

Abstract
Background
Parameter estimation represents one of the most significant challenges in systems biology. This is because biological models commonly contain a large number of parameters among which there may be functional interrelationships, thus leading to the problem of non-identifiability. Although identifiability analysis has been extensively studied by analytical as well as numerical approaches, systematic methods for remedying practically non-identifiable models have rarely been investigated.
Results
We propose a simple method for identifying pairwise correlations and higher order interrelationships of parameters in partially observed linear dynamic models. This is made by derivation of the output sensitivity matrix and analysis of the linear dependencies of its columns. Consequently, analytical relations between the identifiability of the model parameters and the initial conditions as well as the input functions can be achieved. In the case of structural non-identifiability, identifiable combinations can be obtained by solving the resulting homogenous linear equations. In the case of practical non-identifiability, experiment conditions (i.e. initial condition and constant control signals) can be provided which are necessary for remedying the non-identifiability and unique parameter estimation. It is noted that the approach does not consider noisy data. In this way, the practical non-identifiability issue, which is popular for linear biological models, can be remedied. Several linear compartment models including an insulin receptor dynamics model are taken to illustrate the application of the proposed approach.
Conclusions
Both structural and practical identifiability of partially observed linear dynamic models can be clarified by the proposed method. The result of this method provides important information for experimental design to remedy the practical non-identifiability if applicable. The derivation of the method is straightforward and thus the algorithm can be easily implemented into a software packet.
Electronic supplementary material
The online version of this article (doi:10.1186/s12918-015-0234-3) contains supplementary material, which is available to authorized users.
Keywords: Linear model, Parameter estimation, Identifiability analysis, Parameter correlation, Remedy of non-identifiability, Experimental design
Background
Model-based analysis and synthesis become increasingly important in systems biology [1–4]. However, a significant obstacle to effective model-based studies comes from the fact that it is highly difficult to achieve the values of model parameters. A straightforward way to address this issue is to fit the model to the measured data by proper experimental design [5–7]. Nevertheless, such a fitting may usually fail, even for quite simple models, because some parameters in the model can be non-identifiable.
There are two major reasons for model non-identifiability. On the one hand, many biological models contain a large number of parameters to be estimated, among which some parameters may have functional interrelationships. This is largely because of the model structure when considering compound reaction networks [8–10]. More important is that biologists experiment with living cells and therefore the possibilities to stimulate the cells are limited, i.e. the control signals and the initial condition cannot be chosen at will. This limitation leads to challenges in parameter estimation [11–13], in particular, the model can be non-identifiable, which is the concern of this paper.
As a consequence, the effect of one parameter will compensate that of another. These parameters are correlated each other and therefore non-identifiable [14, 15]. On the other hand, because of limiting experimental facility, the measured data for parameter estimation are incomplete; in particular, in many cases only a part of the variables in the model can be measured. The input-output relations of a partially observed model may become highly complicated and lead to implicit parameter correlations, even if the model structure itself contains no functional relationships between the parameters [16, 17].
The existence of parameter correlations will lead to enormous difficulties in estimating the model parameters. As a consequence, the parameters cannot be correctly constrained, the landscape of the predicting errors is quite flat, and the sensitivities of the resulting parameters are sloppy [18–20]. Therefore, identifiability analysis presents a very important and necessary task before performing parameter estimation. Although identifiability analysis of biological models has been extensively investigated in the past, the issue is far from being satisfactorily addressed [21–23].
In general, non-identifiable parameters in a model can be classified into structurally and practically non-identifiable parameters. Structurally non-identifiable parameters are those which cannot be estimated based on any measurement data with any quality and quantity, since the parameter correlations in effect are independent of the experimental condition. In contrast, the interrelationships of practically non-identifiable parameters are either due to a partial observation or due to inaccurate data [16]. As a result, it is possible to uniquely estimate the parameters based on datasets generated in experimental design by properly determining the experimental condition and improving the quality of the measurement. In this way, the non-identifiability of the model can be remedied. The “practical identifiability” in this paper means the case in which a non-identifiable model becomes identifiable if the initial condition and control signals are properly selected and meanwhile if the measured datasets are noise-free. Thus this provides a necessary condition for a practically identifiable model, i.e. even if this condition is satisfied, the model can be non-identifiable because of noisy data.
Therefore, the aim of identifiability analysis should be not only to figure out the structural and/or practical identifiability of the model but also, most importantly, to find the dependences of the identifiability on experimental conditions, so that proper experiments can be designed to remedy the non-identifiability when indicated. In particular, the impact of control signals and the initial condition of the identifiability has rarely been emphasized in the previous studies.
Linear ordinary differential equations (ODEs) are widely used to describe biological systems [24]. Many studies on identifiability analysis of linear dynamic models have been made and, in particular, methods for determining the structural identifiability have been developed for partially observed models [24–29]. The Laplace transformation methods were used for identifiability analysis of linear models [30, 31], but these studies did not consider parameter correlations based on analyzing the output sensitivity matrix. Another aspect in this area is the detection of explicit identifiable combinations of non-identifiable parameters which can help for model reparameterization [32–35]. More recently, identifiability conditions of fully observed linear models from one single dataset were presented; these conditions are related to the initial conditions of the system [36].
Using differential algebra, a priori methods were proposed to analyze structural identifiability of linear and nonlinear biological models without any requirement of measurements [33–35, 37–40], based on which effective software tools have been established [35, 41, 42]. In [43] it was pointed out that problems can arise by using differential algebra methods in testing the identifiability of systems started at some special initial conditions. However, from the previous studies for structural identifiability there are no suitable measures developed for remedying existing non-identifiability of a model. As a consequence, the accessible software tools will fail to run when unexpected but meaningful initial conditions and/or controls are provided, even for very simple linear models [35].
The measured data are always associated with noisiness and limitation of the number of sampling points which also make model parameters non-identifiable [8, 16]. Therefore, a posteriori methods detect the identifiability of a model by numerically solving the fitting problem based on available data [16, 17, 44, 45]. Using the method of profile likelihood, it is possible to find pairwise functional relations of the non-identifiable parameters if the corresponding manifold is one-dimensional [16]. Since the initial concentrations can be regarded as parameters to be estimated, the relation of the non-identifiability to the initial condition can be numerically characterized. As a result, the non-identifiability due to correlations can be remedied by means of defining proper initial conditions.
In a recent study [15], we proposed a method that is able to analytically identify both pairwise parameter correlations and higher order interrelationships among parameters in nonlinear dynamic models. Correlations are interpreted as surfaces in the subspaces of correlated parameters. Explicit relations between the parameter correlations and the control signals can be derived by simply analyzing the sensitivity matrix of the right-hand side of the model equations. Based on the correlation information obtained in this way both structural and practical non-identifiability can be clarified. The result of this correlation analysis provides a necessary condition for experimental design for the control signals in order to acquire suitable measurement data for unique parameter estimation. However, this method can only identify parameter correlations in fully observed models, i.e. it is required that all state variables be measurable, thus leading to limited applications of this method.
