary, we will present the mathematical formalization of a network to give a precise account of the algorithm and its functionality in the subsequent section. Table 1 lists the most important variables. In mathematical terms, a network is described by a (directed) graph G = {V, E}, where V denotes a set of vertices or nodes and E ⊆ V × V represents a set of connections between nodes, called edges [26]. In a neuroscience application, V may represent a set of individual functional units v i, e.g. neurons, sources in MEG analysis, or voxels in functional magnetic resonance imaging data; E may represent some sort of connection between two units, for example significant functional interactions. An edge is written as a tuple (v i, v j), representing an edge between any two sources v i and v j. Note, that such a tuple (v i, v j) defines an edge as an ordered pair of two vertices and as such indicates a directed connection between these two sources (the two elements of the tuple are not interchangeable, such that (v i, v j) ≠ (v j, v i)). We further assume that edges are weighted by a weighting function that maps the set of edges to the natural numbers. Here, these natural numbers are chosen proportionally to the timing information as precisely and as parsimoniously as possible. We call w (vi, vj) the weight of edge (v i, v j).
Table 1. Notation.
| Graph representation | |
| G | graph, consisting of the sets V and E |
| V | set of vertices |
| E | set of edges |
| v i | vertex with index i |
| (v i, v j) | edge from v i to v j |
| w (vi, vj) | weight of edge (v i, v j) |
| v i ⇝ v j | path from v i to v j |
| path from v i to v j with summed weight k | |
| l | path length, i.e. no. edges in a path |
| Algorithm | |
| (v a, v b) | edge under investigation in current algorithmic iteration |
| w (va, vb) | weight of the edge under investigation |
| θ | threshold to account for imprecisions in interaction delay reconstruction |
| w crit | critical path weight, w crit = w (va, vb) + θ (target weight of the algorithm) |
| v s, v t | start and target node (v s = v a, v t = v b) |
| set of solutions in algorithmic step n, that solve the subproblem | |
For any edge (v i, v j), v i is considered the predecessor of v j. v j is called the child of v i. A path v 0 ⇝ vl is defined as a sequence of vertices 〈v 0, v 1, …, v i, …, v l−1, v l〉, where every two consecutive vertices v i v i+1 are connected by an edge (v i, v i+1). We call l the length (number of edges) of the path and we will refer to this length l as a path’s graphical length, describing the number of edges used to graphically represent the path in the graph. The total weight of a path is the sum of the weights of all individual edges comprising the path, ∑i w (vi, vi+1).
Fig 4 gives a schematic overview of the construction of a graph from time series data recorded from a set of neural sources. Edges in the graph represent significant interactions between sources (vertices); edge weights represent reconstructed interaction delays. We here use TE to analyze directed interactions, using the estimator proposed in [19] to recover significant TE and corresponding interaction delays, but other approaches are possible.
Fig 4. Graph representation of neural data.

(A) Recorded signals from various sources in the brain; (B) Pairwise estimation of transfer entropy (TE) and reconstruction of interaction delays u between any two sources; (C) Adjacency matrix: representation of estimated delay times between all source combinations, every entry represents an information transfer from the ith row to the jth column; (D) Adjacency matrix after test for statistical significance; (E) Visualization of the graph represented by the connectivity matrix: every source is represented by a vertex, every significant information transfer is represented by an edge. (The blue circle indicates the respective representation of an exemplary interaction between source 1 and source 3 throughout all steps of graph reconstruction.)
Rationale and implementation of the algorithmic solution
Rationale of the algorithm
Based on the graph representation of reconstructed directed interactions, their delays, and the theoretical preliminaries presented in the last subsection, we will now propose an algorithm that detects potentially spurious interactions by exploiting the timing signature of CE and simple CD.
As input the algorithm expects a directed, delay-weighted graph G ≔ {V, E}, represented by its connectivity matrix. Connections are weighted with the estimated interaction delays , i.e., the estimated physical delays between the processes represented by v a and v b. Note that such a graph needs to be constructed from a connectivity measure, which is (a) directed and (b) allows for the reconstruction of interaction delays. Additionally, the user has to provide a threshold θ to account for noise in empirical measurements as well as imprecision in analysis methods (described in detail below). We furthermore assume that weights have been linearly scaled, such that they do not have any decimal places and can be represented by integer values.
As a first step, we identify potential CEs by assuming that if a CE is present in the data, the bivariate interaction represented by any edge (v a, v b) ∈ E with weight w (va, vb) can be explained by an alternative routing of information via intermediate vertices (see an example in Fig 2B). Thus, iteratively for every edge (v a, v b) in E the algorithm sets v a = v s as the starting and v b = v t as the target node of the current iteration. Then the algorithm searches for an alternative path for (v s, v t), where a path is assumed to be an alternative path if the summed delay interaction times ∑i w (vi, vi+1) of all edges in the path are (approximatively) equal to w (vs, vt), i.e., w (vs, vt) − θ < ∑i w (vi, vi+1) < w (vs, vt) + θ. For an example see Fig 2B, where edge (v s, v t) (dashed arrow) has a graphically longer, alternative path 〈v s, v 1, v 2, v t〉 with equal summed weight (solid arrows). If the algorithm finds such an alternative path, the edge currently under investigation is tagged as potentially spurious.
In a second step, the algorithm additionally identifies potential simple CD effects based on the results from the first analysis step. Simple CD effects occur in graph motifs that form acyclic “triangles” (Fig 2C). We define an acyclic triangle as any three nodes that are acyclic, pairwise connected. We suspect a spurious link due to simple CD if a triangle motif exhibits a suspicious timing signature; these suspicious triangles are identified from the results of the first analysis step by listing all edges with alternative paths of graphical length two. We propose to tag two edges in each of these identified triangles: (1) the direct edge due to a CE (edge (v s, v t) in Fig 2C) and (2) the second edge due to a simple CD (edge (v 1, v t) in Fig 2C). Note however, that of both tagged edges one has to be a non-spurious interaction for this rationale to hold: if the CE link (v s, v t) is rejected, a possible driver-target relationship between nodes v s and v t is destroyed, thus nullifying the argument for the simultaneous rejection of edge (v 1, v t). The same argument holds vice versa: a rejection of the tagged edge (v 1, v t) due to CD destroys the information cascade from v s to v t and thus cancels the CE causing the detection of (v s, v t). Thus, tagging both edges in a triangle motif yields a slightly too conservative approach to network representation. For the treatment of tagged links in neuroscience we refer to the Discussion section.
A further important consideration is that once the algorithm has detected an alternative path va ⇝ vb for an edge (v a, v b), this alternative path stays intact, even if, at a later step, some edge in va ⇝ vb is tagged (and probably removed). Assume, that we have an edge (v a, v b) with an alternative path va ⇝ vb and that at a later step, one or more edges in this path get tagged. Then, for each of these tagged edges, leaving a ‘gap’ in va ⇝ vb, an alternative path of equal summed weight exists by definition of the algorithm. This alternative path closes the “gap” in va ⇝ vb, such that nodes v a and v b are still connected by a new path va′ ⇝ vb′. This new path has the same summed delay as va ⇝ vb, but is graphically longer. Therefore, alternative paths identified at some step in the algorithm remain intact even if links within the paths are tagged at a later point in the algorithm’s execution.
Implementation overview
We now present the implementation of the strategy described above; more precisely, we present an algorithm that finds all alternative paths for any given edge (v a, v b) ∈ E, given a directed, weighted graph G = {V, E}. See Fig 5 for an overview of the algorithm.
Fig 5. Overview of the proposed algorithm.

The algorithm expects a weighted and directed graph G = {V,E} and a threshold θ as input. In a preprocessing step, the algorithm creates graph G′ from input G, as an input for the dynamic programming algorithm, by removing edge (v a, v b) and by relabeling and reordering nodes. Then, in the next step, alternative paths for (v a, v b), are searched through dynamic programming (see also main text). If at least one alternative path is found, paths are reconstructed using a depth first search (DFS, [27]) to ensure that alternative paths do not contain loops. If an alternative path contains no loops, the currently investigated edge (v a, v b) is tagged as potentially spurious. If no alternative edge is found, (v a, v b) is considered non-spurious. The algorithm then enters the next iteration, in which the next edge (v a, v b) ∈ E is investigated for alternative paths.
