

Abstract
In 1991 Keiding published a relation between the age-specific prevalence and incidence of a chronic disease (in Age-specific incidence and prevalence: a statistical perspective. J. Roy. Stat. Soc. A, 154, 371–412). For special cases alternative formulations by differential equations were given recently in Brinks et al. (2013, Deriving age-specific incidence from prevalence with an ordinary differential equation. Statist. Med., 32, 2070–2078) and in Brinks & Landwehr (2014, Age- and time-dependent model of the prevalence of non-communicable diseases and application to dementia in Germany, Theor. Popul. Biol., 92, 62–68). From these works, we generalize formulations and discuss the advantages of the novel approach. As an implication, we obtain a new way of estimating the incidence rate of a chronic disease from prevalence data. This enables us to employ cross-sectional studies where otherwise expensive and lengthy follow-up studies are needed. This article illustrates and validates the novel method in a simulation study about dementia in Germany.
Keywords: incidence, prevalence, mortality, compartment models, chronic diseases, dementia
1. Introduction
One of the objectives of epidemiology is the description of health-related states and events in populations. To achieve this objective, incidence and prevalence are important quantitative concepts. Incidence refers to the occurrence of new cases in a specific health-related state during a time period, whereas prevalence measures the proportion of subjects who are in the state at a point in time. Both measures are fundamental in epidemiological research.
For analysing quantitative aspects of infectious diseases, state models (synonymously: compartment models) are widely used and have a history going back at least to the 1920s (see, for example, Brauer, 2005). With respect to chronic diseases, compartment models are less common and have appeared later (Fix & Neyman, 1951). The infrequent use of mathematical models in this field is in contrast to the tremendous worldwide burden of chronic diseases. For example, two-thirds of all global cases of death in 2010 have been attributed to chronic diseases (Lozano, 2012). Hence, we feel the urgent need to contribute to the mathematical understanding of the worldwide epidemics of chronic diseases.
A typical model in the epidemiology of chronic diseases considers a population in three states: healthy (H), diseased (I) and dead (D) (Keiding, 1991). Subjects of the population may undergo irreversible transitions between these states as shown in Fig. 1. The transition rates are the incidence 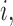 and the mortalities
and the mortalities 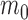 and
and 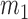 of the healthy and the diseased subjects, respectively.
of the healthy and the diseased subjects, respectively.
Fig. 1.
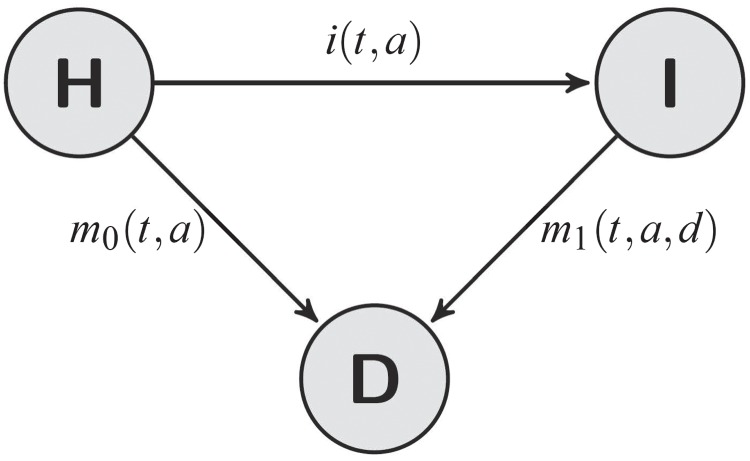
Compartment model with three states and transition rates depending on different time scales: calendar time 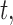 age
age 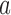 and duration
and duration 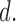
In many situations, it is important to keep track of different time scales (Keiding, 2006). Mortality, for instance, crucially depends on the age of the subjects, but also on secular progress in hygiene, nutrition and medical care. Hence, the rates 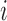 and
and 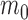 may depend on age
may depend on age 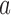 and on calendar time
and on calendar time 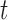 . In addition, the rate
. In addition, the rate 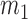 may also depend on the duration
may also depend on the duration 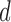 of the disease (Fig. 1).
of the disease (Fig. 1).
In the literature, two approaches can be found in dealing with the state model and its transition rates. Keiding (1991) chose a stochastic nomenclature, whereas the group around Murray & Lopez preferred differential equations (Murray & Lopez, 1994, 1996; Barendregt et al., 2003). According to the long tradition of differential equations in modelling infectious diseases, we follow the way of differential equations. We show that our approach is able to obtain Keiding's result (Keiding, 1991).
2. Methods
Let 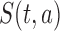 denote the absolute number of subjects aged
denote the absolute number of subjects aged 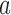 at time
at time 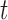 in state H. Moreover, let
in state H. Moreover, let 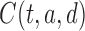 be the number of people age
be the number of people age 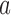 at time
at time 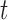 who are in state I for exact duration
who are in state I for exact duration 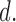 The total number of subjects aged
The total number of subjects aged 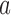 at
at 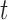 who have the chronic disease is
who have the chronic disease is 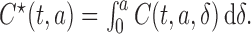
In this article, we made three assumptions:
The population is closed, i.e. there is no migration.