In this paper, we propose a simple method which can be used for identifying pairwise and higher order parameter correlations in partially observed linear dynamic models. An idealized measurement (i.e. noise-free and continuous data) is assumed in this study. It means that we derive the necessary condition of identifiable systems when such data are available. Unlike previous approaches, explicit relations of the identifiability to initial condition and control functions can be found by our method, thus providing a useful guidance for experimental design for remedying the non-identifiability if available. Our basic idea is to derive the output sensitivity matrix and detect the linear dependences of its columns, which can be simply made by using the Laplace transformation and then solving a set of homogenous linear equations. The computations are quite straightforward and thus can be easily implemented into a software packet.
For parameter estimation, different species (substances) measured from experiment leads to different output equations, due to which the model parameters may be non-identifiable. Therefore, prior to the experiment for data acquisition, it is important to analyze the identifiability of the parameters, when some certain species will be measured. The method presented in this paper can be used for a priori identifiability analysis. In this way, the question which species should be measured, so that unique parameter estimation will be achieved, can be answered. Thus, this is important for experimental design.
Both structural and practical non-identifiability can be addressed by using the proposed method. In the case of structural non-identifiability, the identifiable parameter combinations can be determined, while, in the case of practical non-identifiability, this method can provide suggestions for experimental design (i.e. initial condition, constant control signals, and noise-free datasets) so as to remedy the non-identifiability. Five linear compartmental models including an insulin receptor dynamics model are taken to demonstrate the effectiveness of our approach.
Methods
Output sensitivity matrix
In this paper, we consider general time-invariant linear state space models described as
| 1 |
| 2 |
where Eq. (1) and Eq. (2) are state and output equations in which are state, control and output vectors, respectively. x0 is the initial state vector. For the purpose of parameter estimation, the controls u and the initial condition x0 are regarded as being defined by experimental design.
The outputs y are considered as variables with available datasets (time courses) measured from experiment. In many situations, due to limiting experimental facility, only part of the state variables can be measured, i.e. ny < nx, which means that the model is partially observed. If, in the particular situation, ny = nx, the model is called fully observed. Similarly, the initial state vector x0 may also be partially or fully observed, depending on the measurement facility. In the following, it will be seen that the impact of the availability of partial or full observations of x and/or x0 are significant on the parameter correlations and thus the identifiability of the model under consideration.
It should be noted that, in the case of an observable system, the state profiles can be uniquely reconstructed even if ny < nx. However, such a reconstruction can be made by different value sets of the parameters if there is a parameter correlation. This is due to the fact that the observability of a system depends only on the matrixes A and C, but the identifiability depends not only on A and C but also on the control signal and initial condition.
In Eq. (1) and Eq. (2), are constant matrices with appropriate dimensions which contain nA, nB, nC, nD parameters denoted in the vector form , respectively. Then the vector of the whole parameters to be estimated is
| 3 |
It is noted that the corresponding vectors in pT will fall out, when one or more matrices among (A, B, C, D) contains no parameters to be estimated. To estimate the model parameters, one needs at first to check their identifiability. Here we address this issue by identifying correlations among the parameters. To do this, it is necessary to analyze the linear dependencies of the columns of the output sensitivity matrix
| 4 |
where are the matrices of the output sensitivities to the parameters in (A, B, C, D), respectively. Thus the output sensitivity matrix has ny rows and np = nA + nB + nC + nD columns. The necessary condition of completely identifiable parameters of the model is that the columns of this matrix are linearly independent.
Solving the state Eq. (1) in the Laplace form we have
| 5 |
where is an identity matrix. It follows from the output equation Eq. (2)
| 6 |
From Eq. (6), it is straightforward to achieve the output sensitivities in the Laplace form
| 7 |
where , , and are partial derivative matrices with , , and , in which the corresponding elements are linear to the elements of X(s) and U(s), respectively. Therefore, the output sensitivity matrix Eq. (4) can be written as
| 8 |
According to Eq. (5) and Eq. (7), the elements in the output sensitivity matrix Eq. (8) are functions of the parameters in the matrices A, B, C, D, the elements of the input vector U(s) and of the initial condition vector x0. In this way, explicit relationships of parameter sensitivities with the controls and the initial condition can be achieved, base on which both structural and practical identifiability issues can be addressed.
It is noted that in most previous studies on identifiability analysis of linear models only parameters in the matrix A were considered as being estimated. In this case, MB = 0, MC = 0, MD = 0 and thus only the first term in Eq. (8) remains, i.e.
| 9 |
Moreover, in the case of y = x, then Eq. (9) reduces to
| 10 |
Therefore, the parameter correlations can be determined easily by checking the linear dependencies of the columns of MA(X(s)). The identification of parameter correlations in the case of y = x was in detail discussed in [15].
Identification of parameter correlations
To identify the correlations among the parameters, it is necessary to analyze the linear dependencies of the output sensitivity matrix Eq. (8) which can be expressed as (see Additional file 1)
| 11 |
where Δ = det(sI − A) and
| 12 |
In Eq. (12), each of the elements qi,j(s), (i = 1, ⋯, ny, j = 1, ⋯, np) is a polynomial with the indeterminate s. As mentioned above, the coefficients of these polynomials will be functions of the parameters in pA, pB, pC, pD, the elements in the input vector U(s) and in the initial condition vector x0. It can be shown from Additional file 1 that the highest order of the polynomials in the 4 matrices in Eq. (12) will be 2(nx − 1), 2nx − 1, 2nx − 1, 2nx, respectively. Based on Eq. (12), Eq. (11) can be rewritten as
| 13 |
where are the columns of the matrices in Eq. (12). To check the linear dependencies of the columns in Eq. (13), we introduce a vector and let
| 14 |
According to Eq. (11) and Eq. (12), Eq. (14) consists of ny linear equations with respect to as unknowns. Since qj(s), (j = 1, ⋯, np) are explicitly expressed polynomials, we can reorder the terms in Eq. (14) and present it in the following polynomial form
| 15 |
where the coefficients γi,k, (k = 1, ⋯, 2nx + 1) are linear to the elements of . Since s in Eq. (15) is indeterminate, each coefficient of the polynomials in Eq. (15) should be zero, i.e.
| 16 |
where the coefficients βi,k,l, (l = 1, ⋯, np) are some functions of the model parameters, of the elements in the input vector as well as in the initial state vector. Therefore, Eq. (16) represents a set of homogeneous linear equations with as unknowns. The maximum number of the equations is ny(2nx + 1).
