

Abstract
Background
Women with a family history of breast cancer face considerable uncertainty about whether to pursue standard screening, intensive screening, or prophylactic surgery. Accurate and individualized risk-estimation approaches may help these women make more informed decisions. Although highly penetrant genetic variants have been associated with familial breast cancer (FBC) risk, many individuals do not carry these variants, and many carriers never develop breast cancer. Common risk variants have a relatively modest effect on risk and show limited potential for predicting FBC development. As an alternative, we hypothesized that additional genomic data types, such as gene-expression levels, which can reflect genetic and epigenetic variation, could contribute to classifying a person’s risk status. Specifically, we aimed to identify common patterns in gene-expression levels across individuals who develop FBC.
Methods
We profiled peripheral blood mononuclear cells from women with a family history of breast cancer (with or without a germline BRCA1/2 variant) and from controls. We used the support vector machines algorithm to differentiate between patients who developed FBC and those who did not. Our study used two independent datasets, a training set of 124 women from Utah (USA) and an external validation (test) set from Ontario (Canada) of 73 women (197 total). We controlled for expression variation associated with clinical, demographic, and treatment variables as well as lymphocyte markers.
Results
Our multigene biomarker provided accurate, individual-level estimates of FBC occurrence for the Utah cohort (AUC = 0.76 [0.67-84]) . Even at their lower confidence bounds, these accuracy estimates meet or exceed estimates from alternative approaches. Our Ontario cohort resulted in similarly high levels of accuracy (AUC = 0.73 [0.59-0.86]), thus providing external validation of our findings. Individuals deemed to have “high” risk by our model would have an estimated 2.4 times greater odds of developing familial breast cancer than individuals deemed to have “low” risk.
Conclusions
Together, these findings suggest that gene-expression levels in peripheral blood cells reflect genomic variation associated with breast cancer risk and that such data have potential to be used as a non-invasive biomarker for familial breast cancer risk.
Electronic supplementary material
The online version of this article (doi:10.1186/s12920-015-0145-6) contains supplementary material, which is available to authorized users.
Keywords: Breast cancer, Disease risk, Biomarker
Background
Current clinical standards define a woman's breast cancer risk based on population averages. For individuals deemed to have a lifetime risk over 20 %, based primarily on family history, a strict surveillance regimen is recommended; this regimen typically includes twice-yearly clinical breast exams, yearly mammograms, and yearly breast MRI. For the five to ten percent of women who have a strong inherited predisposition to breast cancer [1], more aggressive prevention strategies—such as chemoprevention or prophylactic mastectomy/oophorectomy—may be recommended in addition to or instead of surveillance. However, many women with a family history of breast cancer, including many who carry BRCA1 or BRCA2 mutations, never develop breast cancer. Indeed, 40-50 % of women with a BRCA1 or BRCA2 mutation do not develop breast cancer by 70 years of age [2]. This situation leads to uncertainty for both patient and physician regarding whether to pursue these aggressive prevention strategies, which can cause health and lifestyle effects that many women consider to be severe. For example, side effects of chemoprevention can include osteoporosis, blood clots, endometrial cancer, hot flushes, joint pain, and depression [3, 4]. Thus there is a critical need to accurately differentiate individuals from high-risk families who will develop breast cancer from those who will not develop breast cancer. Screening and prevention resources could then be focused on those women who carry the highest risk for familial breast cancer (FBC), while women with a lower risk could be spared the risks and inconveniences of prophylaxis or intensive screening. Optimally, such an approach would be non-invasive and provide estimates of risk that are tailored to each individual.
One existing method for estimating breast-cancer risk is based on personal health history, family health history, and demographic variables [5]; however, this approach is designed as a population-wide screening tool—not specifically for individuals from high-risk families—and the predictive accuracy of this method is limited [6]. Others have examined the potential to predict breast-cancer risk based on genetic or epigenetic variation, and these approaches have improved prediction accuracy [7–9]. We evaluated an alternative approach, hypothesizing that by quantifying gene-expression activity in peripheral-blood cells, we would be able to identify patterns that indicate a woman’s risk for developing breast cancer, as gene-expression profiling of normal cells has previously provided information about disease development [10–13]. This approach aims to overcome limitations of using genetic variants to predict risk. For example, due to genetic heterogeneity, individuals who develop breast cancer differ considerably in the risk variants that they carry, and most such variants are believed to have a subtle effect on risk. Gene-expression levels reflect biological activity within cells and serve as proxies for genetic (and epigenetic) variation within normal cells as well as tumor cells [10, 14, 15]. Indeed, it has been shown that global expression levels in lymphoblastoid cells reflect a person’s BRCA1 or BRCA2 mutation status, even when the mutations lie at different genomic loci within these genes [16]. Aberrant expression resulting from BRCA1 and BRCA2 mutations may not be reflected phenotypically in peripheral-blood cells; however expression levels in these cells may indicate a propensity for normal cellular activity within breast cells to become disrupted. Gene-expression levels in breast tumors have been shown to reflect functional germline variation. For example, expression patterns in tumors from patients with germline BRCA1 and BRCA2 variants exhibit distinctive patterns compared to tumors from individuals who do not carry these mutations [14–26]. Accordingly, we hypothesized that gene-expression-levels in normal cells should be similar across many women who develop FBC and thus indicative of disease risk, even though the underlying genetic and epigenetic variation may vary considerably across these women.
For this study, we examined the potential to use peripheral-blood gene-expression levels to identify women who possess the highest risk for developing FBC. We obtained peripheral blood mononuclear cells (PBMCs) for two independent patient cohorts and evaluated how well this gene-expression data could be used to differentiate between women who have developed FBC and women who have not, independent of BRCA1/BRCA2 mutation status. Our findings indicate that this approach has potential to provide women from breast cancer families with individualized estimates of breast cancer risk and therefore to guide patient decisions regarding medical management.
