

Abstract
Network based time series analysis has made considerable achievements in the recent years. By mapping mono/multivariate time series into networks, one can investigate both it’s microscopic and macroscopic behaviors. However, most proposed approaches lead to the construction of static networks consequently providing limited information on evolutionary behaviors. In the present paper we propose a method called visibility graph based time series analysis, in which series segments are mapped to visibility graphs as being descriptions of the corresponding states and the successively occurring states are linked. This procedure converts a time series to a temporal network and at the same time a network of networks. Findings from empirical records for stock markets in USA (S&P500 and Nasdaq) and artificial series generated by means of fractional Gaussian motions show that the method can provide us rich information benefiting short-term and long-term predictions. Theoretically, we propose a method to investigate time series from the viewpoint of network of networks.
Introduction
Complex network based time series analysis has attracted noteworthy attention in recent years across various domains. By mapping a time series to a network, one can investigate visually the structural patterns at different time scales from microscopic to macroscopic levels [1]. As a result, several novel ways have been proposed on how to convert time series data into complex networks. Zhang et al. [2–4] construct a network from pseudo periodic time series where each cycle is represented by a single node, and a threshold is set to link node pairs with strong cross-correlations. From the viewpoint of phase space reconstruction, one can also take all the possible series segments with a certain length as nodes. Xu et al propose an approach that links each node with its closest k neighbors [5–8]. While in the references [9, 10] the nodes are networked according to the correlation strength between the nodes, which turns out to be a special case of the widely used recurrence network approach [11–24]. Lacasa et al propose the widely used visibility graph algorithms [25–35] by linking visible elements in a series. Each of these approaches was quickly adopted and widely used among various researchers to extract information embedded in time series from varied domains.
However, in the cited methods, a time series is projected to a static network. As a result, one can hardly find the evolutionary behaviors of the system. A complicated system contains generally many elements, monitoring which produces a multivariate time series. In literature, several novel methods are designed to extract from segments of the multivariate time series relationship networks between the elements, as being the state representatives of the corresponding time intervals. To cite examples, Munnix et al. [36] use the correlation matrix between stocks to represent state of a stock market; In reference [37] Zheng, et al. employ the principal component analysis to extract further believable information from the cross-correlation matrix; Gao et al. [16, 17, 20, 21] embed a multivariate time series in a multi-dimensional phase space, and calculate correlation between each pair of the phase tensors. Each segment of series corresponding to each variate is mapped to a node. Strong relationships are reserved by introducing different thresholds to filter out links between segments coming from the same series and from different series, respectively. By this way, the recurrence network approach is extended to investigate multivariate series; Buccheri et al. [38] construct from the correlation matrix the plenary maximally filtered graphs (an extension of the simple spanning-tree), in which the largest weights are retained while constraining the subgraph to be globally a planar graph; While Gao [39, 40] conduct linear regressions of every element to other elements and the set of values of fitting parameters are used to measure local states. The successive occurring states are then linked into a transmission network.
The motivation of the present work is twofold. First, we try to find evolutionary behaviors of a system embedded in one-dimensional time series. The existing algorithms to map a time series to a network are generally designed in the framework of phase space reconstruction. For a deterministic dynamical system, one can determine the embedding dimension of the system m. All the segments with length m in the original time series are depicted in the phase space, as being the states visited in the dynamical process. Every pair of states is linked if they are close enough, which results into a network (e.g., recurrence network). But in the downstream procedures of constructing networks, detailed information stored in the states is used in a rough way. For example, in the recurrence plots one calculate the Euclidean distance between each pair of the segments to measure the relationship between the states, in which the state information is all lost except the distance. This roughness in using the information embedded in the states covers up some interesting dynamical behaviors and this leads the focus only to the global characteristics. Consequently, the states are not properly distinguished hence one cannot monitor the system’s evolutionary behavior.
Quite often in practice, people are interested in the short-term prediction of a state. For instance, one maybe interested in the present state of a stock, and its probable state in the following week. He may be concerned about the intensity of increase or decrease with reference to historical data, an investigation that may not be obviously attained from literature review. This guides our second motivation in this work in lieu of providing as concise as possible information from a series segment (state).
In order to address the above stated motivations, we endeavor to extract state patterns concisely while preserving the internal characteristics, and explore the transfer relations between the distinguishable states. Contributions of the present work thus include,
We propose a method to construct a transmission network from a one-dimensional time series, in which the nodes are the local states and the links the transfers between states. Technically, from an initial time series, one can extract all the segments in the series with a predefined window size. We map each segment to a visibility graph, which is used to represent the state of the system at the corresponding time interval. The successively occurring visibility graphs are linked in turn, which leads to a transfer network of distinguishable states. The weights of links reflect the transfer behaviors of the distinguishable states. This algorithm thus produces a ‘network of visibility graphs’.
Some interesting findings are found from empirical data. To illustrate the functionality of our algorithm, we investigate the Nasdaq and S&P500 daily stock indices. We find several motifs, i.e., the states occurring with significant high frequencies compared with that in the shuffled series. Similarly, there are several hub nodes, which occur with significantly high frequencies compared with that of the other nodes. A transfer loop is also found between the hubs, which can be used in short-term prediction, i.e, from the state at present time one predicts what will happen at the next time step. Some motifs are positioned in the time series according to fractal behaviors, exhibiting long-term persistence of the time series. To validate our approach, we also conduct detailed calculations for artificial time series generated with fractional Gaussian motions, as being reference to understand the results for empirical data. The fractional Gaussian motions exhibit similar characteristic behavior with that in recordings of the stock markets.
In a nutshell, in the present work we propose a approach to convert a time series to a temporal network as well as a network of visibility graphs. By this way, the theories and tools in the two speedy developing branches of complex network (network of networks [41] and temporal networks [42]) can be extended to the field of time series analysis.
Method and Materials
Represent local States with visibility graphs
Let a window with size s slide along a time series, {y 1, y 2, …, y N}. The covered segments read as follows;
| (1) |
We propose the visibility graph as the tool to extract structural information embedded in the segments. The resulting visibility graphs can capture the key structural characteristics of the corresponding segments, and consequently are taken as the description of the local sates in different time durations.
Now we map the segment Y k to a visibility graph [25]. Each data value is considered to be a node. Two nodes are connected if they can see each other, namely, a straight visibility line exists between them. Formally, two arbitrary data values y a and y b are visible to each other if each point y c between them satisfies the criterion;
| (2) |
The constructed visibility graph can be represented with an adjacency matrix, g k, whose element g k(a − k + 1, b − k + 1) equals 1(0) if y a and y b are visible (invisible). Here, the identification numbers of the nodes corresponding to y a and y b are assigned to be a − k + 1 and b − k + 1, to be sure they are in the interval of [1, s]. This results into an s by s matrix for the kth segment. Covering the whole series, a set of adjacency matrices, G = {g 1, g 2, …, g N−s+1} is obtained.