As a preprocessing step, we construct a graph G′ by removing the edge (v a, v b) from G and relabeling nodes v a, v b as starting and target nodes v s, v t of the current iteration of the algorithm. The target weight of the alternative path is set to w crit = w (va, vb) + θ. Furthermore, G′ is represented as an inverted adjacency list, i.e., a list of all nodes in V, where for every node all of its predecessors are listed. v s is set as the first node in this list (note that we assume that v s has index 1), v t is set as the last node (has index ∣V∣). Therefore, for all other nodes v j in the adjacency list it now holds that 2 ≤ j ≤ ∣V∣.
After preprocessing the input, alternative paths vs ⇝ vt with weight w (vs, vt) ± θ are detected in two steps: (1) a memoized dynamic programming approach [27] is used to determine, whether any path vs ⇝ vt of a total weight w (vs, vt) ± θ exists; (2) a modified depth first search (DFS, see [27] for a description) is used to reconstruct all paths with weights in the interval w (vs, vt) ± θ from the solution obtained in step (1). The second step is necessary to reject paths that contain loops and to allow for further analysis (for example the identification of triangle motifs).
The algorithm was implemented as part of the open source toolbox TRENTOOL [20].
Dynamic programming
We use a dynamic programming approach in step (1) to handle the inherent complexity of the problem at hand (see Discussion). Dynamic programming allows for the solution of a complex problem by decomposing it into easily solvable subproblems. By starting with trivial base cases, subproblems of increasing complexity are solved iteratively by taking recourse to tabulated solutions of previous (more simple) subproblems. This reduces computational demand and is repeated until the algorithm reaches the most complex subproblem, which represents the input problem. In the following, we will first define the subproblems to the present problem, and then describe the algorithmic solution to an individual subproblem. A detailed, graphical account of both steps is presented in Fig 6.
Fig 6. Visualization of the proposed algorithm.

Search for alternative paths to edge (1, 6) (dotted arrow), i.e., v s = 1 and v t = 6. Solutions to subproblems are managed in a two dimensional solution array indexed by path weight w i and vertex number v j. Solutions are calculated iteratively over w i (rows) and v j (columns). (A) Solution matrix after first iterative step (subproblem ): There are two edges leading to vertex 2 of which only edge (1, 2) yields a valid solution by pointing to an earlier solved subproblem (green box), whereas edge (5, 2) has a weight of 7 leading to a negative difference in weights i − w (5,2) (red box) for which no earlier solution exists; (B) Solution matrix after third iterative step : Here, no valid solution exists (none of the arrows leading to vertex 2 are part of a path with summed weight 1); (C) Solution array after iteration over all vertices v j for w i = 1 (all vertices have been checked for a path of weight 1, originating from the start vertex 1); (D) Solution to subproblem : edge (4, 6) together with the solution form a valid path, whereas edge (5, 6) is not part of a valid solution as is empty; (E) The algorithm terminates after iteration over all vertices v j and path weights up to w (vs, vt) + θ, where θ is a user defined threshold of 1. Backtracking is conducted for all entries in the reconstruction interval w (vs, vt) ± θ (entries marked blue); (F) Reconstructed alternative path by backtracking of subproblems.
Formulation and ordering of subproblems
The overall problem of finding a path from v s to v t with weight w (vs, vt) ± θ is divided into subproblems by asking, whether a “simpler” path exists; v j is any node in V and w i is any path weight w i ≤ w crit = w (vs, vt) + θ. For example, finding a path is a subproblem to finding path where v 1 = v s and v 10 = v t.
The presented algorithm solves subproblems iteratively for increasing complexity using a dynamic programming approach. It is thus necessary to order the subproblems by their complexity and to make their solutions immediately accessible for reuse in subsequent algorithmic steps. This is realized by organizing solutions in a two-dimensional solution array, in which solutions are ordered by path weights and node indices, the two parameters determining complexity. Starting with the most simple base case where w i = 0 and v s = v 1 = v j (this subproblem describes a path ), subsequent subproblems are formulated by increasing path weights and node indices in integer steps. Thus subproblems are formulated for all combinations w i = 1, 2, …, w crit and v j ∈ V (see for example Fig 6C for the first iteration of path weights and a complete iteration over all vertices). Individual solutions to subproblems are tabulated in the solution array of size [0; w crit] by [1;∣ V∣] and are indexed by the current values for w i and v j. This organization of subproblems allows for the easy retrieval of solutions from earlier iterations to solve the subproblem currently at hand (see below and Fig 6).
Finding solutions to subproblems
For any given subproblem the algorithm determines whether a path of weight w i leads into node v j. The algorithm does this by testing whether any single edge leading into v j together with the solution to a simpler subproblem forms the path . In particular, for every edge (v p, v j) leading into v j (where v p is a predecessor of v j), the algorithm checks if this edges extends a path leading into v p such that the resulting path solves the current subproblem (see Fig 7A). We call the treatment of one edge (v p, v j) an algorithmic step. In one algorithmic step, the algorithm checks (1) if there exists a path to v p and if so, (2) whether the path has length w p = w i − w (vp, vj). If both conditions are met, the currently considered edge (v p, v j) together with the path to predecessor v p solves the current subproblem (because a path exists, that together with (v p, v j) forms a path of summed weight w i = w p + w (vp, vj)). The algorithm terminates once the most complex subproblem has been investigated, i.e., it has been tested if a path of length w crit, connecting node v s to v t can be found.
Fig 7. Schematic example of a subproblem of the proposed algorithm.

(A) Example subproblem : At the n th algorithmic step, we search for all paths of weight w i leading to node v j; (B) Finding a solution for the current subproblem by investigating solutions to prior subproblems: We investigate all predecessors v p of the current node v j; if there exists a solution to , i.e., there is a solution to the prior subproblem of finding a path of weight w p leading from v s to v p, and w p + w (vp, vj) = w i, we find a solution to the current subproblem .
Note that “checking” if a path of weight w p to node v p exists corresponds to looking up whether a solution to the subproblem exists in the solution array, i.e., the algorithm has to look up the entry in the solution array at row p (for node v p) and column w i − w (vp, vj) (for weight w p). In doing so, the algorithm solves the subproblem by reusing earlier solutions. Note also, that relevant subproblems are guaranteed to have been solved at an earlier point in the execution of the algorithm as the algorithm treats subproblems in the order of increasing complexity: subproblems are solved by first iterating over all path weights w i = 1, 2, …, w crit in an outer loop, and second iterating over all nodes from v s: = v 1 to v t: = v ∣V∣ in an inner loop; a relevant subproblem is guaranteed to have been solved because it always holds that w p < w i per definition of w p.
To tabulate solutions to subproblems, for every edge solving the subproblem and its weight, we add a tuple (w (vp, vj), v p) to a set of solutions. More specifically, when iterating over all N potential incoming edges (v p, v j), we enter valid solutions in a sequence of sets indexed by the current algorithmic step n: . Each tuple in then indicates the existence of one alternative path for the subproblem. The collection later allows the reconstruction of all alternative paths for the overall problem.
Formally, after initially setting , we can define each algorithmic step n as
| (3) |
Here, denotes the current set of tuples contributing to the solution of the subproblem , i.e., a path leading from v s to v j, that has a summed weight of w i in algorithmic step n. is a set of solutions to the subproblem investigated earlier (where solutions were collected over M algorithmic steps). Formula 3 expressed that for every edge (v p, v j), it is tested if two conditions are met (see also Fig 7B):
there exists a solution to the previous subproblem , i.e., a path to the predecessor v p with weight w p = w i − w (vp, vj);
the edge (v p, v j) from predecessor to current node has a weight such that w p + w (vp, vj) = w i.