We consider only diseases contracted after birth. Thus, it holds
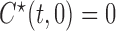 for all
for all 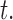
The functions
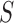 and
and 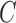 are sufficiently smooth.
are sufficiently smooth.
2.1. Keiding's equation
If we look at the change rates of the subjects in the states, balance equations for 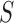 and
and 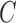 can be formulated as follows:
can be formulated as follows:
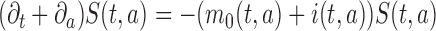 |
(2.1) |
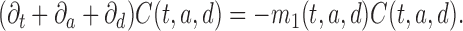 |
(2.2) |
For ease of notation we have written 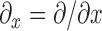 for
for 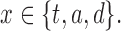 Equations (2.1–2.2) are partial differential equations (PDEs) that describe the outflows from the states H and I, respectively. The first of these equations implies that leaving the state H is a competing risk of the events Death without having contracted the disease and Contracting the disease (Putter et al., 2007). The system of PDEs (2.1–2.2) is extended by the following initial conditions:
Equations (2.1–2.2) are partial differential equations (PDEs) that describe the outflows from the states H and I, respectively. The first of these equations implies that leaving the state H is a competing risk of the events Death without having contracted the disease and Contracting the disease (Putter et al., 2007). The system of PDEs (2.1–2.2) is extended by the following initial conditions:
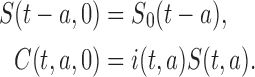 |
The first initial condition describes the number of (disease-free) newborns, and the second describes the number of newly diseased persons at 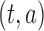 .
.
The PDEs with the initial conditions have the following solutions:
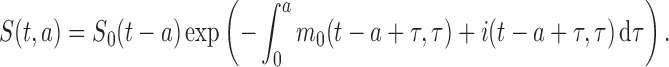 |
(2.3) |
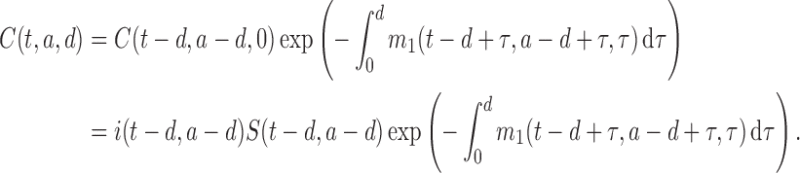 |
For brevity we define
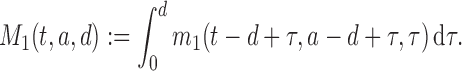 |
Then, the total number 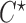 of diseased subjects is
of diseased subjects is
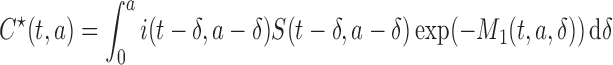 |
(2.4) |
By inserting Equations (2.3) and (2.4) into the definition of the age-specific prevalence
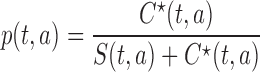 |
we get the following theorem.
Theorem 2.1 (Keiding, 1991) —
The prevalence
of those aged
at time
can be calculated by
(2.5) with
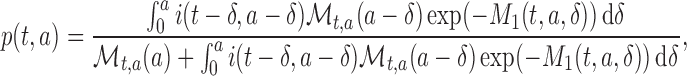
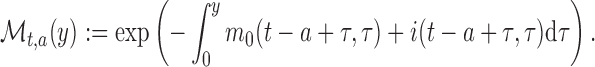
Given the incidence rate 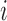 and the mortality rates
and the mortality rates 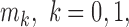 Equation (2.5) analytically describes the prevalence
Equation (2.5) analytically describes the prevalence 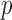 of the chronic disease for a specific age
of the chronic disease for a specific age 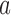 and at a specific point in time
and at a specific point in time 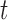 . The formula reflects the complex interplay of the involved incidence and mortality rates.
. The formula reflects the complex interplay of the involved incidence and mortality rates.
Unfortunately, Equation (2.5) is rarely used in epidemiology or public health contexts. One of the reasons may be that only a few researchers are aware of the equation and its potential. A huge advantage of the equation is the possibility of simulating scenarios. For instance, in the context of planning future health resources one might ask: What would be the effect of reducing the incidence of a specific chronic disease by 25% on the prevalence in the age group 60–80? What would be the effect of lowering the mortality 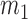 of the diseased persons by 10%?
of the diseased persons by 10%?
These are important questions in predicting the effects (e.g. outcomes, costs, budget impact etc.) of interventions or health programmes. Thus, we think the equation can contribute in planning the allocation of health resources or in the field of health policy decision-making.