State transfer network
Here, we define a state transfer network to describe transfer probabilities between distinguishable local states. In the time series, if a state at time b occurs immediately after another state at time a, then we construct a directional link from g a to g b. Accordingly, the link means a transfer from one state to the other state. By using this procedure a state chain with directional links is attained, which reads;
| (3) |
Here we find out all the distinguishable states. Let us scan through G comparing each state with the others. If any two states are identical (their adjacency matrices are the same) one replaces the later one with the the reference state. For instance, if g 1 = g 4, the state g 4 is replaced with g 1. This process is done iteratively for all states. The survival states are unique states, which are defined to be nodes. We reckon the number of links between each pair of the nodes (survival states), which is the weight of the link between them. By this procedure, the time series is mapped further to a network of distinguishable states (visibility graphs), called state transfer network, with edge direction being the transfer direction and edge weight being the transfer times.
Properties of the state transfer network
Herein, we are interested in several properties of the state transfer network, including,
Occurring frequency. The occurring frequency of a node in the duration of recording is herein called degree. A hub node means its occurrence number is significantly larger compared with that of the other nodes. Though hubs are clearly observed, the behavior may be common even in null models hence holding less non-trivial characteristics. If the occurring frequency of a node in the original time series is significantly larger than that in a shuffled time series, the node is called motif [43], which can be used as a global representative of the time series.
Transmission probability. Strong correlation usually exists in time series, which means occurrence of a state depends strongly on the previous states rather than its occurring stochastically. We expect there exist significant large link weights between some hubs or motifs, which can be greatly helpful in short-term prediction, i.e, based upon the state at present time one predicts what will happen at the next time step.
Long-term persistence. A large amount of research works have reported the self-similar structures of time series in diverse research fields (see, e.g., [44]). This kind of fractal behavior makes it possible for us to predict behaviors of complex systems in macroscopic time scales. We will show that the fractal structure can be displayed by the occurring positions of some motifs on time series.
The re-scaled range analysis (R/S) is used [45]. For a specified motif, one can record the positions it occurs at, denoted with ω k, k = 1, 2, ⋯, M, where M is the occurring frequency of the motif. The increment series reads, ω k+1 − ω k, k = 1, 2, ⋯, M − 1. All the possible segments with length n read, Ω j ≡ (ω j+1 − ω j, ω j+2 − ω j+1, ⋯, ω j+n − ω j+n−1), j = 1, 2, ⋯, M − n. The corresponding accumulated departures for the jth segment can be constructed,
| (4) |
The re-scaled range is estimated as,
| (5) |
If there exists scaling invariance in the occurring position series, we have R/S(n)∼n δ, where δ is the Hurst exponent.
Why use visibility graph to measure local states?
It should be pointed out that using visibility-graph as being state representative is not a trivial selection. Obviously, rather than the visibility-graph we have alternative methods to extract the state information. For example, one can simply compare the values of successive elements in a segment and record the increasing, keeping unchanged, and decreasing with +1, 0, and −1, respectively. By this way each segment is symbolized to a series of discrete values.
The advantages of the visibility-graph include, (1) It can capture precise information of a state. Comparing with the symbolizing procedure, the visibility-graph can extract detailed information of sub-segments at different scales in each segment, at the same time keeps reasonably simple. On the contrary, the symbolizing procedure can only reserve the immediate increase/decrease information; (2) It can be used in analyzing non-stationary time series. A stochastic process, e.g., the fractional Brownian motion, is generally non-stationary, which makes the probability distribution function of the phase vector (series segment) time-dependent [22]. Accordingly, if we use an improper solution to represent states (e.g., the original phase vector in multi-dimensional phase space), the estimations of transfer probabilities (the links) between the states may change with time. Fortunately, this non-stationary effect is eliminated effectively by using visibility graph. Because a segment is very short, its trend can be mainly described with a straight line. Accordingly, visibility graph for the corresponding de-trended segment is identical with that for the original segment, called invariance under affine transformations [25]).
Window size selection
How to select a proper value of the window size, s, is a key problem in the present algorithm. If it is unreasonably small, the number of state patterns is too limited to distinguish different states. On the other hand, the number of state patterns will increase geometrically with the increase of the window size. A larger set of state patterns requires subsequently a longer time series to guarantee statistical significance of the transfer properties, motifs, hubs, and long-term persistence. However, even so, the computational time increases requiring high performance computers to execute, which may not always be readily available.
For deterministic dynamics, a reasonable way is to use the embedding dimension of the considered time series determined in the framework of phase space reconstruction. But for stochastic processes such as the fractional Brownian motion, one meets an essential problem, i.e, the embedding dimension is infinite [22]. Any finite embedding dimension leads to loss of relevant information. Therefore, phase-space reconstruction can not provide us a unified framework to determine the value of the window size s.
Stimulated by the interpretation of the recurrence network’s approach to stochastic processes [22], here we propose to understand our approach in an alternative way analogous with the ideas in random geometric network [46]. For a time series, no matter whether it is generated by a deterministic or a stochastic process, we specify an embedding dimension s, and embed the series in the s-dimensional phase space. Properties of a state transfer network could be computed solely from the occurrent sequence of visibility graphs corresponding to the phase vectors (segments) of the dynamical process. The deviations of a special case from the expectations come from the statistical dependencies between the different embedding components, the finite samples, and the finite-scale effects. Comparing the results for the original series with that for the shuffled and/or theoretical modelling series will show us nontrivial properties of the investigated process.
Hence, the criterions for the selection of the window size include, (1) It is large enough to distinguish different states; (2) It is small enough to be sure the state transfer network and the subsequent structural characteristics are statistically significant; (3) For deterministic dynamical processes the minimum embedding dimension can be used as a reference; (4) If there exists a natural period (or people are interested in a special period), this period should be selected as the window size. The key point is that a proper window size can help us find non-trivial characteristics embedded in the original series comparing with that in the shuffled/modelling series.
Data
We investigate fractional Brownian motions [47, 48] as being the reference to understand the results for series in reality. A fBm refers to a continuous-time Gaussian process whose characteristics depend on its Hurst exponent 0 ≤ H ≤ 1. It is scale-invariant, namely, the probability distribution function of its increment x(t − s) ≡ fBm(t) − fBm(s) satisfies . It has a convergent variance of increment that obeys a power-law, Var[x(t − s)] ∼ |t − s|2H. The built-in program wfbm.m in Matlab is used to generate the fBm series. For each generated fBm series, we consider in calculations the increment series, called fractional Gaussian motion (fGm). The increment series is stationary.