If both conditions are met, then the tuple (w (vp, vj), v p) is added to . When all edges (v p, v j) have been tested, the next subproblem (inner loop) or (outer loop) is considered. The algorithm terminates once all subproblems have been investigated.
Backtracking
In a second step, the algorithm uses backtracking to reconstruct relevant paths from the solution array returned by the dynamic programming step described in the last subsection (see Fig 6F). Paths are considered relevant, if they lead to the current target node v t and have a summed weight of w (vs, vt) ± θ. Thus, paths are reconstructed from all entries that correspond to the solutions to subproblems vs ⇝ vt with weight w (vs, vt) ± θ (we call these relevant entries in the solution array reconstruction interval).
The backtracking algorithm uses depth first search (DFS, for a more detailed description see for example [27]) to reconstruct all paths starting from one entry in the reconstruction interval at a time; it is therefore called for each entry in the reconstruction interval individually (for example, in Fig 6F, this corresponds to three calls of the backtracking algorithm for fields [5, 6], [6, 6] and [7, 6]). The backtracking is done by recursively expanding each entry in the currently considered field (i.e., visiting the next field, indicated by the currently considered solution to a subproblem). For example, in Fig 6F, the field [6, 6] points to the field [5, 4], which points to [3, 3] and so on. While expanding one path, the algorithm checks, whether a node in the currently reconstructed path has already been visited during the recursion. If this is the case, the path contains a loop, i.e., a node is visited twice in one path, and the respective path is discarded as it is not a valid solution to the overall problem.
All remaining reconstructed paths are considered alternative paths to the edge (v s, v t). If at least one such alternative path exists, (v s, v t) is considered potentially spurious due to a CE.
Additional analysis of triangle motifs
As laid out in the subsection Rationale of the algorithm, the algorithm identifies simple CD in an additional step. Simple CD occurs in triangle motifs, which can be identified by listing all edges with valid alternative paths of length two. In each triangle, the second edge of the alternative path is considered as potentially spurious due to a simple CD effect additionally to the edge considered spurious due to CE (see coupling motifs shown in Fig 2C).
Output
The algorithm returns a list of potentially spurious edges in E, and tags these spurious edges as a CE (identified by an alternative path) or a simple common drive effect (identified in a triangle motif).
Evaluation
To test the proposed algorithm for correctness and performance in terms of execution times, we simulated networks of different sizes and densities to serve as input graphs. To further demonstrate the algorithm’s applicability to neuroscience data, we applied it to networks derived from electrophysiological recordings during a face recognition task.
Performance of the algorithm in simulated networks
We simulated networks of different types: small-world networks [28], scale-free networks [29] and random networks of different densities [30, 31]. We chose these topologies because small-worldness and scale-freeness have frequently been reported to occur in functional and anatomical networks derived from neuroscience experiments [21, 32, 33] (for a review see also [7] and [34]).
The performance of the proposed algorithm on the simulated networks was tested by (1) varying the size ∣V∣ of simulated networks and (2) varying the critical path weight for alternative paths w crit. Higher values for both parameters increased computational demand by either increasing input size directly (higher values for ∣V∣) or by increasing the likelihood for the detection of an alternative path (higher values for w crit).
The dependency of the likelihood of detecting an alternative path on w crit is especially relevant in random network topologies: here, the number of possible alternative paths increases exponentially in w crit, as higher values for w crit (relative to individual path weights) increase the number of possible combinations of edges that form a path of weight w crit. More precisely, given a random graph G = {V, E} and w crit > ∣V∣, the probability for the existence of an edge is (where ρ is the density of G); furthermore, the probability of the edge having weight w is uniformly distributed with . The number of possible alternative paths can then be calculated as
| (4) |
where is the number of compositions, i.e., the number of ordered sequences of integers that sum to w′, the currently considered summed edge weight. The inner sum is dominated by the growth of the number of compositions given by . Thus, the number of alternative paths grows in Ω(2wcrit), i.e., it grows exponentially in the critical path weight given a sufficiently dense, random network topology.
Small-world networks
For the simulation of small-world networks we modified the rule for network generation proposed by Watts and Strogatz in [28]. The network generation was done in two steps with parameters ∣V∣ (number of nodes), n (neighborhood coefficient) and p (rewiring probability):
Construct a regular ring lattice with V nodes, where every node v i ∈ V is connected to its n nearest neighbors v j (such that (v i, v j) ∈ E). Given that V = v 1, …, v ∣V∣, each node v i is connected to its neighbors v i+1, …, v i+n/2 and v i−1, …, v i−n/2.
For every node v i all edges (v i, v j) are rewired with probability p by replacing (v i, v j) with (v i, v k) where n is chosen randomly with uniform probability from V∖v i while avoiding loops and multiple edges.
Every edge is weighted by a random weight w (vi, vj) drawn from an interval [1;w max] with uniform probability
Note, that we made two extensions to the original generation rule proposed in [28]: we simulated network edges as directed and weighted, while the original work by Watts and Strogatz assumes undirected and unweighted edges. We defined connections from every node v i to its n nearest neighbors as directed and weighted them with values randomly drawn from an interval [1; w max]. We set w max to the maximum interaction delay found in an MEG data set also used as a second test case described below. Thus, strictly speaking, only the undirected and unweighted network underlying our test cases had small-world properties (i.e., a high clustering coefficient and a short characteristic path length). We used this approximation of small-world properties in a weighted and directed network, as there is no agreement over how directedness and edge weights are to be incorporated into the original notion of small-worldness (as both parameters may alter the global behavior commonly observed in undirected and unweighted small-world networks) [35].
Scale-free networks
Scale-free networks were simulated using an algorithm proposed in [36], following an implementation of the rationale by Barabási and Albert [29] in [37] (see also [38]).
Scale-free networks resemble small-world networks in their topology, i.e., they exhibit high local clustering and low characteristic path lengths. Both network types differ however in their degree distributions p(n), the probability that a node interacts with n other nodes in the network: in small-world networks the degrees are normally distributed, while in scale-free networks the degrees follow a power law p(n) ∼ n −γ (where γ may vary for different networks) [29].
Random networks
We created random networks of size ∣V∣ by independently including weighted edges with probability ρ[31], where ρ denotes the density or edge probability of a graph:
| (5) |
i.e., the the ratio of edges actually present in a graph to the number of possible edges [39]. Compared to small-world networks, a random graph typically exhibits a small average minimum path length and small average clustering coefficient [35], depending on the graph’s density. In the present study, we created two test cases with ρ = 0.25 and ρ = 0.50 respectively.
Performance results for simulated networks
Running times of the algorithm increased as a function of graph size ∣V∣ and critical path weight w crit (Fig 8). For the dynamic programming part of the algorithm, running times increased in a linear fashion in both network size ∣V∣ (Fig 8A) and critical path weight (Fig 8B). Running times thus correspond to theoretically expected running times. The time needed for backtracking the obtained solutions grew exponentially in ∣V∣ (Fig 8C) and critical path weight (Fig 8D) for random networks and scale-free networks, where running times were least favorable for random networks. For small-world networks on the other hand, running times did not increase dramatically for higher values ∣V∣ and w crit.
Fig 8. Results running time.

Running times [log(s)] for dynamic programming (A, B) and backtracking (C, D) by number of vertices ∣V∣ and maximum path weight w crit. Running times are shown for different graph types (SW: small-world, SF: scale-free, RN: random networks with density ρ). Red markers indicate cases of intractability (execution was aborted after a pre-defined limit of reconstructed alternative paths was reached).