2.2. Partial differential equations
In this section we formulate another relation between prevalence and incidence. We start with a lemma.
Lemma 2.1 —
The total number
of diseased persons aged
at
is the solution of the initial value problem
with
(2.6)
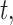
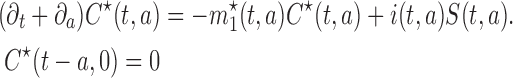
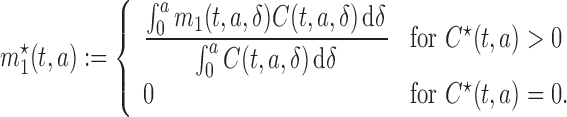
Proof —
May be found in Appendix.
With the lemma we are able to derive the main result of this article.
Theorem 2.2 —
The age-specific prevalence
is the solution of the initial value problem
(2.7) with
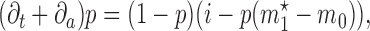
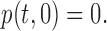
Proof —
By applying the quotient rule to
and substituting the expressions for
and
we get Equation (2.7).
Before we describe the advantages of Equation (2.7), we show that it is a generalization of the relations found in Brinks et al. (2013) and Brinks & Landwehr (2014). If 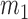 is independent from
is independent from 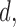 i.e.
i.e. 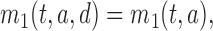 then it holds
then it holds 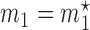 and (2.7) becomes
and (2.7) becomes
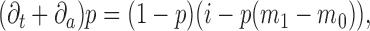 |
(2.8) |
which has been shown in Brinks & Landwehr (2014). If in addition all rates are independent from 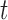 , one obtains the ordinary differential equation as in Brinks et al. (2013). Hence, Equation (2.7) is an extension of our previously published results if the mortality
, one obtains the ordinary differential equation as in Brinks et al. (2013). Hence, Equation (2.7) is an extension of our previously published results if the mortality 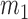 of the diseased depends on the duration
of the diseased depends on the duration 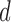 . For some chronic diseases, there is epidemiological evidence that
. For some chronic diseases, there is epidemiological evidence that 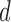 plays a crucial role for
plays a crucial role for 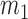 , for example, in diabetes (Carstensen et al., 2008) and systemic lupus erythematosus (Bernatsky et al., 2006).
, for example, in diabetes (Carstensen et al., 2008) and systemic lupus erythematosus (Bernatsky et al., 2006).
Compared with Keiding's Equation (2.5) the PDE approach is simpler and has a greater flexibility, which is illustrated in three points. The first point is a new possibility of estimating incidence rates from prevalence data. This is an important application in epidemiology and is demonstrated in the next section. The second advantage of the PDE approach becomes obvious, when the information about the mortality is not given in terms of the mortality rates 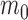 and
and 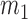 of the healthy and the diseased population, respectively, but in terms of the general mortality
of the healthy and the diseased population, respectively, but in terms of the general mortality
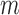 of the whole population and the relative mortality
of the whole population and the relative mortality 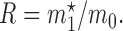 While Keiding's Equation (2.5) is not able to calculate the prevalence
While Keiding's Equation (2.5) is not able to calculate the prevalence 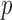 in this situation, the PDE is. A brief calculation using the relation
in this situation, the PDE is. A brief calculation using the relation 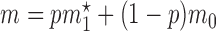 shows that
shows that 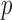 is the solution of the PDE
is the solution of the PDE
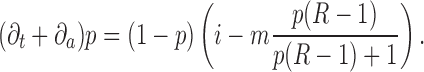 |
(2.9) |
The situation of given 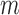 and
and 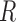 is very common in epidemiology and public health. Often, the general mortality
is very common in epidemiology and public health. Often, the general mortality 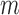 can be obtained from official vital statistics or life tables. The relative mortality
can be obtained from official vital statistics or life tables. The relative mortality 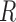 is taken from disease-specific surveys. Then, Equation (2.9) is able to calculate the prevalence whereas Keiding's formula is not. An anonymous reviewer gave us the valuable hint that Brunet & Struchiner (1999) also derived a relation between prevalence odds
is taken from disease-specific surveys. Then, Equation (2.9) is able to calculate the prevalence whereas Keiding's formula is not. An anonymous reviewer gave us the valuable hint that Brunet & Struchiner (1999) also derived a relation between prevalence odds 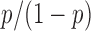 , incidence
, incidence 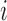 and mortalities
and mortalities 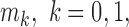 in terms of a PDE, which is similar to Equation (2.8). Similar to Keiding's formula, the approach of Brunet & Struchiner (1999) is not able to cope with the situation when
in terms of a PDE, which is similar to Equation (2.8). Similar to Keiding's formula, the approach of Brunet & Struchiner (1999) is not able to cope with the situation when 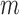 and
and 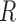 are given instead of
are given instead of 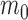 and
and 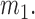
Remark 2.1 —
The fraction on the right-hand side in (2.9) is the population attributable fraction, a well-known epidemiological quantity (Kirkwood & Sterne, 2003).