It is to note that the highest order of the polynomials in Eq. (15) is 2nx when all four matrices A, B, C, D contain parameters to be estimated. If the problem under consideration is not in this case, the highest order in Eq. (15) should vary accordingly. For instance, if the model has parameters only in matrix A, as described by Eq. (9), the highest order in Eq. (15) will be 2nx − 2 and thus the maximum number of the equations in Eq. (16) will be ny(2nx − 2).
In general, the solution of Eq. (16) consists of the following 2 possible cases.
-
All unknowns are zero, i.e.
17 In this case, there is no correlation relationship among the parameters. It means that all parameters in the model are identifiable and one dataset is enough to uniquely estimate them.
-
A sub-group of k unknowns αl+1 ≠ 0, αl+2 ≠ 0,⋯, αl + k ≠ 0 which lead to
18 where l + k ≤ np. This means that the corresponding k parameters (pl+1,⋯, pl+k) are correlated in one group. If by solving Eq. (18), U(s) and x0 are cancelled, the solutions will be independent of the controls and the initial condition. Then the corresponding parameters are structurally non-identifiable. This means that the parameters cannot be estimated based on any datasets.
If a model is structurally non-identifiable, there will exist identifiable combinations of the parameters and these combinations may have one or a finite number of solutions [34, 35, 39]. Identifiable combinations are sub-groups of the correlated parameters expressing their explicit interrelationships, which can be obtained by solving the homogenous linear partial-differential equations (from Eq. (13) and Eq. (18)) based on the result of αl+1, αl+2,⋯, αl+k.
In contrast, if the solutions of Eq. (18) depend on the controls U(s) and/or the initial condition x0, the corresponding parameters are practically non-identifiable. Since Eq. (18) describes the parameter correlation based on U(s) and x0 which cause a specific dataset, using (noise-free) datasets from different controls and initial conditions, Eq. (18) can be written as19 where (r) denotes using the dataset r caused by U(r)(s) and x(r)0. In this paper, for one dataset we mean the measured output profiles caused by an initial state condition and constant control signals during the experiment. If nd datasets with different controls and/or initial conditions are used, i.e. r = 1, ⋯, nd, for the parameter estimation, the columns of the following matrix will be independent20 where . The number of datasets nd should be so selected, that the total number of equations (i.e. nd times the number of equations in Eq. (19)) is greater than k. As a result, there will be αl+1 =⋯= αl+k = 0. This means that the practical non-identifiability described as Eq. (18) is remedied. In this way, the corresponding parameters (pl+1, ⋯, pl+k) can be uniquely estimated.
In Eq. (18) and Eq. (19), the parameters are pairwise correlated if k = 2, whereas there is a higher order interrelationship among the parameters if k > 2. In a model with a large number of parameters to be estimated, there may be many sub-groups with different numbers of correlated parameters. All sub-groups can be determined by solving Eq. (16). We denote nmax as the maximum number of parameters among the sub-groups. Therefore, the number of (noise-free) datasets from different control signals and initial conditions should be equal to or larger than the number of nmax divided by the number of equations in Eq. (19), in order to remedy the practical non-identifiability of the model. The impact of control signals and the initial condition on the linear dependency of the columns in Eq. (20) is implicitly given in Eqs. (5)-(7).
In summary, the method presented above can be used to identify parameter correlations related both to control signals and to the initial condition for partially observed linear systems. This is an extension of the method proposed in [15] where the necessary conditions of parameter correlations were given only based on the model structure and a full state observation. However, the application of the method of this paper is limited due to the computations using symbolic algebra for solving Eq. (14), since symbolic algebra has its limits in the size of the problem (i.e. the number of parameters) it can solve. During this study, we have solved a series of problems with a maximum size of ten parameters with a commonly used personal computer.
Results
Example 1
A linear two-compartment model [39, 45]
| 21 |
This model describes a simple biochemical reaction network as shown in Fig. 1a. This model is partially observed and the partial observation causes structural non-identifiability. Unlike previous studies of this well-known model, the impact of the initial conditions on the identifiability is highlighted here. In this example, there are 5 parameters, i.e. pA = (p1, p2, p3, p4)T, pC = V and then we have
| 22 |
Fig. 1.
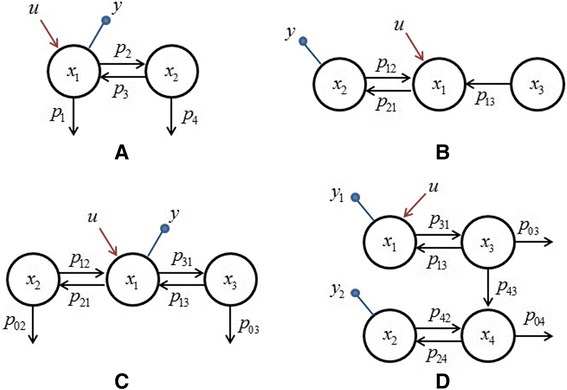
Biochemical reaction networks of the compartment models used in examples 1—4. a: 2-compartment model in example 1; b: 3-compartment model in example 2; c: 3-compartment model in example 3; d: 4-compartment model in example 4
The Laplace form of the state variables can be achieved by solving the state equations in Eq. (21)
| 23 |
where Δ = (s + p1 + p2)(s + p3 + p4) − p2p3. According to Eq. (13), the output sensitivity vector (not a matrix, since there is only one output variable in this example) is expressed as
| 24 |
Applying the expressions of Eq. (22) to Eq. (23), it follows
| 25 |
To analyze the linear dependencies of the 5 functions in Eq. (25) we introduce 5 unknowns (α1, ⋯, α5). By using the method described in the above section (see Additional file 1), we find α5 = 0, i.e. the parameter V is uncorrelated with any other parameters and thus is uniquely identifiable. This result is trivial in fact, since V is immediately fixed if y(0) and x1(0) are known, according to the last line of Eq. (21).
It can be seen from Eq. (25) that U(s) and x10 have the same impact on the output sensitivities. Thus, to see the influence of the initial conditions on the identifiability of the 4 parameters (p1, p2, p3, p4), we let U(s) = 0 in the following analysis.
-
x10 ≠ 0, x20 = 0. The resulting output sensitivity to the individual parameters has the following relationship (see Additional file 1)
26 This means that the 4 parameters are correlated in one group and their interrelationship is independent of the value of x10 ≠ 0, i.e. they are structurally non-identifiable. By solving Eq. (26) we can find the interrelationships of the sub-groups (also called identifiable combinations) of the parameters as {p2p3, p1 + p2, p3 + p4}. This result is the same as reported in the literature [39, 45]. In this situation, it is impossible to uniquely estimate the parameters (p1, p2, p3, p4) based on any measured datasets of the output (y = x1).