Running times for backtracking depend on the number of alternative paths to be reconstructed from the solution array. Since the number of paths increases exponentially in w crit (given a sufficient graph size ∣V∣), exponential running times were expected for higher values for both parameters. We therefore defined an a priori limit of 20,000 for the number of alternative paths to be reconstructed. If this limit was reached, the algorithm’s execution was aborted. These problem instances were considered intractable (red markers in Fig 8). Intractable test cases were found for random graphs only and occurred earlier for graphs with higher densities of ρ = 0.50 (for comparison: the scale-free graphs had a density of approx. 0.15, small-world graphs of approx 0.5). Cases of intractability were found for random graphs of sizes ∣V∣ ≥ 65 with a density ρ = 0.50 and ∣V∣ ≥ 130 for graphs with density ρ = 0.25 respectively. Furthermore, intractable cases occurred for path weights w crit ≥ 21 for random graphs with density ρ = 0.50 and for path weights w crit ≥ 25 for random graphs with density ρ = 0.25.
Thus, network size as well as network structure influenced the computational demand of a given input to the presented algorithm. Note that intractable cases may well occur in a neuroscience application, where inputs can not be assumed to be bounded in any respect (e.g. in terms of graph density or graph size). Here, the network size may be used to determine whether an input may prove intractable. In the present simulation, network sizes smaller than 25 nodes posed no problem for the algorithm; of course, these limits are subject to moderate changes with increasing computational power.
Detection of spurious interactions in networks derived from electrophysiological time series
Ethics statement
To test the algorithms applicability to biological time series, we used MEG data recorded from 15 healthy human subjects during a face recognition task as described in [40]. All subjects gave written informed consent before the experiment. The study was approved by the local ethics committee (Johann Wolfgang Goethe University, Frankfurt, Germany).
Preparation and MEG data acquisition
MEG data was obtained from 30 healthy subjects, recruited from the local community. All participants had normal or corrected-to-normal vision and were right-handed (assessed by the Edinburgh Handedness Inventory [41]).
MEG data were recorded using a 275-channel whole-head system (Omega 2005, VSM MedTech Ltd., BC, Canada) at a rate of 600 Hz in a synthetic third order axial gradiometer configuration (Data Acquisition Software Version 5.4.0, VSM MedTech Ltd., BC, Canada). Data were filtered with 4th order butterworth filters with 0.5 Hz high-pass and 150 Hz low-pass. Behavioral responses were recorded using a fiber-optic response pad (Lumitouch, Photon Control Inc., Burnaby, BC, Canada). Trials with excessive head movement (more than 5 mm) were excluded from further analysis.
Structural magnetic resonance images were obtained with a 3 T Siemens Allegra, using 3D magnetization-prepared rapid-acquisition gradient echo sequence. Anatomical images were used to create individual head models for MEG source reconstruction.
Task
The participants were presented with a randomized sequence of degraded two tone images of human faces (Mooney Faces, [42], see Fig 9C for an example stimulus) and scrambled stimuli, where black and white patches were randomly rearranged to minimize the likelihood of detecting a face. The participants had to indicate the detection of a face by button press. Only trials in which faces were correctly identified entered further analysis.
Fig 9. Results empirical data sets.

(A) Running time of the complete algorithm by number of nodes plus number of edges ∣V∣ + ∣E∣; (B) Mean percentage of tagged, potentially spurious edges by chosen threshold θ after application of the algorithm, error bars indicate 1 standard deviation (SD); the value for θ obtained from bootstrapping in two example data sets is marked in red; (C) Mooney Stimulus [42]; (D) Cortical sources after beamforming of MEG data (l.,left; r., right: l. orbitofrontal cortex (OFC); r. middle frontal gyrus (MiFG); l. inferior frontal gyrus (IFG left); r. inferior frontal gyrus (IFG right); l. anterior inferotemporal cortex (aTL left); l. cingulate gyrus (cing); r. premotor cortex (premotor); r. superior temporal gyrus (STG); r. anterior inferotemporal cortex (aTL right); l. fusiform gyrus (FFA); l. angular/supramarginal gyrus (SMG); r. superior parietal lobule/precuneus (SPL); l. caudal ITG/LOC (cITG); r. primary visual cortex (V1)), see also [40]; (E) Example of removal of tagged edges: MEG data of a face detection task in two subjects. First column shows transfer entropy values prior to detection of potentially spurious edges (Pre). The second column shows color-coded tagged edges (red: Potential cascade effects, blue: potential common drive effects; θ = 3ms). The third column shows the network of directed interactions after removal of all tagged edges (Post).
Data analysis
MEG data were analyzed using MathWorks MATLAB (2008b, The MathWorks, Natick, MA) and the open source MATLAB toolboxes FieldTrip (version 2008-12-08; [43]), SPM2 (http://www.fil.ion.ucl.ac.uk/spm), and TRENTOOL [20]. We will briefly describe the applied analysis here, for a more in depth treatment refer to [40].
For data preprocessing, we defined experimental trials from the continuously recorded MEG data. A trial was defined as the epoch from -1000 ms prior to stimulus presentation until 1000 ms after stimulus presentation. Trials contaminated by artifacts (eye blinks, muscle activity, or jump artifacts in the sensors) as well as trials with wrong responses were discarded. Trials were baseline corrected by subtracting the mean amplitude between -500 to -100 ms before stimulus onset.
To investigate differences in source activation in the face and non-face condition, we used a frequency domain beamformer [44] at frequencies of interest identified at the sensor level (80 Hz with a spectral smoothing of 20 Hz). We computed the frequency domain beamformer filters for combined trials (“common filters”) consisting of activation (multiple windows, duration, 200 ms; onsets at every 50 ms from 0 to 450 ms) and baseline data (-350 to -150 ms). To compensate for the short duration of the data windows, we used a regularization of λ = 5% [45].
To find significant source activation in the face versus non-face condition, we first conducted a within-subject t-test for activation versus baseline effects. Next, the t-values of this test statistic were subjected to a second-level randomization test at the group level to obtain effects of differences between face and no-face conditions; a p-value < 0.01 was considered significant. We identified 14 sources with differential spectral power between both conditions in the frequency band of interest in occipital, parietal, temporal, and frontal cortices (see Fig 9D and [40] for exact anatomical locations). Namely, our network representing information flow between sources has 14 nodes. We then reconstructed source time courses for TE analysis, this time using a broadband beamformer with a bandwidth of 10 to 150 Hz.
We estimated TE between beamformer source time courses [20, 46] within an analysis window of 500 ms (-50–450 ms) and tested resulting TE values for their statistical significance [20]. We furthermore reconstructed information transfer delays for significant information transfer by scanning over a range of assumed interaction delays from 5 to 17 ms (resolution 2 ms), following the approach in [19] and parameters used in a similar analysis in [46]. We thus obtained a delay weighted, directed network of information transfer during a face recognition task, consisting of 14 nodes and edges with weights in the range from 5 to 17. We then applied the proposed algorithm to the resulting delay-weighted networks of directed interactions. For two example data sets, we used bootstrapping (1000 resampled cases) to obtain an estimate of the standard error of the delay estimation [47] and used this estimated standard error as input parameter θ for a more detailed example application of the algorithm.
Performance results for “empirical” networks
For empirical data running times increased almost linearly in ∣V∣ + ∣E∣ (Fig 9A). We chose to present running times as function of the sum of the number of nodes and number of edges because a systematic variation of network size was not possible here (rather, network size was determined by previous source reconstruction). Cases of intractability did not occur even though some data sets exhibited high network densities (ranging from 0.07 to 0.43 with a mean of 0.24 and a SD of 0.09).
The percentage of potentially spurious edges increased with higher thresholds θ up to 32% of potentially spurious edges for θ = 7ms (Fig 9B). Edges were considered potentially spurious if at least one alternative path existed or a simple CD was present. Note, that the threshold serves to adjust the algorithm’s sensitivity and may lead to the erroneous exclusion of edges if chosen too high. Thus, the value for θ should be chosen such that imprecisions in interaction reconstruction are accounted for, while the false discovery rate is not increased. As a rule of thumb, a user may use prior knowledge about the minimum interaction delay to be expected in the data as an upper bound for θ or use bootstrapping to obtain an error estimate for reconstructed delays.