Obtained from yahoo finance [49], we use the daily closing value of Nasdaq and S&P500 stock indices ranging between 3rd January, 2000 and 14th November, 2014. Each contains a set of 3742 original data records. Daily return series is considered, i.e.,
| (6) |
where p k is the value of stock index.
The length of segment, s, is selected to be 5 for the generated fGm series and the stock market series. For the stock markets, there exists a natural period of 5 days (one week). For the fractional Gaussian motions the reason is three-fold. First, the fractional Brownian motion is widely used to mimic stock price in mathematical finance, such as that in the fractional Black&Scholes pricing model (see, e.g., [50]). Window size is selected to be 5 to provide a comparable reference to understand the results for the stock markets. Second, this selection leads to a total of 25 state patterns. For a series with about four thousand length, the average occurring number for each pattern is about 160. Deviations of real occurring numbers of the patterns from the average value are statistically significant. Third, by using two different methods for determining embedding dimension [51, 52], the numerical results suggested that the minimum embedding dimension for fGm series with several thousands length is 5 [22, 53], though it is pointed out that this result is length-dependent and may lead to serious tricks in the framework of phase-space reconstruction. Here it is used just as a reference.
For comparison purpose we present also the calculation results for s = 6. As for the selection of s = 4, there appear only four visibility graphs, so limited number of which can not distinguish the two stock markets (not shown).
Results
As stated above, the window size, s = 5, was deemed appropriate to unearth the nontrivial characteristics buried within the original series. Herein, we provide the results for both reference and empirical data using the preferred window size; but also include results for window size, s = 6 for comparison purposes.
Window size s = 5
Fig 1 illustrates the total of 25 local states (visibility graphs) that occur in the considered fGm and stock market series, where each is assigned a unique identifier number.
Fig 1. All the states occurring in the state transfer networks for the fGm and stock market index series.

Segment length is selected to be s = 5. Each state is assigned an identifier number as presented below it.
Fractional Gaussian motions
The first column in Fig 2, i.e., the subplots of Fig 2(a1)–2(f1), show the state transfer networks for fGm series with Hurst exponents H = 0.5, 0.6, 0.65, 0.7, 0.75 and H = 0.8, respectively. The length of the generated series is 4000 (to be comparable with that for the stock index series). For visual convenience the weak links (whose strength ≤25) are filtered out, which results into the so-called strong networks, as shown in the subplots of Fig 2(a2)–2(f2). For each original series, one can shuffle it and reconstruct a state transfer network for the shuffled series. State transfer networks averaged over 1000 shuffling realizations each are presented in the third column in Fig 2, including the subplots of Fig 2(a3)–2(f3) respectively, called shuffled networks. In the strong and shuffled networks, the size of a node indicates the occurring degree of the visibility graph and the width of a link indicates the edge’s weight. The label x(y) means the visibility graph numbered y occurs for the first time at position x along the time series.
Fig 2. State transfer networks for fGms series.

Segment length is selected to be s = 5. Subplots (a1)-(f1) are the original state transfer networks for the fGm series with H = 0.5, 0.6, 0.65, 0.7, 0.75, and 0.8, respectively. The nodes that have self-links are marked with red color. The label x(y) means the state occurs for the first time at the position x along the time series (the x’th segment), and its identifier number is y; (a2)-(f2) The strong state transfer networks constructed by filtering out weak links (less than 25) in the original state transfer networks; (a3)-(f3) Shuffled networks. One can shuffle each original fGm series, and construct from the resulting series a shuffled network. Each displayed shuffled network is an average over 1000 realizations. Weak links also are filtered out. Except in the networks shown in (a1)-(f1), the size of a node indicates the occurring degree of the state. The width of an edge is the link’s weight.
For H = 0.5, in the strong network one can find four hubs with Nos 12(4), 22(9), 13(5) and 14(6), which are linked by significant strong edges into a pattern. A simple comparison show that this pattern reoccurs almost exactly in the shuffled network. Actually, except some structure-details formed by weak edges, the pattern of the shuffled network is identical with that for the strong network, i.e., the structural behaviors of the strong network are series-element-order independent. We will not consider the case of H = 0.5 for further calculations. Herein, we take the results for H = 0.65 and H = 0.75 as typical examples to illustrate the behaviors of the generated fGm series.
Though rather seldom, the self-link is observed in some states, such as the states with id 73(13), 41(20) for H = 0.65, and 30(20) for H = 0.75. The occurrence of these self-links is weak and thus disappears in the subsequent strong networks. Some states will occur with high frequencies (hubs) in the networks, as represented by the size of nodes in the strong networks (see Fig 2(a2)–2(f2)) (see also the degrees of the nodes in the subplots of Fig 3(a1)–3(e1)). The nodes with Nos 6(4), 7(5), 57(6), and 10(9) are the top four hubs for H = 0.65, while the top four hubs for H = 0.75 are the nodes with Nos 3(4), 4(9), 10(6) and 52(1). Similarly, over time, certain states will strongly tend to evolve to a specific state as demonstrated by the size of links between any two states. For instance, in the H = 0.65, there is strong link between nodes 6(4) and 10(9), and 6(4) and 7(5) (unidirectional), while in the H = 0.75 there exists a strong bidirectional link between 3(4) and 4(9). Consequently, these occurrences present us with some degree of immediate predictability, as shown in the strong network (Fig 2(c2)) for H = 0.65, the observance of state 6(4) will most likely lead to a behavior similar to 7(5) which in turn may lead to state 57(6).
Fig 3. Degree, degree ratio, and persistent behaviors of motifs for fGm series.