Methods
Description of patient cohorts and data sets and consent to publish
Utah
We recruited participants via the High Risk Breast Cancer Clinic at the Huntsman Cancer Institute (Utah, USA) under Institutional Review Board approved protocols (#00022886 and #00004965). We have obtained consent from these patients to report individual patient data. We collected blood samples after breast cancer occurrence and after participants had been in remission for at least six months. In general, we considered participants to have a family history of breast cancer if two or more first-degree relatives (mother, sister, daughter) had been diagnosed with breast cancer. Among eligible participants who met these criteria, we included all those from whom we could obtain fresh mononuclear cells at the time of the study. Among 83 individuals in the Utah cohort who had a family history of breast cancer, 39 had been diagnosed with breast cancer, whereas 44 women had never been diagnosed with breast cancer and were at least 55 years of age (Table 1). Of the participants with a breast cancer family history, 38 carried a known pathogenic mutation (identified via commercial testing) in BRCA1 or BRCA2. We excluded women who carried a BRCA1/BRCA2 mutation but lacked a family history of breast cancer. To ensure that our findings were specific to familial breast cancer, we recruited 41 individuals with no known family history of breast cancer; 22 of these women had developed sporadic (non-familial) breast cancer. We matched the patients by age. The median age of blood draw was consistent across all patient subgroups in the Utah cohort (Table 2). We used an analysis-of-variance test to ensure that the difference in age across the subgroups was not statistically significant (p = 0.064). In addition, because our goal was to demonstrate an ability to differentiate between individuals who developed familial breast cancer and individuals who did not, we also verified that there was not a significant difference in ages between these two groups (t-test p-value = 0.28).
Table 1.
Summary of patient subgroups in the Utah and Ontario populations
| Category | Utah | Ontario |
|---|---|---|
| Family history, BRCA1/2, Cancer | 16 | 11 |
| Family history, BRCAX, Cancer | 23 | 17 |
| Family history, BRCA1/2, No Cancer | 18 | 14 |
| Family history, BRCAX, No Cancer | 26 | 18 |
| No family history, Cancer | 22 | 8 |
| No family history, No Cancer | 19 | 5 |
| Total | 124 | 73 |
Patients fell into one of six groups, depending on whether 1) they had a family history of breast cancer, 2) had been diagnosed with breast cancer previously, or 3) were known to carry a pathogenic variant in BRCA1 or BRCA2. The number of patients in each group is listed for each cohort
Table 2.
Summary of ages at which blood samples were acquired
| Description | Minimum | Median | Maximum |
|---|---|---|---|
| Family history, BRCA1/2, Cancer | 45 | 59.0 | 77 |
| Family history, BRCAX, Cancer | 56 | 58.5 | 78 |
| Family history, BRCA1/2, No Cancer | 46 | 60.0 | 78 |
| Family history, BRCAX, No Cancer | 55 | 63.0 | 83 |
| No family history, Cancer | 53 | 65.5 | 79 |
| No family history, No Cancer | 51 | 58.0 | 86 |
For participants within each group, this table indicates the minimum, average, and maximum age at which blood samples were drawn. These data represent 117 participants from the Utah cohort. The remaining 8 Utah participants were at least 55 years old; however, it was not feasible to collect their exact ages in retrospect. The median age at which blood samples were acquired was consistent across the groups (p = 0.064)
Ontario
We obtained de-identified samples via the Ontario, Canada site of the Breast Cancer Family Registry (BCFR). We also obtained consent from these patients to report individual patient data. This cohort included 28 samples from women with a family history of breast cancer who had developed breast cancer, 32 from women who had a family history of breast cancer but had not developed breast cancer, and 13 from women with no family history of breast cancer, 8 of whom had developed breast cancer. Of these 73 women, approximately half were post-menopausal. We obtained, isolated, and stored blood samples for these women when they first enrolled in the BCFR.
Genomic data acquisition and deposition
We used the RNeasy Kit (Qiagen, Hilden, Germany) to isolate PBMCs from whole blood in cell-preparation tubes following manufacturer (Becton-Dickinson) protocol. Within two hours, we extracted RNA using the RiboPure RNA Isolation Kit, and hybridized the RNA to Affymetrix Genechip Human Exon 1.0 ST microarrays. Hybridization and scanning were performed at Duke University (for Utah samples and for half of the Ontario samples) and at Boston University School of Medicine (for the remaining Ontario samples).
Microarray data normalization
To correct for array- and probe-level background noise, we applied our Single-channel Array Normalization algorithm [27] to the Affymetrix microarray data. We subsequently used the PLANdbAffy database [28] to limit our analysis to microarray probes that were classified as high quality ("green") and that did not map to a single-nucleotide variant. For each microarray, we summarized the remaining 2,201,005 probes into gene-level values using a 10 % trimmed mean. In addition, we excluded genes that contained fewer than five probes.
Because the microarrays had been processed at different facilities and at different times, we used the ComBat tool [29] to adjust for confounding effects that might arise due to these differences. We used cohort and processing facility to define the batches. We applied ComBat two separate times: 1) to the Utah samples and Ontario samples that were processed at Duke University and 2) to the same Utah samples (processed at Duke University) and to the Ontario samples that were processed at Boston University. Strong batch effects existed before adjustment, but after ComBat adjustment, no clear pattern remained between batches and gene-expression levels (Additional file 1: Figure S1). We have deposited the raw and processed data files in Gene Expression Omnibus (GSE47862).
Gene-expression data filtering
To identify blood markers that could influence mRNA expression but that may cause confounding effects, we used a total lymphocyte enumeration test to evaluate the blood cells. This test provided total counts of CD4-positive T cells, CD8-positive T-cells, CD3-positive T-cells, B-cells and NK-cells. These counts were available for 22 samples from the Utah cohort. Furthermore, we obtained epidemiological and demographic data via a health-assessment survey for 63 patients from the Utah cohort. The health survey variables we collected were age, education level, marital status, religious preference, health status, physical activity, age at menarche, contraceptive use, total number of pregnancies, total number of live births, age at first live birth, age at last live birth, breastfeeding status, time since last menstrual period, age of menopause, chemopreventive drug use (selective estrogen receptor modulators), alcohol use, tobacco use, occupational history, immunological disorder history, hypertension drug use, and anti-inflammatory drug use. Additional files 2, 3 and 4 list these values. Additional file 5 indicates cancer, family-history, and BRCA1/2 status for these patients. Using a multifactor analysis of covariance model, we excluded genes whose expression patterns correlated with any of these variables at a 0.01 significance level. Additional file 6 indicates which genes were excluded.
Evaluation of normal breast cell expression
We downloaded data from Gene Expression Omnibus (GSE17072), which had been produced by Lim, et al. [30]. These data contained gene-expression levels for normal breast cells—acquired via prophylactic mastectomy or reduction mammoplasty—for women who had a strong family history of breast cancer and for controls, respectively. Then using the top 250 genes that were expressed more highly (according to average fold change rank) in our PBMC cells from women who had developed FBC, we used the Gene Set Enrichment Analysis analytical technique [31] to assess whether these genes were up-regulated in the Lim, et al. samples. For this tool, we used default settings, except that we did not collapse genes, and we used gene-based permutation to estimate significance.