In Fig 9E, we show results for two example MEG data sets from the validation test-set before and after analysis with the proposed algorithm. We used bootstrapping to estimate the standard error in the reconstruction of the interaction delays. We found an average error over channels of 2.6 ms for subject one and 2.9 ms for subject two. Accordingly, we set θ = 3ms as this corresponded to the next integer value in ms. The average reconstructed interaction delay was found to be 7.06 ms (SD: 3.57 ms) for subject one and 6.94 ms (SD: 3.32 ms) for subject two. We also calculated the average path length as the average weight of the shortest path for each node to every other node in the network; the average path length was 6.84 ms for subject one and 6.81 ms for subject two. Note that the graphs are highly connected prior to the application of the algorithm, such that the shortest path between any two nodes consists of just one edge; thus the average path length is close to the average edge weight.
After application of the algorithm, the recovered networks of information transfer consisted of 20 links for subject one and 34 links for subject two; networks showed an overlap of nine edges, which corresponds to an 45% overlap and is 20 times higher than an overlap of 2% expected purely by chance. Thus, the network can be considered highly consistent.
Discussion
Algorithmic detection of potentially spurious edges in delay weighted networks
We have presented an algorithm that finds potentially spurious links arising from bivariate analysis of multi-node networks based on interaction timing. The algorithm identifies the most common motifs causing the reconstruction of spurious links, such that identified links can be subjected to further testing, or removed. By removing all potentially spurious edges, the user obtains a sub-network that is guaranteed to contain only non-spurious edges; this improves the validity of the network representation itself as well as the validity of potential subsequent network analysis. The algorithm thus allows the user to find an approximate representation of multivariate interactions in the data, using only bivariate interaction reconstruction and avoiding the computationally heavy problem of an approximately or even fully multivariate approach.
The presented algorithm may be used in neuroscience to post-process any network of reconstructed bivariate interactions, where interactions are directed and weighted by their estimated delays. We demonstrated the application of the algorithm using a reference implementation in MATLAB as part of the open source toolbox TRENTOOL [20].
Application in neuroscience
Based on findings in [19], we propose to identify spurious links by their characteristic timing signatures in networks of reconstructed bivariate interactions [14]. In particular, we propose that a link is likely to be spurious if an alternative path with identical timing exists (Fig 2).
We assume that a bivariate information transfer between two nodes and a corresponding alternative path constitute a redundant routing of information. Such a redundant routing conflicts with the hypothesis that the brain evolves under the objective of maximizing economy and efficacy [6, 48] while minimizing biological costs [49, 50] (see for example the “save-wire hypothesis” in [51]). We thus argue that any redundant routing of information between two sources of neural activity –with identical timing– would be implausible, given the brain’s organizational principles. Therefore, whenever a redundant routing for a bivariate information transfer is found, our rationale implies spuriousness of either the bivariate information transfer or the alternative path. Of the two, we consider the bivariate interaction spurious, because (1) spurious bivariate interactions are a likely artifact in bivariate analysis of multi-node networks; and (2) if a bivariate and thereby direct means of information transfer between a source and a target existed, the maintenance of a physiologically more costly alternative path of identical information transfer would be unlikely.
Note, that this rationale exclusively applies to neural systems. Also remember, that the algorithm does not tag all alternative routings of information, but only those with a certain timing signature; alternative routings with different delays than the bivariate interaction are not considered redundant and are not tagged.
Treatment of tagged links in neuroscience applications
Our algorithm tags potentially spurious edges to let the user decide if a tagged edge should be ultimately excluded from the network representation. To minimize erroneous exclusions, the user may inform the decision by additional evidence, e.g. previous anatomical or functional findings. If such previous findings do not exist, we recommend the exclusion of tagged edges.
We consider the erroneous rejection of links favorable over erroneous inclusion, i.e., we suggest to rather commit a false negative error if in doubt. We favor false negative errors because in statistical terms, false negatives are considered less severe than false positives (erroneously including a spurious link), as they yield more conservative results. If the user removes all tagged links, the resulting network is guaranteed to contain non-spurious links only, but some links may be missing from the network.
In triangle motifs, the exclusion of all tagged links will definitely lead to false negatives: Here, two links are tagged but the exclusion of both edges is mutually exclusive; more precisely, the exclusion of one of the two tagged edges destroys the motif giving rise to the second, potentially spurious link. This is illustrated in Fig 2C, where the exclusion of link (v 1, v t) destroys the CE leading to the tagging of edge (v s, v t), and on the other hand, the exclusion of (v s, v t) destroys the CD leading to the tagging of (v 1, v t). In triangle motifs, the rejection of both edges thus produces a false negative error; here, prior anatomical or functional evidence are required to decide which of the two tagged edges is non-spurious.
It is further possible to use modeling approaches to test if tagged links are actually present in the network of bivariate interactions. For example dynamic causal modeling (DCM, [52–54]) may be used to test whether a model containing a certain link is favorable given the observed data over a second model missing this link.
Types of multivariate effects not identified by the algorithm
The correction performed by the presented algorithm is not exhaustive with respect to all types of multivariate interactions potentially occurring in neuroscience data. The interactions not targeted by the algorithm are of two types: (1) more general cases of CD; (2) synergistic effects [17], i.e., combined effects of two or more sources on a third source. In the following we will discuss the conceptual and practical limitations that prevent an exhaustive algorithmic correction for these two types of multivariate interactions.
Detection of general common drive effects
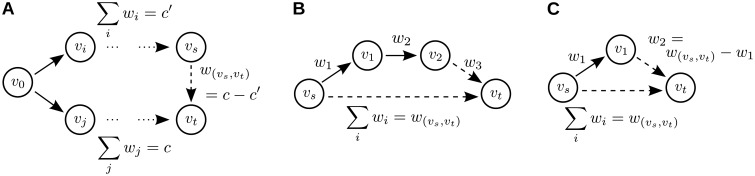
The presented algorithm detects simple CD in triangle motifs by listing all links with alternative paths of length two. Our algorithm can theoretically be extended to explicitly search for general cases of CD, where two nodes are commonly driven via arbitrarily long cascades of information transfer (Fig 2A).
General CD may be identified by searching for paths of equal summed interaction delays that have a common source and target node. We again assume that equal summed delays hint at redundant and therefore spurious information transfer. It can then be tested if the source node is a common driver for the last and second to last node in one of the two paths by looking at the information transfer delay between these last two nodes. For an example, see Fig 2A, where the bivariate information transfer in the network forms two paths of equal delays connecting nodes v 0 and v t: The link (v s, v t) is tagged as spurious because its weight corresponds to the difference in the summed path weights and : w (vs, vt) = c − c′. In this scenario, v 0 is a common driver of nodes v s and v t. This approach also allows to test for higher order CD, i.e., one source driving three or more nodes simultaneously. A similar algorithm was proposed by Marinazzo and colleagues [55] to identify spurious bivariate links using a network of multivariately reconstructed interactions (see next section).
Even though an extension to general CD is hypothetically possible, its realization is not feasible in practice: The extension requires that for each network node all originating paths of arbitrary length need to be listed. An algorithm fulfilling this task would have an asymptotic running time many times higher than the algorithm presented in this work: For each node in V, O(∣V − 1∣!) paths of arbitrary length and weight exist (in the first step O(∣V∣ − 1) nodes can be reached from the current starting node, in the second step O(∣V∣ − 2) nodes can be reached, and so forth). The asymptotic running time of such an algorithm thus amounts to O(∣V∣ ⋅ ∣V − 1∣!). Such a factorial running time is commonly not considered feasible in practice and would limit the application to networks of very small size.
Detection of synergistic effects
Synergistic effects describe information that is transferred from a set of sources to a common target, whereby information is combined in a non-trivial fashion [17, 18, 56, 57]. In this case, looking at the set of sources simultaneously provides information about the target that is not obtainable from looking at each source separately. As a toy example, one can think of three nodes implementing a logical XOR operator, where two nodes serve as binary input and the third node serves as output node. Each state of the output node is the exclusive OR of the two previous input states. A bivariate analysis of every pairwise interaction between the three nodes will not detect any significant interaction, because the pairwise mutual information between any two nodes is 0. Analyzing the triplet of nodes simultaneously will however detect an interaction; e.g. the conditional mutual information (TE) will be greater than zero, because it “decodes” the information in one source by conditioning on the second source.