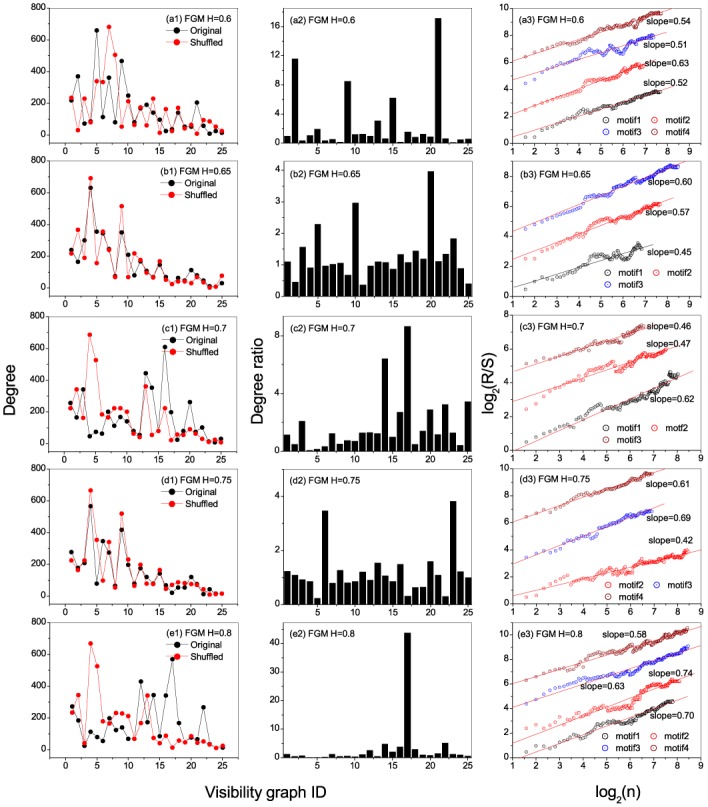
Segment length is selected to be s = 5. (a1)-(e1) show the occurrence degrees of the states in the original and shuffled fGm series with H = 0.6, 0.65, 0.7, 0.75 and 0.8, respectively; (a2)-(e2) present the degree ratios for all the states (visibility graphs) in the series with H = 0.6, 0.65, 0.7, 0.75, and 0.8, respectively; (a3)-(e3) Relations of R/S versus n obtained from occurring position series of the motifs, from which one can find persistent behaviors of the motifs’ occurring along the series.
From the patterns for shuffled networks (see Figs 2(a3)–3(f3)), one can find that the distribution of the increment values alone can also lead to some hubs and strong links between some pairs of states. However, the network patterns for the shuffled series are significantly different with that for the original series. For instance, in the strong network of H = 0.65, the hubs 6(4), 7(5) and 57(6) form a directional transfer loop, while in the shuffling network the node 7(5) is replaced by the state 2(2). The findings from the original series are thus non-trivial, in that the values are series-element-order dependent rather than value distribution dependent.
Fig 3(a2)–3(e2) show the ratios between degrees of local states for the original series versus that in the shuffled ones, from which one can identify the leading motifs. For H = 0.65 the leading four motifs are the visibility graphs with ID numbers 41(20), 25(10), 7(5) and 3(23), while that for H = 0.75 are the visibility graphs with ID numbers 438(23), 10(6), 30(20) and 21(13). The top four motifs are called herein motif1, motif2, motif3 and motif4, respectively.
A natural question is, do the motifs occur randomly along the time series or not? To understand this, we extract the occurring positions of the motifs. The positions for each motif form a time series. We then use the re-scaled range analysis to ascertain the long-term memory behavior in the position series as shown in Fig 3(a3)–3(e3). The identified motifs display the existence of fractal nature. This is exhibited by the existence of power-law behaviors in the relations between R/S versus n of the motifs. For H = 0.65, the scaling exponent for motif3 (the state 7(5)) is δ = 0.60, and for H = 0.75 that of motif3 (the state 30(20)) is δ = 0.69. If we consider only the maximum value δ m among all the values of scaling exponent for each specified H ∈ [0.5, 1], we have δ m = 0.63, 0.60, 0.62, 0.69, 0.74 corresponding to H = 0.6, 0.65, 0.70, 0.75, 0.8. One can find that the maximum value of scaling exponent has a positive cross-correlation with H, however, a reliable conclusion requires much more works to be done.
Stock market series
Fig 4(a1)–4(a3) and 4(b1)–4(b3) present the state transfer networks, the strong networks, and the shuffled networks for the stock markets S&P500 and Nasdaq respectively. Self-links are observed in states with id 80(13) and 7(20) for the Nasdaq stock index and 29(13) and 115(20) for S&P500 stock index, and disappear in the subsequent strong and shuffled networks. Out of the possible 3737 occurrences, this self reference is observed 12 times for 80(13), 13 times for 7(20) both in Nasdaq; and 7 and 10 times respectively for the two cases of S&P500. Since stock markets are highly dynamic and controlled by various market forces, it is unexpected for a certain state to persist for long hence these weak occurrences are real and acceptable within these networks.
Fig 4. State transfer networks for stock markets.

Segment length is selected to be s = 5. (a1) and (b1) display the original state transfer networks for S&P500 and Nasdaq respectively. The label x(y) means the state occurs for the first time at the position x along the time series (the x’th segment), and its identifier number is y; (a2) and (b2) are the strong state transfer networks constructed by filtering out weak links (less than 25) in (a1) and (a2), respectively. While, (a3) and (b3) are the corresponding networks (weak links also are filtered out) constructed from shuffled series. Statistical average is conducted over 1000 realizations. Except in networks shown in (a1) and (b1), the size of a node indicates the occurring degree of the state. The width of an edge is the link’s weight.
As can be seen by the size of nodes in the strong networks (see Figs 4, 5(a1) and 5(b1) showing the degrees of the nodes), the nodes with Nos 4(4), 12(9), 5(5), and 6(6) are the top four hubs for S&P500 stock index network, while the top four hubs for Nasdaq stock index are nodes with Nos 4(4), 1(9), 30(6) and 48(5). The significant differences of the link sizes tell us that certain states will strongly tend to evolve to a specific state. For instance, in the S&P500 stock index, there is strong link between nodes 4(4) and 12(9), and 6(6) and 4(4). Whereas in the former the relationship is bidirectional almost in equal measure, the later is only unidirectional. Consequently, the observance of state 6(6) will most likely lead to a behavior similar to 4(4) which in turn may lead to state 12(9). For the two stock markets, we find an identical loop of three hubs linked by strong edges, namely, 4(4)→5(5)→6(6)→4(4) for S&P500 index, and 4(4)→48(5)→30(6)→4(4) for Nasdaq index. Stock markets thus will tend to fluctuate between known behaviors across various times. Actually, there exist some differences in details of the two strong networks, but these differences distribute in the details formed by weak links and non-hubs. The main part of the two strong networks, especially the parts formed by strong links and hubs, are almost identical. What influences a specific behavior and its transitions is an interesting study but not the focus of this work though.
Fig 5. Degree, degree ratio, and persistent behaviors of motifs for the stock markets.

Segment length is selected to be s = 5. (a1)and (b1) show the occurrence degrees of the states in the original and shuffled S&P500 and Nasdaq index series, respectively. From the occurrence degrees one can easily identify hubs in the original and shuffled series; (a2)-(e2) present the degree ratios for all the states in the S&P500 and Nasdaq index series, respectively. From the ratios one can easily find the the motifs. A state being called a motif means that its degree in the original series is significantly larger than that in the shuffled series; (a3)-(e3) Relations of R/S versus n obtained from occurring position series of the motifs, from which one can find persistent behaviors of the motifs’ occurring along the series.
