

Abstract
Methods of multiblock bilinear factorizations have increased in popularity in chemistry and biology as recent increases in the availability of information-rich spectroscopic platforms has made collecting multiple spectroscopic observations per sample a practicable possibility. Of the existing multiblock methods, consensus PCA (CPCA-W) and multiblock PLS (MB-PLS) have been shown to bear desirable qualities for multivariate modeling, most notably their computability from single-block PCA and PLS factorizations. While MB-PLS is a powerful extension to the nonlinear iterative partial least squares (NIPALS) framework, it still spreads predictive information across multiple components when response-uncorrelated variation exists in the data. The OnPLS extension to O2PLS provides a means of simultaneously extracting predictive and uncorrelated variation from a set of matrices, but is more suited to unsupervised data discovery than regression. We describe the union of NIPALS MB-PLS with an orthogonal signal correction (OSC) filter, called MB-OPLS, and illustrate its equivalence to single-block OPLS for regression and discriminant analysis.
Keywords: Multiblock data, CPCA-W, MB-PLS, OnPLS, MB-OPLS
1. Introduction
The method of nonlinear iterative partial least squares (NIPALS) has firmly entrenched itself in the field of chemometrics. Implementations of principal component analysis (PCA) and projections to latent structures (PLS) that utilize NIPALS-type algorithms benefit from its numerical stability, as well as its flexibility and simplicity [1-3]. Only a few subroutines from level 2 of the basic linear algebra subprograms (BLAS) specification are required to construct a complete NIPALS-type algorithm [4, 5], making it an attractive means of constructing PCA and PLS models of high-dimensional spectroscopic datasets.
One particularly recent addition to the NIPALS family of algorithms, called orthogonal projections to latent structures (OPLS), integrates an orthogonal signal correction (OSC) filter into NIPALS PLS [6, 7]. By extracting variation from its computed PLS components that is uncorrelated (orthogonal) to the responses, OPLS produces a more interpretable regression model compared to PLS. In fact, when trained on the same data and responses, an OPLS model and a PLS model with the same total number of components will show no difference in predictive ability [8]. Despite its relative novelty to the field, the enhanced interpretability of OPLS over PLS has made it a popular method in exploratory studies of spectroscopic datasets of complex chemical mixtures (e.g., metabolomics [9], food and soil science [10], and chemical process control [11]).
Extensions of NIPALS PCA and PLS to incorporate blocking information that partitions the set of measured variables into multiple ‘blocks’ of data have recently gained attention in the field as more experimental designs involve the collection of data from multiple analytical platforms per sample. In such experiments, referred to as ‘class II’ multiblock schemes by Smilde et al. [12], correlated consensus directions are sought from the blocks that maximally capture block variation and (optionally) maximally predict a set of responses. Of the available extensions of NIPALS to multiblock modeling, a class of methods exists that bears attractive computational qualities, namely computability from single-block bilinear factorizations. When both super weights and block loadings are normalized in consensus PCA (i.e. CPCA-W), the obtained super scores are equivalent to those obtained from PCA of the concatenated matrix of blocks [13]. Likewise, scores obtained from PLS of the concatenated matrix are equivalent to super scores from multiblock PLS (MB-PLS) when super scores are used in the deflation step [13, 14]. As a result, these multiblock bilinear factorizations inherit many of the useful properties of their single-block equivalents.
A second class of multiblock methods exists in which every block is predicted in a regression model by every other block. In the first of such methods, known as nPLS, the MAXDIFF criterion [15] is optimized one component at a time (i.e. sequentially) to yield a set of predictive weight vectors for each block [16]. The recently described OnPLS algorithm also falls within this class [16]. OnPLS extends O2PLS to three or more matrices and may be considered a prefixing of nPLS with an OSC filtering step. OnPLS deflates non-globally predictive variation that may or may not be orthogonal to all blocks from each matrix, and then computes an nPLS model from the filtered result [16]. While fully symmetric OnPLS is a powerful and general addition to the existing set of multiblock modeling frameworks, it is arguably an over-complication when the regression of a single response matrix on multiple data blocks (i.e. MB-PLS) is sought. For such situations, a novel algorithm termed MB-OPLS for multiblock orthogonal projections to latent structures is introduced that embeds an OSC filter within NIPALS MB-PLS, thus solving an inherently different problem from OnPLS. It will be shown that MB-OPLS, in analogy to CPCA-W and MB-PLS, is computable from a single-block OPLS model of the matrix of concatenated data blocks. Thus, MB-OPLS forms a bridge between this special class of consensus component methods and the highly general symmetric regression framework of OnPLS.
2. Theory
MB-OPLS belongs to a set of multiblock methods that exhibit an equivalence to their single-block equivalents. A short discussion on these methods follows, in which the optimization criterion of each method is shown to belong to the MAXBET family of objective functions. This is contrasted to nPLS and OnPLS, which have been shown to optimize a MAXDIFF objective. The principal difference between MAXBET and MAXDIFF is one of explained variation: while MAXBET captures between-matrix covariances and within-matrix variances, MAXDIFF only captures the former [15, 17]. Finally, the equivalence of MB-OPLS and OPLS is demonstrated, which highlights its differences from OnPLS.