Consequently, synergistic effects between a set of sources and a target node can only be revealed if the whole set is considered simultaneously in some multivariate reconstruction of interactions or by explicitly reconstructing synergistic interactions [18, 58]. Such synergistic effects are not targeted by design of our algorithm as it simply post-processes results from bivariate network analyses. To include synergistic effects, a multivariate interaction analysis would have to replace the estimation of bivariate interactions. Note however, that any fully multivariate method for interaction reconstruction would need to identify the optimal subset of sources that exert some meaningful influence on a given target node. The identification of such an optimal set of sources would require the exhaustive testing of the power set of all network sources, due to the non-additivity of information contributions from individual sources (because of redundant and synergistic effects). The power set has size , i.e., testing all sources brute force has a theoretical running time of O(2∣V∣). In fact, it has been shown that optimal subset selection in regression is an NP-hard problem [10]. This proof extends to source selection for TE due to the equality of TE with Granger causality for jointly Gaussian variables [22]. Thus, the reconstruction of truly multivariate interactions in arbitrarily large networks poses a computationally intractable problem (if P ≠ NP). In the next subsection we will present approaches that try to approximate fully multivariate methods to circumvent the inherent computational complexity of the problem at hand.
Comparison to other approximative methods for multivariate network reconstruction
The proposed algorithm provides an approximative method for the inference of networks of multivariate interactions to handle the computational intractability of exact network reconstruction. Methods with a similar purpose have been proposed by various authors. In the following we will review some of these methods and list scenarios that may benefit from the application of our algorithm.
Multivariate reconstruction of effective networks by Lizier and Rubinov
Lizier and Rubinov [12] proposed a greedy algorithm which for each network node Y (the target) infers a set of influential source variables V Y. A source is considered influential if it adds significantly to the information transfer from V Y to Y. The set V Y is thus built by iteratively adding sources, which have significant information transfer into Y, conditional on the previously included sources. Finally, information transfer is re-evaluated conditional on the complete set of included sources:
i.e., the mutual information between each source X ∈ V Y and target Y while conditioning on all remaining relevant sources in V Y, except X. If a source fails to provide statistically significant information about the present of Y, it is removed from V Y. After this “pruning step”, the set V Y consists of all relevant sources that contribute information about the target. The approach is robust against the detection of spurious interactions due to CD and CE, because for each interaction reconstruction it conditions on all relevant sources in the network.
Note that the greedy strategy used by Lizier and Rubinov is approximative insofar as it does not guarantee a maximal informative set V Y over all sets . For example, purely synergistic effects between two or more sources may be missed. The authors propose to extend their greedy method by also testing tuples and higher order combinations of sources, but they note that this requires considerable computational resources, which may not be worth the gain in information. The testing of tuples may however be feasible for small networks.
Partial conditioning of information transfer by Marinazzo and colleagues
Marinazzo and colleagues [55] proposed a greedy algorithm resembling the approach by Lizier and Rubinov. Again, the algorithm tries to account for other relevant network sources when evaluating the information transfer from a source X to a target Y in a multivariate system. To identify relevant sources, Marinazzo et al. propose to iteratively construct a “partial conditioning set” Z from all sources V∖{X, Y}. In each iterative step k the algorithm includes the source Z k that maximizes the mutual information between Z k and the source X, i.e., Zk = maxZ (I(X; Zk)), where Zk = Zk−1 ∪ Z.
The partial conditioning approach may miss interactions if sources share a lot of redundant information about a target: If an existing source-target relationship is evaluated while conditioning on sources providing redundant information about the target, the source-target relationship under investigation is not detected. Therefore, Stramaglia and colleagues [59] extended partial conditioning with a graph algorithm that identifies these missed interactions. The authors proposed to reconstruct interactions multivariately (e.g. with partial conditioning) and bivariately. The multivariate network is then used to algorithmically separate bivariate links in two sets: (1) links explained by an indirect path of information transfer in the multivariate network (CE), and (2) links not explained by an indirect path. Bivariate links in the second group, which are missing from the multivariate network, are assumed to reflect non-spurious information transfer that was missed by the multivariate approach. These bivariate links are then merged with the multivariate network.
Note that the rationale underlying the algorithm proposed in [59] resembles the rationale presented in this paper because spurious bivariate interactions are identified by alternative paths; however, the aim of both approaches differs: The algorithm presented by Stramaglia and colleagues improves multivariate interaction reconstruction, while the algorithm presented in this paper tries to approximate a multivariate approach from bivariate interaction reconstruction alone. The approach proposed by Stramaglia thus still requires the potentially intractable reconstruction of multivariate interactions from data.
Non-uniform multivariate embedding by Faes and colleagues
Faes and colleagues [60] proposed a non-uniform embedding technique to estimate the information transfer from one source variable to a target in the presence of further potentially relevant sources of information transfer. The authors propose to iteratively build a non-uniform embedding vector from a set of candidate time points from the past of all sources in a network up to a certain predefined limit. Points are included in the vector if they add significant information about the next state of the target. Information transfer between a source and a target may then be estimated while conditioning on this non-uniform embedding vector.
The iterative construction of the embedding vector follows a greedy strategy that is similar to the strategies discussed above [12, 55]. Accordingly, the returned embedding vector is not guaranteed to yield the set of maximally informative source time points with respect to the target, as it will miss purely synergistic contributions of two or more points to the target. As said above, an exhaustive testing of all possible subsets of source time points poses an intractable computational problem. This is explained next.
Exhaustive brute force analysis
A brute force analysis of interactions between all possible subsets (m-tuples) in a set of nodes would yield an exact solution to the problem of inferring the network of multivariate interactions from data. For the example of m = 3, one would enumerate all 3-tuples or triplets in the set of nodes and for each triplet evaluate the six possible interaction motifs—three potential targets and for each target two possible combinations of source and conditioning node. Note that here the mandatory conditioning takes care of potential synergies. For the general case of m-tuples, this would generalize to possible subsets of size m, where for each tuple m ⋅ (m − 1) possible interaction motifs exist. As for approximative approaches, such an analysis is feasible for small numbers of m only.
Application scenarios for the proposed algorithm
The most basic application scenario for the proposed algorithm is as post-processing step after bivariate reconstruction of directed, delay-weighted interactions from a set of neural sources. Here, the algorithm helps to prune potentially spurious edges to obtain an approximative, statistically conservative network representation of the physical interactions. In this scenario, our algorithmic correction is favorable over multivariate interaction reconstruction whenever available data is limited or high-dimensional, such that data points are not sufficient to estimate highly multivariate interactions. Here, our algorithm is more data-efficient because it relies on bivariate interaction reconstruction only. Such data-efficiency is especially relevant for information theoretic measures, where quantities are often estimated using kernel estimators or neighbor methods (as for example proposed in [61]); applying these kernel estimators to the estimation of highly multivariate data may lead to very high dimensional search spaces, which suffer from the curse of dimensionality, hindering a reliable estimation of the quantities of interest.
The application of our algorithm may prove beneficial prior to calculating graph theoretical measures from networks of reconstructed interactions. We argue that these measures are more reliable when applied to a statistically conservative network representation.
The algorithm may further be used in conjunction with modeling approaches such as DCM, where it serves to limit the model space to be tested. DCM may also help to identify the most plausible network representation from models, after in- and excluding individual tagged edges respectively.