-
x10 = 0, x20 ≠ 0. Solving the linear homogenous linear equations (see Additional file 1) in this case leads to α3 = 0, i.e. p3 is identifiable. And the output sensitivity to the other parameters has the following relationship
27 which means that (p1, p2, p4) are correlated in one group and thus structurally non-identifiable. It is interesting to note from Eq. (27) that the correlation relation of (p1, p2, p4) is also related to the identifiable parameter p3.
x10 ≠ 0, x20 ≠ 0. According to Eq. (25) and the Additional file 1, it can be seen that the functional relationship of the 4 parameters (p1, p2, p3, p4) depend on the initial condition (x10, x20) if both x10 ≠ 0 and x20 ≠ 0. In this situation, the parameters are practically non-identifiable. The 4 parameters are correlated in one group, i.e., nmax = 4, and the number of equations in the form of Eq. (19) is ny(2nx − 2) = 2. Therefore, the 4 parameters can be uniquely estimated based on fitting the model to at least nd = 2 datasets (such that nd ≥ nmax/(ny(2nx − 2))) of the output (y = x1) from different initial values of x10 ≠ 0 and x20 ≠ 0, respectively.
To verify the above achieved results, we perform numerical parameter estimation by using the method developed in [46–48]. The true parameter values in the model are assumed to be p1 = 0.7, p2 = 0.7, p3 = 1.0, p4 = 0.4 and we generate noise-free output data at 100 time points by simulation. For case 1, one dataset for y is generated by x10 = 15, x20 = 0. To check the identifiable combinations {p2p3, p1 + p2, p3 + p4}, we repeat the parameter identification run by fixing p1 with a different value for each run. Figure 2 shows the relationships of the parameters after the fitting which illustrate exactly the expected function values, i.e. p2p3 = 0.7, p1 + p2 = 1.4, p3 + p4 = 1.4.
Fig. 2.
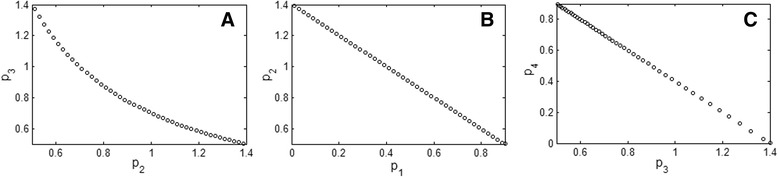
Estimation results of example 1. The identifiable combinations of the parameters are validated by repeatedly fitting the model to one dataset from the initial condition x 10 ≠ 0, x 20 = 0. The curves are from the results of 90 runs each of which with a different fixed value of p 1. a: p 2 p 3 = 0.7; b: p 1 + p 2 = 1.4; c: p 3 + p 4 = 1.4
For case 2, one dataset for y is generated by x10 = 0, x20 = 15. Indeed, only the true value of p3 = 1.0 can be identified when fitting the 4 parameters to the dataset. For case 3, we generate 2 datasets for y by x(1)10 = 15, x(2)20 = 5 and x(2)10 = 5, x(2)20 = 15, respectively. Then we fit the 4 parameters simultaneously to the 2 datasets, from which we obtain the estimated values of the parameters exactly as their true values.
Furthermore, if the model in Eq. (21) is fully observed, e.g., y1 = x1, y2 = x2, then all parameters in the model are identifiable. This can be easily seen from MA(X(s)) in Eq. (22), since its columns are linearly independent. As a result, one single dataset including the trajectories of y1 = x1, y2 = x2 is enough to uniquely estimate the parameters in the model.
Example 2
A linear three-compartment model [43]
| 28 |
The reaction network corresponding to this model is shown in Fig. 1b. This model was studied in [43] to demonstrate the failure of the identifiability test by using the differential algebra methods when x30 = 0. This can be easily recognized by using our method. Let pA = (p21, p12, p13)T, according to Eq. (13), the functions in the output sensitivity vector will be (see Additional file 1).
| 29 |
According to Eq. (14) and Eq. (15) we obtain the following 4 homogeneous linear equations (see Additional file 1)
| 30 |
It can be easily seen that if x30 = 0, then α3 will disappear from Eq. (30), i.e. α3 can be any value, which means that p13 is non-identifiable. On the contrary, if x30 ≠ 0, we have in Eq. (30) 4 linearly independent homogeneous equations with 3 unknowns and thus there should be α1 = α2 = α3 = 0, which means that all three parameters are identifiable.
Example 3
A linear three-compartment model [39]
| 31 |
The reaction network described by this model is shown in Fig. 1c. The parameters to be estimated in this model are pA = (p21, p31, p12, p13, p02, p03)T. The solution of the state equations in Eq. (31) leads to
| 32 |
Similar to Example 2 we can obtain the Laplace functions in the output sensitivity vector as follows
| 33 |
By introducing 6 unknowns (α1, ⋯, α6), the dependencies of the output sensitivities on the control and the initial condition can be derived from Eq. (32) and Eq. (33). If x20 = x30 = 0 and U(s) + x10 ≠ 0, the resulting homogeneous linear equations in the form of Eq. (16) are as follows
| 34 |
where a = p13 + p03, b = p12 + p02. It can be seen that U(s) + x10 ≠ 0 does not appear in Eq. (34). Solving the 5 equations for the 6 unknowns in Eq. (34) with respect to α1, we find
| 35 |
Thus the output sensitivities to the parameters has the following relation
| 36 |
which means that all 6 parameters are correlated in one group and their interrelationship is independent of U(s) + x10 ≠ 0. Thus the parameters in this model are structurally non-identifiable when x20 = x30 = 0. In addition, we can solve Eq. (36) to obtain its local solutions as {p02 + p12, p03 + p13, p21 + p31, p12p21, p13p31} as well as its global solutions as
| 37 |
which are the identifiable combinations of the parameters, as given in [39]. To verify these parameter relations, numerical parameter estimation is carried out by assuming p02 = 2, p12 = 3, p03 = 3, p13 = 0.4, p21 = 1, p31 = 2 as the true values of the parameters. A dataset for y containing 400 sampling points in the time period [0, 2] is generated by x10 = x20 = x30 = 0, u(t) = 25. Then we repeatedly fit the parameters to the dataset, except for p21 which is fixed with different values in the range [0.7, 1.5]. The estimation results are shown in Fig. 3, exactly validating the global solutions expressed as Eq. (37).
Fig. 3.
