

Abstract
Continuous-time random walks (CTRWs) on discrete state spaces, ranging from regular lattices to complex networks, are ubiquitous across physics, chemistry, and biology. Models with coarse-grained states (for example, those employed in studies of molecular kinetics) or spatial disorder can give rise to memory and non-exponential distributions of waiting times and first-passage statistics. However, existing methods for analyzing CTRWs on complex energy landscapes do not address these effects. Here we use statistical mechanics of the nonequilibrium path ensemble to characterize first-passage CTRWs on networks with arbitrary connectivity, energy landscape, and waiting time distributions. Our approach can be applied to calculating higher moments (beyond the mean) of path length, time, and action, as well as statistics of any conservative or non-conservative force along a path. For homogeneous networks, we derive exact relations between length and time moments, quantifying the validity of approximating a continuous-time process with its discrete-time projection. For more general models, we obtain recursion relations, reminiscent of transfer matrix and exact enumeration techniques, to efficiently calculate path statistics numerically. We have implemented our algorithm in PathMAN (Path Matrix Algorithm for Networks), a Python script that users can apply to their model of choice. We demonstrate the algorithm on a few representative examples which underscore the importance of non-exponential distributions, memory, and coarse-graining in CTRWs.
I. INTRODUCTION
We can model many dynamical systems in physics, chemistry, and biology as random walks on discrete state spaces or network structures. For example, random walks can represent proteins folding on a coarse-grained network of conformational states,1,2 particles diffusing in disordered, fractal-like media,3,4 populations evolving in DNA or protein sequence space,5,6 and cells differentiating across epigenetic landscapes of regulatory states.7,8 One can also use random walks to probe the structure of empirical complex networks, such as protein-protein interaction networks or the World Wide Web.9–11 The central problem in these models is characterizing the statistical properties of paths taken by the system as it evolves from one state to another, especially for systems out of equilibrium. This entails understanding not only the distribution of lengths and times for these paths but also their distribution in the state space, which may reveal bottlenecks and indicate the diversity of intermediate pathways.
There is extensive literature for random walks on lattices,4,12,13 fractals,3,4 and random and scale-free networks9,11,14 in the absence of an energy landscape or other objective function. Much of this work has focused especially on the scaling behavior of first-passage times and the mean square displacement, the latter being important to identifying anomalous diffusion.3 More complex models, especially those with energy landscapes derived from empirical models or experimental data, generally require numerical approaches. One such approach is transition path theory,15 which relies on numerical solutions of the backward equation. This technique has been used to study Markov state models of molecular kinetics such as protein folding.1,2
Standard transition path theory, however, is not applicable to general continuous-time random walks13 (CTRWs) where states may have non-exponential waiting time distributions, nor does it address the complete distribution of first-passage times beyond the mean. These problems are important in many systems. For example, molecular Markov state models require grouping large numbers of microscopic conformations of molecules into a small number of effective states;16 the stochastic dynamics are then analyzed on this effective model.1,2 However, this coarse-graining is known to lead to qualitative differences with the underlying microscopic dynamics.16 In particular, the loss of information due to coarse-graining can lead to the appearance of memory, manifested as non-exponential waiting time distributions, in the coarse-grained states. Indeed, there is evidence of non-exponential distributions of time in protein conformation dynamics17,18 and enzyme kinetics.19,20 Non-exponential distributions can also arise from spatial disorder, as in glassy systems.21,22 Other linear algebra-based methods besides transition path theory have been developed to treat general CTRWs,23–25 but such methods are complicated and provide relatively little physical insight.
An alternative, more intuitive approach to CTRWs uses the path representation: statistical properties of CTRWs are decomposed into averages over the ensemble of all possible stochastic paths through state space. Some analytical results with this approach for arbitrary energy landscapes and waiting time distributions have been obtained, but only for 1D lattices, due to the difficulty of enumerating paths.26–28 On the other hand, path sampling methods29 are able to treat arbitrary network topologies, but these methods have not been developed for non-exponential waiting time distributions, and in any case, sampling is likely to be inefficient for calculating higher moments of path statistics, which are crucial when non-exponential distributions are expected.
Here we develop a generalized formalism for the path ensemble of a CTRW on a network of discrete states, regardless of their connectivity, energy landscape, or intermediate state waiting time distributions. In Sec. II we use statistical mechanics of the nonequilibrium path ensemble for a CTRW to obtain expressions for arbitrary moments of path statistics including path length, time, action, and any conservative or nonconservative force along a path. We use this formalism to deduce general relationships among the distributions of path length, time, and action, as well as several exact relationships for the case of homogeneous networks. In Sec. III we derive recursion relations, reminiscent of transfer matrix and exact enumeration techniques, to efficiently calculate various path statistics numerically, including distributions of paths in the state space. We have implemented our approach in a user-friendly Python script called PathMAN (Path Matrix Algorithm for Networks), freely available at https://github.com/michaelmanhart/pathman, that users can apply to their own models.
In Sec. IV we demonstrate the numerical algorithm on a few examples. After illustrating some basic concepts on a simple 1D random walk, we apply our method to a 1D comb to show how coarse-graining can lead to the appearance of memory, in the form of non-exponential waiting time distributions. We quantify the effect of the memory on the distribution of total path times. We further demonstrate the effect of coarse-graining in a 2D double-well potential, from which we deduce some general properties of memory arising from coarse-graining. Finally, we use our method to show how spatial disorder can also lead to non-exponential distributions of path statistics in the 2D random barrier model.
II. DISTRIBUTIONS IN THE PATH ENSEMBLE
A. Continuous-time random walks and memory
Consider a stochastic process on a finite set S of N states: the process makes discrete jumps between states with continuous-time waiting at each state in between jumps. Such a process is known as a CTRW,13 and it can describe many physical or biological systems, such as a protein traversing a coarse-grained network of conformations toward its folded state1,2 or a particle traveling through a disordered material.3,4 The time the system waits in a state σ before making a jump to σ′ is distributed according to ψ(t|σ → σ′). In many models, this distribution depends only on the current state σ and not on the destination σ′, so that ψ(t|σ → σ′) = ψ(t|σ); such waiting time distributions are known as “separable.”30 We will mostly assume separable distributions throughout this paper. However, since non-separable distributions arise crucially in coarse-grained models, we will also briefly discuss how to extend our results to the non-separable case. Let the raw moments of the waiting time distributions be denoted as
| (1) |
We assume every state σ has at least one finite moment for n > 0; the zeroth moment is always θ(0)(σ) = 1 by normalization. In the special case of a discrete time process, ψ(t|σ) = δ(t − θ(1)(σ)) and the moments are θ(n)(σ) = (θ(1)(σ))n.
Given the system has finished waiting in σ and makes a jump out, the probability of jumping to σ′ is given by the matrix element 〈σ′|Q|σ〉, where Q is an N × N matrix and |σ〉 denotes an N-dimensional vector with 1 at the position corresponding to the state σ and 0 everywhere else. The jump probabilities out of each state σ are therefore normalized according to , with 〈σ|Q|σ〉 = 0 by definition (since a jump must leave the current state). The matrix Q imposes a network structure over the states in S, with edges directed and weighted by the entries in Q. We can think of the jump process alone as a discrete-time projection of the model, since it describes the system’s dynamics if we integrate out the continuous waiting times.
An ordinary Markov process is a special case of the above CTRW construction. A continuous-time Markov process is typically defined by a rate matrix W such that in a small time interval Δt, the probability of making a jump σ → σ′ is 〈σ′|W|σ〉Δt. Therefore, the probability of making the jump σ → σ′, given that the system makes any jump out of σ during Δt, is
| (2) |
which defines the relation between the Markov rate matrix W and the jump matrix Q. The probability per unit Δt of waiting time t = MΔt in σ and then making a jump out is given by
| (3) |
The waiting time distribution ψ(t|σ) is then the continuous limit of Eq. (3),
| (4) |
where
| (5) |
is the mean waiting time in σ. Hence, waiting times in a Markov process always have an exponential distribution. The higher moments of exponential waiting times are completely determined by the mean: θ(n)(σ) = n!(θ(1)(σ))n.
In general, processes with exponential distributions of times p(t) are important because they are memoryless in the following sense: the probability of taking at least time t, given the process has already taken at least time t0, is the same as taking at least t in the first place. That is, the system “forgets” the time it has already taken. Mathematically, this means that
| (6) |
where is the complementary cumulative distribution function. The only function satisfying Eq. (6) is a simple exponential P(t) = e−t/τ, from which it follows that p(t) = τ−1e−t/τ. For waiting time distributions ψ(t|σ), non-exponential functions are therefore indicative of memory within a state: how much longer the system tends to wait in that state depends on how long it has already waited. In contrast to ordinary Markov models where ψ(t|σ) is always exponential, models where ψ(t|σ) may be non-exponential are sometimes known as semi-Markov processes.
B. The ensemble of first-passage paths
We approach CTRWs using the ensemble of first-passage paths26–29,31–33 that first reach a particular final state or a set of final states from some initial conditions. We are interested in statistical properties of this ensemble such as its distributions in length, time, and space. In addition to situations where first-passage properties themselves are of interest, first-passage paths constitute fundamental building blocks of a stochastic process since the full propagator and steady state can in principle be derived from them.4
Let Sfinal be the set of final states, which we will treat as absorbing (〈σ′|Q|σ〉 = 0 for all σ ∈ Sfinal and σ′ ∈ S) so that the first-passage condition is satisfied. Define a path φ of length ℓ to be an ordered sequence of ℓ + 1 states: φ = {σ0, σ1, …, σℓ}. Denote the probability distribution over initial states as π0(σ). Then the probability density of starting in a state σ0 and completing the path φ at exactly time t is given by
| (7) |
where t0, t1, …, tℓ−1 are the intermediate waiting times and δ is the Dirac delta function. The probability of completing the path φ irrespective of how much time it takes is then
| (8) |
The time-independent path probability is convenient because we can express many path statistics of interest as averages over this distribution, analogous to averages over the Boltzmann distribution in ordinary statistical mechanics.29,32,33 For example, let be a functional that measures some property of the path φ. We use angular brackets to denote the average of this quantity over the path ensemble:
| (9) |
where the sum is over all first-passage paths φ of any length ending at states in Sfinal. Note that the partition function of the first-passage path ensemble, , always equals 1, since the process must reach one of the final states eventually. In this manner we can calculate nonequilibrium (first-passage) properties of the system as equilibrium properties of the path ensemble, which is time-independent by construction.