The presented algorithm may further serve as a preprocessing step for trivariate estimation of information transfer: By testing only the triangle motifs identified by the algorithm, the number of necessary information transfer estimations reduces drastically compared to the brute-force approach discussed in the last subsection. Necessary estimations include bivariate interaction reconstruction (∣V∣ ⋅ (∣V∣ − 1) calculations for ∣V∣ nodes) and subsequent multivariate interaction reconstruction for identified triangle motifs. The actual number of multivariate reconstructions depends on the number of motifs: The approach is asymptotically faster if 90% or less of the possible triangle motifs are actually present in the data (for network sizes ∣V∣ > 12). Trivariate estimation of TE has been implemented in TRENTOOL [20], which also includes the reference implementation of the proposed algorithm. Thus, both analyses may be used in conjunction to estimate multivariate TE of order three. An extension to higher orders is theoretically possible although not implemented as it is not deemed feasible for practical purposes.
Finally, the algorithm is especially suitable for the application in simulated networks where all information transfers have a delay of unity, such as elementary cellular automata, and spurious interactions are therefore easily found.
Data Availability
The reference MATLAB implementation of the algorithm described in the article is available from the GitHub repository at https://github.com/trentool/TRENTOOL3. Magnetoencephalography data are available from the authors for researchers who meet the criteria for access to confidential data imposed by the ethics committee at Johann Wolfgang Goethe University, Frankfurt, Germany.
Funding Statement
MW and PW received financial support from the grant LOEWE “Neuronale Koordination Forschungsschwerpunkt Frankfurt (NeFF)” awarded by the Landes-Offensive zur Entwicklung Wissenschaftlich-ökonomischer Exzellenz of the Land Hessen (LOEWE), https://wissenschaft.hessen.de/loewe. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Bullmore E, Sporns O. Complex brain networks: graph theoretical analysis of structural and functional systems. Nature Reviews Neuroscience. 2009;10(3):186–198. 10.1038/nrn2575 [DOI] [PubMed] [Google Scholar]
- 2. Rubinov M, Sporns O. Complex network measures of brain connectivity: uses and interpretations. Neuroimage. 2010;52(3):1059–1069. 10.1016/j.neuroimage.2009.10.003 [DOI] [PubMed] [Google Scholar]
- 3. Stam CJ, Tewarie P, Van Dellen E, Van Straaten ECW, Hillebrand A, Van Mieghem P. The trees and the forest: characterization of complex brain networks with minimum spanning trees. International Journal of Psychophysiology. 2014;92(3):129–138. 10.1016/j.ijpsycho.2014.04.001 [DOI] [PubMed] [Google Scholar]
- 4. Tewarie P, Van Dellen E, Hillebrand A, Stam CJ. The minimum spanning tree: An unbiased method for brain network analysis. Neuroimage. 2015;104:177–188. 10.1016/j.neuroimage.2014.10.015 [DOI] [PubMed] [Google Scholar]
- 5. Amaral LAN, Ottino JM. Complex networks. The European Physical Journal B—Condensed Matter and Complex Systems. 2004;38(2):147–162. 10.1140/epjb/e2004-00110-5 [DOI] [Google Scholar]
- 6. Boccaletti S, Latora V, Moreno Y, Chavez M, Hwang DU. Complex networks: Structure and dynamics. Physics Reports. 2006;424:175–308. 10.1016/j.physrep.2005.10.009 [DOI] [Google Scholar]
- 7. Stam CJ, Reijneveld JC. Graph theoretical analysis of complex networks in the brain. Nonlinear Biomedical Physics. 2007;1(1):3 10.1186/1753-4631-1-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Börner K, Sanyal S, Vespignani A. Network science. Annual review of information science and technology. 2008;41(1):537–607. [Google Scholar]
- 9. Sporns O. From simple graphs to the connectome: Networks in neuroimaging. Neuroimage. 2012;62(2):881–886. 10.1016/j.neuroimage.2011.08.085 [DOI] [PubMed] [Google Scholar]
- 10. Welch WJ. Algorithmic complexity: three NP-hard problems in computational statistics. Journal of Statistical Computation and Simulation. 1982;15(1):17–25. 10.1080/00949658208810560 [DOI] [Google Scholar]
- 11.Das A, Kempe D. Algorithms for subset selection in linear regression. In: Proceedings of the fortieth annual ACM symposium on Theory of computing. ACM; 2008. p. 45–54.
- 12.Lizier JT, Rubinov M. Multivariate construction of effective computational networks from observational data; 2012. Preprint. Technical Report 25/2012, Max Planck Institute for Mathematics in the Sciences. Available from: http://www.mis.mpg.de/preprints/2012/preprint2012_25.pdf. Accessed 13 March 2015.
- 13. Garey MR, Johnson DS. Computers and intractability. vol. 174 San Francisco, CA: Freeman; 1979. [Google Scholar]
- 14.Wibral M, Wollstadt P, Meyer U, Pampu N, Priesemann V, Vicente R. Revisiting Wiener’s principle of causality-interaction-delay reconstruction using transfer entropy and multivariate analysis on delay-weighted graphs. In: Engineering in Medicine and Biology Society (EMBC), 2012 Annual International Conference of the IEEE. IEEE; 2012. p. 3676–3679. [DOI] [PubMed]
- 15. Kamiński M, Ding M, Truccolo WA, Bressler SL. Evaluating causal relations in neural systems: Granger causality, directed transfer function and statistical assessment of significance. Biological Cybernetics. 2001;85(2):145–157. 10.1007/s004220000235 [DOI] [PubMed] [Google Scholar]
- 16. Blinowska KJ, Kuś R, Kamiński M. Granger causality and information flow in multivariate processes. Physical Review E. 2004;70(5):050902 10.1103/PhysRevE.70.050902 [DOI] [PubMed] [Google Scholar]
- 17.Williams PL, Beer RD. Nonnegative decomposition of multivariate information; 2010. arXiv Preprint. Available: arXiv:10042515. Accessed 13 March 2015.
- 18.Williams PL, Beer RD. Generalized measures of information transfer, 2011. arXiv Preprint. Available: arXiv:11021507. Accessed 13 March 2015.