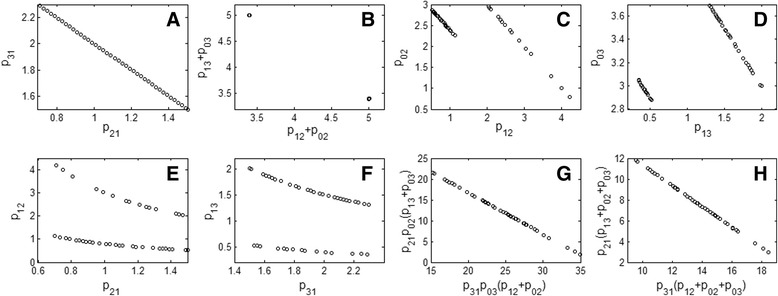
Estimation results of example 3. The identifiable combinations of the parameters are validated by repeatedly fitting the model to one dataset from x 10 = x 20 = x 30 = 0, u(t) = 25. The curves are from the results of 82 runs each of which with a different fixed value of p 21. a: p 21 + p 31 = 3.0; b: The relationship between p 02 + p 12 and p 03 + p 13; c: The relationship between p 02 and p 12; d: The relationship between p 03 and p 13; e: The relationship between p 12 and p 21; f: The relationship between p 13 and p 31; g: p 03 p 31(p 02 + p 12) + p 02 p 21(p 03 + p 13) = 36.8; h: p 31(p 02 + p 12 + p 03) + p 21(p 03 + p 13 + p 02) = 21.4
It can be seen from Fig. 3a that the relationship between p21 and p31 is indeed a straight line, namely p21 + p31 = 3.0. From Fig. 3b, it is interesting to see that the relationship between p02 + p12 and p03 + p13 is shown by two separate points. This is because both their summation and their product are constant, as indicated in φ2, φ3 of Eq. (37). This special property leads to the fact that both p02 + p12 and p03 + p13 have two solutions, i.e., there are two lines to represent the relationship of p02 + p12 as well as p03 + p13, respectively, as shown in Fig. 3c and d. Correspondingly, the relationship of p12p21as well as p13p31 is also twofold, as shown in Fig. 3e and f, respectively. The estimated results corresponding to the last two identifiable combinations in Eq. (37) are shown in Fig. 3g and h.
To remedy the non-identifiability, let x20 ≠ 0, x30 ≠ 0, then similar to Eq. (34), there will be 5 linear equations with respect to (α1, ⋯, α6). This means that the 6 parameters are correlated in one group, i.e., nmax = 6. Since the correlation relationships now depend on U(s) + x10 ≠ 0 and x20 ≠ 0, x30 ≠ 0, the parameters are practically identifiable. The number of equations in the form of Eq. (19) is ny(2nx − 2) = 4. As a result, 2 datasets with different values of U(s) + x10 ≠ 0 and x20 ≠ 0, x30 ≠ 0 are needed to uniquely estimate the parameters of the model.
Example 4
A linear four-compartment model [33, 39]
| 38 |
Figure 1d shows the biochemical reaction network of this model. In this model, there are 7 parameters pA = (p31, p13, p42, p24, p43, p03, p04)T and 4 state variables among which two are output variables. In the case of u ≠ 0, x10 = x20 = x30 = x40 = 0, the parameters are structurally non-identifiable where the identifiable combinations of the correlated parameters are expressed as {p31, p13, p04p42, p24p43, p03 + p43, p24 + p42 + p04} [33, 39]. The same results of the identifiable combinations are obtained by using our method which is much simpler to deal with, as described in the following.
From Eq. (38), we have
| 39 |
and
| 40 |
Since in this example we have two output variables, to determine the parameter correlations we have to consider
| 41 |
where the output sensitivities are expressed in the following form (see Additional file 1)
| 42 |
It can be clearly seen from the first two columns of Eq. (41) and Eq. (42) that α1 = α2 = 0, which means that p31, p13 are uniquely identifiable. From the 5th and 6th columns of the first row in Eq. (42) we have α5 + α6 = 0 , i.e.
| 43 |
Thus p43, p03 are pairwise correlated. Furthermore, based on the second row of Eq. (41) and Eq. (42) the following results can be obtained (see Additional file 1):
| 44 |
| 45 |
Eq. (43)–Eq. (45) indicate that there exist 3 separate correlation groups in this example. The maximum number of parameters among the groups is 3. The (local) solutions of these 3 equations lead to the identifiable combinations of the parameters in the form of p43 + p03, p24p43, p42p04 and p42 + p04 + p24, respectively, beside the two identifiable parameters p31, p13.
To numerically verify the results, p31 = 3.0, p13 = 5.5, p03 = 1.0, p04 = 0.7, p24 = 3.5, p42 = 3.0, p43 = 4.0 are used as the true values of the parameters. One noise-free dataset for y1, y2 is generated by x10 = x20 = x30 = x40 = 0 and u = 5.0 through simulation. Then we repeatedly fit the parameters to the dataset, except for p43 which is fixed with a different value for each run of the fitting. As expected, p31, p13 are always at their true values after each run, whereas the other parameters have correlated relationships in the forms of their identifiable combinations. Figure 4 shows these relationships based on the results of 176 runs for the parameter estimation. It can be seen from Fig. 4a to d that, indeed, p43 + p03 = 5.0, p24p43 = 14.0, p42p04 = 2.1, and p42 + p04 + p24 = 7.2 are obtained by the parameter estimation.
Fig. 4.

Estimation results of example 4. The identifiable combinations of the parameters are validated by repeatedly fitting the model to one dataset from x 10 = x 20 = x 30 = x 40 = 0 and u ≠ 0. The curves are from the results of 176 runs each of which with a different fixed value of p 43. a: p 43 + p 03 = 5.0; b: p 24 p 43 = 14.0; c: p 42 p 04 = 2.1; d: p 42 + p 04 + p 24 = 7.2
Also in this example, we can consider x20 ≠ 0, x30 ≠ 0, x40 ≠ 0 for remedying the non-identifiability. Since the maximum number of correlated parameter groups is nmax = 3, the number of equations in the form of Eq. (19) is ny(2nx − 2) = 12. Therefore, one dataset for y1, y2 from an initial condition x10 ≠ 0, x20 ≠ 0, x30 ≠ 0, x40 ≠ 0 will be enough to uniquely estimate the 7 parameters in the model.
Example 5
Insulin receptor dynamics model [49].
Many physiological processes such as glucose uptake, lipid-, protein- and glycogen-synthesis, to name the most important, are regulated by insulin after binding to the insulin receptor. The latter is located in the cytoplasma membrane [50, 51]. The insulin receptor (IR) is a dynamic cellular macromolecule. Upon insulin binding, a series of processes follow, including endocytosis of the IR-insulin complex, endosomal processing, sequestration of ligand (insulin) from the receptor, receptor inactivation as well as receptor recycling to the cell surface [52].
In several early studies, simple models describing insulin receptor dynamics were proposed [53–57] where either a subset of the whole process was considered or a few subunits were lumped into single reaction steps. More detailed models of insulin signaling pathways were developed and simulation studies were performed in [58–60]. However, parameter values such as rate constants in these models were partially taken from literature and partially estimated through experimental data.