C. Distribution of path lengths
The simplest path property is its length , i.e., the discrete number of jumps along the path. The mean path length is then
| (10) |
Functionals for the higher moments of path length are simply powers of the length functional,
| (11) |
and the path length probability distribution is
| (12) |
where δ is the Kronecker delta. Note that the distribution of path lengths depends only on the jump matrix Q and not on the waiting time distributions ψ(t|σ), and hence it characterizes the discrete-time projection of the underlying continuous-time stochastic process. In Appendix A, we show that the distribution of path lengths ρ(ℓ) is typically exponential asymptotically,
| (13) |
where α is a constant of order 1 with respect to system size and is the mean path length.
D. Distribution of path times
In contrast to the discrete length of a path, there is also the continuous time of the path that accounts for the variable waiting times at the intermediate states. The distribution of total path times (first-passage time distribution) is
| (14) |
Unlike the path length distribution, the path time distribution depends on both the jump matrix Q and the waiting time distributions ψ(t|σ). We cannot evaluate f(t) for arbitrary waiting time distributions ψ(t|σ); however, we can express its moments as simple averages over the time-independent path ensemble using path functionals (cf. Eq. (9)). That is, using Eqs. (7) and (14), we obtain
| (15) |
where the functional for the nth moment of path time is
| (16) |
Each summation in the multinomial expansion is from 0 to n subject to the constraint j0 + j1 + ⋯ + jℓ−1 = n. For example, the first few moments are
| (17) |
Note that Eq. (16) implies that if any accessible intermediate state has a divergent waiting time moment of order n, then all path time moments of order n and higher must be divergent as well.
E. Path action and a general class of path functionals
For many systems, it is important to determine whether their dynamics are highly predictable or highly stochastic; that is, whether the system is likely to take one of a few high-probability paths every time or whether there is a large number of distinct paths with similar probabilities. One way to quantify this notion uses the path action, defined as
| (18) |
so that path probability is . As in classical and quantum mechanics, paths with minimum action dominate, while paths of large action are suppressed. Note that like path lengths, action depends only on the jump probabilities and not on the waiting time distributions.
The mean path action is the Shannon entropy of the path distribution34 (we ignore the path-independent logπ0(σ0) contribution from the initial condition),
| (19) |
This is consistent with the idea that the path action distribution tells us about the diversity of paths in the ensemble: low entropy (small mean action) means that a few paths with large probability dominate the process, while large entropy (large mean action) means that a diverse collection of low-probability paths contribute. The distribution of actions around this mean may be non-trivial, however. For instance, even if the mean action is large, the variance around it could either be small (the system must traverse one of the low-probability paths) or large (the system may traverse paths with a wide range of probabilities). We can characterize the action distribution by considering its higher moments. The functional for the nth moment of path action is
| (20) |
so the total moments of the path action distribution are
| (21) |
The action functionals (Eq. (20)) share a similar multinomial form with the time functionals (Eq. (16)). This leads us to consider a more general class of path functionals with this form. Consider a path functional that sums some property over jumps in a path (or edges in the network), so that for a path φ of length ℓ,
| (22) |
In the case of action, U(σi+1, σi) = − log〈σi+1|Q|σi〉. Equation (22) is a discretized line integral along the path φ, which suggests thinking of U as representing a force acting on the random walker as it traverses a path. The statistics of such forces over paths are especially interesting when the force is nonconservative, i.e., the line integral depends on the whole path φ and not just on the end points. Non-transitive landscapes or non-gradient forces with this property have been considered in evolutionary theory35 and biochemical networks.36 However, even for conservative forces, the distribution of the line integral may be non-trivial over the path ensemble if there are multiple initial and final states. The moment functionals for any such quantity are again of the multinomial form,
| (23) |
This suggests that methods for calculating time or action moments can be applied to any path property in this general class.
F. Path statistics on a homogeneous network
We now consider these statistics of path length, time, and action in the simple case of a network with homogeneous properties. We first assume that the waiting time distributions ψ(t|σ) = ψ(t) are identical for all states, with raw moments θ(n) and cumulant moments . We do not assume anything about the jump matrix Q (i.e., the network connectivity). In Appendix B, we derive an exact relation between path length and time moments for arbitrary ψ(t):
| (24) |
where Bn,k are the partial Bell polynomials.37 For example, the first few moments are
| (25) |
Note that the nth time moment depends on all length moments up to n. Equation (24) holds for the cumulants and as well (Appendix B). In Appendix C, we present an alternative argument for the first two moments of Eq. (25) using the central limit theorem, and in Appendix D we study the special case when ψ(t) is exponential.
As these results show, we can think of path time as a convolution between path length and the intermediate waiting times: the variation in total path times arises from both variation in path lengths and variation in the waiting times. If ψ(t) is a delta function (discrete-time process), then for n > 1 (no variation in waiting times), and exactly: path lengths and times are identical up to an overall scale. This is consistent with our previous notion that the path length distribution fully describes the discrete-time projection of the process. However, even with continuous-time distributions ψ(t), the approximation , and therefore the approximate equivalence of the discrete- and continuous-time processes, may still hold if the waiting times are not too broadly dispersed (so the higher moments of ψ(t) are not too large). We can make this observation more quantitative by expanding Eq. (24) as
| (26) |
where
| (27) |
is the waiting time coefficient of variation (CV), i.e., the standard deviation divided by the mean. The CV measures the relative dispersion of a distribution; it always equals 1 for exponential distributions. Equation (26) holds for the cumulants and as well.
Equation (26) implies that path length and time moments will be approximately proportional, and hence the whole distributions should be similar, if
| (28) |
The quantity is typically of the order of the inverse mean path length ; in particular, this is true when path lengths have an exponential distribution, which is generally the case asymptotically (Appendix A). An important exception to this rule is if lengths have a Poisson distribution, so that in the cumulant version of Eq. (26). Apart from this special case, the condition of Eq. (28) is equivalent to
| (29) |
that is, the waiting time distribution must be sufficiently narrow compared to the mean path length. In many cases we expect this to hold, since θ(cv) ∼ 1 for exponential-like waiting time distributions and the mean path length is usually very large. We will investigate the validity of this condition in later examples.
We also consider path action on a homogeneous network. Path action depends only on the jump matrix Q and not on the waiting time distributions ψ(t|σ), so as a simple example, we take all states in S to have the same number γ of outgoing jumps (nearest neighbors on the network) and all such jumps to have equal probability γ−1. Therefore, the probability of a path is and the action is . This means that the distribution of path actions is exactly equivalent to that of path lengths (rescaled by a factor of logγ), and the moments are
| (30) |
Since path lengths typically have an exponential distribution asymptotically (Eq. (13), Appendix A), path action will therefore also be asymptotically exponential as well, with mean .
III. MATRIX FORMULATION AND NUMERICAL ALGORITHM
Besides gaining general insights into the relationships among distributions of path lengths, times, and actions, the path ensemble formalism is convenient because we can efficiently calculate many ensemble averages using recursion relations that implicitly sum over all paths. We now derive these relations and show how to implement them numerically.
A. Recursion relations
We reformulate the problem in terms of matrices to express the sums over paths more explicitly. Let be an N × N matrix (N is the number of states in S) such that the matrix element is the nth time moment of all paths of exactly length ℓ from σ to σ′. In particular, the zeroth-order matrix gives the total probability of all paths going from σ to σ′ in exactly ℓ jumps. The initial condition is
| (31) |
where 1 is an N × N identity matrix. If our path ensemble is the set of first-passage paths to final states Sfinal with an initial distribution vector , then
| (32) |
is the nth time moment for all paths of exactly length ℓ, and
| (33) |
is the moment averaged over paths of all lengths. This expression illustrates how to express the previous path ensemble averages in the matrix formulation.
The key advantage of the matrices is that they obey the following recursion relation (Appendix E):
| (34) |
where Θ(n) is an N × N matrix with waiting time moments for each state along the diagonal:
| (35) |
Appendix E also shows how this recursion relation for the path time moments generalizes to the case of non-separable waiting time distributions ψ(t|σ → σ′). For the total probability (n = 0), the recursion relation of Eq. (34) is simply multiplication by the jump matrix: , since the total probability of going from one state to another in exactly ℓ jumps must be given by the product of the jump matrices .
Owing to the similar multinomial form of their path functionals (compare Eqs. (16) and (20)), the path action moments obey a similar recursion relation. Define to be the nth action moment of all paths of length ℓ from σ to σ′, so that
| (36) |
In Appendix E, we show that these matrices obey the recursion relation
| (37) |
where the matrix is defined so that
| (38) |
In fact, if is the matrix such that
| (39) |
for any path functional in Eq. (22), it obeys the recursion relation
| (40) |
where 〈σ′|Ω(j)|σ〉 = 〈σ′|Q|σ〉(U(σ′, σ))j (Appendix E). Therefore, recursion relations of this form extend to a wide class of path statistics.