In all following discussions, it will be understood that there exist n data matrices X1 to Xn, each having N rows (observations) and Ki columns (variables). The matrix X = [X1] … [Xn] of all concatenated blocks will be used in cases of single-block modeling. Finally, a response matrix Y having N rows and M columns will be assumed to exist for the purposes of regression (i.e. PLS-R, MB-PLS-R, etc.) or discriminant analysis (i.e. PLS-DA, MB-PLS-DA, etc.).
2.1. nPLS and OnPLS
In their initial description of the OnPLS modeling framework [16], Löfstedt and Trygg introduced nPLS as a generalization of PLS regression to cases where n > 2, and a model is sought in which each matrix Xi is predicted by all other matrices Xj≠i. The nPLS solution involves identifying a set of weight vectors Wi that simultaneously maximize covariances between each pair of resulting scores ti = Xiwi via the following objective function:
| (1) |
subject to the constraints ‖wi‖ = 1. This objective was subsequently recognized to be a member of the MAXDIFF family of functions, whose solution is obtainable using a general algorithm from Hanafi and Kiers [17]. After the identification of a set of weight vectors, the scores
and loadings
may be computed for each matrix, which is then deflated prior to the computation of subsequent component weights:
| (2) |
This deflation scheme follows the precedent set by two-block PLS regression. Because their described approach used a distinct deflation scheme from single-component (sequential) MAXDIFF, it was given the name “nPLS” by the authors to distinguish it from MAXDIFF [16, 18].
OnPLS extends nPLS by decomposing each matrix into a globally predictive part and a non-globally predictive (orthogonal) part using an orthogonal projection. By removing orthogonal variation from each block prior to constructing an nPLS model, OnPLS optimizes the following MAXDIFF-type objective function:
| (3) |
where Zi represents the orthogonal projector identified by OnPLS for matrix i:
where To,i = [to,i,1| … |to,i,Ao], the concatenation of all orthogonal score vectors for the block, and to,i,a = Xiwo,i,a. In OnPLS, each orthogonal weight wo,i,a is chosen such that its score to,i,a contains maximal covariance with the variation in Xj≠i that is not jointly predictive of Xi. The OnPLS framework provides a powerful set of methods for unsupervised data mining and path modeling [16, 19-21].
2.2. CPCA-W and MB-PLS
The consensus PCA method, introduced by Wold et al. as CPCA and modified by Westerhuis et al. as CPCA-W, identifies a set of weights pi that maximally capture the within-block variances and between-block covariances of a set of n matrices [13]. It was further proven by Westerhuis, Kourti and MacGregor that the results of CPCA-W computed on matrices X1 to Xn are identical to those from PCA of the concatenated matrix X = [X1] … [Xn]. It immediately follows from this equivalence that the CPCA-W algorithm optimizes the following objective function:
| (4) |
subject to the constraint ‖p‖ = 1, where pT = [P1T| … |PnT]. Maximizing the above function yields a set of super scores t that relate the N observations in X to each other based on the extracted consensus directions in p, as well as block scores ti and loadings pi that describe each block. This objective function is of the MAXBET variety, in contrast to the MAXDIFF objective of nPLS and OnPLS. As a result, the CPCA-W NIPALS algorithm may be considered a special case of the general algorithm from Hanafi and Kiers [17].
The multiblock PLS (MB-PLS) method, when deflation is performed using super scores [14], shares an equivalence with single-block PLS as proven by Westerhuis et al. [13]. Therefore, the MB-PLS objective takes on a similar form as in CPCA-W, with the addition of a weighting matrix:
| (5) |
where once again ‖w‖ is constrained to unity. In analogy to Höskuldsson's interpretation of PLS as a regression on orthogonal components, where YYT is used to weight the covariance matrix, the above function corresponds to a MAXBET objective with an inner weighting of YYT [2]. Alternatively, equation (5) could be interpreted as a MAXBET computed on the n cross- covariance matrices YTX1 to YTXn.
2.3. MB-OPLS
Extension of prior multiblock NIPALS algorithms to incorporate an OSC filter rests on the observation that, in both the case of CPCA-W and MB-PLS, deflation of each computed component is accomplished using super scores. For any super score deflation method, a loading vector is computed for each block:
and the super scores t and block loadings are then used to deflate their respective block:
| (6) |
Equation (6) differs from equation (2) used in nPLS and OnPLS, which uses block-specific scores and loadings during deflation. This method of super score deflation ensures that the super scores are an orthogonal basis, while allowing scores and loadings to become slightly correlated at the block level, and is a necessary condition for the equivalences between CPCA-W and MB-PLS and their single-block counterparts [13]. We shall employ this condition in MB-OPLS by deflating each matrix by a set of orthogonal super scores To, which shall be shown to be equal to the orthogonal scores obtained from single-block OPLS. By constructing an MB-PLS model on the set of matrices after deflation by To, we effectively arrive at another MAXBET objective:
| (7) |
where w is constrained to unit norm and Z is the orthogonal projector for the super scores To:
2.3.1. The MB-OPLS Model
MB-OPLS constructs an OPLS model for each matrix Xi, where the predictive and orthogonal loadings for each matrix are interrelated by a set of predictive and orthogonal super scores, respectively:
| (8) |
where each Ei is a data residual matrix that holds all variation in Xi not explained by the model. Concatenation of all block-level matrices together in equation (8) results in a top-level consensus model, which is in fact equivalent to an OPLS model trained on the partitioned data matrix X:
| (9) |
Like PLS and MB-PLS, an MB-OPLS model contains a second equation that relates the predictive super scores and responses:
| (10) |
where C is the response loadings matrix that relates the super scores to the responses, and F is the response residual matrix that holds Y-variation not captured by the model.