A general five-compartment IR dynamics model was developed in [49] and its parameters were estimated based on simultaneously fitting to the measured datasets published in [55, 61, 62]. This model describes the endosomal trafficking dynamics of hepatic insulin receptor consisting of IR autophosphorylation after receptor binding, IR endosomal internalization and trafficking, insulin dissociation from and dephosphorylation of internalized IR, and finally recycling of the insulin-free, dephosphorylated IR to the plasma membrane [49]. The state equations of the general five-compartment model are given as follows [49]
| 46 |
where the state variables denote the concentrations of the components, with x1 as unbound surface IR, x2 as bound surface IR, x3 as bound-phosphorylated surface IR, x4 as bound-phosphorylated internalized IR, and x5 as unbound internalized IR. The control variable u is considered as a constant insulin input (100 nM), while the initial condition of Eq. (46) is given as x1(0) = 100 %, and xi(0) = 0 for i ≠ 1 [49].
Since the control variable u is a constant, the nonlinear term p21u in Eq. (46) can be regarded as a parameter p′21 to be estimated. As a result, Eq. (46) becomes a linear model which can be analyzed by our method. Here, we consider three measured datasets used in [49] for parameter estimation, i.e. IR autophosphorylation from [61], IR internalization from [55], and remaining surface IR from [55]. These measured species are mixtures of the components denoted as state variables in Eq. (46), respectively, leading to the following output equations [49]
| 47 |
| 48 |
| 49 |
where y1 is the percentage of total (surface and intracellular) phosphorylated IR, y2 is the percentage of total internalized IR, y3 is the percentage of total IR on the cell surface.
We are concerned with the identifiability of the 7 parameters in Eq. (46), when one or a combination of the above output equations is used for parameter estimation. Based on our method, it is found that, when only Eq. (47) is employed as an output equation, 4 parameters (i.e. p′21, p51, p12, p32) are non-identifiable, while 3 parameters (i.e. p43, p54, p15) are identifiable. In particular, the relationship of the 4 correlated parameters is expressed as follows
| 50 |
This means that, using a dataset of IR autophosphorylation (i.e. y1 = x3 + x4), it is impossible to estimate all of the parameters of the model (even if the data are noise-free). Nevertheless, our computation results show that all of the 7 parameters are identifiable, i.e. there is no parameter correlation, when either Eq. (48) or Eq. (49) is used as an output equation. As a result, either a dataset of the IR internalization (i.e. y2 = x4 + x5) or a dataset of the remaining surface IR (i.e. y3 = x2 + x3) is enough for unique estimation of the 7 parameters of the model, when the measured data are noise-free. Obviously, unique estimation can also be achieved when a combination of the 3 output equations are used (i.e., simultaneously fitting the model to two or three datasets from [55] and [61]), as was performed in [49].
Conclusions
A partial observation of state variables usually leads to non-identifiable parameters even for pretty simple models. To address this problem, a method for identifying parameter correlations in partially observed linear dynamic models is presented in this paper. The basic idea is to derive the output sensitivity matrix and analyze the linear dependences of the columns in this matrix. Thus the method is quite simple, i.e. only the Laplace transformation and linear algebra are required to derive the results. A special feature of our method is its explicit coupling of parameter correlations to control signals and the initial condition which can be used for experimental design, so that proper (noise-free) datasets can be generated for unique parameter estimation. In this way, the practically non-identifiable parameters can be estimated. Several partially observed linear compartmental models are used to demonstrate the capability of the proposed method for identifying the parameter correlations. Results derived from our method are verified by numerical parameter estimation. The extension of this method to partially observed nonlinear models could be a future study.
Acknowledgements
We thank Dr. Sebastian Zellmer for his suggestions for improving the description of the insulin receptor dynamics model. In addition, we thank the anonymous reviewers for their comments that improved the manuscript. We acknowledge support for the Article Processing Charge by the German Research Foundation and the Open Access Publication Fund of the Technische Universität Ilmenau.
Additional file
Derivation of the sensitivity matrix and solutions of the homogeneous linear equations in example 1, 2 and 4. This file contains detailed derivations and descriptions of the methods and associated results of the examples. (PDF 190 kb)
Footnotes
Competing interests
The authors declare that they have no competing interests.
Author’s contributions
PL developed the methodology, wrote the manuscript and supervised the study. QDV wrote the software and designed the case studies. Both authors read and approved the final manuscript.
Contributor Information
Pu Li, Email: pu.li@tu-ilmenau.de.
Quoc Dong Vu, Email: quoc-dong.vu@tu-ilmenau.de.
References
- 1.O’Brien EJ, Palsson BO. Computing the functional proteome: recent progress and future prospects for genome-scale models. Curr Opin Biotech. 2015;34:125–134. doi: 10.1016/j.copbio.2014.12.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Gunawardena J. Models in biology: ‘accurate descriptions of our pathetic thinking’. BMC Biol. 2014;12:29. doi: 10.1186/1741-7007-12-29. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Bartl M, Kötzing M, Schuster S, Li P, Kaleta C. Dynamic optimization identifies optimal programmes for pathway regulation in prokaryotes. Nat Commun. 2013;4:2243. doi: 10.1038/ncomms3243. [DOI] [PubMed] [Google Scholar]
- 4.Wessely F, Bartl M, Guthke R, Li P, Schuster S, Kaleta C. Optimal regulatory strategies for metabolic pathways in Escherichia coli depending on protein costs. Mol Sys Biol. 2011;7:515. [DOI] [PMC free article] [PubMed]