B. Transfer matrices
To calculate the nth moment of time or action, we must carry out the recursion relation of Eq. (34) or (37) for all moments up to n. We can unify all these steps into a single transfer matrix operation convenient for numerical use. Let nmax be the maximum moment of interest. Define the N(nmax + 1)-dimensional column vector |τ(ℓ)〉 as a concatenation of for all n ∈ {0, 1, …, nmax}:
| (41) |
Define the basis vectors |σ, n〉 for σ ∈ S and n ∈ {0, 1, …, nmax} so that the (σ, n) entry of |τ(ℓ)〉 is the nth time moment at state σ at the ℓth jump: . We similarly define the action vector
| (42) |
Now define the N(nmax + 1) × N(nmax + 1) matrices:
| (43) |
where each 0 is an N × N zero matrix. We can express the recursion relations of Eqs. (34) and (37) for all n ∈ {0, 1, …, nmax} as
| (44) |
These recursion relations have the solutions
| (45) |
where the initial conditions are
| (46) |
Here each 0 represents a zero column vector of length N. We can think of K and G as transfer matrices that iteratively generate sums over the path ensemble to calculate moments. This is analogous to transfer matrices in spin systems that generate the sums over spin configurations to calculate the partition function.38 The zeroth-order version of this formalism, which simply calculates powers of the jump matrix Q, is equivalent to the exact enumeration method for discrete-time random walks.3,39
We can obtain most path statistics of interest by various matrix and inner products on these vectors. Define the cumulative moment vectors:
| (47) |
Elements of these vectors are (using Eqs. (41) and (42))
| (48) |
These represent the total nth moments of time and action for all paths through each state σ, but weighted by the number of visits to that state since the sum over ℓ counts a path’s contribution each time it visits σ. In the case of n = 0,
| (49) |
since (Eqs. (34) and (37)). This is actually the average number of visits v(σ) to a state σ, since the probability of a path is counted each time it visits σ. For an intermediate state σ, multiplying the mean number of visits v(σ) by the mean waiting time θ(1)(σ) gives the average time spent in σ. When σ is a final state in Sfinal, the random walk can only visit it once (if it absorbs at that final state) or zero times (if it absorbs at a different final state), and thus the average number of visits v(σ) equals the probability of reaching that final state σ (commitment probability).
If there are multiple final states in Sfinal, we often wish to sum path statistics over all of them. Define the N-dimensional row vector (with 1 at the position for each final state and 0 everywhere else) and the (nmax + 1) × N(nmax + 1) matrix
| (50) |
where each 0 is a zero row vector of length N. Multiplying this matrix on a corresponding vector will sum over all final states for each moment, leaving an (nmax + 1)-dimensional vector with the total moments. For example,
| (51) |
where we use the shorthand for the total nth time moment absorbed at the ℓth jump. Note that is the probability of reaching any of the final states in exactly ℓ jumps. Thus this method automatically calculates the entire path length distribution. On the cumulative time vector |τ〉, F returns the total time moments,
| (52) |
where is the total time moment over all paths. The matrix F similarly acts on the action vectors |η(ℓ)〉 and |η〉,
| (53) |
where is the nth action moment absorbed in all final states at the ℓth jump and is the total nth action moment.
Finally, for any function of state B(σ), we can calculate the average value of that function at the ℓth intermediate jump. Define two N(nmax + 1)-dimensional row vectors, one for intermediate states and one for final states:
| (54) |
where each vector has nmax zero row vectors 0 of length N. Acting with the row vector 〈Bint| on |τ(ℓ)〉 and returns the value of B(σ) averaged over the probability distribution across all states at the ℓth jump:
| (55) |
For the final states we must sum over path lengths up to ℓ to account for the total probability absorbed at final states thus far. For example, if B(σ) = θ(1)(σ), tells us the unconditional mean time spent at the ℓth intermediate jump. If B(σ) is set to a position in space corresponding to state σ (for systems that allow embedding of states into physical space), is the average position at the ℓth intermediate jump, which over all ℓ traces the average path of the system.
C. Convergence and asymptotic behavior of path sums
To numerically calculate the foregoing matrix quantities, we must truncate the sums over path lengths ℓ at some suitable cutoff Λ. If there are no loops in the network, then the jump matrix Q is nilpotent, meaning there is a maximum possible path length Λ such that Qℓ = 0 for all ℓ > Λ. In this case, all sums converge exactly after Λ jumps. If the network has loops, paths of arbitrarily long length have nonzero probability. We must then choose a desired precision ϵ ≪ 1 and truncate the sums at ℓ = Λ when
| (56) |
The first condition guarantees that the total probability has converged: all remaining paths have total probability less than ϵ. The second condition indicates that the Λth contribution to the maximum moment nmax is sufficiently small relative to the total moment calculated so far.
A potential problem with the second convergence condition arises when the state space is periodic, so the final states can only be reached in a number of jumps ℓ that is an integer multiple of the periodicity (plus a constant). For instance, square lattices have a periodicity of 2. In that case, will alternate between zero and nonzero values as ℓ alternates between even and odd values. To prevent these zero values of from trivially satisfying the second condition in Eq. (56), we also require that be nonzero. A more subtle problem can arise if there are very low probability paths with very large contributions to the higher time moments. For example, one can construct a model where there are extremely long paths with probabilities much smaller than ϵ but which make arbitrarily large contributions to the total time moments due to the waiting time moments at those states. The algorithm will satisfy the convergence criteria before these paths are summed and therefore miss their contributions. This is an extreme example, but in general one may need to reconsider the convergence test depending on the properties of the model at hand.
How does the cutoff Λ depend on the maximum moment nmax? To address this, we must determine the asymptotic behavior of for different n. As long as the network has loops, the path length probability distribution ρ(ℓ) is asymptotically exponential (Eq. (13); see Appendix A). To estimate the asymptotic dependence of the higher time moments on path length, we consider the special case of identical waiting time distributions as in Sec. II F. Since
| (57) |
we can use the approximation from Eq. (26) (valid when the waiting time distributions are not too dispersed) to obtain
| (58) |
Since , the higher moments decay nearly exponentially (up to a logarithmic correction) with the same rate as the probability, set by the mean path length . We expect this asymptotic behavior to remain valid even when the waiting time distributions are not all the same, as long as the length and time moments are approximately proportional; we will empirically verify this expectation in later examples.
Although all asymptotically decay with exponential dependence on ℓ, the logarithmic correction in the exponent shifts the exponential regime toward larger ℓ for higher moments; this is why we must test convergence on the maximum moment nmax in Eq. (56). Indeed, in Eq. (58) is maximized at , after which exponential decay sets in. Thus, we expect scaling for the cutoff to be to leading order.
The approximate exponential dependence of the moments also enables a convergence scheme more sophisticated than Eq. (56). We can simply calculate the moments for path lengths until all have reached their exponential tails, fit exponential functions, and then extrapolate to infer the contributions of the longer paths. Conceptually, this means that all long path behavior is contained in the statistics of shorter paths, since long paths are simply short paths with many loops.31,32 In practice, this procedure can help to avoid calculating extremely long paths unnecessarily.
D. Numerical implementation in PathMAN
We have implemented the aforementioned matrix formulation in a Python script called PathMAN (Path Matrix Algorithm for Networks), available at https://github.com/michaelmanhart/pathman with additional scripts for generating examples and analyzing output. Figure 1 shows the pseudocode. Since the jump matrix Q is typically very sparse, we can store all matrices in sparse formats for efficient storage and computation using SciPy’s sparse linear algebra module.40 The script is general enough to treat any CTRW on a finite discrete space given a list of states, their jump probabilities, and at least their first waiting time moments. The current implementation assumes separable waiting time distributions, but modifying it to run the calculations for non-separable distributions (Appendix E) is straightforward. The user can specify any path boundary conditions (initial distribution and final states) and functions of state B(σ) to average over. The script reads all input data from plain text files in a simple format (see GitHub repository for documentation).
FIG. 1.

Pseudocode for the matrix calculations implemented in PathMAN.
The rate-limiting step of the algorithm is multiplying the transfer matrices K and G with the vectors |τ(ℓ − 1)〉 and |η(ℓ − 1)〉 (Fig. 1) to obtain |τ(ℓ)〉 and |η(ℓ)〉, so we use this step to estimate the time complexity of the algorithm. Assume that each state has an average of γ outgoing jumps, so that the jump matrix Q has γN nonzero entries. Each transfer matrix has (nmax + 1)(nmax + 2)/2 nonzero blocks (Eq. (43)), yielding approximately γN(nmax + 1)(nmax + 2)/2 total nonzero entries in K and G. Since we multiply these matrices by the N(nmax + 1)-dimensional state vectors at each of the Λ total jumps, the algorithm scales as
| (59) |
Assuming there are loops in the model (i.e., there is no maximum possible path length), the cutoff Λ scales linearly with the mean path length , as well as the maximum moment nmax as argued in Sec. III C. For simple random walks, the mean path length scales as a power of the total number of states:
| (60) |
where dw is the dimension of the random walk and df is the fractal dimension of the space.11,14 Strictly speaking, these scaling relations depend on the boundary conditions (proximity of the initial and final states) and the presence of an energy landscape; the scaling relations in Eq. (60) are a “worst-case scenario” when the landscape is flat and the initial and final states are very far from each other. Altogether this implies that the algorithm will scale as
| (61) |
Alternative recursive expressions for first-passage time moments on 1D lattices scale as ,41 as do general methods for solving the backward equation (a linear system) in transition path theory;42 our scaling will be equivalent in the extreme case of a fully connected network where γ = N − 1.
IV. EXAMPLES
We now illustrate the path ensemble approach on a series of simple examples.
A. 1D lattice
We first consider a Markov CTRW on a 1D lattice. Let the lattice have L sites with equal and symmetric transition rates between neighboring sites:
| (62) |
From the rate matrix W, we can obtain the jump matrix Q and the waiting time moments θ(n) using Eqs. (2) and (5); note that the reflecting boundary conditions mean the “bulk” states (1 < x < L) have , while the “edge” states (x = 1, x = L) have due to their different connectivities (numbers of outgoing jumps). We consider the ensemble of first-passage paths from one end of the lattice (x = 1) to the other (x = L). Figure 2(a) shows the distributions of path time moments over path lengths; the path length probability distribution is very close to exponential except for small ℓ, while the higher moments illustrate the Erlang-like function derived in Eq. (58). In particular, we confirm that the higher time moments decay approximately exponentially for large ℓ. Since the connectivity is nearly the same everywhere for large L (γ = 2 for all states except x = 1 and x = L), Eq. (30) indicates the distribution of path action will also be exponential with mean action (path entropy) .