2.3.2. The MB-OPLS Algorithm
The proposed MB-OPLS algorithm described herein admits a matrix of responses Y, but also supports vector-y cases. Direct and normed assignment will be indicated by “←” and “∝”, respectively. All assignments to block-specific structures (e.g. wi) that are to be performed over all values of i from 1 to n are suffixed with “∀i ∈ {1, …, n}”.
-
For each m ∈ {1, …, M} do
vi,m ← XiTym · (ymTym)−1 ∀i ∈ {1, …, n}
Vi ← [Vi|vi,m] ∀i ∈ {1, …, n}
Initialize u to a column of Y
wi ∝ XiTu ∀i ∈ {1, …, n}
ti ← Xiwi ∀i ∈ {1, …, n}
R ← [t1| … |tn]
wT ∝ RTu
t ← RwT
c ← (YTt) · (tTt)−1
u ← (Yc) · (cTc)−1
-
If ‖u – uold‖/‖uold‖ > ∈, return to step (3).
Otherwise, continue to step (11).
pi ← (XiTt) · (tTt)–1 ∀i ∈ {1, …, n}
-
To compute an orthogonal component, continue to step (13).
Otherwise, proceed to step (21).
wo,i ← pi ∀i ∈ {1, …, n}
-
For each m ∈ {1, …, M} do
wo,i ← wo,i – φvi,m ∀i ∈ {1, …, n}
to,i ← Xiwo,i ∀i ∈ {1, …, n}
po,i ← (XiT to) · (toT to)−1 ∀i ∈ {1, …, n}
Xi ← X− topo,iT ∀i ∈ {1, …, n}
Return to step (2).
Xi ← Xi− tpiT ∀i ∈ {1, …, n}
-
To compute another component, return to step (2).
Otherwise, end.
In the above algorithm, the value of ∈ is set to a very small number, e.g. 10−9. For each predictive component in the model, a set of orthogonal components is extracted. After the computation of a new orthogonal component, the current predictive component is updated to reflect the removal of orthogonal variation from the matrices Xi. The MB-OPLS algorithm closely follows the matrix-Y OPLS algorithm presented by Trygg and Wold [6], but replaces the standard PLS computation (steps 4-10 in OPLS) with an MB-PLS computation (steps 2-11 above). However, as described below, the mechanism by which orthogonal variation is removed (steps 13-19 above) is identical to that of OPLS.
2.3.3. Equivalence to OPLS
In both the vector-y and matrix-Y OPLS algorithms proposed by Trygg and Wold [6], a basis V for the response-correlated variation in X is constructed by regressing the data onto each column of responses:
| (11) |
where ym and vm denote the m-th columns of Y and V, respectively. When X is partitioned into multiple blocks, the computed basis also bears the same partitioning, i.e. VT = [V1T| … |VnT], where each of the n submatrices corresponds to the regression of its respective block Xi onto the responses:
| (12) |
where vi,m is the m-th column of Vi. Given a single-block PLS loading vector p, the OPLS algorithm computes an orthogonal weight wo by orthogonalizing p to the columns of V:
| (13) |
after wo has been initialized to p. From the proof of Westerhuis et al. [13], it is known that the single-block PLS loading p equals the concatenation of all block loadings from MB-PLS, i.e. that pT = [p1T| … |pnT]. Expansion of all vector terms in the above equation into their partitioned forms results in the following new assignment rule:
| (14) |
The scalar term in equation (14) should be recognized as φ in the MB-OPLS algorithm. By the same reasoning, step (15) in the algorithm is equivalent to scaling wo to unit norm. In effect, by computing φ as the fraction of orthogonal variation to remove from its loadings, MB-OPLS yields the same orthogonal weights (wo) as OPLS of the concatenated matrix. Therefore, because wo equals the column-wise concatenation of all weights wo,i, it is then apparent that the orthogonal super scores extracted by MB-OPLS are identical to those from OPLS of the concatenated matrix X, as illustrated in the following equation:
| (15) |
From this equivalence, and the fact that steps (2-11) and (21) in MB-OPLS constitute an MB-PLS iteration, we arrive at the equivalence between MB-OPLS and OPLS. Thus, orthogonality between the responses and orthogonal super scores to computed by MB-OPLS is also ensured. However, because the computation of orthogonal weights involves all blocks, the resulting orthogonal block scores to,i are not guaranteed to be orthogonal to the responses.