Software
To identify genes whose expression differed most between FBC patients and controls, we used the Support Vector Machines-Recursive Feature Elimination (SVM-RFE) algorithm. We used the SVMAttributeEval module within the Weka software package [32] and configured the algorithm to remove 10 % of genes in each iteration.
We used the Support Vector Machines (SVM) classification algorithm to predict whether each participant had or had not developed FBC. To facilitate this analysis, we used the e1071 R package (http://cran.r-project.org/package=e1071) and the LIBSVM library [33]. We used the radial-basis-function SVM kernel and tuned the “C” parameter via nested cross validation. Additionally, we used the ML-Flex software package [34] to execute the analysis on a high-performance computing cluster.
To plot receiver operating characteristic curves, we used the ROCR package [35]. We used a bootstrapping procedure (10,000 iterations) to calculate 95 % confidence intervals [36].
Software scripts used for this study are available from https://github.com/srp33/BCSP.
Results
Multigene predictions perform well for both a Utah cohort and an external validation cohort from Ontario
We filtered the genome-wide PBMC gene-expression data by identifying genes whose expression best differentiated individuals who developed FBC from controls (see Methods). Controls were of three types: individuals with a family history of breast cancer who themselves did not develop breast cancer by age 55 or greater; individuals with no family history of breast cancer who also did not develop breast cancer; and individuals with no family history of breast cancer who did develop (sporadic) breast cancer. We then used expression values for those genes to predict FBC status for each individual using the SVM algorithm [37]. Two cohorts of samples were used for this study: a cohort from Utah and an independent cohort from Ontario; both included high-risk unaffected and affected women (see Methods for cohort details). Initially, we evaluated this approach in the Utah cohort via ten-fold cross validation. Our gene expression-based estimates of FBC development were consistently higher for women from FBC families who had developed cancer than for any subset of controls (Fig. 1a), attaining an AUC value of 0.76 (95 % CI = 0.67-0.85). Similar levels of accuracy were attained for women who carried a BRCA1/2 mutation as for women with a family history of breast cancer but with no known BRCA1/2 mutation (termed BRCAX) (Fig. 1a; Additional file 1: Table S1). Even at the lower confidence bounds, these AUC values are competitive with results observed in previous studies that used alternative approaches [7–9]. To further evaluate this result, we randomly permuted the class labels and observed that the biomarker’s accuracy was highly significant (p = 0.001). We also repeated cross-validation 1,000 times on the Utah data and observed that on average the best prediction results were attained using 250 genes; however accuracy was consistently high, independent of gene number (Fig. 2).
Fig. 1.
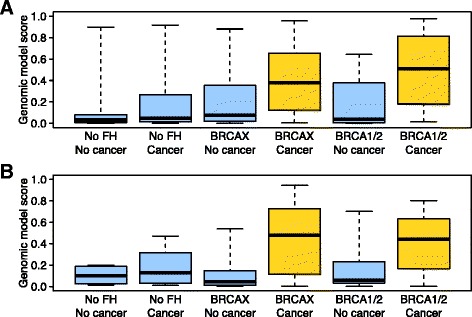
Predictions of familial breast cancer status in two independent cohorts. a In a cross-validated design, we predicted familial breast cancer status for 124 women from Utah. This cohort included women who did or did not have a family history (FH) of breast cancer, who did or did not carry a BRCA1 or BRCA2 mutation (BRCAX if not), and who had or had not developed breast cancer. The “Genomic model score” values represent probabilistic predictions made by the support vector machines algorithm. Higher values indicate a higher probability that a given individual had developed familial breast cancer. These scores were much higher for individuals who had a family history of breast cancer and developed a breast tumor, irrespective of BRCA1/BRCA2 mutation status. b In a training/testing design, we predicted whether individuals in the independent Ontario cohort had developed familial breast cancer. The support vector machines algorithm was trained on the full Utah data set. Again, the scores were considerably higher for women with a family history of breast cancer who had developed a breast tumor
Fig. 2.
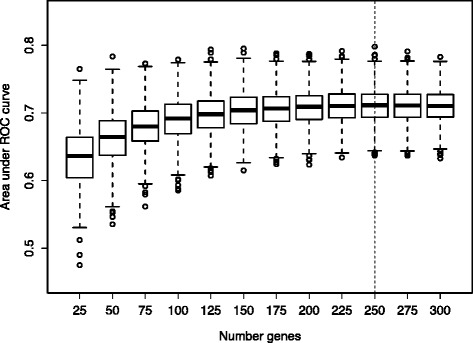
Cross-validation performance of gene-expression biomarker with different quantities of genes. For the gene-expression biomarker, we used the SVM-RFE method to identify genes whose expression differed most consistently between individuals who developed familial breast cancer and individuals who did not. The sizes of these gene subsets ranged in size between 25 and 300 genes. In repeated cross-validation (1,000 iterations), predictive accuracy peaked at 250 genes and was consistent when the number of genes was 150 or higher
To test whether this biomarker approach could be applied more generally via external validation, we derived an SVM model from the full Utah data set alone, and then used this model to predict FBC development in the external and independent Ontario data set. In accordance with Institute of Medicine recommendations [38], model derivation was performed solely on the Utah data before it was tested on the Ontario samples. These predictions attained an AUC of 0.73 (95 % CI = 0.59-0.86; permutation p-value = 0.002), showing a consistently high level of accuracy between the cohorts (Figs. 1 and 3; Additional file 1: Table S2).
Fig. 3.