Finally, the greater flexibility of the PDE compared with Keiding's and Brunet and Struchiner's formula is apparent if we release the assumption of a closed population. Keiding and Brunet & Struchiner do not cover this case, whereas by an extension of the PDE (2.7) this is easily possible. The necessary steps are described in Brinks & Landwehr (2014).
Remark 2.2 —
Equation (2.7) uses calendar time
and age
as underlying (independent) variables and describes the change of the prevalence as a function of
and
. This may seen in the light of the celebrated McKendrick–Von Foerster Equation, which does the same for the population density (in a closed population). For a review of the history and further references, see the excellent overview by Keiding (2011).
2.3. Estimation of the age-specific incidence from two cross-sectional studies
The primary advantage of the PDE approach over Keiding's Equation (2.5) is a possibility of deriving incidence rates from prevalence data. We start with the observation that in contrast to (2.5), the PDE (2.7) can be solved for the incidence rate 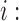
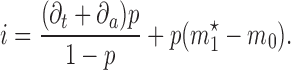 |
(2.10) |
This equation provides a way to estimate the age-specific incidence from two cross-sectional studies. Consider two points in time, 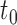 and
and 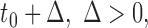 and assume we know the age-specific mortalities
and assume we know the age-specific mortalities 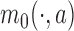 and
and 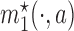 at calendar time
at calendar time 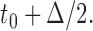 Then, Equation (2.10) is the basis for the following algorithm:
Then, Equation (2.10) is the basis for the following algorithm:
Algorithm 2.1 (Incidence from two cross-sections) —
Let the age-specific prevalence
be given at
and
Set
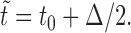
by
(2.11) at
by
(2.12)
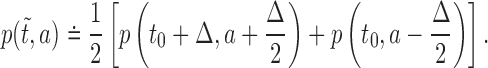
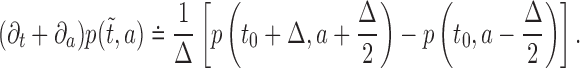
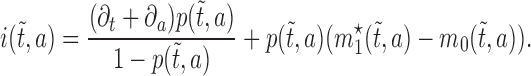
While the last step in Algorithm 2.1 is mathematically exact, the algorithm comprises two approximation steps (indicated by the ‘ ’ sign), which are sources for errors. First, an error occurs for approximating the prevalence
’ sign), which are sources for errors. First, an error occurs for approximating the prevalence 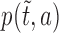 by the mean of
by the mean of 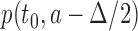 and
and 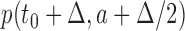 in Equation (2.11). The second error arises in estimating the partial derivative
in Equation (2.11). The second error arises in estimating the partial derivative 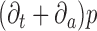 by the finite difference in (2.12).
by the finite difference in (2.12).
In both approximations, the underlying idea is linearization, i.e. the assumption that the intermediate value in (2.11) and that the derivative in (2.12) can be approximated by linear functions. If the prevalence 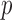 was a linear function, both steps would yield the associated exact values and the errors would be equal to zero. In practical applications, one would not choose the time lag
was a linear function, both steps would yield the associated exact values and the errors would be equal to zero. In practical applications, one would not choose the time lag 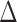 between the two cross-sections too long [but long enough to gain a reliable estimate in (2.11) and (2.12)].
between the two cross-sections too long [but long enough to gain a reliable estimate in (2.11) and (2.12)].
3. Example
For illustration of the practical relevance, we apply the theory to an example motivated by dementia in German males. The mortality 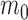 of the non-diseased is chosen to be
of the non-diseased is chosen to be
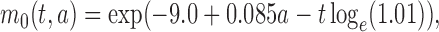 |
which is an approximation of the age-specific mortality of the male German population aged 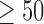 in the past six decades (Federal Statistical Office of Germany, 2011). The calendar time
in the past six decades (Federal Statistical Office of Germany, 2011). The calendar time 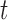 is given in years since 1960.
is given in years since 1960.
The age-specific incidence of dementia is assumed to be
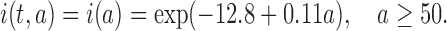 |
(3.1) |
This is an approximation of the observed rate in males (Ziegler & Doblhammer, 2009). As there are indications that the age-specific incidence is relatively stable (Qiu et al., 2009), we consider it to be independent from calendar time 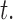
Concerning the mortality 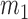 of the men with dementia, we examine two cases:
of the men with dementia, we examine two cases: 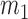 being independent and being dependent on the disease duration
being independent and being dependent on the disease duration 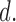 In both cases, we use Keiding's Equation (2.5) to calculate the age-specific prevalence of dementia in the years 2010 and 2015. This mimics two cross-sectional studies with a time lag of 5 years (
In both cases, we use Keiding's Equation (2.5) to calculate the age-specific prevalence of dementia in the years 2010 and 2015. This mimics two cross-sectional studies with a time lag of 5 years (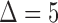 ). The two cross-sections are used to derive the age-specific incidence rate in at
). The two cross-sections are used to derive the age-specific incidence rate in at 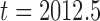 by Algorithm 2.1. As we know the true incidence underlying the simulation, we can compare the estimates of Algorithm 2.1 with the true values given by (3.1). In this way, we compare our estimate with our own input and do not need additional data for validation.