2.3.4. Computation from an OPLS Model
The equivalence between MB-OPLS super scores and OPLS scores may be leveraged to generate an MB-OPLS model from an existing OPLS model of a partitioned data matrix, saving computation time during cross-validated model training. The following algorithm details the extraction of MB-OPLS block scores and loadings from an OPLS model:
Initialize a = 1, b = 1
to ← [To]a
wo,i ← [Wo]i ∀i ∈ {1, …, n}
to,i ← Xiwo,i ∀i ∈ {1, …, n}
po,i ← (XiT to) · (toT to)–1 ∀i ∈ {1, …, n}
To,i ← [To,i|to,i] ∀i ∈ {1, …, n}
Po,i ← [Po,i|Po,i] ∀i ∈ {1, …, n}
Wo,i ← [Wo,i|Wo,i] ∀i ∈ {1, …, n}
If another orthogonal component exists, increment a and return to step (2). Otherwise, continue to step (10).
Xi ← Xi− ToPo,iT ∀i ∈ {1, …, n}
u ← [U]b
t ← [T]b
wi ∝ XiT u ∀i ∈ {1, …, n}
ti ← Xiwi ∀i ∈ {1, …, n}
pi ← (XiT t) · (tT t)−1 ∀i ∈ {1, …, n}
Ti ← [Ti|ti] ∀i ∈ {1, …, n}
Pi ← [Pi|Pi] ∀i ∈ {1, …, n}
Wi ← [Wi|wi] ∀i ∈ {1, …, n}
Xi ← Xi − tpiT ∀i ∈ {1, …, n}
If another predictive component exists, increment and return to step (1). Otherwise, end.
The keen observer will recognize the equivalence between steps (10-19) above and the procedure outlined by Westerhuis et al. for extracting MB-PLS block components from a PLS model [13]. By using the above algorithm to compute MB-OPLS models, the analyst avoids the unnecessary computation of block components during cross-validated model training. For example, a G-fold Monte Carlo cross-validation having R iterations requires the construction of RG models in order to yield R cross-validated response matrix estimates. In each of these RG models, MB-PLS requires 2Nn additional floating-point multiplications (per power iteration) over PLS. In addition, computation of multiblock components from single-block models ensures greater stability of super scores and loadings, especially in cases of missing data [13].
3. Datasets
Two datasets will be described to illustrate how MB-OPLS effectively integrates an OSC filter into an MB-PLS decomposition of a set of n matrices. The first synthetic dataset contrasts the mixing of predictive information in MB-PLS with its separation in MB-OPLS using a contrived three-block regression example similar to that introduced by Löfstedt and Trygg [16]. The second dataset, a joint set of nuclear magnetic resonance (NMR) and mass spectrometry (MS) observations [22, 23], is used to demonstrate the enhanced interpretability of MB-OPLS models over MB-PLS in a real example of discriminant analysis. All modeling and validation wereperformed using routines available in the MVAPACK chemometrics toolbox (http://bionmr.unl.edu/mvapack.php) [24].
3.1. Synthetic Example
In the first dataset, three matrices (all having 100 rows and 200 columns) were constructed to hold one y-predictive component (tpiT) and one y-orthogonal component (topo,iT). The score vectors were non-overlapping (orthogonal) Gaussian density functions, and all block loading vectors were mutually overlapping Gaussian density or square step functions. The true synthetic block loadings are illustrated in Figure 1A. A two-component MB-PLS-R regression model was trained on the synthetic three-block example dataset, as well as a 1+1 (one predictive, one orthogonal) component MB-OPLS-R regression model. Block loadings extracted by MB-PLS-R and MB-OPLS-R are shown in Figures 1B and 1C, respectively.
Figure 1.
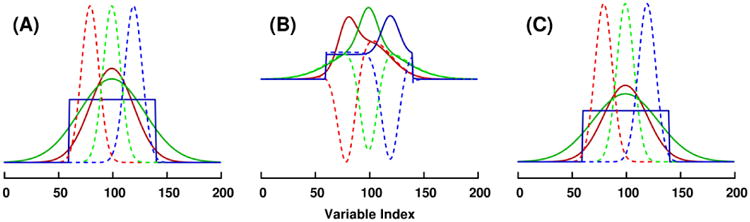
Block loadings in the synthetic multiblock example dataset. (A) True predictive loadings (solid) and orthogonal loadings (dashed) used to construct the three-block dataset. First, second and third block loadings are colored in red, green and blue, respectively. (B) First component (solid) and second component (dashed) loadings identified by MB-PLS modeling of the three data blocks. (C) Predictive (solid) and orthogonal (dashed) block loadings identified by MB-OPLS, illustrating the separation of y-uncorrelated variation accomplished by the integrated OSC filter.