- 19. Wibral M, Pampu N, Priesemann V, Siebenhühner F, Seiwert H, Lindner M, et al. Measuring information-transfer delays. PLoS ONE. 2013;8(2):e55809 10.1371/journal.pone.0055809 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Lindner M, Vicente R, Priesemann V, Wibral M. TRENTOOL: A Matlab open source toolbox to analyse information flow in time series data with transfer entropy. BMC Neuroscience. 2011. November;12(1):119 10.1186/1471-2202-12-119 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Bassett DS, Bullmore E. Small-world brain networks. The Neuroscientist. 2006;12(6):512–523. 10.1177/1073858406293182 [DOI] [PubMed] [Google Scholar]
- 22. Barnett L, Barrett AB, Seth AK. Granger causality and transfer entropy are equivalent for Gaussian variables. Physical Review Retters. 2009;103(23):238701. [DOI] [PubMed] [Google Scholar]
- 23. Chen Y, Rangarajan G, Feng J, Ding M. Analyzing multiple nonlinear time series with extended Granger causality. Physics Letters A. 2004;324(1):26–35. 10.1016/j.physleta.2004.02.032 [DOI] [Google Scholar]
- 24. Vakorin VA, Krakovska OA, McIntosh AR. Confounding effects of indirect connections on causality estimation. Journal of Neuroscience Methods. 2009;184(1):152–160. 10.1016/j.jneumeth.2009.07.014 [DOI] [PubMed] [Google Scholar]
- 25. Blinowska KJ. Review of the methods of determination of directed connectivity from multichannel data. Medical and Biological Engineering and Computing. 2011;49(5):521–529. 10.1007/s11517-011-0739-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Diestel R. Graph theory. 4th ed New York: Springer; 2010. [Google Scholar]
- 27. Cormen TH, Leiserson CE, Rivest RL, Stein C. Introduction to Algorithms (Third Edition). Cambridge: The MIT Press; 2009. [Google Scholar]
- 28. Watts DJ, Strogatz SH. Collective dynamics of small-world networks. Nature. 1998;393(6684):440–442. 10.1038/30918 [DOI] [PubMed] [Google Scholar]
- 29. Barabási AL, Albert R. Emergence of scaling in random networks. Science. 1999;286(5439):509–512. 10.1126/science.286.5439.509 [DOI] [PubMed] [Google Scholar]
- 30. Erdős P, Rényi A. On random graphs. Publicationes Mathematicae Debrecen. 1959;6:290–297. [Google Scholar]
- 31. Gilbert EN. Random graphs. Annals of Mathematical Statistics. 1959;30:1141–1144. 10.1214/aoms/1177706098 [DOI] [Google Scholar]
- 32. Sporns O, Chialvo DR, Kaiser M, Hilgetag CC. Organization, development and function of complex brain networks. Trends in Cognitive Sciences. 2004;8(9):418–425. 10.1016/j.tics.2004.07.008 [DOI] [PubMed] [Google Scholar]
- 33. Power JD, Fair DA, Schlaggar BL, Petersen SE. The development of human functional brain networks. Neuron. 2010;67(5):735–748. 10.1016/j.neuron.2010.08.017 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Stam CJ. Characterization of anatomical and functional connectivity in the brain: a complex networks perspective. International Journal of Psychophysiology. 2010;77(3):186–194. 10.1016/j.ijpsycho.2010.06.024 [DOI] [PubMed] [Google Scholar]
- 35. Albert R, Barabási AL. Statistical mechanics of complex networks. Reviews of Modern Physics. 2002;74:47–97. 10.1103/RevModPhys.74.47 [DOI] [Google Scholar]
- 36. Batagelj V, Brandes U. Efficient generation of large random networks. Physical Review E. 2005;71(3):036113 10.1103/PhysRevE.71.036113 [DOI] [PubMed] [Google Scholar]
- 37. Bollobás B, Riordan O, Spencer J, Tusnády G, et al. The degree sequence of a scale-free random graph process. Random Structures & Algorithms. 2001;18(3):279–290. 10.1002/rsa.1009 [DOI] [Google Scholar]
- 38. Bollobás B, Riordan O. The diameter of a scale-free random graph. Combinatorica. 2004;24(1):5–34. 10.1007/s00493-004-0002-2 [DOI] [Google Scholar]
- 39. Wasserman S, Faust K. Social network analysis: Methods and applications. vol. 8 Cambridge: Cambridge University Press; 1994. [Google Scholar]
- 40. Grützner C, Uhlhaas PJ, Genc E, Kohler A, Singer W, Wibral M. Neuroelectromagnetic correlates of perceptual closure processes. Journal of Neuroscience. 2010;30(24):8342–8352. 10.1523/JNEUROSCI.5434-09.2010 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41. Oldfield RC. The assessment and analysis of handedness: the Edinburgh inventory. Neuropsychologia. 1971;9(1):97–113. 10.1016/0028-3932(71)90067-4 [DOI] [PubMed] [Google Scholar]
- 42. Mooney CM, Ferguson GA. A new closure test. Canadian Journal of Psychology/Revue canadienne de psychologie. 1951;5(3):129 10.1037/h0083540 [DOI] [PubMed] [Google Scholar]
- 43. Oostenveld R, Fries P, Maris E, Schoffelen JM. FieldTrip: Open Source Software for Advanced Analysis of MEG, EEG, and Invasive Electrophysiological Data. Computational Intelligence and Neuroscience. 2011;2011:1–9. 10.1155/2011/156869 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44. Groß J, Kujala J, Hämäläinen M, Timmermann L, Schnitzler A, Salmelin R. Dynamic imaging of coherent sources: studying neural interactions in the human brain. Proceedings of the National Academy of Sciences. 2001;98(2):694–699. 10.1073/pnas.98.2.694 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45. Brookes MJ, Vrba J, Robinson SE, Stevenson CM, Peters AM, Barnes GR, et al. Optimising experimental design for MEG beamformer imaging. Neuroimage. 2008;39(4):1788–1802. 10.1016/j.neuroimage.2007.09.050 [DOI] [PubMed] [Google Scholar]
- 46. Wollstadt P, Martínez-Zarzuela M, Vicente R, Díaz-Pernas FJ, Wibral M. Efficient transfer entropy analysis of non-stationary neural time series. PLoS ONE. 2014;9(7):e102833 10.1371/journal.pone.0102833 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47. Kulesa A, Krzywinski M, Blainey P, Altman N. Points of significance: sampling distributions and the bootstrap. Nature Methods. 2015;12:477–478. 10.1038/nmeth.3414 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48. Laughlin SB, Sejnowski TJ. Communication in neuronal networks. Science. 2003;301(5641):1870–1874. 10.1126/science.1089662 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49. Kötter R, Sommer FT. Global relationship between anatomical connectivity and activity propagation in the cerebral cortex. Philosophical Transactions of the Royal Society B: Biological Sciences. 2000;355(1393):127–134. 10.1098/rstb.2000.0553 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50. Chklovskii DB, Koulakov AA. Maps in the brain: what can we learn from them? Annual Review of Neuroscience. 2004;27:369–392. 10.1146/annurev.neuro.27.070203.144226 [DOI] [PubMed] [Google Scholar]
- 51. Cherniak C. Neural component placement. Trends in Neuroscience. 1995;18(12):522–527. 10.1016/0166-2236(95)98373-7 [DOI] [PubMed] [Google Scholar]
- 52. Friston KJ, Harrison L, Penny W. Dynamic causal modelling. Neuroimage. 2003;19(4):1273–1302. 10.1016/S1053-8119(03)00202-7 [DOI] [PubMed] [Google Scholar]
- 53. David O, Kiebel SJ, Harrison LM, Mattout J, Kilner JM, Friston KJ. Dynamic causal modeling of evoked responses in EEG and MEG. NeuroImage. 2006;30(4):1255–1272. 10.1016/j.neuroimage.2005.10.045 [DOI] [PubMed] [Google Scholar]
- 54. Kiebel SJ, David O, Friston KJ. Dynamic causal modelling of evoked responses in EEG/MEG with lead field parameterization. NeuroImage. 2006;30(4):1273–1284. 10.1016/j.neuroimage.2005.12.055 [DOI] [PubMed] [Google Scholar]
- 55. Marinazzo D, Pellicoro M, Stramaglia S. Causal information approach to partial conditioning in multivariate data sets. Computational and Mathematical Methods in Medicine. 2012;2012 10.1155/2012/303601 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56. Bertschinger N, Rauh J, Olbrich E, Jost J, Ay N. Quantifying unique information. Entropy. 2014;16(4):2161–2183. 10.3390/e16042161 [DOI] [Google Scholar]
- 57. Griffith V, Koch C. Quantifying synergistic mutual information In: Guided Self-Organization: Inception. Berlin, Heilderberg: Springer; 2014. p. 159–190. [Google Scholar]
- 58. Harder M, Salge C, Polani D. Bivariate measure of redundant information. Physical Review E. 2013;87(1):012130 10.1103/PhysRevE.87.012130 [DOI] [PubMed] [Google Scholar]
- 59. Stramaglia S, Cortes JM, Marinazzo D. Synergy and redundancy in the Granger causal analysis of dynamical networks. New Journal of Physics. 2014;16:105003 10.1088/1367-2630/16/10/105003 [DOI] [Google Scholar]
- 60. Faes L, Nollo G, Porta A. Information-based detection of nonlinear Granger causality in multivariate processes via a nonuniform embedding technique. Physical Review E. 2011;83(5):051112 10.1103/PhysRevE.83.051112 [DOI] [PubMed] [Google Scholar]
- 61. Kraskov A, Stögbauer H, Grassberger P. Estimating mutual information. Physical Review E. 2004;69(6):066138 10.1103/PhysRevE.69.066138 [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The reference MATLAB implementation of the algorithm described in the article is available from the GitHub repository at https://github.com/trentool/TRENTOOL3. Magnetoencephalography data are available from the authors for researchers who meet the criteria for access to confidential data imposed by the ethics committee at Johann Wolfgang Goethe University, Frankfurt, Germany.