by Algorithm 2.1. As we know the true incidence underlying the simulation, we can compare the estimates of Algorithm 2.1 with the true values given by (3.1). In this way, we compare our estimate with our own input and do not need additional data for validation.
3.1. Independence from duration
In the first example, we assume that the mortality 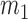 of the diseased is independent from the duration
of the diseased is independent from the duration 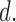 Even more,
Even more, 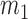 is considered proportional to
is considered proportional to 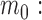
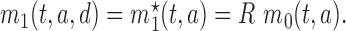 The relative mortality
The relative mortality
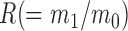 is chosen to be
is chosen to be 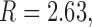 which is the average value of the relative mortality in the first 6 years after diagnosis of dementia in a comparable English population (Rait et al., 2010).
which is the average value of the relative mortality in the first 6 years after diagnosis of dementia in a comparable English population (Rait et al., 2010).
The age courses of the prevalence in 2010 and 2015 are calculated by Keiding's Equation (2.5) in steps of 2.5 years length 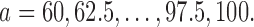 The integrals have been calculated using Romberg's method, which allows a prescribed accuracy (Dahlquist & Björck, 1974). The results are shown in Fig. 2.
The integrals have been calculated using Romberg's method, which allows a prescribed accuracy (Dahlquist & Björck, 1974). The results are shown in Fig. 2.
Fig. 2.
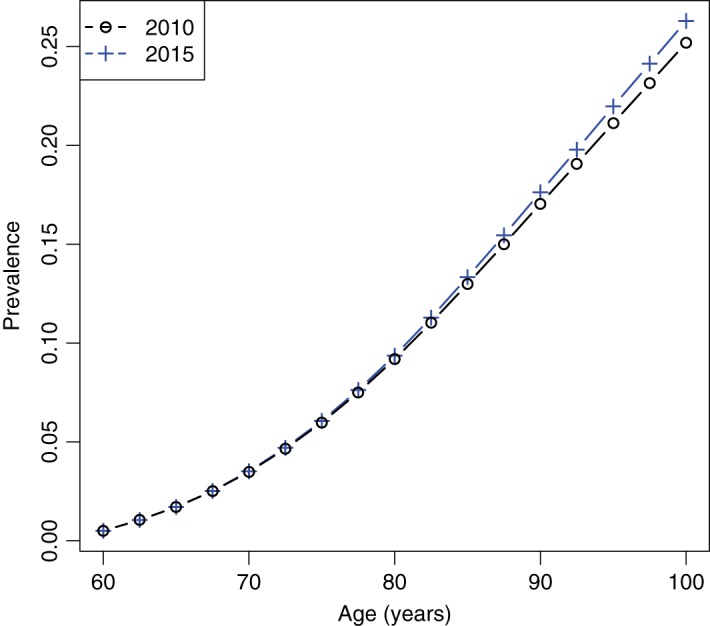
Age-specific prevalence in 2010 and 2015 (example without duration dependency).
Based on the age course of the prevalence in Fig. 2, we apply Algorithm 2.1 with 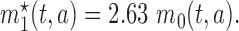 The results are shown in Table 1.
The results are shown in Table 1.
Table 1.
Comparison between the true and the calculated age-specific incidence rates in the first example.
Age 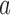
|
True incidence | Calculated incidence | Relative error (%) |
|---|---|---|---|
| 62.5 | 0.0026718 | 0.0027006 | 1.08 |
| 65.0 | 0.0035175 | 0.0035542 | 1.04 |
| 67.5 | 0.0046309 | 0.0046861 | 1.19 |
| 70.0 | 0.0060967 | 0.0061226 | 0.42 |
| 72.5 | 0.0080266 | 0.0080156 |
 0.14 0.14 |
| 75.0 | 0.0105672 | 0.0105659 |
 0.01 0.01 |
| 77.5 | 0.0139120 | 0.0138738 |
 0.28 0.28 |
| 80.0 | 0.0183156 | 0.0181919 |
 0.68 0.68 |
| 82.5 | 0.0241131 | 0.0238324 |
 1.16 1.16 |
| 85.0 | 0.0317456 | 0.0312618 |
 1.52 1.52 |
| 87.5 | 0.0417941 | 0.0411196 |
 1.61 1.61 |
| 90.0 | 0.0550232 | 0.0540997 |
 1.68 1.68 |
| 92.5 | 0.0724398 | 0.0712442 |
 1.65 1.65 |
| 95.0 | 0.0953692 | 0.0938397 |
 1.60 1.60 |
| 97.5 | 0.1255564 | 0.1238085 |
 1.39 1.39 |
Comparing the true and the calculated incidence rates, we see that the absolute value of the relative error for all ages 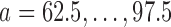 is less than 2%.
is less than 2%.