FIG. 2.

Distributions of path lengths and times on a 1D lattice. (a) The nth time moments for paths of length ℓ, normalized as fractions of the total moments , in the absence of a potential energy. (b) Path length probability distribution ρ(ℓ) for several choices of β on a linear energy landscape V(x) (inset). (c) The mean path length (scaled by the mean waiting time θ(1) = 1/2 for bulk states), mean path time , path length CV , and path time CV as functions of β. (d) Skewness , kurtosis , hyperskewness , and hyperkurtosis of path time as functions of β. Values of β in (c) and (d) are shifted by 1 to show β = 0 on a log scale. In all panels, we use a lattice of length L = 1000 with transition rates given by Eq. (63).
We now introduce a potential energy V(x) = (L − x)/(L − 1) that provides a constant force down the lattice (Fig. 2(b), inset). If we use Metropolis transition rates38 〈y|W|x〉 = min(1, e−β(V(y)−V(x))), where β is the inverse temperature, we obtain a biased random walk with forward rate of 1 and backward rate of e−β/(L−1):
| (63) |
As we increase the inverse temperature β from zero, the bias becomes exponentially stronger, leading to a distribution of path lengths more tightly concentrated around the minimum length ℓ = L − 1 (Fig. 2(b)). Since only a single path with probability 1 is available in the limit β → ∞, the distributions of path lengths and actions become delta functions; in particular, path entropy is zero because the process is completely deterministic.
What is the distribution of path times as a function of β? In Fig. 2(c), we show the mean path time , which decreases dramatically as the bias is increased through β. It is almost exactly proportional to the mean path length for all β, as predicted by Eq. (26) since θ(cv) = 1 and . We also show the CVs , of the path length and time distributions, which measure the dispersion. For β = 0 both CVs are very close to 1, suggesting that the distributions of path lengths and times are approximately exponential. However, as β becomes large, the length CV drops to zero, since the length distribution becomes a delta function, but the time CV decreases to a small but nonzero value, indicating that the distribution becomes narrowly but finitely distributed around its mean.
Besides CV, standardized moments offer a useful way to characterize the shape of a distribution.43 They are defined as dimensionless moments of a random variable X shifted and rescaled to have mean 0 and standard deviation 1:
| (64) |
Since the first and second standardized moments are 0 and 1 by construction, the lowest non-trivial moment is the third moment, traditionally known as skewness since it measures the asymmetry of the distribution around the mean. The fourth standardized moment is the kurtosis; the fifth and sixth standardized moments are sometimes called the hyperskewness and hyperkurtosis. For an exponential distribution, the nth standardized moment is !n, i.e., the subfactorial or the number of derangements of n objects. Therefore, exponential skewness, kurtosis, hyperskewness, and hyperkurtosis are 2, 9, 44, and 265, respectively. For a Gaussian distribution, the first four standardized moments are 0, 3, 0, and 15, respectively.
Figure 2(d) shows the first four non-trivial (n ≥ 3) standardized moments of path time on the 1D lattice as functions of β. For β = 0 the standardized moments are very close to their exponential values, confirming that the distribution of first-passage times for a simple random walk is very close to exponential. However, as we increase the rightward bias by increasing β, the moments undergo a rapid transition near β ≈ 10. Note that this transition happens at rather low temperature (T = β−1 = 10−1) compared to the total change in energy across the lattice, which is set to 1. For very large β, the standardized time moments saturate at the Gaussian values of 0, 3, 0, and 15. This is because a single path of minimal length ℓ = L − 1 dominates at low temperatures (Fig. 2(b)), and thus the total path time is just the sum of the waiting times along the single path. By the central limit theorem, this sum will be approximately Gaussian for large L. Since in this limit (bulk and edge states are the same since travel along the lattice is one-way), the mean and variance of path time in this limit should be the path length ℓ = L − 1 = 999 times the mean and variance of each waiting time: and , leading to a coefficient of variation . This agrees with Fig. 2(c). This simple model is reminiscent of downhill folding in proteins17 and linear biochemical pathways such as those used in kinetic proofreading,44 where non-exponential kinetics and the transition between exponential and deterministic (narrow Gaussian distribution) regimes have been previously investigated.
Equation (26) suggests that the length and time distributions should be very similar even for β → ∞, since the correction term is still small (θ(cv) = 1 and ). Indeed, the time distribution is a Gaussian narrowly distributed around its mean, whereas the length distribution is a delta function; the differences in the moments are of the order . However, this slight difference is better resolved by considering the complete relation between length and time moments (Eq. (24)) with cumulants and instead of the raw moments. For β → ∞, all for n ≥ 2, which means that we cannot expand Eq. (24) for the cumulants as in Eq. (26). Instead, the only nonzero terms in Eq. (24) yield the exact equation for all n.
B. 1D comb and memory from coarse-graining
We now turn to an example that explores the effects of waiting memory on distributions of path times. We consider the 1D comb: a 1D backbone of length Lbackbone where each site has a 1D tooth of length Ltooth extending from it (Fig. 3(a)). Combs have traditionally represented simple models of diffusion on percolation clusters and other fractal structures in disordered materials;4,45 more recently, they have also been proposed as a model for cancer cell proliferation.46 As in the previous example (Eq. (62)), we use symmetric transition rates of 1 between neighboring sites in the comb. If we are primarily interested in diffusion along the backbone rather than within the teeth, it is natural to coarse-grain each tooth into a single effective backbone state with some effective waiting time distribution ψ(t) that describes the time spent exploring the tooth before returning to make a jump along the backbone (Fig. 3(a)).4,45 The waiting times within each coarse-grained backbone state are therefore the first-passage times to return to the backbone after exploring the tooth. The distribution of these return times, ftooth(t), has the approximate form4
| (65) |
where τ is a time scale that is in Ltooth. Since the distributions of path times and lengths are very similar on 1D lattices in the absence of potential (cf. the β = 0 limit in Fig. 2(c)), the crossover time is essentially the characteristic time scale to explore a 1D lattice of length Ltooth (Eq. (60)). In Fig. 3(b) we show the path length distribution ρtooth(ℓ) to exit the tooth, which according to Eq. (26) should be approximately the same as the distribution of times ftooth(t) for large Ltooth. Indeed, ρtooth(ℓ) follows the form of Eq. (65) very clearly: there is a power law regime of ℓ−3/2 until approximately , after which there is an exponential decay. To estimate the tooth waiting time moments θ(n) from ψ(t) = ftooth(t), we make the approximation that the power-law regime dominates the moment integrals:4
| (66) |
In Fig. 3(c) we verify this scaling by numerically calculating the moments from first-passage paths that exit the tooth.
FIG. 3.

Distributions of path lengths and times on a 1D comb. (a) Schematic of a comb with backbone of length Lbackbone and teeth of length Ltooth. We coarse-grain the teeth into single states (orange) along the backbone with effective waiting time distributions ψedge(t) and ψbulk(t). (b) Path length distribution ρtooth(ℓ) to exit a tooth of different lengths Ltooth, along with the power law ℓ−3/2 for comparison. (c) Mean and second moment of ψbulk(t) as functions of tooth length Ltooth; points are numerical calculations, while dashed lines show expected scaling behavior from Eq. (66). (d) Skewness , and kurtosis , of length and time distributions for paths along the backbone as functions of Lbackbone, with Ltooth = 100.
The dominant power-law regime of ψ(t) means that its statistics are very different from those of an exponential distribution. For example, the CV is rather than ∼1, indicating a much broader distribution of times compared to the exponential case. The non-exponential nature of the waiting time distribution is indicative of memory within an effective backbone state: how much longer the system waits in the state depends on how long it has already waited. Mathematically, this apparent memory arises from coarse-graining each tooth into a single state, which erases information about the position of the system within the tooth. Indeed, for the distribution of times in Eq. (65), the mean waiting time starting from t = 0 is ∼Ltooth, since it is dominated by the power-law regime (Eq. (66)). However, if the system waits at least time , the mean additional waiting time becomes , due to the exponential regime. In other words, if the system does not leave by time —meaning that it has diffused far from the backbone—it is likely to wait much longer as the exponential regime of ψ(t) takes over.
One effect of this memory is that it can lead to significant differences between the distributions of path times and path lengths along the effective backbone states. Equation (26) shows that the moments of path time and path length are approximately proportional if the waiting time distributions are not too broad relative to ratios of path length moments; that is, the correction term in Eq. (26) is small if . We estimate the size of this correction for the comb model, focusing on first-passage paths from one end of the backbone to the other. The waiting time CV is as previously mentioned. The path length distribution, meanwhile, appears to be very close to exponential: Fig. 3(d) shows that its skewness and kurtosis are consistent with their exponential values (2 and 9) for any backbone length. Since the mean path length should be (Eq. (60)), this implies that the higher moments are . Therefore, the correction term in Eq. (26) is approximately
| (67) |
Thus, when , we expect path lengths and times along the backbone to have similar statistics, with a pronounced difference in the opposite limit. In Fig. 3(d), we calculate skewness and kurtosis of path time moments, varying Lbackbone while fixing Ltooth = 100. Indeed, for , there is a large discrepancy between path length and time moments, while for Lbackbone > 10, they become very close. The fact that the length of the teeth must be large compared to the square of the backbone length to have an appreciable effect on the path statistics indicates that dynamics along the backbone, rather than within the teeth, tend to dominate the first-passage process.