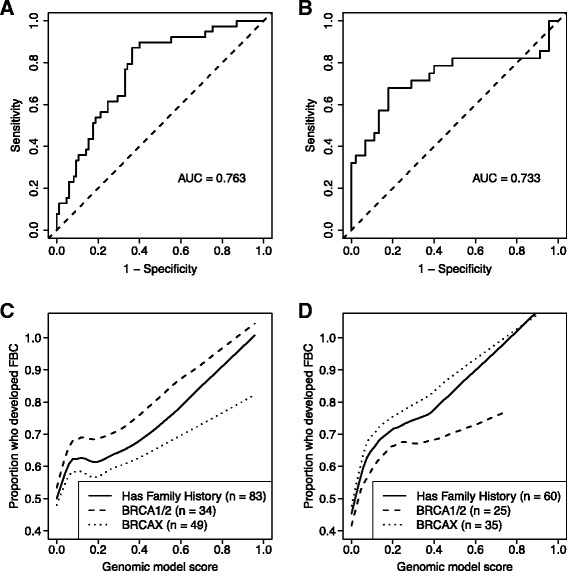
Sensitivity and specificity of biomarker predictions. Because the support vector machines predictions (genomic model score) are probabilistic, we evaluated various cutoff thresholds at which patients could be considered to have had a “high” probability of developing familial breast cancer. a-b Receiver operating characteristic curves illustrate the balance between sensitivity and specificity across many probability thresholds for the Utah and Ontario cohorts. c-d As the genomic model scores increase, a larger proportion of patients who fell above the threshold would have been predicted accurately to develop familial breast cancer. As the threshold approaches its maximum, the predictive accuracy for patients above the threshold is nearly perfect; however, such high thresholds would result in low sensitivity levels. A threshold near 0.2 may be optimal. Panel C represents predictions for Utah participants who had a family history of breast cancer; Panel D represents the Ontario cohort. The dashed lines represent predictions for individuals who carried a BRCA1 or BRCA2 mutation. The dotted lines represent predictions for BRCAX individuals. (Plotted lines were fitted using a LOESS model [span = 0.5] for smoothing)
Risk prediction accuracy is independent of treatment effect
Blood samples for these patients were collected retrospectively—at least six months after treatment had been administered to individuals who developed breast cancer. To alleviate the concern that gene-expression changes in women who developed FBC were caused by lingering treatment effects, we also collected PBMC samples for women who had developed sporadic (non-familial) breast cancer and had received treatment. In our initial analysis, we grouped these women with the participants who had no history of breast cancer and broadly classified this group as “controls”. To further assess whether the predictive gene-expression patterns we identified are specific to women who develop FBC and thus have potential to predict disease risk, we assessed how well the SVM algorithm could distinguish between individuals who developed FBC and those who developed a sporadic tumor. This comparison was identical to the initial assessment, except that the control group excluded individuals who did not develop breast cancer. In this setting, the predictions attained similar levels of accuracy (Utah AUC = 0.77 [0.64-0.88]; Ontario AUC = 0.69 [0.49-0.89]) as the initial analysis, although the confidence intervals were wider due to the smaller sample sizes. These findings indicate that PBMC gene-expression patterns may be useful to predict FBC risk.
In addition, we tested whether similar genes were dysregulated in our predictive model if the sporadics-only control group was included or not. The SVM-RFE algorithm ranks each gene according to how strongly the gene-expression values differ between the patient groups. We found that the rankings were highly similar (Spearman's rank correlation rho statistic = 0.43), whether the control group contained sporadic patients only or the full control set. This finding suggests that individuals who develop familial breast cancer exhibit different gene-expression patterns than individuals who do not develop familial breast cancer, even when compared solely against individuals who had received prior diagnosis/treatments.
To affirm that the expression differences in the FBC women were not confounded by treatment with estrogen receptor pathway inhibitors, we independently evaluated a publicly available data set that profiled PBMC gene-expression levels for post-menopausal women who had or had not been treated with tamoxifen or aromatase inhibitors, respectively (http://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE12517). We applied the Support Vector Machines algorithm to rank the genes according to differences in expression between women who had received a given treatment and post-menopausal women who had not received either treatment. We compared these gene rankings from this study to the original analysis that compared women who had developed familial breast cancer against controls. The gene rankings were not correlated for either treatment (Spearman’s rho for taxomifen = 0.030, aromatase inhibitors = 0.029). This result suggests that the genes perturbed by hormone treatments are different from those that discriminate between women who develop familial breast cancer and those who do not.
Evaluating the balance between sensitivity and specificity of predictions
The SVM prediction scores are probabilistic values ranging between zero and one. Higher values suggest a relatively high risk of familial breast cancer, and lower values suggest a relatively low risk. In clinical settings, it is often desirable to identify a single cutoff threshold above which individuals are considered to have “high” risk. We used receiver operating characteristic curves to confirm that the sensitivity and specificity of our predictions remain strong across a broad range of thresholds (Fig. 3a-b). Then to identify a single threshold that may be best in clinical settings, we plotted the proportion of patients who were predicted to have “high” risk and who actually developed FBC, against a range of thresholds (Fig. 3c-d). As expected, this value increased as the threshold increased. Accordingly, at higher thresholds, a large proportion of patients predicted to have “high” risk would received accurate predictions. However, a tradeoff would be lower sensitivity (fewer individuals who actually developed FBC would be predicted to carry a high risk). Visual inspection of Fig. 3c-d suggests that a cutoff threshold near 0.2 may be optimal because the slope begins to level off (or drop temporarily). If a threshold of 0.2 were used to identify individuals at the highest risk of breast cancer in the Ontario cohort, the sensitivity would be 0.68 and the specificity would be 0.71, equating to a positive likelihood ratio of 2.35 and a negative likelihood ratio of 0.45. Put another way, for a woman with a 50 % chance of breast cancer based on family history and BRCA status, a prediction greater than 0.2 would suggest a 70 % chance of developing breast cancer, and a score less than 0.2 would indicate a 31 % chance of developing breast cancer.
Biological interpretation
Interestingly, many genes—for example, DSC1, FN1, ST6GALNAC5, TP63, SHB, and WNT3—used in the above biomarker are known to play important roles in regulating cell–cell adhesion and cell–ECM interactions (see Additional files 7 and 8 for complete lists). To evaluate these genes at the biological pathway level, we applied the GATHER algorithm [39] to the 250 genes that best distinguished affected FBC women from controls in the Utah and Ontario data (Additional files 9 and 10); this approach indicated a significant association between FBC development and pathways that play a role in cell adhesion, including KEGG Adherens Junctions and Extracellular Matrix-receptor Interaction (p-values < 0.05, Table 3). This finding suggests that these pathways may be fundamentally dysregulated in multiple cell types, potentially including asymptomatic breast tissue, which may be a mechanism that leads to increased risk of familial breast cancer. To assess whether the gene-expression patterns associated with FBC status in our PBMC samples also occur in normal breast cells, we examined publicly available data from Lim et al. [30] and found that patients with a strong family history of breast cancer have significantly higher overall expression (p = 0.001, see Methods) for genes that were overexpressed in our FBC samples.
Table 3.