3.2. Duration dependency
The second example mimics the mortality 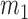 being dependent on the duration since onset of the disease. According to the values reported in the study of Rait et al. , we model
being dependent on the duration since onset of the disease. According to the values reported in the study of Rait et al. , we model
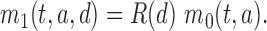 |
Again, we calculate the age-specific prevalence in the years 2010 and 2015 using Keiding's Equation (2.5). The resulting age-specific prevalence is similar to the prevalence shown in Fig. 2.
If we want to extract the age-specific incidence as in the previous section, we should know 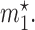 Although
Although 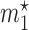 may be accessible by epidemiological surveys, in our setting we do not know the exact rate, because the distribution
may be accessible by epidemiological surveys, in our setting we do not know the exact rate, because the distribution 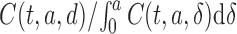 in Equation (2.6) is unknown. We present two ways to overcome this problem in practice: (a) we apply Algorithm 2.1 as in the previous section with setting
in Equation (2.6) is unknown. We present two ways to overcome this problem in practice: (a) we apply Algorithm 2.1 as in the previous section with setting 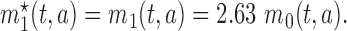 The value 2.63 is the average of all the reported relative mortalities from year 1 to year 6 after diagnosis. (b) In the study by Rait et al. it has been observed that the persons aged
The value 2.63 is the average of all the reported relative mortalities from year 1 to year 6 after diagnosis. (b) In the study by Rait et al. it has been observed that the persons aged 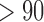 die quite soon after diagnosis of dementia. Thus, we set
die quite soon after diagnosis of dementia. Thus, we set 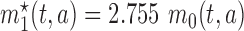 for
for 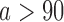 , where 2.755 is the average relative mortality from year 1 to year 4 after diagnosis. The comparisons of the estimated incidence rates with the true values are shown in Table 2. The third and fourth columns refer to method (a) and the fifth and sixth columns refer to method (b).
, where 2.755 is the average relative mortality from year 1 to year 4 after diagnosis. The comparisons of the estimated incidence rates with the true values are shown in Table 2. The third and fourth columns refer to method (a) and the fifth and sixth columns refer to method (b).
Table 2.
Comparison between the true and the calculated age-specific incidence rates in the second example.
Age 
|
True incidence | Calc. inc.
|
Rel. error (%) (%) |
Calc. inc.
|
Rel. error (%) (%) |
|---|---|---|---|---|---|
| 62.5 | 0.0026718 | 0.0026940 | 0.83 | 0.0026940 | 0.83 |
| 65.0 | 0.0035175 | 0.0035196 | 0.06 | 0.0035196 | 0.06 |
| 67.5 | 0.0046309 | 0.0046868 | 1.21 | 0.0046868 | 1.21 |
| 70.0 | 0.0060967 | 0.0062091 | 1.84 | 0.0062091 | 1.84 |
| 72.5 | 0.0080266 | 0.0081738 | 1.84 | 0.0081738 | 1.84 |
| 75.0 | 0.0105672 | 0.0107598 | 1.82 | 0.0107598 | 1.82 |
| 77.5 | 0.0139120 | 0.0141145 | 1.46 | 0.0141145 | 1.46 |
| 80.0 | 0.0183156 | 0.0186430 | 1.79 | 0.0186430 | 1.79 |
| 82.5 | 0.0241131 | 0.0244683 | 1.47 | 0.0244683 | 1.47 |
| 85.0 | 0.0317456 | 0.0318820 | 0.43 | 0.0318820 | 0.43 |
| 87.5 | 0.0417941 | 0.0414960 |
 0.71 0.71 |
0.0414960 |
 0.71 0.71 |
| 90.0 | 0.0550232 | 0.0537769 |
 2.27 2.27 |
0.0537769 |
 2.27 2.27 |
| 92.5 | 0.0724398 | 0.0693771 |
 4.23 4.23 |
0.0739852 | 2.13 |
| 95.0 | 0.0953692 | 0.0889364 |
 6.75 6.75 |
0.0951201 |
 0.26 0.26 |
| 97.5 | 0.1255564 | 0.1134120 |
 9.67 9.67 |
0.1215714 |
 3.17 3.17 |
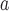 Assumed relative mortality
Assumed relative mortality 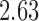 .
.