C. Memory in coarse-grained metastable states
As the previous example showed, memory, in the form of non-exponential distributions of waiting times, naturally arises from coarse-graining because information about the microscopic states of the system is lost. This principle plays a crucial role in the generation of discrete stochastic models for protein folding and other molecular processes.16 In these models, a high-dimensional space of “microscopic” states (e.g., protein conformations) is coarse-grained into a discrete set of “macroscopic” states with some effective transition probabilities. The resulting coarse-grained model is more amenable to calculating statistical properties of dynamics over long time scales, such as the mean protein folding time or kinetic bottlenecks.1,2 However, the coarse-graining can result in qualitative differences between the approximate macroscopic model and the true underlying microscopic dynamics,16 including non-exponential waiting times in the effective states that are not addressed by conventional transition path theory.15
As a simple illustration of this phenomenon, we consider a 2D double-well potential
| (68) |
as shown in Fig. 4(a). This potential has two local minima at (±1, 0) with V = 0, a central barrier at (0, 0) with V = 1, and reflecting boundaries at x, y = ± 2. At low temperatures, the system will spend most of its time in the basins around the two minima. Therefore, it is natural to coarse-grain the “microscopic” 2D space into two metastable states, A and B, separated by the central energy barrier (Fig. 4(a)). To characterize the statistics of the two-state dynamics, it is common to calculate a single reaction rate (inverse of the mean time) from one state to another. However, using a single rate parameter implicitly assumes that waiting times in the coarse-grained states are distributed exponentially. Here we show this to be a poor approximation.
FIG. 4.

Effect of memory in coarse-grained metastable states. (a) Double-well potential (Eq. (68)) exactly coarse-grained into states A and B with boundary along the green dashed line. We also show example paths (solid blue and red lines) that both exit B (circles) but start from different initial conditions within B (squares). (b) Length distributions ρ(ℓ) of paths (with β = 10) that exit B but start at different initial conditions (at the central barrier, corresponding to the blue square in (a), or in the low-energy basin, corresponding to the red square in (a)), along with the power law ℓ−3/2 for comparison. For paths that exit the coarse-grained state B, (c) the mean time and CVs , of length and time, and (d) skewness , and kurtosis , of length and time, all as functions of β. All calculations use a discretized square lattice with Δx = 0.05 over the space (x, y) ∈ [ − 2, 2] × [ − 2, 2].
When the system first transitions to B from A, it starts just to the right of the interface separating the two states (Fig. 4(a)). The effective waiting time in the coarse-grained state B is therefore the time until the system first returns to that interface, starting from one step off it. We explicitly calculate the first-passage paths for this microscopic process using our numerical method. We discretize the space into a 2D lattice with Δx = 0.05 and assume a Markov CTRW on the lattice with Metropolis transition rates for jumps between nearest neighbors. Although the system can enter state B at any point along the interface with A, for simplicity we assume that it entered through the central barrier at (0, 0) (the lowest-energy point along the boundary) and therefore starts in B at (Δx, 0) (marked by the blue square in Fig. 4(a)). In Fig. 4(b) we show the distributions of path lengths (blue line) starting from this point and returning anywhere along the interface for low temperature (β = 10); an example of such a path is shown in Fig. 4(a) (blue line). The distribution has a power-law regime for small ℓ and exponential regime for large ℓ. These two asymptotic limits are the same as the distribution of waiting times in the 1D tooth (Eq. (65), Fig. 3(b)), and indeed, they have a similar physical basis: the power-law regime arises from paths that quickly return to the interface without falling into the low-energy basin, while the exponential regime arises from paths that fall into the low-energy basin before returning. In contrast to the 1D comb, though, there is a broad flat region of the distribution between the power-law and exponential regimes. This is actually part of the distribution of paths that fell into the low-energy basin before returning; it corresponds to an intermediate regime before that distribution hits its asymptotic exponential tail (cf. path length distributions on a 1D lattice in Fig. 2(b)). We confirm this by directly calculating paths with the starting point in the basin (red line in Fig. 4(b); an example path is shown in Fig. 4(a) from the red square to the red circle).
In Figs. 4(c) and 4(d), we demonstrate that the distribution of path times, i.e., the waiting times in the coarse-grained state B (or A by symmetry), is nearly identical to the path length distribution shown in Fig. 4(b). Besides the mean time , we also calculate the CV and standardized moments for both length and time distributions, which are indistinguishable over the entire range of β (despite the heterogeneities in waiting time distributions across the lattice). Hence, the path length distribution in Fig. 4(b) also describes the effective waiting time distribution in the coarse-grained state. The power-law regime of this distribution for short paths leaves a distinct signature in the moments. Even at β = 10, which represents a temperature that is 10 times smaller than the lowest energy barrier (such that we expect the metastable approximation of A and B to be very good), the distribution of times deviates strongly from an exponential distribution: the CV is nearly 3, while the skewness and kurtosis are much larger than their exponential expectations. At lower β (higher temperatures), the deviation from an exponential distribution becomes even more pronounced. As with the comb, this enrichment of the distribution for very short paths means that given the system just transitioned to B, it is likely to quickly transition back to A. But if it does not transition back quickly, it is likely to wait much longer as it falls into the basin and the waiting times become exponentially distributed.
From the comb and double-well examples, we can deduce some general principles for the waiting memory that results from coarse-graining a state space. Assume that the microscopic state space for a system is d-dimensional Euclidean space, which we coarse-grain into Nmacro effective macroscopic states, each consisting of Nmicro microscopic states. The interfaces between coarse-grained states have dimension d − 1. When the system first enters one of these coarse-grained states, it begins just inside an interface. Therefore, the waiting time distribution ψ(t) in the coarse-grained state is the first-passage time to return to that (d − 1)-dimensional interface. This return process is effectively a 1D random walk, since only the direction normal to the interface matters (at least within a neighborhood of the initial state, assuming the interface is locally flat). Therefore, the distribution of first-passage times to return to the interface will be the same as for the 1D tooth in the comb (Eq. (65)):
| (69) |
where the crossover time between these regimes is the characteristic time scale to explore the coarse-grained state (Eq. (60); ν = 2 for d = 1, ν = 1 for d ≥ 2), and τ is a microscopic time scale which is in Nmicro. The waiting time moments are approximately
| (70) |
In particular, the CV is
| (71) |
As with the 1D comb, the CV scales as a power of the coarse-grained state size, but rather slowly.
We can now determine whether such waiting time distributions will lead to different statistics of path lengths and times in the coarse-grained model. Since the mean path length in the coarse-grained model is (assuming the microscopic and coarse-grained spaces have the same dimensionality), the condition (Eq. (29)) for equivalent path length and time statistics becomes
| (72) |
This is consistent with the condition found for the 1D comb where Nmicro = Ltooth and Nmacro = Lbackbone. For the double-well model, Nmicro ≈ 3200 (number of microscopic lattice points in A or B) and Nmacro = 2; Eq. (72) does not hold in this case, so we expect significant differences in the statistics of path lengths (jumps between A and B) and path times in the coarse-grained model. In general, Eq. (72) implies that the more coarse-graining there is (resulting in fewer but larger coarse-grained states), the more significant the memory effects are on the effective CTRW.
D. Random barrier model (RBM) and memory from spatial disorder
To further demonstrate the effects of a complex energy landscape on path statistics, we consider the random barrier model (RBM),3,30 a simple model of transport in disordered systems. In this model, a particle diffuses across a lattice with quenched energy barriers of random height between neighboring points. Here we consider a 2D lattice with energy barriers drawn from an exponential distribution , where E0 is the average energy.47 We assume a Markov CTRW on this lattice with symmetric transition rates between neighboring states that depend exponentially on the intervening energy barrier:
| (73) |
where Γ0 is the rate of traversing a barrier of zero height (maximum possible rate) and E(x′, y′; x, y) is the energy barrier between (x′, y′) and (x, y). We use reflecting boundary conditions and set Γ0 = E0 = 1 without loss of generality, as these two quantities set the overall time and energy scales. From the rates in Eq. (73), we determine jump probabilities and exponential waiting time moments using Eqs. (2) and (5).
Figure 5 shows a single (quenched) realization of the RBM on a 10 × 10 lattice for different values of β. In each panel, cells correspond to lattice points, while the gray-scale bars between them indicate the height of the intervening energy barriers (same in all panels). Due to the exponential distribution of energies, most barriers are low (black), with only a few relatively high barriers (white). We consider the ensemble of first-passage paths on this landscape from (1, 1) (bottom-left corner) to (10, 10) (top-right corner). First, we determine path statistics for β = 0 (Fig. 5(a)), where all transition rates are equal and the barriers have no effect (Eq. (73)). The leftmost panel of Fig. 5(a) shows the mean waiting time θ(1)(x, y) in each state. When all transition rates are equal, θ(1)(x, y) depends only on the state’s connectivity: the states in the bulk with more neighbors have shorter mean waiting times than do the edge and especially the corner states, which have fewer neighbors. The middle panel of Fig. 5(a) shows the average number of visits v(x, y) to each state during the first-passage process (Sec. III B). For β = 0, the number of visits depends on both the distance to the final state and the state’s connectivity: edge and corner states with fewer neighbors are visited less often than are bulk states the same distance from the final state. When we consider the mean fraction of time spent in each state (the product of θ(1)(x, y) and v(x, y), normalized by the total mean path time ; rightmost panel of Fig. 5(a)), the connectivity-dependence largely disappears, so that the fraction of time depends mostly just on the distance to the final state.
FIG. 5.

Spatial properties of first-passage paths in the random barrier model. For a 10 × 10 lattice, we show statistics of first-passage paths from (1, 1) to (10, 10) for a single quenched realization of the energy barriers. Each colored cell corresponds to a lattice point (x, y), with gray-scale bars indicating energy barriers between lattice points (higher energies are white, lower energies are black). Energy barriers are randomly sampled from an exponential distribution with mean E0 = 1, and the transition rate across a zero energy barrier is Γ0 = 1. The leftmost column shows the mean waiting time θ(1)(x, y), the middle column is the average number of visits v(x, y), and the rightmost column is the average fraction of time spent at each lattice point. Rows correspond to different inverse temperatures: (a) β = 0, (b) β = 1, and (c) β = 5. Magenta points show the average particle position for every 100th jump (connected by straight lines to guide the eye).