3.2. Joint 1H NMR and DI-ESI-MS Datasets
The second dataset is a pair of processed and treated data matrices, collected on 29 samples of metabolite extracts from human dopaminergic neuroblastoma cells treated with various neurotoxic agents [23]. The first matrix, collected using 1H NMR spectroscopy, contains 16,138 columns and the second, collected using direct injection electrospray ionization mass spectrometry (DI-ESI-MS), contains 2,095 columns. Prior to all modeling, block weighting was applied after Pareto scaling to ensure equal contribution of each block to the models (fairness) [12].
In previously performed work, a two-component, two-class (vector-y) multiblock discriminant analysis (MB-PLS-DA) model was trained on the dataset in order to discriminate between untreated and neurotoxin-treated cell samples. To highlight the improved interpretability of MB-OPLS over MB-PLS, a 1+1 MB-OPLS-DA model was trained on the data using an identical vector of class labels. Block components were extracted from an OPLS-DA model of the concatenated matrix X = [XNMR|XMS] using the above algorithm. For both models, fifty rounds of Monte Carlo seven-fold cross-validation [25, 26] were performed to compute per-component Q2 statistics [3], in addition to the R2 statistics available from model training. CV-ANOVA significance testing was also applied to further assess model reliability [27].
4. Results and Discussion
In both the contrived dataset and the real spectroscopic dataset, the interpretative advantage offered by MB-OPLS over MB-PLS is strikingly apparent. In the synthetic example, MB-OPLS capably identifies the true predictive and orthogonal loadings in the presence of y-orthogonal variation that clouds the interpretation of MB-PLS loadings (Figure 1). By design, this comparison between MB-OPLS and MB-PLS is highly similar to the first example presented by Löfstedt and Trygg to compare nPLS and OnPLS for general data discovery [16]. However, as is evidenced by the differences between equations (3) and (7) above, MB-OPLS solves an inherently distinct problem from OnPLS: the identification of consensus variation in multiple blocks of data that predicts a single set of responses.
The ability of MB-OPLS to separate predictive and orthogonal variation from multiple data matrices is further exemplified in the discriminant analysis of the real spectroscopic dataset. From the rotated discrimination axis in the MB-PLS-DA scores (Figure 2A), it is clear that predictive and orthogonal variation have become mixed in the corresponding block loadings (Figure 3). Integration of an OSC filter into the multiblock model in the form of MB-OPLS-DA achieves the expected rotation of super scores to place more predictive variation into the first component (Figure 2B). As a consequence of this rotation, spectral information that separates paraquat treatment from other neurotoxin treatments is also moved into the orthogonal component. For example, strong loadings from citrate in the 1H NMR MB-PLS block loadings (Figure 3A, 2.6 ppm) are substantially diminished in the predictive block loadings from MB-OPLS (Figure 4), as separation between paraquat and other treatments has been isolated along the orthogonal component in super scores. Inspection of the orthogonal block loadings from MB-OPLS (Supplementary Figure S-4) will reveal, as expected, that citrate contributes more to separation between neurotoxin treatments than to separation between treatments and controls. Similar patterns were observed in the DI-ESI-MS block loadings at m/z 203.058 and 233.067, which were assigned via accurate mass and tandem MS measurements as sodium adducts of hexose and heptose, respectively [23]. These results agree with detailed prior analyses of pairwise MB-PLS-DA models between each drug treatment and untreated cells, which indicate that paraquat treatment uniquely alters metabolic flux through glycolysis and the pentose phosphate pathway [22]. In contrast to the multiple MB-PLS-DA models employed by Lei et al. to arrive at this conclusion [22], the MB-OPLS-DA model has provided the same set of core results in a single, substantially more interpretable model.
Figure 2.
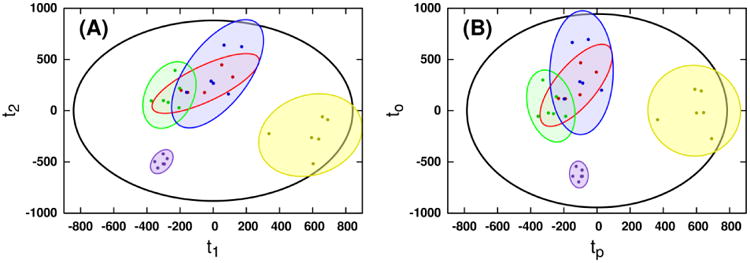
Super scores identified by (A) MB-PLS and (B) MB-OPLS modeling of the joint 1H NMR and DI-ESI-MS data matrices. Extraction of y-orthogonal variation from the first PLS component is clear in the MB-OPLS scores. Ellipses represent the 95% confidence regions for each sub-class of observations, assuming normal distributions. Colors indicate membership to the untreated (yellow), 6-hydroxydopamine (red), 1-methyl-4-phenylpyridinium (green) and paraquat (violet) sub-classes. Cross-validated super scores for each model are shown in Supplementary Figure S-1. Block scores for each model are shown in Supplementary Figures S-2 and S-3.
Figure 3.