Fig 5(b1) and 5(b2) show the ratios between degrees of local states in the original stock index series versus that in the shuffled ones. One can identify the leading four motifs (motif1, motif2, motif3 and motif4), namely, visibility graphs with ID numbers 12(9), 4(4), 41(15) and 6(6) for S&P500 and, visibility graphs with ID numbers 1(9), 11(7), 30(6) and 4(4) for Nasdaq.
From Fig 5(a3) and 5(b3), one can find significant persistence of the motifs’ occurring along the series, as exhibited by the power-laws of R/S versus n in motif4 (6(6)) in the S&P500 whose δ = 0.65, and also in motif1 and motif4 (1(9) and 4(4)) for the Nasdaq stock whose δ = 0.61 and δ = 0.66.
Window size s = 6
Like in window size, s = 5, for comparison purpose, we re-calculate the results for fGm series with H = 0.6, 0.65, 0.7, 0.75 and 0.8, as well those of the empirical data, by using the window size of s = 6. The total number of state patterns that have occurred increases to 132 for s = 6 from 25 for s = 5. Figs 6 and 7 present only the visibility graphs (with their identifier numbers) that turn out to be motifs in the reference data and the empirical data respectively.
Fig 6. All the states that turn out to be motifs in the fGm series with H = 0.6, 0.65, 0.7, 0.75, 0.8 (the total number of occurrence states is 132).
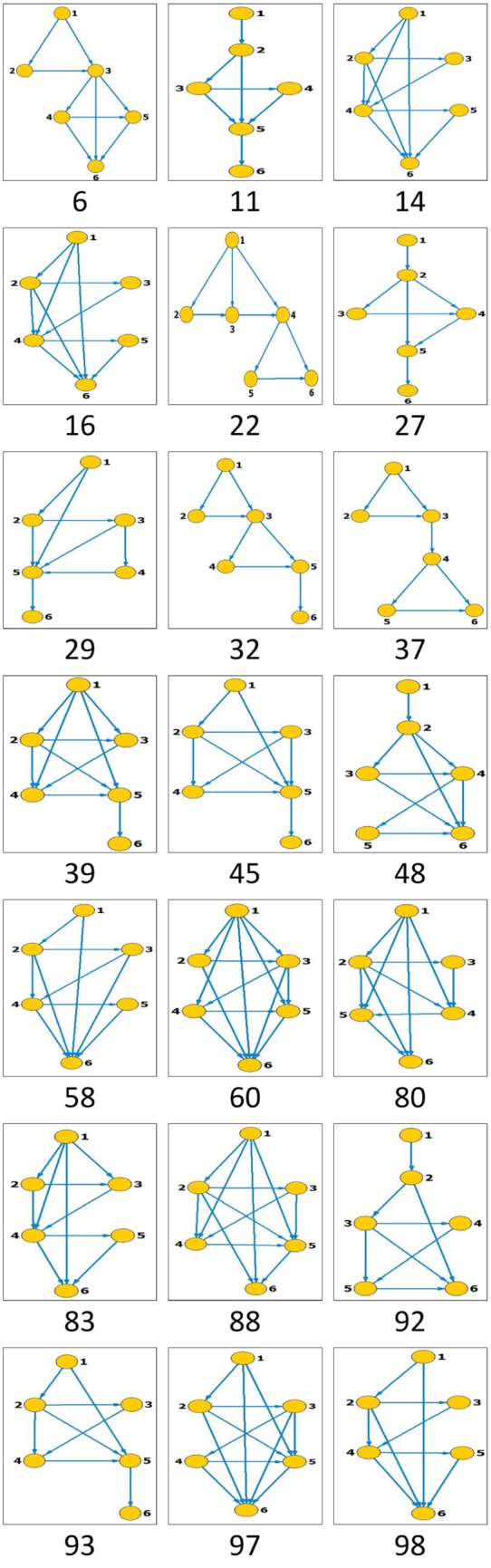
Segment length is selected to be s = 6.
Fig 7. All the states that turn out to be motifs in the stock market index series.

Segment length is selected to be s = 6.
Consequently, the node degrees, degree ratios (original to shuffled) and the persistence of the occurring motifs are presented in Figs 8 and 9 for reference and real data respectively. Referencing the H = 0.65 and H = 0.75 for the reference data, hubs are observed to be 10(36), 17(9), 6(6) and 57(42); and 32(34), 11(1), 3(97) and 10(30) respectively. The occurring motifs for each can equally be identified. For instance, in H = 0.65, the motifs are identified as 80, 39, 93 and 6; and among the four top motifs the nodes 9 and 42 occur along the series according to fractal behaviors with scaling exponents δ = 0.64 and 0.61 respectively.
Fig 8. Degree, degree ratio, and persistent behaviors of motifs for fGm series.
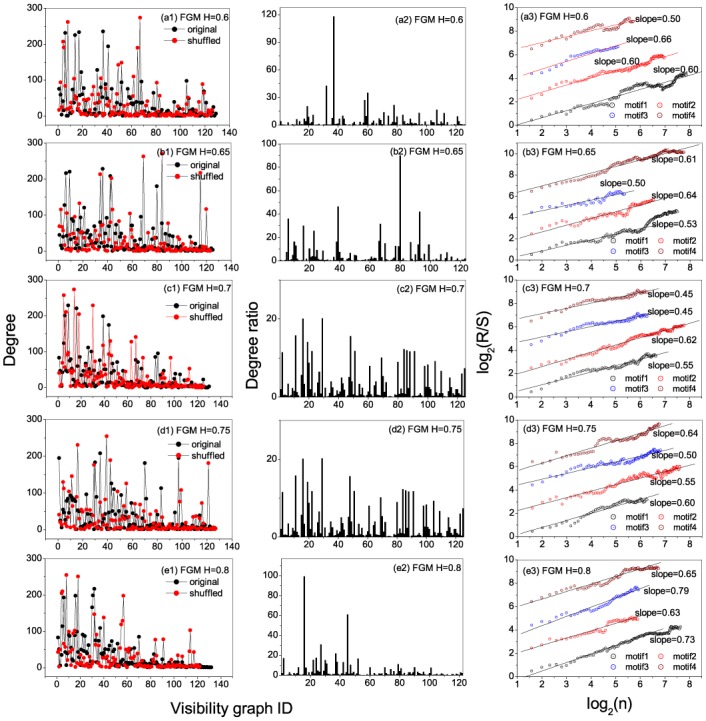
Segment length is selected to be s = 6. (a1)-(e1) show the occurrence degrees of the states in the original and shuffled fGm series with H = 0.6, 0.65, 0.7, 0.75 and 0.8, respectively; (a2)-(e2) present the degree ratios for all the states (visibility graphs) in the series with H = 0.6, 0.65, 0.7, 0.75, and 0.8, respectively; (a3)-(e3) Relations of R/S versus n obtained from occurring position series of the motifs, from which one can find persistent behaviors of the motifs’ occurring along the series.