For β > 0, the effects of the random energy barriers emerge. In Figs. 5(b) and 5(c), we show path statistics for β = 1 and β = 5. States with large barriers around them acquire significantly longer mean waiting times, leading to a very broad distribution of time scales; at β = 5 the mean waiting times span three orders of magnitude (Fig. 5(c), leftmost panel). However, states with extremely long mean waiting times also tend to have many fewer visits on average (Figs. 5(b) and 5(c), middle panels). This is because the high energy barriers that make these states difficult to exit also make them difficult to enter in the first place. In contrast with β = 0, where v(x, y) was determined by both the distance to the final state and the state’s local connectivity, for large β the average number of visits becomes predominately determined by the state’s local properties, i.e., its mean waiting time, rather than its global position on the lattice. However, the heterogeneity of θ(1)(x, y) and v(x, y) across the lattice nearly vanishes when considering their product, the mean fraction of time (Figs. 5(b) and 5(c), rightmost panels): as with β = 0, the distance to the final state primarily determines the fraction of time spent at a lattice point. Instead of varying smoothly across states as for β = 0, though, at β = 5 the fraction of time appears to have four distinct plateaus on the 2D lattice. Within each plateau, the particle spends approximately the same fraction of total time at each lattice point.
Figure 5 also shows the average of all first-passage paths (magenta lines). We calculate the average path by defining state functions for each spatial coordinate as Bx(x, y) = x and By(x, y) = y and using Eq. (55) to determine the mean positions and as functions of the intermediate jump ℓ along a path. We plot these mean positions for every 100th jump in Fig. 5 to represent the average path of the particle. For β = 0, the average path is necessarily symmetric across the diagonal and asymptotically converges toward the final state (Fig. 5(a)). For β > 0, the energy barriers slightly distort the average path at the beginning, but as the path approaches the final state, these asymmetries largely average out (Figs. 5(b) and 5(c)).
We next consider the distributions of path length, time, and action for the RBM. For β = 0, all of these distributions are close to exponential in shape, as expected from previous examples. For example, the length distribution has CV , skewness , and kurtosis . The moments for path time and action are also very close to these values: indeed, Eqs. (26) and (30) imply that these distributions should all be very similar since the network is nearly homogeneous.
What happens to these distributions in the presence of a complex energy landscape (β > 0)? Figure 6 shows distributions of the first four moments over many quenched realizations of the RBM at different β. For β = 1, both the mean path length and time are mostly close to their values at β = 0 (Fig. 6(a)), and their CVs and standardized moments indicate that the distributions are still close to exponential (Figs. 6(b)–6(d)). Larger β, however, leads to a very wide range of possible length and time moments, which can span several orders of magnitude across realizations. The correlations between path lengths and times are also significant. Mean lengths and times are mostly clustered along the diagonal, indicating their proportionality for most realizations, but there are some realizations with mean time much larger than mean length (Fig. 6(a)). For CVs and standardized moments, many realizations that deviate from exponential distributions do so equally in both length and time, resulting in points along diagonal. However, there are also many realizations with highly non-exponential distributions of path times, even though the length distribution is close to exponential (Figs. 6(b)–6(d)). In this case, the approximate equivalence between path length and time in Eq. (26) breaks down not because —this is never true in our RBM model since θ(cv)(x, y) = 1 for all (x, y) and is always large—but because of the spatial disorder. Equation (26) is derived for a network with identical waiting time distributions at all states, but the RBM has a very broad range of mean waiting times for large β, as the example in Fig. 5(c) shows. Thus, a rugged energy landscape even with Markovian waiting times can lead to non-exponential path statistics, and hence the appearance of memory; such non-exponential kinetics have long been discussed in the context of glasses.21,22
FIG. 6.

Distributions of path statistics in the random barrier model. For 1000 quenched realizations of the energy barriers on a 10 × 10 lattice, we show: (a) mean path length versus mean path time ; (b) length CV versus time CV ; (c) length skewness versus time skewness ; (d) length kurtosis versus time kurtosis ; (e) mean length versus mean action ; (f) length CV versus action CV ; (g) length skewness versus action skewness ; and (h) length kurtosis versus action kurtosis . Blue points are β = 1, red points are β = 3, and green points are β = 5; the horizontal and vertical dashed magenta lines correspond to the values of the moments for β = 0. We also show a diagonal gray line with slope 1 to guide the eye.
Figures 6(e)–6(h) show similar distributions of moments for path action (plotted against path length moments for reference). Equation (30) shows that the moments of length and action are proportional for networks with homogeneous connectivity. While the 2D lattice in the RBM is not exactly homogeneous due to boundary conditions, Fig. 6(e) shows mean length and action to be very nearly proportional for almost all realizations. Since mean action is equivalent to path entropy, its wide range of possible values indicates that first-passage in some realizations is dominated by a few relatively high-probability paths, while in other realizations, it is dominated by a large number of much lower-probability paths. The higher moments of action in Figs. 6(f)–6(h) indicate that usually action is nearly exponentially distributed even for larger β. In particular, many of the realizations with non-exponential length distributions still have exponentially distributed actions. This suggests that the distribution of path actions is much more weakly affected by the energy landscape compared to path lengths and times.
V. DISCUSSION
We have studied CTRWs on networks using statistical mechanics of the path ensemble. A particular convenience of the path formalism lies in exploring the relationship between the distributions of path lengths and path times, which can be viewed as the relationship between the full continuous-time process and its discrete-time projection. Discrete-time models have generally dominated the theory of random walks not only due to their simplicity but also because we expect a continuous-time process on the same network to be nearly equivalent under certain conditions.3,13 A well-known exception to this expectation is for waiting time distributions ψ(t) without a characteristic time scale (divergent mean), which can produce anomalous diffusion even on regular lattices.3 Using our approach, we have identified two more important exceptions. If all states have identical waiting time distributions ψ(t), Eq. (26) shows that continuous- and discrete-time dynamics will have different statistics if , where θ(cv) is the CV of the waiting time distribution ψ(t) and is the mean path length. We should therefore expect significant differences between continuous- and discrete-time dynamics to occur when ψ(t) is much more broadly dispersed than an exponential distribution (large θ(cv)) and for small state spaces, which tend to produce small (Eq. (60)). Furthermore, the 2D double-well example suggests this condition is still valid (Fig. 4(d)) even if the waiting time distributions and jump probabilities vary across states, as long as they do not vary too much. If they do, however, we find another exception to the equivalence of continuous- and discrete-time dynamics: even with exponential waiting times, spatial disorder can produce very different distributions of path lengths and path times, as illustrated in the random barrier model (Fig. 6).
Although we have focused primarily on moments of path statistics in this work, ideally we would like to know the entire distributions of these quantities. In principle, one can fit a parameterized distribution to the moments. In most statistical applications, this “method of moments” typically produces a good approximation for well-behaved distributions, especially using a very general parameterization such as the Pearson distribution.43 For path distributions, a linear combination of exponential functions may be a more appropriate choice. Since path length, time, and action distributions are frequently very similar and since our method explicitly calculates the entire path length distribution already, fitting distributions from moments would be most valuable in cases where the continuous- and discrete-time processes are very different.
In any case, the moments of path statistics themselves are valuable for quantifying deviations from a simple exponential distribution. These deviations are important because they represent a form of memory: the amount of time for a process to occur depends on how much time has already passed. We have emphasized how coarse-graining many “microscopic” states of a system into a smaller number of effective “macroscopic” states generally leads to non-exponential ψ(t) in the coarse-grained states; we explicitly demonstrated this by coarse-graining teeth in a 1D comb (Fig. 3) and low-energy basins in a double-well potential (Fig. 4). Furthermore, we have argued that ψ(t) in coarse-grained states will frequently obey Eq. (69), with a power-law regime for short times and an exponential regime for long times. Physically, this distribution arises because the system always starts just inside the boundary of a coarse-grained state; therefore, it can either quickly recross the boundary, leading to the power-law regime, or explore the rest of the coarse-grained state, leading to the exponential regime. Compared to a simple exponential distribution, this hybrid distribution is enriched by the power law at short times, meaning that very short waiting times are much more likely than would be expected if the system started in the middle of the coarse-grained state rather than near the boundary. However, if the system does not quickly exit, it is likely to wait much longer as it explores the rest of the coarse-grained state. This effective ψ(t) is typically much broader than an exponential distribution, indicated by its larger CV (Eq. (71)); linking this with our condition on path length and time statistics , we obtain a condition that shows how much coarse-graining is necessary to see significant memory effects in the statistics of path times (Eq. (72)).
Representing complex state spaces by simpler, coarse-grained representations has long been an implicit element of stochastic models. In recent years, it has been explored in Markov models of molecular systems such as proteins.1,2,16 Non-exponential effects may be important in these systems, especially if the coarse-grained networks are not very large. Indeed, non-exponential distributions of transition times have previously been found for both protein folding17 and enzyme kinetics;19 Reuveni et al.20 showed that these memory effects could lead to qualitatively different properties of enzyme unbinding within the Michaelis-Menten framework. Our observations underscore the importance of going beyond characterizing such processes by single rates, which implicitly assumes an exponential distribution of times.
Besides waiting memory in the form of non-exponential time distributions, an additional form of memory induced by coarse-graining is in the jump process. For example, consider a triple-well potential coarse-grained into states A, B, and C. When the system crosses the barrier from A into B, it is much more likely to jump back into A rather than jump to C, since it begins much closer to A in the microscopic space. We can account for this in our framework by extending the state space to include not only the current state of the system (e.g., A, B, or C) but also the previous state; the jump process in this extended state space is once again Markovian (although the waiting time distributions remain non-exponential). We also note that this coarse-graining may require non-separable waiting time distributions ψ(t|σ → σ′), since the distribution of times to return to A from B may be quite different from the distribution to reach C. Our framework can readily address this generalization (Appendix E). We look forward to studying the combined roles of jump and waiting memory in coarse-grained molecular models.