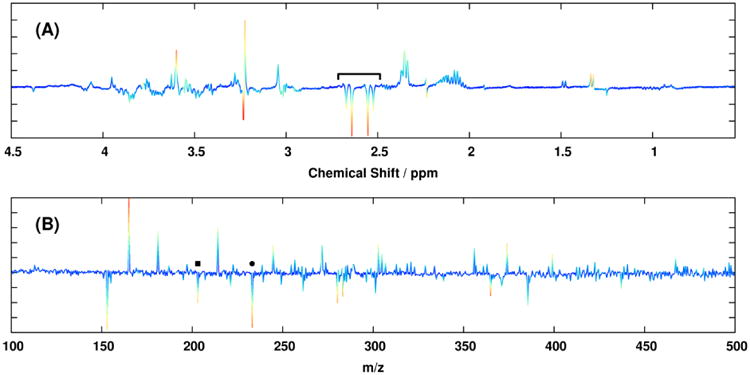
Backscaled first-component block loadings from the MB-PLS model of the (A) 1H NMR and (B) DI-ESI-MS data matrices. Coloring of each loading vector ranges from blue to red based on the amount of point-wise weighting applied during Pareto scaling. It is important to note that a second PLS component exists in the MB-PLS model that is not shown. Spectral contributions from citrate in the 1H NMR MB-PLS block loadings (2.6 ppm) are indicated by a bracket, and contributions from hexose and heptose in the DI-ESI-MS loadings are indicated by black squares and circles, respectively.
Figure 4.
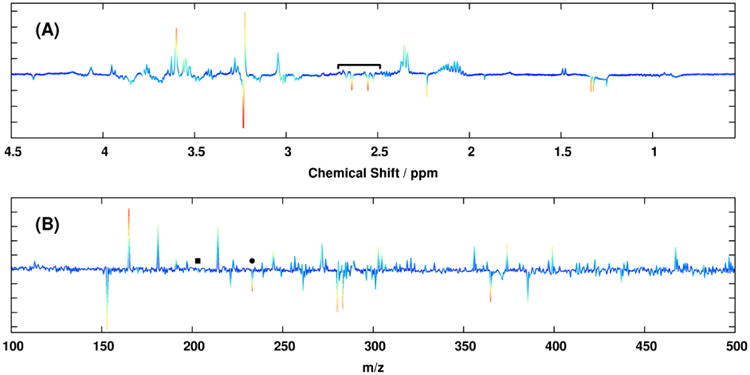
Backscaled first-component block loadings from the MB-OPLS model of the (A) 1H NMR and (B) DI-ESI-MS data matrices. Coloring of each loading vector is identical to that of Figure 3. Spectral contributions from citrate in the 1H NMR MB-OPLS block loadings (2.6 ppm) are indicated by a bracket, and contributions from hexose and heptose in the DI-ESI-MS loadings are indicated by black squares and circles, respectively. Unlike the two-component MB-PLS model, the single predictive MB-OPLS component here fully separates observations between the classes under discrimination. Backscaled orthogonal block loadings from the same model are shown in Supplementary Figure S-4.
The partial correlation of both predictive and orthogonal block scores in MB-OPLS is readily observed in the comparison of block scores from MB-PLS and MB-OPLS (Supplementary Figures S-2 and S-3). While the super scores in Figure 2B are rotated to separate predictive and orthogonal variation, block scores in Figures S-2B and S-3B have rotated back into alignment with the MB-PLS block scores. This partial correlation and re-mixing of predictive and orthogonal variation in MB-OPLS block scores is a consequence of the use of super score deflation in the proposed algorithm. When all matrices contain similar patterns of orthogonal variation, their MB-OPLS block scores will reflect this by retaining the OSC-induced rotation captured at the consensus level by the super scores. However, because the interpretative advantage of MB-OPLS over MB-PLS lies in the relationship between super scores and block loadings, the fact that orthogonal block scores have partial y-correlation is relatively benign.
Because the MB-OPLS-DA model of the real spectral data matrices was trained using the single-block OPLS routine already present in MVAPACK, all readily available cross-validation metrics were available in the model without further computational expenditure. Monte Carlo cross-validation of the MB-PLS model produced cumulative R2Y and Q2 statistics of 0.903 and 0.819±0.024, respectively, and validation of the MB-OPLS model resulted in statistics of 0.903 and 0.736±0.021, respectively. As expected, the MB-OPLS model captured the same fraction of response variation (R2Y) as MB-PLS, reaffirming the fact that the two methods have the same predictive ability. In addition, MB-OPLS modeling yielded R2Xp and R2Xo statistics of 0.378 and 0.245 for the first block, and 0.236 and 0.083 for the second block. Monte Carlo cross-validated super scores from MB-PLS and MB-OPLS are depicted in Supplementary Figure S-1. Compared to MB-PLS scores in Figure S-1A, MB-OPLS scores (Figure S-1B) exhibit an increased uncertainty during cross-validation due to the coupled nature of predictive and orthogonal components in OPLS models. Further validation of the MB-OPLS-DA model via CV-ANOVA produced a p value equal to 2.88×10-6, indicating a sufficiently reliable model.