Fig 9. Degree, degree ratio, and persistent behaviors of motifs for the stock markets.
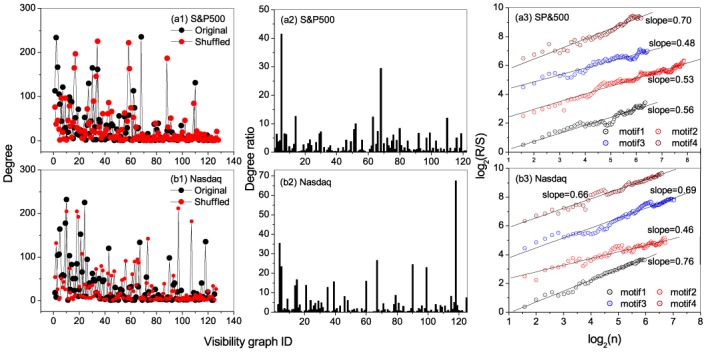
Segment length is selected to be s = 6. (a1)and (b1) show the occurrence degrees of the states in the original and shuffled S&P500 and Nasdaq index series, respectively. (a2)-(e2) present the degree ratios for all the states in the S&P500 and Nasdaq index series, respectively; (a3)-(e3) Relations of R/S versus n obtained from occurring position series of the motifs, from which one can find persistent behaviors of the motifs’ occurring along the series.
In the empirical data, the top four hubs for S&P500 stock index are identified with the nodes numbered 68, 2, 3 and 30, while the top four motifs are the nodes with nos 5, 68, 14 and 63, among which the forth motif is positioned along the series according to a fractal behavior with δ = 0.70. For the Nasdaq stock index, the top four hubs are 10, 24, 9 and 5, the top four motifs are 118, 4, 67 and 90, most of which are positioned along the series according to fractal behaviors (the scaling exponents are 0.76, 0.46, 0.69 and 0.66 respectively).
Comparing the results in both window size, s = 5 and s = 6, the strong networks tend to exhibit (qualitatively) similar structural outlook. However, even so, their evolutionary behaviors are highly varied as shown by the various occurring motifs which are representative of the non-trivial features in the series. Whereas Nasdaq shows a stronger fractal nature, the S&P500 index motifs averagely indicate weak fractality (see Fig 5(a3) and 5(b3) for s = 5 and Fig 9(a3) and 9(b3) for s = 6). Although the close structural nature may be as a result of their regional proximity affected by the same fiscal and political policies, their evolutionary divergence may be attributed to the operational nature of the two indices. While the S&P500 index comprises of the top 500 different companies in the USA, the Nasdaq index mostly represents companies within the IT industry which will mostly tend to fluctuate in same direction. Besides, the divergence in the S&P 500 composition and its weighting methodology while calculating the index may as well have an effect on the behavior of the stock over time hence the difference between the stocks.
Conclusion and Discussion
Network based time series analysis has reached fruitful achievements in recent years. By mapping mono/multivariate time series into networks one can investigate the time series from microscopic to macroscopic scales. However, the networks generated by most algorithms in literature are static thus cannot provide a detailed account of the evolutionary information on the system. Though there appear limited efforts in constructing transmission networks from mono/multivariate time series in literature, how to use the network viewpoint to extract evolutionary properties embedded in a series still remains an open problem. The study of only structural behaviors as exhibited in most approaches overlooks detailed evolutionary information as well as the ability to conduct short term prediction. These works thus provide the following contributions,
First, we propose a method to convert a mono-variate time series to a weighted network of networks while preserving the local network behavior by using the visibility graph. By this, one can detect evolutionary behaviors of the system. Starting from the phase-space reconstruction procedure, the series segments with a predefined length are converted to visibility graphs as being descriptions of the states corresponding to the time intervals. Linking successively occurring states leads to a state transfer network of distinguishable states. The hubs, motifs, and nontrivial patterns (strong links, loops, etc.) between the nodes tell us the transfer probabilities which are helpful in immediate prediction. The occurring positions of the motifs show the long-term behaviors that are useful in macroscopic prediction.
Second, the paper presents several interesting findings in both empirical and reference data sets. Various nontrivial patterns (hubs, motifs, and loops, etc.) are identified in the fGm networks as well as in the empirical data by using different window sizes. In both cases of window size, s = 5 and s = 6, the findings indicate that the Nasdaq stock index exhibits a more fractal behavior than its counterpart S&P500. Though the structural behavior tend to be similar, their quantitative features are diverse. While their similarity maybe due to their geographical operation, the evolutionary behavior is diverse perhaps due to their varied index computation methods as well as firms composition. Similarly, similar results are exhibited in the generated fGm series for hurst exponent, H > 0.5.
Ultimately, by using visibility graphs as being descriptions of local states, the proposed approach maps a time series to a temporal network (network of graph-lets). Accordingly, the theories and tools in the temporal network can be extended to time series analysis, and by extension financial study. By this, the present works present a method that can be used to study various time series research works whose interest is in understanding the evolutionary behaviors of a dynamical system.
Supporting Information
(RAR)
Data Availability
NASDAQ and SP 500 data are available from Yahoo Finance (http://finance.yahoo.com/q/hp?s=\%5EGSPC+Historical+Prices).
Funding Statement
The work is supported by the National Science Foundation of China under Grant Nos 10975099 and 11505114, the Program for Professor of Special Appointment (Orientational Scholar) at Shanghai Institutions of Higher Learning under Grant Nos D-USST02 and QD2015016, and the Shanghai project for construction of discipline peaks. S. Mutua acknowledges the financial support from Shanghai Municipal Government under Scholarship No. SH2013SLA004.