Top pathway results from GATHER analysis
| Term ID | Term | p-value |
|---|---|---|
| hsa04520 | Adherens junction | 0.00149 |
| hsa00590 | Prostaglandin and leukotriene metabolism | 0.00775 |
| hsa04350 | TGF-beta signaling pathway | 0.0132 |
| hsa04510 | Focal adhesion | 0.014 |
For genes that exhibited consistent fold-change directions in the Utah and Ontario gene-expression data (Additional files 7 and 8), we sorted the genes by average rank of fold change and t-test p-values. The 250 top-ranked genes were used to query GATHER [39] for KEGG pathways most strongly associated with this gene list. Pathways that attained a p-value less than 0.05 are shown
Discussion
Women from FBC families face greater uncertainty regarding their personal risk of breast cancer than the general population [40]. Accurate risk prediction is important in part because 54 % of high-risk women fail to follow appropriate screening procedures for breast-cancer prevention, even when they have health insurance, receive reminders, and have a positive attitude toward screening [41]; however, increased perceived risk translates into increased willingness to consider effective prevention strategies such as tamoxifen [42]. Various risk-prediction models based on clinical and/or genomic data have been proposed, yet the discriminatory accuracy of these models has been modest (AUC 0.56-0.70) [6–9, 43]. Multiple studies have shown that higher accuracy levels can be obtained using gene-expression profiles of peripheral blood cells in the context of early detection [44, 45]. However, these studies have focused on general breast-cancer risk, and their approaches were tested in single cohorts. Our goal was to develop a classification approach specific to women from high-risk families—based on PBMC gene expression—and to validate this approach in an external cohort consisting of women from a different geographical location.
Researchers have placed much emphasis on identifying additional susceptibility variants [46]; however, known susceptibility variants account for at most ~30 % of familial breast cancer risk [47], and common variants currently show only moderate predictive capabilities for risk [8]. Here, we identify expression-based changes reflective of a person's risk to develop breast cancer. We emphasize the importance of additional, prospective studies with larger sample sizes to further evaluate the clinical potential of our approach (and alternative approaches); however, the confidence intervals for our results demonstrate that our sample size was large enough to obtain statistically meaningful results. Furthermore, previous studies that have used transcriptomic predictors for prognostic and diagnostic purposes have been deemed informative using similar or smaller cohort sizes [44, 45, 48].
We propose that additional approaches could be used to inform women about their personal breast cancer risk. In this study, we identified multigene expression patterns in peripheral blood cells that differ between individuals who have developed familial breast cancer and those who have not. Importantly, the peripheral-blood expression patterns were predictive of familial breast cancer, independent of BRCA1/BRCA2 mutation status. In addition, our approach distinguished between individuals who developed familial breast cancer and those who developed sporadic breast cancer, suggesting that our approach’s predictive ability was not the result of prior cancer or its treatment and that the gene-expression patterns may be driven by inherited risk factors common to many women from high-risk families. [49]. Additional studies are critical to prospectively evaluate the risk-predictive utility of our approach in different clinical settings.
Conclusion
Our approach has the possibility to alter how women with a family history of breast cancer make decisions regarding their health. Indeed, the risk-estimation approach we present here has the ability to provide a risk assessment for each individual woman. For example, each woman within a given family or multiple women who carry a known susceptibility variant could be assigned different individual risks based on their gene-expression profile, leading to more personalized prevention decisions. These risk assessments could provide reassurance for women who are not as highly predisposed and thus may opt for monitoring and/or chemoprevention rather than prophylactic mastectomy. Alternatively, a high predicted risk could provide evidence to support prophylactic surgeries or chemopreventive intervention.
Further studies will be needed to develop multi-data risk models that incorporate gene-expression based models with other informative data such as family history, clinical and demographic characteristics, and germline variants. Additionally, it will be helpful in the future to evaluate whether our findings generalize to women who have only one known first-degree relative with breast cancer (in this study, we focused on women with multiple affected first-degree relatives). However, the accuracy of our results indicates that gene expression based biomarkers hold promise for assessing individual breast cancer risk in a minimally invasive manner and that they can be applied broadly to women from high-risk families.
Ethical approval
The institutional/ethical review boards at the University of Utah and Mount Sinai Hospital approved collection and dissemination of data for this study.
Acknowledgements
We thank the study participants without whom this project would not have been possible. We acknowledge Patricia Bild and Mary Johnson who inspired this study. We acknowledge allocations of computer time from the Center for High Performance Computing at the University of Utah and the Fulton Supercomputing Lab at Brigham Young University. Dr. Holly Dressman provided advice and processed microarray samples.
Funding
A Bild was supported by R01GM085601 (NIH), institutional funds, and a private donor. S Piccolo received funding via 5T32CA093247 (NIH). W Johnson and S Piccolo received support from 1R01HG005692. The Utah Breast Cancer Family Registry was supported through cooperative agreement from the National Institutes of Health U01CA69446, the National Center for Research Resources, and the National Center for Advancing Translational Sciences, National Institutes of Health grant UL1RR025764, and by award number P30CA042014 from the National Cancer Institute. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NCI or the NIH. This work was also supported by grant UM1 CA164920 from the National Cancer Institute. The content of this manuscript does not necessarily reflect the views or policies of the National Cancer Institute or any of the collaborating centers in the Breast Cancer Family Registry (BCFR), nor does mention of trade names, commercial products, or organizations imply endorsement by the US Government or the BCFR.