- 5.Eydgahi H, Chen WW, Muhlich JL, Vitkup D, Tsitsiklis JN, Sorger PK. Properties of cell death models calibrated and compared using Bayesian approaches. Mol Sys Biol. 2013;9:644. doi: 10.1038/msb.2012.69. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Tummler K, Lubitz T, Schelker M, Klipp E. New types of experimental data shape the use of enzyme kinetics for dynamic network modeling. FEBS J. 2013;281:549–71. doi: 10.1111/febs.12525. [DOI] [PubMed] [Google Scholar]
- 7.Kreutz C, Timmer J. Systems biology: experimental design. FEBS J. 2009;276:923–942. doi: 10.1111/j.1742-4658.2008.06843.x. [DOI] [PubMed] [Google Scholar]
- 8.Bachmann J, Raue A, Schilling M, Böhm ME, Kreutz C, Kaschek D, Busch H, Gretz N, Lehmann WD, Timmer J, Klingmüller U. Division of labor by dual feedback regulators controls JAK2/STAT5 signaling over broad ligand range. Mol Sys Biol. 2011;7:516. doi: 10.1038/msb.2011.50. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Chu Y, Hahn J. Parameter selection via clustering of parameters into pairwise indistinguishable groups of parameters. Ind Eng Chem Res. 2009;48:6000–6009. doi: 10.1021/ie800432s. [DOI] [Google Scholar]
- 10.Cracium G, Pantea C. Identifiability of chemical reaction networks. J Math Chem. 2008;44:244–259. doi: 10.1007/s10910-007-9307-x. [DOI] [Google Scholar]
- 11.Wiechert W, Noack S. Mechanistic pathway modeling for industrial biotechnology: challenging but worthwhile. Curr Opin Biotech. 2011;22:604–610. doi: 10.1016/j.copbio.2011.01.001. [DOI] [PubMed] [Google Scholar]
- 12.Heijnen JJ, Verheijen PJT. Parameter identification of in vivo kinetic models: Limitations and challenges. Biotechnol J. 2013;8:768–775. doi: 10.1002/biot.201300105. [DOI] [PubMed] [Google Scholar]
- 13.Link H, Christodoulou D, Sauer U. Advancing metabolic models with kinetic information. Curr Opin Biotech. 2013;29:8–14. doi: 10.1016/j.copbio.2014.01.015. [DOI] [PubMed] [Google Scholar]
- 14.McLean KAP, McAuley KB. Mathematical modelling of chemical processes-obtaining the best model predictions and parameter estimates using identifiability and estimability procedures. Can J Chem Eng. 2012;90:351–365. doi: 10.1002/cjce.20660. [DOI] [Google Scholar]
- 15.Li P, Vu QD. Identification of parameter correlations for parameter estimation in dynamic biological models. BMC Syst Biol. 2013;7:91. doi: 10.1186/1752-0509-7-91. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Raue A, Kreutz C, Maiwald T, Bachmann J, Schilling M, Klingmüller U, Timmer J. Structural and practical identifiability analysis of partially observable dynamical models by exploiting the profile likelihood. Bioinformatics. 2009;25:1923–1929. doi: 10.1093/bioinformatics/btp358. [DOI] [PubMed] [Google Scholar]
- 17.Steiert B, Raue A, Timmer J, Kreutz C. Experimental design for parameter estimation of gene regulatory networks. PLoS ONE. 2012;7:e40052. doi: 10.1371/journal.pone.0040052. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Chen WW, Schoeberl B, Jasper PJ, Niepel M, Nielsen UB, Lauffenburger DA, Sorger PK. Input–output behavior of ErbB signaling pathways as revealed by a mass action model trained against dynamic data. Mol Sys Biol. 2009;5:239. doi: 10.1038/msb.2008.74. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Achard P, De Schutter E. Complex parameter landscape for a complex neuron model. PloS Comput Biol. 2006;2(7):94. doi: 10.1371/journal.pcbi.0020094. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Gutenkunst RN, Waterfall JJ, Casey FP, Brown KS, Myers CR, Sethna JP. Universally sloppy parameter sensitivities in systems biology models. PloS Comp Biol. 2007;3:1871–1878. doi: 10.1371/journal.pcbi.0030189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Ashyraliyev M, Fomekong-Nanfack Y, Kaandorp JA, Blom JG. Systems biology: parameter estimation for biochemical models. FEBS J. 2009;276:886–902. doi: 10.1111/j.1742-4658.2008.06844.x. [DOI] [PubMed] [Google Scholar]
- 22.Chou IC, Voit EO. Recent developments in parameter estimation and structure identification of biochemical and genomic systems. Math Biosci. 2009;219:57–83. doi: 10.1016/j.mbs.2009.03.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Villaverde AF, Banga JR. Reverse engineering and identification in systems biology: strategies, perspectives and challenges. J R Soc Interface. 2014;11(91):20130505. doi: 10.1098/rsif.2013.0505. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Lamberton TO, Condon ND, Stow JL, Hamilton NA. On linear models and parameter identifiability in experimental biological systems. J Theor Biol. 2014;358:102–121. doi: 10.1016/j.jtbi.2014.05.028. [DOI] [PubMed] [Google Scholar]
- 25.Bellman R, Aström KJ. On structural identifiability. Math Biosci. 1970;7:329–339. doi: 10.1016/0025-5564(70)90132-X. [DOI] [Google Scholar]
- 26.Audoly S, D’Angio L. On the identifiability of linear compartmental systems: a revisited transfer function approach based on topological properties. Math Biosci. 1983;66:201–228. doi: 10.1016/0025-5564(83)90089-5. [DOI] [Google Scholar]
- 27.Godfrey KR, Chapman ML. Identifiability and indistinguishability of linear compartmental models. Math Comp Simul. 1990;32:273–295. doi: 10.1016/0378-4754(90)90185-L. [DOI] [Google Scholar]
- 28.Ljung L, Glad T. On global identifiability for arbitrary model parametrizations. Automatica. 1994;39:265–376. doi: 10.1016/0005-1098(94)90029-9. [DOI] [Google Scholar]
- 29.Audoly S, D’Angio L, Saccomani MP, Cobelli C. Global identifiability of linear compartmental models – a computer algebra algorithm. IEEE Trans Biomed Eng. 1998;45:37–45. doi: 10.1109/10.650350. [DOI] [PubMed] [Google Scholar]
- 30.Godfrey KR, Jones RP, Brown RF, Norton JP. Factors Affecting the Identifiability of Compartmental Models. Automatica. 1982;18(3):285–293. doi: 10.1016/0005-1098(82)90088-7. [DOI] [Google Scholar]
- 31.Kachanov BO. Symmetric Laplace transform and its application to parametric identification of linear systems. Automat Rem Contr. 2009;70(8):1309–1316. doi: 10.1134/S0005117909080049. [DOI] [Google Scholar]
- 32.Meshkat N, Sullivant S. Identifiable reparametrizations of linear compartment models. J Symbol Comp. 2014;63:46–67. doi: 10.1016/j.jsc.2013.11.002. [DOI] [Google Scholar]
- 33.Evans ND, Chappell MJ. Extensions to a procedure for generating locally identifiable reparameterisations of unidentifiable systems. Math Biosci. 2000;168:137–159. doi: 10.1016/S0025-5564(00)00047-X. [DOI] [PubMed] [Google Scholar]