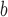 Assumed relative mortality
Assumed relative mortality 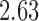 for
for 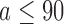 and
and 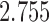 for
for 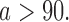
Although the relation 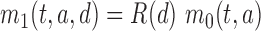 that has been used to generate the input data has not been utilized in Algorithm 2.1, the estimated age-specific incidence rates deviate only slightly for
that has been used to generate the input data has not been utilized in Algorithm 2.1, the estimated age-specific incidence rates deviate only slightly for 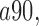 namely less than 2% in absolute terms. For ages 90 and more, the deviations increase with age in method (a), which has given rise to increase the relative mortality of this age group in method (b). The rationale behind method (b) is that in the age group
namely less than 2% in absolute terms. For ages 90 and more, the deviations increase with age in method (a), which has given rise to increase the relative mortality of this age group in method (b). The rationale behind method (b) is that in the age group 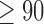 only a small percentage survive
only a small percentage survive 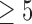 years after diagnosis. Thus, averaging the relative mortality over years 1 to 6 gives too much weight on the later years after diagnosis, when the relative mortality is lower than in the early years after diagnosis.
years after diagnosis. Thus, averaging the relative mortality over years 1 to 6 gives too much weight on the later years after diagnosis, when the relative mortality is lower than in the early years after diagnosis.
4. Summary
In this article we have formulated and proven a new relation between the age-specific prevalence, the incidence and the mortality rates in terms of a PDE. The relation generalizes differential equations published recently in Brinks et al. (2013) and Brinks & Landwehr (2014). Compared with the relations from Keiding (1991) and Brunet & Struchiner (1999), the PDE is simpler and has a greater flexibility. The flexibility has been illustrated in three points: (i) a new way of deriving incidence rates from prevalence data, (ii) the use of the method if the general mortality is given instead of the mortality rates of the healthy and diseased and (iii) the possible extension in case of migration. A fourth aspect may be mentioned if we allow a transition from the disease state (I) back to the state (H). Again the PDE is capable to deal with this situation and Keiding is not, see Brinks & Landwehr (2014) for details.
The new method of deriving incidence rates from prevalence data may be very useful in epidemiology. While prevalence data may be obtained by cross-sectional studies, the estimation of incidence rates mostly require lengthy and costly follow-up studies. Especially in low or middle income countries data about incidence of many diseases have not been surveyed yet. Furthermore, in some situations, estimates from cross-sectional data might be more reliable than estimates by follow-up studies. For example, in surveying occurrence of health states where subjects might feel uncomfortable or even stigmatized, losses to follow-up or withdrawals of consent are very likely. An anonymous cross-section may be found more acceptable and less intrusive for study participants than repetitive re-examinations.
With a view to practical applications of Algorithm 2.1, apart from the approximation errors, sampling errors in surveying the age-specific prevalence have to be considered. The sampling error depends on several parameters and a discussion is beyond the scope of this article. For an introduction about this issue we refer to Brinks et al. (2013) and the associated technical appendix, where sampling error was assessed in simulation studies. Error bounds arising from uncertainties in raw population data may be obtained by bootstrap methods as described and demonstrated in Brinks et al. (2013).
In summary, we have presented a new relation between the age-specific prevalence, the incidence and the mortality rates. The relation is applicable in many contexts from epidemiology, public health and demography. Furthermore, it is simpler and more flexible than a previously found equation. With our findings, we hope to contribute to the quantitative understanding of how basic epidemiological rates and processes may impact global health and burden of chronic diseases.
Appendix: Proof of Lemma 2.1
We have to show that 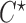 is the solution of the PDE
is the solution of the PDE 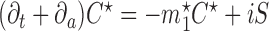 . With
. With 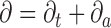 it holds:
it holds:
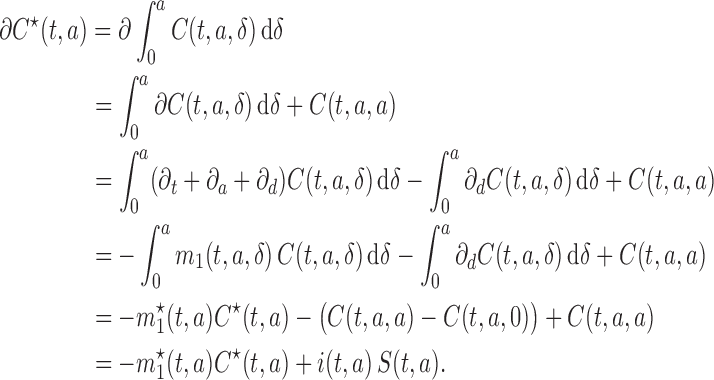 |
For the second equality Leibniz's integral rule has been used.