Abbreviations
- MRI
Magnetic resonance imaging
- FBC
Familial breast cancer
- PMBC
Peripheral blood mononuclear cells
- BCFR
Breast Cancer Family Registry
- SVM-RFE
Support Vector Machines-Recursive Feature Elimination
- SVM
Support Vector Machines
- AUC
Area under receiver operating characteristic curve
- KEGG
Kyoto Encyclopedia of Genes and Genomes
Additional files
Supplementary Tables and figures. (DOC 313 kb)
Summarized clinical, demographic, and treatment data. Summary of clinical, demographic, and prior treatment data for 61 individuals who responded to the health-assessment survey. (PDF 36 kb)
Raw clinical, demographic, and treatment data. Raw clinical, demographic, and prior treatment data for 61 individuals who responded to the health-assessment survey. (PDF 50 kb)
Descriptions of variables used in health-assessment survey. Descriptions of variables that were used in the health-assessment survey. (PDF 41 kb)
Cancer, family-history, and BRCA1/2 status for all patients. This file indicates cancer, family history, and BRCA1/2 status for patients in the Utah and Ontario cohorts. (PDF 51 kb)
Genes filtered based on correlation with potential confounders. Genes filtered based on association between gene-expression levels and clinical, demographic, prior treatment, or lymphocyte enumeration data. (PDF 82 kb)
Genes selected for the first half of the Ontario cohort. Genes selected via SVM-RFE from the Utah cohort for the Ontario (36 samples) biomarker predictions. (PDF 53 kb)
Genes selected for the second half of the Ontario cohort. Genes selected via SVM-RFE from the Utah cohort for the Ontario (remaining samples) biomarker predictions. (PDF 67 kb)
Gene-level summary of expression data for Utah and Ontario cohorts. Fold change values represent the ratio of average gene expression for FBC individuals who developed cancer relative to expression levels for those who did not. (PDF 4554 kb)
Summary of differentially expressed genes. Genes for which the average expression was consistently either higher or lower in FBC individuals relative to controls for the Utah and Ontario cohorts. (PDF 987 kb)
Footnotes
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
AHB, WEJ, and SRP designed the study and performed data analysis. SRP performed computational analyses. PJM and ALC provided intellectual input. AHB, IA, SSB, ALC, TC, AES developed the clinical and genomic resources used in the study. AHB, WEJ, and SRP wrote the manuscript. ALC, AES, PJM, and SSB provided critical review of the manuscript. All authors read and approved the final manuscript.
Contributor Information
Stephen R. Piccolo, Email: stephen_piccolo@byu.edu
Irene L. Andrulis, Email: ANDRULIS@lunenfeld.ca
Adam L. Cohen, Email: adam.cohen@hci.utah.edu
Thomas Conner, Email: tom.conner@hci.utah.edu.
Philip J. Moos, Email: Philip.Moos@pharm.utah.edu
Avrum E. Spira, Email: aspira@bu.edu
Saundra S. Buys, Email: saundra.buys@hci.utah.edu
W. Evan Johnson, Phone: 617-638-2541, Email: wej@bu.edu.
Andrea H. Bild, Phone: 801-581-6353, Email: andreab@genetics.utah.edu
References
- 1.Lalloo F, Evans DG. Familial breast cancer. Clin Genet. 2012;82:105–114. doi: 10.1111/j.1399-0004.2012.01859.x. [DOI] [PubMed] [Google Scholar]
- 2.Chen S, Parmigiani G. Meta-analysis of BRCA1 and BRCA2 penetrance. J Clin Oncol. 2007;25:1329–1333. doi: 10.1200/JCO.2006.09.1066. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Fisher B, Costantino JP, Wickerham DL, Redmond CK, Kavanah M, Cronin WM, Vogel V, Robidoux A, Dimitrov N, Atkins J, Daly M, Wieand S, Tan-Chiu E, Ford L, Wolmark N. Tamoxifen for prevention of breast cancer: report of the National Surgical Adjuvant Breast and Bowel Project P-1 Study. J Natl Cancer Inst. 1998;90:1371–1388. doi: 10.1093/jnci/90.18.1371. [DOI] [PubMed] [Google Scholar]
- 4.Cuzick J, Sestak I, Forbes JF, Dowsett M, Knox J, Cawthorn S, Saunders C, Roche N, Mansel RE, von Minckwitz G, Bonanni B, Palva T, Howell A. Anastrozole for prevention of breast cancer in high-risk postmenopausal women (IBIS-II): an international, double-blind, randomised placebo-controlled trial. Lancet. 2014;383:1041–1048. doi: 10.1016/S0140-6736(13)62292-8. [DOI] [PubMed] [Google Scholar]
- 5.Gail MH, Brinton LA, Byar DP, Corle DK, Green SB, Schairer C, Mulvihill JJ. Projecting individualized probabilities of developing breast cancer for white females who are being examined annually. J Natl Cancer Inst. 1989;81:1879–1886. doi: 10.1093/jnci/81.24.1879. [DOI] [PubMed] [Google Scholar]
- 6.Rockhill B, Spiegelman D, Byrne C, Hunter DJ, Colditz GA. Validation of the Gail et al. model of breast cancer risk prediction and implications for chemoprevention. J Natl Cancer Inst. 2001;93:358–366. doi: 10.1093/jnci/93.5.358. [DOI] [PubMed] [Google Scholar]
- 7.Sawyer S, Mitchell G, McKinley J, Chenevix-Trench G, Beesley J, Chen XQ, Bowtell D, Trainer AH, Harris M, Lindeman GJ, James PA. A role for common genomic variants in the assessment of familial breast cancer. J Clin Oncol. 2012;30:4330–4336. doi: 10.1200/JCO.2012.41.7469. [DOI] [PubMed] [Google Scholar]