Acknowledgments
We thank Pavel Khromov and William Jacobs for careful reading of the manuscript and helpful comments. M.M. was supported by NIH under Award No. F32 GM116217 and A.V.M. was supported by an Alfred P. Sloan Research Fellowship.
APPENDIX A: ASYMPTOTIC FORM OF THE PATH LENGTH DISTRIBUTION
The path length distribution ρ(ℓ) is formally given by Eq. (12), which involves the sum of path probabilities for all paths φ of length ℓ. More explicitly, we can write ρ(ℓ) using matrix elements of powers of the jump matrix Q and summing over all final states,
| (A1) |
where is the vector of initial state probabilities. We can decompose Q into its Jordan form
| (A2) |
where D is a diagonal matrix with the eigenvalues of Q, N is a nilpotent matrix, and P is an invertible matrix.48 Powers of Q are therefore
| (A3) |
If Q is exactly diagonalizable, then N = 0, and so for large ℓ, the leading order term in Eq. (A1) is proportional to qℓ = eℓlogq, where q < 1 is the largest eigenvalue of Q. If Q is not diagonalizable, the leading term will still be proportional to eℓlogq, but may also include a polynomial factor in ℓ due to the binomial coefficient in Eq. (A3). However, the polynomial factor only contributes logarithmically to the exponent, i.e., ℓkeℓlogq = eℓlogq+klogℓ, and thus we can neglect it for large ℓ. Therefore, in general we have ρ(ℓ) ∼ eℓlogq for large ℓ, and since this suggests that the mean path length must be , we obtain Eq. (13).
APPENDIX B: EXACT RELATIONS BETWEEN PATH LENGTH AND TIME MOMENTS USING GENERATING FUNCTIONS
Here we derive exact relations between path length and time moments when all states have identical waiting time distributions: ψ(t|σ) = ψ(t). We define the moment-generating function for the path length distribution
| (B1) |
so that the moments are
| (B2) |
where the superscript denotes the derivative:
| (B3) |
The cumulant-generating function is therefore with
| (B4) |
We similarly define the moment- and cumulant-generating functions for the waiting times:
| (B5) |
When the waiting time distributions are ψ(t) for every state, the path time distribution is (Eqs. (7) and (14))
| (B6) |
Therefore, the moment-generating function for path time is
| (B7) |
while the cumulant-generating function for path time is
| (B8) |
We can obtain moments and cumulants of path time by taking derivatives of its generating functions:
| (B9) |
To express these in terms of the length and waiting time moments, we use Faà di Bruno’s formula for derivatives of composite functions:37
| (B10) |
where Bn,k are the partial Bell polynomials and superscripts again denote derivatives. Thus, the path time moments are
| (B11) |
This proves Eq. (24). We can similarly obtain the path time cumulants:
| (B12) |
APPENDIX C: APPROXIMATE RELATIONS BETWEEN PATH LENGTH AND TIME MOMENTS USING THE CENTRAL LIMIT THEOREM
Here we use the central limit theorem to obtain approximate relations between path length and time moments when all states have identical waiting time distributions: ψ(t|σ) = ψ(t). Equation (B6) gives the general relation between the length and time distributions in this case, where the nested integrals represent the probability distribution of the sum of the waiting times. For sufficiently long paths, this distribution will be approximately Gaussian
| (C1) |
and hence,
| (C2) |
From this, we can obtain approximate relations between the moments. For example, the first two path time moments are
| (C3) |
which are in fact identical to the exact result (Eqs. (24) and (25)) as expected.
APPENDIX D: PATH LENGTHS AND TIMES WITH HOMOGENEOUS EXPONENTIAL WAITING TIME DISTRIBUTIONS
When every state has the same exponential waiting time distribution ψ(t) = θ−1e−t/θ, the sum of the ℓ waiting times has an Erlang distribution,
| (D1) |
Thus, the total path time distribution is (using Eq. (B6))
| (D2) |
In this case, we can determine the complete distribution of times f(t) given the complete distribution of lengths ρ(ℓ). We can directly calculate the path time moments to be
| (D3) |
where |sn,k| are the unsigned Stirling numbers of the first kind.37 The first few moments are
| (D4) |
This is consistent with the general result in Eq. (24) since for an exponential distribution and Bn,k(0!, 1!, …, (n − k)!) = |sn,k|.37
APPENDIX E: PROOF OF RECURSION RELATIONS FOR MOMENT MATRICES
We now show that the matrices generated by the recursion relation of Eq. (34) indeed calculate the path time moments according to Eq. (33). We first successively apply the recursion relation to expand the ℓ th-order matrix in terms of lower-order matrices:
| (E1) |
where we have invoked the initial condition from Eq. (31) to obtain the multinomial sum (recall that each summation in the multinomial sum is from 0 to n subject to the constraint j0 + j1 + ⋯ + jℓ−1 = n). Now we take the matrix element of for the initial distribution and σℓ ∈ Sfinal and insert identities of the form to obtain
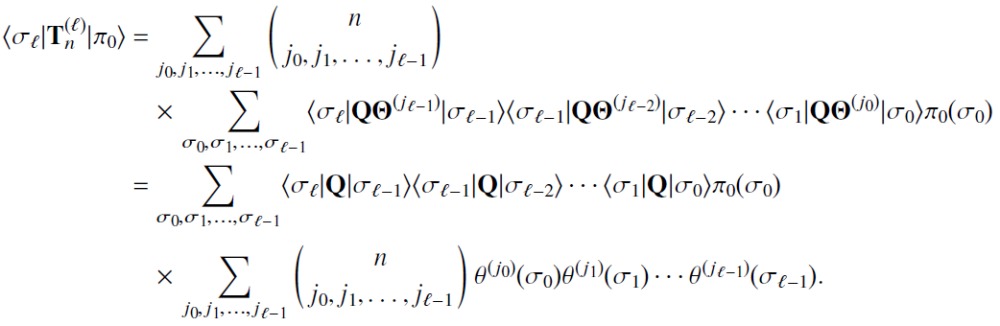 |
(E2) |
Next, we sum over final states σℓ and path lengths ℓ to obtain
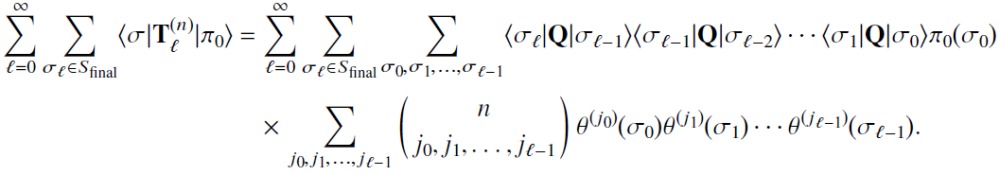 |
(E3) |
Substituting (Eq. (8)), the time moment functional (Eq. (16)), and the sum over paths
| (E4) |
into Eq. (E3), we finally obtain Eq. (33):
| (E5) |
We now show that the recursion relation of Eq. (40) is correct for any functional of the form in Eq. (22); this will prove the action recursion relation (Eq. (37)) as a special case. As in Eq. (E1), successive applications of the recursion relation yield
| (E6) |
After inserting identities and using the definition 〈σ′|Ω(j)|σ〉 = 〈σ′|Q|σ〉(U(σ′, σ))j, we obtain
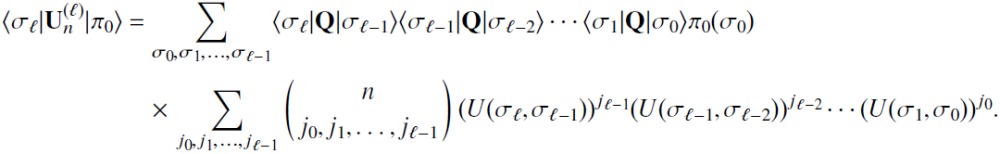 |
(E7) |
Just as in Eqs. (E3) and (E5) for time moments, we can then sum over final states and path lengths to show that the matrices are related to the path ensemble averages via Eq. (39). Finally, we explain how to use the generalized recursion relation in Eq. (40) to calculate path time moments when the waiting time distributions are non-separable. In this case, we define 〈σ′|Ω(j)|σ〉 = 〈σ′|Q|σ〉θ(j)(σ → σ′), where θ(j)(σ → σ′) is the jth moment of the non-separable waiting time distribution ψ(t|σ → σ′). We can then use the recursion relation of Eq. (40) to calculate the time moments .