References
- Barendregt J. J., Van Oortmarssen G. J., Vos T., Murray C. J. (2003) A generic model for the assessment of disease epidemiology: he computational basis of DisMod II. Popul. Health Metr., 1, 4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bernatsky S., Boivin J. F., Joseph L., Manzi S., Ginzler E., Gladman D. D., Urowitz M., Fortin P. R., Petri M., Barr S., Gordon C., Bae S. C., Isenberg D., Zoma A., Aranow C., Dooley M. A., Nived O., Sturfelt G., Steinsson K., Alarcn G., Sencal J. L., Zummer M., Hanly J., Ensworth S., Pope J., Edworthy S., Rahman A., Sibley J., El-Gabalawy H., McCarthy T., St Pierre Y., Clarke A., Ramsey-Goldman R. (2006) Mortality in systemic lupus erythematosus. Arth. Rheumat., 54, 2550–2557. [DOI] [PubMed] [Google Scholar]
- Brauer F. (2005) The Kermack–McKendrick epidemic model revisited. Math. Biosci., 198, 119–131. [DOI] [PubMed] [Google Scholar]
- Brinks R., Landwehr S. (2014) Age- and time-dependent model of the prevalence of non-communicable diseases and application to dementia in Germany. Theor. Popul. Biol., 92, 62–68. [DOI] [PubMed] [Google Scholar]
- Brinks R., Landwehr S., Icks A., Koch M., Giani G. (2013) Deriving age-specific incidence from prevalence with an ordinary differential equation. Statist. Med., 32, 2070–2078. [DOI] [PubMed] [Google Scholar]
- Brunet R. C., Struchiner C. J. (1999) A non-parametric method for the reconstruction of age- and time-dependent incidence from the prevalence data of irreversible diseases with differential mortality. Theor. Popul. Biol., 56, 76–90. [DOI] [PubMed] [Google Scholar]
- Carstensen B., Kristensen J. K., Ottosen P.Borch-Johnsen Steering Group of the National Diabetes Register K. (2008) The Danish National Diabetes Register: trends in incidence, prevalence and mortality. Diabetology, 51, 2187–2196. [DOI] [PubMed] [Google Scholar]
- Dahlquist G., Björck A. (1974) Numerical Methods. New Jersey: Prentice Hall, pp. 292–294. [Google Scholar]
- Federal Statistical Office of Germany (2011) Lifetables for Germany 1896–2009 [Generationensterbetafeln für Deutschland 1896–2009] Wiesbaden, available at https://www.destatis.de/ (last accessed January 28, 2014).
- Fix E., Neyman J. (1951) A simple stochastic model of recovery, relapse, death and loss of patients. Hum. Biol., 23, 205–241. [PubMed] [Google Scholar]
- Keiding N. (1991) Age-specific incidence and prevalence: a statistical perspective. J. Roy. Stat. Soc. A, 154, 371–412. [Google Scholar]
- Keiding N. (2006) Event history analysis and the cross-section. Statist. Med., 25, 2343–2364. [DOI] [PubMed] [Google Scholar]
- Keiding N. (2011) Age-period-cohort analysis in the 1870s: Diagrams, sterograms, and the basic differential equation. Cand. J. Statist., 39, 405–420. [Google Scholar]
- Kirkwood B. R., Sterne J. A. C. (2003) Essential Medical Statistics, 2nd edn Malden, MA: Blackwell, pp. 451–452. [Google Scholar]
- Lozano R. et al. (2012) Global and regional mortality from 235 causes of death for 20 age groups in 1990 and 2010: a systematic analysis for the Global Burden of Disease Study 2010. Lancet, 380, 2095–2128. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Murray C. J. L., Lopez A. D. (1994) Quantifying disability: data, methods and results. Bulletin WHO, 72, 481–494. [PMC free article] [PubMed] [Google Scholar]
- Murray C. J. L., Lopez A. D. (1996) Global and regional descriptive epidemiology of disability: incidence, prevalence, health expectancies and years lived with disability. The Global Burden of Disease (Murray C. J. L., Lopez A. D., eds). Boston: Harvard School of Public Health, pp. 201–246. [Google Scholar]
- Putter H., Fiocco M., Geskus R. B. (2007) Tutorial in biostatistics: competing risks and multi-state models. Statist. Med., 26, 2389–2430. [DOI] [PubMed] [Google Scholar]
- Qiu C., Kivipelta M., von Strauss E. (2009) Epidemiology of Alzheimer's disease: occurrence, determinants, and strategies toward intervention. Dialogues Clin. Neurosci., 11, 111–128. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rait G., Walters K., Bottomley C., Petersen I., Iliffe S., Nazareth I. (2010) Survival of people with clinical diagnosis of dementia in primary care: cohort study. BMJ, 341, C3584. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ziegler U., Doblhammer G. (2009) Prevalence and incidence of dementia in Germany—a study based on data from the public sick funds in 2002. Gesundheitswesen, 71, 281–290. [DOI] [PubMed] [Google Scholar]