- 8.Wacholder S, Hartge P, Prentice R, Garcia-Closas M, Feigelson HS, Diver WR, Thun MJ, Cox DG, Hankinson SE, Kraft P, Rosner B, Berg CD. Performance of common genetic variants in breast-cancer risk models. N Engl J Med. 2010;362:986–993. doi: 10.1056/NEJMoa0907727. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Xu Z, Bolick SCE, Deroo LA, Weinberg CR, Sandler DP, Taylor JA. Epigenome-wide Association Study of Breast Cancer Using Prospectively Collected Sister Study Samples. J Natl Cancer Inst. 2013;105:694–700. doi: 10.1093/jnci/djt045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Morley M, Molony CM, Weber TM, Devlin JL, Ewens KG, Spielman RS, Cheung VG. Genetic analysis of genome-wide variation in human gene expression. Nature. 2004;430:743–747. doi: 10.1038/nature02797. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Cookson W, Liang L, Abecasis G, Moffatt M, Lathrop M. Mapping complex disease traits with global gene expression. Nat Rev Genet. 2009;10:184–194. doi: 10.1038/nrg2537. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Schadt EE, Molony C, Chudin E, Hao K, Yang X, Lum PY, Kasarskis A, Zhang B, Wang S, Suver C, Zhu J, Millstein J, Sieberts S, Lamb J, GuhaThakurta D, Derry J, Storey JD, Avila-Campillo I, Kruger MJ, Johnson JM, Rohl CA. Mapping the genetic architecture of gene expression in human liver. PLoS Biol. 2008;6 doi: 10.1371/journal.pbio.0060107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Mohr S, Liew C-C. The peripheral-blood transcriptome: new insights into disease and risk assessment. Trends Mol Med. 2007;13:422–432. doi: 10.1016/j.molmed.2007.08.003. [DOI] [PubMed] [Google Scholar]
- 14.Hedenfalk I, Duggan D, Chen Y, Radmacher M, Bittner M, Simon R, Meltzer P, Gusterson B, Esteller M, Kallioniemi OP, Wilfond B, Borg A, Trent J, Raffeld M, Yakhini Z, Ben-Dor A, Dougherty E, Kononen J, Bubendorf L, Fehrle W, Pittaluga S, Gruvberger S, Loman N, Johannsson O, Olsson H, Sauter G. Gene-expression profiles in hereditary breast cancer. N Engl J Med. 2001;344:539–548. doi: 10.1056/NEJM200102223440801. [DOI] [PubMed] [Google Scholar]
- 15.Miller LD, Smeds J, George J, Vega VB, Vergara L, Ploner A, Pawitan Y, Hall P, Klaar S, Liu ET, Bergh J. An expression signature for p53 status in human breast cancer predicts mutation status, transcriptional effects, and patient survival. Proc Natl Acad Sci U S A. 2005;102:13550–13555. doi: 10.1073/pnas.0506230102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Waddell N, Ten Haaf A, Marsh A, Johnson J, Walker LC, Gongora M, Brown M, Grover P, Girolami M, Grimmond S, Chenevix-Trench G, Spurdle AB. BRCA1 and BRCA2 missense variants of high and low clinical significance influence lymphoblastoid cell line post-irradiation gene expression. PLoS Genet. 2008;4:e1000080. doi: 10.1371/journal.pgen.1000080. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Bild AH, Chang JT, Yao G, Joshi M-BB, Lancaster JM, Wang Q, Olson JA, Potti A, Marks JR, Dressman HK, Chasse D, Nevins JR, Harpole D, Berchuck A, West M. Oncogenic pathway signatures in human cancers as a guide to targeted therapies. Nature. 2006;439:353–357. doi: 10.1038/nature04296. [DOI] [PubMed] [Google Scholar]
- 18.Liu Z, Wang M, Alvarez JV, Bonney ME, Chen C, D’Cruz C, Pan T, Tadesse MG, Chodosh LA. Singular value decomposition-based regression identifies activation of endogenous signaling pathways in vivo. Genome Biol. 2008;9:R180. doi: 10.1186/gb-2008-9-12-r180. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Rhodes D, Kalyana-Sundaram S, Tomlins S, Mahavisno V, Kasper N, Varambally R, Barrette T, Ghosh D, Varambally S, Chinnaiyan A. Molecular concepts analysis links tumors, pathways, mechanisms, and drugs. Neoplasia. 2007;9:443–454. doi: 10.1593/neo.07292. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Ooi CH, Ivanova T, Wu J, Lee M, Tan IB, Tao J, Ward L, Koo JH, Gopalakrishnan V, Zhu Y, Cheng LL, Lee J, Rha SY, Chung HC, Ganesan K, So J, Soo KC, Lim D, Chan WH, Wong WK, Bowtell D, Yeoh KG, Grabsch H, Boussioutas A, Tan P. Oncogenic pathway combinations predict clinical prognosis in gastric cancer. PLoS Genet. 2009;5:e1000676. doi: 10.1371/journal.pgen.1000676. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Langenau DM, Keefe MD, Storer NY, Guyon JR, Kutok JL, Le X, Goessling W, Neuberg DS, Kunkel LM, Zon LI. Effects of RAS on the genesis of embryonal rhabdomyosarcoma. Genes Dev. 2007;21:1382–1395. doi: 10.1101/gad.1545007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Wong DJ, Liu H, Ridky TW, Cassarino D, Segal E, Chang HY. Module map of stem cell genes guides creation of epithelial cancer stem cells. Cell Stem Cell. 2008;2:333–344. doi: 10.1016/j.stem.2008.02.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Barbie DA, Tamayo P, Boehm JS, Kim SY, Moody SE, Dunn IF, Schinzel AC, Sandy P, Meylan E, Scholl C, Fröhling S, Chan EM, Sos ML, Michel K, Mermel C, Silver SJ, Weir BA, Reiling JH, Sheng Q, Gupta PB, Wadlow RC, Le H, Hoersch S, Wittner BS, Ramaswamy S, Livingston DM, Sabatini DM, Meyerson M, Thomas RK, Lander ES. Systematic RNA interference reveals that oncogenic KRAS-driven cancers require TBK1. Nature. 2009;462:108–112. doi: 10.1038/nature08460. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Singh A, Greninger P, Rhodes D, Koopman L, Violette S, Bardeesy N, Settleman J. A gene expression signature associated with “K-Ras addiction” reveals regulators of EMT and tumor cell survival. Cancer Cell. 2009;15:489–500. doi: 10.1016/j.ccr.2009.03.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Huang F, Reeves K, Han X, Fairchild C, Platero S, Wong TW, Lee F, Shaw P, Clark E. Identification of Candidate Molecular Markers Predicting Sensitivity in Solid Tumors to Dasatinib: Rationale for Patient Selection. Cancer Res. 2007;67:2226–2238. doi: 10.1158/0008-5472.CAN-06-3633. [DOI] [PubMed] [Google Scholar]
- 26.Zhang XH-F, Wang Q, Gerald W, Hudis CA, Norton L, Smid M, Foekens JA, Massagué J. Latent bone metastasis in breast cancer tied to Src-dependent survival signals. Cancer Cell. 2009;16:67–78. doi: 10.1016/j.ccr.2009.05.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Piccolo SR, Sun Y, Campbell JD, Lenburg ME, Bild AH, Johnson WE. A single-sample microarray normalization method to facilitate personalized-medicine workflows. Genomics. 2012;100:337–344. doi: 10.1016/j.ygeno.2012.08.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Nurtdinov RN, Vasiliev MO, Ershova AS, Lossev IS, Karyagina AS. PLANdbAffy: probe-level annotation database for Affymetrix expression microarrays. Nucleic Acids Res. 2010;38(Database issue):D726–D730. doi: 10.1093/nar/gkp969. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Johnson WE, Li C, Rabinovic A. Adjusting batch effects in microarray expression data using empirical Bayes methods. Biostatistics. 2007;8:118–127. doi: 10.1093/biostatistics/kxj037. [DOI] [PubMed] [Google Scholar]