References
- 1. Donner RV, Heitzig J, Donges JF, Zou Y, Marwan N, Kurths J, The Geometry of chaotic dynamics—A complex network perspective. Euro. Phys. J. B. 2011;84: 653–672. 10.1140/epjb/e2011-10899-1 [DOI] [Google Scholar]
- 2. Zhang J, Small M, Complex network from pseudoperiodic time series: Topology versus dynamics. Phys. Rev. Lett. 2006;96: 238701 10.1103/PhysRevLett.96.238701 [DOI] [PubMed] [Google Scholar]
- 3. Zhang J, Luo X, Nakamura T, Sun J, Small M, Detecting temporal and spatial correlations in pseudoperiodic time series. Phys. Rev E. 2007;75: 016218 10.1103/PhysRevE.75.016218 [DOI] [PubMed] [Google Scholar]
- 4. Zhang J, Sun J, Luo X, Zhang K, Nakamura T, Small M, Characterizing pseudoperiodic time series through the Complex Network Approach. Physica D:Nonlinear Phenomena 2008;237(22): 2856–2865. 10.1016/j.physd.2008.05.008 [DOI] [Google Scholar]
- 5. Xu X, Zhang J, Small M, Superfamily phenomena and motifs of networks induced from time series. Proc. Nat. Acad. Sci. (USA) 2008;105(50): 19601–19605. 10.1073/pnas.0806082105 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Zhang J, Zhou C, Xu X, Small M, Mapping from structure to dynamics: A unified view of dynamical processes on networks. Phys. Rev. E 2010;82: 026116 10.1103/PhysRevE.82.026116 [DOI] [PubMed] [Google Scholar]
- 7. Xu X, Zhang J, Li P, Small M, Changing motif distributions in complex networks by manipulating rich-club connections. Physica A 2011;390(23): 4621–4626. 10.1016/j.physa.2011.06.069 [DOI] [Google Scholar]
- 8. Xiang R, Zhang J, Xu X, Small M, Multiscale characterization of recurrence-based phase space networks constructed from time series. Chaos 2012;22(1): 013107 10.1063/1.3673789 [DOI] [PubMed] [Google Scholar]
- 9. Yang Y, Yang H, Complex network-based time series analysis. Physica A 2008;387: 1381–1386. 10.1016/j.physa.2007.10.055 [DOI] [Google Scholar]
- 10. Gao Z, Jin N, Flow-pattern identification and nonlinear dynamics of gas-liquid two-phase flow in complex networks. Phys. Rev. E 2009;79: 066303 10.1103/PhysRevE.79.066303 [DOI] [PubMed] [Google Scholar]
- 11. Marwan N, Donges JF, Zou Y, Donner RV, Kurths J, Complex network approach for recurrence analysis of time series. Phys. Lett. A 2009;373: 4246–4254. 10.1016/j.physleta.2009.09.042 [DOI] [Google Scholar]
- 12. Donner RV, Zou Y, Donges JF, Marwan N, Kurths J, Recurrence networks—A novel paradigm for nonlinear time series analysis. New J. Phys. 2010;12(3): 033025 10.1088/1367-2630/12/3/033025 [DOI] [Google Scholar]
- 13. Donner RV, Zou Y, Donges JF, Marwan N, Kurths J, Ambiguities in recurrence based complex network representations of time series. Phys. Rev. E (Rapid Communication) 2010;81: 015101(R) 10.1103/PhysRevE.81.015101 [DOI] [PubMed] [Google Scholar]
- 14. Donner RV, Small M, Donges JF, Marwan N, Zou Y, Xiang R, et al. Recurrence-based time series analysis by means of complex network methods. Int. J. Bifurcation and Chaos 2011;21(4): 1019–1046 10.1142/S0218127411029021 [DOI] [Google Scholar]
- 15. Zou Y, Heitzig J, Donner RV, Donges JF, Farmer JD, Meucci R, et al. Power-laws in recurrence networks from dynamical systems. EPL 2012;98(4): 48001 10.1209/0295-5075/98/48001 [DOI] [Google Scholar]
- 16. Gao Z, Zhang X, Jin N, Marwan N, Kurths J, Multivariate recurrence network analysis for characterizing horizontal oil-water two-phase flow. Phys. Rev. E 2013;88(3): 032910 10.1103/PhysRevE.88.032910 [DOI] [PubMed] [Google Scholar]
- 17. Gao Z, Zhang X, Jin N, Donner RV, Marwan N, Kurths J, Recurrence networks from multivariate signals for uncovering dynamic transitions of horizontal oil-water stratified flows. EPL 2013;103: 50004 10.1209/0295-5075/103/50004 [DOI] [Google Scholar]
- 18. Gao Z, Zhang X, Du M, Jin N, Recurrence network analysis of experimental signals from bubbly oil-in-water flows. Phys. Lett. A 2013;377: 457–462. 10.1016/j.physleta.2012.12.017 [DOI] [Google Scholar]
- 19. Gao Z, Fang P, Ding M, Yang D, Jin N, Complex networks from experimental horizontal oil-in-water flows:Community structure detection versus flow pattern discrimination. Phys. Lett. A 2015;379: 790–797. 10.1016/j.physleta.2014.09.004 [DOI] [Google Scholar]
- 20. Gao Z, Fang P, Ding M, Jin N, Multivariate weighted complex network analysis for characterizing nonlinear dynamic behavior in two-phase flow. Experimental Thermal and Fluid Science 2015;60: 157–164 10.1016/j.expthermflusci.2014.09.008 [DOI] [Google Scholar]
- 21. Gao Z, Yang Y, Fang P, Zou Y, Xia C, Du M, Multiscale complex network for analyzing experimental multivariate time series. EPL 2015. 109: 30005 10.1209/0295-5075/109/30005 [DOI] [Google Scholar]
- 22. Zou Y, Donner RV, Kurths J, Analyzing long-term correlated stochastic processes by means of recurrence networks: Potentials and pitfalls. Phys. Rev. E 2015;91: 022926 10.1103/PhysRevE.91.022926 [DOI] [PubMed] [Google Scholar]
- 23. Donner RV, Donges JF, Zou Y, Feldhoff JH, Complex network analysis of recurrences In: Webber C. L. Jr, Marwan N. editors. Recurrence Quantification Analysis: Theory and Best Practices; Springer; 2015. pp. 101–163 [Google Scholar]
- 24. Gao Z, Yang Y, Fang P, Jin N, Xia C, Hu L, Multi-frequency complex network from time series for uncovering oil-water flow structure. Scientific Reports 2015;5: 8222 10.1038/srep08222 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Lacasa L, Luque B, Ballesteros F, Luque J, Nuno C, From time series to complex networks. Proc. Natl. Acad. Sci. (USA) 2008;105(13): 4972–4975. 10.1073/pnas.0709247105 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Luque B, Lacasa L, Ballesteros F, Luque J, Horizontal Visibility graphs: Exact results for random time series. Phys. Rev. E 2009;80: 046103 10.1103/PhysRevE.80.046103 [DOI] [PubMed] [Google Scholar]