It is worthy of final mention that the objective solved by MB-OPLS is but a single member of a superfamily of multiblock methods introduced in detail by Hanafi and Kiers [17]. In the first family, nPLS and OnPLS maximally capture the between-matrix covariances before and after orthogonal signal correction, respectively, and thus serve to regress a set of matrices against each other. Methods in the second family capture both within-matrix variances and between-matrix covariances of a set of matrices (CPCA-W), a set of response-weighted matrices (MB-PLS), and a set of response-weighted OSC-filtered matrices (MB-OPLS). By casting these methods in the light of MAXDIFF and MAXBET, we obtain an informative picture of their characteristics, commonalities, and differences. For example, nPLS and OnPLS force an equal contribution of each matrix to the solution through the constraint ‖wi‖ = 1, while CPCA-W, MB-PLS and MB-OPLS allow contributions to float based on the “importance” of each matrix to the modeling problem at hand. This super weight approach necessitates a block scaling procedure to avoid highly weighting any given matrix due to size alone [12, 13].
5. Conclusions
The MB-OPLS method proposed here is a versatile extension of MB-PLS to include an OSC filter, and belongs to a family of MAXBET optimizers that share an equivalence with their single-block factorizations (Supplementary Figure S-5). By removing consensus response-uncorrelated variation from a set of n data matrices, MB-OPLS expands the scope and benefits of OPLS to cases where blocking information is available. The ability of MB-OPLS to separate predictive and orthogonal variation from multiple blocks of data has been demonstrated on both synthetic and real spectral data, both in cases of vector-y regression and discriminant analysis. Of course, while both examples were interpreted in the light of spectroscopic datasets like those used in metabolomics [22, 23], MB-OPLS is a fully general algorithm that admits any multiblock dataset for the purposes of regression or discriminant analysis. For example, recent applications of MB-PLS for investigating food spoilage [28], iron-ore content [29], chemical toxicity [30], the evolution of human anatomy [31], and the assessment of cortical and muscle activity in Parkinson's disease patients [32] would benefit from our MB-OPLS algorithm. The presented algorithm admits either a vector or a matrix as responses, and is implemented in the latest version of the open-source MVAPACK chemometrics toolbox [24].
Supplementary Material
Highlights.
Extension of OPLS to multiblock modeling situations
Relationships established to other multiblock model objectives
Use of NIPALS admits simple implementation of MB-OPLS
Acknowledgments
This manuscript was supported, in part, by funds from grants R01 CA163649, P01 AI083211-06 and P30 GM103335 from the National Institutes of Health. The research was performed in facilities renovated with support from the National Institutes of Health (RR015468-01).
Footnotes
The authors declare no competing financial interest.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- 1.Andersson M. A comparison of nine PLS1 algorithms. J Chemometr. 2009;23:518–529. [Google Scholar]
- 2.Hoskuldsson A. PLS Regression Methods. J Chemometr. 1988;2:18. [Google Scholar]
- 3.Wold S, Sjostrom M, Eriksson L. PLS-regression: a basic tool of chemometrics. Chemometr Intell Lab. 2001;58:109–130. [Google Scholar]
- 4.Golub GH, Van Loan CF. Matrix computations. 3rd. Johns Hopkins University Press; Baltimore: 1996. [Google Scholar]
- 5.Lawson CL, Hanson RJ, Kincaid DR, Krogh FT. Basic Linear Algebra Subprograms for Fortran Usage. ACM Trans Math Softw. 1979;5:308–323. [Google Scholar]
- 6.Trygg J, Wold S. Orthogonal projections to latent structures (O-PLS) J Chemometr. 2002;16:119–128. [Google Scholar]
- 7.Boulet JC, Roger JM. Pretreatments by means of orthogonal projections. Chemometr Intell Lab. 2012;117:61–69. [Google Scholar]
- 8.Verron T, Sabatier R, Joffre R. Some theoretical properties of the O-PLS method. J Chemometr. 2004;18:62–68. [Google Scholar]
- 9.Wiklund S, Johansson E, Sjoestroem L, Mellerowicz EJ, Edlund U, Shockcor JP, Gottfries J, Moritz T, Trygg J. Visualization of GC/TOF-MS-Based Metabolomics Data for Identification of Biochemically Interesting Compounds Using OPLS Class Models. Anal Chem. 2008;80:115–122. doi: 10.1021/ac0713510. [DOI] [PubMed] [Google Scholar]
- 10.Wishart DS. Metabolomics: applications to food science and nutrition research. Trends Food Sci Technol. 2008;19:482–493. [Google Scholar]