- 30.Lim E, Vaillant F, Wu D, Forrest NC, Pal B, Hart AH, Asselin-Labat M-L, Gyorki DE, Ward T, Partanen A, Feleppa F, Huschtscha LI, Thorne HJ, Fox SB, Yan M, French JD, Brown MA, Smyth GK, Visvader JE, Lindeman GJ. Aberrant luminal progenitors as the candidate target population for basal tumor development in BRCA1 mutation carriers. Nat Med. 2009;15:907–913. doi: 10.1038/nm.2000. [DOI] [PubMed] [Google Scholar]
- 31.Subramanian A, Tamayo P, Mootha VK, Mukherjee S, Ebert BL, Gillette MA, Paulovich A, Pomeroy SL, Golub TR, Lander ES, Mesirov JP. Gene set enrichment analysis: A knowledge-based approach for interpreting genome-wide expression profiles. Proc Natl Acad Sci U S A. 2005;102:15545–15550. doi: 10.1073/pnas.0506580102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Hall M, National H, Frank E, Holmes G, Pfahringer B, Reutemann P, Witten IH. The WEKA data mining software. ACM SIGKDD Explor Newsl. 2009;11:10. doi: 10.1145/1656274.1656278. [DOI] [Google Scholar]
- 33.Chang C-C, Lin C-J. LIBSVM: A library for support vector machines. ACM Trans Intell Syst Technol. 2011;2:27:1–27:27. doi: 10.1145/1961189.1961199. [DOI] [Google Scholar]
- 34.Piccolo SR, Frey LJ. ML-Flex : A Flexible Toolbox for Performing Classification Analyses In Parallel. J Mach Learn Res. 2012;13(Mar):555–559. [Google Scholar]
- 35.Sing T, Sander O, Beerenwinkel N, Lengauer T. ROCR: Visualizing the performance of scoring classifiers. 2009. [DOI] [PubMed] [Google Scholar]
- 36.Robin X, Turck N, Hainard A, Tiberti N, Lisacek F, Sanchez J-C, Müller M. pROC: an open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinformatics. 2011;12:77. doi: 10.1186/1471-2105-12-77. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Vapnik VN. Statistical Learning Theory. New York: Wiley; 1998. [Google Scholar]
- 38.Michael CM, Nass SJ, Omenn GS. Evolution of Translational Omics: Lessons Learned and the Path Forward. Washington, D.C.: The National Academies Press; 2012. [PubMed] [Google Scholar]
- 39.Chang JT, Nevins JR. GATHER: a systems approach to interpreting genomic signatures. Bioinformatics. 2006;22:2926–2933. doi: 10.1093/bioinformatics/btl483. [DOI] [PubMed] [Google Scholar]
- 40.Peto J, Mack TM. High constant incidence in twins and other relatives of women with breast cancer. Nat Genet. 2000;26:411–414. doi: 10.1038/82533. [DOI] [PubMed] [Google Scholar]
- 41.Smith RA, Cokkinides V, Brooks D, Saslow D, Shah M, Brawley OW. Cancer screening in the United States, 2011: A review of current American Cancer Society guidelines and issues in cancer screening. CA Cancer J Clin. 2011;61:8–30. doi: 10.3322/caac.20096. [DOI] [PubMed] [Google Scholar]
- 42.Meiser B, Butow P, Price M, Bennett B, Berry G, Tucker K. Attitudes to prophylactic surgery and chemoprevention in Australian women at increased risk for breast cancer. J Womens Health (Larchmt) 2003;12:769–778. doi: 10.1089/154099903322447738. [DOI] [PubMed] [Google Scholar]
- 43.MacInnis RJ, Bickerstaffe A, Apicella C, Dite GS, Dowty JG, Aujard K, Phillips K-A, Weideman P, Lee A, Terry MB, Giles GG, Southey MC, Antoniou AC, Hopper JL. Prospective validation of the breast cancer risk prediction model BOADICEA and a batch-mode version BOADICEACentre. Br J Cancer. 2013;109:1296–1301. doi: 10.1038/bjc.2013.382. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Aarøe J, Lindahl T, Dumeaux V, Saebø S, Tobin D, Hagen N, Skaane P, Lönneborg A, Sharma P, Børresen-Dale A-L. Gene expression profiling of peripheral blood cells for early detection of breast cancer. Breast Cancer Res. 2010;12:R7. doi: 10.1186/bcr2472. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Sharma PP, Sahni NS, Tibshirani R, Skaane P, Urdal P, Berghagen H, Jensen M, Kristiansen L, Moen C, Zaka A, Arnes J, Sauer T, Akslen LA, Schlichting E, Børresen-Dale A-L, Lönneborg A. Early detection of breast cancer based on gene-expression patterns in peripheral blood cells. Breast Cancer Res. 2005;7:R634–R644. doi: 10.1186/bcr1203. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Michailidou K, Hall P, Gonzalez-Neira A, Ghoussaini M, Dennis J, Milne RL, Schmidt MK, Chang-Claude J, Bojesen SE, Bolla MK, Wang Q, Dicks E, Lee A, Turnbull C, Rahman N, Fletcher O, Peto J, Gibson L, dos Santos SI, Nevanlinna H. Large-scale genotyping identifies 41 new loci associated with breast cancer risk. Nat Genet. 2013;45:353–361. doi: 10.1038/ng.2563. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Stratton MR, Rahman N. The emerging landscape of breast cancer susceptibility. Nat Genet. 2008;40:17–22. doi: 10.1038/ng.2007.53. [DOI] [PubMed] [Google Scholar]
- 48.Spira A, Beane JE, Shah V, Steiling K, Liu G, Schembri F, Gilman S, Dumas Y-M, Calner P, Sebastiani P, Sridhar S, Beamis J, Lamb C, Anderson T, Gerry N, Keane J, Lenburg ME, Brody JS. Airway epithelial gene expression in the diagnostic evaluation of smokers with suspect lung cancer. Nat Med. 2007;13:361–366. doi: 10.1038/nm1556. [DOI] [PubMed] [Google Scholar]
- 49.Rossouw JE, Anderson GL, Prentice RL, LaCroix AZ, Kooperberg C, Stefanick ML, Jackson RD, Beresford SAA, Howard BV, Johnson KC, Kotchen JM, Ockene J. Risks and Benefits of Estrogen plus Progestin in Healthy Postmenopausal Women: Principal Results From the Women’s Health Initiative Randomized Controlled Trial. Volume 288. 2002. [DOI] [PubMed] [Google Scholar]