- 27. Yang Y, Wang J, Yang H, Mang J, Visibility graph approach to exchange rate series. Physica A 2009;388(20): 4431–4437. 10.1016/j.physa.2009.07.016 [DOI] [Google Scholar]
- 28. Qi J, Wang J, Wang J, Xiao Q, Yang H, Visibility graphs for time series containing different components. Fluctuation and Noise Letters 2011;10(4): 371–379. 10.1142/S0219477511000636 [DOI] [Google Scholar]
- 29. Xie WJ, Zhou WX, Horizontal visibility graphs transformed from fractional Brownian motions: Topological properties versus Hurst index. Physica A 2011;390(20): 3592–3601. 10.1016/j.physa.2011.04.020 [DOI] [Google Scholar]
- 30. Lacasa L, Nunez AM, Roldan E, Parrondo JMR, Luque B, Time Series Irreversibility: A visibility graph approach. Eur. Phys. J. B 2012;85: 217 10.1140/epjb/e2012-20809-8 [DOI] [Google Scholar]
- 31. Nunez AM, Luque B, Lacasa L, Gomez JP, Horizontal visibility graphs generated by type-I intermittency. Phys. Rev. E 2013;87: 052801 10.1103/PhysRevE.87.052801 [DOI] [PubMed] [Google Scholar]
- 32. Nunez AM, Lacasa L, Gomez JP, Horizontal Visibility graphs generated by type-II intermittency. J. Phys. A 2014;47: 035102 10.1088/1751-8113/47/3/035102 [DOI] [PubMed] [Google Scholar]
- 33. Zou Y, Small M, Liu ZH, Kurths J, Complex network approach to characterize the statistical features of the sunspot series. New J. Phys. 2014;16: 013051 10.1088/1367-2630/16/1/013051 [DOI] [Google Scholar]
- 34. Zou Y, Donner RV, Marwan N, Small M, Kurths J, Long-term changes in the north-south asymmetry of solar activity: A nonlinear dynamics characterization using visibility graphs. Nonlinear Processes in Geophysics 2014;21: 1113–1126. 10.5194/npg-21-1113-2014 [DOI] [Google Scholar]
- 35. Xiao Q, Pan X, Li X, Stephen M, Yang H, Jiang Y, et al. Row column visibility graph approach to two-dimensional landscapes. Chin Phys. B 2014;23: 078904 10.1088/1674-1056/23/7/078904 [DOI] [Google Scholar]
- 36. Munnix MC, Shimada T, Schafer R, Leyvraz F, Seligman TH, Guhr T, et al. Identifying states of a financial market. Scientific Reports 2012;2: 644 10.1038/srep00644 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Zheng Z, Podobnik B, Feng L, Li B, Changes in cross-correlations as an indicator for systemic risk. Scientific Reports 2012;2: 888 10.1038/srep00888 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38. Buccheri G, Marmi S, Mantegna RN, Evolution of correlation structure of industrial indices of U.S. equity markets. Phys. Rev. E 2013;88(1): 012806 10.1103/PhysRevE.88.012806 [DOI] [PubMed] [Google Scholar]
- 39. Gao X, An H, Fang W, Huang X, Li H, Zhong W, et al. Transmission of linear regression patterns between time series: From relationship in time series to complex networks. Phys. Rev. E 2014;90: 012818 10.1103/PhysRevE.90.012818 [DOI] [PubMed] [Google Scholar]
- 40. Gao X, An H, Fang W, Huang X, Li H, Zhong W, Characteristics of the transmission of autoregressive sub-patterns in financial time series. Scientific Report 2014;4: 6290 10.1038/srep06290 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41. Gao J, Buldyrev SV, Stanley HE, Havlin S, Networks formed from interdependent networks. Nature physics 2012;8: 40–48. 10.1038/nphys2180 [DOI] [PubMed] [Google Scholar]
- 42. Holme P, Saramaki J, Temporal networks. Phys. Reports 2012;519(3): 97–125. 10.1016/j.physrep.2012.03.001 [DOI] [Google Scholar]
- 43. Milo R, Shen-Orr S, Itzkovitz S, Kashtan N, Chklovskii D, Alon U, Network motifs: Simple building blocks of complex networks. Science 2002;298(5594): 824–827. 10.1126/science.298.5594.824 [DOI] [PubMed] [Google Scholar]
- 44. Kantelhardt JW, Zschiegner S, Koscielny-Bunde E, Havlin S, Bunde A, Stanley HE, Multifractal Detrended Fluctuation Analysis of Nonstationary Time Series. Physica A 2002;316: 87–114. 10.1016/S0378-4371(02)01383-3 [DOI] [Google Scholar]
- 45. Kristoufek L, Rescaled Range Analysis and Detrended Fluctuation Analysis: Finite Sample Properties and Confidence Levels, AUCO Czech Economic Review 2010;4(3): 315–329 [Google Scholar]
- 46. Dall J, Cristensen M, Random Geometric Graphs. Phys. Rev. E 2002;66: 016121 10.1103/PhysRevE.66.016121 [DOI] [PubMed] [Google Scholar]
- 47. Abry P, Sellan F, The wavelet-based synthesis for the fractional Brownian motion proposed by F. Sellan and Y. Meyer: Remarks and fast implementation. Appl. and Comp. Harmonic Analysis 1996;3(4): 377–383. 10.1006/acha.1996.0030 [DOI] [Google Scholar]
- 48. Bardet JM, Lang G, Oppenheim G, Philippe A, Stoev S, Taqqu MS, Generators of long-range dependence processes: a survey In: Doukhan P, Oppenheim G, Taqqu M, editors. Theory and Applications of long-range dependence. Birkhäuser Basel; 2003. pp.579–623 [Google Scholar]
- 49.Yahoo Finance, Historical Data availiable: http://finance.yahoo.com/q/hp?s=%5EGSPC+Historical+Prices Accessed 2014 Apr 18
- 50. Cheridito P, Arbitrage in fractional Brownian motion models. Finance and Stochastics 2003;7(4): 533–553. 10.1007/s007800300101 [DOI] [Google Scholar]
- 51. Cao LY, Practical method for determing the minimum embedding dimension of a scalar time series. Physica D 1997;110: 43–50. 10.1016/S0167-2789(97)00118-8 [DOI] [Google Scholar]
- 52. Kennel MB, Brown R, Abarbanel HD, Determining embedding dimension for phase space reconstruction using a geometrical construction. Phys. Rev. A 1992;45: 3403–3411. 10.1103/PhysRevA.45.3403 [DOI] [PubMed] [Google Scholar]
- 53. Liu JL, Yu ZG, Anh V, Topological properties and fractal analysis of a recurrence network constructed from fractional Brownian motions. Phys. Rev. E 2014;89: 032814 10.1103/PhysRevE.89.032814 [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
(RAR)
Data Availability Statement
NASDAQ and SP 500 data are available from Yahoo Finance (http://finance.yahoo.com/q/hp?s=\%5EGSPC+Historical+Prices).