REFERENCES
- 1.Noé F., Schütte C., Vanden-Eijnden E., Reich L., and Weikl T. R., “Constructing the equilibrium ensemble of folding pathways from short off-equilibrium simulations,” Proc. Natl. Acad. Sci. U. S. A. 106, 19011–19016 (2009). 10.1073/pnas.0905466106 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Lane T. J., Bowman G. R., Beauchamp K., Voelz V. A., and Pande V. S., “Markov state model reveals folding and functional dynamics in ultra-long MD trajectories,” J. Am. Chem. Soc. 133, 18413–18419 (2011). 10.1021/ja207470h [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.ben-Avraham D. and Havlin S., Diffusion and Reactions in Fractals and Disordered Systems (Cambridge University Press, Cambridge, 2000). [Google Scholar]
- 4.Redner S., A Guide to First-Passage Processes (Cambridge University Press, Cambridge, 2001). [Google Scholar]
- 5.Weinreich D. M., Delaney N. F., DePristo M. A., and Hartl D. L., “Darwinian evolution can follow only very few mutational paths to fitter proteins,” Science 312, 111–114 (2006). 10.1126/science.1123539 [DOI] [PubMed] [Google Scholar]
- 6.Manhart M. and Morozov A. V., “Protein folding and binding can emerge as evolutionary spandrels through structural coupling,” Proc. Natl. Acad. Sci. U. S. A. 112, 1797–1802 (2015). 10.1073/pnas.1415895112 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Enver T., Pera M., Peterson C., and Andrews P. W., “Stem cell states, fates, and the rules of attraction,” Cell Stem Cell 4, 387 (2009). 10.1016/j.stem.2009.04.011 [DOI] [PubMed] [Google Scholar]
- 8.Lang A. H., Li H., Collins J. J., and Mehta P., “Epigenetic landscapes explain partially reprogrammed cells and identify key reprogramming genes,” PLoS. Comput. Biol. 10, e1003734 (2014). 10.1371/journal.pcbi.1003734 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Albert R. and Barabási A. L., “Statistical mechanics of complex networks,” Rev. Mod. Phys. 74, 47–97 (2002). 10.1103/RevModPhys.74.47 [DOI] [Google Scholar]
- 10.Gallos L. K., Song C., Havlin S., and Makse H. A., “Scaling theory of transport in complex biological networks,” Proc. Natl. Acad. Sci. U. S. A. 104, 7746–7751 (2007). 10.1073/pnas.0700250104 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Condamin S., Bénichou O., Tejedor V., Voituriez R., and Klafter J., “First-passage times in complex scale-invariant media,” Nature 450, 77–80 (2007). 10.1038/nature06201 [DOI] [PubMed] [Google Scholar]
- 12.Montroll E. W. and Weiss G. H., “Random walks on lattices. II,” J. Math. Phys. 6, 167–181 (1965). 10.1063/1.1704269 [DOI] [Google Scholar]
- 13.Weiss G. H., Aspects and Applications of the Random Walk (North Holland, Amsterdam, 1994). [Google Scholar]
- 14.Bollt E. M. and ben-Avraham D., “What is special about diffusion on scale-free nets?,” New J. Phys. 7, 26–47 (2005). 10.1088/1367-2630/7/1/026 [DOI] [Google Scholar]
- 15.Metzner P., Schütte C., and Vanden-Eijnden E., “Transition path theory for Markov jump processes,” Multiscale Model. Simul. 7, 1192–1219 (2009). 10.1137/070699500 [DOI] [Google Scholar]
- 16.Prinz J.-H., Wu H., Sarich M., Keller B., Senne M., Held M., Chodera J. D., Schütte C., and Noé F., “Markov models of molecular kinetics: Generation and validation,” J. Chem. Phys. 134, 174105 (2011). 10.1063/1.3565032 [DOI] [PubMed] [Google Scholar]
- 17.Sabelko J., Ervin J., and Gruebele M., “Observation of strange kinetics in protein folding,” Proc. Natl. Acad. Sci. U. S. A. 96, 6031–6036 (1999). 10.1073/pnas.96.11.6031 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Yang H., Luo G., Karnchanaphanurach P., Louie T.-M., Rech I., Cova S., Xun L., and Xie X. S., “Protein conformational dynamics probed by single-molecule electron transfer,” Science 302, 262–266 (2003). 10.1126/science.1086911 [DOI] [PubMed] [Google Scholar]
- 19.Flomenbom O., Velonia K., Loos D., Masuo S., Cotlet M., Engelborghs Y., Hofkens J., Rowan A. E., Nolte R. J. M., der Auweraer M. V., de Schryver F. C., and Klafter J., “Stretched exponential decay and correlations in the catalytic activity of fluctuating single lipase molecules,” Proc. Natl. Acad. Sci. U. S. A. 102, 2368–2372 (2005). 10.1073/pnas.0409039102 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Reuveni S., Urbakh M., and Klafter J., “Role of substrate unbinding in Michaelis–Menten enzymatic reactions,” Proc. Natl. Acad. Sci. U. S. A. 111, 4391–4396 (2014). 10.1073/pnas.1318122111 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Campbell I. A., Flesselles J.-M., Jullien R., and Botet R., “Nonexponential relaxation in spin glasses and glassy systems,” Phys. Rev. B 37, 3825–3828 (1988). 10.1103/PhysRevB.37.3825 [DOI] [PubMed] [Google Scholar]
- 22.Angelani L., Parisi G., Ruocco G., and Viliani G., “Connected network of minima as a model glass: Long time dynamics,” Phys. Rev. Lett. 81, 4648–4651 (1998). 10.1103/PhysRevLett.81.4648 [DOI] [Google Scholar]
- 23.Hunter J. J., “On the moments of Markov renewal processes,” Adv. Appl. Probab. 1, 188–210 (1969). 10.2307/1426217 [DOI] [Google Scholar]
- 24.Yao D. D., “First-passage-time moments of Markov processes,” J. Appl. Probab. 22, 939–945 (1985). 10.2307/3213962 [DOI] [Google Scholar]
- 25.Harrison P. G. and Knottenbelt W. J., “Passage time distributions in large Markov chains,” SIGMETRICS Perform. Eval. Rev. 30, 77–85 (2002). 10.1145/511399.511345 [DOI] [Google Scholar]
- 26.Flomenbom O. and Klafter J., “Closed-form solutions for continuous time random walks on finite chains,” Phys. Rev. Lett. 95, 098105 (2005). 10.1103/PhysRevLett.95.098105 [DOI] [PubMed] [Google Scholar]
- 27.Flomenbom O. and Silbey R. J., “Properties of the generalized master equation: Green’s functions and probability density functions in the path representation,” J. Chem. Phys. 127, 034103 (2007). 10.1063/1.2743969 [DOI] [PubMed] [Google Scholar]
- 28.Flomenbom O. and Silbey R. J., “Path-probability density functions for semi-Markovian random walks,” Phys. Rev. E 76, 041101 (2007). 10.1103/PhysRevE.76.041101 [DOI] [PubMed] [Google Scholar]
- 29.Harland B. and Sun S. X., “Path ensembles and path sampling in nonequilibrium stochastic systems,” J. Chem. Phys. 127, 104103 (2007). 10.1063/1.2775439 [DOI] [PubMed] [Google Scholar]
- 30.Haus J. W. and Kehr K. W., “Diffusion in regular and disordered lattices,” Phys. Rep. 150, 263–406 (1987). 10.1016/0370-1573(87)90005-6 [DOI] [Google Scholar]
- 31.Sun S. X., “Path summation formulation of the master equation,” Phys. Rev. Lett. 96, 210602 (2006). 10.1103/PhysRevLett.96.210602 [DOI] [PubMed] [Google Scholar]
- 32.Manhart M. and Morozov A. V., “Path-based approach to random walks on networks characterizes how proteins evolve new functions,” Phys. Rev. Lett. 111, 088102 (2013). 10.1103/PhysRevLett.111.088102 [DOI] [PubMed] [Google Scholar]
- 33.Manhart M. and Morozov A. V., “Statistical physics of evolutionary trajectories on fitness landscapes,” in First-Passage Phenomena and their Applications, edited by Metzler R., Oshanin G., and Redner S. (World Scientific, Singapore, 2014). [Google Scholar]
- 34.Filyukov A. A. and Karpov V. Y., “Method of the most probable path of evolution in the theory of stationary irreversible processes,” J. Eng. Phys. 13, 416–419 (1967). 10.1007/BF00828961 [DOI] [Google Scholar]
- 35.Mustonen V. and Lässig M., “Fitness flux and ubiquity of adaptive evolution,” Proc. Natl. Acad. Sci. U. S. A. 107, 4248–4253 (2010). 10.1073/pnas.0907953107 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Wang J., Xu L., and Wang E., “Potential landscape and flux framework of nonequilibrium networks: Robustness, dissipation, and coherence of biochemical oscillations,” Proc. Natl. Acad. Sci. U. S. A. 105, 12271–12276 (2008). 10.1073/pnas.0800579105 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Comtet L., Advanced Combinatorics: The Art of Finite and Infinite Expressions (D. Reidel, Dordrecht, 1974). [Google Scholar]
- 38.Yeomans J. M., Statistical Mechanics of Phase Transitions (Oxford University Press, Oxford, 1992). [Google Scholar]
- 39.Majid I., ben Avraham D., Havlin S., and Stanley H. E., “Exact-enumeration approach to random walks on percolation clusters in two dimensions,” Phys. Rev. B 30, 1626–1628 (1984). 10.1103/PhysRevB.30.1626 [DOI] [Google Scholar]
- 40.Jones E., Oliphant T., Peterson P. et al. , SciPy: Open source scientific tools for Python, 2001, online accessed May 15, 2015.
- 41.Goel N. S. and Richter-Dyn N., Stochastic Models in Biology (Academic Press, New York, 1974). [Google Scholar]
- 42.Press W. H., Teukolsky S. A., Vetterling W. T., and Flannery B. P., Numerical Recipes in C: The Art of Scientific Computing, 2nd ed. (Cambridge University Press, Cambridge, 1992). [Google Scholar]
- 43.Stuart A. and Ord J. K., Kendall’s Advanced Theory of Statistics: Volume 1, 6th ed. (Wiley, New York, 1994). [Google Scholar]
- 44.Bel G., Munsky B., and Nemenman I., “The simplicity of completion time distributions for common complex biochemical processes,” Phys. Biol. 7, 016003 (2010). 10.1088/1478-3975/7/1/016003 [DOI] [PubMed] [Google Scholar]
- 45.Weiss G. H. and Havlin S., “Use of comb-like models to mimic anomalous diffusion on fractal structures,” Philos. Mag. B 56, 941–947 (1987). 10.1080/13642818708215329 [DOI] [Google Scholar]
- 46.Iomin A., “Toy model of fractional transport of cancer cells due to self-entrapping,” Phys. Rev. E 73, 061918 (2006). 10.1103/PhysRevE.73.061918 [DOI] [PubMed] [Google Scholar]
- 47.Argyrakis P., Milchev A., Pereyra V., and Kehr K. W., “Dependence of the diffusion coefficient on the energy distribution of random barriers,” Phys. Rev. E 52, 3623–3631 (1995). 10.1103/PhysRevE.52.3623 [DOI] [PubMed] [Google Scholar]
- 48.Curtis C. W., Linear Algebra: An Introductory Approach (Springer, New York, 1984). [Google Scholar]