- 11.Souihi N, Lindegren A, Eriksson L, Trygg J. OPLS in batch monitoring - Opens up new opportunities. Anal Chim Acta. 2015;857:28–38. doi: 10.1016/j.aca.2014.12.003. [DOI] [PubMed] [Google Scholar]
- 12.Smilde AK, Westerhuis JA, de Jong S. A framework for sequential multiblock component methods. J Chemometr. 2003;17:323–337. [Google Scholar]
- 13.Westerhuis JA, Kourti T, MacGregor JF. Analysis of multiblock and hierarchical PCA and PLS models. J Chemometr. 1998;12:301–321. [Google Scholar]
- 14.Westerhuis JA, Coenegracht PMJ. Multivariate modelling of the pharmaceutical two-step process of wet granulation and tableting with multiblock partial least squares. J Chemometr. 1997;11:379–392. [Google Scholar]
- 15.Tenberge JMF. Generalized Approaches to the Maxbet Problem and the Maxdiff Problem, with Applications to Canonical Correlations. Psychometrika. 1988;53:487–494. [Google Scholar]
- 16.Lofstedt T, Trygg J. OnPLS-a novel multiblock method for the modelling of predictive and orthogonal variation. J Chemometr. 2011;25:441–455. [Google Scholar]
- 17.Hanafi M, Kiers HAL. Analysis of K sets of data, with differential emphasis on agreement between and within sets. Comput Stat Data An. 2006;51:1491–1508. [Google Scholar]
- 18.Löfstedt T. Chemistry. Umea University; Umea, Sweden: 2012. OnPLS: Orthogonal projections to latent structures in multiblock and path model data analysis; p. 76. [Google Scholar]
- 19.Lofstedt T, Eriksson L, Wormbs G, Trygg J. Bi-modal OnPLS. J Chemometr. 2012;26:236–245. [Google Scholar]
- 20.Lofstedt T, Hanafi M, Mazerolles G, Trygg J. OnPLS path modelling. Chemometr Intell Lab. 2012;118:139–149. [Google Scholar]
- 21.Lostedt T, Hoffman D, Trygg J. Global, local and unique decompositions in OnPLS for multiblock data analysis. Anal Chim Acta. 2013;791:13–24. doi: 10.1016/j.aca.2013.06.026. [DOI] [PubMed] [Google Scholar]
- 22.Lei S, Zavala-Flores L, Garcia-Garcia A, Nandakumar R, Huang Y, Madayiputhiya N, Stanton RC, Dodds ED, Powers R, Franco R. Alterations in Energy/Redox Metabolism Induced by Mitochondrial and Environmental Toxins: A Specific Role for Glucose-6-Phosphate-Dehydrogenase and the Pentose Phosphate Pathway in Paraquat Toxicity. Acs Chem Biol. 2014;9:2032–2048. doi: 10.1021/cb400894a. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Marshall DD, Lei SL, Worley B, Huang YT, Garcia-Garcia A, Franco R, Dodds ED, Powers R. Combining DI-ESI-MS and NMR datasets for metabolic profiling. Metabolomics. 2015;11:391–402. doi: 10.1007/s11306-014-0704-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Worley B, Powers R. MVAPACK: A Complete Data Handling Package for NMR Metabolomics. Acs Chem Biol. 2014;9:1138–1144. doi: 10.1021/cb4008937. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Shao J. Linear-Model Selection by Cross-Validation. J Am Stat Assoc. 1993;88:486–494. [Google Scholar]
- 26.Xu QS, Liang YZ. Monte Carlo cross validation. Chemometr Intell Lab. 2001;56:1–11. [Google Scholar]
- 27.Eriksson L, Trygg J, Wold S. CV-ANOVA for significance testing of PLS and OPLS (R) models. J Chemometr. 2008;22:594–600. [Google Scholar]
- 28.Xu Y, Correa E, Goodacre R. Integrating multiple analytical platforms and chemometrics for comprehensive metabolic profiling: application to meat spoilage detection. Anal Bioanal Chem. 2013;405:5063–5074. doi: 10.1007/s00216-013-6884-3. [DOI] [PubMed] [Google Scholar]
- 29.Yaroshchyk P, Death DL, Spencer SJ. Comparison of principal components regression, partial least squares regression, multi-block partial least squares regression, and serial partial least squares regression algorithms for the analysis of Fe in iron ore using LIBS. J Anal At Spectrom. 2012;27:92–98. [Google Scholar]
- 30.Zhao J, Yu S. Quantitative structure-activity relationship of organophosphate compounds based on molecular interaction fields descriptors. Environ Toxicol Pharmacol. 2013;35:228–234. doi: 10.1016/j.etap.2012.11.018. [DOI] [PubMed] [Google Scholar]
- 31.Coquerelle M, Prados-Frutos JC, Benazzi S, Bookstein FL, Senck S, Mitteroecker P, Weber GW. Infant growth patterns of the mandible in modern humans: a closer exploration of the developmental interactions between the symphyseal bone, the teeth, and the suprahyoid and tongue muscle insertion sites. J Anat. 2013;222:178–192. doi: 10.1111/joa.12008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Chiang J, Wang ZJ, McKeown MJ. A multiblock PLS model of cortico-cortical and corticomuscular interactions in Parkinson's disease. Neuroimage. 2012;63:1498–1509. doi: 10.1016/j.neuroimage.2012.08.023. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.