- 34.Eisenberg MC, Hayashi MAL. Determining identifiable parameter combinations using subset profiling. Math Biosci. 2014;256:116–126. doi: 10.1016/j.mbs.2014.08.008. [DOI] [PubMed] [Google Scholar]
- 35.Meshkat N, Kuo CE, DiStefano J., III On finding and using identifiable parameter combinations in nonlinear dynamic systems biology models and COMBOS: a novel web implementation. PloS ONE. 2014;10:e11061. doi: 10.1371/journal.pone.0110261. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Stanhope S, Rubin JE, Swigon D. Identifiabiliy of linear and linear-in-parameters dynamical systems from a single trajectory. SIAM J App Dyn Syst. 2014;13:1792–1815. doi: 10.1137/130937913. [DOI] [Google Scholar]
- 37.Chappel MJ, Godfrey KR, Vajda S. Global identifiability of the parameters of nonlinear systems with specified inputs: a comparison of methods. Math Biosci. 1990;102:41–73. doi: 10.1016/0025-5564(90)90055-4. [DOI] [PubMed] [Google Scholar]
- 38.Chis OT, Banga JR, Balsa-Canto E. Structural identifiability of systems biology models: a critical comparison of methods. PloS ONE. 2011;6:e27755. doi: 10.1371/journal.pone.0027755. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Meshkat N, Eisenberg M, DiStefano J., III An algorithm for finding globally identifiable parameter combinations of nonlinear ODE models using Gröbner bases. Math Biosci. 2009;222:61–72. doi: 10.1016/j.mbs.2009.08.010. [DOI] [PubMed] [Google Scholar]
- 40.Cole DJ, Morgan BJT, Titterington DM. Determining the parametric structure of models. Math Biosci. 2010;228:16–30. doi: 10.1016/j.mbs.2010.08.004. [DOI] [PubMed] [Google Scholar]
- 41.Chis O, Banga JR, Balsa-Canto E. GenSSI: a software toolbox for structural identifiability analysis of biological models. Bioinformatics. 2011;27:2610–2611. doi: 10.1093/bioinformatics/btr431. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Bellu G, Saccomani MP, Audoly S, D’Angio L. DAISY: A new software tool to test global identifiability of biological and physiological systems. Comp Meth Prog Biomed. 2007;88:52–61. doi: 10.1016/j.cmpb.2007.07.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Saccomani MP, Audoly S, D’Angio L. Parameter identifiability of nonlinear systems: the role of initial conditions. Automatica. 2003;39:619–632. doi: 10.1016/S0005-1098(02)00302-3. [DOI] [Google Scholar]
- 44.Hengl S, Kreutz C, Timmer J, Maiwald T. Data-based identifiability analysis of nonlinear dynamical models. Bioinformatics. 2007;23:2612–2618. doi: 10.1093/bioinformatics/btm382. [DOI] [PubMed] [Google Scholar]
- 45.Roper R, Saccomani MP, Vicini P. Cellular signaling identifiabilities: a case study. J Theor Biol. 2010;264:528–537. doi: 10.1016/j.jtbi.2010.02.029. [DOI] [PubMed] [Google Scholar]
- 46.Faber R, Li P, Wozny G. Sequential parameter estimation for large-scale systems with multiple data sets. I: computational framework. Ind Eng Chem Res. 2003;42:5850–5860. doi: 10.1021/ie030296s. [DOI] [Google Scholar]
- 47.Zhao C, Vu QD, Li P. A quasi-sequential parameter estimation for nonlinear dynamic systems based on multiple data profiles. Korean J Chem Eng. 2013;30:269–277. doi: 10.1007/s11814-012-0158-1. [DOI] [Google Scholar]
- 48.Vu QD. Parameter estimation in complex nonlinear dynamical systems. PhD Thesis, Technische Universität Ilmenau, 2015.
- 49.Hori S, Kurland IJ, DiStenfano JJ. Role of endosomal trafficking dynamics on the regulation of hepatic insulin receptor activity: model for Fao cells. Ann Biomed Eng. 2006;34:879–892. doi: 10.1007/s10439-005-9065-5. [DOI] [PubMed] [Google Scholar]
- 50.White MF. The insulin signaling system and IRS proteins. Diabetologia. 1997;40:S2–S17. doi: 10.1007/s001250051387. [DOI] [PubMed] [Google Scholar]
- 51.Taha C, Klip A. The insulin signaling pathway. J Membrane Biol. 1999;169:1–12. doi: 10.1007/PL00005896. [DOI] [PubMed] [Google Scholar]
- 52.Knutson VP. Cellular trafficking and processing of the insulin receptor. FASEB J. 1991;5:2130–2138. doi: 10.1096/fasebj.5.8.2022311. [DOI] [PubMed] [Google Scholar]
- 53.Corin R, Donner D. Insulin receptors convert to a higher affinity state subsequent to hormone binding. A two-state model for the insulin receptor. J Biol Chem. 1982;257:104–110. [PubMed] [Google Scholar]
- 54.Standaert MJ, Pollet RJ. Equilibrium model for insulin-induced receptor down-regulation. Regulation of insulin receptors in differentiated BC3H-I myocytes. J Biol Chem. 1984;259:2346–2354. [PubMed] [Google Scholar]
- 55.Backer J, Kahn C, White MF. Tyrosine phosphorylation of the insulin receptor during insulin-stimulated internalization in rat hepatoma cells. J Biol Chem. 1989;264:1694–1701. [PubMed] [Google Scholar]
- 56.Quon MJ, Campfield L. A mathematical model and computer simulation study of insulin receptor regulation. J Theor Biol. 1991;150:59–72. doi: 10.1016/S0022-5193(05)80475-8. [DOI] [PubMed] [Google Scholar]
- 57.Wanant S, Quon MJ. Insulin receptor binding kinetics: modeling and simulation studies. J Theor Biol. 2000;205:355–364. doi: 10.1006/jtbi.2000.2069. [DOI] [PubMed] [Google Scholar]
- 58.Sedaghat AR, Sherman A, Quon MJ. A mathematical model of metabolic insulin signaling pathways. Am J Physiol Endocrinol Metab. 2002;283:E1084–E1101. doi: 10.1152/ajpendo.00571.2001. [DOI] [PubMed] [Google Scholar]
- 59.Koschorreck M, Gilles ED. Mathematical modeling and analysis of insulin clearance in vivo. BMC Syst Biol. 2008;2:43. doi: 10.1186/1752-0509-2-43. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Ho CK, Rahib L, Liao JC, Sriram G, Dipple KM. Mathematical modeling of the insulin signal transduction pathway for prediction of insulin sensitivity from expression data. Mol Gen Metab. 2015;114:66–72. doi: 10.1016/j.ymgme.2014.11.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.White MF, Haring HU, Kasuga M, Kahn CR. Kinetic properties and sites of autophosphorylation of partially purified insulin receptor from hepatoma cells. J Biol Chem. 1984;259:255–264. [PubMed] [Google Scholar]
- 62.Backer JM, Kahn CR, White MF. Tyrosine phosphorylation of the insulin receptor is not required for receptor internalization: studies in 2,4-dinitrophenol-treated cells. Proc Natl Acad Sci USA. 1989;86:3209–3213. doi: 10.1073/pnas.86.9.3209. [DOI] [PMC free article] [PubMed] [Google Scholar]